Water Relationships in the U.S. Southwest: Characterizing Water Management Networks Using Natural Language Processing


Abstract
:1. Introduction
2. Background
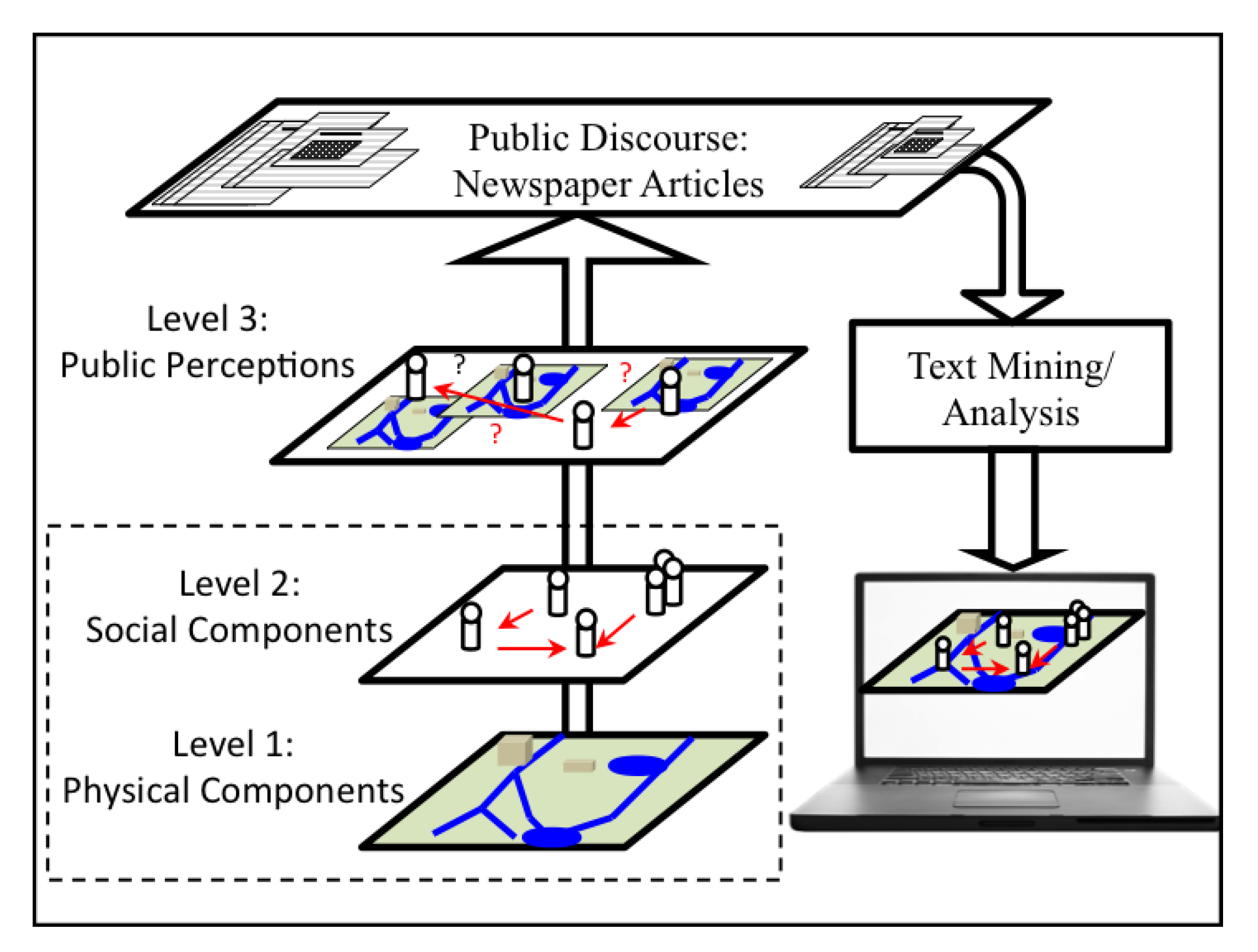
2.1. A Structural View
2.2. Using Media as Public Discourse
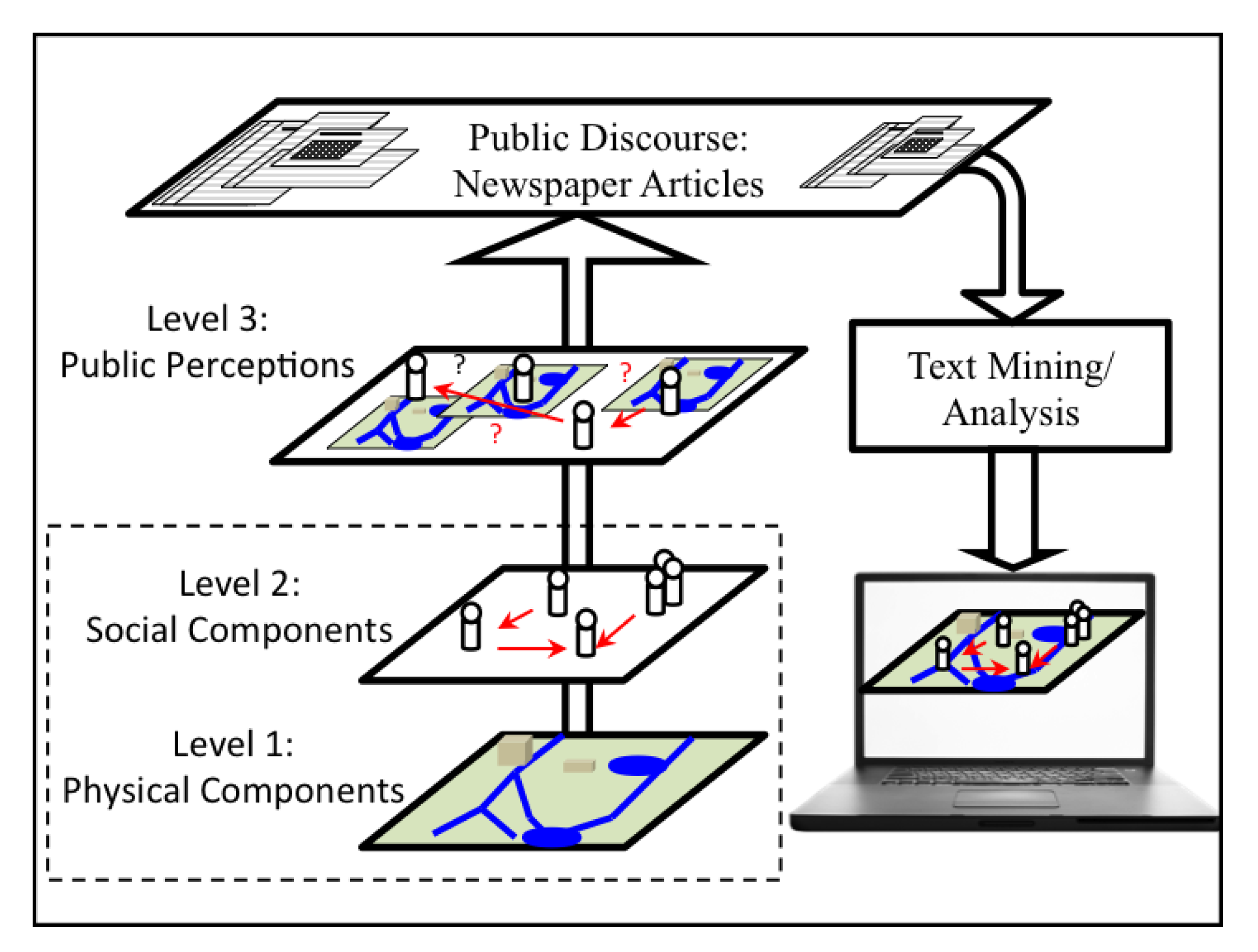
2.3. Advantages and Limitations
3. Case Study Areas

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Urban Area | Population (2010) | Water Sources | Water Management Structure |
|---|---|---|---|
| Flagstaff, AZ | 65,870 | Dams on Walnut Creek + increasing use of groundwater | Simple, centralized; isolated |
| Tucson, AZ | 520,116 (Pima County: 980,263) | Aquifer + Central Arizona Project Canal (Colorado River) | Large, centralized; partial water importer |
| Las Vegas, NV | 583,756 | Lake Mead (90%), groundwater (10%); | Large, centralized; water importer |
| The Grand Valley, CO | 146,723 (Mesa County) | Colorado and Gunnison Rivers (irrigation); groundwater from Grand Mesa and areas to E, SE (potable) | Complex; interlinked; communities |
3.1. Summary and Expectations
4. Methods
4.1. Acquiring Data Sources
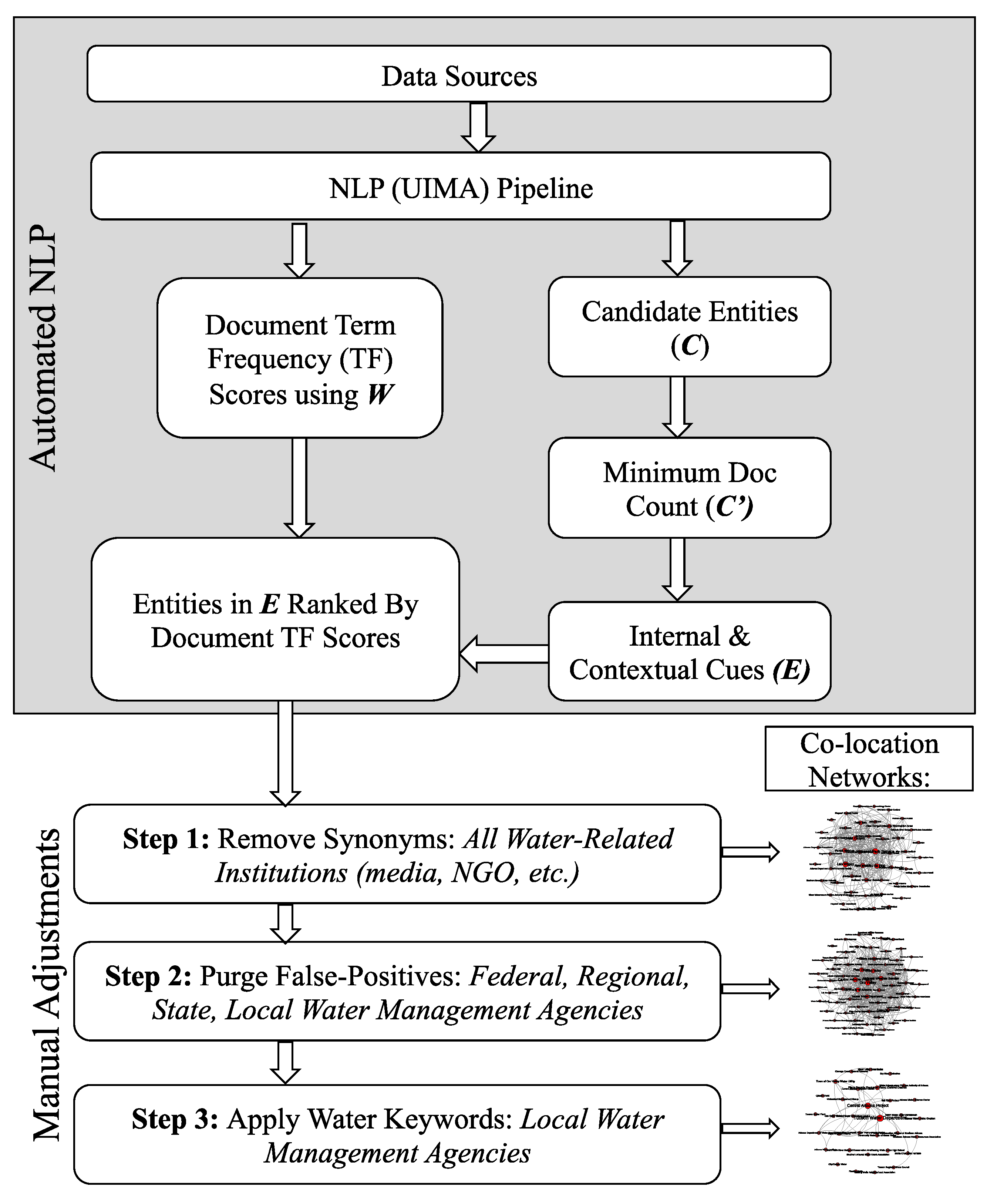
4.2. Establishing Document Relevance
4.3. Extracting “Water Authorities”
| Feature | Symbol | Definition | Value |
|---|---|---|---|
| Count of terms | l | Number of tokens in the phrase | Integer |
| Count of non-NNP terms | n | Count of terms in phrase that appear in N’ | Integer |
| Count of initial geographic terms | gi | Number of tokens in Gi that are found contiguously at the start of the phrase | Integer |
| Count of end geographic features | gf | Number of tokens in Gf that are found contiguously at the end of the phrase | Integer |
| Includes water | W | Phrase includes one or more tokens from W | T/F |
| Includes admin | A | Phrase includes one or more tokens from A | T/F |
| Ends with street | S | Final token in phrase is a member of S | T/F |
