Towards Annotopia—Enabling the Semantic Interoperability of Web-Based Annotations

Abstract
:1. Introduction and Background
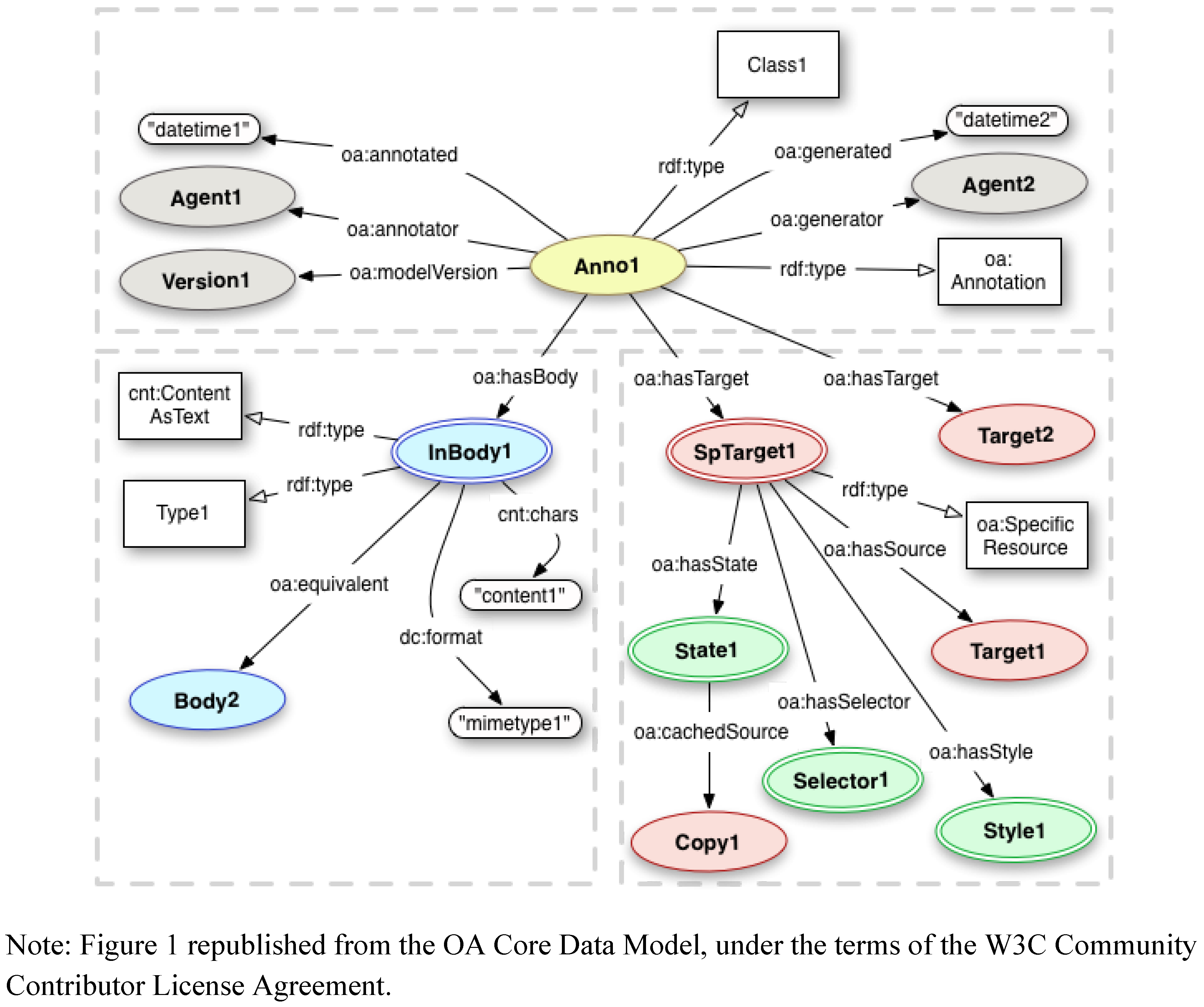
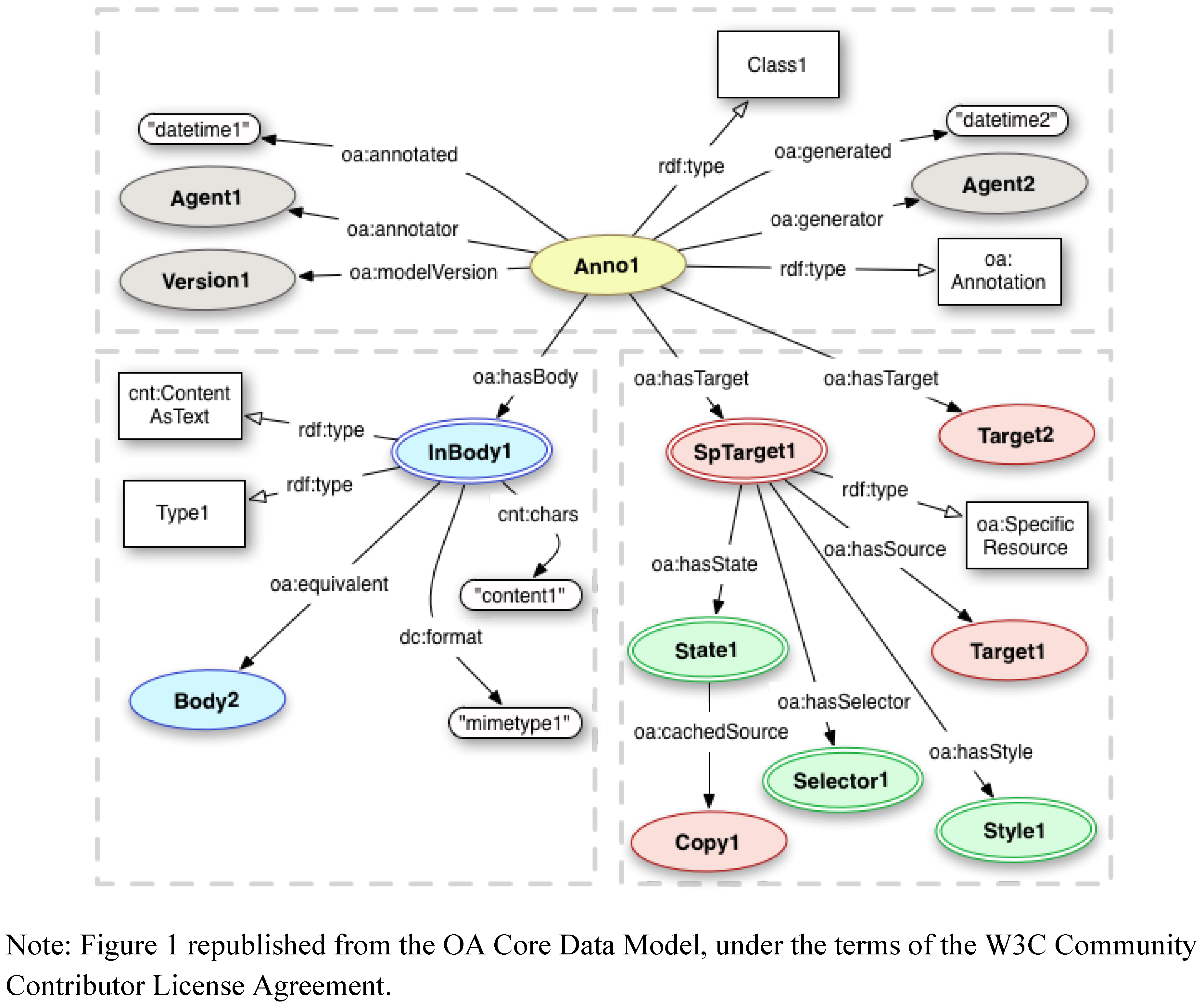
1.1. The Open Annotation Collaboration (OAC) Data Model
1.2. The Annotation Ontology (AO)
1.3. The Merged Open Annotation Model (OA)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
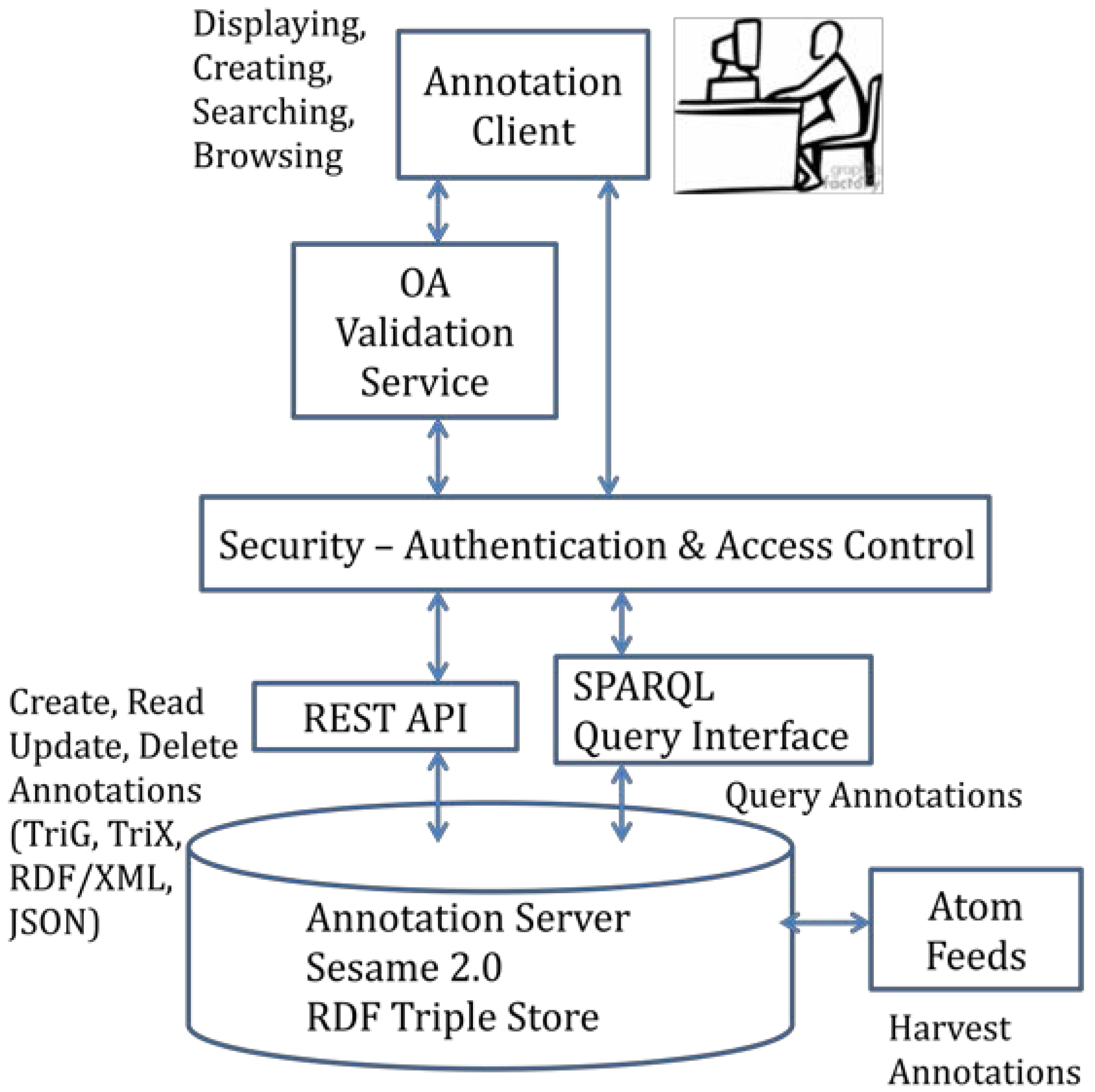{kind=link}
| Feature | Model | |
|---|---|---|
| OAC | OA | |
| Provenance | Recommends use of Dublin Core creator, created etc. | Defines provenance properties, distinguishing between annotator and generator |
