
Moving Object Detection Using Scanning Camera on a High-Precision Intelligent Holder

Abstract
:1. Introduction
2. Related Work
2.1. Intelligent Visual Surveillance
2.2. Moving Object Detection
2.3. Dynamic Background Modeling
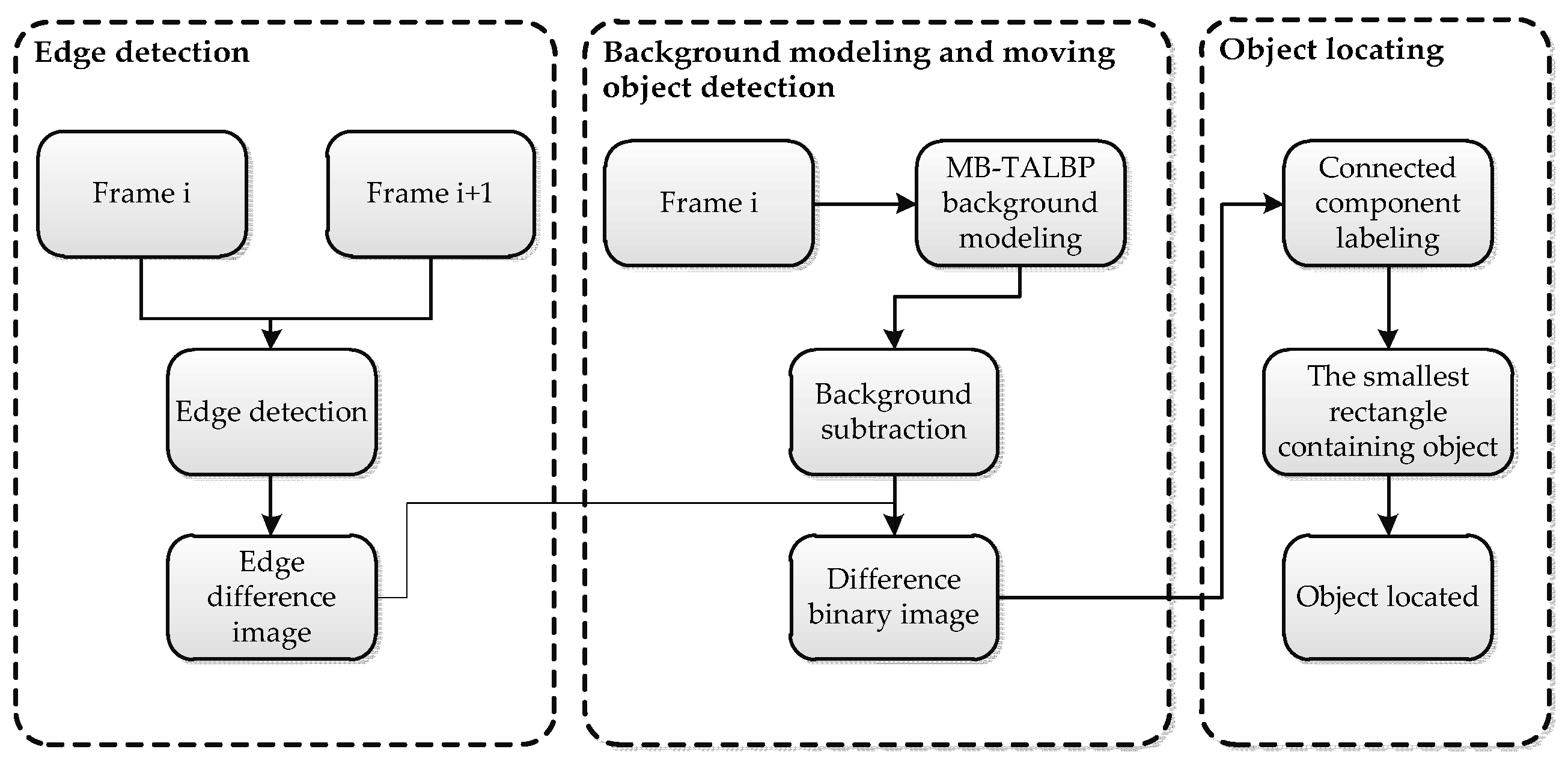
3. Moving Object Detection
3.1. Moving Edge Detection
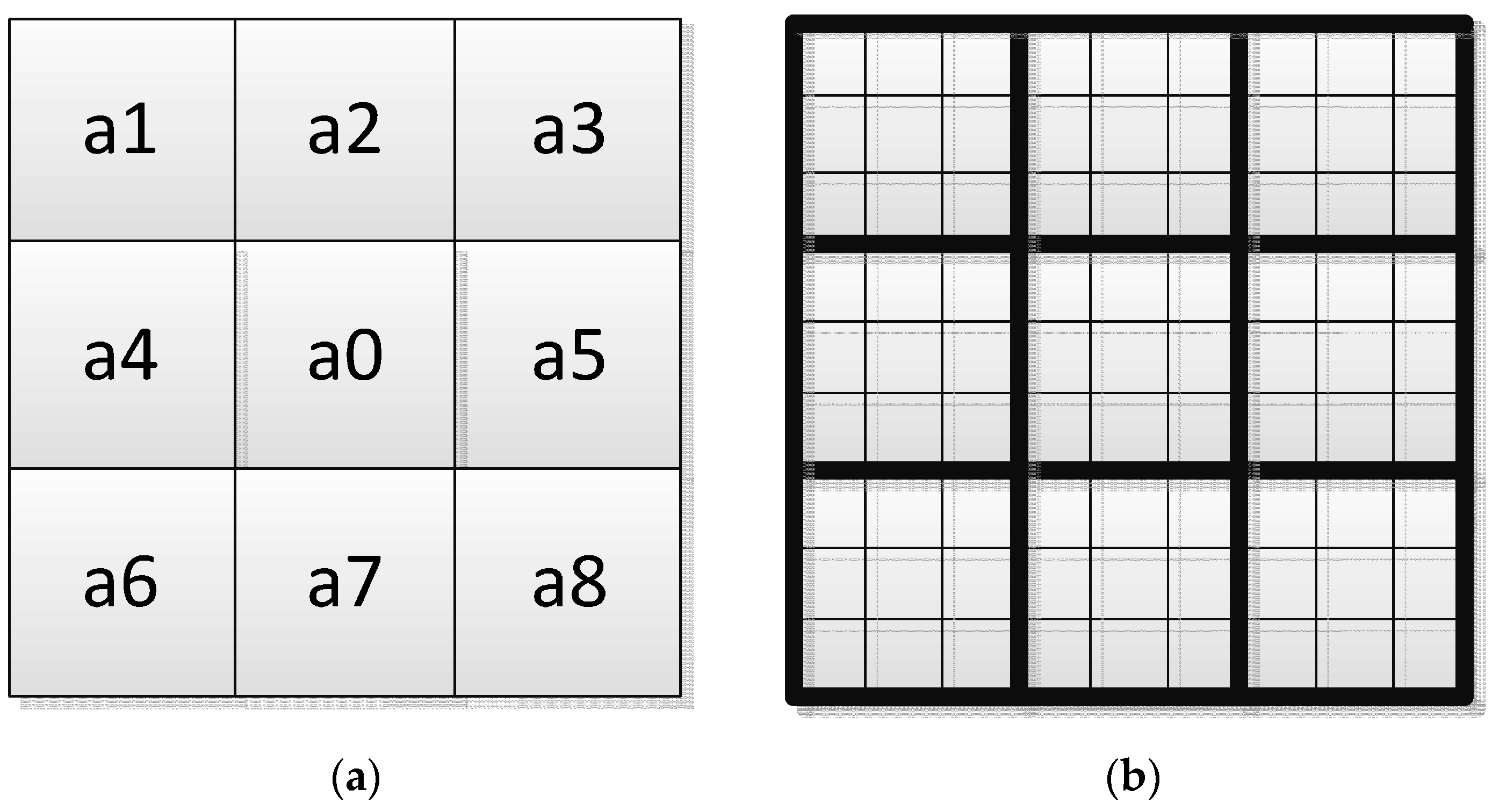
3.2. Background Modeling
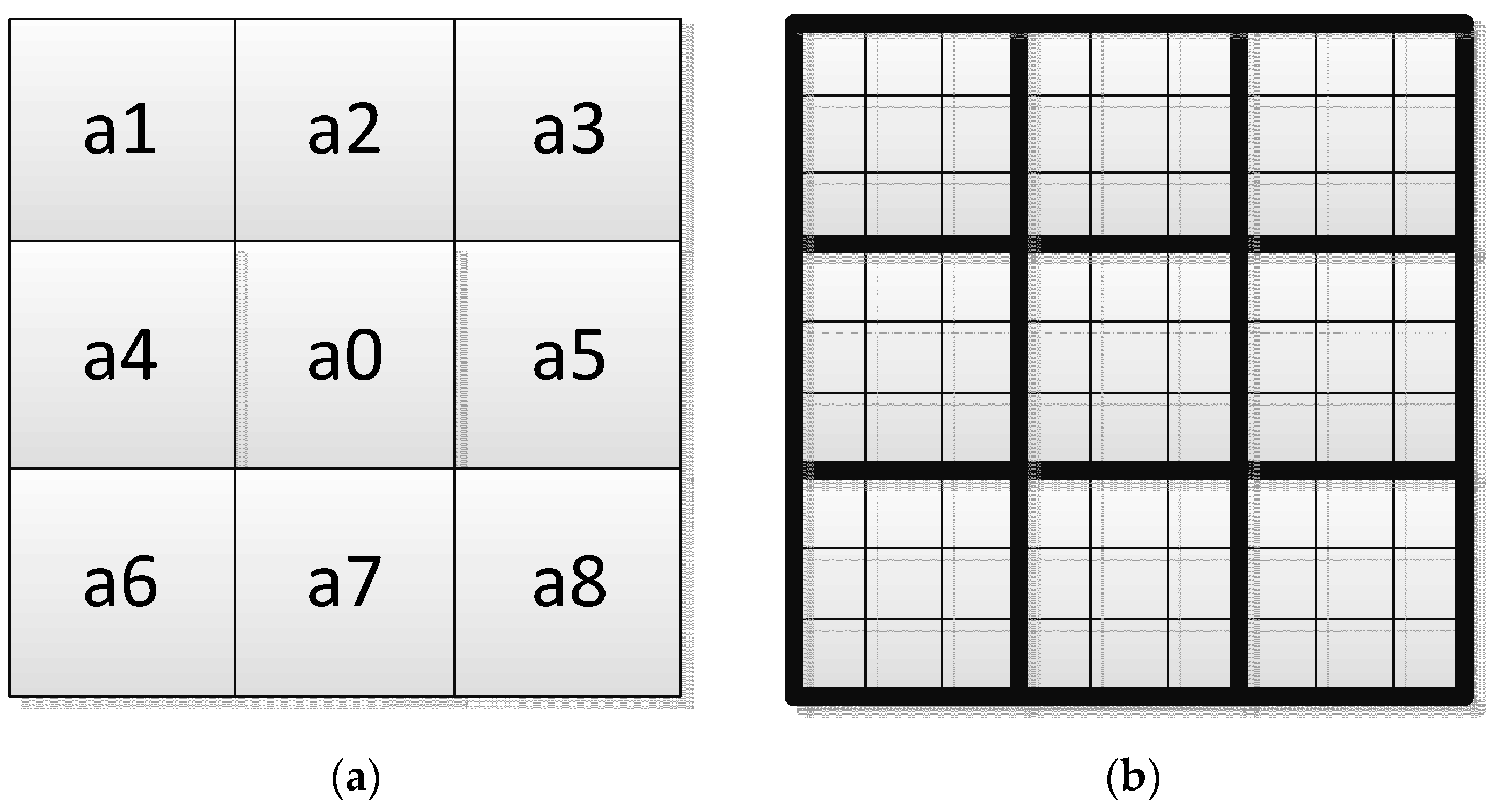
3.3. Object Locating
- Progressive scan the images: Put each line in a continuous white pixels form a sequence called a “group”, and note down its starting point, end point and the line number.
- Except for the first row of all the rows: If it has no overlap area with the previous row, then give this row a new tab; if it has only one overlap area with previous row, then give it the same tab with the above one; if it has two or more overlap areas with the above area, then give it the smallest number of those areas and note down all these groups into an equivalent pair, indicating that they belong to the same class.
- Convert the equivalent pair to equivalent sequences: Give each sequence the same reference numeral, since it is equivalent. Starting from Step 1, we give each equivalent sequence a tab.
- Traverse the groups from the beginning one: Find each equivalent sequence, and give it a new tab.
- Fill the label of each group in the marked image.
4. Experiment and Analysis
4.1. Experimental Setup
4.1.1. Methods for Comparison
