1. Introduction
Mobile Opportunistic Networks (MONs) can be formed by wireless portable devices such as iPads, PDAs, smartphones, etc., which are usually carried around by human beings. Due to the random mobility of nodes, there are no persistent connections between any two nodes. For data transmission, each node stores data to be sent and then forwards them to the encounter nodes. Such a data delivery process refers to the “storage-carry-and-forward” mechanism, which is the basic principle for data transmission and routing in MONs. Since the path from a source to a destination is intermittently connected, the conventional routing protocols are generally not applicable, and routing becomes a challenging issue in MONs [
1].
Based on the “storage-carry-and-forward” data transmission mode, two simple algorithms were proposed in the research on opportunistic routing. One is Epidemic Routing [
2], and the other is Direct Transmission [
3]. In Epidemic Routing, each node simply forwards data to all encountering nodes. Obviously, Epidemic Routing has the highest data delivery success rate among all routing algorithms but also has the highest network overhead. On the contrary, in Direct Transmission, the source node stores the data to be sent and does not forward them to any nodes until it reaches the destination. Direct Transmission had the lowest network overhead but also the lowest data delivery success rate. The other research works on routing in MONs tried to create a possible tradeoff between data delivery rate and network overhead.
As human beings take part in network activities, the behavior of mobile nodes thus shows certain social attributes. Some research works [
4] had shown that social relationships among nodes had an important impact on node encounter events and their duration time, which would be useful for reducing routing overhead improving the success rate of data transmission. Accordingly, a number of researchers made good use of nodes’ social attributes to design data forwarding mechanisms and received good results. In the long run, the data transfer mechanism based on social relationships among nodes will be more stable than the other forwarding modes [
4].
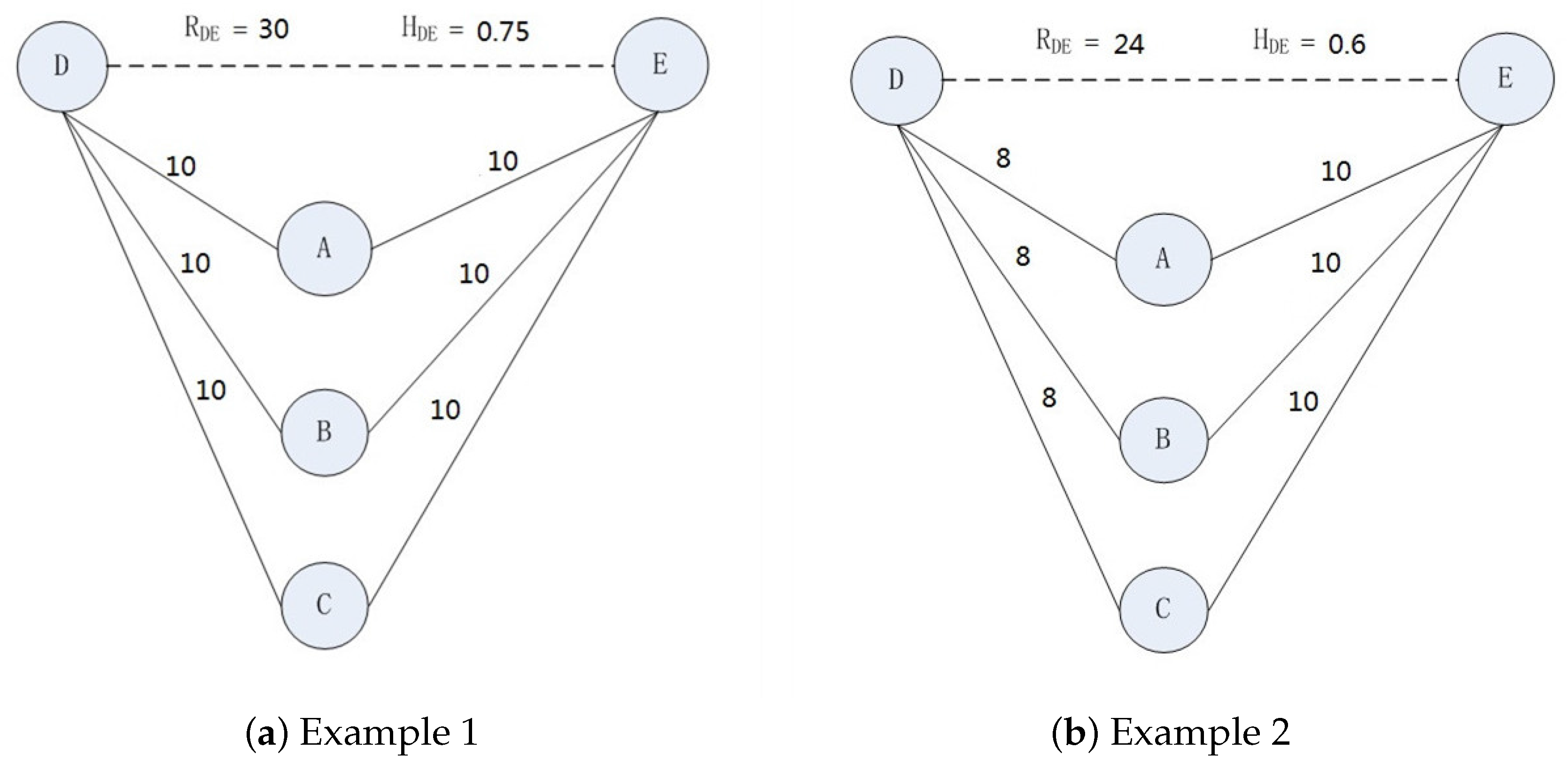
In social based routing, the key point is to find and measure the social relationships among nodes, which depend on the analysis of the historical data of encounters of nodes [
5,
6]. Some works used historical data to predict the probability of the nodes’ encounters, and thereby designed optimal algorithms for message forwarding. Some works measured strength of social relationships among nodes based on nodes’ encounter frequency, formed social clusters of nodes, and proposed cluster-based routing mechanism for message forwarding. However, as for social relationship finding and measurement, there are still some important points not considered in the existing research work. For example, there is such a social phenomenon in the real world: Bob has two grandmothers represented by
D and
E,
D is the mother of Bob’s mother, and
E is the mother of Bob’s father. Although
D and
E are close relatives, they may never contact each other because of their opposing personalities. In this phenomenon, with
D and
E acting as two nodes in MONs, they have no direct encounter and link, but, in fact, there is a strong social relationship between them. Therefore, in some conditions, we may fail to find and measure the social relationship between two nodes only from their direct encounter records.