| Annotation types | Defines two subtypes of oac:Annotation: (1) oac:Reply and (2) oac:DataAnnotation. OAC encourages subtyping. | Common subtypes described in OAX rather than the core model. Provides guidelines for subtyping. OA recommends explicitly including oa:Annotation type for all annotations. |
| Equivalent serializations | No equivalent concept in OAC. | Defines equivalent property for maintaining a relationship between re-published copies of an annotation |
| Body | Does not specify cardinality of annotation bodies. | Explicitly allows annotations without a body, does not allow multiple bodies. |
| Resource segments |
|
|
| State | No equivalent concept in OAC. | Defines oa:hasState which associates an oa:State with an oa:SpecificResource to allow clients to retrieve the correct representation of the resource (e.g., version, format, language etc). |
| Style | No equivalent concept in OAC. | Defines oa:hasStyle which associates an oa:Style with an oa:SpecificResource to enable hints to be provided to the client recommending how to display the Annotation and/or Selector. |
| Extensions | No equivalent concept in OAC. | Splits the model into a stable core (OA), and extension (OAX), which may change. OAX includes subtypes of Annotation, Selector, State and Style, hasSemanticTag and support for Named Graphs for structured data. |
2. Case Studies
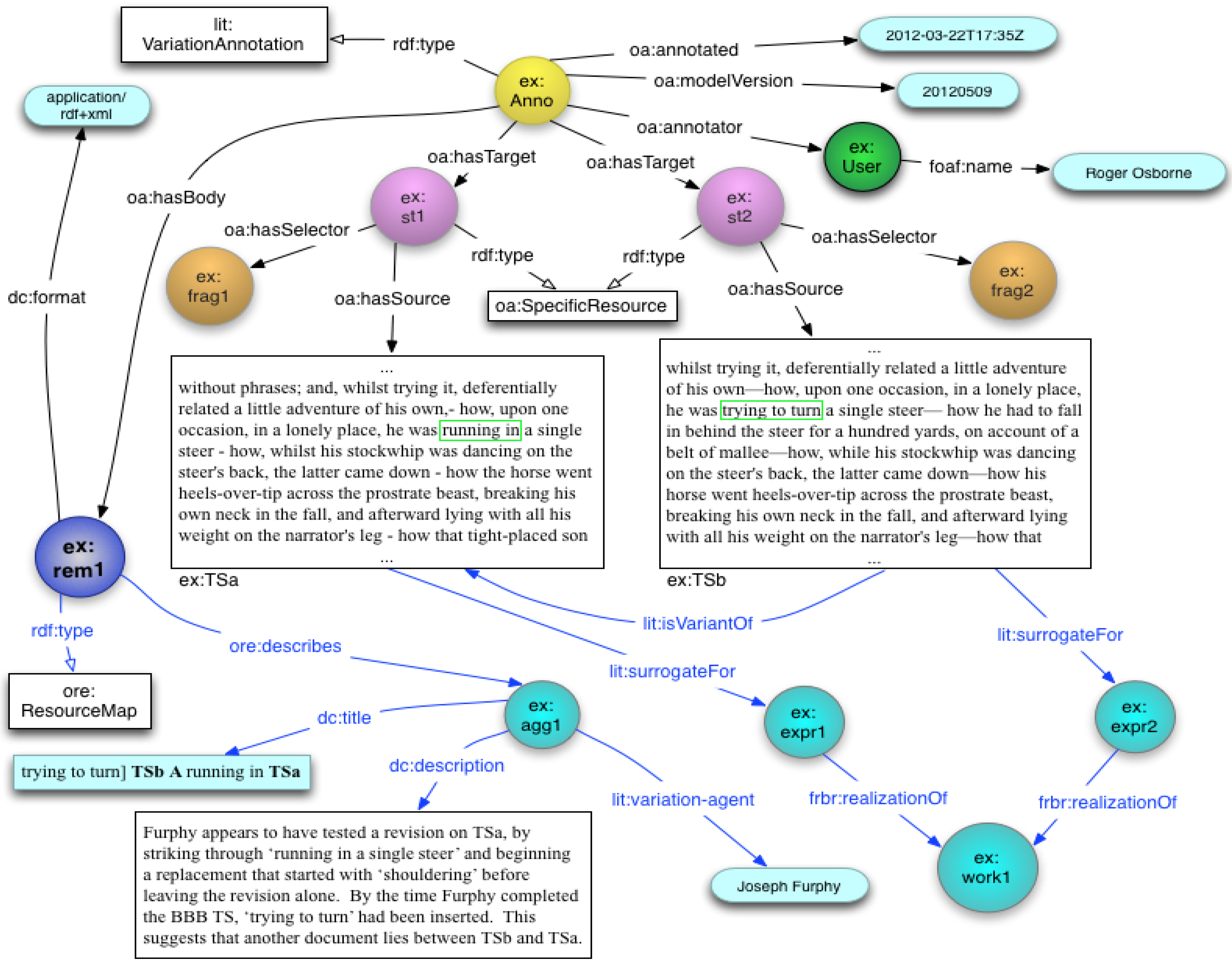
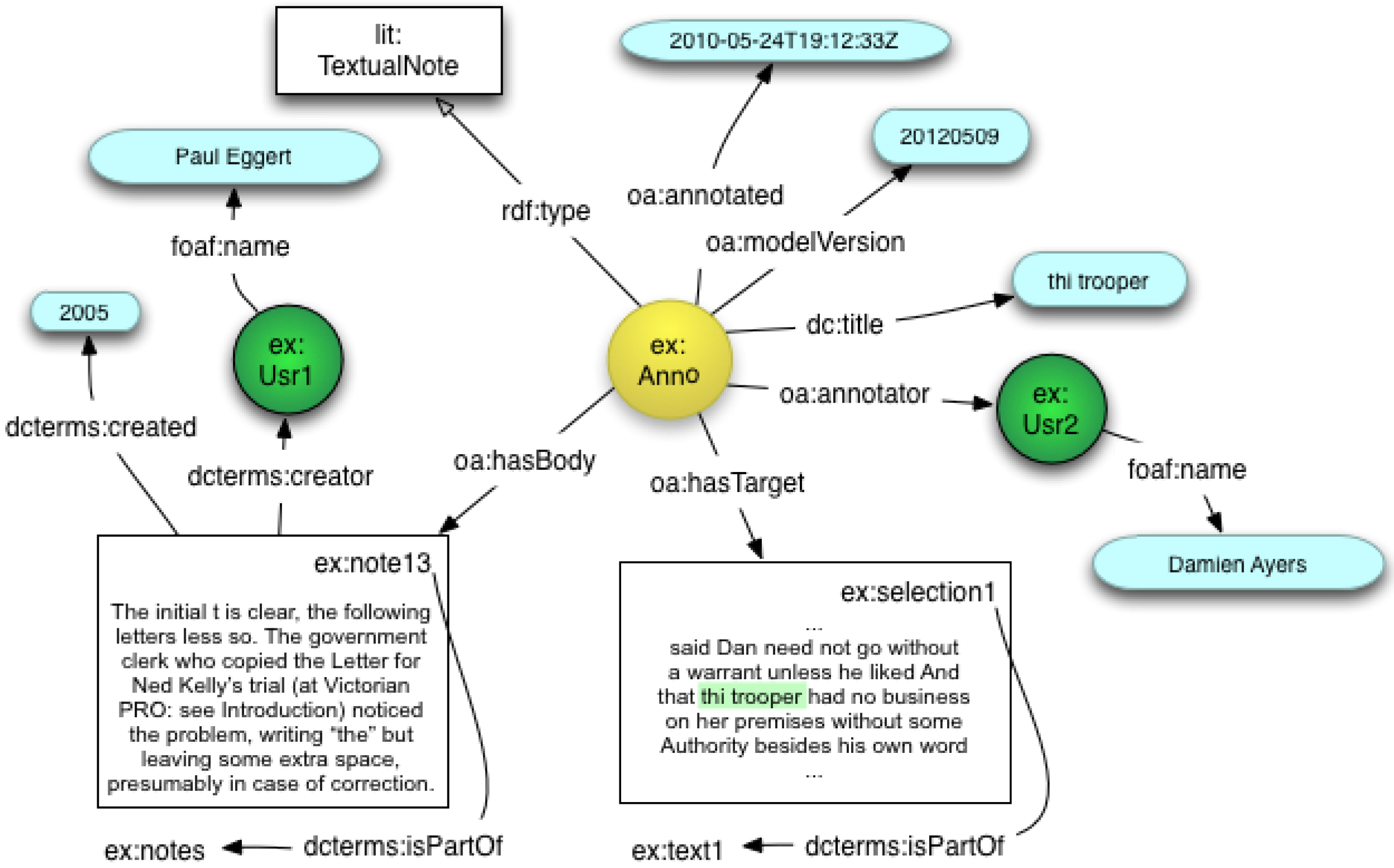
