3D Joint Speaker Position and Orientation Tracking with Particle Filters

Abstract
: This paper addresses the problem of three-dimensional speaker orientation estimation in a smart-room environment equipped with microphone arrays. A Bayesian approach is proposed to jointly track the location and orientation of an active speaker. The main motivation is that the knowledge of the speaker orientation may yield an increased localization performance and vice versa. Assuming that the sound produced by the speaker is originated from his mouth, the center of the head is deduced based on the estimated head orientation. Moreover, the elevation angle of the head of the speaker can be partly inferred from the fast vertical movements of the computed mouth location. In order to test the performance of the proposed algorithm, a new multimodal dataset has been recorded for this purpose, where the corresponding 3D orientation angles are acquired by an inertial measurement unit (IMU) provided by accelerometers, magnetometers and gyroscopes in the three-axes. The proposed joint algorithm outperforms a two-step approach in terms of localization and orientation angle precision assessing the superiority of the joint approach.1. Introduction
In recent years, significant research efforts have been focused on developing human-computer interfaces in intelligent environments that aim to support human tasks and activities. The knowledge of the position and the orientation of the speakers present in a room constitutes valuable information allowing for better understanding of user activities and human interactions in those environments, such as the analysis of group dynamics or behaviors, deciding which is the active speaker among all present or determining who is talking to whom. In general, it can be expected that the knowledge about the orientation of human speakers would permit the improvement of speech technologies that are commonly deployed in smart-rooms. For instance, an enhanced microphone network management strategy for microphone selection can be developed based on both speaker position and orientation cues.
Very few methods have been proposed to solve the problem of speaker localization and speaker orientation estimation from acoustic signals. They differ mainly in how they approach the problem and can be coarsely classified in to two groups. The first group assumes the task of localization and orientation estimation as two separate and independent problems, working as a two-step algorithm: first locate the speaker, and then, the head orientation is estimated [1–6]. The main advantage of this approach is the simplicity and processing speed. However, the main drawback of this method is that the head orientation estimation process is highly dependent on the speaker tracking accuracy. This kind of approach does not take advantage of the fact that speaker orientation information could be used to improve the speaker localization precision.
The second group of approaches [7,8] considers the localization and the estimation of the orientation of the speaker as a joint process, which aims at improving the performance of the localization by proper weighting of the cross-correlation between microphone pairs, depending on their relative angle with the speaker, thus minimizing the degrading effects of the head orientation in the localization algorithm [9].
No previous work has been found that tackles the task of three-dimensional (3D) speaker orientation estimation with microphone arrays. This can be attributed to the fact that most smart environments have the microphones placed in nearly the same plane in order to maximize the localization performance in the xy coordinates, making it very difficult to estimate the head elevation angle, due to the low microphone placement diversity in the z-axis. Another possible cause may be the lack of acoustic databases with annotated speaker orientation and not even 3D orientation labels.
In this paper, a Bayesian approach is proposed to jointly track the location and orientation of a speaker. The main motivation is that the knowledge of the speaker orientation may yield to an increased localization performance and vice versa. The position and orientation of the speaker are estimated in the 3D space by means of a joint particle filter (PF) with coupled dynamic and observation models. Furthermore, the part from the vertical angle of the speaker's head can be inferred by the algorithm solely from the acoustic cues. In order to test the performance of the proposed algorithm, a new multimodal dataset has been purposely recorded, where the corresponding 3D orientation angles are acquired by an inertial measurement unit (IMU) provided by accelerometers, magnetometers and gyroscopes in the three axes. The position of the center of the head of the speaker is automatically provided by a video particle filter tracker from multiple cameras. The effectiveness of the proposed technique is assessed by means of a new proposed set of metrics derived from the multiple person tracking task [10] in Section 6.2 over the cited database, showing an increased performance for the joint PF approach in relation to the two two-step algorithms that first estimate the position and then the orientation of the speaker.
The remainder of this paper is organized as follows. In Section 2, the head rotation representation is described. Section 3 introduces the speaker localization and orientation estimation algorithms as a two-step approach. Section 4 presents an alternative two-step algorithm employing a PF at each step. Section 5 describes the joint PF. Sections 6 and 7 show the experiments and results. Finally, Section 8 gives the conclusions.
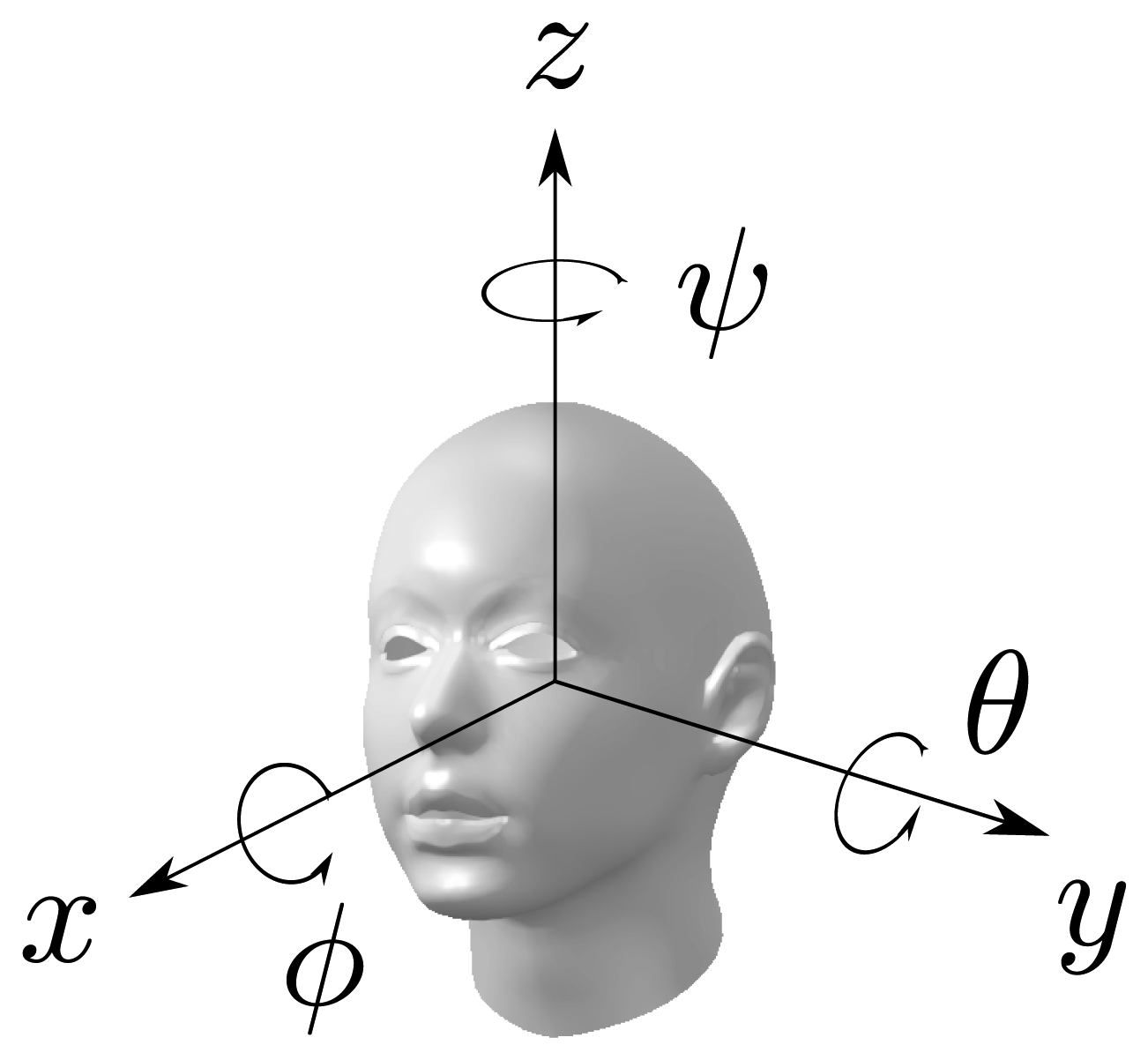
2. Head Rotation Representation
The parametrization of the head rotation in this work is based on the decomposition into Euler angles (ϕ, θ, ψ) with the x−y−z convention of the rotation matrix of the head into the room's frame of reference, where (ϕ, θ, ψ) denote the three basic rotations, one for every axis. By the x − y − z convention, the following rotations are chosen:
Rotate by angle ψ about the head z-axis
Rotate by angle θ about the head y-axis
Rotate by angle ϕ about the head x-axis
The rotation matrix, R(ϕ, θ, ψ), is given by:
The Euler angles (ϕ, θ, ψ) are also known as the roll, tilt and pan; or roll, pitch and yaw angles of the head. In this work, it seems not feasible to estimate the roll of the head with acoustic signals. Therefore, only the pan and tilt will be considered. Thus, the rotation of the head will be parametrized as R(θ, ψ) = R(0, θ, ψ) = Rz(ψ)Ry(θ). Nevertheless, the knowledge of the horizontal and vertical head angles, in addition to the head location, gives a good representation of the speaker in the 3D space. In order to estimate what the speaker may be referring to, the direction vector of his head in the 3D space can be computed from the rotation matrix as follows:
3. Two-Step Speaker Localization-Orientation Algorithm
The two-step algorithm to estimate the location and the orientation of speakers is based on the work presented in [11]. First, the position of the speaker is estimated by the steered response power-phase transform (SRP-PHAT) algorithm and the time difference of arrival (or time delay of arrival) (TDOA) for each microphone pair with respect to the detected position is computed. In the second step, the energy of the cross-correlation nearby the estimated time delay is used as the fundamental characteristic from where to derive the speaker orientation.
3.1. Acoustic Source Localization
3.1.1. GCC-PHAT Algorithm
In a multi-microphone environment, one of the observable clues with positional information more commonly used in acoustic localization algorithms is the time difference of arrival of the signal between microphone pairs. Consider a smart-room provided with a set of M microphones from which we choose N microphone pairs. Let x denote a ℝ3 position in space. Then, the time difference of arrival, τp,i,j, of an hypothetical acoustic source located at p between two microphones, i, j, with positions mi and mj is:
The cross-correlation function is well-known as a measure of the similarity between signals for any given time displacement, and ideally, it should exhibit a prominent peak in correspondence to the delay between the pair of signals [12]. A commonly used weighting function in acoustic event localization is the phase transform (PHAT), also known in the literature as cross-power-spectrum phase technique [13], which is usually considered useful in reverberant conditions. It can be expressed in terms of the inverse Fourier transform of the estimated cross-power spectrum (Gij(f)) with the following equation:
The estimation of the TDOA for each microphone pair is computed as follows:
3.1.2. SRP-PHAT Algorithm
The contributions of each microphone pair can be combined to derive a single estimation of the source position. However, in the general case, the availability of multiple TDOA estimations leads to a minimization of an over-determined and non-linear error function. A very efficient approach is the SRP-PHAT or global coherence field introduced in [14]. The SRP-PHAT algorithm performs very robustly in reverberant environments, due to the PHAT weighting, and actually, it has turned out to be one of the most successful state-of-the-art approaches to microphone array sound localization.
The basic operation of the SRP-PHAT algorithms consists of exploring the three-dimensional (3D) space, searching for the maximum of the global contribution of the PHAT-weighted generalized cross-correlations (GCC-PHAT) from all the microphone pairs. The 3D room space is quantized into a set of positions with a typical separation of 5–10 cm. The theoretical TDOA, τp,i,j, from each exploration position to each microphone pair are precomputed and stored.
The set of GCC-PHAT functions are combined to create a spatial likelihood function (SLF) F(p), which gives a score for each position, p, in space by means of the following equation:
The estimated acoustic source location is the position of the quantized space that maximizes the contribution of the GCC-PHAT of all microphone pairs:
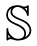 is the set of microphone pairs. Then, the TDOA for each microphone pair, τp̂,i,j, is estimated using the obtained location.
is the set of microphone pairs. Then, the TDOA for each microphone pair, τp̂,i,j, is estimated using the obtained location.3.2. Orientational Features
3.2.1. GCC-PHAT-A
The orientational cues used in this work are based on GCC-PHAT averaged peak (GCC-PHAT-A), described in [11]. It consists on computing the energy of the cross-correlation nearby the estimated time delay by the following equation:
Basically, the GCC-PHAT-A measure reduces to the sum of the energy of the band-filtered PHAT-weighted cross-correlation around the estimated TDOA, and essentially, it measures the proportion of the signal between frequencies f1 and f2 that contributes to the main peak in the localization. It is also important to note that this measure is commensurable across all microphone pairs independent of microphone gains, due to the PHAT weighting and, therefore, constitutes a valuable orientational feature.
3.2.2. Orientation Angle Estimation
In order to estimate the orientation of a speaker based on the GCC-PHAT-based orientational measures, a simple vectorial method is employed, similar to that described in [8]. The technique first needs the position of the active person to be known beforehand or estimated by means of the SRP-PHAT or any other source localization method. Then, the vectors, vij, from the speaker to the center of each microphone pair are computed, adjusting their magnitude |vij| to the orientational measure of the microphone pair, ρij. The orientational measures consists in the min-max-normalization scaled GCC-PHAT-A values, which fit in the range [−γ, (1 − γ)].
