
A Formal Approach to the Selection by Minimum Error and Pattern Method for Sensor Data Loss Reduction in Unstable Wireless Sensor Network Communications


Abstract
:1. Introduction
- Detection of accidents or events: What accidents or events occurred?
- Main agents of accidents or events: What or who brought about the accidents or events?
- Cause, time, or place of accidents or events: Why, when, or where did the accidents or events occur?
- Progress of accidents or events: How did the accidents or events proceed?
- Analysis of the cause of accidents or events: What or who was the cause of accidents or events?
- Analysis of effects of accidents or events: What or whom did the accidents or events have effects on and what were these effects?
- Prediction of future trends: What will be changed by accidents or events, and how, when, where, or why will these changes occur?
2. Related Work
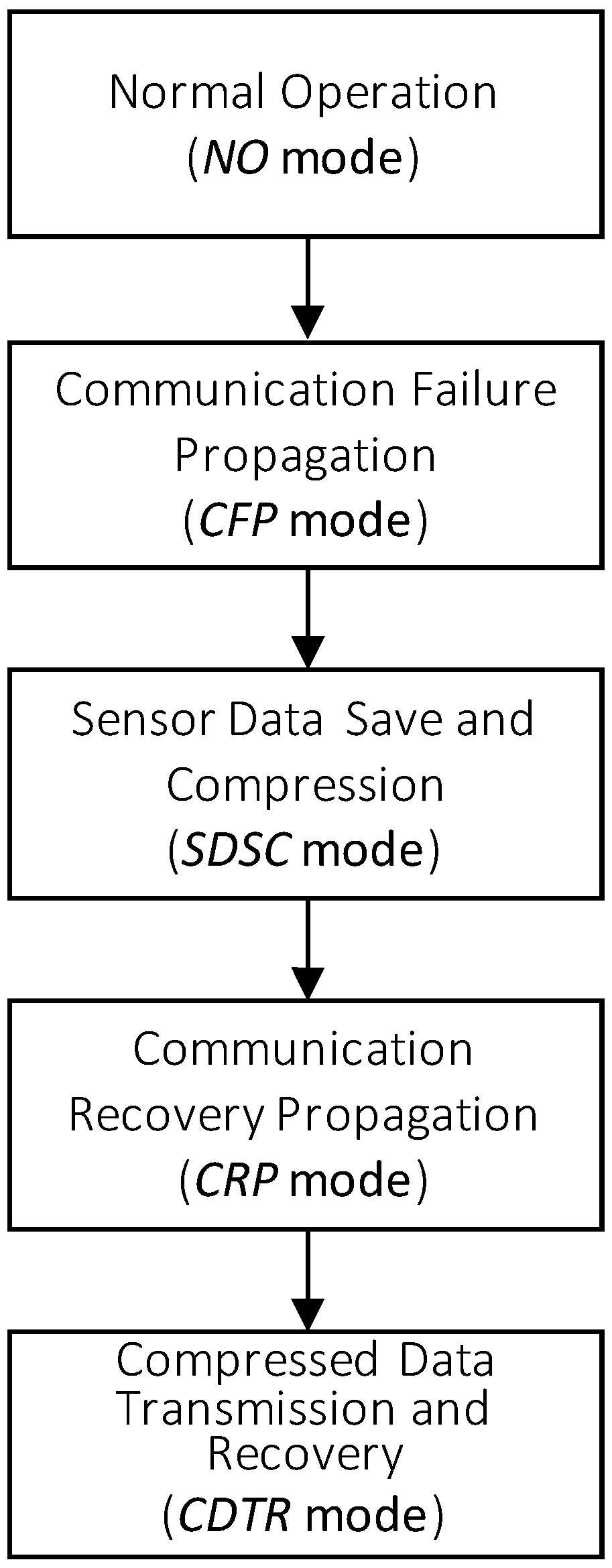
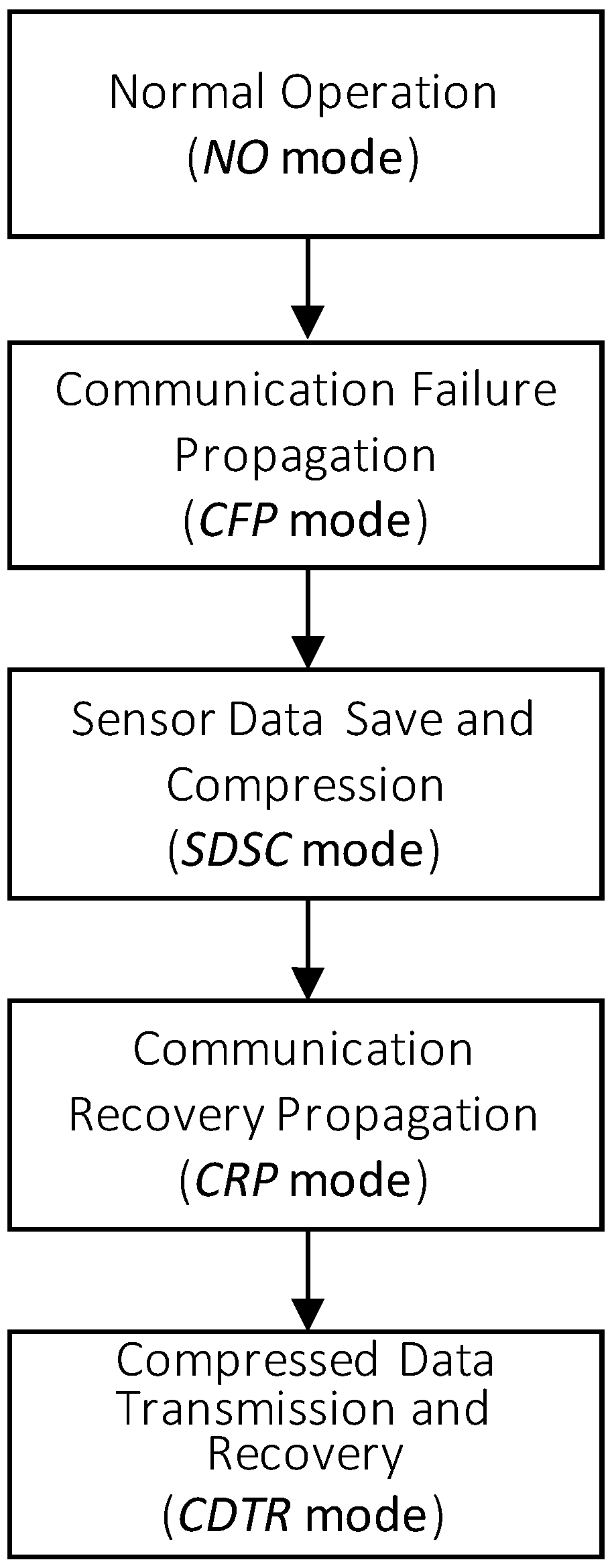
3. Communication Framework Overview for Sensor Data Loss Reduction
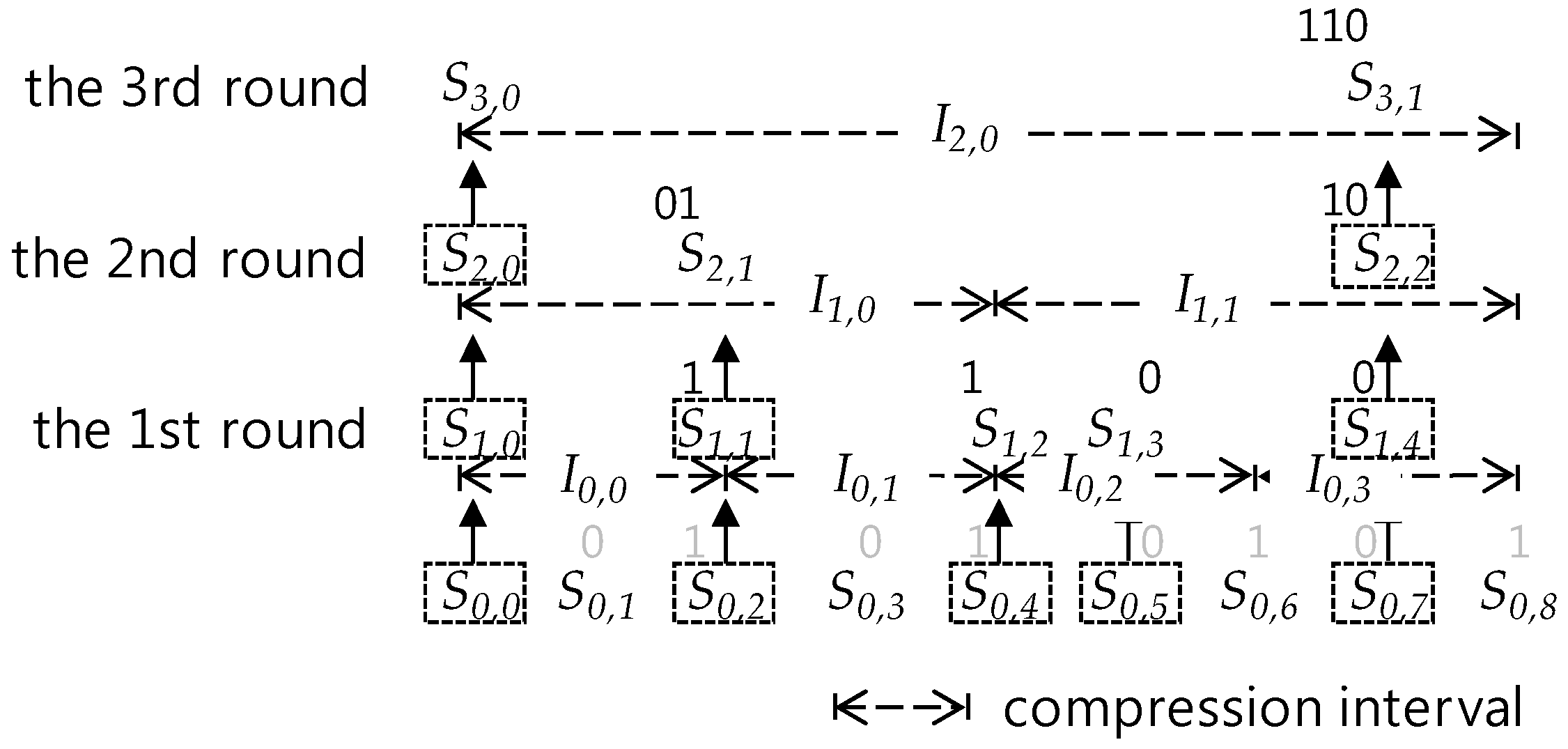
4. Basic Definitions and Properties
- (i)
- A ground sequence is in the 0-th round compression.
- (ii)
- The i-th round compression is a compression executed when S is a sensor data sequence corresponding to a full data queue and each sensor data in S have been derived through the i-1 th compression.
