Characteristics of Heavily Edited Objects in OpenStreetMap

Abstract
:1. Introduction
2. Literature Overview
3. Experimental Setup
3.1. Processing Historical OSM Data
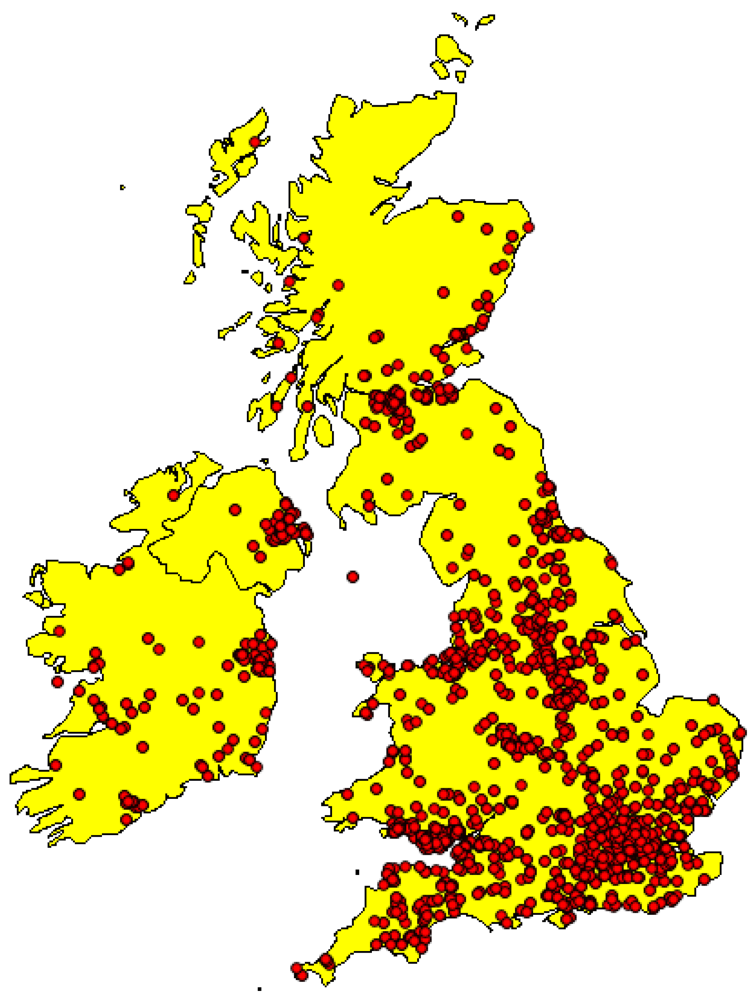
3.2. Selection of Study Area and Historical Objects

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Version | Number of Objects | Total % | Cumulative % |
|---|---|---|---|
| 1 | 2,246,369 | 59.211 | 59.211% |
| 2 | 780,320 | 20.568 | 79.779% |
| 3 | 329,342 | 8.681 | 88.460% |
| 4 | 169,831 | 4.477 | 92.937% |
| 5 | 91,488 | 2.412 | 95.349% |
| 6 | 72,347 | 1.907 | 97.256% |
| 7→9 | 68,485 | 1.805 | 99.061% |
| 10→14 | 19,991 | 0.527 | 99.588% |
| 15→20 | 11,210 | 0.295 | 99.883% |
| 21→30 | 3,381 | 0.089 | 99.972% |
| 31→40 | 706 | 0.019 | 99.991% |
| > 40 | 343 | 0.009 | 100% |
| Total | 3,793,813 | 100% | 100% |
4. Experimental Analysis and Results
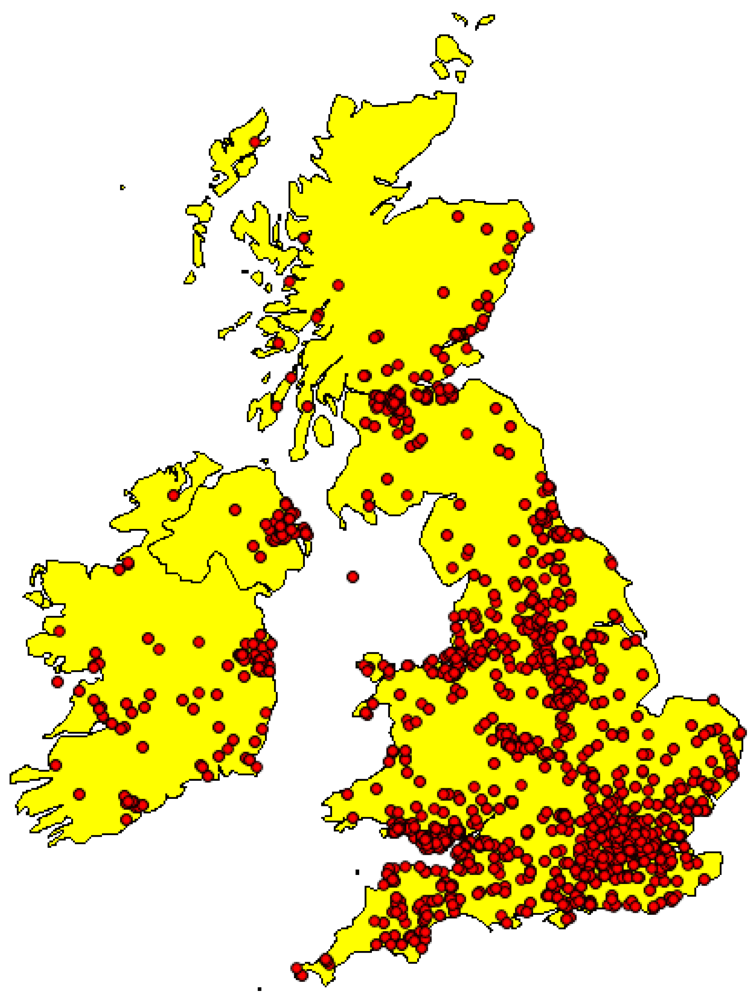
4.1. Characteristics of the Study Area
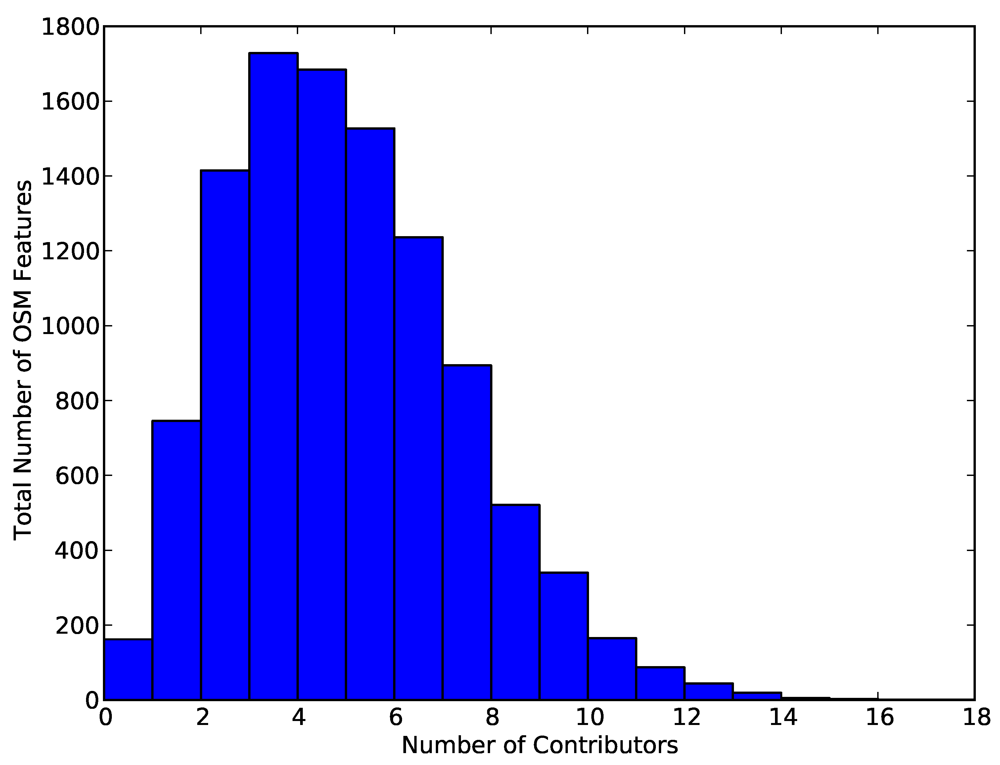
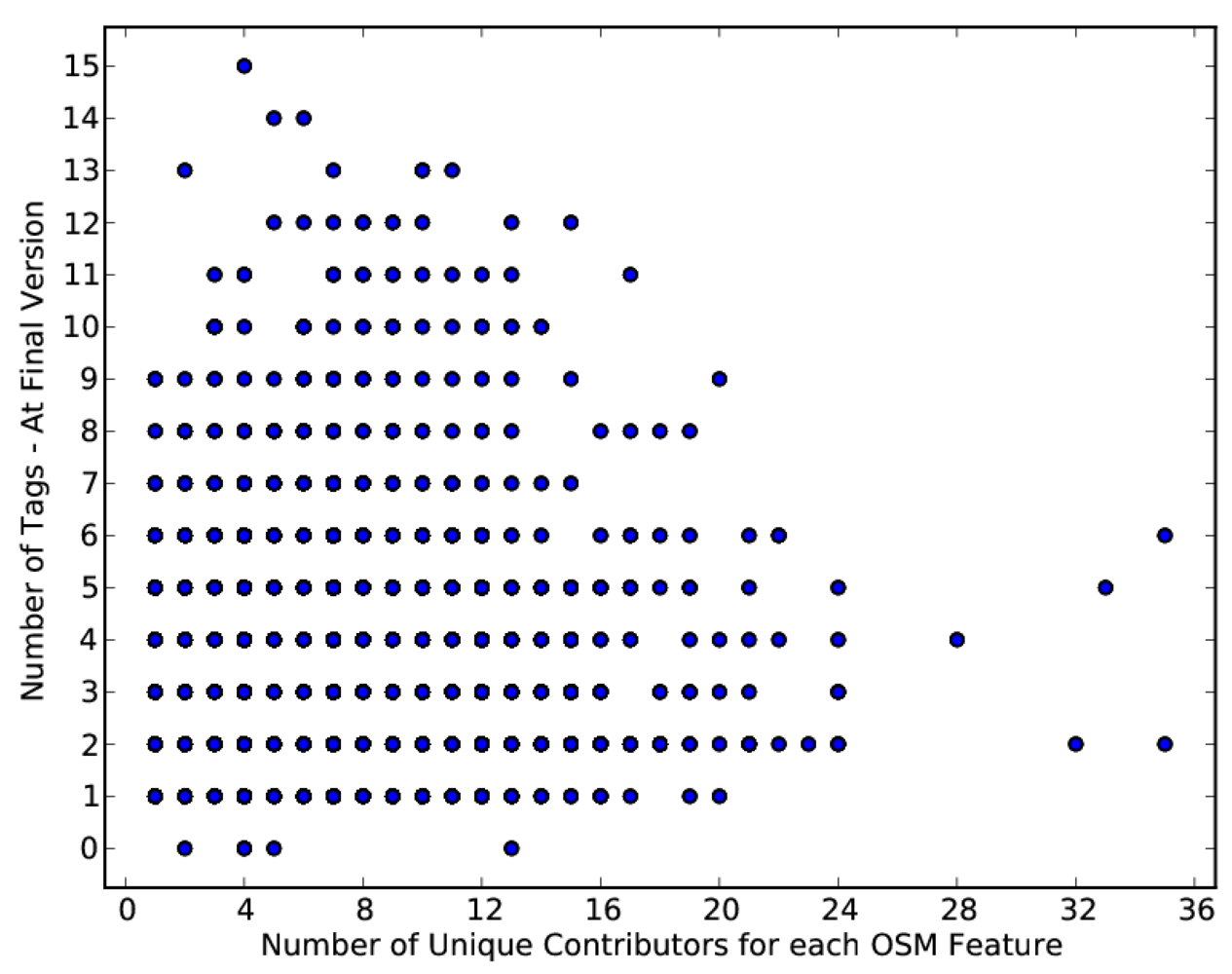
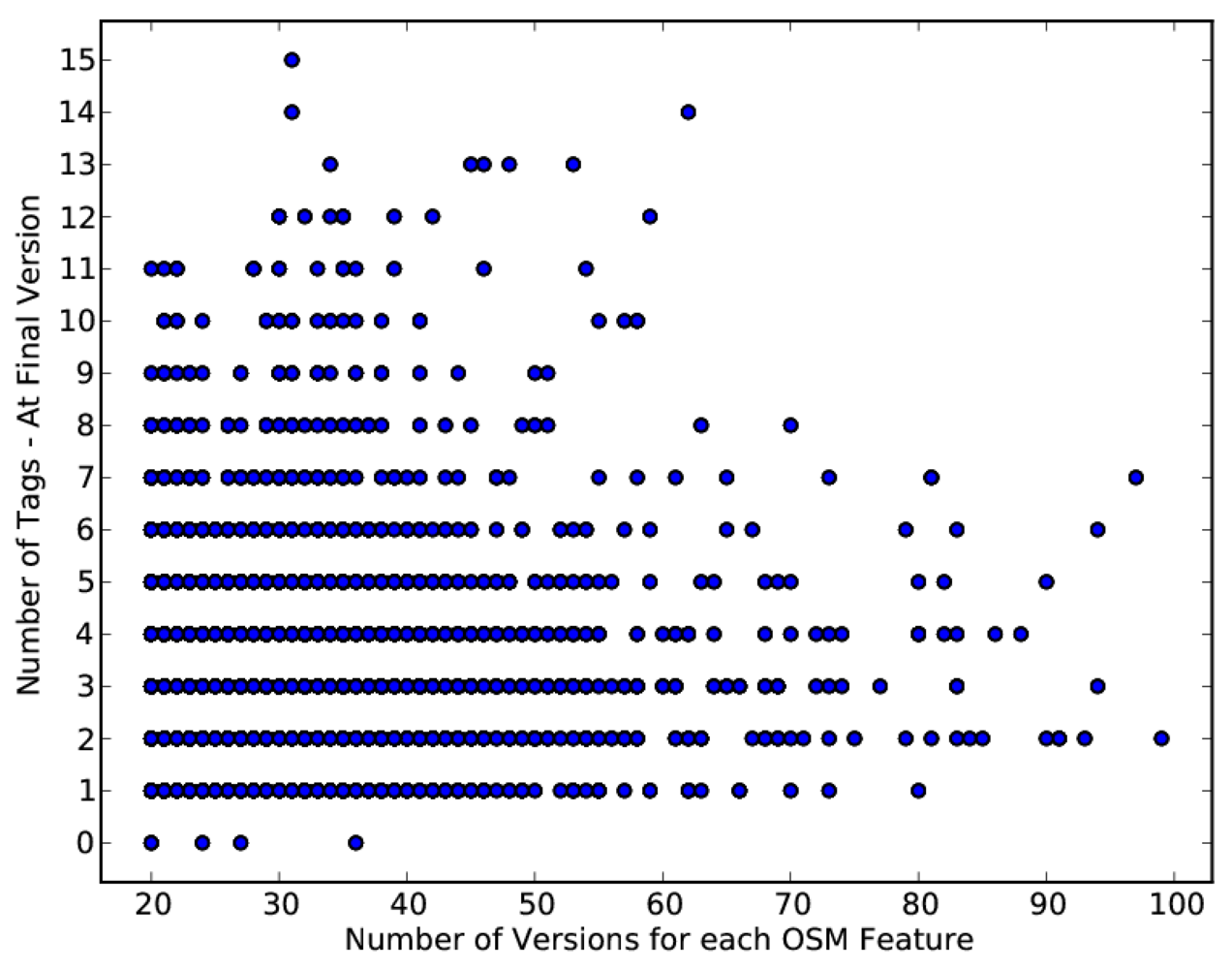
4.2. Contribution Rates
| Contributions | #Unique Contributors | % Contributors | Total % |
|---|---|---|---|
| ≤ 5 | 2128 | 51.55 | 51.55 |
| 5-10 | 521 | 12.62 | 64.17 |
| 10-20 | 404 | 9.78 | 73.95 |
