
A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem

 ,
, 
Abstract
:
1. Introduction
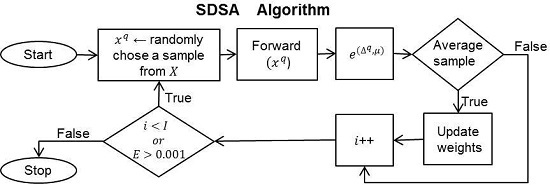
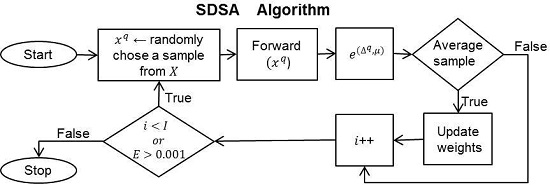
2. Selective Dynamic Sampling Approach
- Safe samples are those with a high probability of being correctly labeled by the classifier, and they are surrounded by samples of the same class [42].
- During training: The proposed method selects the average samples to update the neural network weights. From the balanced training dataset, it chooses average samples to use in the neural network training. With the aim to identify the average samples, we propose the next function:Variable is the normalized difference amongst the real neural network outputs for a sample q,where and are respectively the real neural network outputs corresponding to a q sample. The ANN only has two neural network outputs ( and ), because it has been designed to work with datasets of two classes [43].
| Algorithm 1 The Selective Dynamic Sampling Approach (SDSA) based on the stochastic back-propagation multilayer perceptron. |
| Input: X (input dataset), N (number of features in X), K (number of classes in X), Q (number of samples in X), M (number of middle neurodes), J (number output neurodes), I number of iterations and learning rate η. Output: the weights w u . INIT( ):
|
2.1. Selecting μ Values
- 1.0 for safe samples. It is expected that ANN classifies with a high accuracy level, i.e., it is expected that the real ANN outputs for all neurons () will be values close to (1, 0) and (0, 1) for Classes A and B, respectively. Whether we apply Equation (2), the expected value is 1.0, at which the γ function has its maximum value.
- 0.0 for border samples. It is expected that the classifier misclassifies. The expected ANN outputs for all neurons are values close to (0.5, 0.5), then the Δ is approximately 0.0, at which the γ function has its maximum value for these samples.