5. Basic Concepts for the SMEP Method
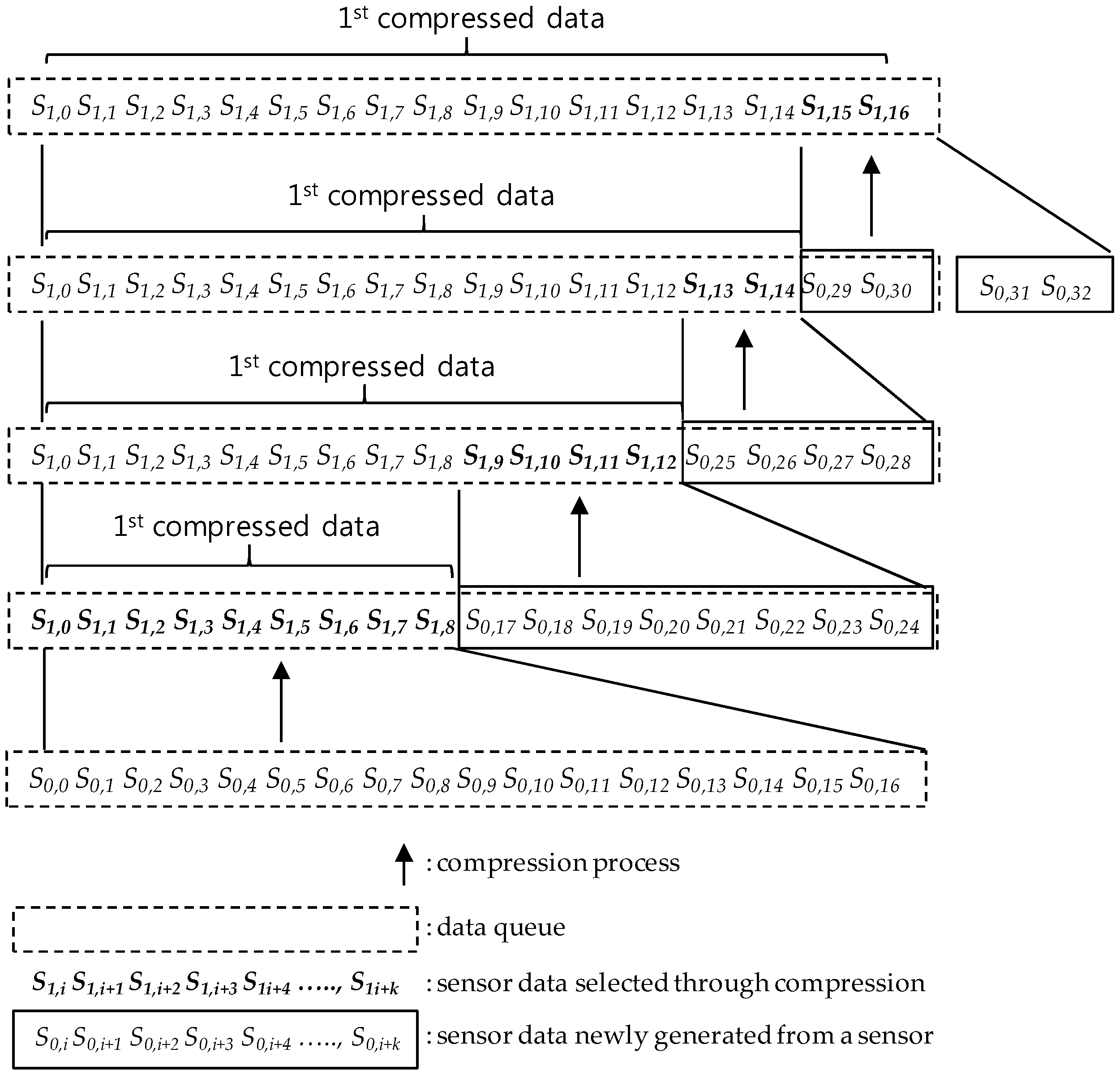
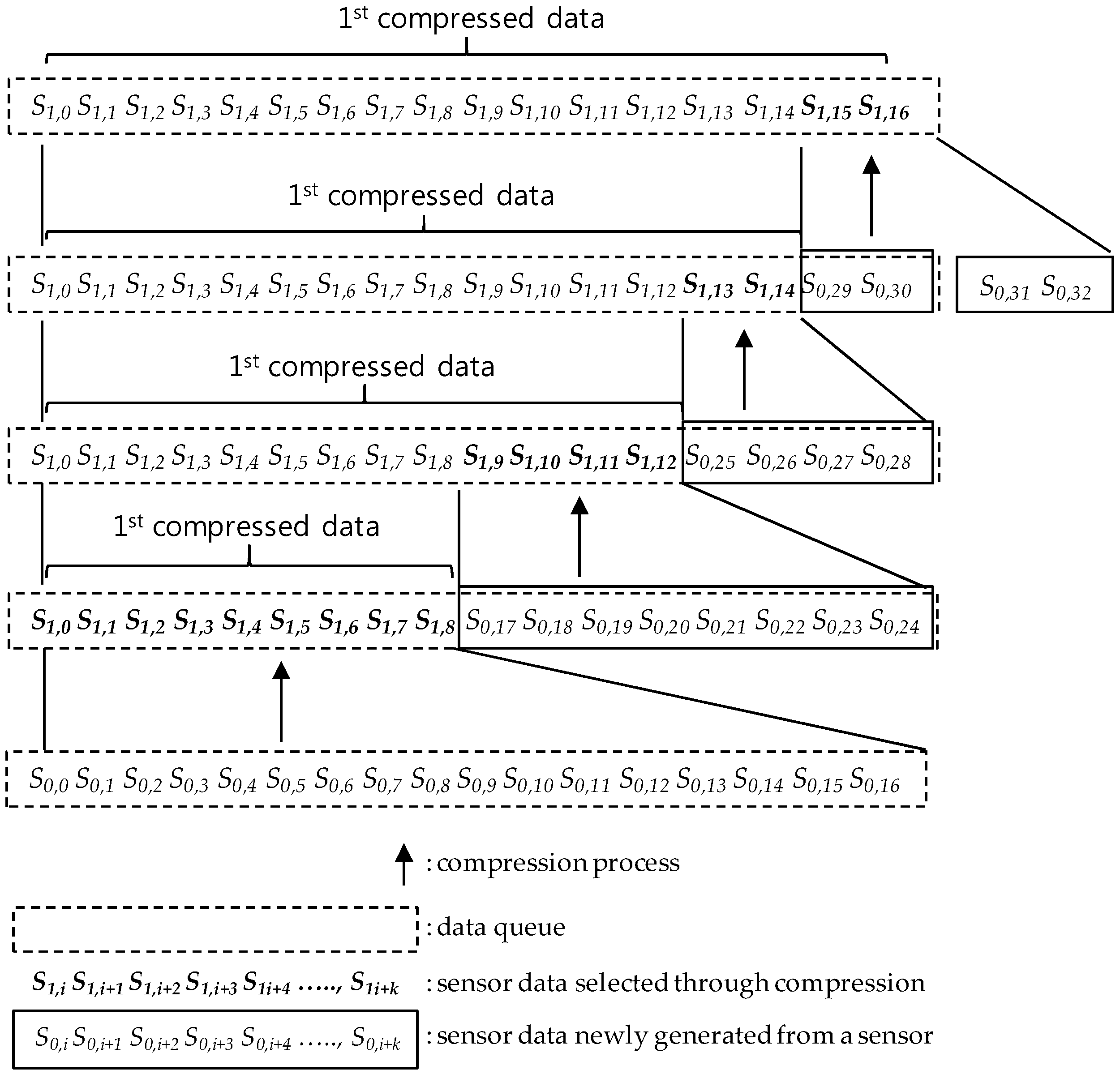
5.1. SMEP Compression Process Overview
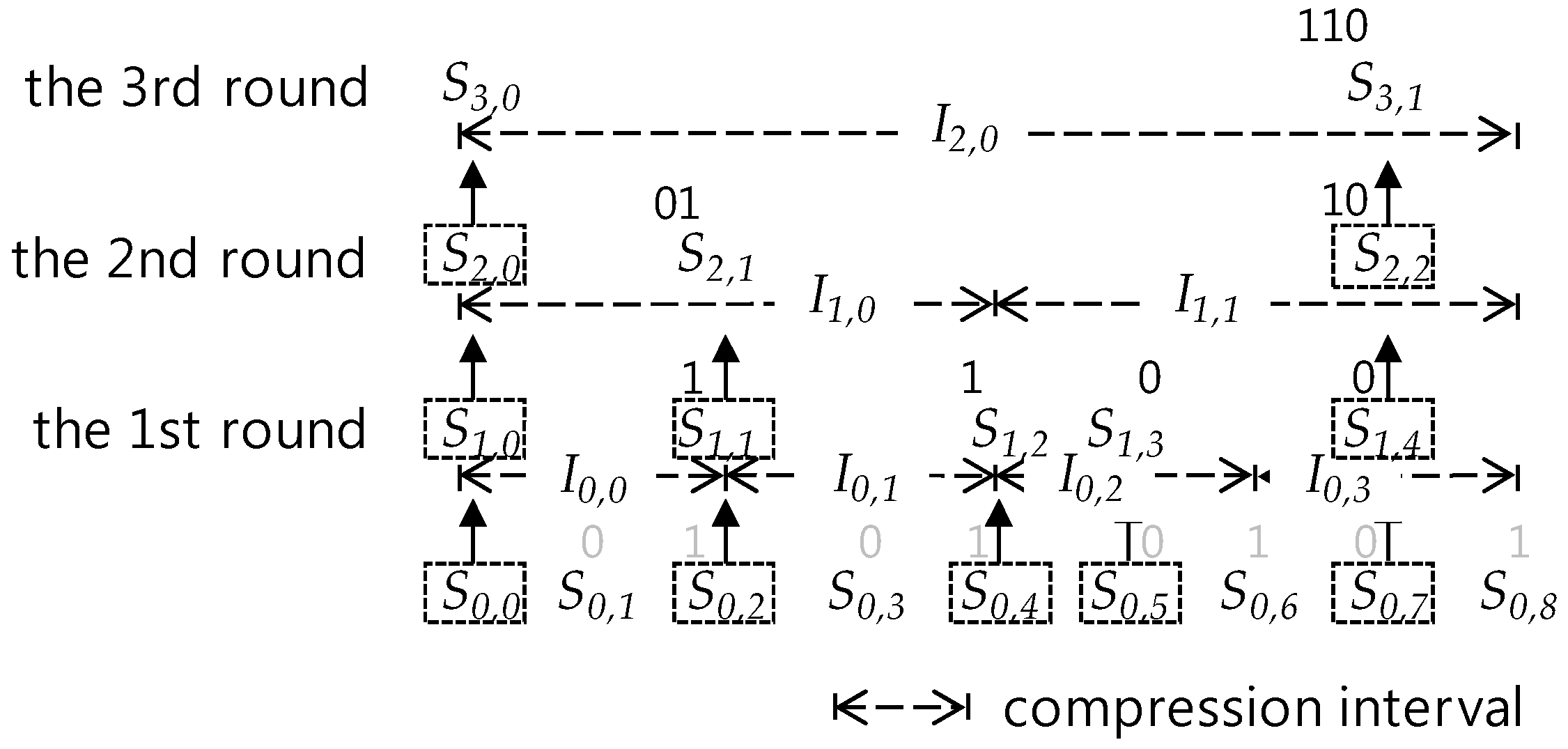
5.2. I-bit Position and Generation
5.3. Absolute Position
- (i)
- i = 0, if k = 0
- (ii)
- i = (k−1)2c + (I-bit position(Sc,k))10 + 1, if k ≥ 1
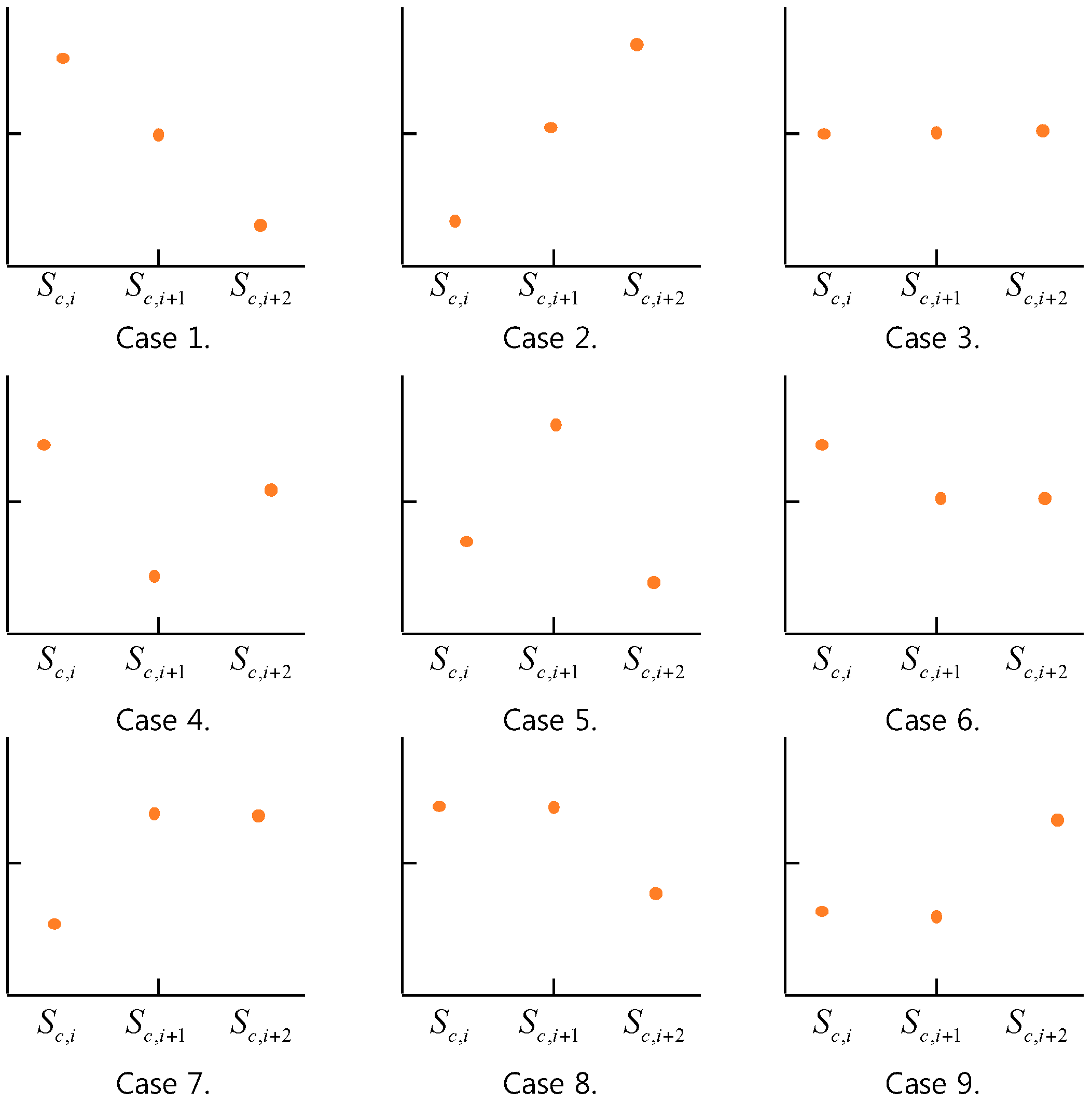
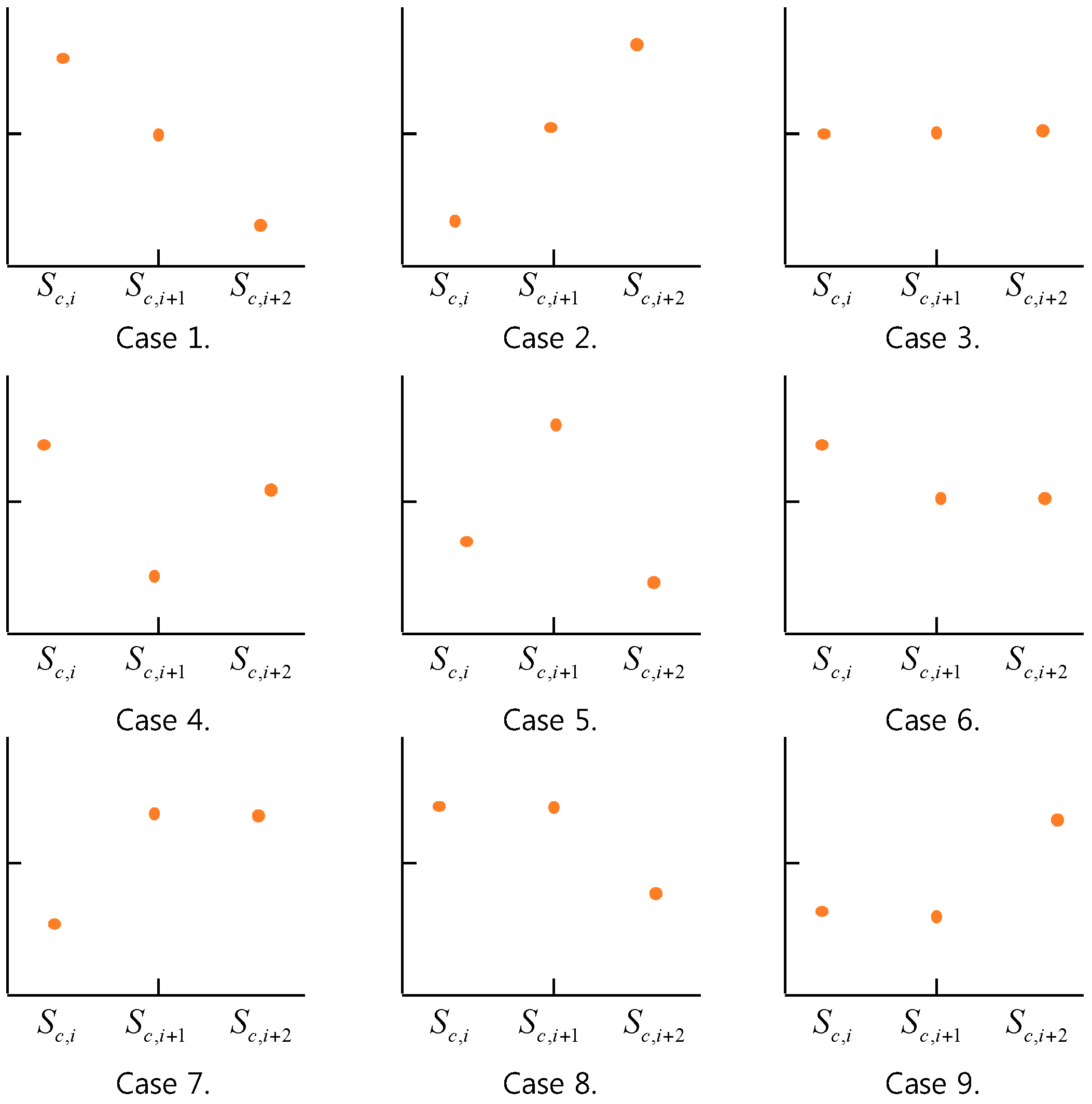
5.4. Selection by Compression Interval Pattern Rule
- Case 1. (Pattern 1) Sc,i > Sc,i+1 > Sc,i+2
- Case 2. (Pattern 2) Sc,i < Sc,i+1 < Sc,i+2
- Case 3. (Pattern 3) Sc,i = Sc,i+1 = Sc,i+2
- Case 4. (Pattern 4) Sc,i > Sc,i+1 < Sc,i+2
- Case 5. (Pattern 5) Sc,i < Sc,i+1 > Sc,i+2
- Case 6. (Pattern 6) Sc,i > Sc,i+1 = Sc,i+2
- Case 7. (Pattern 7) Sc,i < Sc,i+1 = Sc,i+2
- Case 8. (Pattern 8) Sc,i = Sc,i+1 > Sc,i+2
- Case 9. (Pattern 9) Sc,i = Sc,i+1 < Sc,i+2
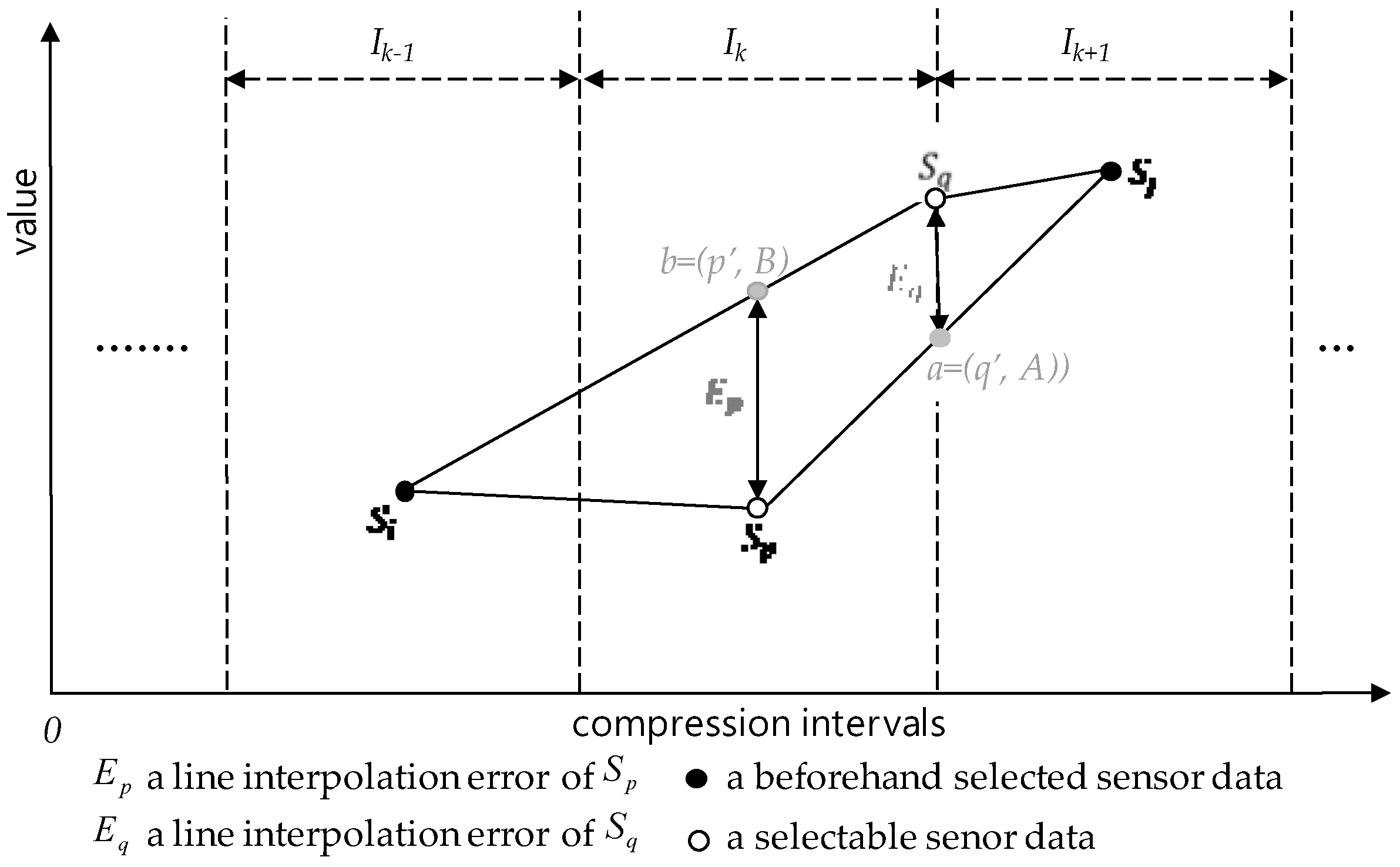
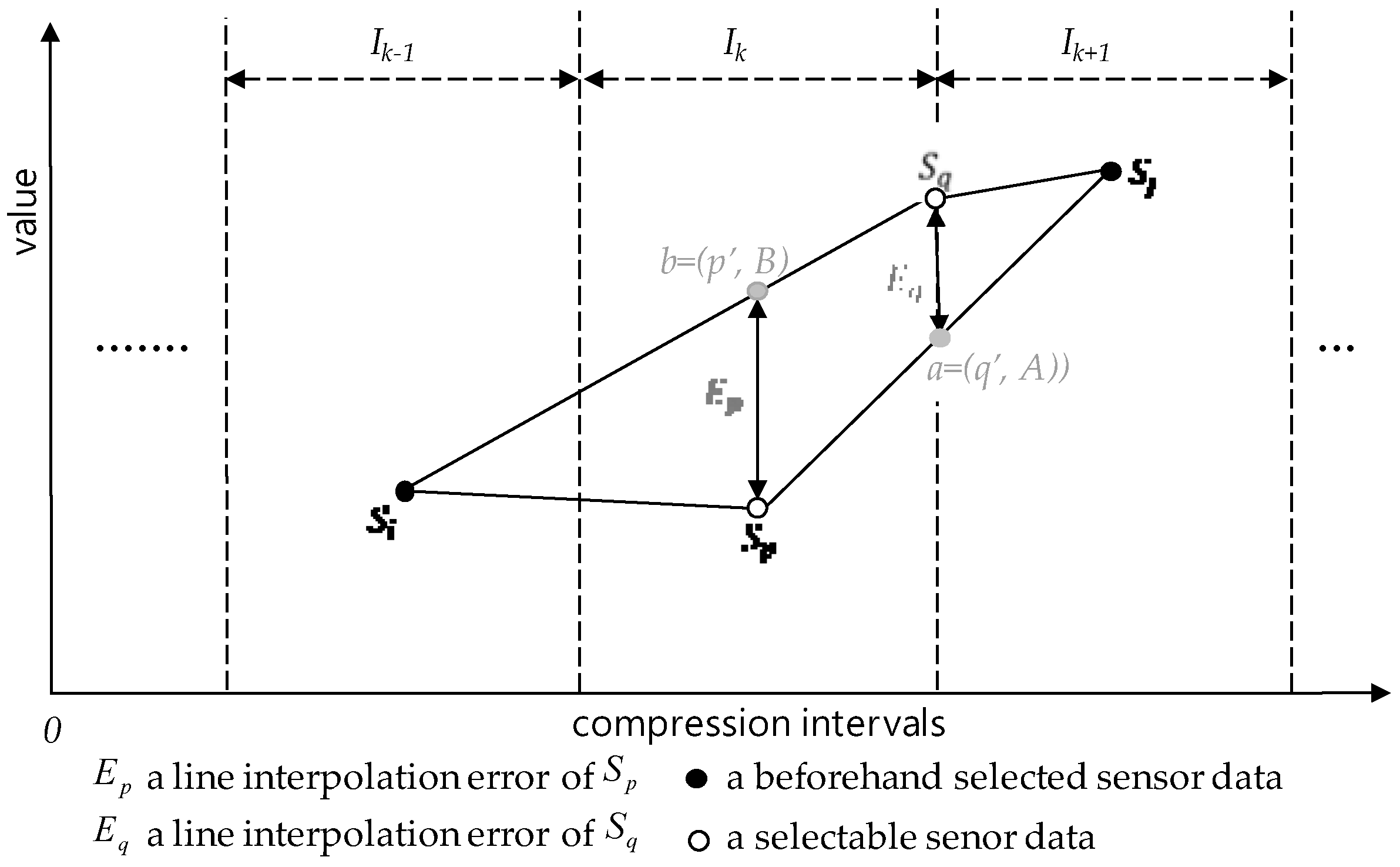
5.5. Selection by Minimum Error Rule
6. Main SMEP Elements
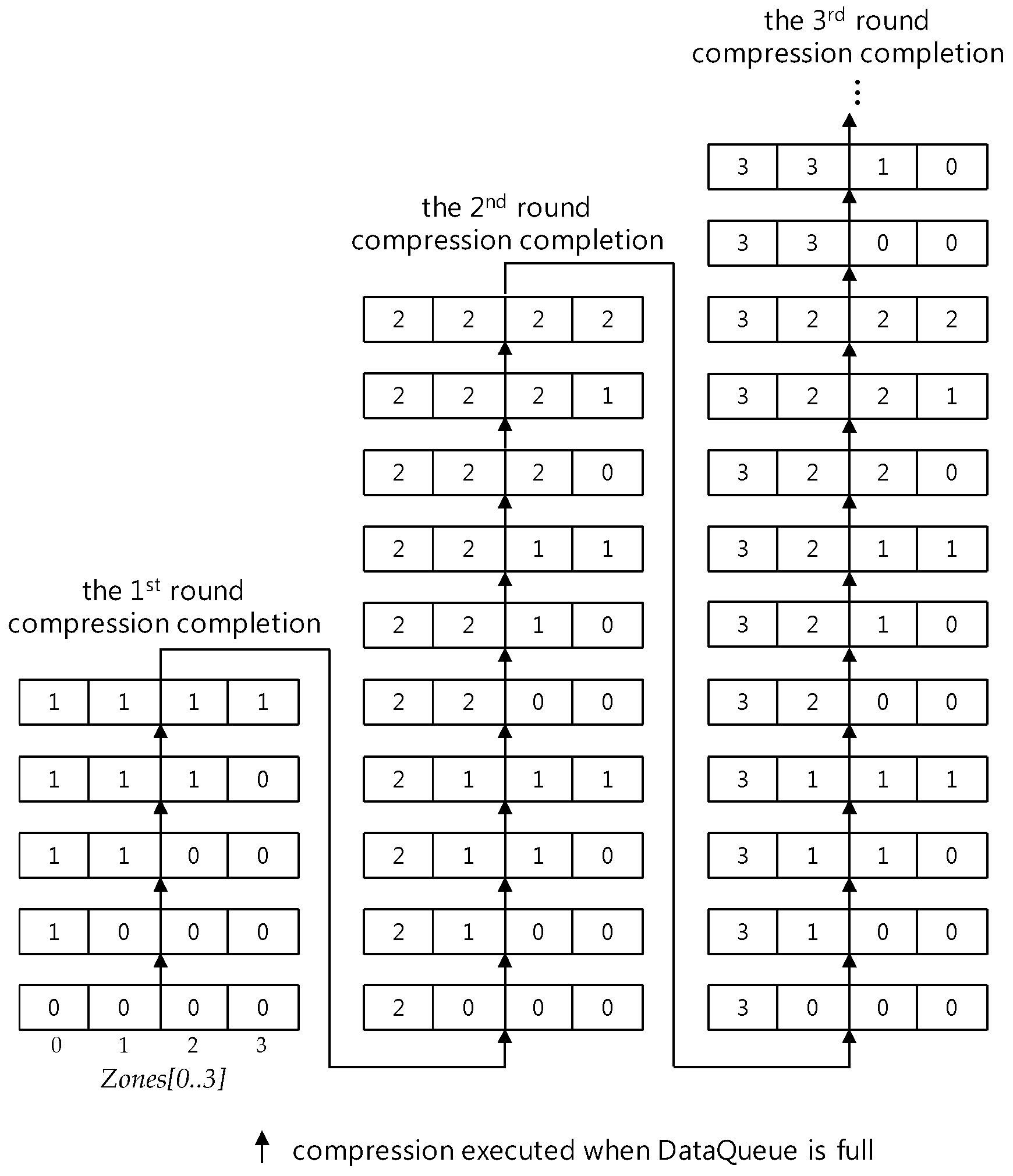
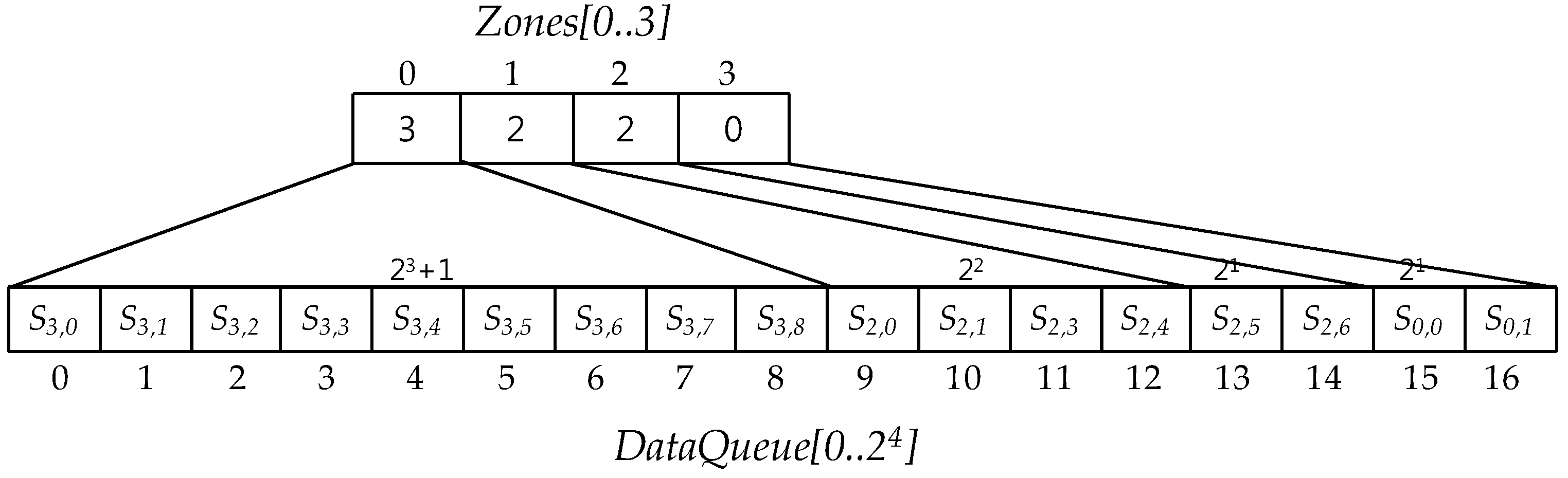
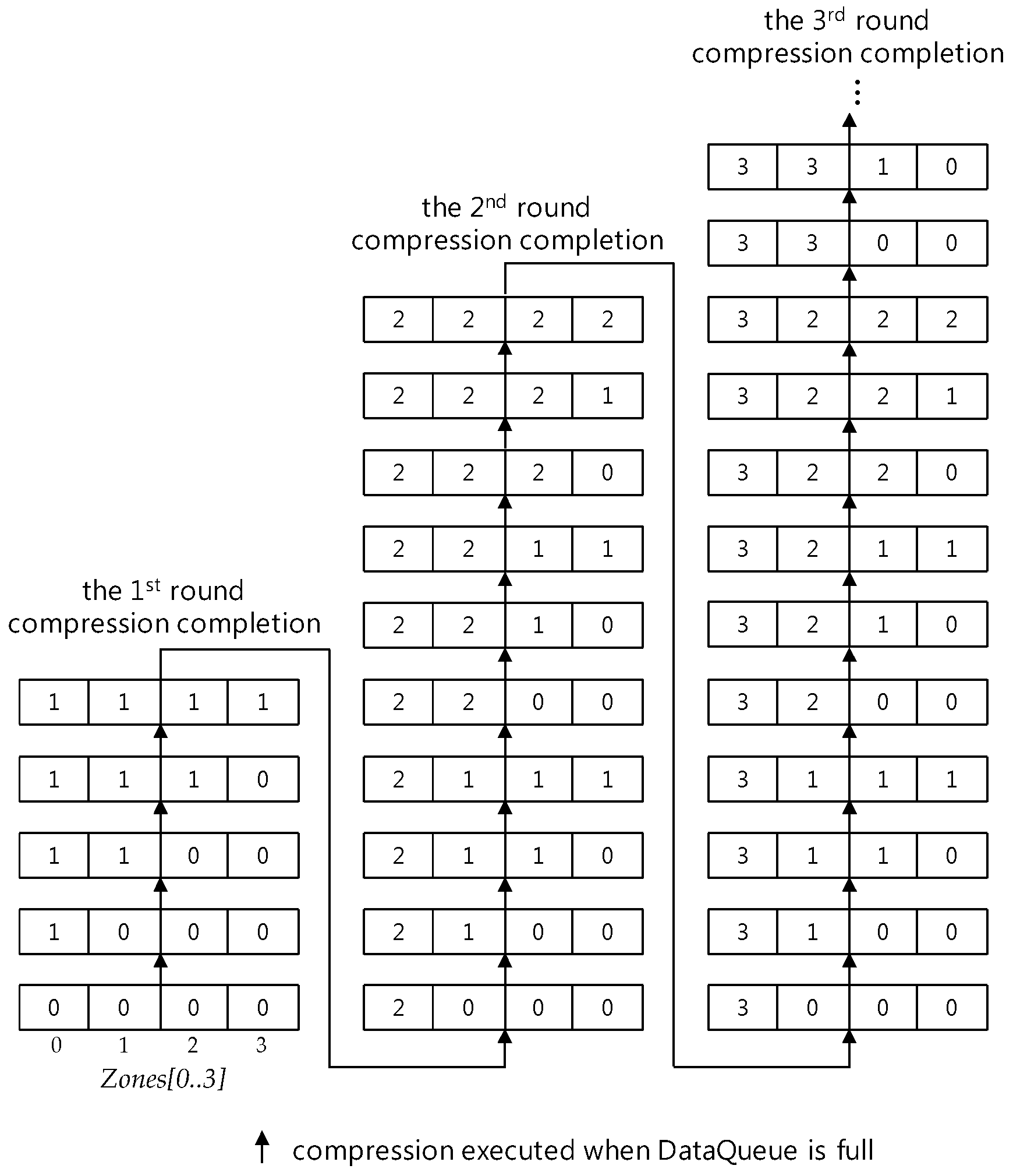
6.1. Data Queue and Zones
- (1)
- Zones[0] corresponds to the range DataQueue[k] for k, 0 ≤ k ≤ 2m−1.
- (2)
- Zones[i] for i = 1,…,m − 2 corresponds to the range DataQueue[k] for k, .
- (3)
- Zones[m − 1] corresponds to the range DataQueue[k] for k, 2m − 1 ≤ k ≤ 2m.
- (4)
- Each value of Zones[m − 1] represents the number of compressions through which all sensor data in the data queue corresponding to the Zones[m − 1] have been compressed.
- Rule 1.
- At first, ground sensor data are saved into DataQueue starting from DataQueue[0], this is, the first location of the DataQueue region corresponding to Zones[0], and the values of Zones are until DataQueue is filled up with ground sensor data and.
- Rule 2.
- Given , if after a compression at the last zone Zones[m − 1], then
- (i)
- the th compression on DataQueue is executed on the zones from such that to ,
- (ii)
- the result of Zones after the i) compression is .
- (iii)
- Additionally, new ground sensor data are saved into DataQueue starting from DataQueue[, this is, the first location of DataQueue covered by .
6.2. Zone Bit Sequence
- (i)
- i exits in the zone for 1 ≤ I ≤ 2m − 1 and i exists in the zone m − 1 for i = 2m.
- (ii)
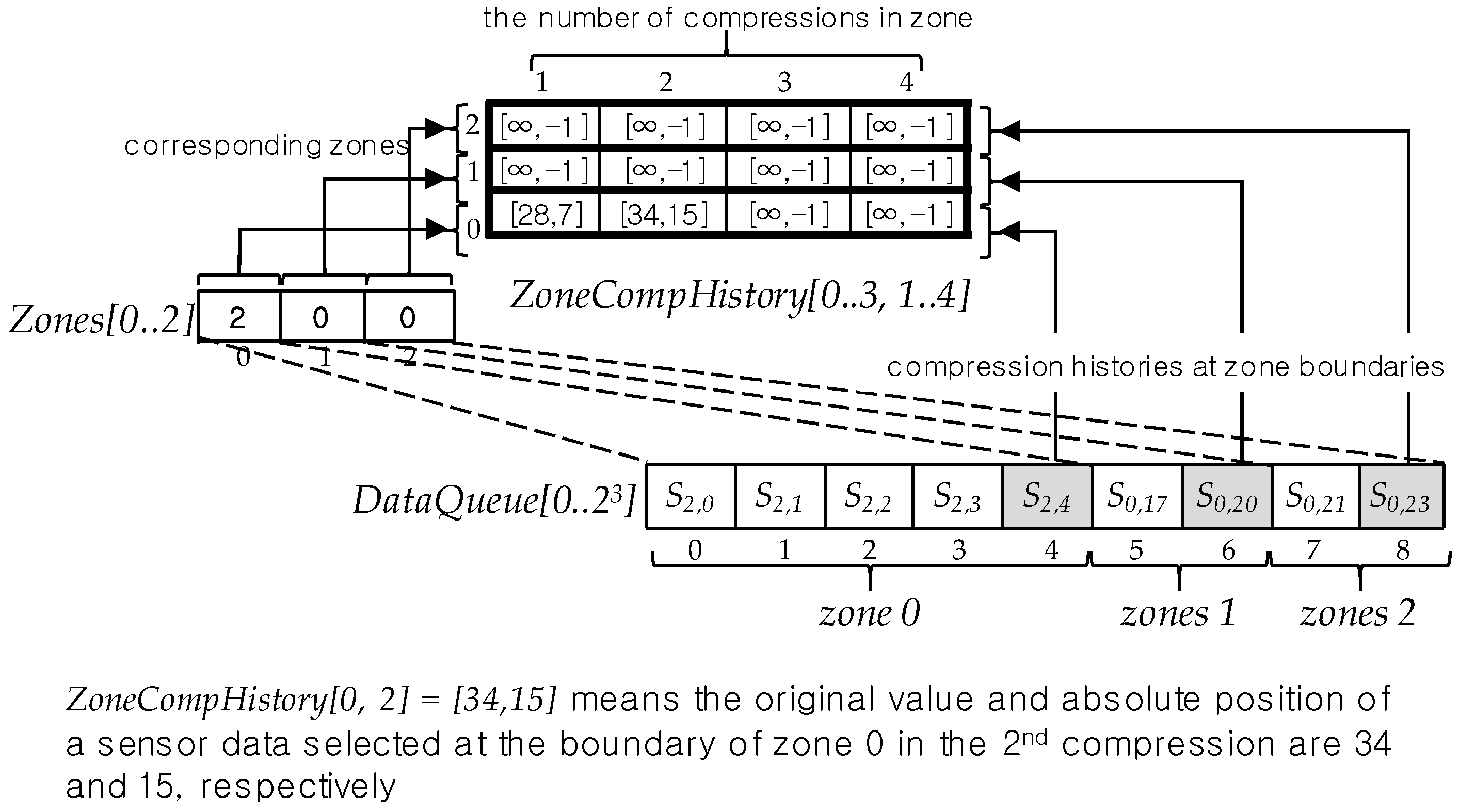
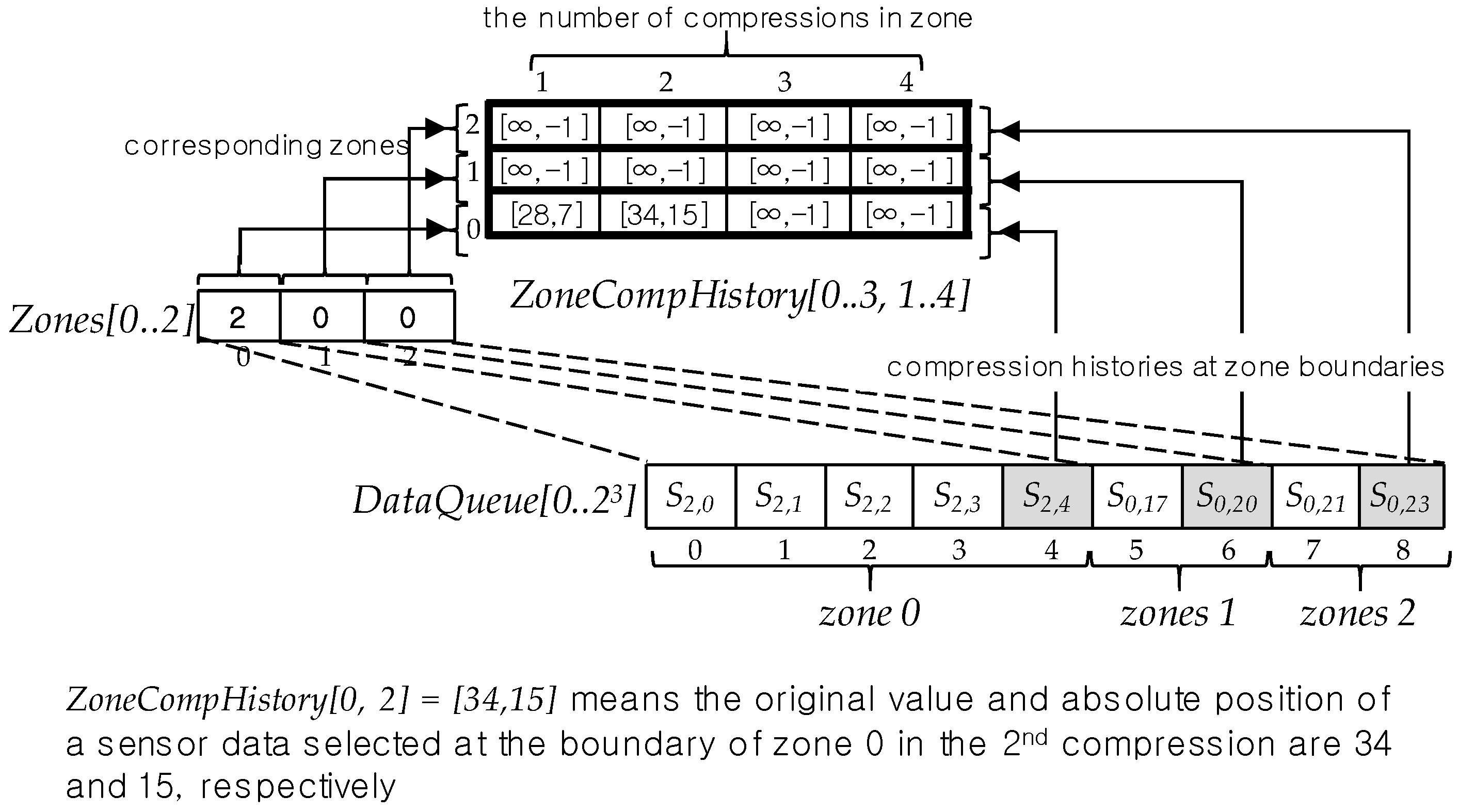
6.3. Zone Compression History
6.4. Auxiliary Data Queue
7. SMEP Algorithms
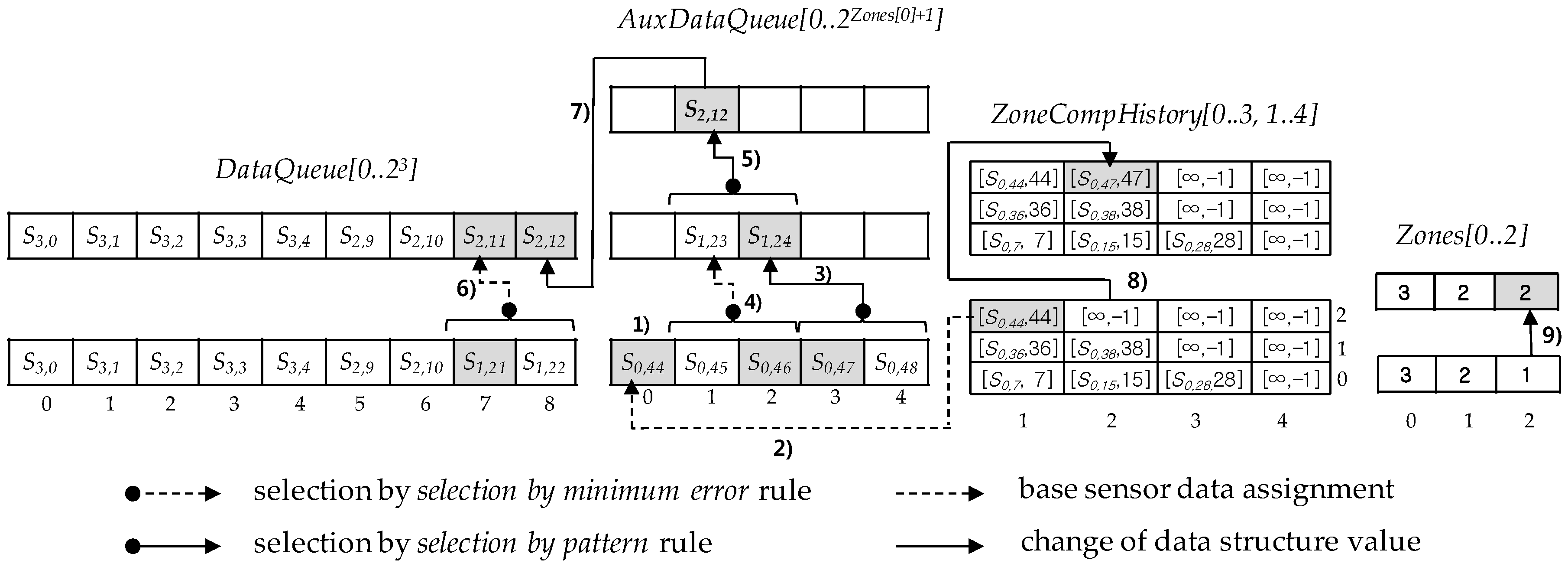
7.1. AuxDataQueue Compression Algorithm
| Algorithm 1: AuxDataQueueCompression(AuxDataQueue, m) |
