Soil Moisture Monitoring Using Remote Sensing Data and a Stepwise-Cluster Prediction Model: The Case of Upper Blue Nile Basin, Ethiopia



Abstract
1. Introduction
2. Materials and Methods
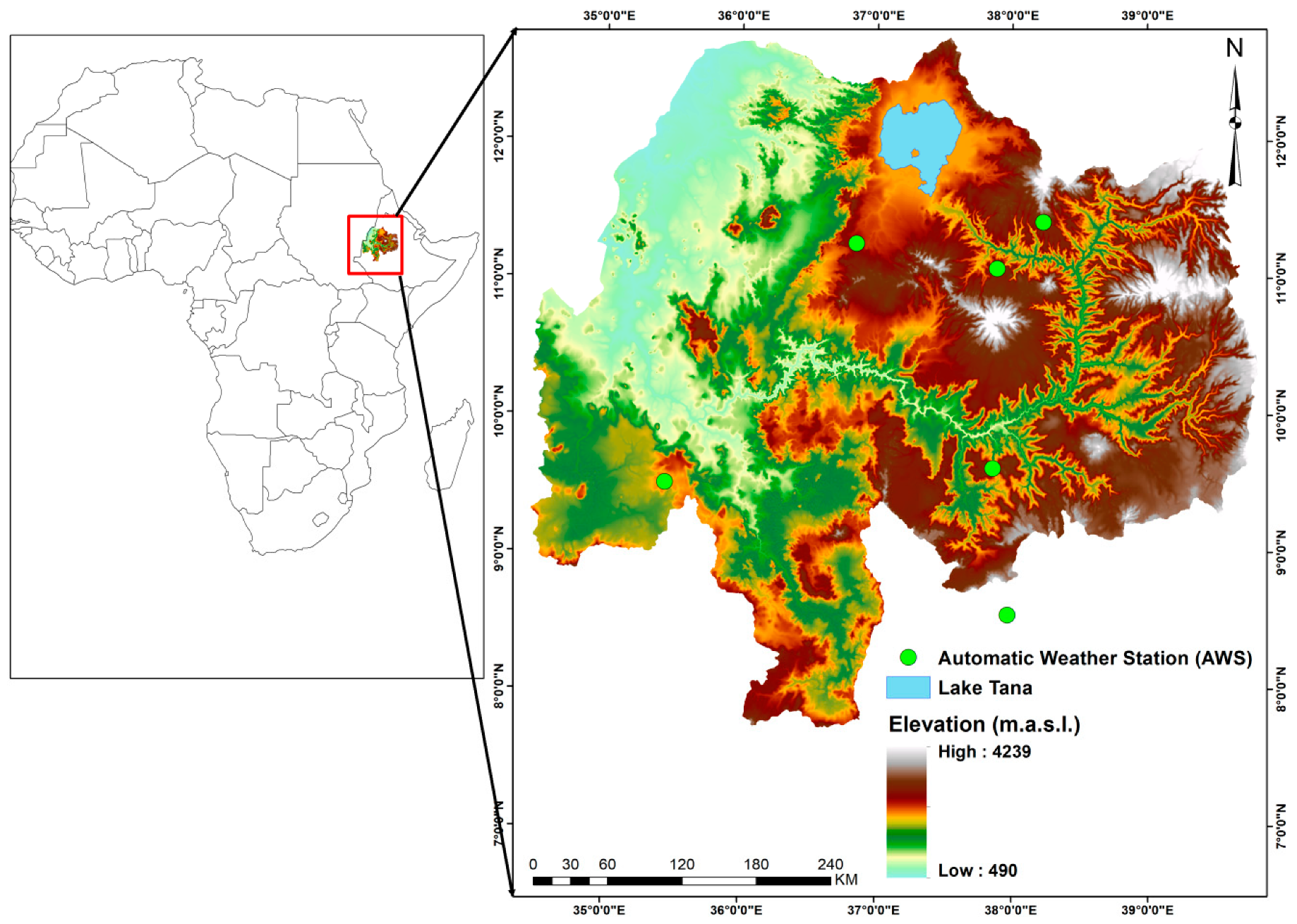
2.1. Site Description
2.2. Data
2.2.1. Remote Sensing Data
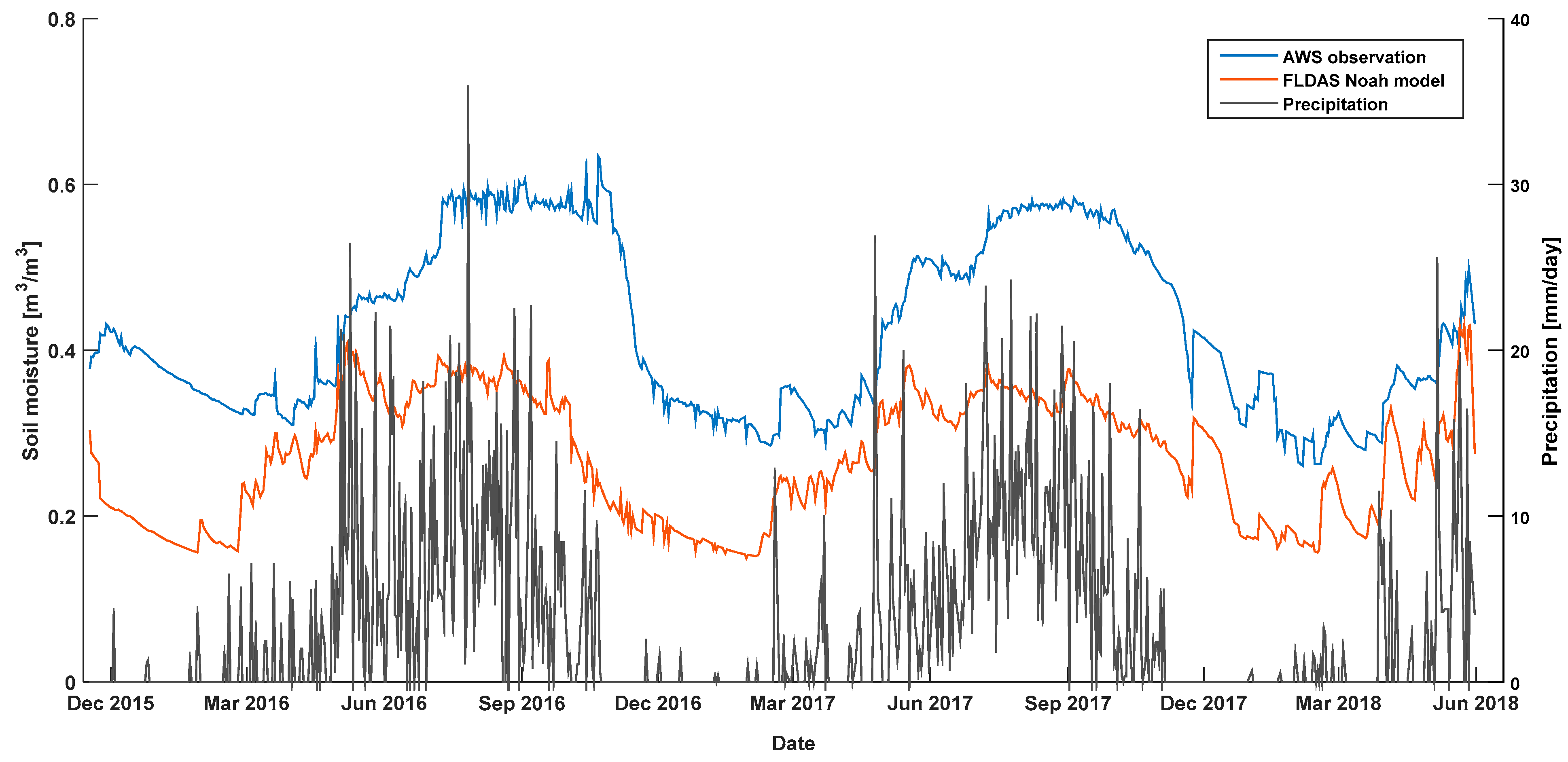
2.2.2. Soil Moisture
Ground Observed Soil Moisture Data
FLDAS Noah Model
2.3. Methods
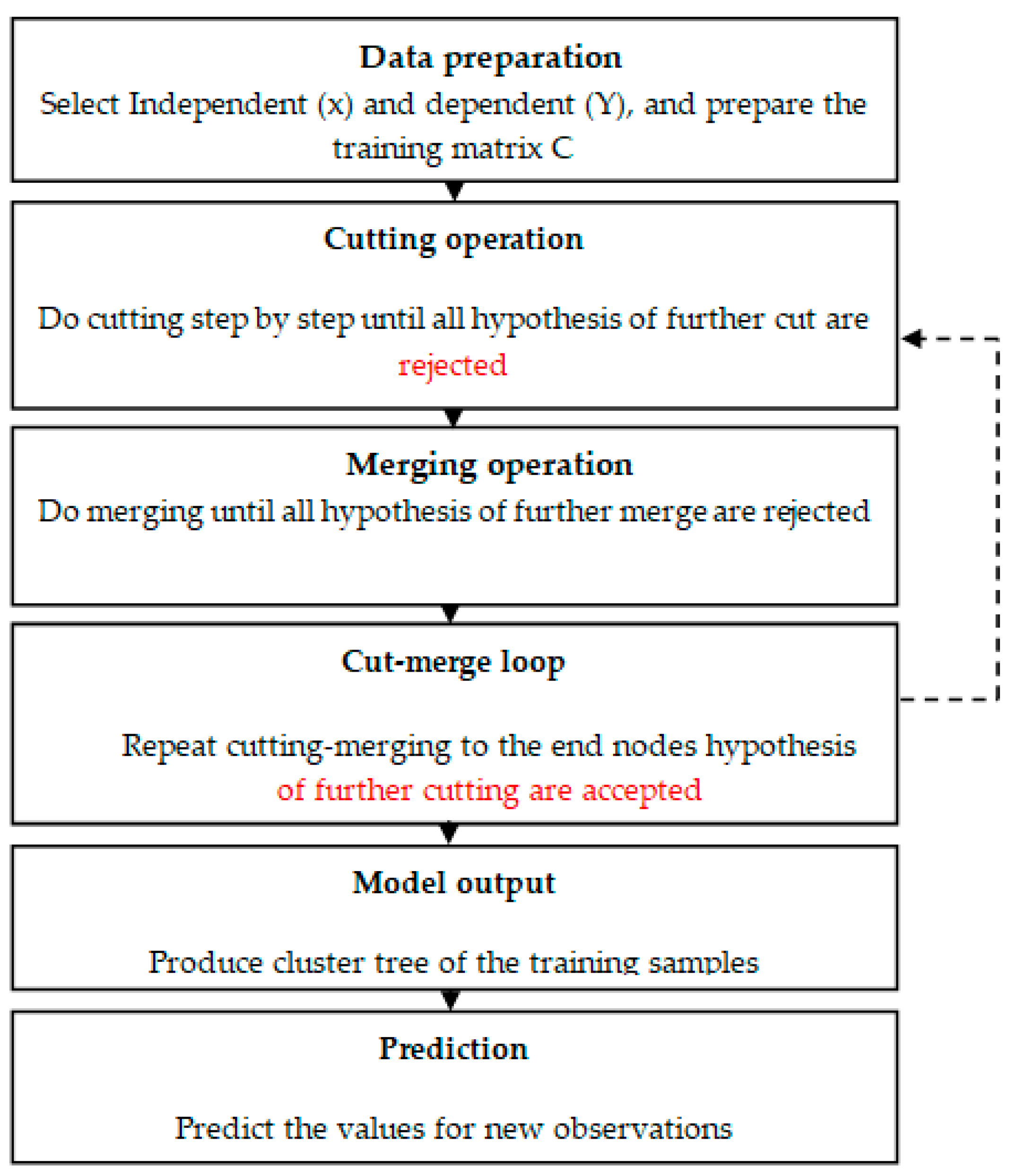
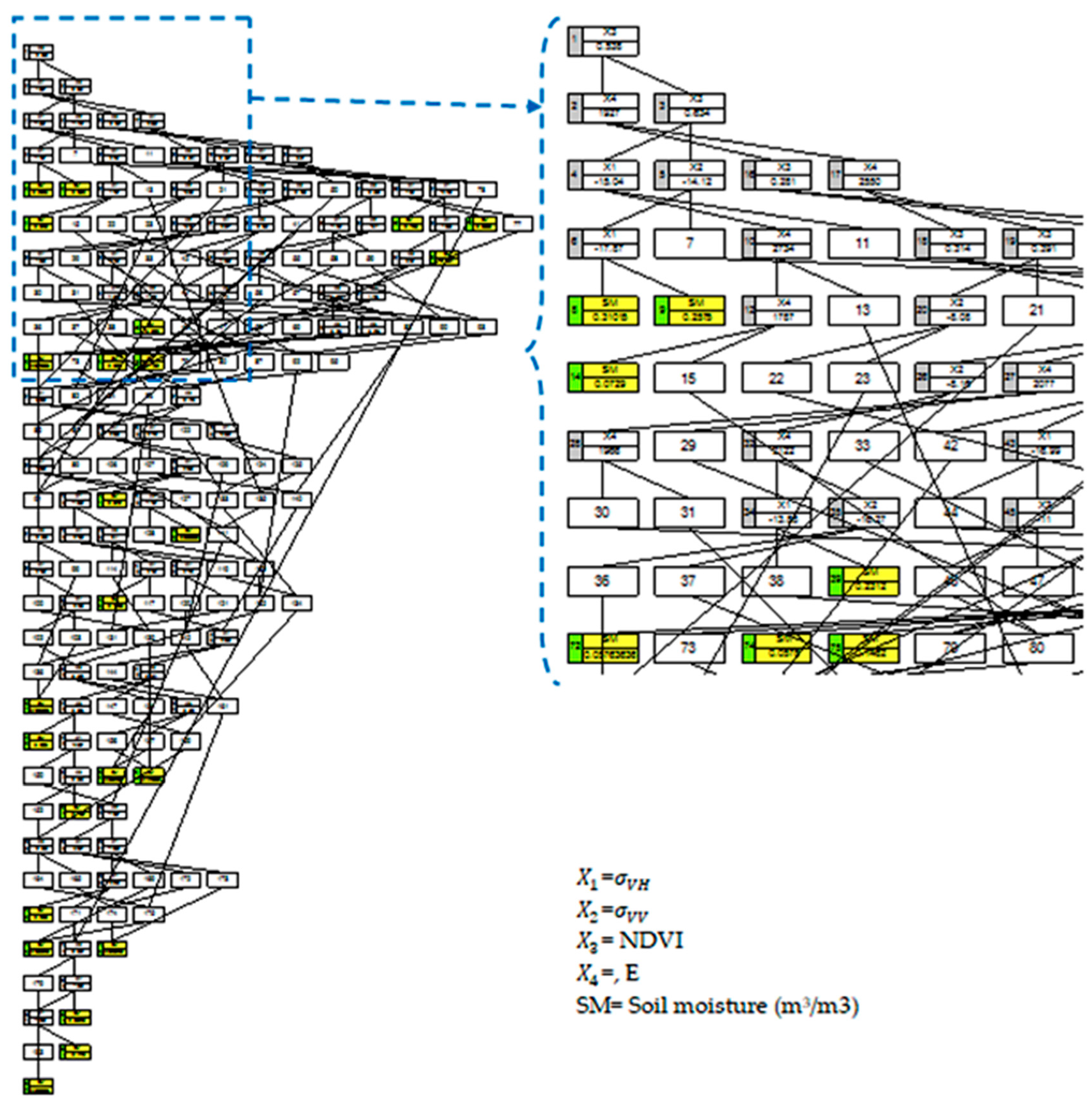
2.3.1. A Stepwise Cluster Analysis (SCA)
Model Development
Training
Prediction
2.3.2. Support Vector Regression (SVR)
3. Results
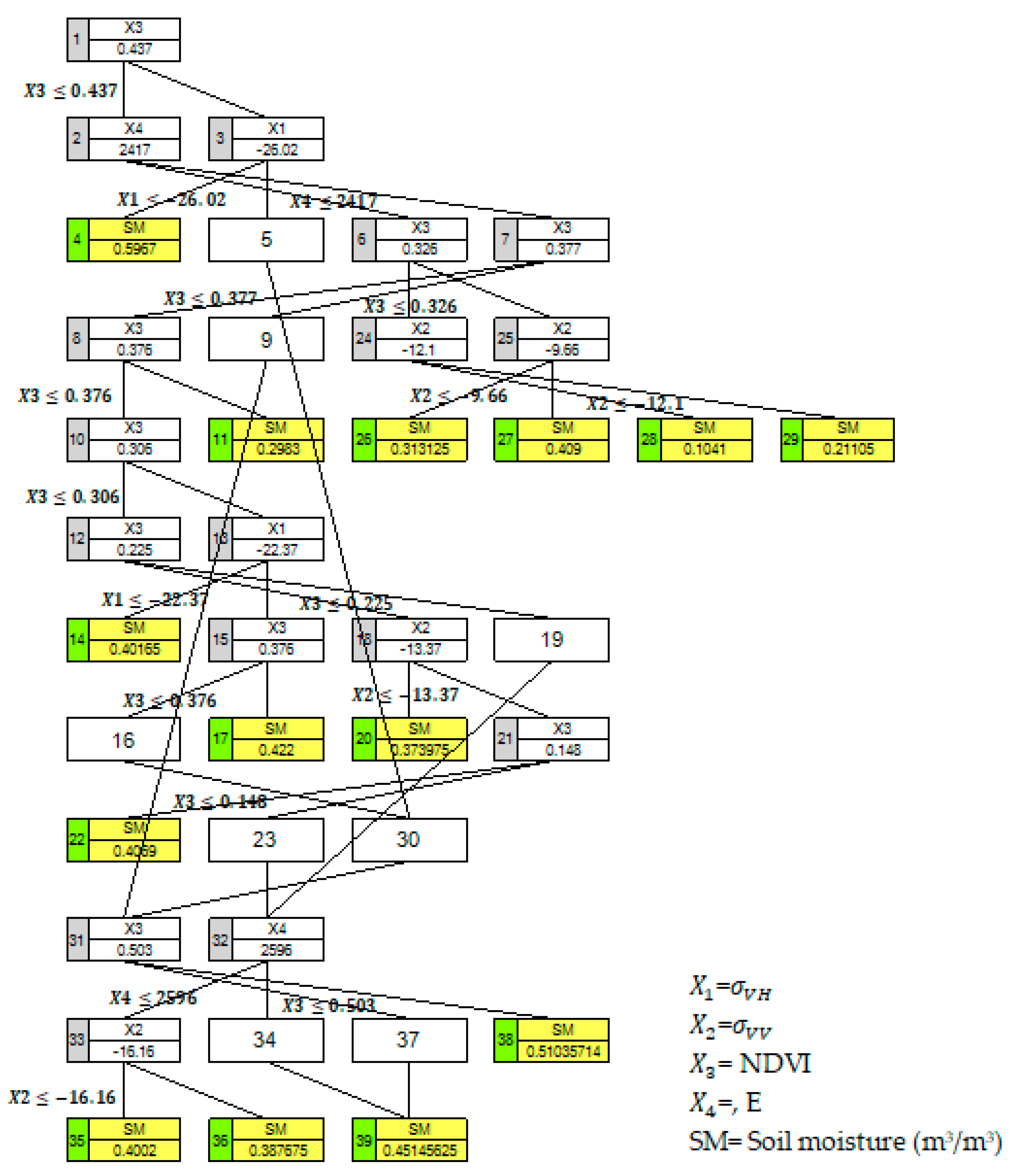