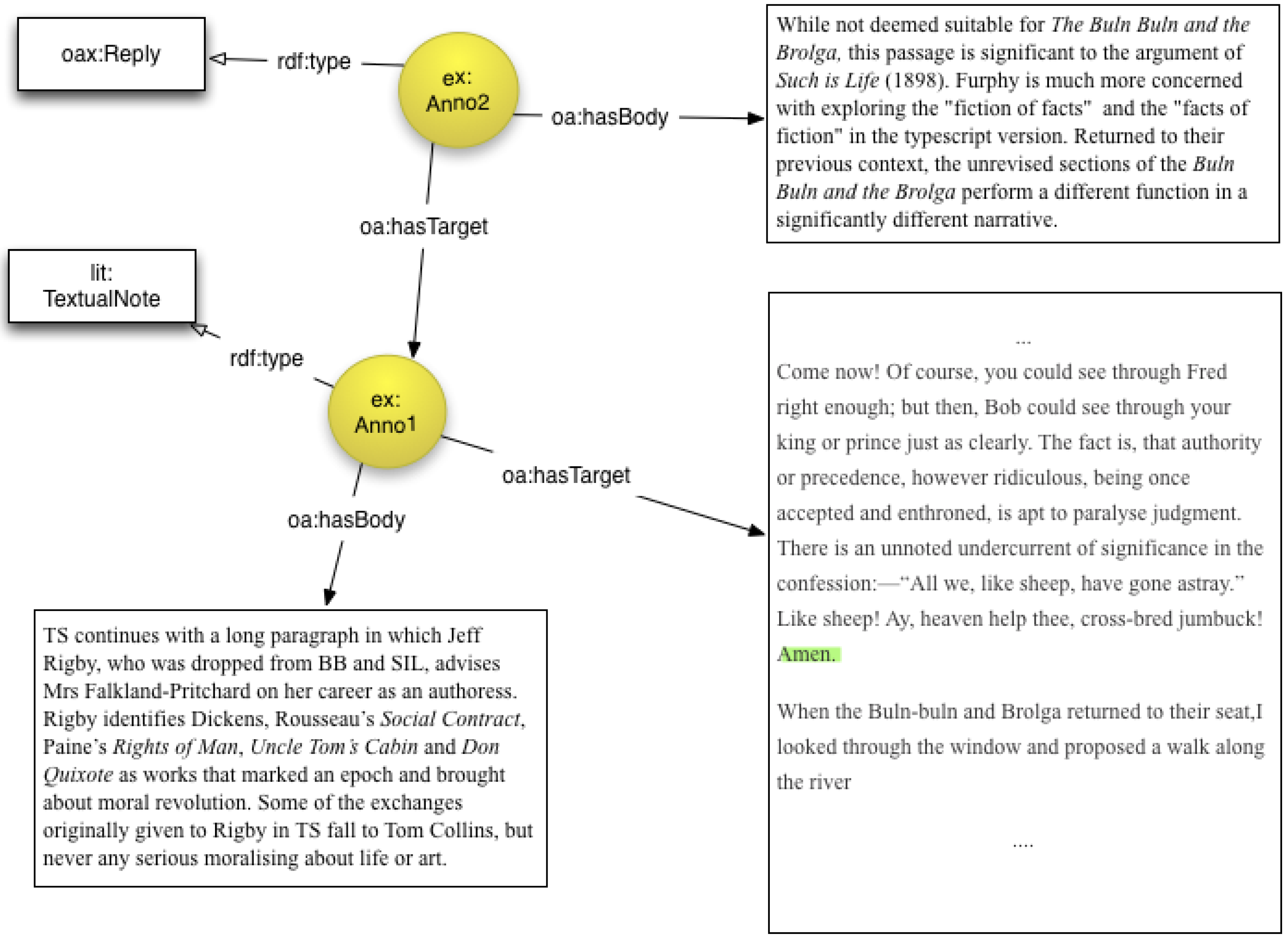
2.1. Annotations for Electronic Scholarly Editions
- • Create annotations that relate transcripts with facsimiles;
- • Attach notes to text and image selections;
- • Reference secondary sources;
- • Annotate textual variations—record information about the reason for or the source of the variation;
- • Engage in collaborative discussion about texts through comments, questions and replies.


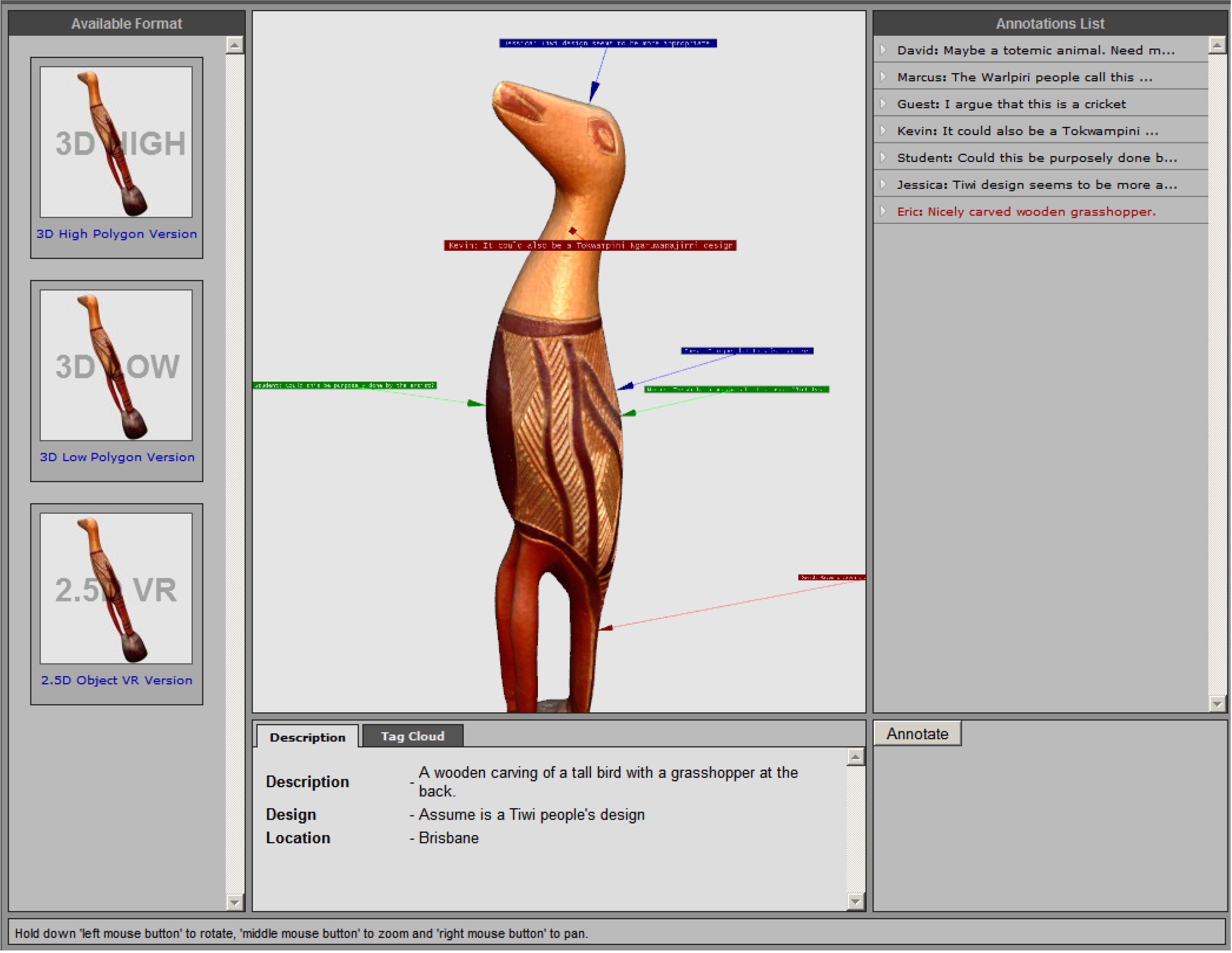
2.2. Migrating Annotations across Multiple Representations of Museum Artefacts
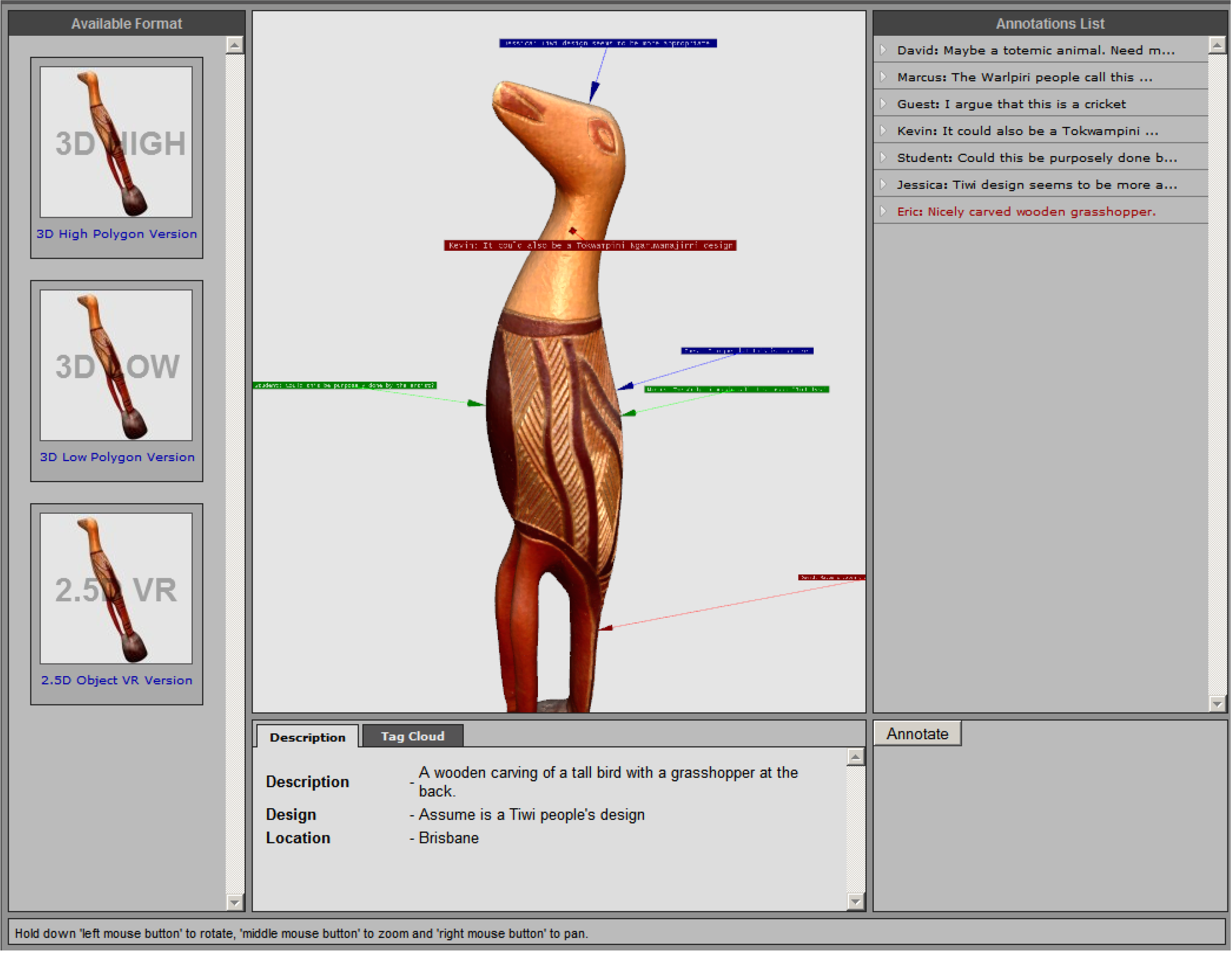
| Attribute | Format | ||
|---|---|---|---|
| High quality 3D | Low quality 3D | 2.5D VR | |
| Format | X3D | X3D | Flash |
