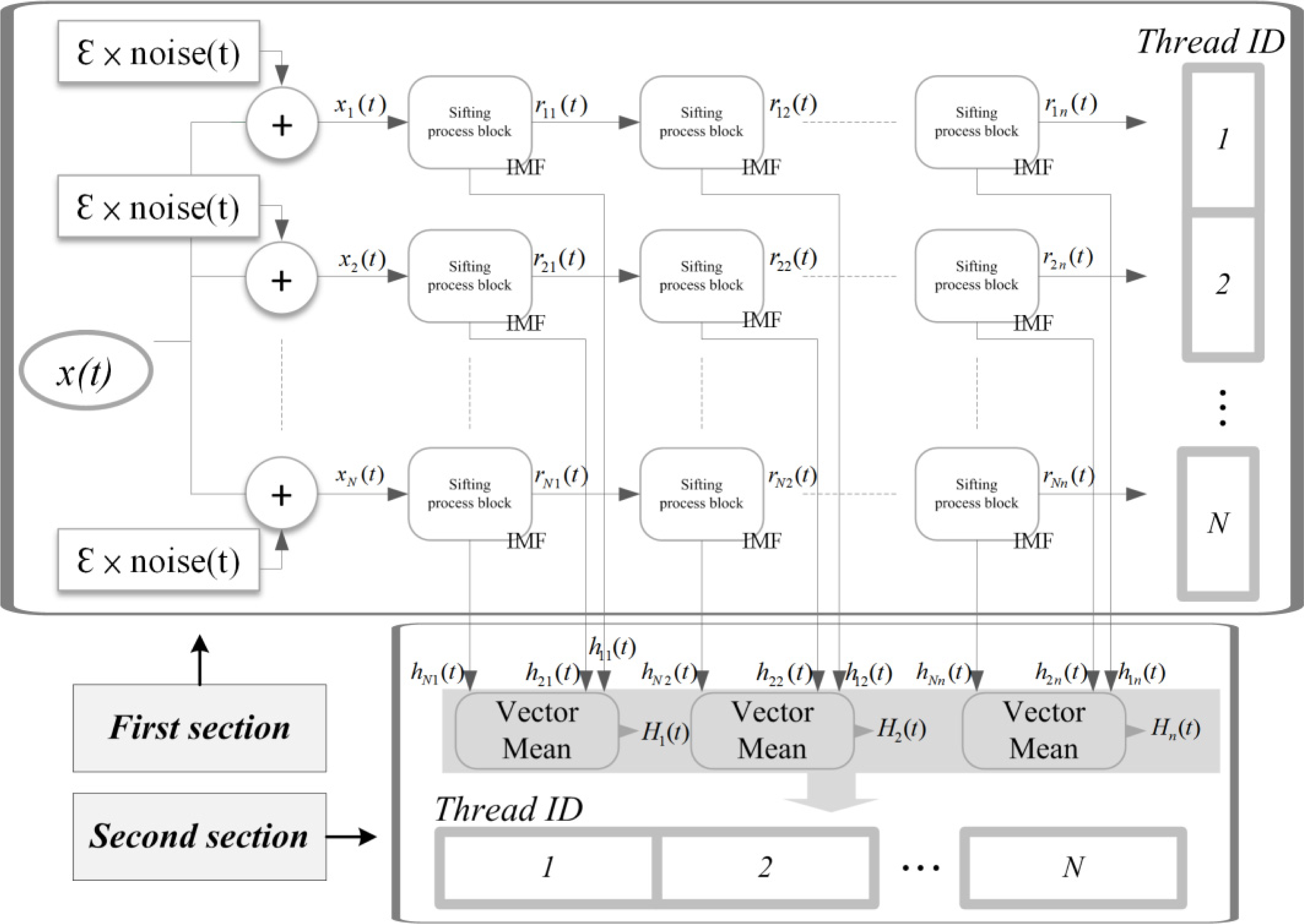
The proposed method is a two-stage process to measure the spectral similarity of two pixel vectors. In the first stage, EEMD is adopted to decompose a series of IMFs, and a set of IMFs is accumulated to enhance absorption features. Secondly, SAM is utilized as the distance measure for spectral similarity. Because of the computational complexity, parallel processing architecture is also implemented.