In fact, although D and E have no direct relationship, they have common close friends including Bob and his parents. Observing their circles of friends, we can find out how close the social relationship between D and E is. Consequently, the social relationship between two nodes can be divided into two parts. One part comes from direct contact events, which are called Explicit Social Relationships in this paper. Another part is called Implicit Social Relationships obtained from the common friends of the two nodes. Like the communication networks such as Facebook, Twitter, Wechat and so on, the circles of friends can be used to find the relationship between two people.
In this paper, we study social relationships among nodes, and propose social based clustering and routing mechanisms in WONs. Inspired by some social phenomena, we present the definitions of explicit and implicit social relationships, which are used to determine the strength of social relationships among nodes. Our experiment results show that the proposed methods can exactly evaluate social relationships among nodes, which is helpful for routing mechanisms to improve data delivery rates. The contributions of this paper are listed as follows:
We present the definitions of explicit social relationships (ExSRs) and implicit social relationship (ImSRs), and combine both ExSRs and ImSRs to measure social relationships between nodes. Adaptive weights are given to ExSRs and ImSRs in the measurement of social relationships, which can be adjusted to the contact feature of the nodes, and thus accuracy measurement of social relationship will be achieved. In addition, the distributed computing scheme of common friends is proposed for the calculation of ImSR.
We propose a novel social-based clustering and routing scheme. Each node selects the nodes with closed social relationships to form a local cluster, and the self-control method is used to keep all cluster members always having close relationships with each other. A cluster-based message forwarding mechanism is designed for opportunistic routing, in which each node only forwards the copy of the message to nodes with the destination node as a member of local cluster.
The rest of this paper is structured as follows. In
Section 2, we describe and analyze the related work. In
Section 3, definitions and computing methods are presented for explicit and implicit social relationships. In
Section 4, social-based clustering and routing is presented and analyzed. Simulation results are presented in
Section 5. The last section concludes this paper.
2. Related Work
Opportunistic routing has been extensively studied, and various types of message-forwarding methods and routing algorithms were proposed for “storage-carry-and-forward” data transmission with the goal of reducing network overhead and improving data delivery rate. Epidemic Routing [
2] flooded the message to all nodes without consideration of routing overhead. Theoretically, Epidemic Routing had the highest success rate of data delivery, but at the price of highest routing overhead. Direct Transmission [
3] required that the source stored the data to be sent, and did not forward the data to any nodes but the destination. Direct Transmission had the lowest overhead among all routing algorithms, but also had the lowest success rate of data delivery. Other works in opportunistic routing tried to make a balance between Epidemic Routing and Direct Transmission, and create a possible tradeoff between data delivery rate and routing overhead. Lindgren et al. [
7] used historical data of nodes’ encounters and transmission records to compute forwarding probabilities between nodes and the proposed forwarding-probability based routing mechanism PRoPHET, which had the approximate success rate of data delivery of Epidemic Routing [
2] with the low routing overhead. Spyropoulos et al. [
8] took the advantages of Epidemic Routing and Direct Transmission into consideration and proposed a routing scheme called Spray and Wait, which “sprayed” a number of copies into the network, and then “waited” until one of these nodes met the destination. Erramilli et al. [
9] proposed a delegation forwarding solution for opportunistic routing, which required a node to forward data to only the node with the highest forwarding performance so far. Balasubramanian et al. [
10] treated opportunistic routing as a resource allocation problem, and each node replicated packets according to packet utility value, which was determined by the delay to destination and encounter probability with destination. Zhang et al. [
11] proposed a novel mobility prediction-based routing, and the computation of the probability for a node destined to an area was based on the semi-Markov model. In [
12,
13,
14], the authors used network coding in opportunistic routing to improve throughput. The above routing schemes used a variety of mechanisms, including discovering the meeting probabilities among nodes, packet utility, and network coding. The primary focus of these mechanisms was to increase the likelihood of finding a path with limited information, and the effectiveness had a relationship with the accuracy of prediction models or evaluation methods.
As human beings take part in network activities, the behavior of mobile nodes therefore shows some certain social attributes. Research work [
4] had shown that social relationships among nodes could be used to improve the performance of opportunistic routing. Recently, there have been some interesting works based on social relationships among nodes. Hui et al. [
15] proposed a social-based routing named BUBBLE. The authors exploited two social and structural metrics, namely, centrality and community. Based on the social activity of nodes, they calculated the global ranking of the nodes in the whole network and the local ranking of the nodes in the community. The message was forwarded to the nodes with high social activity ranking. Gao et al. [
16] studied multicast in Delay Tolerant Networks (DTNs) from the social network perspective, used the cumulative probability of node encounter to get node centrality and social community structures, and selected the nodes with high node centrality as the relay nodes in multicast. Fan et al. [
17] explored the relationship between geographic and social regularities of human mobility, proposed the concepts of geocommunity and geocentrality, used the semi-Markov process to model user mobility based on the geocommunity structure of the network, and proposed route algorithms to minimize total duration or maximize the dissemination ratio. Wei et al. [
18] took the use of frequency and duration of node contacts to generate the social graph, addressed the community evolution problem, proposed distributed algorithms based on the social graph to detect the overlapping communities and bridge nodes, and designed a social-based routing scheme. Orlinski et al. [
19] studied cluster based routing, and proposed a routing scheme with cluster size adjusted dynamically. Mtibaa et al. [
20] developed the PeopleRank approach for node ranking, which was similar to PageRank. PeopleRank gave higher weight to nodes that were socially connected to other important nodes of the network. In message forwarding, a node
u forwarded a message to a node
v that it encountered if the rank of
v was higher than the rank of
u. Mei et al. [
21] proposed a socially aware and stateless routing scheme called SANE, in which message forwarding was based on the interest similarity between nodes. SANE had the advantage of requiring less of a buffer of nodes than other approaches. However, the interest is just one of the social ties between nodes. For the nodes having no common interest, but frequent contact with the destination, they can often make a great contribution to message delivery, as is not considered in SANE.
From different viewpoints of social relationships among nodes, the above works proposed the effective routing solutions for a variety of problems, which had shown that social relationships among nodes had a major impact on the performance of opportunistic routing. With the growing popularity of smartphones, more and more people have the opportunity to participate in a variety of applications of MONs, and comprehensive study of the social relationships among nodes will be more important than before in MONs.
Different to the existing research work, in this paper, we take a real social phenomenon as an example to discuss the measurement methods of social relationships, and propose a novel social-based scheme for clustering and routing in MONs. In our daily lives, we can get a lot of information from the circles of friends in social communication networks such as Facebook, Twitter, Wechat, and so on, which inspires us to analyze the social relationships among nodes in MONs. In the real world, the social relationship between two people is not only shown in direct contact with each other, but also in their common circles of friends. For example, in our lives, there is often such a phenomenon: Bob has two grandmothers D and E: D is the mother of Bob’s mother, and E is the mother of Bob’s father. Although D and E are close relatives, they may never contact each other because of their opposing personalities. In this phenomenon, there is no direct contact between D and E, but, in fact, they have strong social relationships because they have a common “circles of friends”. As the saying goes, “like attracts like”, and we have many types of circles of friends such as working circles, classmate circles, common hobby circles and so on. Real-life experience tells us that we can get important information from circles of our friends.