| 20-50 | 378 | 9.15 | 83.11 |
| 50-100 | 252 | 6.10 | 89.22 |
| 100- 200 | 175 | 4.23 | 93.46 |
| 200- 500 | 163 | 3.94 | 97.41 |
| 500- 1000 | 67 | 1.62 | 99.03 |
| 1000- 2000 | 20 | 0.48 | 99.51 |
| 2000- 5000 | 18 | 0.43 | 99.95 |
| ≥ 5000 | 3 | 0.048 | 99.99 |

4.3. Editing the Name Tag Attribute
| Version | Name Tag | User ID | Date of Edit |
|---|---|---|---|
| v1 | NULL | 11895 | 06/07/2008 |
| v2 | Station Road | 11895 | 06/08/2008 |
| v8 | Oswald Road | 11985 | 07/08/2008 |
| v11 | Frodingham Road | 26825 | 10/10/2008 |
| v23 | Ferry Road | 11985 | 02/06/2009 |
| v25 | Old Crosby | 11985 | 17/06/2009 |
| Version | User | HIGHWAY | Edited on |
|---|---|---|---|
| 1 | 7,070 | Trunk | 15/11/09 |
| 4 | 20,510 | Construction | 16/11/09 |
| 5 | 7,070 | Trunk | 17/11/09 |
| 7 | 19,889 | Construction | 17/11/09 |
| 10 | 7,070 | Trunk | 17/11/09 |
| 11 | 19,889 | Construction | 17/11/09 |
| 12 | 7,070 | Trunk | 19/11/09 |
| … | … | … | … |
| 78 | 206,986 | Construction | 19/12/09 |
| 79 | 7,070 | Trunk | 20/12/09 |
| 80 | 206,986 | Construction | 20/12/09 |
| 81 | 210,596 | Trunk | 20/12/09 |
| 88 | 145,231 | Construction | 16/02/11 |
4.4. Using String Matching to Understand Tag Changes
 where
where  is the set of tags (possibly empty) at the first version of P and