2.1. Ensemble Empirical Mode Decomposition (EEMD)
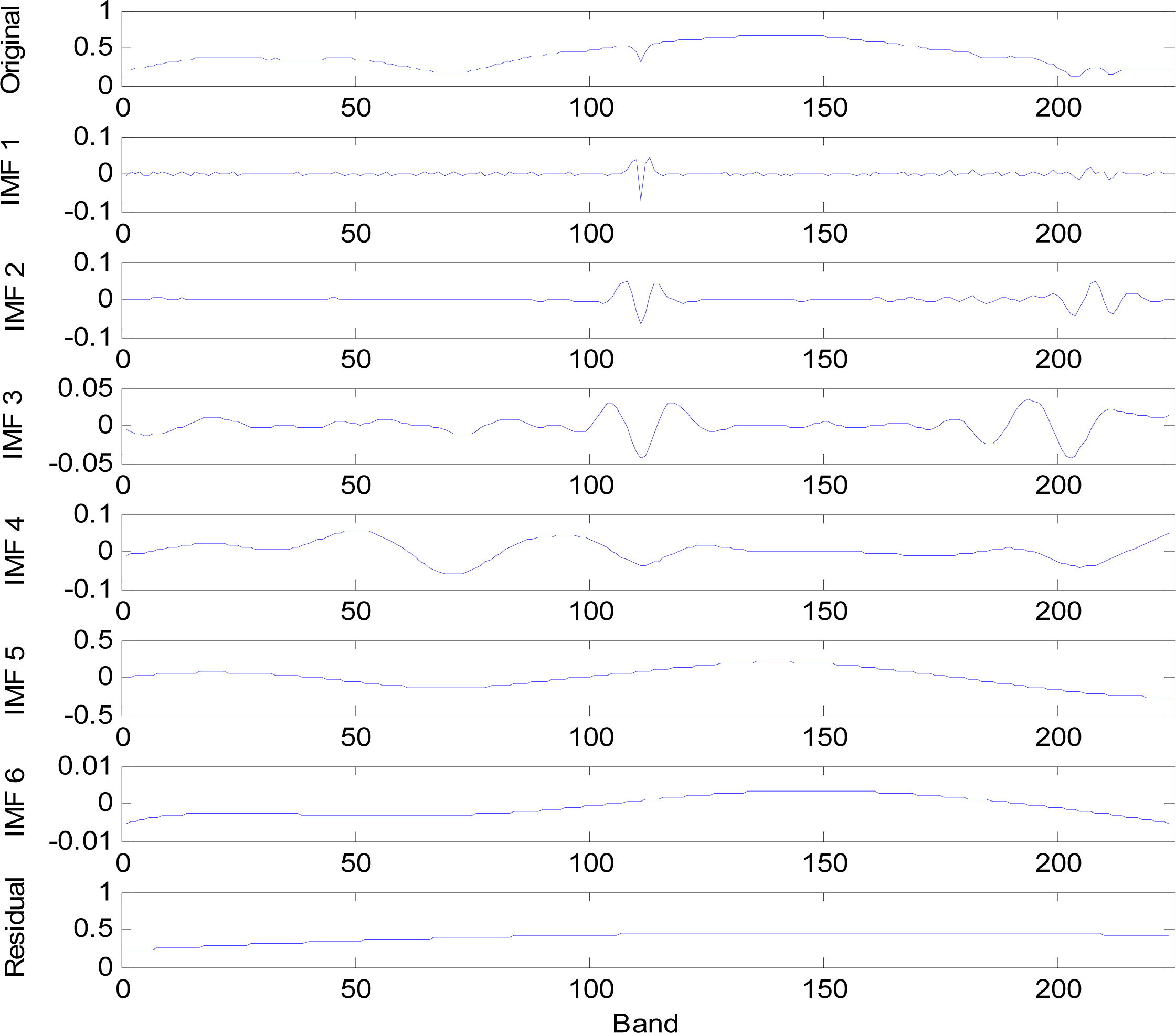
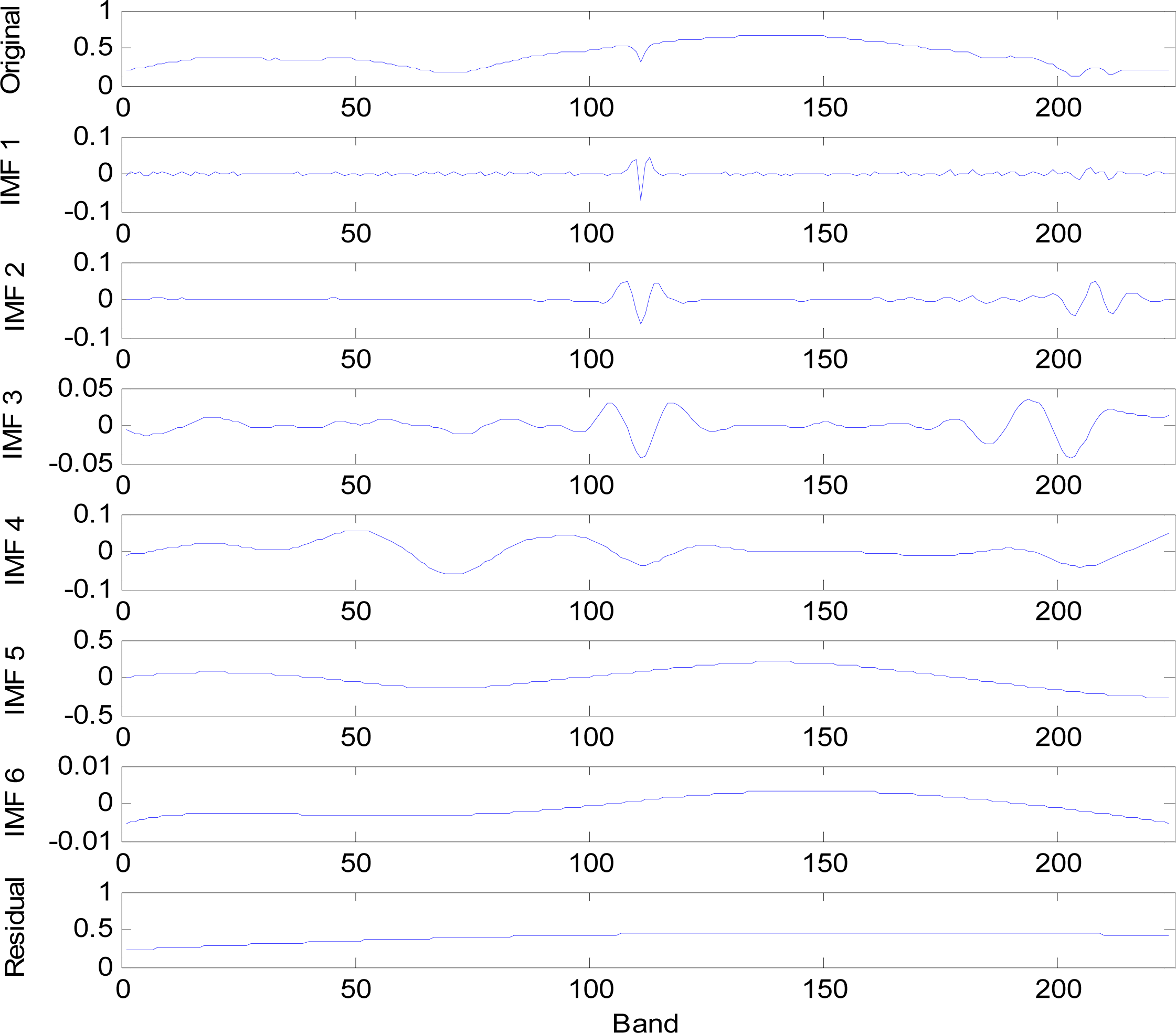
EEMD is a self-adaptive algorithm. In comparison, the traditional Fourier transform needs to convert the signal by frequency-domain integral analysis, but EMD can be directly performed for decomposition on a time-domain signal. After a special sifting process, a signal x(t) can be decomposed to n units of hj representing IMFs, and an item rn as its trend.