| File size | 18–21 MB | 4–6 MB | 1 MB |
| Polygon count | 0.3 million | 65, 000 | N/A |

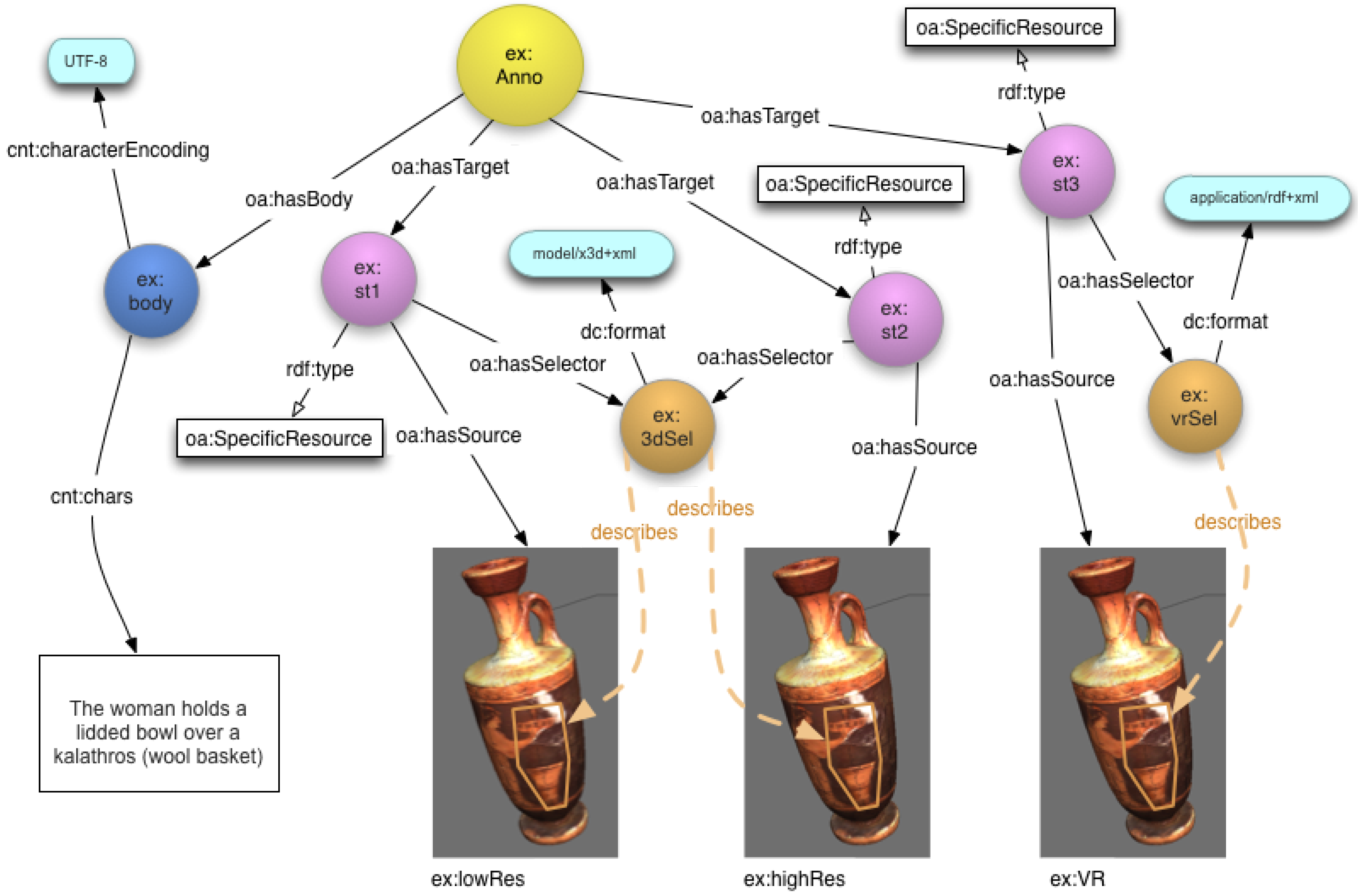
- @prefix oa: <http://www.openannotation.org/ns/>
- @prefix oax: <http://www.openannotation.org/ns/>
- @prefix cnt: <http://www.w3.org/2011/content#>
- @prefix ex: <http://www.example.org/#>
- ex:Anno1 a oa:Annotation;
- oa:hasBody ex:Body1
- oa:hasTarget ex:ST1
- oa:hasTarget ex:ST2
- oa:hasTarget ex:ST3
- ex:ST1 a oa:SpecificResource;
- oa:hasSelector ex:3dSel;
- oa:hasSource <http://itee.uq.edu.au/eresearch/3dsa/vase1_highres.x3d>.
- ex:ST2 a oa:SpecificResource;
- oa:hasSelector ex:3dSel;
- oa:hasSource <http://itee.uq.edu.au/eresearch/3dsa/vase1_lowres.x3d>.
