1. Introduction
Abnormal operations induced by gear or bearing failures should be detected as early as possible to avoid serious and even fatal accidents. A variety of methods have been applied for the diagnosis of rotating machinery based on vibration and acoustic signals [
1,
2], thermal features [
3] and oil debris [
4], among which the vibration based analysis is one of the most commonly used technique [
5,
6]. According to the characteristics of the data, it is feasible to detect abnormalities in vibration signals and make decisions about the health conditions of gear or bearing by employing appropriate data analysis algorithms such as empirical mode decomposition (EMD) [
7], spectral kurtosis [
8], wavelet analysis [
9], and time synchronous averaging [
10]. Nevertheless, most of these methods depend on careful observation and recognition of the corresponding features of the vibration signals to identify the faults, which require a great deal of expertise to apply them successfully. On the other hand, because of the complexity of the equipment and the variety of the fault categories, massive real-time data are required to fully inspect the health conditions of the equipment. It would be labour-intensive and time-consuming for diagnosticians to analyze massive data based on appropriate methods. Therefore, simpler approaches are needed which allow relatively unskilled operators to make reliable and rapid decisions with less expertise and labour. Artificial intelligence (AI) techniques, which can effectively analyze massive amounts of fault data and automatically provide accurate diagnosis results, have been successfully applied to detect abnormalities in rotating machinery [
11,
12,
13,
14,
15]. Li et al. proposed a novel feature extraction and selection scheme to obtain a more compact feature subset, and then applied four types of AI techniques for the hybrid fault diagnosis of a gearbox [
1]. Cheng et al. proposed a fault diagnosis framework for rolling bearing based on scale invariant feature transform, kernel principal component analysis and SVM [
16]. Samanta et al. extracted time-domain features and employed ANNs and SVM to diagnose bearing faults [
17]. Zhao et al. presented a new back propagation neural network (BPNN) based on an improved shuffled frog leaping algorithm for the fault diagnosis of bearings [
18].
Throughout the previous researches, we find that ANNs are one of the most commonly used classifiers in intelligent fault diagnosis, among which back propagation neural network (BPNN) is the representative one based on supervised learning [
19]. It consists of the input layer, the output layer and the hidden layers, and is generally trained to find a function that can best map a set of inputs and the corresponding outputs by using back propagation algorithm. The SVM is another well-known classifier that is based on statistical learning theory, VC dimension and structural risk minimization. This method has better generalization than ANNs have and can solve the learning problem of smaller number of samples quite well. Meanwhile, it has advantages on nonlinearity problems and high dimensional pattern recognition problems [
20,
21,
22]. Nevertheless, one of the salient challenges to these techniques is the capability to capture relevant health condition information from the massive datasets associated with practical applications. Modern rotating machinery components produce datasets that are usually complex and noisy because of actual operating conditions. Accurate modelling of such complex data can hardly be achieved by conventional AI methods because they can accommodate only a small number of non-linear operations [
23,
24,
25,
26]. To overcome this deficiency, domain specific features that are more relevant to the health conditions are preferred for subsequent fault classification. Nevertheless, developing domain specific features through feature extraction and feature selection is overwhelmingly dependent on prior knowledge about signal processing techniques and diagnostic expertise, which is unpractical in industrial applications because of the significant variety of equipment and working conditions [
23]. These problems have greatly limited the practical application of conventional AI diagnosis methods.
Deep learning [
26,
27,
28,
29] has recently proven its capability for unsupervised feature learning in various fields such as speech recognition [
30,
31], motion capture [
32], visual recognition [
33,
34], and physiology [
35,
36]. This new technique takes full advantage of unsupervised feature learning to extract features from unlabelled time domain data instead of features selected by a human operator, eliminating the conventional dependence on prior knowledge of signal processing techniques and diagnostic expertise. Besides, the deep architectures in the networks are more capable of modelling complex structures in the data compared with conventional shallow methods. Therefore, deep learning represents a substantial improvement over conventional AI techniques and offers the potential to address the challenges facing fault diagnosis of rotating machinery [
37,
38,
39]. Li et al., applied a Gaussian-Bernoulli deep Boltzmann machine (GDBM) to diagnose fault patterns in gearbox and bearing [
39]. Tran et al., presented a new method based on a deep belief network (DBN) for the fault diagnosis of valves in reciprocating compressors [
40]. Gao et al., utilized the deep quantum inspired neural network (DQINN) to the aircraft fuel system fault diagnosis [
41]. Jeong et al., developed autonomous orbit shape recognition systems for the purpose of rotor diagnosis using the deep learning algorithm [
42]. However, there still exist manual signal processing or feature selection techniques in these methods, and the powerful ability of deep learning in unsupervised feature learning has not been fully investigated. Jia et al., integrated a Fourier transform (FFT) and deep neural networks (DNNs) to diagnose faults in rotating machinery [
43]. In this method, the frequency spectra of the measured signals calculated by the FFT were used as input data for the DNNs. Nevertheless, the deviations caused by the assumptions of linearity, periodicity and stationarity could not be avoided when the Fourier spectral analysis is applied to nonstationary data [
44]. Therefore, it is favourable to train the deep network directly from the raw signals in the time domain.
This paper proposes a novel AI method based on a DBN to achieve unsupervised feature learning and automatic fault diagnosis of a gear transmission chain. In this method, the DBN is first pre-trained layer by layer in an unsupervised manner and then fine-tuned with a back propagation (BP) algorithm under supervision. The unsupervised process aims to obtain representative features characterizing the health conditions of machinery from the raw data directly, and the supervised process is implemented to discover the discriminative information from these features. Besides, the genetic algorithm is used to optimize the structural parameters of the network. Compared to the conventional AI methods, the proposed method can adaptively exploit robust features related to the faults from the unlabelled time domain data, which little field expertise is needed. Besides, the proposed deep network has superiorities to model complex structured data, thus can discover the discriminative information of these data and achieve accurate classification. To illustrate the application of the proposed method, the rest of this paper is organized as follows:
Section 2 introduces this method, in which the DBN is trained directly by the unlabelled time domain data to learn domain specific features and a back propagation (BP) algorithm is used to fine-tune the network to achieve fault classification.
Section 3 describes the problems that limit supervised learning methods applied to the fault diagnosis of rotating machinery.
Section 4 presents the diagnosis results of experimental rolling bearing data and public gearbox fault datasets based on the proposed method.
