1. Introduction
Methicillin-resistant
Staphylococcus aureus (MRSA) is a growing health concern. It is the agent of many chronic bacterial infections in hospitals as well as in the community. Its resistance to beta-lactamases severely limits treatment options, drives up the price for therapy, increases unwanted side effects, and leads in many cases to worse clinical outcomes [
1]. MRSA has been classified as a high-priority pathogen on the 2017 list of antibiotic-resistant priority pathogens published by the World Health Organization [
2]. Pathogens on this list are considered to pose the greatest threat to human health and to require urgently discovery and development of new antibiotics.
Phage therapy has been proposed as a promising substitute for conventional antibiotics or a co-treatment in the treatment of multi-resistant bacterial pathogens [
3,
4,
5,
6,
7]. Of the
S. aureus phage known to date, most are temperate phages and belong to the Siphoviridae family [
8]. Strictly lytic staphylococcal phages, as are typically required for therapy, are almost exclusively found in the Podoviridae and Myoviridae families [
8].
The Hirszfeld Institute of Immunology and Experimental Therapy of the Polish Academy of Science in Wroclaw (HI) has been producing staphylococcal phages for therapeutic purposes since the 1970s [
9]. At present, its collection consists of nine monovalent staphylococcal phages (see Materials and Methods) [
10]. Those phages are used at the Phage Therapy Unit in Wrocław under the rules of a therapeutic experiment to conduct treatment of patients with chronic bacterial infections resistant to antibiotic therapy. The result have been encouraging, as a good response has been observed in one third of patients [
6].
However, in order for phage therapy to be efficient, it is necessary to have a good understanding of the specific interaction between phage and host. There are many strategies by which bacteria aim to evade predation by phages, which is a significant fitness factor and therefore under high evolutionary pressure.
S. aureus is known to be deficient in CRISPR, one of the major phage defense mechanisms [
11]. Instead, its principle defense against invading DNAs are extensive restriction-modification (RM) systems [
12]. RM systems are two-part system composed of a methylase and a nuclease. The methylase introduces specific modifications on the organism’s DNA, thereby marking it is as self. DNA lacking those modifications, i.e., DNA of foreign origin, will be cleaved by the nuclease. All four types of RM systems known to date are present in
S. aureus [
12]. Another, highly specialized phage defense mechanism is present in the form of staphylococcal pathogenicity islands (SaPIs) [
13]. These mobile genetic elements interfere with the packaging of phage DNA in the late phase of infection, instead packaging and thereby disseminating copies of themselves. However, a small percentage of phage particles are still produced normally, leading to a reduced load of phage progeny instead of a total block. It has been implied that this may be an advantage to
S. aureus as a species as it facilitates gene transfer [
14]. Akin to abortive infection mechanisms, phage resistance by SaPI includes the lysis of the infected cell [
13].
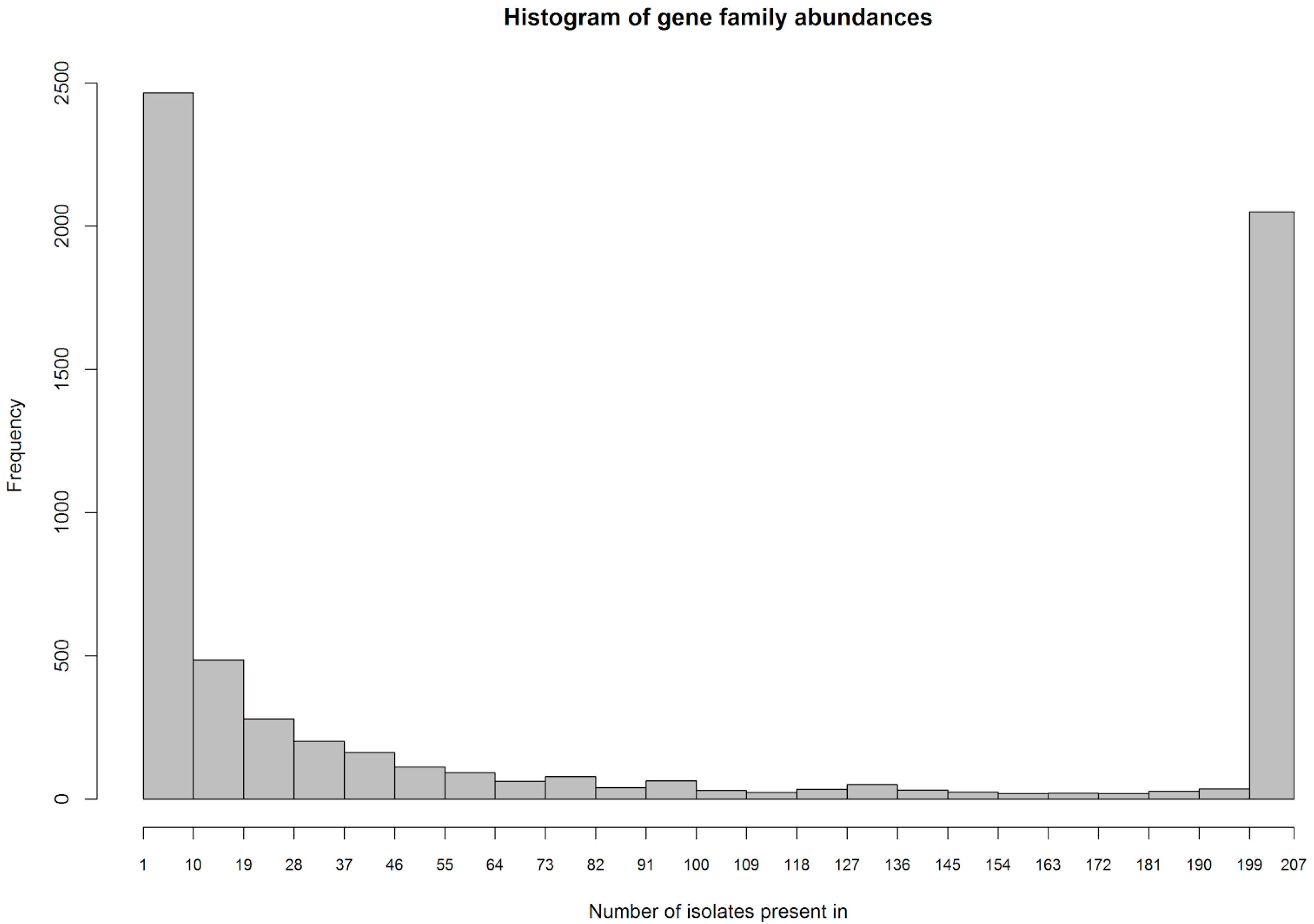
S. aureus is known to have a rather large accessory genome that can make up as much as 25% of total genome size [
8]. We therefore hypothesize in this study that
S. aureus may be carrying accessory genes that encode various mechanisms that are geared toward phage resistance. The presence of such mechanisms may hamper the efficacy of phage therapy, and it is therefore important to study these in order to perform optimization of phages used for treatment. With the advent of affordable high-throughput sequencing methods, it is now becoming possible to determine the whole genome sequences of the infecting strain in a clinical setting, making them accessible to this kind of investigation.
