1. Introduction
Air pollution has become one of the most important environment problems, which can significantly affect the sustainable urban development. In particular, atmospheric pollutants not only are harmful to health [
1,
2,
3,
4], but also can cause substantial economic loss [
5], especially in many developing countries. For example, it is shown in [
6] that the economic loss due to air pollution in China in 2010 reached 1.1 trillion (1 trillion =
) yuan, accounting for 13.7% of the total Gross Domestic Product (GDP) of that year. Therefore, the prevention or control of air pollution has become a top issue in socioeconomic development.
However, the policy of prevention or control of air pollution in developing counties has usually lagged behind the socioeconomic development. As a result, ambient air quality has deteriorated significantly. Air pollution is mainly due to the air pollutant emissions [
7,
8,
9], the rapid urban growth [
10] and the shrinking green space [
11]. Recently, a number of control technologies on air pollution have been proposed and developed [
12]. One of the most important prerequisites of the effective prevention of air pollution lies in the evaluation of air pollution on socioeconomic development.
A number of efforts have been put into evaluating the impact of air pollution on economic development [
13,
14,
15,
16,
17,
18]. Most of these studies are mainly based on the evaluation of domain experts or government officers. However, the evaluation results are often affected by the knowledge, experience and the emotional state of the experts or officers. As a result, the evaluation results are often biased or subjective and cannot accurately reflect the real impact of air pollution. Therefore, it is necessary to propose an accurate and objective evaluation framework to investigate the impact of air pollution on the economic development.
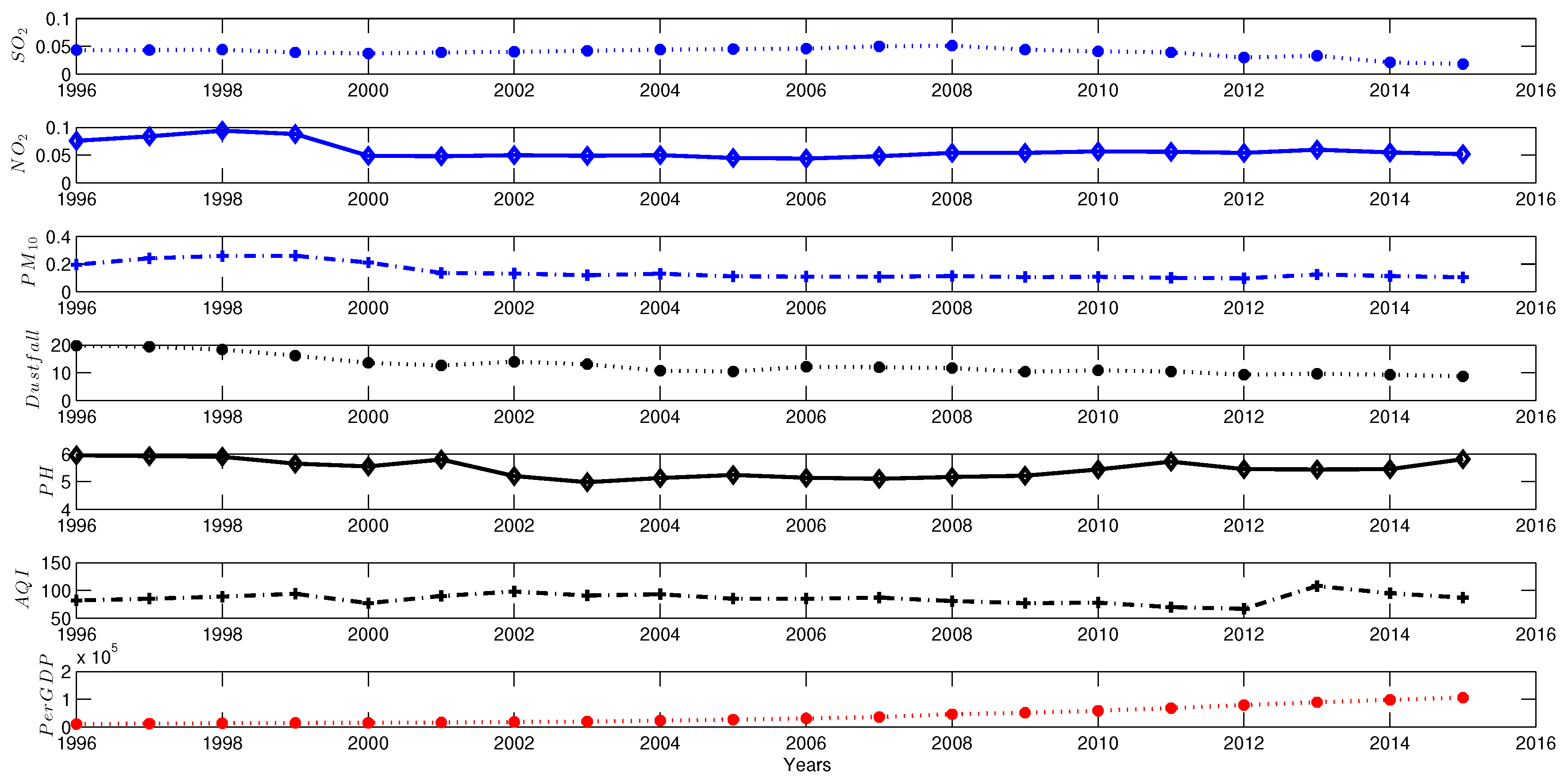
The air quality is often affected by many factors, which fluctuates from time to time. For example,
Figure 1 shows that Air Quality Index (AQI) varies with air pollution indicators (such as SO
, NO
, PM
, dustfall and pH) in Wuhan City in China from 1996 to 2016. Essentially, air pollution is a result of multi-factor interaction in the complex atmosphere system. There are multiple pollutants affecting the air quality [
19]. Thus, the evaluation of air pollution and the economic development can be regarded as a Multiple Criteria Decision Making (MCDM) problem that involves many conflicting evaluation indicators, such as various air pollutants, AQI and GDP per capital.
The Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) [
20,
21] is a kind of MCDM method. Compared with other MCDM methods, such as fuzzy-set theory [
22,
23] and the Analytic Hierarchy Process (AHP) [
24], TOPSIS has many merits such as the simplicity and insensitivity to the number of alternatives (or indicators) [
25]. However, TOPSIS has difficulties in determining the weights of multiple alternatives and keeping the consistency of judgment [
26]. For example, most of the TOPSIS methods require the weight evaluations given by domain experts [
27]; this inevitably leads to the bias in the evaluation and the subjective decision [
28]. Besides, most of studies on TOPSIS are mainly focused on business decision making problems [
29,
30]. To the best of our knowledge, there are few studies on the evaluation of the impact of air pollution on economic development by using the TOPSIS method.
In this paper, we propose a novel TOPSIS-based MCDM method (named the Smart MCDM) to evaluate the impact of air pollution on the economic development. The primary research contributions of this paper can be summarized as follows:
We propose the entropy method to obtain the initial weights of indicators of air pollution. This method can overcome the disadvantages of conventional TOPSIS methods in determining initial weights (recall that conventional methods obtain the weights given by domain experts).
Besides, we integrate Bayesian regularization and the Back-Propagation (BP) neural network in our Smart MCDM framework in order to obtain the objective weights since there is a correlation between the weights. The benefit of using Bayesian regularization in the BP neural network lies in the performance improvement in training the weights.
Moreover, we have applied Smart MCDM to evaluate the impact of air pollution on the economic development of Wuhan City in China. The empirical study is conducted on data collected from 1996 to 2015, focusing on seven indicators (including six major air pollution indicators and one economic indicator). The empirical results not only validate the effectiveness of our proposed MCDM framework, but also provide many implications on balancing the economic development and environment protection.