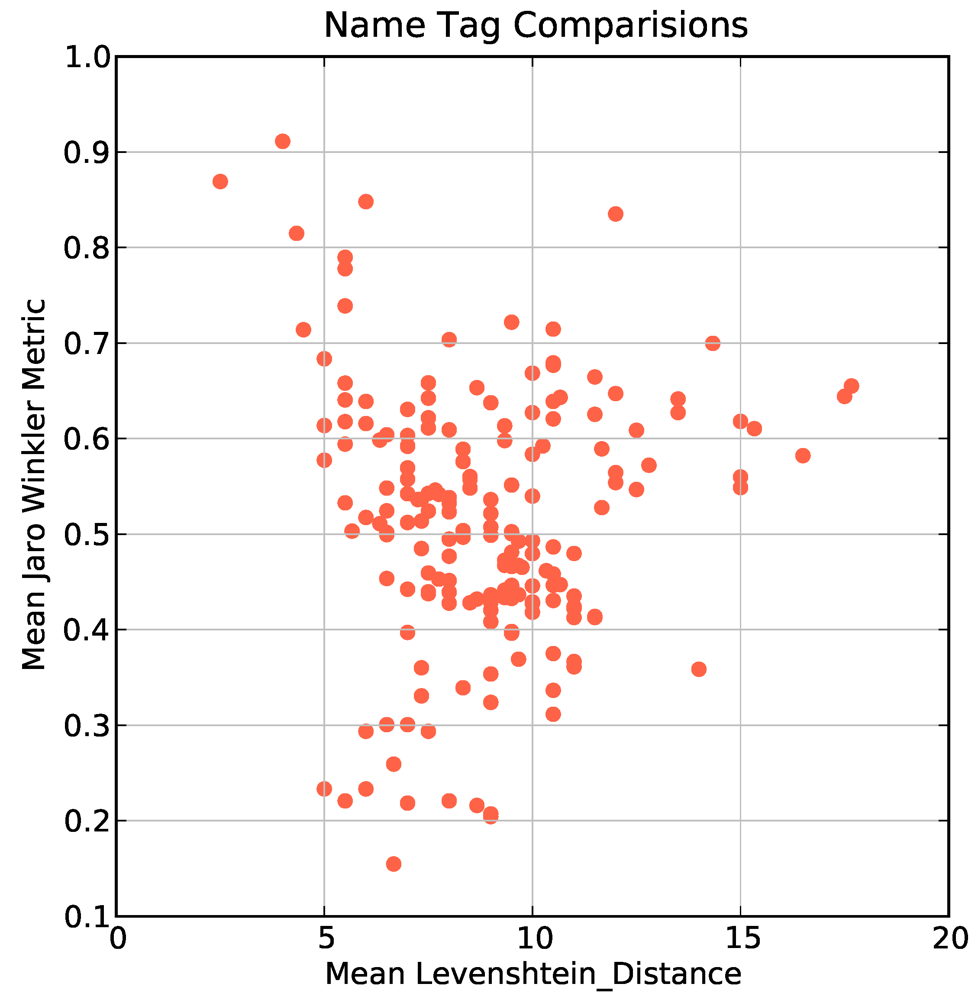
is the set of tags (possibly empty) at the first version of P and  is the set of tags (possibly empty) at the final version of P. For each object with 3 or more changes to the “name” tag attribute we clustered the assigned name tags into chronological groups and then compared the transformation of tags into one another using two well known string matching metrics to quantify how similar the name tags were. The Levenshtein distance is defined as the minimal number of characters you have to replace, insert or delete to transform from one string to another [48]. The JaroWinkler distance [49] is a similar metric used mostly for duplicate detection in databases. The metric is normalized such that 0 equates to no similarity and 1 is an exact match between the two strings. In Figure 3 we show a plot of the mean Levenshtein distance against the mean JaroWinkler distance for 412 objects. Most objects are clustered around a mean Levenshtein distance of 10 and mean JaroWinkler distance of 0.5 which indicates that the changes from one name tag to the next name tag are substantially different. This is potentially caused by contributors: spelling placenames incorrectly, providing local variations on official placenames, incorrect naming of streets, performing correction of placename spellings.
is the set of tags (possibly empty) at the final version of P. For each object with 3 or more changes to the “name” tag attribute we clustered the assigned name tags into chronological groups and then compared the transformation of tags into one another using two well known string matching metrics to quantify how similar the name tags were. The Levenshtein distance is defined as the minimal number of characters you have to replace, insert or delete to transform from one string to another [48]. The JaroWinkler distance [49] is a similar metric used mostly for duplicate detection in databases. The metric is normalized such that 0 equates to no similarity and 1 is an exact match between the two strings. In Figure 3 we show a plot of the mean Levenshtein distance against the mean JaroWinkler distance for 412 objects. Most objects are clustered around a mean Levenshtein distance of 10 and mean JaroWinkler distance of 0.5 which indicates that the changes from one name tag to the next name tag are substantially different. This is potentially caused by contributors: spelling placenames incorrectly, providing local variations on official placenames, incorrect naming of streets, performing correction of placename spellings. 