| Parameters m: the number of zones such that DataQueue[0..2m] Global Variables Local Variables 01 zoneCValue: the number of compressions of sensor data sequence in the DataQueue[m − 1] zone 02 c: the number of compressions for sensor data sequence in AuxDataQueue 03 DQMaxABP: the greatest absolute position covered by DataQueue 04 ZoneBpSeq0, ZoneBpSeq1: bit string variables for an I-bit sequence generation Procedure 01 Set zoneCValue = Zones[m − 1]; 02 Set DQABP = 03 Initialize c = 1 04 Initialize ZoneBpSeq0 = (an empty bit string) 05 while (c ≤ czoneCValue) do 06 Set C to the 2-size compression interval covering on a sensor data sequence in AuxDataQueue[0..2zoneCValue+1] 07 Initialize ZoneBpSeq1 = (an empty bit string) 08 Set AuxDataQueue[0] = ZoneCompHistory[m − 1, c].Value 09 for each in C such that 0 ≤ k ≤ 2zoneCValue) do 10 Select Sc−1,j from by the selection by pattern Rule 11 Select Sc−1,p from by the selection by minimum error Rule using ZoneCompHistory[m − 1, c] as a base sensor data and its absolute position, this is, 12 Set DataQueue[k + 1] = Sc−1,p 13 Set DataQueue[k + 2] = Sc−1,j 14 Set ZoneBpSeq1 = ZoneBpSeq1 Θ I-bit position(Sc,k+1) Θ I-bit position(Sc,k+2) by using ZoneBpSeq0 15 endfor 16 Set ZoneBpSeq0 = ZoneBpSeq1 17 Set c = c + 1 18 endwhile 19 Select Sc,j from by the selection by pattern rule 20 Set AuxDataQueue[1] = Sc,j 21 Set ZoneBpSeq0 = I − bit position(Sc+1,1) by using ZoneBpSeq1 22 Set j = the position of Sc,j with respect to AuxDataQueue by using ZoneBpSeq0 23 return [AuxDataQueue[1], DQMaxABP+j, ZoneBpSeq0] Endprocedure |
7.2. Last Zone Compression Algorithm
| Algorithm 2: LastZoneCompression(DataQueue, m) |
| Parameters |
| 01 m: the number of zones such that DataQueue[0..2m] |
| Global Variables |
| 01 AuxDataQueue[0..2Zones[m−1]+1]: an auxiliary data queue for compressing a sensor sequence in the last zone |
| 02 Ap: a variable for the absolution position of the latest ground sensor data |
| Local Variables |
| 01 c: the number of compressions for a sensor data sequence in Zones[m − 1] |
| 02 AuxDQinx: an index for AuxDataQueue |
| 03 ZoneBpSeq0: a temporal bit string variable for I-bit sequence |
| Procedure |
| 01 Set c=Zones[m − 1] |
| 02 Initialize ZoneBpSeq0 = (an empty bit string) |
| 04 Allocate memory AuxDataQueue[0..2c+1] |
| 05 Initialize AuxDQinx = 1 |
| 06 while(AuxDQinx ≤ 2c+1) do |
| 07 Set Ap=Ap+1 |
| 08 Read a ground sensor data S0,Ap from a sensor |
| 09 Insert S0,Ap into AuxDataQueue[AuxDQinx] |
| 10 if (receive(CRmessage) = true) |
| 11 then return ‘FinishMode’ |
| 12 else Set AuxDQinx=AuxDQinx+1 |
| 13 Continue |
| 14 endif |
| 15 endwhile |
| 16 Set [Value, j, ZoneBpSeq0] = AuxDataQueueCompression(AuxDataQueue, m) |
| 17 Select Sc,p from the positioned interval of DataQueue by the selection by minimum |
| error rule by using ZoneCompHistory[m − 2, c + 1] as a base sensor data and its absolute |
| position and by using [Value, j] as the value and absolute position of the sensor |
| data selected in the next interval in the c+1 th compression, |
| this is, Set |
| 18 Set DataQueue[2m − 1] = Sc,p |
| 19 Set ZoneBpSeq0 = I-bit position(DataQueue[2m − 1]) Θ ZoneBpSeq0 by using ZoneBpSeq[m − 1] |
| 20 Set DataQueue[2m] = Value |
| 21 Set ZoneBpSeq[m − 1] = ZoneBpSeq0 |
| 22 Set ZoneCompHistory[m − 1, c+1] = [Value, j] |
| 23 return ‘Continue’ |
| Endprocedure |
7.3. Consecutive Equivalent Zones Compression Algorithm