- 0.5 for average samples. It is expected that ANN classifies correctly, but with less accuracy. In addition, the average samples are between safe () and border () samples.
3. State-of-the-Art of the Class Imbalance Approaches
3.1. Under-Sampling Approaches
3.2. Over-Sampling Approaches
4. Dynamic Sampling Techniques to Train Artificial Neural Networks
4.1. Method 1. Dynamic Sampling
- Randomly fetch a sample q from the training dataset.
- Estimate the probability p that the example should be used for the training.where . is the i-th real ANN output of the sample q and j is the class label to which q belongs. is the class ratio; is the number of samples belonging to class c; and Q is the sample number.
- Generate a uniform random real number μ between zero and one.
- If , then use the sample q to update the weights by the back-propagation rules.
- Repeat Steps 1–4 on all samples of the training dataset in each training epoch.
4.2. Method 2. Dynamic Over-Sampling
- Before training: The training dataset is balanced at 100% through an effective over-sampling technique. In this work, SMOTE [8] is utilized.
- During training: The MSE by class is used to determine the number of samples by class (or class ratio) in order to forward it to the ANN. The equation employed to obtain the class ratio is defined as:where J is the number of classes in the dataset and identifies the largest majority class. Equation (5) allows balancing the MSE by class, reducing the impact of the class imbalance problem on the ANN.
5. Experimental Set-Up
5.1. Database Description
5.2. Parameter Specification for the Algorithms Employed in the Experimentation
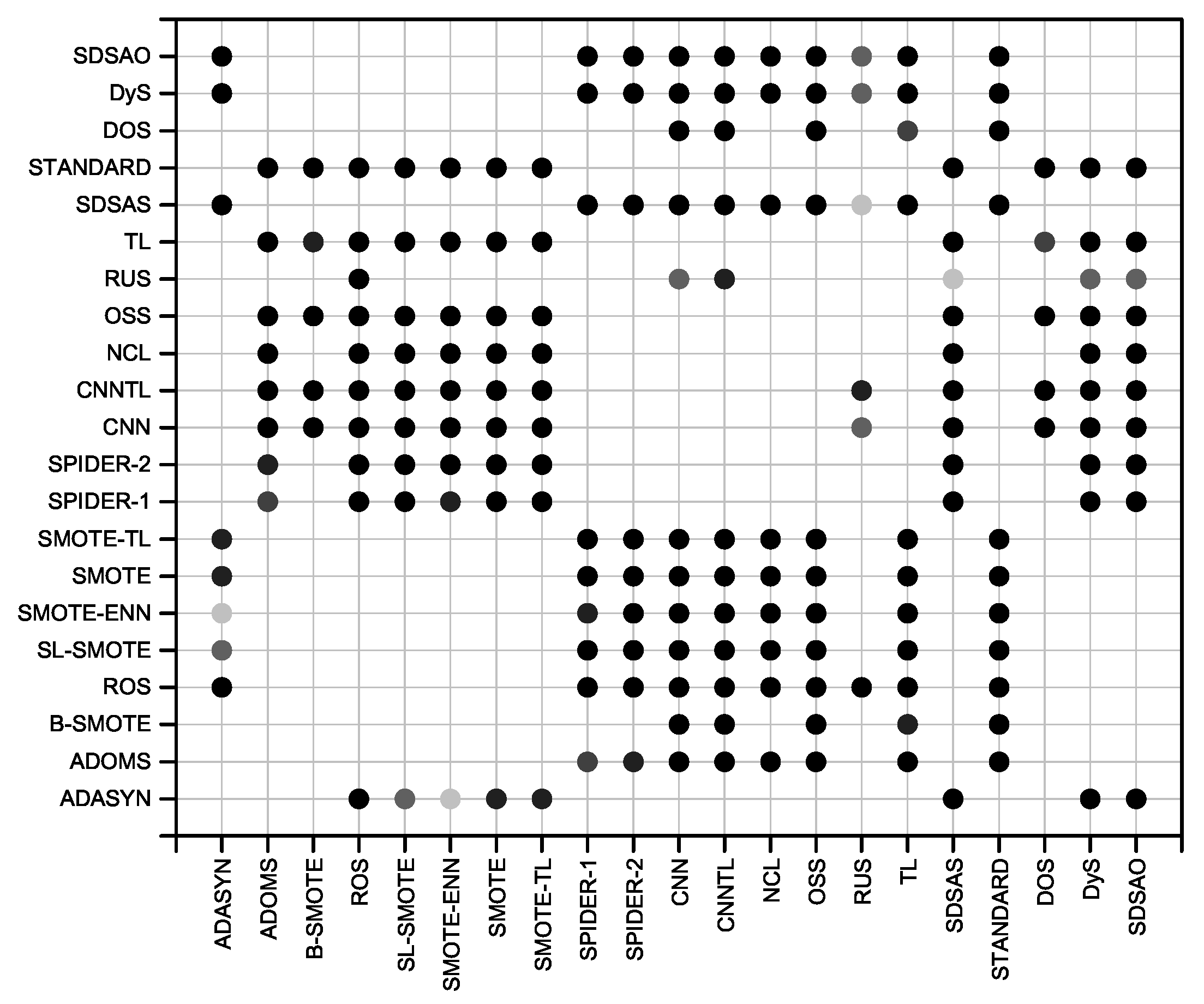
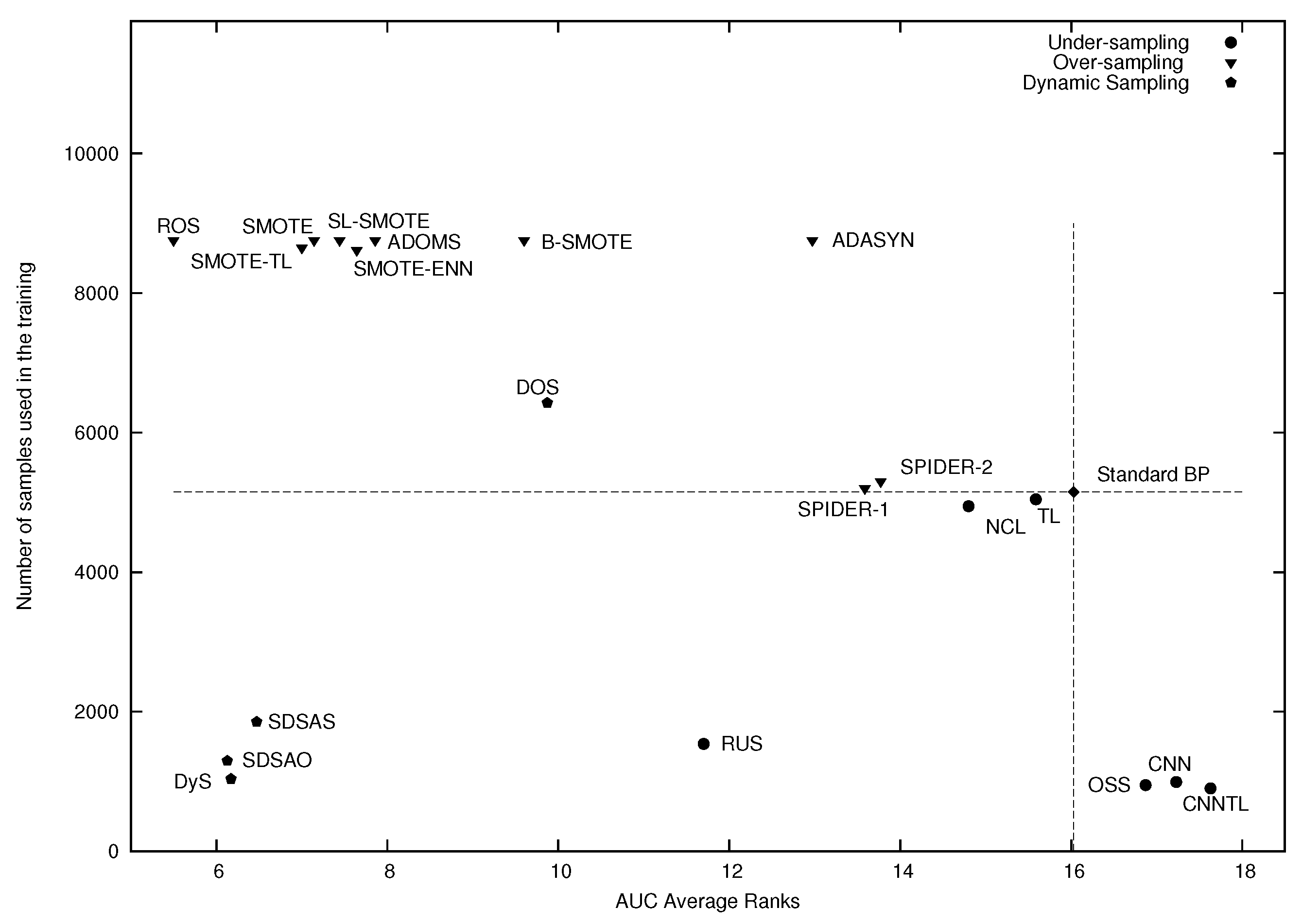
5.3. Classifier Performance and Significant Statistical Test
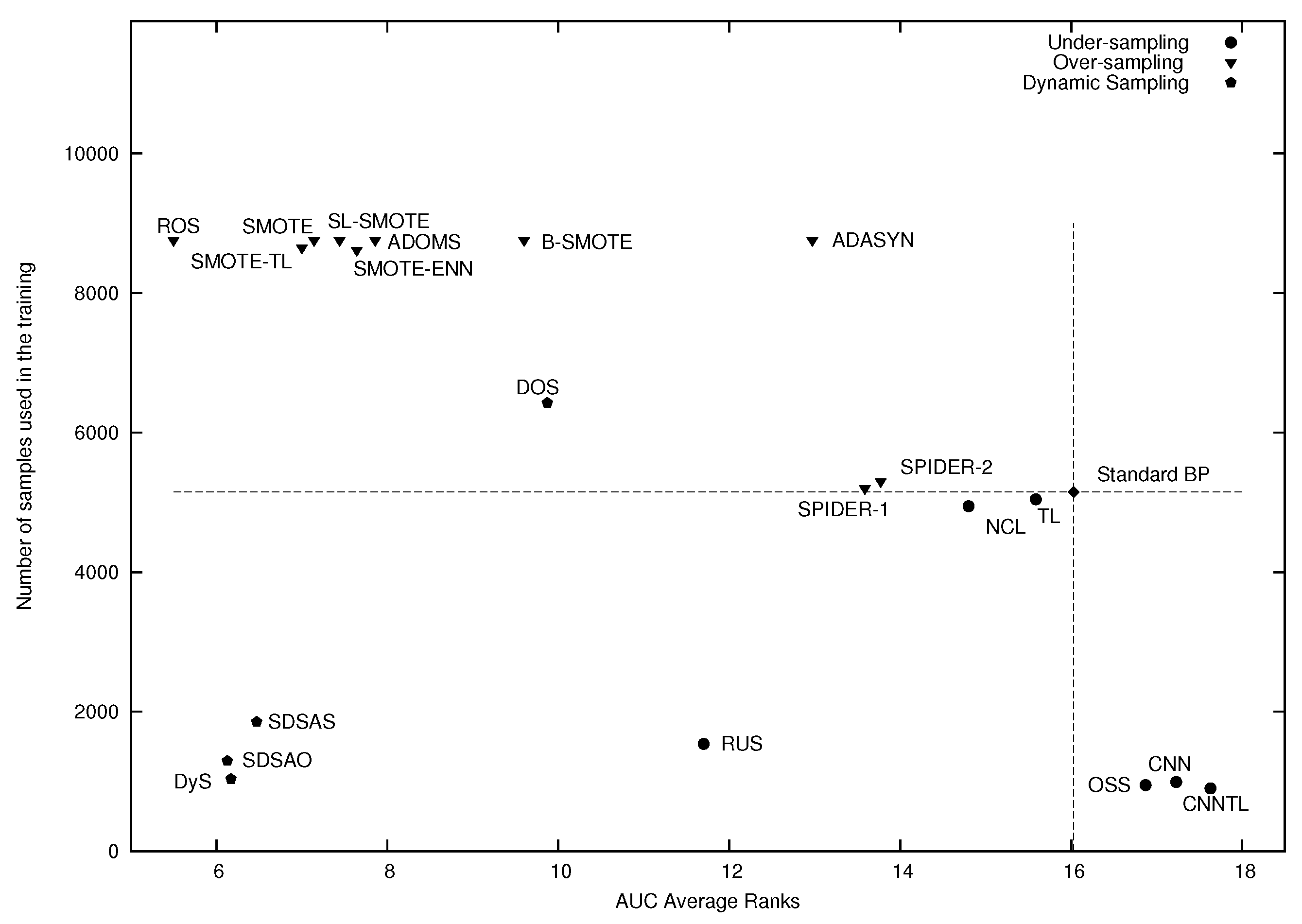
6. Experimental Results and Discussion
