1. Introduction
Population estimations make indispensable contributions to the activities of organizations, businesses and governments, since the dispersion of energy and resources among different geographical regions is strongly dependent on the population size [
1]. From an urban geographical perspective, Clark [
2] initially studied monocentric models, where the population density was determined by the distance to the Central Business District (CBD), and proposed a negative exponential model with a constant gradient. Though other researchers, such as Newling [
3] and Parr [
4], improved this model by adding or modifying different parameters, Tobler [
5] put forward that the exponential distance decay function was an approximation for the entire urban area, whereas its repeated use away from the urban center seemed unreasonable.
Undoubtedly, the negative exponential function was an empirical estimation [
6]. Then, areal interpolations began to be realized by many scholars, such as Tobler [
7], Lam [
8] and Rase [
9], who utilized census data as the model input to interpolate or disaggregate original data and obtained a refined population distribution surface. Besides, accuracy of methods in areal interpolation was largely improved when various ancillary data were incorporated, such as land use types, street networks and statistical surfaces, and one of the most representative models was the dasymetric mapping. Wright [
10] performed binary divisions iteratively to disaggregate population density from general zones to detailed zones in Cape Cod (MA, USA) while keeping the volume preserved through a dasymetric model. However, Wright’s model was not easy to implement, therefore, Langford and Unwin [
11] applied multivariable regression to compute population densities in dasymetric subzones. Other researchers such as Yuan et al. [
12], Eicher and Brewer [
13] and Mennis [
14] classified land use into different types and redistributed census data among them. In addition, some researchers still aimed at further optimizing this method, which included Zandbergen and Ignizio [
15] who compared the accuracy of different types of ancillary data used in dasymetric mapping; Nagle et al. [
16] who represented and quantified the uncertainties in dasymetric modeling by the Penalized Maximum Entropy Dasymetric Model (P-MEDM); Stevens et al. [
17] who produced a gridded population density at a 100 m spatial resolution through the Random Forest model. However, it was Mennis [
18] who pointed out that the biggest challenge of dasymetric mapping was to develop standardized dasymetric mapping techniques.
Another approach commonly accepted by many researchers was statistical modeling, which was first proposed by Kraus [
19]. To explore the relationship between population and remote sensed variables, there were usually six categories of ancillary datasets: urban areas (Tobler, [
20]) including urban lights (Prosperie and Eyton [
21]; Lo [
22]; Zeng et al. [
23]), land use (Kraus et al. [
19]; Weber [
24]; Langford and Harvey [
25]; Lo [
26]), dwelling units (Porter [
27]; Collins and EI-Beik [
28]; Lo and Chan [
29]; Lo [
30]), image pixel characteristics (Iisaka and Hegedus [
31]; Lo [
32]; Harvey [
33]), impervious surface (Lu et al. [
34] and Li and Weng [
35]) and other physical or socioeconomic characteristics (Dobson et al., [
36]; Liu and Clarke [
37]; Balk et al. [
38]). However, some problems have not been solved. Taking land use types as an example, the accuracy of population estimations was largely based on the detail of land use classes and the methods ignored the heterogeneity of population inside the same land use type. In addition, the spatial resolution of population estimation was also limited.
With the development of society, demographic information at finer resolutions had a significant impact on the economic, social, technological and humanitarian development of cities and is an indispensable component used in policymaking and planning [
39]. Li and Weng [
40] compared different ancillary data in getting fine-scale population estimations based on Landsat ETM+ imagery, and two conclusions were drawn: the land use-based method performed better than impervious surface and vegetation fractions; dasymetric mapping yielded better results than choropleth mapping. Leyk et al. [
41] coupled spatial allocation procedures with a dasymetric model to allocate population to household microdata based on maximum entropy models, which refined the population distribution solution to a subtract level. However, a number of experiments demonstrated that land use data could not be used to conduct accurate population estimations at a fine scale [
42]. Moreover, these methods were constrained by the selection of the spectral response variables or by a reliable validation during non-census years.
Considering that a large number of building units that are vertically stacked cannot be easily identified from 2-D photographs as only the roofs are visible, the height information is essential for the real structure of the buildings [
43]. Besides, the 3D properties of urban buildings represent the three-dimensional nature of living space [
44] and serve as essentially direct factors in estimating fine-scale populations. Wu et al. [
45] used a deterministic model to estimate sub-block-level population through building volumes derived from geographic information system (GIS) building data and three housing statistics, and proposed a deterministic population estimation model relating with housing occupancy rate and average number of population per floor. However, there were some limitations that needed to be improved. For instance, researchers needed to know how to obtain housing statistics during intercensal years and how to get building footprints and volumes without extra model input. Alahmadi et al. [
46] found that height information was helpful to improve the prediction accuracy compared with conventional population models. Qiu et al. [
43] also adopted building volumes derived from LIDAR as an index to estimate population at the census block level. Xie et al. [
47] estimated fine-scale population distribution from LiDAR-derived residential variables by a morphological algorithm and refining classification of residential buildings and realized that the height of buildings could be regarded as a crucial component for the corresponding models, but the cost of LiDAR datasets was high and periodical LiDAR data was unavailable. The coverage of specific areas needed to be assured ahead, then users can schedule fights to acquire data, which to a certain degree resulted in a lack of timeliness and cost-effectiveness.
To sum up, traditional population estimation models were time-consuming to conduct or subjected to the assumption that subzones were evenly distributed, which indicates they have limitations for fine-scale population estimation in heterogeneous urban regions [
6]. Moreover, existing methods of estimating population in finer resolutions are subject to the availability of census data or the accuracy of classification methods. As for 3D building models, LIDAR data was mostly used but not timely to some degree. The above issues are supposed to be addressed appropriately. When the diversity and variability of urban buildings are taken into account by a majority of researchers, it is necessary to consider imagery with a finer resolution in order to improve the recognition [
48], so HR imagery is necessary. Furthermore, morphological operations are appropriate for extracting features from HR images when spectral, texture, structure, scale and granularity are taken into account [
49,
50,
51].
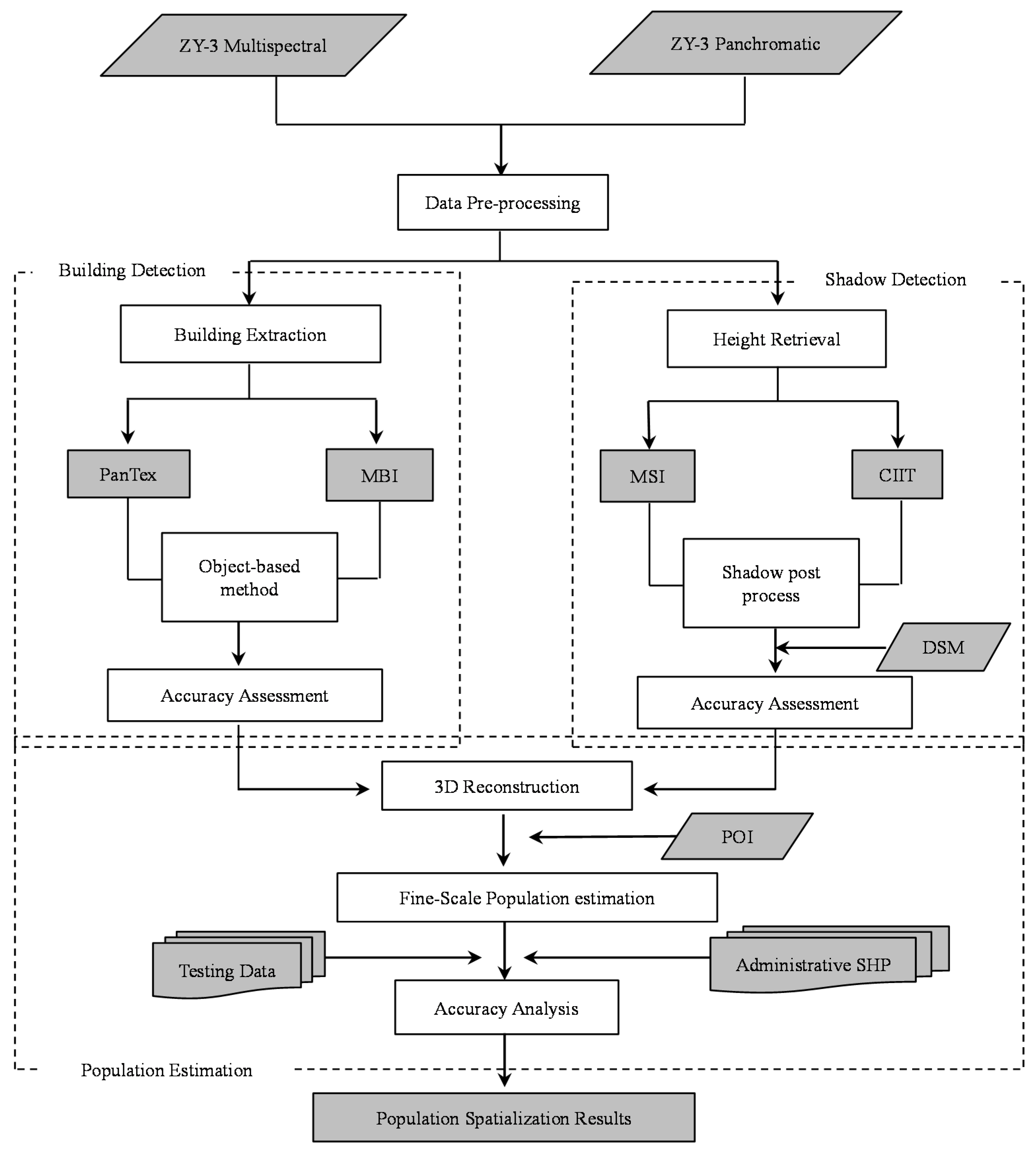
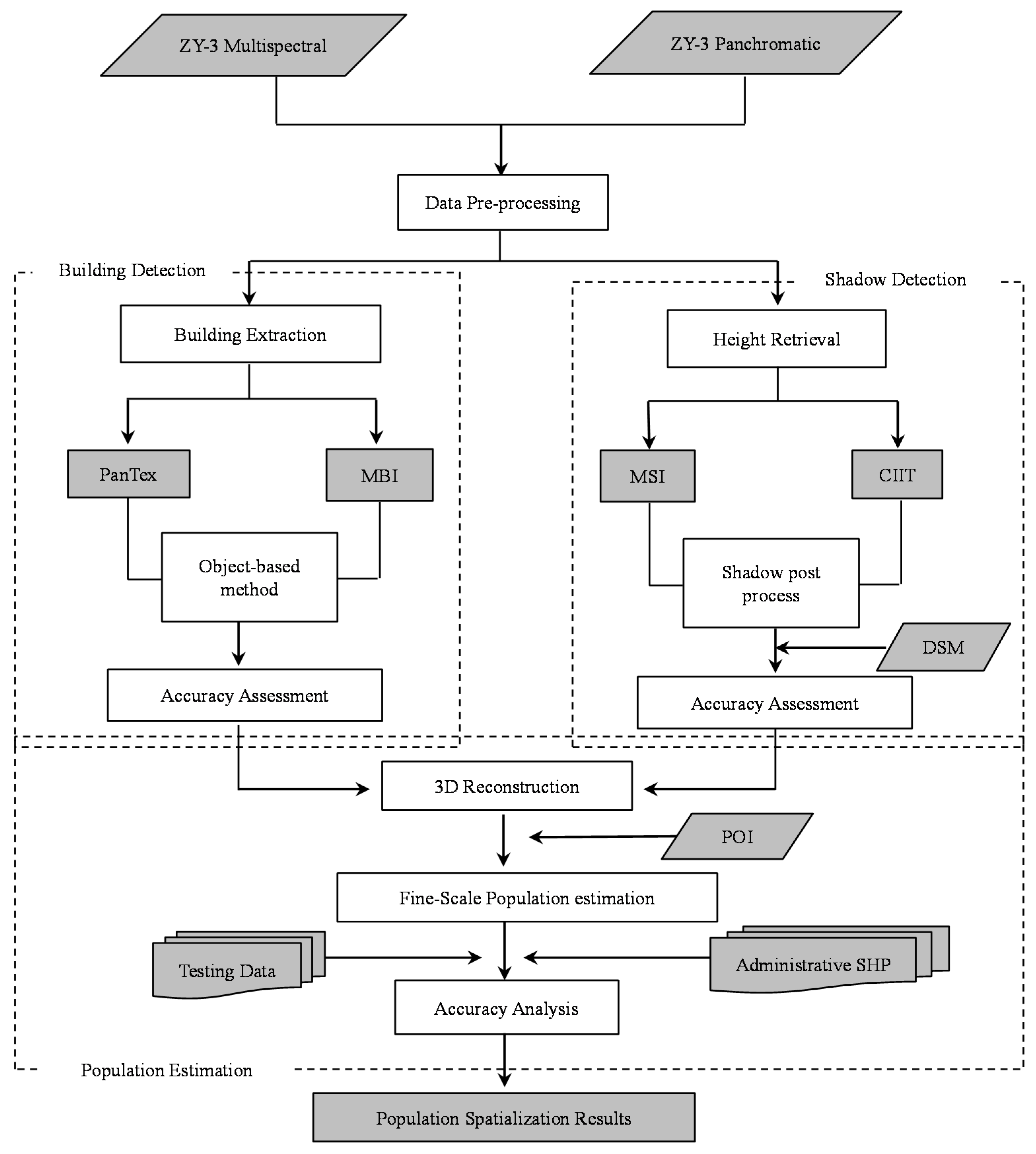
After considering all the factors listed before, this paper aims to acquire population distributions at a finer scale using HR satellite data (ZY-3) to reconstruct 3D information of urban residential buildings through morphological operations.