The relationship between
S. aureus and its phages is intricate. A large proportion of
S. aureus virulence factors are phage-encoded [
8], and phages are the major agents of horizontal gene transfer in this species [
11]. Furthermore,
S. aureus is known to harbor prophages with a very high frequency, as detailed in a review by Lindsay in 2010 that states that all
S. aureus sequenced up to that point contained at least one prophage [
15]. In accordance with that, there is a sizeable body of research into staphylococcal phages, their genomes, their influence on their host’s evolution, and their contribution to
S. aureus’ virulence (see for example [
8,
14,
16]). Furthermore, phage susceptibility patterns have been used to classify
S. aureus before the advent of molecular typing methods [
17]. Despite that, there is a distinct lack of studies investigating the genetic basis for phage susceptibility and resistance in
S. aureus from the host perspective, in particular with regard to whole genome approaches as opposed to studies focusing on single loci.
In this study, we seek to elucidate the interplay between
S. aureus and therapeutic phage preparations. To do so, we have tested the susceptibility of a collection of clinical MRSA isolates towards a collection of staphylococcal phage preparations from HI. Both the bacterial and phage collections we used are of great relevance to the phage therapy efforts, since the phages are either already in use or under consideration for experimental therapy in accordance with European Union (EU) rules concerning compassionate use. Furthermore, the bacterial isolates were provided by Hvidovre Hospital in Hvidovre, Denmark and were obtained from patients showing complicated nosocomial MRSA infections. This strain set represents the most prevalent clonal complexes observed in Denmark. MRSA is predominantly imported, making the collection very diverse [
18]. However, it is not representative of MRSA in all localities. The genomes of the bacterial strains were determined by whole genome sequencing and through employing a number of bioinformatics tools and machine-learning methods. We attempted to shed light on the genes of MRSA that play a role in determining the susceptibility or resistance towards phages. A similar approach but with different methodology was proposed by Allen et al., who tested for associations between phage and antibiotic resistance profiles with phylogenetic similarity in
E. coli [
19].
In this way, we aim to contribute to the development of predictive tools of phage susceptibility in the phage therapy–targeted bacteria and ultimately to devising strategies for the prevention, delay, or circumvention of phage resistance in a phage therapy setting.
3. Discussion
In this study, we sought to model the host-genetic determinants of MRSA phage susceptibility with a two-step logistic regression model fitted via ridge regression. We succeeded in building models of acceptable performance for nine of the 12 tested phage preparations with AUCs ranging from 0.65 to 0.87. By doing so, we identified 167 host gene families that influence S. aureus’ interaction with those nine phages.
Our dataset is, with 207 observations, rather small for this type of analysis, since there are many more covariates—i.e., gene families—than observations. We have addressed this by building a two-step model and including a filtering step based on
p-values, thereby greatly reducing the number of covariates going into the analysis. As biological entities are shaped by evolution, the strains share some degree of relatedness, and the testing results are not completely independent observations. We have partitioned the data according to phylogeny in a way that ensures highly similar strains are located to the same partition. Doing that ensures that the observations we are aiming to predict are more independent from the ones we feed into the model during training. The partitioning was maintained at all steps, ensuring that data from highly similar strains was never used to predict the outcome. Furthermore, there was an uneven partitioning of the data due to a high percentage of strains from two very related sequence types, which may lead to bias. The challenge of uneven partitions was addressed by subsampling the oversized partition 1 so we could obtain a realistic distribution of
p-values for the association of all genes to the observed phenotype. Finally, our set of strains with its composition of clonal complexes is specific to Denmark [
18]. It is not necessarily representative of
S. aureus populations observed in different settings.
It should further be noted that our approach can only identify gene families that are part of the accessory genome, since the first selection step is based on differential abundance of those gene families in susceptible vs. resistant strains. Furthermore, this analysis does not consider point mutations as far wild type and mutant version of a gene are more than 90% identical, since we have clustered genes into families with that threshold.