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Prati, R.C.; Batista, G.E.A.P.A.; Monard, M.C. Data mining with imbalanced class distributions: Concepts and methods. In Proceedings of the 4th Indian International Conference on Artificial Intelligence (IICAI 2009), Tumkur, Karnataka, India, 16–18 December 2009; pp. 359–376.
- Galar, M.; Fernández, A.; Tartas, E.B.; Sola, H.B.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cyber. Part C 2012, 42, 463–484. [Google Scholar] [CrossRef]
- García, V.; Sánchez, J.S.; Mollineda, R.A.; Alejo, R.; Sotoca, J.M. The class imbalance problem in pattern classication and learning. In II Congreso Español de Informática; Thomson: Zaragoza, Spain, 2007; pp. 283–291. [Google Scholar]
- Wang, S.; Yao, X. Multiclass imbalance problems: Analysis and potential solutions. IEEE Trans. Syst. Man Cyber. Part B 2012, 42, 1119–1130. [Google Scholar] [CrossRef] [PubMed]
- Nanni, L.; Fantozzi, C.; Lazzarini, N. Coupling different methods for overcoming the class imbalance problem. Neurocomput 2015, 158, 48–61. [Google Scholar] [CrossRef]
- Loyola-González, O.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A.; García-Borroto, M. Study of the impact of resampling methods for contrast pattern based classifiers in imbalanced databases. Neurocomputing 2016, 175, 935–947. [Google Scholar] [CrossRef]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- He, H.; Garcia, E. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Intelligent Computing (ICIC 2005), Hefei, China, 23–26 August 2005; pp. 878–887.
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-SMOTE: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Proceedings of the 13th Pacific-Asia Conference (PAKDD 2009), Bangkok, Thailand, 27–30 April 2009; Volume 5476, pp. 475–482.
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IJCNN 2008), Hong Kong, China, 1–8 June 2008; pp. 1322–1328.