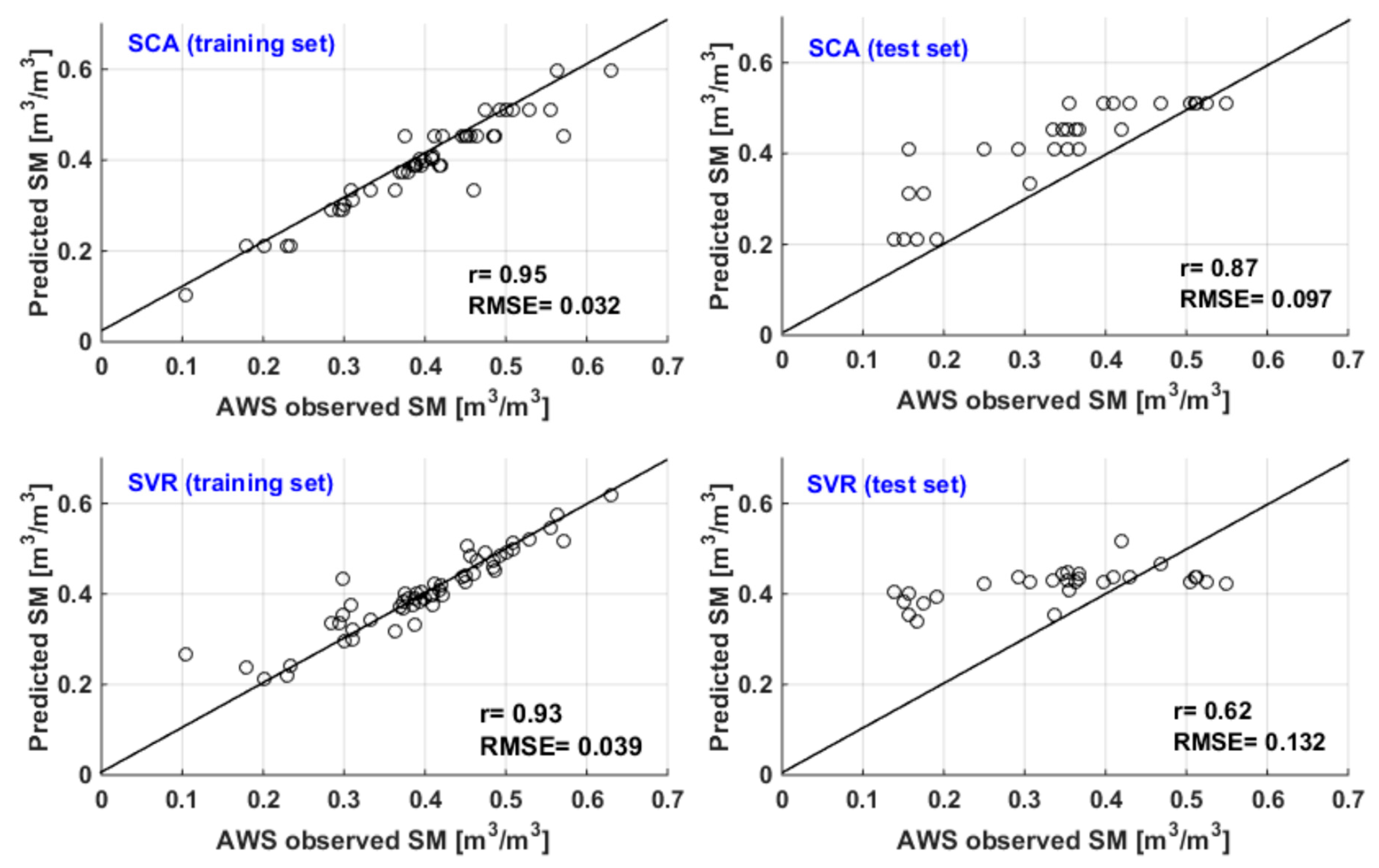
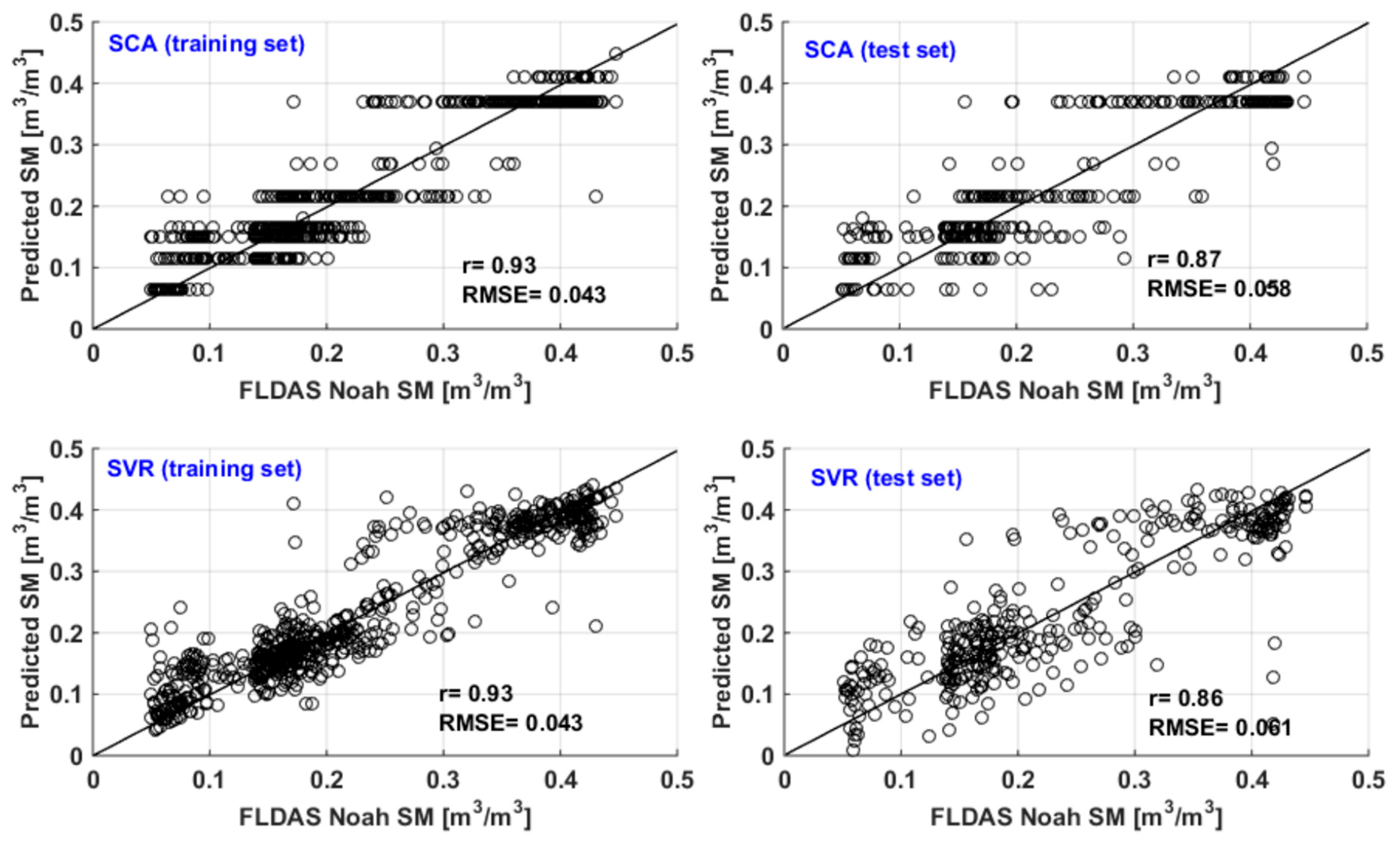
3.1. Stepwise Cluster Analysis
3.2. Comparing SCA with SVR Method
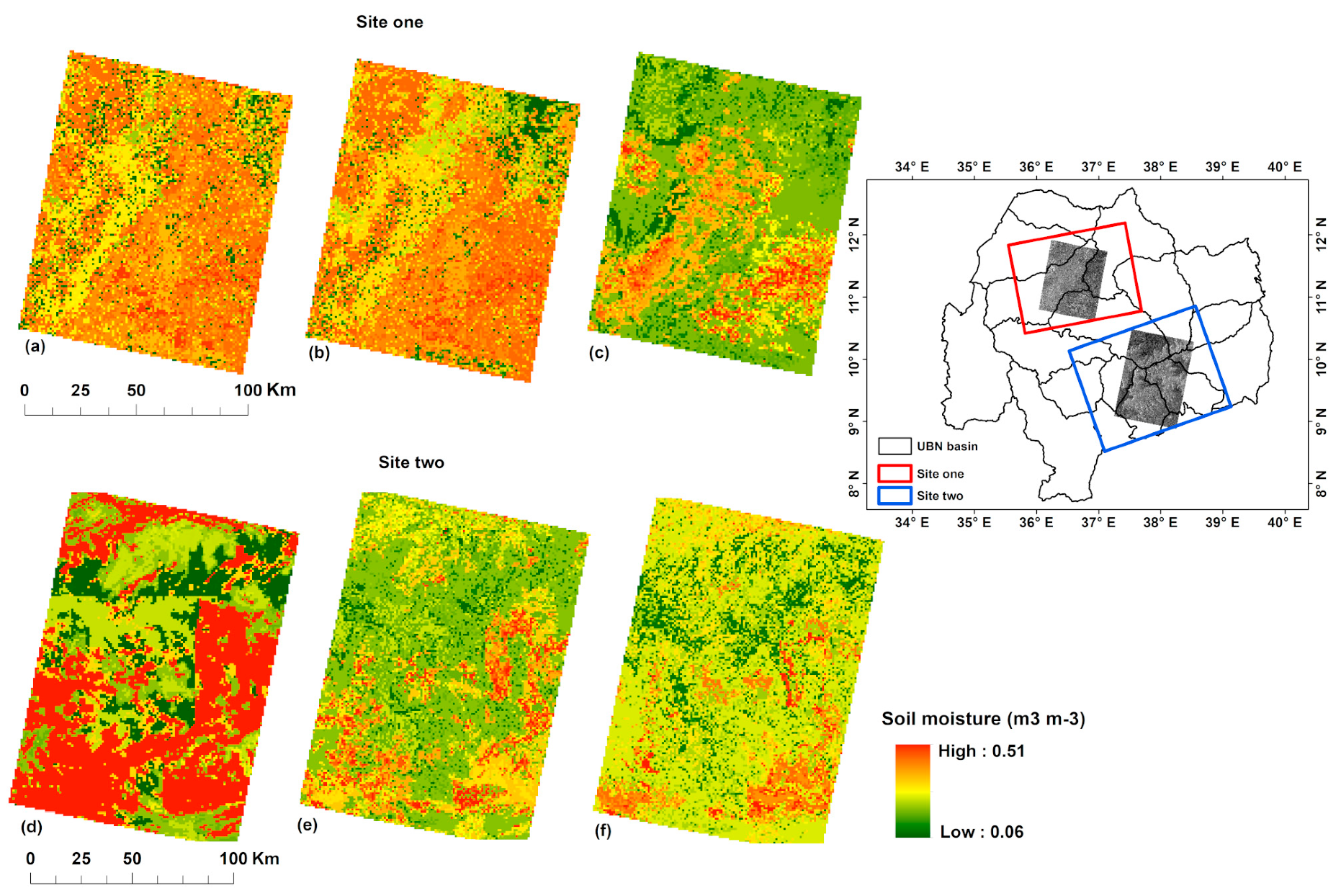
3.3. Spatial Patterns of Estimated Soil Moisture
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SN | Acquisition Date | N | Pol. | Orbit | Product | SN | Acquisition Date | N | Pol. | Orbit | Product |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 20 January 2016 | 2 | VV, VH | Desc. | GRD | 17 | 11 September 2017 | 2 | VV, VH | Desc. | GRD |
| 2 | 28 September 2016 | 2 | VV, VH | Desc. | GRD | 18 | 30 September 2017 | 2 | VV, VH | Desc. | GRD |