| Ends with legislative term | L | Final token in phrase is a member of L | T/F |
| Preceded by definite article | Db | Contextual: token in document immediately preceding phrase is a definite article | T/F |
| Preceded by personal title | Tb | Contextual: token in document immediately preceding phrase is a personal title (from T) | T/F |
| Has representative | R | Contextual: will be true in two cases: (1) the word or words immediately preceding the phrase is “for”, “from”, “of”, “for the”, “from the” or “of the”, and the word immediately before this is from R or T; or (2) if the word immediately following the phrase is from R or T, with the exception of “Dr.” (which, in this, position usually means “Drive”) | T/F |
| Followed by acronym | Ua | Contextual: true if the token immediately following is two or more capital letters enclosed in parentheses | T/F |
˄ ¬ (¬R ˄ (((gf > 0) ˄ (n > 0)) ˅ ((l − gi) = 1)))
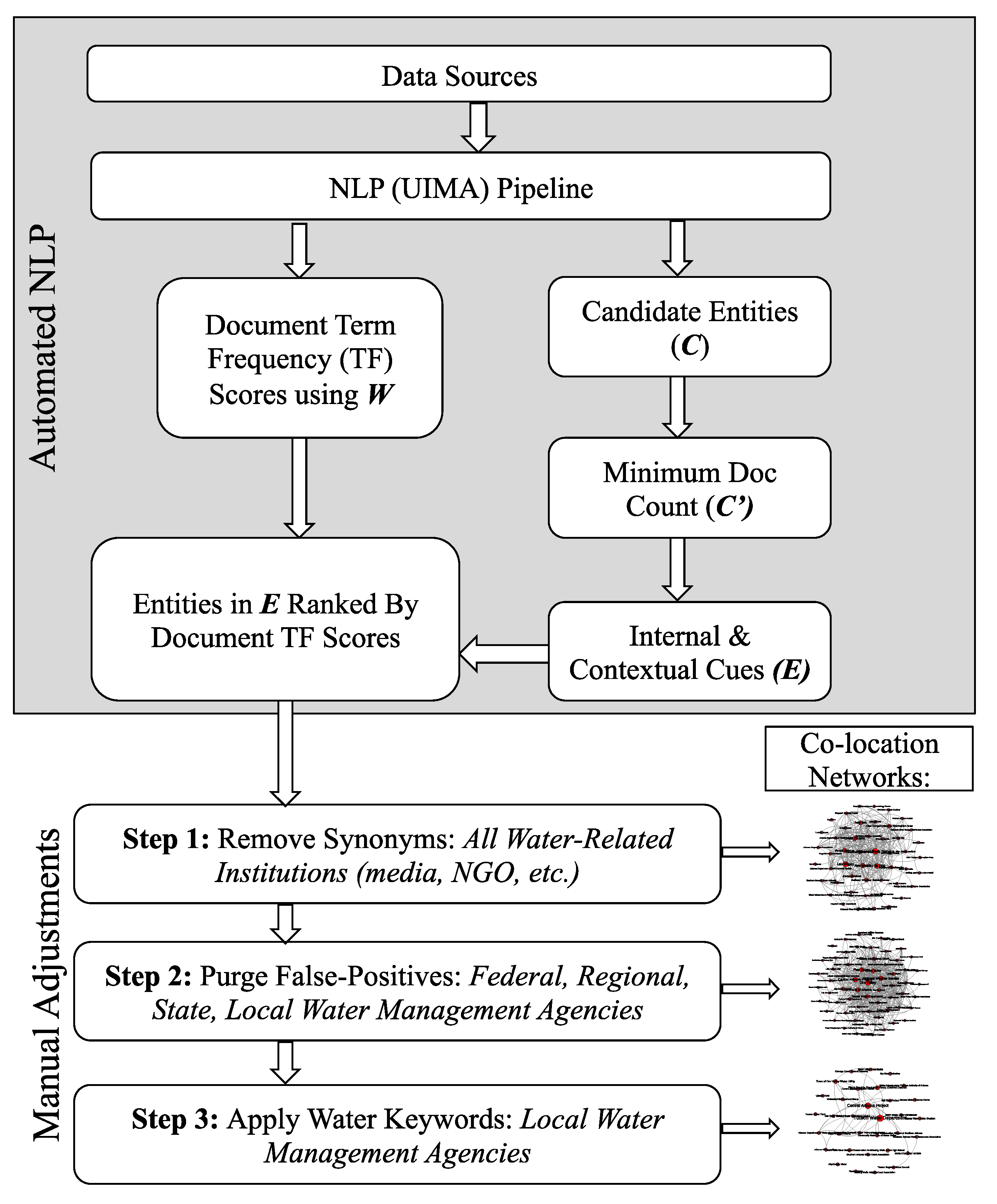
4.4. Candidate Institutions and Document Relevance
4.5. Targeted Manual Revisions
4.5.1. Step 1: Remove Synonyms
4.5.2. Step 2: Purge False Positives
4.5.3. Step 3: Apply “Water” Keywords
4.6. Network Analyses
5. Results
| Urban Area | News Source | Time Period(s) | Articles |
|---|---|---|---|
| Flagstaff | Arizona Daily Sun | 25 August 2005–7 October 2012 | 11,519 |
| Tucson | Arizona Daily Star | 1 January 2004–31 December 2011 | 20,190 |
| Las Vegas | Las Vegas Sun | 1 January 2005–3 February 2009; 1 January 2011–4 October 2012 | 66,672 |
| Grand Valley | Grand JunctionFree Press | 13 April 2005–5 October 2012 | 12,187 |
5.1. Document Relevance
| Scorer Rating | Top 50 | Random | |||||
|---|---|---|---|---|---|---|---|
| Top 1/3 | Mid 1/3 | Bottom 1/3 | Top 1/2 | Bottom 1/2 | Zero | ||
| Flagstaff | − − | 1 | 7 | 3 | 4 | 2 | 33 |
| − + | 1 | 2 | 2 | 3 | 2 | ||
| + + | 13 | 6 | 12 | ||||
| Tucson | − − | 2 | 1 | 4 | 3 | 27 | |
| − + | 2 | 1 | 1 | ||||
| + + | 14 | 12 | 13 | 1 | 1 | ||
