In this section, we describe the privacy-preserving context, privacy-preserving data publishing methodology, and existing anonymization techniques. In addition, we discuss background knowledge with the privacy threats in bike sharing data publishing.
2.1. Privacy-Preserving Context
For preserving user privacy, we have to define a meaningful privacy context for the privacy-preserving data publishing. To determine specific privacy context, recently published research [
21,
22,
23,
24] identified the necessary privacy terms for the cyberspace, and these are the sender, recipient, attacker, identifiability, anonymity, pseudonymity, unlinkability, undetectability, unobservability, identity confidentiality and identity management. Pfitzmann and Hansen [
22,
23,
24] describe a privacy setting that defines the relationship between essential privacy terms.
In the privacy context, a sender sends his data to a recipient where an attacker cannot gain any information about that data. This privacy setting could be followed in the privacy-preserving data publishing circumstance. In the privacy-preserving data publishing setting, a data publisher releases the data to the public, and it is open to everyone. An attacker also receives that published data, and he might use some background knowledge to identify a person by linking with some publicly available data sources [
13]. Hence, the demand for anonymity is necessarily present in the privacy-preserving data publishing context [
21]. Anonymity is the anonymous properties of a dataset in which an attacker cannot identify the record owner within a set of other records, which is called the anonymity set [
24]. By applying some anonymizations operation on the published dataset, we can create the anonymity set which will protect the dataset from creating such link to identify a person. Consequently, the anonymous dataset will be protected from linking attacks and it will ensure the identity confidentiality in the published dataset.
2.2. Privacy-Preserving Data Publishing
To publish a dataset, there are trusted and untrusted model of data publishing [
25]. In the untrusted publishing model, a data publisher might attempt to identify a user record and corresponding sensitive information from the dataset. Several anonymous communications and cryptographic solutions were proposed for collecting user data anonymously [
26]. In the trusted privacy model, a data publisher remains trustworthy, and the record owners are reliable to provide their personal information for further processing. For example, a patient is ready to give her medical records to a hospital to obtain the needed medical service. Privacy-preserving data publishing is a trusted model of data publishing.
The data publishing states that an organization is the data owner and the public is the data miner who wants to do significant research on the published dataset. An organization wants to publish its own microdata table
T to the public. Microdata table
T could be released directly to the public if it contains no sensitive information. Usually, a microdata table
T contains sensitive information and the data owner cannot give
T to the public in the raw format. When a dataset has been published to the other parties for data mining, privacy-preserving techniques are mandatory to reduce the possibilities of identifying the sensitive information about a person [
27]. In privacy-preserving data publishing, one conjecture is that the data receiver could be an adversary. For example, a data mining research center is a responsible entity, but every staff in that organization will not be accountable as well. This hypothesis makes the privacy-preserving data publishing problems and solutions to be very distinct from the encryption and cryptographic methods, in which only authorized and reliable receivers are allowed for the private key toward accessing the cipher text [
27,
28]. For privacy-preserving data publishing, the published microdata tables stand open to everyone. A significant challenge in privacy-preserving data publishing is to protect the privacy of a user without disclosing their sensitive information. In addition, we have to ensure the data utility with the data privacy, namely the published dataset can be used for data mining and knowledge discovery.
To preserve sensitive information, an anonymization techniques need to be applied to a published microdata table. The anonymization approach tries to protect the identity and the sensitive information of a user, assuming that sensitive data must be preserved for data analysis. At the time of data publishing, unique identifiers of a user must be removed from the datasets. Even after all unique identifiers being removed, Sweeney [
13] showed a real-life privacy threat to a former governor of the state of Massachusetts. In Sweeney’s example, a user’s name in a public voter list was linked to his record in a released medical dataset through the combination of zip code, date of birth, and sex. Each of these attributes does not uniquely identify a record owner. However, the aggregation of these attributes, which is
QI, usually find a unique or a small number of record holders. According to Sweeney [
13], 87% of the residents of the USA could be uniquely identified by using
QI attributes.
In the above example, the user is identified by linking his
QI attributes. To perform such linking attacks [
13,
18], the adversary needs two pieces of prior knowledge: (1) published dataset of a record holder and (2) the
QI of the user. To limit linking attacks on the published dataset, we can provide an anonymization version of microdata table
T*(
Quasi-identifier, Sensitive attributes) by applying anonymization operation such as randomization [
19], generalization [
29] and perturbation [
30]. In the modified microdata table
T*,
QI is an anonymous version of the original
QI of the primary dataset. Anonymization processes preserve some particular information so that numerous records become indistinguishable with respect to
QI values. If a person remains linked to a record through
QI, and the same person is connected to all other records that have the same
QI values, then the association will be ambiguous. The anonymization process produces an anonymous version of
T such that it satisfies a given privacy model like
k-anonymity [
13] or
l-diversity [
31], and preserves as much data utility as possible.