- ex:ST3 a oa:SpecificResource;
- oa:hasSelector ex:vrSel;
- oa:hasSource <http://itee.uq.edu.au/eresearch/3dsa/vase1.qtvr>.
- ex:Anno1 oax:hasSemanticTag <http://itee.uq.edu.au/eresearch/3dsa_ontology#lekythos>.
- ex:Anno1 oax:hasSemanticTag <http://itee.uq.edu.au/eresearch/3dsa_ontology#attic>.
- ex:Body1 a cnt:ContentAsText;
- cnt:characterEncoding "UTF-8";
- cnt:chars "The woman holds a lidded bowl over a large kalathos">.
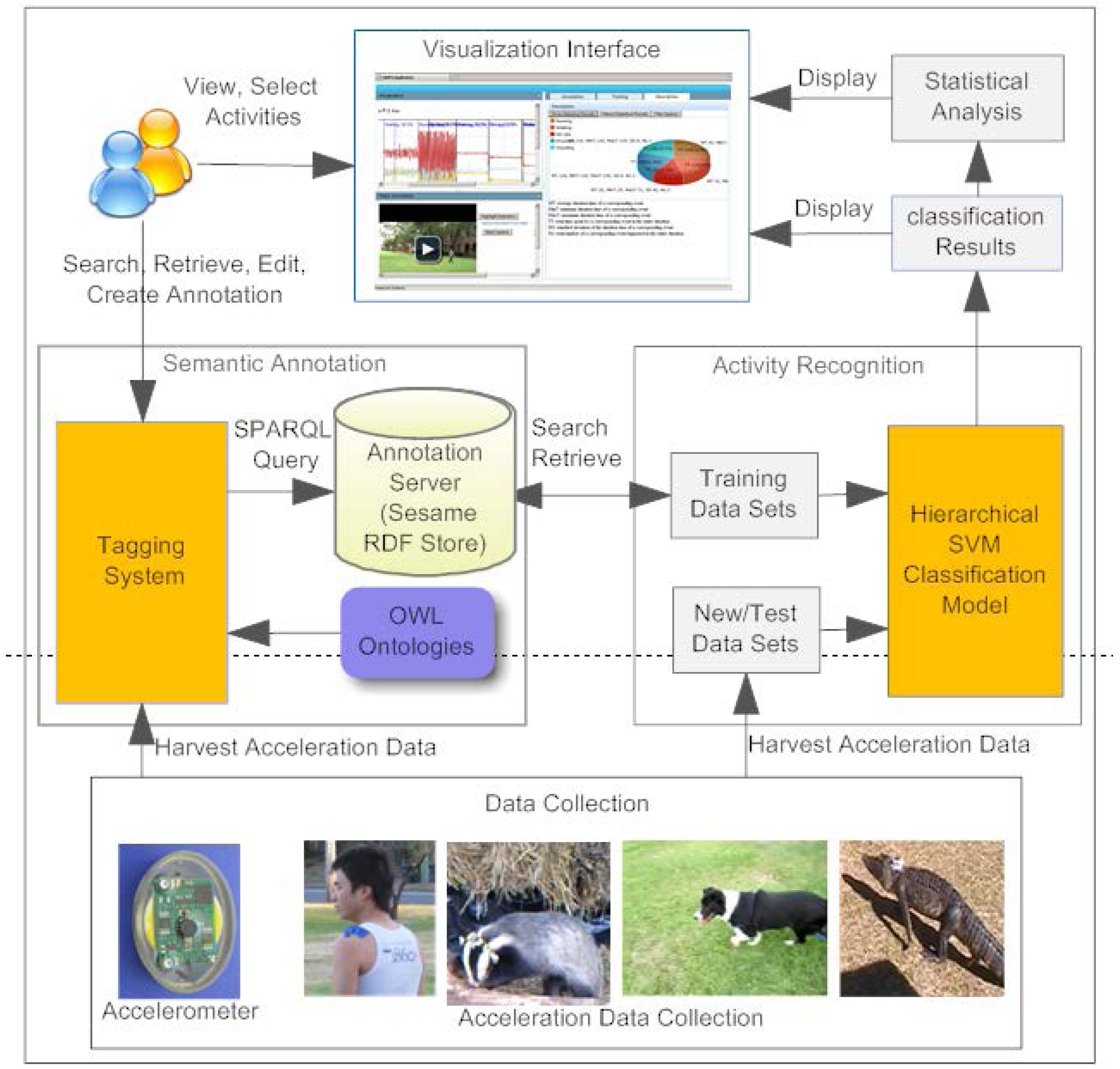
2.3. Automatic Semantic Tagging of Species Accelerometry Data and Video Streams
- • To provide a set of Web services and Graphical User Interfaces (GUIs) that enable ecologists to quickly and easily analyse and tag 3D accelerometry datasets and associated video using terms from controlled vocabularies (pre-defined ontologies) that describe activities of interest (e.g., walking, running, foraging, climbing, swimming, standing, lying, sleeping, feeding);
- • To build accurate, re-usable, automatic activity recognition systems (using machine learning techniques (Support Vector Machines))—by training classifiers using training sets that have been manually annotated by domain experts.
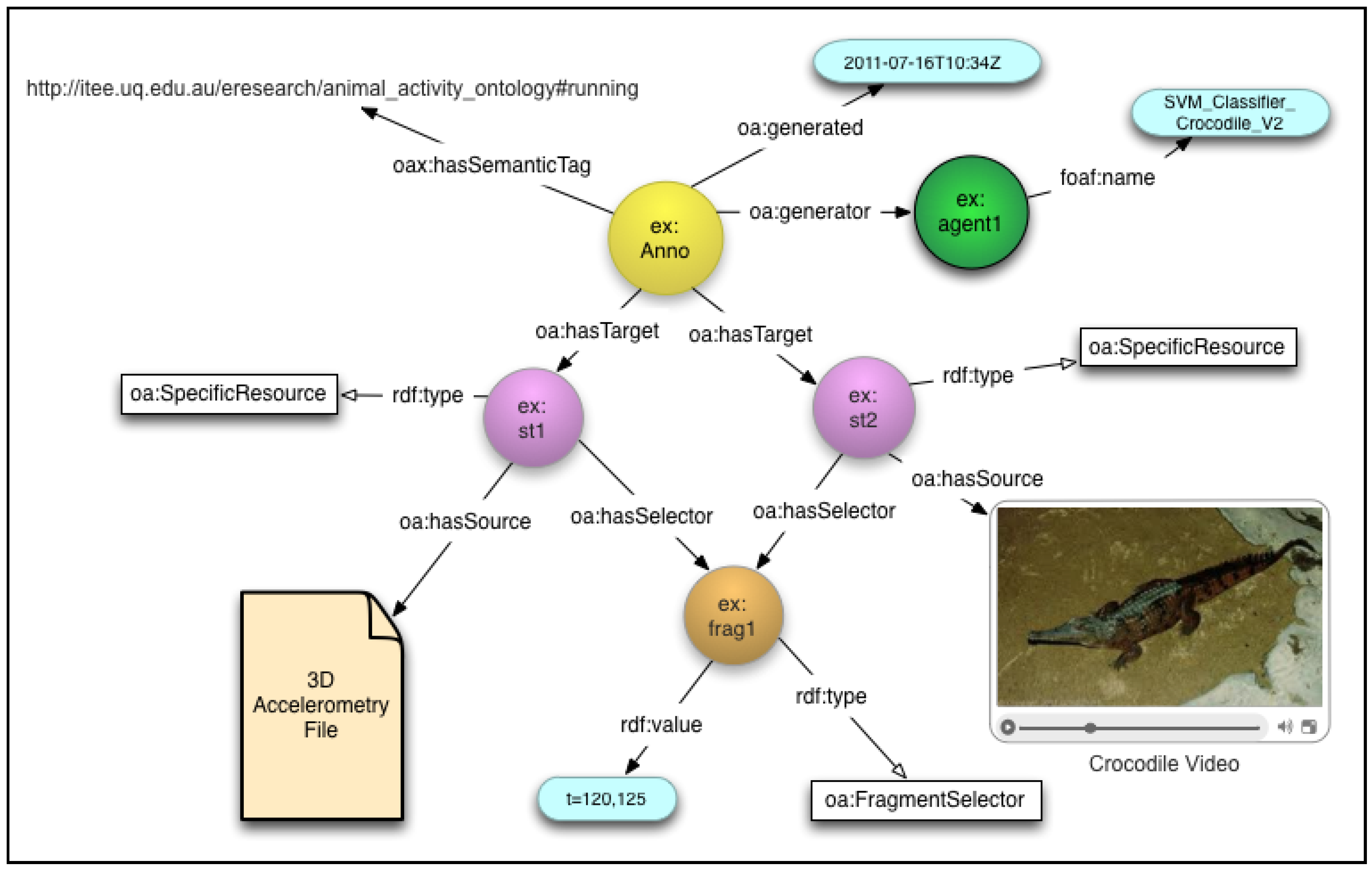
- • It provides a situation whereby the tags, that describe animal activities (running, walking, swimming, climbing, standing, lying, sleeping, feeding), are generated automatically by the SVM Classification model;
- • It provides an example of the application of the OA Fragment Selector—tags are attached to a temporal segment of the 3D accelerometry streams as well as the associated video content where available.
