
Real-Time Tracking Framework with Adaptive Features and Constrained Labels

Abstract
:1. Introduction
1.1. Motivations
1.2. Contributions
- (1)
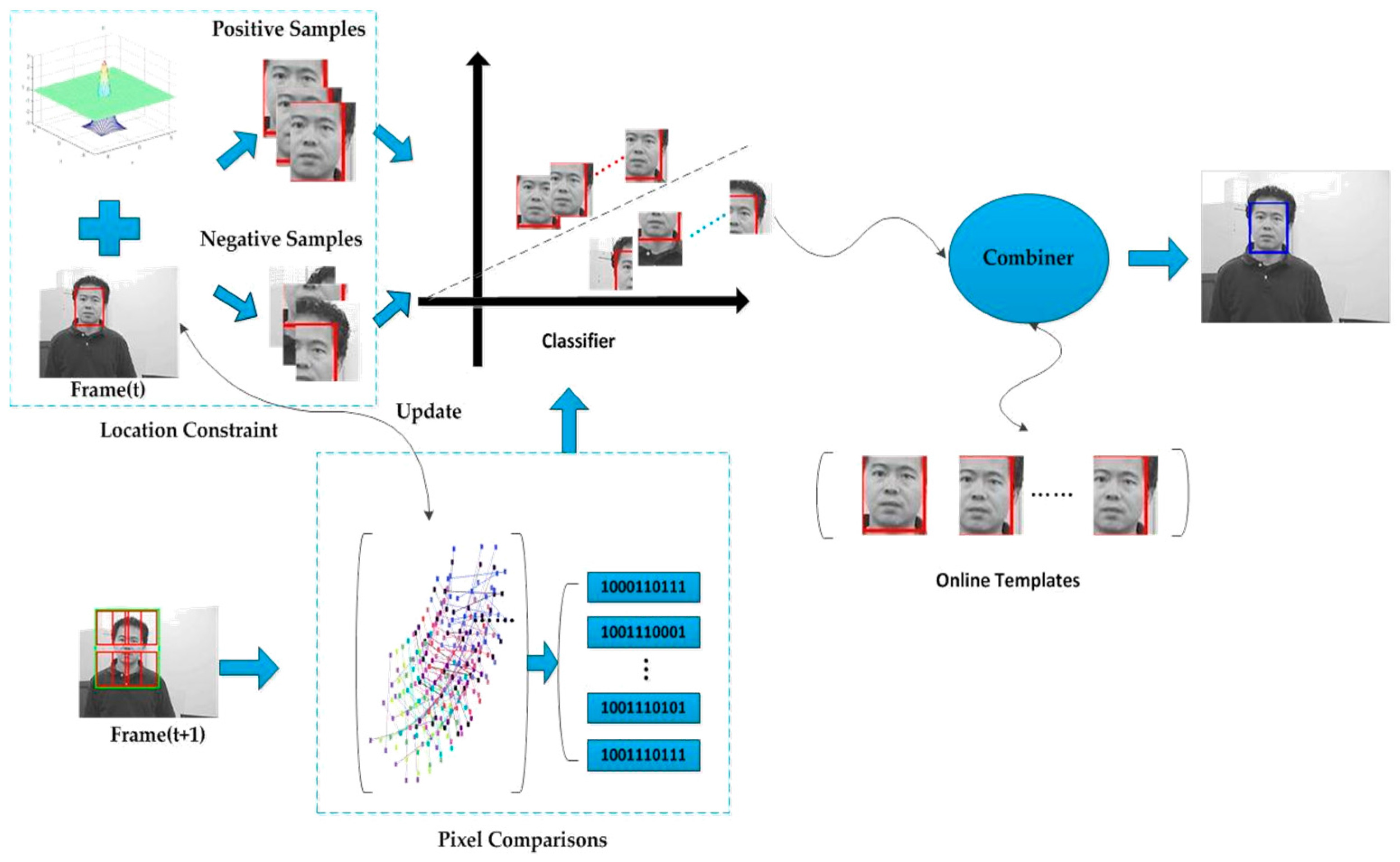
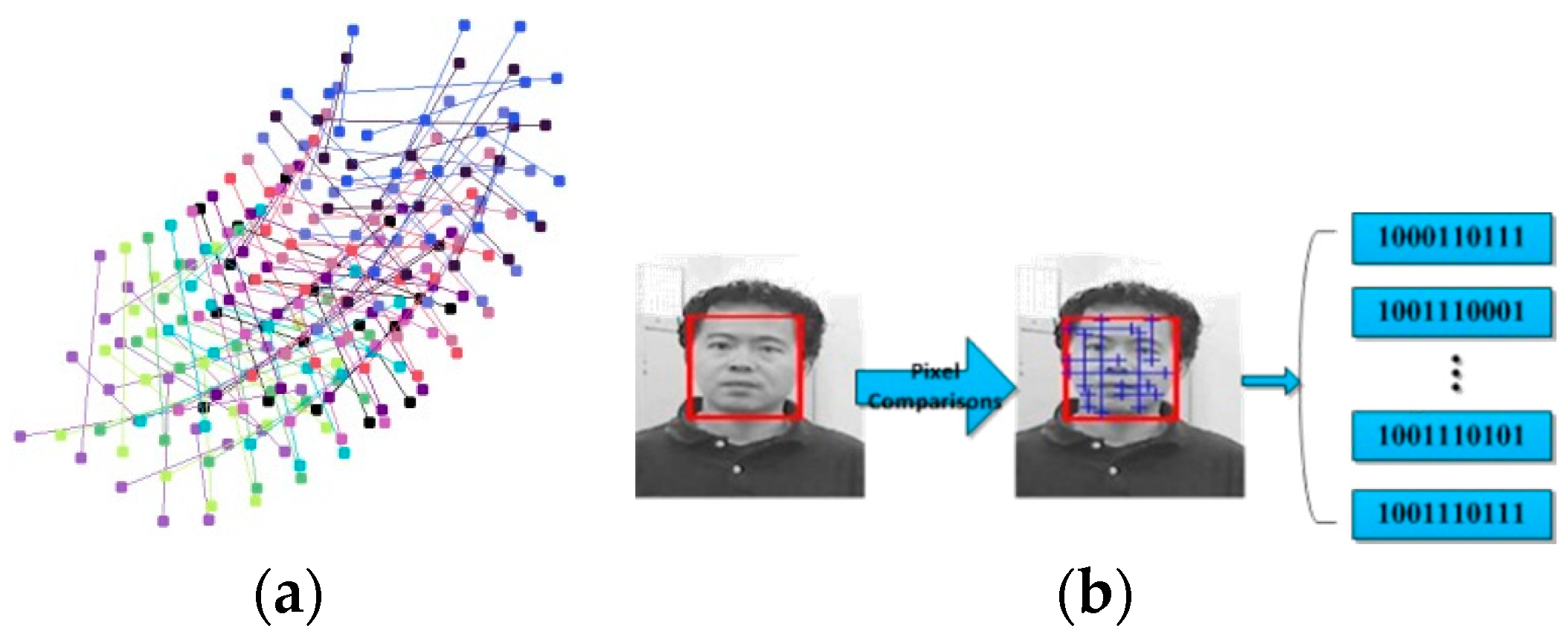
- The feature vectors are improved. We adopt the Forward–Backward error [18] to update the pixel pairs. In this way, each fern can be adaptive in runtime and effectively avoid the deviation caused by object noise. In this paper, we adopt the ferns as the base classifier, and each fern is based on a set of pixel comparisons [11]. We take advantage of the pixel pairs which are used as comparison in the last frame, recording their information and predicting the locations in the next frame by using Lucas–Kanade tracking [19].