| Algorithm 3: EquivalentZonesCompression(DataQueue, StartZone, m) |
| Parameters |
| 01 StartZone: a compression start zone |
| 02 m: the number of zones such that DataQueue[0..2m] |
| 03 c: the number of compressions for a sensor data sequence in the zone StartZone |
| Global Variables |
| Local Variables |
| 01 DQGP: the greatest position (index) among DataQueue positions (indices) covered by zones before the zone StartZone. This position is used to calculate DataQueue positions from the StartZone zone to the last m − 1 zone |
| 02 APos: an absolute position of the last sensor data in the zone StartZone after the compression |
| Procedure |
| 01 Set c = Zones[StartZone] |
| 02 if DQGP =0 then Set DQGP = 0 else Set DQGP = endif |
| 03 Initialize ZoneBpSeq0 = ϵ b (an empty bit string) |
| 04 Set = a 2-size compression interval covering with respect to a sensor data sequence from DataQueue[DQGP+1] to DataQueue[2m] (if StartZone≠0, set including to this sensor data sequence ZoneCompHistory[StartZone − 1, c + 1].Value as a base sensor data and its absolute position as ZoneCompHistory[StartZone − 1, c + 1].Position) |
| 05 for each in such that k is an integer and 0 ≤ k < 2m−StartZone−2 do |
| 06 Select Sc,j from by the selection by pattern rule |
| 07 Select Sc,p from the selection by minimum error Rule, |
| this is, |
| 08 Set DataQueue[DQGP+2k+1] = Sc,p |
| 09 Set DataQueue[DQGP+2k+2] = Sc,j |
| 10 Set ZoneBpSeq0 = ZoneBpSeq0 Θ I-bit position(Sc+1, DQGP+2k+1) Θ I-bit position(Sc+1, DQGP+2k+2) using I-bit position(Sc,p), I-bit position(Sc,j) and the zone bit strings corresponding to p and j |
| 11 endfor |
| 12 Set ZoneBpSeq[StartZone] = ZoneBpSeq0 |
| 13 Set APos = an absolute position of Sc,j calculated by the theorem using Zones[StartZone] and ZoneBpSeq[StartZone] |
| 14 return [Sc,j, APos] |
| Endprocedure |
7.4. Main Algorithm
| Algorithm 4: Main SMEP (Selection by Minimum Error and Pattern) |
| Constant |
| 01 cmax: the maximum number of compressions |
| Global Variables |
| 01 DataQueue[0..2m]: a data queue array for saving sensor data or compressing a sensor data sequence |
| 02 Zones[0..m − 1]: an array of zones with respect to DataQueue[0..2m], where Zone[i] ≤ cmax |
| 03 AuxDataQueue[0.. 2Zones[m−1]]: an auxiliary data queue for the compressing a sensor sequence in the last m − 1 zone |
| 04 ZoneBpSeq[0..m − 1]: an array of pointers to refer to I-bit position sequences of the sensor data sequences corresponding to each zones |
| 05 ZoneCompHistory[0..m − 1, 1..cmax]: an array of pairs, [S, p]s, where ZoneCompHistory[i, c] = [S, p] and S and p are the sensor data value and its absolute position of the last c-th compressed sensor data in the zone i |
| 06 Ap: a variable for the absolution position of the latest ground sensor data |
| Local Variables |
| 01 DQinx: an index variable for the latest sensor data insertion to DataQueue |
| 02 ZNinx: an index variable in Zones array |
| Procedure |
| 01 for each k such that 0 ≤ k ≤ m − 1 do |
| 02 Initialize Zones[k] = 0 |