All IMFs are orthogonal to each other, and each IMF represents a unique range of energy and frequency. The sum of all IMFs is equal to the original data. The IMF must satisfy the following two conditions [
9]:
The numbers of extrema and zero-crossings of IMFs must be either equal or differ at most by one.
At any point, the mean of local maxima and local minima envelopes is zero.
In reality, the nature of a signal
x(
t) does not satisfy the definition of IMF. That is to say, a large part of the data consists of various frequencies. To satisfy the definition of IMF, the use of EMD incorporates the sifting process [
7]. This process serves two purposes: (1) to eliminate ride waves; and (2) make the IMF wave profiles more symmetric.
By using EMD for signal decomposition, the input signal must satisfy the following three conditions:
The signal has at least two extrema; one is the maximum and the other the minimum.
The time-period scale is defined by the time lapse between two extrema.
If the data have no extrema, only the inflection point is recorded, and the extrema can then be estimated by differentiation.
Finally, the results can be calculated by integration of these components.
The algorithm is summarized as follows:
- (1)
Identify all extrema of x(t)
- (2)
Interpolate between minima (resp. maxima) with “envelopes” emin(t) (resp. emax(t))
- (3)
Compute the mean envelope
, where k is the iteration number.
- (4)
Extract the detail hj = x(t)–mk(t).
- (5)
Repeat (1)–(4) until hj(t) meets the definition of IMF, and IMF converges.
- (6)
Repeat (1)–(5) to generate a residual rn(t), rn(t) = x(t)–hn(t)
In practice, the above procedure has to be refined by a sifting process which repeats steps (1)–(4) on the signal r(t), until it can be considered as having zero-mean according to the stopping criteria. Once this is achieved, the result is considered as the effective IMF. Then step (6) is applied to generate the corresponding residual rn(t).
To make sure the EMD decomposition process generates IMFs that meet its conditions, Huang
et al. [