- (2)
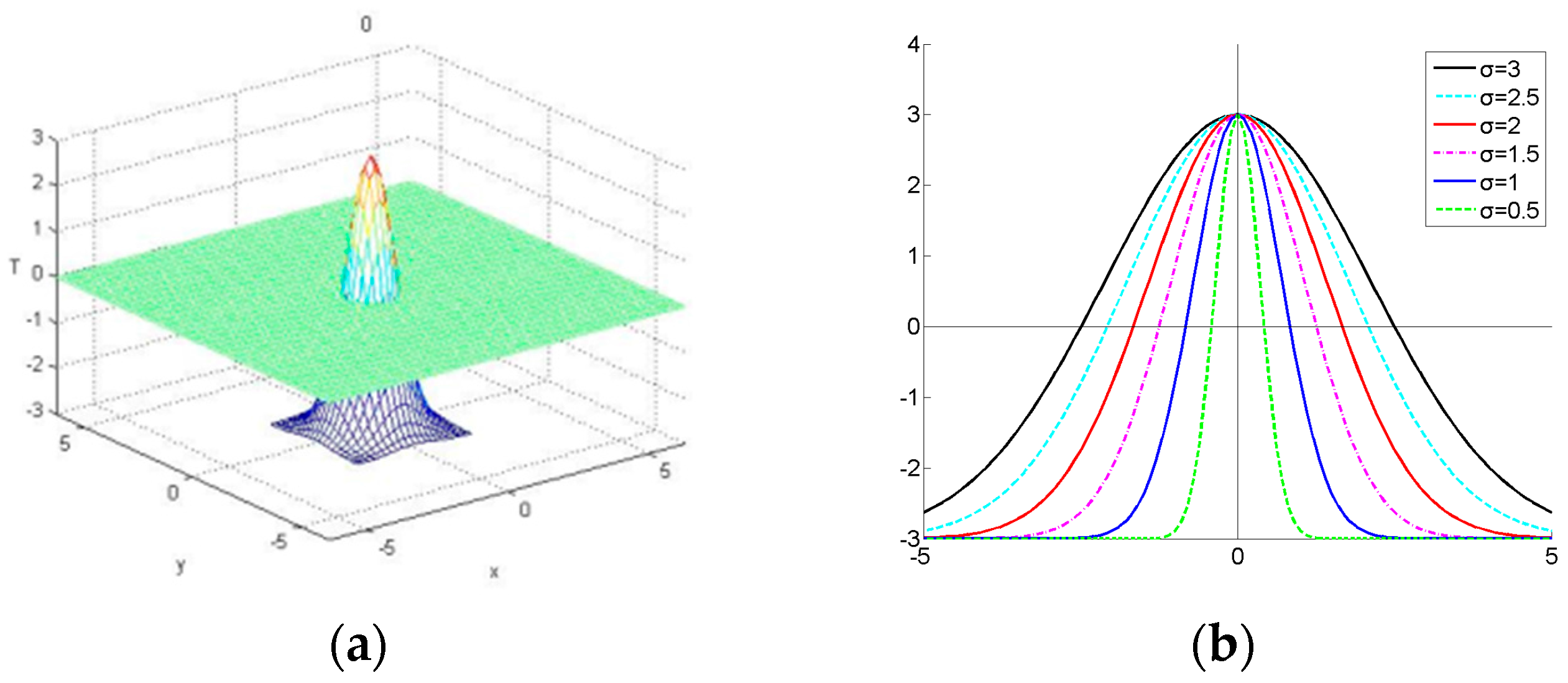
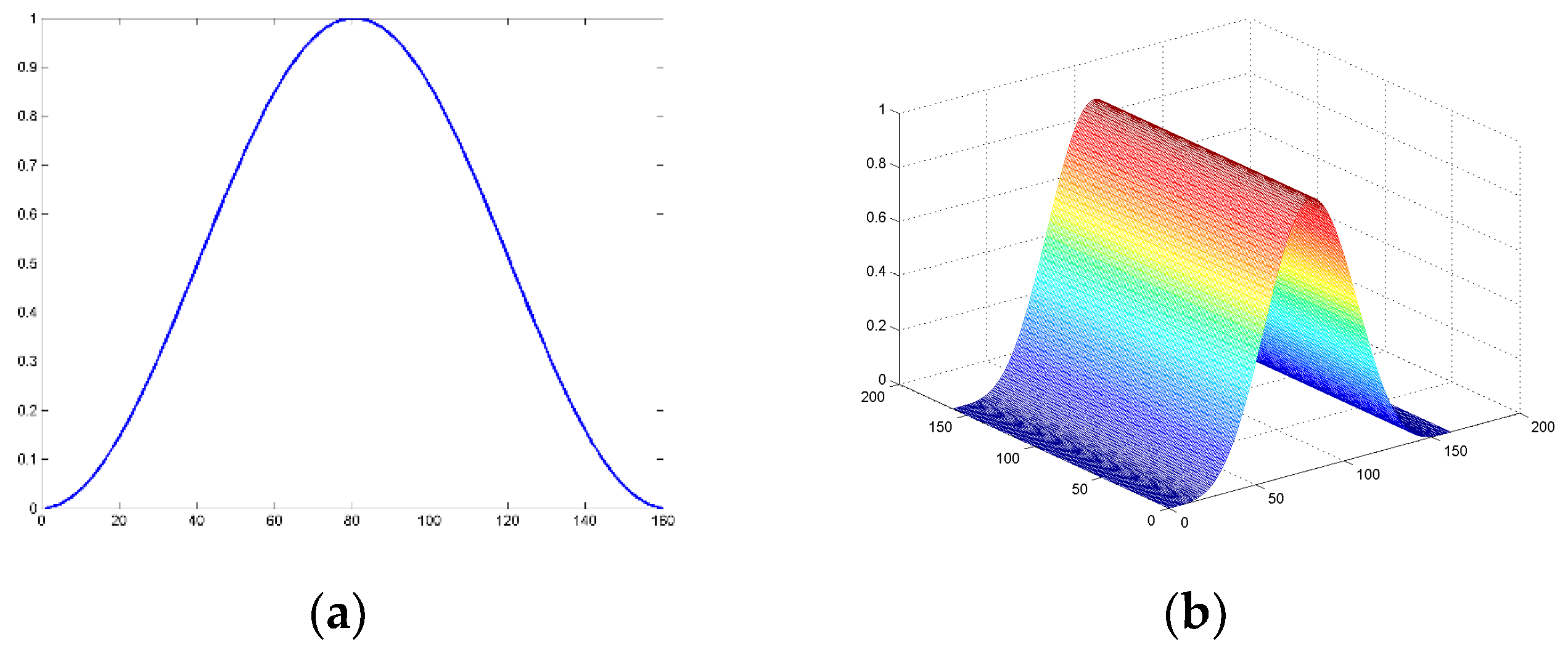
- The label noise is decreased. To divide the samples more objectively and import the information of the samples’ transformations, a novel location constraint comes up. It is a Gaussian fashion function, which can assign the weight to each sample according to the location. We can change the amount of the samples and label them in runtime by controlling the scaling factors. Therefore, all the positive or negative samples can be treated as uncoordinated samples according to their weights.
- (3)
- Adopt the combiner to assist learning. After filtering the patches by the ensemble classifier, we have several bounding boxes left that are supposed to be included in the target. To reach the target, we adopt the combiner to evaluate the most valuable bounding box, and regard it as the target to train the classifier in current frame. Firstly, we transmit the posterior probability of each box into the combiner. Secondly, we match the box with the compressed templates by using normalized cross-correlation (NCC). Finally, by combining the outputs from the NCC, the posterior probability and the value from location-weighted function, we ensure that the bounding box includes the target in real time.