| Las Vegas | − − | 1 | 4 | 4 | 39 | ||
| − + | 3 | ||||||
| + + | 17 | 13 | 16 | 2 | |||
| The Grand Valley | − − | 1 | 3 | 4 | 39 | ||
| − + | 1 | 2 | |||||
| + + | 16 | 14 | 16 | 2 | |||
5.2. Reduction of Candidate Entities: C → C’ → E
| Stage | Flagstaff | Tucson | Las Vegas | Grand Valley |
|---|---|---|---|---|
| Total Distinct Entities (C) | 59,914 | 92,874 | 271,824 | 63,684 |
| Total Distinct Entities in > 2 Documents (C’) | 6,309 | 6,668 | 24,514 | 7,152 |
| Entities Meeting Institution Criteria (E) | 2,709 | 2,681 | 8,864 | 3,037 |
| Step 1: | ||||
| Number of Synonym Corrections | 11 | 11 | 9 | 5 |
| Resulting Number of Entities | 2,706 | 2,678 | 8,863 | 3,038 |
| Step 2: (Top 100 of list from Step 1) | ||||
| Synonym Corrections | 11 | 6 | 13 | 9 |
| False Positives Removed | 27 | 32 | 20 | 25 |
| Resulting Entities (Of Top 100) | 63 | 64 | 67 | 66 |
| Step 3: | ||||
| Synonym Corrections | 1 | 4 | 10 | 1 |
| Water Keywords Manually Set to “True” | 4 | 2 | 0 | 7 |
| Water Keywords Manually Set to “False” | 75 | 35 | 180 | 42 |
| Final Number of Entities | 42 | 33 | 32 | 35 |
| Data Source | N | Ind + | % + Correct | False + Fraction |
|---|---|---|---|---|
| Arizona Daily Sun (Flagstaff) | 1518 | 342 | 92% | 1.42 |
| Arizona Daily Star (Tucson) | 1014 | 226 | 92% | 1.02 |
| Las Vegas Sun | 952 | 158 | 96% | 1.81 |
| Grand Junction Free Press | 2037 | 453 | 83% | 1.45 |
| Overall | 5521 | 1179 | 89% | 1.41 |
| Flagstaff | Tucson |
|---|---|
| 1. Caesars Palace | 1. National Weather Service |
| 2. Colorado River Water Users Association | 2. Tucson Water Department |
| 3. Southern Nevada Water Authority | 3. Tucson International Airport |
| 4. National Park Service | 4. Pima County Regional Flood Control District |
| 5. New Mexico | 5. Central Arizona Project |
| 6. North Beaver | 6. Tucson Fire Department |
| 7. Colorado River Energy Distributors Association | 7. Mount Lemmon |