The rest of the paper is organized as follows.
Section 2 presents the Smart MCDM framework. We then present a case study in
Section 3.
Section 4 concludes the paper.
2. Smart MCDM Framework
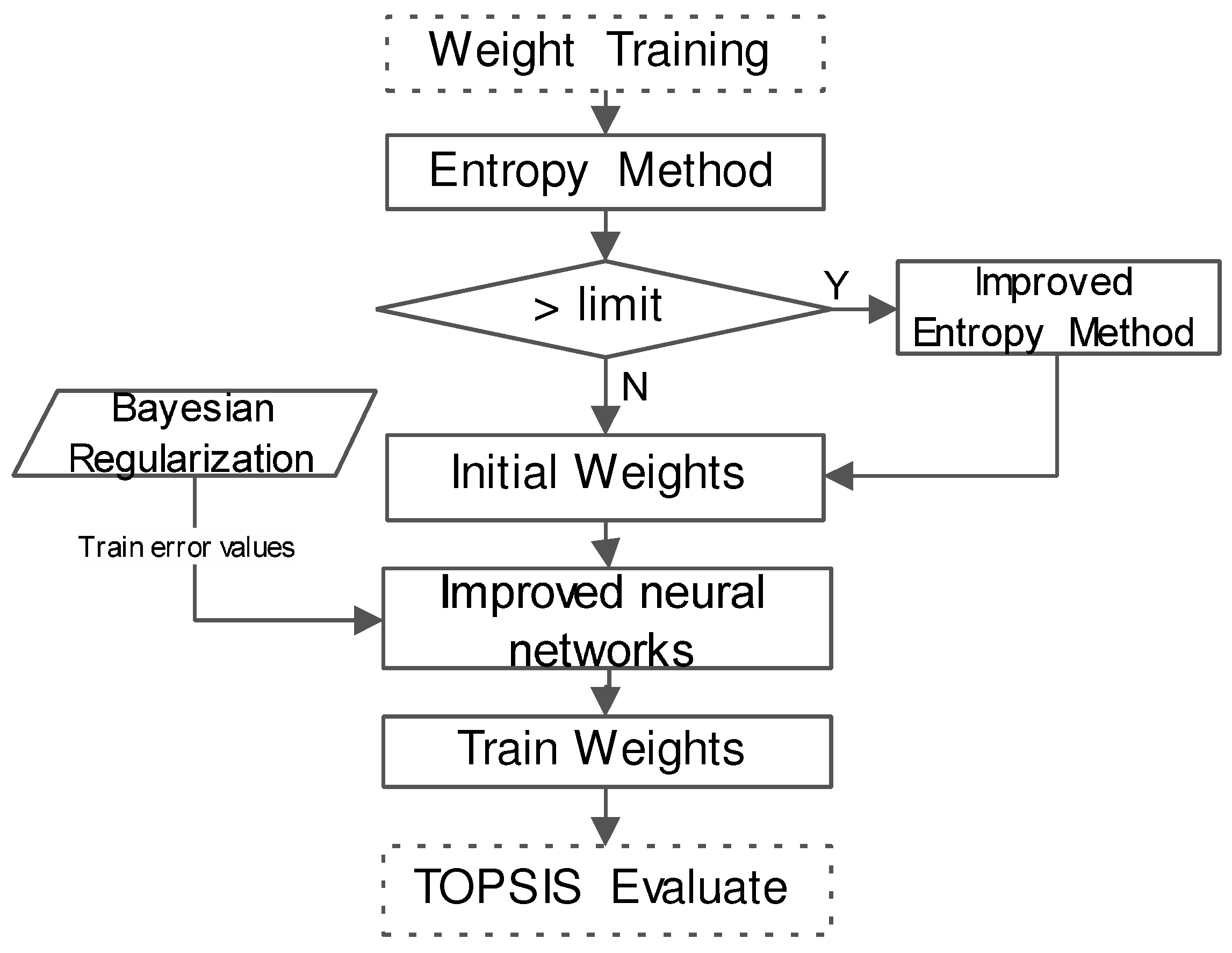
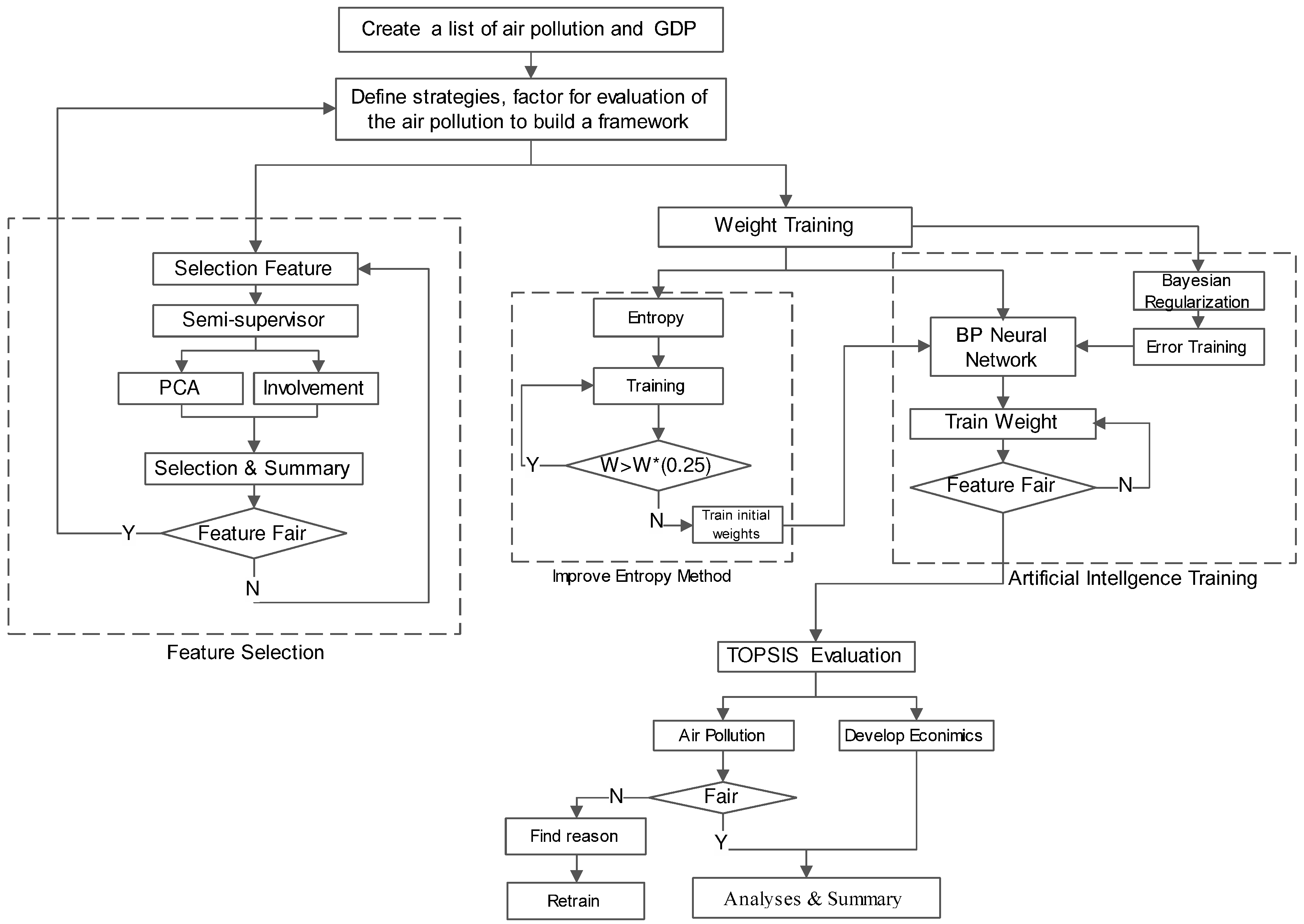
In order to address the aforementioned concerns, we propose a Smart MCDM framework based on TOPSIS. As shown in
Figure 2, our framework consists of four key phases: feature transformation (as shown in
Section 2.1), feature selection (as shown in
Section 2.2), weight training (as shown in
Section 2.3) and evaluation (as shown in
Section 2.4). We then describe them in detail as follows.
2.1. Feature Transformation
Since the indicators (also named as features interchangeably throughout the whole paper) of air pollutants are in different units, we need to normalize them before conducting feature selection. In particular, we convert the absolute value of an indicator into the relative one. Moreover, the positive indicator value and the negative indicator value represent different meanings. For example, air pollution is the negative indicator, while GDP is the positive indicator. Therefore, we choose the MAX-MIN scaling method to normalize the positive and negative values. More specifically, we have:
Negative values:
where
represents the original value,
represents the value after normalization,
is the minimum value and
is the maximum value.
2.2. Feature Selection
Air pollution is a result of multi-factor interaction in the Earth’s complex atmosphere. There are multiple pollutants having an influence on air pollution. To simplify our analysis, we need to identify several major pollutants that have a significant impact on urban air pollution [
31]. In this paper, we mainly consider the following major air pollutants according to China ambient air quality standards (i.e., GB3095-2012 standard [
32]): sulfur dioxide (SO
), nitrogen dioxide (NO
), Particulate Matter with a diameter of 10
m or less (PM
