
Geometry-Based Distributed Spatial Skyline Queries in Wireless Sensor Networks

Abstract
:
1. Introduction
- We design the cut of skyline region based on convex hull vertices method, which can cut out a lot of the non-skyline region by the rectangular B strategy and reduce the comparison times between nodes and improve the efficiency.
- We propose a distributed query method based on the data node tree concept to traverse all the neighbor sensor monitoring regions, and enter them into the queue according to the distance by the monotone function, so it can implement the execution in parallel.
- We design a clustering strategy for the parallel execution of general skyline queries on the non-spatial attributes of the spatial skyline, and conduct the spatial skyline query on the remaining spatial skyline points which are still not found by the tree method at the same time, so we can implement a distributed execution between different sub-regions.
- We propose the concepts of cuts among sub-regions and cuts in sub-regions for the collection. This can reduce the data transmissions in the network and reduce the sensor energy cost.
2. Related Work
2.1. The Non-Spatial Skyline Query Method
2.2. Spatial Skyline Query Method
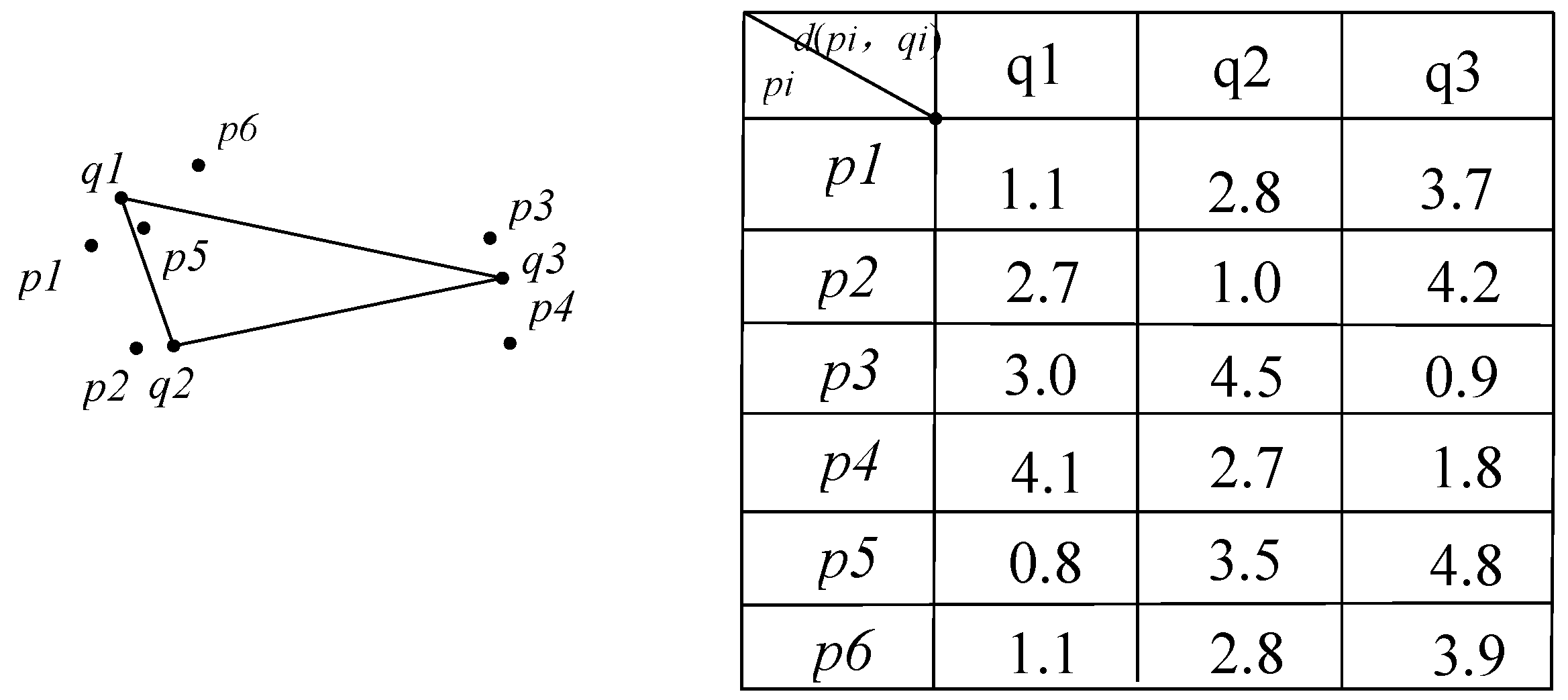
- The spatial dominance relation
- The spatial skyline
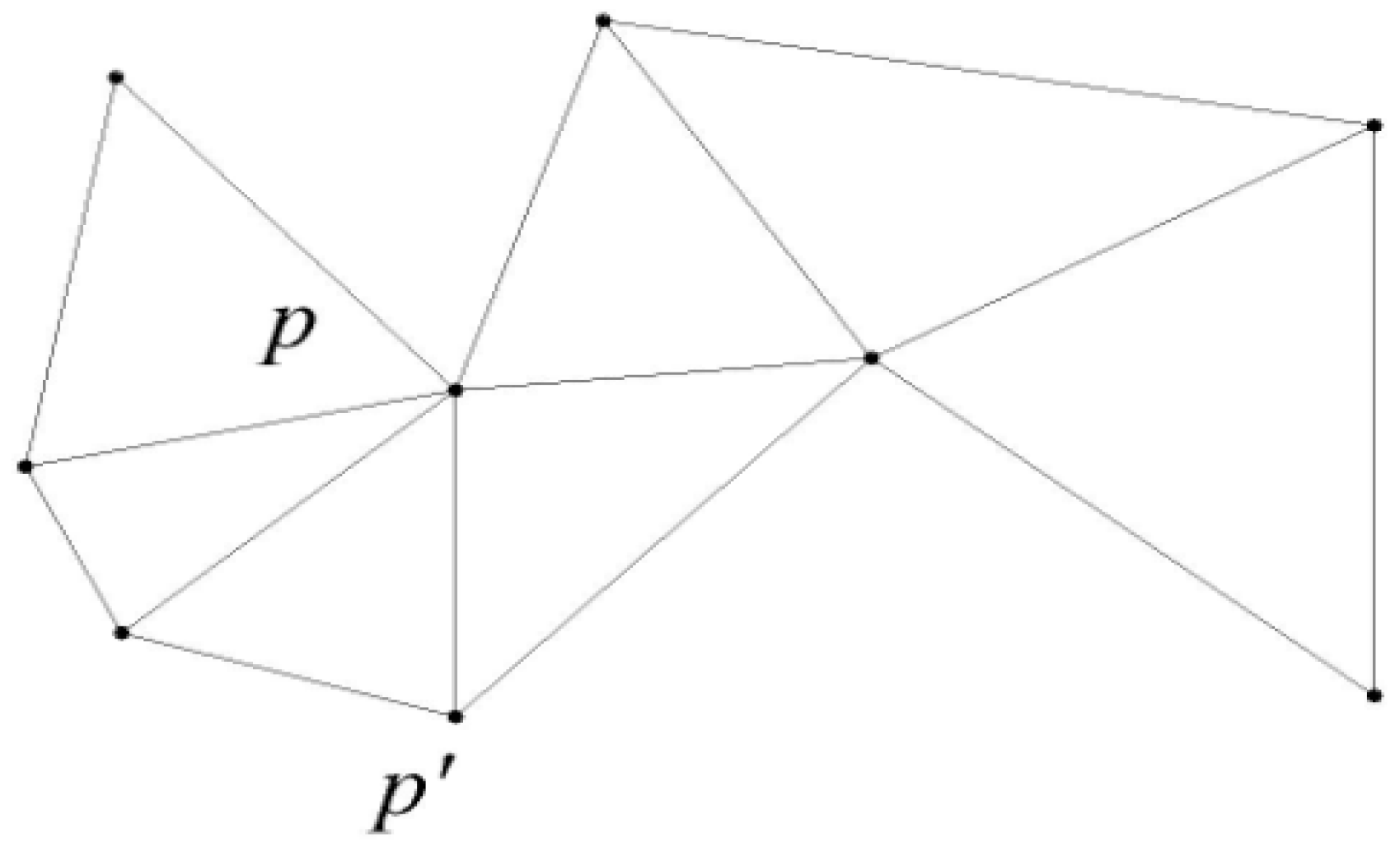
so that D(p, qi) ≤ D(p’, qi)
3. Geometry-Based Spatial Skyline Queries
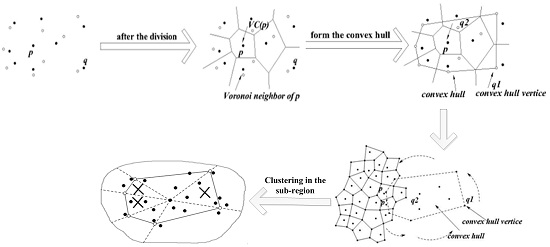
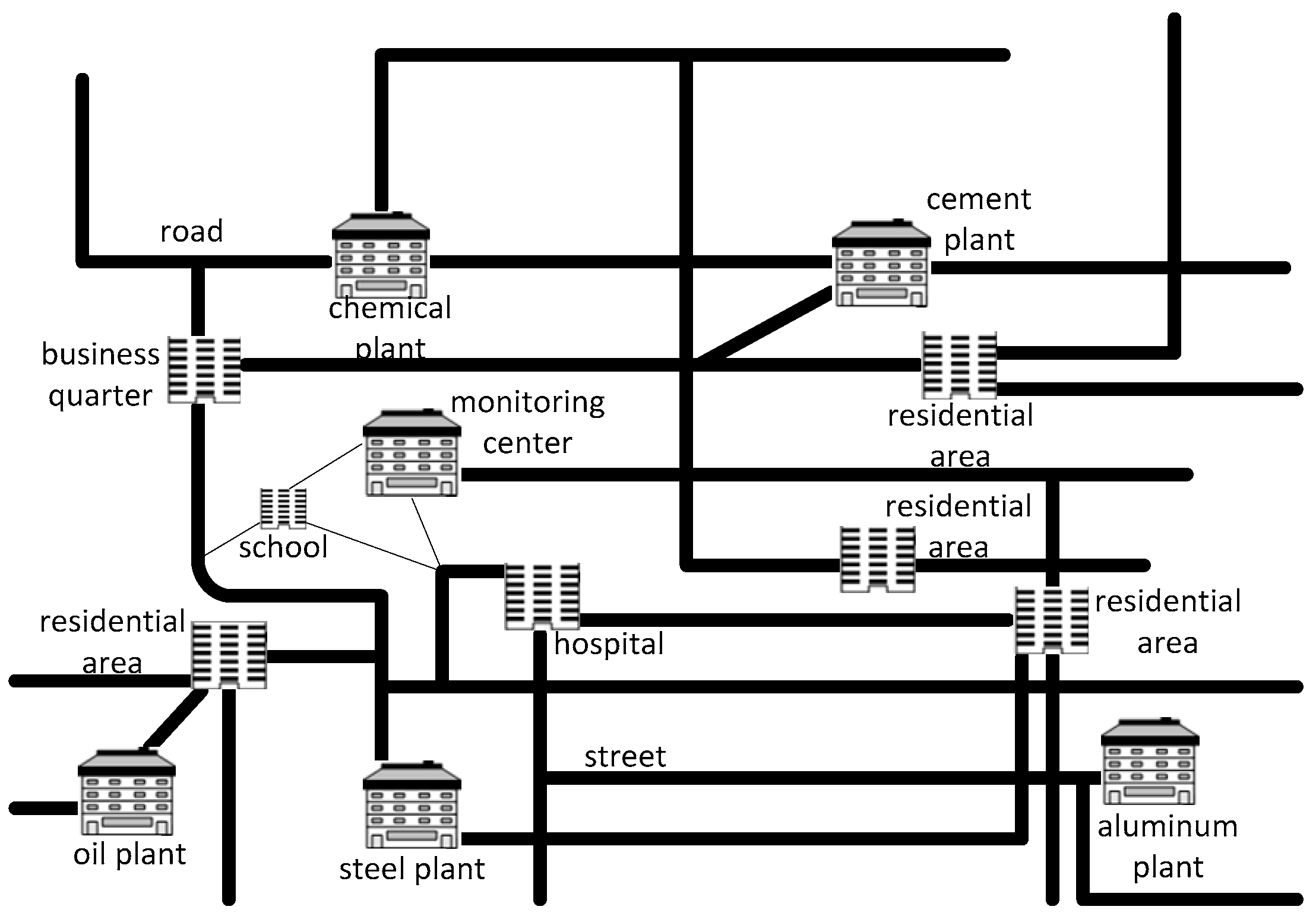
3.1. Regional Division Based on Sensor Deployment
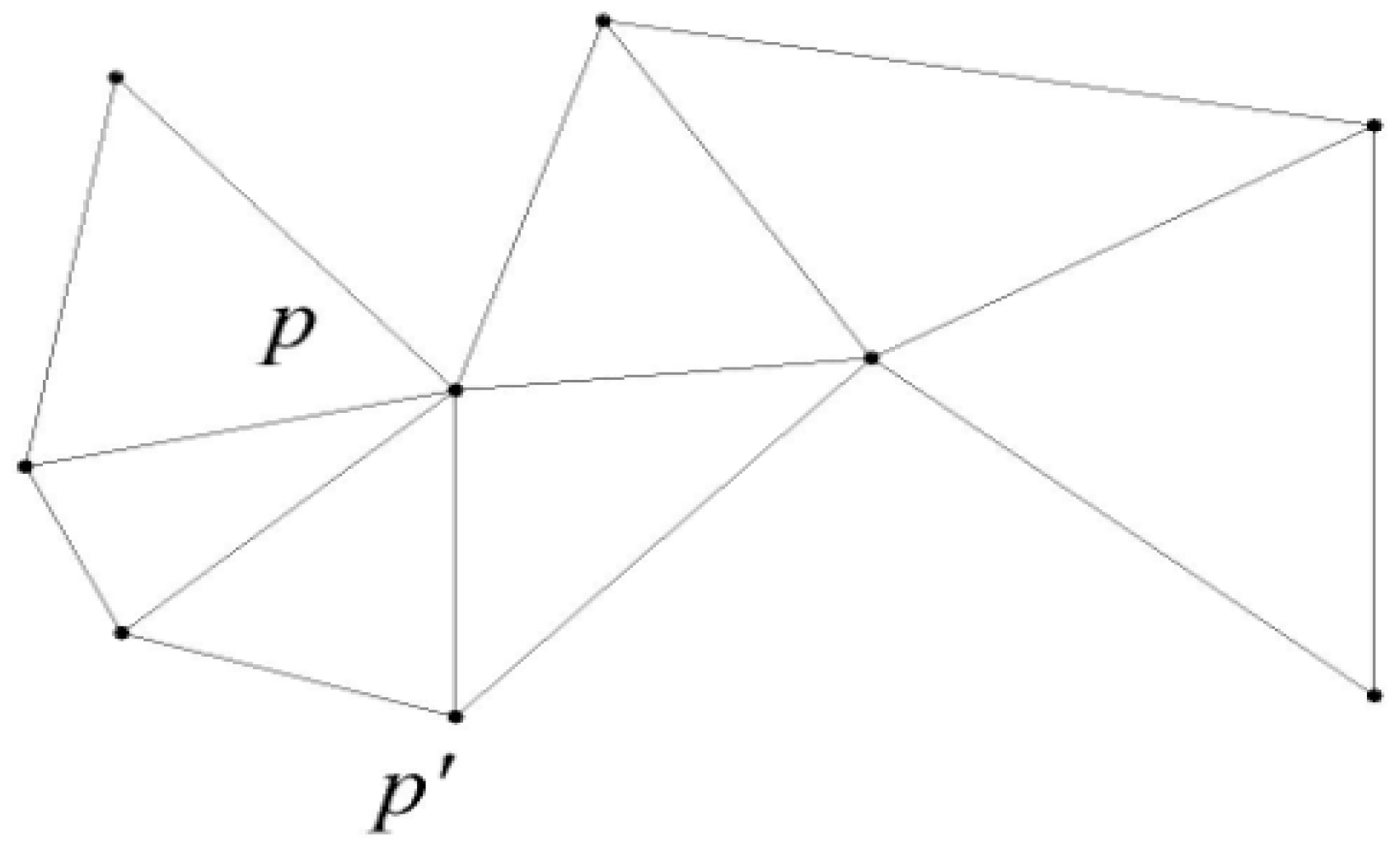
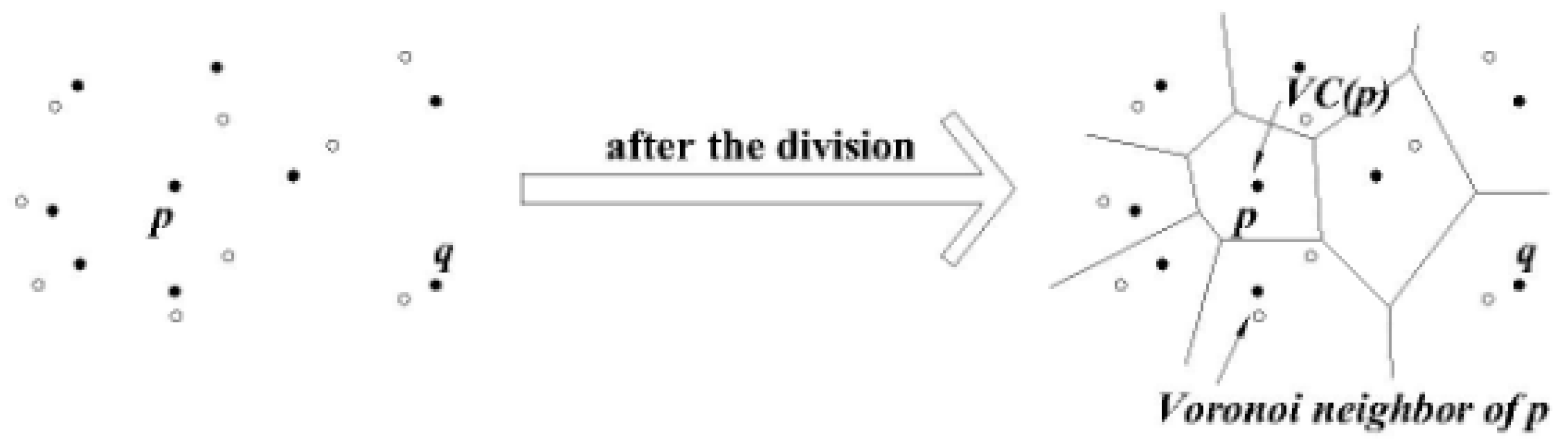
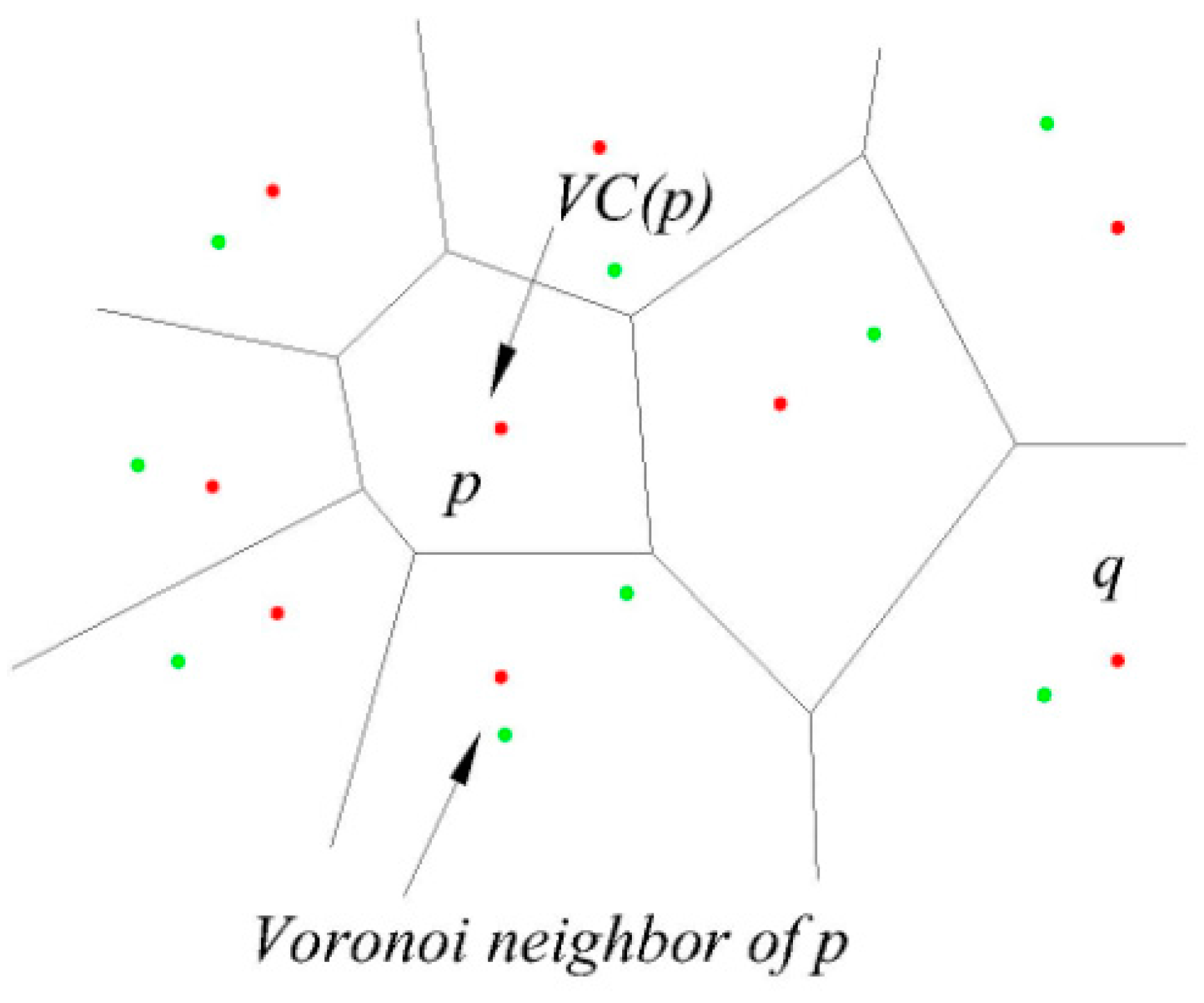
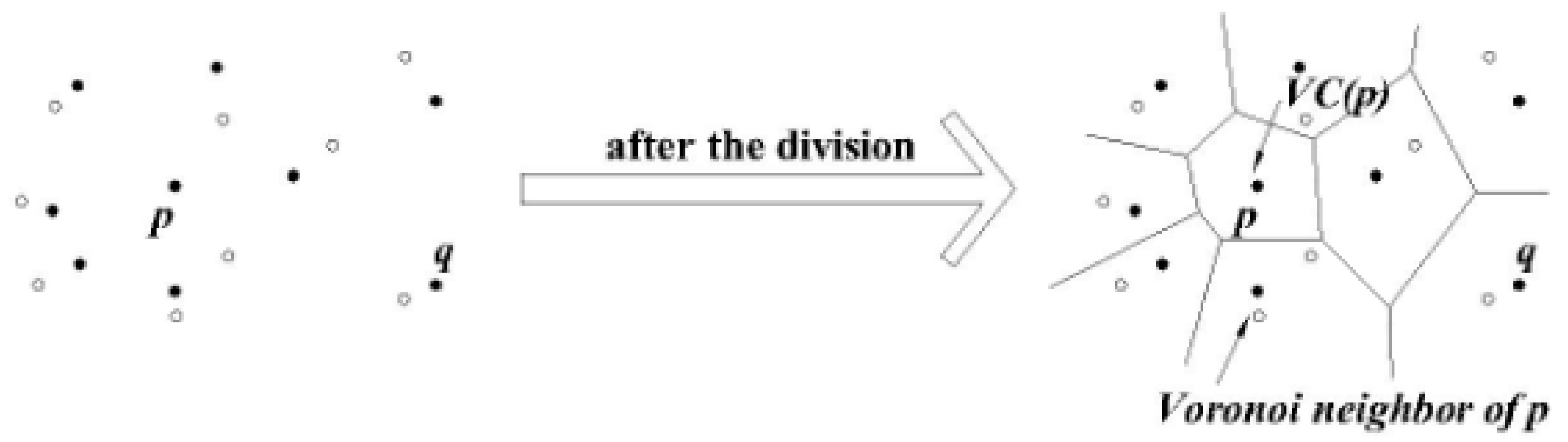
3.1.1. Voronoi Diagram
3.1.2. Delaunay Graph
3.1.3. The Region Division Method
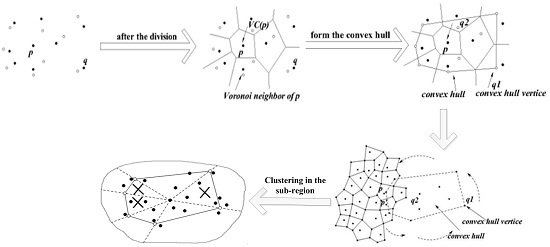
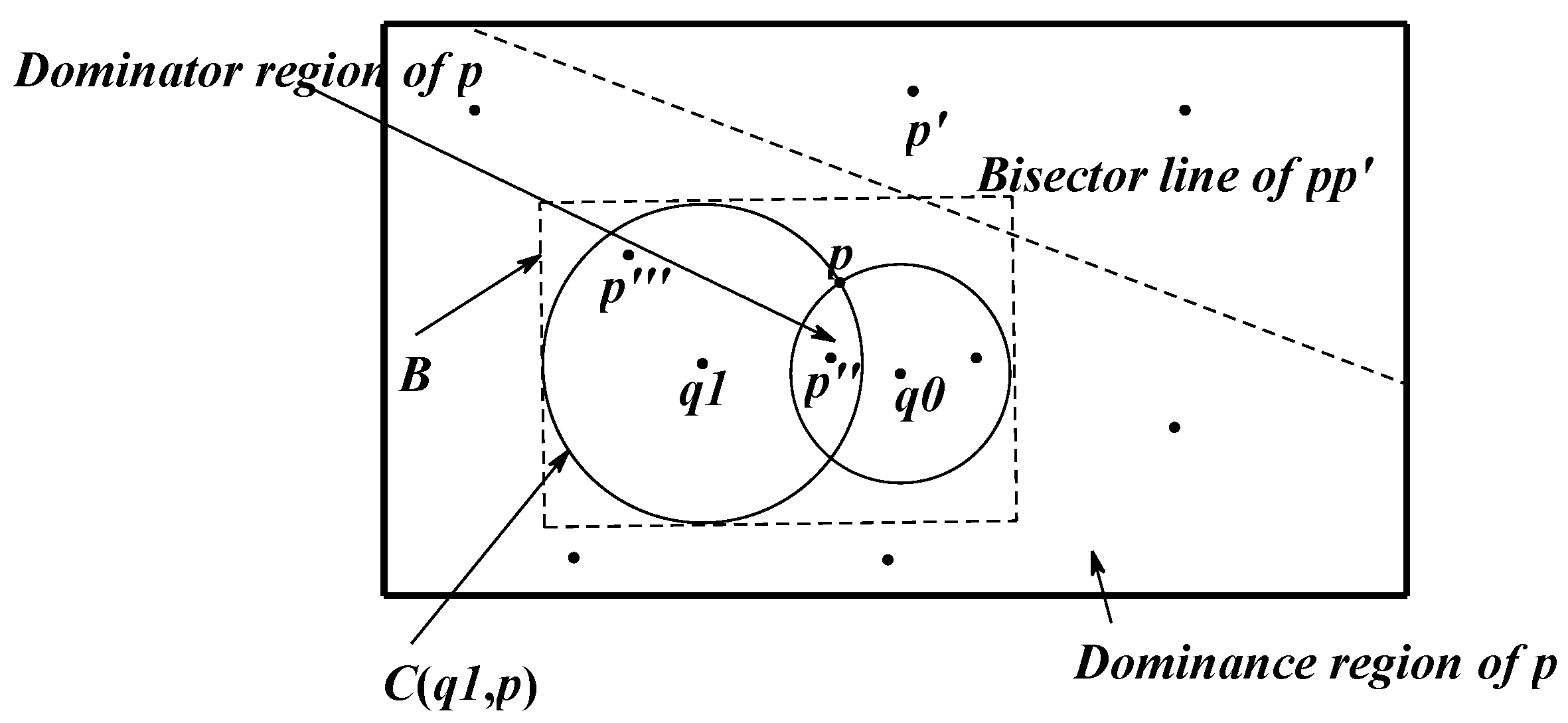
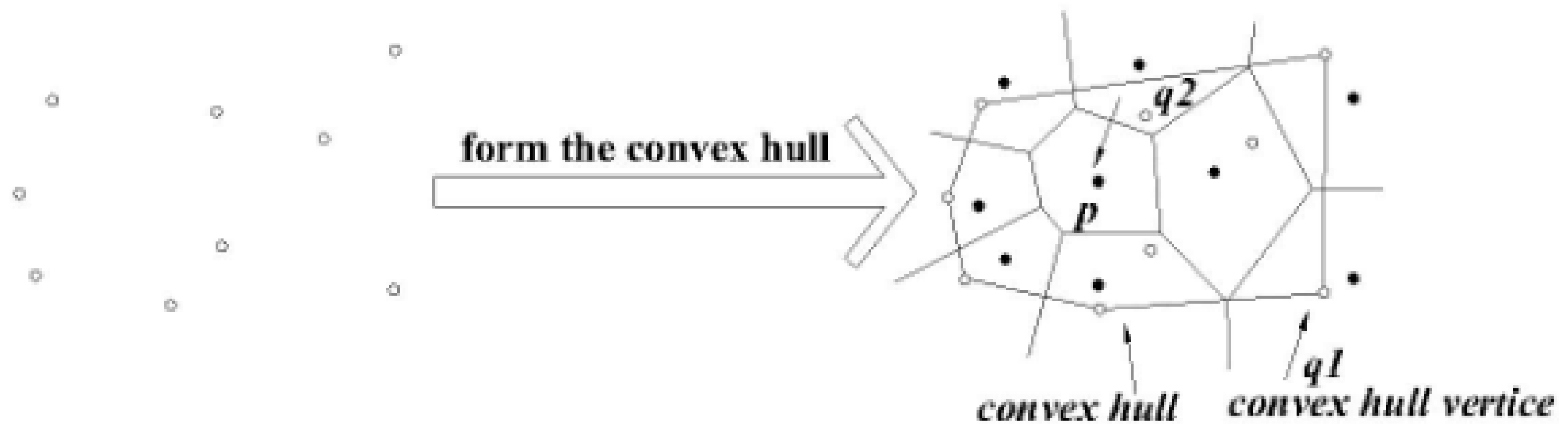
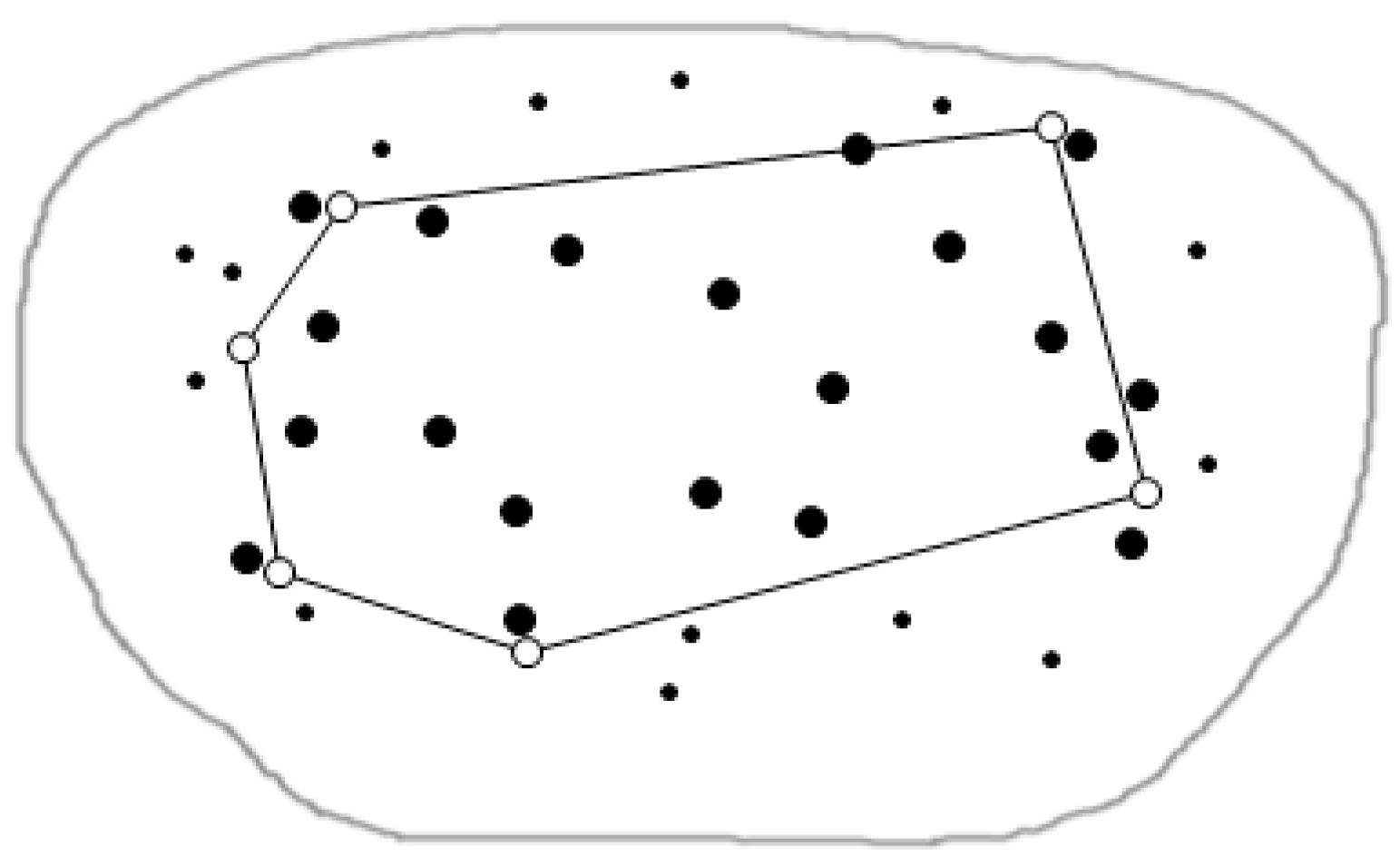
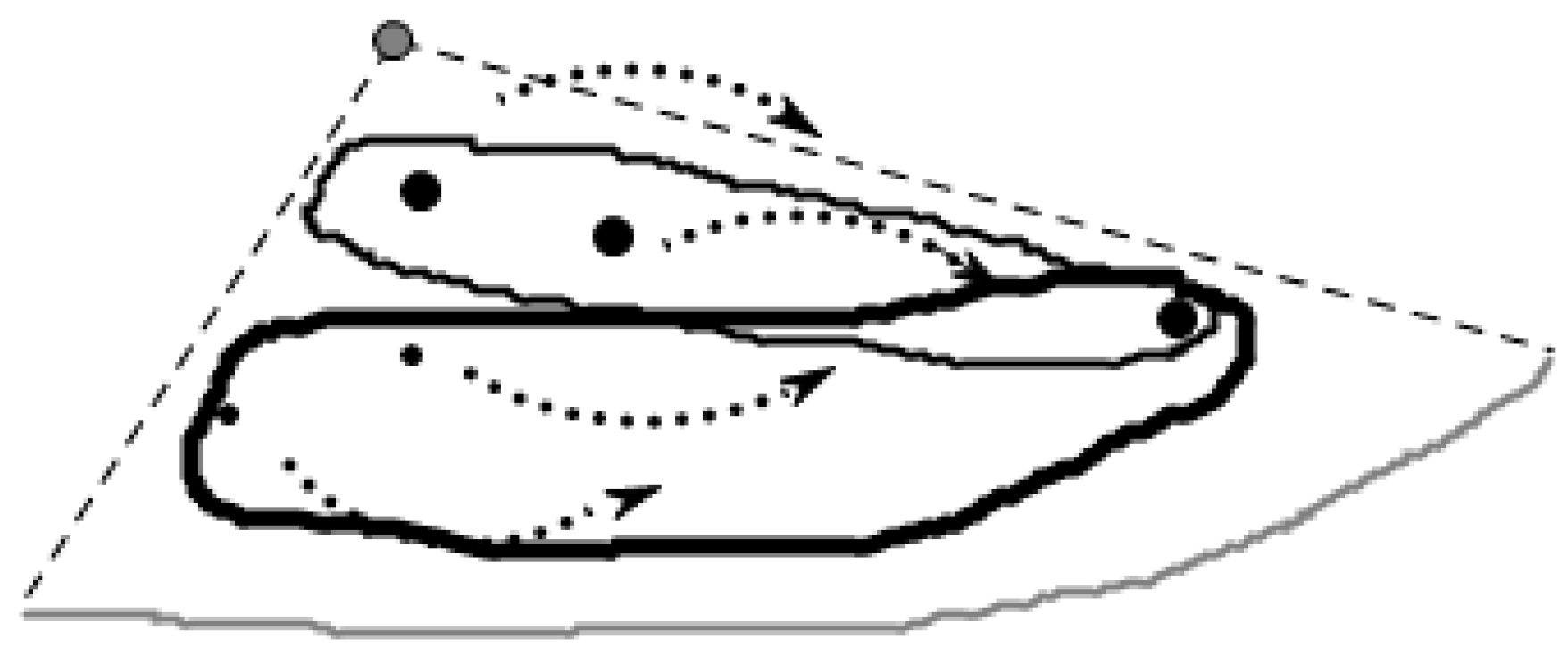
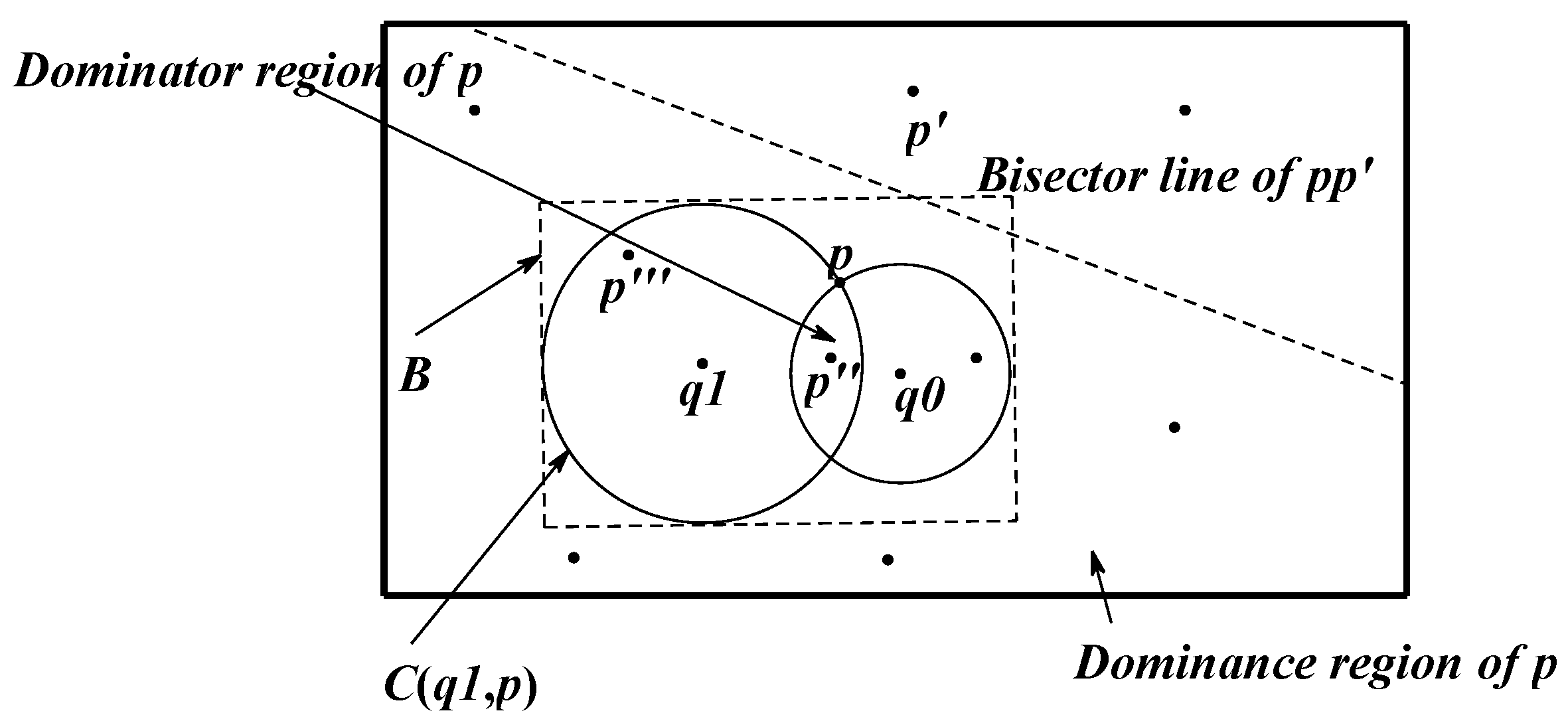
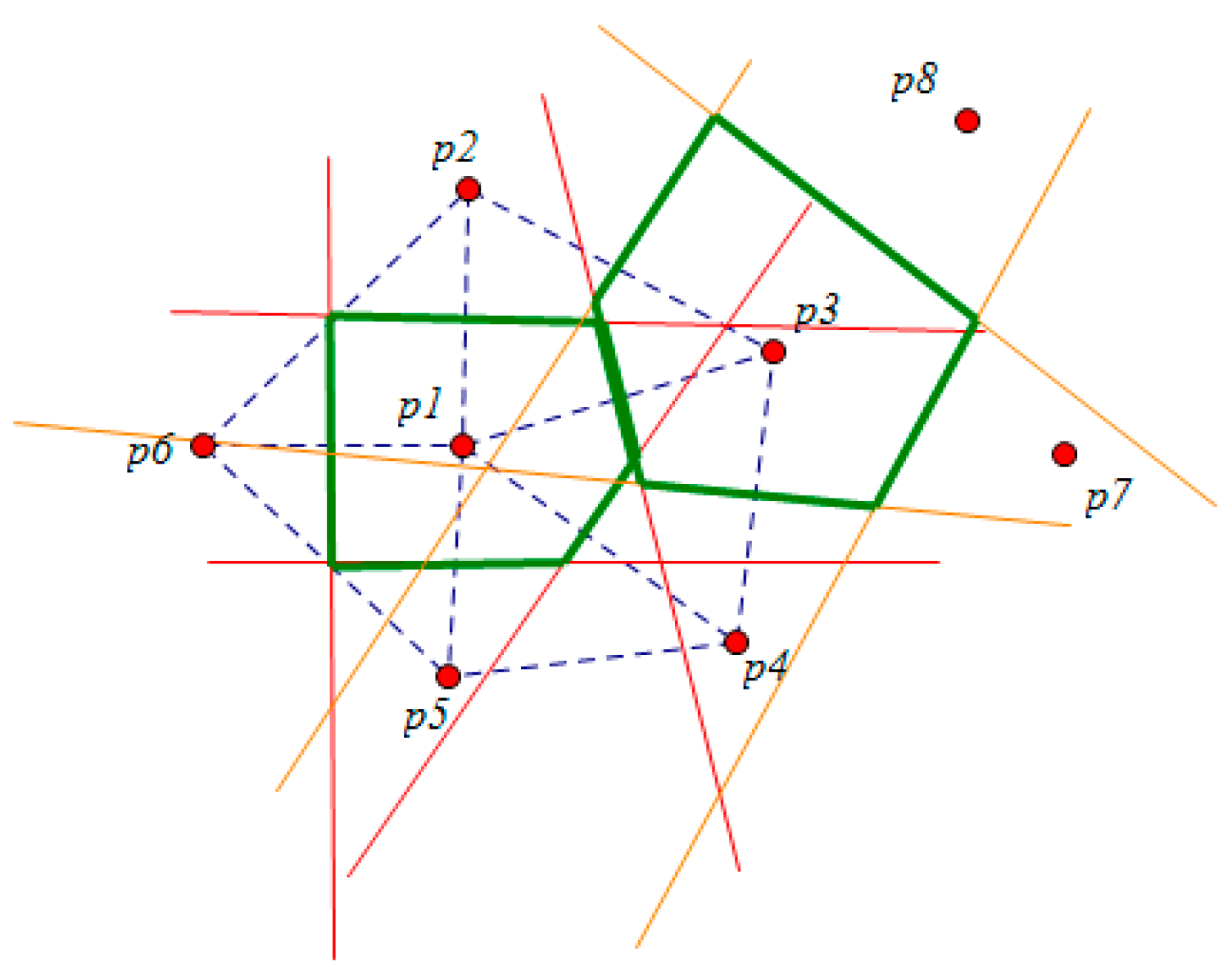
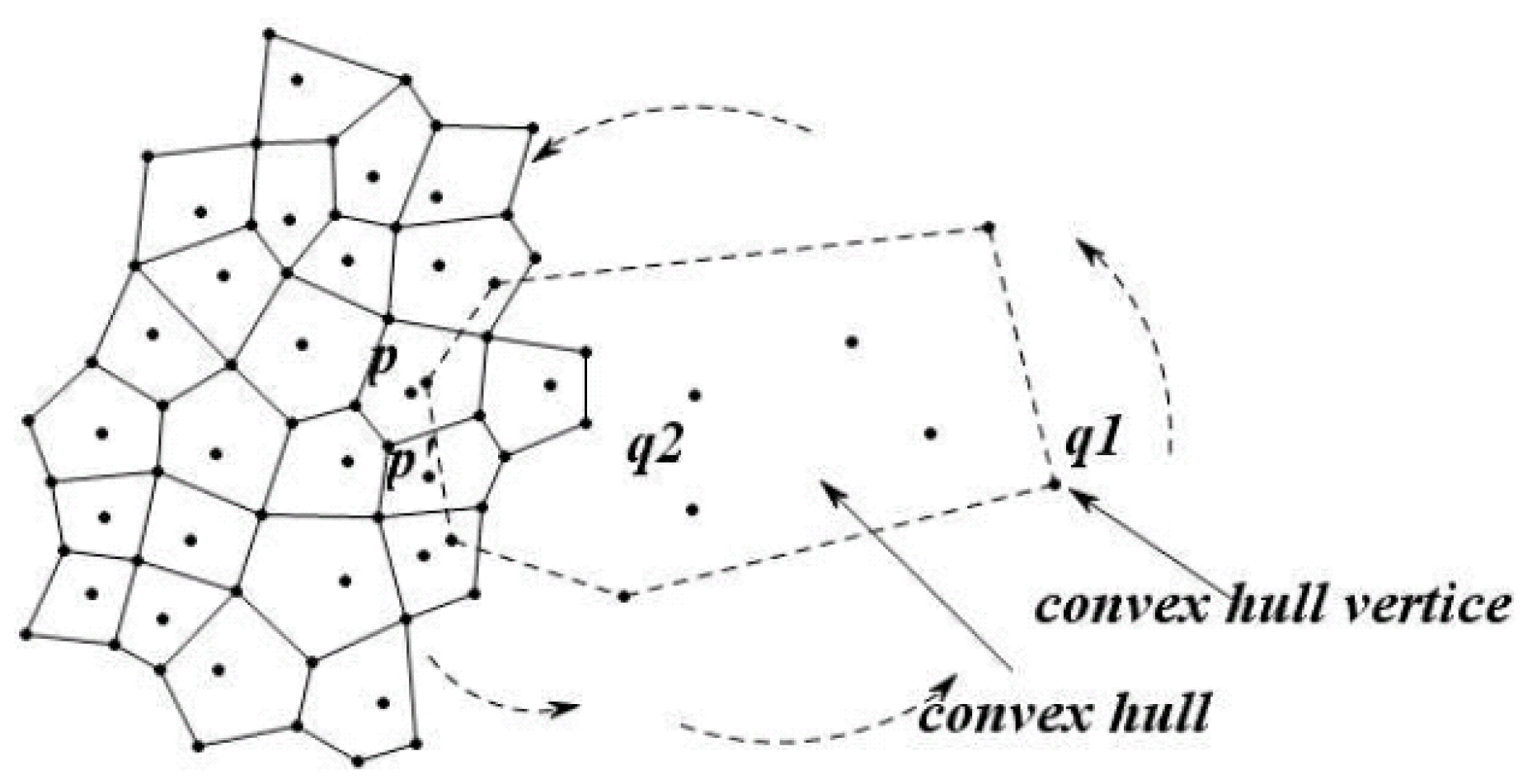
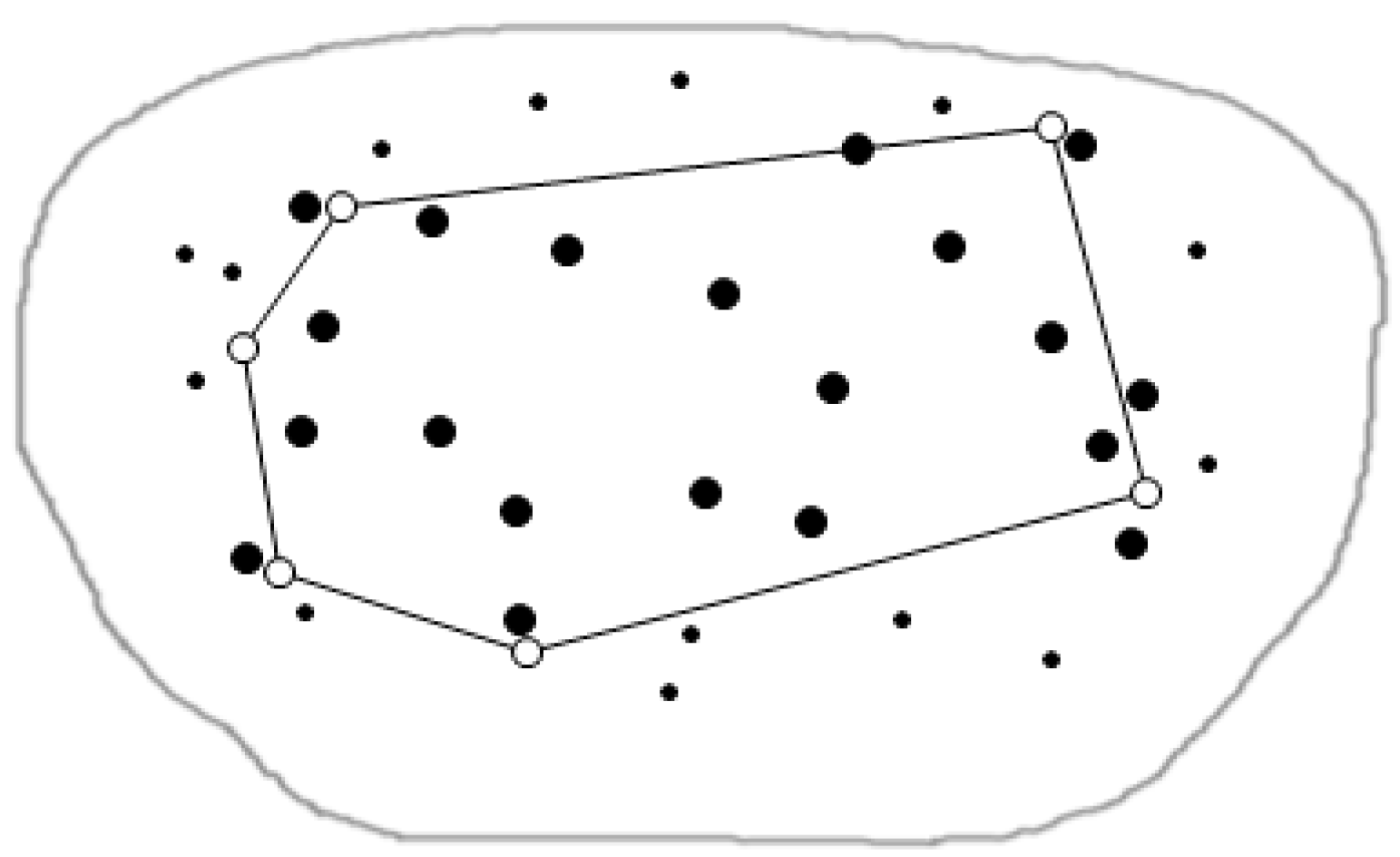
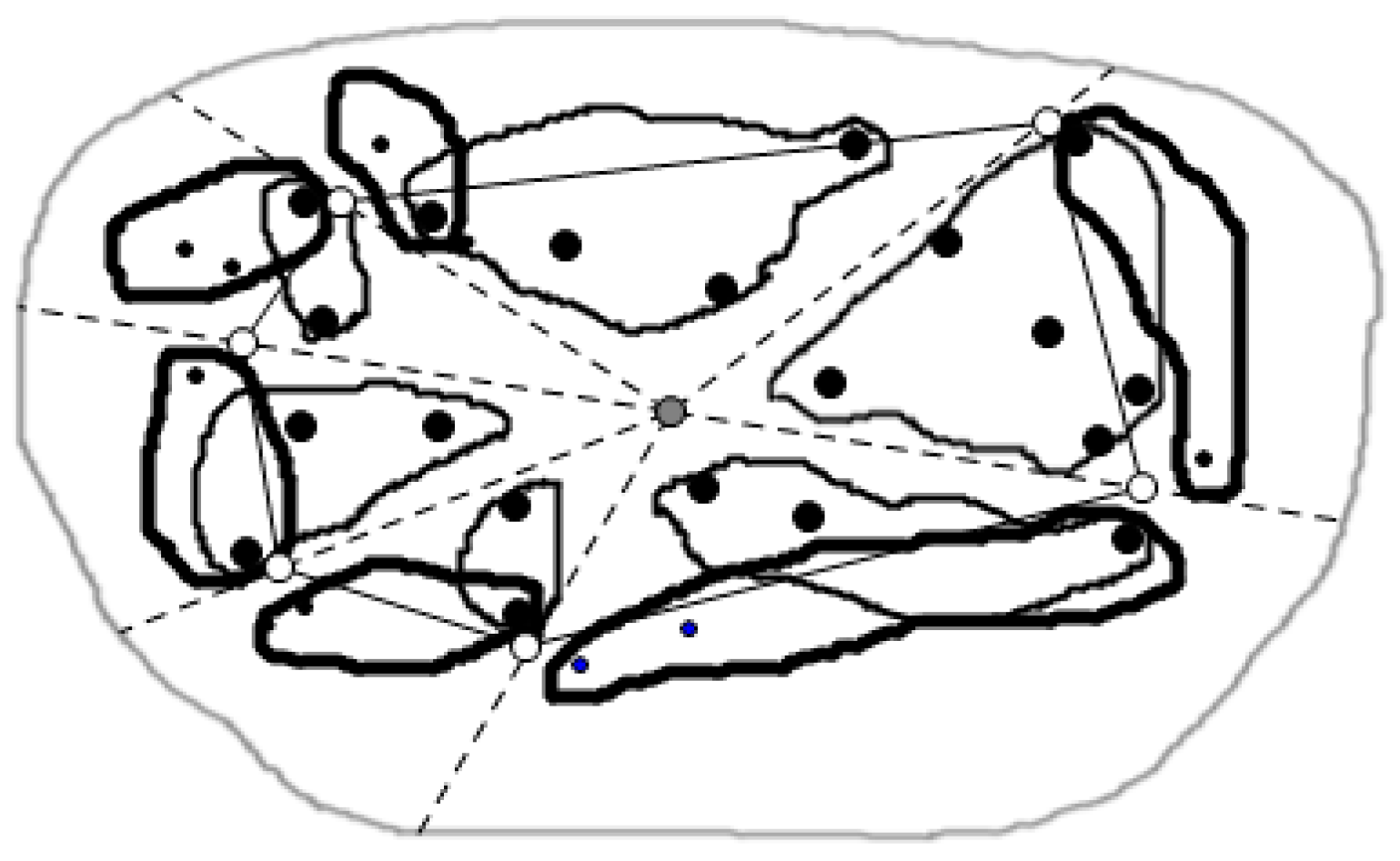
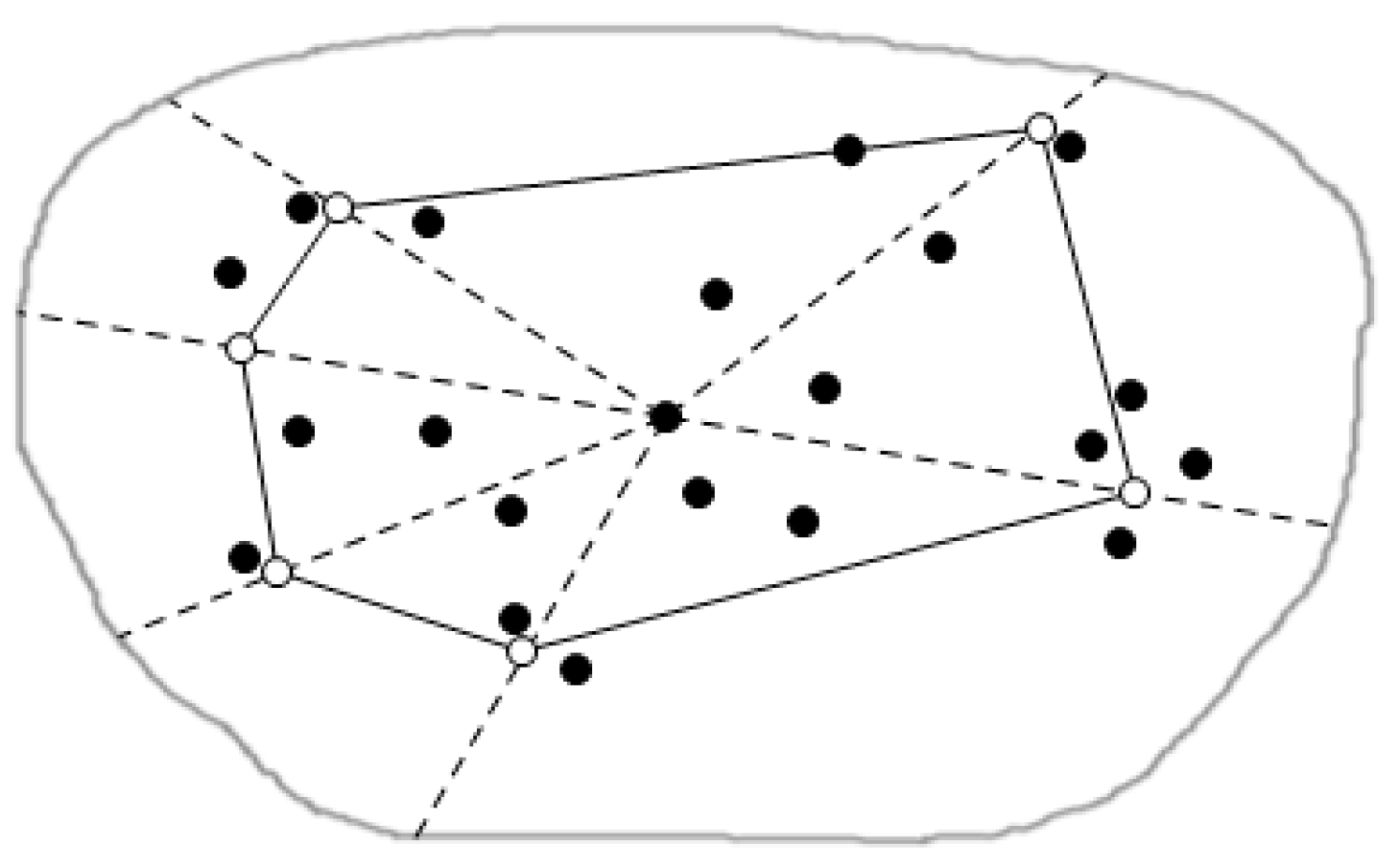