Section 5 discusses these results, and
Section 6 summarizes the conclusions.
2. Methods
In this section, a DBN-based AI method is proposed to achieve unsupervised feature learning and automatic classification.
2.1. DBN Conceptual Framework
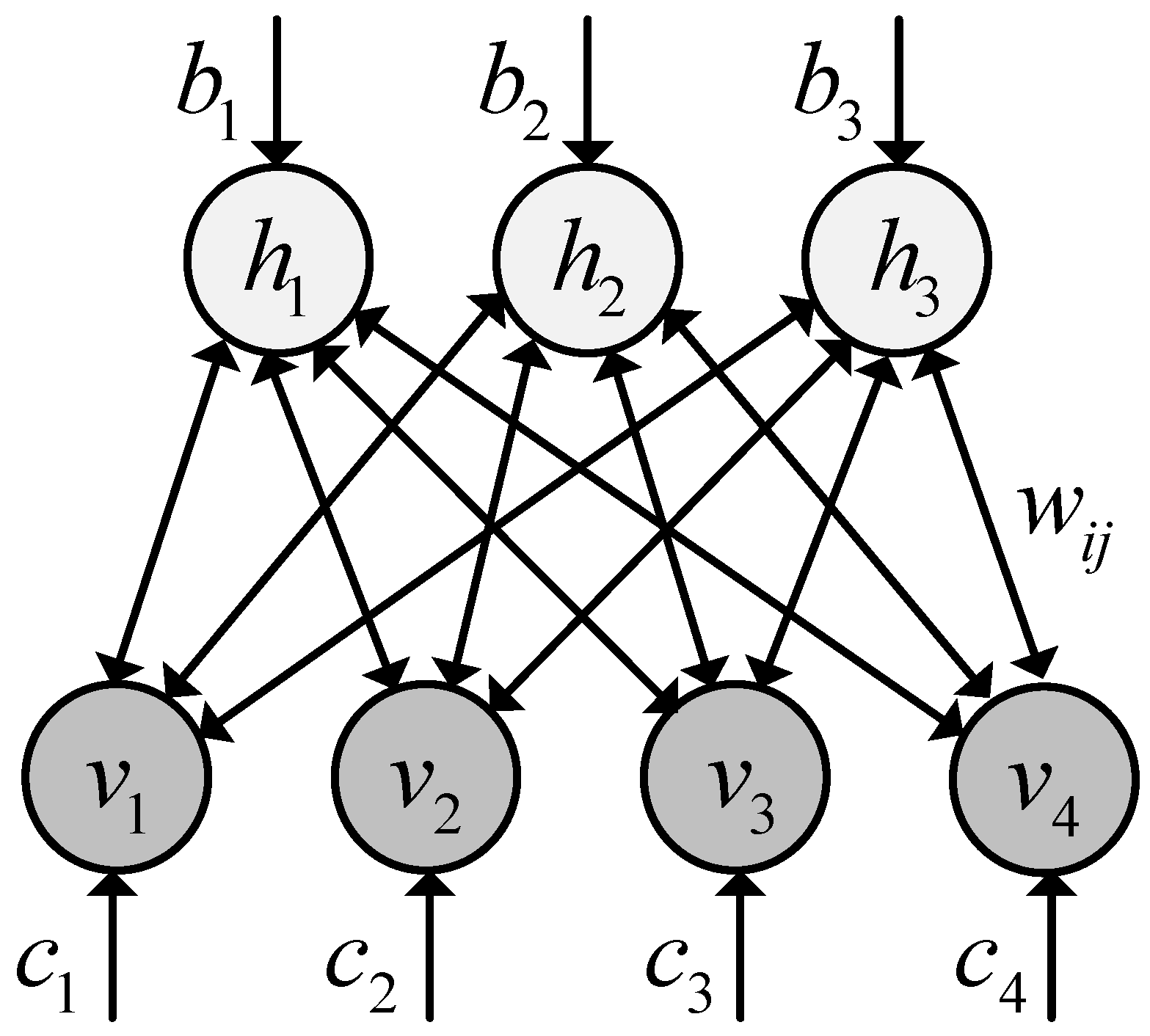
DBN is an unsupervised feature learning model with deep architecture. Each layer of the DBN is a restricted Boltzmann machine (RBM) [
28,
35,
45], which is a generative probabilistic model with input units (visible units)
, and hidden units
. The visible and hidden units are connected with a weight matrix
and have bias vectors
and
, respectively. There are no visible-visible connections and no hidden-hidden connections. The architecture of the RBM is depicted in
Figure 1.
For given visible and hidden units, the energy function is defined as:
where
and
are the binary states of visible unit
and hidden unit
;
and
are their biases and
is the weight between them;
and
are the number of visible and hidden units. The joint distribution for the visible and hidden units is defined via the energy function as:
where
is the partition function that ensures that the distribution is normalized. For binary visible and hidden units, the probability that hidden unit
is activated given visible vector
, and the probability that visible unit
is activated given hidden vector
, are given by:
respectively, where
is the activation function. The logistic function
is a common choice for the activation function. Equation (3) describes the positive phase learning process that transforms the input data from a high-dimensional space into characteristic vectors in a low-dimensional space, and Equation (4) describes the negative phase learning process that reconstructs the input data from the characteristic vectors. The parameter
,
and
, are trained simultaneously to minimize the reconstruction error. The mean square error (MSE):
is usually used as the standard loss function, where
is an input sample from a dataset
and
is the corresponding reconstruction.
