
Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Collection and Data Set Construction
2.1.1. Collection of Tea Samples
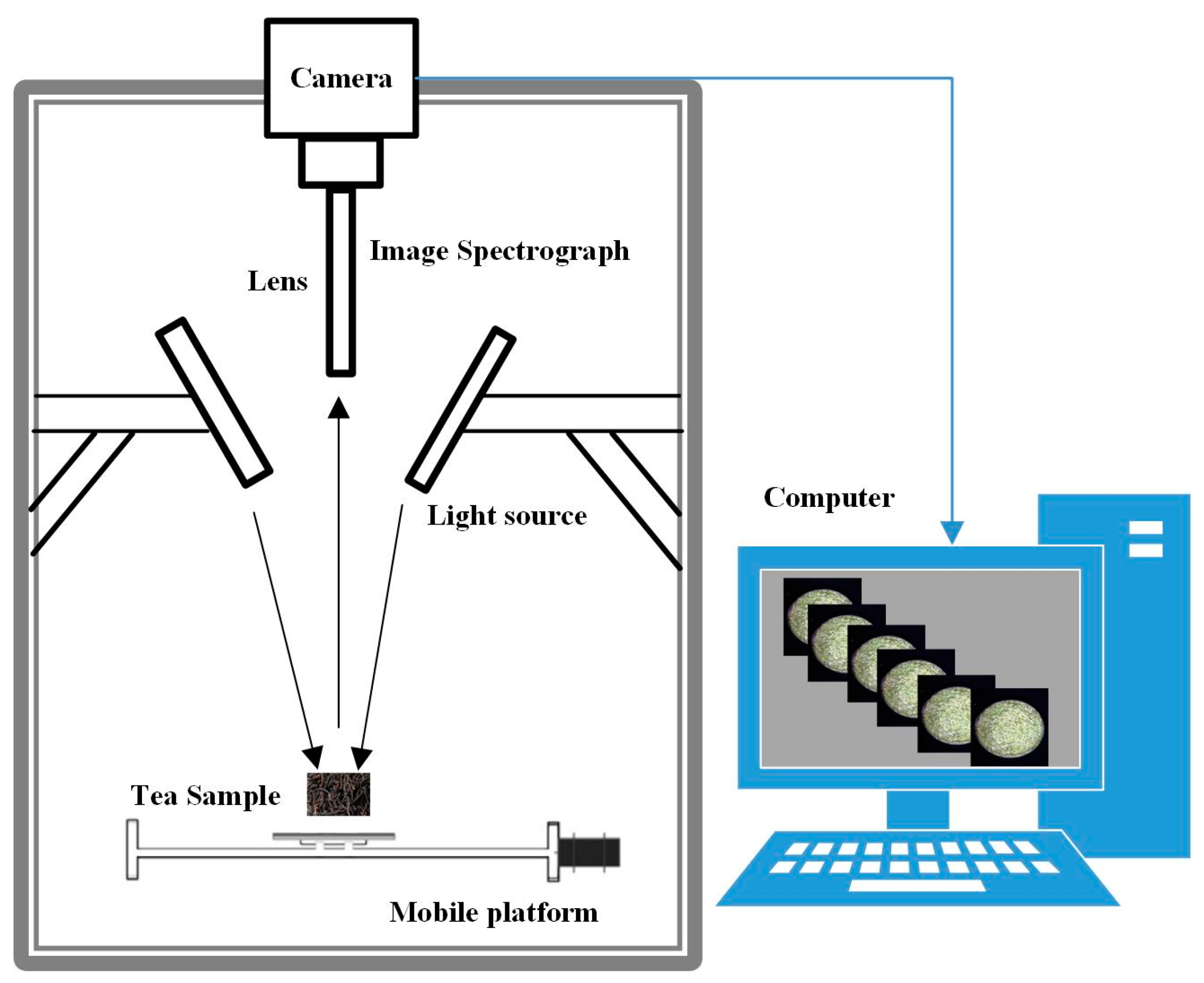
2.1.2. Acquisition of Hyperspectral Images of Tea
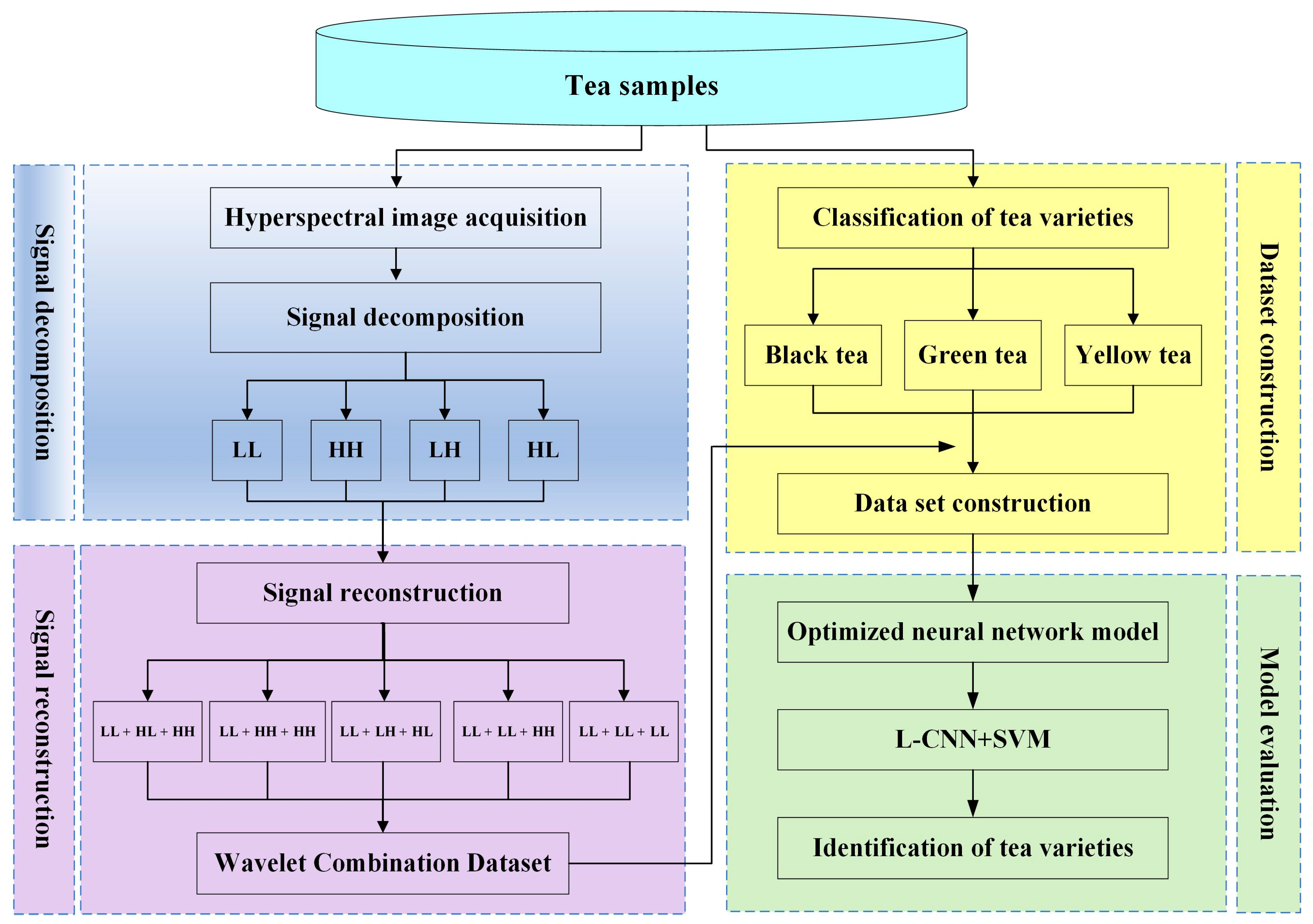
2.2. Method
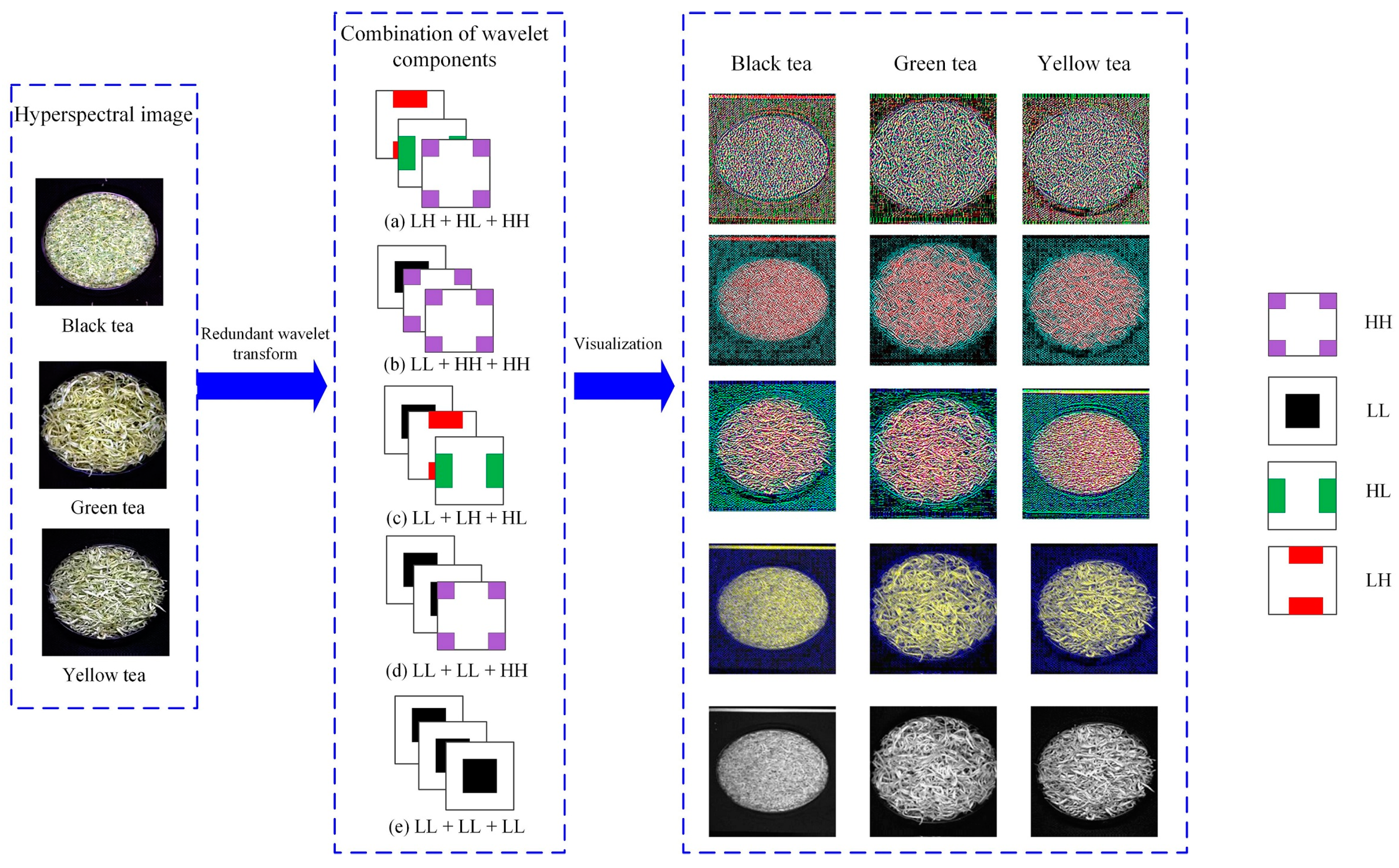
2.2.1. Decomposition and Reconstruction of Image Signal by Wavelet
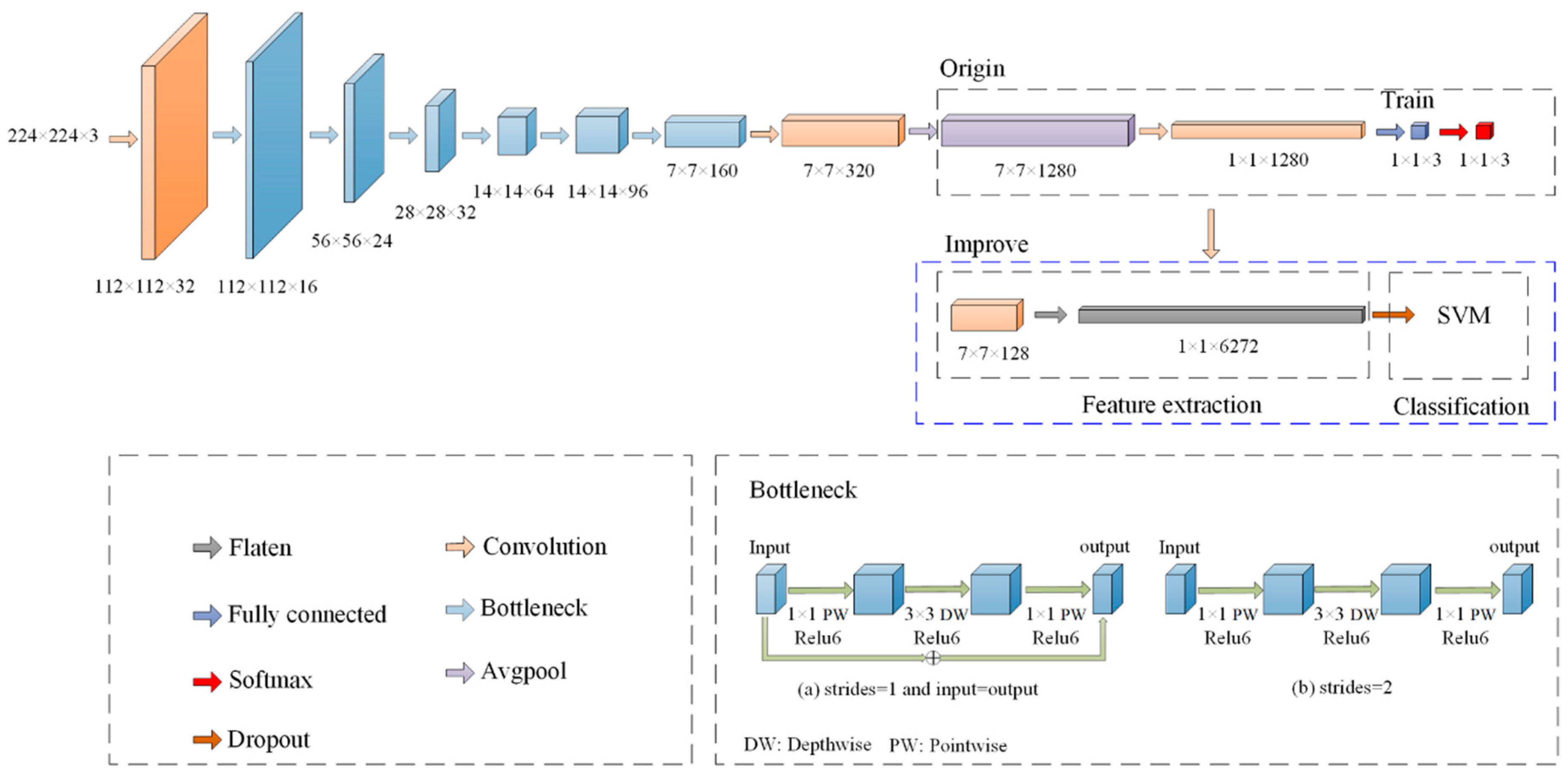
2.2.2. Classification Model Based on Improved Lightweight CNN
2.2.3. Tea Classification Model Based on Optimized L-CNN
2.2.4. Evaluation Indicator of Classification Model
3. Results
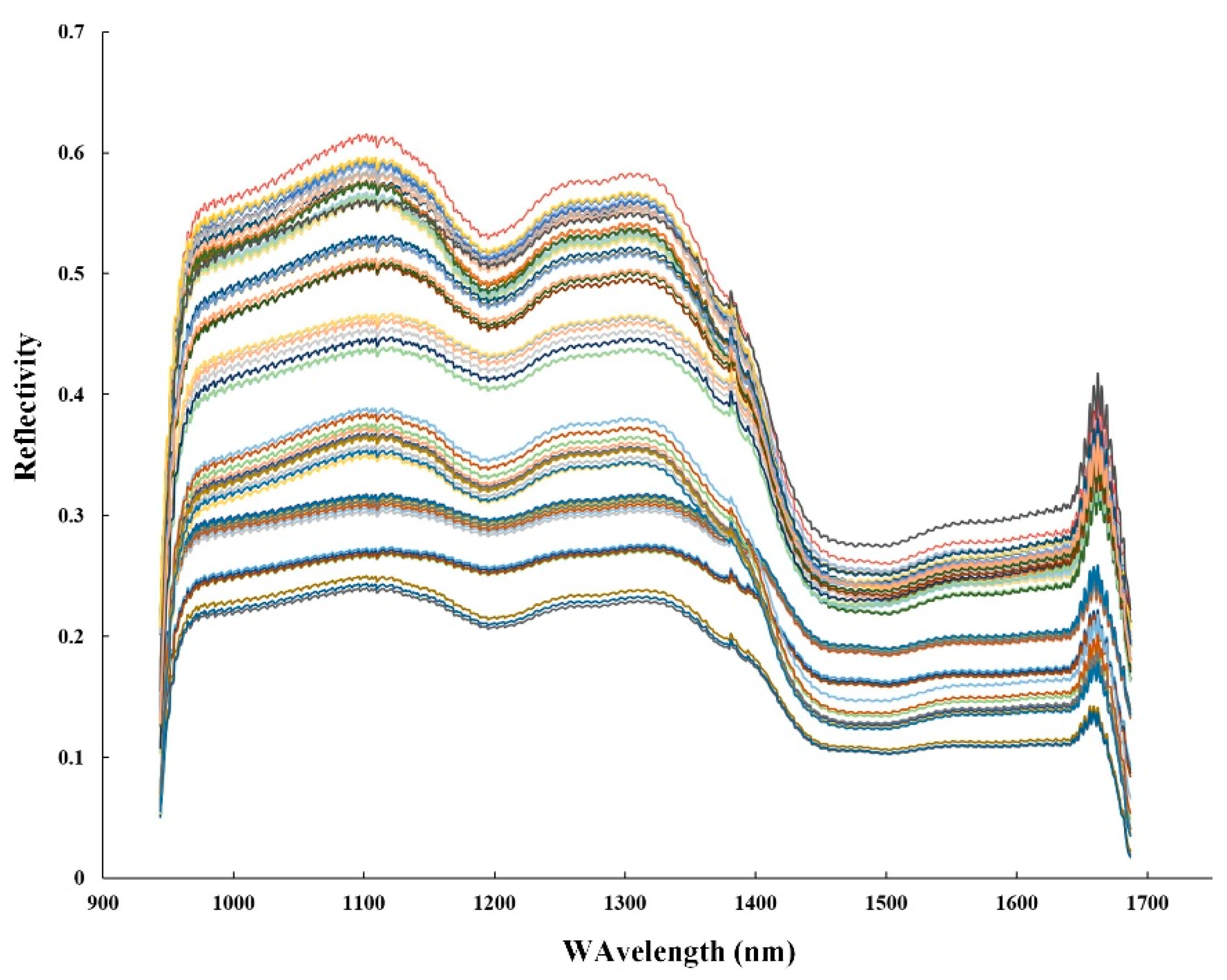
3.1. Hyperspectral Images and Spectral Reflectance of Different Types of Tea
3.2. Multi-Component Combination of Wavelet Decomposition of Hyperspectral Image of Tea
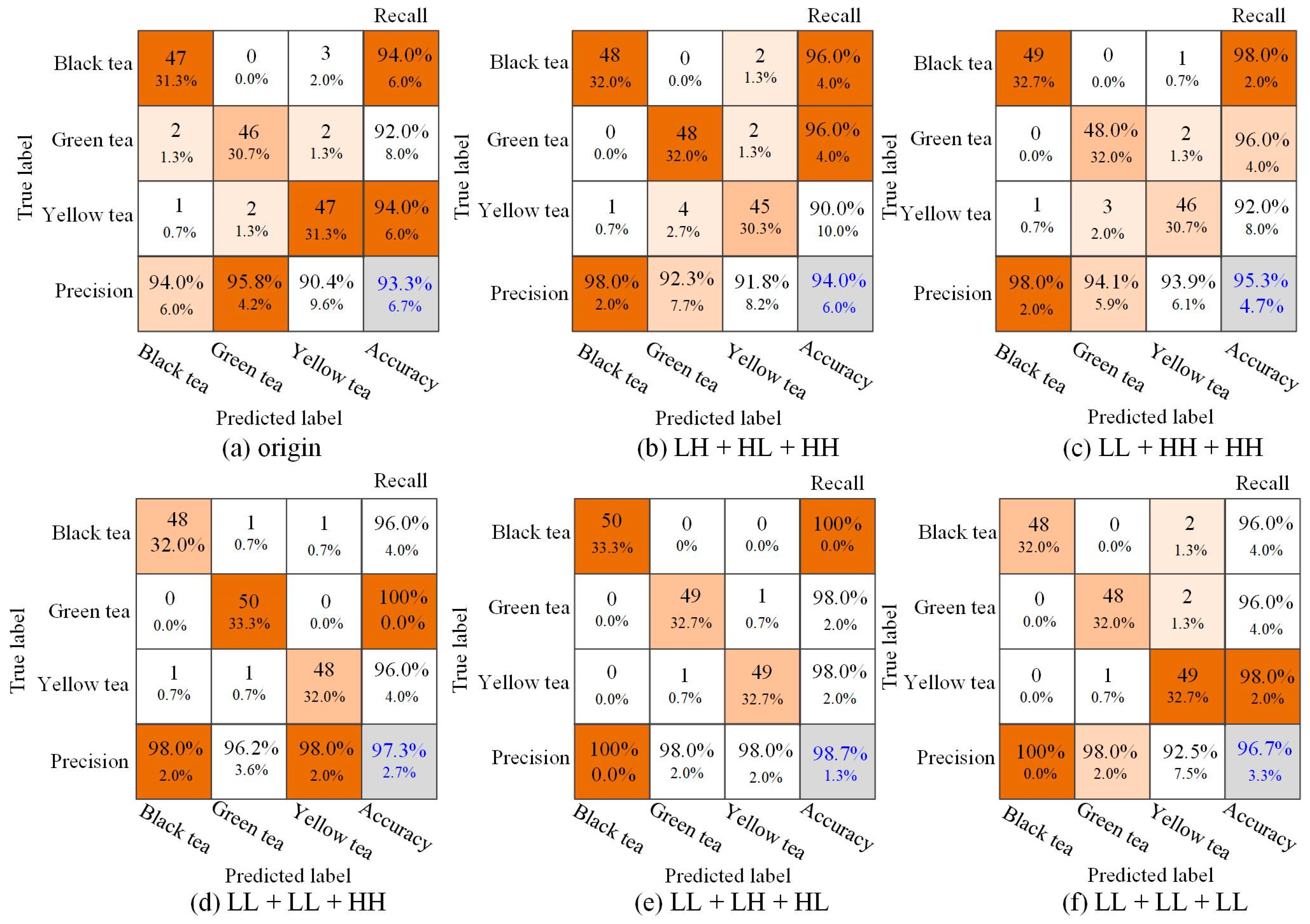
3.3. Tea Classification Results Based on the L-CNN-SVM Model
4. Discussion
4.1. Compare Tea Classification Based on Different Wavelet Component Combinations
4.2. Compare Classification Results Based on Different Deep Learning Models
4.3. Different Network Visualization Based on Grad-CAM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sereshti, H.; Samadi, S.; Jalali-Heravi, M. Determination of volatile components of green, black, oolong and white tea by optimized ultrasound-assisted extraction-dispersive liquid–liquid microextraction coupled with gas chromatography. J. Chromatogr. A 2013, 1280, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Yohei, S.; Masahito, S. Possible mechanisms of green tea and its constituents against cancer. Molecules 2018, 23, 2284. [Google Scholar]
- Kujawska, M.; Ewertowska, M.; Adamska, T.; Jodynis-Liebert, J.; Ignatowicz, E.; Gramza-Michalowska, A. Protective effect of yellow tea extract on N-nitrosodiethylamine-induced liver carcinogenesis. Pharm. Biol. 2016, 54, 1891–1900. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kujawska, M.; Ewertowska, M.; Ignatowicz, E.; Adamska, T.; Szaefer, H.; Gramza-Michalowska, A.; Jodynis-Liebert, J. Evaluation of safety and antioxidant activity of yellow tea (Camellia sinensis) Extract for Application in Food. J. Med. Food 2016, 19, 330–336. [Google Scholar] [CrossRef]
