1. Introduction
Electronic nose (E-nose), a device composed of a sensor array and an artificial intelligence algorithm, has been successfully used in many fields. It is able to deal with a multitude of problems efficiently, such as food analysis [
1,
2,
3,
4], disease diagnosis [
5,
6,
7,
8], environment control [
9,
10], etc.
Traditional methods for a doctor to diagnose the type of wound infection usually require observing features of the plaie and take a long time to analyse the patient’s blood, urine and other aspects, delaying the best time for treatment. In particular, with the development of medical technology as well as higher requirements on disease detection speed and accuracy, the E-nose has great prospects in disease diagnosis. Our previous work has proved that the E-nose can be used to distinguish the classes of wound infections through their special odor [
11,
12,
13,
14].
In practice, however, if we want to get an E-nose that can distinguish wound infections efficiently and accurately, quantities of wound infection samples are needed to train the classifier, which would cost a lot of money. Such experimental infection samples are not that easy to obtain, let alone labeled wound infection samples. While our wound infection samples are limited, there are some other unlabeled pollutant gas samples which are numerous and obviously easier to obtain, for a lower cost. If we ignore the usage of these samples in other fields, it can lead to waste. To take advantage of them, we introduce transfer learning in our paper.
Transfer learning is the ability to transfer knowledge from one field to other fields, and these fields can share different labels, which distinguish it from traditional machine learning techniques. That is to say, through transfer learning, we can use some samples from other fields to make up the lack of wound infection samples in our field. Thus, in this paper, we purchase inexpensive chemical solutions to obtain four types of pollutant gases, and can, as a result, get thousands of unlabeled samples through this approach, at low cost.
These unlabeled gas samples are introduced to cope with the lack of labeled wound infection samples, and an enhanced quantum-behaved particle swarm optimization (EQPSO) [
15,
16] is proposed to improve the performance of classifiers. In the machine learning field, there are some classical algorithms that can roughly be placed in two categories [
17]: supervised learning, which concerns obtaining its classifier based on labeled data; and unsupervised learning, which is concerned with obtaining its classifier from unlabeled data. Unavoidably, however, both methods have significant shortcomings: supervised learning needs a large amount of labeled data, while unsupervised learning classifies samples by their different distribution, which makes the accuracy far lower than that of supervised learning. Therefore, semi-supervised learning, a combination of these two types learning framework, is widely adopted in practical application and improves the generalization ability of model. It broadens the range of data set, but because semi-supervised learning is typically based on the assumption that labeled data and unlabeled data can be tagged with the same labels, a new group of machine learning is put forward, which is called “self-taught learning”.
Self-taught learning [
18,
19] is a new machine learning framework and also a type of transfer learning, corresponding to human learning, using unlabeled data in supervised classification tasks. What distinguishes self-taught learning from other learning methods is that self-taught learning can solve such problems as the fact that labeled data and unlabeled data do not share the same class labels, that they may be from entirely different distributions, or that the labeled data might be far less than unlabeled data.
In recent years, self-taught learning has undergone considerable development in many fields [
20,
21,
22]. In self-taught learning, we construct basis vectors from the unlabeled data. In turn, these basis vectors are used to rebuild input representation, converting training data into representations related to unlabeled data. These new representations are programmed into the classification task and significantly improve the performance of the E-nose. In the algorithm, the most significant step is to contrast basis vectors from the unlabeled data and to rebuild new representations. To rebuild new representations, we take advantage of the neural network and apply the sparsity constraint, which makes the representation of each layer sparse (most of nodes become zero).
However, this is yet to be applied in the field of E-nose for the purpose of distinguishing the label information of wound infection data. In this paper, self-taught learning is proposed to perfect the accuracy of classification. In the rest of this paper, we first describe details of the material and odor sampling experiments in
Section 2, then the self-taught learning framework is elaborated on in
Section 3. In
Section 4, we apply some classical classification algorithms and compare their results, such as partial least squares discriminant analysis (PLSDA) and radial basis function (RBF) [
23,
24].
2. Experiments and Data Preprocessing
2.1. E-Nose System and Experimental Setup
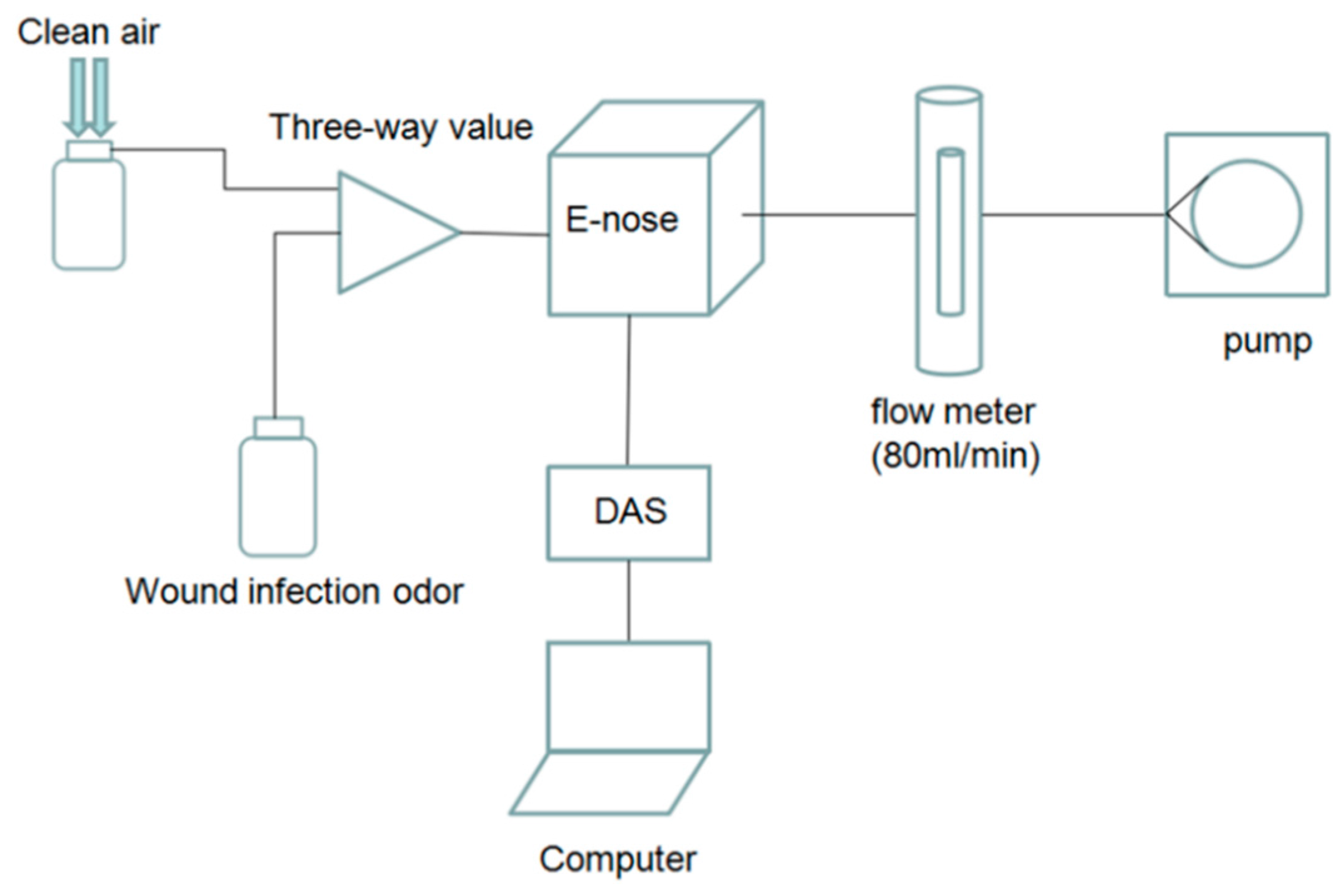
The labeled wound infection data set and unlabeled gas data set are needed in our project. An E-nose system is used to prepare the data set. In constructing the system, we employ an E-nose, a data acquisition system (DAS), a pump, a rotor flow meter, a three way value, a filter, glass bottles and a computer. The schematic diagram of the experimental system is shown in
Figure 1 and the experimental setup is shown in
Figure 2.