| 3 | 05 October 2016 | 1 | VV, VH | Desc. | GRD | 19 | 05 October 2017 | 2 | VV, VH | Desc. | GRD |
| 4 | 22 October 2016 | 2 | VV, VH | Desc. | GRD | 20 | 12 October 2017 | 2 | VV, VH | Desc. | GRD |
| 5 | 29 October 2016 | 4 | VV, VH | Desc. | GRD | 21 | 17 October 2017 | 2 | VV, VH | Desc. | GRD |
| 6 | 22 November 2016 | 3 | VV, VH | Desc. | GRD | 22 | 24 October 2017 | 2 | VV, VH | Desc. | GRD |
| 7 | 09 December 2016 | 2 | VV, VH | Desc. | GRD | 23 | 29 October 2017 | 2 | VV, VH | Desc. | GRD |
| 8 | 16 December 2016 | 3 | VV, VH | Desc. | GRD | 24 | 05 November 2017 | 2 | VV, VH | Desc. | GRD |
| 9 | 02 January 2017 | 2 | VV, VH | Desc. | GRD | 25 | 10 November 2017 | 2 | VV, VH | Desc. | GRD |
| 10 | 09 January 2017 | 2 | VV, VH | Desc. | GRD | 26 | 17 November 2017 | 1 | VV, VH | Desc. | GRD |
| 11 | 26 January 2017 | 1 | VV, VH | Desc. | GRD | 27 | 22 November 2017 | 2 | VV, VH | Desc. | GRD |
| 12 | 28 January 2017 | 1 | VV, VH | Desc. | GRD | 28 | 29 November 2017 | 2 | VV, VH | Desc. | GRD |
| 13 | 02 October 2017 | 2 | VV, VH | Desc. | GRD | 29 | 04 December 2017 | 2 | VV, VH | Desc. | GRD |
| 14 | 07 October 2017 | 1 | VV, VH | Desc. | GRD | 30 | 11 December 2017 | 2 | VV, VH | Desc. | GRD |
| 15 | 14 October 2017 | 3 | VV, VH | Desc. | GRD | 31 | 16 December 2017 | 3 | VV, VH | Desc. | GRD |
| 16 | 06 September 2017 | 3 | VV, VH | Desc | GRD | 32 | 23 December 2017 | 2 | VV, VH | Desc | GRD |
References
- Western, A.; Grayson, R.; Bloschl, G. Scaling of soil moisture: A hydrologic perspective. Ann. Rev. Earth Planet. Sci. 2002, 30, 149–180. [Google Scholar] [CrossRef]
- Bekabil, U.T. Review of challenges and perspectives of agricultural production and productivity in Ethiopia. J. Nat. Sci. Res. 2014, 4, 70–77. [Google Scholar]
- Food and Agricultural Organization (FAO). Ethiopia Country Programming Framework; Office of the FAO Representative to Ethiopia: Addis Ababa, Ethiopia, 2014. [Google Scholar]
- Central Statistical Agency (CSA). Report on the Year 2000 Welfare Monitoring Survey; Central Statistical Authority: Addis Ababa, Ethiopia, 2001.