7] proposed that a stopping criterion in the sifting process is needed for the EMD process. The criterion can be implemented by limiting the size of the standard deviation (
SD) by twice sifting the results as defined below:
A typical value is between 0.2 and 0.3 [
7]. When the computed SD value lies in the specified range, the sifting process is automatically stopped.
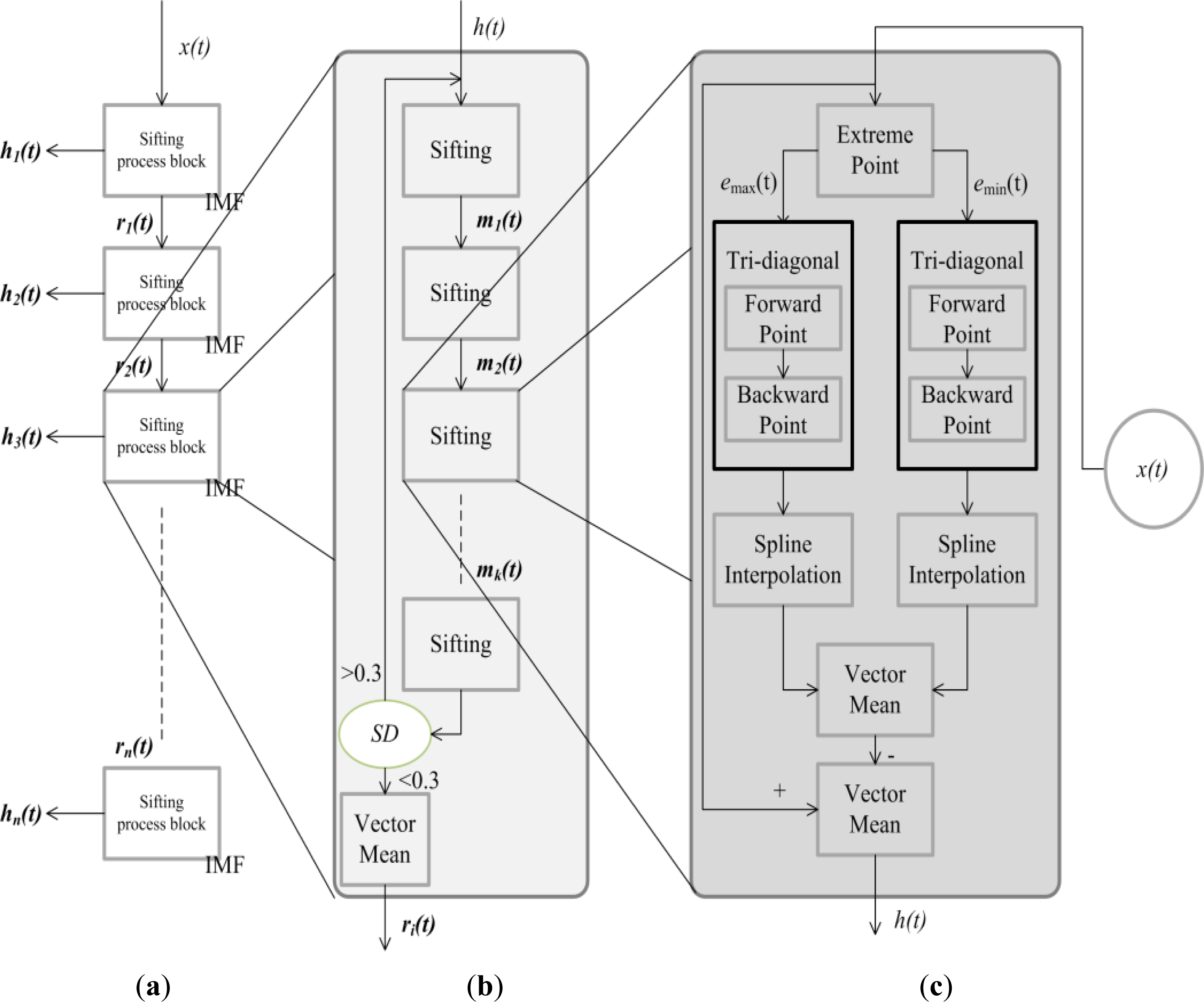
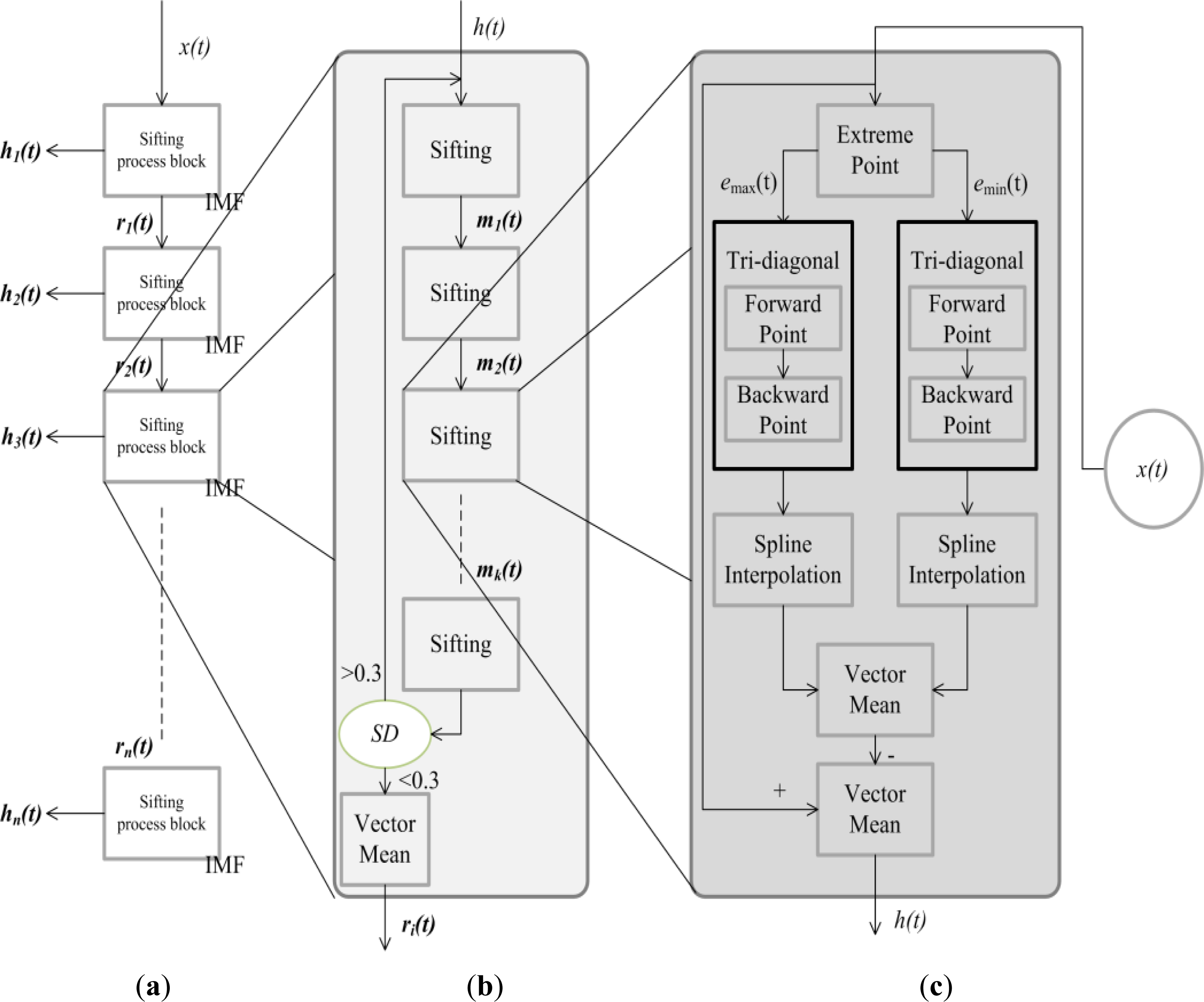
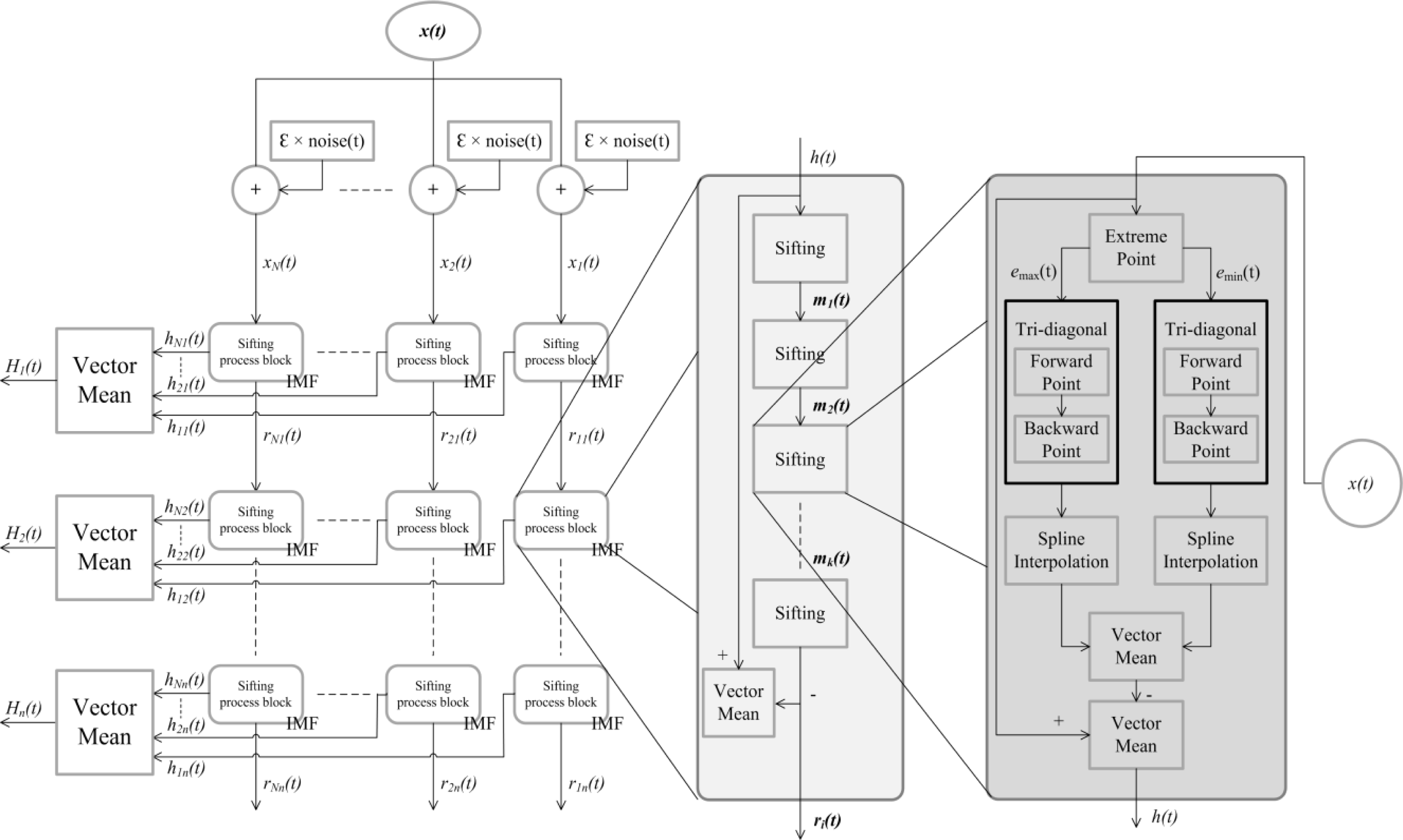
Figure 1 shows the operating procedures of EMD. First, in
Figure 1(a), the signal
x(
t) is input and decomposed to n IMFs. Each IMF is calculated by the “
k times” sifting process until the SD is less than 0.3 as shown in
Figure 1(b). The sifting process (see
Figure 1(c)) computes the difference between the signal
x(
t) and the mean of the maxima and minima envelopes.
Although the use of EMD has made significant contributions in many applications, its ability to handle signal-processing problems is still insufficient. Rilling and Flandrin [
8,
