Registration Combining Wide and Narrow Baseline Feature Tracking Techniques for Markerless AR Systems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Researches
- The method needs no man-made markers for both indoor and outdoor AR applications and can work with arbitrary geometric shapes including planar, near planar and non planar structures which really enhance the usability of AR systems.
- To initialize the system, we use adaptive classification tree based matching strategy which can provide fast and accurate initialization even when the initial camera is different from the reference image to a large degree.
- Due to the reduced SIFT based augmented optical flow tracker, the virtual objects can still be augmented on the specified areas even under the circumstances of occlusion and large changes in viewpoint during the online process.
3. Scene Reconstruction Using Direct Bundle Adjustment
4. Natural Features Tracking and Camera Pose Computing
- Search over all scales and image locations to identify potential interest points that are invariant to scale and orientation change.
- Determine the location and scale at each candidate location; select the keypoint based on measures of their stability.
- Assign one or more orientations to each keypoint based on local image gradient directions.
- Generate keypoint descriptor by measuring local image gradients at the selected scale in the region around each keypoint.
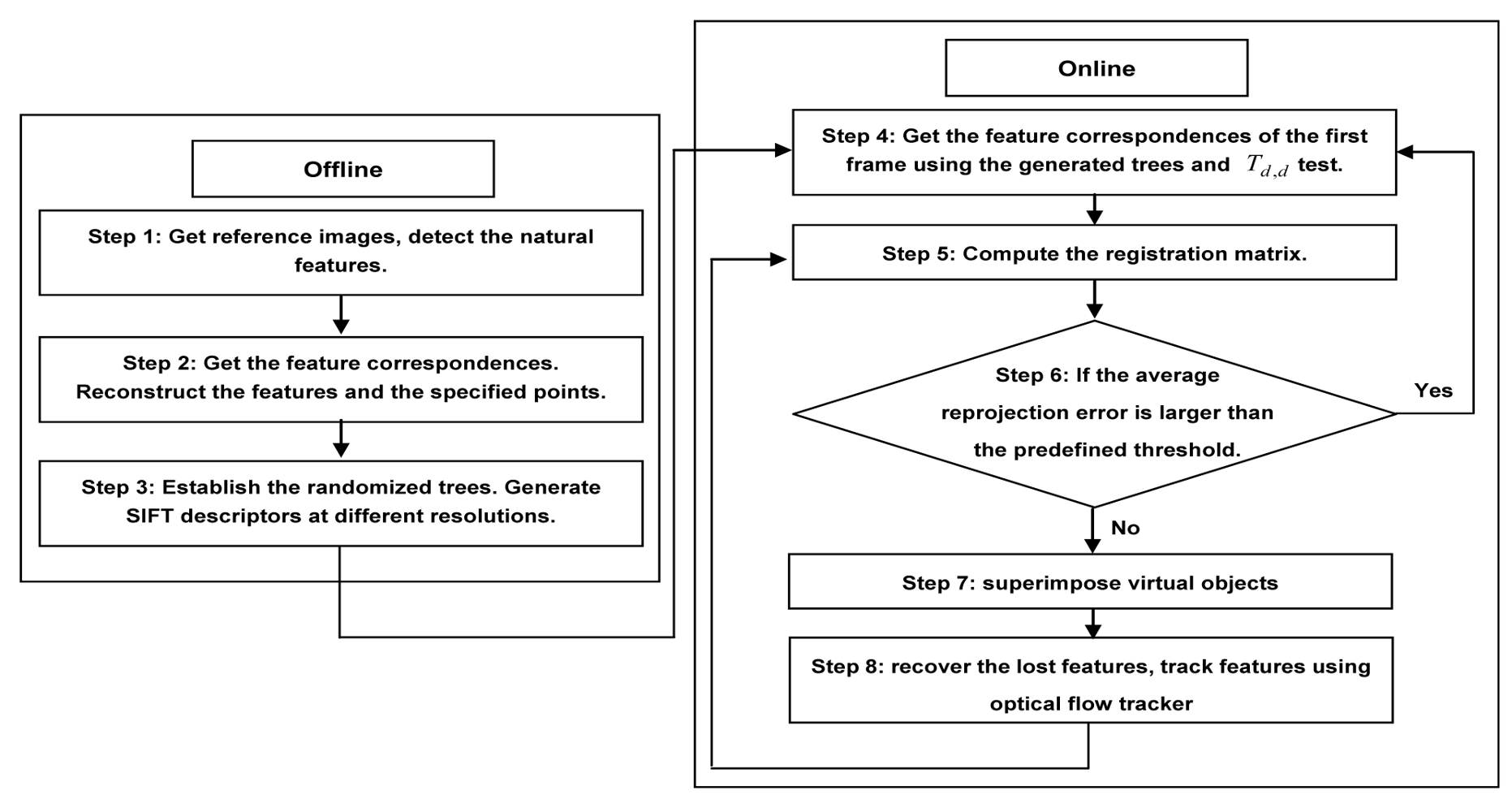
5. Registration Algorithm
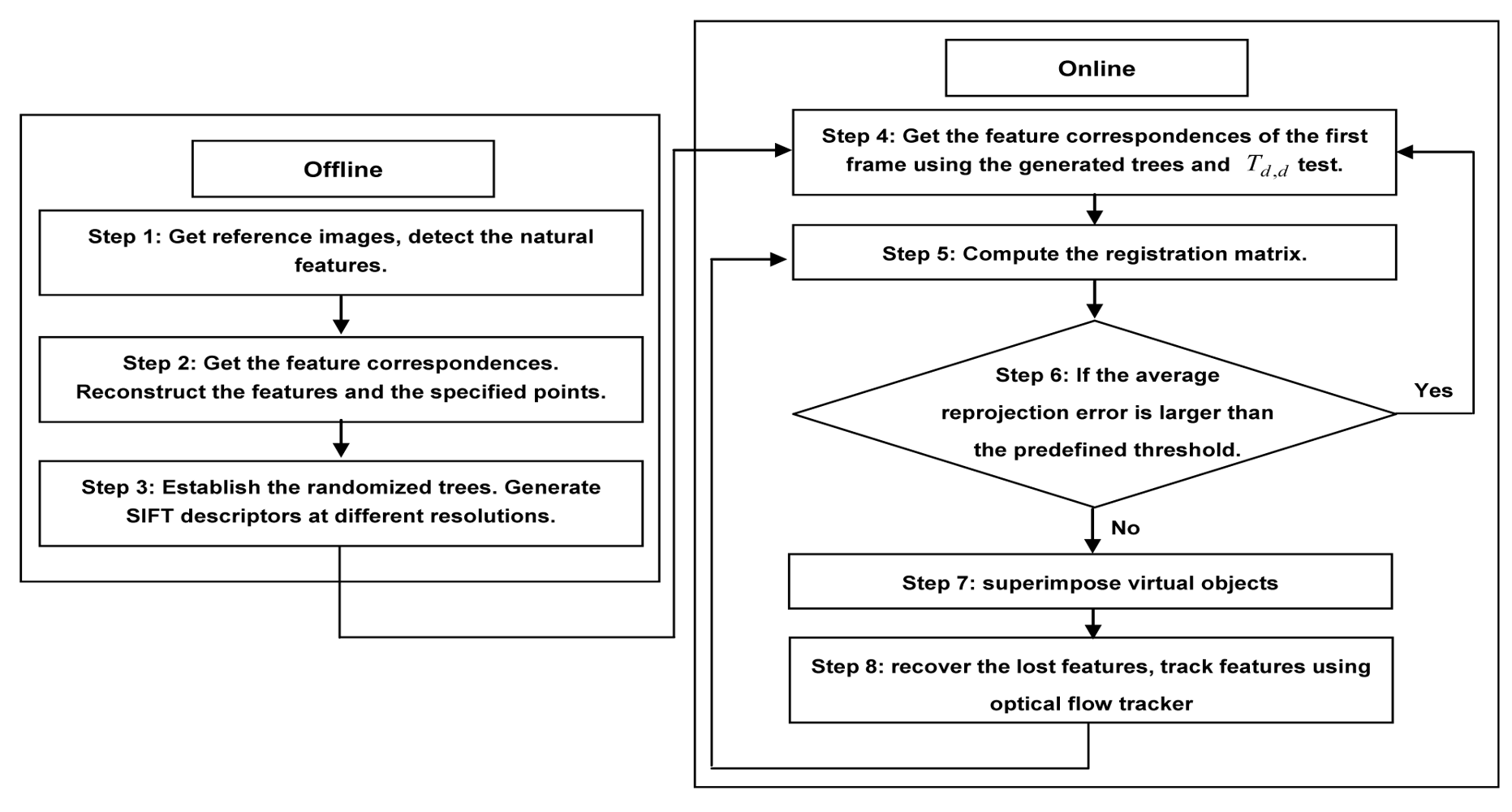
- Step 1: Select two images of the scene as references, detect the natural features using fast corner detector.
- Step 2: Get the correct feature matches between the two selected images by repeatedly using the cross-correlation operation and the epipolar constraint. Calculate the camera parameters and the scene structure simultaneously using the direct bundle adjustment method discussed in Section 3.