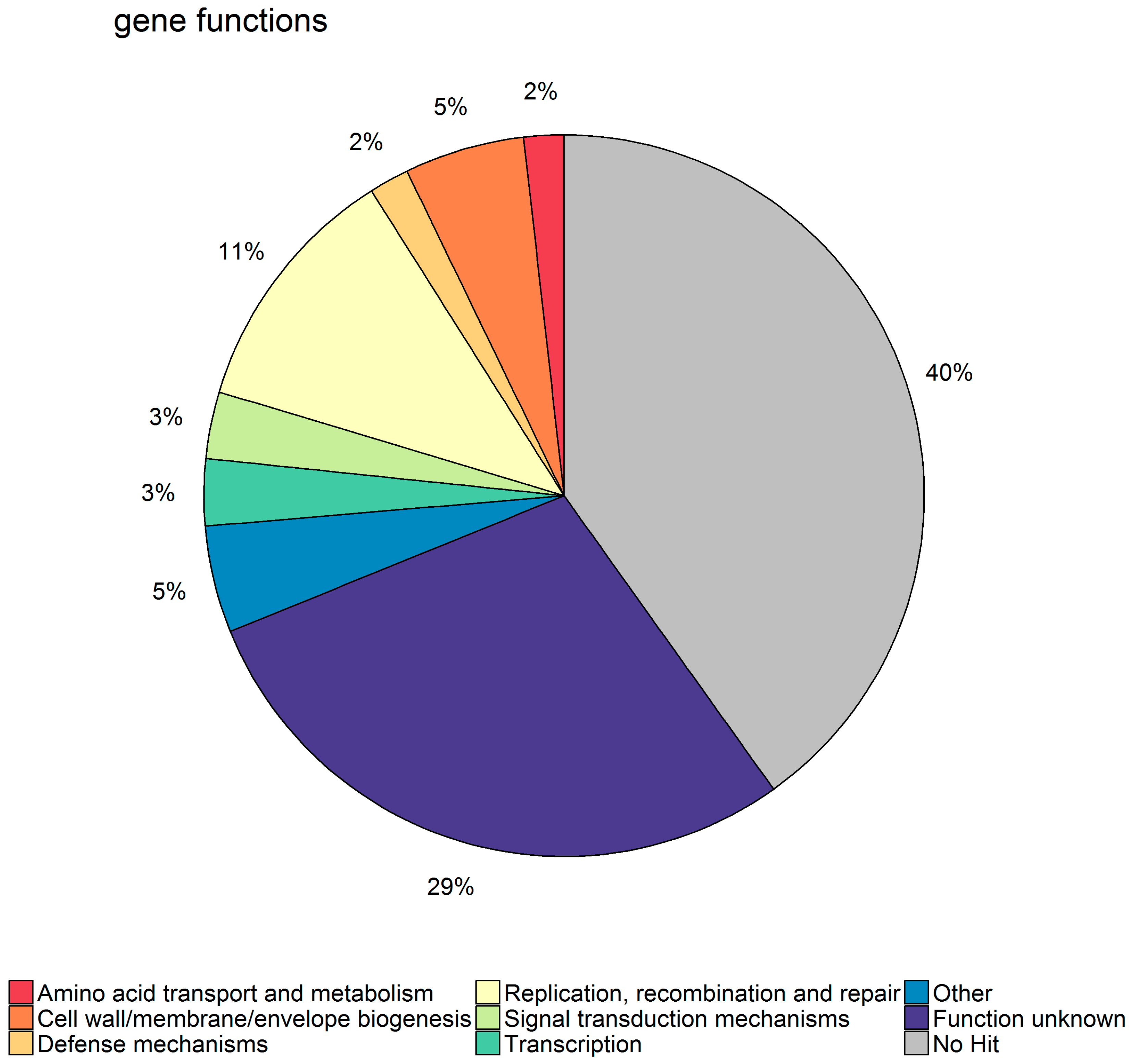
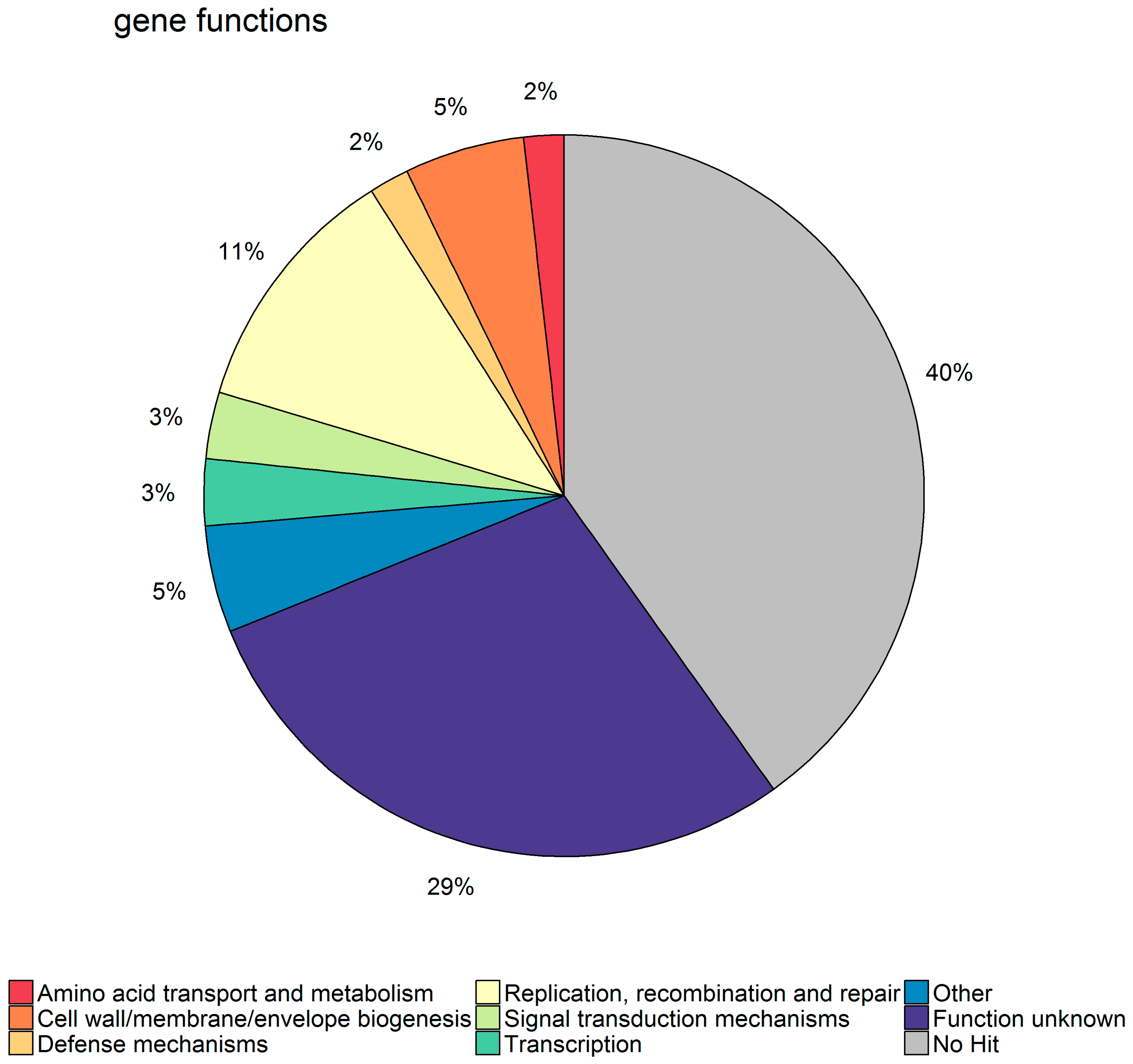
Regarding the electronic gene family annotation, we were able to identify four gene families related to restriction-modification systems and three related the genes found in SaPIs, all of which increased the resistance to phage as expected. Further, six of the significant gene families were related to transcriptional regulation, which fits well with the fact that phages try to shut down host transcription during takeover.