- Adhikary, B.; Yadav, S.K.; Roy, K.; Bandyopadhyay, S.K.; Chattopadhyay, S. Black tea and theaflavins assist healing of indomethacin-induced gastric ulceration in mice by antioxidative action. Evid. Based Complement. Altern. Med. 2011, 8, 546560. [Google Scholar] [CrossRef]
- Qin, Z.H.; Pang, X.L.; Dong, C.; Cheng, H.; Hu, X.S.; Wu, J.H. Evaluation of Chinese tea by the electronic nose and gas chromatography–mass spectrometry: Correlation with sensory properties and classification according to grade level. Food Res. Int. 2013, 53, 864–874. [Google Scholar] [CrossRef]
- Li, X.L.; Zhang, Y.Y.; He, Y. Study on Detection of Talcum Powder in Green Tea Based on Fourier Transform Infrared (FTIR) Transmission Spectroscopy. Spectrosc. Spectr. Anal. 2017, 37, 1081–1085. [Google Scholar]
- Hong, Z.L.; Ze, J.L.; Hua, J.L.; Shu, J.S.; Feng, N.C.; Kai, H.W.; Da, Z.M. Robust Classification of Tea Based on Multi-Channel LED-Induced Fluorescence and a Convolutional Neural Network. Sensors 2019, 19, 4687. [Google Scholar]
- Bhattacharya, N.A.; Tudu, B.B.; Jana, A.A.; Ghosh, D.A.; Bandhopadhyaya, R.B.; Bhuyan, M.C. Preemptive identification of optimum fermentation time for black tea using electronic nose. Sens. Actuators B Chem. 2008, 131, 110–116. [Google Scholar] [CrossRef]
- Chen, Q.S.; Zhao, J.W.; Chen, Z.; Lin, H.; Zhao, D.A. Discrimination of green tea quality using the electronic nose technique and the human panel test, comparison of linear and nonlinear classification tools. Sens. Actuators B Chem. 2011, 159, 294–300. [Google Scholar] [CrossRef]