2. Study Area and Dataset
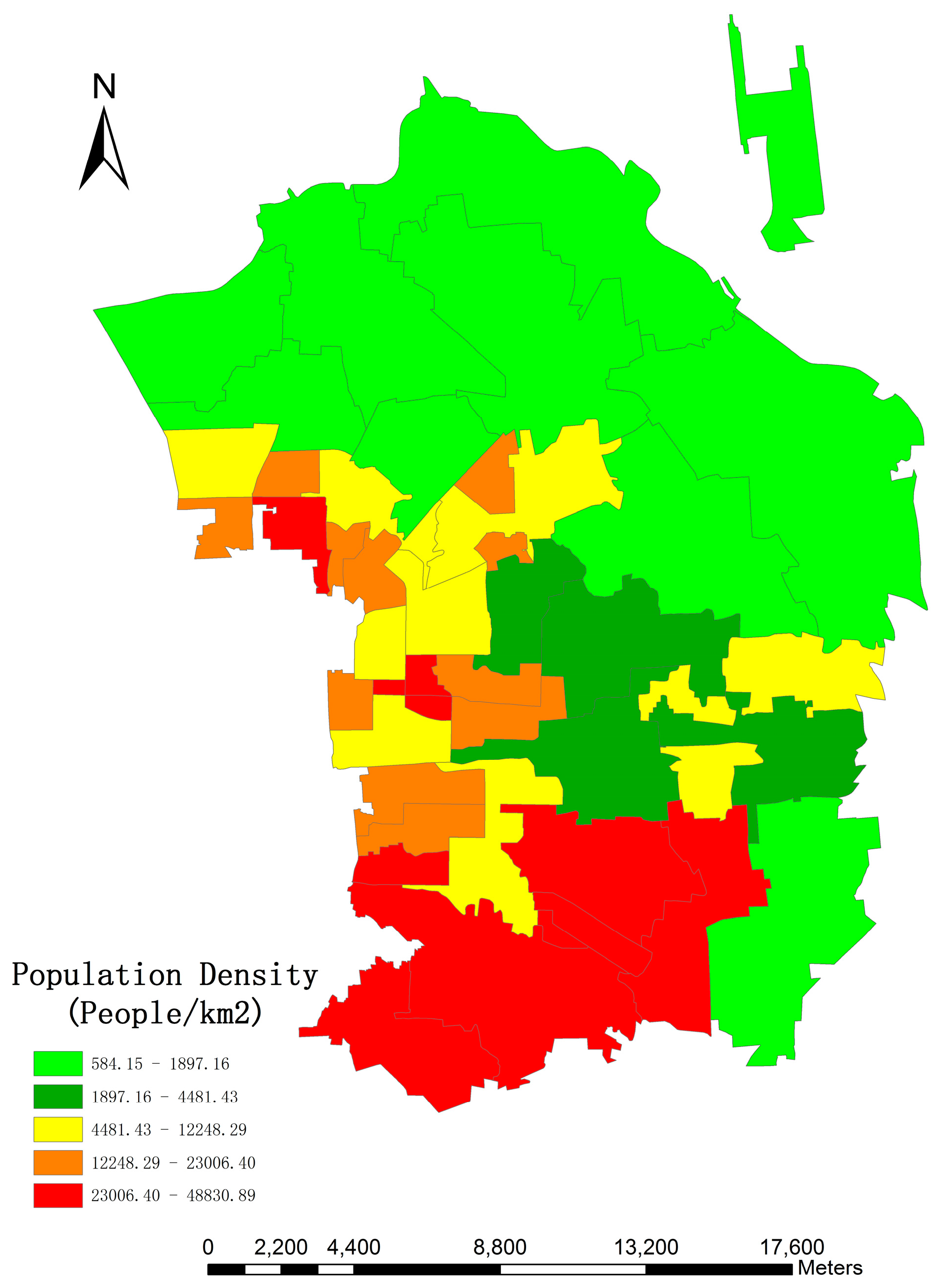
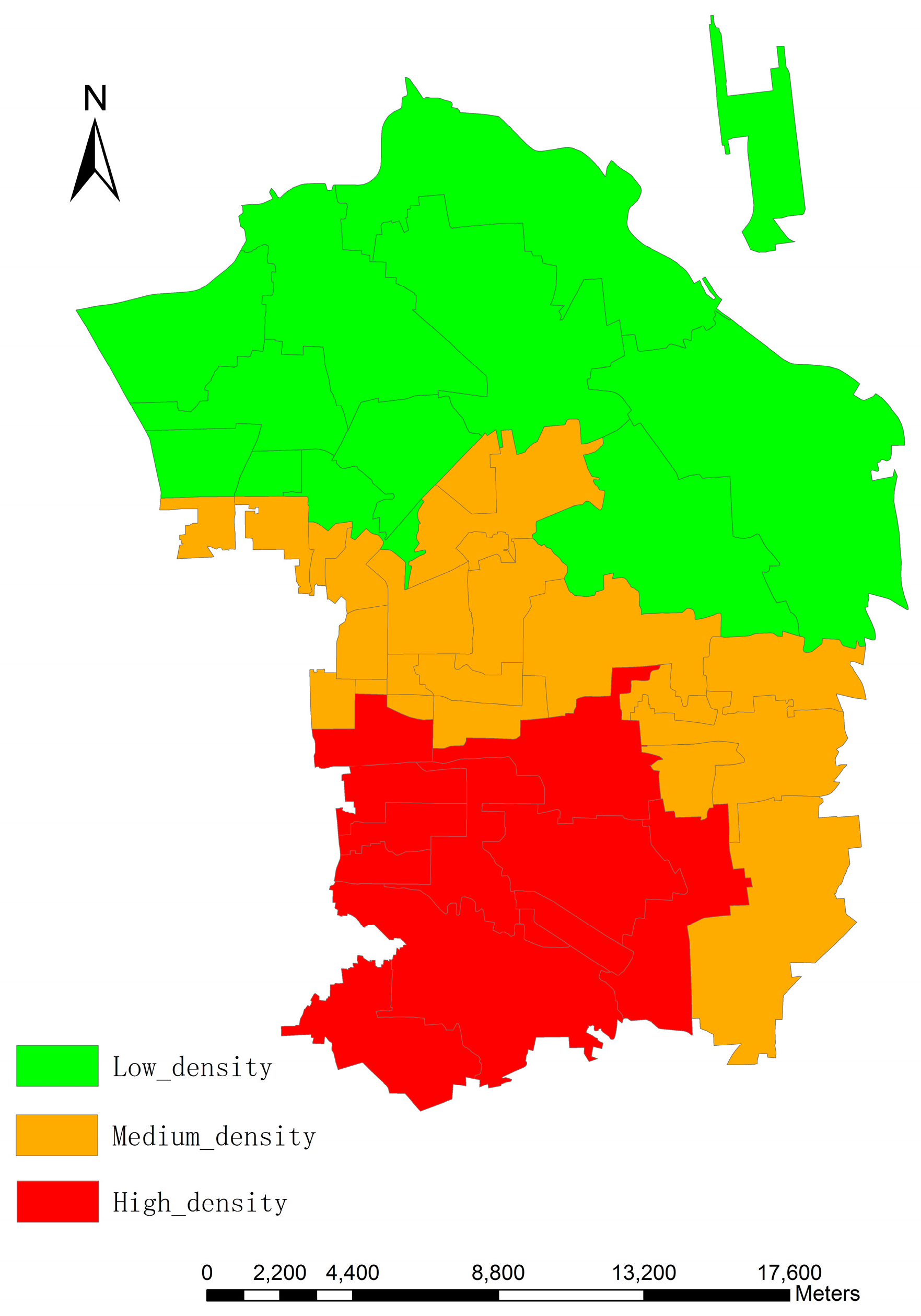
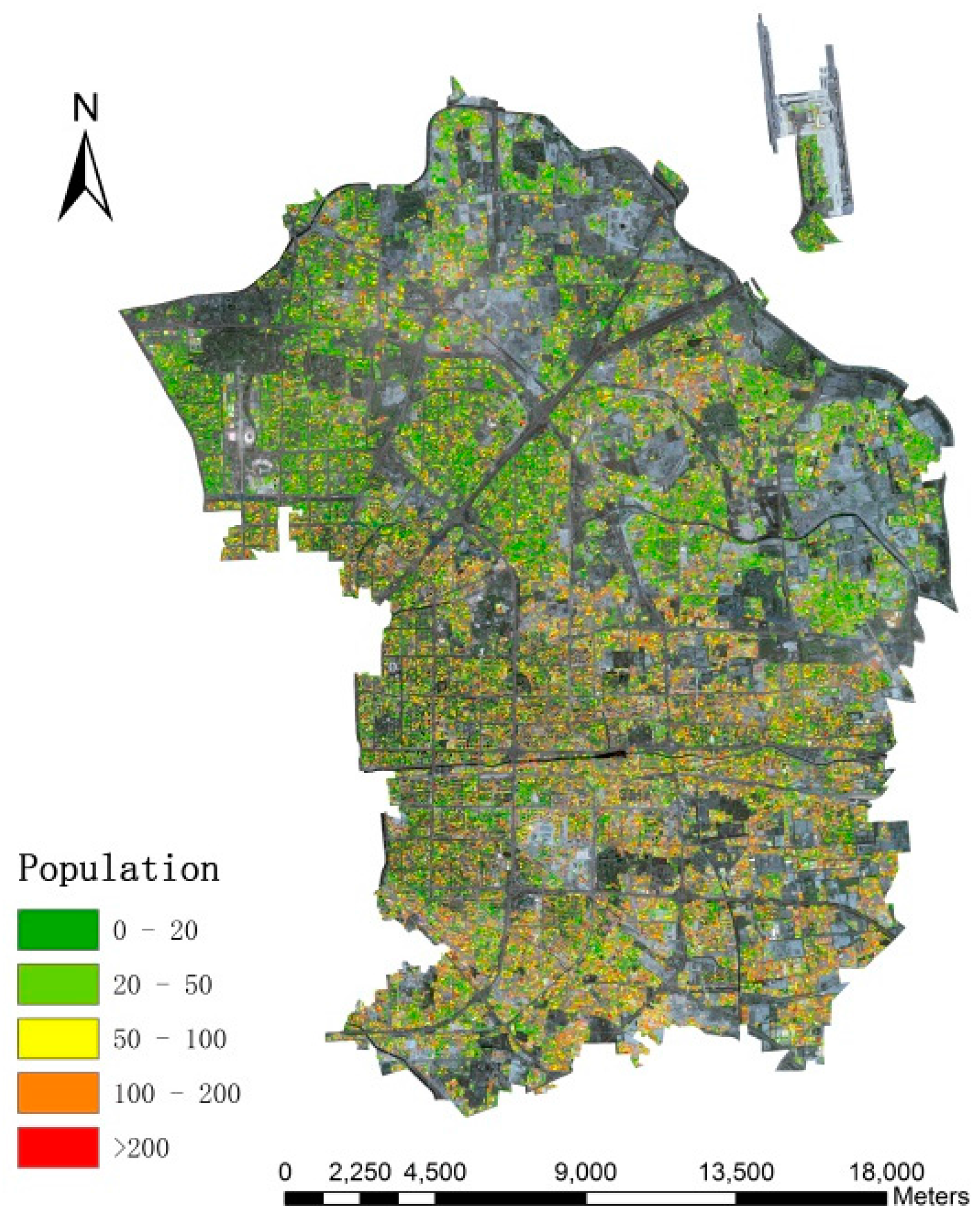
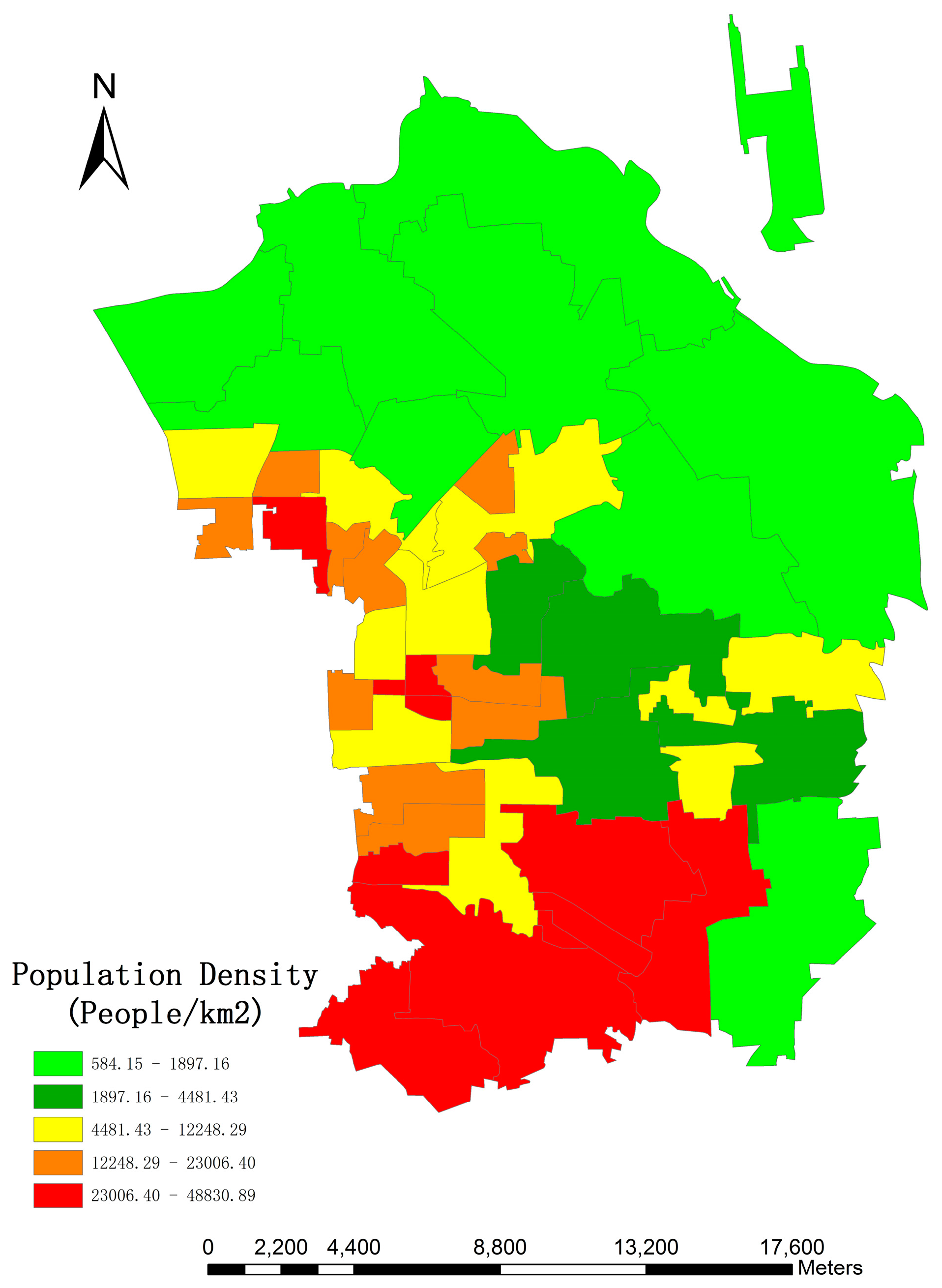
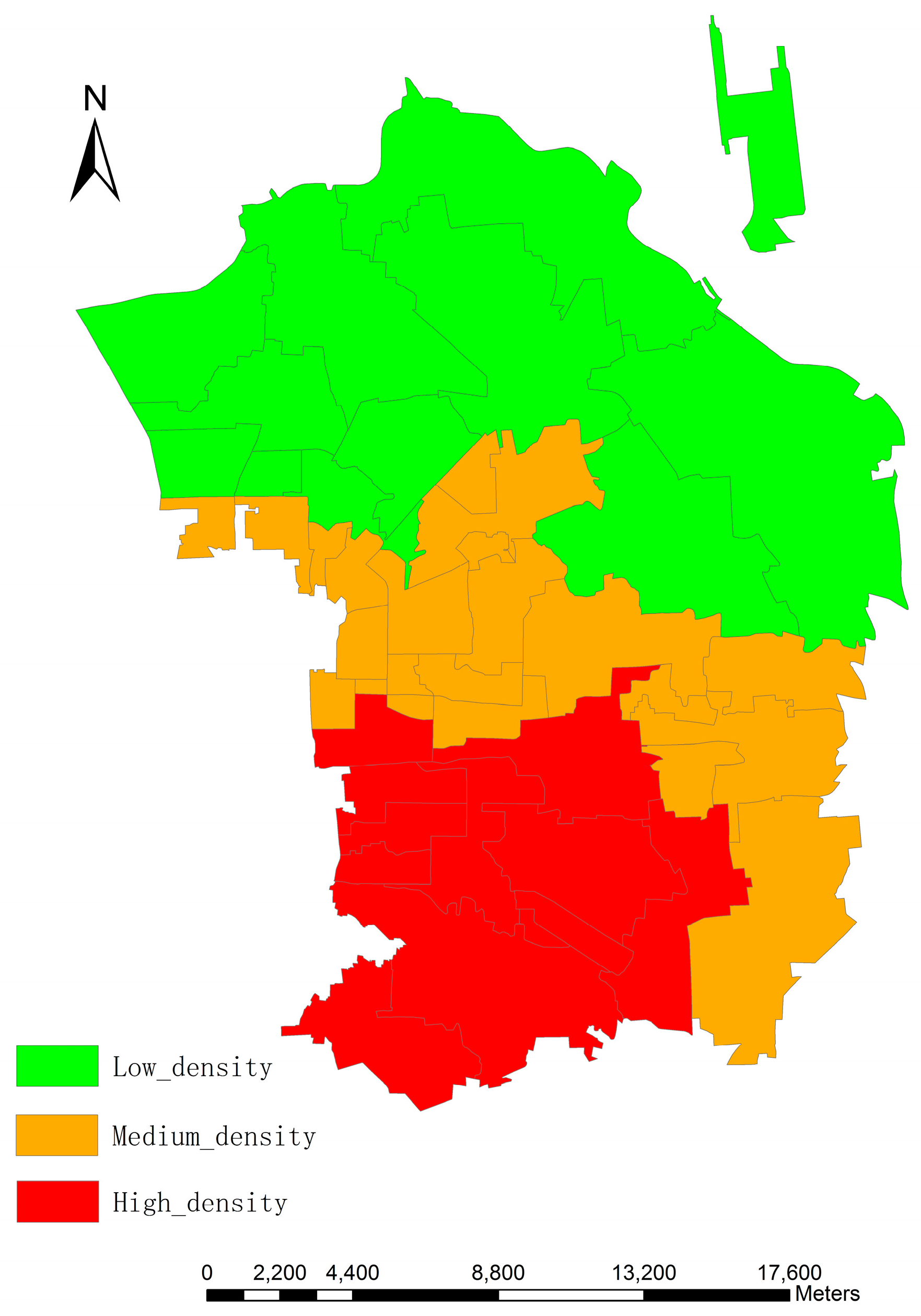
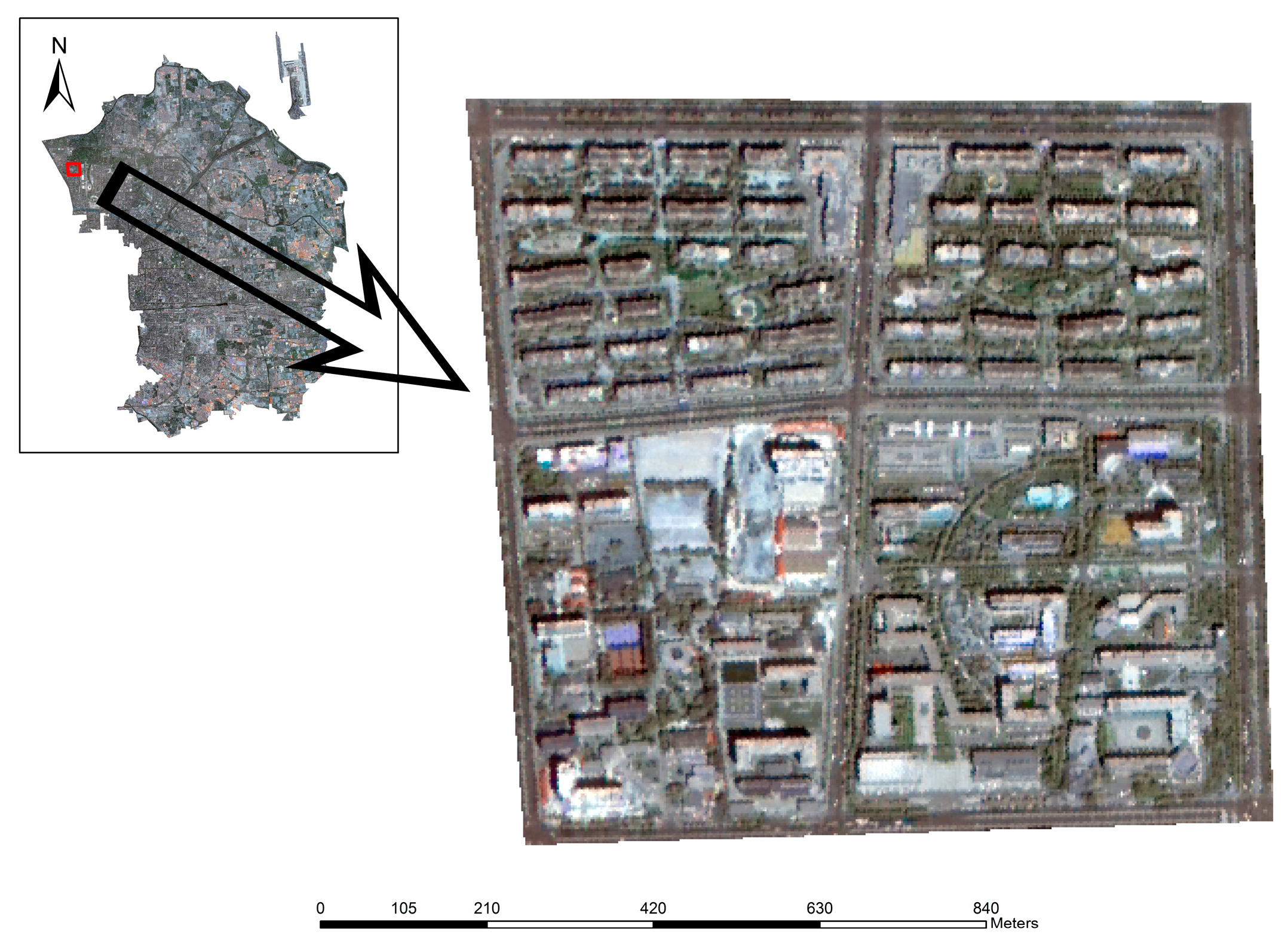
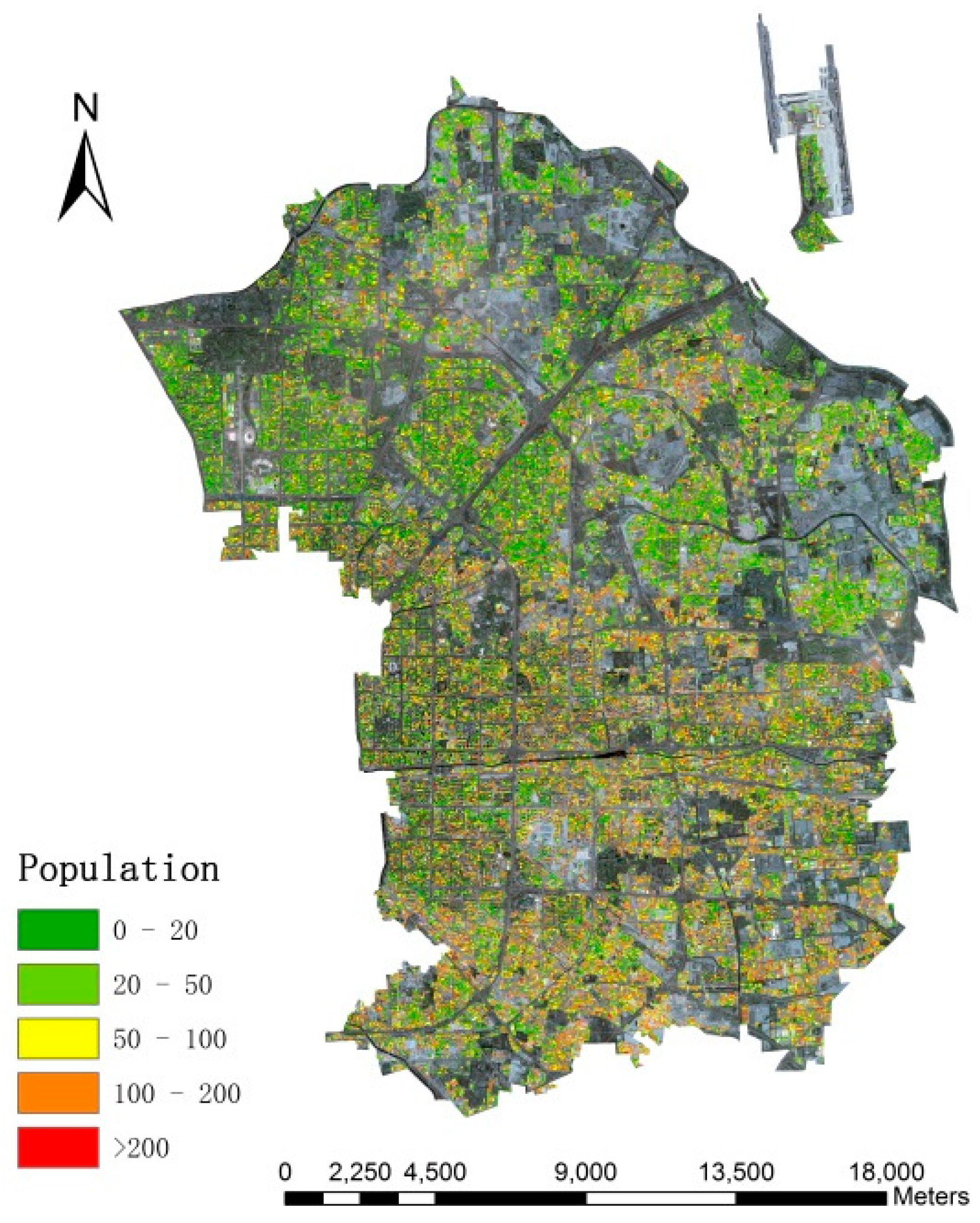
The study area is located in Chaoyang District, Beijing, which incorporates 42 administrative units covered by 10,153 × 13,295 pixels with a pixel size of 2.5 m, and serves as a typical example when the different population distribution from south to north due to unbalanced social and economic development is taken into account.