) and particulate matter with a diameter of 2.5
m or less (PM
). It is worth mentioning that PM
has been considered only after 1 January 2016 when China’s new ambient air quality standard came into force (though Wuhan City released the four-year data of PM
from 2012 to 2016 since it is one of the experimental cities in China). Since most of the information of PM
is missing for the years from 1996 to 2015, we do not consider PM
in this paper.
2.3. Weight Training
Figure 3 shows the weight training procedure. In particular, we first use the entropy method to obtain the initial weights for the indicators, as shown in
Section 2.3.1. In order to solve the correlation of initial weights, we then use Back-Propagation (BP) neural networks to train the weights, as shown in
Section 2.3.2.
2.3.1. Entropy Method to Determine Initial Weights
In information theory, entropy is a measure of uncertainty [
33]. In this paper, we use the entropy method [
27] to determine the weights of the indicators. In particular, we have the following equation to calculate the entropy denoted by
of information
:
where
is the
i-th value (there are in total
m states) and
is the probability of the
i-th state.
The entropy can be used to evaluate the randomness and the disorder degree of an event (or an indicator). In other words, the bigger the indicator is, the higher the influence on the comprehensive evaluation, implying smaller entropy. In this paper, we select m data samples and n indicators for evaluation, which construct a matrix .
We propose Algorithm 1 to generate the initial weights. The main idea of Algorithm 1 can be summarized as the following steps.
Normalization of indicators: Since the indicators of air pollutants are in different units, we need to normalize them first. In particular, we can use the feature transformation method in
Section 2.1 to solve this issue.
Calculation of the entropy measure: We then calculate the entropy measure of the
i-th sample under indicator
j (
j is ranging from one to
n) by the following equation:
where
k is the proportional parameter [
34]. If we choose
, then
[
27].
We next have
from Equation (
4).