- Yu, H.C.; Wang, Y.W.; Wang, J. Identification of Tea Storage Times by Linear Discrimination Analysis and Back-Propagation Neural Network Techniques Based on the Eigenvalues of Principal Components Analysis of E-Nose Sensor Signals. Sensors 2009, 9, 8073–8082. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sinija, V.R.; Mishra, H.N. Fuzzy Analysis of Sensory Data for Quality Evaluation and Ranking of Instant Green Tea Powder and Granules. Food Bioprocess Technol. 2011, 4, 408–416. [Google Scholar] [CrossRef]
- Bhattacharyya, N.; Bandyopadhyay, R.; Bhuyan, M.; Tudu, B.; Ghosh, D.; Jana, A. Electronic Nose for Black Tea Classification and Correlation of Measurements with “Tea Taster” Marks. IEEE Trans. Instrum. Meas. 2008, 57, 1313–1321. [Google Scholar] [CrossRef]
- Yu, H.C.; Wang, J.; Yao, C.; Zhang, H.M.; Yu, Y. Quality grade identification of green tea using E-nose by CA and ANN. LWT—Food Sci. Technol. 2008, 41, 1268–1273. [Google Scholar] [CrossRef]
- Laddi, A.; Prakash, N.R.; Sharma, S.; Kumar, A. Discrimination analysis of Indian tea varieties based upon color under optimum illumination. J. Food Meas. Charact. 2013, 7, 60–65. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, J.; Cai, J. Identification of tea varieties using computer vision. Trans. ASABE 2008, 51, 623–628. [Google Scholar] [CrossRef]
- Kelman, T.; Ren, J.C.; Marshall, S. Effective classification of Chinese tea samples in hyperspectral imaging. J. Artif. Intell. Res. 2013, 2, 87. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.W.; Chen, Q.S.; Cai, J.R.; Ouyang, Q. Automated tea quality classification by hyperspectral imaging. Appl. Opt. 2009, 48, 3557–3564. [Google Scholar] [CrossRef]
- Tu, Y.X.; Bian, M.; Wan, Y.K.; Fei, T. Tea cultivar classification and biochemical parameter estimation from hyperspectral imagery obtained by UAV. PeerJ 2018, 6, e4858. [Google Scholar] [CrossRef] [Green Version]
- Sohara, Y.; Ryu, C.; Suguri, M.; Park, S.B.; Kishino, S. Estimation of catechins concentration of green tea using hyperspectral remote sensing. IFAC Proc. Vol. 2010, 43, 172–177. [Google Scholar] [CrossRef]
