1. Introduction
Object tracking is an important computer vision task that has many practical applications, such as security and surveillance, motion analysis, augmented reality, traffic control and human–computer interaction. A real-time visual tracking system combines software and hardware design. A digital camera captures video. To achieve a smooth output video impression for human eyes, a frame-rate of at least 15 frames per second (FPS) is required. A two-axis turntable will be used to pivot the camera horizontally (yaw) and vertically (pitch). Object tracking will be accomplished through software on the main control computer. An interface allows the user to select a target and to see what the camera is tracking. The system attempts to always keep the object in the center of its field of view. It is noteworthy that target tracking algorithms play a decisive role in this system.
Single object tracking is the most common task within the field of computer vision. Many methods for object tracking have been proposed. Adam et al. [
1] presented a part-based algorithm called FragTrack which models the object appearance based on multiple parts of the target. Grabner et al. [
2] proposed an on-line boosting algorithm (OAB) to select features for tracking. In [
3], Babenko et al. adopted Multiple Instance Learning (MIL), which puts all ambiguous positive and negative samples into bags to learn a discriminative model. Kalal et al. [
4] proposed a novel tracking framework (TLD) that decomposes the tasks into three components: tracking, learning and detection. Struck [
5] presents a framework for adaptive visual object tracking based on structured output prediction. Xu et al. [
6] proposed the structural local sparse appearance (ASLA) model which exploits both partial information and spatial information. In [
7], a robust tracking framework based on the locality sensitive histograms is proposed. Wang et al. [
8] present a novel probability continuous outlier model (PCOM) to depict the continuous outliers that occur in the linear representation model. The approach [
9] formulates the spatio-temporal relationships between the object of interest and its local context based on a Bayesian framework. In [
10], Oron presented Extended Lucas Kanade or ELK that it casts the original LK algorithm as a maximum likelihood optimization. These methods rely on intensity or texture information for the image description and include complex appearance models and optimization methods. It is difficult for most of them, when executed on a standard PC, to keep up with the 25 frame-per-second demand without parallel computing when real-time processing is required [
11].
Recently, correlation filters for object tracking began to receive more attention because they have an impressively high-speed. Several state-of-the-art methods using correlation filters have been proposed for a variety of applications, such as object detection and recognition and object tracking. Bolme et al. [
12] propose a tracker that is based on the Minimum Output Sum of Squared Error (MOSSE) filter, which is robust to variations in lighting, scale, pose, and non-rigid deformations while operating at 669 frames per second. Henriques et al. [
13] provide a link to Fourier analysis using the well-established theory of circulant matrices and devise Kernel classifiers with the same characteristics as the correlation. Their tracker is called a CSK tracker. Boddeti et al. [
14] propose a vector correlation filter (VCF) with HOG features and demonstrate the efficacy and speed of the proposed approach on the challenging task of multi-view car alignment. Galoogahi et al. [
15] propose an extension to canonical correlation filter theory that can efficiently handle multi-channel signals. In contrast to object tracking, color descriptors have been shown to obtain excellent results for object recognition and detection [
16,
17,
18,
19,
20]. Most early color detectors use simple color representations for image description. The linguistic study of Berlin and Kay [
21] on basic color terms is one of the most influential works in color naming. In [
17], the authors show that the color names (CN) learned from real-world images outperform chip-based color names on real-world applications. Danelljan et al. [
22] extend the CSK tracker [
13] with color names (CN), which provides superior performance for visual tracking. Recently, Henriques et al. [
23] derived a new Kernelized Correlation Filter (KCF), which is the journal version of CSK and can use HOG features very well.