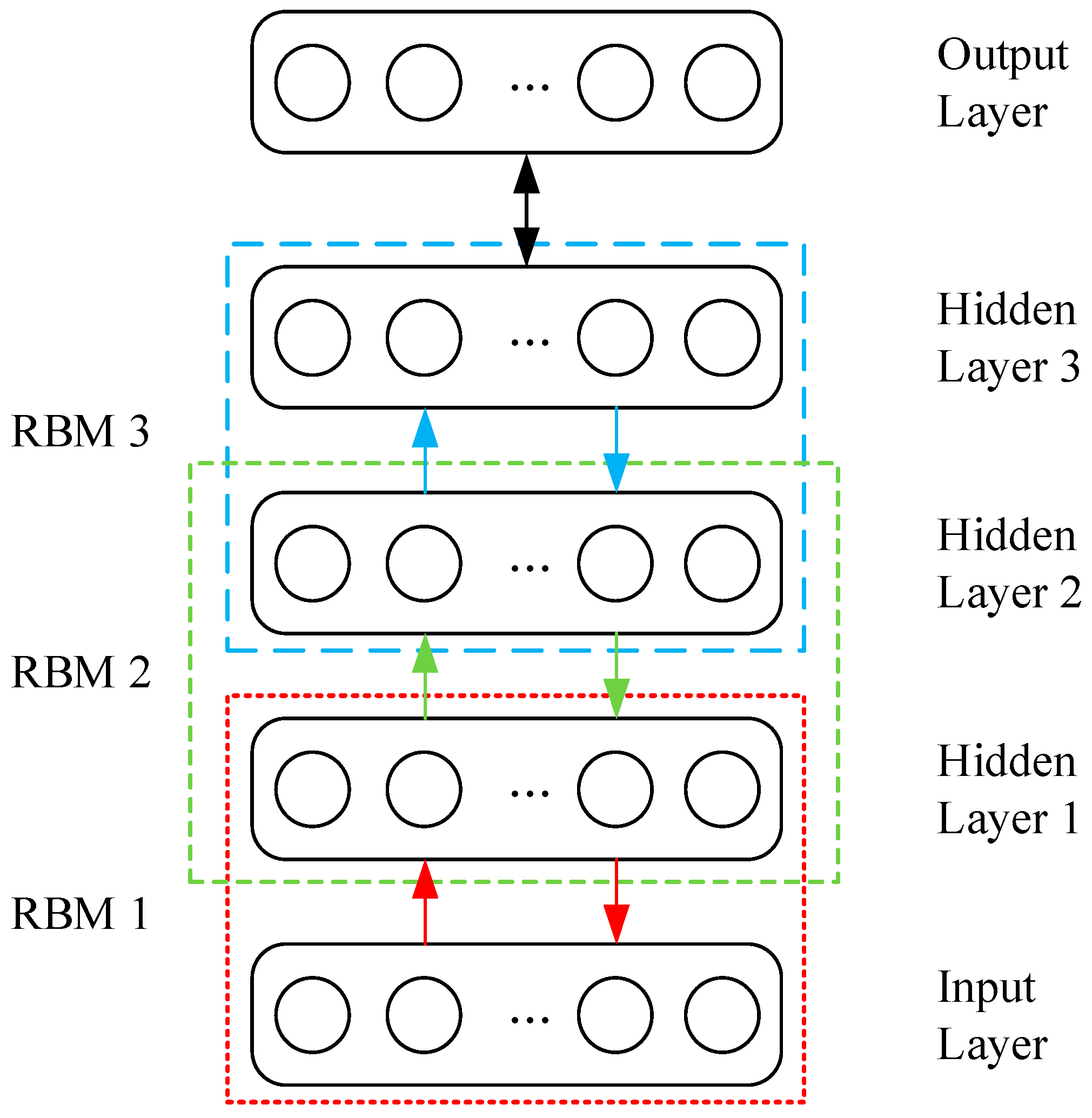
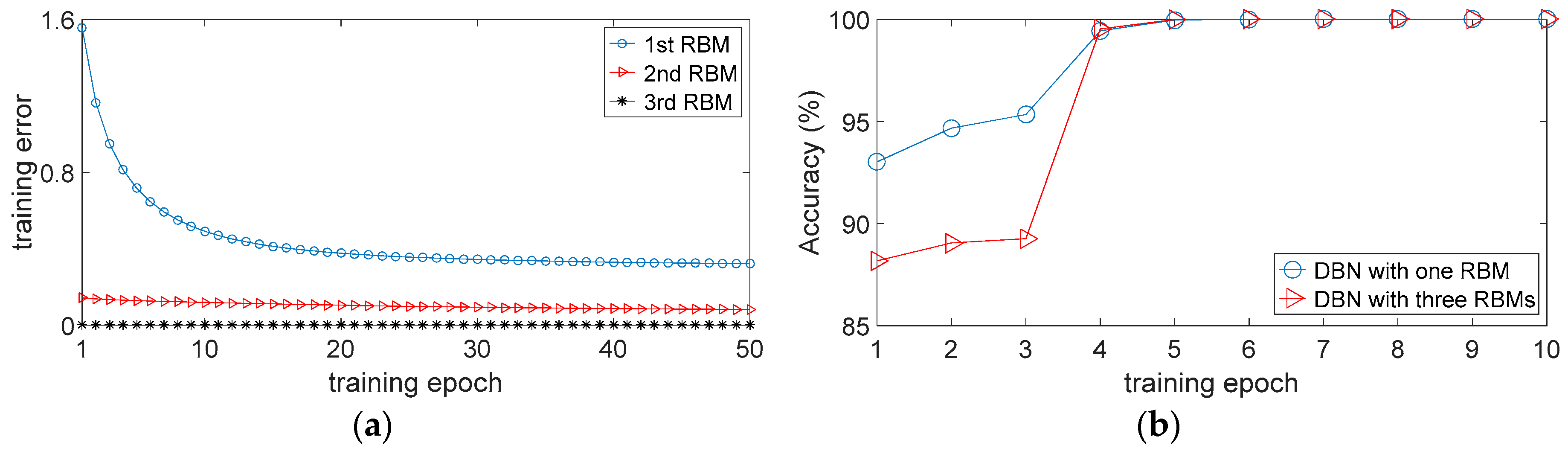
Several RBMs can be stacked to produce a DBN, the output of a lower-layer RBM is the input to a higher-layer RBM.
Figure 2 displays a DBN structure with three stacked RBMs, layer 1 (input layer) and layer 2 (hidden layer 1) form the first RBM, layer 2 (hidden layer 1) and layer 3 (hidden layer 2) form the second RBM, layer 3 (hidden layer 2) and layer 4 (hidden layer 3) form the third RBM, and finally is the output layer. It should be noted that the hidden layer of the first RBM, i.e., layer 2, is also the visible layer of the second RBM, and so is the second RBM and the third RBM.
2.2. Training Process of DBN Classifier Model
The DBN classifier model is trained according to two main steps: (1) pre-training of each individual RBM layer by layer with unsupervised learning and (2) further fine-tuning of the DBN with a back propagation (BP) algorithm for classification.