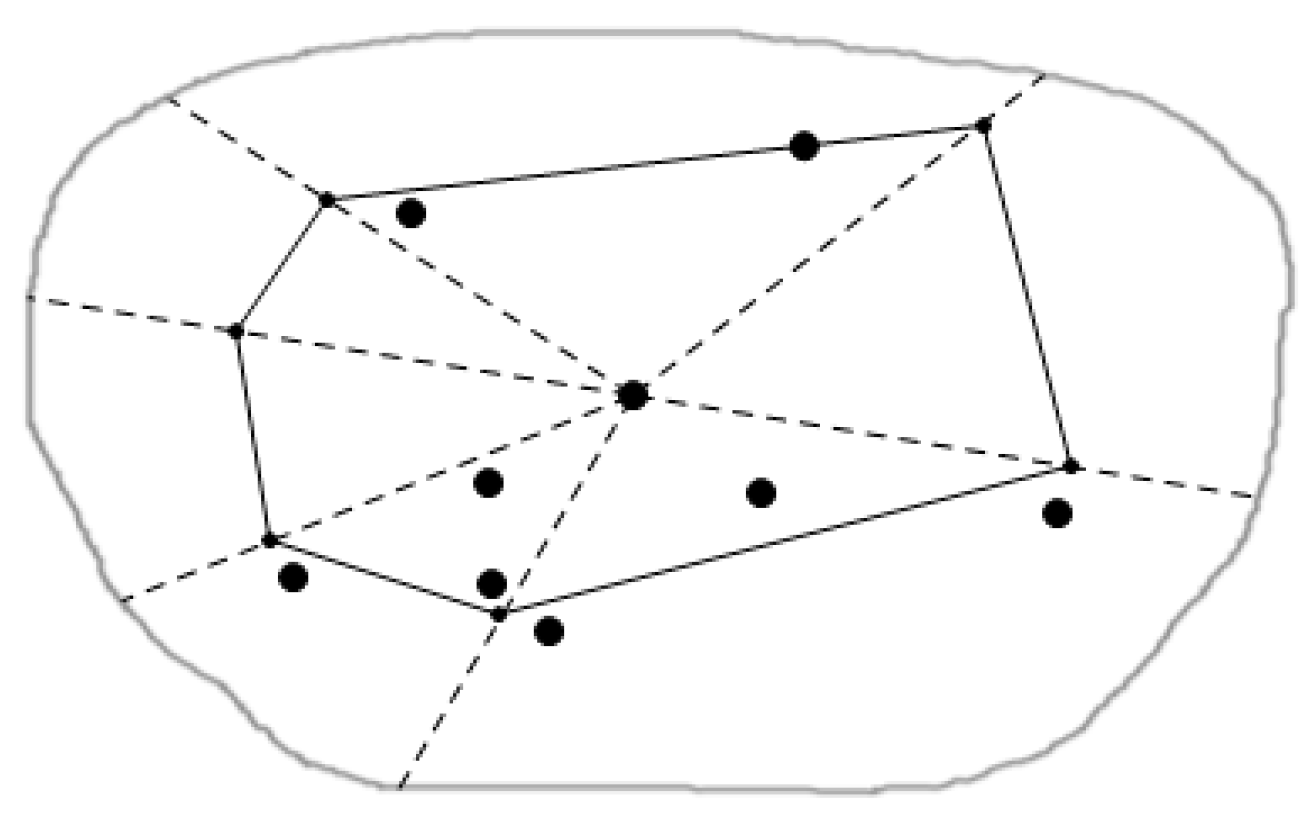
3.2. Cutting of Skyline Regions Based on Convex Hull Vertices
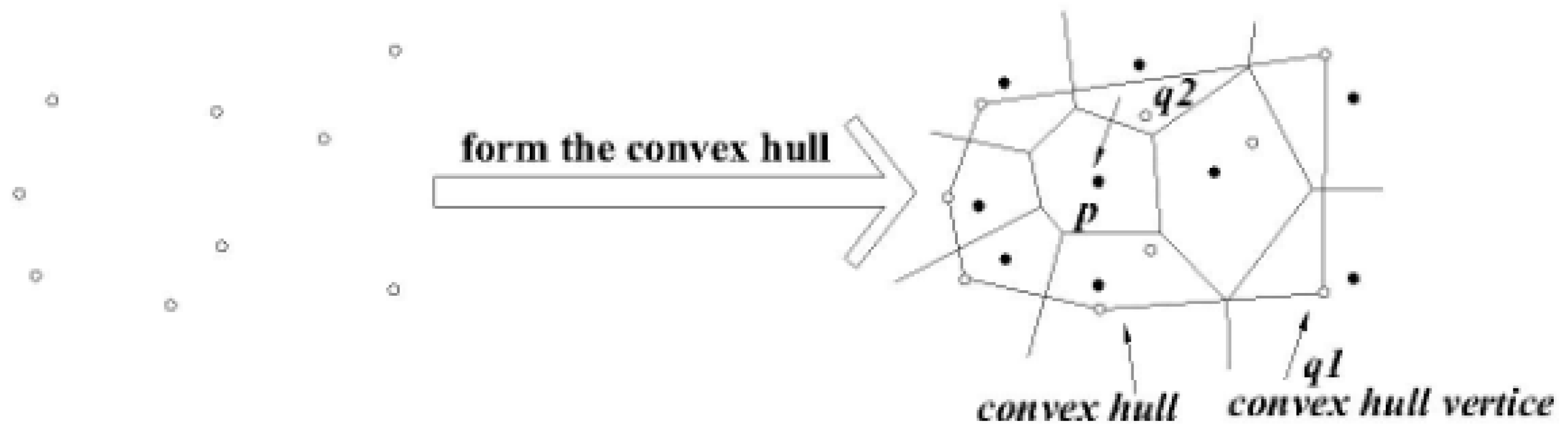
3.2.1. Convex Hull
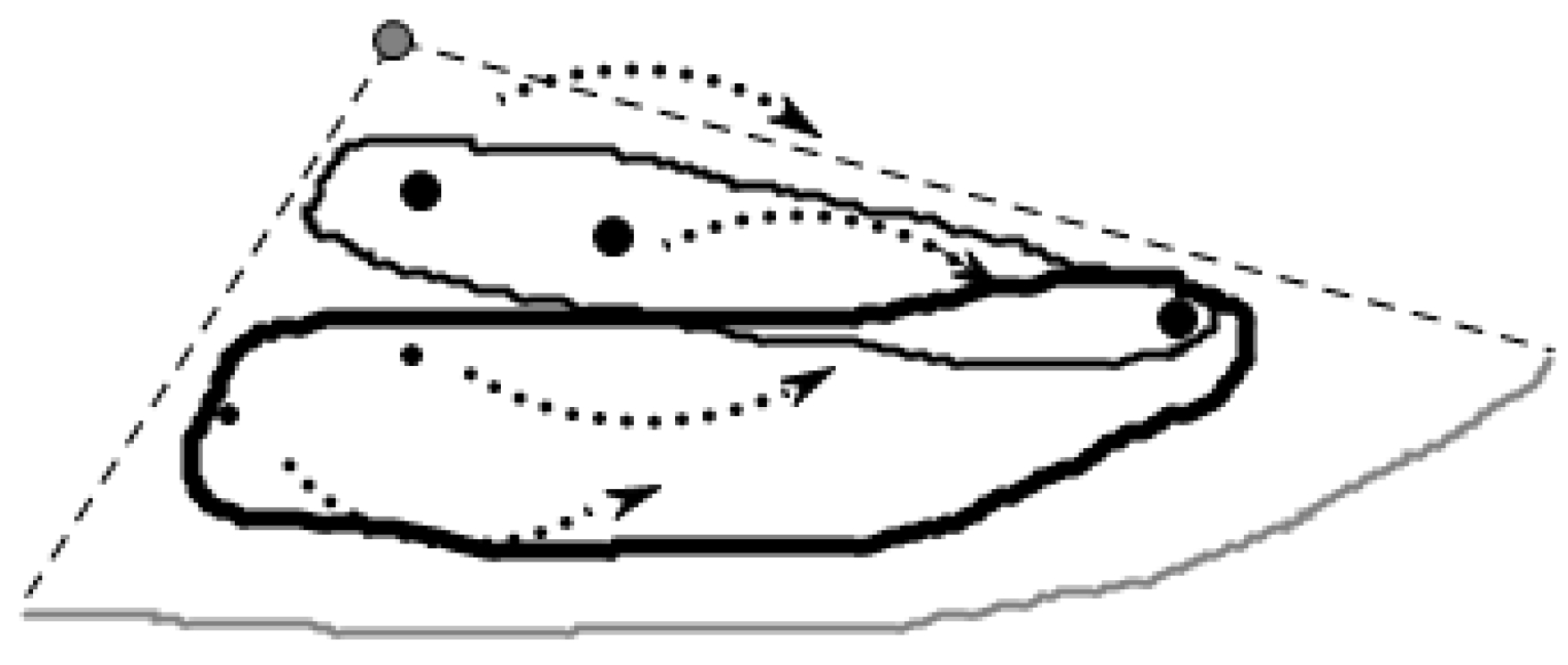
3.2.2. Cut Method for Skyline Region
- The point location query
- Cutting method for the skyline region
| Algorithm 1: Cutting of the skyline region based on the convex hull vertices |
| Input: data node set P, query node set Q |
| Output: the skyline set S |
| 1: initialize the skyline data table SCH and data access table Visited |
| 2: calculates the CH(Q) by the monitor center |
| 3: for begin with V(p) including some query node q(q2CHv(Q)) and put p into table SCH |
| 4: do traverse Delaunay graph along each edge of CH(Q) |
| 5: if V(p’)(p’2P) is adjacent to V(p) and intersecting with CH(Q) or in CH(Q) |
| 6: then by Theorem 1 and Theorem 3, insert node p into table SCH and table Visited. Issues the current skyline data to those |
| 7: else if V(p’) is adjacent to V(p) and not intersecting with CH(Q) or not in CH(Q) |
| 8: then insert node p’ into table Visited |
| 9: back to the initial data node p |
| 10: end for |
- Monotonic function sorting
4. Geometry-Based Distributed Skyline Query
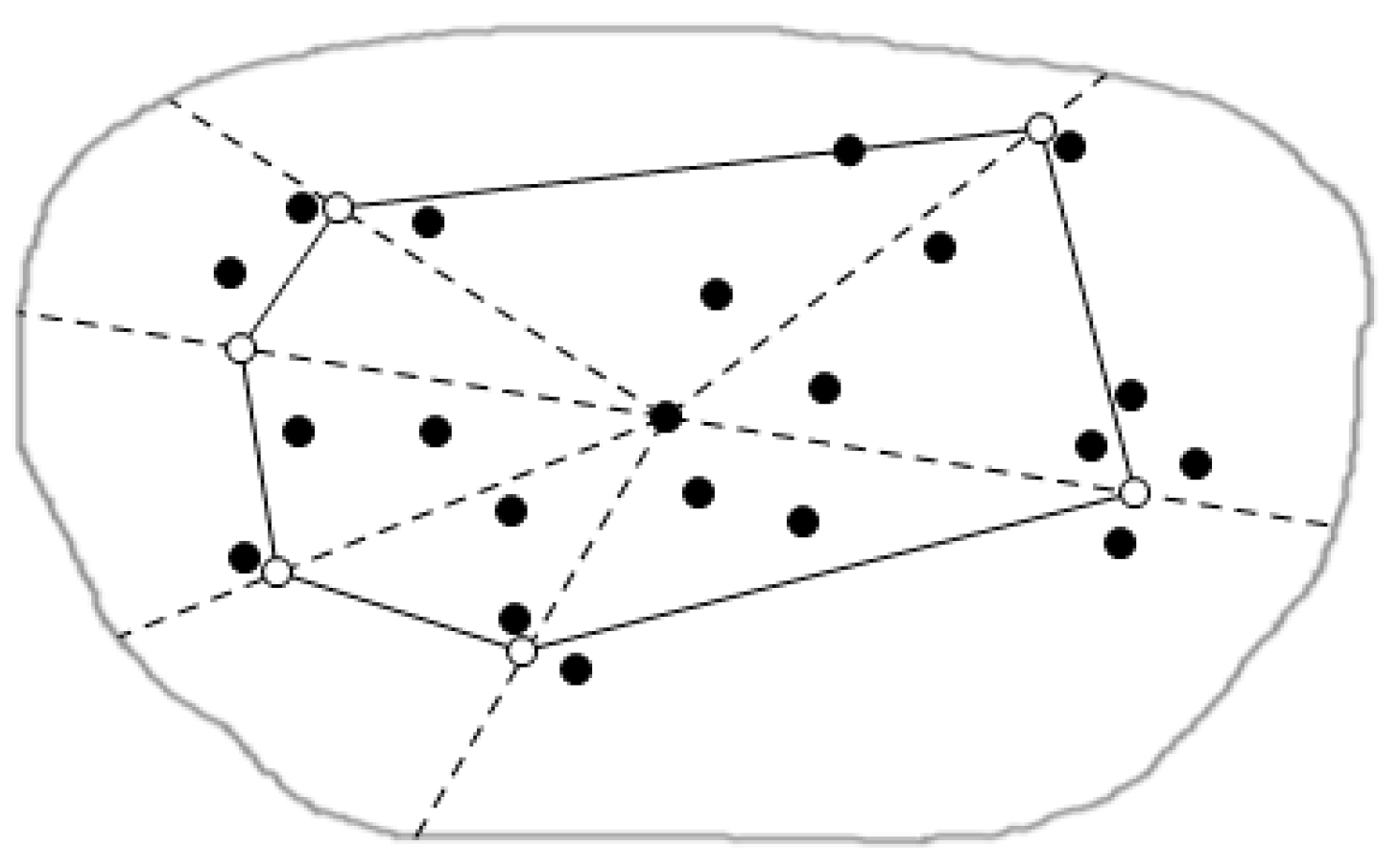
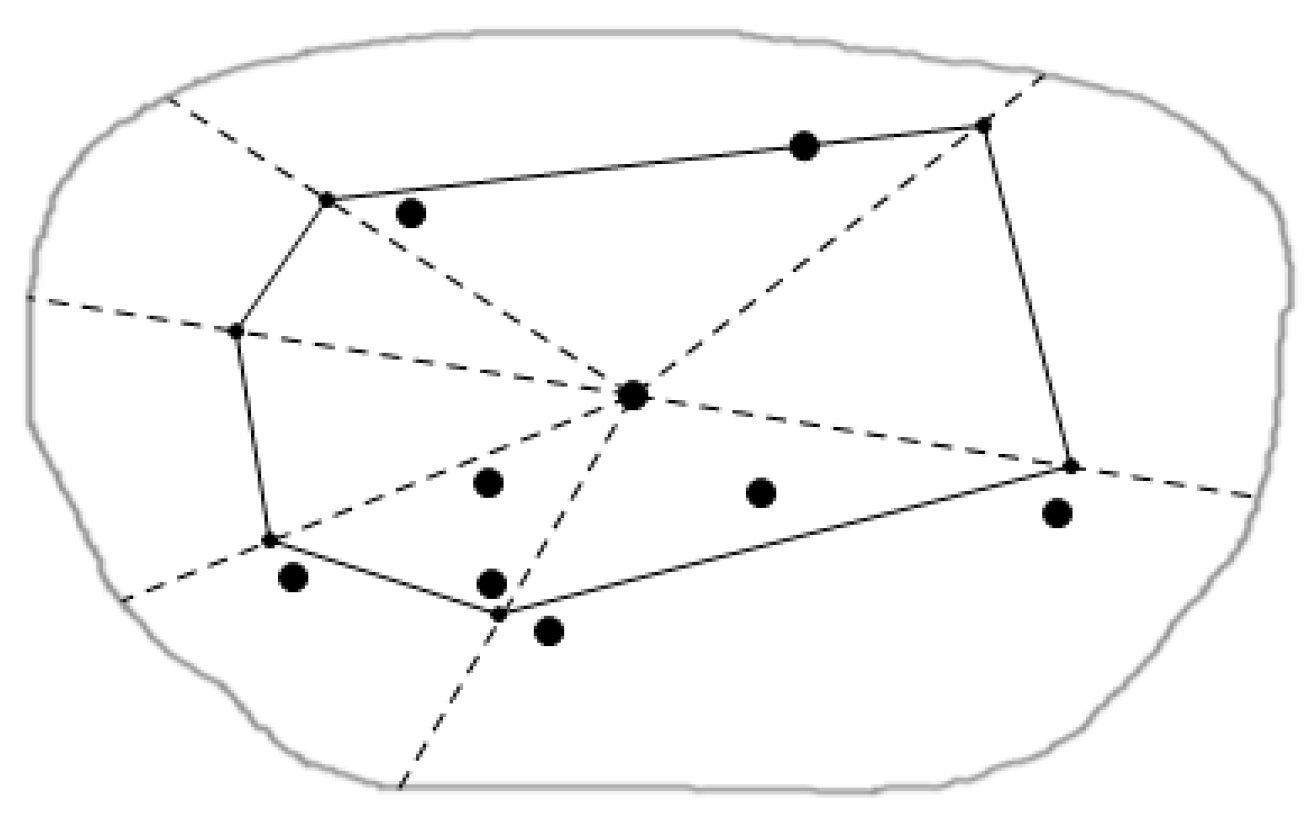
4.1. Regional Division
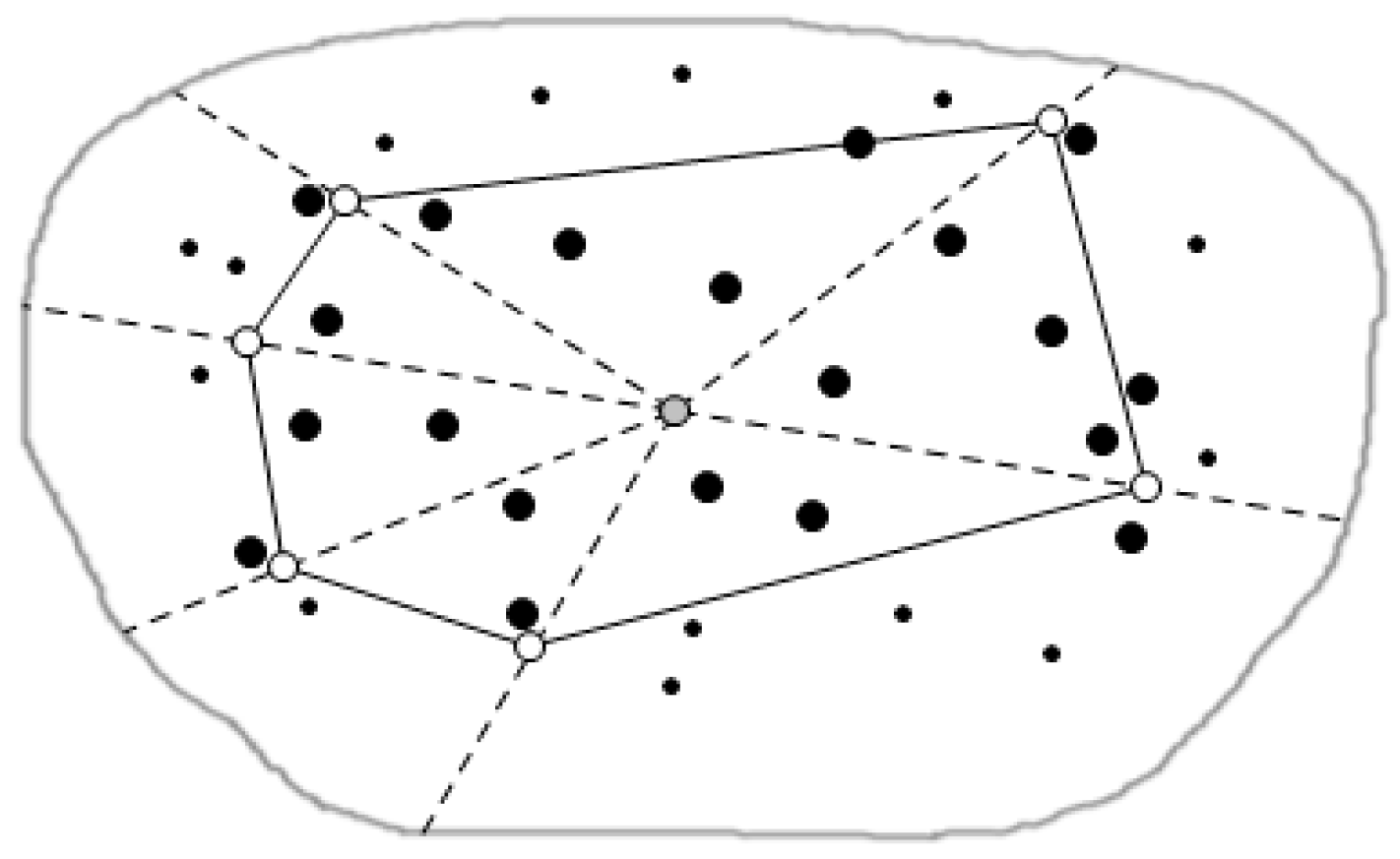
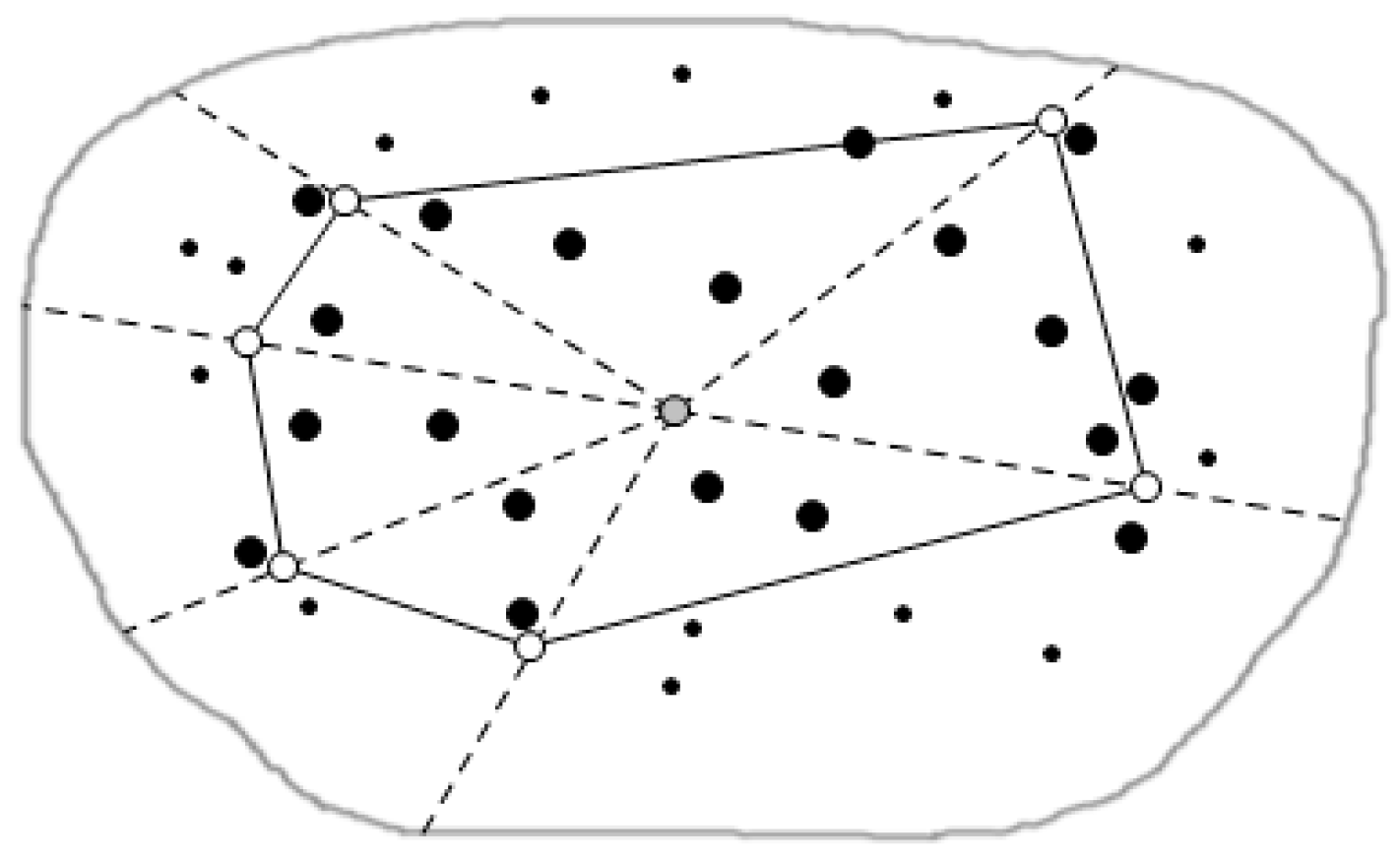
4.1.1. Regional Division Based on Triangulation Method
4.1.2. Clustering in the Sub-Region
4.2. Distributed Regional Queries
4.2.1. Queries in Parallel within Sub-Regions
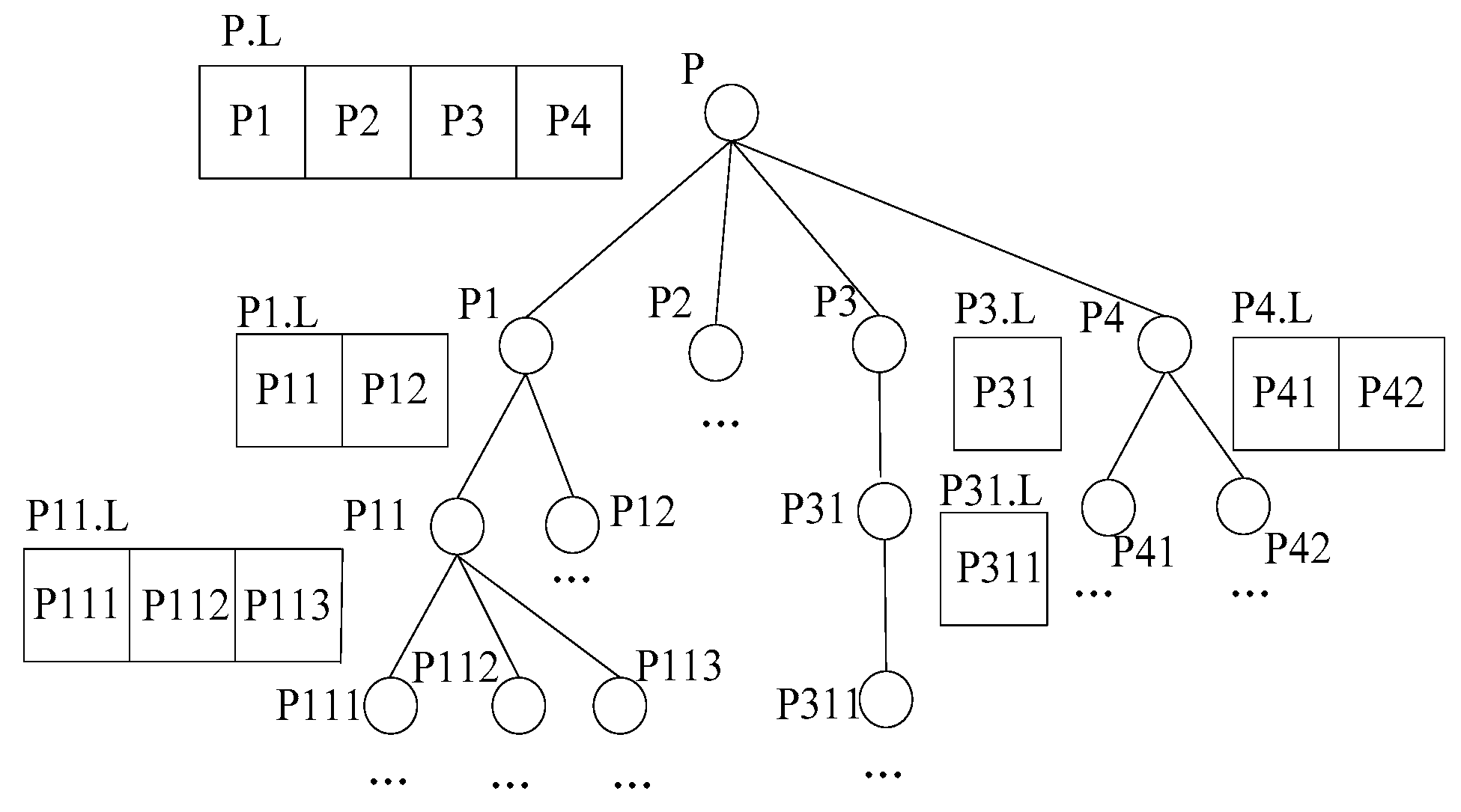
- The generation of the data node tree
- skyline queries based on data node trees
| Algorithm 2: Skyline query based on the data node tree algorithm |
| Input: table SCH, table Visited, data node tree T, local queue L, query node set Q |
| Output: the spatial skyline data ST based on T |
| 1: regard the root node of data node tree T as the father node |
| 2: for each of the father node do |
| 3: if the father node has the local queue L |
| 4: then the pointer point to the first record of the father node local queue L, determine dominance relation of the data point p corresponding to the record with the data node in the local table SCH |