- Step 3: Create the view sets to establish the randomized trees. Generate SIFT descriptors of the natural features at different resolutions.
- Step 4: Get the feature correspondences between the first and reference images using the generated randomized trees and the Td,d test algorithm.
- Step 5: Compute the registration matrix of the current frame by the obtained feature correspondences.
- Step 6: If the average reprojection error is larger than the predefined threshold (3 pixels in our case), go back to step 4, otherwise, turn to the next step.
- Step 7: Superimpose virtual objects using the calculated registration matrix.
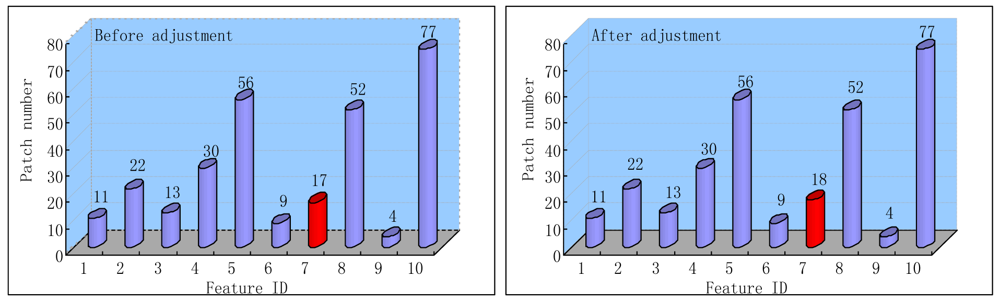
- Step 8: Recover the lost features, adjust trees and SIFT descriptors. Obtain the corresponding natural features between the next and reference