Calculation of the entropy weight: We then calculate the entropy weight of each
j as follows,
Calculation of redundancy (weight correction): When any element
needs to be corrected (i.e.,
), we first correct the weight as
. Then, the remaining part of
will be assigned to other
weights proportionally according to the following equation:
where
k is the index of the element that needs to be corrected and
. We then obtain the corrected entropy weight
. If any weight in
needs the correction again (i.e.,
), we repeat the above steps until no more corrections are need.
| Algorithm 1 Improved entropy weight method. |
- 1:
- 2:
for to n do - 3:
calculate each - 4:
end for - 5:
- 6:
- 7:
while do - 8:
correct the n weights according to Equation ( 6). - 9:
end while
|
2.3.2. Integration of Bayesian Regularization and BP Neural Networks to Train Weights
Although the entropy method is an objective evaluation method to obtain the initial weights, there is a correlation between the weights. In order to obtain objective weights, we introduce the Back-Propagation (BP) neural network to train initial weights obtained by the aforementioned entropy method. Since the parameters of the neural networks are generally selected according to experiential knowledge (resulting in the local optimum [
35]), we use Bayesian regularization to improve the training procedure of BP neural networks. Before the formal introduction of our method, we firstly briefly review the Artificial Neural Network (ANN) as follows.
Artificial Neural Network
ANN [
35] was proposed to simulate the intelligent process of the human brain. ANN is mainly composed of artificial neurons, the ANN learning model and network topology.
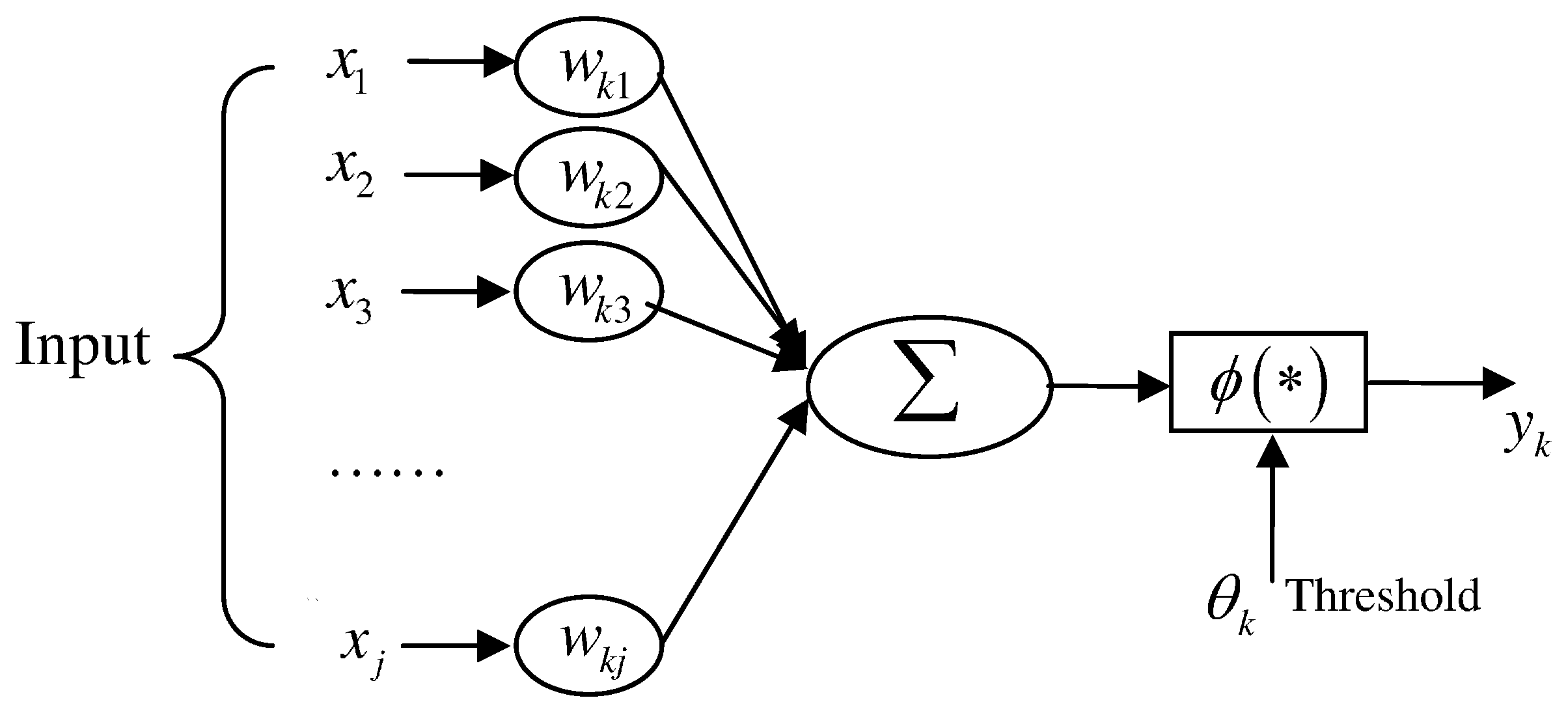
Figure 4 depicts a neural network training procedure. In particular, there are four basic elements in ANN:
A set of neurons (corresponding to the synapses of biological neurons).
