Distributed Principal Component Analysis for Wireless Sensor Networks


Abstract
:1 Introduction
2 Principal component aggregation in wireless sensor networks
2.1 Data aggregation
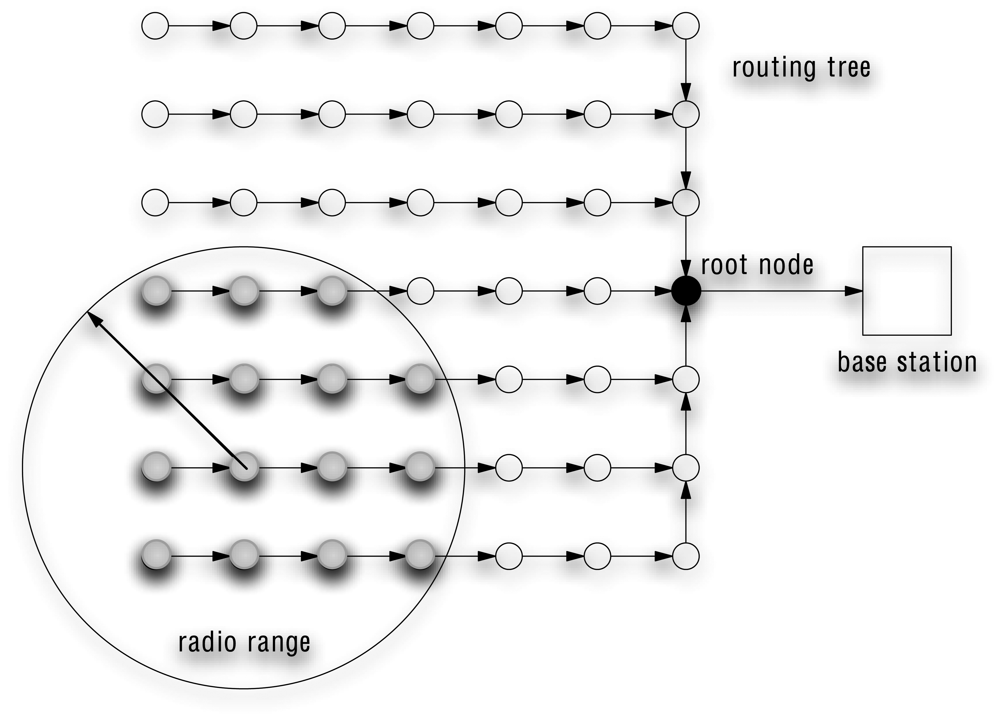
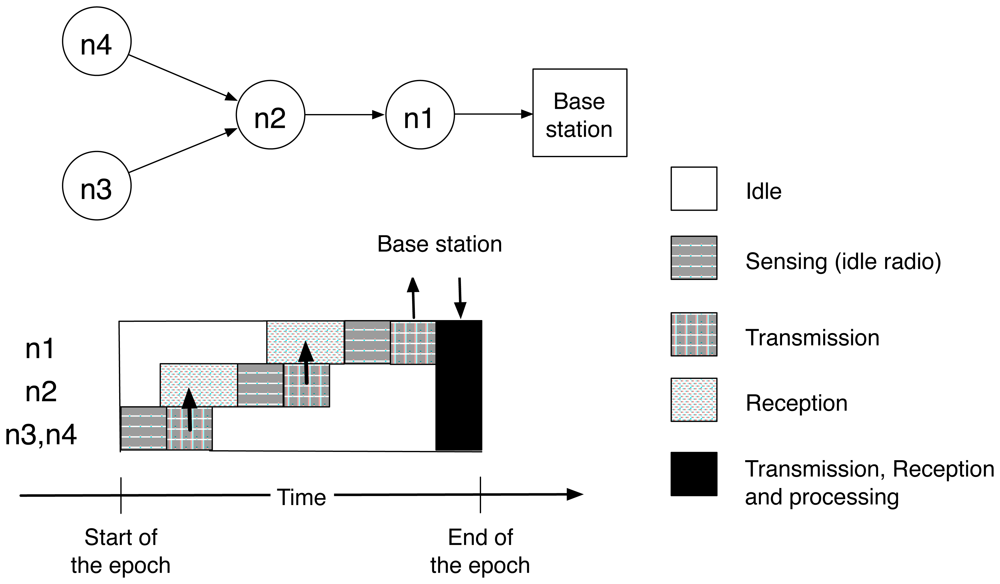
2.1.1 Aggregation service
2.1.2 Aggregation primitives
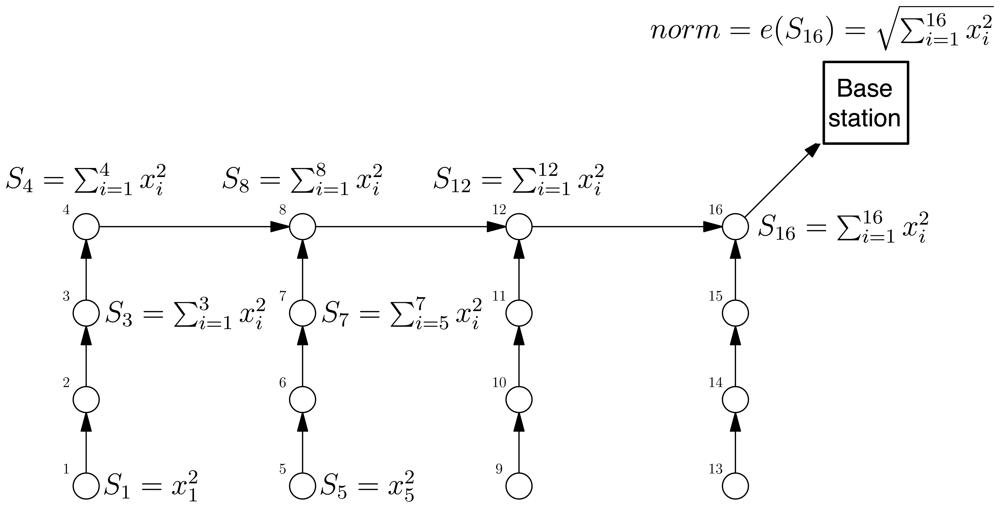
- an initializer init which transforms a sensor measurement into a partial state record,
- an aggregation operator f which merges partial state records, and
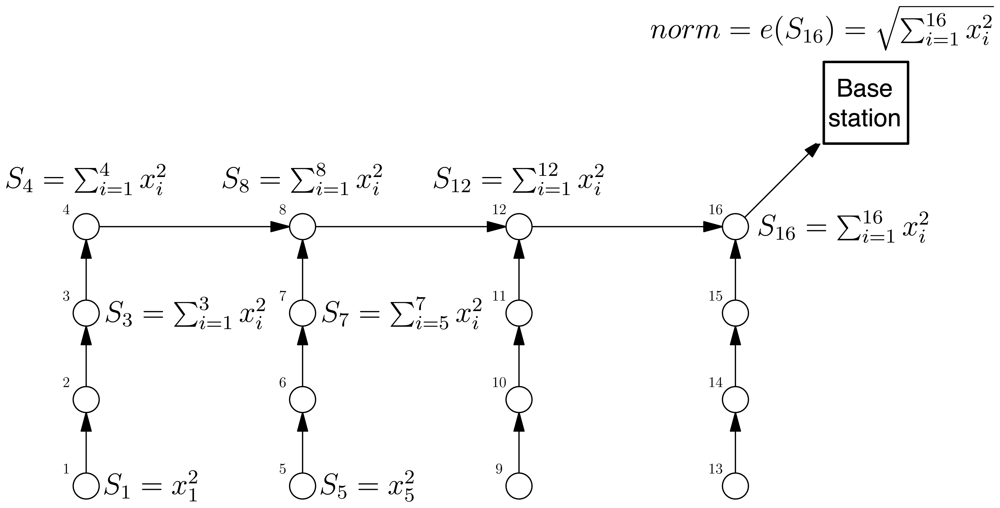
- an evaluator e which returns, on the basis of the root partial state record, the result required by the application.