| 5: if P is dominated by the node in table SCH |
| 6: then regard p as the new father node, then conduct step 2 |
| 7: if p is not dominated by the node in table SCH and do not dominate any node in SCH |
| 8: then insert p to ST, and regard p as new father node, then conduct step 2 |
| 9: if p is not dominated by the node in table SCH and dominate the node in table SCH |
| 9: if p is not dominated by the node in table SCH and dominate the node in table SCH |
| 10: then insert p to ST, delete the dominated node in SCH, and regard p as new father node, then conduct step 2 |
| 11: if the father node do not has the local queue L |
| 12: then return to the local queue of the father node of p, move the pointer to the next one and regard it as the new father node, then conduct step 2 |
| 13: end for |
| Algorithm 3: Syline parallel query algorithm |
| Input: table SCH, table Visited, the data node tree T, the local queue L, the query node set Q, the major cluster, the assisted cluster |
| Output: the skyline data in sub-region Slocal |
| 1: divide the skyline in SCH into the major cluster, |
| 2: conduct the distributed query algorithm based on the data node tree algorithm |
| 3: divide the data in ST into the assisted cluster and transmit them to the cluster head node |
| 4: at the same time, conduct the general skyline query on the non-spatial attribute of the data in the major cluster to get the skyline Smaj |
| 5: transmit all the skyline data in the major cluster to the cluster head node |
| 6: the cluster head node makes the dominance relation judgment between the non-spatial attributes of the spatial skyline in the assisted cluster with the existing skyline data Smaj in the major cluster |
| 7: then the cluster head node regards the data that are not dominated by others as the local skyline data of the sub-region Slocal |
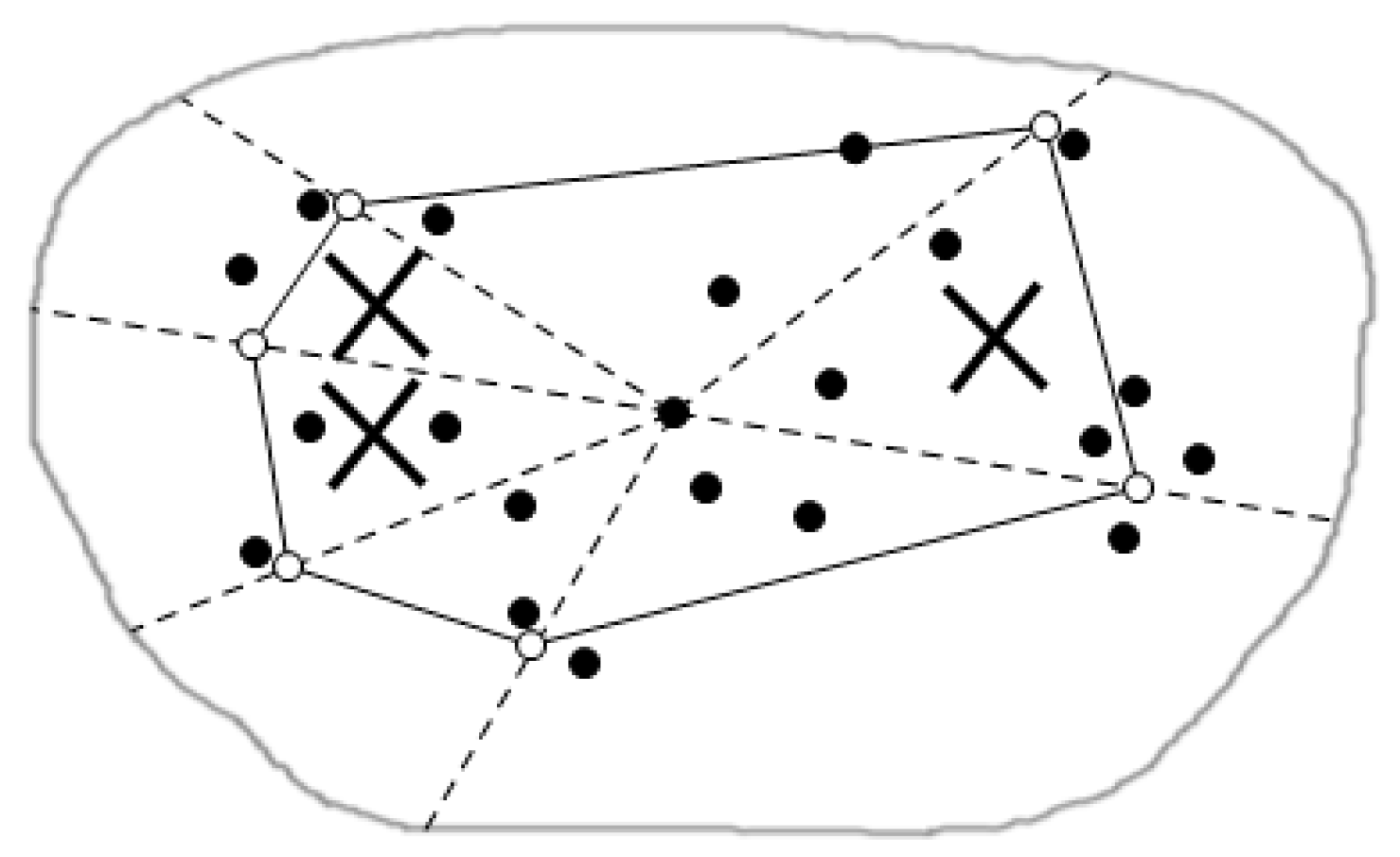
4.2.2. Query Result Merging in the Inter-Region
4.3. The Geometry-Based Distributed Skyline Query Algorithm
| Algorithm 4: Geometry-based distributed spatial skyline query algorithm |
| Input: data node set P, query node set Q |
| Output: the skyline set S |
| 1: divide the spatial region by Voronoi diagram |