- Stefanowski, J.; Wilk, S. Selective pre-processing of imbalanced data for improving classification performance. In Proceedings of the 10th International Conference in Data Warehousing and Knowledge Discovery (DaWaK 2008), Turin, Italy, 1–5 September 2008; pp. 283–292.
- Napierala, K.; Stefanowski, J.; Wilk, S. Learning from Imbalanced Data in Presence of Noisy and Borderline Examples. In Proceedings of the 7th International Conference on Rough Sets and Current Trends in Computing (RSCTC 2010), Warsaw, Poland, 28–30 June 2010; pp. 158–167.
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar]
- Liu, X.; Wu, J.; Zhou, Z. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cyber. Part B 2009, 39, 539–550. [Google Scholar]
- Alejo, R.; Valdovinos, R.M.; García, V.; Pacheco-Sanchez, J.H. A hybrid method to face class overlap and class imbalance on neural networks and multi-class scenarios. Pattern Recognit. Lett. 2013, 34, 380–388. [Google Scholar] [CrossRef]
- Alejo, R.; García, V.; Pacheco-Sánchez, J.H. An efficient over-sampling approach based on mean square error back-propagation for dealing with the multi-class imbalance problem. Neural Process. Lett. 2015, 42, 603–617. [Google Scholar] [CrossRef]
- Wilson, D. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cyber. 1972, 2, 408–420. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-sided Selection. In Proceedings of the 14th International Conference on Machine Learning (ICML 1997), Nashville, TN, USA, 8–12 July 1997; pp. 179–186.
- Tomek, I. Two modifications of CNN. IEEE Trans. Syst. Man Cyber. 1976, 7, 679–772. [Google Scholar]
- Hart, P. The condensed nearest neighbour rule. IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2006, 18, 63–77. [Google Scholar] [CrossRef]
- Drummond, C.; Holte, R.C. Class Imbalance, and Cost Sensitivity: Why Under-Sampling Beats Over-Sampling. In Proceedings of the Workshop on Learning from Imbalanced Datasets II, (ICML 2003), Washington, DC, USA; 2003; pp. 1–8. Available online: http://citeseerx.ist.psu.edu/ viewdoc/summary?doi=10.1.1.132.9672 (accessed on 4 July 2016). [Google Scholar]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications, 1st ed.; John Wiley & Sons, Inc Press: Hoboken, NJ, USA, 2013. [Google Scholar]
- Lin, M.; Tang, K.; Yao, X. Dynamic sampling approach to training neural networks for multiclass imbalance classification. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 647–660. [Google Scholar] [PubMed]
- Wang, J.; Jean, J. Resolving multifont character confusion with neural networks. Pattern Recognit. 1993, 26, 175–187. [Google Scholar] [CrossRef]
- Ou, G.; Murphey, Y.L. Multi-class pattern classification using neural networks. Pattern Recognit. 2007, 40, 4–18. [Google Scholar] [CrossRef]
- Murphey, Y.L.; Guo, H.; Feldkamp, L.A. Neural learning from unbalanced data. Appl. Intell. 2004, 21, 117–128. [Google Scholar] [CrossRef]
- Fernández-Navarro, F.; Hervás-Martínez, C.; Antonio Gutiérrez, P. A dynamic over-sampling procedure based on sensitivity for multi-class problems. Pattern Recognit. 2011, 44, 1821–1833. [Google Scholar] [CrossRef]
- Fernández-Navarro, F.; Hervás-Martínez, C.; García-Alonso, C.R.; Torres-Jiménez, M. Determination of relative agrarian technical efficiency by a dynamic over-sampling procedure guided by minimum sensitivity. Expert Syst. Appl. 2011, 38, 12483–12490. [Google Scholar] [CrossRef]
- Chawla, N.V.; Cieslak, D.A.; Hall, L.O.; Joshi, A. Automatically countering imbalance and its empirical relationship to cost. Data Min. Knowl. Discov. 2008, 17, 225–252. [Google Scholar] [CrossRef]
- Debowski, B.; Areibi, S.; Gréwal, G.; Tempelman, J. A Dynamic Sampling Framework for Multi-Class Imbalanced Data. In Proceedings of the Machine Learning and Applications (ICMLA), 2012 11th International Conference on (ICMLA 2012), Boca Raton, FL, USA, 12–15 December 2012; pp. 113–118.
- Alejo, R.; Monroy-de-Jesus, J.; Pacheco-Sanchez, J.; Valdovinos, R.; Antonio-Velazquez, J.; Marcial-Romero, J. Analysing the Safe, Average and Border Samples on Two-Class Imbalance Problems in the Back-Propagation Domain. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications—CIARP 2015; Springer-Verlag: Montevideo, Uruguay, 2015; pp. 699–707. [Google Scholar]
- Lawrence, S.; Burns, I.; Back, A.; Tsoi, A.; Giles, C.L. Neural network classification and unequal prior class probabilities. Neural Netw. Tricks Trade 1998, 1524, 299–314. [Google Scholar]
- Laurikkala, J. Improving Identification of Difficult Small Classes by Balancing Class Distribution. In Proceedings of the 8th Conference on AI in Medicine in Europe: Artificial Intelligence Medicine (AIME 2001), Cascais, Portugal, 1–4 July 2001; pp. 63–66.
- Prati, R.; Batista, G.; Monard, M. Class Imbalances versus Class Overlapping: An Analysis of a Learning System Behavior. In Proceedings of the Third Mexican International Conference on Artificial Intelligence (MICAI 2004), Mexico City, Mexico, 26–30 April 2004; pp. 312–321.
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. Balancing Strategies and Class Overlapping. In Proceedings of the 6th International Symposium on Intelligent Data Analysis, (IDA 2005), Madrid, Spain, 8–10 September 2005; pp. 24–35.