A multitude of gene families found appear to be mobile elements of some kind. Interestingly, Ram et al. have stated that “Most genes involved in phage resistance are carried by plasmids and other mobile genetic elements, including bacteriophages and their relatives” [
14], though this statement is quite possibly related to SaPIs and phage-inducible chromosomal islands (PICIs) in general. Those mobile element related gene families had varying direction of influence. They may be related to the interplay of integrated prophages and external phages, which can either complement each other or oppose each other. An integrated prophage may for example protect from further infection via a principle known as superinfection-exclusion [
21]. For a large proportion of the significant gene families, however, no hit could be found in the eggNOG database, and of those that had a hit, the most common category was “Function unknown”. This may be due to the fact
S. aureus has a large accessory genome that is made up mostly of different types of mobile genetic elements, among them prophages, that are highly diverse and not well characterized [
8]. We have not determined whether either the gene families with hits to phage related proteins or those without hits or with hits to proteins of unknown functions are parts of integrated prophages. Identification of the prophages present in our strain set could add to the interpretation of the analysis; however, it is out of the scope of this study.
We also found that there is only a minor overlap between the sets of significant gene families identified for different phages. This means that each phage had a different and specific interaction with the set of bacterial strains.
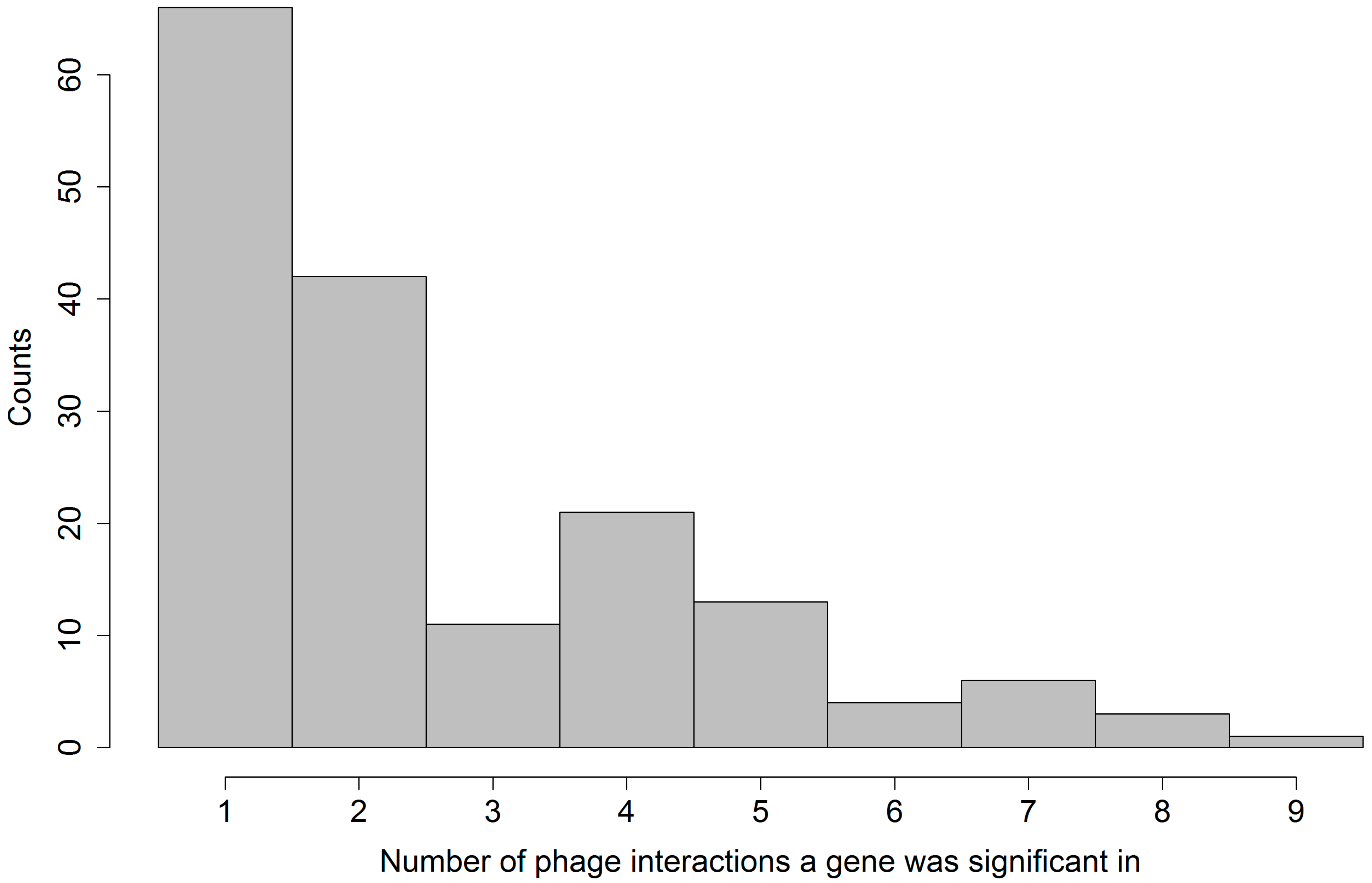
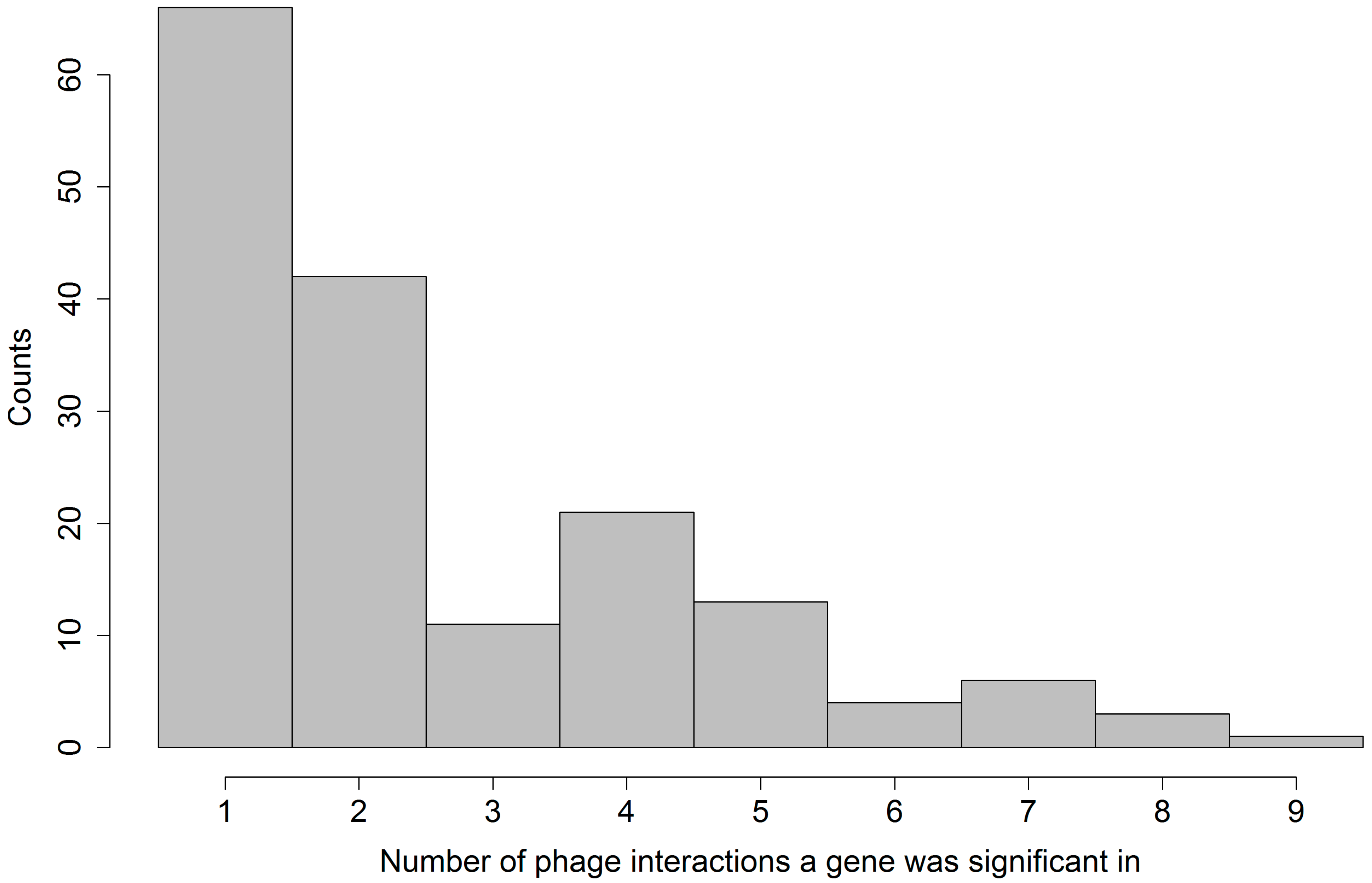
Further, we found that generally more gene families promoted resistance than susceptibility. Among the four gene families that were found significant in interaction with at least eight different phages, three promote resistance, and one was ambiguous (see
Table 3). This overrepresentation of gene families promoting resistance was expected, since in our set-up resistance to phage can more easily be explained by a gain of function model, meaning the gaining of a defense mechanism of which there are plenty found in nature. We were unfortunately unable to identify the nature of the defense mechanism in most resistance promoting gene families from electronic annotation alone.