2.3. Anonymization Techniques
For data anonymization, there are several privacy models, such as the partition-based model [
13,
31], the randomization-based model [
19], and the differential privacy based model [
32]. Among them, partition-based and randomization-based techniques are popular for privacy-preserving data publishing. In addition, recently differential privacy has received significant consideration for privacy-preserving data publishing. In the partitioning and randomization methods, the data values of
QI (e.g., birth year, gender, start and end location) are generalized to construct a
QI group. Therefore, an individual cannot be identified with their sensitive values in the group. Conversely, differential privacy answers the statistical queries based on the user request.
In partition and randomization based anonymization techniques, there are some popular anonymization methods which have been proposed for privacy preserving in one-time data publishing. Among them,
k-anonymity [
13] and
l-diversity [
31] methods are more popular.
k-anonymity [
13] is the first proposed privacy model for data publishing. It requires that all records in a published dataset cannot be distinguished from at least
k-1 other records.
k-anonymity does not consider sensitive attributes so that attackers may learn the relationship between sensitive data and individuals through a background knowledge attack. Background knowledge attack was proposed in [
31]. Background knowledge attack means that an adversary could use background knowledge to discover sensitive information, such as general understanding or professional knowledge about the published dataset.
To address the drawbacks of the
k-anonymity methodology, the
l-diversity privacy model was proposed [
31]. A
QI group is
l-diverse if the probability that any tuple in this group remains associated with a sensitive value is at most 1/
l. Both
k-anonymity and
l-diversity use the generalization technique to anonymize the microdata. For the generalization, the data table loses an enormous amount of information, particularly for higher dimensional data [
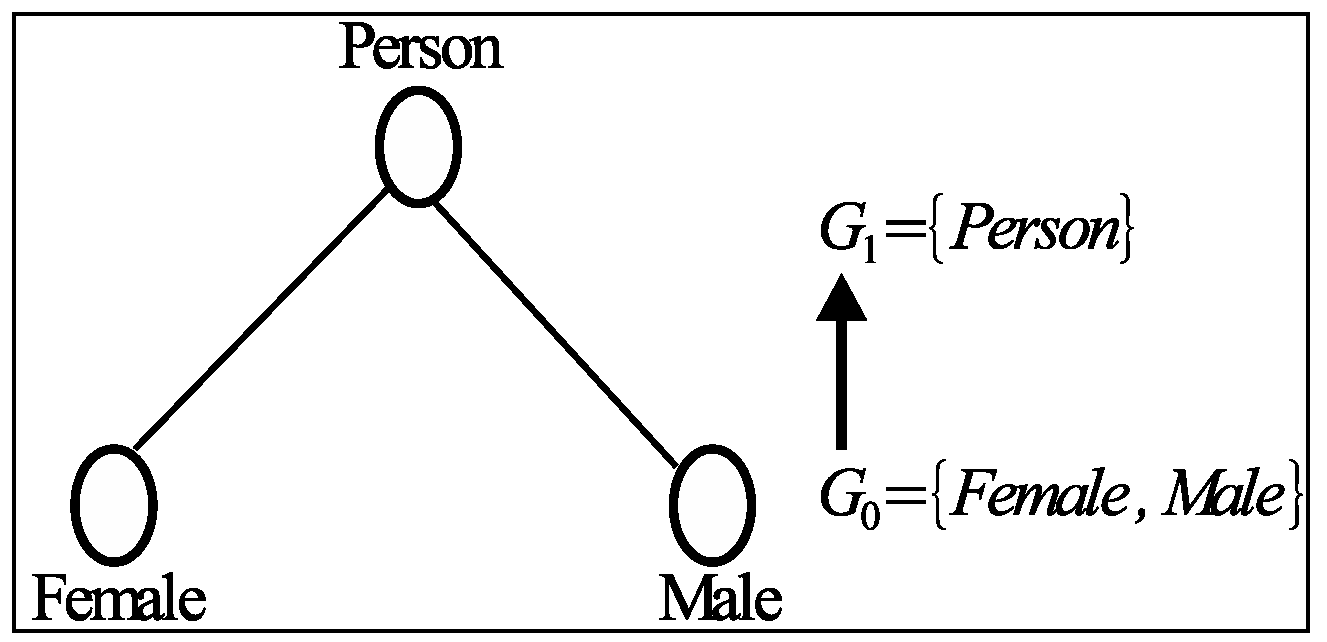
19]. Generalization breaks the correlation between attributes and it assumes that any possible combinations of attribute values are equally possible, i.e., Person (
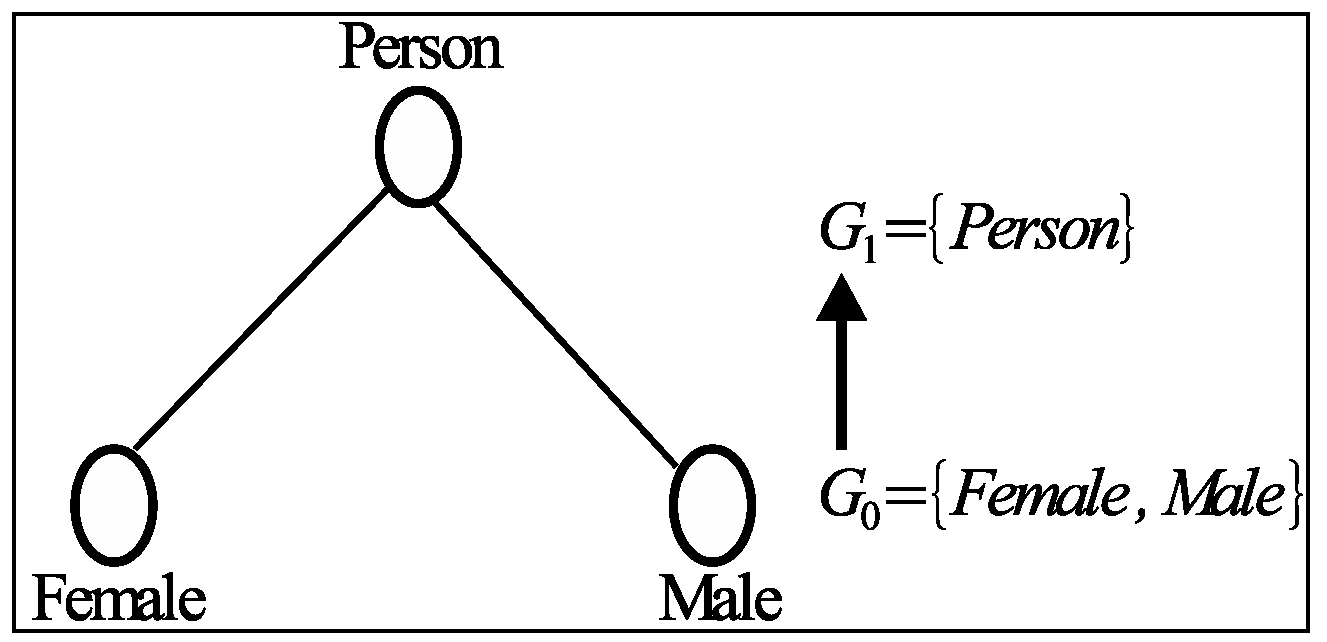