A unit to calculate the weighted sum (linear combination) of the input signals.
A non-linear activation function.
A threshold .
More specifically, we can represent the above process as the following equation:
where
are input signals,
are weights of neurons,
is the value of neural networks,
is the linear combination,
is the threshold,
is activation function and
is the output.
Training Parameter Selection on the BP Neural Network
The BP neural network is a nonlinear general transformation unit composed of a feed-forward network. There are two phases in the BP neural network: propagation and weight updating. Specifically, an input vector is propagated in the layer-by-layer manner through the network until it finally reaches the output layer. A comparison between the output and the desired output is then conducted, and an error value is calculated for each neuron in the output layer. Then, the error values are propagated back to the network starting from the output to each backward layer. In this manner, each neuron is then associated with an error value (roughly representing the contribution to the original output). This process will repeat until the error reaches an acceptable level.
In this paper, the idea of training weight is to use the existing features as the input vector. We then choose the training sample set as the input sample. We next choose the initial weights as the output so that we can determine the number of layers, the number of neurons in each layer and the learning parameters. In the sample set, the factor quantization value is known (i.e., the factor score). After initialization, the network weights are obtained through network training. In order to obtain the corrected weights in features, we need to calculate the correlation between the network weights. During the process, how to choose the appropriate training parameters is a key for the efficiency of BP neural networks. We next analyze the selection of the training parameters.
Expected error: In BP neural network training process, it is important to choose a proper value of the expected error. For example, if the expected error is too small, the same set of sample data will be used repeatedly, resulting in over-fitting, while choosing a larger value of the expected error can also lead to a larger number of training times. In general, the empirical value is 0.0001, while we choose 0.00049 by using the Bayesian regulation method (shown as follows) in this paper.
Number of hidden nodes: In this paper, we use a method named the Trial-And-Error (TAE) method to determine the number of hidden nodes. First, we set fewer hidden nodes in the network. We then gradually increase the number of hidden nodes. When the error reaches the minimum, we then obtain the number of the hidden nodes.
Number of layers: It is shown in [
35] that the feed-forward network with a single hidden layer can map all continuous functions. It is true that increasing the number of hidden layers can reduce the training error while it can also result in the complex structure. In fact, as indicated above, increasing the number of nodes can also reduce the training error. Therefore, we choose a three-layer feed-forward network with a single hidden layer in this paper.