In an MON, the nodes are often wireless devices carried by human beings, and thus the activities of nodes are inevitable for showing some social characteristics described above. Consequently, the study of social relationships should reveal the explicit relationships among nodes via direct contact events, and also determine the implicit social relationships among them from their circles of friends. In this paper, we divide the social relationships between two nodes into two parts. One part comes from direct contact events, which are called Explicit Social Relationships (ExSRs). Another part of relationships should be relayed by their common friends, called Implicit Social Relationships (ImSRs). We present the measure methods of ExSRs and ImSRs, which are used in the design of clustering and routing. In short, what we focus on in this paper is measuring implicit social relationships between nodes from their circles of friends, and the accurate measurement of social relationships can improve the performance of the social-based routing proposed in this paper.
4. Social-Based Clustering and Routing
With effective measurement of social relationships among nodes, we propose a Social-based Clustering and Routing scheme (SCR) in MONs, including the construction and update of clusters, and cluster-based routing.
4.1. Cluster Construction and Update
In the SCR scheme, each node has an encounter table recording the set of encounter nodes and corresponding encounter times during recent time T. Based on the encounter table, each node can calculate the ExSR with other nodes. In addition, each node has a common friend table recording its common friends with other nodes, which can be called circles of friends and is used to compute ImSR with other nodes. After social relationship measurement, each node selects the nodes with close social relationships to join its local cluster, which will be updated dynamically to control the size and keep the close relationship among members. For cluster updating, each node has a delete list marking the nodes going to be dropped from the local cluster. For node i, , and are its sets of encounter nodes, local cluster and delete list, respectively.
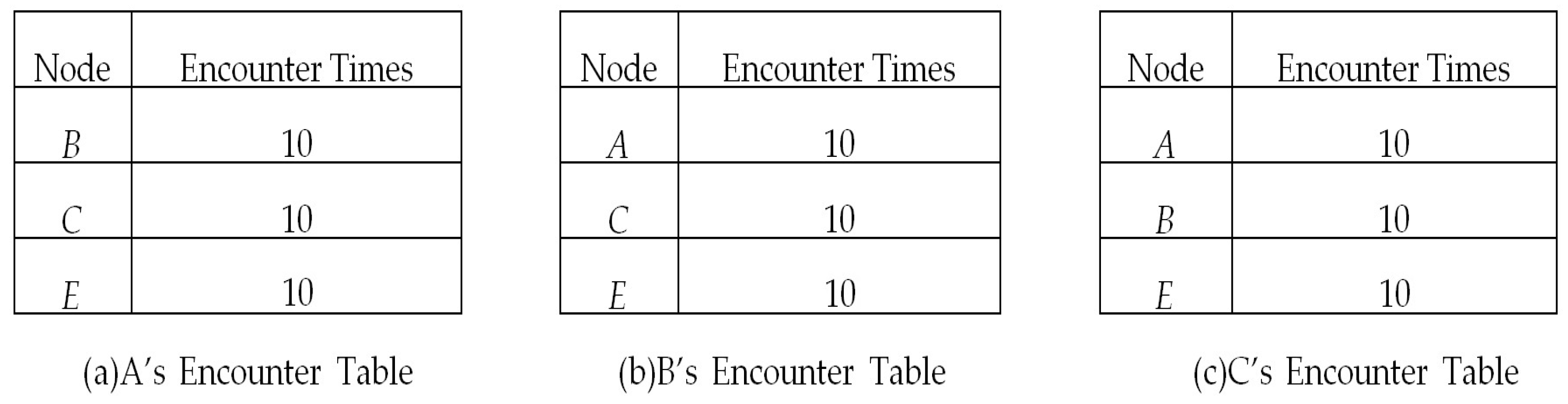
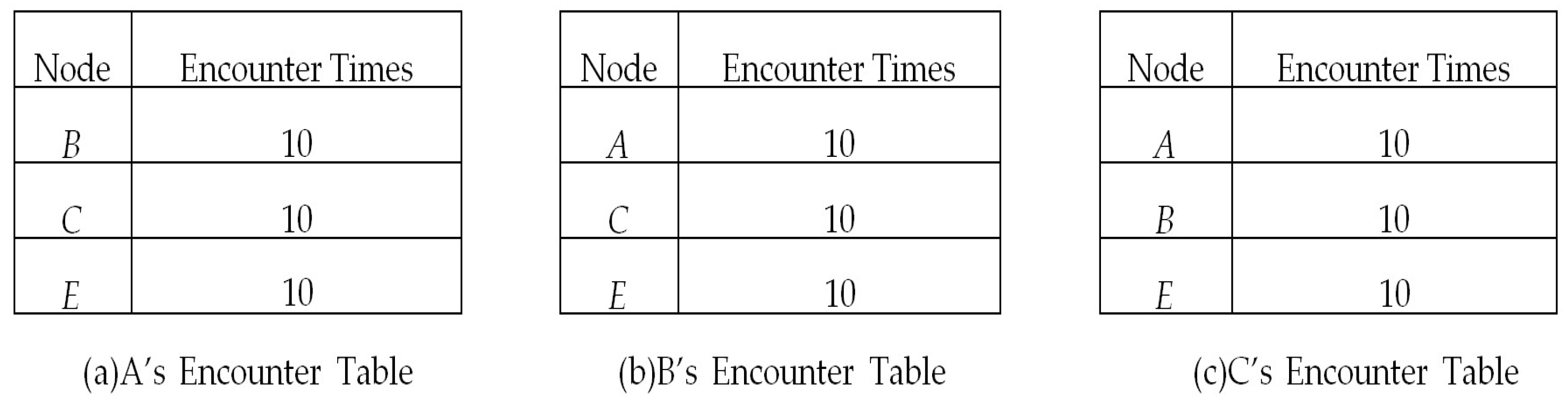
Initially, the related tables and lists in each node are empty. When two nodes encounter each other, they update their encounter table and exchange encounter information. After information exchange, they update their common friend tables similar to the example shown in
Figure 3 and
Figure 4. Then, based on Equations (
1) to (
7), they calculate their strength of social relationship with other nodes. The encounter of two nodes may bring the change of their common friends with other nodes, thus their social relationship strength with other nodes may change.