| 8. U.S. Forest Service | 8. Arizona Daily Star |
| 9. Bureau of Reclamation | 9. University of Arizona |
| 10. Las Vegas Review-Journal | 10. Green Valley |
| 11. Daily Sun | 11. Tanque Verde Guest Ranch |
| 12. Northern Arizona Dermatology Center | 12. Town Too Tough |
| 13. National Weather Service | 13. Southern Arizona |
| 14. Forest Service | 14. Randolph Golf Course |
| 15. Snow on Peaks | 15. Sweetwater Wetlands |
| 16. Glen Canyon National Recreation Area | 16. Arlene Fire |
| 17. Deseret News | 17. Lakeview Campground |
| 18. Big Chino | 18. Sierra Vista District Ranger for the U.S. Forest Service |
| 19. Grand Canyon | 19. Oro Valley |
| 20. Las Vegas | 20. Northwest Side |
| Las Vegas | Grand Junction |
| 1. Lower Basin of the Colorado River | 1. Water Center |
| 2. Bureau of Reclamation | 2. Colorado Mesa University |
| 3. Colorado River | 3. Upper Gunnison River Water Conservancy District |
| 4. Southern Nevada Water Authority | 4. WATER Club |
| 5. CHASING LAKE MEAD'S WATER | 5. Mesa County |
| 6. Southern Nevada | 6. Colorado Water Conservation Board |
| 7. Water Authority | 7. Redlands Water |
| 8. Interior Department | 8. Interbasin Compact Committee |
| 9. Lake Mead National Recreation Area | 9. Gunnison Basin Roundtable |
| 10. River Commission | 10. Colorado River Basin Roundtable |
| 11. Hoover Dam | 11. Bureau of Reclamation |
| 12. National Park Service | 12. Grand Valley Water Users Association |
| 13. White Pine | 13. Grand Mesa |
| 14. Colorado River Water Users Association | 14. Glenwood Springs |
| 15. Urban Water Institute | 15. Grand Valley |
| 16. Arizona Department of Water Resources | 16. River District |
| 17. Metropolitan Water District of Southern California | 17. Glenwood Springs Community Center |
| 18. Southern California | 18. Colorado River District |
| 19. Las Vegas Valley Water District | 19. Mesa County Irrigation District |
| 20. Upper Basin | 20. Colorado Foundation for Water Education |
