
A Novel Hybrid-Copy Algorithm for Live Migration of Virtual Machine


Abstract
:
1. Introduction
2. Background
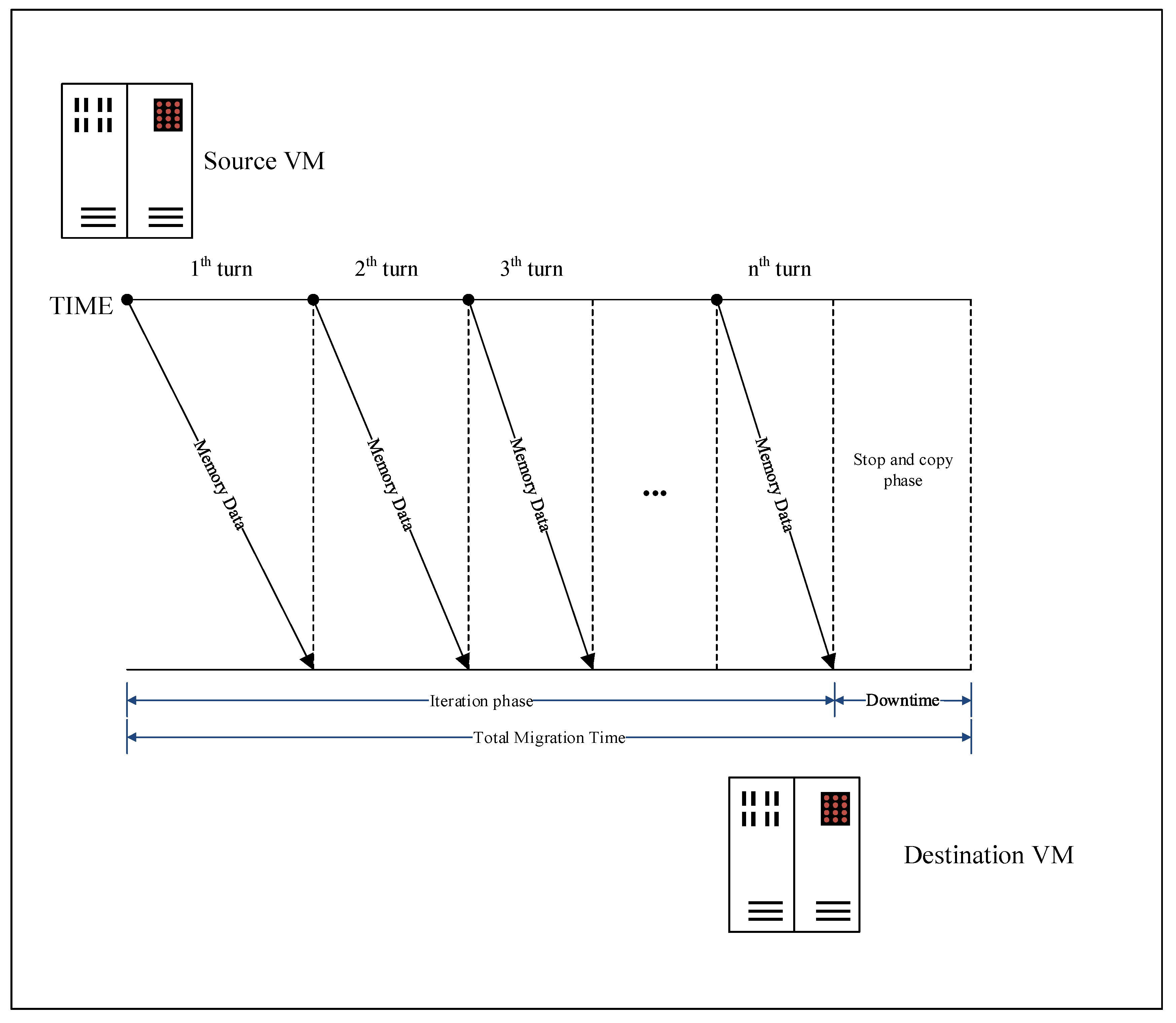
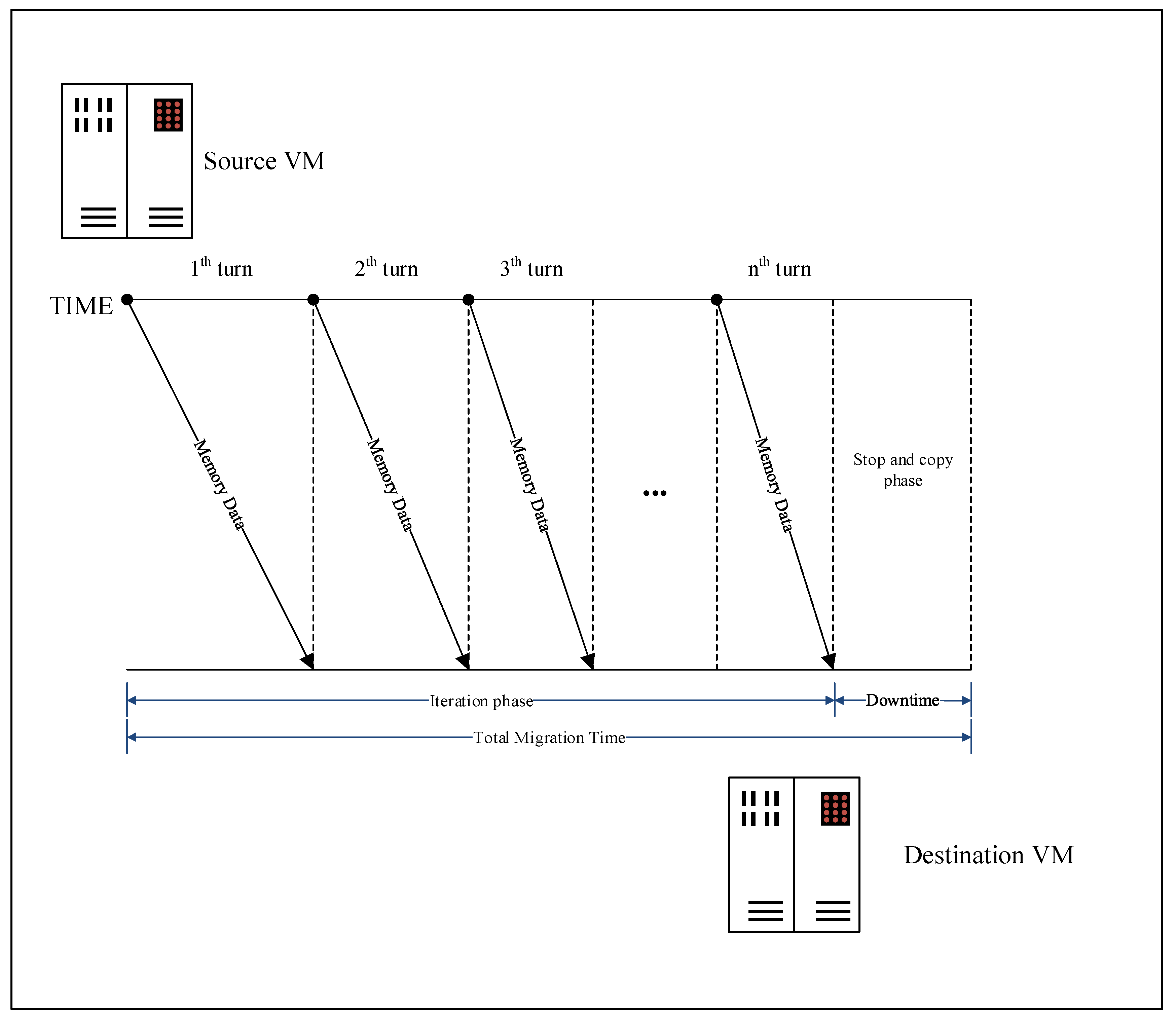
2.1. Pre-Copy
- (1)
- Iteration phase: In this phase, memory mirroring synchronization between the source host and the destination host will be maximized by iteratively copying the memory data from the source to the destination. In this phase, the source VM still works, so part of memory pages would be modified during the previous transmission turn. These memory pages should be synchronized until the number of the remaining memory pages is less than a threshold or the iteration turn is greater than an iterative threshold.
- (2)
- Stop-and-copy phase: In this phase, the source VM will be stopped and the remaining pages will be copied to the destination VM. Then the new VM in the destination host is started.
2.2. Post-Copy
2.3. Hybrid-Copy
3. Novel Hybrid-Copy Algorithm
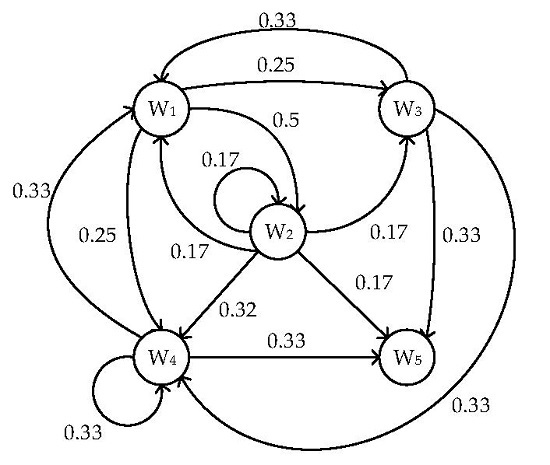
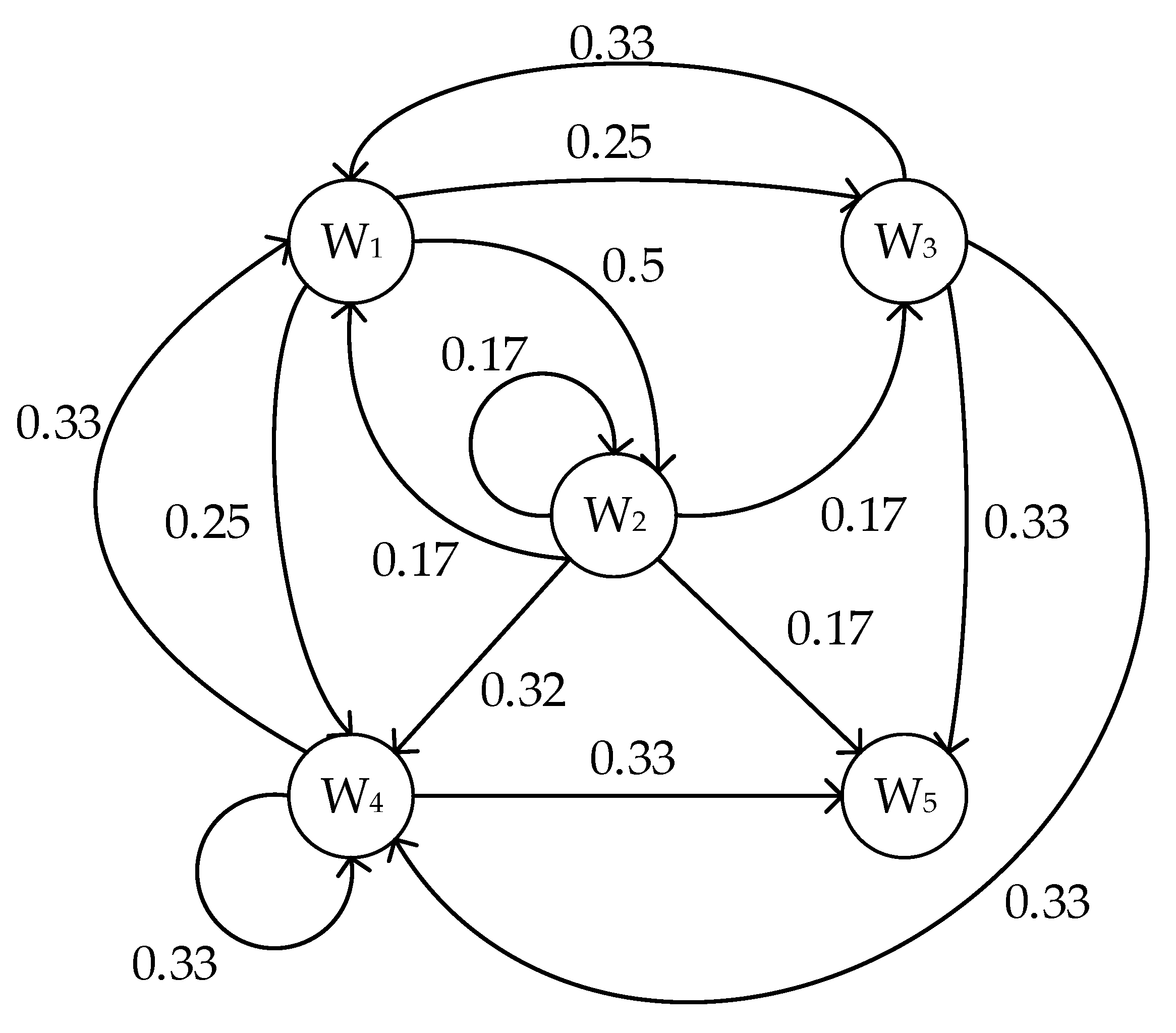
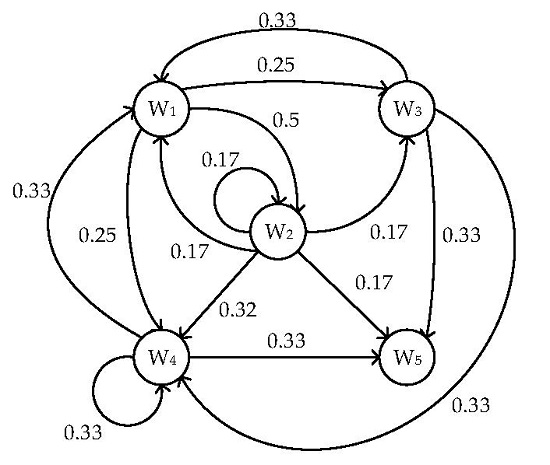
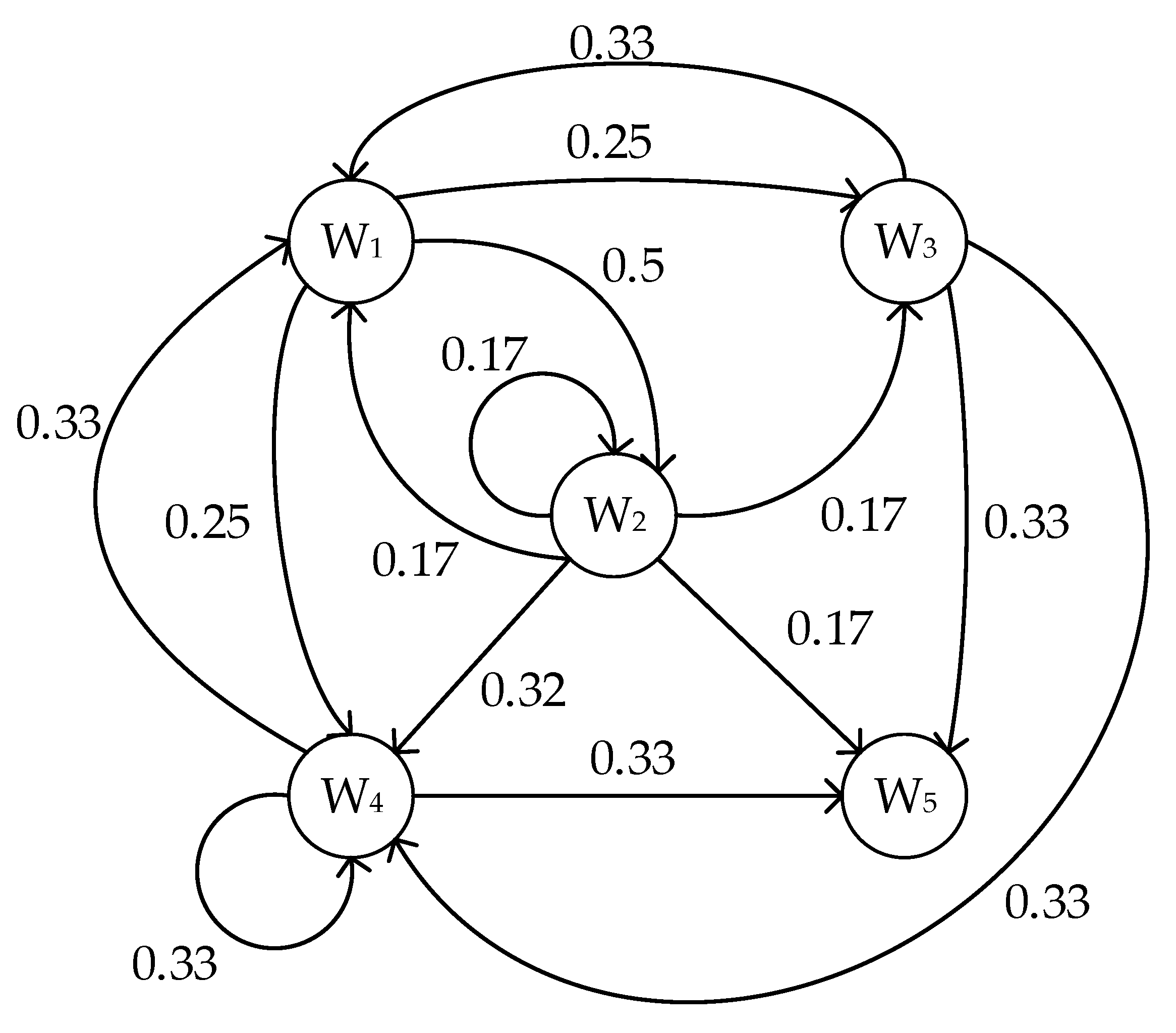