- GMM (Gaussian Mixture Modeling) is a background modeling based approach, which is based on each pixel in the time domain to build the distribution model of each pixel sequentially to achieve the background modeling purposes [36,37,38]. Gaussian mixture background model is a weighted finite number of Gaussian functions which can describe the state of the pixel multimodal, suitable for light gradient, swaying trees and other complex background accurately modeled. Through continuous improvement of many researchers, the method has become the most common background extraction method.
- ViBe (Visual Background extractor) is a high-efficiency algorithm. This algorithm adopts a new thought to detect targets using random principles in the object detection work. The basic idea is, for each pixel, random sampling radius R within the scope of the model as a background pixel, and the default is 20 sampling points. Compared to some other detection algorithms, ViBe has a small amount of calculation, small footprint, fast processing speed, good detection effect, faster speed and the ablation area of Ghost stable and reliable characteristics respond noise.
- GMG (an algorithm for finding the Global Minimum with a Guarantee) combines the static background image and each pixel Bayesian estimation division. It uses very little information before (the default is 120 before) the image background modeling. It uses probability prospects estimation algorithm (using a Bayesian estimation to identify prospects). This is an adaptive estimation, the new observed objects have more weight than the old object, which means the results adapt to light changes. Some morphological operations such as opening operation, closing operation, etc. are used to remove unwanted noise.
- KDE (Kernel Density Estimation) is a well-known moving object detection algorithm. By employing a few frames of the method data, the algorithm can do background modeling with a fast extraction of moving targets in subsequent frames. However, the noise is large and some small moving objects are easily lost. The model is based on estimating the intensity density directly from sample history values. The main feature of the model is that it represents a very recent model of the scene and adapts to changes quickly. A framework was presented to combine a short-term and a long-term model to achieve more robust detection results [49,50].
- LBAdaptiveSOM (Local Background Adaptive Self-Organizing Modeling) [62] is a self-organizing method for modeling background by learning motion patterns and so allowing foreground/background separation for scenes from stationary cameras. The method is strongly required in video surveillance systems. This method learns background motion trajectories in a self-organizing manner, which makes the neural network structure much simpler. The approach is suitable to be adopted in a layered framework, where operating at region-level, it can improve detection results allowing to more efficiently tackle the camouflage problem and to distinguish moving objects from those that were initially moving and have stopped.
