Bilinear CNN Model for Fine-Grained Classification Based on Subcategory-Similarity Measurement

Abstract
1. Introduction
2. Related Work
3. Materials and Methods
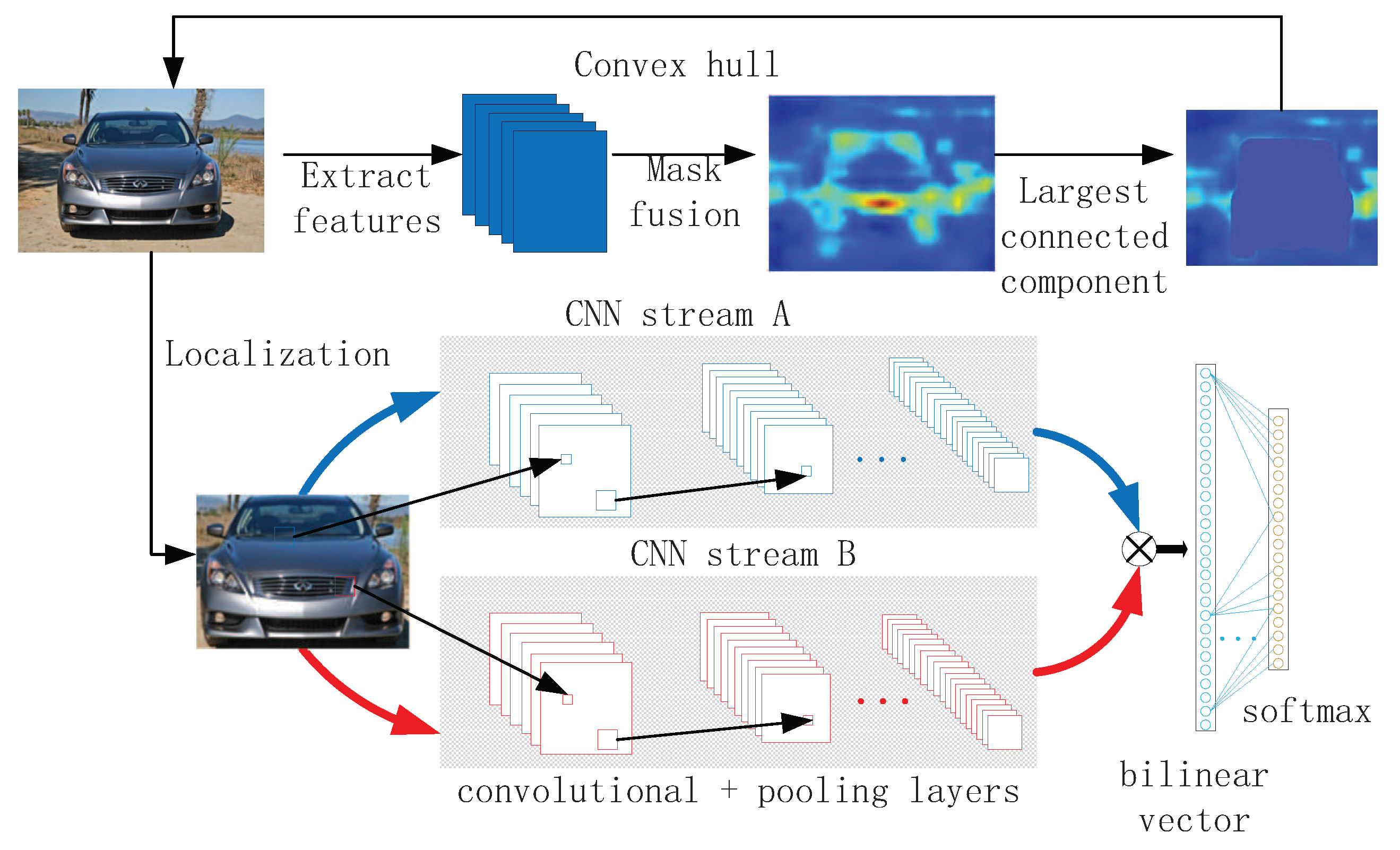
3.1. Weakly Supervised Localization
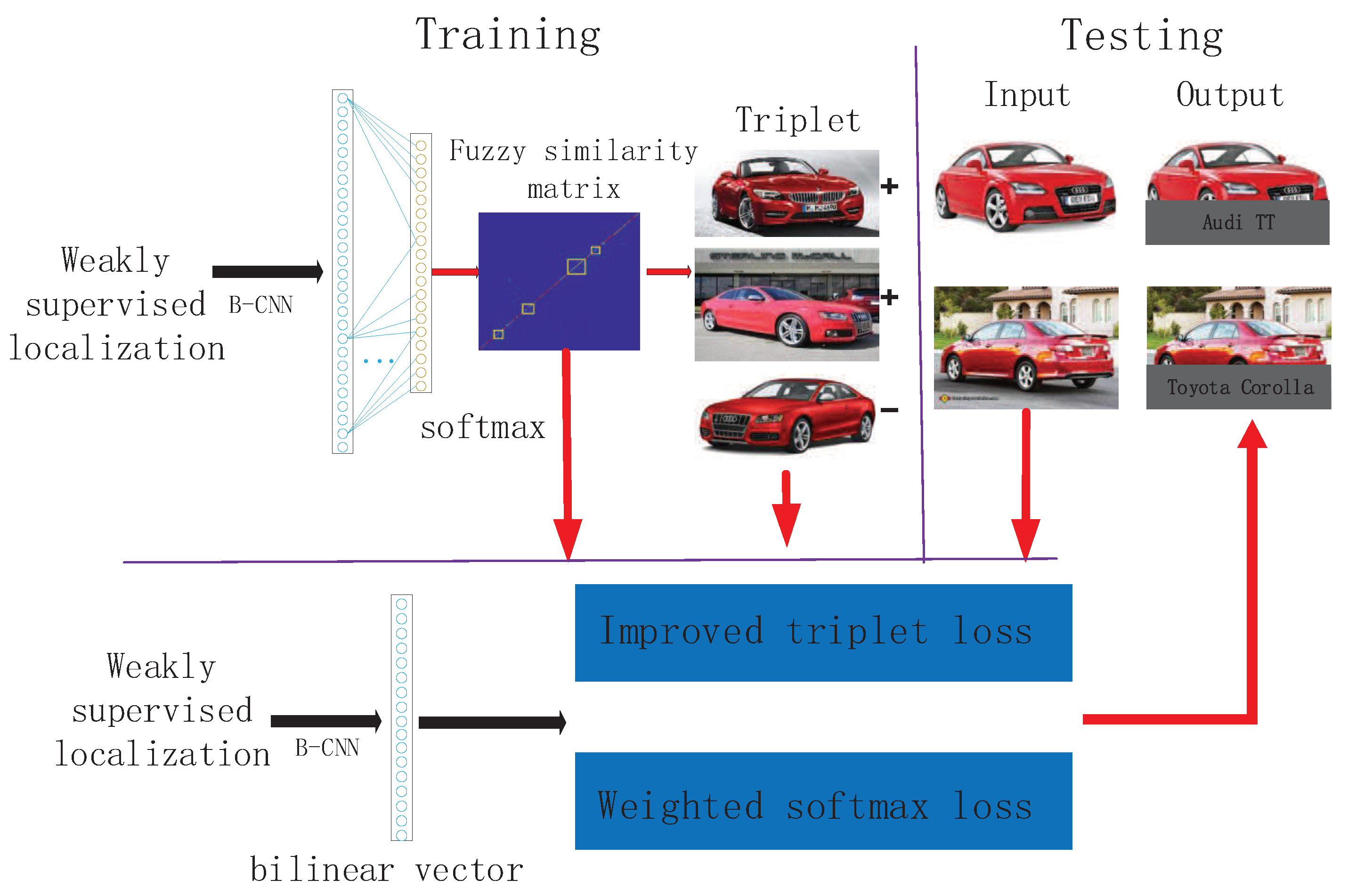
3.2. Classification Based on Subcategory-Similarity Measurement
3.2.1. Generate Fuzzying Similarity Matrix
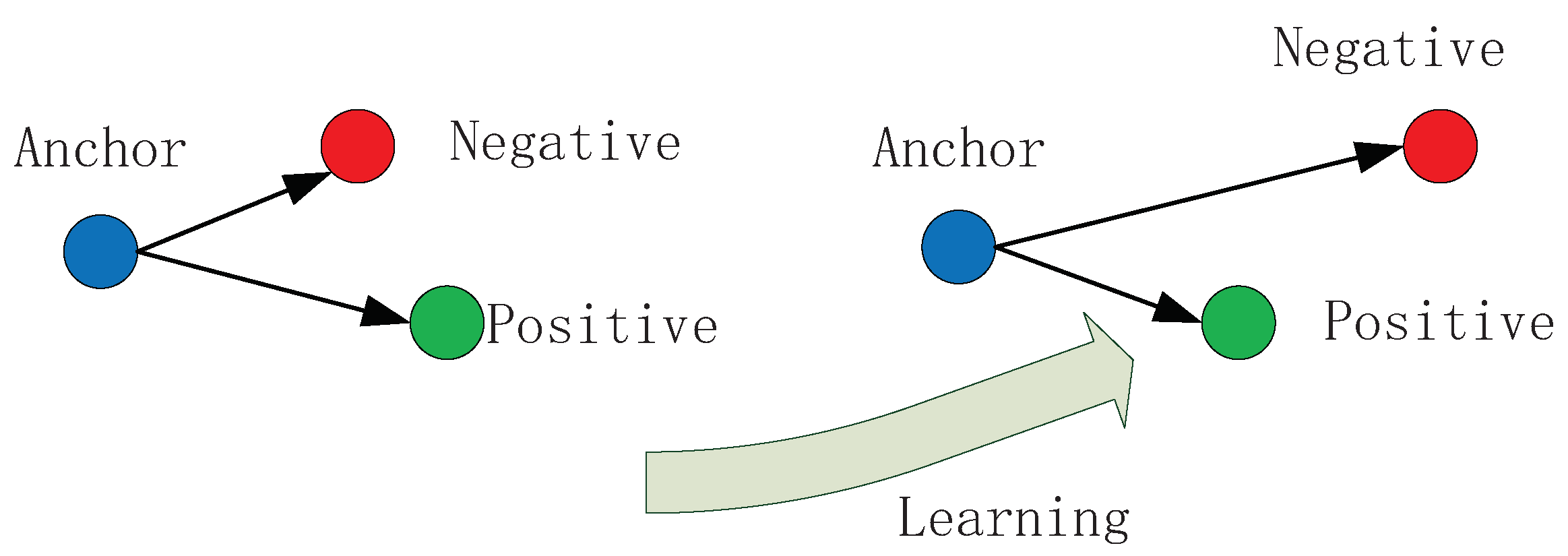
3.2.2. Jointly Learned Loss Function
4. Results
4.1. Datasets and Implementation Details
4.2. Model-Configuration Study
4.2.1. Weakly Supervised Localization
4.2.2. Softmax Effectiveness
4.2.3. Effectiveness of Different Components
4.3. Experiment and Analysis on Stanford Cars-196
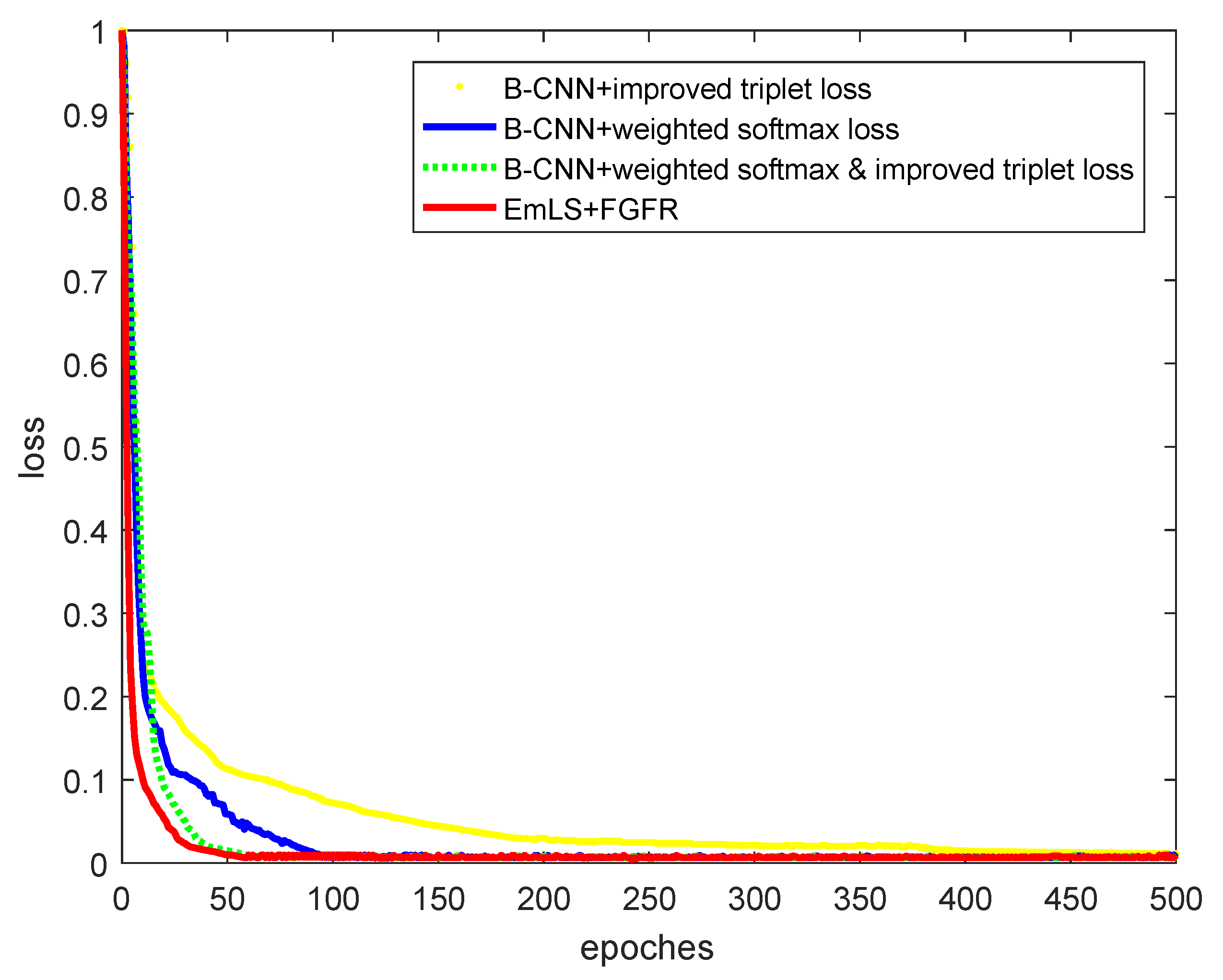
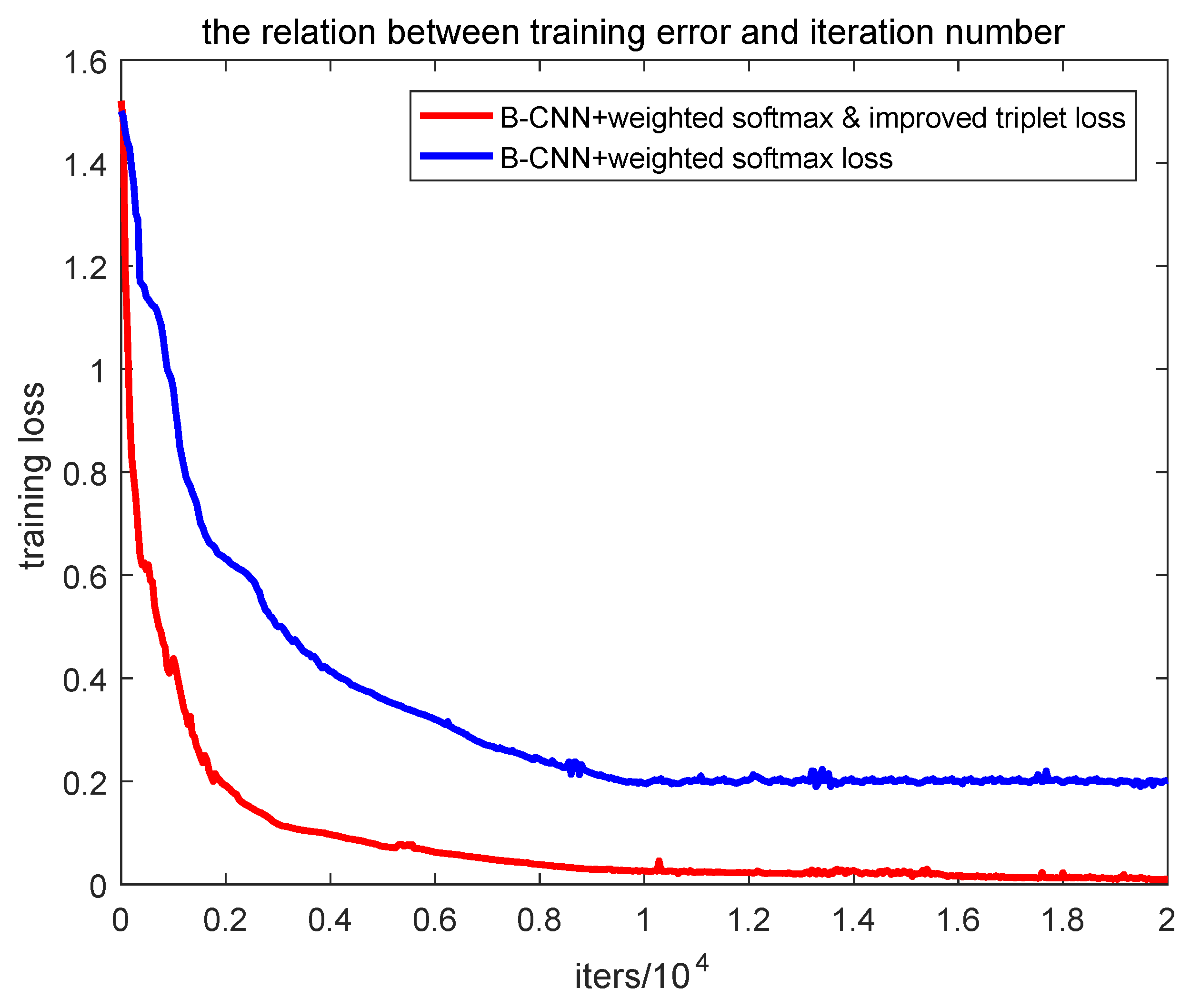
4.3.1. Experimental Analysis of Improved Loss Function
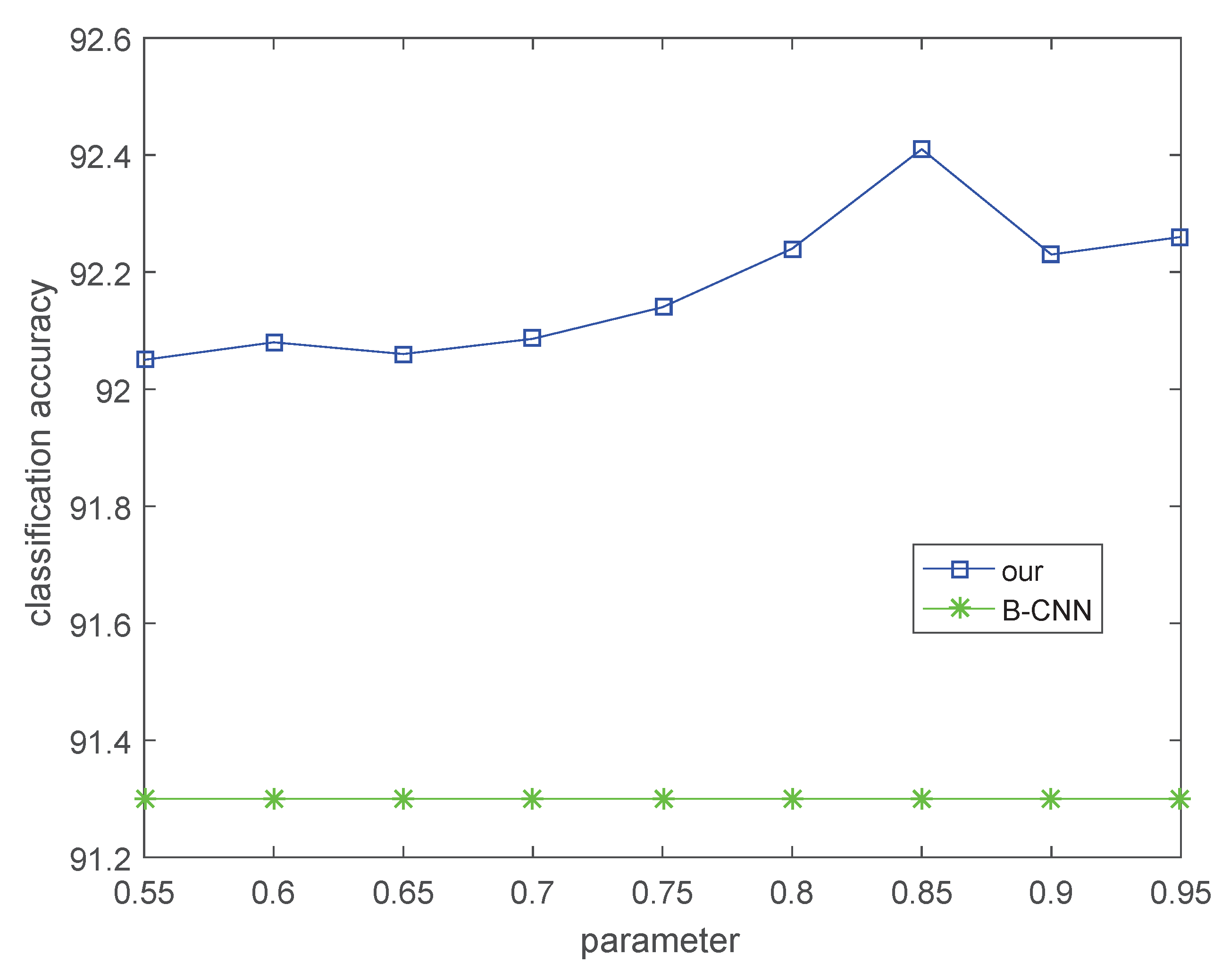
4.3.2. Experimental Analysis of Parameter Sensitivity
4.3.3. Comparison with Previous Works
4.4. Experiment and Analysis on CUB-200-2011
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Luo, J.H.; Wu, J.X. A Survey on Fine-grained Image Categorization Using Deep Convolutional Features. Acta Autom. Sin. 2017, 43, 1306–1318. [Google Scholar] [CrossRef]