Traditional object trackers based on correlation filters typically use a single type of feature. In this paper, we attempt to integrate multiple feature types to improve the performance. The fusion of multiple features leads to a significant increase in the performance for object detection [
16,
18]. In reference [
16], the authors extend the description of the local features with color information. A boosted CN-HOG detector is proposed by [
18], where CN descriptors are combined with HOGs to incorporate texture information. These investigators show that their approach can significantly improve the detection performance on the challenging PASCAL VOC datasets. Shi et al. [
24] specifically show that the correct features to use are exactly those that make the tracker work best. To obtain an effective and efficient tracking algorithm, we propose a new DD-HOG fusion feature that consists of a discriminative descriptor (DD) and histograms of oriented gradients (HOG). Khan et al. [
20] show that their discriminative descriptor (DD) outperforms other pure color descriptors and the color name (CN) descriptor. The DD feature has been used for object tracking [
25]. In addition, Dalal and Triggs [
26] proposed histograms of oriented gradients (HOG), which are widely used for object detection. However, the DD-HOG is a multi-vector descriptor and therefore cannot be directly used in prior correlation filters [
12,
13,
14,
15,
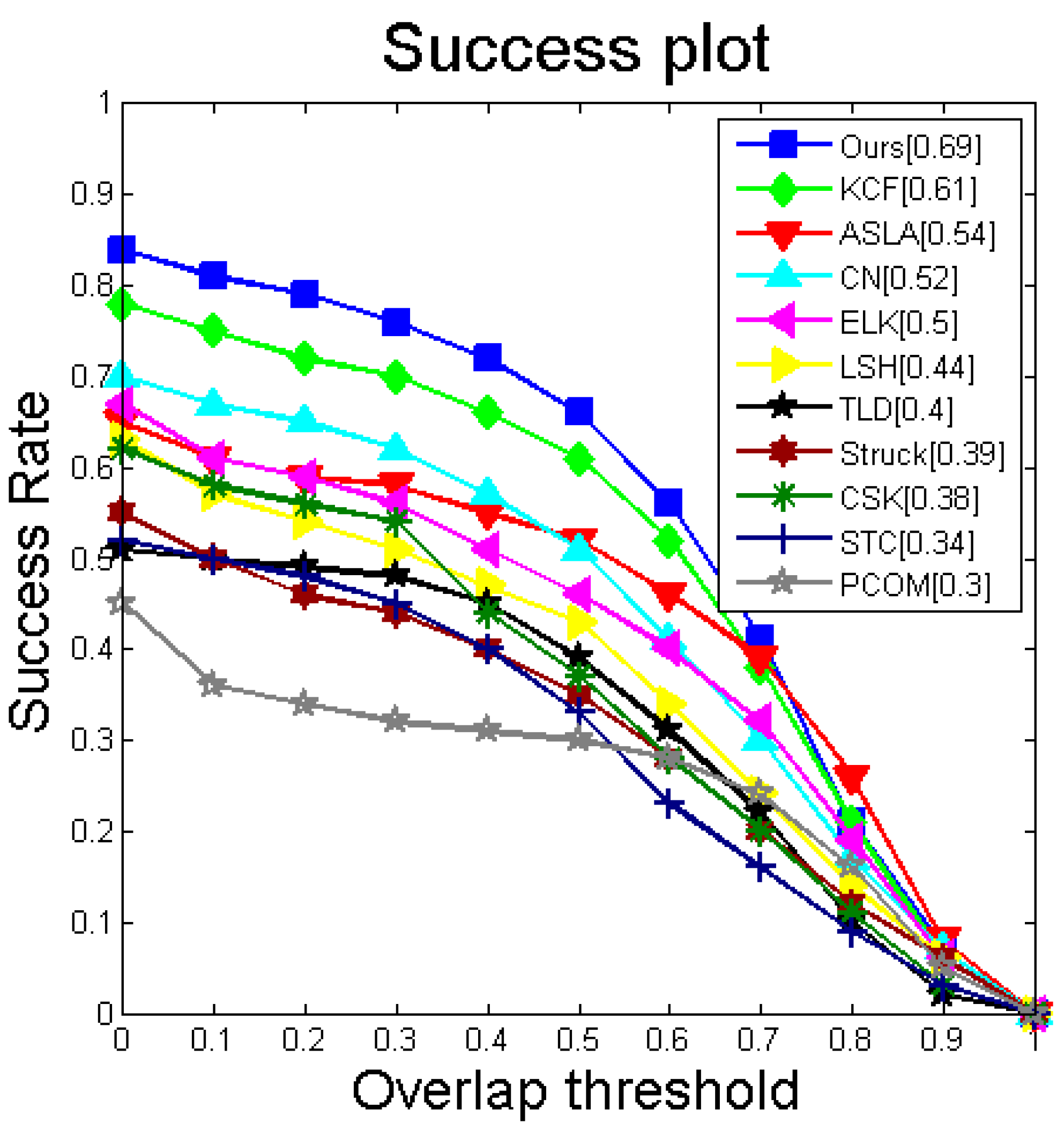
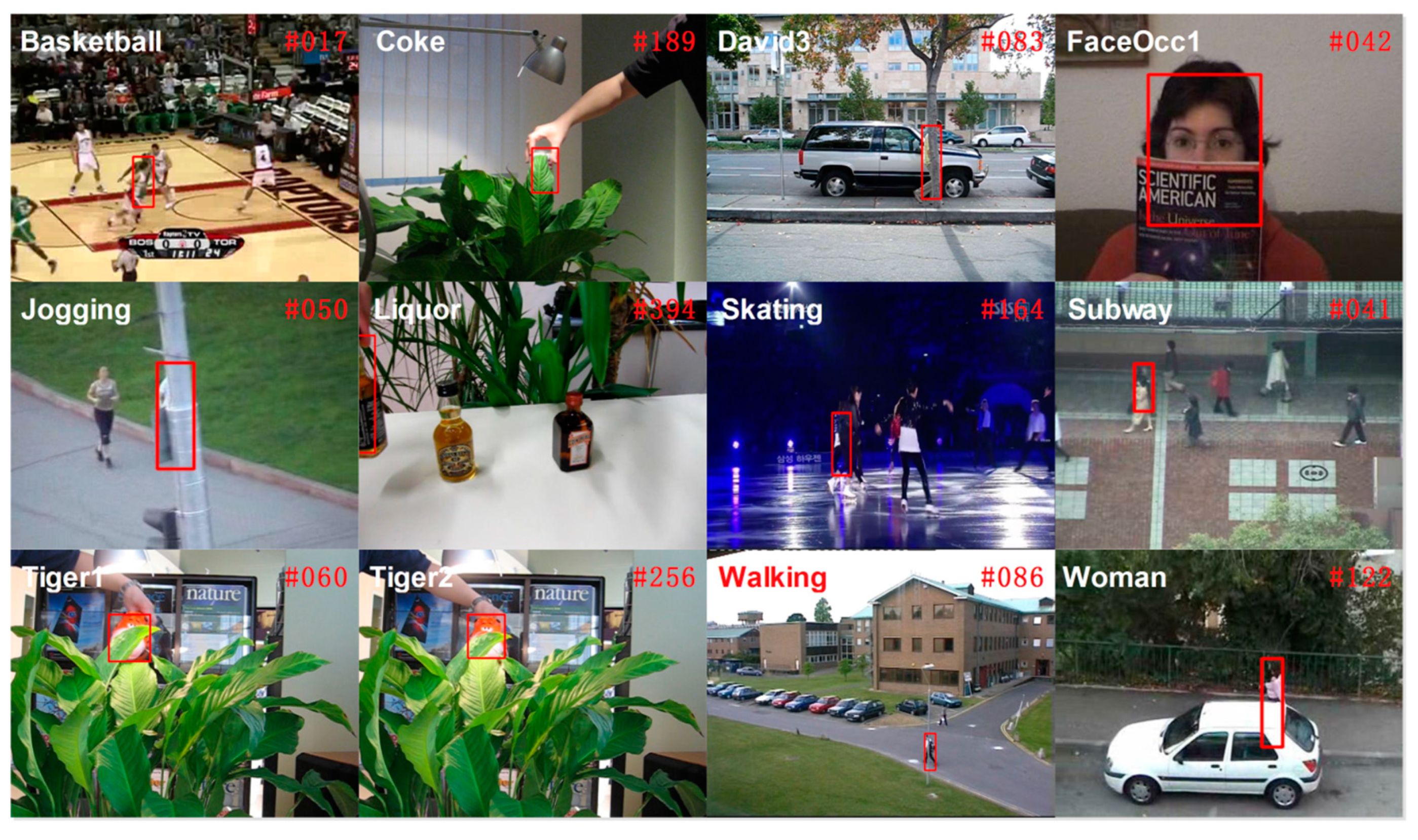
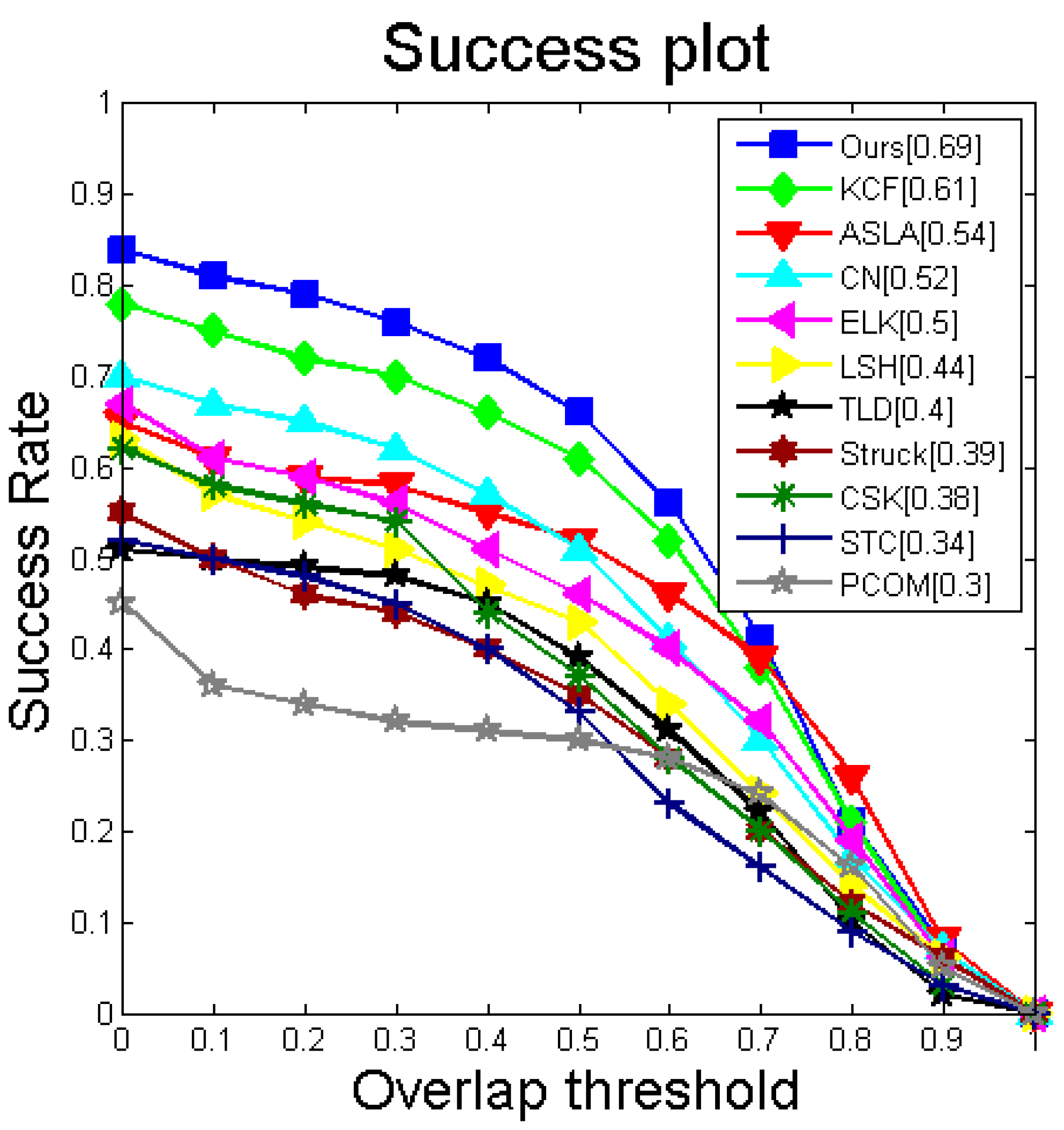
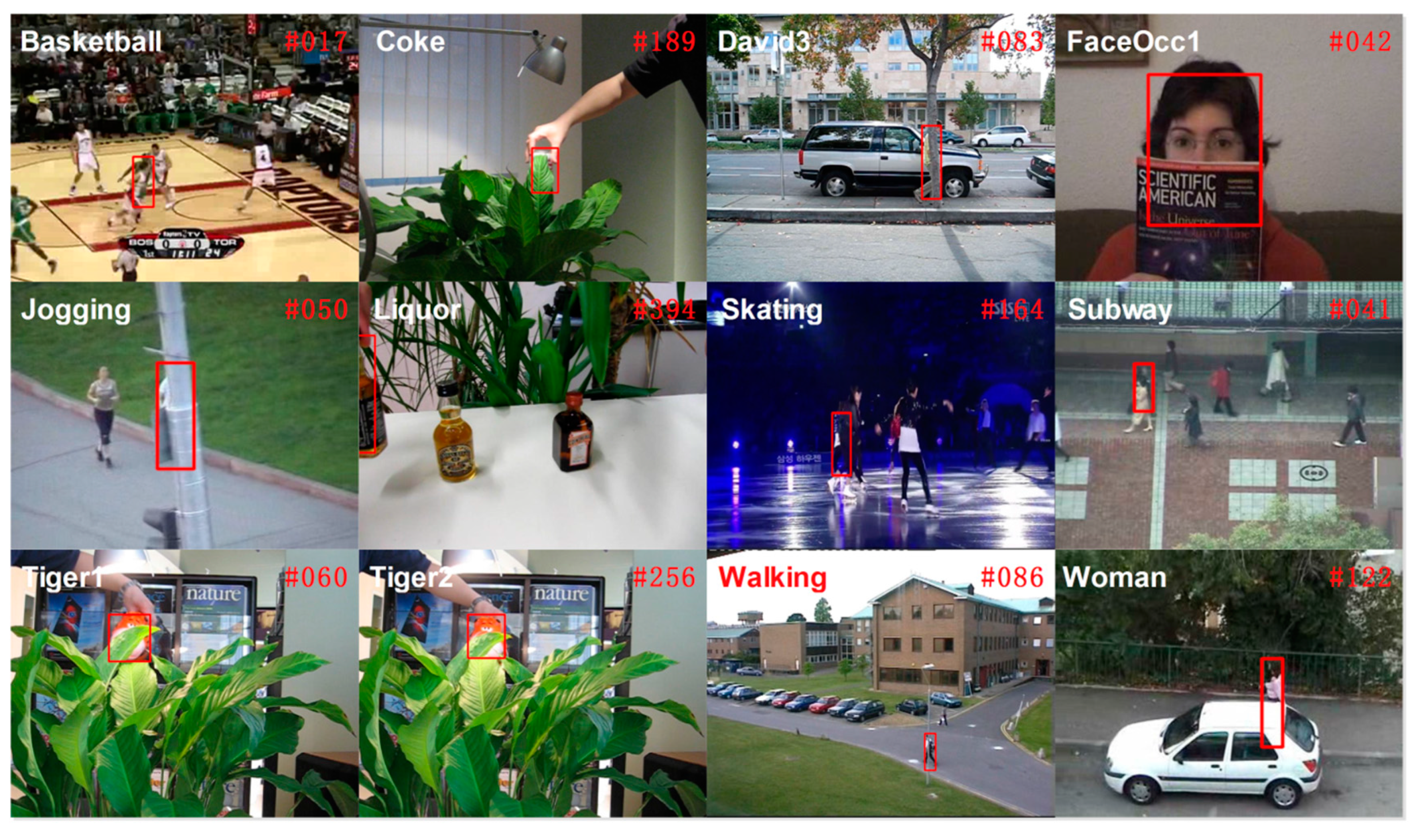
16]. Those correlation filters have been traditionally designed to be used with scalar or single vector feature representations only. In our paper, we propose a multi-vector correlation filter (MVCF) to resolve this problem. A multi-vector correlation filter interpreted literally is made up of multiple vector correlation filters. The vector correlation filter is composed of one correlation filter. The DD-HOG feature is correlated with our multi-vector correlation filter for obtaining a single-channel response. The peak of the responses indicates the target center. A similar process can be done for other multi-vector features. The tracker that is based on a multi-vector correlation filter (MVCF) that comprises four main components: (1) a scale adjustment that makes all of the elements of a multi-vector feature have the same size; (2) a multi-vector structure that a multi-vector descriptor can be convolved with directly; (3) an update scheme that multiple object appearance models must update separately (and all of the previous frames are considered); and (4) a dimensionality reduction technique that reduces the dimension for each element of the multi-vector feature independently. A quantitative evaluation is conducted on the CVPR2013 tracking benchmark [