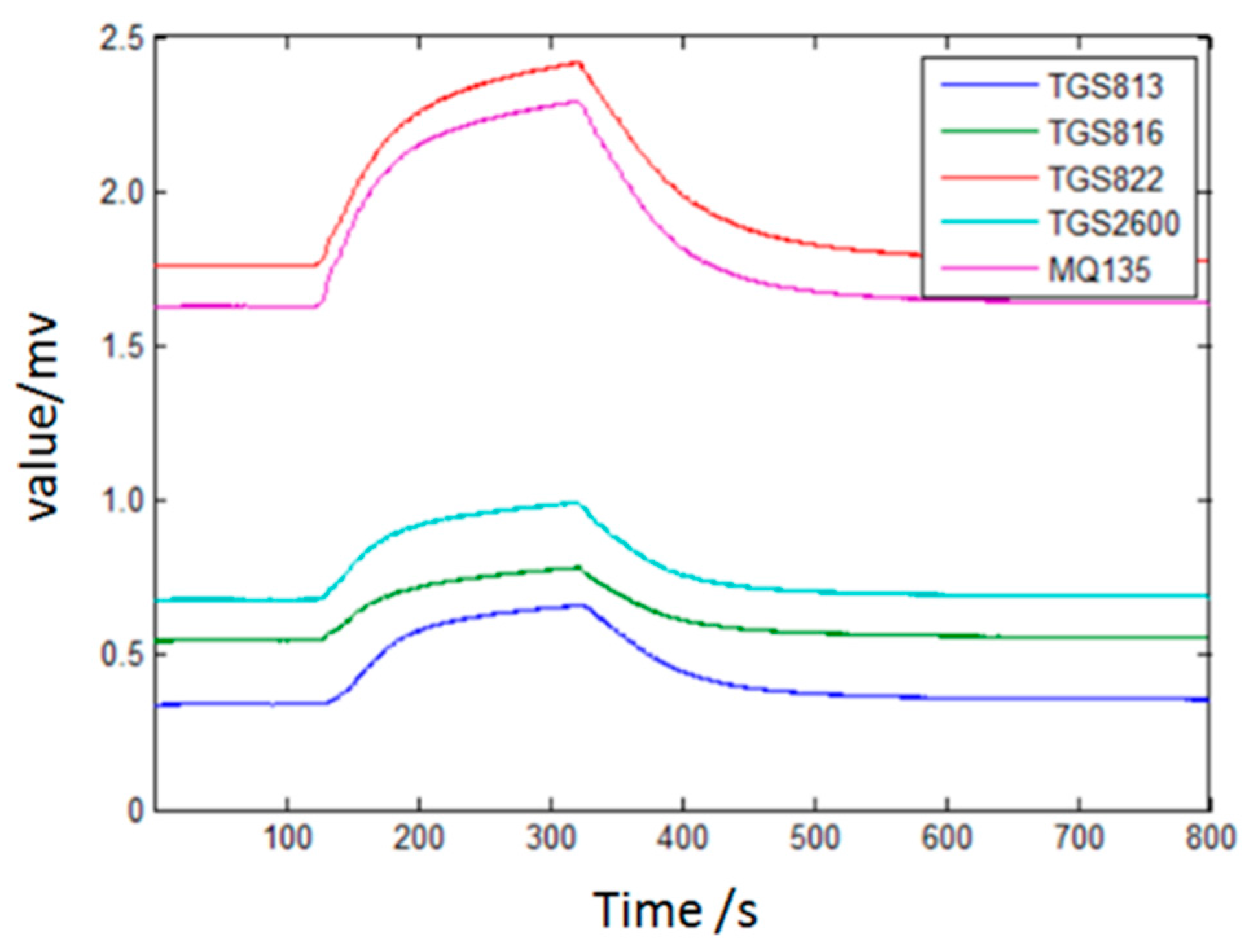
When air passes the filter, the air is purified. The flow meter controls the rate of the gas, making it keep at 80 mL/min, and at the same time the pump provides energy for the gas flow. The response signals processed by E-nose will be sampled and saved in a computer via the DAS, which is 32-channel and 14-bit high precision. The sampling frequency is set at 1 Hz. According to the metabolites of pathogens and the response characteristics of gas sensors, a sensor array composed of six sensors is employed to collect the response curve of wound infections and pollutant gases, and response characteristics of gas sensors are shown in
Table 1.
Each sampling experiment is composed of the following three steps:
Step 1: the sensors are exposed to clean air for 3 min;
Step 2: the gas stream containing VOCs of the wound passes over the sensor array for 5 min;
Step 3: the sensors are exposed to clean air again for 15 min.
The sample interval between two experiments is 5 min.
2.2. Experiments and Sampling
Twenty Sparague-Dawley (SD) male rats are used in the experiment in this paper to prepare the labeled data set. These rats are divided into four groups averagely:
All rats are healthy and in similar condition, and each type has five rats, respectively. Every rat has a 1 cm long wound in the right hind leg, and pathogens are injected into the wound in accordance with their group. The metabolites of three pathogens are shown in
Table 2. A total of 20 sampling data are collected for each kind of rat, that is to say, there exist 80 labeled wound infection samples in our project.
And four kinds of pollutant gases including benzene (C6H6), formaldehyde (CH2O), acetone (C3H6O), ethylalcohol (C2H5) are sampled as the unlabeled data set.
Before the sampling experiments, we firstly set the temperature and humidity of the chamber as 25 °C and 40%. Then we began the gas sampling experiments. Because some of the gases are liquid, a decompression device is used to convert the liquid to the gas phase. We took advantage of the same setup and sensor array used for wound infections to get the pollutant gases’ data set and each sampling experiment was strictly executed according to the 3 steps in
Section 2.1. In total, we collected 2664 samples of pollutant gases.
To get the real concentration of each gas in the chamber, we extract each gas from the chamber and import it into the gas bag. Then spectrophotometric method is employed to get the concentration of formaldehyde, and the concentration of benzene, acetone and ethylalcohol is determined by gas chromatography (GC). The real concentration of three gas is shown in
Table 3. For the four gas, there are 12, 11, 12 and 21 concentration points, respectively, and 12 sampling experiments are made on each concentration point.
In most experiments, we only applied 652 samples and detailed information is shown at
Table 4.
Figure 3 illustrates the sensor response process when the sensor array is exposed to four types wound infection odor. It is clear that each curve has a rise when the target gas passes over the sensor array.
2.3. Data Preprocessing
To find which feature matrix can obtain the best performance, we extract five different features to construct our data set. These features include:
- (1)
Maximum value of steady-state response;
- (2)
Maximum slope of rising edge;
- (3)
Maximum slope of falling edge;
- (4)
Integral;
- (5)
Wavelet transform.
Except for wavelet transform, all other features are easy to understand. Wavelet transform is a kind of local transformation of time and frequency domain, which can efficiently fetch information from the signal, and it also has been used in the E-nose before [
25]. It inherited and developed the localization of the short time Fourier transform (STFT), at the same time overcoming the shortcomings, such as window size, which does not vary with frequency change. Wavelet transform can provide a time–frequency window that changes with the frequency, and is an ideal signal time–frequency analysis and processing tool.
After feature extraction, the labeled data set and unlabeled data set share the same dimension. We use the five features to construct original feature matrices, each row is a feature, and each column is a sensor selected from the 5 sensors. Then, we transform this matrix into matrix, building the data set , and represents the dimension of . To get training sample, we randomly pick 15 samples from each wound infection sample (in total, 20 samples in each wound infection type), then we have 60 training samples and 20 test samples. We also construct a data set comprised of all unlabeled samples to train a basis , and contains four types of gas. In this paper, is set as 3, 4, 5 to find which is most efficient to improve the performance of the E-nose.
3. Self-Taught Learning
In this paper, we apply the self-taught learning paradigm with sparse autoencoder and classification algorithms (like RBF) to build a classifier for distinguishing different types of wound infection.
Suppose there is a labeled data set of m samples . Each denotes an original input feature vector. Each denotes corresponding class label. Additionally, we assume there are unlabeled samples
We propose a bold hypothesis, the class labels of unlabeled data set and the class labels of labeled data set have no intersection. Then, we apply the sparse autoencoder algorithm to study a sparse autoencoder from It can be used to rebuild the representation of input training data set , converting it into a new labeled training set . These activations are put into the classifier as the new input feature vector, and PLSDA and RBF are employed as classifiers in this paper.
3.1. Sparse Autoencoder
3.1.1. Neural Network
The sparse autoencoder algorithm is an unsupervised learning algorithm that applies back-propagation, which is widely applied to image identification [
20,
26,
27].