- Conway, D. The climate and Hydrology of the Upper Blue Nile River. Geogr. J. 2000, 166, 49–62. [Google Scholar] [CrossRef]
- Engida, N.A.; Esteves, M. Characterization and disaggregation of daily rainfall in the upper Blue Nile Basin in Ethiopia. J. Hydrol. 2011, 399, 226–234. [Google Scholar] [CrossRef]
- Topp, G.C.; Davis, J.L.; Annan, A.P. Electromagnetic determination of soil water content: Measurements in coaxial transmission lines. Water Resour. Res. 1980, 16, 574–582. [Google Scholar] [CrossRef]
- Benke, K.K.; Lowell, E.K.; Hamilton, J.A. Parameter uncertainity, sensitivity analysis and prediction error in a water-balance hydrological model. Math. Comput. Model. 2008, 47, 1134–1149. [Google Scholar] [CrossRef]
- Ulaby, T.F.; Batlivala, P.P. Optimum radar parameters for mapping soil moisture. IEEE Trans. Geosci. Electron. 1976, 14, 81–93. [Google Scholar] [CrossRef]
- Engman, E.T. Progress in microwave remote sensing of soil moisture. Can. J. Remote Sens. 1990, 16, 6–14. [Google Scholar] [CrossRef]
- Petropoulos, G.P.; Ireland, G.; Petropoulos, G.P.; Ireland, G.; Barrett, B. Surface soil moisture retrievals from remote sensing: Current status, products & future trends. Phys. Chem. Earth Parts A/B/C 2015, 83–84, 36–56. [Google Scholar]
- Singh, D.; Kathpalia, A. An efficient modeling with GA approach to retrieve soil texture, moisture, and roughness from ERS-2 SAR data. Prog. Electromagn. Res. 2007, 77, 121–136. [Google Scholar] [CrossRef]
- Ulaby, F.T.; Batlivala, P.P.; Dobson, M.C. Microwave backscatter dependence on surface roughness, soil moisture, and soil texture: Part I-bare soil. IEEE Trans. Geosci. Electron. 1978, 16, 286–295. [Google Scholar] [CrossRef]
- Dobson, M.C.; Ulaby, F.T. Microwave backscatter dependence on surface roughness, soil moisture, and soil texture: Part III-soil tension. IEEE Trans. Geosci. Remote Sens. 1981, 19, 51–61. [Google Scholar] [CrossRef]
- Karthikeyan, L.; Pan, M.; Wanders, N.; Kumar, N.D.; Wood, E.F. Four Decades of Microwave Satellite Soil Moisture Observations: Part 1. A Review of Retrieval Algorithms. Adv. Water Resour. 2017, 109, 106–120. [Google Scholar] [CrossRef]
- Ulaby, F.T.; Moore, R.K.; Fung, A.K. Microwave Remotesensing: Active and Passive, Volume II—Radar Remote Sensing and Surface Scattering and Mission Theory; Advanced Book Program; Addison-Wesley: Reading, MA, USA, 1982; p. 609. [Google Scholar]
- Fung, A.K.; Li, Z.; Chen, K.S. Backscattering from a randomlyrough dielectric surface. IEEE Trans. Geosci. Remote Sens. 1992, 30, 356–369. [Google Scholar] [CrossRef]
- Chen, K.S.; Wu, T.D.; Tsang, L.; Li, Q.; Shi, J.; Fung, A.K. The emissionof rough surfaces calculated by the integral equation method with acomparison to a three-dimensional moment method simulation. IEEE Trans. Geosci. Remote Sens. 2003, 41, 90–101. [Google Scholar] [CrossRef]
- Oh, Y.; Sarabandi, F.T.; Ulaby, F. An empirical model and aninversion technique for radar scattering from bare soil surfaces. IEEE Trans. Geosci. Remote Sens. 1992, 30, 370–381. [Google Scholar] [CrossRef]
- Dubois, C.P.; Van Zyl, J.; Engman, T. Measuring soil moisture with imaging radars. IEEE Trans. Geosci. Remote Sens. 1995, 33, 915–926. [Google Scholar] [CrossRef]
- Wagner, W.; Noll, J.; Borgeaud, M.; Rott, H. Monitoring Soil Moisture over the Canadian Prairies with the ERS Scatterometer. IEEE Trans. Geosci. Remote Sens. 1999, 37, 206–216. [Google Scholar] [CrossRef]
- Wickel, A.J.; Jackson, T.J.; Wood, E.F. Multitemporal monitoring of soil moisture with RADARSAT SAR during the 1997 Southern Great Plains hydrology experiment. Int. J. Remote Sens. 2001, 22, 571–1583. [Google Scholar] [CrossRef]
- Zribi, M.; Chahbi, A.; Shabou, M.; Lili-Chabaane, Z.; Duchemin, B.; Baghdadi, N.; Amri, R.; Chehbouni, A. Soil surface moisture estimation over a semi-arid region using ENVISAT ASAR radar data for soil evaporation evaluation. Hydrol. Earth Syst. Sci. 2011, 15, 345–358. [Google Scholar] [CrossRef]
- He, B.; Xing, M.; Bai, X. A Synergistic Methodology for Soil Moisture Estimation in an Alpine Prairie Using Radar and Optical Satellite Data. Remote Sens. 2014, 6, 10966–10985. [Google Scholar] [CrossRef]
- Chai, X.; Zhang, T.; Shao, Y.; Gong, H.; Liu, L.; Xie, K. Modeling and Mapping Soil Moisture of Plateau Pasture Using RADARSAT-2 Imagery. Remote Sens. 2015, 7, 1279–1299. [Google Scholar] [CrossRef]
- Tomer, S.; Al Bitar, A.; Sekhar, M.; Zribi, M.; Bandyopadhyay, S.; Sreelash, K.; Sharma, A.; Corgne, S.; Kerr, Y. Retrieval and multi-scale validation of soil moisture from multi-temporal SAR data in a semi-arid tropical region. Remote Sens. 2015, 7, 8128–8153. [Google Scholar] [CrossRef]
- Gao, Q.; Zribi, M.; Escorihuela, M.; Baghdadi, N. Synergetic use of Sentinel-1 and Sentinel-2 data for soil moisture mapping at 100 m resolution. Sensors 2017, 17, 1966. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Tang, X.; Gao, X.; Zhao, H. Multitemporal soil moisture retrieval over bare agricultural areas by means of alpha model with multisensory SAR data. Adv. Meteorol. 2018, 2018, 17. [Google Scholar] [CrossRef]
- Hosseni, R.; Newlands, N.; Dean, C.; Takemura, A. Statistical modeling of soil moisture, integrating satellite remote sensing (SAR) and ground based data. Remote Sens. 2015, 7, 2752–2780. [Google Scholar] [CrossRef]
- Satalino, G.; Mattia, F.; Davidson, M.; Le Toan, T.; Pasquariello, G.; Borgeaud, M. On current limits of soilmoisture retrieval from ERS-SAR data. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2438–2447. [Google Scholar] [CrossRef]