11]. It is a comprehensive dataset that is specially designed to facilitate the evaluation of performance. Extensive experiments demonstrate that the proposed tracker based on the multi-vector correlation filter (MVCF) can outperform state-of-the-art trackers. Tracking results in the CVPR2013 benchmark are shown in
Figure 1.
We also show that our MVCF tracker can obtain substantial performance in multi-object tracking. The goal of multi-object tracking is to estimate the states of multiple objects. In complex scenes, multi-object tracking remains a challenging problem for many reasons, including frequent occlusion by other objects, similar appearances of different objects, and real-time processing. In this paper, we argue that our MVCF tracker has an extraordinary ability to address partial occlusion and can run at an impressively high-speed. Therefore, the MVCF tracker appears to be a good choice for multi-object tracking. Our experimental evaluations show that the MVCF tracker performs very well on videos that are used [
27] for multiple-object tracking. We use a simple approach to tracking multiple objects in which we only run multiple instances of our MVCF tracker without spatial constraints between the objects. The speed of our algorithm to track approximately four objects simultaneously is more than 25 fps. Therefore, the multi-vector correlation filter (MVCF) can be used as a basic framework in multi-object tracking such as Random Forests (RFs) and Support Vector Machines (SVMs).
The contributions of this paper are as follows.
MVCF: We propose a new type of correlation filter, a multi-vector correlation filter (MVCF), which can directly convolve with a multi-vector descriptor. Extensive experiments demonstrate that the proposed tracker, which is based upon MVCF, can outperform state-of-the-art trackers.
Feature Selection: We select optimal features to a multi-vector correlation filter based on how the tracker that uses MVCF works. The new proposed DD(11)-HOG fusion feature is the optimal feature for MVCF tracking. We also show that MVCF with DD(11)-HOG obtains superior performance compared with current state-of-the-art correlation filters with other features.
Multi-object Tracking: We apply our approach across multi-object tracking tasks. We demonstrate that MVCF is well suited to use as a basic framework in multi-object tracking, such as with RFs and SVMs. The speed of our algorithm for tracking approximately four objects simultaneously is more than 25 fps.
The remainder of this paper is organized as follows. In
Section 2, we review the CSK tracker. In
Section 3, we introduce a new robust tracker that is based on a multi-vector correlation filter. In
Section 4, we show our experimental results. Finally, we present our conclusions in
Section 5.