Activation function: According to the characteristics of ANN approximation, the activation function of the hidden layer is sigmoidal function that can be expressed as follows,
where
is the modifier [
35]. Without loss of generality, we choose
= 1 in this paper.
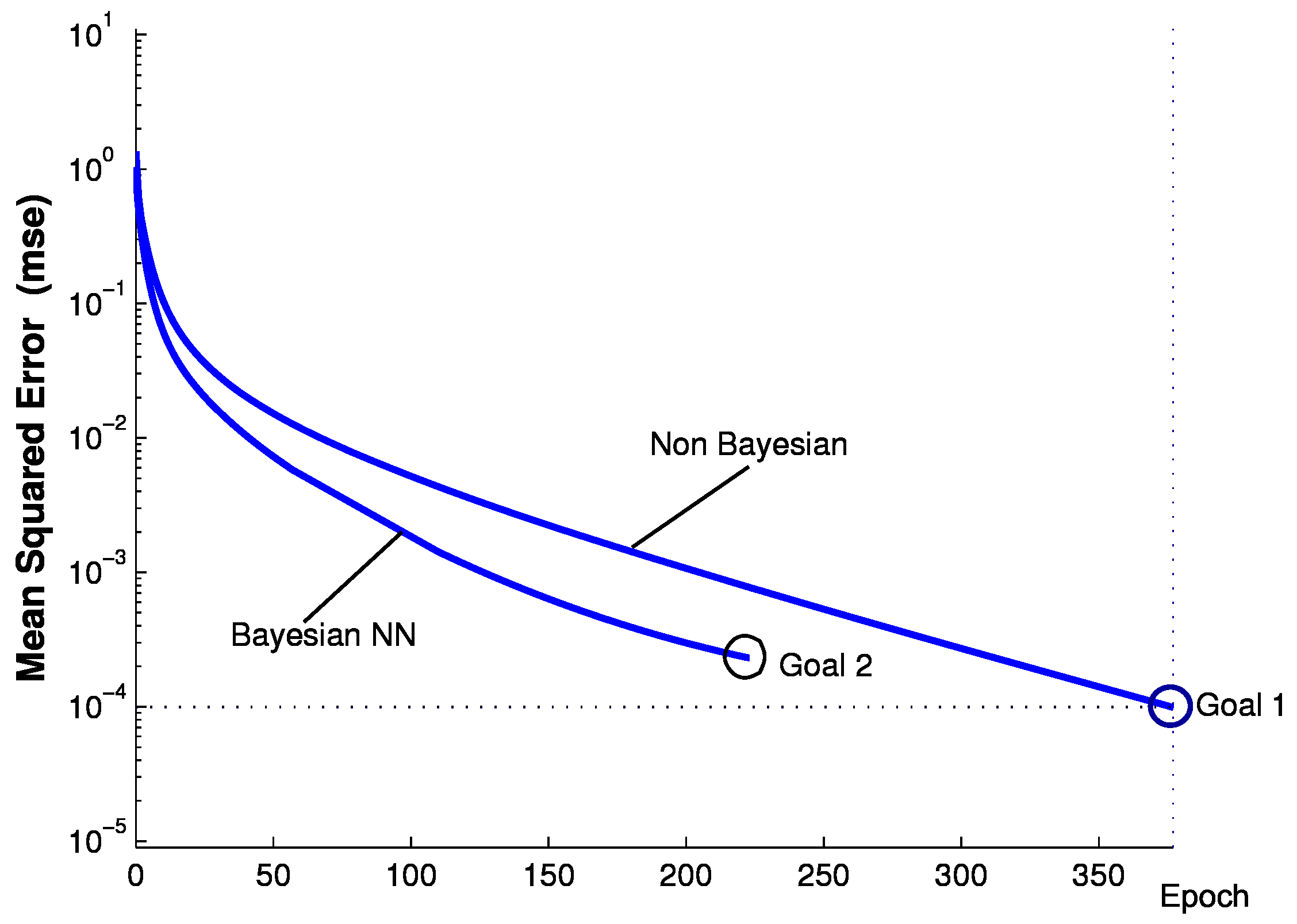
Bayesian Regularization Improves the BP Neural Network
One of disadvantages of the BP neural network is that the learning process is easily trapped in the local minimum resulting in poor network scalability. In this paper, we use regularization to limit the scale of network weights so that we can improve the generalization of neural networks. In particular, we consider Bayesian regularization, which is a method to estimate the regularization parameters based on Bayesian methods [
36]. It is worth mentioning that there are many methods to improve or optimize the weights of the neural networks, including Genetic Algorithms (GA), Particle Swarm Optimization (PSO), etc. [
37,
38,
39]. In this paper, we choose Bayesian regularization mainly because the data in our study are scarce, and the Bayesian method can improve the performance of neural networks (by reducing the training iterations) [
36]. One of our future works is to use other methods, such as GA and PSO, to optimize the weights in neural networks.
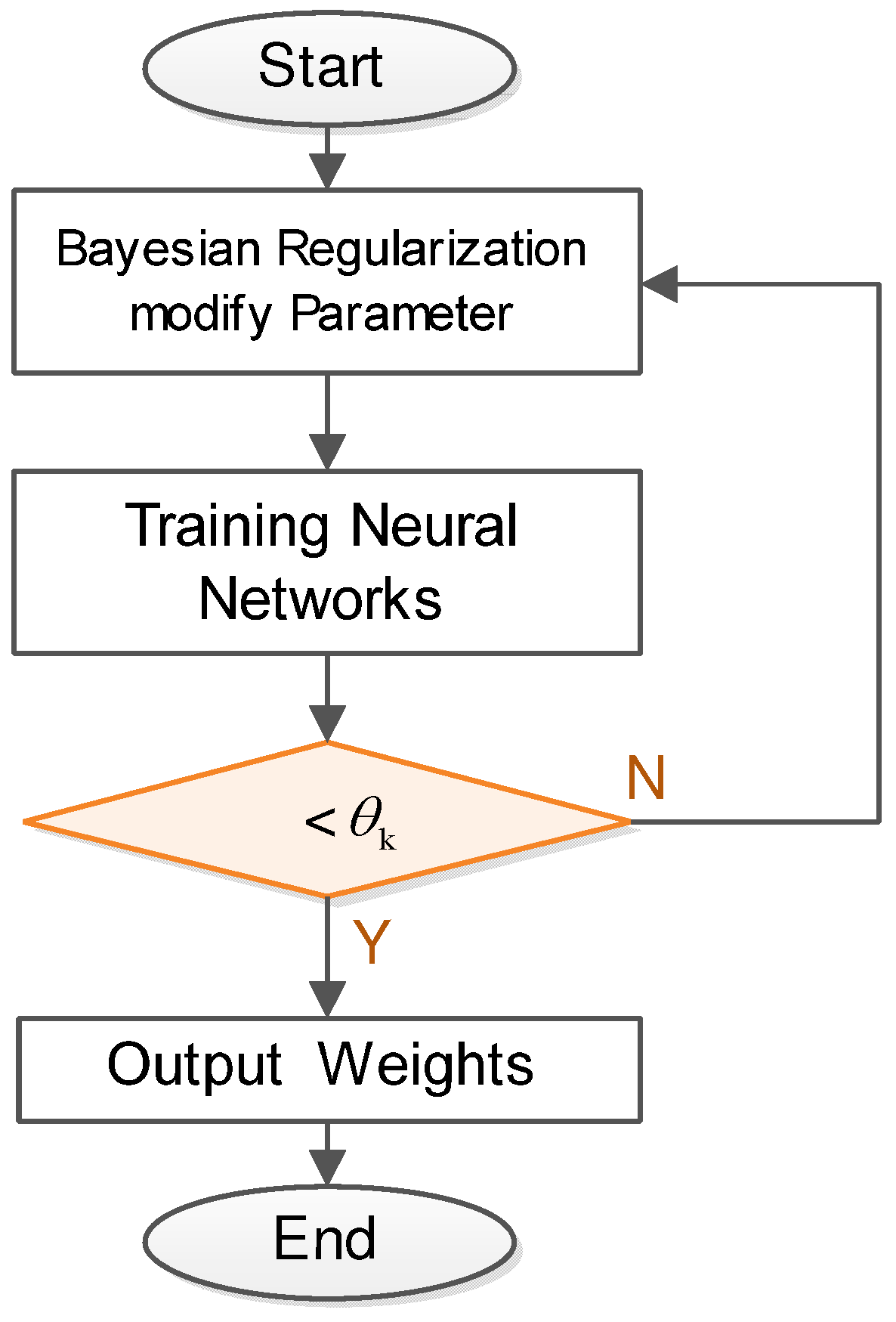
The main idea of Bayesian regularization is described as follows: (1) we first give a set of training samples
; (2) we then find the effective approximation function to minimize the error through neural network learning process.
Figure 5 depicts a Bayesian neural network training procedure. In particular, we choose the mean square sum error function defined as follows,
where
n is the number of samples,
is the expected output value and
is the actual output value for the network. In order to improve the generalization ability, we can add the arithmetic average of the network weights in the objective function. We then have the objective function as follows,
where
is the summation of the squares of the network weights,
is the neural network connection weight,
m is the number of neural network connection weights and
and
are the parameters of the objective function. Bayesian regularization can adjust
and
in the network training process so that it can effectively control the complexity of the network under the promise of the square sum error. In
Section 3.2, we will demonstrate the significant performance improvement of Bayesian regularization neural networks over the conventional neural networks.
2.4. Evaluation Based on TOPSIS
The main idea of TOPSIS is that the optimal evaluation object should have the shortest geometric distance from the positive ideal solution and the longest geometric distance from the negative ideal solution. In this paper, we use TOPSIS to evaluate the impacts of various air pollutants on the air pollution. In particular, we first use Equation (