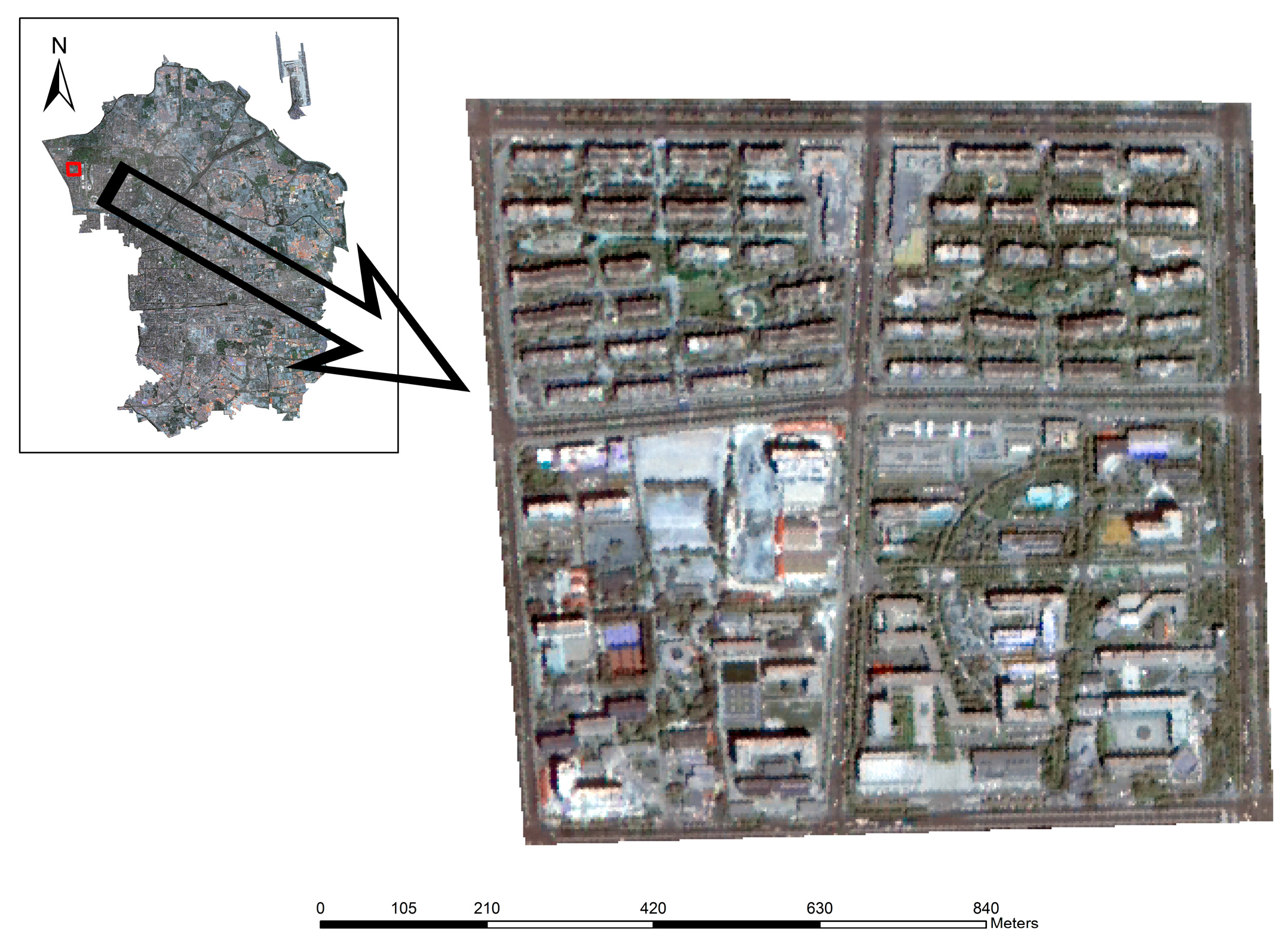
Figure 1 indicates the specific location of the study area. Furthermore, numerous urban segments (e.g., buildings, roads, parking lots and a park) and undeveloped regions (e.g., bare soil, grasslands, and watersheds) are included. Though there are a variety of urban land use types, the research focused on residential buildings.
HR imagery is essential in the extraction of urban objects since most of them are noticeably smaller than natural features, and thus a significantly small pixel size is necessary for urban applications [
52]. Accordingly, this experiment utilized two ZY-3 datasets (which principle parameters are listed in
Table 1) obtained from the Satellite Surveying and Mapping Application Center (NASG), with a commonly Universal Transverse Mercator (UTM) coordinate system of 50N based on the WGS84 ellipsoid. The administrative map of Beijing at the county level for 2014 was obtained from the National Geomatics Center of China. Besides, validation data referred to the statistical yearbook downloaded from Beijing Chaoyang Statistical Information Net (
http://www.chystats.gov.cn) in 2014. Furthermore, DSM was obtained from the National Administration of Survey, Mapping and Geoinformation, and point of interest (POI) data, which was collected from an urban digital map and incorporated five different types of buildings according to their utility (i.e., public services, financial buildings, commercial facilities, entertainment constructions and residential buildings), is also included since the location of buildings outperforms other ancillary datasets in population estimations [