A single-layer autoencoder [
28,
29] is a kind of neural network [
30,
31,
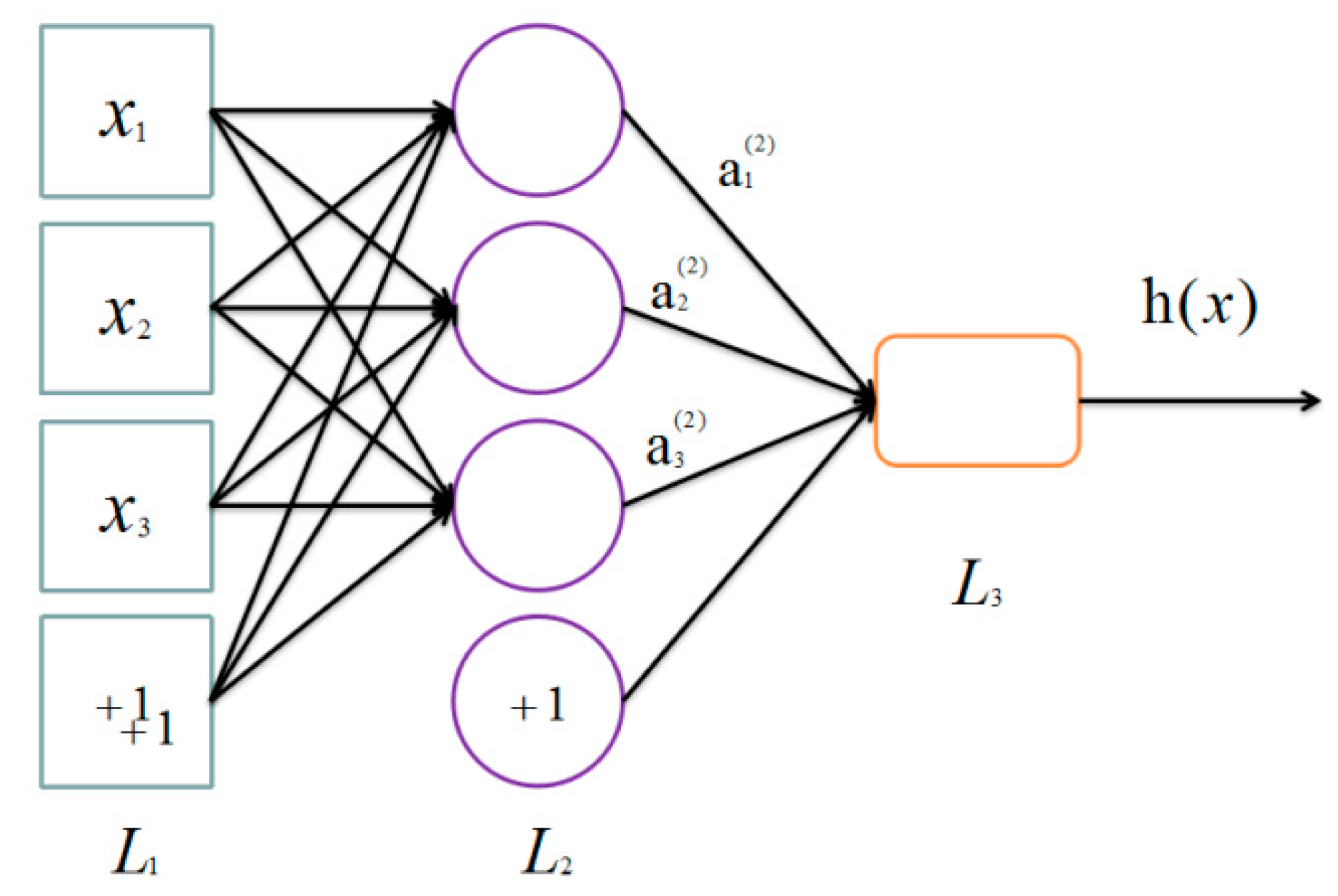
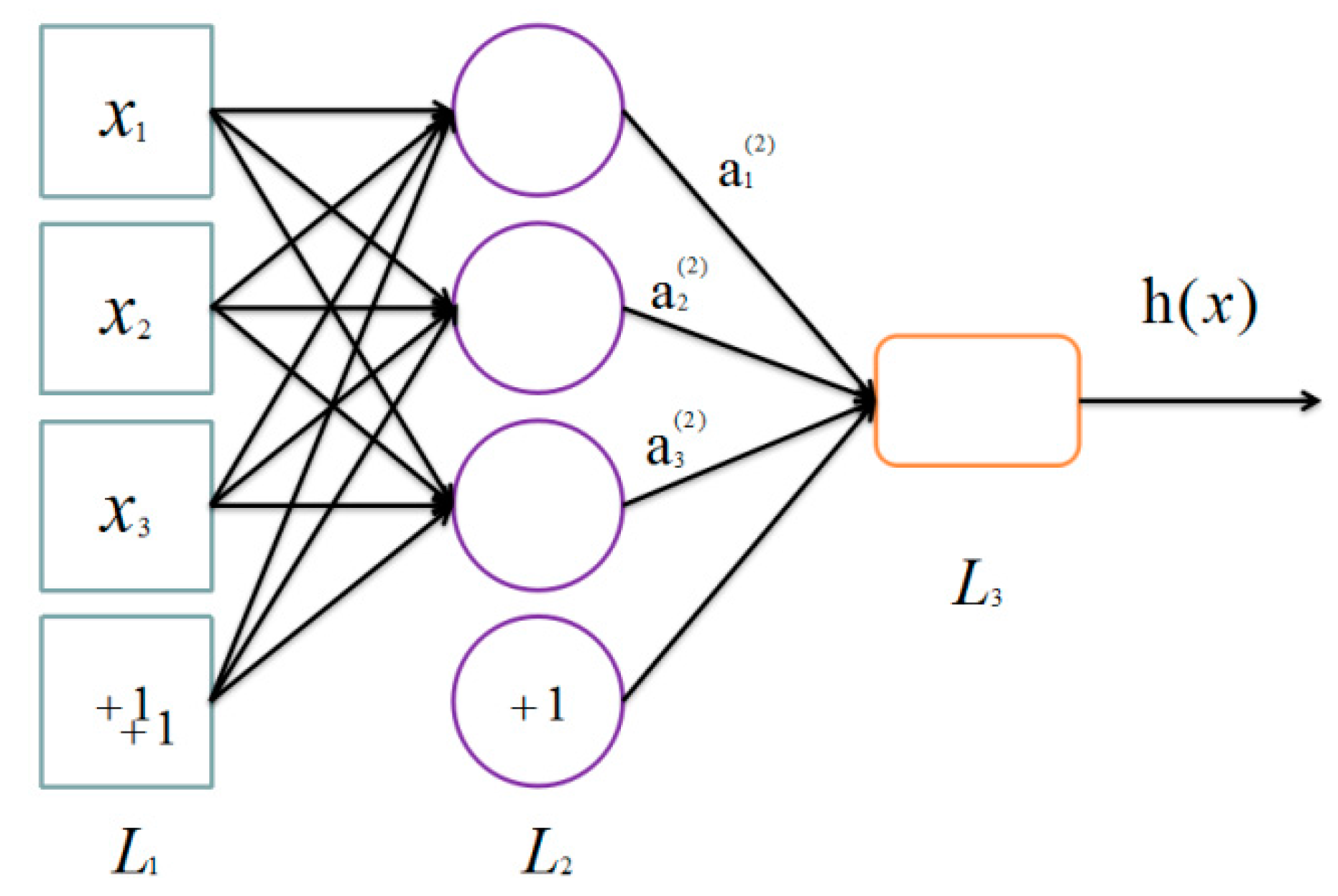
32] that only has one hidden layer. By hooking together many simple “neurons”, a neural network is created. In this paper, each
is a neuron. For example, here is a small neural network (
Figure 4).
Then, there is a way of defining a complex non-linear form of hypotheses
, with parameters
W,
b that can fit our data. Formally, corresponded to an input
, the activations of
are
where we define
to be the sigmoid function
, and
denotes the activation (output value) of unit
in layer
,
represents the bias associated with unit
in layer
,
is the parameter (or weight) associated with the connection between unit
in layer
, and unit
in layer
.
We can write these equations more compactly as
In this sequel, is the vector of activations of layer, is the weight matrix of, and similarly is the bias vector that computes .
More generally, we define a equation that
Therefore we have. For a neural network which owes layers, we have output, and we call the process to compute from to () as “the feedforward pass”.
After performing a feedforward pass, we initialize and to the value near 0 nearly, then the gradient descent algorithm incorporated with BP (backpropagation) is employed as an optimization algorithm.
The cost function is defined as follows:
There is
for each sample, and because we have
unlabeled samples, thus the overall cost function can be written as:
where
controls the relative importance of the two terms. In our project, we set
as 3 × 10
−3. Our target is to minimize
, here we repeatedly implement the batch gradient descent to reduce our cost function
. One iteration of batch gradient descent is shown as follows:
Notably, BP is not that easy to debug and get right. In the following section, we provide a derivative checking procedure to check the correctness of the code and make sure our implementing of gradient descent is correct. In a correct code we have:
If the equation is satisfied, it proves that we indeed get the correct derivations. In practice, we define
as a vector unrolling the parameters
. Thus, when a function
is given, we can verify its correctness by checking that whether the following formula is satisfied.
In practice, we set which is always around 10−4 to a small constant.