- Tang, Y.; Gao, J. Improved classification for problem involving overlapping patterns. IEICE Trans. 2007, 90-D, 1787–1795. [Google Scholar] [CrossRef]
- Inderjeet, M.; Zhang, I. KNN approach to unbalanced data distributions: A case study involving information extraction. In Proceedings of the International Conference on Machine Learning (ICML 2003), Workshop on Learning from Imbalanced Data Sets, Washington, DC, USA, 21 August 2003.
- Stefanowski, J. Overlapping, Rare Examples and Class Decomposition in Learning Classifiers from Imbalanced Data. In Emerging Paradigms in Machine Learning; Ramanna, S., Jain, L.C., Howlett, R.J., Eds.; Springer Berlin Heidelberg: Berlin, Germany, 2013; Volume 13, pp. 277–306. [Google Scholar]
- Duda, R.; Hart, P.; Stork, D. Pattern Classification, 2nd ed.; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Tang, S.; Chen, S. The Generation Mechanism of Synthetic Minority Class Examples. In Proceedings of the 5th International Conference on Information Technology and Applications in Biomedicine (ITAB 2008), Shenzhen, China, 30–31 May 2008; pp. 444–447.
- Bruzzone, L.; Serpico, S. Classification of imbalanced remote-sensing data by neural networks. Pattern Recognit. Lett. 1997, 18, 1323–1328. [Google Scholar] [CrossRef]
- Lichman, M. UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2013. [Google Scholar]
- Baumgardner, M.; Biehl, L.; Landgrebe, D. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3; Purdue University Research Repository, School of Electrical and Computer Engineering, ITaP and LARS: West Lafayette, IN, USA, 2015. [Google Scholar]
- Madisch, I.; Hofmayer, S.; Fickenscher, H. Roberto Alejo; ResearchGate: San Francisco, CA, USA, 2016. [Google Scholar]
- Wilson, D.R.; Martinez, T.R. Improved heterogeneous distance functions. J. Artif. Int. Res. 1997, 6, 1–34. [Google Scholar]
- Alcalá-Fdez, J.; Fernandez, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. KEEL data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult. Valued Logic Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Iman, R.L.; Davenport, J.M. Approximations of the critical region of the friedman statistic. Commun. Stat. Theory Methods 1980, 9, 571–595. [Google Scholar] [CrossRef]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- Luengo, J.; García, S.; Herrera, F. A study on the use of statistical tests for experimentation with neural networks: Analysis of parametric test conditions and non-parametric tests. Expert Syst. Appl. 2009, 36, 7798–7808. [Google Scholar] [CrossRef]
- García, S.; Herrera, F. An extension on “statistical comparisons of classifiers over multiple data sets” for all pairwise comparisons. J. Mach. Learn. Res. 2008, 9, 2677–2694. [Google Scholar]
- García, V.; Mollineda, R.A.; Sánchez, J.S. On the k-NN performance in a challenging scenario of imbalance and overlapping. Pattern Anal. Appl. 2008, 11, 269–280. [Google Scholar] [CrossRef]
- Denil, M.; Trappenberg, T.P. Overlap versus Imbalance. In Proceedings of the Canadian Conference on AI, Ottawa, NO, Canada, 31 May–2 June 2010; pp. 220–231.