- Yang, B.H.; Gao, Y.; Li, H.M.; Ye, S.B.; He, H.X.; Xie, S.R. Rapid prediction of yellow tea free amino acids with hyperspectral images. PLoS ONE 2019, 14, e0210084. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmad, H.; Sun, J.; Nirere, A.; Shaheen, N.; Zhou, X.; Yao, K.S. Classification of tea varieties based on fluorescence hyperspectral image technology and ABC-SVM algorithm. J. Food Process. Preserv. 2021, 45, e15241. [Google Scholar] [CrossRef]
- Ning, J.M.; Sun, J.J.; Li, S.H.; Sheng, M.G.; Zhang, Z.Z. Classification of five Chinese tea categories with different fermentation degrees using visible and near infrared hyperspectral imaging. Int. J. Food Prop. 2017, 20, 1515–1522. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Tang, K.; Wu, X.H.; Dai, C.X.; Chen, Y.; Shen, J.F. Nondestructive identification of green tea varieties based on hyperspectral imaging technology. J. Food Process Eng. 2018, 41, e12800. [Google Scholar] [CrossRef]
- Yu, Y.J.; Wang, Q.Q.; Wang, B.Y.; Chen, J.; Sun, W.J. Identification of tieguanyin tea grades based on hyperspectral technology. Food Sci. 2014, 35, 159–163. [Google Scholar]
- Ge, X.; Sun, J.; Lu, B.; Chen, Q.S.; Xun, W.; Jin, Y.T. Classification of oolong tea varieties based on hyperspectral imaging technology and BOSS-LightGBM model. J. Food Process Eng. 2019, 42, e13289. [Google Scholar] [CrossRef]
- Matsuyama, E.; Tsai, D.Y.; Lee, Y.; Tsurumaki, M.; Takahashi, N.; Watanabe, H.; Chen, H.M. A modified undecimated discrete wavelet transform based approach to mammographic image denoising. J. Digit. Imaging 2013, 26, 748–758. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.H.; Qi, L.; Wang, M.X.; Hussain, S.; Wang, H.B.; Wang, B.; Ning, J.M. Cross-category tea polyphenols evaluation model based on feature fusion of electronic nose and hyperspectral imagery. Sensors 2020, 20, 50. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Yang, J.; Wang, S. Tea category identification based on optimal wavelet entropy and weighted k-nearest neighbors algorithm. J. Multimed. Tools Appl. 2018, 77, 3745–3759. [Google Scholar] [CrossRef]