| 03 for each l such that 0 ≤ l ≤ cmax do |
| 04 Initialize ZoneCompHistory[k, l] = [∞, −1] |
| 05 endfor |
| 06 endfor |
| 07 Initialize Ap = 0, DQinx = 0, and ZNinx=0 |
| 08 while(true) do |
| 09 Read a ground sensor data S0,Ap from a sensor |
| 10 Insert S0,Ap into DataQueue[DQinx]; |
| 11 if (DQinx ≤ 2m) |
| 12 cthen if (receive(CRmessage) = true) |
| 13 then return [DataQueue, Zones, ZonesBpSeq, ZoneCompHistory, Ap] |
| 14 else Set Ap=Ap+1, DQinx=DQinx+1 |
| 15 Continue |
| 16 endif |
| 17 else Set ZNinx=m − 1 |
| 18 while(Zones[ZNinx−1] < Zones[ZNinx]) do |
| 19 Set RFsate=LastZoneCompression(DataQueue, m) |
| 20 if(RFstate=‘FinishMode’) |
| 21 then return [DataQueue, Zones, ZonesBpSeq, ZonesCompHistory, Ap, AuxDataQueue] |
| 22 endif |
| 23 Set Zones[ZNinx]=Zones[ZNinx]+1 |
| 24 endwhile |
| 25 Find |
| 26 Set ZoneCompHistory[Start, Zones[Start]] = EquivalentZonesCompression(DataQueue, StartZone, m) |
| 27 Set Zones[Start]=Zones[Start]+1 |
| 28 for each k such that Start + 1 ≤ k ≤ m − 1 do |
| 29 Set Zones[k]=0 |
| 30 Set ZoneBpSeq[k]=null |
| 31 for each l such that 0 ≤ l ≤ Zone[k] do |
| 32 Initialize ZoneCompHistory[k, l] = [∞, −1] |
| 33 endfor |
| 34 endfor |
| 35 Set DQinx = |
| 36 endif |
| 37 endwhile |
| Endprocedure |
8. Compressed Sensor Data Decompression and Lost Sensor Data Recovery
8.1. Sensor Data Line Interpolation Algorithm
| Algorithm 5: SensorDataLineInterplolation( |
| Parameters |
| 01 : the leftmost sensor data value of an interval for recovering compressed sensor data |
| 02 : the leftmost absolute position of an interval for recovering compressed sensor data |
| 03 : the rightmost sensor data value of an interval for recovering compressed sensor data |
| 04 : the leftmost absolute position of an interval for recovering compressed sensor data |
| Global Variables |
| Local Variables |
| 01 x: the absolute position of a lost sensor data to be recovered |
| 02 : the value of a recovered lost sensor data with the absolute position x |
| Procedure |
| 01 Output |
| 02 Set |
| 03 while(x<lpos) do |
| 04 Set |
| 05 Output |
| 06 Set |
| 07 endwhile |
| Endprocedure |
8.2. Sensor Data Recovery Algorithm
| Algorithm 6: SensorDataRecovery(DataQueue, Zones, ZoneBpSeq, ZoneCompHistory, Ap, AuxDataQueue) |
| Parameters |
| 01 DataQueue, Zones, ZoneBpSeq, ZoneCompHistory, Ap, AuxDataQueue: arrays or variables corresponding to SMEP main algorithm parameters |
| Global Variables |
| Local Variable |
| 01 DQinx: an index variable for DataQueue array |
| 02 ZNMaxDQinx: the maximum among indices of DataQueue space corresponding to a zone |
| 03 CompZoneMax: the maximum among indices, js, such that Zones[j] is not zero |
| 04 CompZoneMaxAp: the maximum among absolute positions covered by the CompZoneMax zone |
| 05 ZNinx: an index variable in Zones array |
| 06 Sp, Sj: the leftmost and rightmost values used to recover lost sensor data in an interval, [p, j] |
| 07 p, j: the leftmost and rightmost absolute position used to recover lost sensor data in an interval, [p, j] |