9] stated that EMD decomposition capability strongly depends on the frequencies and amplitudes, and the differences in both frequencies and amplitudes of two signals must be sufficient for EMD decomposition analysis. If the criteria for the differences between two signals are not met, the sifting process derives an IMF with a single tone modulated in amplitude instead of a superposition of two unimodular tones. This phenomenon is called the beat effect. To overcome the problem of mode mixing, Wu and Huang [
10] proposed EEMD. A uniform distribution of white noise is added to signals before decomposition to reduce the effect of the mode mixing in the EMD process [
20]. As a result, the EEMD method is capable of resolving both the issues of mode mixing and multi-dimensional computation [
11].
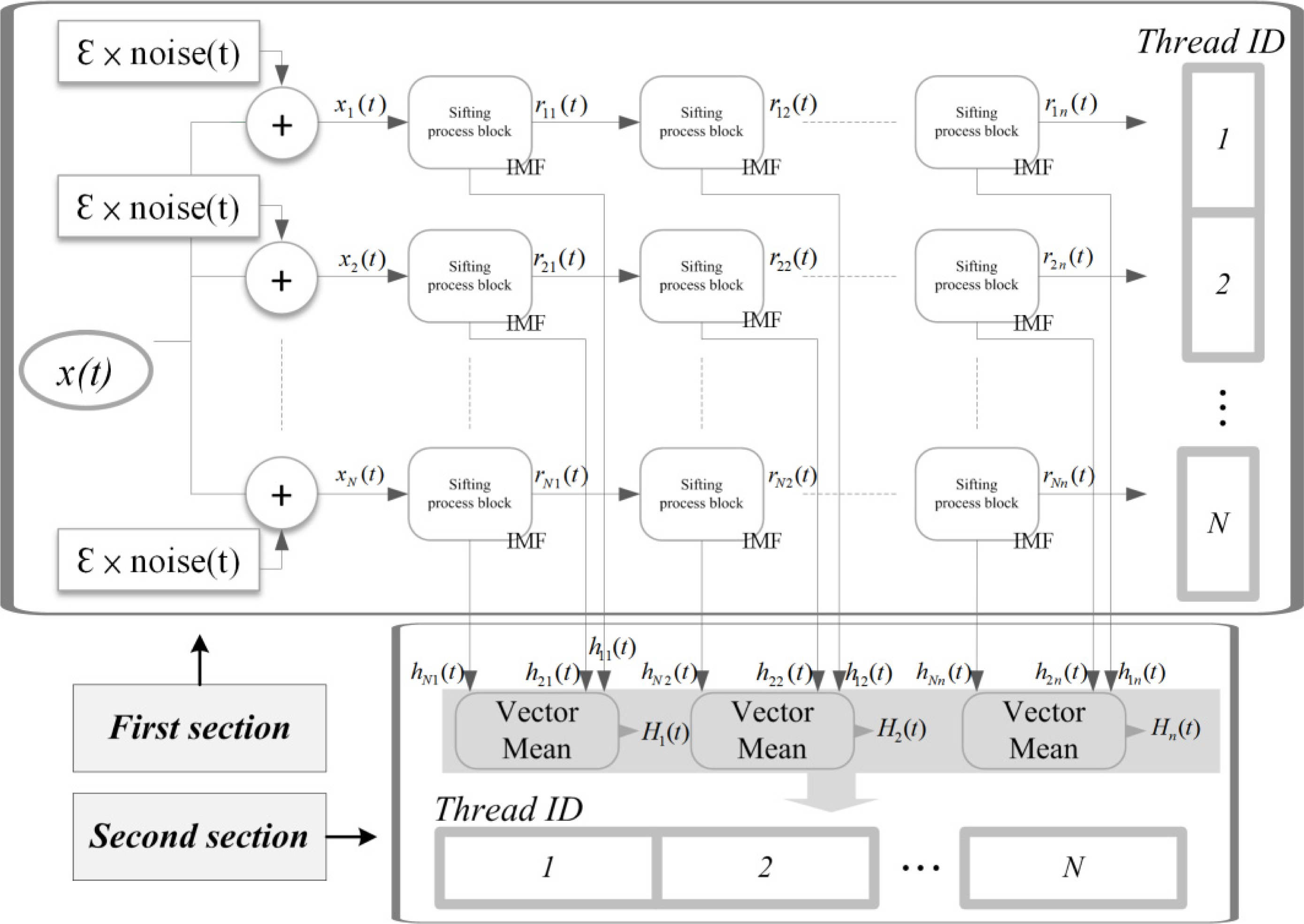
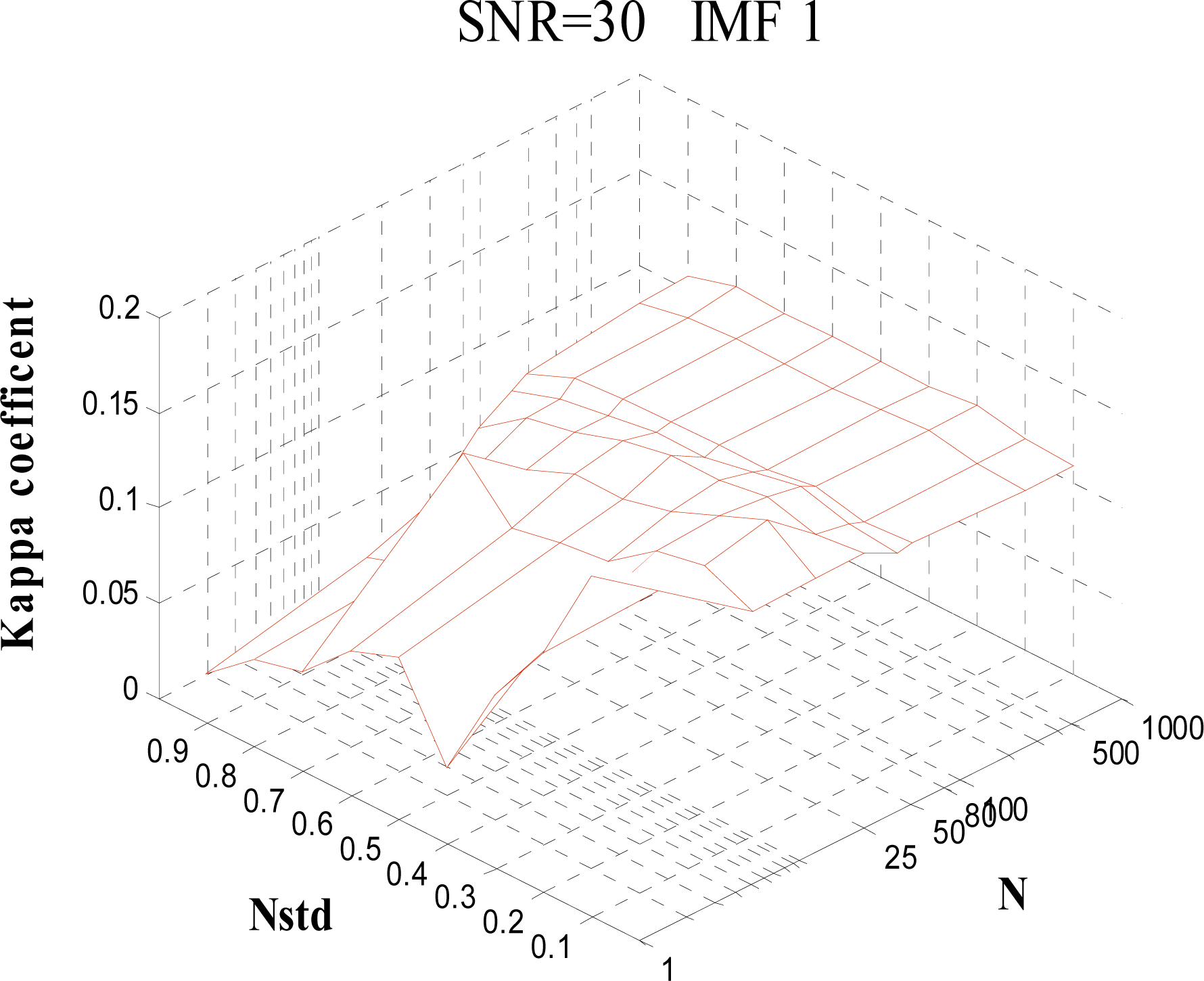
For EEMD, the ratio of the added white noise and the number of signals in the ensemble must be predetermined. According to the number in the ensemble, different white noise wi(t) with the same amplitude is added N times to an original signal x(t) to generate N modified signals xi(t).