In the first step, each RBM can be trained by performing a stochastic gradient descent on the negative log-likelihood probability of the training data. The gradient of the negative logarithmic probability of the visible layer with respect to parameter
is defined as:
where
denotes the expectation under the distribution of the data, and
ndenotes the expectation under the distribution of the model. In practice, because the exact computation of
is exceedingly difficult, an approximation referred to as contrastive divergence after
k iterations of Gibbs sampling (often
k = 1) is usually used to train the RBM [
46,
47]. When given input data
from a dataset,
the Gibbs sampling of one step is given as:
Therefore, the update rule of the parameter
can be given by:
The parameters and , are updated conforming to the same rule. In general, all parameters of each RBM will be continuously optimized until a maximum number of training epochs are reached, which are determined by a human operator. In this way, the iterative training of one RBM is completed and the process will be continued layer by layer until all RBMs in the DBN structure are trained.
After the DBN is pre-trained, fine-tuning process is utilized in the next step of the DBN training. The fine-tuning process further reduces the training error and improves the classification accuracy of the DBN-based classifier model. As for classification tasks, the output of the DBN calculated from the input sample
is expected to approximate the label corresponding to
. The BP algorithm is usually utilized to minimize the error between the output of the DBN and the label by adjusting the parameters in the DBN. Supposing that the output of the DBN is
and the label of
is
, the training error is defined as:
where
is the parameter set of the DBN and can be updated as
where
is the learning rate. Similarly, this fine-tuning process will be continued until a maximum number of training epochs are reached.
2.3. DBN-Based AI Fault Diagnosis Method
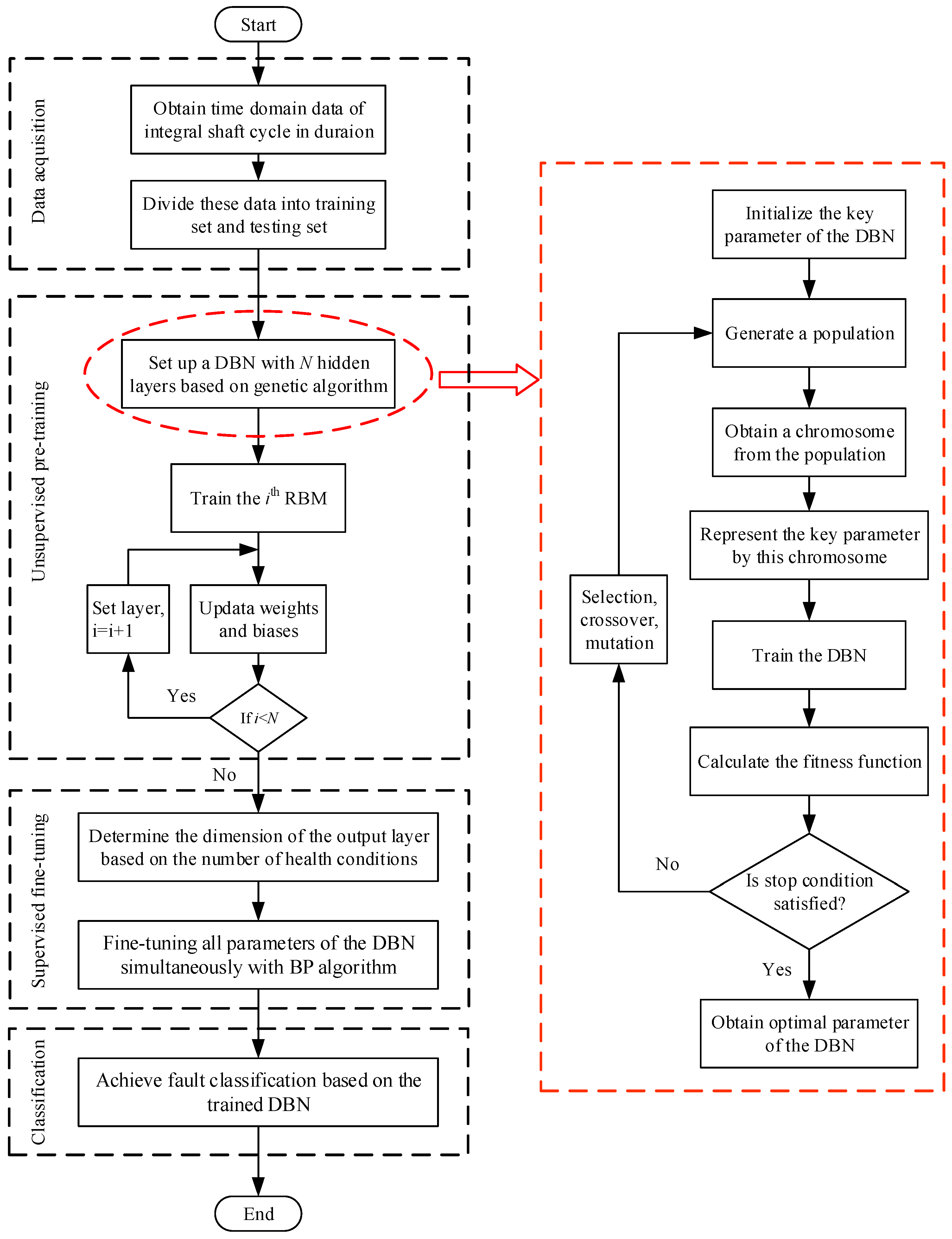
Based on the DBN, this paper proposes a new AI fault diagnosis method that can learn representative features from the raw signals of a gear transmission chain, instead of using features selected by a human operator, to automatically provide accurate classification results. The basic procedures of the proposed method are briefly illustrated in
Figure 3.
First, the measured signals must be arranged to fulfil the constraints on the DBN. Conventional AI methods use human-selected features to form the sample set. Here, the measured signals are directly segmented to form the sample sets. The segmentation process has two main steps: (1) determine the axis crossing corresponding to one revolution of the shaft through the measured tachometer signal; and (2) interpolate the time domain data between each of these axis crossings using cubic spline interpolation. The main reason for interpolating the time domain data is that the raw data points between each of these axis crossings may be different because of unstable speed or other complex operating conditions. Each set of time domain data is integrated over the shaft cycle, with durations containing the same number of points to guarantee the capture of all the useful information during each shaft cycle and to correlate the phase features. Following standard practice, the data is interpolated at exactly 2N evenly spaced points, where N is the next integer power of two from the length of the raw data. The whole process requires neither conversion between the time and frequency domains nor any other signal processing techniques, thus avoiding some potential problems associated with different signal processing techniques. Finally, these intercepted time domain data form the sample set , where is the mth sample, is the classification label of and is the sample size. The number of training and testing samples can be determined for specific applications.