2. AFCL Framework
2.1. Adaptive Features
2.1.1. Forward–Backward Error
2.1.2. Adaptive Features
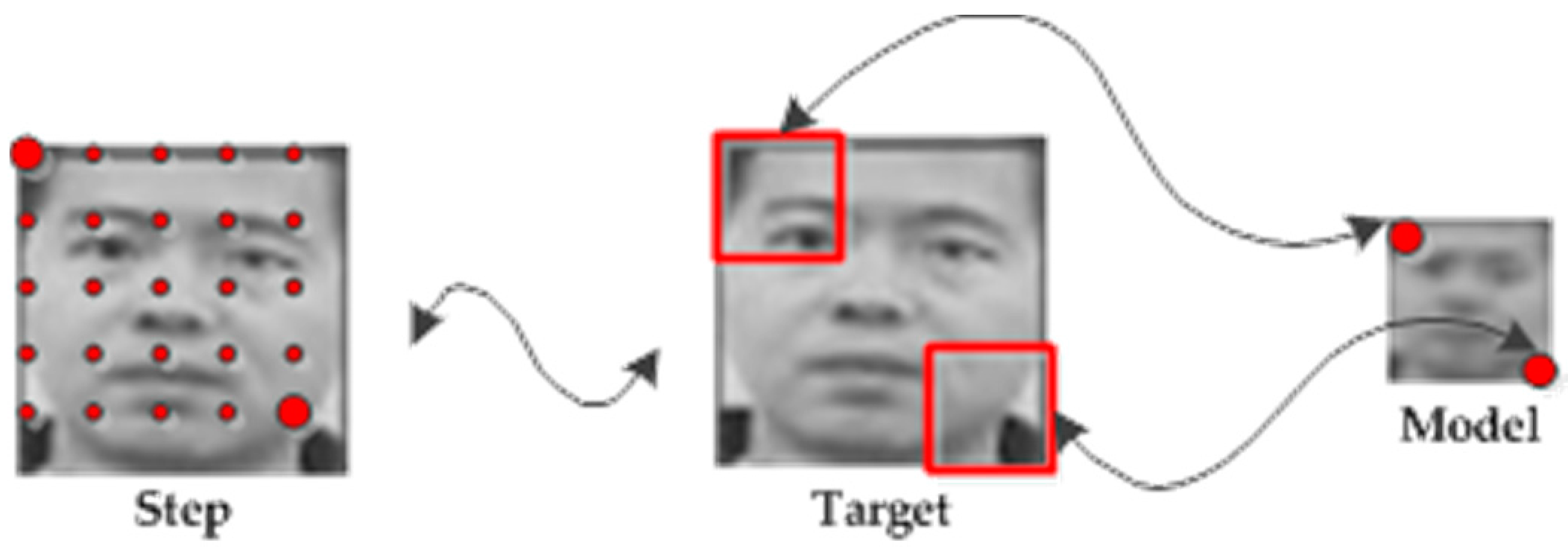
2.2. Location Constraint
2.2.1. Scanning Grids
2.2.2. Location Constraint
2.3. Combination and Learning
2.3.1. Output of the Ensemble Classifier
2.3.2. Location-Weighted Function
2.3.3. Online Templates
2.3.4. Combination and Learning
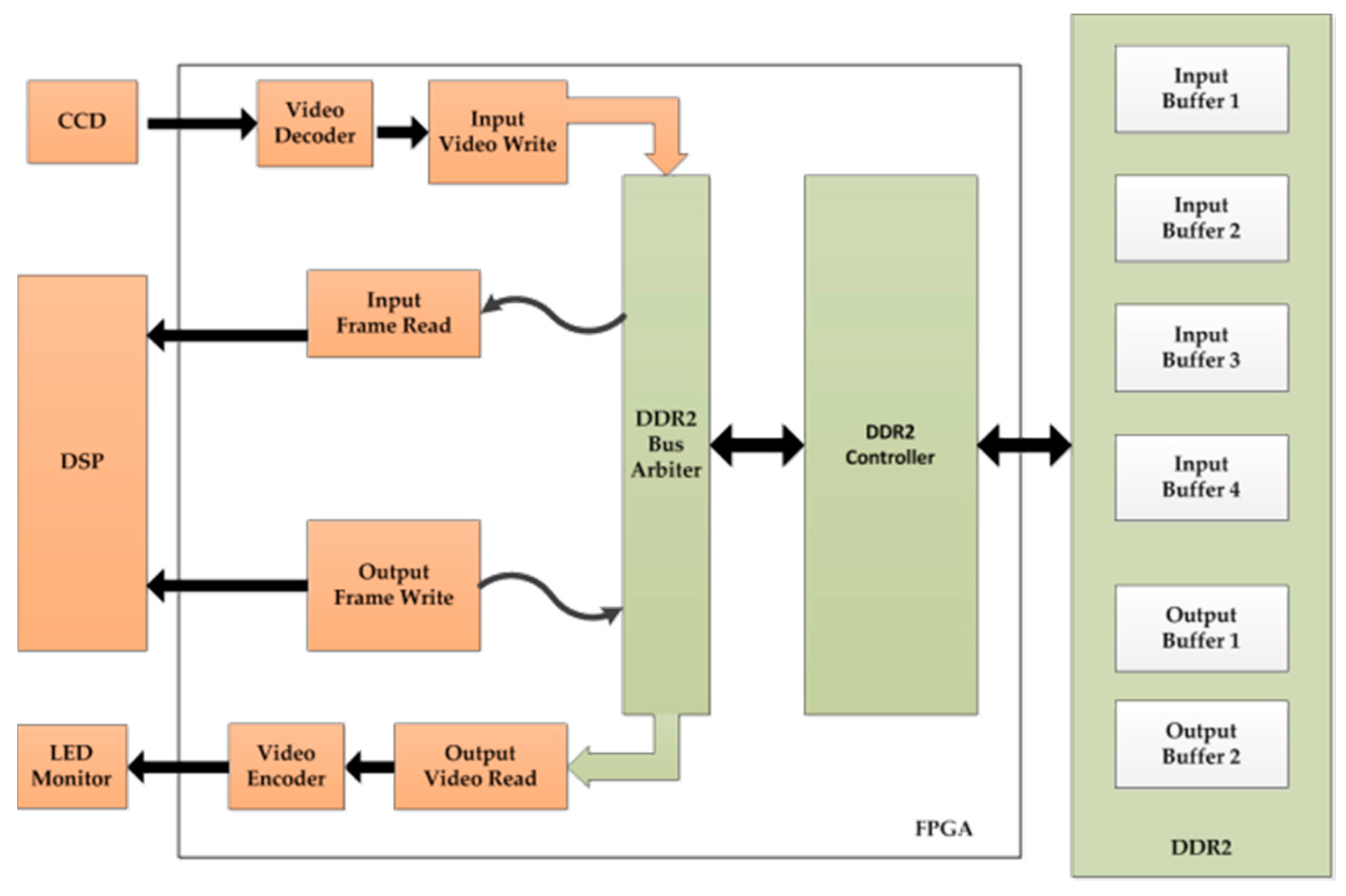
3. The Embedded System
4. Experimental Validation
4.1. Software Experiment
4.1.1. Experimental Setup
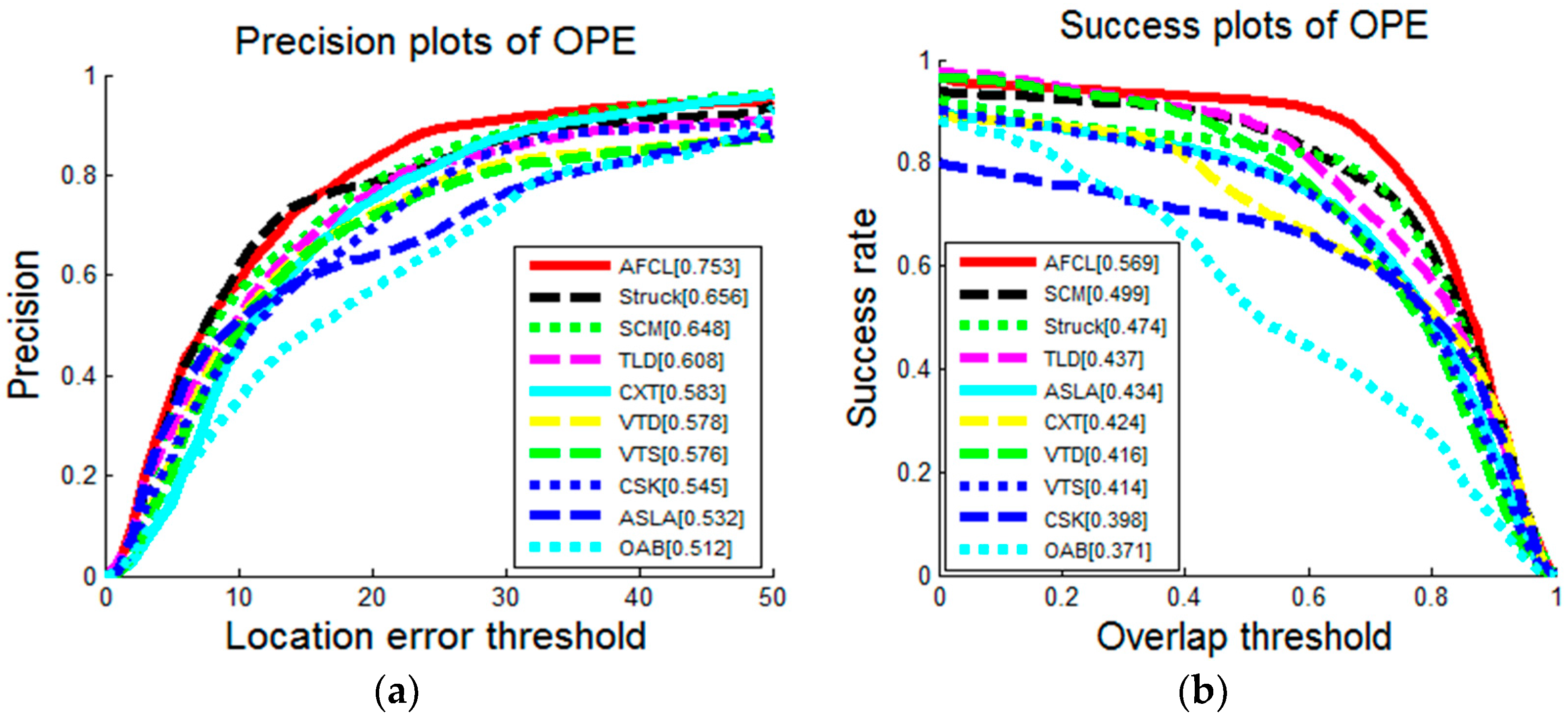
4.1.2. Results
4.2. Hardware Experiment
4.2.1. Real-Time Tracking System
4.2.2. Experimental Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013.
- Pan, S.; Shi, L.; Guo, S. A kinect-based real-time compressive tracking prototype system for amphibious spherical robots. Sensors 2015, 15, 8232–8252. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.X.; Tang, L.B.; Yang, J.L.; Zhao, B.J.; Wang, S.G. Visual tracking based on extreme learning machine and sparse representation. Sensors 2015, 15, 26877–26905. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Huang, P.F.; Zhang, B.; Wang, D.K. A TSR Visual servoing system based on a novel dynamic template matching mehtod. Sensors 2015, 15, 32152–32167. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.J.; Kim, Y.G. A target model construction algorithm for robust real-time mean-shift tracking. Sensors 2014, 14, 20736–20752. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lepetit, V.; Fua, P. Keypoint recognition using randomized trees. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1465–1479. [Google Scholar] [CrossRef] [PubMed]
- Ozuysal, M.; Fua, P.; Lepetit, V. Fast keypoint recognition in ten lines of code. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007.
- Calonder, M.; Lepetit, V.; Fua, P. BRIEF: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010.
- Kalal, Z.; Mikolajczyk, K.; Mata, J. Online learning of robust object detectors during unstable tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009.
- Kalal, Z.; Mikolajczyk, K.; Mata, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009.
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed]
- Grabner, H.; Leistner, C.; Bischof, H. Semi-supervised on-line boosting for robust tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008.
- Saffari, A.; Godec, M.; Leistner, C.; Bischof, H. Robust multi-view boosting with priors. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Greece, 5–11 September 2010.
- Zhang, K.; Zhang, L.; Yang, M.H. Fast compressive tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Kalal, Z.; Mikolajczyk, K.; Mata, J. Forward–Backward error: Automatic detection of tracking failures. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010.
- Oron, S.; Bar-Hille, A.; Avidan, S. Extended Lucas-Kanade tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014.
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured Output Tracking with Kernels. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.
- Zhang, K.; Zhang, L.; Yang, M.H.; Zhang, D. Fast tracking via spatio-temporal context learning. 2013; arXiv:1311.1939. [Google Scholar]
- Yang, B.; Cao, Z.; Letaief, K. Analysis of low-complexity windowed DFT-based MMSE channel estimator for OFDM systems. IEEE Trans. Commun. 2001, 49, 1977–1987. [Google Scholar] [CrossRef]
- Yoo, J.C.; Han, T.H. Fast normalized cross-correlation. Circuits Syst. Sigal Process. 2009, 28, 819–843. [Google Scholar] [CrossRef]
- Grabner, H.; Grabner, M.; Bischof, H. Real-Time tracking via on-line boosting. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006.
- Zhong, W.; Lu, H.; Yang, M.H. Robust object tracking via sparse collaborative appearance model. IEEE Trans. Image Process. 2014, 23, 2356–2368. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Lu, H.; Yang, M.H. Visual tracking via adaptive structural local sparse appearance model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012.
- Dinh, T.B.; Vo, N.; Medioni, G. Context tracker: Exploring supporters and distracters in unconstrained environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011.
- Kwon, J.; Lee, K.M. Visual tracking decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010.