- Peng, Y.X.; He, X.T.; Zhao, J.J. Object-Part Attention Model for Fine-Grained Image Classification. IEEE Trans. Image Process. 2017, 99. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, G.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Koprowski, R.; Lanza, M.; Irregolare, C. Corneal Power Evaluation after Myopic Corneal Refractive Surgery Using Artificial Neural Networks. Biomed. Eng. Online 2016, 15, 121. [Google Scholar] [CrossRef] [PubMed]
- Jia, D.; Krause, J.; Li, F.F. Fine-Grained Crowdsourcing for Fine-Grained Recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 580–587. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, S.L.; Zhang, Y.; Tao, D.C. Augmenting Strong Supervision Using Web Data for Fine Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2524–2532. [Google Scholar] [CrossRef]
- Zhang, N.; Donahue, J.; Girshick, R. Part-Based R-CNNs for Fine-Grained Category Detection. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar] [CrossRef]
- Lin, D.; Shen, X.Y.; Lu, C.W.; Jia, J.Y. Deep LAC: Deep Localization, Alignment and Classification for Fine-grained Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1666–1674. [Google Scholar] [CrossRef]
- Branson, S.; Van Horn, G.; Belongie, S.; Perona, P. Bird Species Categorization Using Pose Normalized Deep Convolutional Nets. arXiv, 2014; arXiv:1406.2952. [Google Scholar]
- Simon, M.; Rodner, E. Neural Activation Constellations: Unsupervised Part Model Discovery with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1143–1151. [Google Scholar] [CrossRef]