Second, set up a DBN with N hidden layers based on genetic algorithm and pre-train layer by layer in an unsupervised manner. It should be noted that the number of RBMs refers to the number of hidden layers because each RBM only contains one hidden layer. Specifically, the input samples are first given to the visible layer of the first RBM. Then the parameters of this RBM are continuously optimized based on the updated rule. While the training epoch reaches its maximum number and the training of the first RBM is accomplished, the hidden layer of this RBM becomes the visible layer of the second RBM. Then the training process is continued for the second RBM. Finally, by training N individual RBMs, all of the hidden layers of the DBN are pre-trained.
Third, determine the dimension of the output layer based on the number of health conditions. Then the BP algorithm is utilized to fine-tune all of the parameters of the DBN by minimizing the error between the output calculated from the input samples and the corresponding labels. Unlike the unsupervised pre-training process, in which each RBM is trained independently, the supervised fine-tuning is applied to all layers simultaneously. Finally, the completely trained DBN is utilized to fault classification of a gear transmission chain.
Besides, it should be noted that some parameters could greatly affect the performance of the DBN. Some researchers have proposed several guidance on how to determine the parameters [
43,
47]. However, for a specific application, there is no universal rule on the optimized selection of parameter values. In this paper, structural parameters are determined using the genetic algorithm (GA). The main procedures are as follows: (1) Randomly generate an initial population of chromosomes which represent the values of parameters in the DBN. (2) Train the DBN and calculate the fitness function. The fitness function refers to the classification accuracy of the DBN, which is defined as
, where
and
represent the number of true and false classifications respectively. (3) Generate a new population in the next generation by the three GA operations, i.e., selection, crossover and mutation, and then continue to search the appropriate parameters. This evolutionary process proceeds until the stop condition is satisfied or a maximum number of generations are reached.
Through the proposed method, unlabelled time domain data, which are easy to obtain and do not require diagnostic expertise, are utilized and the features are learned from the data instead of being selected by a human operator. Meanwhile, the complex relationship between input data and health conditions can be established to achieve accurate classification. Therefore, the proposed method is capable of the fault diagnosis of a gear transmission chain.
3. Fault Diagnosis Based on Supervised Learning Scheme
Signals originating from the gear transmission chain are complicated because of the system’s complexity and its operating conditions [
8]. This section describes the rolling bearing experimental system and the problems that limit supervised learning methods applied to the fault diagnosis of rotating machinery.
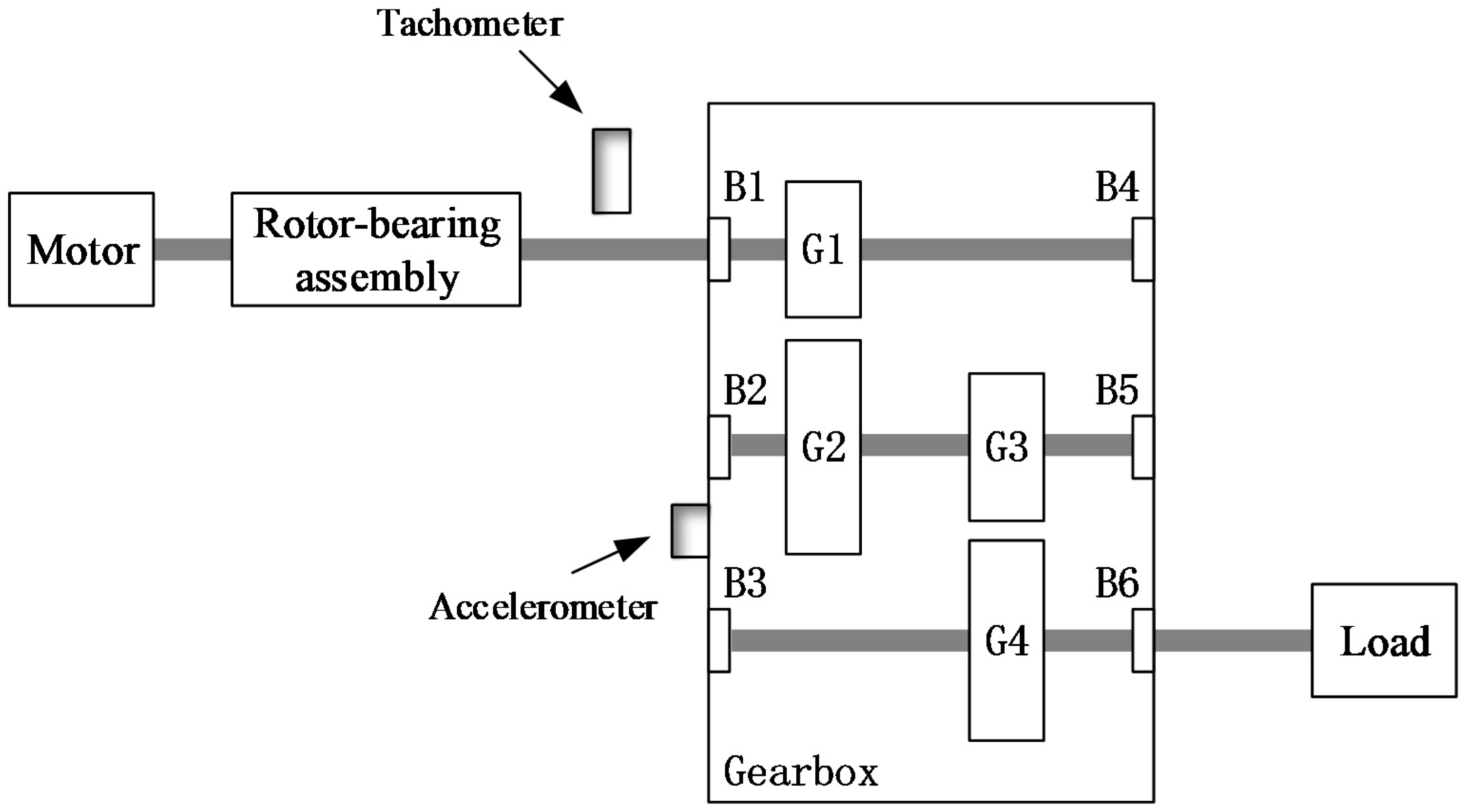
Figure 4 shows the experimental system designed for this work, a two-stage fixed-axis gearbox is driven by a motor (0.75 KW, three-phase, Siemens, Yangzhou, China) and the rotating speed is controlled by the converter (SINAMICS V20, Siemens, Nanjing, China), and a data acquisition system (cDAQ-9234, NI, Austin, TX, USA) is used to collect the data.