| 08 ZNCV: a value variable of ZoneCompHistory[zone, Zones[zone]].Value for some zone |
| 09 ZNBP: an absolute position variable of ZoneCompHistory[zone, Zones[zone]].Position for some zone |
| Procedure |
| 01 Set DQinx = 0 |
| 02 if (Zones[0]≠0) |
| 03 then Find |
| 04 Set ZNinx = 0, CompZoneMaxAp = |
| 05 while(0 ≤ ZNinx and ZNinx ≤ CompZoneMax) do |
| 06 if (ZNinx=0) |
| 07 then Set [Sp, p] = [DataQueue[0], 0] |
| 08 else Set [Sp, p] = ZoneCompHistory[ZNinx−1, Zones[ZNinx]] |
| 09 endif |
| 10 if (ZNinx = m − 1) |
| 11 then ZNMaxDQinx = DQinx+ |
| 12 else ZNMaxDQinx = DQinx+ |
| 13 endif |
| 14 Set DQinx = DQinx + 1 |
| 15 while (DQinx<ZNMaxDQinx) do |
| 16 Set Sj = DataQueue[DQinx] |
| 17 Set j = FindAbsoluteAddress(DQinx, Zones, ZoneBpString) |
| 18 SensorDataLineInterpolation(Sp, p, Sj, j) |
| 19 Set [Sp, p] = [Sj, j] |
| 20 Set DQinx = DQinx + 1 |
| 21 endwhile |
| 22 if (ZNinx = CompZoneMax) |
| 23 then Set [ZNCV, ZNBP] = ZoneCompHistory[ZNinx, 1] |
| 24 else Set [ZNCV, ZNBP] = ZoneCompHistory[ZNinx, Zones[ZNinx]] |
| 25 endif |
| 26 if (DQinx=ZNMaxDQinx and j≠ZNBP) |
| 27 then SensorDataLineInterpolation(Sj, j, ZNCV, ZNBP) |
| 28; else Output Sj, j |
| 29; endif |
| 30; endwhile |
| 31 endif |
| 32 if (CompZoneMax > 0 and CompZoneMax < m − 1 and ZNBP≠CompZoneMaxAp) |
| 33 then SensorDataLineInterpolation(ZNCV, ZNBP, DataQueue[DQinx + 1], CompZoneMaxAp + 1) |
| 34 else if(CompZoneMax = m − 1 and ZNBP≠ CompZoneMaxAp) |
| 35 then SensorDataLineInterpolation(ZNCV, ZNBP, AuxDataQueue[1], CompZoneMaxAp + 1) |
| 36 endif |
| 37 endif |
| 38 if (CompZoneMaxAp<m − 1) |
| 39 then Set offset = Ap-CompZoneMaxAp |
| 40 for each i such that 1 ≤ I ≤ offset do |
| 41 Output DataZone[DQinx+i], CompZoneMaxAp + i |
| 42 endfor |
| 43 else Set offset=Ap – CompZoneMaxAp |
| 44 for each i such that 1 ≤ i ≤ offset do |
| 45 Output AuxDataQueue[i], CompZoneMaxAp + i |
| 46 endfor |
| 47 endif |
| 48 return |
| Endprocedure |
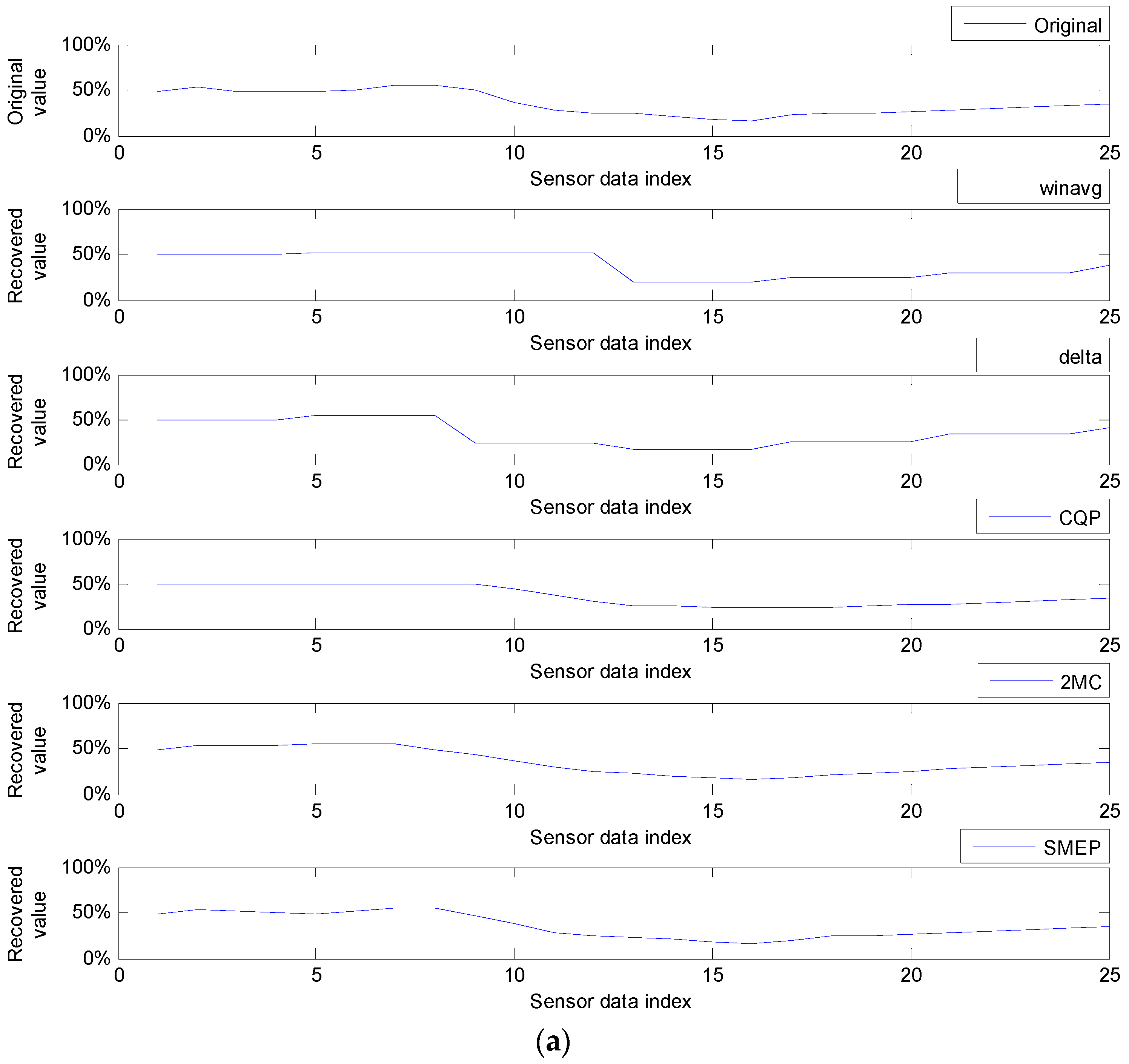
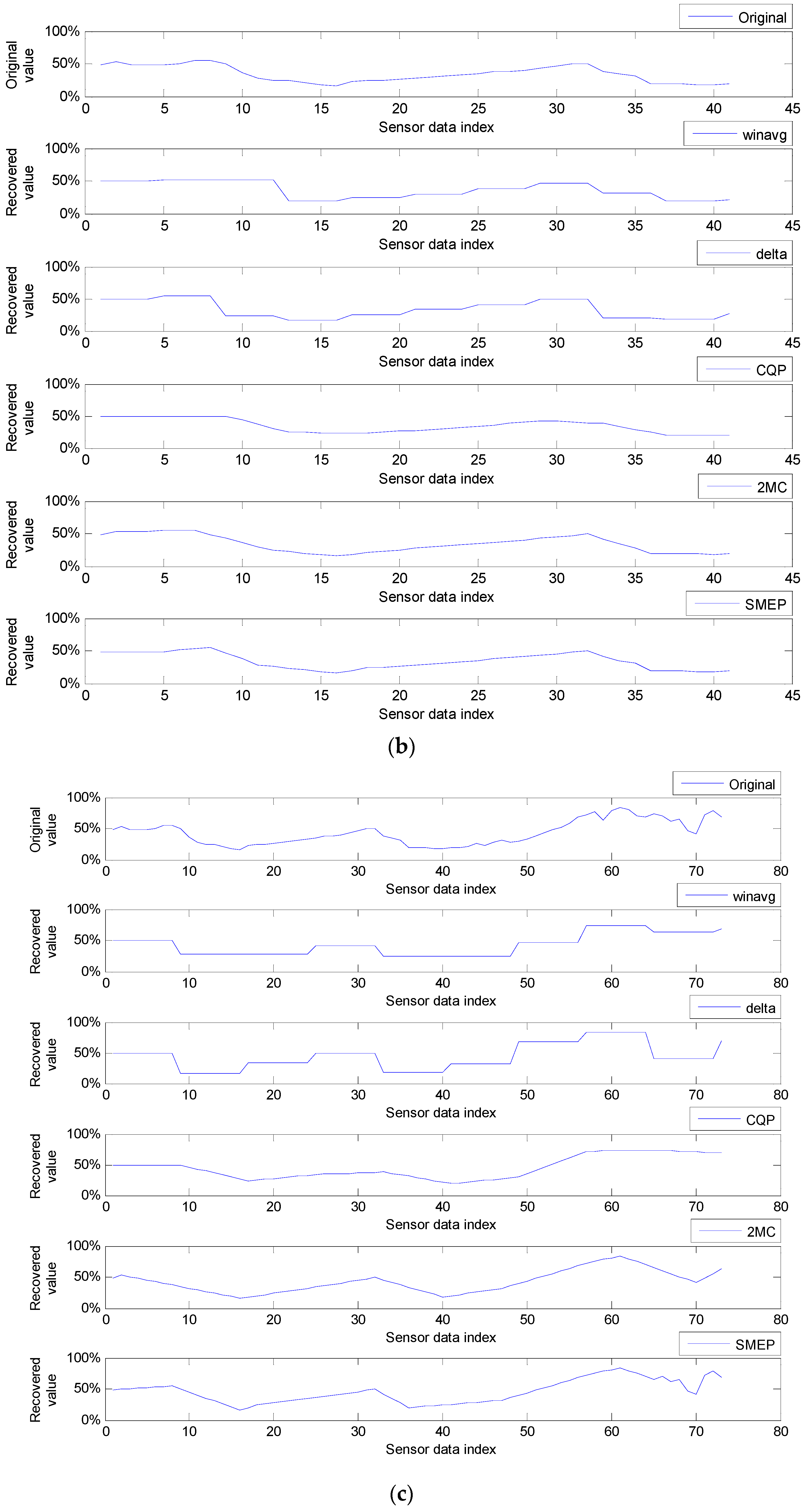
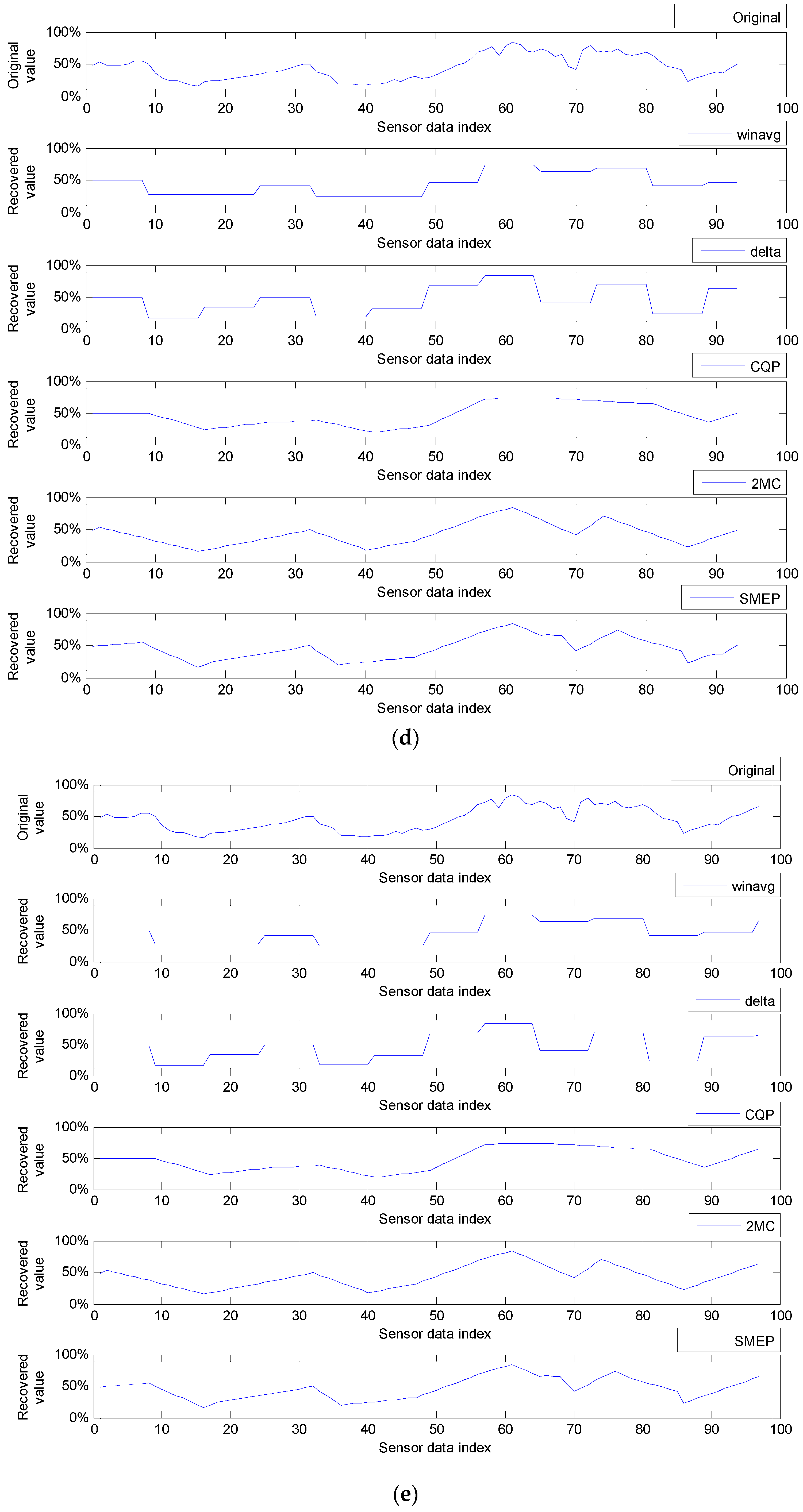
9. Performance Comparisons and Analysis
9.1. Experimental Environments and Evaluation Measure
9.1.1. Experimental Sensor Data Sets and Samples
9.1.2. Comparison Target Methods
9.1.3. Performance Evaluation Measure
9.1.4. Experimental Tool and Method
9.2. Experiments, Experimental Results and Analysis
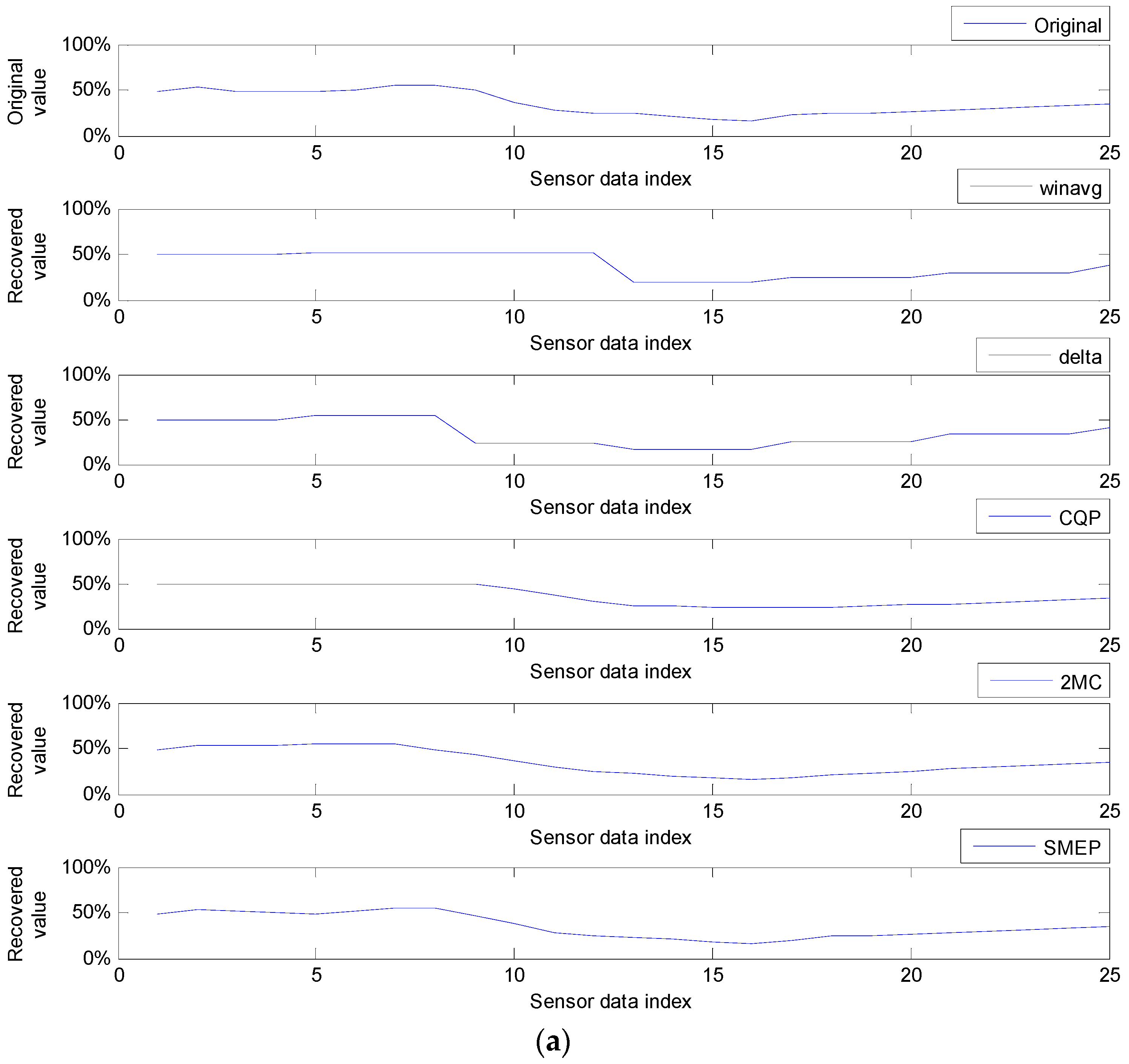
9.2.1. Average Error Rates in Round Compressions
9.2.2. Average Error Rates in Zones Value Patterns
10. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 3
Appendix C. Proof of Theorem 4
Appendix D. Proof of Theorem 5
Appendix E. Proof of Theorem 7
Appendix F. Proof of Theorem 8
Appendix G. Proof of Theorem 9
Appendix H. Proof of Lemma 1
Appendix I. Proof of Lemma 2
Appendix J. Proof of Lemma 3
Appendix K. Proof of Lemma 4
Appendix L. Proof Lemma 5
j’ = (j − 1)2c + (BitSubstring(Bp, c, j))10,
p’ = (p − 1)2c + (BitSubstring(Bp, c, p))10,
q’ = (q − 1)2c + (BitSubstring(Bp, c, q))10.
