
A Context-Aware Mobile User Behavior-Based Neighbor Finding Approach for Preference Profile Construction †



Abstract
:1. Introduction
Main Idea of This Paper
2. State-of-the-Art
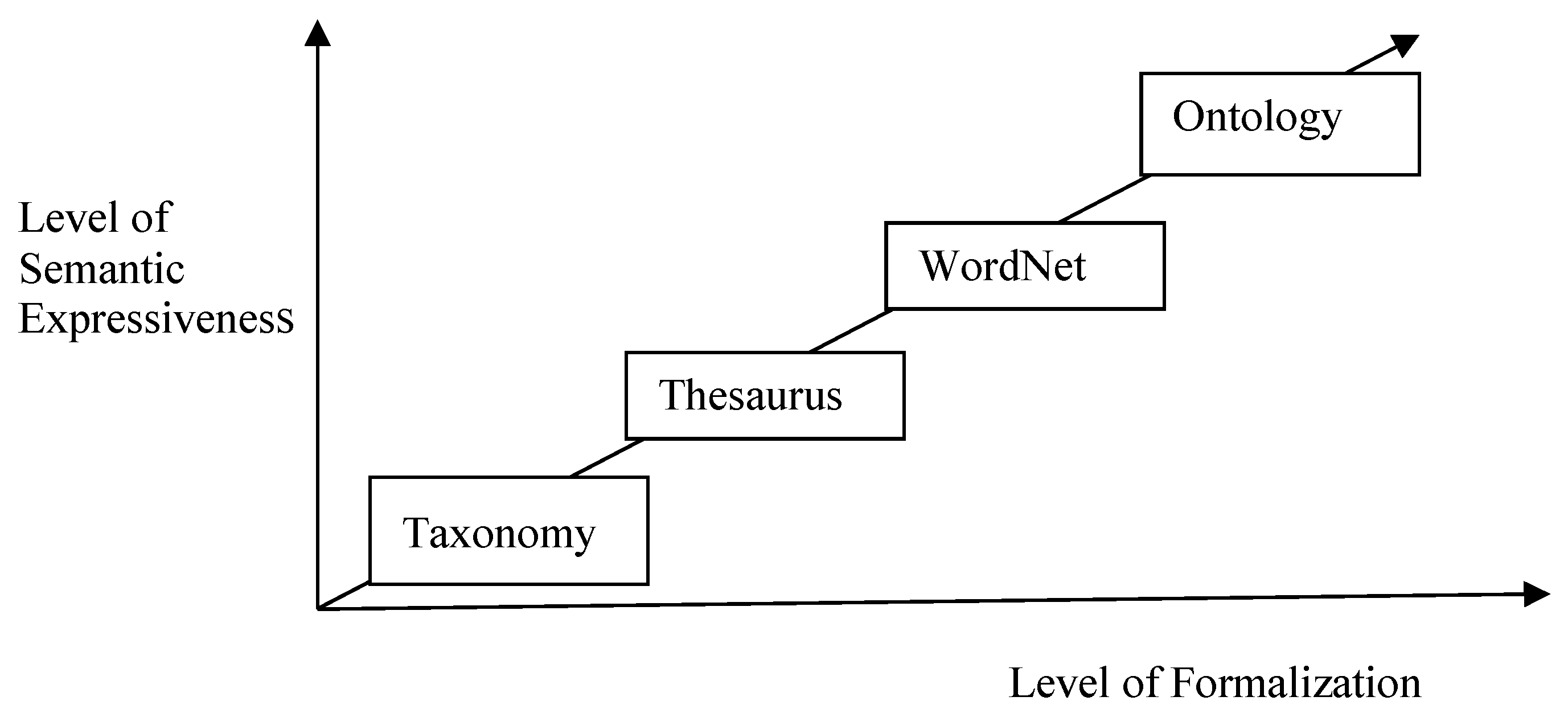
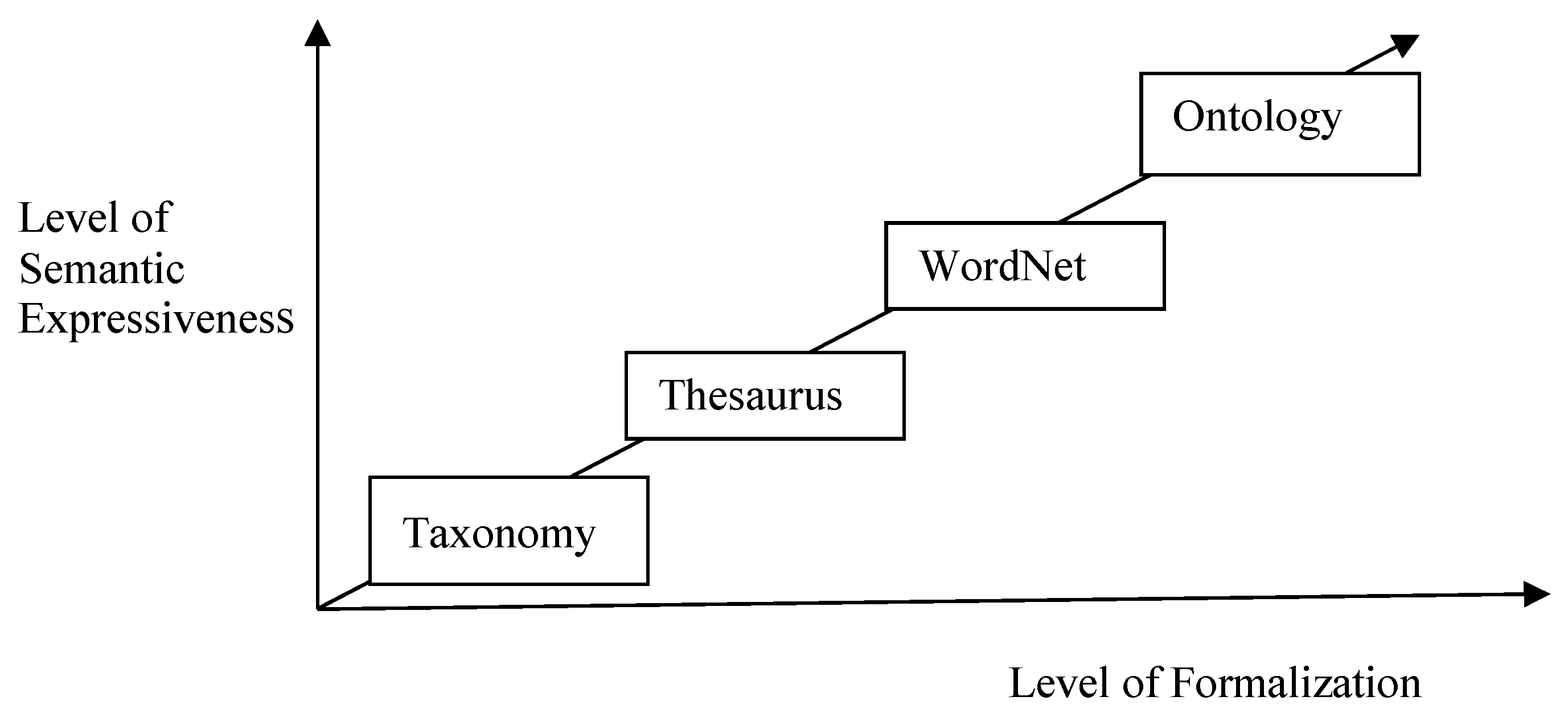
3. The Context-Awareness Mobile User Preference Profile Construction Approach and Experiments
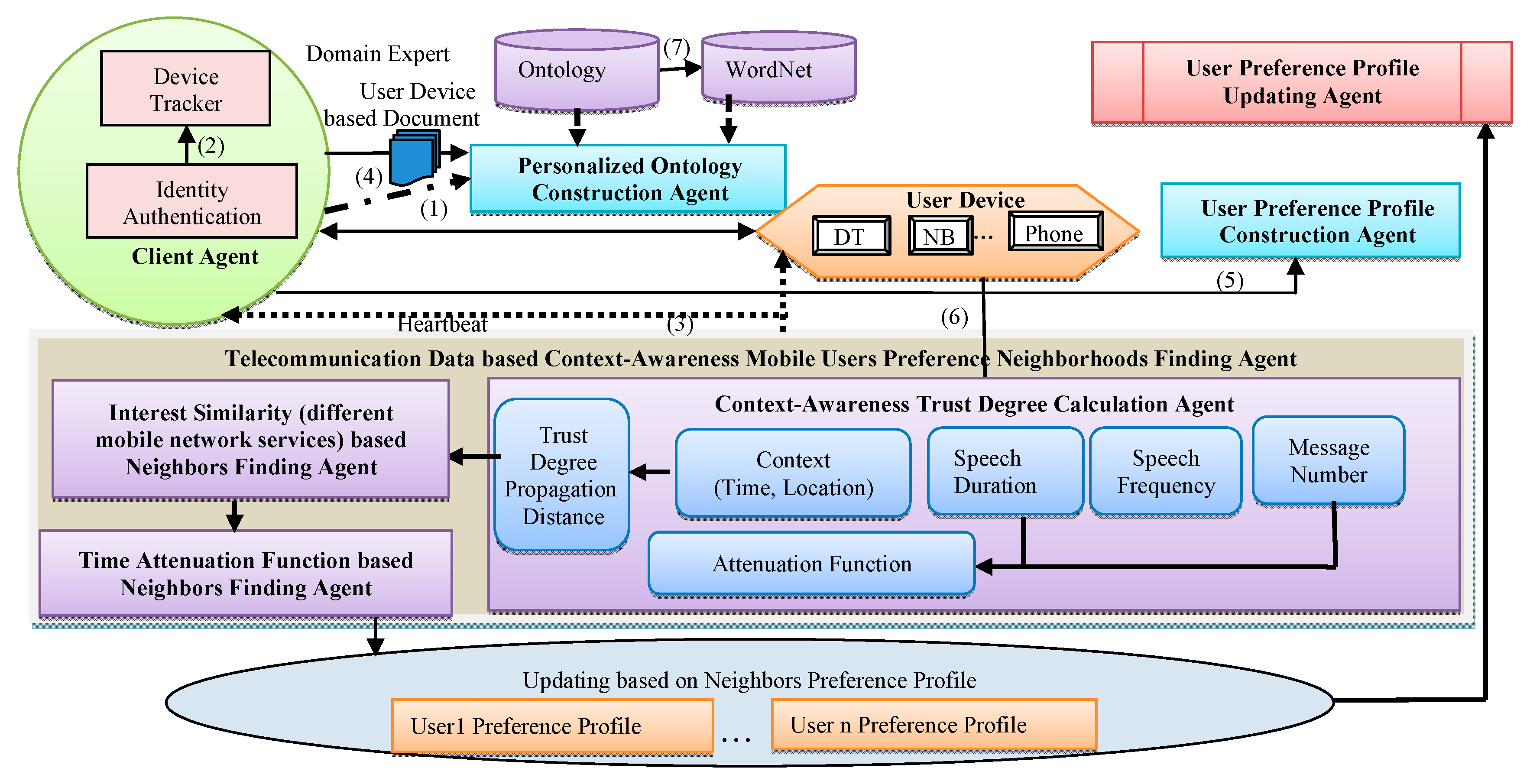