- Bakhshipour, A.; Zareiforoush, H.; Bagheri, I. Application of decision trees and fuzzy inference system for quality classification and modeling of black and green tea based on visual features. J. Food Meas. Charact. 2020, 14, 1402–1416. [Google Scholar] [CrossRef]
- Borah, S.; Hines, E.; Bhuyan, M. Wavelet transform based image texture analysis for size estimation applied to the sorting of tea granules. J. Food Eng. 2007, 79, 629–639. [Google Scholar] [CrossRef]
- Zhang, Y.D.; Muhammad, K.; Tang, C. Twelve-layer deep convolutional neural network with stochastic pooling for tea category classification on GPU platform. J. Multimed. Tools Appl. 2018, 77, 22821–22839. [Google Scholar] [CrossRef]
- Hasan, M.M.; Chopin, J.P.; Laga, H.; Miklavcic, S.J. Detection and analysis of wheat spikes using convolutional neural networks. J. Plant Methods 2018, 14, 100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El-Latif, E.; Taha, A.; Zayed, H.H. A passive approach for detecting image splicing based on deep learning and wavelet transform. J. Arab. J. Sci. Eng. 2020, 45, 3379–3386. [Google Scholar] [CrossRef]
- Qi, Z.; Jung, C.; Xie, B. Subband Adaptive Image Deblocking Using Wavelet Based Convolutional Neural Networks. IEEE Access 2021, 9, 62593–62601. [Google Scholar] [CrossRef]
- Wang, Z.; Li, X.; Duan, H.; Zhang, X.; Wang, H. Multifocus image fusion using convolutional neural networks in the discrete wavelet transform domain. Multimed. Tools Appl. 2019, 78, 34483–34512. [Google Scholar] [CrossRef]
- Masquelin, A.H.; Cheney, N.; Kinsey, C.M.; Bates, J.H.T. Wavelet decomposition facilitates training on small datasets for medical image classification by deep learning. J. Histochem. Cell Biol. 2021, 155, 309–317. [Google Scholar] [CrossRef]
- Coffey, M.A.; Etter, D.M. Image coding with the wavelet transform. In Proceedings of the ISCAS’95-International Symposium on Circuits and Systems, Seattle, WA, USA, 30 April–3 May 1995; pp. 1110–1113. [Google Scholar]