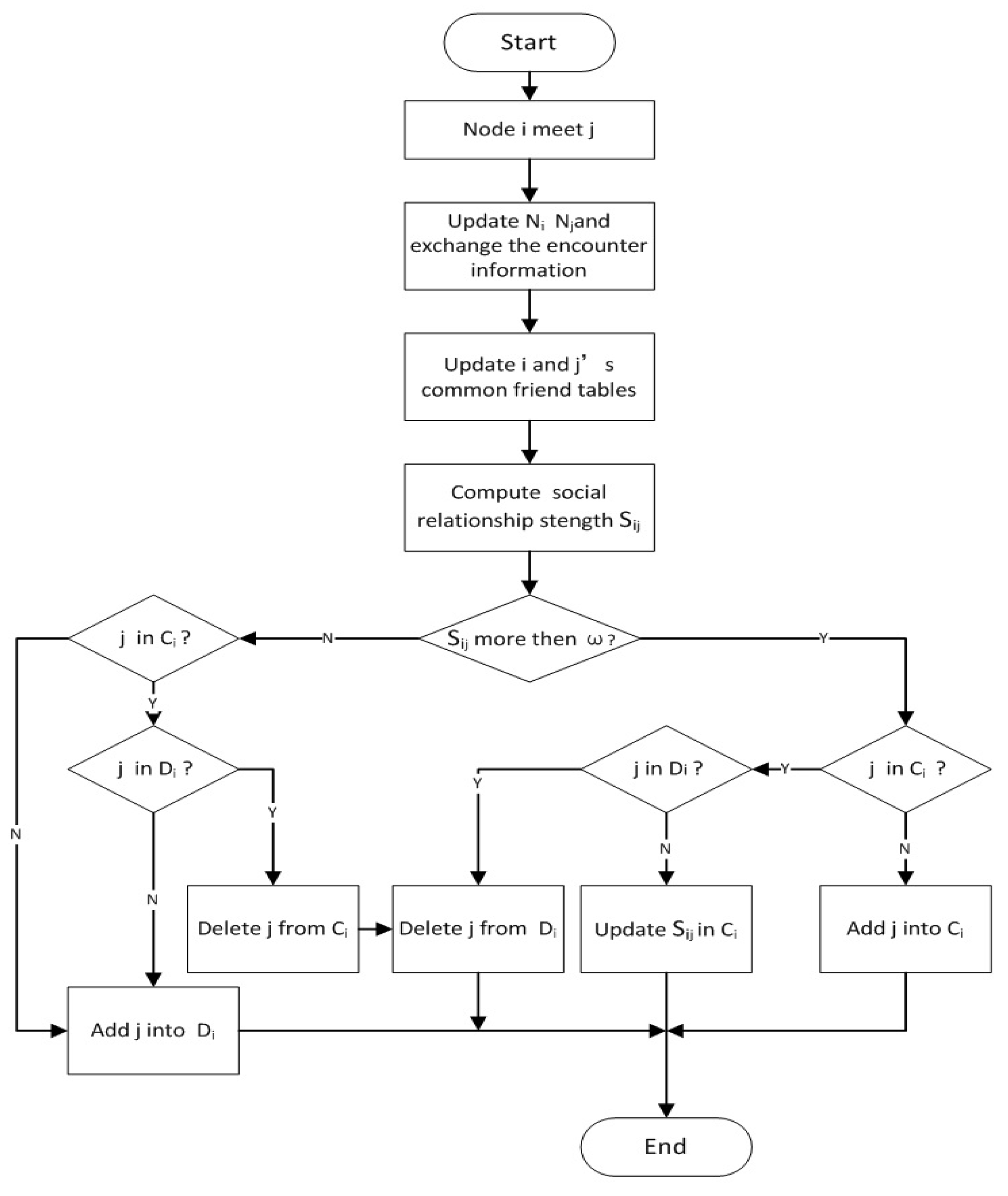
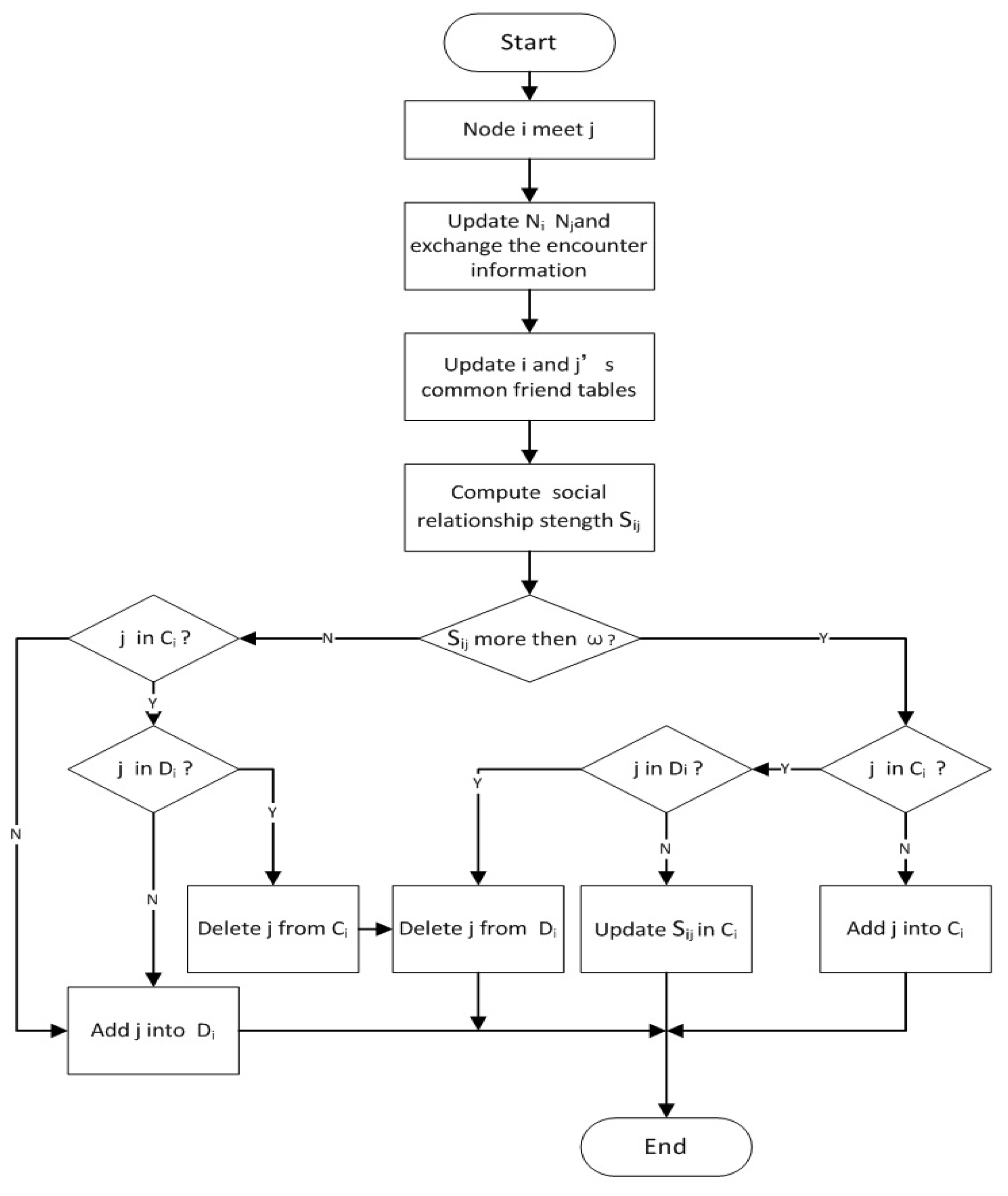
When node i encounters node j, it is supposed that is the strength of the social relationship between nodes i and j at time t, and the parameter is the threshold of social relationship strength for cluster members. Cluster construction and update are discussed as follows according to different conditions of and .