53].
5. Discussion
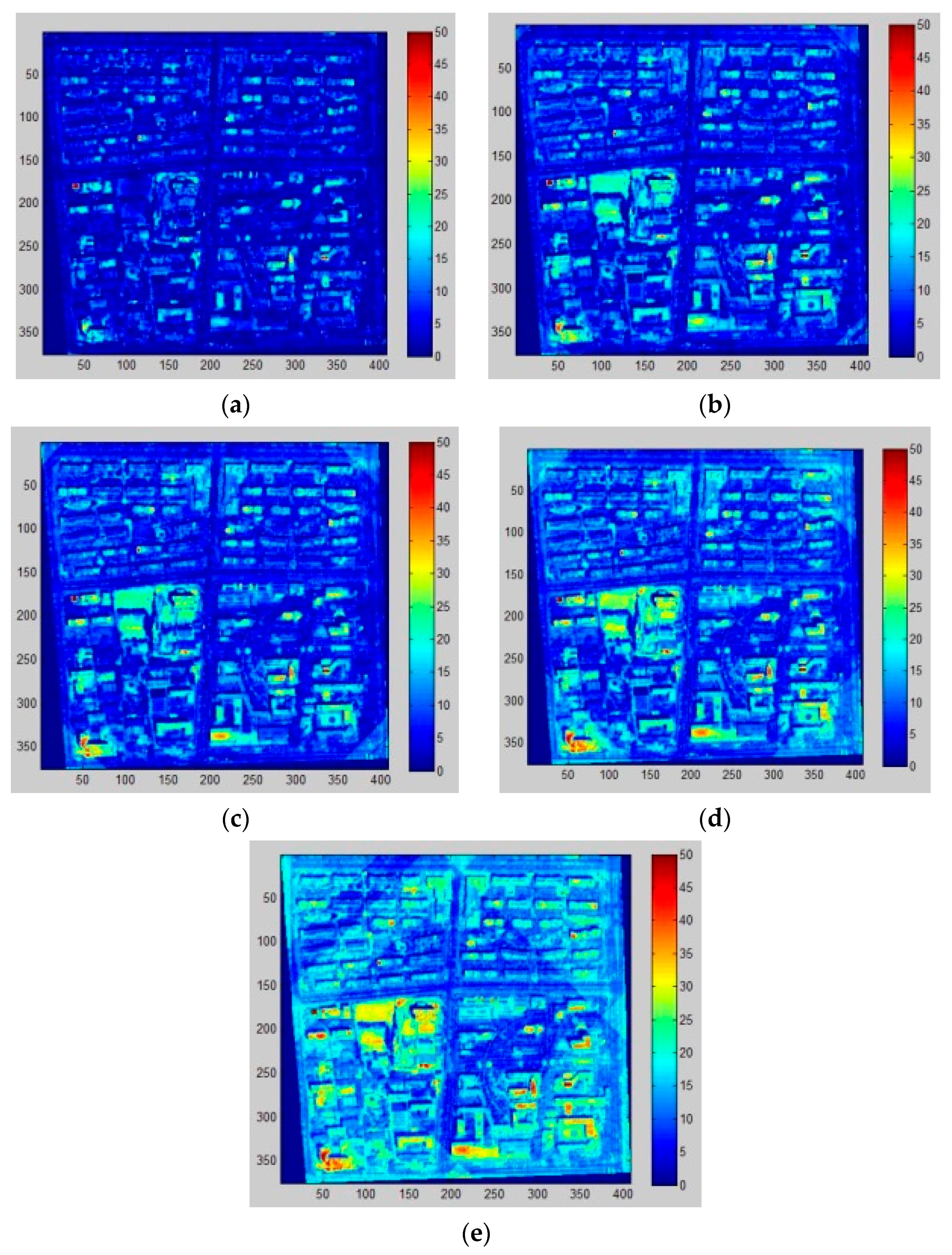
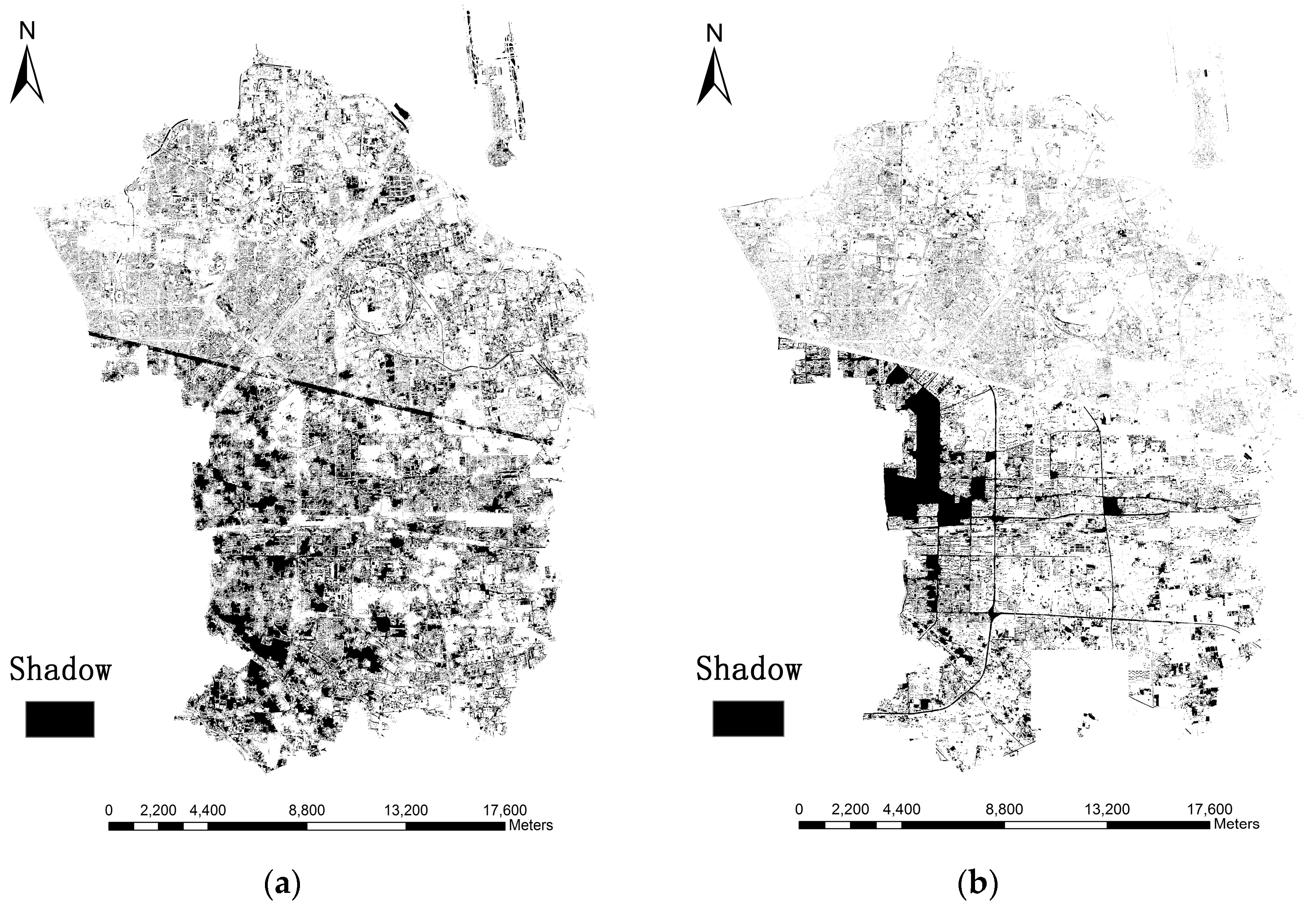
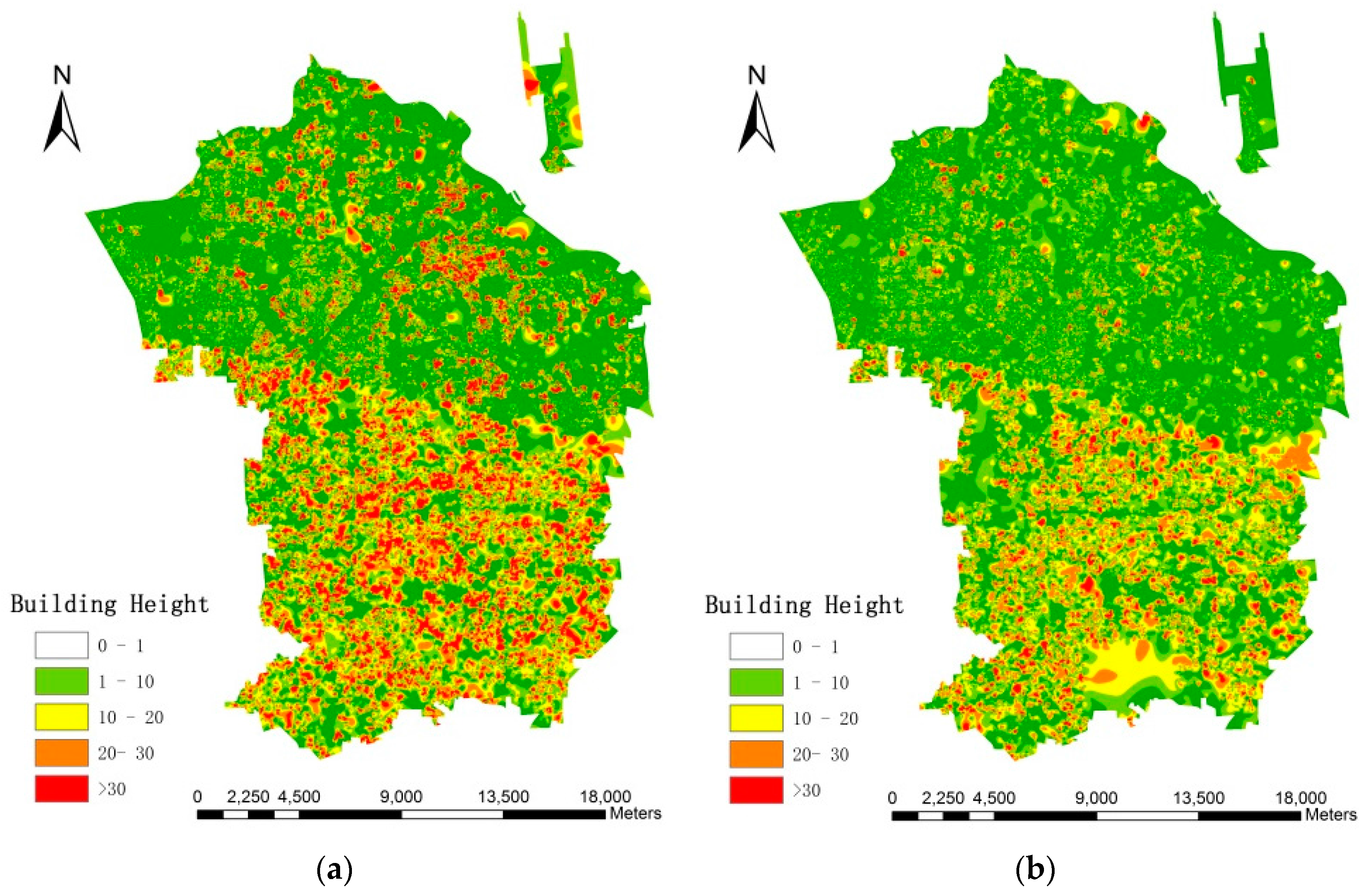
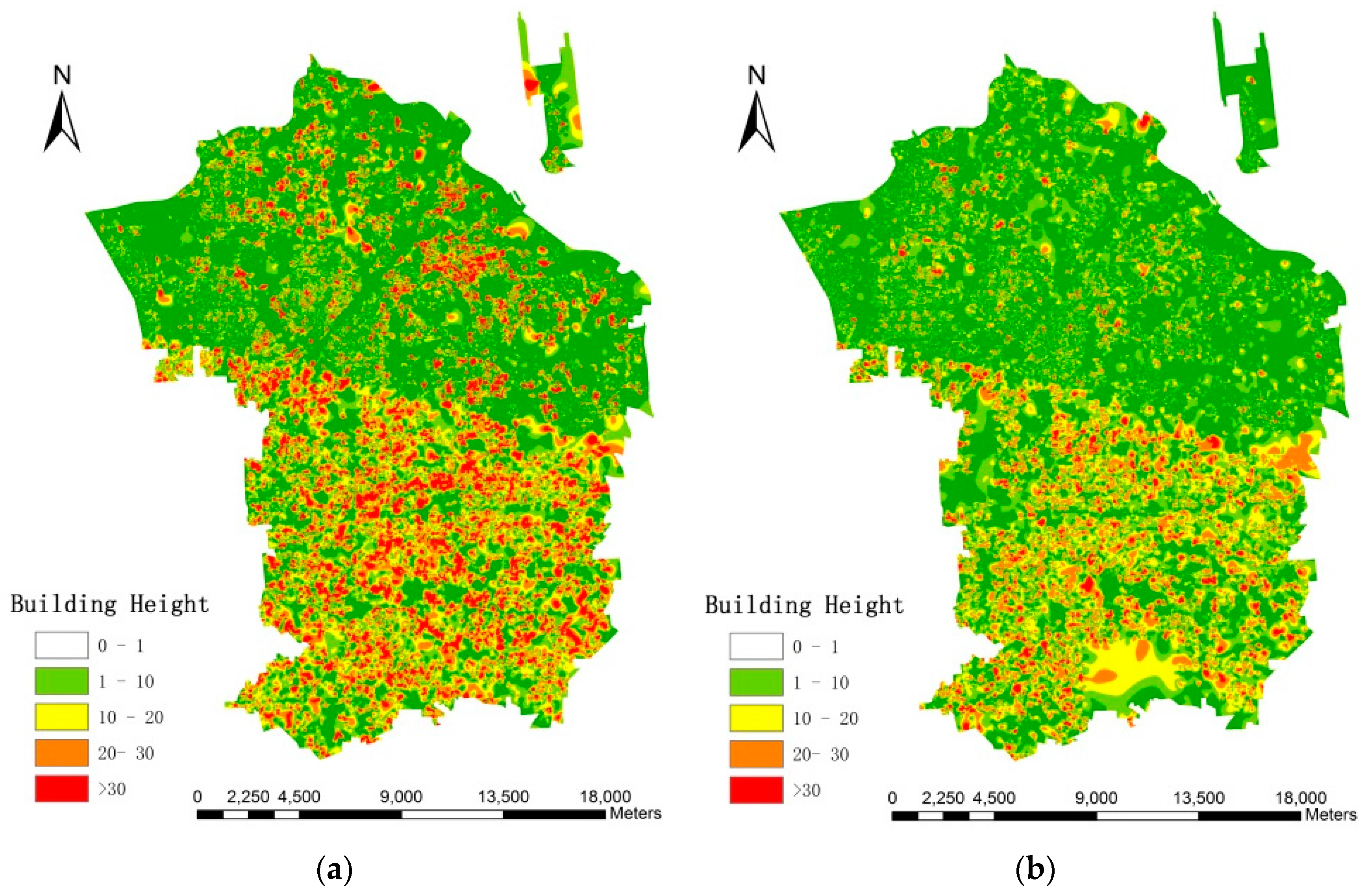
In this paper, we proposed the idea that fine-scale population distribution could be estimated by 3D reconstruction of urban residential buildings through building detection and height retrieval with HR images. Specifically, we compared the methods of building detection through two morphological operations (i.e., MBI and PanTex) in large heterogeneous urban regions, and the final results demonstrate that MBI outperforms the PanTex method. Such comparisons are essential in choosing the most appropriate morphological index when researchers decide to extract building footprints. Besides, shadow is a unique characteristic that was easily ignored before, but it has been of concern to most researchers in the current state with the development of HR images. In this experiment, MSI and CIIT were compared in shadow extraction and building height retrieval, which has not been done before, and this provides an innovative way to extract 3D information without heavy field surveys. Moreover, this research combined building detection and height retrieval to reconstruct 3D information of residential buildings to estimate fine-scale population, which has not been researched so far, and it produces reasonable results. In the population estimation process, dasymetric mapping models are successfully incorporated by dividing the research area into different density regions, and such step greatly improves the accuracy of parameters (LA and AH) estimation and population distribution.