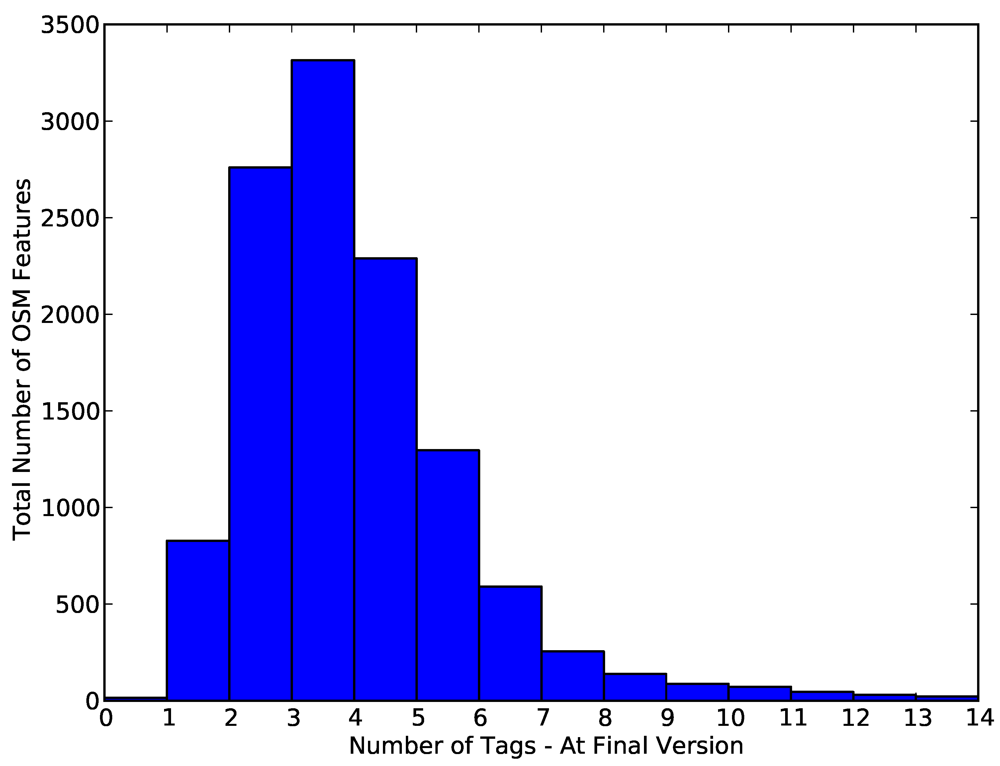
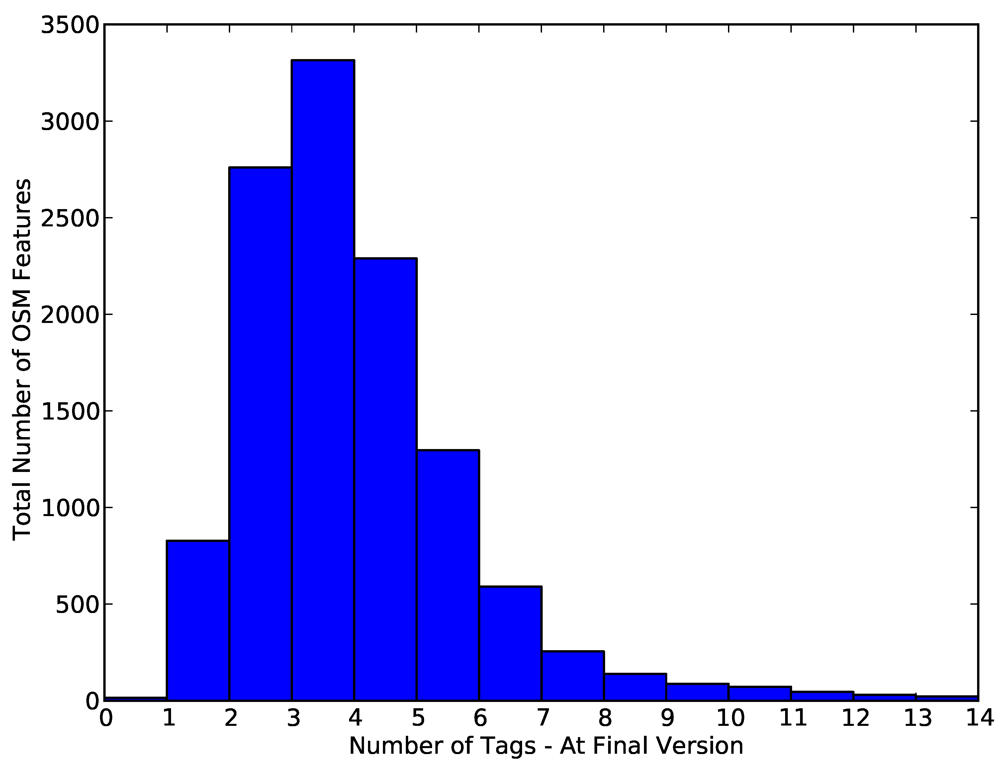
4.5. General Tagging of Objects
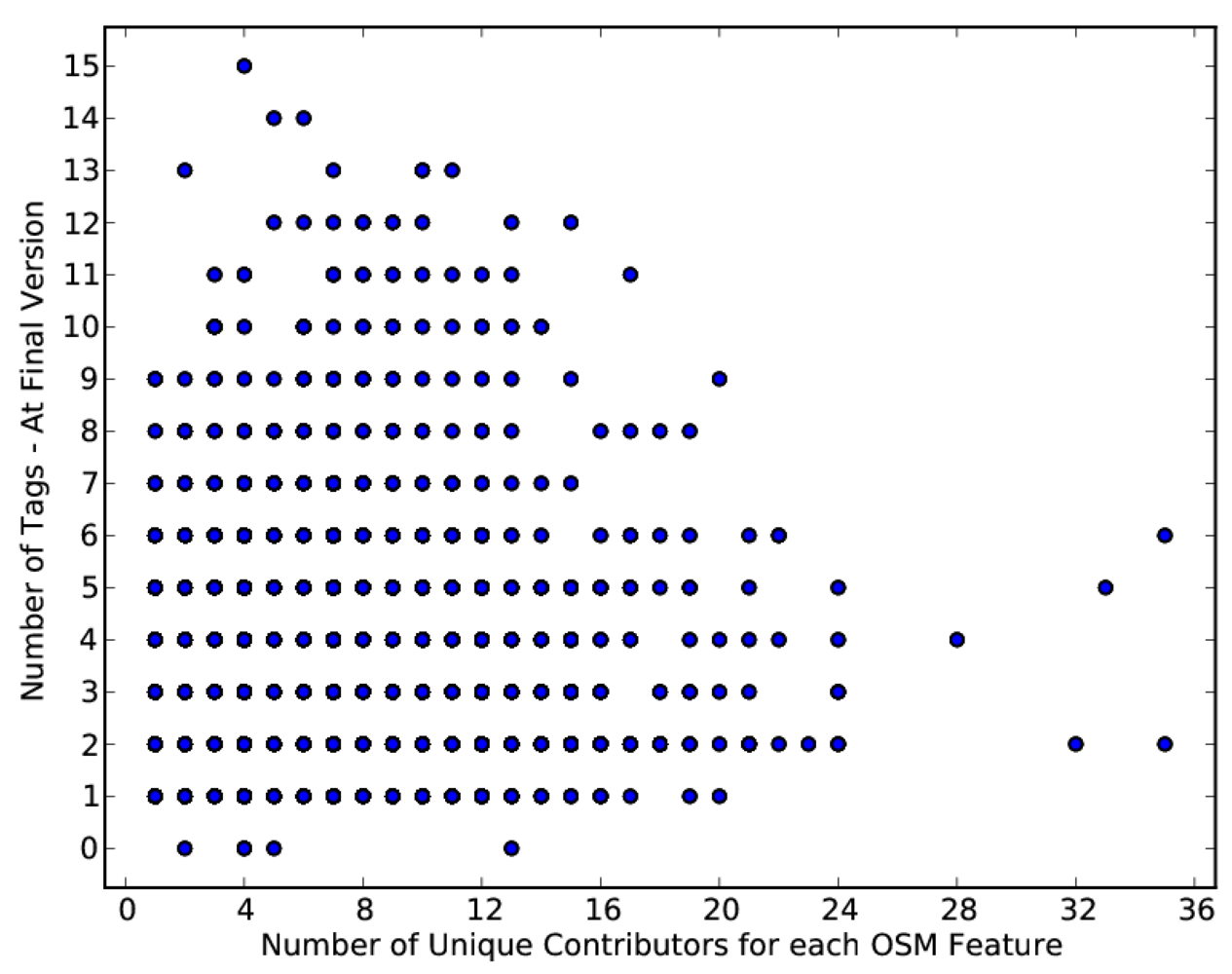

4.6. Changes to Object Geometry
| Consecutive Versions | Total | (Same User) |
|---|---|---|
| Invalid,Invalid | 25,107 (8%) | 21,843 (87%) |
| Valid,Valid | 285,598 (91%) | 237,046 (83%) |
| Invalid,Valid | 1685 (<1%) | 1145 (68%) |
| Valid,Invalid | 1455 (<1%) | 1091 (75%) |
| Node Edit Action | Total | (Same User) |
|---|---|---|
| Nodes Unchanged | 50,216 (16%) | 41,678 (83%) |
| Nodes Deleted | 15,692 (5%) | 9,729 (62%) |
| Nodes Added | 247,937 (79%) | 223,143 (90%) |
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
References
- Goodchild, M. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- OpenStreetMap. An Introduction to OpenStreetMap. From the OSM Wiki. 2011. Available online: http://wiki.openstreetmap.org/wiki/Main_Page (accessed on 15 March 2012).
- Coast, S. How OpenStreetMap is Changing the World. In Proceedings of the 10th International Symposium on Web & Wireless GIS; Tanaka, K., Fr¨ohlich, P., Kim, K.S., Eds.; Springer: Berlin, Germany, 2010; 6574, p. 4. [Google Scholar]