1) or Equation (
2) to normalize the original datasets. More specifically, we denote
by the normalized matrix.
We then determine the optimal sample and the worst sample of each indicator. Specifically, the optimal sample is constructed by using the maximum value of each indicator in all samples. The minimum sample of each indicator is used to construct the worst sample. We denote the optimal sample and the worst sample by
and
, respectively. More specifically, they can be represented by the following equations:
where
and
.
We next calculate the relative distance from each sample point to the optimal sampling point denoted by
, which can be calculated by the following equation,
where
is the distance from each sample point to the optimum sample point and
is the distance from each sample point to the worst sample point. More specifically,
. In this paper, we mainly concentrate on the indicator of air pollution denoted by
and the joint indicator of both air pollution and GDP denoted by
. In
Section 3, we will evaluate them by using our proposed MCDM framework.
4. Conclusions and Future Works
Air pollution has a significant impact on the sustainable development of cities, especially for cities in developing countries. How to effectively evaluate the impacts of air pollution on socioeconomic development is an important issue in the sustainability of city development. However, it is quite difficult to conduct an effective evaluation on the impact of air pollution since the conventional evaluation is mainly based on the experience or the domain knowledge of environment experts, which inevitably have bias or subjectivity, consequently leading to a deviation or inaccuracy in air pollution evaluation.
In this paper, we propose a novel Multiple Criteria Decision Making (MCDM) framework to address the above concerns. In particular, our proposed MCDM method is based on an improved TOPSIS, in which Bayesian regularization and BP neural networks have been used to train the weights of multiple indicators. We apply our framework to evaluate the air pollution and the economic development of Wuhan city, which is a typical developing city in China. Our empirical results show that the evaluation scores of air pollution have fluctuated from time to time; this effect is contradictory to the common sense that air pollution always becomes worse. In fact, our results imply that sustainable socioeconomic development can be achieved without environment deterioration if we can take effective environment protection measures. We believe that the appropriate pollution control technologies, the enforcement of emissions reduction policy and the adjustment of industry layout will reduce the air pollution and support the sustainable urban development. One of our future studies is to conduct a fine-grained study on the impacts of various environment protection measures on air pollution and socioeconomic development, which is also an MCDM problem and is expected to be solved in a different approach.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}