3.1. The Framework and Implementation of the Proposed Method
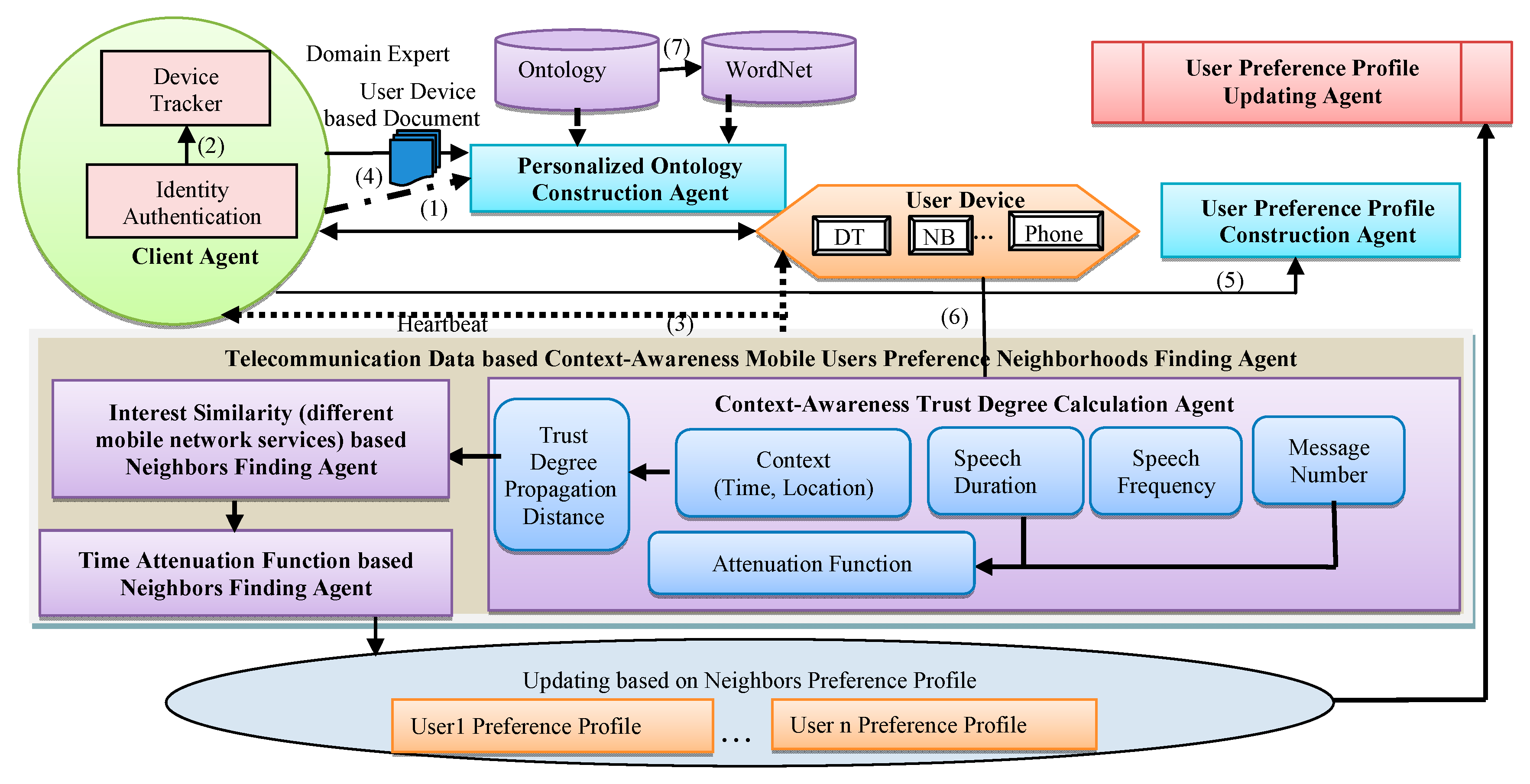
3.2. Telecommunication Data-Based Context-Awareness Mobile User Preference Neighborhood Finding Agent
3.2.1. Used Data Set
- (1)
- Collection of mobile web service contents used by users: (Ui, Sij) indicates the network services Sij (j ∈ [1,m]) used by user u1, u2, …, un.