- Wang, D.Q.; Shen, Z.Q.; Shao, J.; Zhang, W.; Xue, X.Y.; Zhang, Z. Multiple Granularity Descriptors for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2399–2406. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuogu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Krause, J.; Stark, M.; Jia, D.; Li, F.F. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar] [CrossRef]
- Xiao, T.; Xu, Y.; Yang, K. The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P. The Caltech-UCSD Birds 200–2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4476–4484. [Google Scholar] [CrossRef]
- Lin, T.Y.; Roychowdhury, A.; Maji, S. Bilinear CNN Models for Fine-grained Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar] [CrossRef]
- Kong, S.; Fowlkes, C. Low-Rank Bilinear Pooling for Fine-Grained Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7025–7034. [Google Scholar] [CrossRef]
- Wei, X.S.; Luo, J.H.; Wu, J.; Zhou, Z.H. Selective Convolutional Descriptor Aggregation for Fine-grained Image Retrieval. IEEE Trans. Image Process. 2017, 26, 2868–2881. [Google Scholar] [CrossRef] [PubMed]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the IEEE Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 539–546. [Google Scholar] [CrossRef]
- Wah, C.; Van Horn, G.; Branson, S. Similarity Comparisons for Interactive Fine-grained Categorization. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 859–866. [Google Scholar] [CrossRef]