5.3. Step 1: Remove Synonyms
5.4. Step 2: Remove False Positives
| Category | Flagstaff | Tucson | Las Vegas | Grand Junction |
|---|---|---|---|---|
| Act | 1 | |||
| Business | 5 | 4 | 6 | 5 |
| Event | 2 | 4 | 2 | 2 |
| Local Government (Non-Water) | 4 | 6 | 4 | |
| Local NGO | 2 | 1 | 1 | 1 |
| Media | 5 | 1 | 1 | 2 |
| National NGO | 1 | 1 | 1 | 1 |
| Person | 4 | |||
| Place | 27 | 21 | 25 | 18 |
| Research Org. | 3 | 9 | 2 | 6 |
| Road | 3 | |||
| Federal (Water) | 15 | 7 | 16 | 11 |
| State (Water) | 8 | 8 | 5 | 5 |
| Regional (Water) | 9 | 3 | 15 | 12 |
| Local (Water) | 6 | 18 | 12 | 16 |
| Other/Spurious | 13 | 13 | 14 | 13 |
5.5. Step 3: Water Keywords
5.6. Network Analyses
| Source | Scope | Water | Government | Business | NGO | University | Place | Other | Total |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 8 | 10 | |||
| Arizona Daily Sun | Federal | 12 | 1 | 1 | 14 | ||||
| State | 1 | 10 | 1 | 1 | 13 | ||||
| Local | 13 | 7 | 4 | 2 | 5 | 5 | 36 | ||
| Total | 1 | 35 | 7 | 6 | 2 | 6 | 6 | 63 | |
| Arizona Daily Star | Federal | 1 | 5 | 1 | 7 | ||||
| State | 2 | 6 | 1 | 9 | |||||
| Local | 5 | 9 | 6 | 5 | 6 | 12 | 3 | 46 | |
| Total | 8 | 20 | 6 | 6 | 7 | 12 | 3 | 62 | |
| Las Vegas Sun | Federal | 14 | 2 | 1 | 17 | ||||
| State | 5 | 6 | 1 | 3 | 15 | ||||
| Local | 7 | 9 | 5 | 10 | 4 | 35 | |||
| Total | 12 | 29 | 6 | 15 | 1 | 4 | 67 | ||
| Grand Junction Free Press | Federal | 9 | 1 | 2 | 12 | ||||
| State | 5 | 3 | 3 | 1 | 12 | ||||
| Local | 15 | 11 | 2 | 2 | 2 | 4 | 5 | 41 | |
| Total | 20 | 23 | 3 | 7 | 2 | 4 | 6 | 65 |
6. Analysis and Discussion
6.1. Step 1 Analysis
6.2. Step 2 Analysis
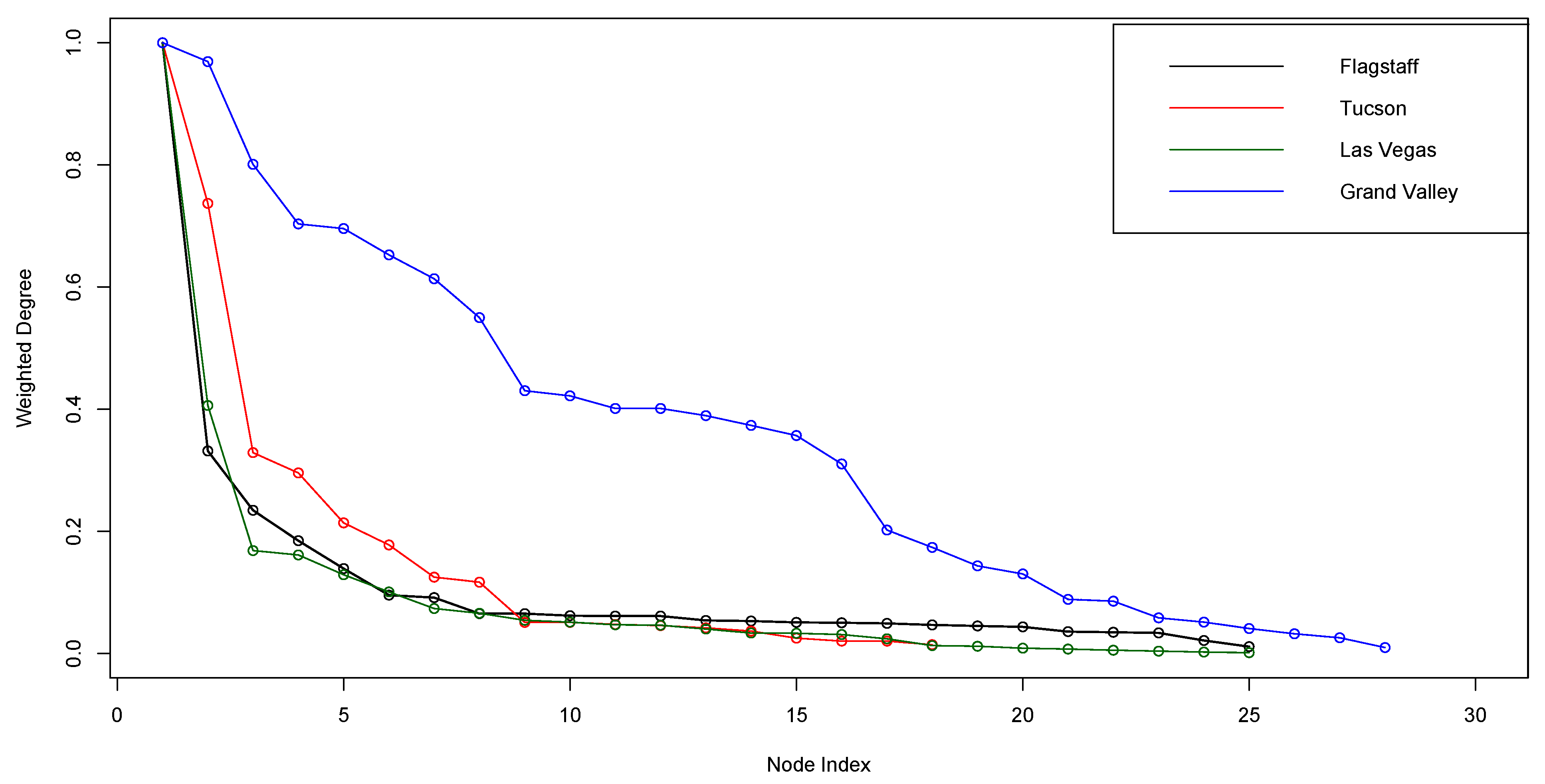
6.3. Step 3 Analysis
| Weighted Degree | Flagstaff | Tucson | Las Vegas | The Grand Valley |
|---|---|---|---|---|
| 0.8–1 | Flagstaff City Council | Central Arizona Project | Southern Nevada Water Authority | Colorado River Water Conservation District Ute Water Conservancy District City of Grand Junction |