- Arrais, E.; de Medeiros Valentim, R.A.; Brandão, G.B. Real-time premature ventricular contractions detection based on Redundant Discrete Wavelet Transform. Res. Biomed. Eng. 2018, 34, 187–197. [Google Scholar] [CrossRef]
- Borana, S.; Yadav, S. Comparison of model validation techniques for land cover dynamics in Jodhpur City. Int. J. Emerg. Trends Technol. Comput. Sci. 2017, 6, 215–219. [Google Scholar]
- Zhao, J.; Jiang, H.; Di, J. Recording and reconstruction of a color holographic image by using digital lensless fourier transform holography. Opt. Express 2008, 16, 2514–2519. [Google Scholar] [CrossRef]
- Lee, M.C.; Pun, C.M. Texture Classification Using Dominant Wavelet Packet Energy Features. In Proceedings of the 4th IEEE Southwest Symposium on Image Analysis and Interpretation, Austin, TX, USA, 2–4 April 2000; pp. 301–304. [Google Scholar]
- Li, X.L.; Nie, P.C.; Qiu, Z.J.; He, Y. Using wavelet transform and multi-class least square support vector machine in multi-spectral imaging classification of Chinese famous tea. Expert Syst. Appl. 2011, 38, 11149–11159. [Google Scholar] [CrossRef]
- Bakhshipour, A.; Sanaeifar, A.; Payman, S.H.; Guardia, M. Evaluation of data mining strategies for classification of black tea based on image-based features. Food Anal. Methods 2018, 11, 1041–1050. [Google Scholar] [CrossRef]
- Wulandari, M.; Basari; Gunawan, D. Evaluation of wavelet transform preprocessing with deep learning aimed at palm vein recognition application. AIP Conf. Proc. 2019, 2139, 050005. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kim, H.; Chung, Y. Improved Handwritten Hangeul Recognition using Deep Learning based on GoogLenet. J. Korea Contents Assoc. 2018, 18, 495–502. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tea Category | Tea Variety | Abbreviations | Number | Geographical Origins |
|---|---|---|---|---|
| Black tea | QMBT from ACBT | ACBT | 30 | Anhui |
| QMBT from XLBT | XLBT | 30 | Anhui | |