Conversely, a gain in susceptibility linked to the presence of a certain gene family is more difficult to explain. The most ready interpretation is that these gene families somehow improve conditions for the phage. The observation can also be explained by integrated prophages that may become activated upon infection or stress caused by the adsorption of an external phage and then lyse their host after completing the lytic cycle. Since the products of the bacterial lysis by the phages were not sequenced, we cannot say whether the external, therapeutic phage or an integrated prophage is the agent of the lysis. Intriguingly, evidence of an interplay between virulence and phage resistance has also been shown. Laanto et al. report that after co-cultivation with lytic phage, strains of the fish pathogen
Flavobacterium columnare that have acquired phage-resistance have also lost their virulence compared to phage-sensitive paternal strains [
22]. Similar observations have been made for
S. aureus by Capparelli et al. [
23], who show that phage-resistance is associated with reduced fitness. Accordingly, the opposite correlation may hold as well, meaning that genes associated with higher virulence and host fitness may at the same time effect higher susceptibility to phages. As our strain set was isolated from patients displaying severe
S. aureus infections, it is conceivable that these strains are both very virulent and of high fitness.
In conclusion, we have shown that while our methodology does not have predictive power, it allows for the association of the observed phenotype with the genetic background, thereby producing interpretable results that can be used for gene function discovery. This type of analysis, which combines phenotypic and whole genome sequencing (WGS) data, can be used to identify genetic determinants of observed bacterial phenotypes in other settings as well and is expected to be a useful tool in future analyses of phage-host relationships
4. Materials and Methods
4.1. Collection of Clinical MRSA Strains Used for Susceptibility Testing
The collection of 207 MRSA strains tested in this project as well as their whole genome sequences (WGS) were obtained from the Clinical Microbiology Department of Hvidovre Hospital, Hvidovre, Denmark. The strains originate from patient samples. They were selected to represent a broad genetic diversity of the more than 5000 WGS MRSA from Hvidovre Hospital. The fasta sequences of the 207 selected strains have been submitted to the European Nucleotide Archive (Hinxton, Cambridgeshire, UK) [
24] with the accession numbers ERZ485118–ERZ485325. They can be viewed under the link:
http://www.ebi.ac.uk/ena/data/view/<Accession Numbers>.
Although no methicillin-sensitive (MSSA) strains were included in the study, we nonetheless chose MRSA strains of the spa-types that are common in MSSA infections [
25]. Spa-typing is a single-locus classification scheme for
S. aureus based on the polymorphic region in protein A [
26]. We included MRSA strains positive for PVL and containing
mecC. All inclusion criteria are listed
Supplementary Section 1 ‘List of inclusion criteria for MRSA strains’ and the properties of selected isolates can be found in the
Supplementary Table S3.