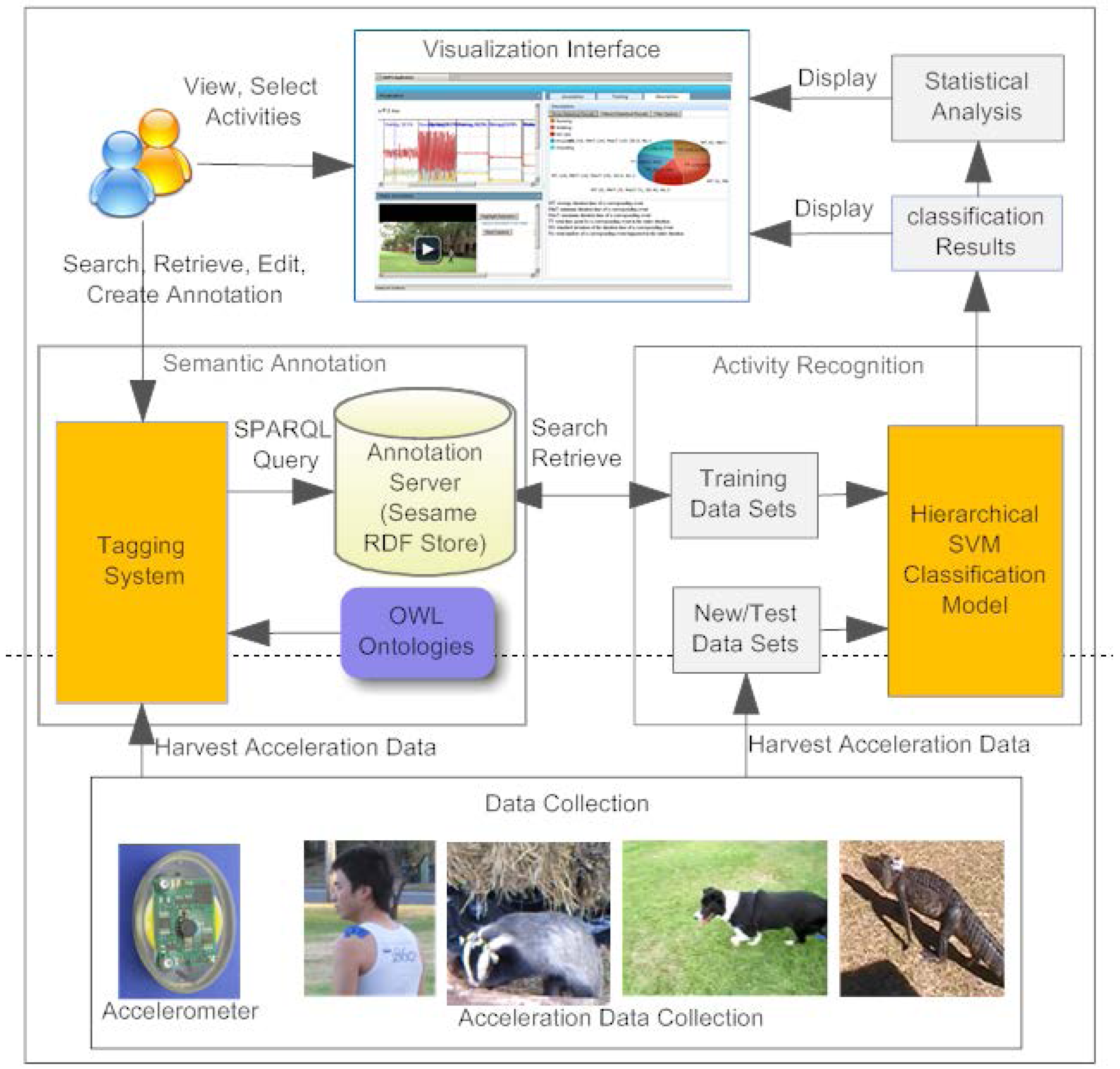

3. Implementation

4. Discussion and Evaluation
- • The OA model supports multiple targets, and each can be associated with a selector for specifying the segment of interest. This has allowed us to create annotations that describe textual variation across multiple textual documents, to migrate a single annotation across multiple representations of a 3D museum object, and to attach a semantic tag to both accelerometry data streams and video that documents an animal’s movements—without extending the model or creating aggregate targets. By comparison, previous annotation data models, such as the Annotea ontology that underpins AO were designed with the assumption of a single target, so they provide no mechanism for associating an Annotea Context (used for describing the segment of a target resource) with a specific target.
- • Bodies and Targets can be any media type and can be located on any server. This flexibility means that we can directly annotate digital resources that have been made available through online collections, such as those digitized and published by archives, museums, libraries and publishers. It also allows us to create Bodies that are RDF, so that metadata properties associated with the Body can be stored separately rather than included in the annotation graph, making the provenance of the Body, the Target and the Annotation clear and explicit.
- • Because the OAC model is RDF-based, it is a trivial exercise to extend the model and include properties from existing domain-specific ontologies within the annotation graph. For example, for the scholarly editions case study, we use custom properties to link target documents to FRBR entities, allowing us to query and retrieve annotations across multiple versions of the same FRBR expression or work.
- • The relative complexity of the OA model for basic use cases. It is possible that many developers who want to implement simple tagging of Web pages or whole digital resources, will find the OA model too complex for their needs and hence it will not be widely adopted. (On the other hand it is the flexibility afforded by such complexity that enables the OA model to represent complex scholarly annotation use cases, that simpler models like Annotea are not capable of supporting.)