- (2)
- The evaluation score about the web service Sij graded by users: S (S1 < ui, Si1 >, S2 < ui, Si2 >, …, St < ui, Sit >) (t <= m). Here < ui, Sij > is the evaluation score about the web service Sj given by user ui. The evaluation score of a certain web service is first mined by the feedback information and evaluation record of a user about different services that he/she used, and is then comprehensively amended by the usage condition about the related mobile services of a user.
- (3)
- Trust degree set of mobile users: TRij < ui, uj > indicates the trust degree of mobile users ui and uj. The trust degrees of different mobile users are obtained by analyzing communication behavior among different mobile users. The more frequently mobile users ui and uj contact with each other, the higher is the trust degree between them.
3.2.2. The Overview of the Proposed Algorithm.
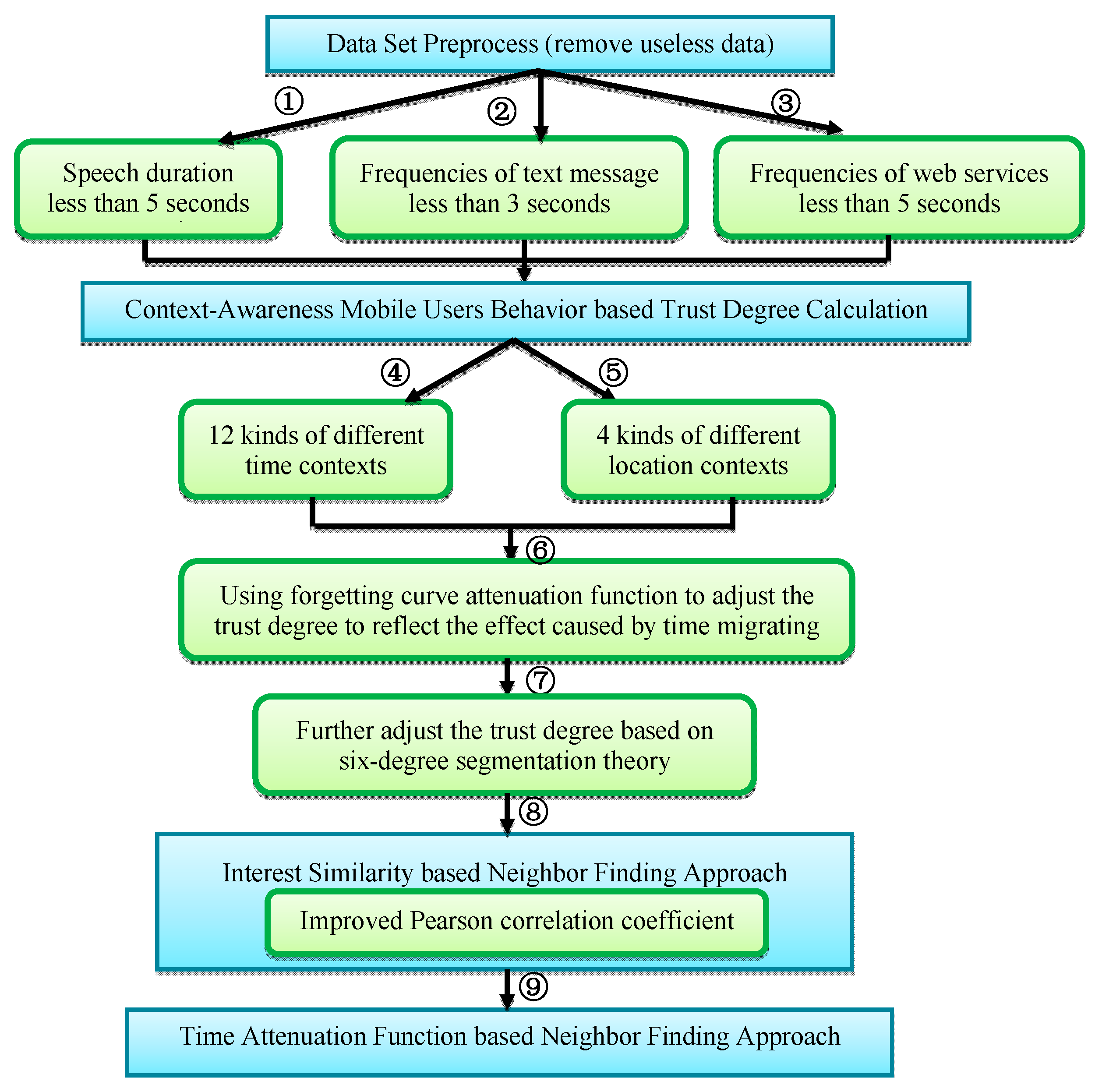
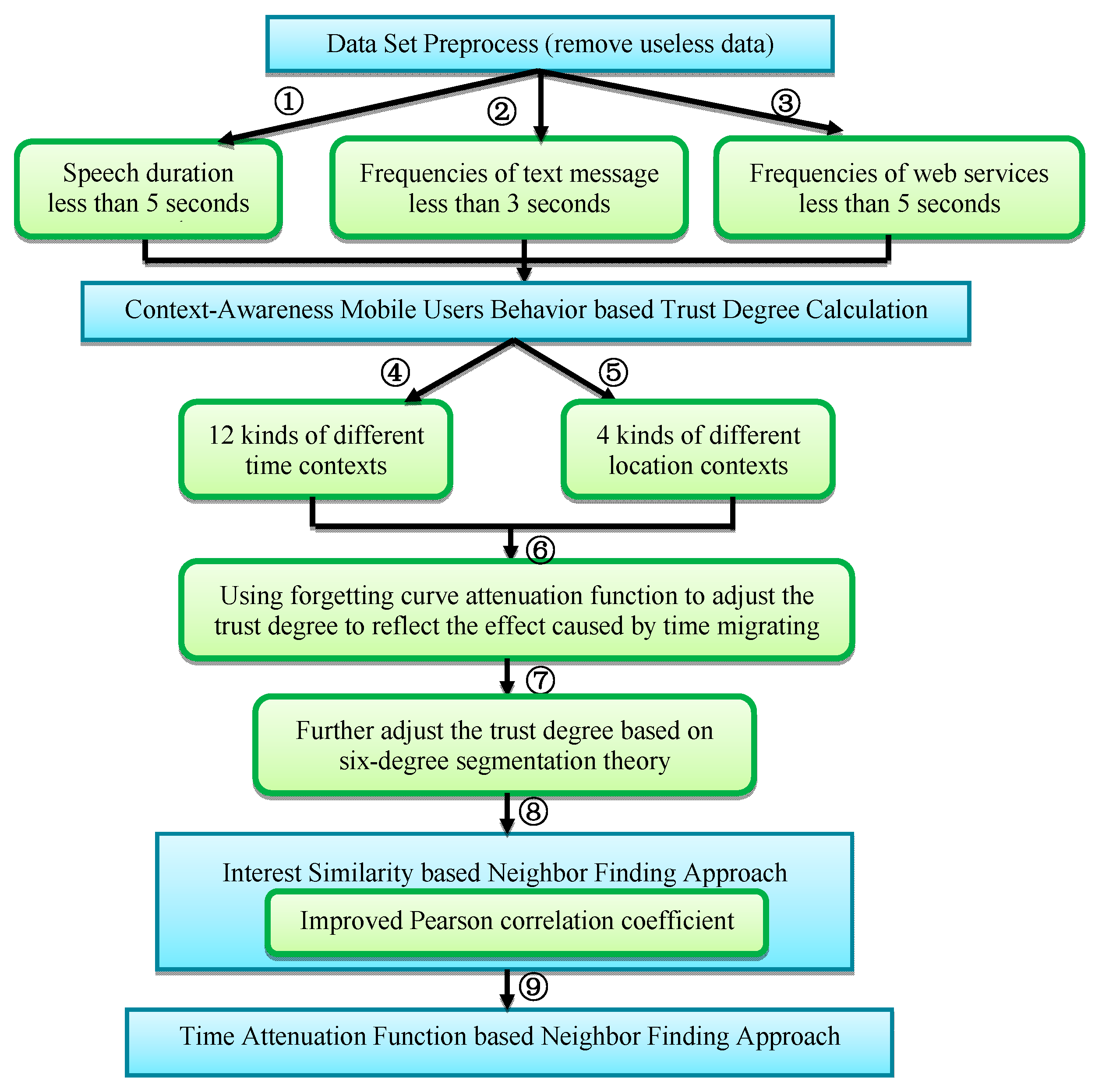
3.2.3. Data Preprocessing
- (1)
- Conversation information with the speech duration less than 5 s is deleted.
- (2)
- The frequencies less than 3 are deleted as the noneffective text message conversation behavior.
- (3)