3.1.2. Autoencoders and Sparsity
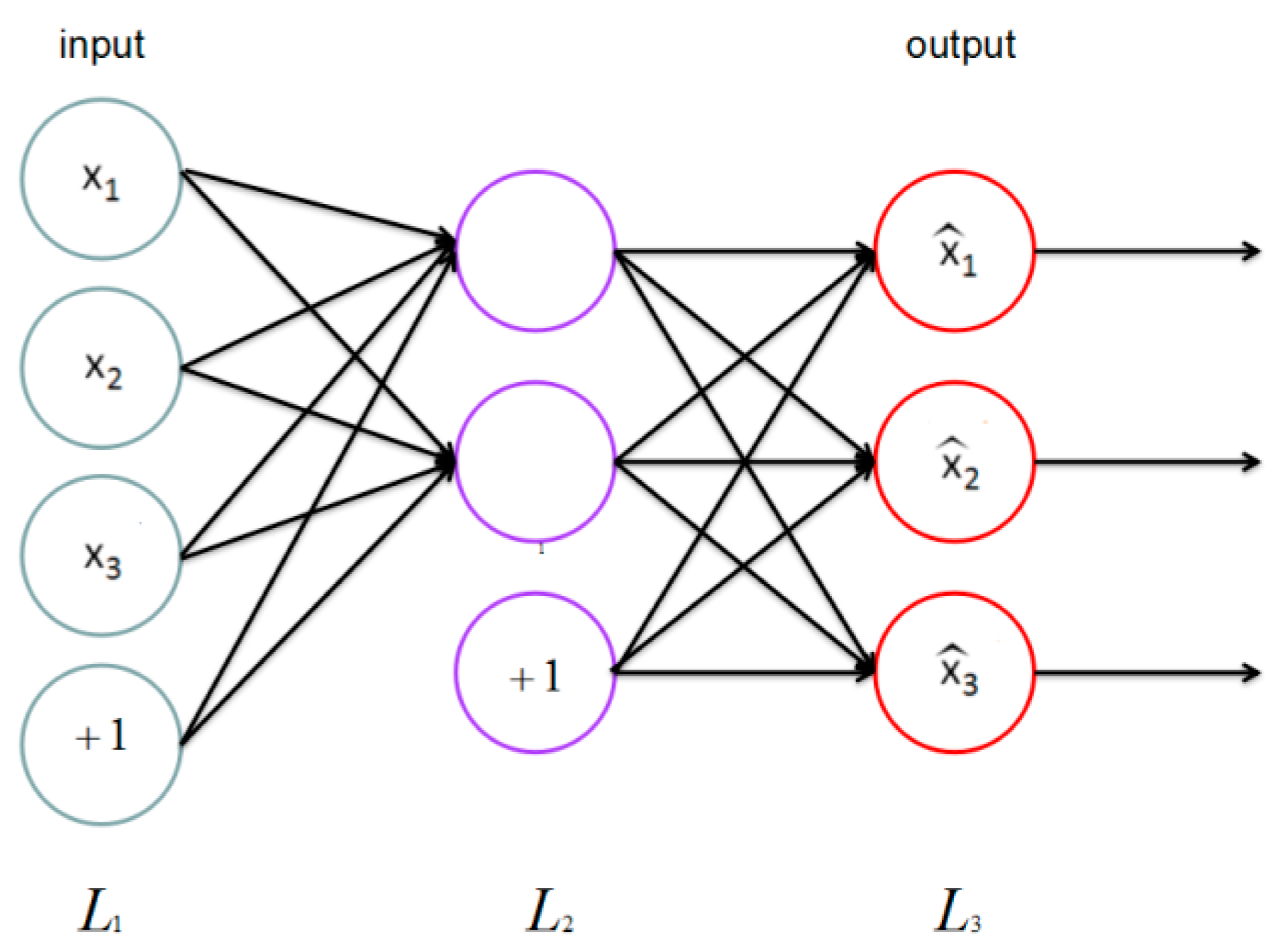
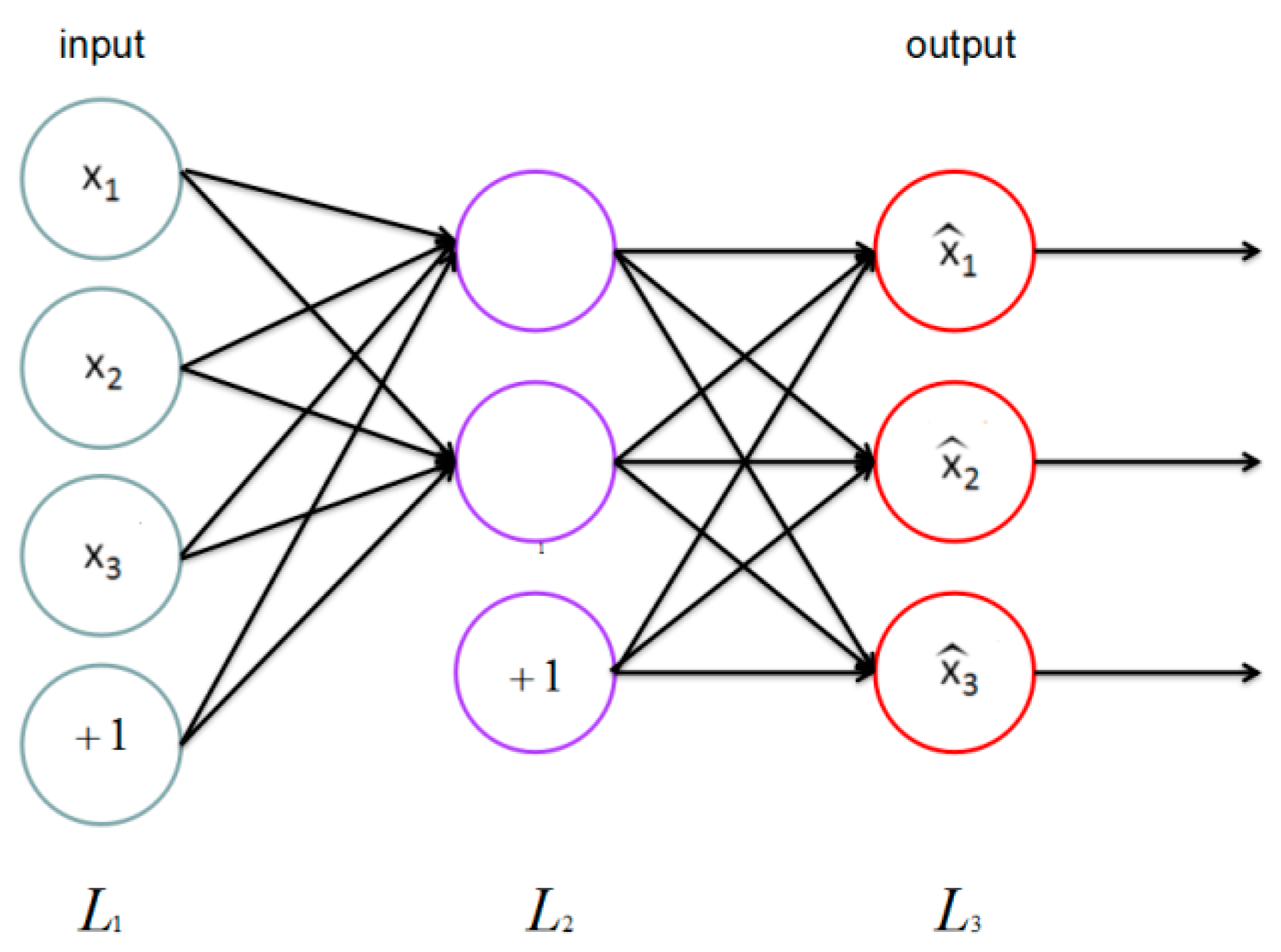
Thus far, we have described the application of neural network to supervised learning, but we have only used the unlabeled training data set; an autoencoder neural network that combines BP is introduced to deal with such a situation.
The auto encoder tries to learn an identity function that enforces which means the target value is .
As
Figure 5 shows, this is a simple auto encoder. Our goal is to enforce output
to be similar to input
. To achieve this, we set constraints on the ordinary neural network.
We let
denote the activation of this hidden unit when the network is given a specific input
. And next step we compute the average activation of hidden unit
.
We impose a constraint to that where is a sparsity parameter whose value is close to zero. In our paper, we set it as 0.01. is the sum of whole hidden units in the network.
Performing the above two equations, we are ready to complete the overall cost function on the basis of Equation (4) to be
where
is the same as the original one,
is set as 3 in our project, controlling the weight of the sparsity penalty term.
denotes the number of nodes in the hidden layer; and as Equation (13) shows, we apply KL-divergence as the penalty term, which can be expressed as
Until now, the KL-divergence term has been adopted to satisfy the constraints, also, to integrate the KL-divergence into our derivative calculation, we adjust Equation (8):
Other steps are the same as the neural network algorithm, and we perform a gradient descent on the new objective . Still we apply the derivative checking method to verify our code. The algorithm, therefore, encourages the activations to be sparse, in other words, for most of its elements to be zero. At the same time we learn the basis vector (unrolling parameters into a long vector). It is the basis of both and .