4.1.2. Test Video Sequences
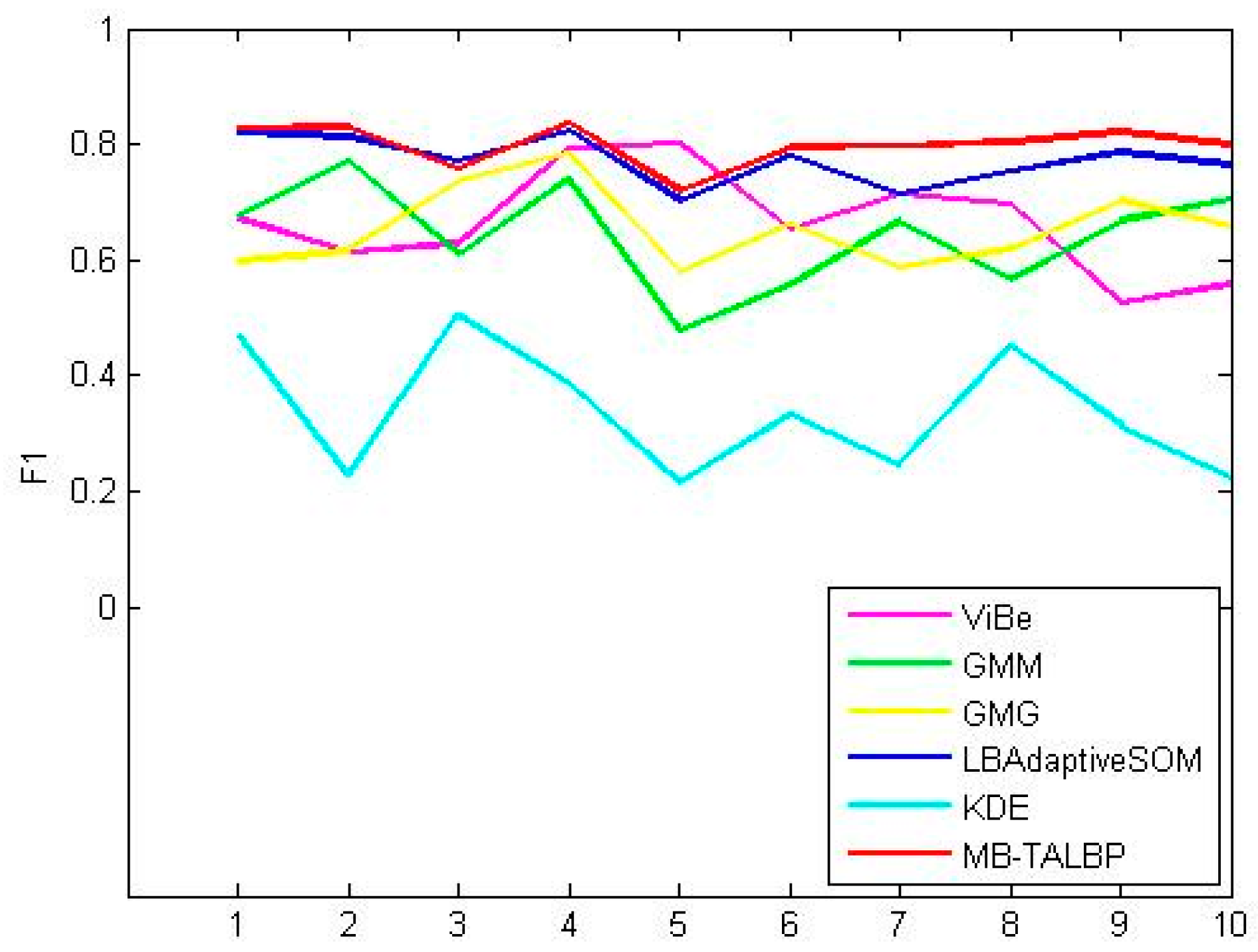
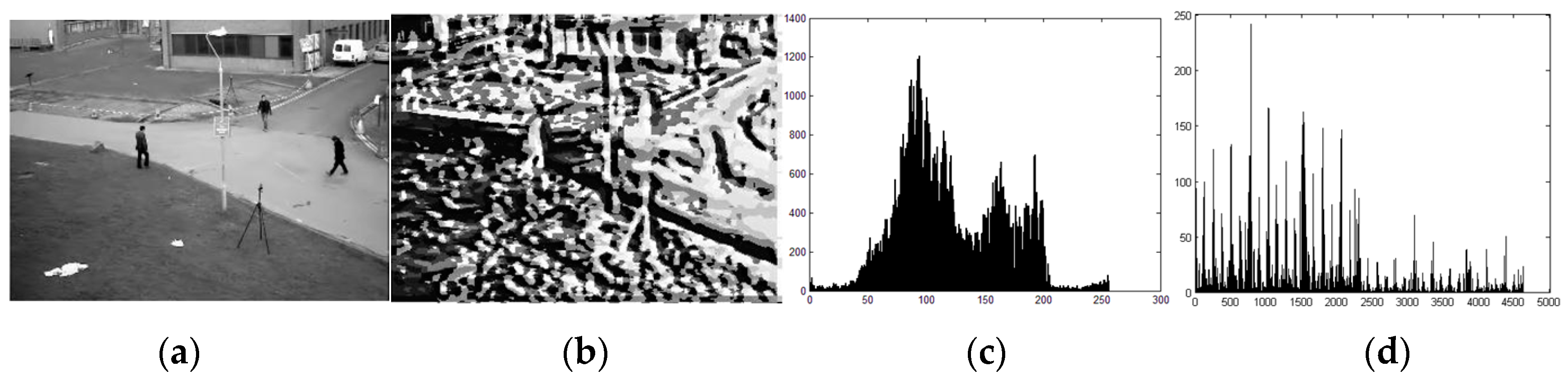
4.2. Visual Comparisons
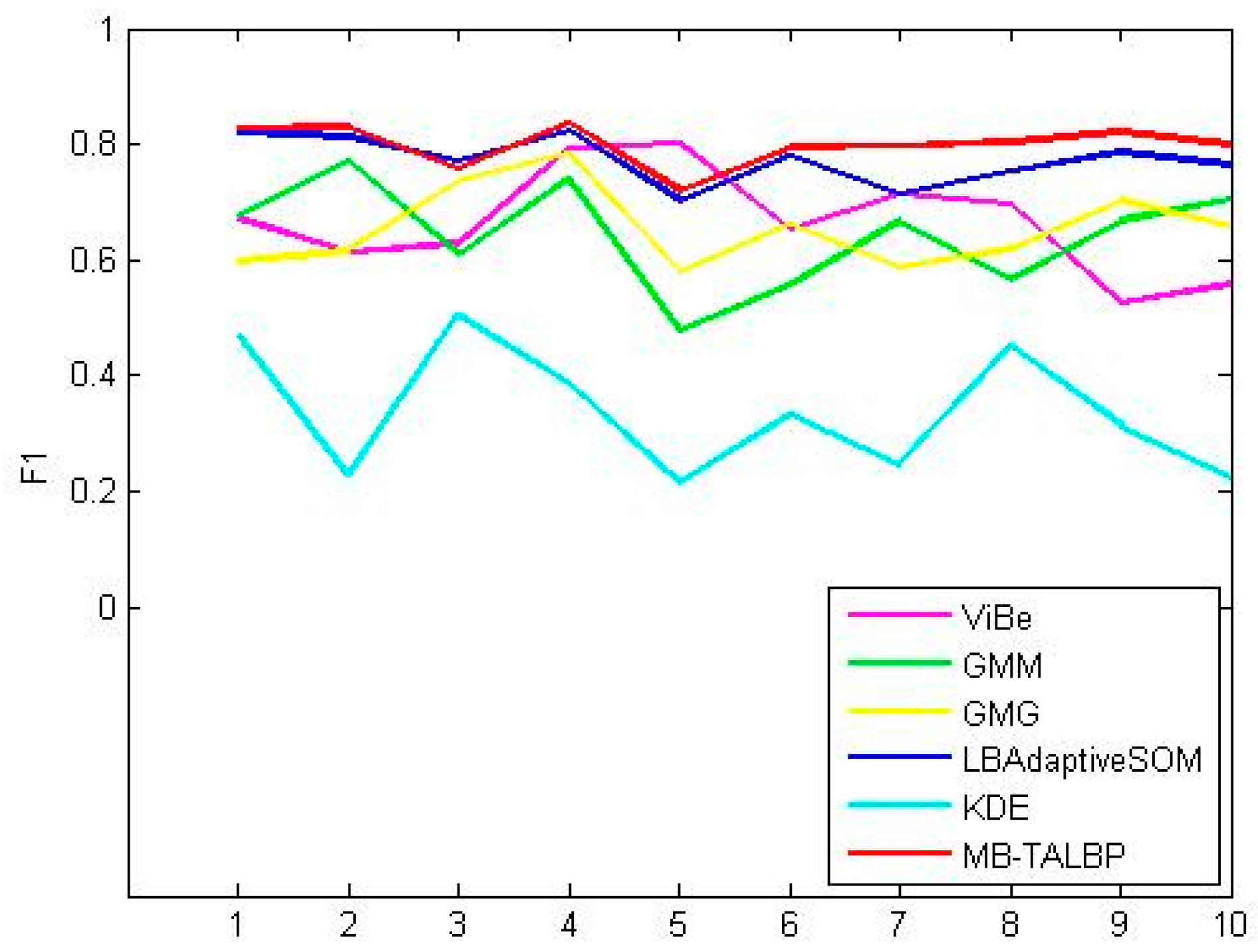
4.3. Quantitative Comparisons
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chiranjeevi, P.; Sengupta, S. Moving object detection in the presence of dynamic backgrounds using intensity and textural features. J. Electron. Imaging 2011, 20, 043009. [Google Scholar] [CrossRef]
- Hassanpour, H.; Sedighi, M.; Manashty, A.R. Video frame’s background modeling: Reviewing the techniques. J. Signal Inf. Process. 2011, 2, 72. [Google Scholar] [CrossRef]
- Jiménez-Hernández, H. Background subtraction approach based on independent component analysis. Sensors 2010, 10, 6092–6114. [Google Scholar] [CrossRef] [PubMed]
- Jones, G.A.; Paragios, N.; Regazzoni, C.S. Video-Based Surveillance Systems: Computer Vision and Distributed Processing; Springer: New York, NY, USA, 2012. [Google Scholar]
- Joshi, K.A.; Thakore, D.G. A survey on moving object detection and tracking in video surveillance system. Int. J. Soft Comput. Eng. 2012, 2, 44–48. [Google Scholar]
- Bouwmans, T. Recent advanced statistical background modeling for foreground detection—A systematic survey. Recent Patents Comput. Sci. 2011, 4, 147–176. [Google Scholar] [CrossRef]
- Tu, G.J.; Karstoft, H.; Pedersen, L.J.; Jørgensen, E. Illumination and reflectance estimation with its application in foreground detection. Sensors 2015, 15, 21407–21426. [Google Scholar] [PubMed]
- Varcheie, P.D.Z.; Sills-Lavoie, M.; Bilodeau, G.-A. A multiscale region-based motion detection and background subtraction algorithm. Sensors 2010, 10, 1041–1061. [Google Scholar] [CrossRef] [PubMed]