| 2: conduct cut of skyline region based on convex hull vertices, acquire part of the spatial skyline data SCH, and transmit them to each nodes, and divide them into the major cluster |
| 3: divide the space region into several triangle sub-region by the triangulation |
| 4: for each closest node, conduct generation data node tree algorithm, conduct the general skyline query on the data in major cluster, and return the result to the cluster head node |
| 5: conduct distributed query algorithm. |
| 6: conduct skyline parallel query algorithm |
| 7: conduct the process of cut among sub-region, use the threshold to cut the dominated sub-region |
| 8: conduct the process of cut inside sub-region, transmit the nodes which are not dominated to the monitor center |
5. Experimental Performance Analysis
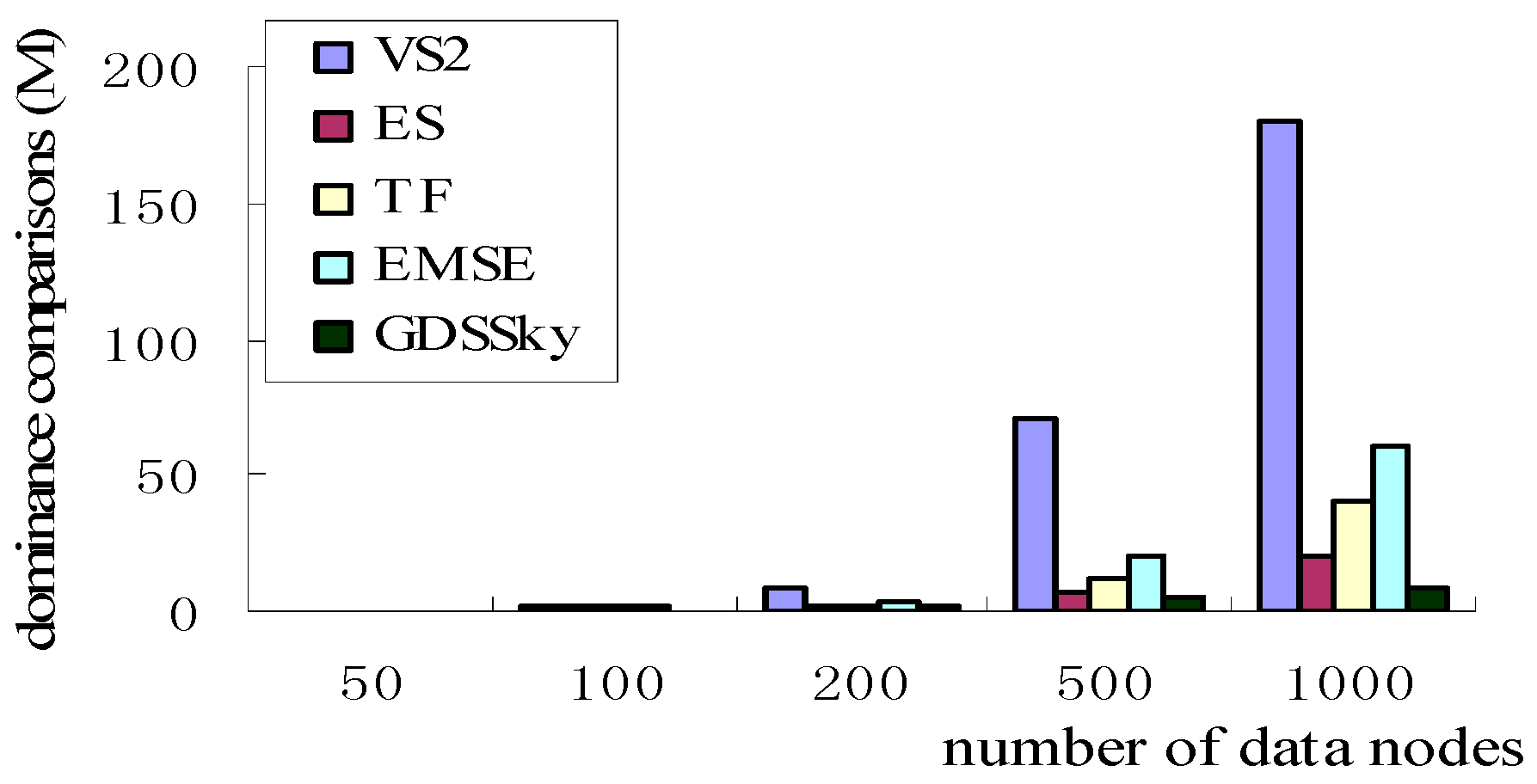
5.1. Number of Data Nodes with Dominance Comparisons
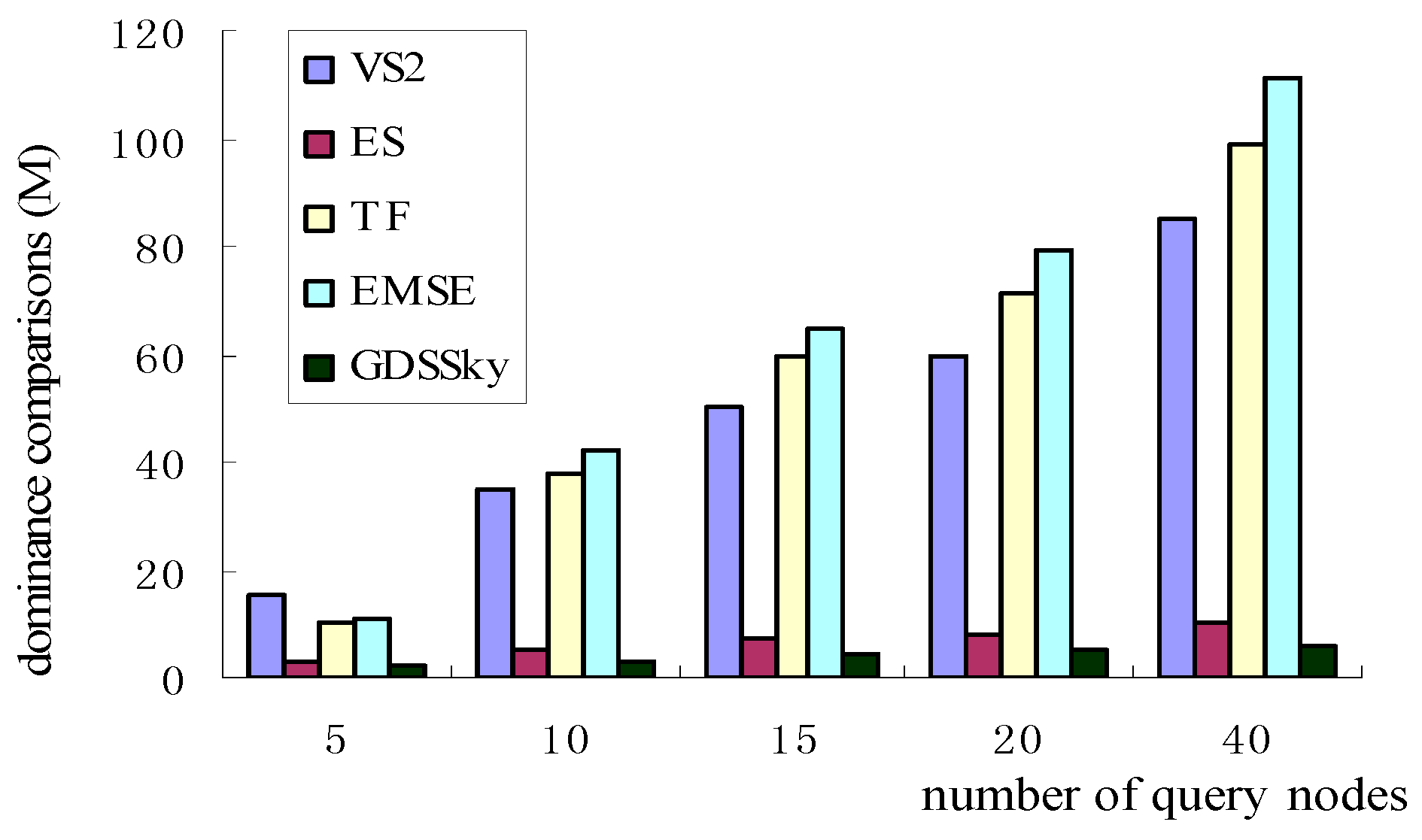
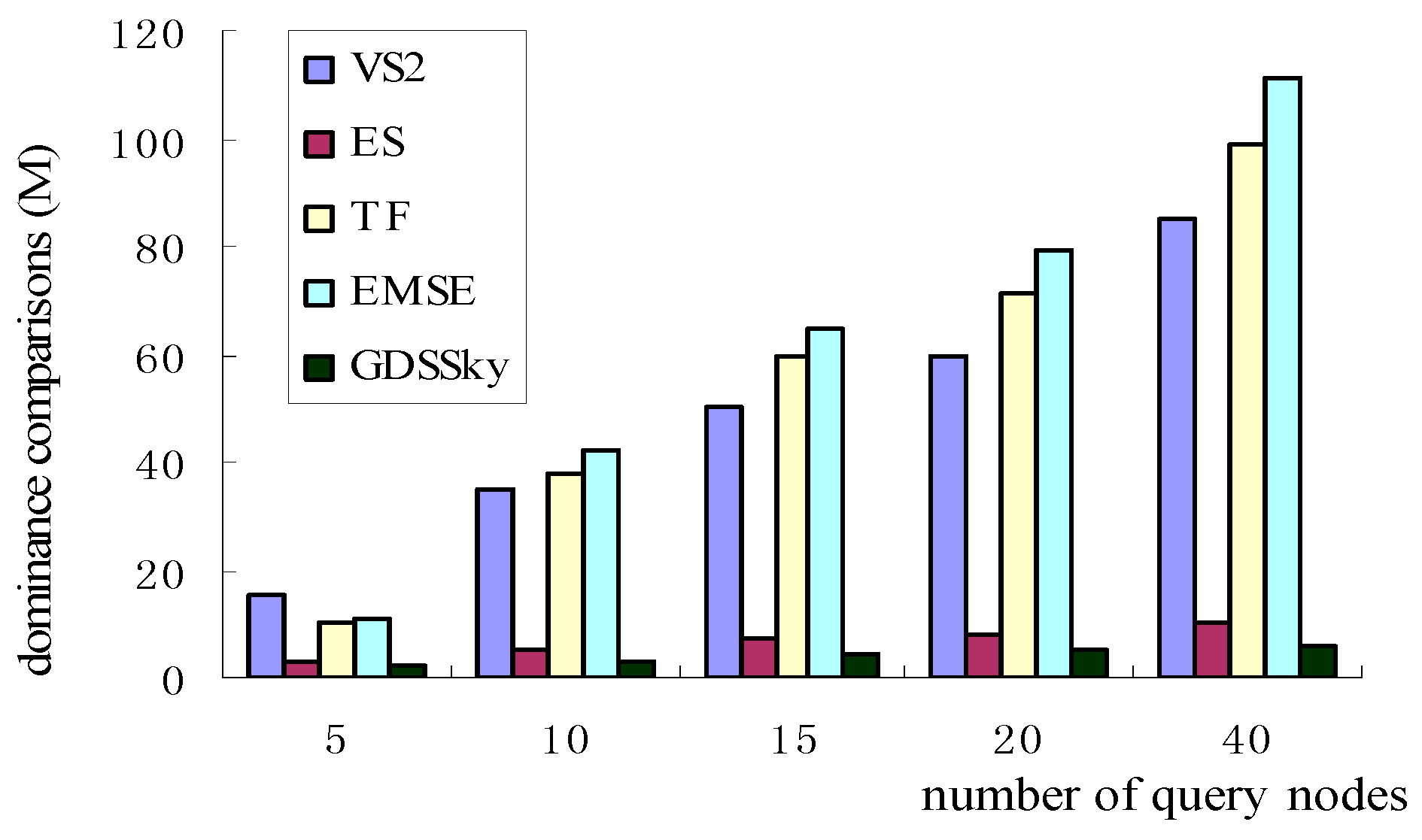
5.2. Number of Query Nodes with Dominance Comparisons
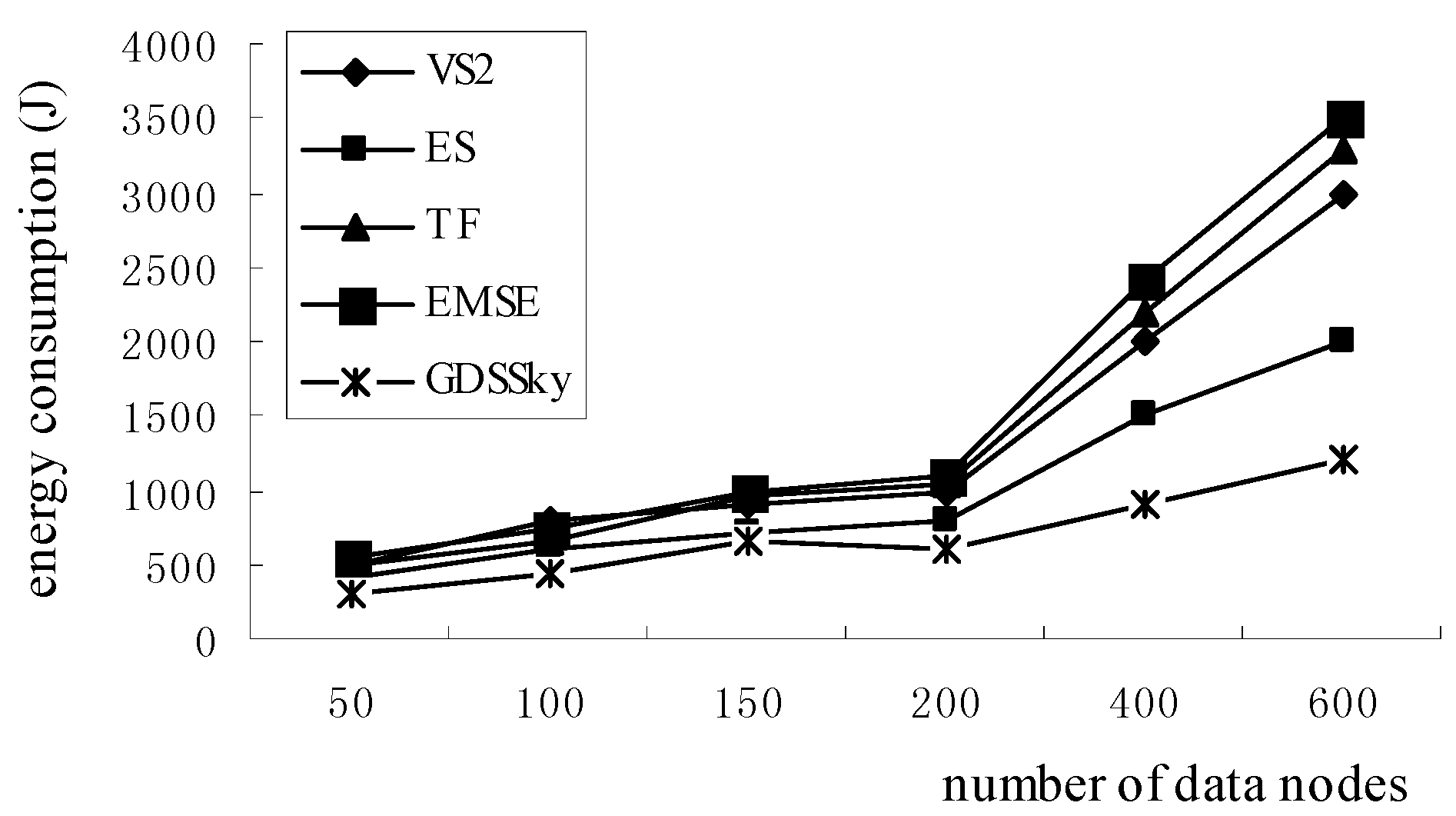
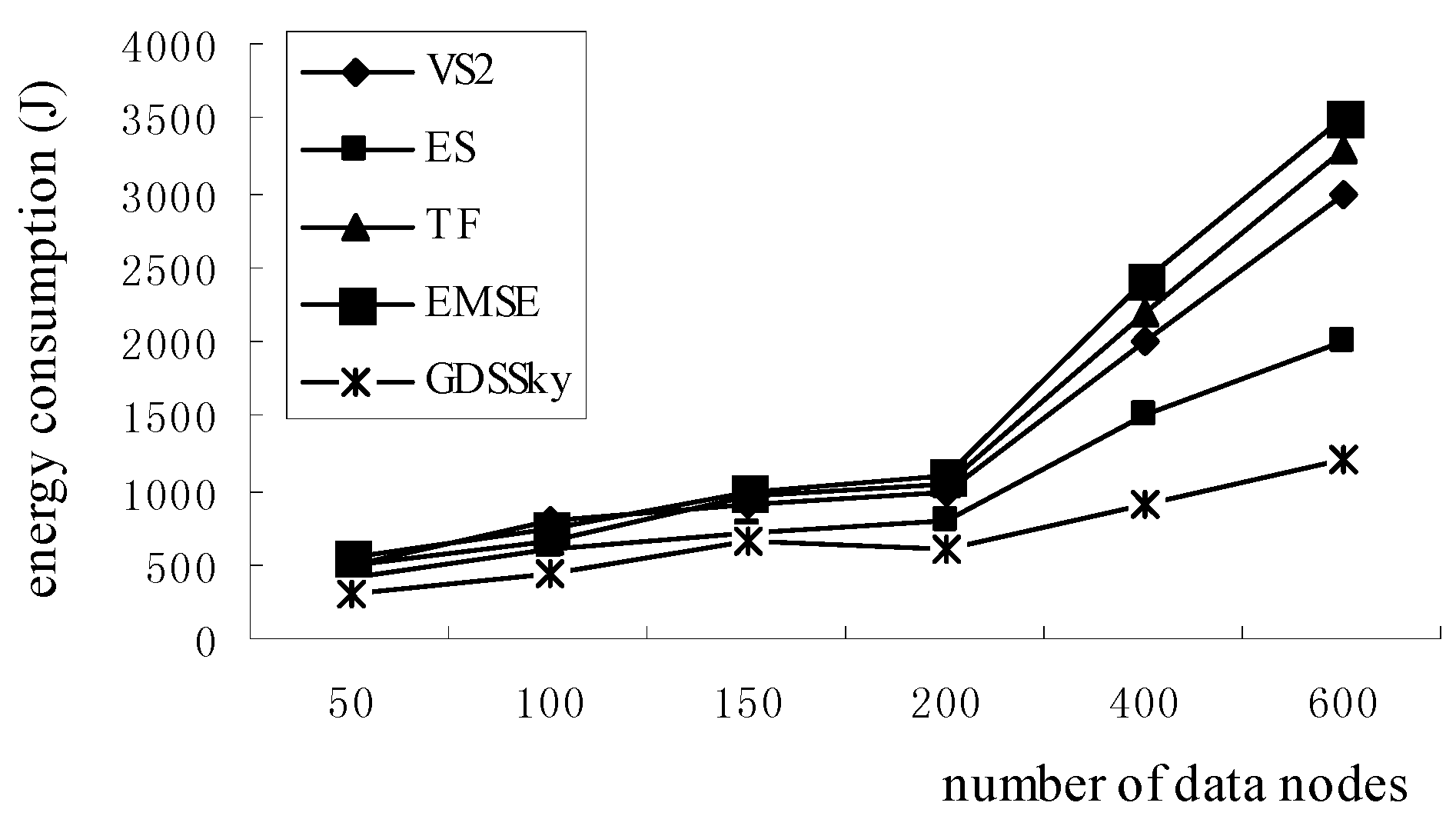
5.3. Sensor Energy Consumption
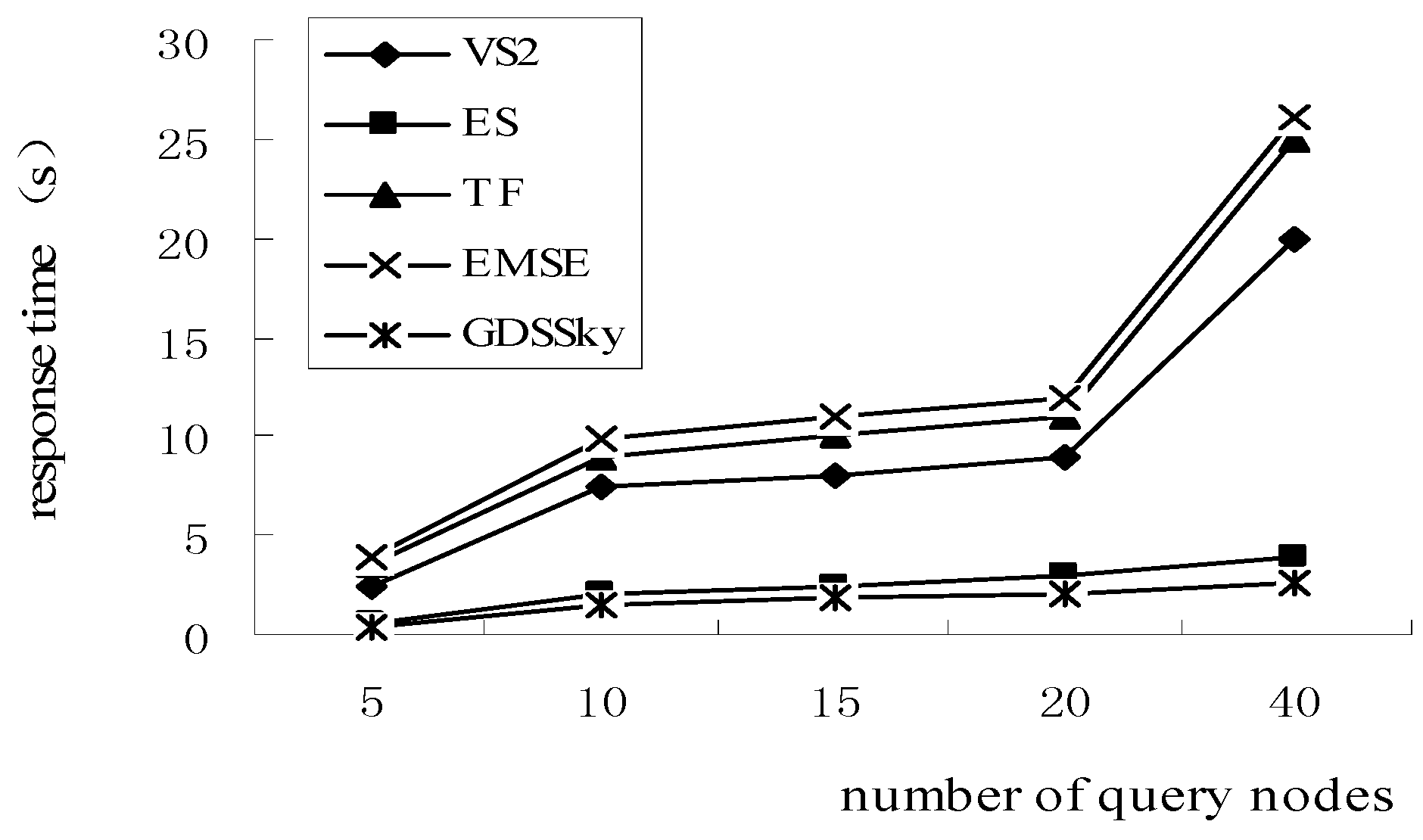
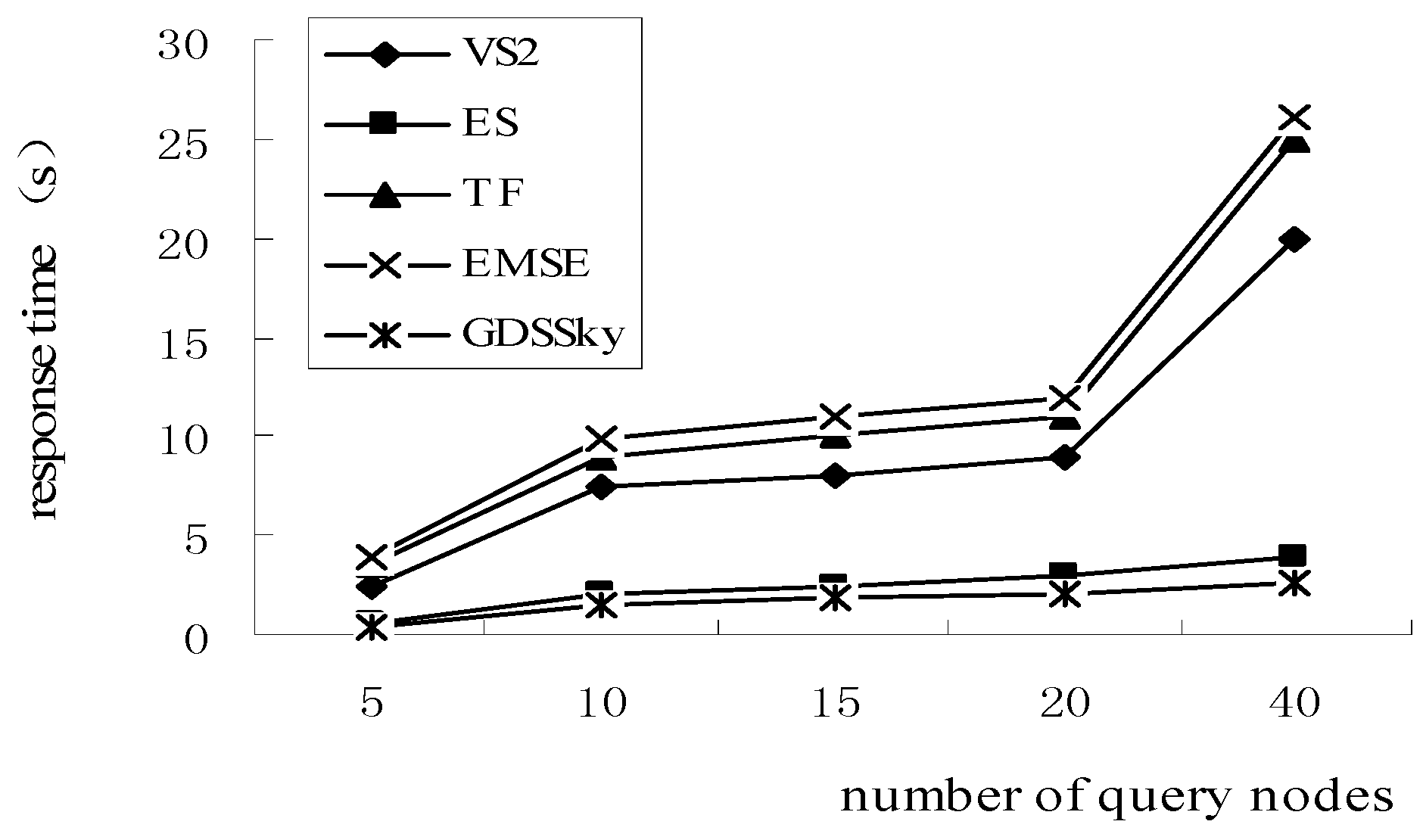
5.4. Effect of the Number of Query Nodes on the Response Time
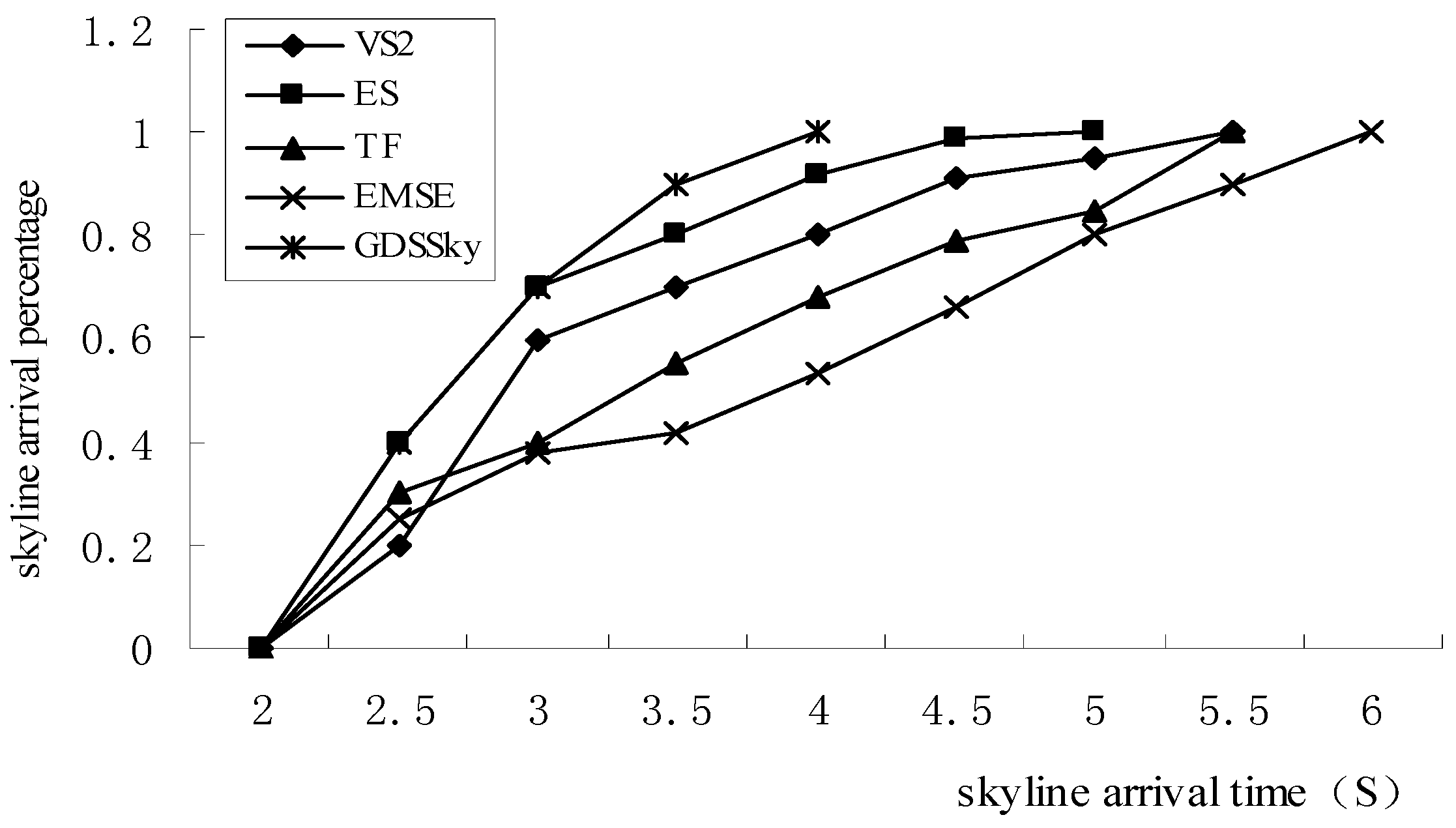
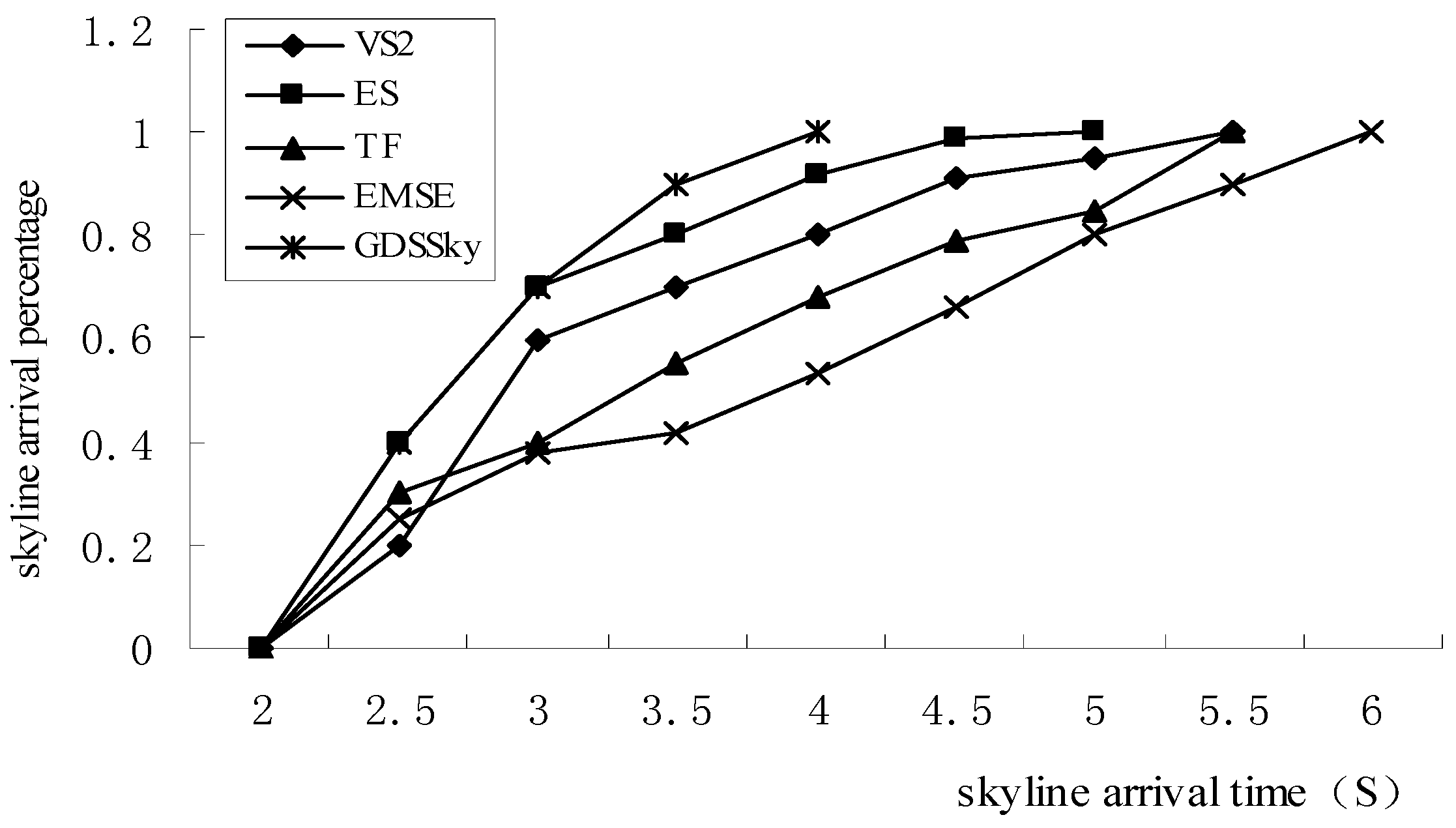
5.5. Execution Efficiency Percentage
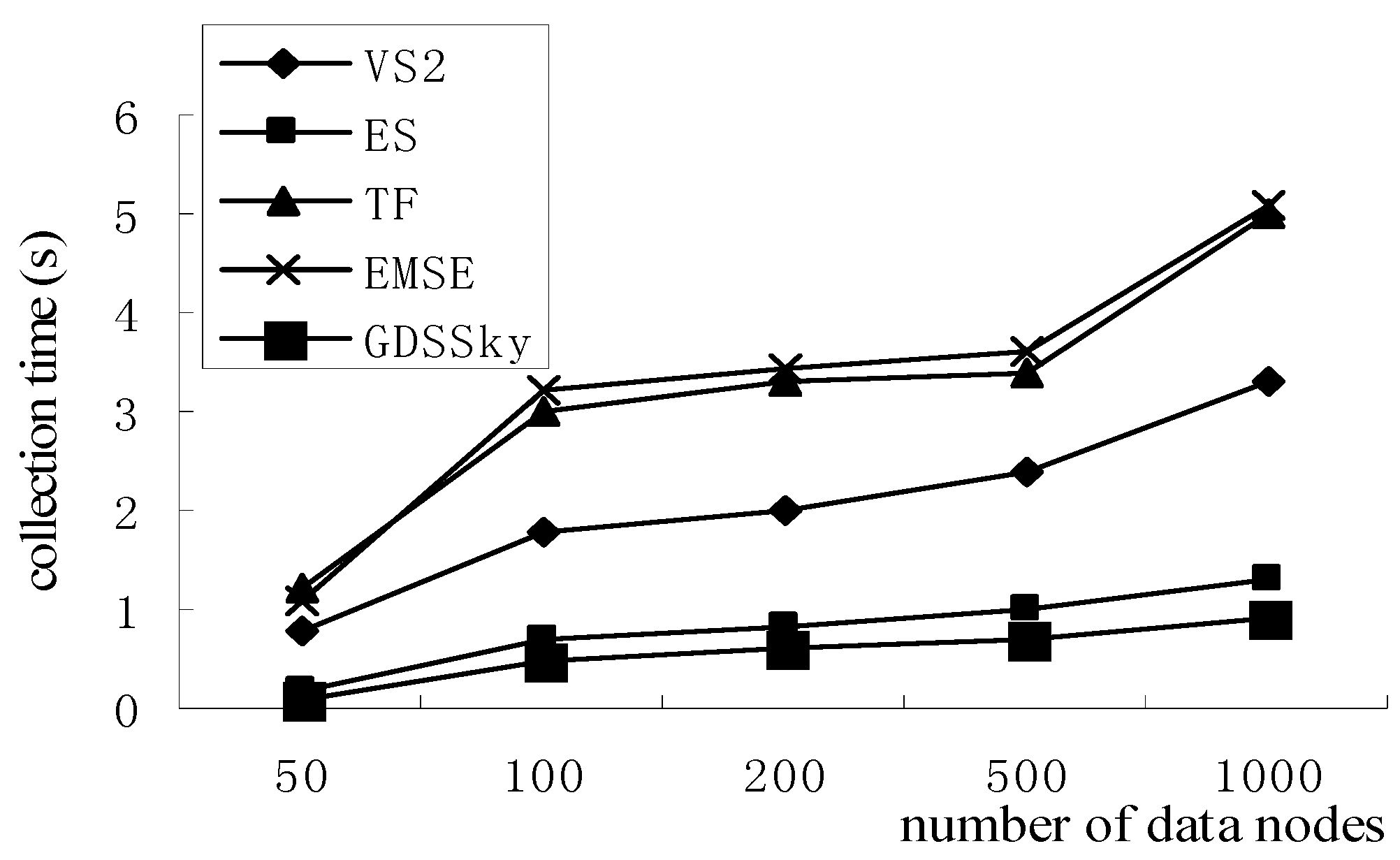
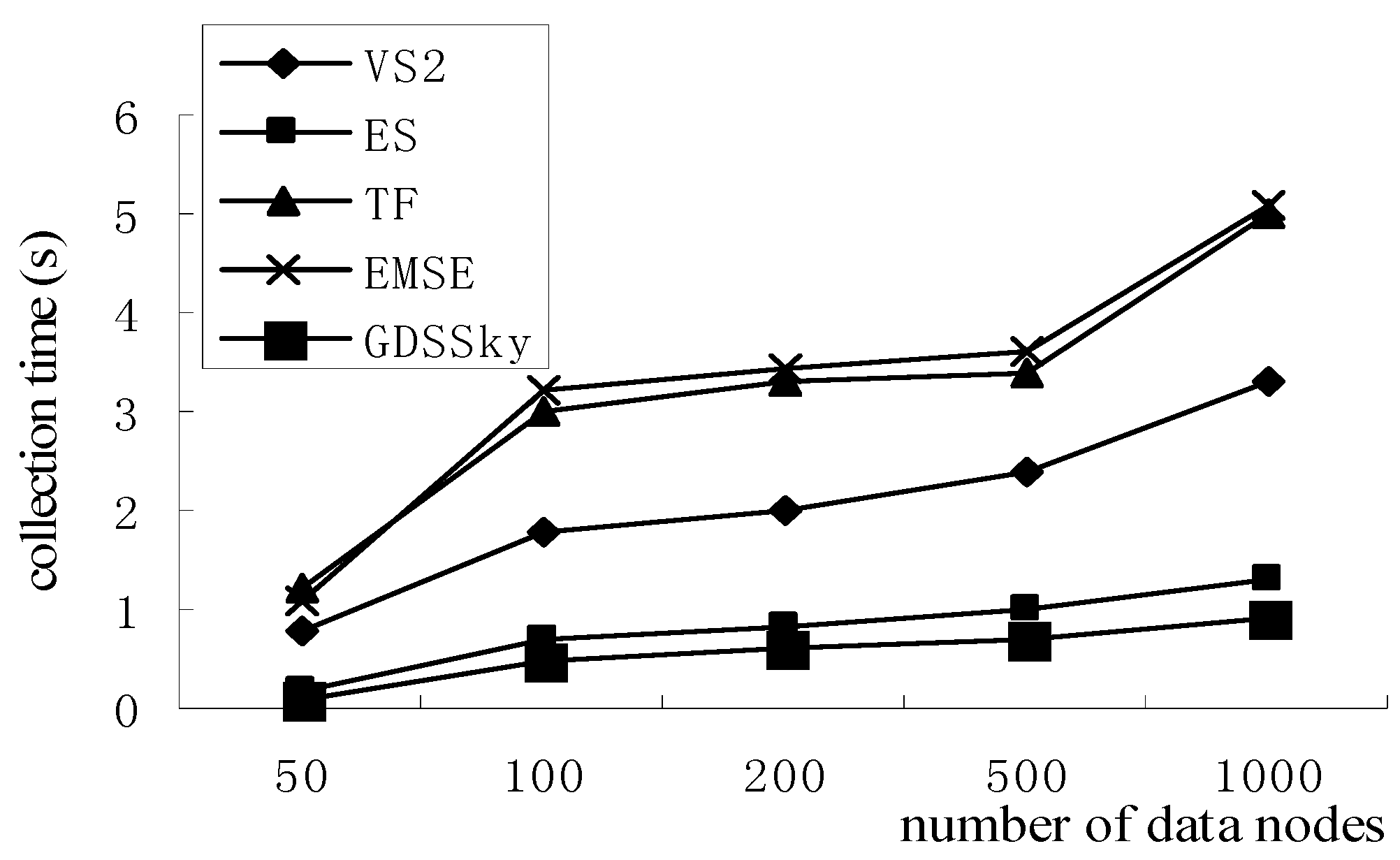
5.6. Skyline Collection Efficiency
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sun, Y.; Yu, X.; Bie, R.; Song, H. Discovering Time-dependent Shortest Path on Traffic Graph for Drivers towards Green Driving. J. Netw. Comput. Appl. 2016. [Google Scholar] [CrossRef]
- Sun, Y.; Lu, C.; Bie, R.; Zhang, J. Semantic Relation Computing Theory and Its Application. J. Netw. Comput. Appl. 2016. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, J.; Bie, R. Measuring Semantic-based Structural Similarity in Multi-relational Networks. IJDWM 2016. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Zhu, J.; Qiao, X. A Synergetic Mechanism for Digital Library Service in Mobile and Cloud Computing Environment. Pers. Ubiquitous Comput. 2014. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, J.; Xiong, Y.; Zhu, G. Data Security and Privacy in Cloud Computing. Int. J. Distrib. Sens. Netw. 2014. [Google Scholar] [CrossRef]