Figure 5 shows the configuration of the gearbox, there are three shafts inside the gearbox, which are mounted to the gearbox housing with bearings. The input gear has 32 teeth, the idler gear has 64 teeth and the output gear has 96 teeth. In this work, the bearing mounted on the input side of the gearbox is set as test bearing. A mono-axial accelerometer (ICP, KD 1005 L, Yangzhou, China) is mounted on the 12 o’clock position of the input side of the gearbox adjacent to the test bearing for acquiring the vibration signals. A tachometer is used to acquire the input shaft speed in real time. The driven speed of the motor is 2700 rpm, and the sampling frequency is 25.6 kHz.
All bearings used in this work are SKF 6004-2RSH deep groove ball bearing. Some parameters of the bearing are listed as follows: inside diameter: 20 mm; outside diameter: 42 mm; ball diameter: 6.4 mm; pitch diameter: 31 mm; ball number: 9.
Various faults are introduced to the test bearing using the WEDM method. These faulty bearings are shown in
Figure 6. Detailed descriptions of the eight health conditions are summarized in
Table 1. Additionally, all the outer race faults are located at 6 o’clock position.
Figure 7 presents the raw vibration signals of the eight health conditions and their corresponding spectra. However, it is difficult to identify the different health conditions as the characteristic frequencies have no significant difference. Thus, it is necessary to apply a more efficient method to extract the fault characteristics.
In this work, we utilize the statistical features to characterize the bearing health conditions and employ the BPNN for fault classification.
Figure 8 displays the flowchart of fault diagnosis method presented in this section. Here, 10,000 samples can be obtained for each health condition. These samples are randomly partitioned into a training set and a testing set by using
k-fold cross-validation method, where
k is chosen as four. Therefore, four subsets are generated where one subset containing 20,000 samples is used as the testing set and the other three subsets containing 60,000 samples are used as the training set. Eleven features in the time domain and four features in the frequency domain, which are listed in
Table 2, are calculated from each sample. Specifically,
may reflect the vibration amplitude and energy in time domain.
may represent the time series distribution of the signal in time domain.
may indicate the vibration energy in frequency domain.
may reflect the position change of the main frequencies.
may describe the convergence of the spectrum power. As the amplitude and distribution of the vibration signals may change when faults occur, these changes can be captured by the listed statistical features in
Table 2.
To reduce feature dimensionality and improve classification accuracy, feature selection is critical to the subsequent classification. Several researchers have proposed effective methods of feature selection. Because of its simplicity and reliability, the distance evaluation technique (DET) is widely used to feature selection [
48]. This method has three main steps: (1) calculate the average distance of each feature inside the same condition pattern
, where
is the feature number of each sample; (2) calculate the average distance of each feature between different condition pattern
; (3) define the distance evaluation criteria as
. Following standard practice, we can obtain the normalized distance evaluation criteria
. It is clear that the lager
means that the corresponding feature is better to increase the separation among different conditions. In this work, the DET is applied to evaluate the importance of all features. The normalized distance evaluation criteria of 15 features are shown in
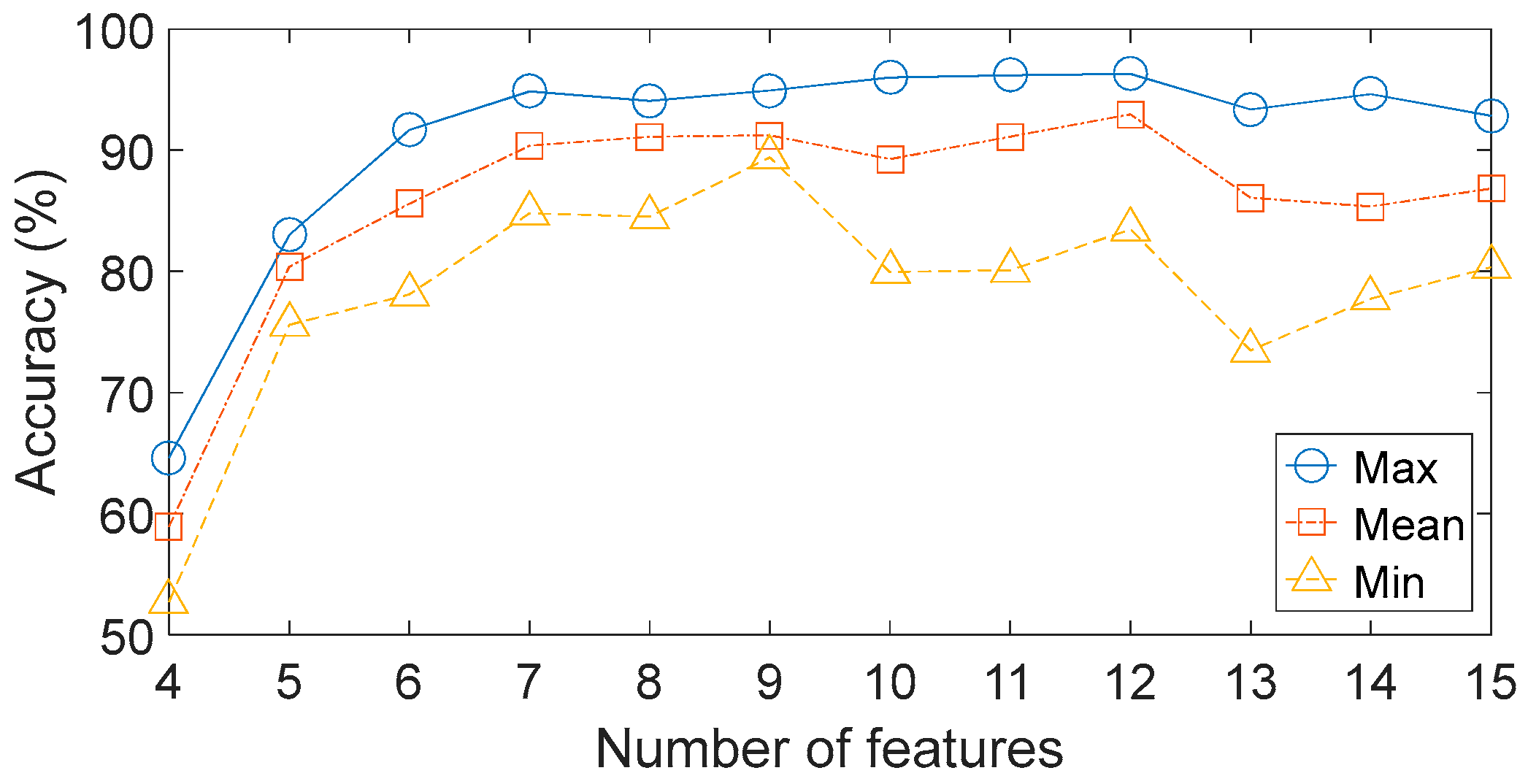
Figure 9. The next problem is how many features should be selected. It is obvious that fewer features may lead to lack of critical information, while a larger number of features do not necessarily result in higher classification accuracy because there may be irrelevant or redundant information in these features. Here, different numbers of features with lager criteria are evaluated by the BPNN-based method respectively. The designed BPNN has three hidden layers: the unit numbers of the first layer, the second layer and the third layer are 100, 50 and 10 respectively. The maximum training epoch is 500, and the learning rate is 0.05. The results are shown in
Figure 10. The classification accuracy defined in this paper refers to the ratio of samples that are correctly classified to the total sample set, which is defined as follows:
where
and
represent the number of true and false classifications respectively.