frames using optical flow tracker and RANSAC and turn back to the step 5.
6. Experimental Results
6.1. Indoor Experiments
6.2. Outdoor Experiments
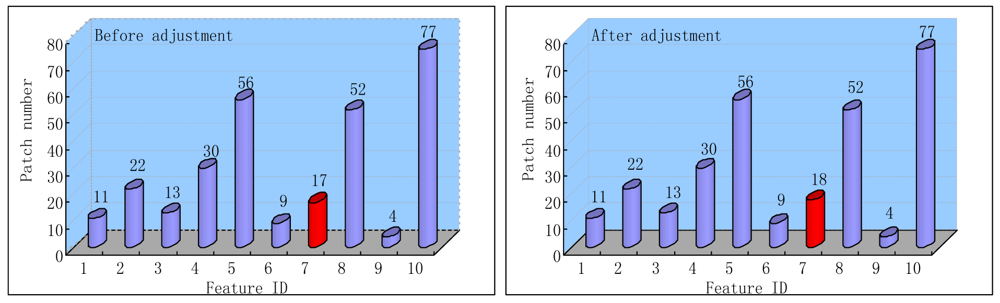
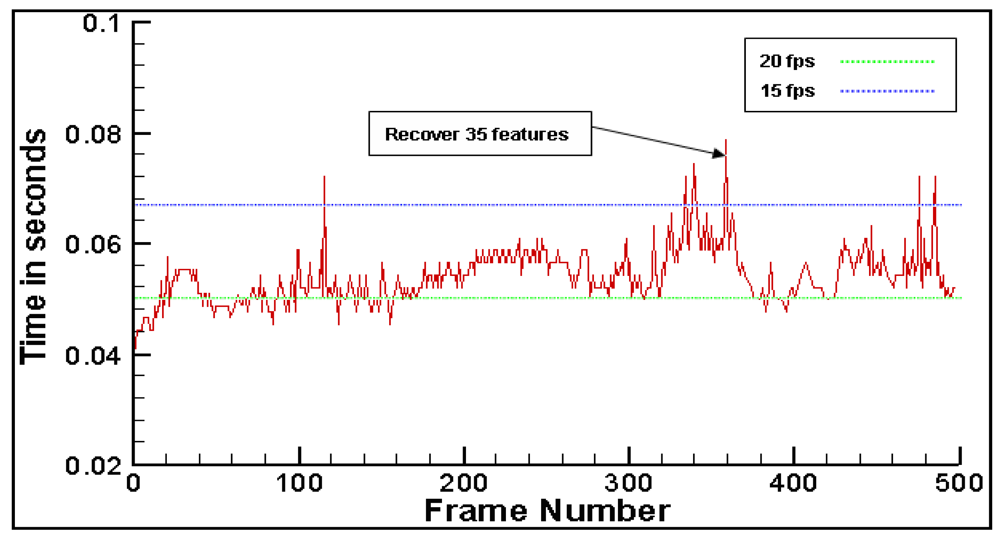
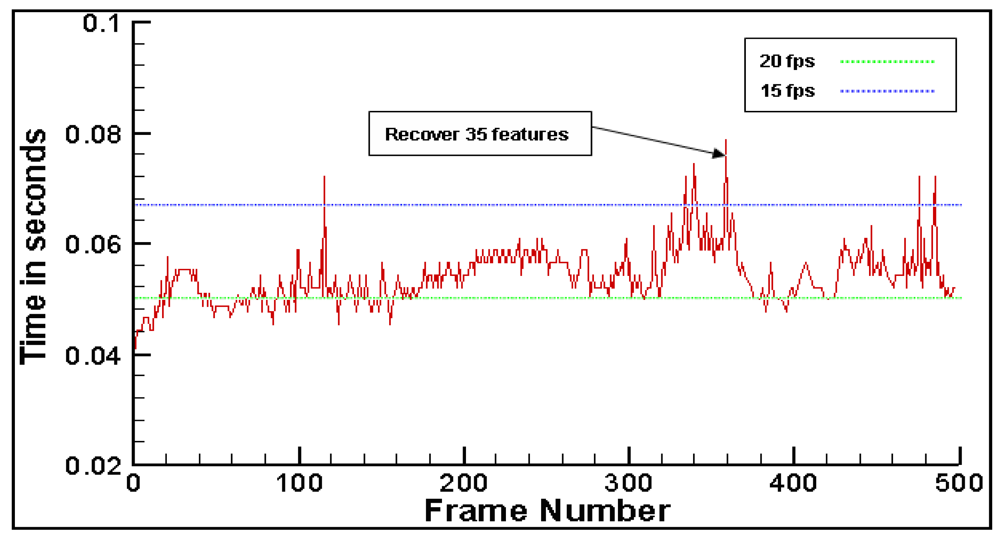
6.3. Compute Time and Feature Recover Performance
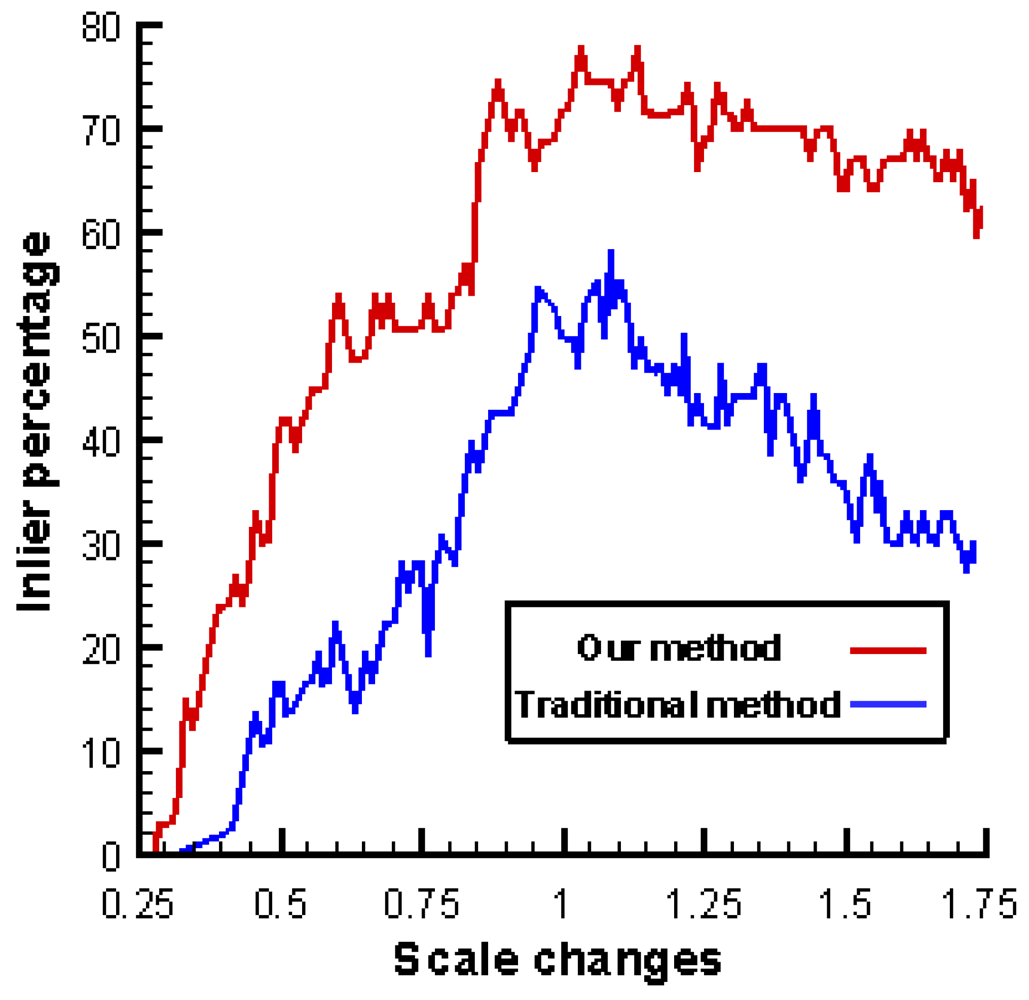
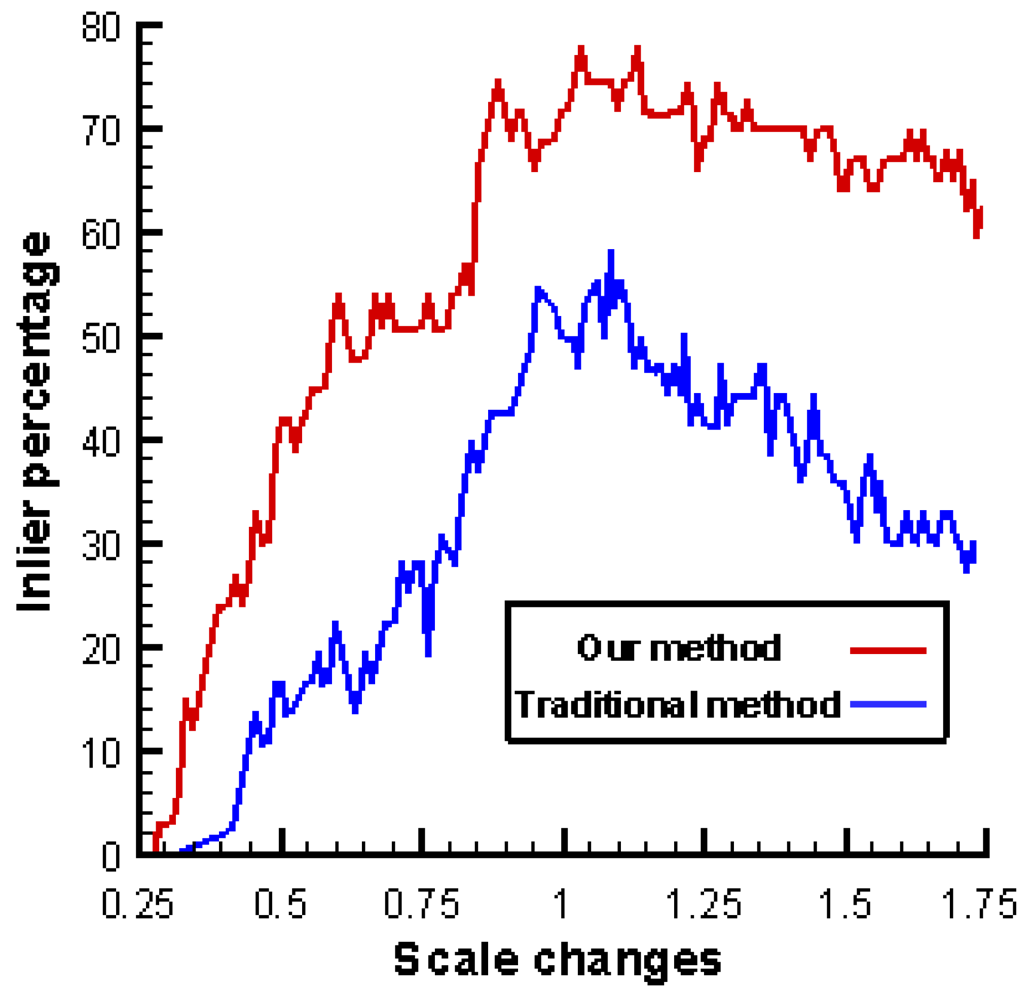