- Sun, Y.; Jara, A.J. An extensible and active semantic model of information organizing for the Internet of Things. Pers. Ubiquitous. Comput. 2014, 18, 1821–1833. [Google Scholar] [CrossRef]
- Guo, J.; Zhang, H.; Sun, Y.; Bie, R. Square-root unscented Kalman filtering-based localization and tracking in the Internet of Things. Pers. Ubiquitous Comput. 2014, 18, 1824–1829. [Google Scholar] [CrossRef]
- Sun, Y.; Yan, H.; Lu, C.; Bie, R.; Zhou, Z. Constructing the web of events from raw data in the Web of Things. Mob. Inf. Syst. 2014. [Google Scholar] [CrossRef]
- Zhuge, H.; Sun, Y. Schema Theory for Semantic Link Network. Future Gener. Comput. Syst. 2010. [Google Scholar] [CrossRef]
- Sun, Y.; Bie, R.; Yu, X.; Wang, S. Semantic Link Networks: Theory, Applications, and Future Trends. J. Internet Technol. 2013, 14, 365–378. [Google Scholar]
- D’Arienzo, M.; Iacono, M.; Marrone, S.; Nardone, R. Estimation of the energy consumption of mobile sensors in WSN environmental monitoring applications. In Proceedings of the 2013 27th International Conference on Advanced Information Networking and Applications Workshops (WAINA), Barcelona, Spain, 25–28 March 2013; pp. 1588–1593.
- Sun, Y.; Song, H.; Jara, A.J.; Bie, R. Internet of Things and Big Data Analytics for Smart and Connected Communities. IEEE Access. 2016. [Google Scholar] [CrossRef]
- Sun, Y.; Yan, H.; Zhang, J.; Xia, Y.; Wang, S.; Bie, R.; Tian, Y. Organizing and Querying the Big Sensing Data with Event-Linked Network in the Internet of Things. Int. J. Distrib. Sens. Netw. 2014, 4, 610–617. [Google Scholar]
- Chen, B.; Liang, W. Progressive skyline query processing in wireless sensor networks. In Proceedings of the 5th International Conference on Mobile Ad-hoc and Sensor Networks, Fujian, China, 14–16 December 2009; pp. 17–24.
- Yin, B.; Lin, Y.; Yu, J.; Liu, P. Skyline monitoring in wireless sensor networks. IEICE Trans. Commun. 2013. [Google Scholar] [CrossRef]
- Navarro, M.; Davis, T.W.; Liang, Y.; Liang, X. ASWP: A long-term WSN deployment for environmental monitoring. In Proceedings of the 12th International Conference on Information Processing in Sensor Networks, Philadelphia, PA, USA, 8–11 April 2013.