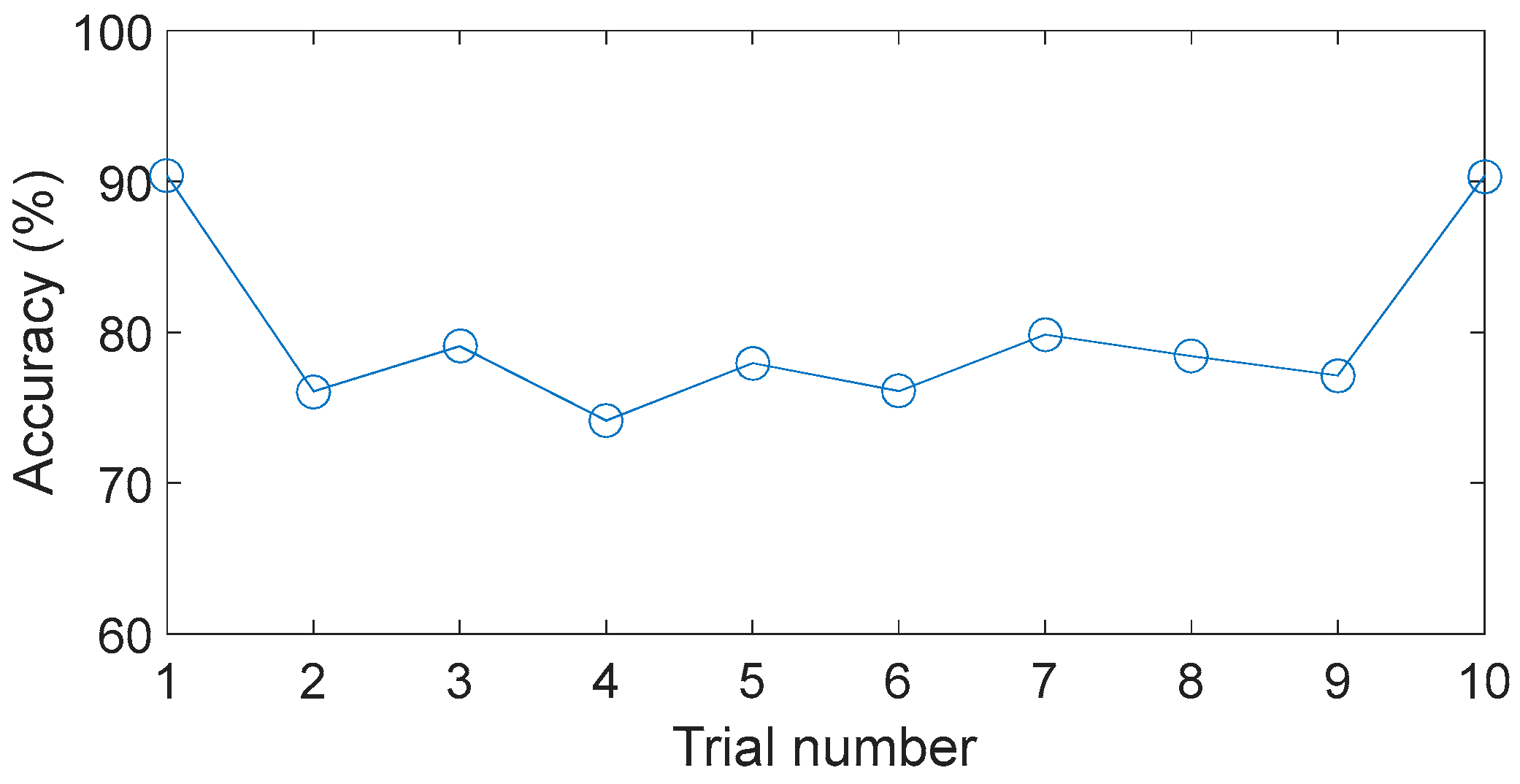
The results show the poor accuracies when only four or five features are used. Meanwhile, when the number of features is larger than five, the average accuracies improve slightly but are still unsatisfactory under several engineering applications. The performances of different feature subsets have not improved when increasing the number of features, which implies that the original feature set contains irrelevant or redundant information. In addition, the performances for each feature subset vary greatly over the four trials. For instance, when seven features are included in the feature subset, the highest and the lowest accuracies are respectively to be 94.86% and 84.79%. These results indicate that the BPNN-based method offers poor stability and unacceptable robustness.