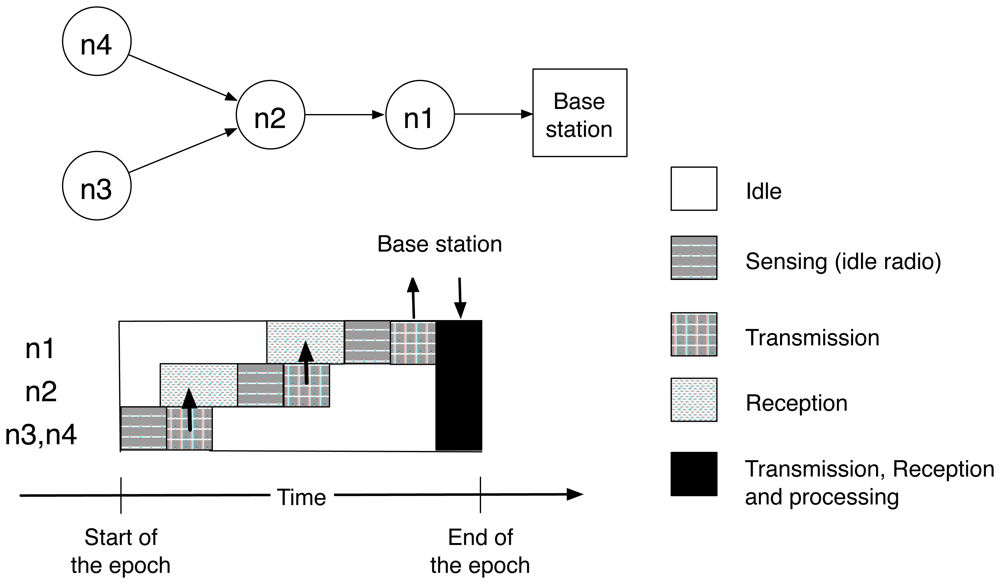
2.1.3 Communication costs
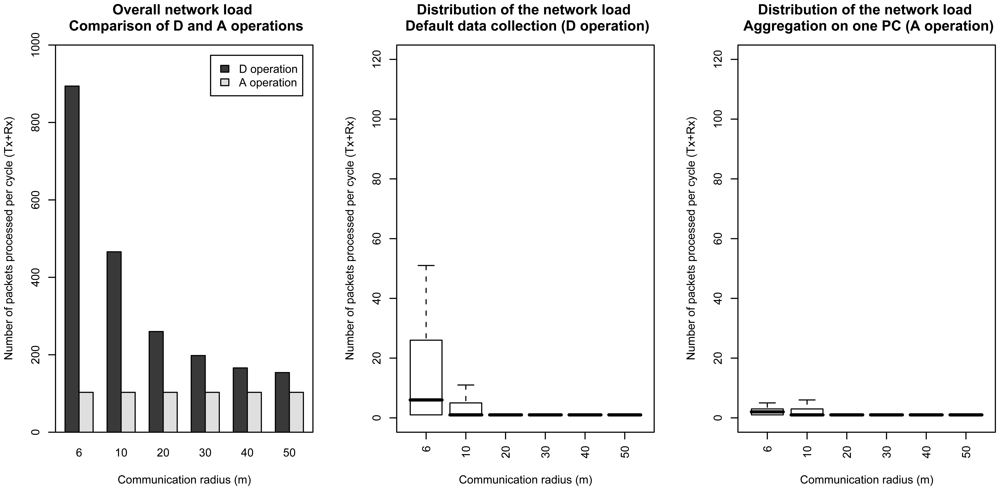
D operation
A operation
F operation
2.2 Principal component analysis
2.3 Principal component aggregation
2.4 Applications
2.4.1 Approximate monitoring
2.4.2 Dimensionality reduction
2.4.3 Event detection
2.5 Tradeoffs
3 Computation of the principal components
3.1 Outline
3.2 Centralized approach
3.2.1 Scalability analysis
Highest network load
Computational and memory costs
3.3 Distributed estimation of the covariance matrix
3.3.1 Positive semi-definiteness criterion
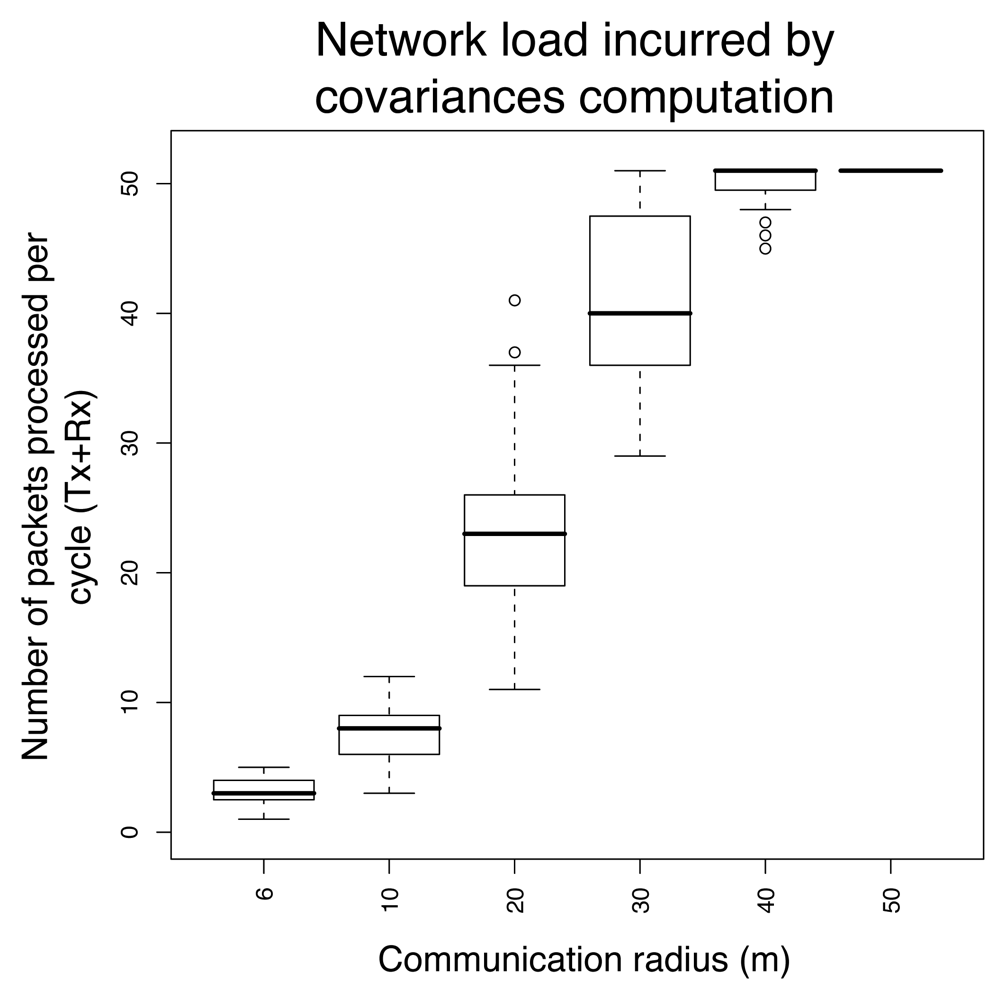
3.3.2 Scalability analysis
Highest network load
Computational and memory costs
3.4 Distributed estimation of the principal components
3.4.1 Power iteration method
3.4.2 Computation of subsequent eigenvectors
3.4.3 Implementation in the aggregation service
Computation of Cv
Normalization and orthogonalization
3.4.4 Synchronization
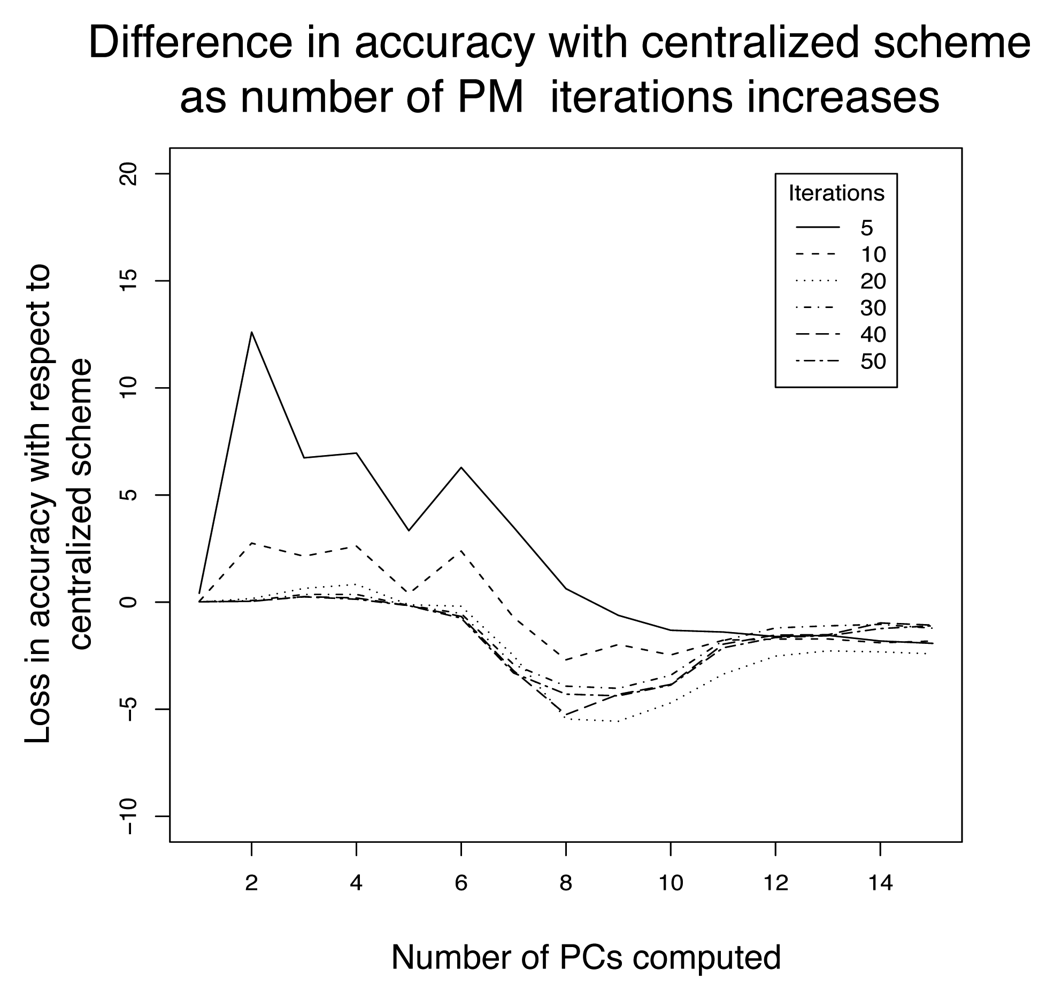
3.4.5 Scalability analysis
Highest network load
Computational and memory costs
3.5 Summary
4 Experimental results
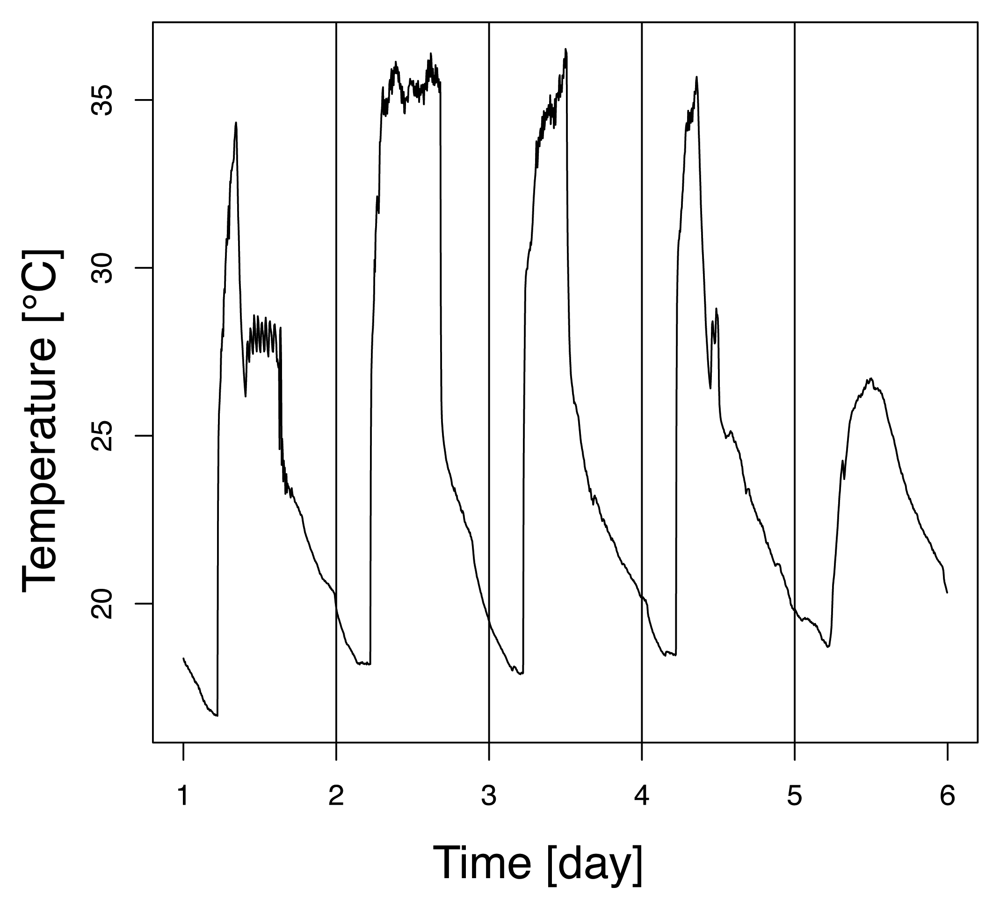
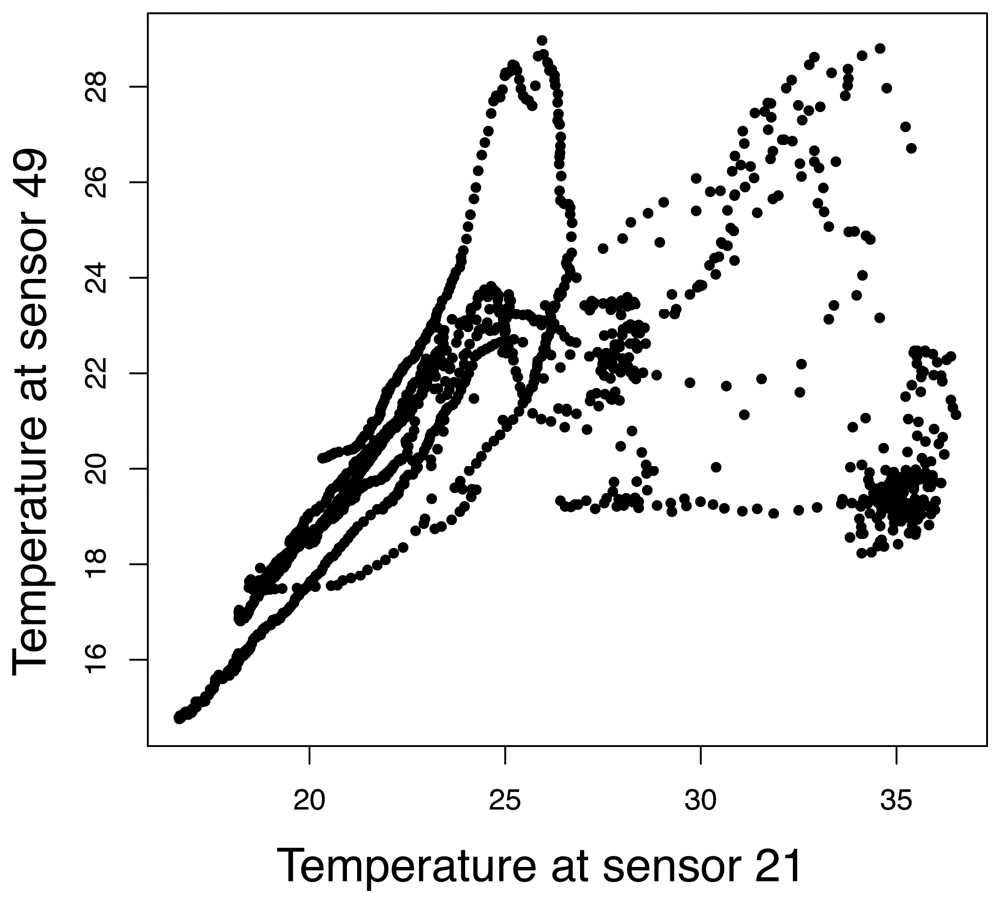
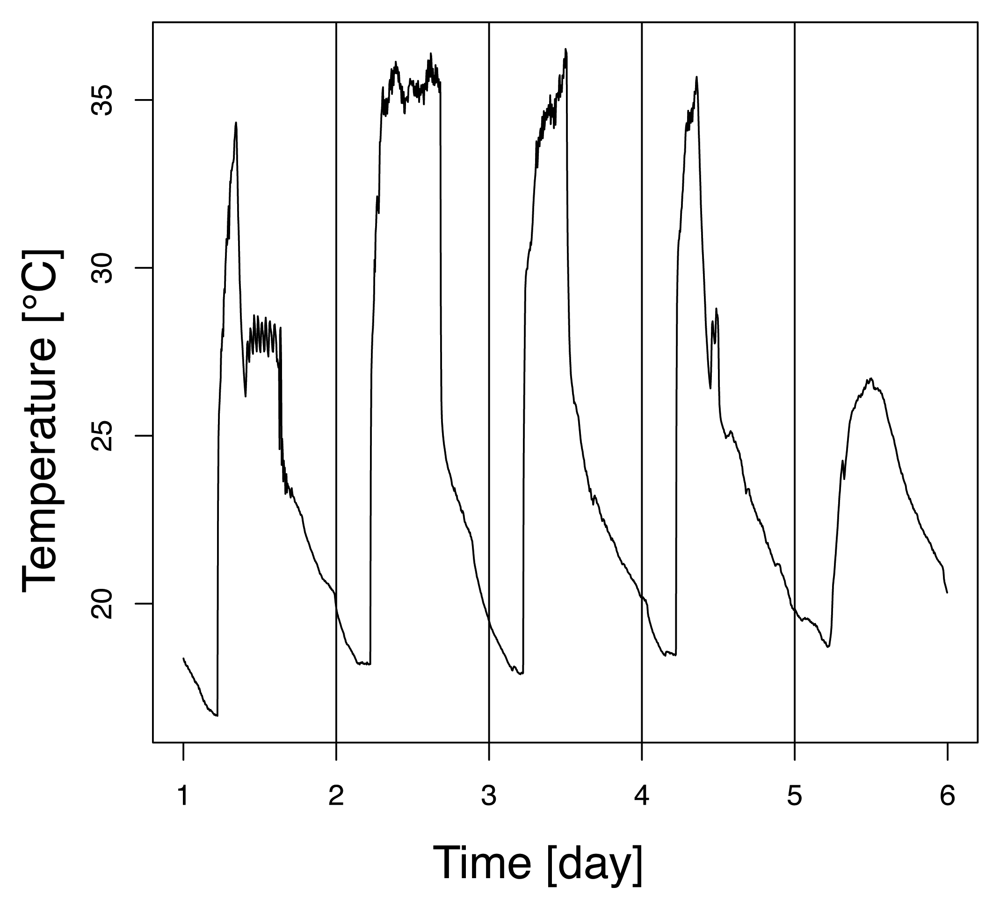
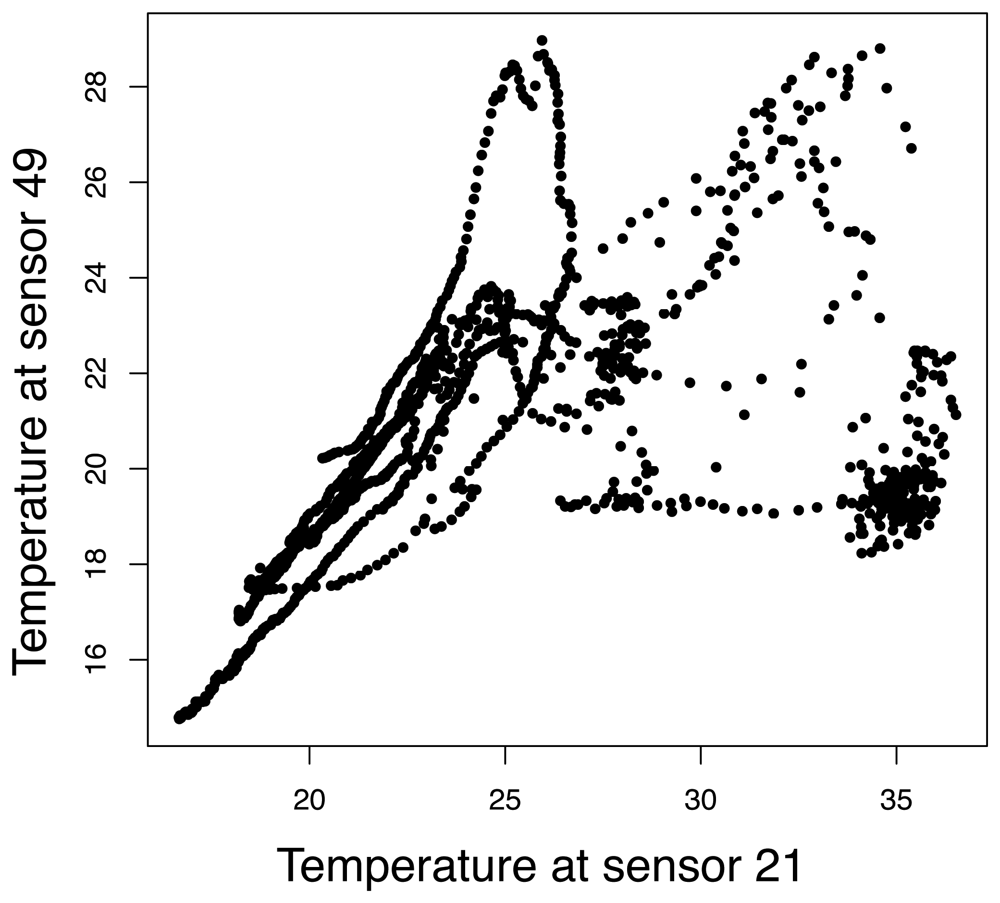
4.1 Dataset description
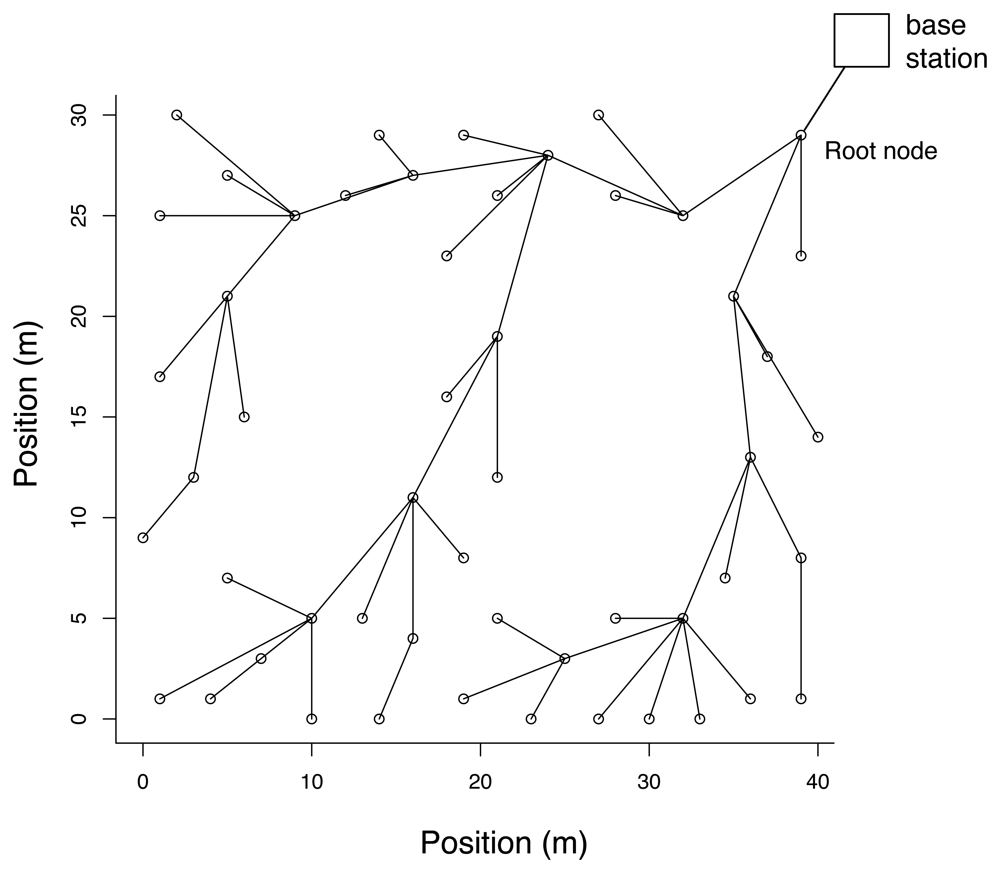
4.2 Network simulation
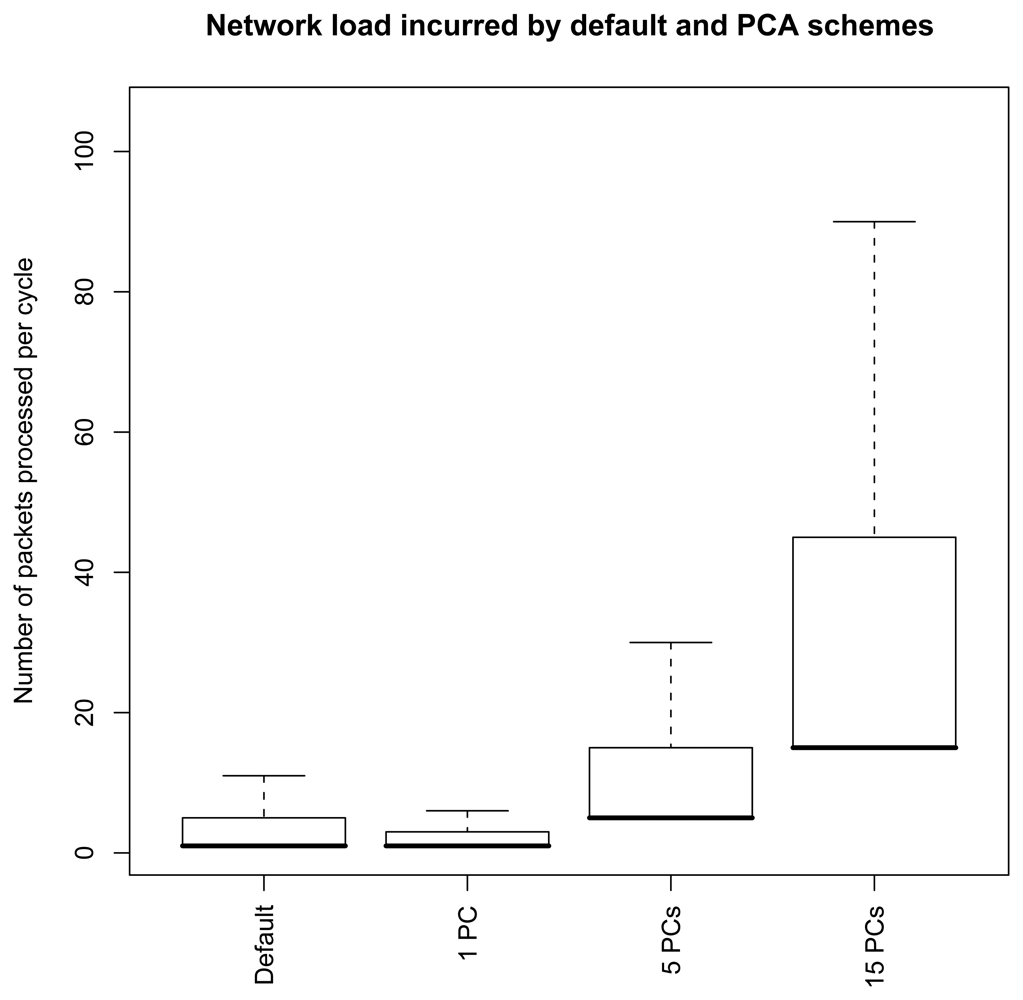
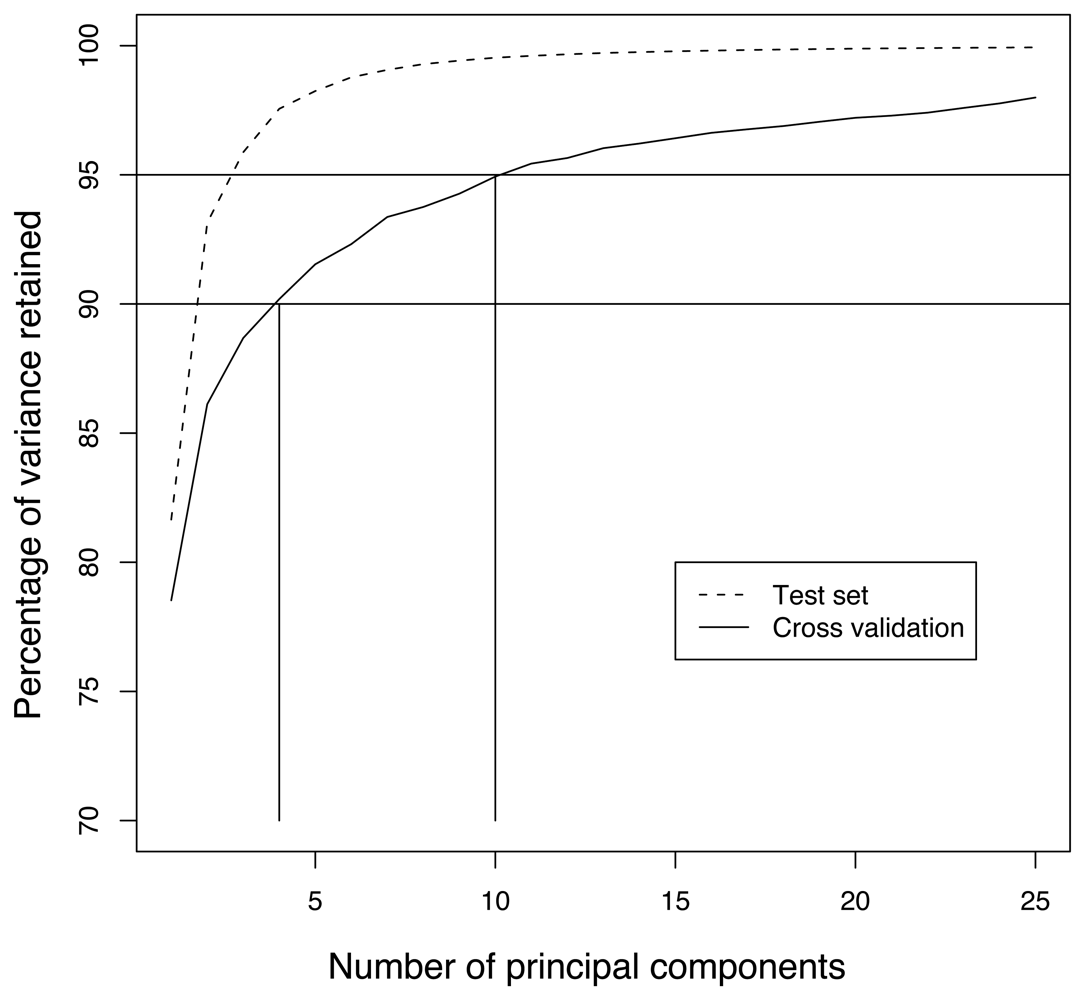
4.3 Principal component aggregation
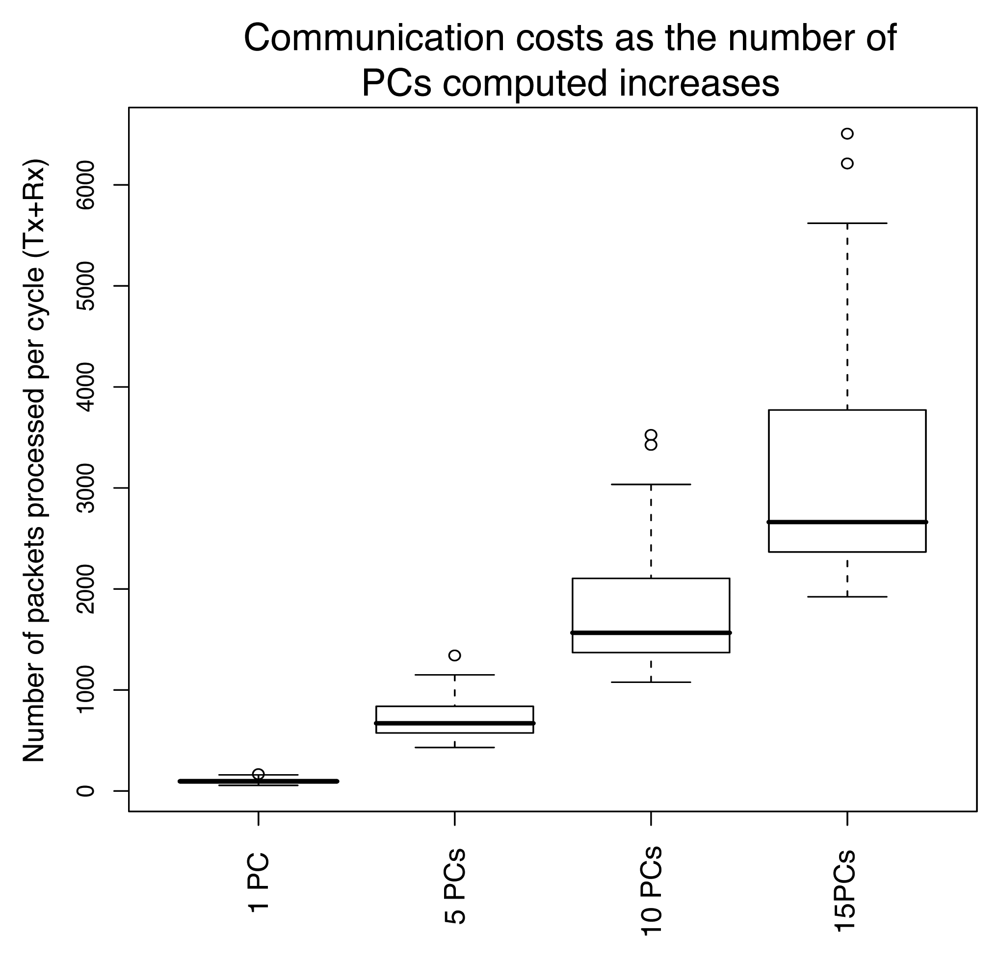
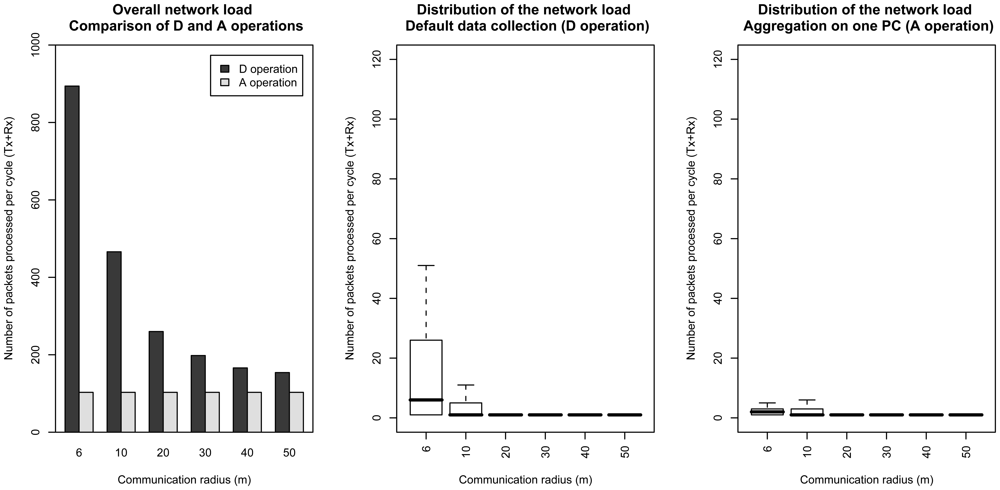
4.4 Communication costs