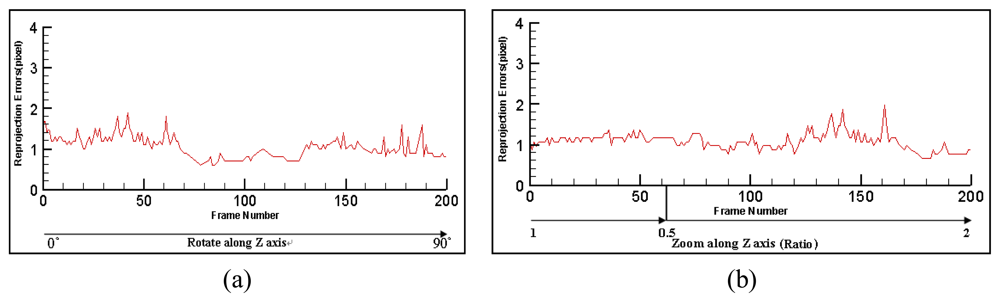
6.4. Tracking Accuracy
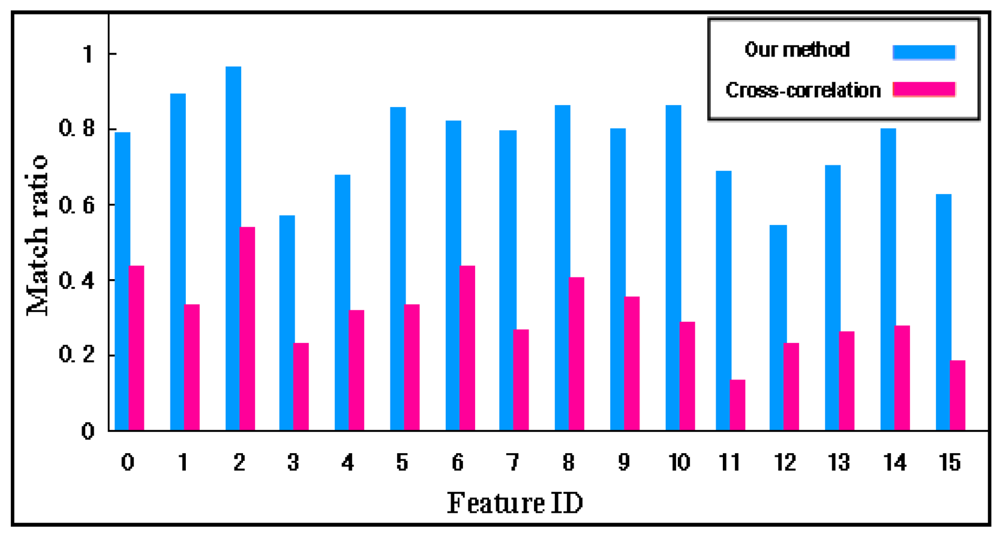
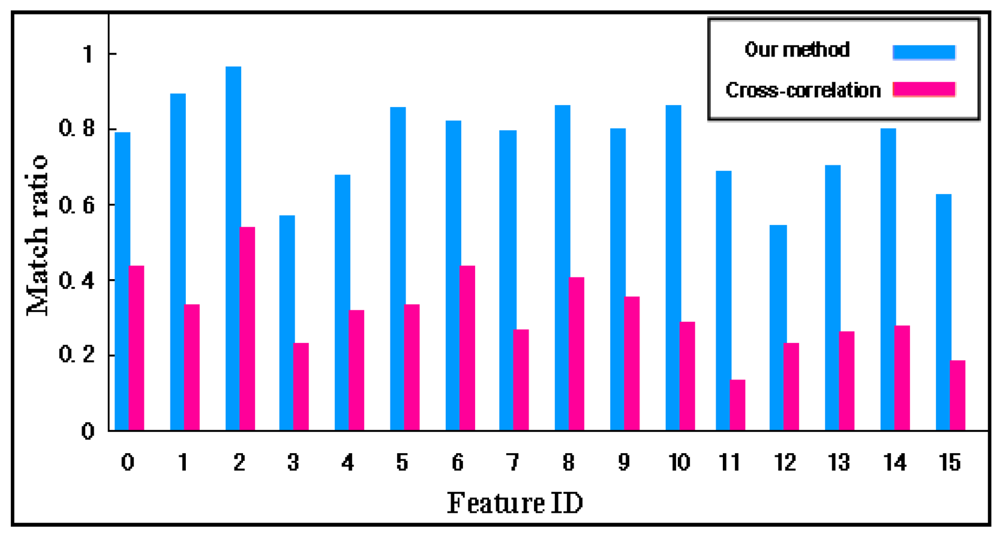
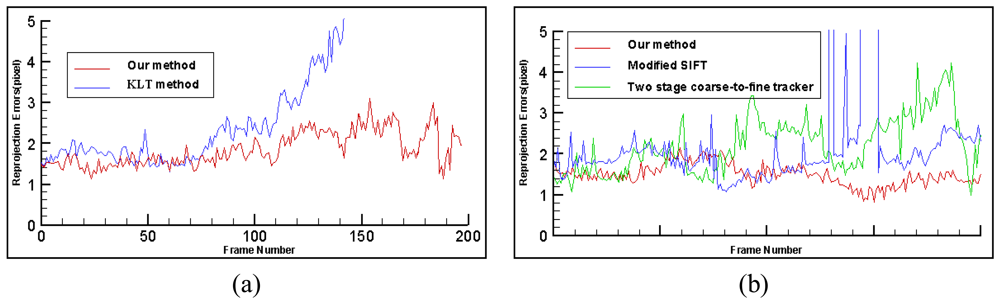
6.5. Comparison with Previous Work
7. Conclusions
Acknowledgments
References
- Shi, J.; Tomasi, C. Good features to track. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR'94), Seattle, WA, USA, June, 1994; pp. 593–600.
