The address mapping scheme includes the load/store schemes and the bank/row mapping formula. Firstly, load/store schemes are used at different stages to maintain the topological structure for any N and to realize normal-ordered I/O operation. Then the bank/row mapping formula is used to map the load/store indexes to realize the in-place and concurrent I/O.
The problem of traditional RFFT architecture is that their address mapping scheme exists bank conflict when considering normal order I/O and in-place operation even under the same parallelism with ours. Besides, their address mapping scheme did not consider the address mapping derivation between frames. In their implementation, they all need an extra permutation to adjust the frame output. Our derived address mapping scheme makes concurrent I/O conflict-free. Meanwhile, as the permutations between stages and frames appear periodically, the address mapping scheme is periodic. Thus the extra permutation can be avoided. In the following, we first demonstrate the load/store scheme including a generalisation of N and P. Then, based on the bank address mapping scheme and in-place constraint, we obtain the periodic presentation of the row address mapping scheme.
For an
N-point RFFT, we use an
-bits counter
to count the clock cycles in each stage. As mentioned before, we use
a to represent the indices of each element. At first, we define a novel address mapping scheme modified from [
8] as an initial condition:
in which,
and ⊕ denotes bit-wise XOR operation.
is the mapped row address for the first stage in the first frame, and
is the mapped bank address in NAT representation.
3.1.1. Conflict-Free Property of the Bank Address Mapping Scheme
For each computation cycle, we use and to represent the ith operand of the kth PE and the ith result of the kth PE, respectively, where and . Specifically, let . We conclude that there are four load/store modes as follows.
(1) In the first stage, each PE inputs 8 real data and outputs 4 real data and 2 complex data. We use
to represent the time domain index of the
ath element. For example, in
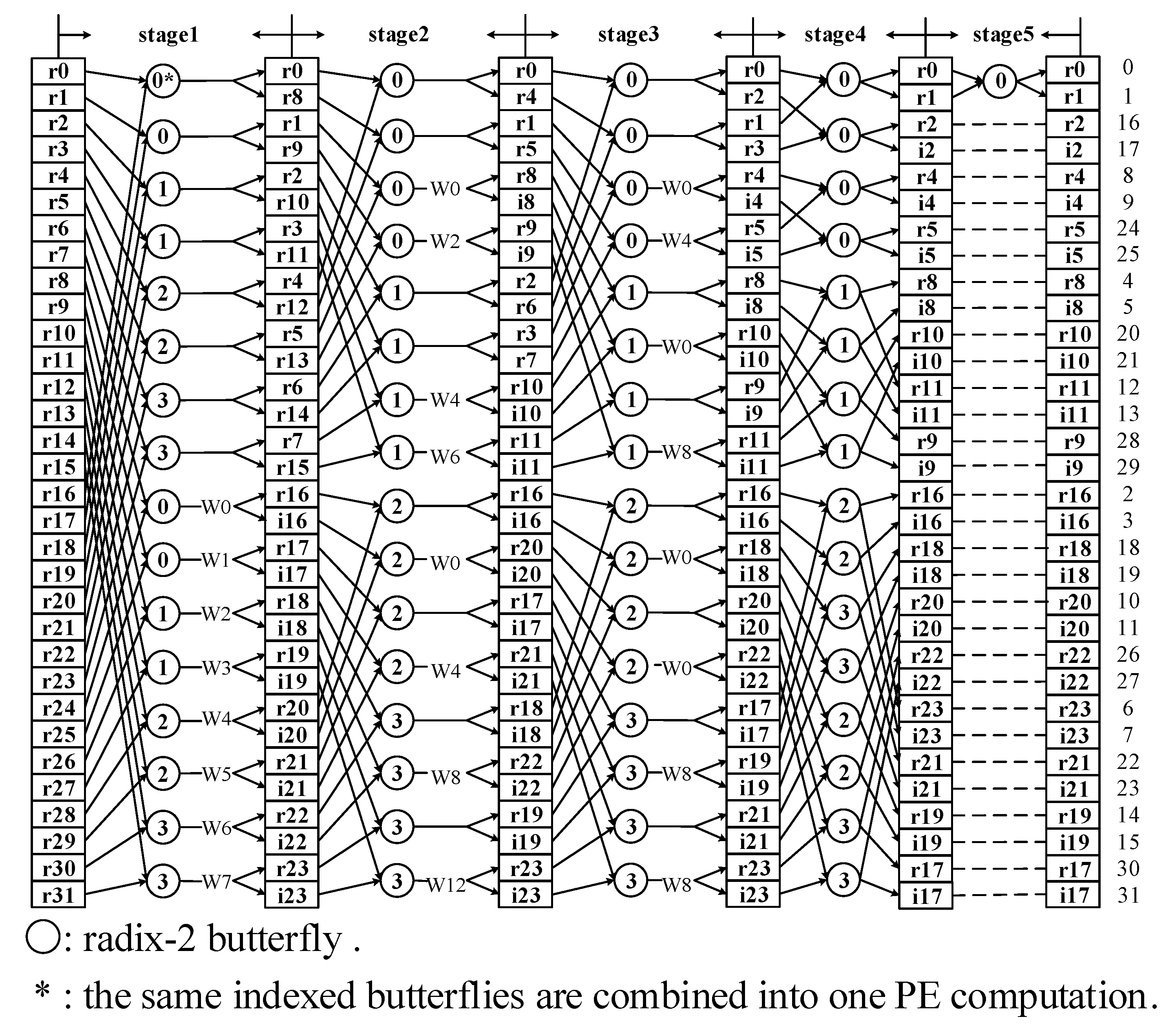
Figure 1, Ti(1) in stage 2 equals to 8. The strategy involves two steps. Step 1 is to float the real outputs in the upper half and to sink the complex outputs in the below half. Step 2 is to arrange the output with odd Ti to locate below those with even Ti. The load/store scheme is given as below:
To avoid bank conflict, the following conditions should be satisfied if
, or
:
In Equation (
5), the variation of
i can be represented by
,
and
, where
is the
mth bit of
. Moreover,
k can be represented by
. According to Equation (4),
,
,
, and
are mapped into the 0th to the
th bit of m(LD) respectively. Therefore, the combinations of
i and
k are one-to-one mapped into
. Therefore, Equation (
7) can be satisfied. Equation (
8) can also be proved to be true. Thus, the conflict-free property of the bank address mapping scheme is proved in the first stage.