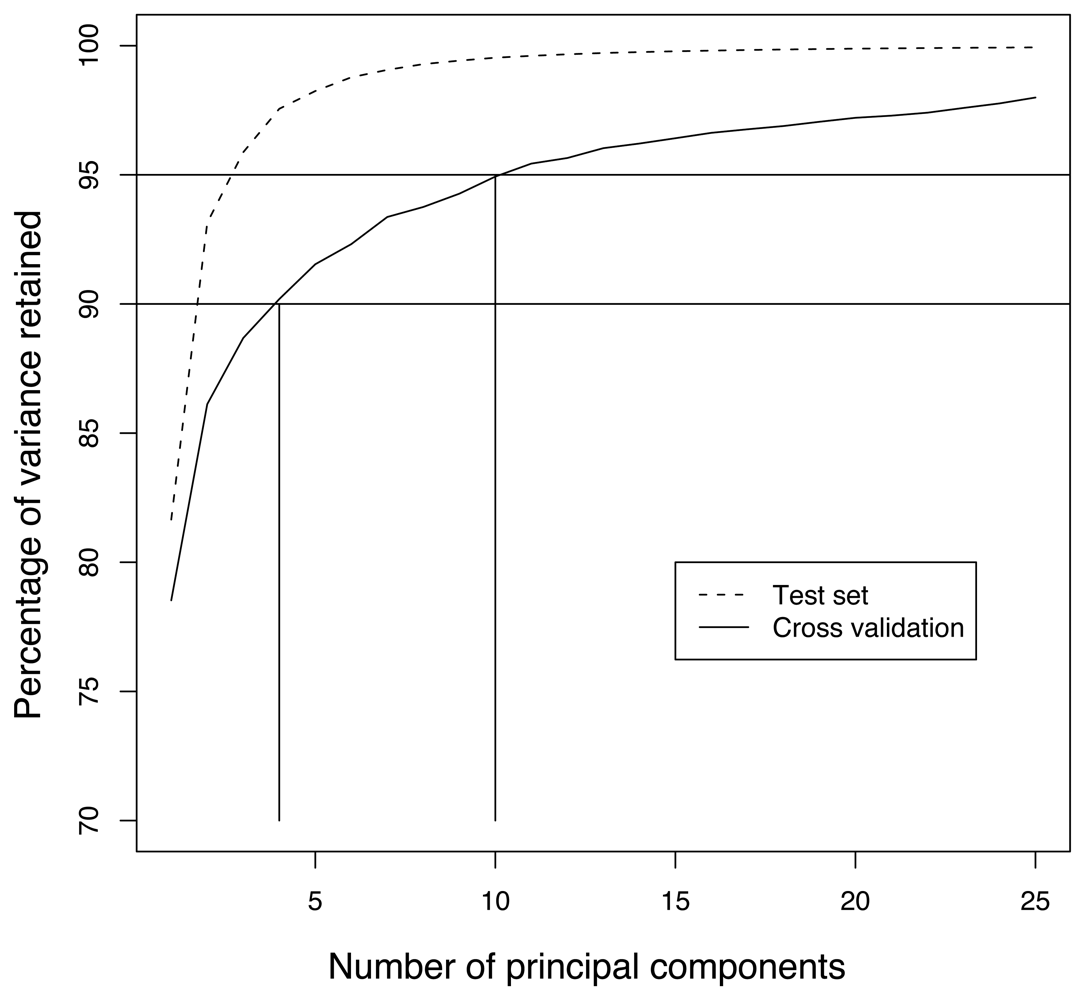
4.5 Distributed covariance matrix
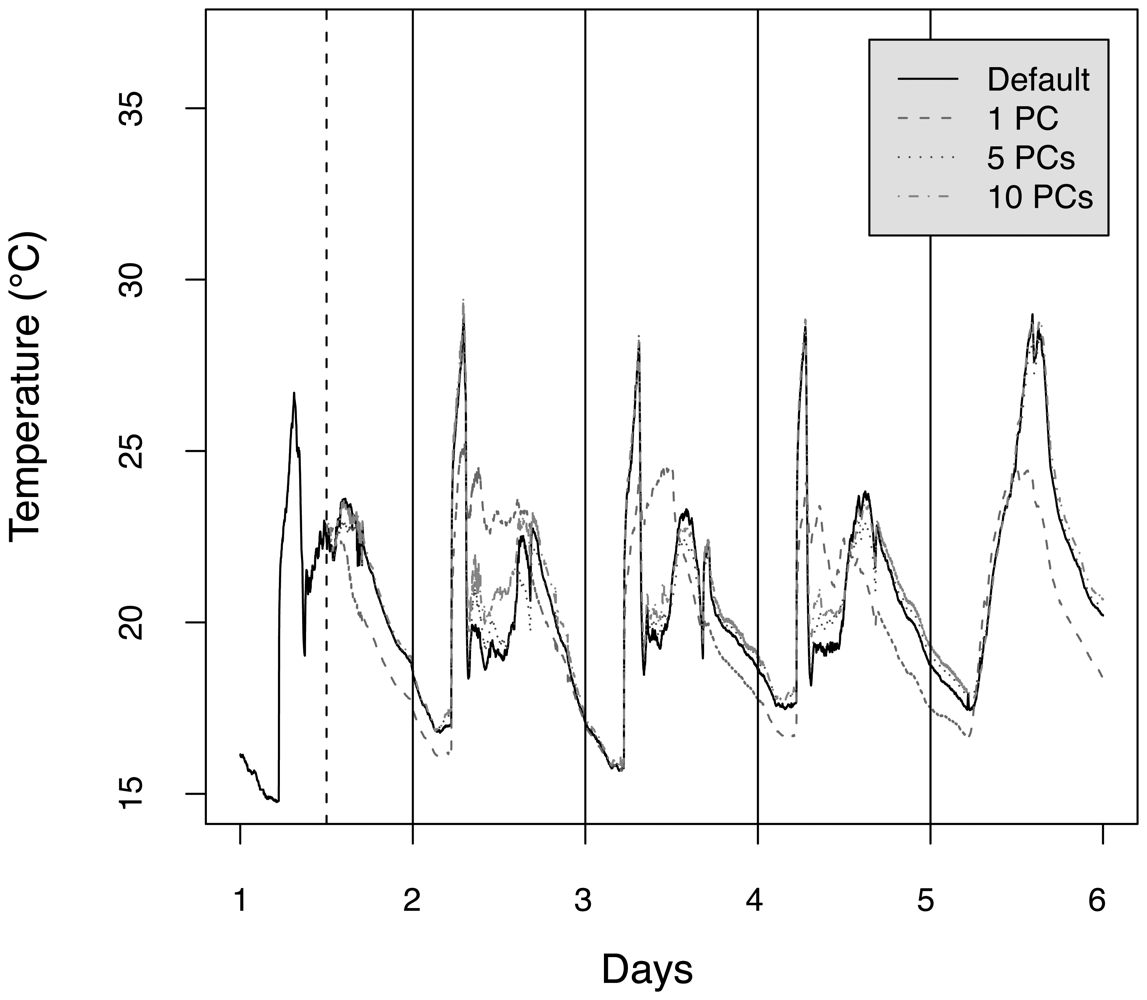
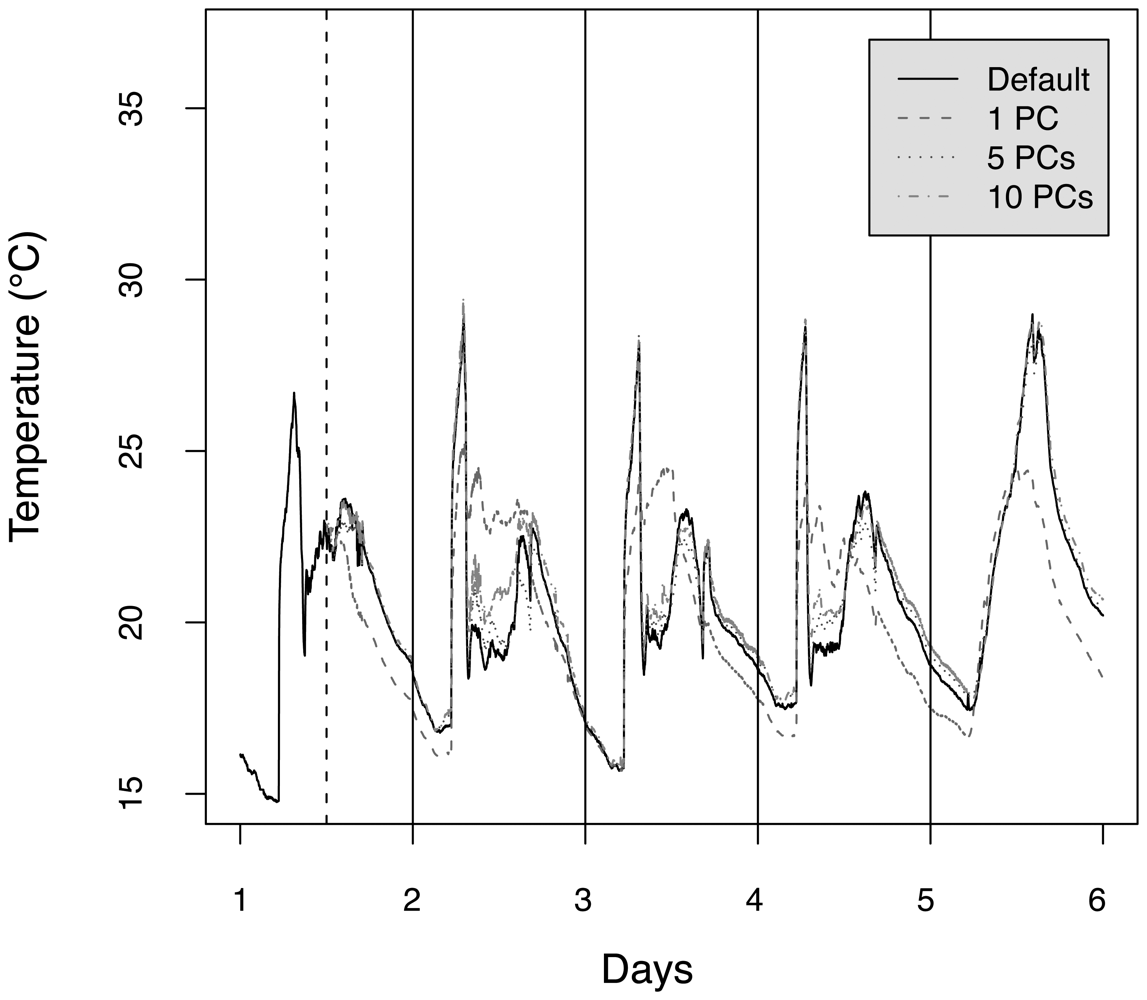
4.6 Distributed principal component computation
4.7 Summary
5 Related work
Conclusion
Acknowledgments
References
- Kumar, S.; Zhao, F.; Shepherd, D. Collaborative signal and information processing in microsensor networks. Signal Processing Magazine, IEEE 2002, 19(2), 13–14. [Google Scholar]
- Intanagonwiwat, C.; Govindan, R.; Estrin, D. Directed diffusion: A scalable and robust communication paradigm for sensor networks. In Proceedings of the ACM/IEEE International Conference on Mobile Computing and Networking; pp. 56–67. 2000. [Google Scholar]
- Pattem, S.; Krishnamachari, B.; Govindan, R. The impact of spatial correlation on routing with compression in wireless sensor networks. In Proceedings of the third international symposium on Information processing in sensor networks; pp. 28–35. ACM Press, 2004. [Google Scholar]
- Xiong, Z.; Liveris, A.; Cheng, S. Distributed source coding for sensor networks. Signal Processing Magazine 2004, 21(5), 80–94. [Google Scholar]
- Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: a survey. Computer Networks 2002, 38(4), 393–422. [Google Scholar]
- Ilyas, M.; Mahgoub, I.; Kelly, L. Handbook of Sensor Networks: Compact Wireless and Wired Sensing Systems.; CRC Press, 2004. [Google Scholar]
- Krishnamachari, L.; Estrin, D.; Wicker, S. The impact of data aggregation in wireless sensor networks. Proceedings of the Distributed Computing Systems Workshops 2002, 575–578. [Google Scholar]