- Li, Z.; Wang, Y.; Song, B.; Li, X.; Hao, X. Geometry-based spatial skyline query in wireless sensor network. In Proceedings of the 2014 11th Web Information System and Application Conference, Tianjin, China, 12–14 September 2014.
- Kwon, Y.; Choi, J.H.; Chung, Y.D.; Lee, S. In-network processing for skyline queries in sensor networks. Ieice Trans. Commun. 2007. [Google Scholar] [CrossRef]
- Roh, Y.J.; Song, I.; Jeon, J.H.; Woo, K.G.; Kim, M.H. Energy-efficient two-dimensional skyline query processing in wireless sensor networks. In Proceedings of the 2013 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2013; pp. 294–301.
- Xin, J.C.; Wang, G.R. Continuous Skyline nodes query processing over wireless sensor networks. Chin. J. Comput. 2012, 35, 2415–2430. [Google Scholar] [CrossRef]
- Xin, J.; Wang, G.; Chen, L.; Oria, V. Energy-Efficient Evaluation of Multiple Skyline Queries over a Wireless Sensor Network; Springer: Berlin, Heidelberg, Germany, 2009; pp. 247–262. [Google Scholar]
- Wang, G.; Xin, J.; Chen, L.; Liu, Y. Energy-efficient reverse skyline query processing over wireless sensor networks. IEEE Trans. Knowl. Data Eng. 2012, 24, 1259–1275. [Google Scholar] [CrossRef]
- Chen, B.; Liang, W.; Yu, J.X. Energy-efficient skyline query optimization in wireless sensor networks. Wirel. Netw. 2012, 18, 985–1004. [Google Scholar] [CrossRef]
- Sharifzadeh, M.; Shahabi, C. The spatial skyline queries. In Proceedings of the 32nd international conference on Very large data bases, Seoul, Korea, 12–15 September 2006.
- Son, W.; Lee, M.W.; Ahn, H.K.; Hwang, S. Spatial Skyline Queries: An Efficient Geometric Algorithm; Advances in Spatial and Temporal Databases; Springer: Berlin, Heidelberg, Germany, 2009; pp. 247–264. [Google Scholar]
- Yoon, S.; Shahabi, C. Distributed Spatial Skyline Query Processing in Wireless Sensor Networks. In Proceedings of the IPSN, San Francisco, CA, USA, 13–16 April 2009.
- Lin, X.; Xu, J.; Hu, H. Range-based skyline queries in mobile environments. Knowl. Data Eng. 2013, 25, 835–849. [Google Scholar] [CrossRef]
- Son, W.; Stehn, F.; Knauer, C.; Ahn, H. Top- k manhattan spatial skyline queries. In Algorithms and Computation; Springer International Publishing: Cham, Switzerland, 2014; pp. 22–33. [Google Scholar]