- Jo, T.; Japkowicz, N. Class imbalances versus small disjuncts. SIGKDD Explor. Newsl. 2004, 6, 40–49. [Google Scholar] [CrossRef]
- Ertekin, S.; Huang, J.; Bottou, L.; Giles, C. Learning on the border: Active learning in imbalanced data classification. In Proceedings of the ACM Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007.

{kind=link}
{kind=link}
{kind=link}
| Dataset | # of Features | # of Minority Classes Samples | # of Majority Class Samples | Imbalance Ratio |
|---|---|---|---|---|
| CAY0 | 4 | 838 | 5181 | 6.18 |
| CAY1 | 4 | 293 | 5726 | 19.54 |
| CAY2 | 4 | 624 | 5395 | 8.65 |
| CAY3 | 4 | 322 | 5697 | 17.69 |
| CAY4 | 4 | 133 | 5886 | 44.26 |
| CAY5 | 4 | 369 | 5650 | 15.31 |
| CAY6 | 4 | 324 | 5695 | 17.58 |
| CAY7 | 4 | 722 | 5297 | 7.34 |
| CAY8 | 4 | 789 | 5230 | 6.63 |
| CAY9 | 4 | 833 | 5186 | 6.23 |
| CAY10 | 4 | 772 | 5247 | 6.80 |
| FELT0 | 15 | 3531 | 7413 | 2.10 |
| FELT1 | 15 | 2441 | 8503 | 3.48 |
| FELT2 | 15 | 896 | 10,048 | 11.21 |
| FELT3 | 15 | 2295 | 8649 | 3.77 |
| FELT4 | 15 | 1781 | 9163 | 5.14 |
| SAT0 | 36 | 1508 | 4927 | 3.27 |
| SAT1 | 36 | 1533 | 4902 | 3.20 |
| SAT2 | 36 | 703 | 5732 | 8.15 |
| SAT3 | 36 | 1358 | 5077 | 3.74 |
| SAT4 | 36 | 626 | 5809 | 9.28 |
| SAT5 | 36 | 707 | 5728 | 8.10 |
| SEG0 | 19 | 330 | 1140 | 3.45 |
| SEG1 | 19 | 50 | 1420 | 28.40 |
| SEG2 | 19 | 330 | 1140 | 3.45 |
| SEG3 | 19 | 330 | 1140 | 3.45 |
| SEG4 | 19 | 50 | 1420 | 28.40 |
| SEG5 | 19 | 50 | 1420 | 28.40 |
| SEG6 | 19 | 330 | 1140 | 3.45 |
| 92A0 | 38 | 190 | 4872 | 25.64 |
| 92A1 | 38 | 117 | 4945 | 42.26 |
| 92A2 | 38 | 1434 | 3628 | 2.53 |
| 92A3 | 38 | 2468 | 2594 | 1.05 |
| 92A4 | 38 | 747 | 4315 | 5.78 |
| 92A5 | 38 | 106 | 4956 | 46.75 |
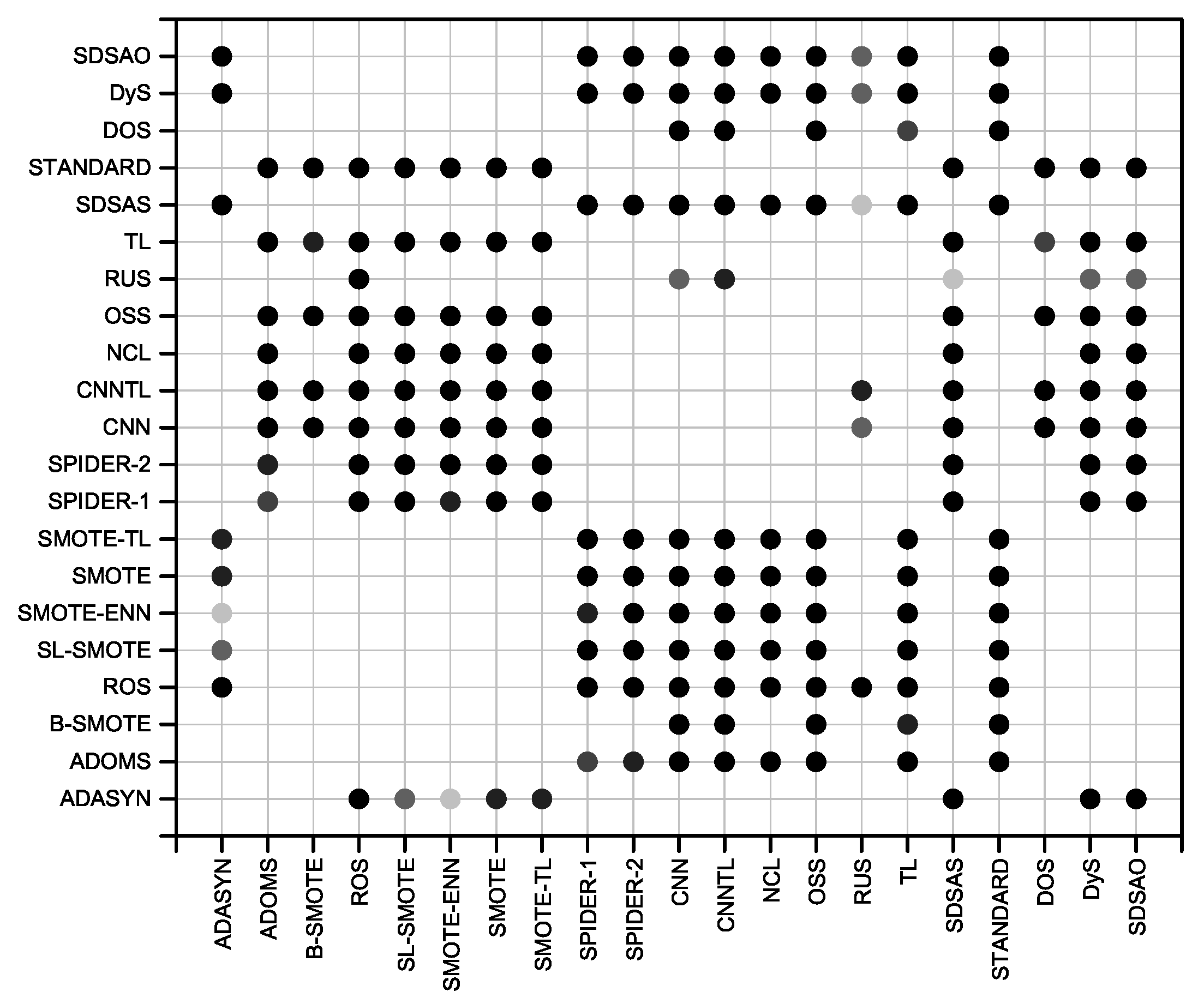
| DATA | ROS | SDSAO | DyS | SDSAS | SMOTE-TL | SMOTE | SL-SMOTE | SMOTE-ENN | ADOMS | B-SMOTE | DOS | RUS | ADASYN | SPIDER-1 | SPIDER-2 | NCL | TL | STANDARD | OSS | CNN | CNNTL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CAY0 | 0.976 | 0.986 | 0.985 | 0.978 | 0.976 | 0.976 | 0.976 | 0.976 | 0.977 | 0.968 | 0.984 | 0.970 | 0.967 | 0.937 | 0.938 | 0.937 | 0.936 | 0.933 | 0.803 | 0.833 | 0.795 |
| CAY1 | 0.969 | 0.979 | 0.975 | 0.968 | 0.969 | 0.969 | 0.970 | 0.970 | 0.970 | 0.966 | 0.985 | 0.955 | 0.965 | 0.735 | 0.789 | 0.745 | 0.717 | 0.752 | 0.931 | 0.916 | 0.918 |
| CAY2 | 0.968 | 0.959 | 0.958 | 0.967 | 0.969 | 0.968 | 0.968 | 0.969 | 0.968 | 0.968 | 0.952 | 0.959 | 0.964 | 0.952 | 0.957 | 0.952 | 0.952 | 0.949 | 0.961 | 0.960 | 0.958 |
| CAY3 | 0.985 | 0.985 | 0.983 | 0.981 | 0.986 | 0.985 | 0.984 | 0.985 | 0.984 | 0.973 | 0.991 | 0.950 | 0.975 | 0.948 | 0.949 | 0.940 | 0.929 | 0.941 | 0.809 | 0.826 | 0.839 |
| CAY4 | 0.974 | 0.994 | 0.991 | 0.971 | 0.971 | 0.968 | 0.971 | 0.968 | 0.968 | 0.964 | 0.962 | 0.922 | 0.967 | 0.914 | 0.936 | 0.888 | 0.865 | 0.846 | 0.946 | 0.934 | 0.956 |
| CAY5 | 0.952 | 0.922 | 0.956 | 0.943 | 0.952 | 0.950 | 0.949 | 0.951 | 0.951 | 0.950 | 0.908 | 0.933 | 0.951 | 0.781 | 0.834 | 0.773 | 0.769 | 0.772 | 0.666 | 0.618 | 0.617 |