4.2. Collection of Phages Used for Susceptibility Testing
A total of 12 therapeutic staphylococcal phage preparations were used for susceptibility testing. They contain phages which are part of the proprietary collection of therapeutic phages used by the phage therapy unit of the Hirszfeld Institute of Immunology and Experimental Therapy of the Polish Academy of Science in Wroclaw (HI) [
27]. Nine of the preparations are monovalent phage lysates: 1N/80, 676/F, 676/T, 676/Z, A3/R, A5/L, A5/80, P4/6409, and phi200/6409. Crude phage lysates were prepared according to the modified method of Ślopek et al. [
9]. Six of those phages (1N/80, 676/Z, A3/R, A5/80, P4/6409, and phi200/6409) were sequenced and confirmed to be obligatory lytic and belonging to a Twortlikevirus genus of a Spounavirinae subfamily of Myoviruses. A detailed report on characteristics of these six phages can be found in Łobocka et al. [
28]. All monovalent phage preparations were standardized to routine test dilution (RTD) and had a titer between 10
6 and 10
8. RTD is the highest dilution that still gives confluent lysis on the designated propagating strain of
S. aureus [
17] and the standardization method of choice at HI.
MS.1, OP_MS.1, and OP_MS.1_TOP were equal mixtures of A5/80, P4/6409, and 676/Z phages prepared at the Institute of Biotechnology, Sera and Vaccines BIOMED S.A. in Cracow, Poland. MS-1 phage cocktail lysate contained each component phage in a titer no less than 5 × 10
5 pfu/mL, OP_MS-1_TOP cocktail of purified phages was suspended in phosphate buffered saline containing each phage at no less than 10
9 pfu/mL [
29], and OP_MS-1 phage cocktail had similar characteristics as OP_MS-1_TOP but contained up to 10% of saccharose as a phage stabilizer.
4.3. Susceptibility Testing Procedure
Testing for phage susceptibility was performed as described by Ślopek et al. [
30]. In short, 50 μL of phage preparation was applied onto a fresh bacterial lawn from day culture and the results were assessed the next day following 6 h incubation at 37 °C.
Results were assessed according to a 7-point scale as described by Ślopek et al. [
30] and shortly summarized in the
supplement Section 9 ‘Details on susceptibility testing as described by Ślopek et al.’ Results were further discretized into two levels: “susceptible” and “resistant”. The “susceptible” label was applied to the two strongest reactions, resulting in confluent or semi confluent lysis. According to standards applied at the Bacteriophage Laboratory of the HI, those two levels enable the phage procurement for therapeutic phage preparation. All other weak reactions as well as a negative reaction and opaque lysis were regarded as “resistant”. Susceptibility testing results in these two levels, as used for the modelling, can be found in
Table 1, while
Supplementary Table S4 details results in three levels: resistant, weakly susceptible and strongly susceptible.
The full set of 207 strains was challenged with each of the 12 phage preparations. We call the result of susceptibility testing to a preparation the “interaction” of our strain set with said phage.
4.4. Data Partitioning
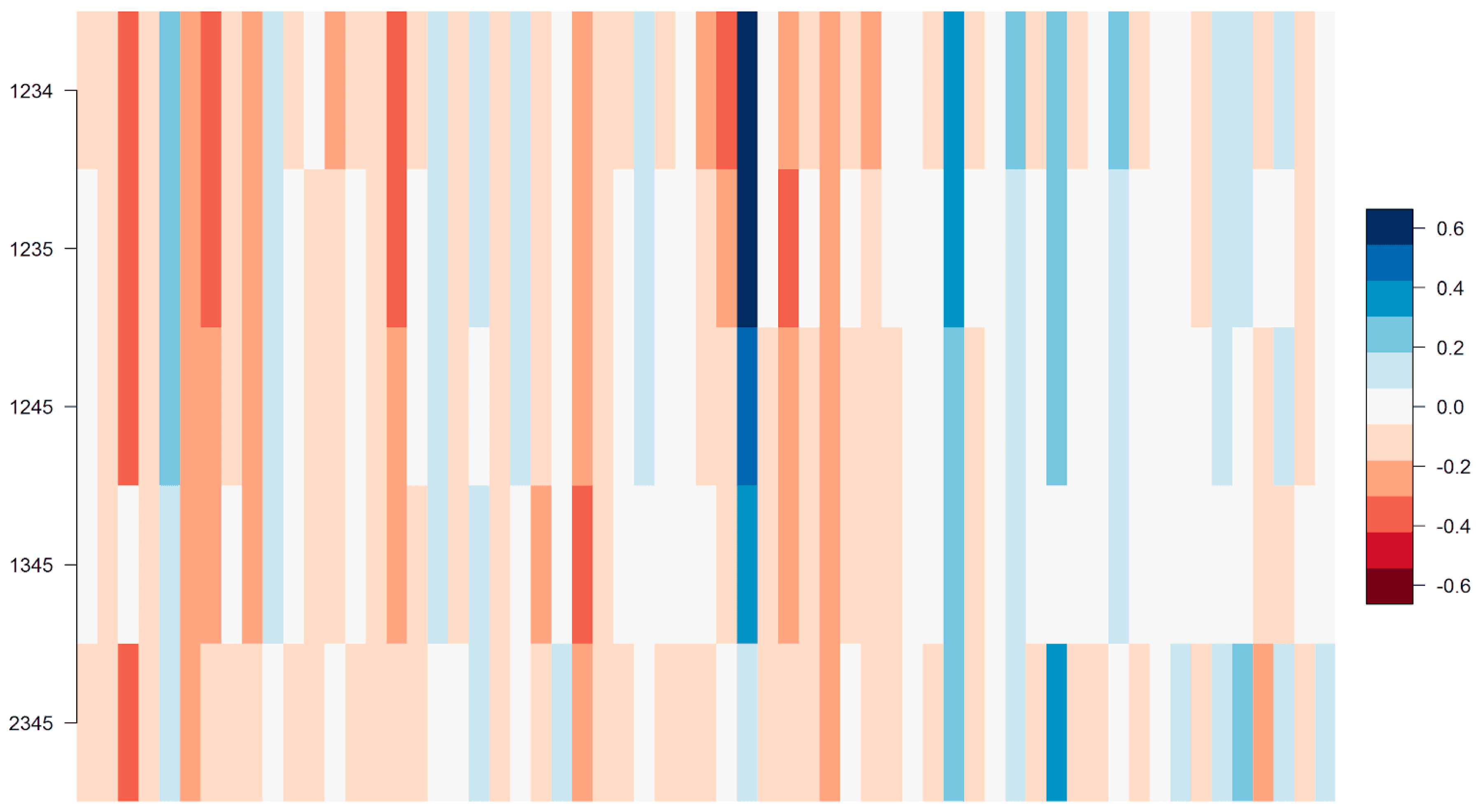
For the purpose of modelling the phage response from the genomic composition of the bacterial strains, the 207 MRSA strains were divided into five partitions. This division was based on the orthogonal average nucleotide identity (orthoANI) as described by Lee et al. [
31]. OrthoANI is suitable for creating a distance matrix, because it is a symmetric measure of distance, unlike the traditional ANI. Calculations were performed on all pairs of strains with the standalone tool OAT by Lee et al. Distances were subsequently calculated as 1-orthoANI, and a heat map was generated that can be found in
Figure 1.