The sum of the vectors formed by all the orientational measures of each microphone pair is considered the estimated head direction, vsum, as follows:
The estimated head orientation angle, ψ̂, is computed as the angle of the projection of vsum in the xy-plane with the x-axis.
4. Two-Step Particle Filter Tracking
In this section, a two-step approach to estimate the location and orientation of the speaker is proposed, employing a particle filter in each stage, which is introduced here to enable a fair comparison with the joint particle filter approach.
4.1. Particle Filter Tracking
The concept of tracking can be defined as the recursive estimation of the hidden state of a target based on the partial observations at every time instant. Assuming that the evolution of the state sequence is defined by a Markov process of first order, the dynamics of the state can be described by the transition equation:
Tracking aims to estimate xk based on the set of all available measurements z1:k = {zi, i = 1,…, k} up to time k. One solution is to use the Bayesian approach to reconstruct the probability density function (pdf) of xk given all the data, z1:k, up to time k, or in a compact notation, p(xk∣z1:k). The pdf, p(xk∣z1:k), is known as the posterior density and contains all statistical information gathered by the measurements up to time k. The posterior density may be obtained recursively by means of the Bayesian approach based on two fundamental iteration steps, namely, prediction and update.
In the prediction step, the prior pdf, p(xk∣z1:k−1), is obtained making use of the transition pdf, p(xk∣xk−1), which is derived from transition Equation (15):
In the update stage, the new measurement, zk, is used to update the prior pdf via the Bayes' rule and obtain the required posterior density of the current state:
Particle filters (PF) [16] approximate the Bayesian filter approach by representing the probability distribution recursively with a finite set of samples, known as particles, that are updated according to their measured likelihood for a given dynamical and observational model. Applications of PF to acoustic localization can be found in [17–19] with a comprehensive research in [20].
Let denote a set of Ns random samples of the state with associate weights normalized such that . Then, the posterior density, p(xk∣z1:k), can be approximated as:
Considering that the samples, are drawn from a sampling distribution, called importance density, and taking some widely accepted assumptions [16], the weights can be computed recursively by the following expression:
In the literature regarding other domains, some techniques aim at constructing efficient importance density functions through Markov Chain Monte Carlo methods [21] or exploiting independence among variables in the state space using Rao-Blackwellized particle filters [22]. Although there is a large number of methods to compute the associated particle weights, one approach that is the most largely accepted, in part for its convenience, is to choose the importance density to be the prior:
A common problem with the PF is the degeneracy phenomenon, where, after a few iterations, all the weight concentrates in just one particle, and the rest of the particles have almost zero contribution to the approximation of the posterior. A measure of the degeneracy of the PF is the effective sample size introduced in [23] and [24], defined as:
The best estimation of the state at time k, x̂k, is derived based on the discrete approximation of Equation (20). The most common solution is the Monte Carlo approximation of the expectation:
The design parameters of the PF are the state model, the dynamical model and the observational model, which are defined in the following sections.
4.2. Location Tracking
4.2.1. State and Dynamical Models
A common approach is to characterize the human movement dynamics as a Langevin process [25], since it is reasonably simple and has been proven to work well in practical applications [19,25]. In this case, the state variable, xk, is defined as:
For the sake of simplicity, consider the Langevin process in the x-coordinate as follows:
 (0, 1) is a normally distributed random variable, T is the time step unit between consecutive updates of the state vector and the two constants are defined as:
(0, 1) is a normally distributed random variable, T is the time step unit between consecutive updates of the state vector and the two constants are defined as:
4.2.2. Observational Model
The particle filter approach requires the definition of the likelihood function, in order to update the weight of every particle. In this case, the observation, zk, is not limited to the estimated source location [19], and the full SRP-PHAT SLF generated by Equation (9) or a modification thereof can be employed [26]. Other works [17] construct the likelihood function employing solely the TDOA estimations.
In this work, the localization likelihood is derived from a spatial likelihood function F(p) obtained by the SRP-PHAT algorithm with the PHAT-weighted cross-correlation smoothed by the convolution with a triangular window, Ω(τ), of five samples:
The likelihood function, F(p), is usually precomputed for a discrete set of space positions for every audio frame in order to gain speed in the evaluation of p(zk,loc∣xk) in the case of a PF with a large number of particles, at the expense of localization precision. In this work, the quantization step is set to 5 cm.
4.3. Orientation Tracking
4.3.1. State and Dynamical Models
The state vector of the particle filter used to estimate the orientation consists only of the pan angle and the dynamical model as follows:
The state head direction vector in 3D space dk(ψk) = [cos(ψk) sin(ψk) 0]T.
4.3.2. Observational Model
The orientation likelihood is obtained from the GCC-PHAT averaged peak features described in Section 3.2. A vector, vn, is created from the estimated speaker's position, pk, to the center of each microphone pair, adjusting their magnitude |vn| to the normalized orientational measure of the microphone pair as defined in Section 3.2.2. The orientation observation is formed by the resulting vector, vsum, of the vectorial sum of vn. The orientation likelihood function is then defined as the scalar product of the state head direction vector and the normalized resulting vector as follows:
The scalar product of the two unitary vectors is scaled into the range [0, 1] to better resemble a likelihood function. The exponent, n|vsum|, is used as a confidence factor for the orientational observation, with the constant, n, set empirically to four. The magnitude of the observation vector, |vsum|, models the likelihood function, where a very small value of the vector length yields to the constant likelihood function independent of the state. On the other hand, higher values of the observation vector magnitude will narrow the likelihood function to observation angles close to the state angle.
5. Joint Localization-Orientation Particle Filter Tracker
In this work, a particle filter approach is proposed to jointly track the location and orientation of a speaker. The main motivation is that the knowledge of the speaker orientation may yield to an increased localization performance and vice versa. The position and orientation of the speaker are estimated in the 3D space by means of a joint particle filter with coupled dynamic and observation models. The proposed system makes the assumption that the voice of a speaker is produced around the mouth, and the knowledge about the orientation yields to a better estimate of the head position. On the other hand, in this work, it is proposed to assume that the person movement is dependent on his orientation and vice versa. Next sections describe the proposed state and coupled dynamic and observation models.
5.1. State Model
The state of the particles is composed by the position of the center of the speaker's head pk = [xk yk zk]T, the velocity of the speaker ṗk = [ẋk ẏk żk]T and the tilt and pan of his head.