Next, the EMD decomposition is performed on each modified signal
xi(
t). Assume the signal is decomposed into n units of IMF and one residue as a trend. Further, by the EEMD method, it will get
N × n IMF signals and
n trends
rin(
t). Then,
xi(
t) can be rewritten as:
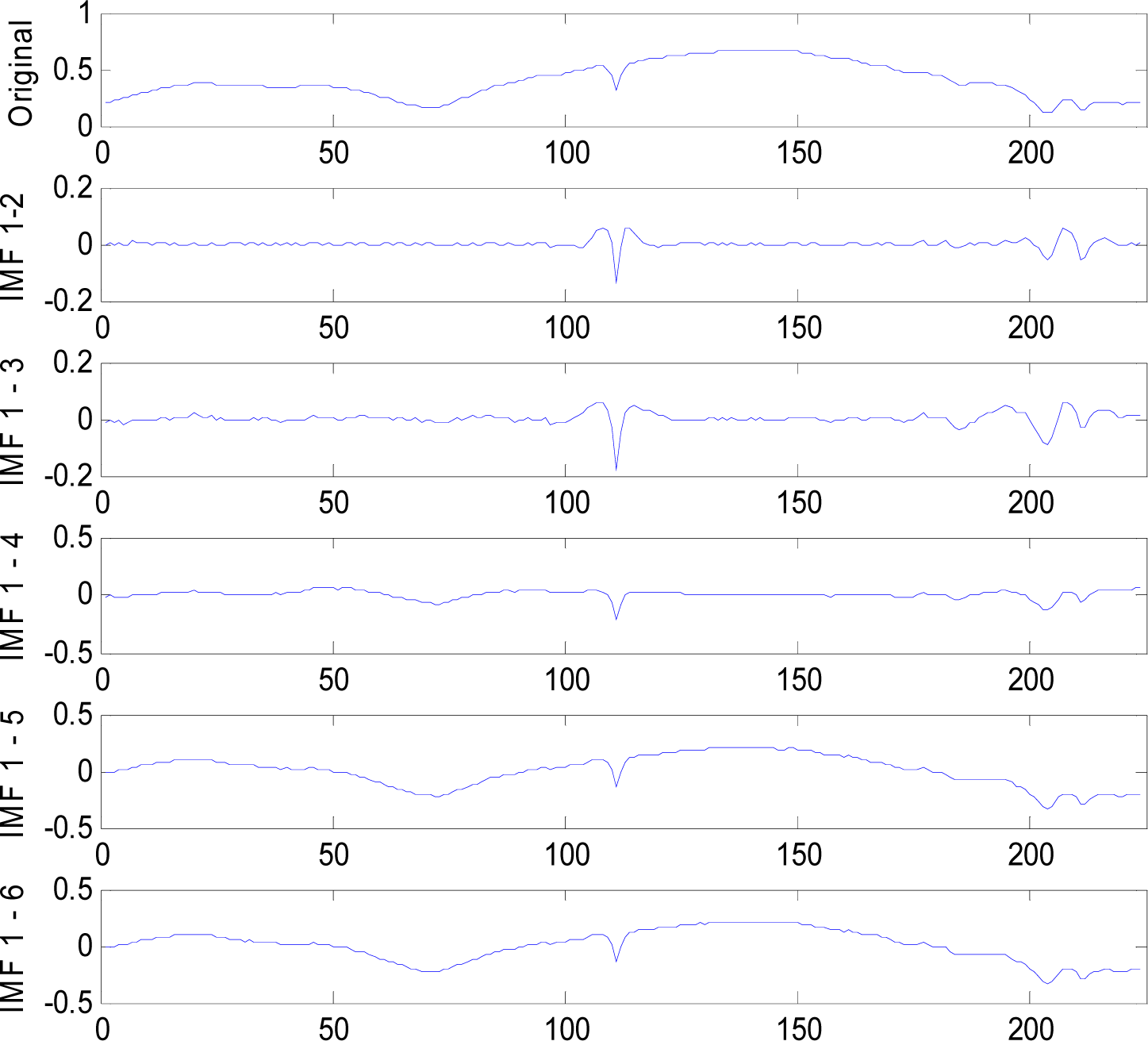
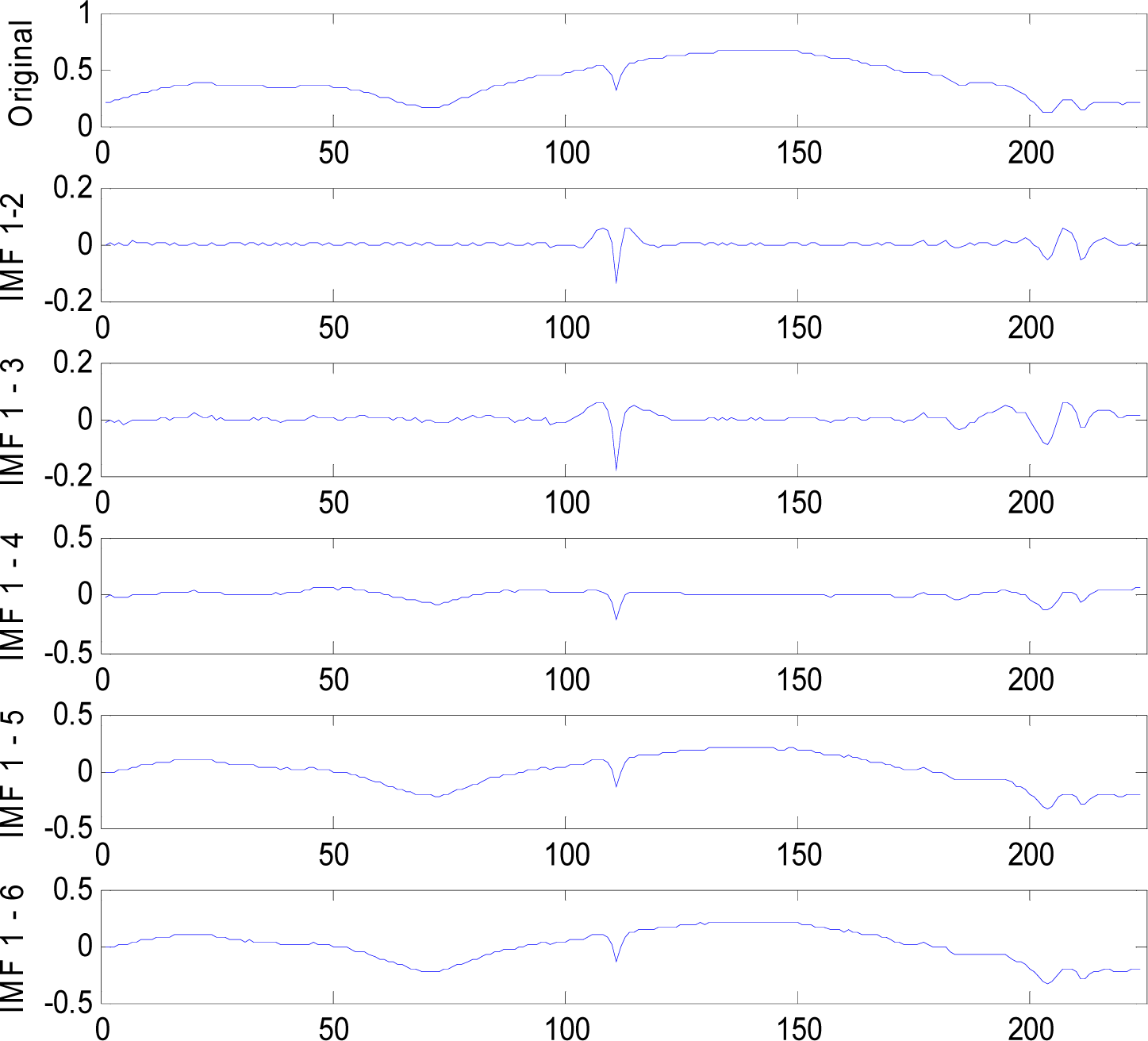
To reduce the mode mixing, the EEMD method averages the result of the IMF set Hj(t) and the trend R(t) derived from EMD.