3.2. Construct New Representation
So far, we have trained a basis vector
(a set of parameters
), which would be used to construct the new labeled data set
based on original labeled data set. We pose the following formulation to solve the problem, for each
, we have
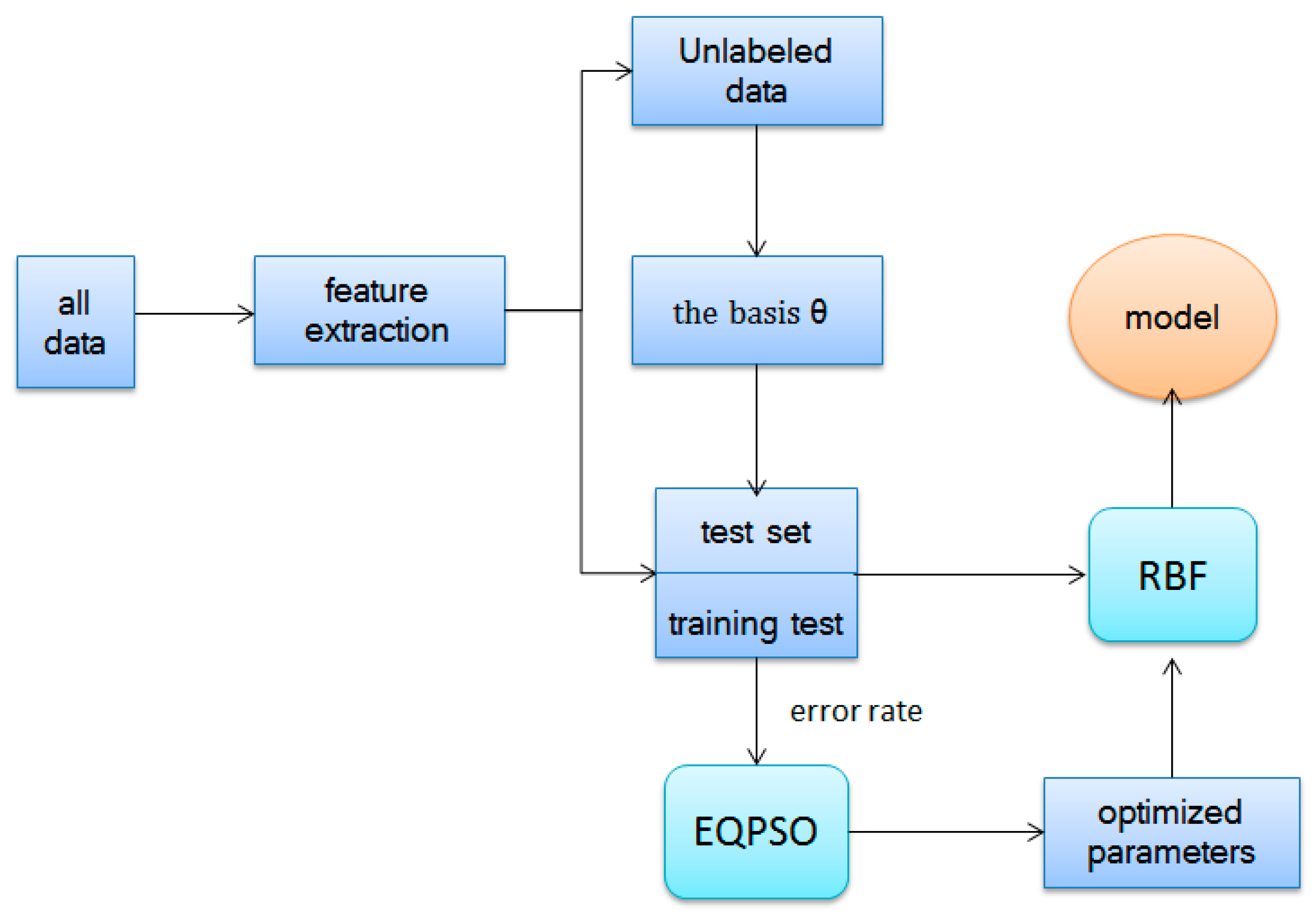
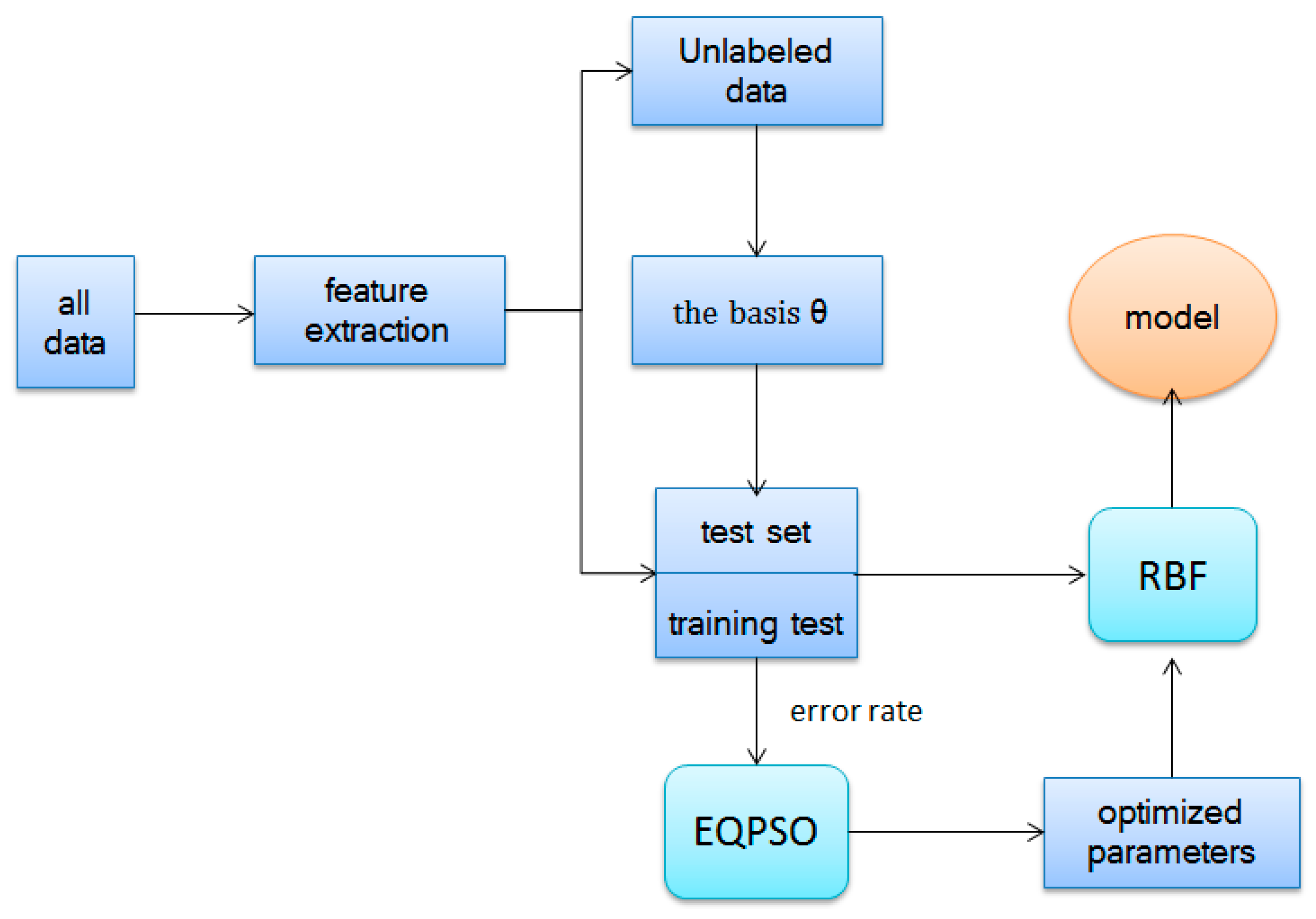
The reconstructing procedure decreases the difference between the labeled data and unlabeled data as well as transfers knowledge from different domains. These new features are put into multiple types of classifications, such as RBF. The whole algorithm of self-taught learning based on sparse autoencoder is illustrated in Algorithm 1 and
Figure 6.
| Algorithm 1. Self-taught learning algorithm |
| Step 1: Minimize train the basis vector (unrolling parameters into a long vector) from unlabeled data. |
| Step 2: Take advantage to construct new representation, replacing original data set . |
| Step 3: Learn a classifier by applying efficient algorithm (we apply RBF and PLSDA optimized by EQPSO here). |
| Step 4: Calculate the classification accuracy. |
4. Results and Discussion
To verify the feasibility of the model we performed some experiments and obtained some results, which will be shown in this section. In order to improve the performance of the classifier, EQPSO is applied to optimize the parameters, both for RBF and PLSDA.