Condition 1: is greater than
If is greater than , and node j is not a member of , node j will join . Otherwise, if node j is a member of and in the delete list , node j will be removed from , and node j is avoided being dropped out from the cluster.
Condition 2: is equal to or less than
If is equal to or less than , and node j is not a member of , node i will do nothing for node j. Otherwise, if node j exists in , node j will be removed from and , which means that node j is dropped out from the local cluster of node i. However, if node j does not exist in , node j will enter the delete list waiting for future consideration of removal from the local cluster.
The local cluster in each node will be updated dynamically, and the above processing will be done if the related information has a change. The processing of cluster update can be shown in
Figure 5.
In every calculation of a social relationship between a node and its cluster members based on Equations (
1) to (
7), the result will be stored in the local cluster table. Before the next calculation, the stored strength of the social relationship will decrease a certain value over time, which can be helpful for dropping the out-of-date nodes from the local cluster, controlling the size of cluster, and keeping the close relationship between a node and its cluster members. It is mentioned above that the time
T is the period for node encounter information collection, thus if no information shows that a node is alive, the node will enter an observing window for consideration of dropping out from the local cluster. It is supposed that there are
n periods for the social relationship strengths to decrease to the threshold
. Consequently, the social relationship strengths in cluster table will be self-decreased by a value
every
time. To social relationship strength between node
i and its cluster member
j, the decreasing value in each period is
shown in Equation (
8). If node
j is one of cluster members of node
i, and the recorded social relationship strength
has not been updated for a period of time
T, it will be self-decreased to
. Then, node
j will put onto the delete list of node
i, and wait for consideration of dropping from the local cluster of node
i:
4.2. Cluster-Based Routing
As described above, each node selects the nodes with a close social relationship to form a local cluster. Making full use of the close relationship among cluster members, cluster-based routing can improve the success rate of data delivery, and also cut down on routing overhead. In this paper, when two nodes encounter each other, message forwarding happens only if the destination is in the local cluster of the encountering node. The process of routing can be described in two stages. One is information exchange and the other is message forwarding.
(1) Information exchange
When two nodes encounter each other, they send a “hello” message to each other, and then they get node identity and node encounter information of the other node. With the received information, they can update their encounter table and common friend table, which are used to calculate the strength of the social relationship with other nodes, and set up their local cluster.
(2) Message forwarding
It is supposed that node i encounters node j, and node i has the message to forward. If node j is the destination of the message, node i will forward the message to j and delete the message from its sending queue. Otherwise, there are the following two cases for node i to forward the message.
Case 1: Intra-cluster message forwarding
If the destination of the message is in the local cluster of node i, and node j is also a member of the cluster, node i will forward a copy of the message to node j. Otherwise, node i does not forward the message to node j.
Case 2: Inter-cluster message forwarding
If the destination of the message is not a member of the local cluster of node i, node i will send a “Request” packet to node j requesting whether the destination is in its local cluster. After node j receives the “Request” packet and checks the cluster table according to the request, node j will reply to node i with a “Response” packet notifying it about whether or not the destination is a cluster member of node j. If node i receives the “Response” packet and the destination is a cluster member of node j, node i will forward the message to node j. Otherwise, node i does not forward the message to node j.
The message to be sent can stay in the buffer of node i for a period of time that is dependent on the buffer size of node i. During this period of time, if node i encounters the forwarding objectives mentioned in the above rules, the message will be scheduled to be sent. Otherwise, the message will be dropped from the buffer of node i according to the buffer management algorithm. There exists a possibility that the message can not be forwarded if none of the nodes have destinations as local cluster members, and the large buffer size will be helpful for message delivery.
5. Simulations
We implement the proposed scheme SCR in the Opportunistic Network Environment simulator (ONE) [
27] simulator, and evaluate SCR by performance comparison with PRoPHETv2 [
7], DRAFT [
19] and BUBBLE [
15]. In simulation, the real datasets
,
,
and
are used for node activity driving, which can be downloaded from CRAWDAD [
28]. The last updating date of the datasets was in August 2016, and the detailed information is shown in
Table 1. In simulation, the node buffer size is set to
, the message size is
, and the node number and TTL are different to the four datasets shown in
Table 2. In SCR, the parameters are set as
,
, and
as
times the average encounters among all nodes in each dataset. In DRAFT, the parameters are set as
,
and
s.
We compare the performance of each routing algorithm in the same simulation environment and analyze the impact of parameters on SCR. The following metrics are used in the performance comparison.
Packet Delivery Ratio (PDR): The ratio of the number of data packets that successfully reached the destination and the amount of data packets sent by the source within a certain time.
Transmission Delay (TD): The delay is the average time it takes for a packet to reach the destination after it leaves the source.