- Record the information about web services used by the mobile users, and set the using frequency threshold as 5. The frequencies less than the threshold 5 are deleted as misoperations or disinterested network services.
3.2.4. Context-Awareness Mobile Users Behavior Based Trust Degree Calculation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terms | Meaning |
|---|---|
| speech duration | The time users spent on voice calls |
| speech frequency | The number of the voice calls between two users |
| message frequency | The number of the text messages between two users |
| Along duration | The total time of two uses when they stay in a short distance (such as in the same office) which is within the range of Bluetooth detection. |
| Along frequency | The total number of two uses when they stay in a short distance (such as in the same office) which is within the range of Bluetooth detection. |
3.2.5. Interest Similarity-Based Neighbor Finding Approach
3.2.6. Time Attenuation Function Based Neighbor Finding Agent
4. Simulation, Results and Discussion
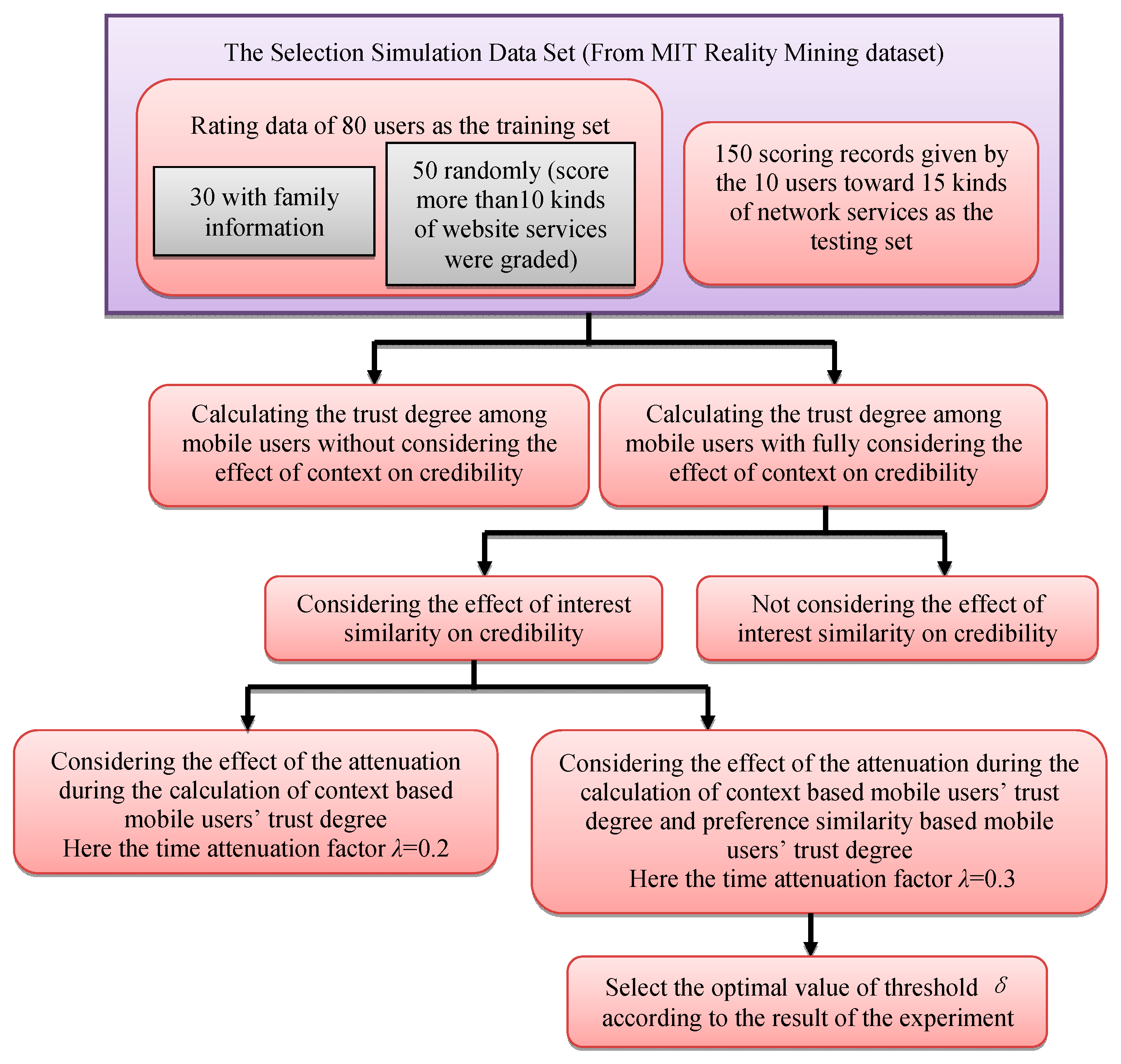
4.1. Simulation Data Sets
4.2. Simulation Steps
- Step 1:
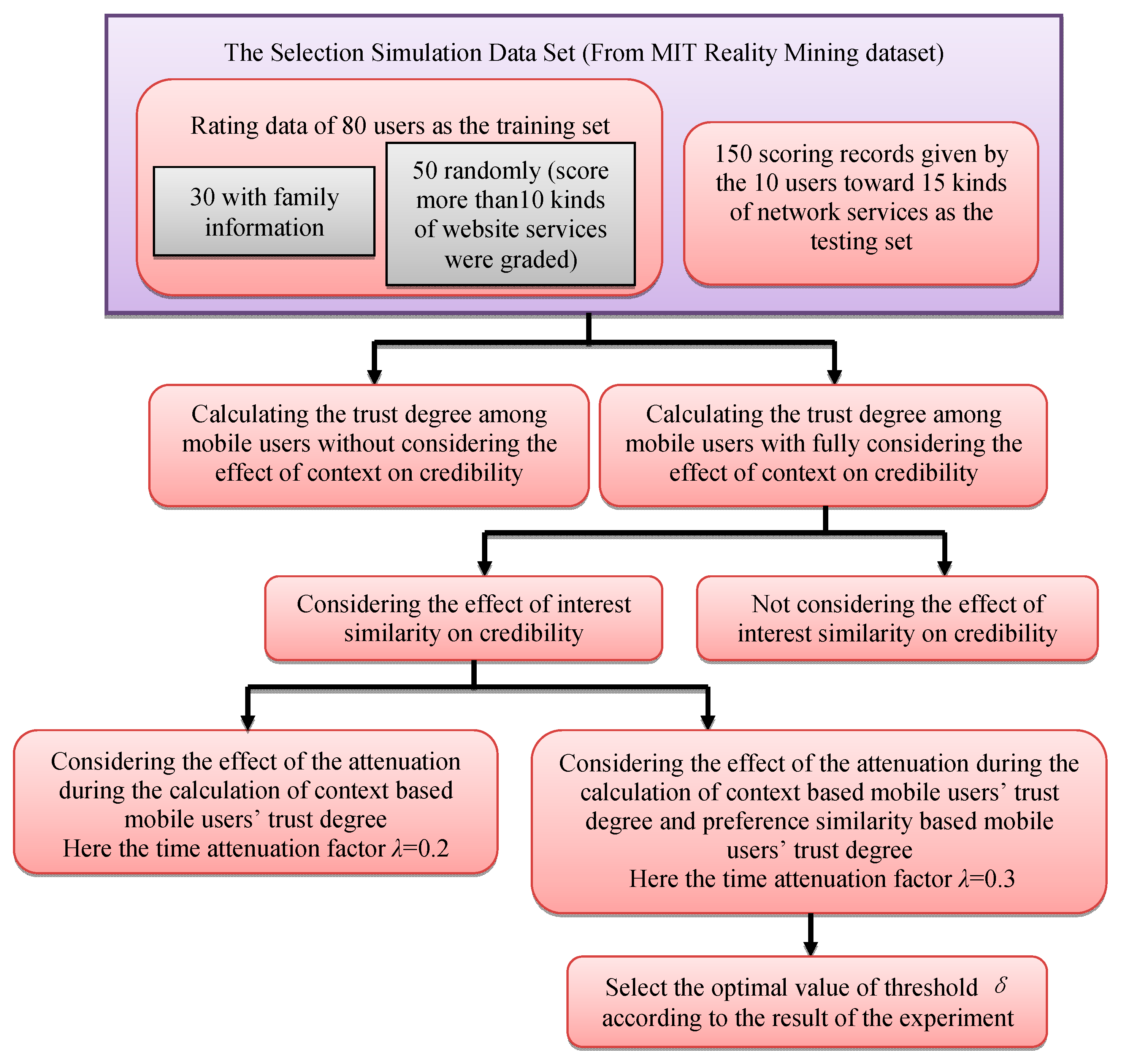