The performances of different feature types are also evaluated in this work. Ten feature subsets, each containing seven features, are selected from the original feature set, and the features in each subset are not necessarily the same. The features in the first subset are selected based on DET, whereas the others are selected randomly. The results of this analysis are shown in
Figure 11, where it is clear that the performances of the ten feature subsets vary greatly, implying that some typical features are inappropriate for fault diagnosis in this case. Besides, several feature subsets with the number of features respectively to be 1~15 have been investigated and the results of these cases have no significant difference.
From the above analysis, it is clear that learning representative features for each task is crucial for classification. In this work, 15 statistical features in the time domain and frequency domain are extracted from the raw signals and the DET is used to select the sensitive features. It is feasible that by employing other appropriate data analysis algorithms, better classification accuracy may be obtained. However, this process largely depends on prior knowledge of signal processing techniques and diagnostic expertise. In addition, the signal processing techniques adopted to solve one specific issue may not be suitable for others. Because of these problems, unsupervised feature learning is expected to be more effective against the challenges facing fault diagnosis of gear transmission chains.
5. Discussion
The analysis in
Section 4 shows that the proposed method can effectively learn relevant features and accurately classify various health conditions in rotating machinery. The experiment in
Section 4.1 is aimed at the fault diagnosis of rolling bearings in the gearbox. The collected data are very complicated because of the system’s structure and operating conditions. Nevertheless, the average accuracy of the proposed method is 99.26%, with a standard deviation of 0.02% when the combination of sample size is 60,000 training samples & 20,000 testing samples, indicating that this method can effectively and stably distinguish not only bearing fault categories but also fault severities. The experiment in
Section 4.2 investigates the fault diagnosis of a gearbox, including more fault categories and different fault locations in the gearbox. The performance of the proposed method remains excellent. In contrast, the performance of the BPNN-based method and the SVM-based method in both analyses are comparatively poor. These results confirm that the unsupervised feature learning model with deep architectures has superior capacity to accurately model complexly structured data compared to the shallow neural network model. Besides, many researches focus on the application of deep learning in the fault diagnosis of rotating machinery. In a previous study [
39], a deep statistical feature learning for vibration measurement has been proposed to diagnose fault patterns in rotating machinery. Two typical rotating machinery systems (gearbox fault diagnosis system and bearing fault diagnosis system) are constructed to validate its method. In the first experiment, the method is used to distinguish ten gear health conditions under different loads and 95.17% classification accuracy is obtained. In the second experiment, the method is used to distinguish seven bearing faults and 91.75% classification accuracy is obtained. Both the design of experiments and fault categories are similar to that in this paper, and the results show that the proposed method can obtain higher classification accuracies compared with the deep learning method in [
39].
Feature extraction and feature selection are crucial steps in fault diagnosis because the relevance of the extracted features directly affects the classification accuracy. In this work, we present the results of the BPNN-based method applied to raw data and different time domain features, and it is found that the classification accuracies vary dramatically at unsatisfactory levels. To overcome these limitations, developing robust features that capture the relevant information for each issue may improve the classification accuracy. However, this process is time-consuming and largely depends on diagnostic expertise. In contrast, the proposed method uses unsupervised feature learning to obtain representative features from the raw data and achieve accurate classification. This offers the advantage of using raw data instead of extracting features based on the expertise of a human operator. The whole process requires neither conversion between the time and frequency domains nor other signal processing techniques, thus avoiding some potential problems associated with different signal processing techniques. To verify the ability of the proposed method in adaptively exploiting fault features, we set the features exploited through unsupervised feature learning as the input of BPNN and SVM to achieve fault classification. In the first experiment, the average accuracy is 98.94% when using the unsupervised feature learning and BPNN, and 98.49% when using the unsupervised feature learning and SVM. In the second experiment, the average accuracies even reach 100%. Compared to the results list in
Table 3 and
Table 7, the accuracies are much higher than that of the conventional BPNN-based method and SVM-based method. The results reveal that the proposed method could adaptively exploit the fault features of balling bearings and gearbox.
The architecture selection is an important process for most neural network models. In this paper, the DBN contains one hidden layer with 1000 hidden units, which is determined through the genetic algorithm. To further evaluate the proposed method, we changed the number of hidden units and calculated the classification accuracy. This analysis showed that the limited variation of some architecture parameters has little effect on the performance of the DBN.
The influence caused by different sample sizes has also been considered. In
Section 4.1, four combinations between the training samples and the testing samples are tested to evaluate the robustness of the proposed method. The results show that the accuracies of all trials are higher than 98%, confirming the strong robustness of the proposed approach to different choices of training & testing samples.
In this paper, the unlabelled time domain data of integrated shaft cycles are utilized for classification. The only pre-processing step is to apply the tachometer signal to determine the shaft cycle duration. Beyond that, no other signal processing technique is required. Currently, some data acquisition systems can adjust the data sample rate based on a tachometer signal so that 2N data points are captured per cycle of rotation. In this way, we can directly train the DBN using raw data in the time domain without any pre-processing.
6. Conclusions
This paper proposes a DBN-based AI method for the fault diagnosis of a gear transmission chain. In this method, the DBN based classifier is first pre-trained layer by layer in an unsupervised manner and then fine-tuned with a BP algorithm under supervision. Besides, the genetic algorithm is used to optimize the structural parameters of the network. In contrast to the supervised neural network, the proposed method takes full advantage of unsupervised feature learning to extract features from the unlabelled time domain data instead of relying on a human operator to extract features. Therefore, the proposed method depends less on field expertise or prior knowledge of diagnostic techniques. Moreover, the proposed method has superiorities to model complex structured data, thus can discover the discriminative information of these data and achieve accurate classification.
Two experiments, i.e., rolling bearing faults and gearbox faults, are conducted to verify the performances of the proposed method. Various fault categories, fault locations and fault severities under different loading conditions are considered in the experiments. The fault classification accuracies are 99.26% for rolling bearings and 100% for gearbox when using the proposed method. Besides, the confusion matrix shows that the accuracy of each health condition retains at high level with strong robustness. In contrast, the performance of the BPNN-based method and the SVM-based method in both experiments are comparatively poor. The above results show that the proposed method performs better in the classification of gear transmission chain faults compared to the conventional AI methods. Besides, the vibration data utilized here is obtained from only one sensor, our future work will focus on a more comprehensive fault diagnosis of rotating machinery based on the multi-sensor data fusion and deep learning methods.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}