- Kwon, J.; Lee, K.M. Tracking by sampling trackers. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SCM | Struck | TLD | ASLA | CXT | VTD | VTS | CSK | OAB | AFCL | |
|---|---|---|---|---|---|---|---|---|---|---|
| IV | 0.473 | 0.428 | 0.402 | 0.429 | 0.368 | 0.420 | 0.428 | 0.369 | 0.302 | 0.639 |
| OPR | 0.470 | 0.432 | 0.423 | 0.422 | 0.418 | 0.435 | 0.425 | 0.386 | 0.359 | 0.451 |
| SV | 0.518 | 0.425 | 0.424 | 0.452 | 0.389 | 0.405 | 0.400 | 0.350 | 0.370 | 0.629 |
| OCC | 0.487 | 0.413 | 0.405 | 0.376 | 0.372 | 0.404 | 0.398 | 0.365 | 0.370 | 0.636 |
| DEF | 0.448 | 0.393 | 0.381 | 0.372 | 0.324 | 0.377 | 0.368 | 0.343 | 0.351 | 0.562 |
| MB | 0.293 | 0.433 | 0.407 | 0.258 | 0.369 | 0.309 | 0.304 | 0.305 | 0.324 | 0.424 |
| FM | 0.296 | 0.462 | 0.420 | 0.247 | 0.388 | 0.303 | 0.299 | 0.316 | 0.362 | 0.558 |
| IPR | 0.458 | 0.444 | 0.419 | 0.425 | 0.452 | 0.430 | 0.415 | 0.399 | 0.347 | 0.644 |
| OV | 0.361 | 0.459 | 0.460 | 0.312 | 0.427 | 0.446 | 0.443 | 0.349 | 0.414 | 0.333 |
| BC | 0.450 | 0.458 | 0.348 | 0.408 | 0.338 | 0.425 | 0.428 | 0.421 | 0.341 | 0.452 |
| LR | 0.279 | 0.372 | 0.312 | 0.157 | 0.312 | 0.177 | 0.168 | 0.350 | 0.304 | 0.286 |
| Overall | 0.499 | 0.474 | 0.437 | 0.434 | 0.424 | 0.416 | 0.414 | 0.398 | 0.371 | 0.569 |
| SCM | Struck | TLD | ASLA | CXT | VTD | VTS | CSK | OAB | AFCL | |
|---|---|---|---|---|---|---|---|---|---|---|
| IV | 0.594 | 0.558 | 0.537 | 0.517 | 0.501 | 0.557 | 0.572 | 0.481 | 0.398 | 0.827 |
| OPR | 0.618 | 0.597 | 0.596 | 0.518 | 0.574 | 0.620 | 0.603 | 0.540 | 0.510 | 0.592 |
| SV | 0.672 | 0.639 | 0.606 | 0.552 | 0.550 | 0.597 | 0.582 | 0.503 | 0.541 | 0.798 |
| OCC | 0.640 | 0.564 | 0.563 | 0.460 | 0.491 | 0.546 | 0.533 | 0.500 | 0.492 | 0.823 |
| DEF | 0.586 | 0.521 | 0.512 | 0.445 | 0.422 | 0.501 | 0.487 | 0.476 | 0.470 | 0.532 |
| MB | 0.339 | 0.551 | 0.518 | 0.278 | 0.509 | 0.375 | 0.375 | 0.342 | 0.360 | 0.550 |
| FM | 0.333 | 0.604 | 0.551 | 0.253 | 0.515 | 0.353 | 0.351 | 0.381 | 0.431 | 0.761 |
| IPR | 0.597 | 0.617 | 0.584 | 0.511 | 0.610 | 0.600 | 0.578 | 0.547 | 0.479 | 0.832 |
| OV | 0.429 | 0.539 | 0.576 | 0.333 | 0.510 | 0.462 | 0.455 | 0.379 | 0.454 | 0.501 |
| BC | 0.578 | 0.585 | 0.428 | 0.496 | 0.443 | 0.571 | 0.578 | 0.585 | 0.446 | 0.786 |
| LR | 0.305 | 0.545 | 0.349 | 0.156 | 0.371 | 0.168 | 0.187 | 0.411 | 0.376 | 0.423 |
| Overall | 0.648 | 0.656 | 0.608 | 0.532 | 0.583 | 0.578 | 0.576 | 0.545 | 0.512 | 0.753 |
| Tracker | SCM | Struck | TLD | ASLA | CXT | VTD | VTS | CSK | OAB | AFCL |
|---|---|---|---|---|---|---|---|---|---|---|
| Average fps | 0.51 | 20.2 | 28.1 | 8.5 | 15.3 | 5.7 | 5.7 | 362 | 22.4 | 30.2 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Xu, T.; Chen, S.; Zhang, J.; Jiang, S. Real-Time Tracking Framework with Adaptive Features and Constrained Labels. Sensors 2016, 16, 1449. https://doi.org/10.3390/s16091449
Li D, Xu T, Chen S, Zhang J, Jiang S. Real-Time Tracking Framework with Adaptive Features and Constrained Labels. Sensors. 2016; 16(9):1449. https://doi.org/10.3390/s16091449
Chicago/Turabian StyleLi, Daqun, Tingfa Xu, Shuoyang Chen, Jizhou Zhang, and Shenwang Jiang. 2016. "Real-Time Tracking Framework with Adaptive Features and Constrained Labels" Sensors 16, no. 9: 1449. https://doi.org/10.3390/s16091449