(2) The 2nd to the
th stages: we use
s to mark the stage index. In these stages, the load/store scheme can be summarized into two types: type I switches four complex data and type II switches four real data and two complex data. Type I will adopt strategy the same with stage 1. Type II only adopt its second step. Using the two strategies, we can derive that PE computations satisfying
are of type I and the rest are of type II. Moreover, the constant geometry in the [2,
n− 2] stages can be maintained for any N. In all, for
, the following loading/storing scheme is given in Algorithm 1. Similarly, the proposed load and store scheme can be proved to satisfy Equations (
7) and (
8), as all bits of
i and
k are mapped into divided bit-wise locations of the bank address.
| Algorithm 1 Load and store scheme of the stages |
if then
else
end if |
(3) The
th stage: In this stage, symbols with the index
and
are managed in one computation and switched to obtain the frequency domain output in NAT order, where
and the tilde notation means negation operation. The load and store scheme is given in Algorithm 2. The variation of
i and
k can be represented by
,
, ...,
,
, where
. The above
b-bits are one-to-one mapped into the
bits of
as shown in Equation (
4). Similar analysis can be applied to the store scheme. Therefore, bank conflicts can be avoided in the
th stage.
(4) The
nth stage and the I/O mode: In the
nth stage, only the first two data are involved and the store indices equal the load indices. In the I/O mode, the NAT and the REV representations are used in turn. If the input data is mapped in the NAT order, the bank mapping scheme at each stage is the same with Equation (
4). When the input is in the REV order, the bank mapping scheme should be bit-reverse symmetric to Equation (
4), which is given in Equation (
9). Based on the symmetric property, the bank conflict in the I/O mode can be avoided.
| Algorithm 2 Load and store scheme of the th stage |
- 1:
; - 2:
ifthen - 3:
; - 4:
; - 5:
else - 6:
; - 7:
- 8:
- 9:
end if
|
3.1.2. Periodicity of the Row Address Mapping Scheme
The address mapping scheme can be implemented by multiplying
a with a non-singular linear transform matrix
[
9,
10].
m is the mapped bank address generated by
and
r is the row address generated by
. We use
s and
f to mark the stage index and the frame index, respectively. Specially, we consider
s in the I/O mode to equal 0. Therefore,
.
is represented in Equations (
4) and (
9), corresponding to the NAT and REV forms, respectively. Then, the initial row address mapping scheme is given in Equation (
3). Using the two initial conditions and the in-place property, all row address mapping schemes can be calculated in the following recursion manner.
We bring in two assist matrices
and
based on the locations of each bit of
c in
in stage 1 and stage
, respectively. Based on Equation (
5),
. Similarly,
by concatenating the
th to the
th rows and the
th row of
, where
is an
identity matrix. As shown in
Figure 1, three elementary permutation matrices
,
, and
can be used to describe the signal flow graph. We use
to define the bit-reverse permutation,
to define Equation (
1), and
to define Equation (
2).
The three matrices summarize the bit permutations between the load and the store duration. If the bit permutation is an identity transformation, then the address mapping transformation in the previous stage can be reused in the next stage. As
, we obtain
. Therefore, the row address appears as a periodic variation. The address mapping scheme is shown in Algorithm 3, where
is defined using Equations (
3) and (
4). During implementation, the difference of the row address mapping scheme among stages and frames can be uniformed by an
-bit cycle shift register. Using this method, the row address mapping implementation can be simplified.
| Algorithm 3 Address mapping transform algorithm |
- 1:
; - 2:
for to do - 3:
; - 4:
end for - 5:
; - 6:
; - 7:
;
|
Table 1 is an instance of the address mapping scheme, in which one PE is used. Thus, the bank address is of 3-bit width and the row address is of
-bit width. The address mapping scheme is periodic with the frame index and the period is 4. The bank address scheme only needs two formulae (the NAT and REV representations), which is very common in continuous-flow operations. The
-bit row address mapping scheme can be realized with a
-bit cycle shift register
b and some fixed bits of
a. Compared with prior address mapping schemes [
4,
5,
7], the address mapping scheme is further controlled by a 2-bit frame index, which makes it a bit more complex. However, by considering the periodicity among the frames, the address mismatch between the input and output of the same frame is tolerated and the extra permutation is avoided.







{kind=link}
{kind=link}
{kind=link}
{kind=link}