- Select data of the first five months as a training set and those of the sixth months as testing set. This experiment selects rating data of 80 users as the training set. Selection rules are as in the following: firstly, select 30 users with family information, and then select 50 users randomly from network services users scoring more than10 kinds of website services. Test sets are 150 scoring records given by the 10 users toward 15 kinds of network services. In the experiment, the initial credibility among family members is set 1, and that from different families is set 0.
- Step 2:
- A logarithmic function is used to analyze the effect of credibility caused by speech duration, speech frequency, message frequency, along duration and along frequency in the trust degree computation, and the context information (time, location and the people around) is taken into consideration. Two approaches are used in the experiment: Equation (5) is used to calculate the trust degree among mobile users without considering the effect of context on credibility, and Equation (8) is adopted when fully considering the effect of context on credibility.
- Step 3:
- Add interest similarity to the calculation of credibility with two contrast methods depending on whether the effect of interest similarity on credibility is considered.
- Step 4:
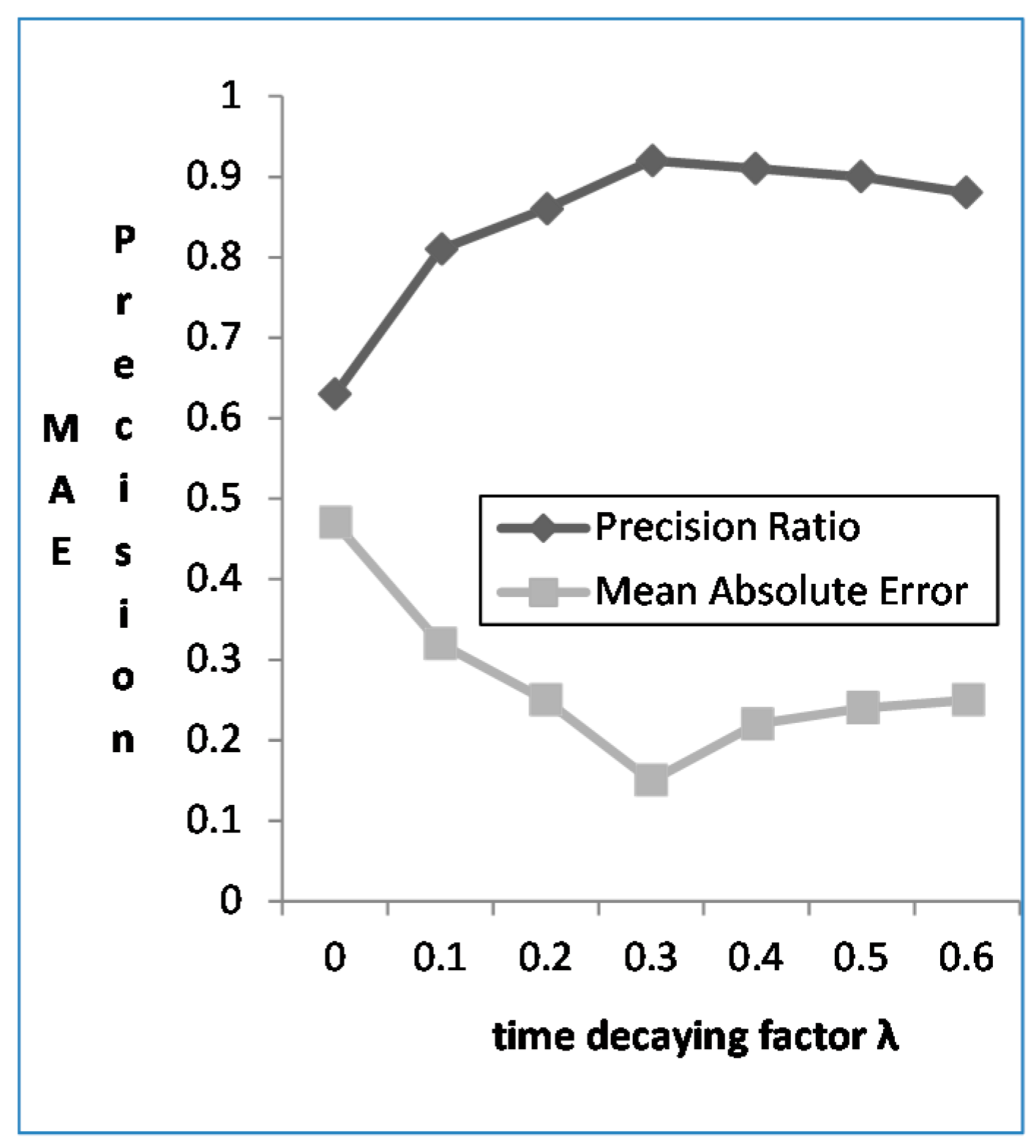
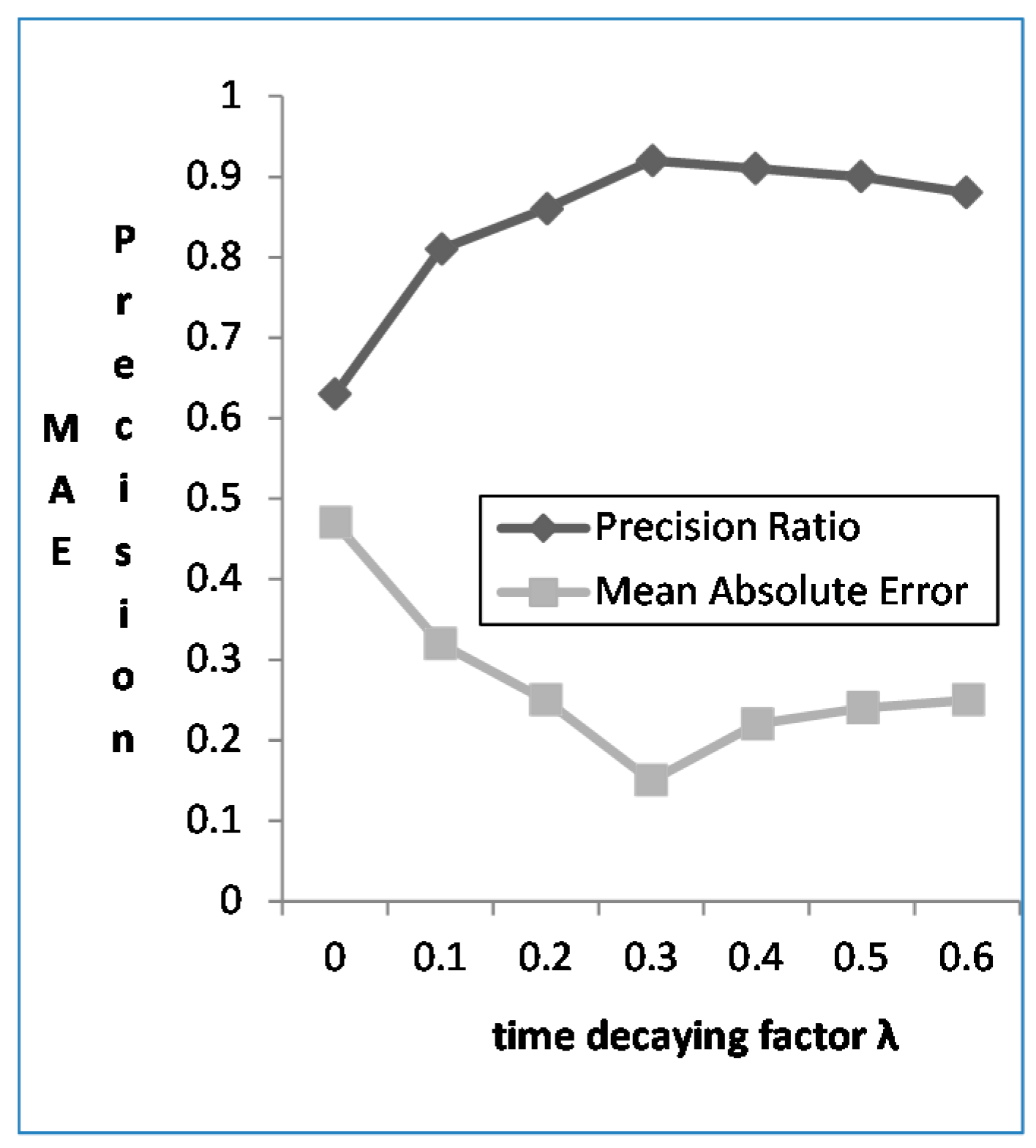
- When calculating the trust degree, consider credibility decay and user preference decay with two contrast methods: (1) Consider the attenuation of credibility during the calculation based on context-based mobile users’ behavior. Set time attenuation factor λ = 0.2 (here a month is the measure of time) through many experiments, i.e., when two mobile users lose contact for more than a year, its credibility decreases to 0; (2) Consider the effect of time context on the credibility calculation based either on mobile users’ behavior or on interest similarity. Through data analysis, this paper sets the preference of the attenuation factor λ = 0.3. When tk − tm > 18 months, f (tk,tm) > 0.045, the user preference decays to 4.5% of the preference in 18 months ago. It can be seen that preference of attenuation speed is slower than that of confidence, because the relationship established between people is longer than that established between people and things.