3. Proposed Algorithm
The novelty of this paper is to present a real-time tracker that is based on the CSK algorithm. Our multi-vector correlation filter (MVCF) can directly use multi-vector descriptors (i.e., DD-HOG, CN-HOG). We present details of the proposed tracking algorithm in this section.
3.1. Input of Multi-Vector Correlation Filter
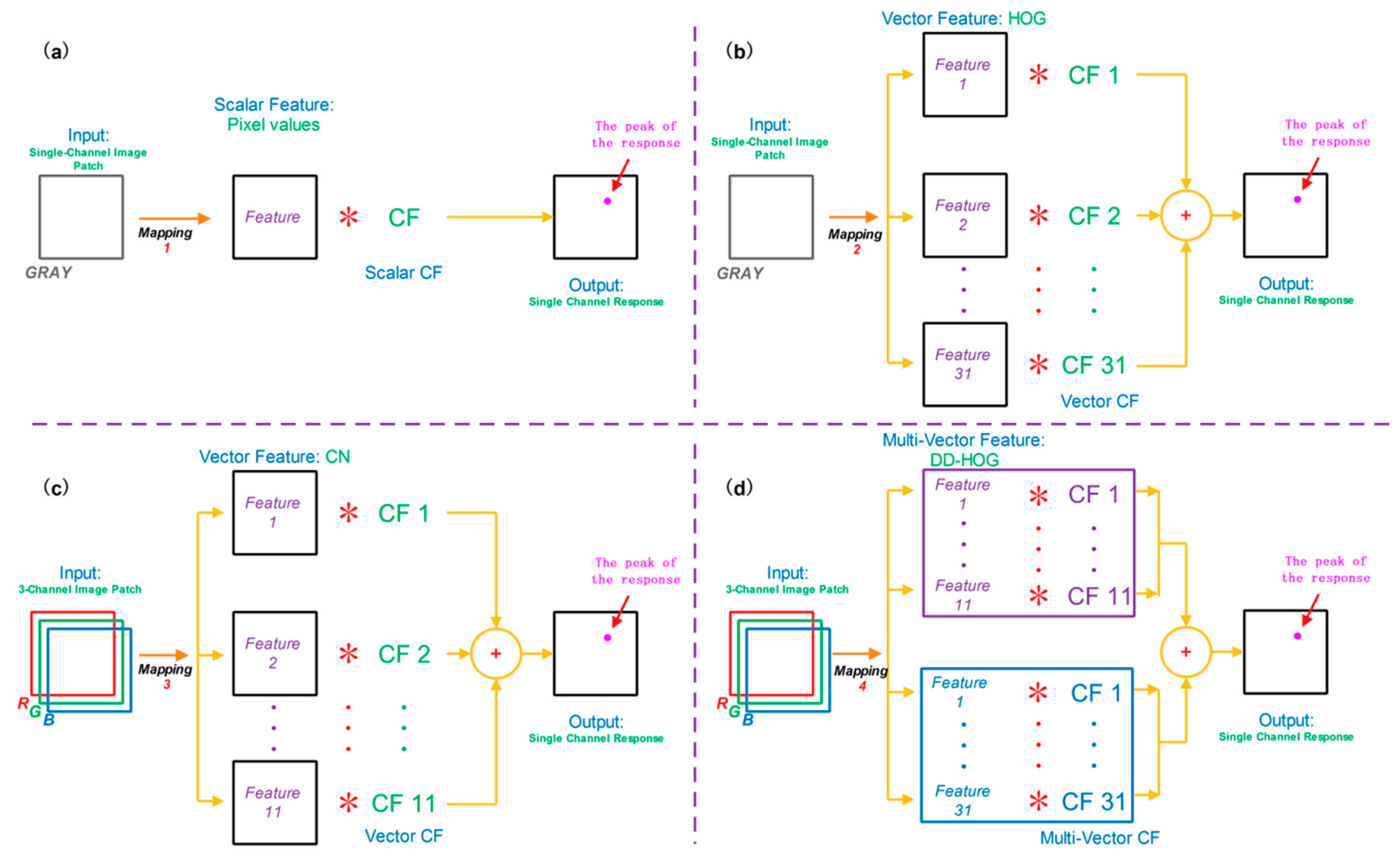
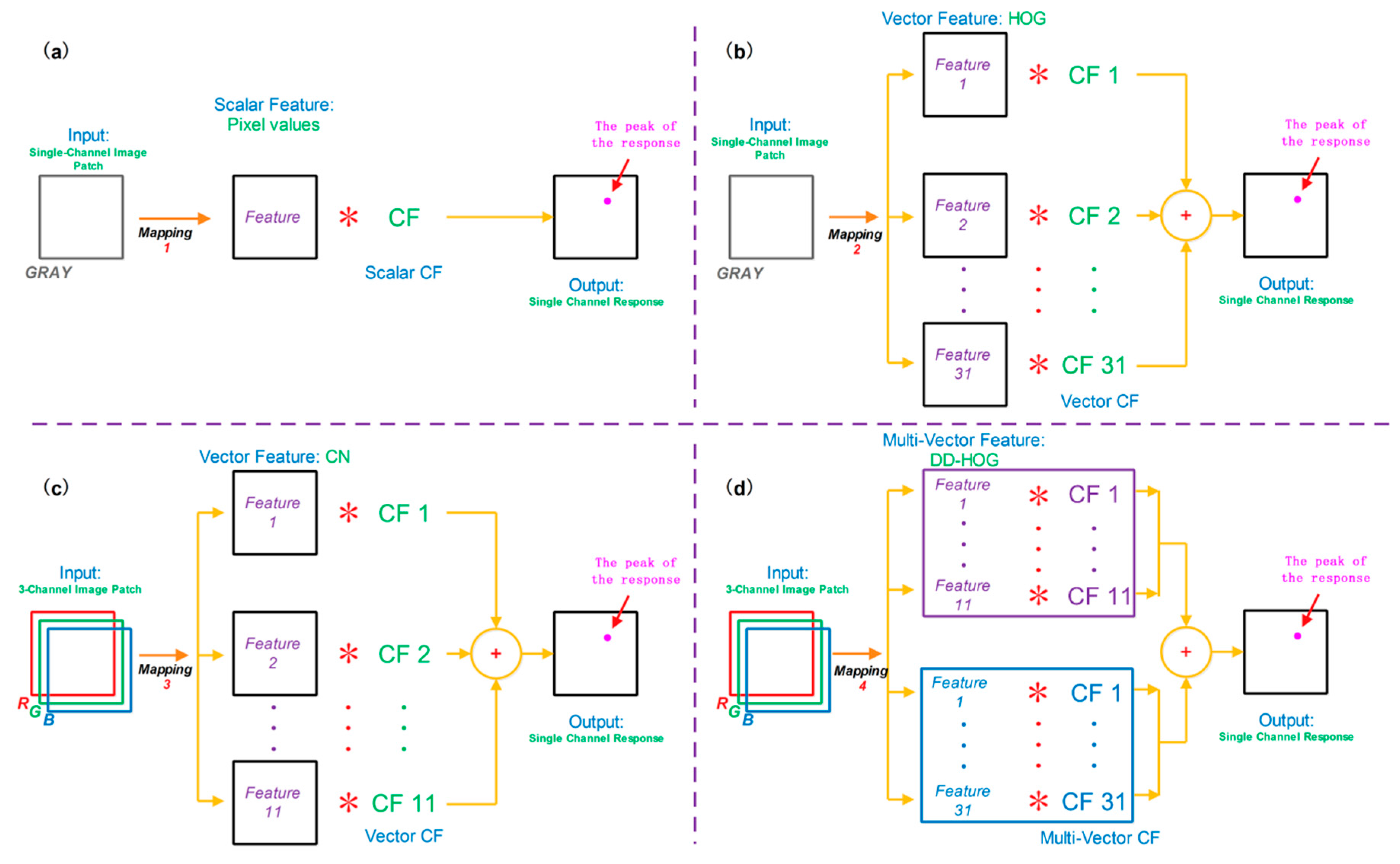
Generally, a unique vector is computed to represent an image patch when only one feature is used in a correlation filter framework. For a multi-vector descriptor, an image patch is mapped to multiple image representations. All of the descriptors carry with them corresponding mappings.
Given an image , each vector feature is defined as , , where is the size of the set of multi-vector features. Then, is the i-th vector feature, and its corresponding mapping is .
The multi-channel is the input of the multi-vector correlation filter. The element is a tensor, where the is an matrix in the th channel of the th element . A fixed number for the channels is allotted for each element. The dimension of the input is , where the number of elements is . The multi-vector feature as a whole is correlated with our multi-vector correlation filter.
It is necessary to consider the size of the different elements . We try to use a pre-processing to ensure that all of the elements could have the same size . In general, different features correspond with different elements by . So, the dimensions of these elements are not the same. But this will not influence the pre-processing. Here, we give a briefing for the CN-HOG feature. Generally, an image is represented by HOG features which are computed densely. The cell is a 8 × 8 non-intersecting pixel region to represent an image. Of course, there are other pixel cells used in practice. For the cell , the representation is obtainedby concatenation, specifically, . For the HOG descriptor, we first compute the intensity channel by the “rgb2gray” function, and then, the representation is computed in each cell ( pixel). The element has a decreasing size, , and the dimension is 31. A similar procedure is built to compute the element for each cell, resulting in the same size as the elements . The RGB values are mapped to an 11-dimensional color representation. The bi-vector feature as a whole has the size , and the dimension of the fusion vector is 42.