- Yagi, Y.; Makihara, Y.; Hua, C. Moving object detection device. US Patent US8958641 B2, 17 February 2015. [Google Scholar]
- Zhou, X.; Yang, C.; Yu, W. Moving object detection by detecting contiguous outliers in the low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 597–610. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Sanchez, E.J.; Diaz, J.; Ros, E. Background subtraction based on color and depth using active sensors. Sensors 2013, 13, 8895–8915. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.-S.; Kwon, J. Moving object detection on a vehicle mounted back-up camera. Sensors 2015, 16. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Park, M. An adaptive background subtraction method based on kernel density estimation. Sensors 2012, 12, 12279–12300. [Google Scholar] [CrossRef]
- Regazzoni, C.S.; Ramesh, V.; Foresti, G.L. Special issue on video communications, processing, and understanding for third generation surveillance systems. Proc. IEEE 2001, 89, 1355–1367. [Google Scholar]
- Kim, I.S.; Choi, H.S.; Yi, K.M.; Choi, J.Y.; Kong, S.G. Intelligent visual surveillance—A survey. Int. J. Control Autom. Syst. 2010, 8, 926–939. [Google Scholar] [CrossRef]
- Mohamed, S.S.; Tahir, N.M.; Adnan, R. Background modelling and background subtraction performance for object detection. In Proceedings of the 2010 6th International Colloquium on Signal Processing and Its Applications (CSPA), Malacca, Malaysia, 21–23 May 2010; pp. 1–6.
- Cucchiara, R.; Grana, C.; Piccardi, M.; Prati, A. Detecting moving objects, ghosts, and shadows in video streams. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1337–1342. [Google Scholar] [CrossRef]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Talukder, A.; Matthies, L. Real-time detection of moving objects from moving vehicles using dense stereo and optical flow. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2004; Volume 7, pp. 3718–3725.