- Heidemann, J.; Silva, F.; Intanagonwiwat, C.; Govindan, R.; Estrin, D.; Ganesan, D. Building efficient wireless sensor networks with low-level naming. In Proceedings of the eighteenth ACM symposium on Operating systems principles; pp. 146–159. ACM Press, 2001. [Google Scholar]
- Intanagonwiwat, C.; Estrin, D.; Govindan, R.; Heidemann, J. Impact of network density on data aggregation in wireless sensor networks. Proceedings of the 22nd International Conference on Distributed Computing Systems 2002, 457–458. [Google Scholar]
- Madden, S.; Franklin, M.; Hellerstein, J.; Hong, W. TAG: a Tiny AGgregation Service for Ad-Hoc Sensor Networks. In Proceedings of the 5th ACM Symposium on Operating System Design and Implementation (OSDI); volume 36, pp. 131–146. ACM Press, 2002. [Google Scholar]
- Madden, S.; Franklin, M.; Hellerstein, J.; Hong, W. TinyDB: an acquisitional query processing system for sensor networks. ACM Transactions on Database Systems 2005, 30(1), 122–173. [Google Scholar]
- Yao, Y.; Gehrke, J. The cougar approach to in-network query processing in sensor networks. ACM SIGMOD Record 2002, 31(3), 9–18. [Google Scholar]
- Burri, N.; Wattenhofer, R. Dozer: ultra-low power data gathering in sensor networks. In Pro-ceedings of the 6th international conference on Information processing in sensor networks; pp. 450–459. ACM Press, 2007. [Google Scholar]
- Le Borgne, Y.; Bontempi, G. Unsupervised and supervised compression with principal component analysis in wireless sensor networks. In Proceedings of the Workshop on Knowledge Discovery from Data, 13th ACM International Conference on Knowledge Discovery and Data Mining; pp. 94–103. ACM Press, 2007. [Google Scholar]