The resulting heat map showed very clear clusters of closely related sequences. Partitioning was therefore done by visual inspection.
The partitions thus obtained were then used in a five-fold cross validation framework, i.e., four of them were combined into the training set, and one was left out for testing. This process was repeated five times so that each partition was in turn the testing set.
4.5. Model Framework
We sought to model a binary outcome (resistant/susceptible) based on weighted binary features (absence/presence of gene families). Logistic regression models were chosen for this task and set-up inside a five-fold cross validation. Each cross validation fold was trained using a Ridge regression to avoid overfitting. A nested cross validation was used to identify the optimal parameter for the Ridge penalty lambda.
Due to challenges posed by the large feature space, the modelling was further split into a two-step process: a first-step model in which we performed feature selection by association testing, and a second-step model whose features were selected based on the regression weights obtained from the first model. The following sections describe details of each modelling step.
4.6. Feature Selection by Association Testing
The genetic background of the MRSA strains was established by first predicting genes and performing functional annotation through the RAST service [
32] for all 207 strains. The predicted genes were then clustered with cd-hit [
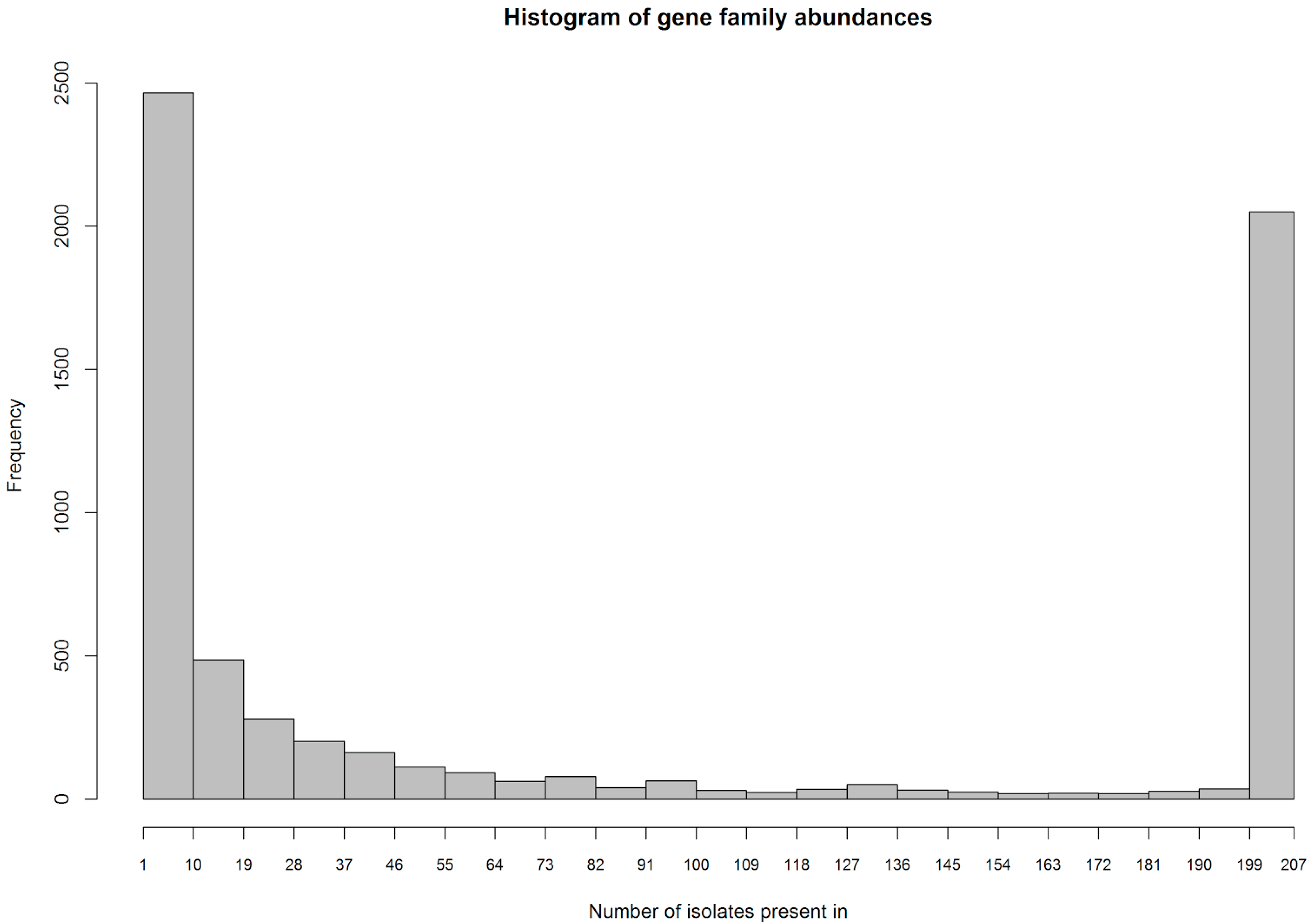
33] using a cutoff of 90% on global sequence identity, word size 5 and the -g 1 option to cluster with the best match instead of the first match. This resulted in a total of 6.419 gene families in the 207 MRSA strains.