- Step 5:
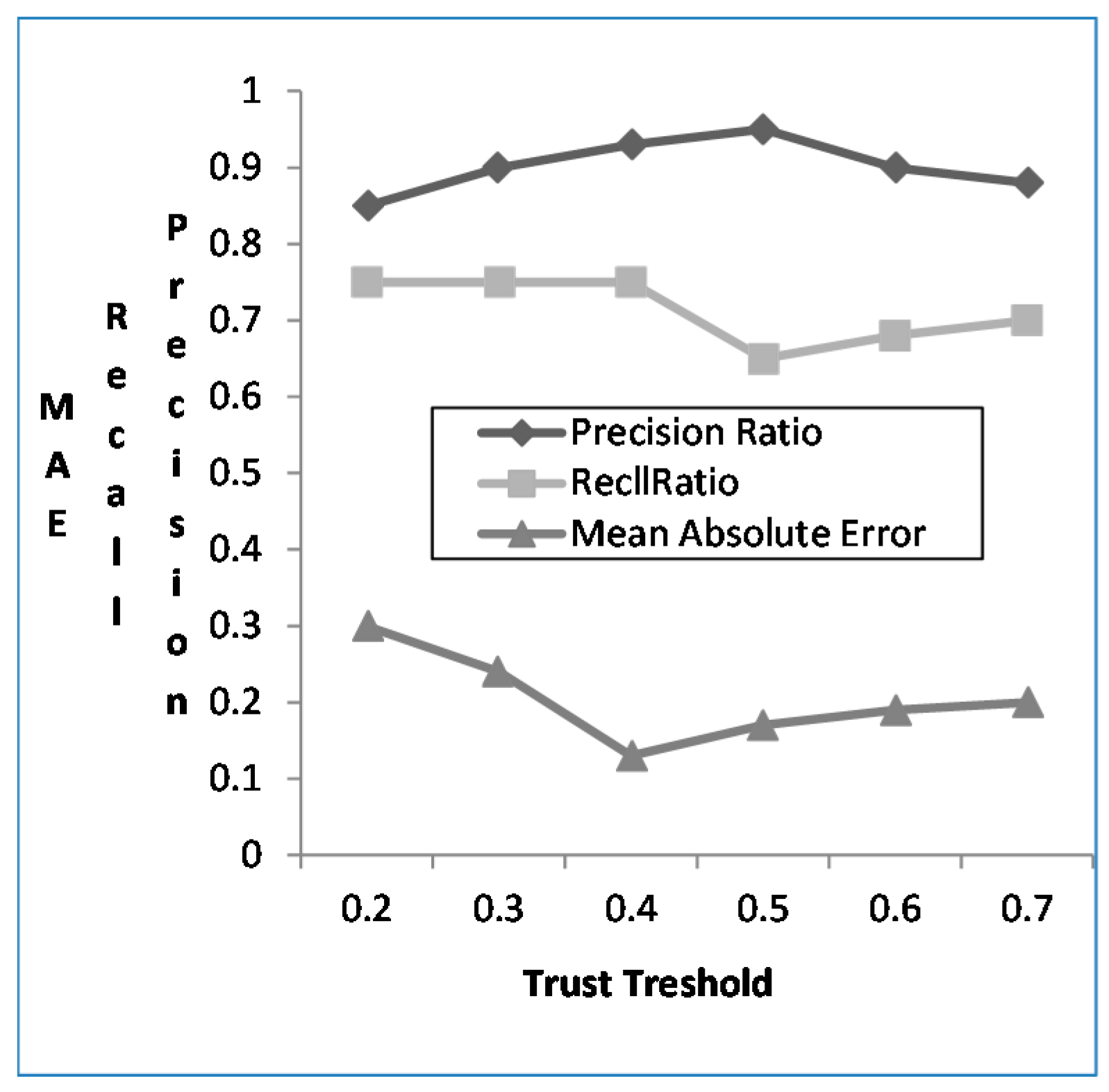
- Since mobile users can reuse some mobile network services, more repetitions result in greater stability of the mobile user preferences, hence higher credibility. Threshold δ = 0.3, 0.4, 0.5 and then select the optimal value according to the result of the experiment.
4.3. Results and Discussion
4.3.1. The Effect of Context on the Credibility Among Mobile Users
| ᵝ1 | ᵝ2 | ᵝ3 | ᵝ4 |
|---|---|---|---|
| 0.5132 | 0.3263 | 0.1968 | 0.1039 |
| Context | Weighting Parameter | Context | Weighting Parameter | Context | Weighting Parameter | Context | Weighting Parameter |
|---|---|---|---|---|---|---|---|
| 000(ᵃ1) | 0.0028 | 001(ᵃ9) | 0.9124 | 002(ᵃ17) | 0.0416 | 003(ᵃ25) | 0.8636 |
| 010(ᵃ2) | 0 | 011(ᵃ10) | 0 | 012(ᵃ18) | 0.0337 | 013(ᵃ26) | 0 |
| 020(ᵃ3) | 0.2316 | 021(ᵃ11) | 0 | 022(ᵃ19) | 0.2739 | 023(ᵃ27) | 0 |
| 030(ᵃ4) | 0.1372 | 031(ᵃ12) | 0 | 032(ᵃ20) | 0 | 033(ᵃ28) | 0 |
| 100(ᵃ5) | 0.5798 | 101(ᵃ13) | 0 | 102(ᵃ21) | 0.2518 | 103(ᵃ29) | 0 |
| 110(ᵃ6) | 0.3216 | 111(ᵃ14) | 0.0409 | 112(ᵃ22) | 0 | 113(ᵃ30) | 0.0357 |
| 120(ᵃ7) | 0.0835 | 121(ᵃ15) | 0.6031 | 122(ᵃ23) | 0.0971 | 123(ᵃ31) | 0.5894 |
| 130(ᵃ8) | 1 | 131(ᵃ16) | 0.9981 | 132(ᵃ24) | 0 | 133(ᵃ32) | 0.8873 |
4.3.2. The Effect of Time Decaying Factor λ
4.3.3. The Effect of Trust Degree Threshold
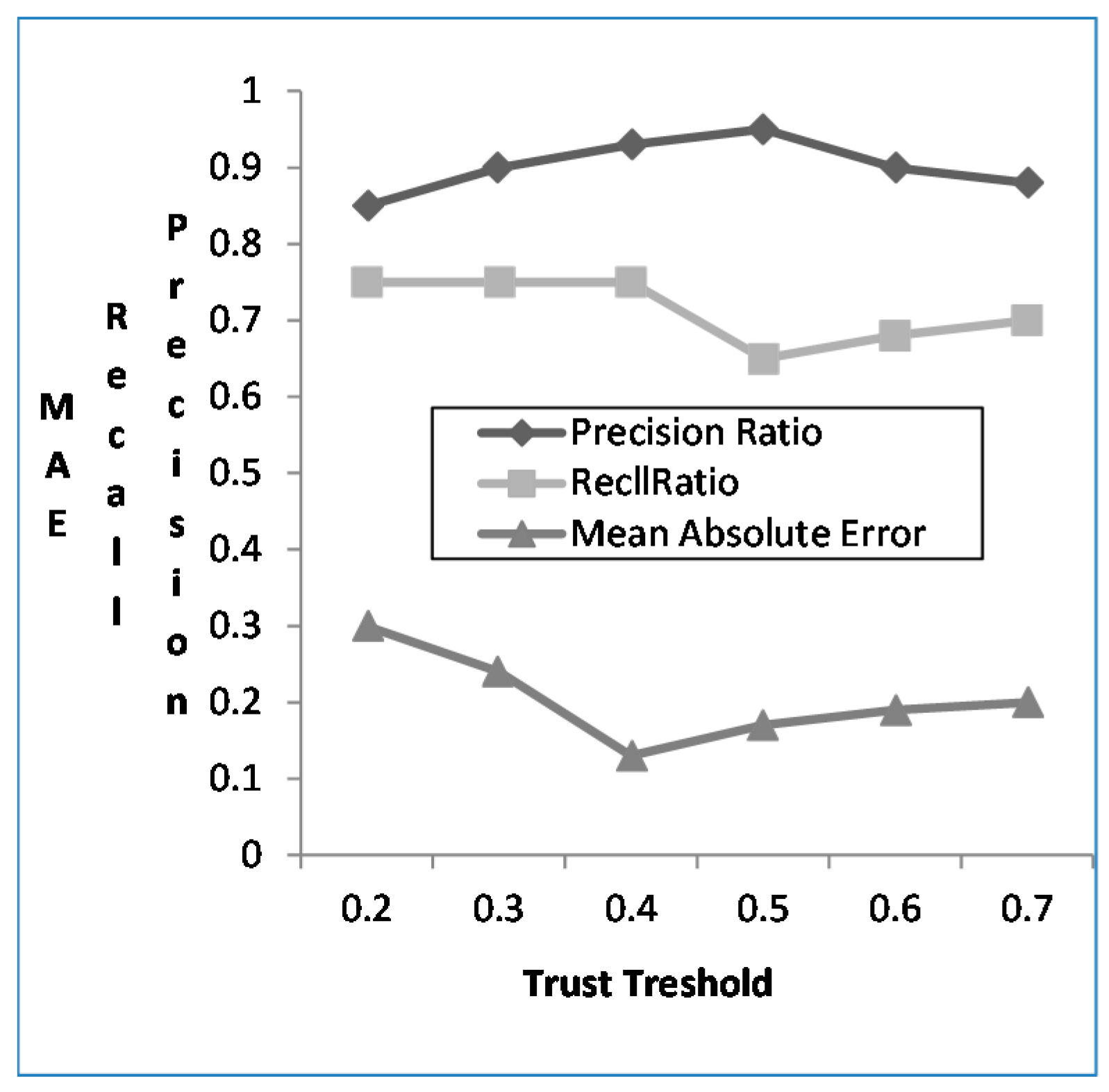
| Classification Method | Precision | The Number of the Correct Nodes |
|---|---|---|
| Not considering interest similarity | 0.62 | 35 |
| Considering interest similarity | 0.73 | 41 |
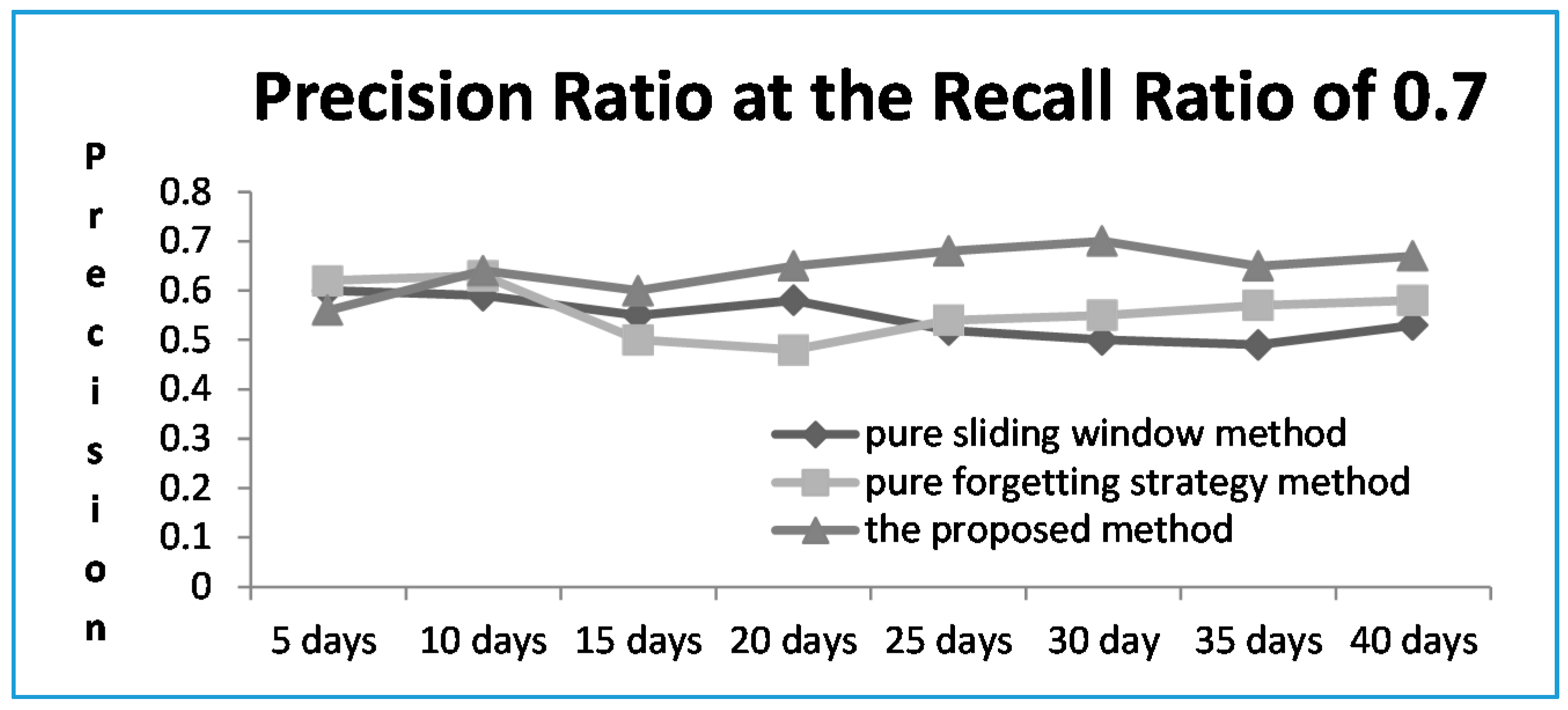
4.4. The Comparative Result of the Proposed Method and the Other Two Methods

5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hust, A. Learning Similarities for Collaborative Information Retrieval. In Proceedings of the KI-2004 workshop “Machine Learning and Interaction for Text-Based Information Retrieval”, Ulm, Germany, 20–24 September 2004.
- Hoashi, K.; Matsumoto, K.; Inoue, N.; Hashimoto, K. Document Filtering method using non-relevant information profile. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 176–183.