- Horprasert, T.; Harwood, D.; Davis, L.S. A statistical approach for real-time robust background subtraction and shadow detection. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1–19.
- Hu, W.; Xiao, X.; Fu, Z.; Xie, D.; Tan, T.; Maybank, S. A system for learning statistical motion patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1450–1464. [Google Scholar] [PubMed]
- Li, L.; Huang, W.; Gu, I.Y.-H.; Tian, Q. Statistical modeling of complex backgrounds for foreground object detection. IEEE Trans. Image Process. 2004, 13, 1459–1472. [Google Scholar] [CrossRef] [PubMed]
- Brutzer, S.; Höferlin, B.; Heidemann, G. Evaluation of background subtraction techniques for video surveillance. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1937–1944.
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst. Man Cybern. C 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Collins, R.T.; Lipton, A.J.; Kanade, T.; Fujiyoshi, H.; Duggins, D.; Tsin, Y.; Tolliver, D.; Enomoto, N.; Hasegawa, O.; Burt, P. A system for video surveillance and monitoring. Robot. Inst. 2000, 5, 329–337. [Google Scholar]
- Siebel, N.T.; Maybank, S. The advisor visual surveillance system. In Proceedings of the ECCV 2004 Workshop Applications of Computer Vision (ACV), Prague, Czech Republic, 11–14 May 2004.
- Shu, C.-F.; Hampapur, A.; Lu, M.; Brown, L.; Connell, J.; Senior, A.; Tian, Y. IBM smart surveillance system (s3): A open and extensible framework for event based surveillance. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance, Como, Italy, 15–16 September 2005; pp. 318–323.