- Hyvarinen, A.; Karhunen, J.; Oja, E. Independent Component Analysis; J. Wiley: New York, 2001. [Google Scholar]
- Li, J.; Zhang, Y. Interactive sensor network data retrieval and management using principal components analysis transform. Smart Materials and Structures 2006, 15, 1747–1757(11). [Google Scholar]
- Bontempi, G.; Le Borgne, Y. An adaptive modular approach to the mining of sensor network data. In Proceedings of the Workshop on Data Mining in Sensor Networks; SIAM SDM; pp. 3–9, SIAM Press; 2005. [Google Scholar]
- Duarte, M.; Hen Hu, Y. Vehicle classification in distributed sensor networks. Journal of Parallel and Distributed Computing 2004, 64(7), 826–838. [Google Scholar]
- Huang, L.; Nguyen, X.; Garofalakis, M.; Jordan, M.; Joseph, A.; Taft, N. In-network PCA and anomaly detection. Scholkopf, B., P, J., Hoffman, T., Eds.; In Proceedings of the 19th conference on Advances in Neural Information Processing Systems.; MIT Press, 2006. [Google Scholar]
- Lakhina, A.; Crovella, M.; Diot, C. Diagnosing network-wide traffic anomalies. In Proceedings of the 2004 conference on Applications, technologies, architectures, and protocols for computer communications; pp. 219–230. ACM Press, 2004. [Google Scholar]
- Bai, Z. others. Templates for the Solution of Algebraic Eigenvalue Problems: A Practical Guide.; Society for Industrial and Applied Mathematics, 2000. [Google Scholar]
- Golub, G.; Van Loan, C. Matrix computations.; Johns Hopkins University Press, 1996. [Google Scholar]