3.1. Markov Model of Memory Write
3.2. Switched Decision Factor(SDF)
3.3. Novel Hybrid-Copy Algorithm
| Algorithm 1: Novel Hybrid-Copy |
| Input: |
| memory_size, dirty_threshold: Integer |
| a: Float |
| Output: |
| Variables: |
| send_list, dirty_list: Array of Integer |
| decision_fac: Float |
| pre_dirty_size, dirty_size, send_size: Integer |
| Instructions: |
| decision_fac = 0; |
| dirty_size = memory_size; |
| pre_dirty_size = memory_size; |
| send_list = NULL; |
| dirty_list = Get_Dirty_List(); |
| While decision_fac < a AND dirty_size > dirty_threshold Do |
| send_list = NULL; |
| send_size = Filter_Dirty(send_list, dirty_list); |
| Send_live_dirty(send_list); |
| dirty_list = Get_Dirty_List(); |
| pre_dirty_size = dirty_size; |
| dirty_size = Get_Dirty_Size(); |
| decision_fac = (pre_dirty_size - dirty_size) / send_size; |
| END While |
| Post-Copy-Algorithm(); |
| END Novel Hybrid-Copy |
| Algorithm 2: Filter_Dirty |
| Input: |
| send_list, dirty_list: Array of Integer |
| Output: |
| send_size: Integer |
| Variables: |
| forecast_list: Array of Integer |
| Instructions: |
| If send_list!= NULL Then |