- • The ambiguity that exists within the model. For example, there are multiple ways to represent resource segments. Such ambiguity increases the development effort required to produce tools that fully implement the model. For example, for annotations on part of an image, the image segment could be specified: using an SVGSelector (with a constrains relationship to the image URI); using a media fragment identifier in the target URI (with an isPartOf relationship to the image URI); or using a media fragment expressed as a oa:FragmentSelector. In all three cases there is no direct link from the annotation object to the image URI, so a query to retrieve all annotations on a given image must examine the target URI (for “whole of image” annotations), as well as URIs related via properties.
- • The explosion of URIs. The Semantic Web/Linked Open Data approach adopted by OA, recommends that every resource (Bodies, Annotations, Targets, Selectors, States, Styles) is accessible on the Web via a persistent URI. Annotation authoring and management tools will need to create, track and manage large numbers of URIs.
- • The current OA model does not support multiple Bodies—only multiple Targets. A common situation that we found in our case studies is the need to attach both multiple semantic tags (or keywords), as well as a textual description to a resource, within a single annotation event. The current model recommends that you create multiple separate annotations. But this creates redundancy and also does not accurately reflect the annotation event. An alternative approach is to attach the textual description as an inline Body and to use the “hasSemanticTag” property to attach the semantic tags. As discussed in the next bullet point, we don’t support the “hasSemanticTag” property that is currently included in the Extension ontology as it is inconsistent with the existing class and property hierarchy.
- • Lack of Support for multiple Semantic Tags. A SemanticTag should ideally be defined as a subClass of the oa:Annotation class in the Extensions ontology. In addition, the Core OA ontology should allow multiple Bodies to be defined. These two changes would enable the model to support the use case that we describe above, and simultaneously maintain a well-structured and consistent ontology.
- • Performance issues when Querying. The complexity of the OA model may lead to slow performance when querying and retrieving on annotation fields that are buried a number of levels down the Annotation graph. For example, the most common query is on Targets e.g., “give me all of the annotations on this Target resource”. The Target resource may be the object of the hasTarget or hasSource properties, or a selection that is retrieved by applying the Selector to hasSource, or part of an Aggregated Target. Resolving all of these alternatives to match the Target URI and retrieve and display the relevant annotations, may require optimization to improve performance.
- • Lack of standards for specifying segments of resources. The ability to use segments or fragments of resources as Bodies or Targets, is extremely useful. However the interoperability of this aspect of the model is limited by a lack of standards across communities for describing/identifying parts of things e.g., text segments across document formats. The W3C Media Fragments Working group recently published a Proposed Recommendation which can be applied to multimedia resources (images, video, audio)—but there is a real need for communities to agree on schemas/mechanism for selectors on textual resources, maps, timelines and 3D objects.
5. Conclusions
Acknowledgments
References
- Hunter, J. Collaborative semantic tagging and annotation systems. Ann. Rev. Inf. Sci. Technol. 2009, 43, 187–239. [Google Scholar]
- Sanderson, R.; van de Sompel, H. Open annotation: Beta data model guide. Open Annot. Collab. 2011. Available online: http://www.openannotation.org/spec/beta/ (accessed on 12 April 2012).
- Kahan, J.; Koivunen, M.R.; Prud’Hommeaux, E.; Swick, R.R. Annotea: An open RDF infrastructure for shared Web annotations. Comput. Netw. 2002, 39, 589–608. [Google Scholar]
- Agosti, M.; Ferro, N. A formal model of annotations of digital content. ACM Trans. Inf. Syst. 2007, 26. [Google Scholar] [CrossRef]
- Boot, P. A SANE approach to annotation in the digital edition. Jahrb. Computerphilogie 2006, 8, 7–28. [Google Scholar]
- Bateman, S.; Farzan, R.; Brusilovsky, P.; Mccalla, G. OATS: The open annotation and tagging system. In Proceedings of the Third Annual International Scientific Conference of the Learning Object Repository Research Network, Montreal, Canada, 8–10 November 2006.
- Ciccarese, P.; Ocana, M.; Garcia Castro, L.J.; Das, S.; Clark, T. An open annotation ontology for science on web 3.0. J. biomed. Semant. 2011, 2, S4:1–S4:24. [Google Scholar]
- Sanderson, R.; Ciccarese, P.; van de Sompel, H. Open Annotation draft data model. Open Annot. Collab. 2012. Available online: http://www.openannotation.org/spec/core/ (accessed on 24 August 2012).
- Koch, J.; Velasco, C.A.; Ackermann, P. Representing Content in RDF 1.0; W3C Working Draft 10 May 2011; W3C: Cambridge, MA, USA. Available online: http://www.w3.org/ TR/Content-in-RDF10/ (accessed on 24 August 2012).
- The Core Open Annotation Namespace. Available online: http://www.w3.org/ns/openannotation/core/ (accessed on 24 August 2012).
- The Extensions Namespace. Available online: http://www.w3.org/ns/openannotation/extension/ (accessed on 24 August 2012).
- International Federation of Library Associations and Institutions (IFLA), Functional Requirements for Bibliographic Records; IFLA: Hague, the Netherlands, 1998.
- AustESE Project. Available online: http://austese.net/ (accessed on 24 August 2012).
- Open Archives Initiative—Object Reuse and Exchange (OAI-ORE). ORE User Guide—Resource Map Implementation in RDF/XML; OAI: New York, NY, USA, 2008. Available online: http://www.openarchives.org/ore/1.0/rdfxml (accessed on 24 August 2012).
- Gerber, A.; Hunter, J. Compound Object authoring and publishing tool for literary scholars based on the IFLA-FRBR. Int. J. Digit. Curation 2009, 4, 28–42. [Google Scholar]
- Eggert, P.; McQuilton, J.; Lee, D.; Crowley, J. Ned Kelly’s Jerilderie Letter: The JITM Worksite. Available online: http://web.srv.adfa.edu.au/JITM/JL/Annotation_Viewer.html (accessed on 24 August 2012).
- Yu, C.H.; Groza, T.; Hunter, J. High Speed capture, retrieval and rendering of segment-based annotations on 3D Museum objects. Lect. Notes Comput. Sci. 2011, 7008, 5–15. [Google Scholar]
- W3C Media Fragments Working Group. Media Fragments URI 1.0 (Basic); W3C Proposed Recommendation; W3C: Cambridge, MA, USA, 2012. Available online: http://www.w3.org/TR/2012/PR-media-frags-20120315/ (accessed on 24 August 2012).
- OzTrack Project. Available online: http://www.oztrack.org/ (accessed on 24 August 2012).
- Flot—Attractive Javascript Plotting for jQuery. Available online: http://code.google.com/p/flot/ (accessed on 24 August 2012).
- VideoJS—The Open Source HTML5 Video Player. Available online: http://videojs.com/ (accessed on 24 August 2012).
- Lorestore on GitHub Home Page. Available online: https://github.com/uq-eresearch/lorestore/ (accessed on 24 August 2012).
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Hunter, J.; Gerber, A. Towards Annotopia—Enabling the Semantic Interoperability of Web-Based Annotations. Future Internet 2012, 4, 788-806. https://doi.org/10.3390/fi4030788
Hunter J, Gerber A. Towards Annotopia—Enabling the Semantic Interoperability of Web-Based Annotations. Future Internet. 2012; 4(3):788-806. https://doi.org/10.3390/fi4030788
Chicago/Turabian StyleHunter, Jane, and Anna Gerber. 2012. "Towards Annotopia—Enabling the Semantic Interoperability of Web-Based Annotations" Future Internet 4, no. 3: 788-806. https://doi.org/10.3390/fi4030788
APA StyleHunter, J., & Gerber, A. (2012). Towards Annotopia—Enabling the Semantic Interoperability of Web-Based Annotations. Future Internet, 4(3), 788-806. https://doi.org/10.3390/fi4030788