However, the research cannot ignore the errors that are produced during the entire process. There mainly refer to three aspects, summarized as follows:
(1) Building extraction errors
It is difficult to acquire the dimensions of densely spaced buildings in a heterogeneous area when the fixed parameters of algorithms are taken into account. In addition, roads, bare soil, and open areas are hard to distinguish from buildings as they have similar textural and spectral features. It may be more accurate to segment different regions with different combinations of parameters.
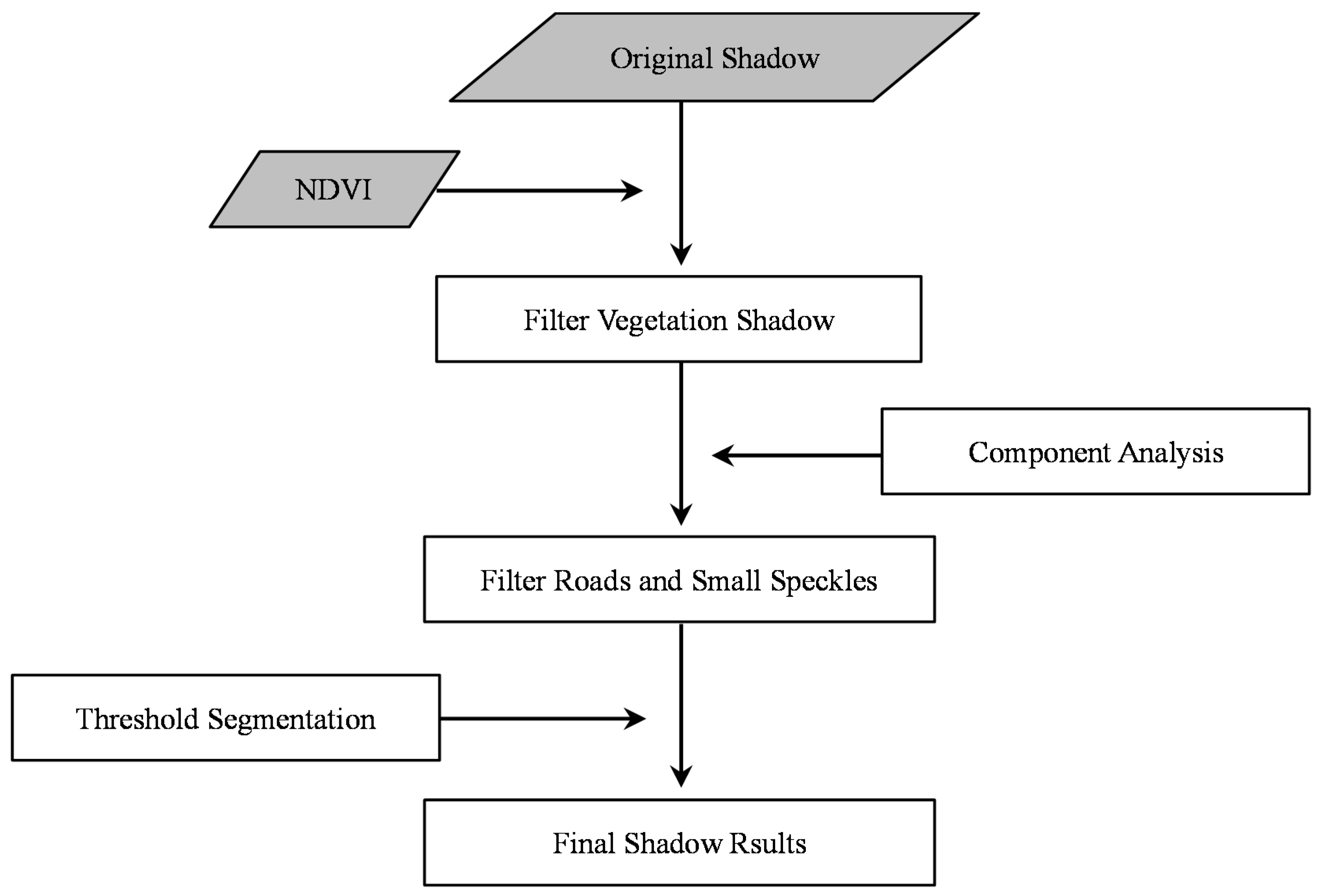
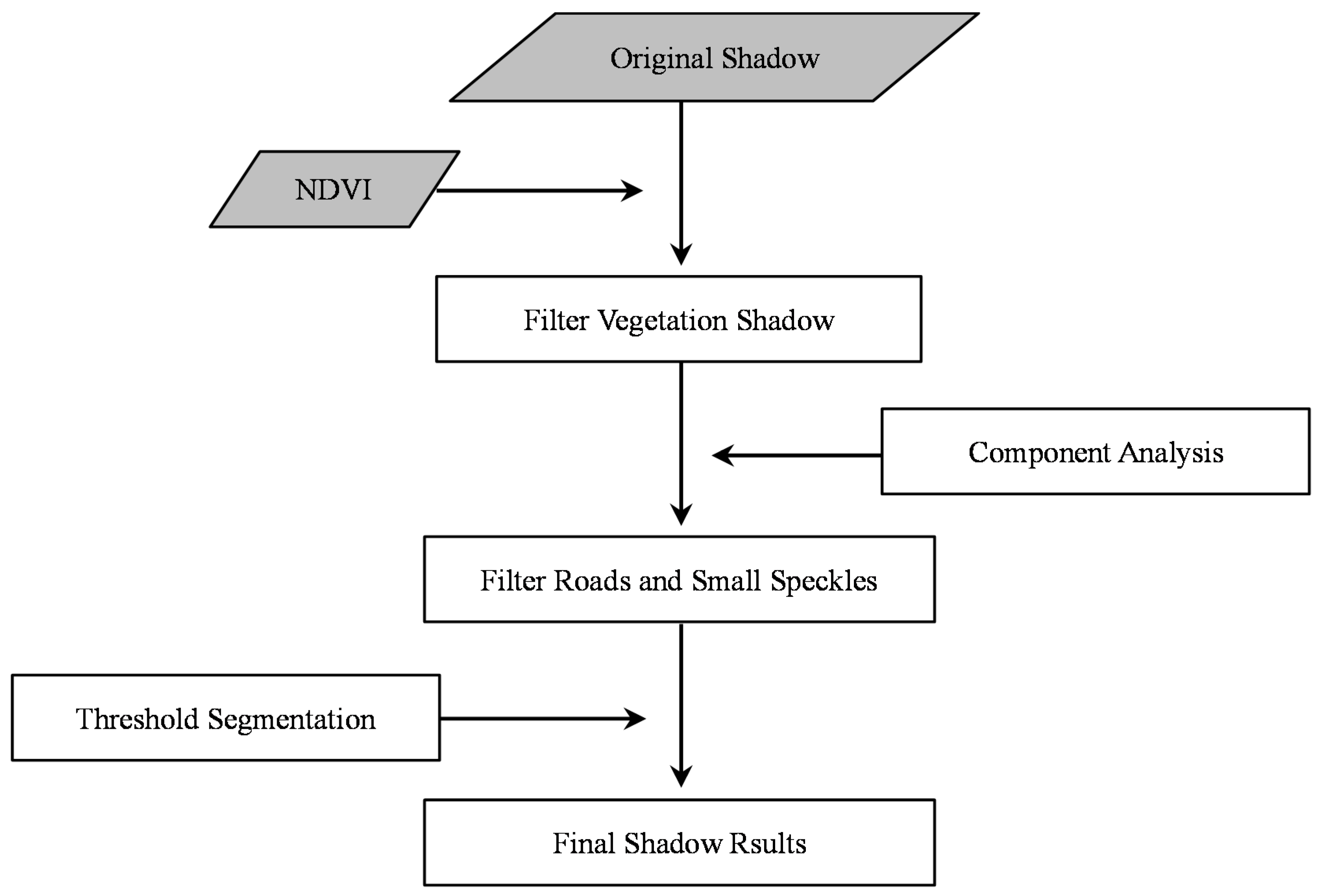
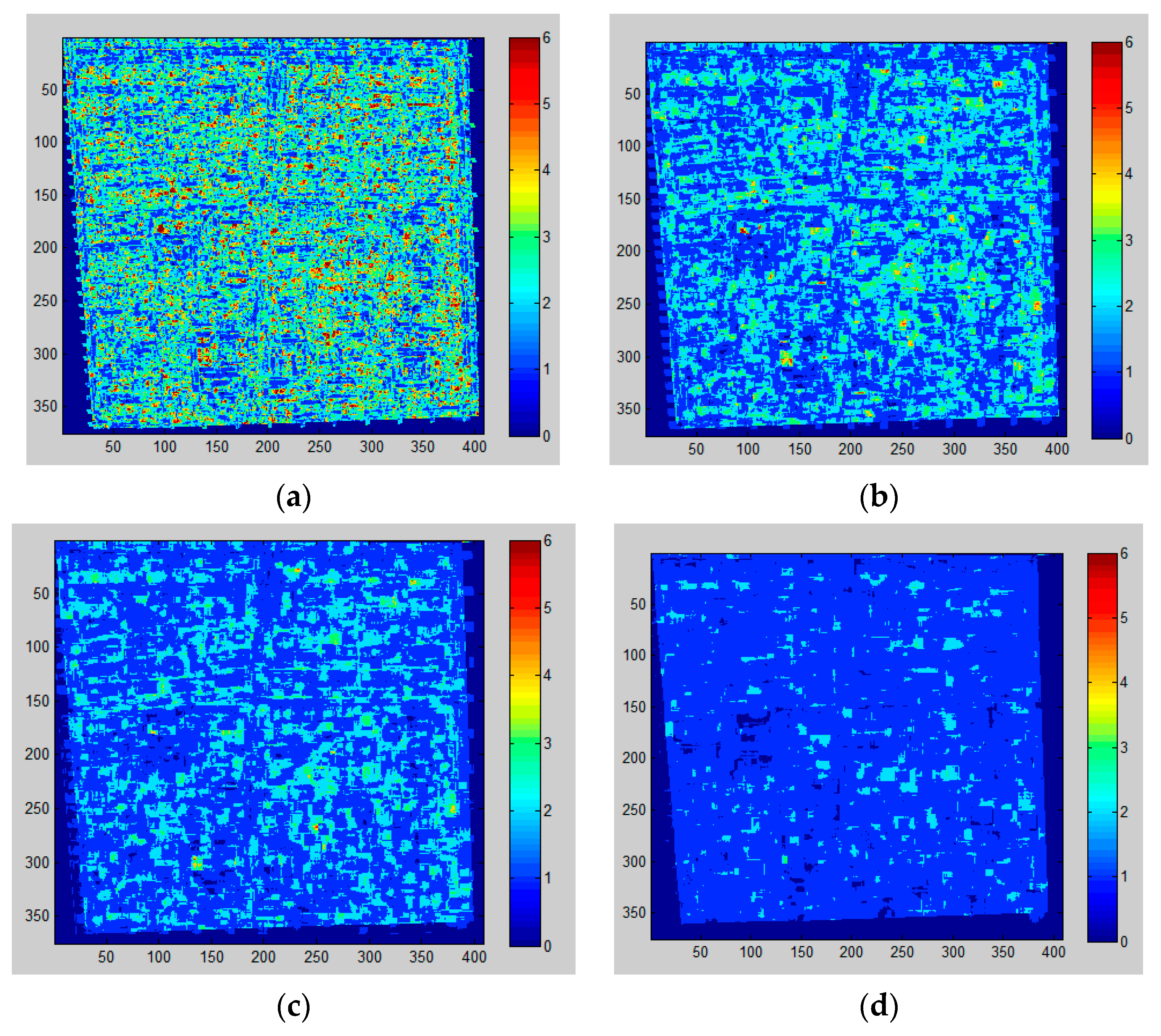
(2) Shadow detection errors
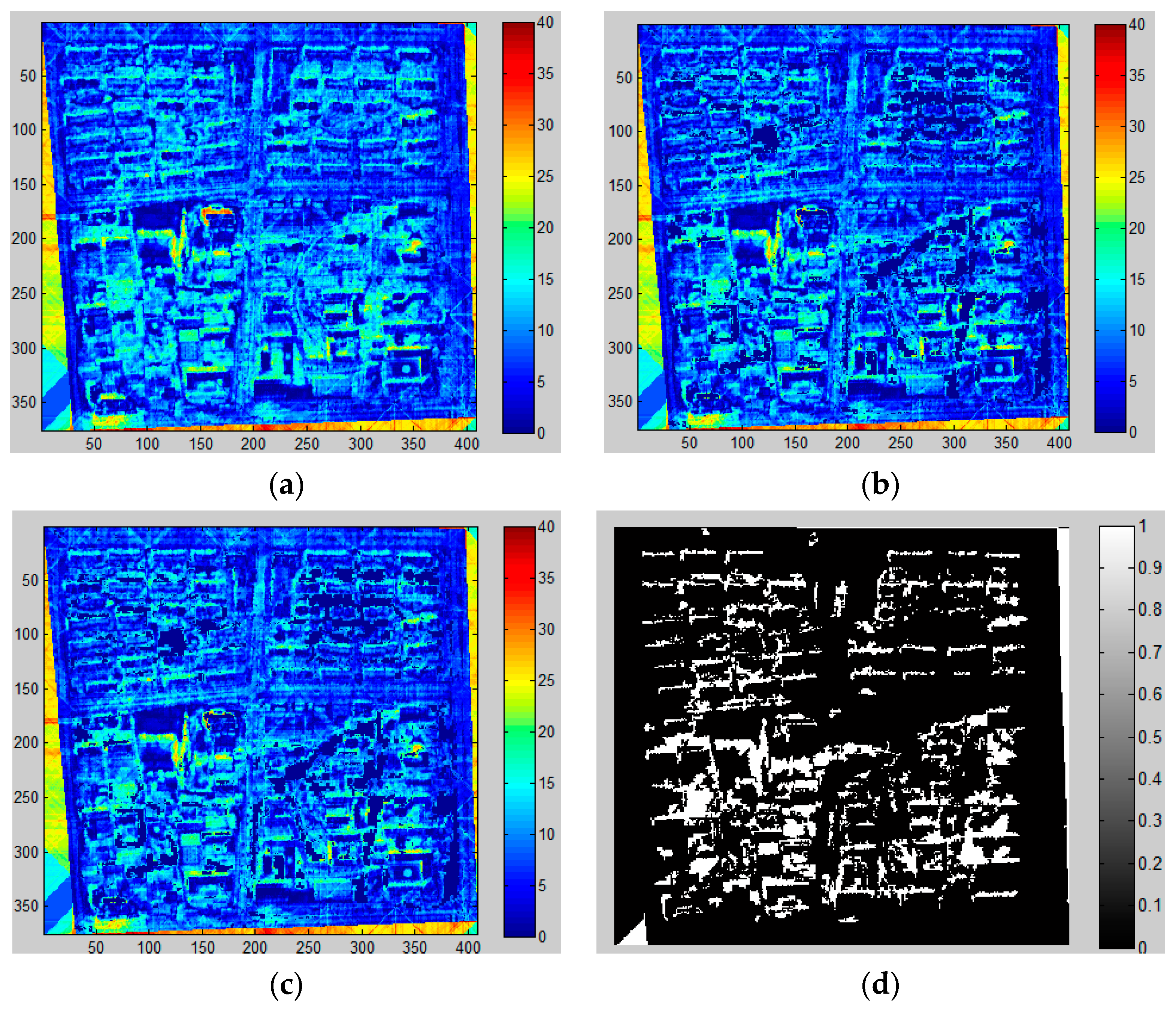
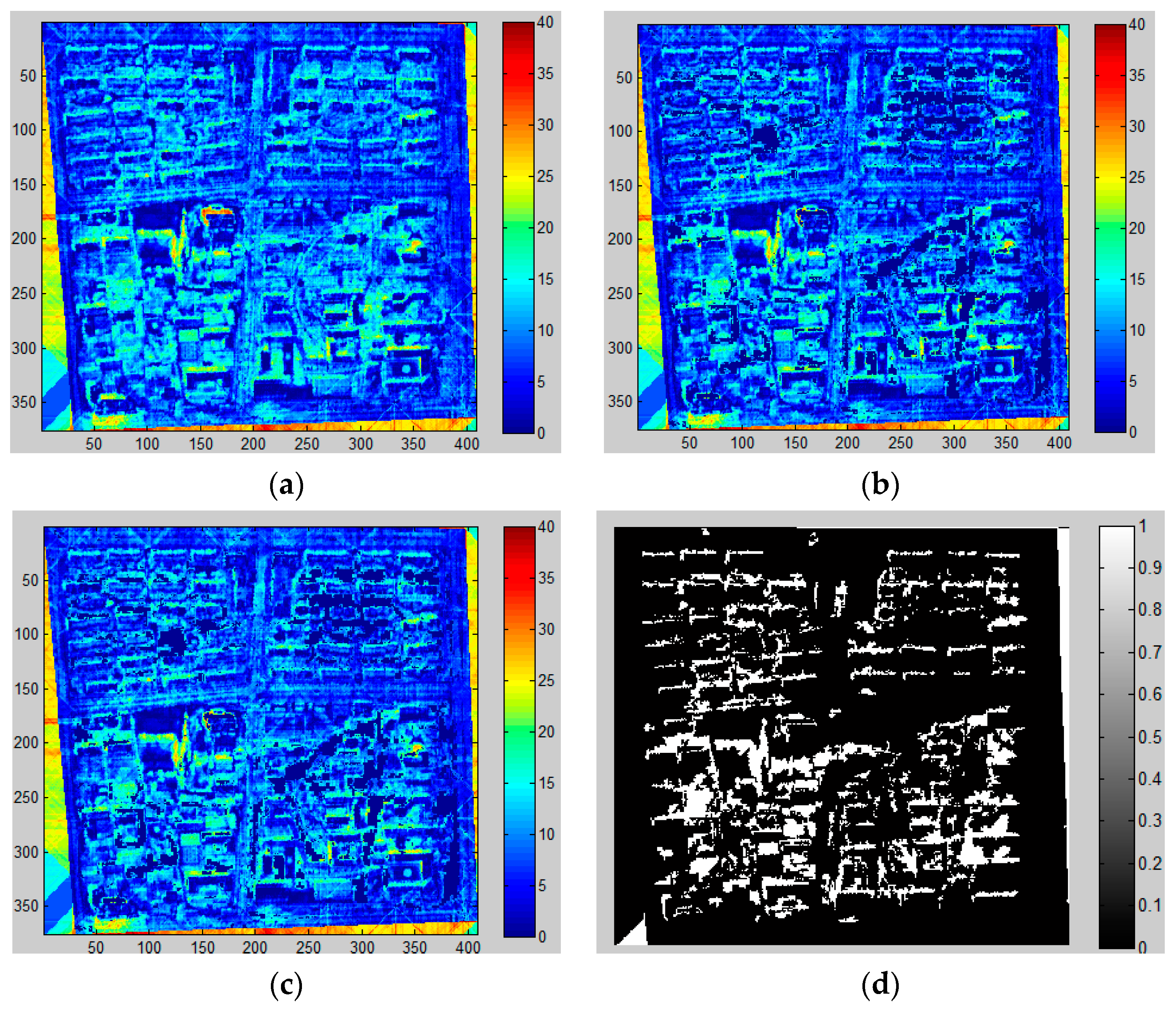
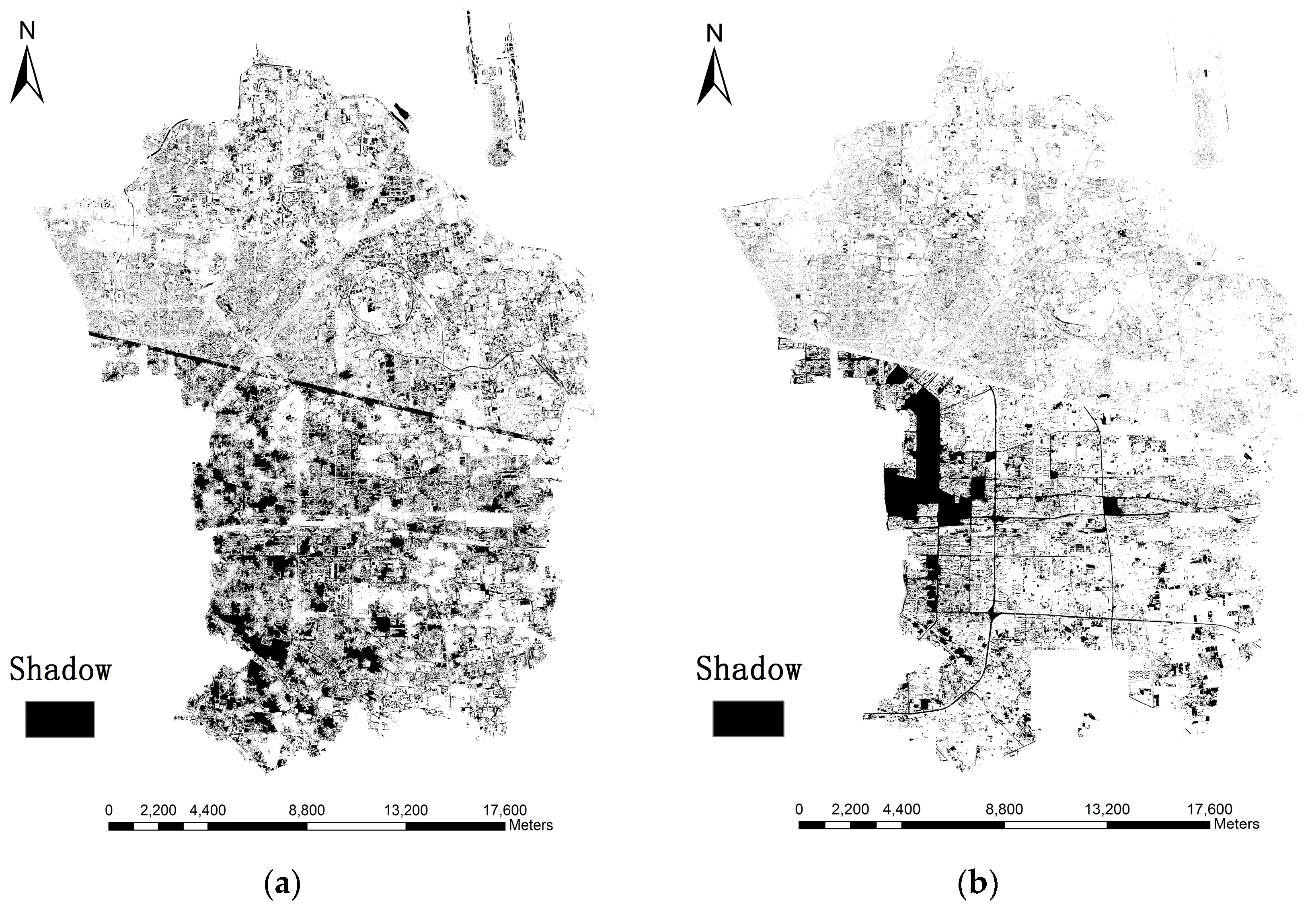
Several errors in shadow extraction may occur: (i) there is no shadow around some buildings due to the fact that the Sun’s angle was near the nadir when the image was acquired; (ii) dense buildings lead to dense shadows, which are gathered as large dark patches and bring about errors in calculation of shadow length; (iii) shadows could not be accurately identified everywhere, so the number of buildings and shadows may not be consistent in the same district; (iv) it is hard to accurately distinguish between the shadows of vegetation, buildings and other tall objects; (v) shadows of buildings with regular shapes (e.g., cuboid and parallelepiped) are easily identifiable, but irregular shadows cast from various building shapes are hard to capture accurately; (vi) the accuracy of shadow detection is influenced by the local surface slope in the research area [