| send_list = NULL; |
| End If |
| forecast_list = NULL; |
| forecast_list = Markov_Forecast(dirty_list); |
| send_list = dirty_list - forecast_list; |
| send_size = Get_Size(send_list); |
| END Filter_Dirty |
4. Experimental Results and Comparative Analyses
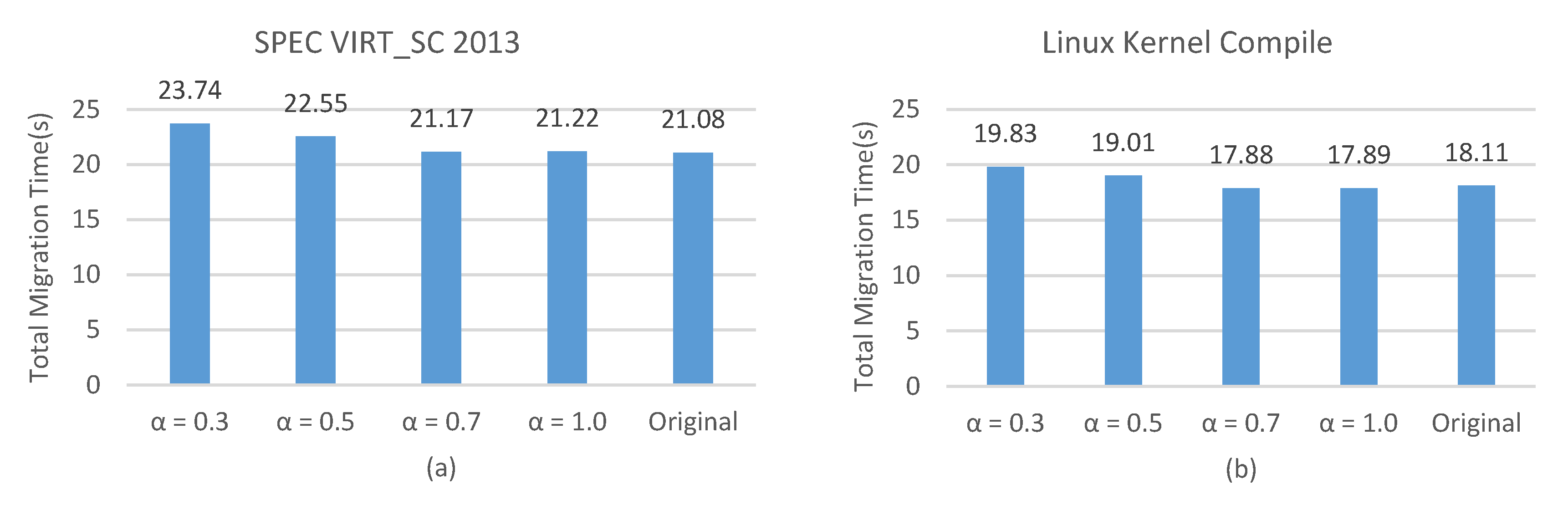
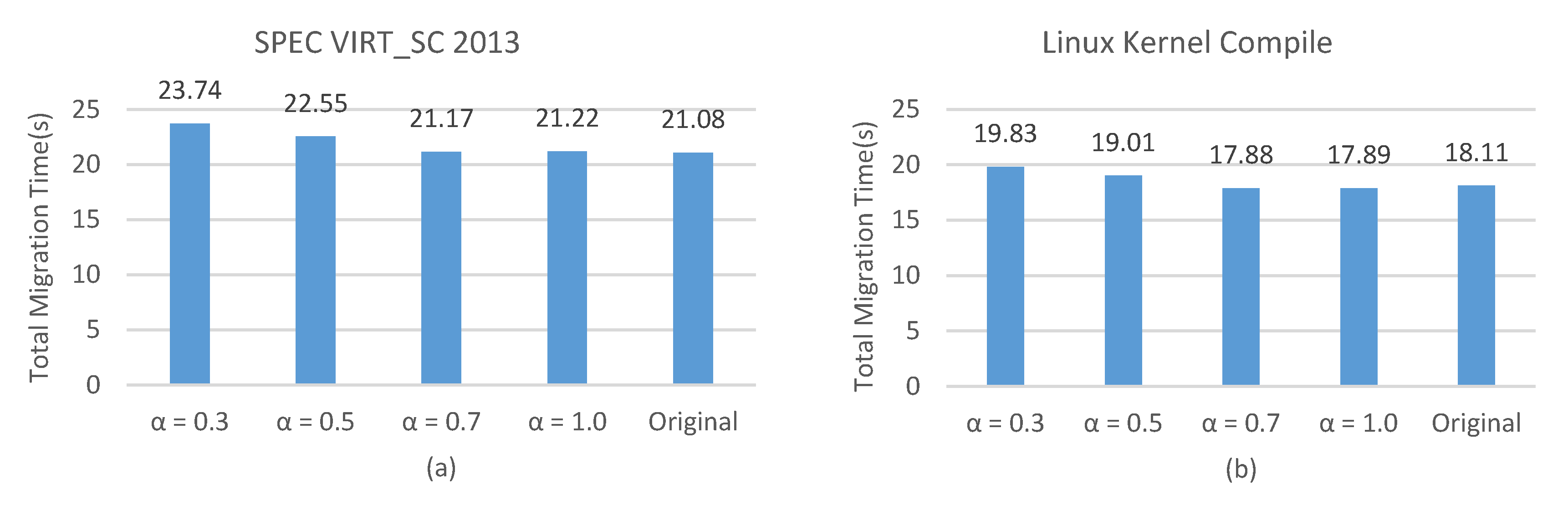
4.1. Total Migration Time
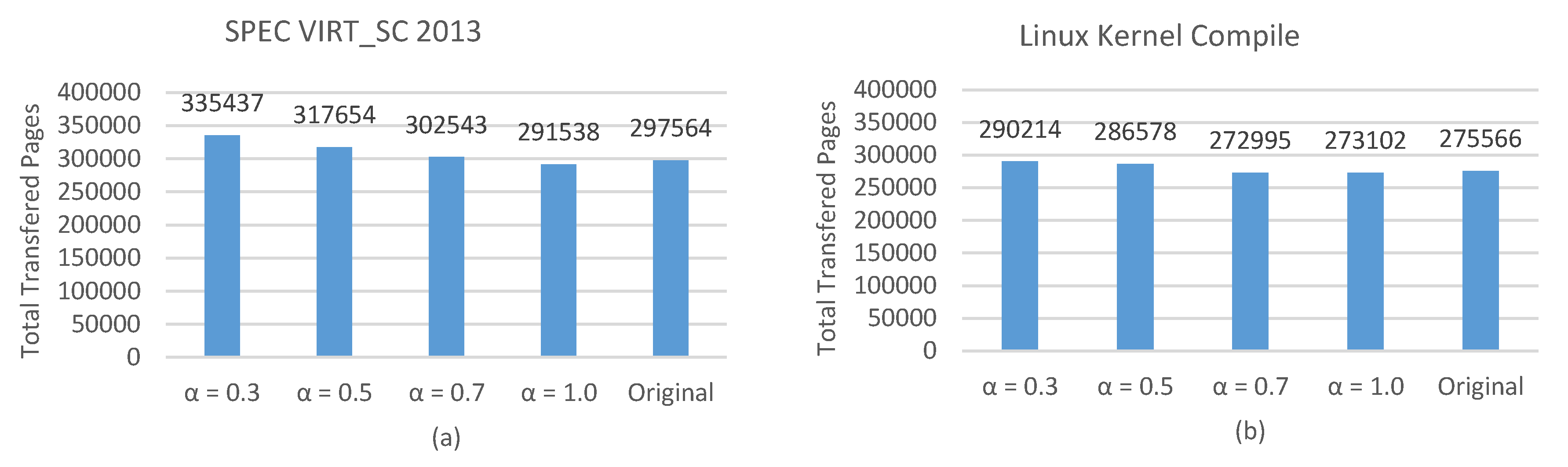
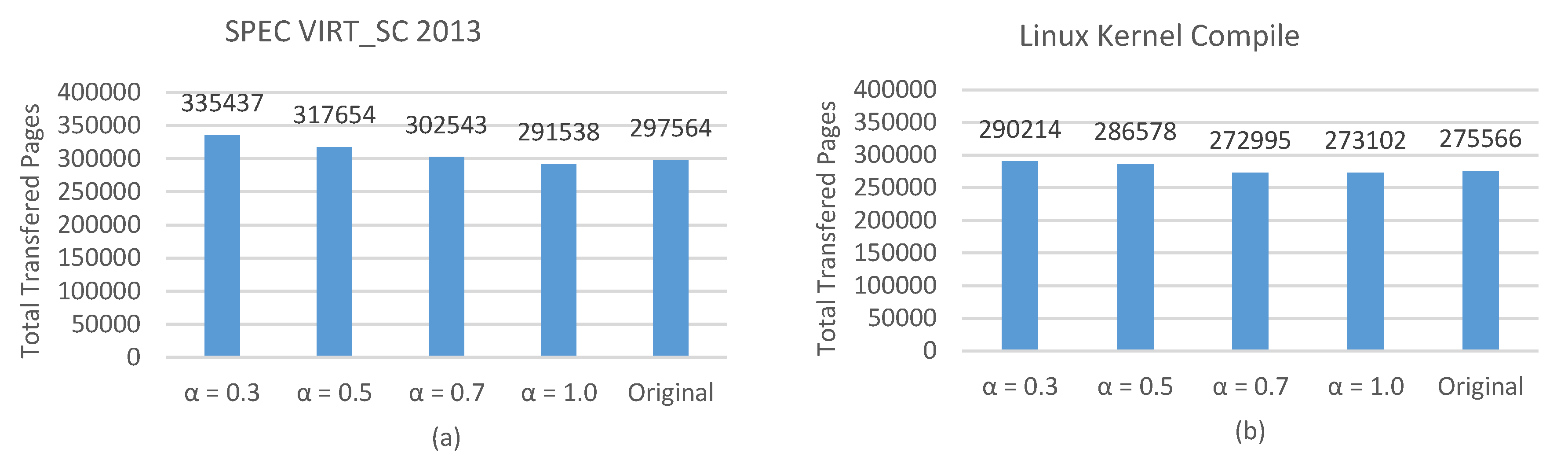
4.2. Total Transferred Pages
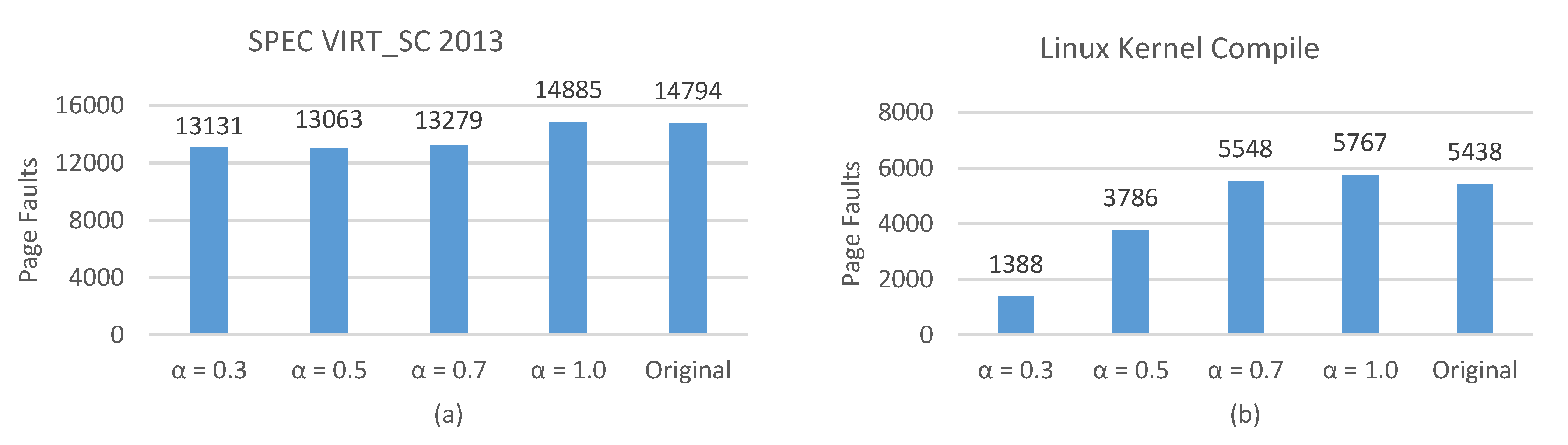
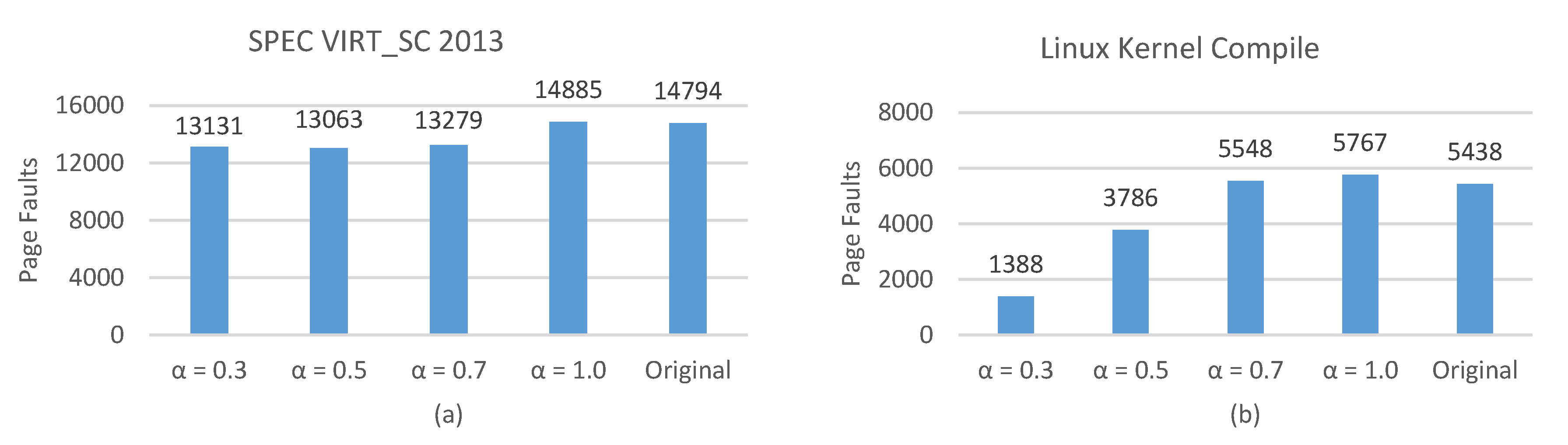
4.3. Number of Page Faults
4.4. Summary of Experiments
5. Related Work
6. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Armbrust, M.; Fox, A. Above the Clouds: A Berkeley View of Cloud Computing; Eecs Department University of California Berkeley: Berkeley, CA, USA, 2010. [Google Scholar]
- Jin, H; Deng, L; Wu, S. Live virtual machine migration with adaptive, memory compression. In Proceedings of the IEEE International Conference on CLUSTER Computing and Workshops, New Orleans, LA, USA, 31 August–4 September 2009; pp. 1–10. [Google Scholar]