Routing Overhead Ratio (ROR): As is shown in Equation (
9), the total number of packets to be forwarded (relayed_number) minus the number of packets successfully transferred to the destination node (delivered_number), and then divided by the number of packets successfully transferred to the destination:
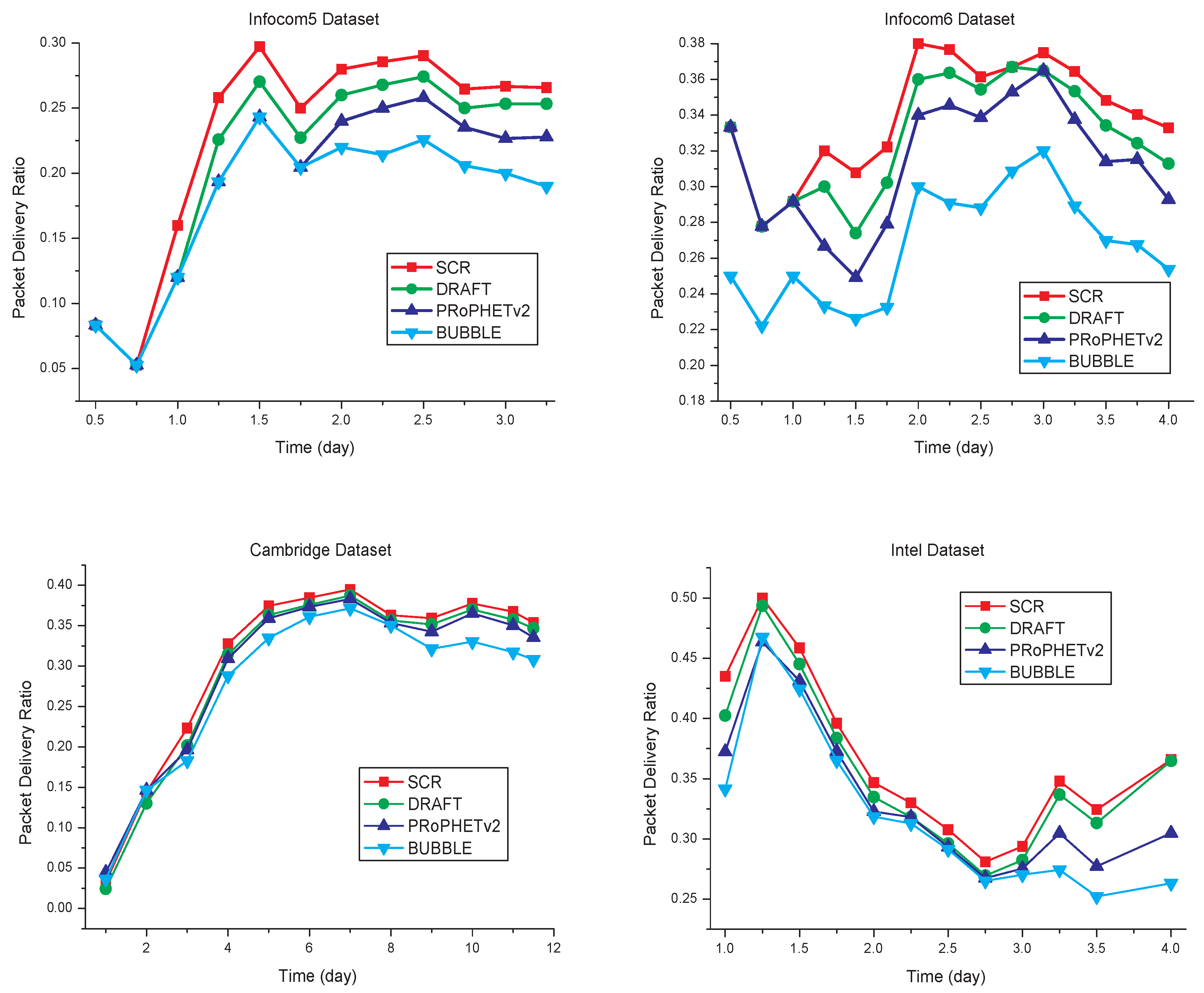
5.1. Packet Delivery Ratio
In the simulation, SCR, PRoPHETv2, DRAFT and BUBBLE run in the four datasets respectively, and the simulation time is the duration of dataset, which is shown in
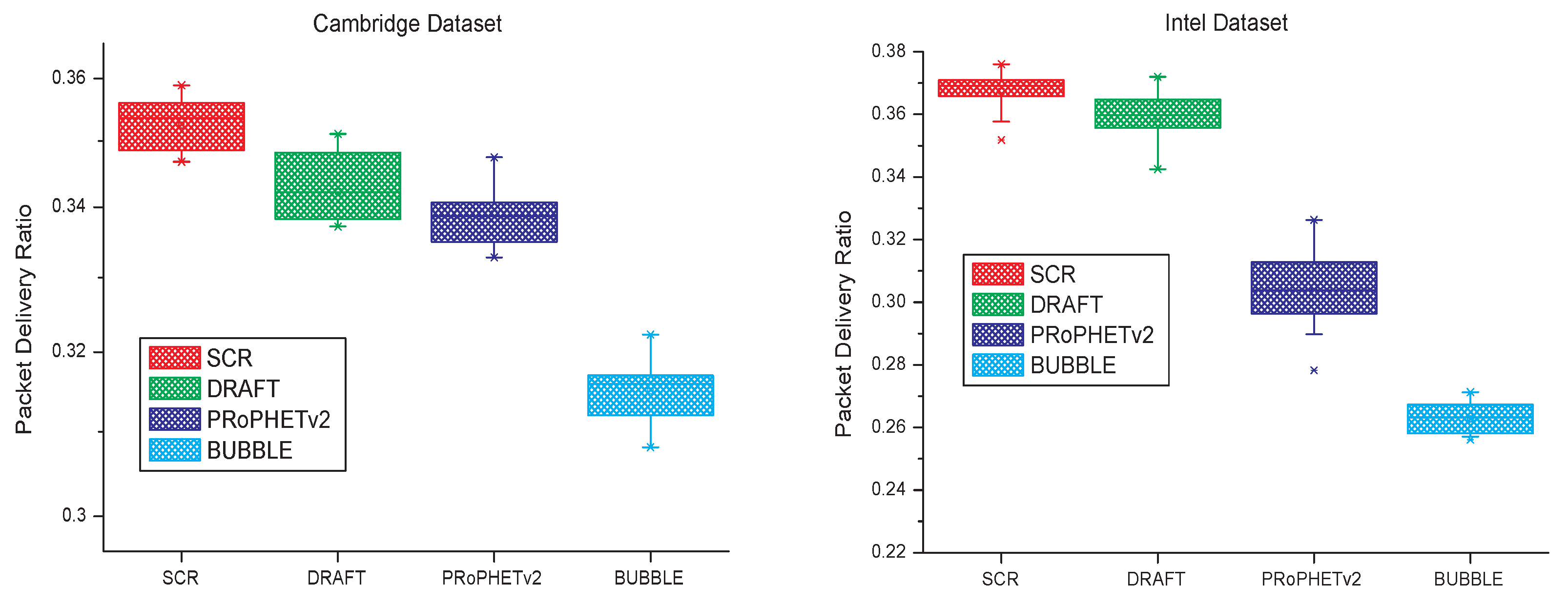
Table 1. Simulation results are shown in
Figure 6. Similar to [
19], quartiles are used to analyze the experimental results. The experimental data is arranged in ascending order and then divided into four equal parts. Then, we can find In
Figure 6 there are five signs (min, first quartile, median, third quartile and max) for the result of each algorithm. In some special situations, two or more signs may have the same value. For example, in the first part of
Figure 6, to the result of BUBBLE, the first quartile and median have the same value. The quartiles shown in
Figure 6 can reflect the distribution center, concentration and spread range of packet delivery ratio. As can be seen from
Figure 6, SCR has a higher distribution center of packet delivery ratio than the other three algorithms, a small spread range and a focus on better range.