| CAY6 | 0.980 | 0.956 | 0.956 | 0.980 | 0.981 | 0.981 | 0.980 | 0.982 | 0.980 | 0.969 | 0.956 | 0.960 | 0.973 | 0.946 | 0.946 | 0.952 | 0.949 | 0.830 | 0.850 | 0.787 | 0.875 |
| CAY7 | 0.991 | 0.983 | 0.983 | 0.990 | 0.990 | 0.990 | 0.991 | 0.991 | 0.991 | 0.983 | 0.986 | 0.988 | 0.967 | 0.986 | 0.985 | 0.984 | 0.984 | 0.985 | 0.776 | 0.824 | 0.788 |
| CAY8 | 0.975 | 0.937 | 0.935 | 0.966 | 0.976 | 0.972 | 0.971 | 0.972 | 0.970 | 0.964 | 0.923 | 0.925 | 0.958 | 0.933 | 0.933 | 0.935 | 0.934 | 0.935 | 0.817 | 0.826 | 0.825 |
| CAY9 | 0.915 | 0.923 | 0.920 | 0.910 | 0.917 | 0.916 | 0.915 | 0.915 | 0.916 | 0.911 | 0.898 | 0.896 | 0.909 | 0.875 | 0.868 | 0.860 | 0.848 | 0.834 | 0.879 | 0.849 | 0.872 |
| CAY10 | 0.967 | 0.979 | 0.965 | 0.968 | 0.963 | 0.968 | 0.968 | 0.969 | 0.968 | 0.965 | 0.973 | 0.885 | 0.970 | 0.883 | 0.902 | 0.860 | 0.877 | 0.922 | 0.833 | 0.786 | 0.808 |
| FELT0 | 0.979 | 0.982 | 0.980 | 0.979 | 0.978 | 0.978 | 0.977 | 0.977 | 0.978 | 0.971 | 0.977 | 0.977 | 0.951 | 0.976 | 0.976 | 0.977 | 0.976 | 0.977 | 0.952 | 0.955 | 0.937 |
| FELT1 | 0.976 | 0.966 | 0.98 | 0.975 | 0.976 | 0.973 | 0.975 | 0.976 | 0.976 | 0.968 | 0.971 | 0.970 | 0.958 | 0.964 | 0.964 | 0.965 | 0.964 | 0.965 | 0.947 | 0.946 | 0.945 |
| FELT2 | 0.976 | 0.947 | 0.960 | 0.976 | 0.974 | 0.975 | 0.976 | 0.974 | 0.975 | 0.959 | 0.969 | 0.959 | 0.963 | 0.914 | 0.921 | 0.918 | 0.901 | 0.890 | 0.952 | 0.948 | 0.948 |
| FELT3 | 0.977 | 0.984 | 0.987 | 0.978 | 0.977 | 0.978 | 0.977 | 0.977 | 0.978 | 0.968 | 0.987 | 0.971 | 0.956 | 0.974 | 0.975 | 0.969 | 0.971 | 0.970 | 0.964 | 0.966 | 0.962 |
| FELT4 | 0.983 | 0.992 | 0.976 | 0.985 | 0.983 | 0.983 | 0.984 | 0.983 | 0.983 | 0.977 | 0.988 | 0.981 | 0.964 | 0.968 | 0.972 | 0.972 | 0.968 | 0.968 | 0.968 | 0.969 | 0.961 |
| SAT0 | 0.920 | 0.910 | 0.916 | 0.917 | 0.915 | 0.915 | 0.916 | 0.914 | 0.916 | 0.918 | 1.000 | 0.913 | 0.907 | 0.909 | 0.912 | 0.909 | 0.894 | 0.881 | 0.899 | 0.881 | 0.865 |
| SAT1 | 0.985 | 0.988 | 0.988 | 0.984 | 0.986 | 0.983 | 0.986 | 0.984 | 0.985 | 0.983 | 0.996 | 0.983 | 0.976 | 0.983 | 0.983 | 0.982 | 0.982 | 0.981 | 0.982 | 0.981 | 0.976 |
| SAT2 | 0.981 | 0.989 | 0.983 | 0.980 | 0.982 | 0.980 | 0.981 | 0.983 | 0.980 | 0.977 | 0.961 | 0.980 | 0.969 | 0.977 | 0.980 | 0.977 | 0.976 | 0.976 | 0.971 | 0.966 | 0.964 |
| SAT3 | 0.961 | 0.965 | 0.958 | 0.960 | 0.958 | 0.962 | 0.962 | 0.961 | 0.963 | 0.960 | 0.911 | 0.957 | 0.955 | 0.957 | 0.958 | 0.950 | 0.955 | 0.943 | 0.954 | 0.956 | 0.945 |
| SAT4 | 0.857 | 0.867 | 0.803 | 0.863 | 0.866 | 0.849 | 0.858 | 0.858 | 0.858 | 0.844 | 1.000 | 0.844 | 0.854 | 0.746 | 0.779 | 0.792 | 0.757 | 0.581 | 0.769 | 0.711 | 0.776 |
| SAT5 | 0.944 | 0.945 | 0.928 | 0.925 | 0.944 | 0.944 | 0.944 | 0.942 | 0.941 | 0.920 | 1.000 | 0.917 | 0.913 | 0.847 | 0.823 | 0.855 | 0.853 | 0.842 | 0.927 | 0.921 | 0.927 |
| SEG0 | 0.998 | 0.965 | 0.970 | 0.995 | 0.993 | 0.994 | 0.996 | 0.992 | 0.988 | 0.997 | 0.895 | 0.995 | 0.993 | 0.993 | 0.992 | 0.994 | 0.993 | 0.994 | 0.994 | 0.993 | 0.994 |
| SEG1 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.988 | 1.000 | 0.991 | 0.999 | 1.000 | 1.000 | 1.000 | 0.999 | 0.999 | 1.000 | 0.925 | 0.909 | 0.914 |