- Clark, C; Fraser, K; Hand, S. Live migration of virtual machines. In Proceedings of the Symposium on Networked Systems Design and Implementation, Berkeley, CA, USA, 2–4 May 2005; DBLP: Trier, Germany, 2005; pp. 273–286. [Google Scholar]
- Tiwari, P.K.; Joshi, S. Dynamic Weighted Virtual Machine Live Migration Mechanism to Manages Load Balancing in Cloud Computing. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research, Chennai, India, 15–17 December 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Arif, M.; Kiani, A.K.; Qadir, J. Machine learning based optimized live virtual machine migration over WAN links. Telecommun. Syst. 2017, 64, 1–13. [Google Scholar] [CrossRef]
- He, J.; Dong, M.; Ota, K. NetSecCC: A scalable and fault-tolerant architecture for cloud computing security. Peer-Peer Netw. Appl. 2014, 9, 1–15. [Google Scholar] [CrossRef]
- Xu, X.; Wu, J.; Yang, G. Low-power task scheduling algorithm for large-scale cloud data centers. Syst. Eng. Eletron. 2013, 24, 870–878. [Google Scholar] [CrossRef]
- Gibson, G.A.; Van Meter, R. Network attached storage architecture. Commun. ACM 2000, 43, 37–45. [Google Scholar] [CrossRef]