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Song, M.; Tao, D.; Maybank, S.J. Sparse camera network for visual surveillance—A comprehensive survey. 2013; arXiv:1302.0446. [Google Scholar]
- Cheng, F.-C.; Chen, B.-H.; Huang, S.-C. A hybrid background subtraction method with background and foreground candidates detection. ACM Trans. Intell. Syst. Technol. 2015, 7. [Google Scholar] [CrossRef]
- Huang, S.-C.; Do, B.-H. Radial basis function based neural network for motion detection in dynamic scenes. IEEE Trans. Cybern. 2014, 44, 114–125. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.-H.; Huang, S.-C. An advanced moving object detection algorithm for automatic traffic monitoring in real-world limited bandwidth networks. IEEE Trans. Multimedia 2014, 16, 837–847. [Google Scholar] [CrossRef]
- Cao, X.; Yang, L.; Guo, X. Total variation regularized rpca for irregularly moving object detection under dynamic background. IEEE Trans. Cybern. 2016, 46, 1014–1027. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhu, C. Camouflage modeling for moving object detection. In Proceedings of the 2015 IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Chengdu, China, 12–15 July 2015; pp. 249–253.
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; pp. 1585–1594.
- Lee, D.-S.; Hull, J.J.; Erol, B. A bayesian framework for gaussian mixture background modeling. In Proceedings of the 2003 International Conference on Image Processing, ICIP 2003, Barcelona, Spain, 14–17 September 2003.
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker verification using adapted gaussian mixture models. Digit. Signal Proc. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Zivkovic, Z. Improved adaptive gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004; pp. 28–31.
- Guo, J.-M.; Hsia, C.-H.; Liu, Y.-F.; Shih, M.-H.; Chang, C.-H.; Wu, J.-Y. Fast background subtraction based on a multilayer codebook model for moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1809–1821. [Google Scholar] [CrossRef]
- Kim, K.; Chalidabhongse, T.H.; Harwood, D.; Davis, L. Background modeling and subtraction by codebook construction. In Proceedings of the International Conference on Image Processing (ICIP), Singapore, 24–27 October 2004; pp. 3061–3064.
- Kim, K.; Chalidabhongse, T.H.; Harwood, D.; Davis, L. Real-time foreground–background segmentation using codebook model. Real Time Imaging 2005, 11, 172–185. [Google Scholar] [CrossRef]
- Wang, H.; Suter, D. Robust adaptive-scale parametric model estimation for computer vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1459–1474. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Suter, D.; Schindler, K.; Shen, C. Adaptive object tracking based on an effective appearance filter. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1661–1667. [Google Scholar] [CrossRef] [PubMed]
- Barnich, O.; Van Droogenbroeck, M. Vibe: A powerful random technique to estimate the background in video sequences. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 945–948.
- Barnich, O.; Van Droogenbroeck, M. Vibe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Cucchiara, R.; Grana, C.; Piccardi, M.; Prati, A.; Sirotti, S. Improving shadow suppression in moving object detection with hsv color information. In Proceedings of the 2001 IEEE Intelligent Transportation Systems Proceedings, Oakland, CA, USA, 25–29 August 2001; pp. 334–339.
- Doliotis, P.; Stefan, A.; McMurrough, C.; Eckhard, D.; Athitsos, V. Comparing gesture recognition accuracy using color and depth information. In Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 25–27 May 2011.
- Liu, F.; Gleicher, M. Learning color and locality cues for moving object detection and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–26 June 2009; pp. 320–327.
- Elgammal, A.; Duraiswami, R.; Harwood, D.; Davis, L.S. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 2002, 90, 1151–1163. [Google Scholar] [CrossRef]
- Elgammal, A.; Harwood, D.; Davis, L. Non-parametric model for background subtraction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 26 June–1 July 2000; pp. 751–767.
- Harville, M. A framework for high-level feedback to adaptive, per-pixel, mixture-of-gaussian background models. In Proceedings of the European Conference on Computer Vision, Zurich, Swizerland, 6–12 September 2002; pp. 543–560.
- Hofmann, M.; Tiefenbacher, P.; Rigoll, G. Background segmentation with feedback: The pixel-based adaptive segmenter. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 38–43.
- Eng, H.-L.; Wang, J.; Kam, A.H.; Yau, W.-Y. Novel region-based modeling for human detection within highly dynamic aquatic environment. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004.
- Zhong, J.; Sclaroff, S. Segmenting foreground objects from a dynamic textured background via a robust kalman filter. In Proceedings of the 9th IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; pp. 44–50.
- Heikkila, M.; Pietikainen, M. A texture-based method for modeling the background and detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 657–662. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Yao, H.; Liu, S. Dynamic background modeling and subtraction using spatio-temporal local binary patterns. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1556–1559.