| 0.6–0.8 | Tucson Water Department | Redlands Water Denver Water Colorado River Conservation Board Town of Palisade | ||
| 0.4–0.6 | Las Vegas Valley Water District | Grand Valley Water Users Association Mesa County Water Association Grand Valley Irrigation Company Mesa County Irrigation District Orchard Mesa Irrigation District | ||
| 0.2–0.4 | Arizona Department of Water Resources Salt River Project | Town of Oro Valley Water Utility Wells Irrigation District Cortaro-Marana Irrigation District | Colorado River Basin Roundtable Clifton Water District Upper Gunnison River Water Conservancy District; Gunnison Basin Roundtable; Interbasin Compact Committee |
| Ranked Sum vs. | Flagstaff | Tucson | Las Vegas | Grand Valley |
|---|---|---|---|---|
| n = 25 | n = 18 | n = 25 | n = 28 | |
| median = 0.054 | median = 0.050 | median = 0.040 | median = 0.365 | |
| Tucson | W = 222.5 | |||
| p = 0.9607 | ||||
| Las Vegas | W = 404.5 | W = 296.5 | ||
| p = 0.0758 | p = 0.0805 | |||
| Grand Valley | W = 163.5 | W = 143.5 | W = 124.5 | |
| p = 0.0009 | p = 0.0151 | p < 0.0001 |
6.4. Discussion
7. Conclusions
Author Contributions
Conflicts of Interest
Acknowledgements
References
- Rahaman, M.M.; Varis, O. Integrated water resources management: Evolution, prospects and future challenges. Sustain. Sci. Pract. Policy 2005, 1, 15–21. [Google Scholar]
- Kenney, D.S. Resource Management at the Watershed level: An Assessment of the Changing Federal Role in the Emerging Era of Community-Based Watershed Management: Report to the Western Water Policy Review Advisory Commission; Natural Resources Law Center, University of Colorado School of Law: Boulder, CO, USA, 1997. [Google Scholar]
- Lubell, M.N.; Robins, G.; Wang, P. Policy Coordination in an Ecology of Water Management Games. Available online: http://opensiuc.lib.siu.edu/pnconfs_2011/22 (accessed on 21 May 2014).