- Nelson, M; Lim, B.H.; Hutchins, G. Fast Transparent Migration for Virtual Machines. In Proceedings of the annual Conference on USENIX Annual Technical Conference, Berkeley, CA, USA, 10–15 April 2005. [Google Scholar]
- Hsu, C.H.; Peng, S.J.; Chan, T.Y. An Adaptive Pre-copy Strategy for Virtual Machine Live Migration. In Internet of Vehicles–Technologies and Services; Springer International Publishing: Cham, Switzerland, 2014; pp. 396–406. [Google Scholar]
- Baruchi, A.; Midorikawa, E.T.; Sato, L.M. Reducing Virtual Machine Live Migration Overhead via Workload Analysis. IEEE Lat. Am. Trans. 2015, 13, 1178–1186. [Google Scholar] [CrossRef]
- Ruan, Y.; Cao, Z.; Cui, Z. Pre-Filter-Copy: Efficient and Self-Adaptive Live Migration of Virtual Machines. IEEE Syst. J. 2016, 10, 1459–1469. [Google Scholar] [CrossRef]
- Hines, M.R.; Gopalan, K. Post-copy based live virtual machine migration using adaptive pre-paging and dynamic self-ballooning. Procedings of the International Conference on Virtual Execution Environments, VEE 2009, Washington, DC, USA, 11–13 March 2009; DBLP: Trier, Germany, 2009; pp. 51–60. [Google Scholar]