- Ciepluch, B.; Mooney, P.; Jacob, R.; Winstanley, A.C. Using OpenStreetMap to deliver location-based environmental information in Ireland. SIGSPATIAL Spec. 2009, 1, 17–22. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. OpenStreetMap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- OpenStreetMap. Getting Started with OpenStreetMap. 2010. Available online: http://wiki.openstreetmap.org/wiki/Beginners_Guide_1.1 (accessed on March 2010).
- OpenStreetMap. The Map Features page. 2010. Available online: http://wiki.openstreetmap.org/wiki/Map_Features (accessed on March 2010).
- Over, M.; Schilling, A.; Neubauer, S.; Zipf, A. Generating web-based 3D City Models from OpenStreetMap: The current situation in Germany. Comput. Environ. Urban Syst. 2010, 34, 496–507. [Google Scholar] [CrossRef]
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How many volunteers does it take to map an area well? The validity of linus' law to volunteered geographic information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef]
- MapQuest. AOL Corporate Communications-MapQuest “Opens Up” in Europe with Open-Source Mapping with UK Launch. AOL Online Blog report. 2010. Available online: http://corp.aol.com/2010/07/09/mapquest-opens-up-in-europe-with-open-source-mapping-with-uk-l/ (accessed on 15 March 2012).
- Bing Maps. Bing Engages Open Maps Community. Microsoft Bing Maps Online Blog report. 2010. Available online: http://www.bing.com/community/site_blogs/b/maps/archive/2010/11/23/bing-engages-open-maps-community.aspx (accessed on 15 March 2012).