| SEG2 | 0.978 | 0.979 | 0.996 | 0.979 | 0.975 | 0.977 | 0.979 | 0.974 | 0.977 | 0.981 | 0.983 | 0.978 | 0.965 | 0.982 | 0.983 | 0.981 | 0.980 | 0.977 | 0.965 | 0.964 | 0.963 |
| SEG3 | 0.973 | 0.967 | 0.976 | 0.963 | 0.971 | 0.973 | 0.972 | 0.970 | 0.911 | 0.971 | 0.952 | 0.961 | 0.961 | 0.969 | 0.966 | 0.970 | 0.974 | 0.957 | 0.961 | 0.960 | 0.957 |
| SEG4 | 0.872 | 0.836 | 0.907 | 0.926 | 0.927 | 0.906 | 0.852 | 0.926 | 0.514 | 0.863 | 0.850 | 0.886 | 0.903 | 0.787 | 0.811 | 0.650 | 0.656 | 0.630 | 0.793 | 0.741 | 0.840 |
| SEG5 | 0.999 | 1.000 | 1.000 | 0.999 | 0.994 | 0.993 | 0.981 | 0.992 | 0.980 | 0.998 | 0.957 | 0.975 | 0.990 | 0.995 | 0.998 | 0.994 | 0.990 | 0.999 | 0.918 | 0.996 | 0.994 |
| SEG6 | 0.995 | 1.000 | 1.000 | 0.995 | 0.995 | 0.995 | 0.995 | 0.995 | 0.994 | 0.995 | 0.970 | 0.995 | 0.987 | 0.995 | 0.995 | 0.995 | 0.995 | 0.995 | 0.912 | 0.922 | 0.887 |
| 92A0 | 0.937 | 0.963 | 0.940 | 0.945 | 0.947 | 0.942 | 0.921 | 0.937 | 0.943 | 0.927 | 0.862 | 0.928 | 0.939 | 0.926 | 0.918 | 0.921 | 0.926 | 0.845 | 0.924 | 0.894 | 0.922 |
| 92A1 | 0.881 | 0.902 | 0.942 | 0.910 | 0.910 | 0.896 | 0.825 | 0.910 | 0.918 | 0.867 | 0.948 | 0.908 | 0.899 | 0.854 | 0.865 | 0.682 | 0.658 | 0.704 | 0.777 | 0.787 | 0.868 |
| 92A2 | 0.853 | 0.861 | 0.858 | 0.861 | 0.834 | 0.848 | 0.845 | 0.844 | 0.856 | 0.839 | 0.833 | 0.850 | 0.842 | 0.851 | 0.828 | 0.843 | 0.843 | 0.838 | 0.829 | 0.846 | 0.786 |
| 92A3 | 0.880 | 0.869 | 0.858 | 0.874 | 0.840 | 0.879 | 0.880 | 0.852 | 0.882 | 0.881 | 0.867 | 0.879 | 0.877 | 0.860 | 0.802 | 0.817 | 0.849 | 0.876 | 0.774 | 0.829 | 0.683 |
| 92A4 | 0.987 | 0.997 | 0.997 | 0.981 | 0.975 | 0.980 | 0.977 | 0.974 | 0.982 | 0.986 | 0.983 | 0.974 | 0.973 | 0.977 | 0.974 | 0.975 | 0.976 | 0.968 | 0.977 | 0.975 | 0.975 |
| 92A5 | 0.995 | 1.000 | 1.000 | 0.993 | 0.987 | 0.978 | 0.965 | 0.985 | 0.989 | 0.990 | 1.000 | 0.974 | 0.977 | 0.988 | 0.987 | 0.968 | 0.955 | 0.971 | 0.946 | 0.902 | 0.912 |
| Ranks | 5.500 | 6.129 | 6.171 | 6.471 | 7.000 | 7.143 | 7.443 | 7.643 | 7.857 | 9.600 | 9.871 | 11.700 | 12.971 | 13.586 | 13.771 | 14.800 | 15.586 | 16.029 | 16.871 | 17.229 | 17.629 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alejo, R.; Monroy-de-Jesús, J.; Pacheco-Sánchez, J.H.; López-González, E.; Antonio-Velázquez, J.A. A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem. Appl. Sci. 2016, 6, 200. https://doi.org/10.3390/app6070200
Alejo R, Monroy-de-Jesús J, Pacheco-Sánchez JH, López-González E, Antonio-Velázquez JA. A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem. Applied Sciences. 2016; 6(7):200. https://doi.org/10.3390/app6070200
Chicago/Turabian StyleAlejo, Roberto, Juan Monroy-de-Jesús, Juan H. Pacheco-Sánchez, Erika López-González, and Juan A. Antonio-Velázquez. 2016. "A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem" Applied Sciences 6, no. 7: 200. https://doi.org/10.3390/app6070200
APA StyleAlejo, R., Monroy-de-Jesús, J., Pacheco-Sánchez, J. H., López-González, E., & Antonio-Velázquez, J. A. (2016). A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem. Applied Sciences, 6(7), 200. https://doi.org/10.3390/app6070200