The estimation of the position of the speaker's mouth tk is determined at every instant by the state vector, and it is synthesized from the head center position and the rotation angles as follows:
The state head direction vector in the 3D space, dk(θk, ψk), is computed, rotating the head direction vector in the head coordinate reference to the 3D space reference:
5.2. Dynamical Model
Similarly to Section 4.2.1, a Langevin process is chosen to characterize the speaker movement dynamics. Usually, the motion model in the x and y coordinates is assumed to be independent and identically distributed, which yields to identical model parameters in both coordinates. However, in this work, it is assumed that the movement in the x and y coordinates is dependent on the pan orientation angle of the person. It is expected as a more probable event that the speaker moves to his forward direction than to his sideways or backward directions. This is modeled as a Rayleigh distribution probability in the speaker's forward direction and a normal distribution in his sideways direction. The Rayleigh distribution,
 (0,1), is scaled and centered in order to have a zero mean expectation and unity variance. The variance of the distributions determined by the σ factor is also different for the forward and sideways directions.
(0,1), is scaled and centered in order to have a zero mean expectation and unity variance. The variance of the distributions determined by the σ factor is also different for the forward and sideways directions.
The random variable, nx, from Equation (28) for the x and y coordinates are obtained by the rotation of nforward and nsideway by the pan angle ψk:
In this work, the horizontal orientation angle of the speaker is assumed to be dependent on his velocity. It is expected that the faster the person moves, the more probable it is that the person is looking to his moving direction. This is modeled by predicting the next state head direction as the weighted sum of the current state head direction vector in the xy plane and the normalized moving direction vector plus a normally distributed random variable, nd, where the weight factor, αψ, depends on the person's velocity and the maximum expected velocity, υmax, as follows:
Finally, the next state yaw orientation is the angle formed by the y and x components of the head direction:
The pitch orientation angle recursion equation, assuming independence with other state variables, is defined as:
5.3. Observational Model
The observation likelihood, p(zk∣xk), is composed from the localization, zk,loc, from Equation (35) and orientation zk,ori from Equation (38) feature observations as follows:
6. Experiments
6.1. Experimental Setup and Database Description
The joint PF tracker performance will be compared with the two two-step algorithms introduced in Sections 3.2.2. and 4 in the task of estimating the position and orientation of the speaker's head. Since the two-step approaches are only able to estimate the horizontal orientation angle, the pitch and roll hypothesis are set to 0 for all time frames. The comparison with the two-step PF approach assesses that the performance increase obtained by the joint method is due to the joint dynamic and observation models and not the filtering itself.
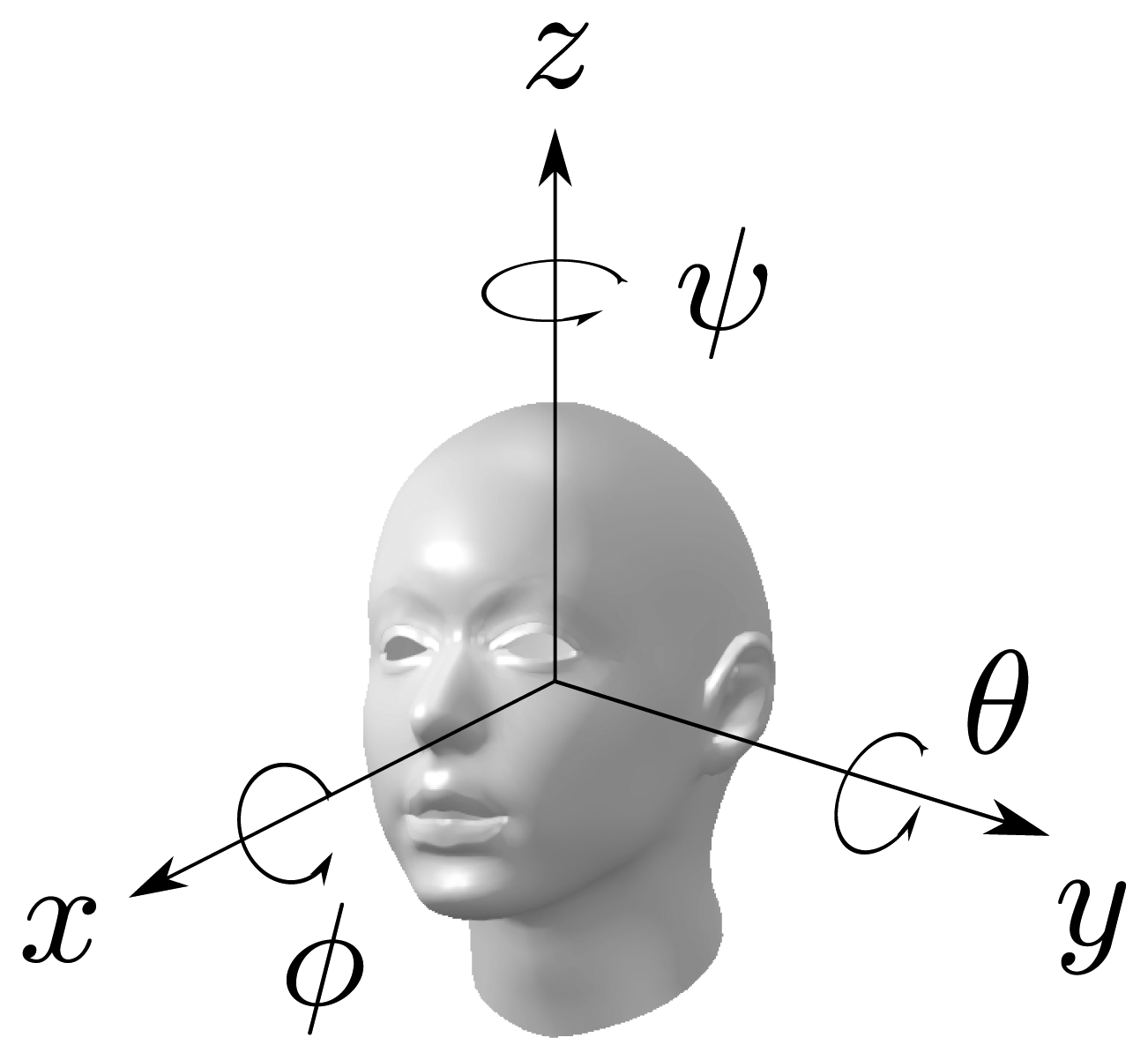
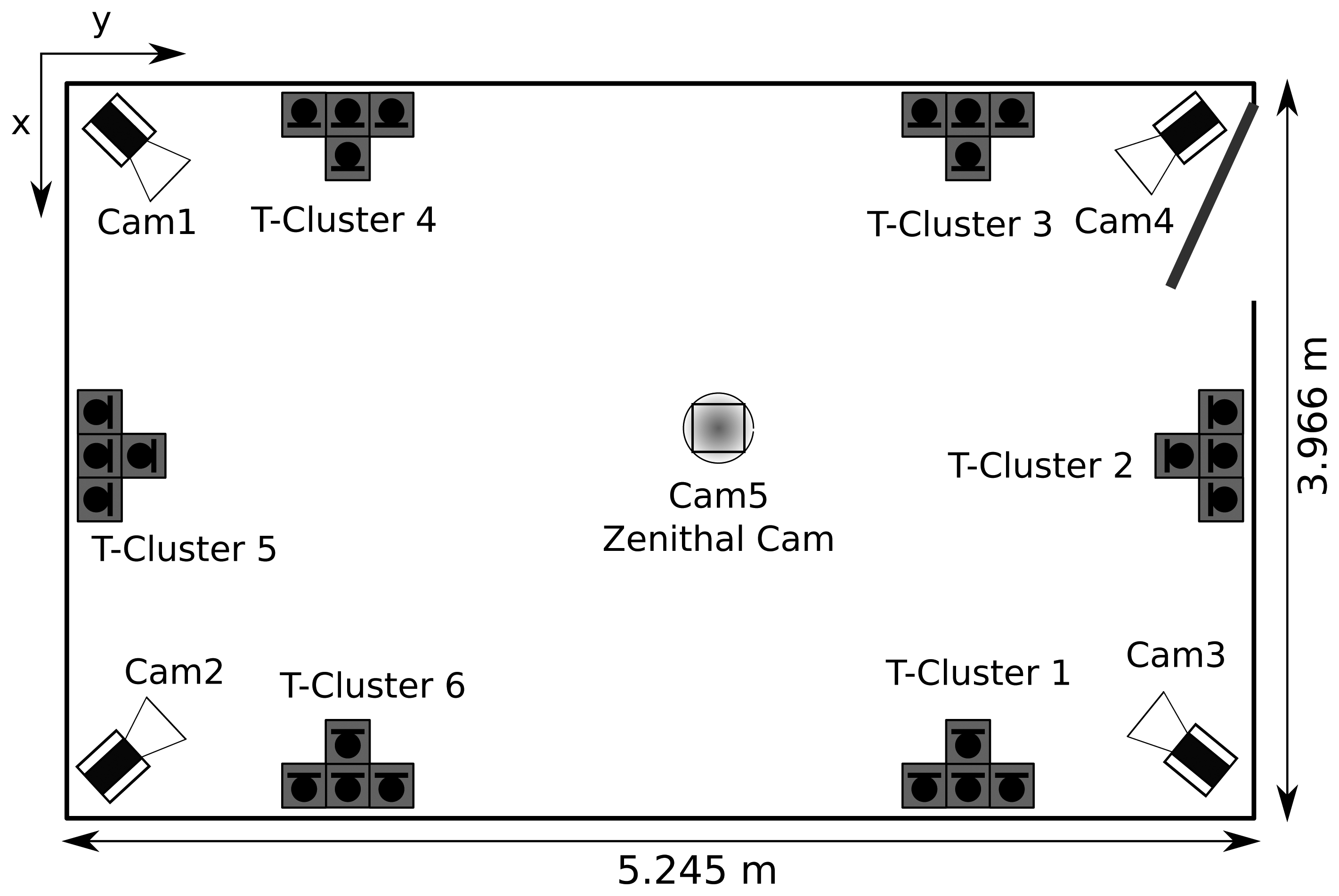
The performance of the proposed head orientation estimation algorithm was evaluated using a purposely recorded database collected in the smart-room at the Universitat Politècnica de Catalunya. It is a meeting room equipped with several multimodal sensors, such as microphone arrays, table-top microphones and fixed or pan-tilt-zoom video cameras. The room dimensions are 3, 966×5, 245×4,000 mm, which correspond to the x, y and z coordinates, respectively, and its measured reverberation time is approximately 400 ms. A schematic figure of the room setup can be observed in Figure 2.