Figure 1) expresses the generalized value for the attribute values Female and Male.
Generalization implies an anonymization technique to coarsen the values by mapping a value to an interval or a particular concept to a more general one [
29]. It has been widely used for data anonymization. An advantage of generalization holds its faithfulness that a generalized value remains coarse but semantically consistent to its original value. For example, when age 24 is generalized to (20–30), we know that the age assumes a value in between 20 to 30 and it cannot assume a value of 32. Due to the faithfulness, when an adversary sees a set of records containing the values of a user ID, the adversary knows that the user’s record remains in the set. Such information facilitates the disclosure risks. Therefore, generalization alone cannot prevent a dataset from a privacy attack [
14].
The bike sharing companies published their datasets in every month, and each released dataset may contain multiple riding information of a single user. We consider that a registered user frequently rides a bike and, for every ride, the dataset will have her riding information. The bike sharing dataset contains the start and end locations of a riding path with the start and end time. A user future movement patterns can be predicted from the past locations [
33]. In addition, some research works show that our actions are easily predictable by nature [
34,
35]. When a dataset contains user information more than one time then, by arranging the
QI values, an adversary may know the user’s identity with the visiting locations, which may lead to a privacy breach [
33].
Privacy protection for a single dataset has been extensively studied where we have considered the information of a user remains only one time. When the information of an individual remains multiple times in multiple datasets or even on the same dataset, an adversary may reveal the privacy of the individual [
36,
37,
38,
39]. Recently, published
hybrid [
14], and
sequential [
38] methods have been proposed for privacy-preserving sequential data publishing. These methods used generalization [
29] and perturbation [
30] to anonymize the
QI values and Sensitive values. Therefore, it reduces the published data utility. In this paper, we propose a Grouping anonymization method based on partition and randomization approach to anonymize the published bike sharing transaction microdata table.