- Lin, T.Y.; Roychowdhury, A.; Maji, S. Bilinear Convolutional Neural Networks for Fine-grained Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99. [Google Scholar] [CrossRef] [PubMed]
- Cai, S.; Zuo, W.; Zhang, L. Higher-order Integration of Hierarchical Convolutional Activations for Fine-grained Visual Categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 511–520. [Google Scholar] [CrossRef]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact Bilinear Pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 317–326. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Freeman, W.T. Separating Style and Content with Bilinear Models. Neural Comput. 2000, 12, 1247–1283. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.S.; Xie, C.W.; Wu, J.; Shen, C. Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Bird Species Categorization. Pattern Recognit. 2018, 76, 704–714. [Google Scholar] [CrossRef]
- Liu, H.; Tian, Y.; Wang, Y. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 2167–2175. [Google Scholar] [CrossRef]
- Wang, Y.; Choi, J.; Morariu, VI. Mining Discriminative Triplets of Patches for Fine-Grained Classification. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 1163–1172. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, F.; Lin, Y. Embedding Label Structures for Fine-Grained Feature Representation. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 1114–1123. [Google Scholar] [CrossRef]
- Donahue, J.; Jia, Y.; Vinyals, O. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar] [CrossRef]
- Li, K.; Huang, Z.; Cheng, Y.C. A Maximal Figure-of-Merit Learning Approach to Maximizing Mean Average Precision with Deep Neural Network Based Classifiers. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar] [CrossRef]
- He, X.; Peng, Y.X.; Zhao, J.J. Fine-grained Discriminative Localization via Saliency-guided Faster R-CNN. In Proceedings of the 25th ACM Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; pp. 627–635. [Google Scholar] [CrossRef]
- He, X.; Peng, Y.X.; Zhao, J.J. Fast Fine-grained Image Classification via Weakly Supervised Discriminative Localization. IEEE Trans. Circuits Syst. Video Technol. 2017, 99. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Cho, M.; Kwak, S.; Schmid, C. Unsupervised Object Discovery and Localization in the Wild: Part-based Matching with Bottom-up Region Proposals. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1201–1210. [Google Scholar] [CrossRef]
- Fukunaga, K.; Narendra, P.M. A Branch and Bound Algorithm for Computing k-Nearest Neighbors. IEEE Trans. Comput. 1975, 24, 750–753. [Google Scholar] [CrossRef]
- Nguyen, B.P.; Tay, W.L.; Chui, C.K. Robust Biometric Recognition From Palm Depth Images for Gloved Hands. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 1–6. [Google Scholar] [CrossRef]