- Abe, Y.; Geambasu, R.; Joshi, K. Urgent Virtual Machine Eviction with Enlightened Post-Copy. In Proceedings of the 12th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, Atlanta, GA, USA, 2–3 April 2016; Volume 51, pp. 51–64. [Google Scholar]
- Su, K.; Chen, W.; Li, G. RPFF: A Remote Page-Fault Filter for Post-copy Live Migration. In Proceedings of the IEEE International Conference on Smart City/socialcom/sustaincom, Chengdu, China, 19–21 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 938–943. [Google Scholar]
- Sahni, S.; Varma, V. A Hybrid Approach to Live Migration of Virtual Machines. In Proceedings of the IEEE International Conference on Cloud Computing in Emerging Markets, Bangalore, India, 11–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–5. [Google Scholar]
- Chen, Y.; Huai, J.P.; Chun-Ming, H.U. Live Migration of Virtual Machines Based on Hybrid Memory Copy Approach. Chin. J. Comput. 2011, 34, 2278–2291. [Google Scholar] [CrossRef]
- Jaswal, T; Kaur, K. An Enhanced Hybrid Approach for Reducing Downtime, Cost and Power Consumption of Live VM Migration. In Proceedings of the International Conference on Advances in Information Communication Technology & Computing, Bangalore, India, 12–13 August 2016; ACM: New York, NY, USA, 2016; p. 72. [Google Scholar]