- Santi, E.; Paloscia, S.; Pettinato, S.; Notarnicola, C.; Pasolli, E.; Pistocchi, A. Comparison between SAR Soil Moisture Estimates and Hydrological Model Simulations over the Scrivia Test Site. Remote Sens. 2013, 5, 4961–4976. [Google Scholar] [CrossRef]
- Baghdadi, N.; Cresson, R.; El Hajj, M.; Ludwig, R.; La Jeunesse, I. Estimation of soil parameters over bare agriculture areas from C-band polarimetric SAR data using neural networks. Hydrol. Earth Syst. Sci. 2012, 16, 1607–1621. [Google Scholar] [CrossRef]
- Lakhankar, T.; Ghedira, H.; Temimi, M.; Sengupta, M.; Khanbilvardi, R.; Blake, R. Non-Parametric methodsfor soil moisture retrieval from satellite remote sensing data. Remote Sens. 2009, 1, 3–21. [Google Scholar] [CrossRef]
- Paloscia, S.; Santi, E.; Pettinato, S.; Mladenova, L.; Jackson, T.; Bindlish, R.; Cosh, M. A comparison between two algorithms for the retrieval of soil moisture using AMSR-E data. Front. Earth Sci. 2015, 3, 1–10. [Google Scholar] [CrossRef]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of machine learning approaches for biomass and soil moisture retrievals from remote sensing data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef]
- Ahmad, S.; Kalra, A.; Stephen, H. Estimating soil moisture using remote sensing data: A machine learning approach. Adv. Water Resour. 2010, 33, 69–80. [Google Scholar] [CrossRef]
- Pasolli, L.; Notarnicola, C.; Bruzzone, L. Estimating soil moisture with the support vector regression technique. IEEE Geosci. Remote Sens. Lett. 2011, 8, 1080–1084. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, B.; Fan, H.; Huang, J.; Zhao, H. The potential use of multi-band SAR data for soil moisture retrieval over bare agricultural areas: Hebei, China. Remote Sens. 2016, 8, 7. [Google Scholar] [CrossRef]
- Huang, G.; Huang, Y.; Wang, G.; Xiao, H. Development of a forecasting system for supporting remediation design and process control based on NAPL-biodegradation simulation and stepwise-cluster analysis. Water Resour. Res. 2006, 6, 1–19. [Google Scholar] [CrossRef]
- Huang, G. A stepwise cluster analysis method for predicting air quality in an urban environment. Atmos. Environ. Part B Urban Atmos. 1992, 3, 349–357. [Google Scholar] [CrossRef]
- Sun, W.; Huang, G.H.; Zeng, G.; Qin, X.; Sun, X. A stepwise cluster microbial biomass inference model in food waste composting. Waste Manag. 2009, 12, 2956–2968. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y. Application of stepwise cluster analysis in medical research. Sci. Sin. 1979, 9, 1082–1094. [Google Scholar]
- Qin, X.; Huang, G.; Chakma, A. A stepwise-inference based optimization system for supporting remediation of petroleum contaminated sites. Water Air Soil Pollut. 2007, 185, 349–368. [Google Scholar] [CrossRef]
- He, L.; Huang, G.H.; Lu, H.W.; Zeng, G.M. Optimization of surfactant-enhanced aquifer remediation for a laboratory BTEX system under parameter uncertainty. Environ. Sci. Technol. 2008, 6, 2009–2014. [Google Scholar] [CrossRef]
- Wang, X.; Huang, G.; Lin, Q.; Nie, X.; Cheng, G.; Fan, Y.; Li, Z.; Yao, Y.; Suo, M. A stepwise cluster analysis approach for downscaled climate projection—A Canadian case study. Environ. Model. Softw. 2013, 49, 141–151. [Google Scholar] [CrossRef]
- Fan, Y.R.; Huang, G.H.; Li, Y.P.; Wang, X.Q.; Li, Z. Probabilistic prediction for monthly stream flow through coupling stepwise cluster analysis and quantile regression methods. Water Resour. Manag. 2016, 30, 5313–5331. [Google Scholar] [CrossRef]
- Li, Z.; Huang, G.; Han, J.; Wang, X.; Fan, Y.; Cheng, G.; Zhang, H.; Huang, W. Development of a stepwise-clustered hydrological inference model. J. Hydrol. Eng. 2015, 20, 4015008. [Google Scholar] [CrossRef]
- Cheng, G.; Huang, G.; Dong, C.; Zhu, J.; Zhou, X.; Yao, Y. High-resolution projections of 21st century climate over the Athabasca River Basin through an integrated evaluation-classification-downscaling-based climate projection framework. J. Geophys. Res. Atmos. 2017, 122, 2595–2615. [Google Scholar] [CrossRef]
- Wang, X.; Huang, G.; Zhao, S.; Guo, J. An open-source software package for multivariate modeling and clustering: Application to air quality management. Environ. Sci. Pollut. Res. 2015, 22, 14220–14233. [Google Scholar] [CrossRef] [PubMed]
- Conway, D. From headwater tributaries to international river: Observing and adapting to climate variability and change in the Nile basin. Glob. Environ. Chang. 2005, 15, 99–114. [Google Scholar] [CrossRef]
- Degefu, G.T. The Nile Historical Legal and Developmental Perspectives; Trafford Publishing: Victoria, BC, Canada, 2003. [Google Scholar]
- Conway, D. Some aspects of climate variability in the northeast Ethiopian highlands-Wollo and Tigray. Sinet Ethiop. J. Sci. 2000, 23, 139–161. [Google Scholar] [CrossRef]
- Kim, U.; Kaluarachchi, J.; Smakhtin, V. Generation of monthly precipitation under climate change for the upper Blue Nile River Basin, Ethiopia 1. JAWRA J. Am. Water Resour. Assoc. 2008, 44, 1231–1247. [Google Scholar] [CrossRef]
- Taye, M.; Willems, P. Temporal variability of hydro-climatic extremes in the Blue Nile basin. Water Resour. Res. 2012, 48, 1–13. [Google Scholar] [CrossRef]
- Sentinel-1 Team. Sentinel-1 User Handbook. 2013. Available online: http://doi.org/GMES-S1op-EOPG-TN-13-0001 (accessed on 4 August 2017).