- de Leeuw, J.; Said, M.; Ortegah, L.; Nagda, S.; Georgiadou, Y.; DeBlois, M. An assessment of the accuracy of volunteered road map production in Western Kenya. Remote Sens. 2011, 3, 247–256. [Google Scholar] [CrossRef]
- Coleman, D.; Georgiadou, P.; Labonte, J. Volunteered geographic information: The nature and motivation of produsers. Int. J. Spat. Data Infrastruct. Res. 2009, 4, 332–358. [Google Scholar]
- OSM History. The Full OpenStreetMap History Dump. 2012. Available online: http://wiki.openstreetmap.org/wiki/Planet.osm/full (accessed on March 2012).
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and ordnance survey datasets. Environ. Plan. B Plan. Des. 2012, 37, 682–703. [Google Scholar] [CrossRef]
- Zielstra, D.; Zipf, A. A Comparative Study of Proprietary Geodata and Volunteered Geographic Information for Germany. In Proceedings of the 13th AGILE International Conference on Geographic Information Science; Painho, M., Santos, M.Y., Pundt, H., Eds.; Springer Verlag: Guimarães, Portugal, 2010. [Google Scholar]
- Girres, J.F.; Touya, G. Quality assessment of the french OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P.; Winstanley, A.C. Towards Quality Metrics for OpenStreetMap. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems; ACM: New York, NY, USA, 2010; pp. 514–517. [Google Scholar]
- Goetz, M.; Zipf, A. Extending OpenStreetMap to Indoor Environments: Bringing Volunteered Geographic Information to the Next Level. In Proceedings of the UDMS: Urban and Regional Data Management: 2011; Rumor, M., Zlatanova, S., LeDoux, H., Eds.; Delft: Delft, The Netherlands, 2011; pp. 47–58. [Google Scholar]
- Goetz, M.; Zipf, A. Towards defining a framework for the automatic derivation of 3D CityGML models from volunteered geographic information. Int. J. 3-D Inf. Model. 2012, 1, 496–507. [Google Scholar]
- Budhathoki, N.R.; Nedovic-Budic, Z.; Bruce, B. An interdisciplinary frame for understanding volunteered geographic information. Geomat. J. Geospat. Inf. Sci. Technol. Pract. 2010, 64, 14–29. [Google Scholar]
- Pultar, E.; Raubal, M.; Cova, T.J.; Goodchild, M.F. Dynamic GIS case studies: Wildfire evacuation and volunteered geographic information. Trans. GIS 2009, 13, 85–104. [Google Scholar] [CrossRef]
- Goodchild, M. Commentary: Whither VGI? GeoJournal 2008, 72, 239–244. [Google Scholar] [CrossRef]
- Qian, X.; Di, L.; Li, D.; Li, P.; Shi, L.; Cai, L. Data cleaning approaches in Web 2.0 VGI application. In Proceedings of 2009 17th International Conference on Geoinformatics, Fairfax, VA, USA, 12–14 August, 2009; pp. 1–4.
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; Grillmayer, R.; Achard, F.; Kraxner, F.; Obersteiner, M. Geo-Wiki.Org: The use of crowdsourcing to improve global land cover. Remote Sens. 2009, 1, 345–354. [Google Scholar] [CrossRef]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Bulterman, D.C.A. Is it time for a moratorium on metadata? IEEE Multimed. 2004, 11, 10–17. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P.; Winstanley, A.C. A Study of Data Representation of Natural Features in OpenStreetMap. In Proceedings of the 6th GIScience International Conference on Geographic Information Science, Zurich, Switzerland, 14–17 September 2010; p. 150.
- Flanagin, A.J.; Metzger, M.J. The role of site features, user attributes, and information verification behaviours on the percieved credibility of Web-based information. New Media Soc. 2007, 9, 319–342. [Google Scholar] [CrossRef]
- Ballatore, A.; Bertolotto, M. Semantically Enriching VGI in Support of Implicit Feedback Analysis. In Web and Wireless Geographical Information Systems; Tanaka, K., Fröhlich, P., Kim, K.S., Eds.; Springer Berlin/Heidelberg: Berlin, Heidelberg, Germany, 2011; Volume 6574, pp. 78–93. [Google Scholar]
- Brando, C.; Bucher, B. Quality in User Generated Spatial Content: A Matter of Specifications. In Proceedings of the 13th AGILE International Conference on Geographic Information Science; Painho, M., Santos, M.Y., Pundt, H., Eds.; Springer Verlag: Guimarães, Portugal, 2010. [Google Scholar]
- Neis, P.; Zielstra, D.; Zipf, A. The Street Network Evolution of Crowdsourced Maps: OpenStreetMap in Germany 2007–2011. Future Internet 2012, 4, 1–21. [Google Scholar]
- Welser, H.T.; Cosley, D.; Kossinets, G.; Lin, A.; Dokshin, F.; Gay, G.; Smith, M. Finding Social Roles in Wikipedia. In Proceedings of the 2011 iConference; ACM: New York, NY, USA, 2011; pp. 122–129. [Google Scholar]
- Anderka, M.; Stein, B.; Lipka, N. Towards Automatic Quality Assurance in Wikipedia. In Proceedings of the 20th International Conference Companion on World Wide Web; ACM: New York, NY, USA, 2011; pp. 5–6. [Google Scholar]
- Korfiatis, N.; Poulos, M.; Bokos, G. Evaluating authoritative sources using social networks: An insight from wikipedia. Online Inf. Rev. 2006, 30, 252–262. [Google Scholar] [CrossRef]
- Yang, H.L.; Lai, C.Y. Motivations of Wikipedia content contributors. Comput. Hum. Behav. 2010, 26, 1377–1383. [Google Scholar] [CrossRef]
- Antin, J. My Kind of People? Perceptions About Wikipedia Contributors and Their Motivations. In Proceedings of the 2011 Annual Conference on Human Factors In Computing Systems; ACM: New York, NY, USA, 2011; pp. 3411–3420. [Google Scholar]
- Hecht, B.J.; Gergle, D. On the "Localness" of User-Generated Content. In Proceedings of the 2010 ACM Conference on Computer Supported Cooperative Work; ACM: New York, NY, USA, 2010; pp. 229–232. [Google Scholar]
- GeoFabrik. GeoFabrik: Download Server for OpenStreetMap data. Web Based DownloadApplication. 2010. Available online: http://download.geofabrik.de/ (accessed on 19 March 2012).