References
- Kumar, A.G.G.; Thiyagarajan, R.; Sripriya, N. Buckshot DV—A Robust Routing Protocol for Wireless Sensor Networks with Unstable Network Topologies and Unidirectional Links. Int. J. Sci. Res. Publ. 2014, 4, 60–65. [Google Scholar]
- Lohs, S.; Karnapke, R.; Nolte, J. Link Stability in a Wireless Sensor Network—An Experimental Study. In Proceedings of the 3rd International Conference on Sensor Systems and Software, Lisbon, Portugal, 4–5 June 2012; pp. 146–161. [Google Scholar]
- Lu, M.; Wu, J. Utility-Based Data-Gathering in Wireless Sensor Networks with Unstable Links. In Proceedings of the 9th International Conference ICDCN, Kolkata, India, 5–8 January 2008; pp. 13–24. [Google Scholar]
- Woo, A.; Tong, T.; Culler, D. Taming the Underlying Challenges of Reliable Multihop Routing in Sensor Networks. In Proceedings of the 1st international conference on Embedded networked sensor systems (SenSys ‘03), Los Angeles, CA, USA, 5–7 November 2003; pp. 14–27. [Google Scholar]
- Arora, A.; Dutta, P.; Bapat, S.; Kulathumani, V.; Zhang, H.; Naik, V.; Mittal, V.; Cao, H.; Demirbas, M.; Gouda, M.; et al. A Line in the Sand: A Wireless Sensor Network for Target Detection, Classification, and Tracking. Comput. Netw. 2004, 46, 605–634. [Google Scholar] [CrossRef]
- Marfievici, R.; Murphy, A.L.; Picco, G.P.; Ossi, F.; Cagnacci, F. How Environmental Factors Impact Outdoor Wireless Sensor Networks: A Case Study. In Proceedings of the IEEE 10th International Conference on Mobile Ad-Hoc and Sensor Systems (MASS), Hangzhou, China, 14–16 October 2013; pp. 565–573. [Google Scholar]
- Anastasi, G.; Falchi, A.; Passarella, A.; Conti, M.; Gregori, E. Performance Measurements of Motes Sensor Networks. In Proceedings of the 7th International Symposium on Modeling, Analysis and Simulation of Wireless and Mobile Systems (MSWiM), Venice, Italy, 4–6 October 2004; pp. 174–181. [Google Scholar]
- Bannister, K.; Giorgetti, G.; Gupta, E.K.S. Wireless Sensor Networking for “Hot” Applications: Effects of Temperature on Signal Strength, Data Collection and Localization. In Proceedings of the 5th Workshop on Embedded Networked Sensors (HotEmNets), Charlottesville, VA, USA, 2–3 June 2008. [Google Scholar]
- Boano, C.A.; Brown, J.; Tsiftes, N.; Roedig, U.; Voigt, T. The Impact of Temperature on Outdoor Industrial Sensornet Applications. IEEE Trans. Ind. Inform. 2010, 6, 451–459. [Google Scholar] [CrossRef]
- Son, D.; Krishnamachari, B.; Heidemann, J. Experimental Analysis of Concurrent Packet Transmissions in Wireless Sensor Networks. In Proceedings of the 4th Conference on Embedded Networked Sensor Systems (SenSys), Boulder, CO, USA, 31 October–3 November 2006; pp. 237–249. [Google Scholar]
- Lin, S.; Zhou, G.; Al-Hami, M.; Wu, Y.; Stankovic, J.A.; He, T.; Wu, X.; Liu, H. Toward Stable Network Performance in Wireless Sensor Networks: A Multilevel Perspective. ACM Trans. Sens. Netw. (TOSN) 2015, 11, 42. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, J.; Zhou, G.; Gu, L.; Stankovic, J.A.; He, T. ATPC: Adaptive Transmission Power Control for Wireless Sensor Networks. In Proceedings of the 4th International Conference on Embedded Networked Sensor Systems, Boulder, CO, USA, 1–6 November 2006. [Google Scholar]
- Xu, L.; Xu, T. Digital Underwater Acoustic Communications; Elsevier Inc.: Amsterdam, Netherlands, 2017. [Google Scholar]
- Mo, H.; Le, S.; Peng, Z.; Shi, Z.; Cui, J.H. Aqua-OS: An Operating System for Underwater Acoustic Networks. In Proceedings of the Wireless Algorithms, Systems, and Applications Proceedings—7th International Conference, Huangshan, China, 8–10 August 2012; pp. 561–573. [Google Scholar]
- Akyildiz, I.F.; Pompili, D.; Melodia, T. Underwater Acoustic Sensor Networks: Research Challenges. Ad Hoc Netw. 2005, 3, 257–279. [Google Scholar] [CrossRef]
- Climent, S.; Sanchez, A.; Capella, J.V.; Meratnia, N.; Serrano, J.J. Underwater Acoustic Wireless Sensor Networks: Advances and Future Trends in Physical, MAC and Routing Layers. Sensors 2014, 14, 795–833. [Google Scholar] [CrossRef] [PubMed]
- Urick, R. Principles of Underwater Sound; McGraw-Hill: New York, NY, USA, 1983. [Google Scholar]
- Milica, S. On the Relationship between Capacity and Distance in an Underwater Acoustic Communication Channel. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2007, 11, 34–43. [Google Scholar]
- Shin, D.H.; Kim, C.H. A Method for Sensor Data Compression Using Maximum/Minimum Values within Compression Interval Unit in WSN Communication Faults. KIPS 2015, 22, 301–304. [Google Scholar]
- Shin, D.H.; Kim, C.H. Data compression method for reducing sensor data loss and error in wireless sensor networks. J. Korea Multimedia Soc. 2016, 19, 360–374. [Google Scholar] [CrossRef]
- Shin, D.H.; Kim, C.H. A 2MC-based Framework for Sensor Data Loss Decrease in Wireless Sensor Network Failures. J. Korea Soc. Simul. 2016, 25, 31–40. [Google Scholar] [CrossRef]
- Shin, D.H.; Kim, C.H. Considerations for On-the-spot Application of Ocean Sensor Network Technologies. KIPS 2015, 22, 351–354. [Google Scholar]
- Madden, S.; Franklin, M.J.; Hellerstein, J.M.; Wei, H. The Design of an Acquisitional Query Processor for Sensor Networks; SIGMOD: San Diego, CA, USA, 2003; pp. 491–502. [Google Scholar]
- Shin, D.H.; Kim, C.H. A Method for Storing and Recovering Sensing Data using Circular Queue in Wireless Sensor Network Communication Failures. In Proceedings of the 2014 Fall Conference of the KIPS, Anaheim, CA, USA, 20–24 September 2014; pp. 207–210. [Google Scholar]
- Krishnamachari, L.; Estrin, D.; Wicker, S. The impact of data aggregation in wireless sensor networks. In Proceedings of the 22nd International Conference on Distributed Computing Systems Workshops, Vienna, Austria, 2–5 July 2002; pp. 575–578. [Google Scholar]
- Al-Karaki, J.N.; Ul-Mustafa, R.; Kamal, A.E. Data aggregation and routing in Wireless Sensor Networks: Optimal and heuristic algorithms. Comput. Netw. 2009, 53, 945–960. [Google Scholar] [CrossRef]
- Patil, N.S.; Patil, P.P.R. Data Aggregation in Wireless Sensor Network. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 29 December 2010. [Google Scholar]
- Chu, D.; Deshpande, A.; Hellerstein, J.M.; Hong, W. Approximate Data Collection in Sensor Networks using Probabilistic Models. In Proceedings of the 22nd International Conference on Data Engineering (ICDE), Atlanta, GA, USA, 3–8 April 2006; pp. 48–59. [Google Scholar]
- Kamal, A.R.M.; Razzaque, M.A.; Nixon, P. 2PDA: Two-phase Data Approximation in Wireless Sensor Network. In Proceedings of the 7th ACM International Workshop on Performance Evaluation of Wireless Ad Hoc, Sensor, and Ubiquitous Networks, Bodrum, Turkey, 17–21 October 2010; pp. 1–8. [Google Scholar]
- Rooshenas, A.; Rabiee, H.R.; Movaghar, A.; Naderi, M.Y. Reducing the Data Transmission in Wireless Sensor Networks Using the Principal Component Analysis. In Proceedings of the 6th International Conference on Intelligent Sensors, Sensor Networks and Informarion Processing (ISSNIP’10), Brisbane, Australia, 7–10 December 2010; pp. 133–138. [Google Scholar]
- Mohamed, M.I.M.; Wu, W.; Moniri, M. Data Reduction Methods for Wireless Smart Sensors in Monitoring Water Distribution Systems. Procedia Eng. 2014, 70, 1166–1172. [Google Scholar] [CrossRef]
- Kamala, A.R.M.; Hamid, M.A. Reliable Data Approximation in Wireless Sensor Network. Ad Hoc Netw. 2014, 11, 2470–2483. [Google Scholar] [CrossRef]
- Morell, A.; Correa, A.; Barcelo, M.; Vicario, J.L. Data Aggregation and Principal Component Analysis in WSNs. IEEE Trans. Wirel. Commun. 2016, 15, 3908–3919. [Google Scholar] [CrossRef]
- Yao, Y.; Gehrke, J. The Cougar Approach to In-network Query Processing in Sensor Networks. ACM Sigmod Rec. 2002, 31, 9–18. [Google Scholar] [CrossRef]
- Madden, S.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TAG: A Tiny Aggregation Service for Ad-hoc Sensor Networks. ACM SIGOPS Oper. Syst. Rev. 2002, 36, 131–146. [Google Scholar] [CrossRef]
- Yao, Y.; Gehrke, J. Query Processing for Sensor Networks. In Proceedings of the 2003 CIDR Conference, Asilomar, CA, USA, 5–8 January 2003; pp. 233–244. [Google Scholar]