Next, the feature space, i.e., the number of gene families included in the model, was reduced by removing gene families with limited power for distinguishing susceptible from non-susceptible bacterial strains. This was done by constructing 2 × 2 contingency tables as illustrated in
Supplementary Table S5, and from these tables calculating a
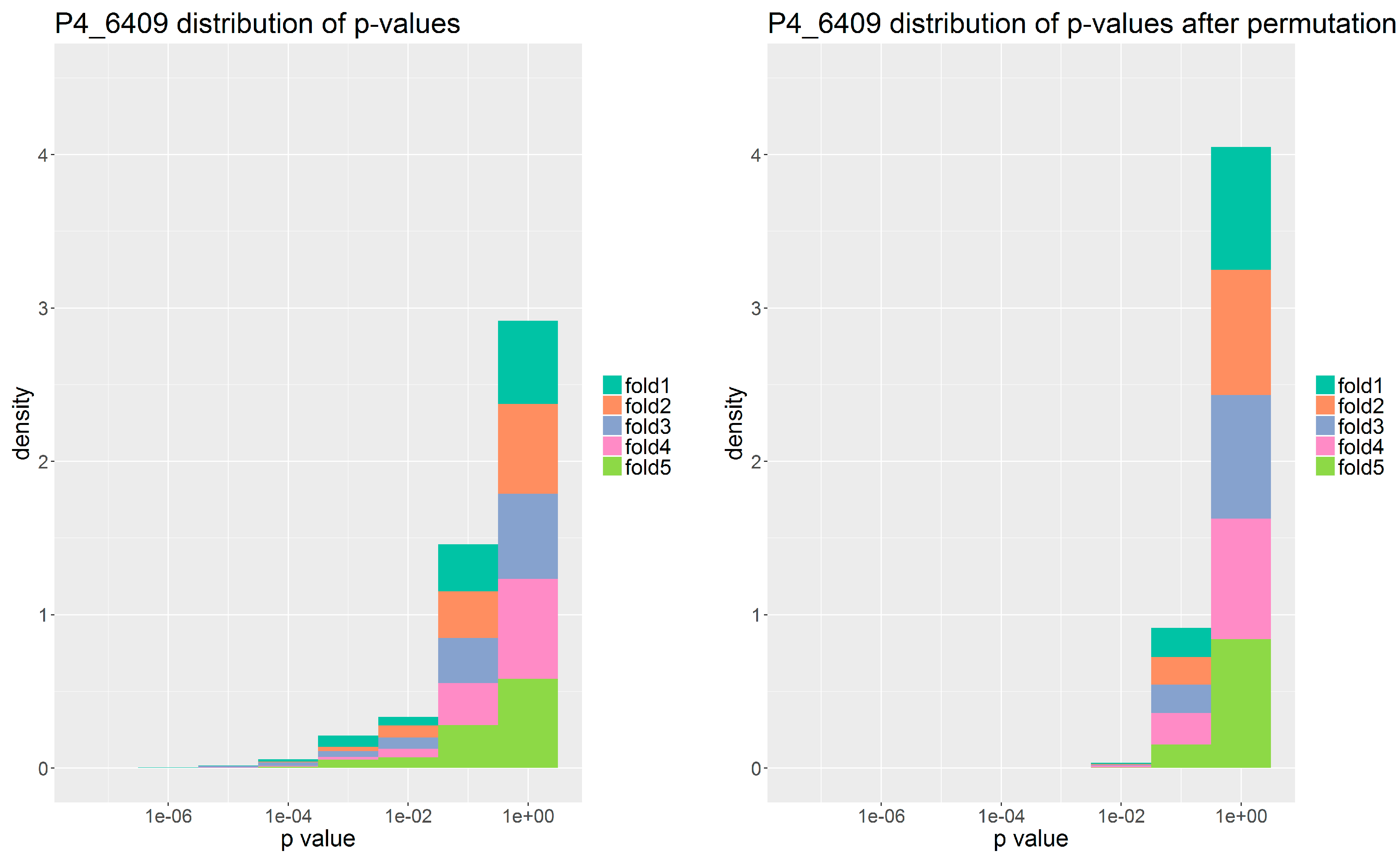
p-value to each gene family in each phage interaction using Fischer-Boschloo’s exact unconditional test. We then imposed a threshold of 0.01 on the
p-value for the gene family to be admitted to the second step of modelling.
As can be seen in
Figure 1, one of the partitions was significantly larger than the other four. This obliged us to employ bootstrapping in every fold that included partition 1 so as to not bias the feature selection on partition size. Details to this can be found in the
Supplementary Section 10 ‘Details on Feature selection by association testing’.
4.7. Feature Selection by Regression Weights
Due to the five-fold cross validation setup, each gene family was assigned five regression weights for interaction with each phage preparation. These may be NA (not applicable) if the gene family was not chosen by association testing for that fold. Weights can be either positive or negative. As we chose to model susceptibility as the positive outcome and resistance as the negative outcome, this means that positive weights point towards increased susceptibility, while negative weights point towards increased resistance.
We hypothesized that gene families with a high weight across many folds drive the response to this particular phage. Therefore, we next trained and tested a second five-fold cross validated regression model with only the genes that (1) were significant according to the Fischer-Boschloo’s test (p ≤ 0.01) and (2) had absolute regression weights greater or equal to 0.01 in at least three folds in the first regression model. We term the gene families selected in this fashion the set of significant gene families. They are the main focus of this study as they are thought to be driving the response to the tested phage preparations.
In order to verify that the set of gene families we identified were indeed descriptive of the phage susceptibility and not an artifact of overfitting, we repeated the model construction and feature selection with shuffled target values. That is, we randomly associated susceptibility outcomes and bacterial genomes while keeping the ratio between susceptible and resistant as in the original data. We then re-ran the modelling and evaluated the predictive performance and the number of predictive gene-families identified.
4.8. Assignment of eggNOGs
We compared each selected gene family to the eggNOG database [
34] by using the eggNog-mapper available on their webpage. eggNOG is a database of non-supervised orthologous groups (NOG) of proteins based on the clustering of the 9.6 million proteins from 2031 genomes. Each NOG has only one annotation term compiled from the integrated and summarized functional annotation of its group members, as well as being part of a broader functional category. EggNOG was chosen primarily because of this functional category assignment that allows a broad overview of the functions present in a set of genes.
To estimate whether the observed distribution of functional categories in the set of significant gene families was different from what could be expected by chance, we employed the cumulative density function (CDF). We first drew 10,000 random subsamples of the same size as the full set of significant genes families from the total set of 6419 gene families. From these data, we established an estimated cumulative density function (eCDF) for each functional category. We could then calculate likelihoods for each category of obtaining the actual observed frequency or lower or, conversely, the actual observed frequency or higher.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}