- Heikkilä, M.; Pietikäinen, M.; Schmid, C. Description of interest regions with local binary patterns. Pattern Recognit. 2009, 42, 425–436. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed]
- Zhan, C.; Duan, X.; Xu, S.; Song, Z.; Luo, M. An improved moving object detection algorithm based on frame difference and edge detection. In Proceedings of the 4th International Conference on Image and Graphics, Jacksonville, FL, USA, 22–24 August 2007; pp. 519–523.
- Liao, S.; Zhu, X.; Lei, Z.; Zhang, L.; Li, S.Z. Learning multi-scale block local binary patterns for face recognition. In Proceedings of the International Conference on Biometrics, Seoul, Korea, 27–29 August 2007; pp. 828–837.
- Liao, S.; Zhao, G.; Kellokumpu, V.; Pietikäinen, M.; Li, S.Z. Modeling pixel process with scale invariant local patterns for background subtraction in complex scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1301–1306.
- Maddalena, L.; Petrosino, A. A fuzzy spatial coherence-based approach to background/foreground separation for moving object detection. Neural Comput. Appl. 2010, 19, 179–186. [Google Scholar] [CrossRef]
- Vacavant, A.; Chateau, T.; Wilhelm, A.; Lequièvre, L. A benchmark dataset for outdoor foreground/background extraction. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; pp. 291–300.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F-1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.7452 | 0.6134 | 0.6729 | 0.4966 |
| GMM | 0.7538 | 0.6085 | 0.6734 | 0.4801 |
| GMG | 0.8801 | 0.4521 | 0.5973 | 0.4007 |
| LBAdaptiveSOM | 0.9426 | 0.7259 | 0.8202 | 0.6847 |
| KDE | 0.5112 | 0.5438 | 0.4681 | 0.3274 |
| MB-TALBP | 0.9521 | 0.7372 | 0.8279 | 0.7142 |
| Method | Precision | Recall | F-1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.7678 | 0.8887 | 0.6130 | 0.4419 |
| GMM | 0.7121 | 0.8431 | 0.7721 | 0.6542 |
| GMG | 0.8546 | 0.4781 | 0.6159 | 0.4788 |
| LBAdaptiveSOM | 0.9216 | 0.7249 | 0.8115 | 0.6630 |
| KDE | 0.3325 | 0.1716 | 0.2263 | 0.1156 |
| MB-TALBP | 0.9332 | 0.7470 | 0.8298 | 0.7049 |
| Method | Precision | Recall | F-1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.6949 | 0.5100 | 0.6286 | 0.5270 |
| GMM | 0.7051 | 0.5349 | 0.6083 | 0.4412 |
| GMG | 0.8325 | 0.6591 | 0.7357 | 0.5869 |
| LBAdaptiveSOM | 0.8547 | 0.7026 | 0.7712 | 0.5940 |
| KDE | 0.5465 | 0.4692 | 0.5049 | 0.3323 |
| MB-TALBP | 0.8456 | 0.6914 | 0.7807 | 0.6912 |
| Method | Precision | Recall | F-1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.8288 | 0.7600 | 0.7929 | 0.6494 |
| GMM | 0.8546 | 0.6527 | 0.7401 | 0.6095 |
| GMG | 0.8167 | 0.7533 | 0.7837 | 0.6681 |
| LBAdaptiveSOM | 0.9254 | 0.7441 | 0.8232 | 0.7354 |
| KDE | 0.4267 | 0.3491 | 0.3840 | 0.1729 |
| MB-TALBP | 0.9400 | 0.7529 | 0.8361 | 0.7456 |
| Method | Precision | Recall | F-1 | Similarity |
|---|---|---|---|---|
| ViBe | 0.9024 | 0.7195 | 0.8006 | 0.6819 |
| GMM | 0.5726 | 0.4117 | 0.4764 | 0.2202 |
| GMG | 0.7649 | 0.4674 | 0.5802 | 0.3519 |
| LBAdaptiveSOM | 0.7752 | 0.6429 | 0.7029 | 0.5461 |
| KDE | 0.1438 | 0.4194 | 0.2142 | 0.0826 |
| MB-TALBP | 0.8053 | 0.6521 | 0.7206 | 0.5583 |
| Video | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Time (ms/frame) | 42.3 | 41.7 | 43.0 | 27.6 | 40.6 | 40.8 | 35.3 | 43.4 | 29.8 | 33.7 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Xu, T.; Li, D.; Zhang, J.; Jiang, S. Moving Object Detection Using Scanning Camera on a High-Precision Intelligent Holder. Sensors 2016, 16, 1758. https://doi.org/10.3390/s16101758
Chen S, Xu T, Li D, Zhang J, Jiang S. Moving Object Detection Using Scanning Camera on a High-Precision Intelligent Holder. Sensors. 2016; 16(10):1758. https://doi.org/10.3390/s16101758
Chicago/Turabian StyleChen, Shuoyang, Tingfa Xu, Daqun Li, Jizhou Zhang, and Shenwang Jiang. 2016. "Moving Object Detection Using Scanning Camera on a High-Precision Intelligent Holder" Sensors 16, no. 10: 1758. https://doi.org/10.3390/s16101758