- Tong, S.; Koller, D. Support Vector Machine Active Learning with Applications to Text Classification. Mach. Learn. Res. 2002, 2, 999–1006. [Google Scholar] [CrossRef][Green Version]
- Liu, X.; Xia, T.; Wang, J. Fully Convolutional Attention Networks for Fine-Grained Recognition. arXiv, 2016; arXiv:1603.06765. [Google Scholar]
- Krause, J.; Stark, M.; Jia, D.; Li, F.F. Fine-grained Recognition without Part Annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5546–5555. [Google Scholar] [CrossRef]
- Cui, Y.; Zhou, F.; Wang, J.; Liu, X.; Lin, Y.; Belongie, S. Kernel Pooling for Convolutional Neural Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3049–3058. [Google Scholar] [CrossRef]
- Zheng, H.; Fu, J.; Mei, T. Learning Multi-attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5219–5227. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, T.; Elhoseiny, M. SPDA-CNN: Unifying Semantic Part Detection and Abstraction for Fine-Grained Recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vega, NV, USA, 26 June–1 July 2016; pp. 1143–1152. [Google Scholar] [CrossRef]
- Simon, M.; Gao, Y.; Darrell, T. Generalized Orderless Pooling Performs Implicit Salient Matching. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 4970–4979. [Google Scholar] [CrossRef]
- He, X.; Peng, Y.X. Weakly Supervised Learning of Part Selection Model with Spatial Constraints for Fine-grained Image Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4075–4081. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | #Category | #Training | #Testing |