In all experiments, the particle number of optimization algorithm is set to 30, and the algorithm iterates 300 times to find the optimal value. Additionally, we set the hidden layer as 10 at first, the sparsity parameter as 0.01, as 3 in this project to get a sparse autoencoder. All the data set, which is the input of classifier, has been normalized before self-taught learning.
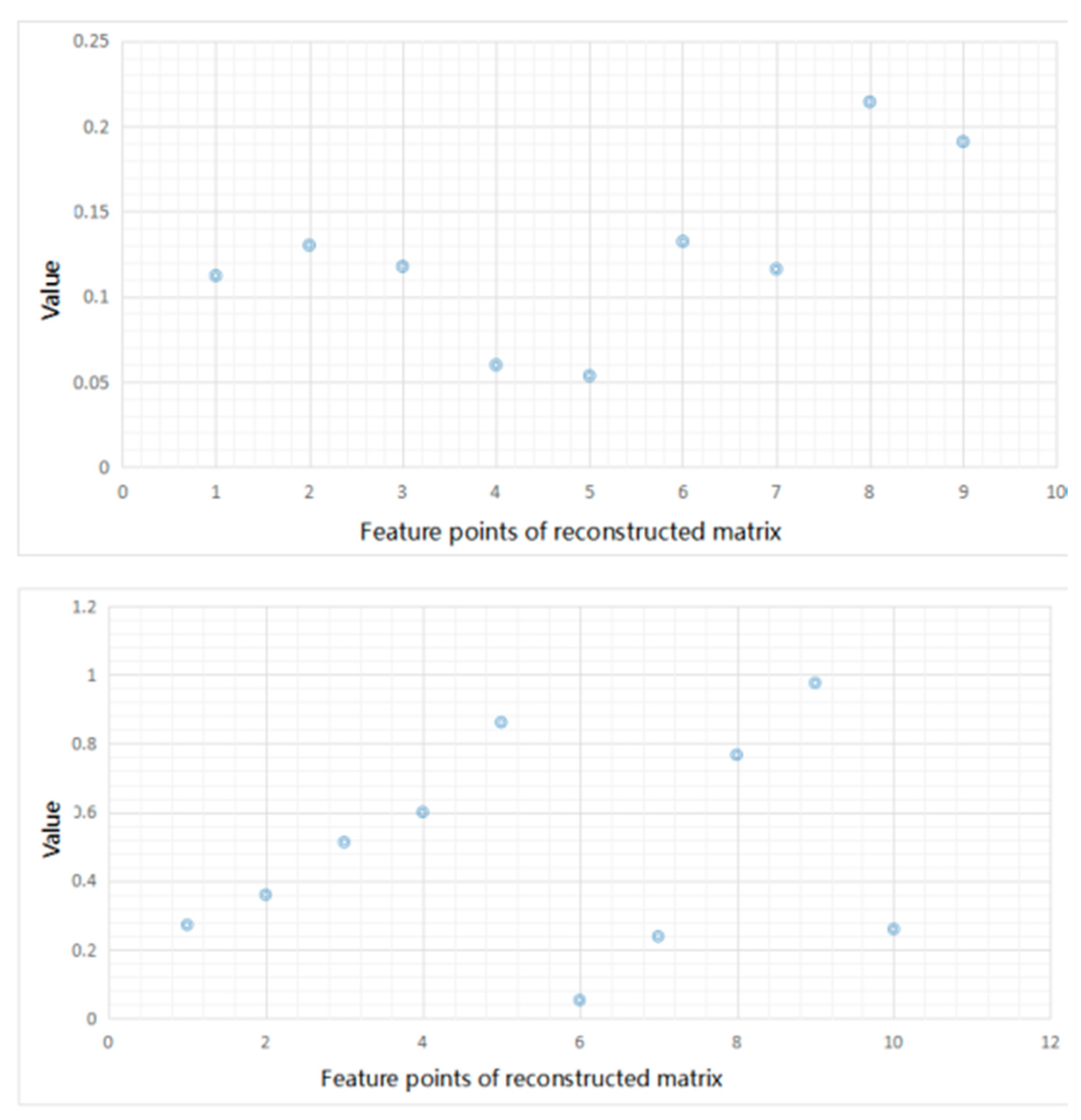
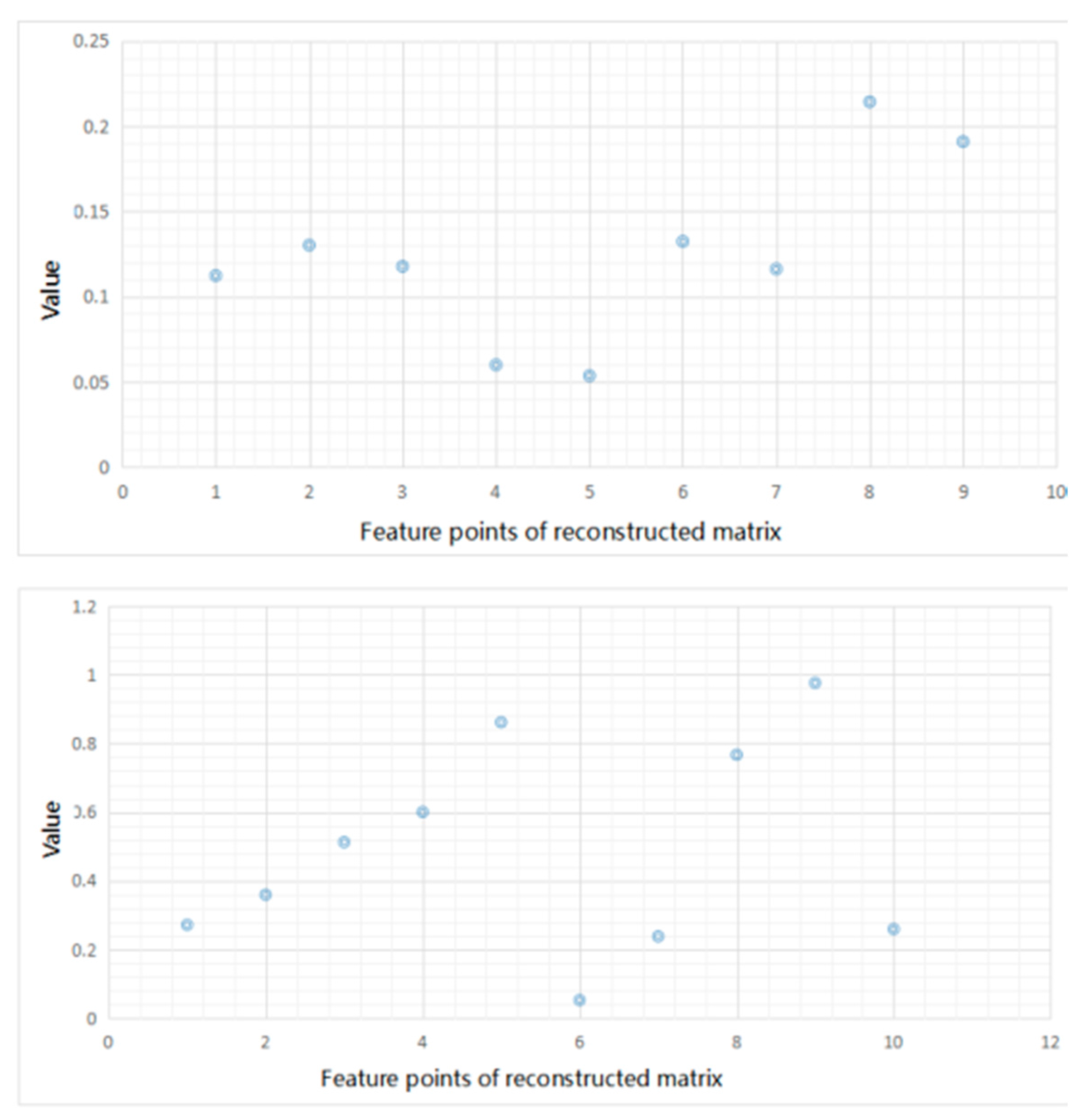
Before showing the results, we display the input feature matrix and the reconstructed ones in
Figure 7. We take one sample of
S. aureus as an example. In this experiment, the hidden layer is set as 10 and the dimension of input matrix is 3 × 3. The left picture of
Figure 7 shows the feature matrix of input matrix and the right one shows the reconstructed matrix.