- Akkaya, K.; Younis, M. A survey on routing protocols for wireless sensor networks. Ad Hoc Networks 2005, 3(3), 325–349. [Google Scholar]
- TinyOS. Project Website: http://www.tinyos.net.
- Polastre, J.; Szewczyk, R.; Culler, D. Telos: enabling ultra-low power wireless research. Proceedings of the 4th International Symposium on Information Processing in Sensor Networks 2005, 364–369. [Google Scholar]
- Zhao, F.; Guibas, L. Wireless Sensor Networks: An Information Processing Approach.; Morgan Kaufmann, 2004. [Google Scholar]
- Raghunathan, V.; Srivastava, C. Energy-Aware Wireless Microsensor Networks. Signal Processing Magazine 2002, 19(2), 40–50. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Springer, 2002. [Google Scholar]
- Miranda, A. A.; Le Borgne, Y.-A.; Bontempi, G. New routes from minimal approximation error to principal components. Accepted for publication in the Neural Processing Letters 2008. [Google Scholar]
- Duda, R.; Hart, P.; Stork, D. Pattern Classification.; Wiley-Interscience, 2000. [Google Scholar]
- Webb, A. Statistical Pattern Recognition.; Hodder Arnold Publication, 1999. [Google Scholar]
- Barrenetxea, G. SensorScope: on-line urban environmental monitoring network. Geophysical Research Abstracts 2007, 9, 07501. [Google Scholar]
- Jindal, A.; Psounis, K. Modeling spatially-correlated sensor network data. Sensor and Ad Hoc Communications and Networks, 2004. IEEE SECON 2004. 2004 First Annual IEEE Communications Society Conference on 2004, 162–171. [Google Scholar]
- Rousseeuw, P.; Molenberghs, G. Transformation of non positive semidefinite correlation matrices. Communications in Statistics-Theory and Methods 1993, 22(4), 965–984. [Google Scholar]