The error in the decomposition caused by the added white noise is given by the following empirical formula of Wu
et al. [
10] for large amounts of data:
where
N is the number of ensembles,
ɛ is the amplitude of the added noise, and
ɛn is the final standard deviation. According to this empirical formula,
wi(
t) can be obtained,
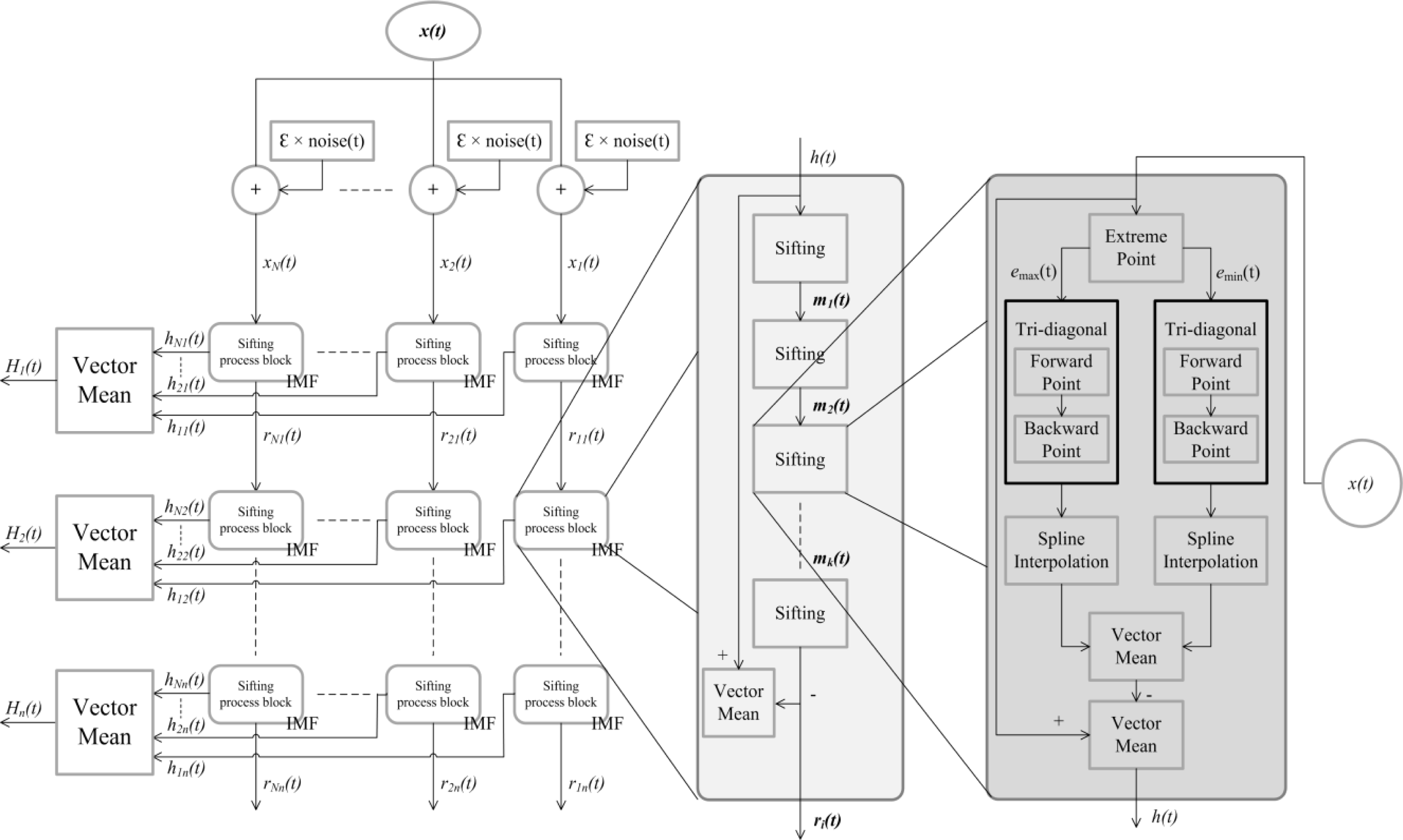
The EEMD process is shown in
Figure 2. Comparing EEMD and EMD (
Figure 1), the only difference is that EEMD needs to average
N hj(
t) to get each IMF, but EMD does not.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}