63].
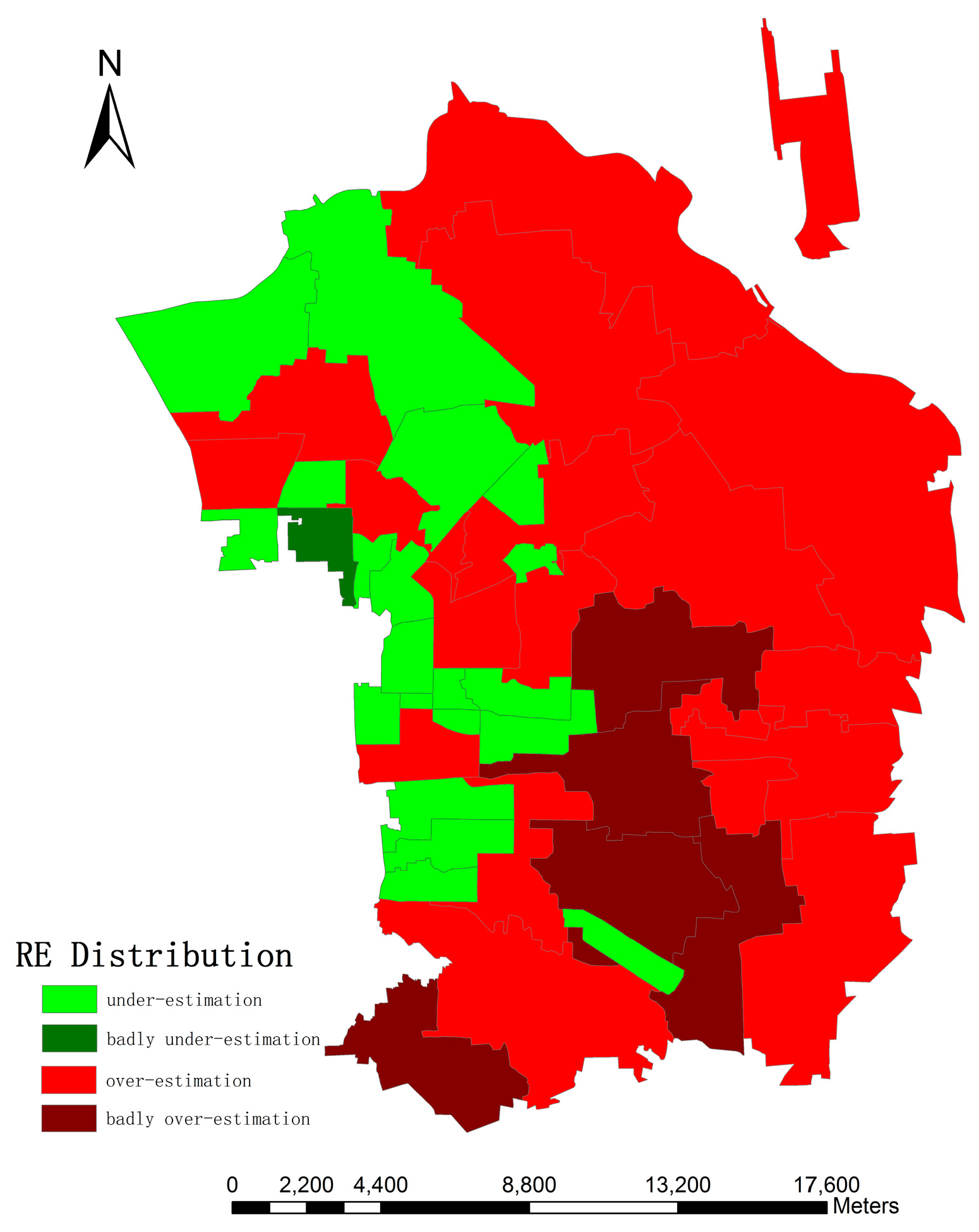
It is noted that the largest positive height error occurs when the buildings are densely distributed and thus shadows are merged together, as previously discussed, which results in longer shadow lengths. Likewise, low buildings with small area are easily neglected and generate negative errors. As a result, it is easier to identify shadows separated from each other with complete and regular shape. However, the shadow of ZY-3 is relatively shorter when the images were acquired and many possible errors could be avoided, such as gather problems and shadows casting on buildings.
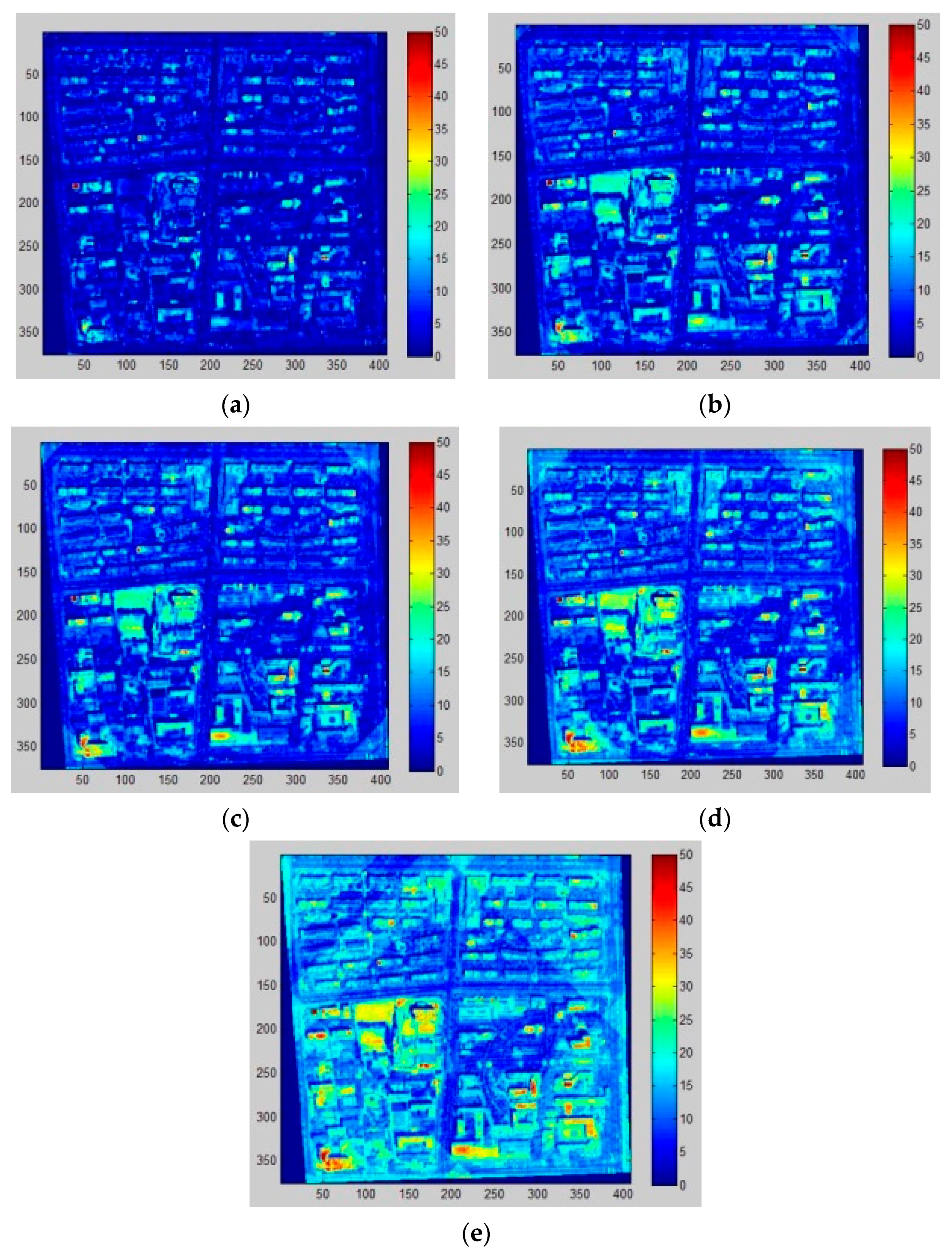
(3) Population estimation errors
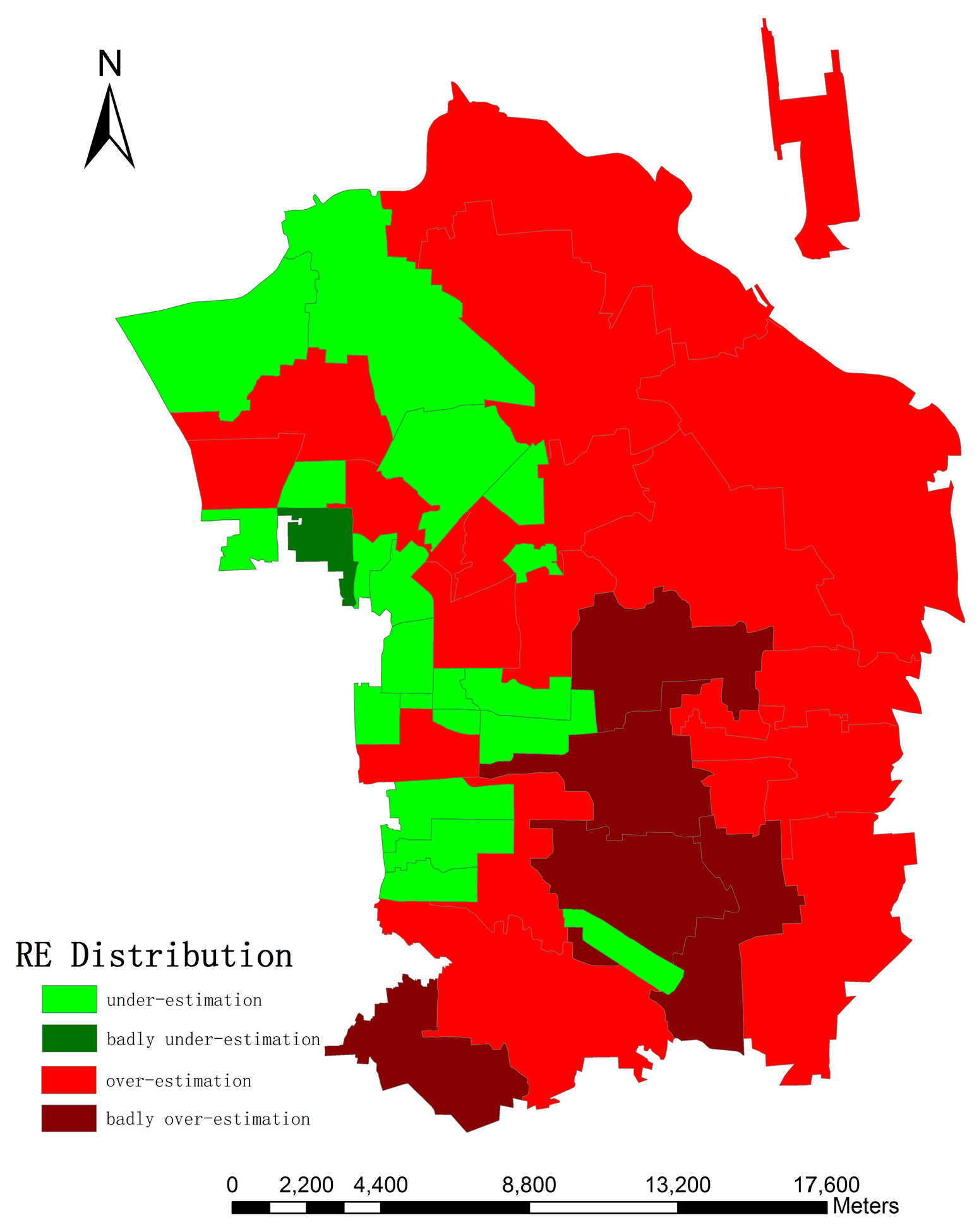
The first type of estimation error may relate to housing occupancy rate. Specifically, newly developed regions, such as the northeastern part of the research area, with a fast growth rate may contain many multi-floored apartments, and their occupancy rate is relatively low. On the other hand, old citizens might have small houses with large yards resulting in high occupancy rates [
45]. Furthermore, census data are de jure population reports which survey all usual residents in the given region, regardless of whether they are physically present there at the certain date [
6]. In addition, some citizens living underground cannot be detected in such a way.