- Fusiello, A.; Trucco, E.; Tommasini, T.; Roberto, V. Improving feature tracking with robust statistics. Pattern Anal. Appl. 1999, 2, 312–320. [Google Scholar]
- Berthold, K.P.H.; Brian, G.S. Determining optical flow. Artif. Intel. 1981, 17, 185–203. [Google Scholar]
- Simon, G.; Berger, M. Reconstructing while registering: a novel approach for markerless augmented reality. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR 2002), Darmstadt, Germany, September, 2002; pp. 285–294.
- Simon, G.; Berger, M.O. Real time registration known or recovered multi-planar structures: application to AR. Proceedings of British Machine Vision Conference (BMVC'02), Cardiff, UK, September, 2002; pp. 567–576.
- Li, J.; Laganière, R.; Roth, G. Online estimation of trifocal tensors for augmenting live video. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'04), Arlington, VA, USA, November, 2004; pp. 182–190.
- Eade, E.; Drummond, T. Scalable monocular slam. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'06), New York, NY, USA, June, 2006; pp. 469–476.
- Davison, A.; Reid, I.; Molton, N.D.; Stasse, O. MonoSLAM: Realtime single camera SLAM. IEEE Trans. Patt. Anal. Mach. Int. 2007, 29, 1052–1067. [Google Scholar]
- Davison, A.; Mayol, W.; Murray, D. Real-time localization and mapping with wearable active vision. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'03), Tokyo, Japan, October, 2003; pp. 18–25.
- Pupilli, M.; Calway, A. Real-time camera tracking using a particle filters. Proceedings of British Machine Vision Conference (BMVC'05), Oxford, UK, September, 2005; pp. 519–528.
- Molton, N.; Ried, I.; Davison, A. Locally planar patch features for real-time structure from motion. Proceedings of British Machine Vision Conference (BMVC'04), London, UK, September, 2004.
- Pupilli, M.; Calway, A. Real-time visual slam with resilience to erratic motion. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'06), New York, NY, USA, June, 2006; pp. 1244–1249.
- Yuan, M.L.; Ong, S.K.; Nee, A.Y.C. Registration based on projective reconstruction technique for augmented reality systems. IEEE Trans. Vis. Comput. Graph. 2005, 11, 254–264. [Google Scholar]
- Yuan, M.L.; Ong, S.K.; Nee, A.Y.C. Registration using natural features for augmented reality systems. IEEE Trans. Vis Comput. Graph. 2006, 12, 569–580. [Google Scholar]
- Yuan, M.L.; Ong, S.K.; Nee, A.Y.C. A generalized registration method for augmented reality systems. Comput. Graph. 2005, 29, 980–997. [Google Scholar]
- Nistér, D.; Naroditsky, O.; Bergen, J.R. Visual odometry. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, June, 2004; pp. 652–659.
- Engels, C.; Stewénius, H.; Nistér, D. Bundle adjustment rules. Photogrammetric Computer Vision (PCV'06), Bonn, Germany, September, 2006.
- Akbarzadeh, A.; Frahm, J.M.; Mordohai, P.; Clipp, B. Towards urban 3D reconstruction from video. Proceedings of the 3rd International Symposium on 3D Data Processing, Visualization and Transmission, Chapel Hill, NC, USA, June, 2006.
- Klopschitz, M.; Schmalstieg, D. Automatic reconstruction of wide-area fiducial marker models. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'07), Nara, Japan, November, 2007; pp. 1–4.
- Bleser, G.; Wuest, H.; Stricker, D. Online camera pose estimation in partially known and dynamic scenes. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'06), San Diego, CA, USA, October, 2006; pp. 56–65.
- Harris, C.; Stephens, M. A combined corner and edge detector. Proceedings of the 4th Alvey Vision Conference, Manchester, UK, September, 1988; pp. 189–192.