| QMBT from GXBT | GXBT | 30 | Anhui | |
| QMBT from QMQH | QMQH | 30 | Anhui | |
| QMBT from HSBT | HSBT | 30 | Anhui | |
| Green tea | Maofeng from ZYYMF | ZYYMF | 30 | Anhui |
| Maofeng from ZWMF | ZWMF | 30 | Anhui | |
| Maofeng from YJYMF | YJYMF | 30 | Anhui | |
| Maofeng from GMMF | GMMF | 30 | Anhui | |
| Liuan Guapian | LAGP | 30 | Anhui | |
| Yellow tea | Junshan Yinzhen | JSYZ | 30 | Hunan |
| Huoshan Huangya | HSHY | 30 | Anhui | |
| Mengding Huangya | MDHY | 30 | Sichuan | |
| Mogan Huangya | MGHY | 30 | Zhejiang | |
| Pingyang Huangtang | PYHT | 30 | Zhejiang |
| Input | Operator | Channel | N | Stride | Out |
|---|---|---|---|---|---|
| 224 × 224 × 3 | conv2d | 32 | 1 | 2 | 112 × 112 × 32 |
| 112 × 112 × 32 | bottleneck | 16 | 1 | 1 | 112 × 112 × 16 |
| 112 × 112 × 16 | bottleneck | 24 | 2 | 2 | 56 × 56 × 24 |
| 56 × 56 × 24 | bottleneck | 32 | 3 | 2 | 28 × 28 × 32 |
| 28 × 28 × 32 | bottleneck | 64 | 4 | 2 | 14 × 14 × 64 |
| 14 × 14 × 64 | bottleneck | 96 | 3 | 1 | 14 × 14 × 96 |
| 14 × 14 × 96 | bottleneck | 160 | 3 | 2 | 7 × 7 × 160 |
| 7 × 7 × 160 | bottleneck | 320 | 1 | 1 | 7 × 7 × 320 |
| 7 × 7 × 320 | conv2d | 1280 | 1 | 1 | 7 × 7 × 1280 |
| 7 × 7 × 1280 | avgpool | - | 1 | - | 1 × 1 × 1280 |
| 1 × 1 × 1280 | conv2d | 3 | 1 | 1 | 1 × 1 × 3 |
| 1 × 1 × 3 | softmax | 3 | 1 | - | 3 |
| Input | Operator | Channel | N | Stride | Out |
|---|---|---|---|---|---|
| 224 × 224 × 3 | conv2d | 32 | 1 | 2 | 112 × 112 × 32 |
| 112 × 112 × 32 | bottleneck | 16 | 1 | 1 | 112 × 112 × 16 |
| 112 × 112 × 16 | bottleneck | 24 | 2 | 2 | 56 × 56 × 24 |
| 56 × 56 × 24 | bottleneck | 32 | 3 | 2 | 28 × 28 × 32 |
| 28 × 28 × 32 | bottleneck | 64 | 4 | 2 | 14 × 14 × 64 |
| 14 × 14 × 64 | bottleneck | 96 | 3 | 1 | 14 × 14 × 96 |
| 14 × 14 × 96 | bottleneck | 160 | 3 | 2 | 7 × 7 × 160 |
| 7 × 7 × 160 | bottleneck | 320 | 1 | 1 | 7 × 7 × 320 |
| 7 × 7 × 320 | conv2d | 128 | 1 | 1 | 7 × 7 × 128 |
| 7 × 7 × 128 | flatten | 6272 | 1 | - | 1 × 1 × 6272 |