The database is composed of one single person dataset involving the recording of multi-microphone audio, multi-camera video and IMU data for seven people moving freely in a smart room speaking most of the time and another multi-person dataset consisting in the recording of a group discussion with four participants. Only the simple person dataset will be considered in this work, since it is oriented toward the person tracking task, while the multi-person dataset is oriented toward the group analysis task. A sample of the database is shown in Figure 3.
The ground truth provided by the database consists in the annotations of the center of the head and the Euler rotation angles of every participant. The center of the head was obtained automatically by means of a multi-camera video PF tracker and the Euler orientation angles are acquired by an inertial measurement unit (IMU) provided by accelerometers, magnetometers and gyroscopes in the three axes.
6.2. Metrics
The metrics proposed in [10] for acoustic and audiovisual person-tracking are considered for evaluation and comparison purposes. These metrics have been used in international evaluation contests [27] and have been adopted by several research projects, such as the European Computers in the Human Interaction Loop (CHIL) [28] or the U.S. VACE [29] thus, they allow an objective and fair comparison with other acoustic tracking methods and with methods from other modalities.
In [10], two metrics are defined for an acoustic and audiovisual person-tracking task. Multiple object tracking precision (MOTP), which shows the trackers ability to estimate precise object positions, whereas multiple object tracking accuracy (MOTA) expresses the performance for estimating the correct number of objects and keeping to consistent trajectories. Additionally, the acoustic multiple object tracking accuracy (A-MOTA) score is defined for the acoustic tracking task, evaluated only for the active speaker at each time instant, k. A new metric is proposed in this work, multiple head orientation tracking precision (MHOTP), which determines the performance for estimating the head orientation of multiple persons.
6.2.1. Multiple Object Tracking Accuracy (MOTA) (%)
This is the accuracy of the tracker when it comes to keeping correct correspondences over time, estimating the number of people, recovering tracks, etc., the tracker, false positives, misses and mismatches, over all frames, divided by the total number of ground truth points.
6.2.2. Multiple Object Tracking Precision (MOTP) (mm)
This is the precision of the tracker when it comes to determining the exact position of a tracked person in the room.
6.2.3. Multiple Head Orientation Tracking Precision (MHOTP) (degrees)
This is the precision of the tracker when it comes to determining the exact orientation of a tracked person in the room. It is the Euclidean angle error for matched ground truth-hypothesis pairs over all frames, averaged by the total number of matches made. It shows the ability of the tracker to estimate the correct orientation and is independent of its tracking accuracy. The Euclidean angle is computed as the angle between the estimated head direction vector, d̂(θ̂, ψ̂), and the ground truth vector, d(θ, ψ). The multiple head orientation tracking precision can be also detailed by three sub-metrics, which account for the angle error in every axis.
7. Results
Experiments were conducted over the cited database to compare the performance of the joint PF tracker and the two two-step approaches. A tight relationship between the tracking accuracy (MOTA) and precision (MOTP and MHOTP) has been observed in the three algorithms, since it is possible to output a localization and orientation hypothesis only when the confidence of the algorithm is above a threshold and achieve a high precision at the expense of tracking accuracy, and vice versa. In order to ensure a fair comparison between the three algorithms, the peak value of the SLF is selected as the confidence for all methods, where a sweep threshold parameter is used to obtain the curve of all possible accuracy and precision results.
