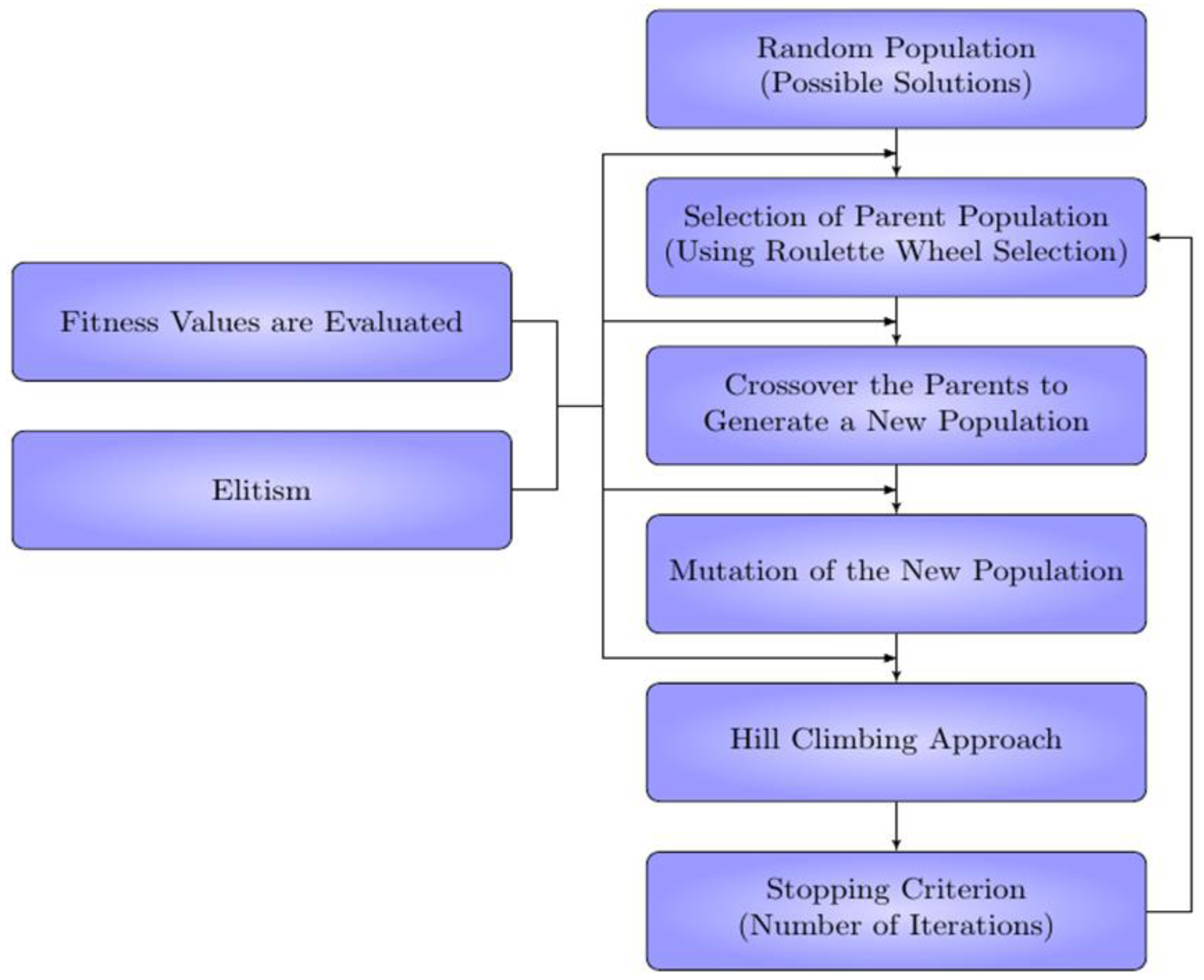
2.1. Hybrid Genetic Algorithm
An HGA combines the exploration of a stochastic GA with the exact convergence of a deterministic algorithm [
21]. The novelty is how these algorithms are combined. HGA has all of the steps of a regular GA (e.g., selection, mating, mutating, elitism), however, after the mutation routine, each candidate is optimized locally, as the flowchart for the algorithm shows in
Figure 2. The combination of these two algorithms leads to an aggressive optimization routine that is capable of exploring the entire variable space and at the same time can converge on the exact local optimum for each candidate. In essence, for a hybrid GA, the placement is governed by natural selection where the best candidate is more likely to determine the placement of new candidates. The main benefit is the ability to extract global optimum values that traditional stochastic algorithms are not capable of detecting. This point is illustrated below with a benchmark and multiple case studies.