3.2. Multi-Vector Structure
To directly use multi-vector features, such as DD-HOG, we design a novel multi-vector structure in
Figure 2. A multi-vector correlation filter, when interpreted literally, is composed of multiple vector correlation filters. The vector correlation filter is composed of a single correlation filter. For each feature channel, its corresponding confidence score is computed, and, an input patch
are mapped using
where
and
. Each input patch is collected around the target. The result
is an
matrix in the
, -th channel of the whole filter.
Equation (1) can then be expressed as
where the number of vectors is
, and the number of channels of the
th vector is
. For each feature channel, there is a corresponding classifier. The confidence score indicates a similarity with the target. A sharp peak can be obtained near the target location. The final confidence score is attained by the aggregate of the outputs of each feature channel.
The aggregate is embodied in the kernel computation . The manipulation of the linear kernel and Gaussian kernel are identical. The inputs and as a whole vector feature are a tensor, where is the total number of locations, and is the number of channels. The single channel is obtained by the aggregate of the outputs of each feature channel. The notation is a matrix of size , and its dimension is one. Therefore, both the solution in training and the confidence score vector denote a matrix.
3.3. Updating Scheme
The scheme needs to update both the learned object appearance and the filter coefficients overtime.
To update the model, all of the previous frames should be considered from the first frame until the current frame
. All of the previous appearances of the target are
. A positive weight constant
is allocated for each frame. Here
is a learning rate parameter that can set the weight
. Equation (4) can then be expressed anew as
where the number of vectors is
, and the number of channels of the
th vector is
.
is a parameter for regularization. In frame
, the corresponding confidence score of input image patch
is
.
Then, the solution
in Equation (2) can then be expressed as
This cost function is minimized by . The derivation of Equation (6) are given in Appendix.
The object appearance
is an
tensor, where the number of vectors is
, and
is an
tensor. In each new frame, the filter is updated by
The object appearance is updated by
3.4. Dimension Reduction
For the current frame , the object appearance consists of object sub-appearances. For each sub-appearance , , we use an eigenvalue decomposition technique (EVD) independently, which reduces the dimension to obtain a boosted speed.
For the first frame, we extract the image patch using the initial ground truth. The multi-vector
is the input of the multi-vector correlation filter mentioned in
Section 3.1, where
is the current frame. For each multi-channel vector feature
, its corresponding covariance matrix
is computed, where
. Covariance matrix
is a square matrix of size
. Then, we perform an eigenvalue decomposition of the matrix
. The covariance matrix is decomposed to the following form:
, where
is composed of eigenvectors of the covariance matrix
, and the sorted eigenvalues are stored in a diagonal matrix
. Let
be a planned low dimension, and
. Then,
is a
diagonal matrix of the eigenvalues from
. The projection matrix
is selected as the first
in
. The low-dimensional sub-appearance
is obtained by
, where
, and the dimension of
is
. The learned appearance
is used to compute the detectionscores
for the next frame. In each new frame, the covariance matrix that is ready for EVD is updated by
, where
and
. The procedure is similar for the subsequent frames.
3.5. Main Differences from CSK, CN and KCF
All types of correlation filters are designed depending on the usage of a feature. The searching for and usage of good features are a significant part of the methodology.
Traditionally, many different correlation filters were designed to be used with scalar feature (most commonly pixel value) representations only. The CSK tracker uses this traditional type of correlation filter, which is a single channel correlation filter. The CN tracker proposes a tracking method that can handle multi-channel color feature vectors (color name descriptors). The vector correlation filter (VCF) used in the CN tracker was designed by Boddeti [
14] and it is a multi-channel correlation filter. The journal version of CSK (called KCF) also uses the VCF and has already been able to address the HOG features very well. The KCF selects the HOG features to obtain better performance.
Reference [
18] shows that the simple fusion of CN and HOG obtains an outstanding performance increase for object detection. We propose a new type of fusion feature (DD-HOG) that can gain a significant improvement in performance for tracking. The multi-vector descriptor cannot be directly used in prior correlation filters. We design a multi-vector correlation filter (MVCF) to solve this difficulty. The MVCF can also use the other multi-vector descriptors readily.
Table 1 shows detailed information about the differences between our method and the above three methods.
Here, we briefly analyze the main factor for why the proposed approach is better than previous ones. In [
29], they find that the feature extractor plays the most important role in a tracker. On the other hand, the observation model often brings no significant improvement. Thus, selecting the right features provides the potential for improving performance. Using the proposed sophisticated fusion features can dramatically improve the tracking performance. This feature could make the correlation filters tracking system work better.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}