|---|---|---|---|
| CUB-200-2011 | 200 | 5994 | 5794 |
| Cars-196 | 196 | 8144 | 8041 |
| Method | CUB-200-2011 | Cars-196 |
|---|---|---|
| WSDL | 46.05% | 56.60% |
| MEAN | 44.93% | 55.79% |
| Unsupervised object discovery | 69.37% | 93.05% |
| SCDA | 76.79% | 90.96% |
| Ours | 77.31% | 91.02% |
| Classifier | CUB-200-2011 | Cars-196 |
|---|---|---|
| softmax | 84.63% | 91.84% |
| SVM | 84.70% | 91.92% |
| k-NN (k = 3) | 65.73% | 71.49% |
| k-NN (k = 4) | 67.88% | 73.96% |
| k-NN (k = 5) | 67.96% | 74.08% |
| k-NN (k = 6) | 68.08% | 74.15% |
| k-NN (k = 7) | 68.17% | 74.24% |
| k-NN (k = 8) | 68.34% | 74.46% |
| k-NN (k = 9) | 68.15% | 74.25% |
| k-NN (k = 10) | 68.02% | 74.12% |
| CDNN (k = 3) | 76.63% | 83.98% |
| CDNN (k = 4) | 77.96% | 85.04% |
| CDNN (k = 5) | 78.08% | 85.13% |
| CDNN (k = 6) | 78.15% | 85.21% |
| CDNN (k = 7) | 78.34% | 85.45% |
| CDNN (k = 8) | 78.16% | 85.27% |
| CDNN (k = 9) | 78.06% | 85.15% |
| CDNN (k = 10) | 77.93% | 85.06% |
| CUB-200-2011 | Cars-196 | ||||
|---|---|---|---|---|---|
| Method | Accuracy | mAP | Accuracy | mAP | Parameter Increment |
| B-CNN | 84.00% | 81.70% | 91.20% | 88.90% | 0 |
| B-CNN + localization | 84.63% | 83.90% | 91.84% | 91.04% | 0.4 M |
| B-CNN + loss function | 84.97% | 85.60% | 92.09% | 92.75% | 15.05 M |
| Ours | 85.31% | 86.75% | 92.43% | 93.64% | 16.6 M |
| Method | Annotation | Accuracy |
|---|---|---|