2.3. Algorithm Parameters for Single and Multivariable Optimization Problems
Population: Population defines the number of candidate solutions to consider for each generation.
Elitism: Defines the top percentage of parent solutions to transfer to the child generation.
Crossover: Defines the percentage of the child population to generate from breeding from the parent generation. The remaining child population is copied directly from the parent generation. Parents to be copied are selected using the roulette wheel probability method. Parents that result in fitness values closer to the goal (maximum or minimum) are more likely to be copied or used as parents.
Mutation: Defines the percentage of the child population to mutate. The alleles of the chosen children are completely randomized. The most elite or fit solution is not a candidate for mutation.
Iterations: Is the number of generations to create.
Lower and Upper Constraints: The lower and upper constraints apply a bound to the results. Constraints are imposed during the roulette wheel selection subroutine. A given constraint is assigned a weight value, which is used to weight the deviation from the bounds of the results. Using this approach, a user can decide which objective functions are more important to obtain within the given bounds. Note: the weight values for the constraints are not the same weight values for the objective functions.
Tolerance: The tolerance determines which solutions are returned as possible answers. If a candidate has a fitness that is within a certain distance from the optimum solution, it is included in the solution set.
Bounds: Lower bound and upper bound are vectors that define the limit for the independent variables. In the single objective example these define the limits for x as:
For the multi-objective optimization example the limits are defined using bounding vectors as:
where the lower bound = (LB1 LB2 LB3) and the upper bound = (UB1 UB2 UB3).
Goal: The goal defines whether to maximize or minimize the fitness function(s).
Weights: Weights can be assigned to the output of the functions to define importance values for each function in reference to the others.
2.4. Case Studies for Testing the Performance of the Hybrid Genetic Algorithm
The HGA was used on the Ackley benchmark function for validation and subsequently on the food processing [
13], biofuel [
14], and biotechnology [
15] case studies. These authors used canonical analysis of response surface methdology, and sequential programming methods to optimize their objective functions.