- Lubell, M. Governing institutional complexity: The ecology of games framework. Policy Stud. J. 2013, 41, 537–559. [Google Scholar] [CrossRef]
- McGinnis, M.D. Networks of adjacent action situations in polycentric governance. Policy Stud. J. 2011, 39, 51–78. [Google Scholar] [CrossRef]
- McGinnis, M.D.; Ostrom, E. SES Framework: Initial changes and continuing challenges. Ecol. Soc. 2014, 19. Available online: http://dx.doi.org/10.5751/ES-06387-190230 (accessed on 22 May 2014).
- Van Meerkerk, I.; Buuren, A.; Edelenbos, J. Water managers’ boundary judgments and adaptive water governance. An analysis of the Dutch Haringvliet sluices case. Water Resour. Manag. 2013, 27, 2179–2194. [Google Scholar] [CrossRef] [Green Version]
- Hajer, M.; Versteeg, W. Performing governance through networks. Eur. Polit. Sci. 2005, 4, 340–347. [Google Scholar] [CrossRef]
- Van Meerkerk, I.; Edelenbos, J.; Klijn, E.-H. Connective management and governance network performance: The mediating role of throughput legitimacy. Findings from survey research on complex water projects in the Netherlands. Environ. Plan. C Gov. Policy 2014. [Google Scholar] [CrossRef] [Green Version]
- Huitema, D.; Mostert, E.; Egas, W.; Moellenkamp, S.; Pahl-Wostl, C.; Yalcin, R. Adaptive water governance: Assessing the institutional prescriptions of adaptive (Co-) management from a governance perspective and defining a research agenda. Ecol. Soc. 2009, 14, 1–19. [Google Scholar]
- Schneider, M.; Scholz, J.; Lubell, M.; Mindruta, D.; Edwardsen, M. Building consensual institutions: Networks and the national estuary program. Am. J. Polit. Sci. 2003, 47, 143–158. [Google Scholar] [CrossRef]
- Bennett, W.L. News: The Politics of Illusion; Longman, Inc.: New York, NY, USA, 1983. [Google Scholar]
- Alessa, L.; Kliskey, A.; Williams, P. The distancing effect of modernization on the perception of water resources in Arctic communities. Polar Geogr. 2007, 30, 175–191. [Google Scholar] [CrossRef]
- Alessa, L.; Kliskey, A.; Williams, P. Forgetting freshwater: Technology, values, and distancing in remote arctic communities. Soc. Nat. Resour. 2010, 23, 254–268. [Google Scholar] [CrossRef]
- Korthagen, I.; van Meerkerk, I. The Effects of media and their logic on legitimacy sources within local governance networks: A three-case comparative study. Local Gov. Stud. 2014, 1–24. [Google Scholar] [CrossRef]
- Gartin, M.; Crona, B.; Wutich, A.; Westerhoff, P. Urban ethnohydrology: Cultural knowledge of water quality and water management in a desert city. Ecol. Soc. 2010, 15, 36. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 1, 1–135. [Google Scholar] [CrossRef]
- City of Flagstaff Utilities. Utilities Integrated Master Plan (Draft): Water Resources Chapter- Water History, Demand, Existing Supplies, and Future Water Needs and Recommended Options; City of Flagstaff-Utilities Division: Flagstaff, AZ, USA, 2011. [Google Scholar]
- Logan, M.F. Fighting Sprawl and City Hall: Resistance to Urban Growth in the Southwest; University of Arizona Press: Tucson, AZ, USA, 1995. [Google Scholar]
- City of Tucson. Annual Water Quality Reports—2011; Archive the Official Website for the City of Tucson: Tucson, AZ, USA. Available online: http://cms3.tucsonaz.gov/water/anwqrpts_archive (accessed on 18 December 2013).
- Southern Nevada Water Authority. Water Resource Plan ’09; Southern Nevada Water Authority: Las Vegas, NV, USA, 2009. [Google Scholar]
- Green, E. Satiating a booming city. Available online: http://www.lasvegassun.com/news/2008/jun/01/satiating-booming-city/ (accessed on 8 November 2013).
- Green, E. The chosen one. Available online: http://www.lasvegassun.com/news/2008/jun/08/chosen-one/ (accessed on 8 November 2013).
- Green, E. The Equation: No water, no growth. Available online: http://www.lasvegassun.com/news/2008/jun/15/equation-no-water-no-growth/ (accessed on 8 November 2013).