- De Berg, M.; van Kreveld, M.; Overmars, M.; Overmars, M. Computational Geometry: Algorithms and Applications; Springer-Verlag: Berlin, Heidelberg, Germany, 2000. [Google Scholar]
- Huang, Y.K.; Chang, C.H.; Lee, C. Continuous distance-based skyline queries in road networks. Inf. Syst. 2012, 37, 611–633. [Google Scholar] [CrossRef]
- Bartolini, I.; Ciaccia, P.; Patella, M. The skyline of a probabilistic relation. Knowl. Data Eng. 2013, 25, 1656–1669. [Google Scholar] [CrossRef]
- Wei, W.; Yang, X.L.; Zhou, B.; Feng, J.; Shen, P.Y. Combined energy minimization for image reconstruction from few views. Math. Probl. Eng. 2012. [Google Scholar] [CrossRef]
- Wei, W.; Qiang, Y.; Zhang, J. A bijection between lattice-valued filters and lattice-valued congruences in residuated lattices. Math. Probl. Eng. 2013, 32, 1437–1450. [Google Scholar]
- Wang, Y.; Wei, W.; Deng, Q.; Liu, W.; Song, H. An energy-efficient skyline query for massively multidimensional sensing data. Sensors 2016. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, K.; Nafi, N.S.; Gregory, M.A. Enhanced distributed dynamic skyline query for wireless sensor networks. J. Sens. Actuator Netw. 2016. [Google Scholar] [CrossRef]
- An, P.T.; Hai, N.N.; Hoai, T.V. Advances in Computer Science and Its Applications; Springer: Berlin, Heidelberg, Germany, 2014. [Google Scholar]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-Tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990.
- Hu, L.; Ku, W.; Bakiras, S.; Shahabi, C. Spatial query integrity with voronoi neighbors. Knowl. Data Eng. 2013, 25, 863–876. [Google Scholar] [CrossRef]
- Guo, L.; Li, J.; Li, G. Spatio-temporal query processing method in wireless sensor networks. J. Softw. 2006, 17, 794–805. [Google Scholar] [CrossRef]
- Mao, X.; Miao, X.; He, Y.; Li, X.Y.; Liu, Y. CitySee: Urban CO2 monitoring with sensors. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 1611–1619.
- Wang, G. Analysis and study of the deicing and anti-icing for catenary. J. Railw. Eng. Soc. 2009, 8, 93–95. [Google Scholar]
- Li, J.; Wang, B.; Wang, G.; Huang, S. A survey of query processing techniques over uncertain mobile objects. J. Front. Comput. Sci. Technol. 2013, 7, 1057–1072. [Google Scholar]