Table 1 indicates the hybrid genetic algorithm parameters used to optimize the benchmark and case studies. Crossover, mutation and elitism rates were optimized for the Ackley benchmark before being applied to the case studies. Parameter rates are based on typical values taken from literature [
24].
The input values for the equations developed in foods, biofuels and biotechnology are coded based on the experimental design followed [
13,
14,
15]. The coded values represent the parameter levels for which the experiments were performed. All of the experiments were performed using a full factorial design and optimized using statistical methods such as response surface methodology.
2.4.1. Ackley Benchmark
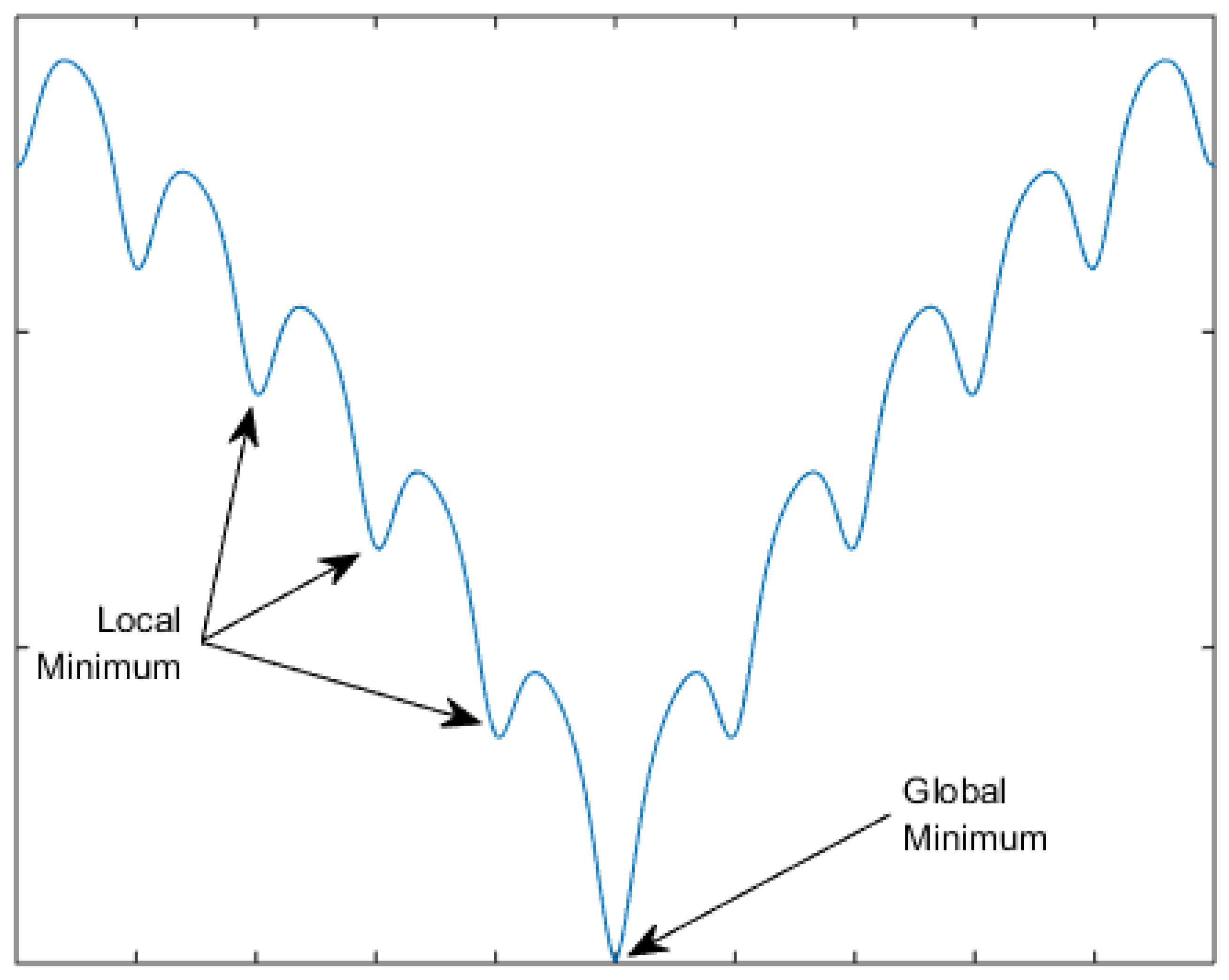
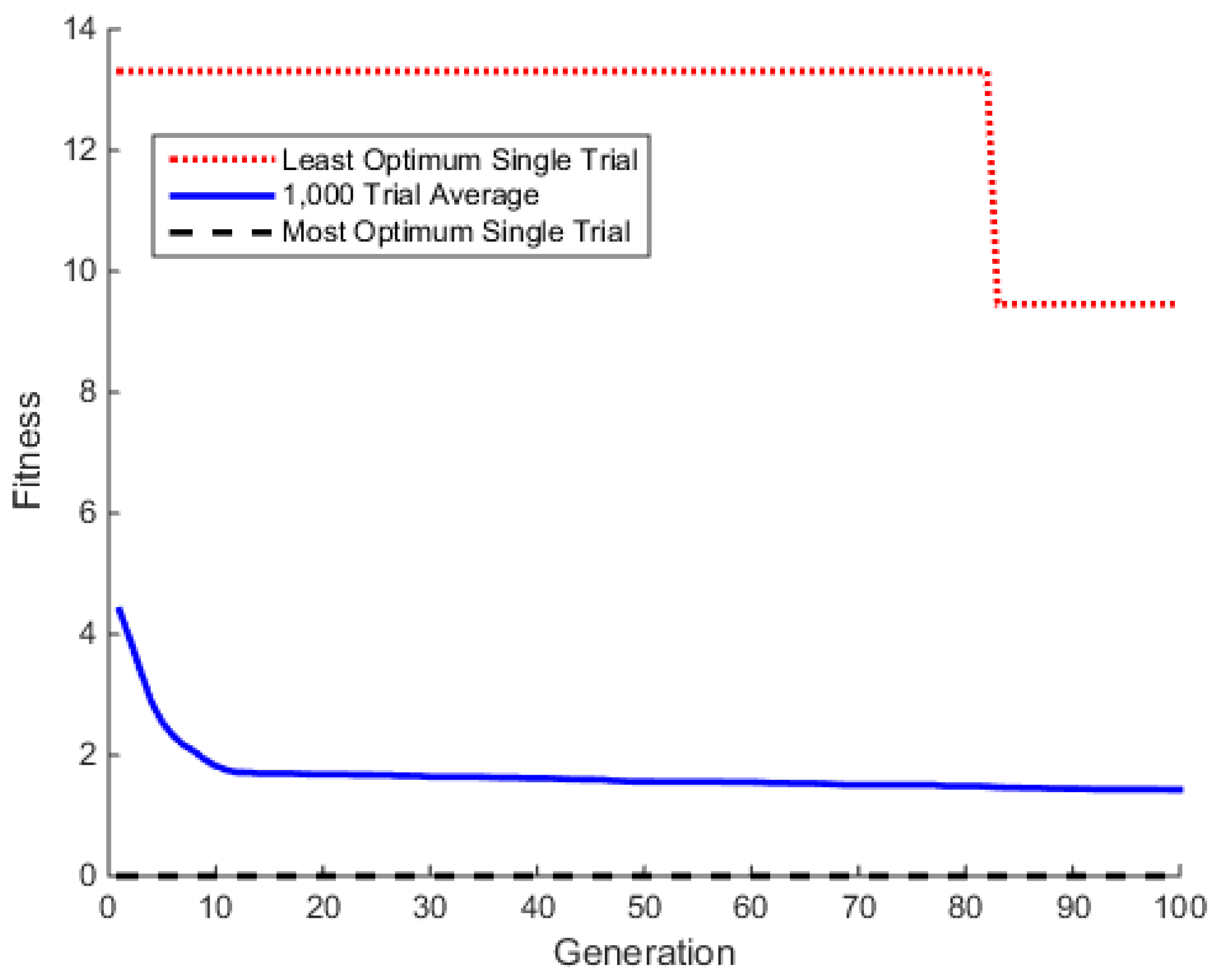
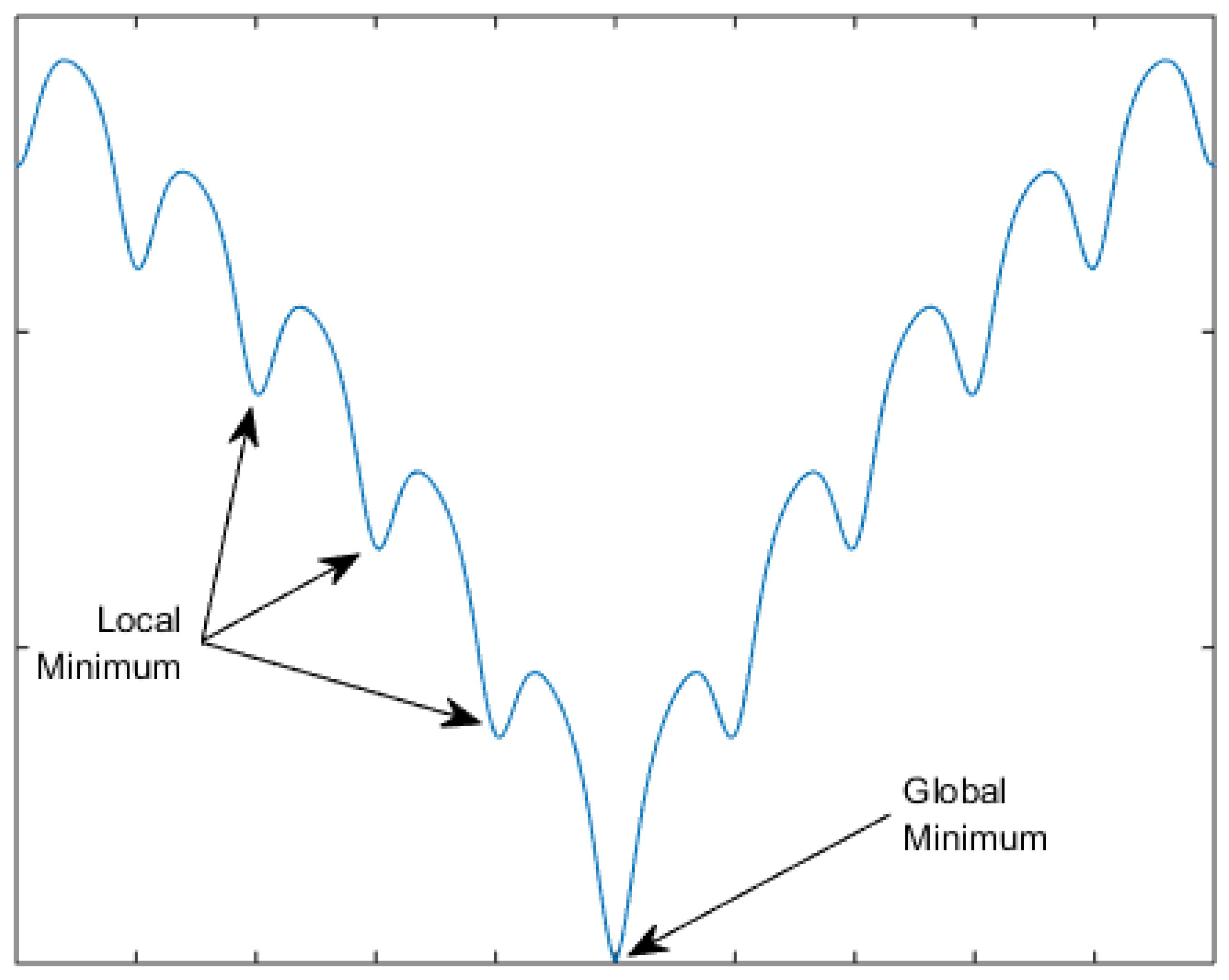
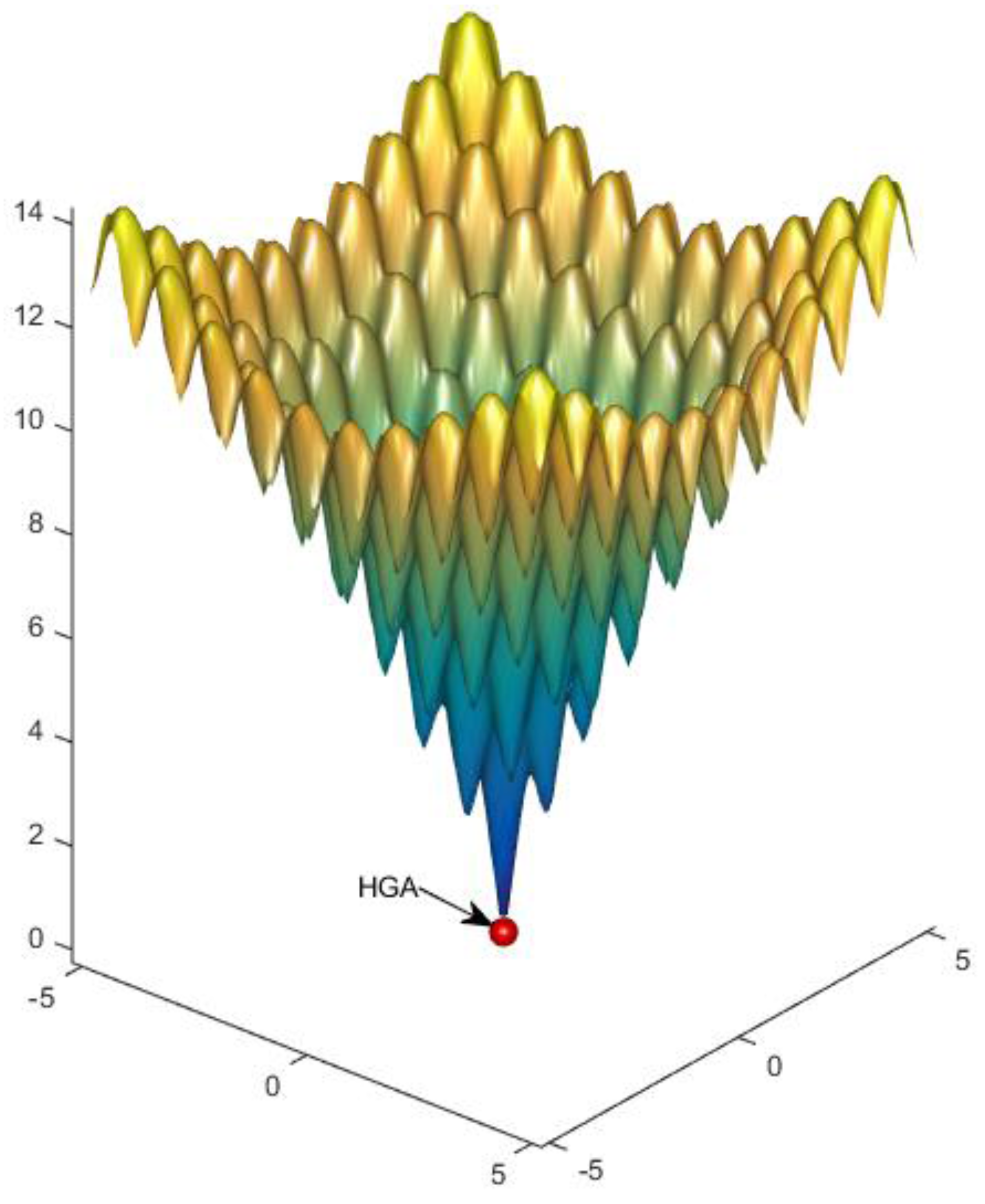
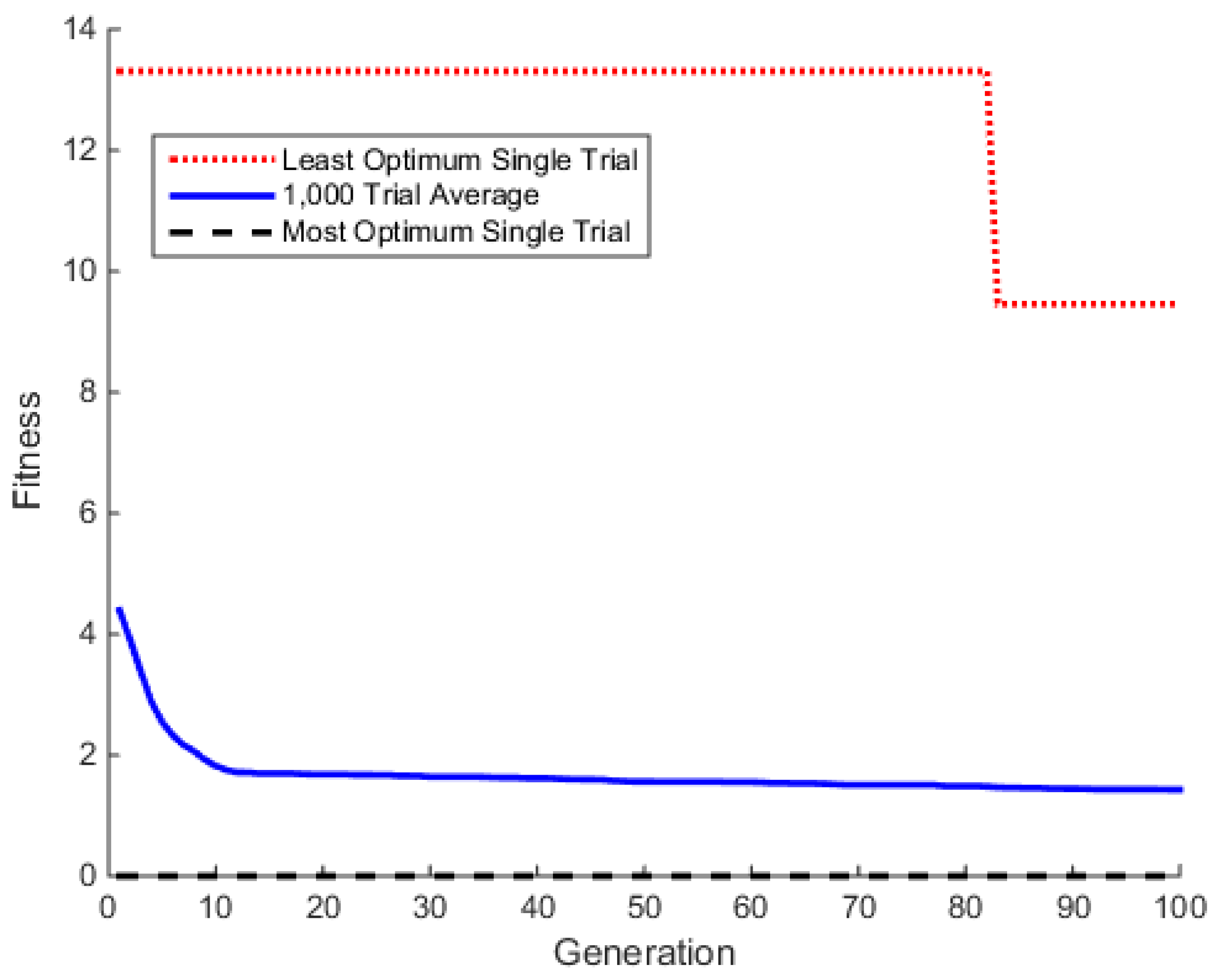
The benefit of hybridization is highlighted by applying the HGA to a complex benchmark function. For this comparison, the Ackley benchmark function was chosen [