- Intel Lab. Data webpage. http://db.csail.mit.edu/labdata/labdata.html.
- Wireless Sensor Lab. Machine Learning Group. University of Brussels. http://www.ulbac.be/di/labo/index.html.
- Vosoughi, A.; Scaglione, A. Precoding and Decoding Paradigms for Distributed Data Compression. IEEE Transactions on Signal Processing 2007. [Google Scholar]
- Pradhan, S.; Ramchandran, K. Distributed source coding using syndromes (DISCUS): design and construction. IEEE Transactions on Information Theory 2003, 49(3), 626–643. [Google Scholar]
- Gastpar, M.; Dragotti, P.L.; Vetterli, M. The Distributed Karhunen-Loève Transform. IEEE Transactions on Information Theory 2006, 52(12), 5177–5196. [Google Scholar]
- Bai, Z.-J.; Chan, R.; Luk, F. Principal component analysis for distributed data sets with updating. In Advanced Parallel Processing Technologies; volume 3756, pp. 471–483. Springer Berlin: Heidelberg, 2005. [Google Scholar]
- Kargupta, H.; Huang, W.; Sivakumar, K.; Park, B.; Wang, S. Collective Principal Component Analysis from Distributed, Heterogeneous Data. In Proceedings of the 4th European Conference on Principles of Data Mining and Knowledge Discovery; pp. 452–457. Springer-Verlag, 2000. [Google Scholar]
- Jelasity, M.; Canright, G.; Engø-Monsen, K. Asynchronous Distributed Power Iteration with Gossip-Based Normalization. In Proceedings of Euro-Par, volume 4641 of Lecture Notes in Computer Science; pp. 514–525. Springer, 2007. [Google Scholar]