- Jin, X.; Zhang, Q.; Zeng, P.; Kong, F.; Xiao, Y. Collision-free multichannel superframe scheduling for IEEE 802.15.4 cluster-tree networks. Int. J. Sens. Netw. 2014, 15, 246–258. [Google Scholar] [CrossRef]
- Peng, Y.; Yu, Y.; Guo, L.; Jiang, D.; Gai, Q. An efficient joint channel assignment and QoS routing protocol for IEEE 802.11 multi-radio multi-channel wireless mesh networks. J. Netw. Comput. Appl. 2013, 36, 843–857. [Google Scholar] [CrossRef]
- Wei, W.; Yong, Q. Information potential fields navigation in wireless Ad-Hoc sensor networks. Sensors 2011, 11, 4794–4807. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Xu, Q.; Wang, L.; Hei, X.H.; Shen, P.Y. GI/Geom/1 queue based on communication model for mesh networks. Int. J. Commun. Syst. 2014, 27, 3013–3029. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node ID | Attribute 1 Value | Attribute 2 Value | Maximum Value | Minimum Value | Multiplication of Each Attribute |
|---|---|---|---|---|---|
| ID | Attribute 1 | Attribute 2 | max | min | D-space |
| ID | Attribute 1 | Attribute 2 | Max | Min | D-Space |
|---|---|---|---|---|---|
| S1 | v1 | v11 | m1 | m11 | d1 |
| S2 | v2 | v22 | m2 | m22 | d2 |
| ID | Attribute 1 | Attribute 2 | Max | Min | D-Space |
|---|---|---|---|---|---|
| S1’ | v1’ | v11’ | m1’ | m11’ | d1’ |
| S2’ | v2’ | v22’ | m2’ | m22’ | d2’ |
| Hardware | Parameter |
|---|---|
| CPU | Pentium 4 (3.2 GHz) |
| Memory | 4 GB |
| Disk | 1 TB |
| Parameter | Setting |
|---|---|
| Dimensionality | 3 |
| Dataset cardinality | 50, 100, 200, 500, 1000 |
| Distribution of data points | Independent |
| The number of points in a query | 5, 10, 15, 20, 40 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Song, B.; Wang, J.; Zhang, L.; Wang, L. Geometry-Based Distributed Spatial Skyline Queries in Wireless Sensor Networks. Sensors 2016, 16, 454. https://doi.org/10.3390/s16040454
Wang Y, Song B, Wang J, Zhang L, Wang L. Geometry-Based Distributed Spatial Skyline Queries in Wireless Sensor Networks. Sensors. 2016; 16(4):454. https://doi.org/10.3390/s16040454
Chicago/Turabian StyleWang, Yan, Baoyan Song, Junlu Wang, Li Zhang, and Ling Wang. 2016. "Geometry-Based Distributed Spatial Skyline Queries in Wireless Sensor Networks" Sensors 16, no. 4: 454. https://doi.org/10.3390/s16040454