In differential privacy,
-
differential [
32] provides a strong privacy guarantee for statistical query answering. A survey on differential privacy can be found in [
40]. Most of the differential privacy methods support interactive settings to satisfy the
-
differential privacy requirements. Mohammed [
41] proposed the first non-interactive setting based algorithm for differentially private data release that protects information for classification analysis. In differential privacy, datasets play a vital role to check the effectiveness of the anonymization techniques. Li [
42] proposed DPSynthesizer, an open-source toolkit for differentially private data synthesis. DPSynthesizer performs a set of state-of-the-art techniques for building differentially private histograms from which synthetic data can be created, and it is eligible for low-dimensional data.
Recently, the cloud platform has become preferred for data management. Cloud computing facilitates end-users to outsource their dataset to a third-party service provider for data management. In the cloud platform, the security and privacy become a major concern for outsourcing data. One of the significant security interests of the outsourcing paradigm is how to protect sensitive information in the outsourced dataset. Dong [
43,
44,
45] proposed data-cleaning-as-a-service (DCaS) paradigm focusing on functional dependency (FD) constraints against data security attack by encrypting a small amount of non-sensitive data. In addition, they designed an FD preserving encryption algorithm that can provide a provable security guarantee against the frequency analysis attack.
2.4. Background Knowledge and Privacy Threats
The adversary’s background knowledge is described as the experience that he already learned and discovered formally from the prior rules of published datasets, or informally from the life experiences. For example, some sensitive attribute values such as ovarian cancer and breast cancer are associated with females only. The adversary’s background knowledge assists with learning relevant sensitive information and finding sensitive records to breach individual privacy in published datasets.
An adversary may know an individual who rides a public bicycle to a bus stop from his home. Consequently, the adversary knows the person’s start and end station, approximates start and end time, and the gender value. This information might be used as the QI values to search in the published bike sharing dataset to find all of the user’s probable visiting places that would breach the user’s privacy.
For bike sharing data publishing, published datasets work as a background knowledge because of its identity nature. An adversary may arrange released bike sharing datasets based on start and end station and could find a person who frequently rides a bike, and the adversary is not sure about the actual identity of the person. Therefore, an adversary might use video surveillance systems [
46,
47,
48,
49] to know the particular bike user.
2.5. Problems in Bike Sharing Data Publishing
Bike sharing data publishing presents a new challenge for privacy and utility for the published microdata table. Bike sharing data publishing is distinct from the traditional multiple time data publications, such as multiple view data publication [
50,
51] and series data publication [
38,
39,
52], since, in a bike sharing dataset, a single user’s records exist multiple times in the dataset. An adversary may use only a single release to conduct the privacy attacks and carry on with every other version of the microdata table. In addition, traditional multiple time data publishing [
38,
39,
52] uses Generalization [
29] to anonymize the microdata table that decreases the data utility.
A bike sharing microdata table consists of user’s riding transaction records that are visited locations with timing information, and these are called points of interests (
POI). A
POI can be any place for a person such as home, workplace, sports center or political party’s office. In an attack against user privacy, the attacker applies user-specific travel information to breach the user’s privacy [
53]. The objective of this attack is to identify a user’s house, workplace, and behavior. Analysis of bike sharing application data could cause a serious privacy breach of any user that might reconstruct her social networks, knowledge of her favorite visited places, her political and religious views.
In the bike sharing published microdata table, an adversary may reveal a user identity and sensitive information by arranging user’s records. For example, a public bike sharing user rides a bicycle to reach a bus stop to go to her workplace and come back home on weekdays. Therefore, the bike sharing transaction database will have the user’s records for every time she rides a bicycle. An adversary may know her bus stop and arrange her records based on the bus stop and can know her Birth Year, Gender, Start Station and Start Time, which may lead to identifying the Stop Station and Stop Time. By using Birth Year, Gender, Start Station and Stop Station, the adversary may further search in the published microdata table and can arrange all of the user’s available records for that particular route. The adversary could use these details of visiting information to initiate a physical or financial harassment to the user [
54].
We explain an example of how a bike sharing transaction dataset may breach a user’s privacy.
Table 1 presents the data segment from a bike sharing company [
16]. By arranging the Birth Year, Gender, Start Station and End Station, we may find the person who frequently uses the bike sharing service. It is observed that a bike sharing transaction microdata table has multiple records of a single user. From
Table 1, it can be recognized that a male user born in 1970 often rides a bike from E 47 St and Park Ave to W 49 St and 8 Ave during the morning session and W 49 St and 8 Ave to E 47 St and Park Ave during the afternoon session. By arranging a particular user’s bike riding information, an adversary might visit those places in person to infer the actual user identity. At present, the adversary has the identity of the person with his
POI. The adversary might be a thief, and from the summary of the above information, the adversary could steal from his house. Therefore, we can conclude that, for bike sharing datasets, an adversary could breach the user privacy based on the published bike sharing transaction microdata table.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}