6. Conclusions
We believe that the principal outcome of our work lies with the following three aspects: (i) high resolution images was utilized to reconstruct 3D model of residential buildings through morphological operations; (ii) different methods of shadow extraction based on ZY-3 images and their final impacts on building height retrieval were compared; (iii) fine-scale population estimation was achieved by 3D reconstruction of urban residential buildings, and a deterministic model in a relatively large scope through a more feasible approach was proposed. This method does not need the classification of land use types for the model input and final result shows great potential in determining urban citizen distributions at finer resolutions in the future.
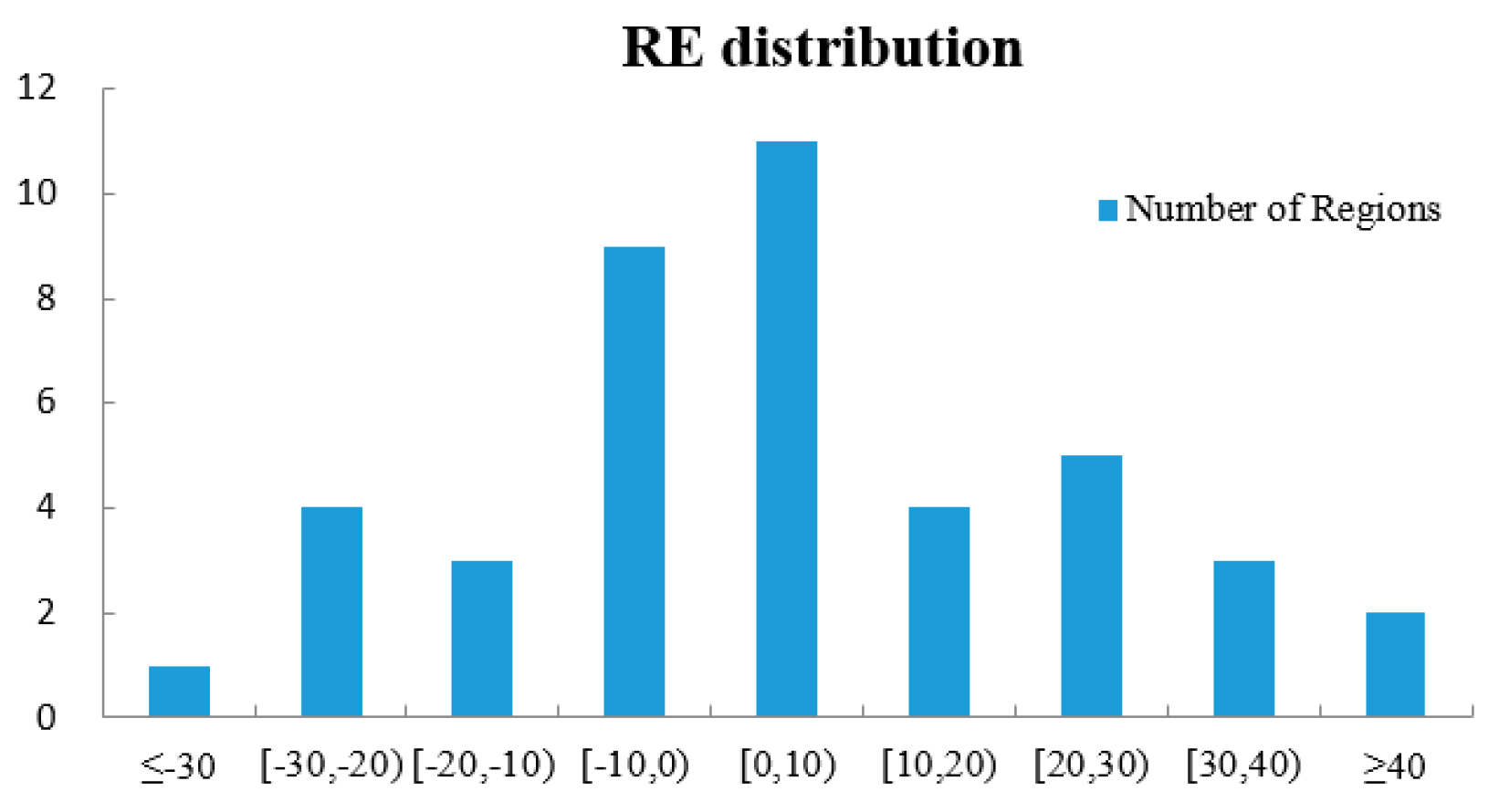
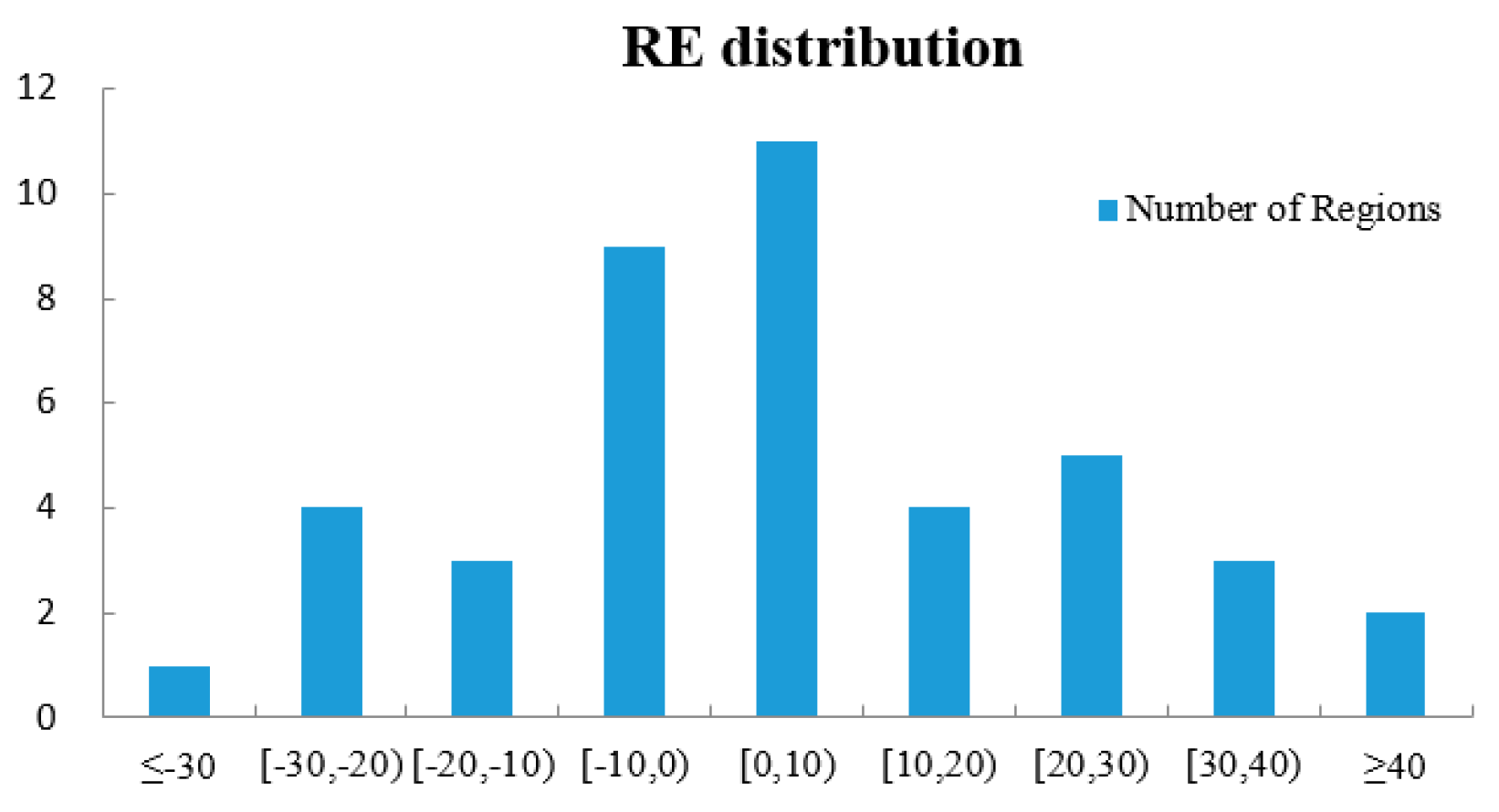
Though the errors are propagated from one step to the next, the overall accuracy within a relatively large and complicated urban area is promising, with a mean relative error of 16.46% and RTAE of 0.158. Frankly speaking, not much more can be expected at this early stage since morphological indexes derived from the remote sensing techniques are probability distributions of buildings and shadows, but it is a significant start to exploring the potential of using the spectral, spatial and textural information of HR images. Besides, inherent uncertainties of ancillary variables also exist, as stated in previous research [
46]. However, it still demonstrates that fine-scale population estimation could be connected well with reconstructing 3D features of residential buildings.
Considering that POI was utilized as ancillary data for the model input, further research would focus on finding a more accurate and fast method for residential building refinement by combining the detailed spectral or textural characteristics of the images. Furthermore, we hope to classify residential buildings into several categories (e.g., single-family dwelling, multi-family dwelling and other types) based on the properties of citizens (e.g., income, age and education) and environmental factors (e.g., green area per capital and transportation accessibility). In addition, the correlation of population density with other factors, such as building density, accessibility of transportation networks, GDP and supporting capability of environmental resources, would be further analyzed in urban landscapes based on empirical sampling, regression analysis and other relevant approaches. Finally, we also intend to study and analyze the dynamics of population migration in an urban environment with a cellular automata model which is useful to simulate the mobility of urban citizens [
71].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}