Firstly, considering that each sensor has a different selectivity pattern, the performances could change without increasing the size of the matrix, but only selecting the best subset of features. So we combine different sensors with different features from dimension 3 × 3 to 5 × 5 and finally find that the results are almost the same when dimensions are the same. Then we discuss whether the self-taught learning could improve the performance of the E-nose and how the dimension of feature matrix influences the classification accuracy. We apply RBF as the classifier here and 15 samples of each wound infection serve as the training data, and 5 samples of each wound infections are the test data. The test set is used to verify the performance of the final model. In
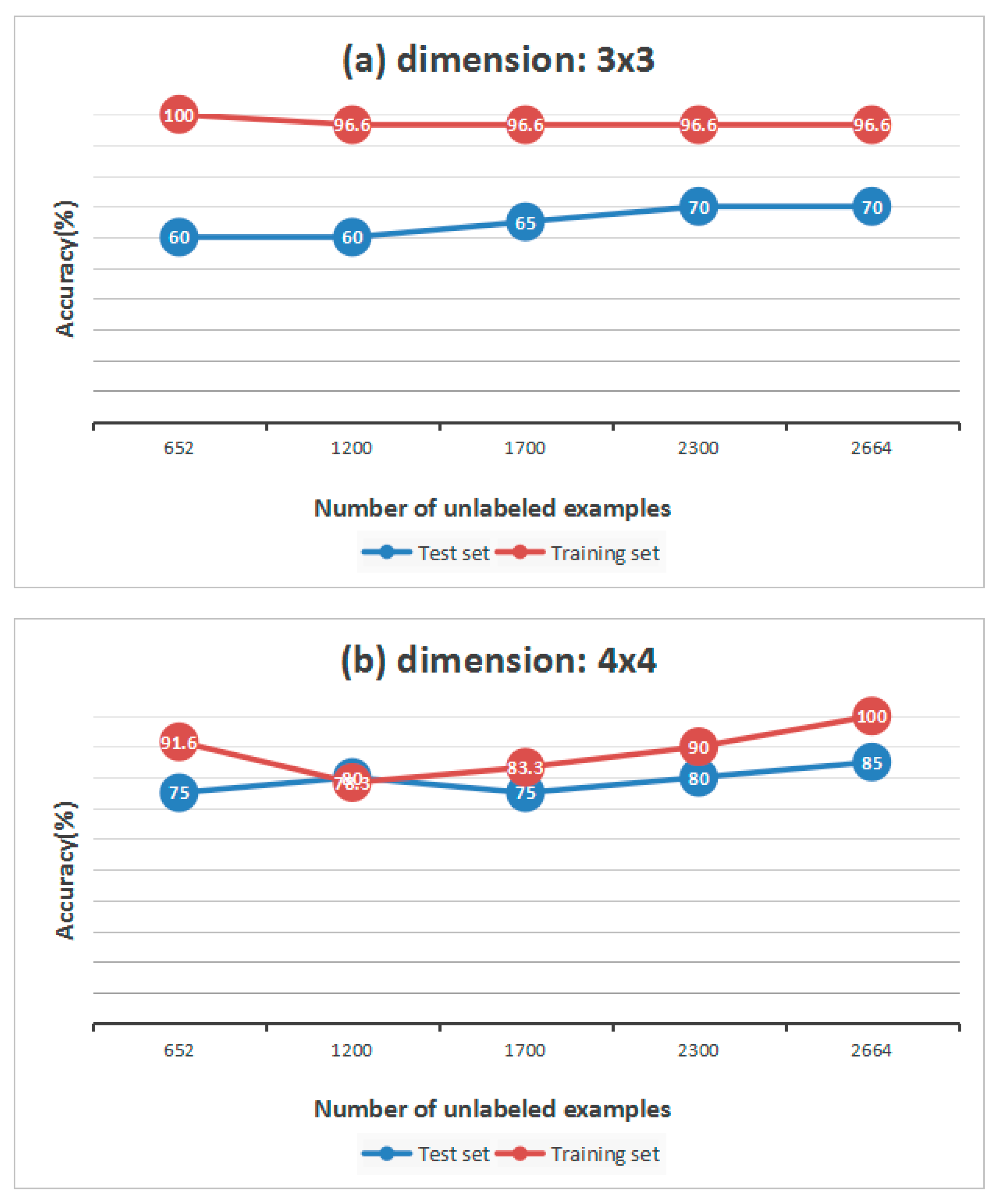
Table 5, we show the results studied from 652 gas samples.
In
Table 5, we find that, compared to the raw matrix, from dimension 3 × 3 to 5 × 5, the matrix studied from unlabeled samples has higher accuracy overall. However, when the dimension is 3 × 3, the accuracy of the training set and test set do not change much, which means that if the dimension is small, the accuracy may not improve. At the same time, however, the number of unlabeled samples also contributes to the results of classification. We change the size of unlabeled data set from 652 to 2664 to explore the relationship between them. All of the results are shown in
Figure 8.
In general we can draw a conclusion that, the more unlabeled samples, the higher the accuracy. If the interval of two sizes is small, the accuracy may not change. When the dimension is 3 × 3, the classification accuracy of the test set keeps rising, while in
Figure 8b, the curve of the training set goes down when the size of unlabeled data set is 1200, and the curve of the test set goes down when the size of the unlabeled data set is 1700.
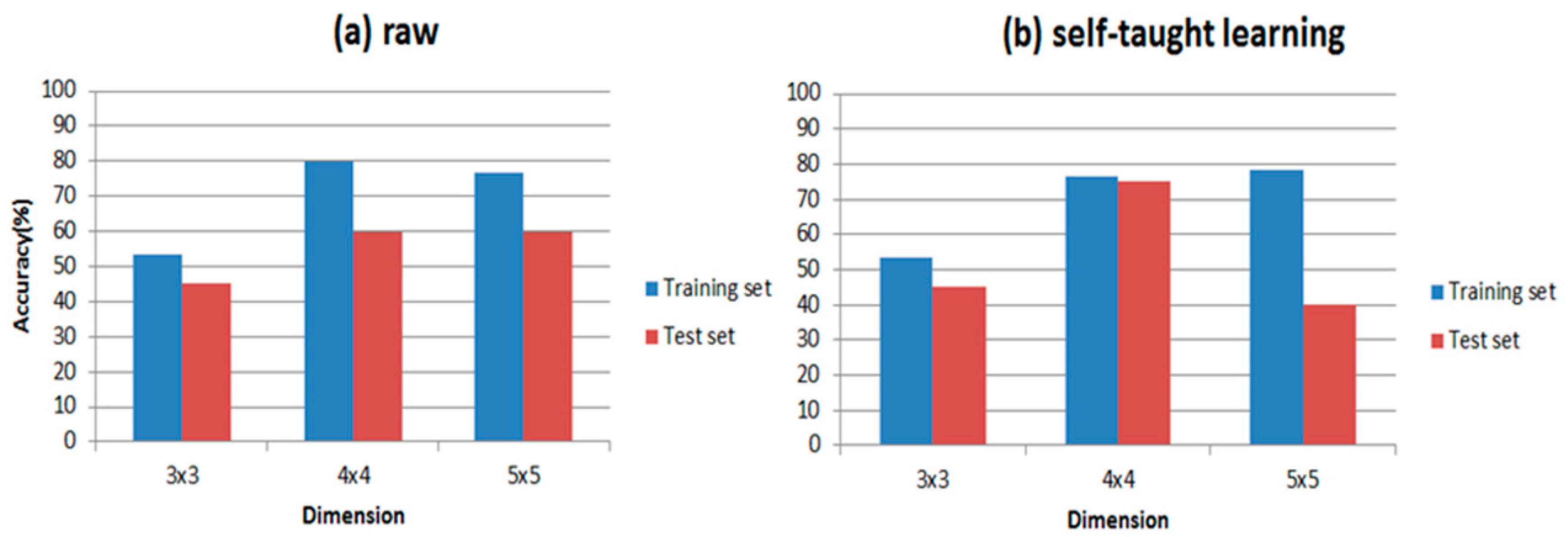
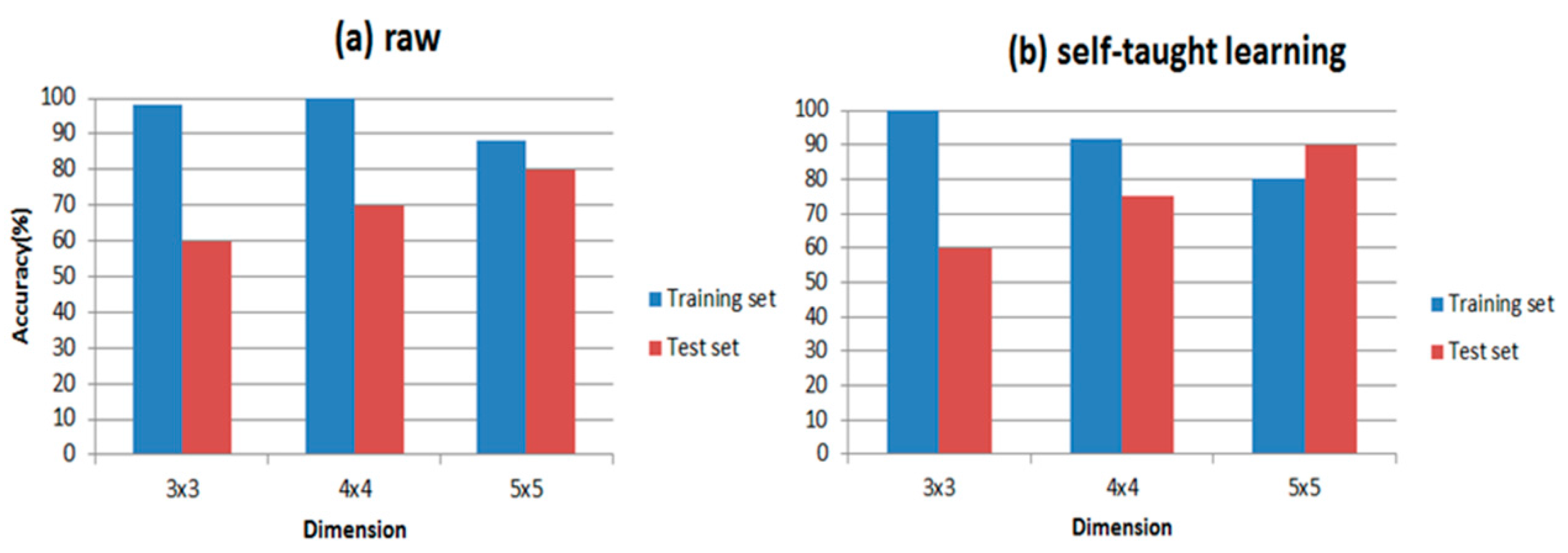
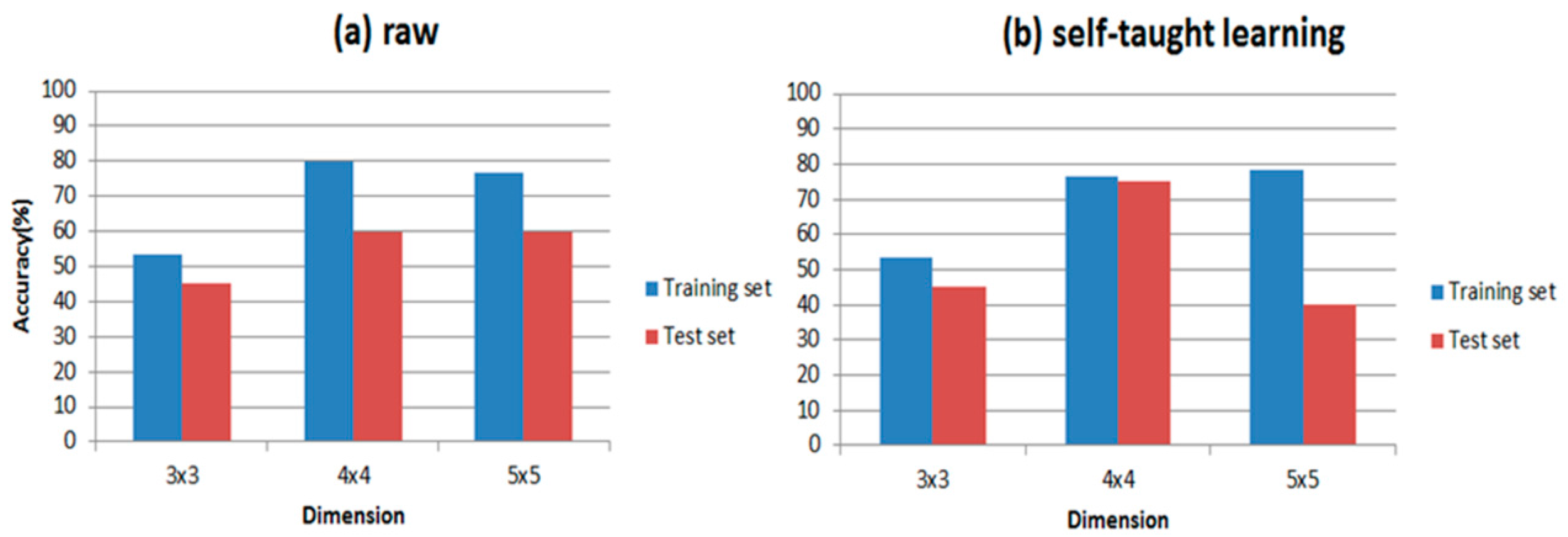
It is well established that the classifier is a major part of the E-nose; thus, PLSDA and RBF are introduced to distinguish wound infection samples respectively in our paper. In order to compare the differences in putting the feature matrix into these two classifiers directly and the representations processed by self-taught learning, we calculate the accuracy of both. The accuracy is shown in
Table 6.
Table 6 shows the results of our experiments and the classification accuracies are clearly presented in it. Comparing
Figure 9 with
Figure 10, RBF is indeed more suitable for self-taught learning than PLSDA, because all of the accuracies of RBF are higher than accuracies of PLSDA, especially for the test data set. Additionally, comparing (a) with (b) in
Figure 9 and
Figure 10, the accuracy of self-taught learning rises more quickly than the raw matrix. As for PLSDA, the results are not very good and steady, when the input is raw matrix, the accuracy of test data grows slowly. All results in
Figure 9 and
Figure 10 prove that RBF is superior to PLSDA in self-taught learning based on the sparse autoencoder. In
Figure 10b, when the input is studied from the unlabeled data set, the accuracy of the test set reaches its peak at 4 × 4, then the curve falls down to 40% at 5 × 5.
All experiments above are established under the condition that the hidden layer is ten. In order to study the difference that the hidden layer brings to the accuracy, we set the hidden layer at 5, 10, 20, 40, 100, 700, 2000, 10,000.
Except for hidden layer, all the other parameters remain the same. On account of the instability of the classification accuracy, to make sure the result of the experiment is correct, each program is repeated 5 times.