- Yu, W.; Le, T.N.; Xuan, D.; Zhao, W. Query Aggregation for Providing Efficient Data Services in Sensor Networks. In Proceedings of the IEEE International Conference on Mobile Ad-Hoc and Sensor Systems, Fort Lauderdale, FL, USA, 25–27 October 2004; pp. 31–40. [Google Scholar]
- Kim, Y.S.; Park, S.H. A Query Result Merging Scheme for Providing Energy Efficiency in Underwater Sensor Networks. Sensors 2011, 11, 11833–11855. [Google Scholar] [CrossRef] [PubMed]
- Kong, L.; Xia, M.; Liu, X.Y.; Chen, G.; Gu, Y.; Wu, M.Y.; Liu, X. Data Loss and Reconstruction in Wireless Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2818–2828. [Google Scholar] [CrossRef]
- Uk, U.S.; Kim, S.H. Data Reconstuction Scheme Using PCA in Sensor Network Environment. In Proceedings of the Institute of Control Robotics and Systems Conference, Jeonbuk, Korea, 13 December 2007; pp. 20–24. [Google Scholar]
- Ehsan, S.; Bradford, K.; Brugger, M.; Hamdaoui, B.; Kovchegov, Y.; Johnson, D.; Louhaichi, M. Design and Analysis of Delay-Tolerant Sensor Networks for Monitoring and Tracking Free-Roaming Animals. IEEE Trans. Wirel. Commun. 2012, 11, 1220–1227. [Google Scholar] [CrossRef]
- Fraire, J.A.; Madoery, P.G.; Finochietto, J.M. On the design and analysis of fair contact plans in predictable delay-tolerant networks. IEEE Sens. J. 2014, 14, 3874–3882. [Google Scholar] [CrossRef]
- Bedon, H.; Miguel, C.; Alcarria, R.; Fernández, A.; Ruiz, F.J. Message Fragmentation Assessment in DTN Nanosatellite-based Sensor Networks. Ad Hoc Netw. 2016, 44, 76–89. [Google Scholar] [CrossRef]
- Filho, J.G.; Patel, A.; Batista, B.L.A.; Junior, J.C. A Systematic Technical Survey of DTN and VDTN Routing Protocols. Comput. Stand. Interfaces 2016, 48, 139–159. [Google Scholar] [CrossRef]
- Gehrke, J.; Madden, S. Query Processing in Sensor Networks. Pervasive Comput. 2004, 3, 46–55. [Google Scholar] [CrossRef]

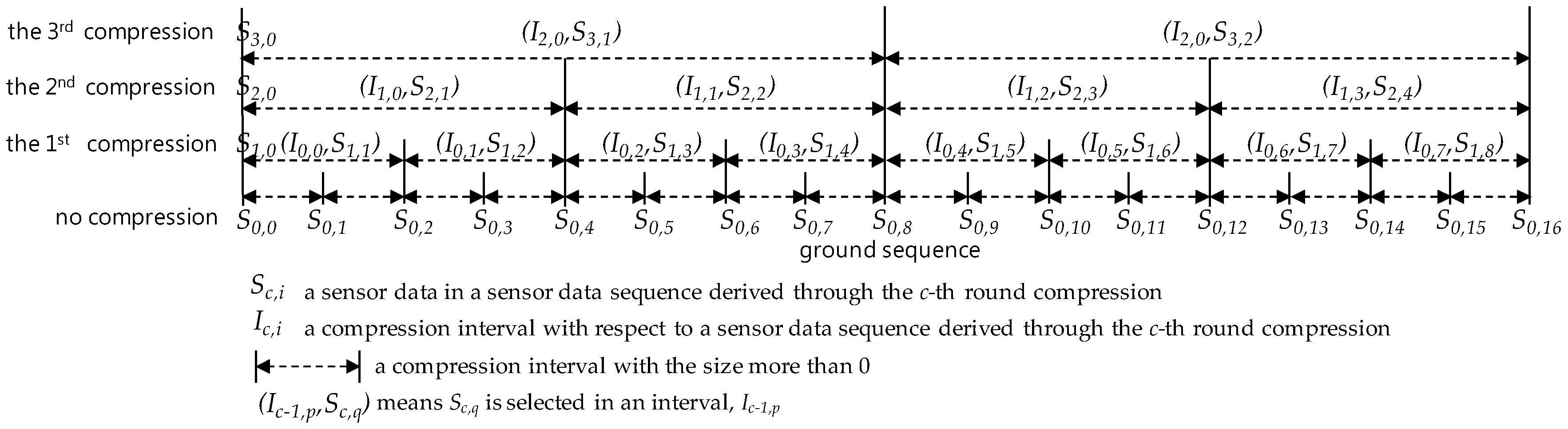





{kind=link}
{kind=link}
{kind=link}
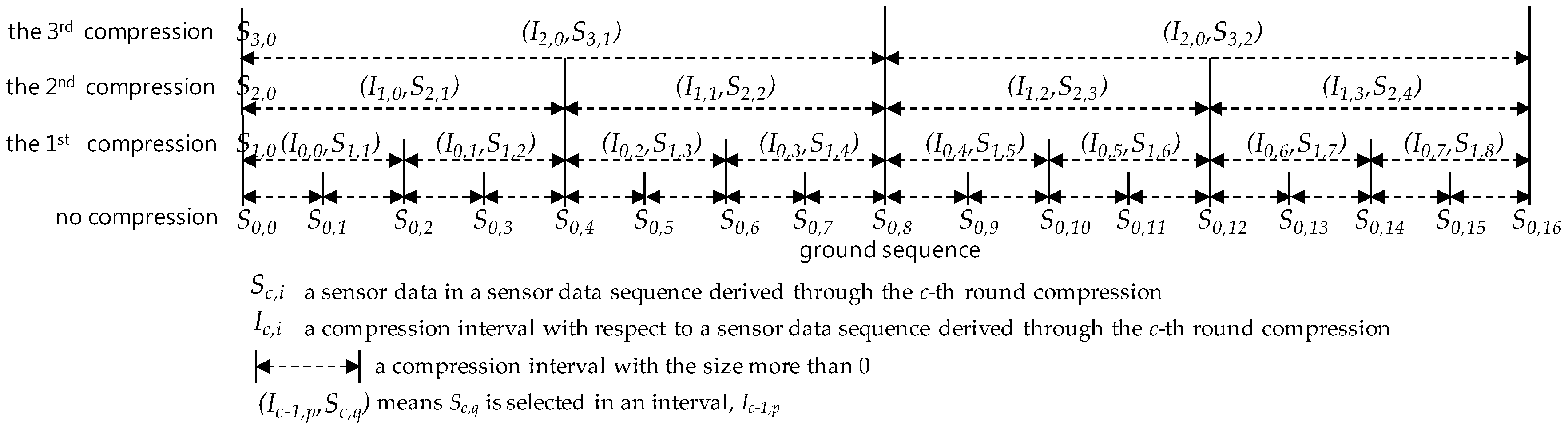{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Terms | Definitions |
|---|---|---|
| S | sensor data sequence | Definition 1 |
| Si | i-th sensor data of S | |
| - | ground sequence (ground data sequence) | Definition 2 |
| - | base sequence | Definition 3 |
| I = Si,Si+1,…,Si+m = [i,i + 1 …,i + m] | compression interval | Definition 4 |
| - | consecutive compression intervals | Definition 5 |
| I ● J | merged compression interval of I and J | Definition 6 |
| CS = (I0, I1, I2, …, Im-1) | compression interval covering on S | Definition 7 |
| Ii | i-th compression interval in CS | |
| - | round compression | Definition 8 |
| Sc | sensor data sequence with the c-th round compression | - |
| Sc,i | i-th sensor data in Sc | - |
| Ic,i (= [p, q]c = [2i,2i + 1]c) | i-th 2-size compression interval in Csc | - |
| - | covers | Definition 9, Definition 10 |
| I-bit position() | I-bit position of | Definition 11 |
| I-bit position sequence of S | Definition 12 | |
| BitSubstring(Bp, c, k) | bit substring from the c(k − 1) th bit to ck-1 th bit in Bp | Definition 13 |
| - | absolute position of Sc,k | Definition 14 |
| - | selection by compression interval pattern with respect to Ic,i | Definition 15 |
| - | selection error of a sensor data | Definition 16 |
| line interpolation errors of | Definition 17 | |
| - | selection by minimum error rule | Definition 18 |
| Zones[0..m − 1] | Zones with respect to the data queue DataQueue[0..2m] | Definition 19 |
| - | operations on [0..m-1] | Definition 20 |
| ZoneBpSeq[0..m − 1] | zone bit sequence array | Definition 21 |
| average error rate (AER) of with respect to in the compression method M | Definition 22 |
| Categories | Experimental Environments and Performance Evaluation Measure |
|---|---|
| Sensor Data Sets | Relative Humidity, Air Temperature, Underwater pH, Underwater Tmperature |
| Samples and Sizes | consecutive 129 sensor data sequence extracted from each set, 25, 41, 73, 93 and 97 consecutive sensor data corresponding to 1-0-0-0, 2-0-0-0, 3-0-0-0, 3-2-2-1, and 3-0-0-0 Zones patterns, respectively, where m-n-o-p Zones pattern means Zones[0]=m, Zones[1]=n, Zones[2]=o, and Zones[3] = p. |
| Experimental Tool | MATLAB R2014a |
| Recovery Method | linear interpolation |
| Comparison Targets | winavg, delta, CQP, 2MC, and SMEP methods |
| Evaluation Measure | the average error rate (AER) |
| Sensor Data Sets | Relative Humidity | Air Temperature | |||||||
| Num. of Round Comps. | 1 CR: 50% | 2 CR: 25% | 3 CR: 12.5% | 4 CR: 6.25% | 1 CR: 50% | 2 CR: 25% | 3 CR: 12.5% | 4 CR: 6.25% | |
| Methods | |||||||||
| winavg | 4.60% | 9.93% | 14.30% | 21.35% | 5.70% | 10.05% | 19.66% | 31.10% | |
| delta | 4.62% | 12.61% | 24.03% | 38.40% | 5.70% | 15.29% | 27.27% | 50.44% | |
| CQP | 3.23% | 6.57% | 10.75% | 21.57% | 2.11% | 4.55% | 14.80% | 34.02% | |
| 2MC | 3.32% | 7.43% | 12.15% | 25.25% | 1.76% | 4.39% | 6.34% | 29.99% | |
| SMEP | 2.80% | 5.72% | 10.75% | 17.66% | 1.24% | 3.92% | 5.83% | 31.94% | |
| Sensor Data Sets | Underwater pH | Underwater Temperature | |||||||
| Num. of Round Comps | 1 CR: 50% | 2 CR: 25% | 3 CR: 12.5% | 4 CR: 6.25% | 1 CR: 50% | 2 CR: 25% | 3 CR: 12.5% | 4 CR: 6.25% | |
| Methods | |||||||||
| winavg | 0.46% | 0.62% | 0.82% | 0.84% | 0.22% | 0.31% | 0.44% | 0.59% | |
| delta | 0.49% | 0.94% | 1.83% | 3.39% | 0.22% | 0.51% | 0.82% | 1.44% | |
| CQP | 0.36% | 0.68% | 1.09% | 1.84% | 0.20% | 0.34% | 0.53% | 0.71% | |
| 2MC | 0.29% | 0.44% | 0.68% | 0.81% | 0.17% | 0.34% | 0.45% | 0.82% | |
| SMEP | 0.24% | 0.39% | 0.62% | 0.62% | 0.16% | 0.32% | 0.45% | 0.69% | |
| Sensor Data Sets | Relative Humidity | Air Temperature | |||||||||
| Zones | 1-0-0-0 CR: 67% | 2-0-0-0 CR: 40% | 3-0-0-0 CR: 22% | 3-2-2-1 CR: 17% | 3-2-2-2 CR:16.7% | 1-0-0-0 CR: 67% | 2-0-0-0 CR: 40% | 3-0-0-0 CR: 22% | 3-2-2-1 CR: 17% | 3-2-2-2 CR: 16.7% | |
| Methods | |||||||||||
| winavg | 4.36% | 11.03% | 14.42% | 14.36% | 14.30% | 5.78% | 12.67% | 20.64% | 19.67% | 19.66% | |
| Delta | 4.62% | 11.93% | 24.10% | 25.10% | 24.03% | 5.93% | 17.78% | 28.29% | 28.47% | 27.27% | |
| CQP | 2.59% | 6.71% | 11.55% | 11.27% | 10.75% | 2.40% | 6.22% | 16.70% | 15.27% | 14.80% | |
| 2MC | 2.35% | 5.15% | 10.99% | 12.05% | 11.50% | 1.65% | 5.56% | 6.97% | 6.26% | 6.08% | |
| SMEP | 2.10% | 2.57% | 7.75% | 8.71% | 8.64% | 1.36% | 3.64% | 5.86% | 5.42% | 5.25% | |
| Sensor Data Sets | Underwater pH | Underwater Temperature | |||||||||
| Zones | 1-0-0-0 CR: 67% | 2-0-0-0 CR: 40% | 3-0-0-0 CR: 22% | 3-2-2-1 CR: 17% | 3-2-2-2 CR:16.7% | 1-0-0-0 CR: 67% | 2-0-0-0 CR: 40% | 3-0-0-0 CR: 22% | 3-2-2-1 CR: 17% | 3-2-2-2 CR: 16.7% | |
| Methods | |||||||||||
| winavg | 1.29% | 1.20% | 0.96% | 0.86% | 0.82% | 0.25% | 0.32% | 0.50% | 0.45% | 0.44% | |
| Delta | 1.35% | 1.95% | 2.30% | 1.91% | 1.83% | 0.27% | 0.53% | 0.91% | 0.83% | 0.82% | |
| CQP | 0.90% | 1.25% | 1.35% | 1.14% | 1.09% | 0.34% | 0.43% | 0.61% | 0.53% | 0.53% | |
| 2MC | 0.48% | 0.70% | 0.83% | 0.74% | 0.71% | 0.28% | 0.36% | 0.52% | 0.46% | 0.46% | |
| SMEP | 0.36% | 0.61% | 0.68% | 0.62% | 0.64% | 0.22% | 0.36% | 0.49% | 0.45% | 0.44% | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, C.; Shin, D. A Formal Approach to the Selection by Minimum Error and Pattern Method for Sensor Data Loss Reduction in Unstable Wireless Sensor Network Communications. Sensors 2017, 17, 1092. https://doi.org/10.3390/s17051092
Kim C, Shin D. A Formal Approach to the Selection by Minimum Error and Pattern Method for Sensor Data Loss Reduction in Unstable Wireless Sensor Network Communications. Sensors. 2017; 17(5):1092. https://doi.org/10.3390/s17051092
Chicago/Turabian StyleKim, Changhwa, and DongHyun Shin. 2017. "A Formal Approach to the Selection by Minimum Error and Pattern Method for Sensor Data Loss Reduction in Unstable Wireless Sensor Network Communications" Sensors 17, no. 5: 1092. https://doi.org/10.3390/s17051092
APA StyleKim, C., & Shin, D. (2017). A Formal Approach to the Selection by Minimum Error and Pattern Method for Sensor Data Loss Reduction in Unstable Wireless Sensor Network Communications. Sensors, 17(5), 1092. https://doi.org/10.3390/s17051092