- osm2pgsql. Osm2pgsql—An OSM data importer for Postgis databases. 2012. Available online: http://wiki.openstreetmap.org/wiki/Osm2pgsql (accessed on 19 March 2012).
- OSMOSIS. OSMOSIS—A command line Java application for processing OSM data. 2012. Available online: http://wiki.openstreetmap.org/wiki/Osmosis (accessed on 19 March 2012).
- Mooney, P.; Corcoran, P. Accessing the History of Objects in OpenStreetMap. In Proceedings of the 14h AGILE International Conference on Geographic Information Science; Geertman, S., Reinhardt, W., Toppen, F., Eds.; Springer Verlag: Utrecht, The Netherlands, 2011; p. 155. [Google Scholar]
- MaZderMind. osm-History-Splitter: A C++ Tool to Split OSM Full-History-Planet-Dumps into Smaller Extracts Based on Bounding-Boxes or Polygons. 2012. Available online: https://github.com/MaZderMind/osm-history-splitter (accessed on 19 March 2012).
- Geofabrik. Clipbounds—Boundary poly Files for the Extract Of Country Regions From OSM-XML Data. 2012. Available online: http://download.geofabrik.de/clipbounds/ (accessed on 19 March 2012).
- Wikipedia. Featured Articles in Wikipedia. 2011. Available online: http://en.wikipedia.org/wiki/Wikipedia:Featured_articles (accessed on 15 March 2012).
- Nemoto, K.; Gloor, P.; Laubacher, R. Social Capital Increases Efficiency of Collaboration Among Wikipedia Editors. In Proceedings of the 22nd ACM Conference on Hypertext and Hypermedia; ACM: New York, NY, USA, 2011; pp. 231–240. [Google Scholar]
- Topf, J. The TagInfo Webservice—Statistics About Tags in The OpenStreetMap Database. 2012. Available online: http://taginfo.openstreetmap.org/keys (accessed on February 2012).
- Yujian, L.; Bo, L. A normalized levenshtein distance metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef]
- Bilenko, M.; Mooney, R.; Cohen, W.; Ravikumar, P.; Fienberg, S. Adaptive name matching in information integration. IEEE Intell. Syst. 2003, 18, 16–23. [Google Scholar]
- Derntl, M.; Hampel, T.; Motschnig-Pitrik, R.; Pitner, T. Inclusive social tagging and its support in Web 2.0 services. Comput. Hum. Behav. 2011, 27, 1460–1466. [Google Scholar] [CrossRef]
- Morrison, P.J. Tagging and searching: Search retrieval effectiveness of folksonomies on the World Wide Web. Inf. Process. Manag. 2008, 44, 1562–1579. [Google Scholar] [CrossRef]
- Overell, S.; Sigurbjörnsson, B.; van Zwol, R. Classifying Tags Using Open Content Resources. In Proceedings of the Second ACM International Conference on Web Search and Data Mining; ACM: New York, NY, USA, 2009; pp. 64–73. [Google Scholar]
- Kessler, C.; Trame, J.; Kauppinen, T. Tracking Editing Processes in Volunteered Geographic Information: The Case of OpenStreetMap. In Proceedings of the COSIT'11 Workshop: Identifying ObjectsProcesses and Events in Spatio-Temporally Distributed Data (IOPE), Belfast, Maine, USA, 12 September 2011; pp. 17–29.
- Roick, O.; Loos, L.; Zipf, A. A Technical Framework for Visualizing Spatio-Temporal Quality Metrics of Volunteered Geographic Information. In Proceedings of the GEOINFORMATIK 2012-Mobility and Environment, Braunschweig, Germany, 28–30 March 2012.
- van Exel, M.; Dias, E.; Fruijtier, S. The Impact of Crowdsourcing on Spatial Data Quality Indicators. In Proceedings of GiScience 2011, Zurich, Switzerland, 14–17 September 2010.
- Mooney, P.; Corcoran, P. Using OSM for LBS—An Analysis of Changes to Attributes of Spatial Objects. In Proceedings of the 8th International Symposium on Location-Based Services; Gartner, G., Ortag, F., Eds.; Springer: Vienna, Austria, 2011; pp. 165–176. [Google Scholar]
- Pirolli, P.; Wollny, E.; Suh, B. So You Know You're Getting the Best Possible Information: A Tool That Increases Wikipedia Credibility. In Proceedings of the 27th International Conference on Human Factors In Computing Systems; ACM: New York, NY, USA, 2009; pp. 1505–1508. [Google Scholar]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Mooney, P.; Corcoran, P. Characteristics of Heavily Edited Objects in OpenStreetMap. Future Internet 2012, 4, 285-305. https://doi.org/10.3390/fi4010285
Mooney P, Corcoran P. Characteristics of Heavily Edited Objects in OpenStreetMap. Future Internet. 2012; 4(1):285-305. https://doi.org/10.3390/fi4010285
Chicago/Turabian StyleMooney, Peter, and Padraig Corcoran. 2012. "Characteristics of Heavily Edited Objects in OpenStreetMap" Future Internet 4, no. 1: 285-305. https://doi.org/10.3390/fi4010285
APA StyleMooney, P., & Corcoran, P. (2012). Characteristics of Heavily Edited Objects in OpenStreetMap. Future Internet, 4(1), 285-305. https://doi.org/10.3390/fi4010285