Table 7,
Table 8 and
Table 9, respectively, show the classification accuracy with different hidden layers when the dimension is 5 × 5, 4 × 4 and 3 × 3. From
Table 7,
Table 8 and
Table 9, we can draw a conclusion that as the hidden layer increases, the classification accuracy always reaches the top at first and falls down later. And when the hidden layer is large, the accuracy always maintains at a certain level; at the same time, it takes more time to train the model, which means increasing the hidden layer can lead to a waste of time.
In conclusion, these results prove that the self-taught learning based on sparse autoencoder demonstrates a good performance in improving the accuracy by studying samples from other fields, and that there are a few reasons for why this is possible with the sparse autoencoder. Firstly, as a typical algorithm of traditional training multi-layer network, the BP algorithm is not ideal for only a few layers of network. If all layers are trained at the same time, the time complexity will be too high; If only one layer is trained, the bias will pass by the layer. This will face the opposite problem of the above supervised learning, which will be badly mismatched. Self-taught learning based on sparse autoencoder is a kind of layer-wise-pre-training, which solves the problem effectively. Furthermore, the sparsity constraint makes the representation of each layer sparse (most of nodes become zero). This kind of representation resembles the human brain—when something comes to our mind, only a small number of neurons are stimulated and other neurons are suppressed. This feature is the same with humans when we want to study new things from other fields.
5. Conclusions
The self-taught learning approach is a new model of transfer learning and has not been used in E-nose before; in this paper, we have applied self-taught learning to wound infections classification.
In this paper we introduce a kind of self-taught learning based on a sparse autoencoder to the E-nose in wound infection detection, and we take advantage of PLSDA and RBF which are optimized by EQPSO to classify four kinds of wound infections. Through comparing the results of self-taught learning and the results of the raw data set, we can draw a conclusion that the performance rises when we apply self-taught learning based on sparse autoencoder, especially with the RBF classifier. We also found that the size of unlabeled data set, the type of classifier and the dimensions of data set all have an impact on the accuracy of pattern-recognition.
These results prove that the self-taught learning based on sparse autoencoder has a good performance in transforming knowledge, and indeed, could improve the accuracy by studying samples from other fields. However, it still has its limits. First of all, when the number of unlabeled samples is small, especially when the order of magnitude is smaller than 10, the algorithm barely improves the performance.
Through self-taught learning, we can reduce costs when we train the E-nose for distinguishing wound infections, which is the purpose of our experiments. We all know that the data of such gas is not easy to obtain, thus we study knowledge from unlabeled data set in other fields, which means that we can have a significant amount of data to study, making up for the lack of wound infection samples and transferring it to the area of wound infections.
In future work, we will further study the self-taught learning applied in E-nose, and we believe E-nose will be further improved in the field of medical science.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}