With the simulation time varying, the results are shown in
Figure 7. When simulation time is less than one day, SCR has similar results to the other algorithms. Due to the formation of clusters in the network requiring a process, in a short simulation time, there are not enough nodes in the local cluster for efficient data transmission. With the increasing of simulation time, SCR has a higher average packet delivery ratio than the other three algorithms. Compared with PRoPHETv2, DRAFT and BUBBLE, SCR has the higher packet delivery ratio, as shown in
Table 3.
5.2. Transmission Delay
The transmission delay of each algorithm is shown in
Figure 8. Compared with the other three algorithms, SCR has the transmission delay decreased by some extent, which is shown in
Table 4. Since SCR is cluster-based routing, and cluster members have strong social relationships with each other, it can reduce unnecessary data transmission, and thereby reduce the transmission delay.
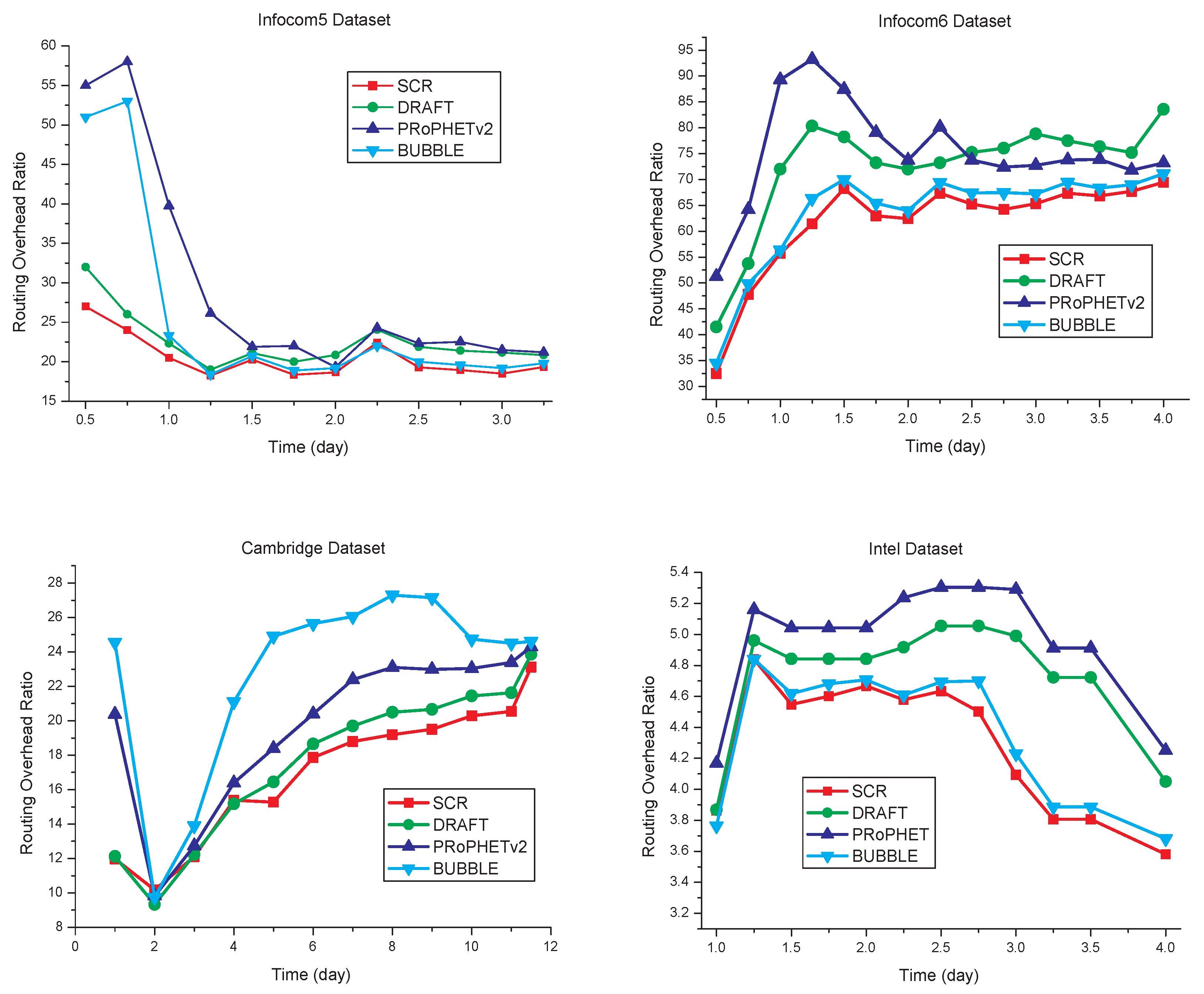
5.3. Routing Overhead Ratio
The comparison of routing overhead is shown in
Figure 9. Compared with the other three algorithms, SCR has the routing overhead ratio decreased by some extent, as shown in
Table 5. Since cluster members have close social relationships in SCR, data transmission has better efficiency than the other three algorithms. In SCR, each node only forwards the copy of the message to nodes that have the destination node as cluster members. Consequently, the total amount of message forwarding is reduced without a negative effect on packet delivery ratio.