| FCAN | √ | 91.30% |
| PA-CNN | √ | 92.60% |
| B-CNN | − | 91.20% |
| Improved B-CNN | − | 92.00% |
| LRBP | − | 90.92% |
| HIHCA | − | 91.70% |
| Kernel Pooling | − | 92.40% |
| RA-CNN | − | 92.50% |
| MA-CNN | − | 92.80% |
| Ours | − | 92.43% |
| Method | Annotation | Accuracy |
|---|---|---|
| SPDA-CNN | √ | 84.55% |
| PN-CNN | √ | 85.40% |
| B-CNN | √ | 84.80% |
| TSC | − | 84.69% |
| LRBP | − | 84.21% |
| HIHCA | − | 85.30% |
| pooling | − | 85.30% |
| MA-CNN | − | 86.50% |
| B-CNN | − | 84.00% |
| Ours | − | 85.31% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, X.; Gong, S.; Zhong, S.; Bao, Z. Bilinear CNN Model for Fine-Grained Classification Based on Subcategory-Similarity Measurement. Appl. Sci. 2019, 9, 301. https://doi.org/10.3390/app9020301
Dai X, Gong S, Zhong S, Bao Z. Bilinear CNN Model for Fine-Grained Classification Based on Subcategory-Similarity Measurement. Applied Sciences. 2019; 9(2):301. https://doi.org/10.3390/app9020301
Chicago/Turabian StyleDai, Xinghua, Shengrong Gong, Shan Zhong, and Zongming Bao. 2019. "Bilinear CNN Model for Fine-Grained Classification Based on Subcategory-Similarity Measurement" Applied Sciences 9, no. 2: 301. https://doi.org/10.3390/app9020301
APA StyleDai, X., Gong, S., Zhong, S., & Bao, Z. (2019). Bilinear CNN Model for Fine-Grained Classification Based on Subcategory-Similarity Measurement. Applied Sciences, 9(2), 301. https://doi.org/10.3390/app9020301