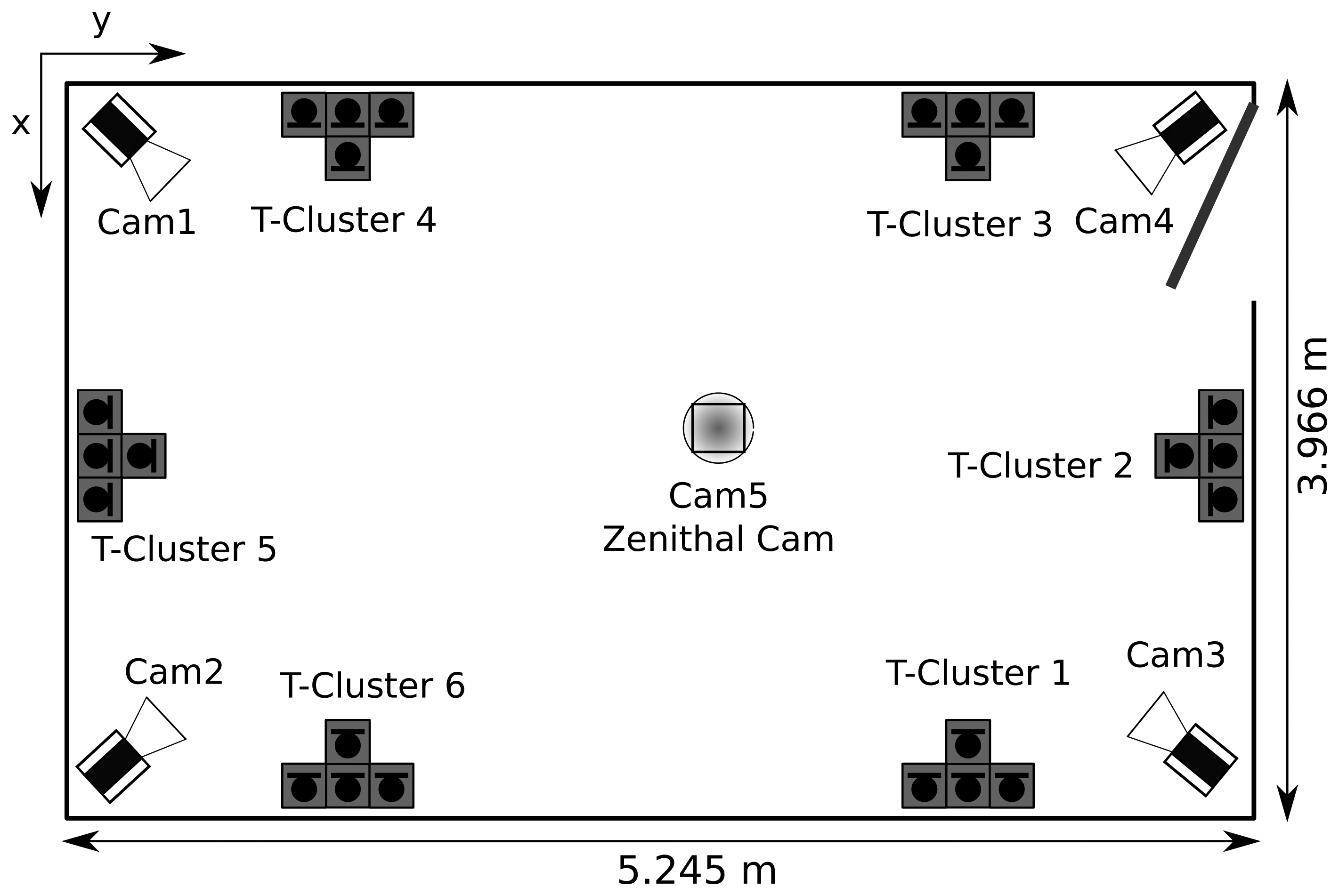
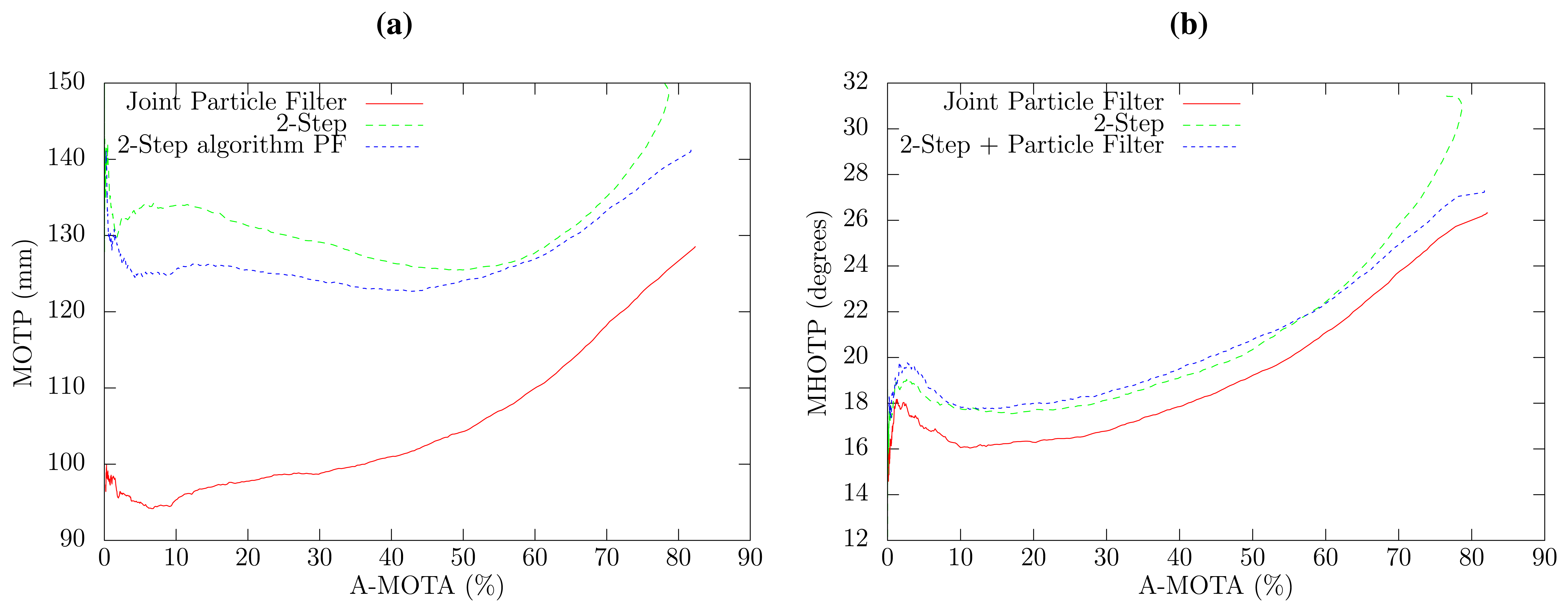
Figure 4a shows the position tracking error in relation to the tracking accuracy for the three methods. The two-step PF approach is slightly better than the two-step algorithm. However, the proposed joint PF approach obtains a notable performance increase in the localization precision with respect to the two-step PF approach, that ranges from 7% to 24% error reduction depending on the A-MOTA working point. This increased localization precision is due to the fact that the database position annotations correspond with the head center position (this is a general fact for almost all tracking databases), whereas the acoustic localization algorithm detects the position of the mouth of the speaker. The proposed joint algorithm takes advantage of the knowledge of the mouth position and head orientation to estimate the center of the head, thus obtaining better localization results. Two A-MOTA working points have been selected to show numerical values, which can be observed in Tables 1 and 2.