- Duarte, M. F.; Sarvotham, S.; Baron, D.; Wakin, M. B.; Baraniuk, R. G. Distributed compressed sensing of jointly sparse signals. Proceedings of the 39th Asilomar Conference on Signals, Systems and Computation 2005, 1537–1541. [Google Scholar]
- Donoho, D. Compressed Sensing. IEEE Transactions on Information Theory 2006, 52(4), 1289–1306. [Google Scholar]
- *Measurements are centered so that the origin of the coordinate system coincides with the centroid of the set of measurements. This translation is desirable to avoid a biased estimation of the basis {wk}1≤k≤q of ℝp towards the centroid of the set of measurements.
- †The time to first failure is the amount of time at which the first node in the network runs out of energy.
- ‡that contains negative eigenvalues


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Communication | Computation | Memory |
|---|---|---|---|
| Covariance | |||
| Centralized | O(pT) | O(p2T) | O(p2) |
| Distributed | |||
| Eigenvectors | |||
| Centralized | O(qp) | O(p3) | O(p2) |
| Distributed | |||
© 2008 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Le Borgne, Y.-A.; Raybaud, S.; Bontempi, G. Distributed Principal Component Analysis for Wireless Sensor Networks. Sensors 2008, 8, 4821-4850. https://doi.org/10.3390/s8084821
Le Borgne Y-A, Raybaud S, Bontempi G. Distributed Principal Component Analysis for Wireless Sensor Networks. Sensors. 2008; 8(8):4821-4850. https://doi.org/10.3390/s8084821
Chicago/Turabian StyleLe Borgne, Yann-Aël, Sylvain Raybaud, and Gianluca Bontempi. 2008. "Distributed Principal Component Analysis for Wireless Sensor Networks" Sensors 8, no. 8: 4821-4850. https://doi.org/10.3390/s8084821