- Green, E. Not this water. Available online: http://www.lasvegassun.com/news/2008/jun/22/not-water/ (accessed on 8 November 2013).
- Green, E. Owens Valley is the model of what to expect. Available online: http://www.lasvegassun.com/news/2008/jun/29/owens-valley-model-what-expect/ (accessed on 8 November 2013).
- Simonds, W.J. Grand Valley Project, 1994. U.S. Bureau of Reclamation. Available online: http://www.usbr.gov/projects//ImageServer?imgName=Doc_1305042485344.pdf (accessed on 21 May 2014).
- Ute Water Conservancy District; City of Grand Junction; Clifton Water District. In Grand Valley Regional Water Conservation Plan; Ute Water Conservancy District, City of Grand Junction, and Clifton Water District: Grand Junction, CO, USA, 2013.
- Shockley, P. Sink or Swim Meeting Wednesday will Shape Palisade’s Water Future. Post Independent. 30 November 2005. Available online: http://www.postindependent.com/article/20051129/local/111290005 (accessed on 21 May 2014).
- Water Fight in Palisade. Daily Sentinel, 29 November 2005.
- Mayor: Plan will “Keep Our Water in Palisade.”. Daily Sentinel, 30 November 2005.
- Analyzing Agents and Aqua. Available online: http://aaa.uchicago.edu (accessed on 21 May 2014).
- Apache UIMA. Available online: http://uima.apache.org/ (accessed on 18 December 2013).
- Chisholm, E.; Kolda, T.G. New Term Weighting Formulas for the Vector Space Method in Information Retrieval; Computer Science and Mathematics Division, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 1999. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Apache OpenNLP. Available online: http://opennlp.apache.org/index.html (accessed on 14 January 2014).
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An open source software for exploring and manipulating networks. In Proceedings of the Third International ICWSM Conference, San Jose, CA, USA, 17–20 May 2009.
- Gephi, an open source graph visualization and manipulation software. Available online: http://gephi.org/ (accessed on 18 December 2013).
- Shannon, P. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef]
- Hu, Y. Efficient, high-quality force-directed graph drawing. Math. J. 2005, 10, 37–71. [Google Scholar]
- Fruchterman, T.M.; Reingold, E.M. Graph drawing by force-directed placement. Softw. Pract. Exp. 1991, 21, 1129–1164. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, NY, USA, 1994. [Google Scholar]
- Barrat, A.; Barthelemy, M.; Pastor-Satorras, R.; Vespignani, A. The architecture of complex weighted networks. Proc. Natl. Acad. Sci. USA 2004, 101, 3747–3752. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Companies we supply services. Available online: http://www.southwesternutility.com/view/193 (accessed on 20 December 2013).
- Tucson_AMA_Map.pdf. Available online: http://www.azwater.gov/AzDWR/WaterManagement/Wells/documents/Tucson_AMA_Map.pdf (accessed on 21 May 2014).
- Southern Arizona Water Utilities Association—Membership. Available online: http://www.sawua.org/members_logo.html (accessed on 21 December 2013).
- Water Systems in Pima County, AZ—Toxic Waters—The New York Times. Available online: http://projects.nytimes.com/toxic-waters/contaminants/az/pima (accessed on 21 May 2014).
- Brown, R.R.; Farrelly, M.A. Delivering sustainable urban water management: A review of the hurdles we face. Water Sci. Technol. 2009, 59, 839–846. [Google Scholar] [CrossRef]
- Pahl-Wostl, C. Transitions towards adaptive management of water facing climate and global change. Water Resour. Manag. 2007, 21, 49–62. [Google Scholar] [CrossRef]
- Edelenbos, J.; Teisman, G.R. Symposium on water governance. Prologue: Water governance as a government’s actions between the reality of fragmentation and the need for integration. Int. Rev. Adm. Sci. 2011, 77, 5–30. [Google Scholar] [CrossRef]
- Lubell, M.; Lippert, L. Integrated regional water management: A study of collaboration or water politics-as-usual in California, USA. Int. Rev. Adm. Sci. 2011, 77, 76–100. [Google Scholar] [CrossRef]
- Pahl-Wostl, C. The implications of complexity for integrated resources management. Environ. Model. Softw. 2007, 22, 561–569. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Murphy, J.T.; Ozik, J.; Collier, N.T.; Altaweel, M.; Lammers, R.B.; Kliskey, A.; Alessa, L.; Cason, D.; Williams, P. Water Relationships in the U.S. Southwest: Characterizing Water Management Networks Using Natural Language Processing. Water 2014, 6, 1601-1641. https://doi.org/10.3390/w6061601
Murphy JT, Ozik J, Collier NT, Altaweel M, Lammers RB, Kliskey A, Alessa L, Cason D, Williams P. Water Relationships in the U.S. Southwest: Characterizing Water Management Networks Using Natural Language Processing. Water. 2014; 6(6):1601-1641. https://doi.org/10.3390/w6061601
Chicago/Turabian StyleMurphy, John T., Jonathan Ozik, Nicholson T. Collier, Mark Altaweel, Richard B. Lammers, Andrew Kliskey, Lilian Alessa, Drew Cason, and Paula Williams. 2014. "Water Relationships in the U.S. Southwest: Characterizing Water Management Networks Using Natural Language Processing" Water 6, no. 6: 1601-1641. https://doi.org/10.3390/w6061601