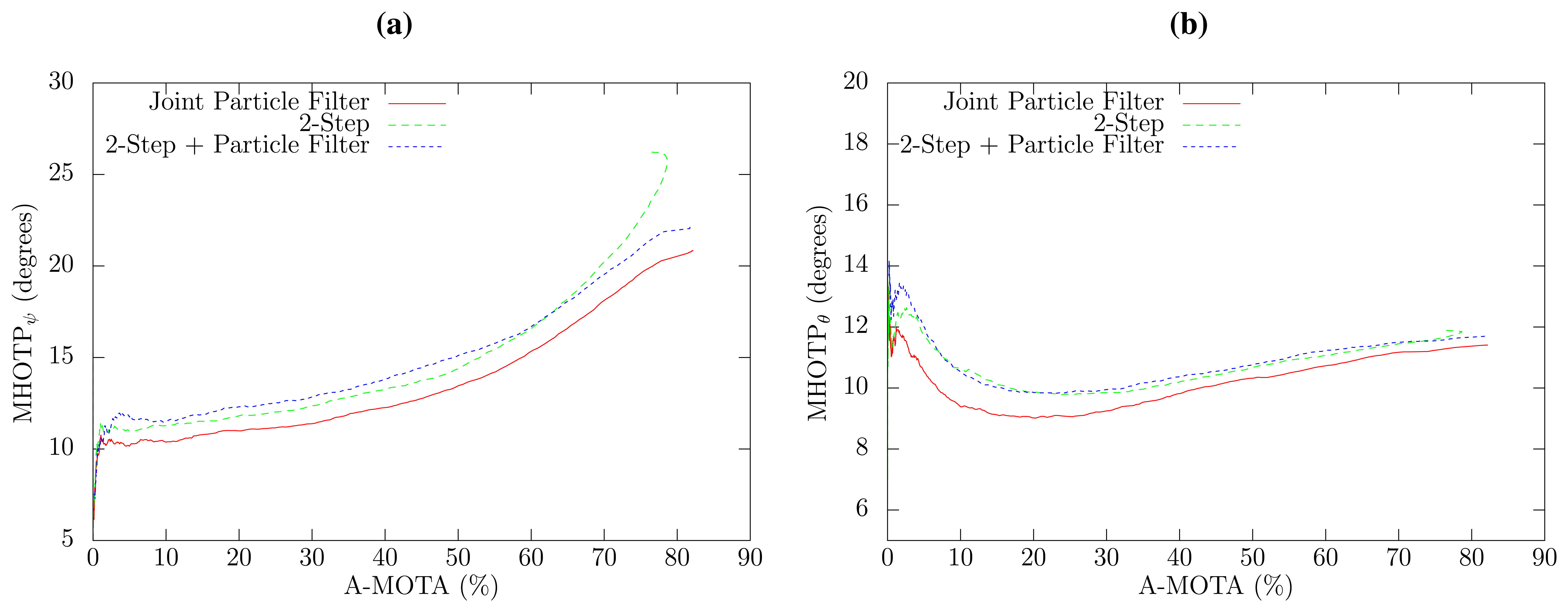
The overall precision of the estimation of 3D direction of the head in relation to the tracking accuracy is shown in Figure 4b for all methods. The joint PF approach exhibits an overall reduction of 1.4 degrees in the 3D angle estimation error with respect to the two-step approaches, which have a very similar performance. The 3D angle error can be split in the horizontal and vertical angle error, which are shown in Figure 5, respectively. The proposed joint method has a horizontal angle error reduction of 8.2% to 9.1%, depending on the selected confidence threshold in comparison to both two-step approaches, which, again, have a very similar angle error. Interestingly, the results obtained for the vertical angle, which are similar to the localization results, have better precision when only high confidence SLF values are employed. This can be explained by the fact that the proposed method estimates the elevation angle from the small term height changes produced by the acoustic localization algorithm and that high confidence SLF values provide a more accurate acoustic source position.
8. Conclusions
A PF approach for joint head position and 3D orientation estimation has been presented in this article. Experiments conducted over the purposely recorded database with Euler angles and head center annotations for seven different people in a smart room showed an increased performance for the joint PF approach in relation to two two-step algorithms that first estimate the position and then the orientation of the speaker. Both two-step approaches have a very similar angle estimation error, with a small increase in the localization precision (MOTP) for the two-step PF. The proposed joint algorithm outperforms both two-step algorithms in terms of localization precision and orientation angle precision (MHOTP), assessing the superiority of the joint approach. Furthermore, by means of the definition of a joint dynamical model, part of the the elevation angle of the head is inferred by the algorithm. Future work will be devoted to extending the joint PF to track multiple speakers and to study the fusion with video approaches with a focus on 3D orientation estimation.
Acknowledgments
This work has been partially funded by the Spanish project SARAI (TEC2010-21040-C02-01).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Brutti, A.; Omologo, M.; Svaizer, P. Oriented global coherence field for the estimation of the head orientation in smart rooms equipped with distributed microphone arrays. Proc. Interspeech 2005, 2337–2340. [Google Scholar]
- Segura, C.; Canton-Ferrer, C.; Abad, A.; Casas, J.; Hernando, J. Multimodal Head Orientation towards Attention Tracking in Smartrooms. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2007), Honolulu, HI, USA, 16–20 April 2007; pp. 681–684.
- Segura, C.; Abad, A.; Hernando, J.; Nadeu, C. Speaker Orientation Estimation Based on GCC-PHAT and HLBR Hybridation. Proceedings of International Conference on Spoken Language Processing (ICSLP′08), Brisbane, Australia, 22–26 September 2008; pp. 1325–1328.