- Joseph, D.; Grunwald, D. Prefetching Using Markov Predictors. IEEE Comput. Soc. 1999, 48, 121–133. [Google Scholar] [CrossRef]
- Rd, P.; Hudzia, B.; Tordsson, J. Evaluation of delta compression techniques for efficient live migration of large virtual machines. In Proceedings of the ACM Sigplan/Sigops International Conference on Virtual Execution Environments, Newport Beach, CA, USA, 9–11 March 2011; ACM: New York, NY, USA, 2011; pp. 111–120. [Google Scholar]
- Esposito, F.; Cerroni, W. GeoMig: Online Multiple VM Live Migration. In Proceedings of the IEEE International Conference on Cloud Engineering Workshop, Berlin, Germany, 4–8 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 48–53. [Google Scholar]
- Sun, G.; Liao, D.; Anand, V. A new technique for efficient live migration of multiple virtual machines. Future Gen. Comput. Syst. 2016, 55, 74–86. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| N | The total number of the VM’s memory pages |
| S(n) | The number of the transmitted memory pages in nth round |
| R(n) | The total number of the transmitted memory pages after nth round |
| T(n) | The number of invalid transfers in nth round |
| V1(n) | The total number of invalid transfers after nth transfer |
| V2(n) | The number of the dirty pages after nth transfer |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Z.; Sun, E.; Chen, S.; Wu, J.; Shen, W. A Novel Hybrid-Copy Algorithm for Live Migration of Virtual Machine. Future Internet 2017, 9, 37. https://doi.org/10.3390/fi9030037
Lei Z, Sun E, Chen S, Wu J, Shen W. A Novel Hybrid-Copy Algorithm for Live Migration of Virtual Machine. Future Internet. 2017; 9(3):37. https://doi.org/10.3390/fi9030037
Chicago/Turabian StyleLei, Zhou, Exiong Sun, Shengbo Chen, Jiang Wu, and Wenfeng Shen. 2017. "A Novel Hybrid-Copy Algorithm for Live Migration of Virtual Machine" Future Internet 9, no. 3: 37. https://doi.org/10.3390/fi9030037
APA StyleLei, Z., Sun, E., Chen, S., Wu, J., & Shen, W. (2017). A Novel Hybrid-Copy Algorithm for Live Migration of Virtual Machine. Future Internet, 9(3), 37. https://doi.org/10.3390/fi9030037