- Hossain, A.A.; Easson, G. Soil moisture estimation in South-Eastern New Mexico using high resolution synthetic aperture radar (SAR) data. Geosciences 2016, 6, 1. [Google Scholar] [CrossRef]
- McNally, A.; Shukla, S.; Arsenault, R.K.; Wang, S.; Peters-Lidard, D.C.; Verdin, P.J. Evaluating ESA CCI soil moisture in East Africa. Int. J. Appl. Earth Obs. Geoinf. 2016, 48, 96–109. [Google Scholar] [CrossRef] [PubMed]
- Ayehu, T.G.; Tadesse, T.; Gessesse, B.; Dinku, T. Validation of new satellite rainfall products over the Upper Blue Nile basin, Ethiopia. Atmos. Meas. Tech. 2018, 11, 1921–1936. [Google Scholar] [CrossRef]
- Qin, J.; Liang, S.; Yang, K.; Kaihotsu, I.; Liu, R.; Koike, T. Simultaneous estimation of both soil moisture and model parameters using particle filtering method through the assimilation of microwave signals. J. Geosphys. Res. 2009, 114, 1–13. [Google Scholar] [CrossRef]
- Sirvastava, S.K.; Yograjan, N.; Jayaraman, V.; Rao, P.P.; Chandrasekhar, G.M. On the relationship between ERS-1 SAR/backscatter and surface/sub-surface soil moisture variation in vertisoils. Acta Astronauica 1997, 40, 693–699. [Google Scholar] [CrossRef]
- Humphrey, E.R. The Dynamics of Active Layer Soil Moisture over Canadian Arctic Tundera in Trail Valley Creek, NT, Observed In-Situ and with Remote Sensing. Master’s Thesis, The University of Guelph, Guelph, ON, Canada, 2015. [Google Scholar]
- Wang, J.; Qu, J.; Tan, L.; Zhang, K. A method to obtain soil-moisture estimates over bare agricultural fields in arid areas by using multi-angle RADARSAT-2 data. Sci. Cold Arid Reg. 2018, 10, 145–150. [Google Scholar]
- Prigent, C.; Aires, F.; Rossow, B.W.; Robock, A. Sensitivity of satellite microwave and infrared observation to soil moisture at a global scale: Relationship of satellite observations to in situ soil moisture measurements. J. Geogr. Res. 2005, 110, 1–15. [Google Scholar] [CrossRef]
- McNally, A.; Arsenault, K.; Kumar, S.; Shukla, S.; Peterson, P.; Wang, S.; Funk, C.; Peters-Lidard, D.C.; Verdin, P.J. A land data assimilation system for sub-Sahran Africa food and water security applications. Sci. Data 2017, 4. [Google Scholar] [CrossRef]
- Fernández-Prieto, D.; Kesselmeier, J.; Ellis, M.; Marconcini, M.; Reissell, A.; Suni, T. Preface “earth observation for land-Atmosphere interaction science”. Biogeosciences 2013, 10, 261–266. [Google Scholar] [CrossRef]
- Hegarat-Mascle, S.; Zribi, M.; Alem, F.; Weisse, A.; Loumangne, C. Soil moisture estimation from ERS/SAR data: Toward an operational methodology. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2647–2658. [Google Scholar] [CrossRef]
- Mattia, F.; Satalino, G.; Dente, L.; Pasquariello, G. Using a priori information to improve soil moisture retrieval from ENVISAT ASAR AP in semi-arid regions. IEEE Trans. Geosci. Remote Sens. 2006, 44, 900–912. [Google Scholar] [CrossRef]
- Fan, R.; Huang, W.; Huang, H.; Li, Z.; Li, P.; Wang, Q.; Cheng, H.; Jin, L. A stepwise-cluster forecasting approach for monthly stream flows based on climate teleconnections. Stoch. Environ. Res. Risk Assess. 2015, 29, 1557–1569. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ho, K. The random subspace method for constructing decision Forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Wilks, S. Mathematics Statistics; John Wiley and Sons: New York, NY, USA, 1962. [Google Scholar]
- Rao, C.R. Advanced Statistical Methods in Biometric Research; A Division of Macmillan Publishing Co, Inc.: New York, NY, USA; Collier-Macmillan Publishers: London, UK, 1952. [Google Scholar]
- Wang, X. An R Package for Stepwise Cluster Analysis. Available online: https://rdrr.io/cran/rSCA/ (accessed on 10 June 2018).
- Vapnik, V. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 1999. [Google Scholar]
- Gunn, S. Support Vector Machines for Classification and Regression; Technical Report; University of Southampton: Southampton, UK, 1998. [Google Scholar]
- Dibike, B.; Velickov, S.; Solomatine, D.; Abbott, M. Model induction with support vector machines: Introduction and application. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- Wagner, W.; Bloschl, G.; Pampaloni, P.; Calvet, C.J.; Bizzarri, B.; Wigneron, P.J.; Kerr, Y. Operational readiness of microwave remote sensing of soil moisture for hydrologic applications. Nord. Hydrol. 2007, 38, 1–20. [Google Scholar] [CrossRef]
- Dostálová, A.; Doubková, M.; Sabel, D.; Bauer-Marschallinger, B.; Wagner, W. Seven years of advanced synthetic aperture radar (ASAR) global monitoring (GM) of surface soil moisture over Africa. Remote Sens. 2014, 6, 7683–7707. [Google Scholar] [CrossRef]
- Gorrab, A.; Zribi, M.; Baghdadi, N.; Mougenot, B.; Fanise, P.; Chabaane, L.Z. Retrieval of Both Soil Moisture and Texture Using TerraSAR-X Images. Remote Sens. 2015, 7, 10098–10116. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Schmugge, T.J. Remote sensing of soil moisture: Recent advances. IEEE Trans. Geosci. Remote Sens. 1983, GE-21, 336–344. [Google Scholar] [CrossRef]









| No | Independent Variables | Dependent Variables (Volumetric Soil Moisture) | |||
|---|---|---|---|---|---|
| AWS Observed | FLDAS Noah Model | ||||
| r | N | r | N | ||
| 1 | 0.36 | 83 | 0.34 | 1000 | |
| 5 | , | 0.41 | 83 | 0.35 | 1000 |
| 6 | , , NDVI | 0.63 | 83 | 0.57 | 1000 |
| 7 | , , NDVI, E | 0.76 | 83 | 0.65 | 1000 |
| X | Y | Total Node | Tip Cluster | Cutting Action | Merging Action | Validation | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training | Test | |||||||||
| r | RMSE | r | RMSE | |||||||
| , , NDVI, E | AWS observation | 0.01 | 21 | 8 | 9 | 2 | 0.93 | 0.038 | 0.81 | 0.096 |
| 0.05 a | 39 | 14 | 17 | 4 | 0.95 | 0.032 | 0.87 | 0.097 | ||
| 0.1 | 52 | 25 | 25 | 1 | 0.94 | 0.038 | 0.83 | 0.088 | ||
| FLDAS Noah model | 0.01 b | 185 | 24 | 69 | 46 | 0.93 | 0.043 | 0.87 | 0.058 | |
| 0.05 | 579 | 131 | 236 | 106 | 0.98 | 0.020 | 0.82 | 0.069 | ||
| 0.1 | 883 | 295 | 392 | 98 | 0.99 | 0.013 | 0.83 | 0.069 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayehu, G.; Tadesse, T.; Gessesse, B.; Yigrem, Y. Soil Moisture Monitoring Using Remote Sensing Data and a Stepwise-Cluster Prediction Model: The Case of Upper Blue Nile Basin, Ethiopia. Remote Sens. 2019, 11, 125. https://doi.org/10.3390/rs11020125
Ayehu G, Tadesse T, Gessesse B, Yigrem Y. Soil Moisture Monitoring Using Remote Sensing Data and a Stepwise-Cluster Prediction Model: The Case of Upper Blue Nile Basin, Ethiopia. Remote Sensing. 2019; 11(2):125. https://doi.org/10.3390/rs11020125
Chicago/Turabian StyleAyehu, Getachew, Tsegaye Tadesse, Berhan Gessesse, and Yibeltal Yigrem. 2019. "Soil Moisture Monitoring Using Remote Sensing Data and a Stepwise-Cluster Prediction Model: The Case of Upper Blue Nile Basin, Ethiopia" Remote Sensing 11, no. 2: 125. https://doi.org/10.3390/rs11020125
APA StyleAyehu, G., Tadesse, T., Gessesse, B., & Yigrem, Y. (2019). Soil Moisture Monitoring Using Remote Sensing Data and a Stepwise-Cluster Prediction Model: The Case of Upper Blue Nile Basin, Ethiopia. Remote Sensing, 11(2), 125. https://doi.org/10.3390/rs11020125