- Mikolajczyk, K.; Schmid, C. An affine invariant interest point detector. Proceedings of the 7th European Conference on Computer Vision, Copenhagen, Denmark; 2002; pp. 128–142. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale–invariant keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar]
- Ke, Y.; Sukthankar, R. PCA–SIFT: A more distinctive representation for local image descriptors. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, June, 2004; pp. 506–513.
- Lepetit, V; Pilet, J.; Fua, P. Point matching as a classification problem for fast and robust object pose estimation. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'04), Washington, DC, USA, June, 2004; pp. 244–250.
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Int. 2005, 27, 1625–1630. [Google Scholar]
- Skrypnyk, I.; Lowe, D. Scene modeling, recognition and tracking with invariant image features. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'04), Arlington, VA, USA, November, 2004; pp. 110–119.
- Wagner, D.; Reitmayr, G.; Mulloni, A.; Drummond, T.; Schmalstieg, D. Pose tracking from natural features on mobile phones. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'07), Cambridge, UK, September, 2008; pp. 125–134.
- Lepetit, V.; Fua, P. Keypoint recognition using randomized trees. IEEE Trans. Pattern Anal. Mach. Int. 2006, 28, 1465–1479. [Google Scholar]
- Ozuysal, M.; Fua, P.; Lepetit, V. Fast keypoint recognition in ten lines of code. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'07), Minneapolis, MN, USA, June, 2007; pp. 1–8.
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 1st ed; Cambridge University: Cambridge, UK, 2000. [Google Scholar]
- Guofeng, Z.; Xueying, Q.; Wei, H. Robust metric reconstruction from challenging video sequences. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'07), Minneapolis, MN, USA, June, 2007.
- Szeliski, R.; Kang, SB. Recovering 3D Shape and Motion from Image Streams Using Non-Linear Least Squares; Technical Report No. CRL 93/3; Digital Equipment Corporation, Cambridge Research Laboratory: Cambridge, UK; March, 1993.
- Brown, M.; Lowe, D.G. Unsupervised 3D object recognition and reconstruction in unordered datasets. Proceedings of 5th International Conference on 3D Digital Imaging and Modeling, Ottawa, Ontario, Canada, June, 2005; pp. 56–63.
- Triggs, W.; McLauchlan, P.; Hartley, R.; Fitzgibbon, A. Bundle adjustment: A modern synthesis. In Vision Algorithms: Theory and Practice; Springer Verlag: Corfu, Greece, 2000; pp. 298–373. [Google Scholar]
- Matas, J.; Chum, O. Randomized RANSAC with Td,d test. Image Vision Comput. 2004, 22, 837–842. [Google Scholar]
- Williams, B.; Smith, P.; Reid, I. Automatic relocalisation for a single-camera simultaneous localisation and mapping system. Proceedings of International Conference on Robotics and Automation, (ICRA 07), Roma, Italy, April, 2007; pp. 2784–2790.
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. Proceedings of European Conference on Computer Vision, Graz, Austria, May, 2006; pp. 430–443.
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. CACM 1981, 24, 381–395. [Google Scholar]
- Philip, J. Critical Point Configurations of the 5-, 6-, 7-, and 8-point Algorithms for Relative Orientation; Technical Report No. TRITA-MAT-1998-MA-13; Department of Mathematics, Royal Institute of Technology: Stockholm, Sweden, 1998. [Google Scholar]
- GML Camera Calibration Toolbox downloads resource. Available online: http://research.graphicon.ru/calibration/gml-c-camera-calibration-toolbox-5.html (accessed on 2 December 2009).
- Klein, G.; Murray, D. Parallel tracking and mapping for small ar workspaces. Proceedings of International Symposium on Mixed and Augmented Reality (ISMAR'07), Nara, Japan, November, 2007; pp. 225–234.





© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Duan, L.; Guan, T.; Yang, B. Registration Combining Wide and Narrow Baseline Feature Tracking Techniques for Markerless AR Systems. Sensors 2009, 9, 10097-10116. https://doi.org/10.3390/s91210097
Duan L, Guan T, Yang B. Registration Combining Wide and Narrow Baseline Feature Tracking Techniques for Markerless AR Systems. Sensors. 2009; 9(12):10097-10116. https://doi.org/10.3390/s91210097
Chicago/Turabian StyleDuan, Liya, Tao Guan, and Bo Yang. 2009. "Registration Combining Wide and Narrow Baseline Feature Tracking Techniques for Markerless AR Systems" Sensors 9, no. 12: 10097-10116. https://doi.org/10.3390/s91210097