25]. The Ackley function is a unique optimization benchmark in the fact that there are many local extrema that are not dramatically better than the surrounding peaks. Deterministic methods get trapped in the local extrema, while the gradual slope of the peaks discourages exploration of the stochastic algorithms. To showcase the benefit of hybridization, that is combining both deterministic and stochastic algorithms, we consider the two-dimensional (2D) Ackley function given in Equation (1) with constants as shown in
Table 2. The analytical solution is a null candidate with all zeros. The goal is to minimize this function with input bounds of
and
. Results for the Ackley benchmark are given in
Section 3.1.
2.4.2. Foods
Food engineering frequently calls for optimization of numerical models. Consider the anthocyanin yield of purple sweet potatoes [
13]. Anthocyanins are beneficial as flavonoids and pigments due to their non-teratogeneses, non-carcinogenicity, non-mutation, and low-ecological impact. Liu et al. [
13] developed a surface response model to predict the anthocyanin yield of purple sweet potatoes. The model input parameters are liquid-to-solid ratio (mL/g), ethanol concentration (
w/
w, %), ammonium sulphate concentration (
w/
w, %), and pH value. The upper and lower limits, along with coded values, are given in
Table 3. The goal of this function is to maximize the anthocyanin yield based on the input variables.
Y is the anthocyanin yield (%),
x1 is the liquid-to-solid ratio,
x2 is ethanol concentration (%),
x3 is ammonium sulphate concentration (%), and
x4 is pH value. Results for the foods case study are given in
Section 3.2.
2.4.3. Biofuel
Biofuel is gaining attention and support due to the volume of global fuel consumption. Eco-friendly alternatives to fossil fuels are being sought to reduce the dependence on finite resources and simultaneously secure national resource independence. Corn-based biodiesels have grown in the last two decades; however, there is a noticeable pressure in the food farming market as subsidized corn crops are going to biodiesel instead of human consumption. Lee et al. [
14] developed a model to predict biodiesel yields from the Jatropha curcas plant by considering the reaction time (h), methanol/oil molar ratio, reaction temperature (°C), and amount of CaO-MgO mixed oxide catalyst (wt. %). The upper and lower limits, along with coded values, are given in
Table 4. The goal of this function is to maximize the fatty acid methyl ester (FAME) yield based on the input variables.
Y is the FAME yield,
x1 is reaction time (h),
x2 is methanol/oil molar ratio,
x3 is reaction temperature (°C), and
x4 is catalyst amount (wt. %). Results for the biofuel case study are given in
Section 3.3.
2.4.4. Biotechnology
Enzymes play a crucial role in many biotechnological applications such as breaking down hemicellulose for biofuel production, bleaching wood pulp for paper production, extracting oils and starches and more. The activity of an enzyme in a particular application is of vital importance, as more activity means less usage, which reduces the cost of enzyme use. Vimalashanmugam and Viruthagiri [
15] developed a model to predict the production of the xylanase enzyme using a wheat bran substrate. The model input parameters are substrate concentration (g), temperature (°C), incubation time (h), initial moisture content (%), and initial pH value. The upper and lower limits, along with coded values, are given in
Table 5. The goal of this function is to maximize the production of the xylanase enzyme based on the input variables.
Y is xylanase activity,
x1 is substrate concentration (g),
x2 is temperature (°C),
x3 is incubation time (h),
x4 is initial moisture content (%),
x5 is initial pH. Results for the biotechnology case study are given in
Section 3.4.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}