- Levi, A.; Silverman, H. A New Algorithm for the Estimation of Talker Azimuthal Orientation Using a Large Aperture Microphone Array. Proceedings of 2008 IEEE International Conference on Multimedia and Expo, Hannover, Germany, 23–26 June 2008; pp. 565–568.
- Sachar, J.; Silverman, H. A Baseline Algorithm for Estimating Talker Orientation Using Acoustical Data from a Large-Aperture Microphone Array. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Montreal, Quebec, Canada, 17–21 May 2004; pp. 65–68.
- Levi, A.; Silverman, H. A robust method to extract talker azimuth orientation using a large-aperture microphone array. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 277–285. [Google Scholar]
- Mungamuru, B.; Aarabi, P. Enhanced sound localization. IEEE Trans Syst. Man Cybern. Part B 2004, 34, 1526–1540. [Google Scholar]
- Abad, A.; Segura, C.; Nadeu, C.; Hernando, J. Audio-Based Approaches to Head Orientation Estimation in a Smart-Room. Proceedings of the 8th Annual Conference of the International Speech Communication Association (INTERSPEECH 2007), Antwerp, Belgium, 27–31 August 2007; pp. 590–593.
- Abad, A.; Macho, D.; Segura, C.; Hernando, J.; Nadeu, C. Effect of Head Orientation on the Speaker Localization Performance in Smart-Room Environment. Proceedings of the 9th European Conference on Speech Communication and Technology (INTERSPEECH 2005—Eurospeech), Lisbon, Portugal, 4–8 September 2005; pp. 145–148.
- Bernardin, K.; Elbs, A.; Stiefelhagen, R. MultipleObject Tracking Performance Metrics and Evaluation in a Smart Room Environment. Proceedings of the Sixth IEEE International Workshop on Visual Surveillance, in conjunction with 9th European Conference on Computer Vision (ECCV 2006), Graz, Austria, 7–13 May 2006.
- Segura, C. Speaker Localization and Orientation in Multimodal Smart Environments. Ph.D. Thesis, Technical University of Catalonia (UPC), Barcelona, Spain, May 2011. [Google Scholar]
- Svaizer, P.; Matassoni, M.; Omologo, M. Acoustic Source Location in a Three-Dimensional Space Using Crosspower Spectrum Phase. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 1997), Munich, Germany, 21–24 April 1997; pp. 231–234.
- Omologo, M.; Svaizer, P. Acoustic Event Localization Using a Crosspower-Spectrum Phase Based Technique. Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP 1994), Adelaide, Australia, 19–22 April 1994; pp. 273–276.
- DiBiase, J.; Silverman, H.; Brandstein, M. Microphone Arrays. In Robust Localization in Reverberant Rooms; Springer: Berlin, Germany, 2001. [Google Scholar]
- Jain, A.; Nandakumar, K.; Ross, A. Score normalization in multimodal biometric systems. Pattern recognition 2005, 38, 2270–2285. [Google Scholar]
- Arulampalam, M.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar]
- Vermaak, J.; Blake, A. Nonlinear Filtering for Speaker Tracking in Noisy and Reverberant Environments. Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2001), Salt Lake City, UT, USA, 7–11 May 2001; pp. 3021–3024.
- Ward, D.; Williamson, R. Particle Filter Beamforming for Acoustic Source Localization in a Reverberant Environment. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2002), Orlando, FL, USA, 13–17 May 2002; pp. 1777–1780.
- Ward, D.; Lehmann, E.; Williamson, R. Particle filtering algorithms for tracking an acoustic source in a reverberant environment. IEEE Trans. Speech Audio Process. 2003, 11, 826–836. [Google Scholar]
- Lehmann, E. Particle Filtering Methods for Acoustic Source Localisation and Tracking. Ph.D. Thesis, Australian National University, Canberra, Australia, July 2004. [Google Scholar]
- Gilks, W.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman and Hall: London, UK, 1996. [Google Scholar]
- Doucet, A.; De Freitas, N.; Gordon, N. Sequential Monte Carlo Methods in Practice; Springer Verlag: New York, NY, USA, 2001. [Google Scholar]
- Bergman, N. Recursive Bayesian Estimation: Navigation and Tracking Applications; Department of Electrical Engineering, Linköping University: Linköping, Sweden, 1999. [Google Scholar]
- Liu, J.; Chen, R. Sequential Monte Carlo methods for dynamic systems. J. Am. Stat. Assoc. 1998. [Google Scholar]
- Vermaak, J.; Gangnet, M.; Blake, A.; Perez, P. Sequential Monte Carlo Fusion of Sound and Vision for Speaker Tracking. Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, Canada, 7–14 July 2001; pp. 741–746.
- Pertilä, P.; Korhonen, T.; Visa, A. Measurement combination for acoustic source localization in a room environment. EURASIP J. Audio Speech Music Process. 2008, 2008, 1–14. [Google Scholar]
- CLEAR - Classification of Events, Activities and Relationships Evaluation and Workshop. Available online: http://www.clear-evaluation.org (accessed on 24 January 2014).
- Waibel, A.; Stiefelhagen, R. Computers in the Human Interaction Loop; Springer: Berlin, Germany, 2009. [Google Scholar]
- VACE—Video Analysis and Content Extraction. Available online: http://www.informedia.cs.cmu.edu/arda/vaceII.html (accessed on 24 January 2014).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | MOTP | MHOTP | MHOTPψ | MHOTPθ |
|---|---|---|---|---|
| 2-Step | 133.94 mm | 17.76° | 11.27° | 10.63° |
| 2-Step PF | 125.58 mm | 17.84° | 11.53° | 10.53° |
| Joint PF | 95.30 mm | 16.06° | 10.38° | 9.39° |
| System | MOTP | MHOTP | MHOTPψ | MHOTPθ |
|---|---|---|---|---|
| 2-Step | 140.86 mm | 28.04° | 22.64° | 11.54° |
| 2-Step PF | 136.62 mm | 26.25° | 21.01° | 11.58° |
| Joint PF | 122.67 mm | 25.08° | 19.60° | 11.30° |
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Segura, C.; Hernando, J. 3D Joint Speaker Position and Orientation Tracking with Particle Filters. Sensors 2014, 14, 2259-2279. https://doi.org/10.3390/s140202259
Segura C, Hernando J. 3D Joint Speaker Position and Orientation Tracking with Particle Filters. Sensors. 2014; 14(2):2259-2279. https://doi.org/10.3390/s140202259
Chicago/Turabian StyleSegura, Carlos, and Javier Hernando. 2014. "3D Joint Speaker Position and Orientation Tracking with Particle Filters" Sensors 14, no. 2: 2259-2279. https://doi.org/10.3390/s140202259