| 1 × 1 × 6272 | SVM | 3 | 1 | - | 3 |
| Settings | Parameters |
|---|---|
| CPU | Intel (R) Core (TM) i7-8700 CPU @ 3.20G Hz |
| GPU | NVIDIA GeForce GTX 1070 Ti |
| RAM | 16.0 GB |
| Operating system | Win 10_64 bit |
| MATLAB version | MATLAB R2019a |
| Lab environment | Deep Learning Toolbox |
| Input Data | Kappa Coefficient | Overall | Black Tea | Green Tea | Yellow Tea |
|---|---|---|---|---|---|
| Original | 0.90 | 0.933 | 0.940 | 0.958 | 0.904 |
| LH + HL + HH | 0.91 | 0.940 | 0.980 | 0.923 | 0.918 |
| LL + HH + HH | 0.93 | 0.953 | 0.980 | 0.941 | 0.939 |
| LL + LL + HH | 0.96 | 0.973 | 0.980 | 0.962 | 0.980 |
| LL + HL + LH | 0.98 | 0.987 | 1.000 | 0.980 | 0.980 |
| LL + LL + LL | 0.95 | 0.967 | 1.000 | 0.980 | 0.925 |
| Method | Overall | Black Tea | Green Tea | Yellow Tea |
|---|---|---|---|---|
| Our method | 0.987 | 1.000 | 0.980 | 0.980 |
| MobileNet v2 + RF | 0.980 | 0.980 | 0.980 | 0.980 |
| MobileNet v2 + KNN | 0.967 | 0.960 | 0.980 | 0.960 |
| MobileNet v2 + AdaBoost | 0.960 | 0.960 | 0.940 | 0.980 |
| MobileNet v2 | 0.973 | 1.000 | 0.960 | 0.960 |
| AlexNet | 0.933 | 0.960 | 1.000 | 0.860 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Q.; Yang, B.; Liu, B.; Li, Y.; Ning, J. Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning. Agriculture 2022, 12, 1085. https://doi.org/10.3390/agriculture12081085
Cui Q, Yang B, Liu B, Li Y, Ning J. Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning. Agriculture. 2022; 12(8):1085. https://doi.org/10.3390/agriculture12081085
Chicago/Turabian StyleCui, Qiang, Baohua Yang, Biyun Liu, Yunlong Li, and Jingming Ning. 2022. "Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning" Agriculture 12, no. 8: 1085. https://doi.org/10.3390/agriculture12081085
APA StyleCui, Q., Yang, B., Liu, B., Li, Y., & Ning, J. (2022). Tea Category Identification Using Wavelet Signal Reconstruction of Hyperspectral Imagery and Machine Learning. Agriculture, 12(8), 1085. https://doi.org/10.3390/agriculture12081085