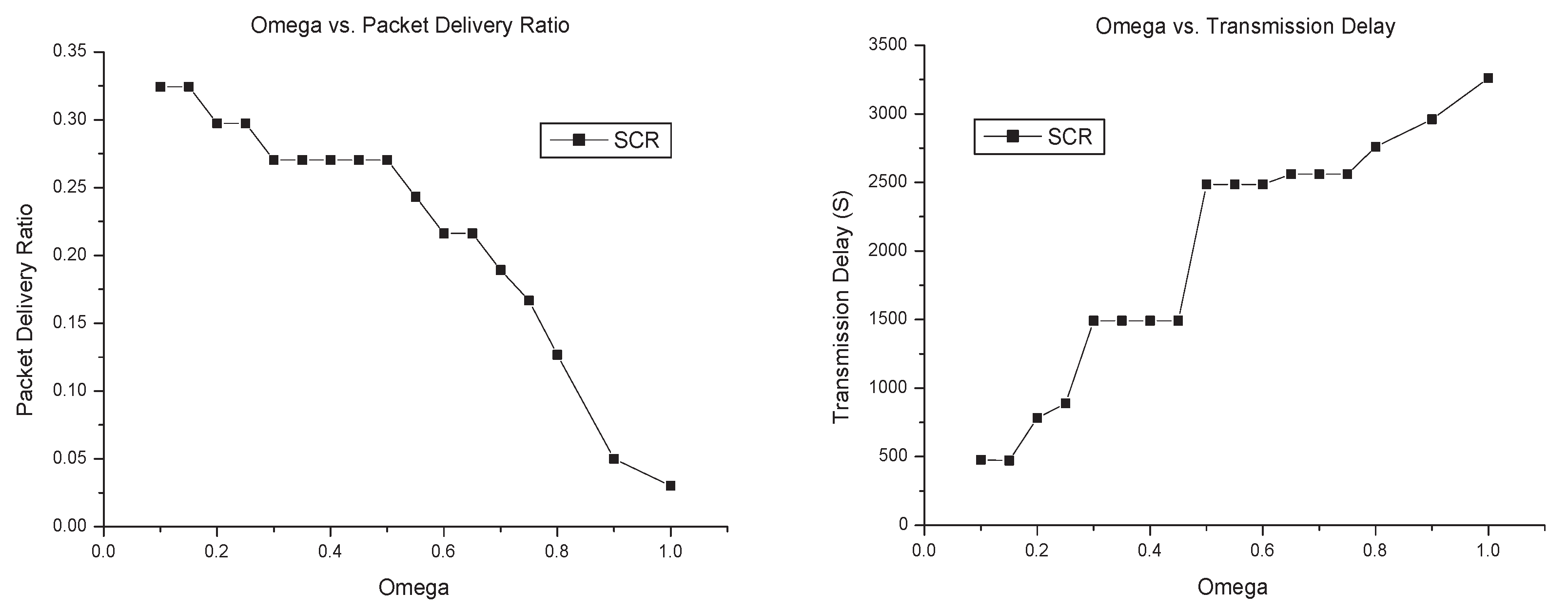
5.4. Impact of Parameters on Performance
In SCR, there are three parameters:
,
and
n. The parameter
is the threshold of social relationship strength for cluster members, and to each node, the size of its local cluster will increase with the decreasing of
. The parameter
is the referring encounter times for the measurement of social relationship between nodes. In a given condition, the bigger
has the smaller value of social relationship between two given nodes. For local cluster constructing,
and
have a similar effect. On the one hand, with fixed
, we can change
to let a node join the cluster. On the other hand, to a given
, we can change the threshold
to have a node join the cluster. It is obvious that changing the value of the social relationship has the same effect as changing the threshold of the cluster for cluster constructing. Consequently, we herein only analyse the impact of
on performance. The parameter
n is the number of self-decreasing times in the time period
T, which is for the social relationship to self-decrease to
, as is shown in Equation (
8). Given that the simulation time is three days, the performance of SCR in
dataset is shown in Figure
10, where
is denoted as “Omega”.
As is shown in Figure
10, the smaller
has the higher packet delivery ratio, the lower transmission delay, and the higher routing overhead ratio. This is consistent with theoretical analysis: the increasing size of the cluster generates more copies of the message forwarded by cluster members, which improves the success of packet transmission and thus decreases the transmission delay, but more copies of the message raises the routing overhead ratio. Considering the tradeoff of packet delivery ratio, transmission delay and routing overhead, we suggest that the parameter
should be
, which is why we set up
in the above simulation.
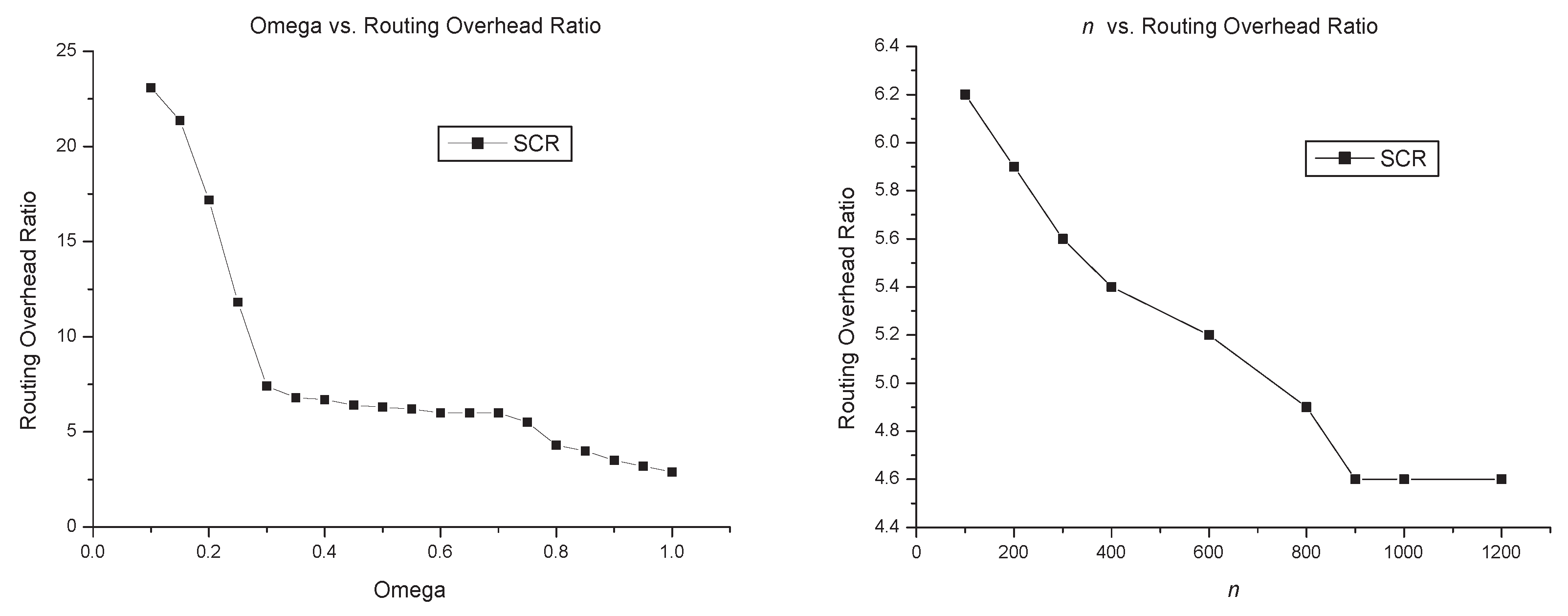
From simulation results, the
n has almost no impact on packet delivery ratio and transmission delay. In our opinion, the
n has a relationship with the speed of an outdated node dropping from the cluster, but no relationship with the key nodes that can forward messages to destinations successfully. As far as routing overhead is concerned, the smaller
n leads to more useless nodes staying in the cluster, and more copies of the message forwarded to the network. Therefore, routing overhead ratio increases, as is shown in the lower right part of Figure
10.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}