- Dwi, H.; Widyantoro, T.; Ioerger, R.; Yen, J. Learning User Interest Dynamics with Three-Descriptor Representation. J. Am. Soc. Inf. Sci. Technol. 2001, 52, 212–225. [Google Scholar]
- Kim, H.; Chan, P. Learning implicit user interest hierarchy for context in personalization. In Proceedings of the 8th international conference on intelligent user interfaces IUI’03, Miami, FL, USA, 12–15 January 2003; pp. 101–108.
- Sugiyama, K.; Hatano, K.; Yoshikawa, M. Adaptive web search based on user profile constructed without any effort from users. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–22 May 2004; pp. 675–684.
- Fellbaum, C.; Miller, G. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Stefani, A.; Strappavara, C. Personalizing Access to Web Sites: The SiteIF Project. In Proceedings of the 2nd Workshop on Adaptive Hypertext and Hypermedia HYPERTEXT’98, Pittsburgh, PA, USA, 20–24 June 1998.
- The Wordnet Website. Available online: http://wordnet.princeton.edu/ (accessed on 30 December 2015).
- Maedche, A.; Staab, S. Mining Ontologies from Text. In Proceedings of the 12th European Workshop on Knowledge Acquisition, Modeling and Management (EKAW 2000), Juan-les-Pins, France, 2–6 October 2000; pp. 189–202.
- Gauch, S.; Speretta, M.; Pretschner, A. Ontology-Based User Profiles for Personalized Search. In Integrated Series in Information Systems; Springer Science + Business Media, LLC: New York, NY, USA, 2007; Volume 14, pp. 665–694. [Google Scholar]
- Xu, F.; Meng, X.; Wang, L. A Collaborative Filtering Recommendation Algorithm Based on Context Similarity for Mobile Users. J. Electron. Inf. Technol. 2011, 11, 2785–2789. [Google Scholar] [CrossRef]
- Quercia, D.; Ellis, J.; Capra, L. Using mobile phones to nurture social networks. IEEE Pervasive Comput. 2010, 9, 12–20. [Google Scholar] [CrossRef]
- Eagle, N.; Pentland, A.; Lazer, D. Inferring friendship network structure using mobile phone data. Proc. Natl. Acad. Sci. USA 2009, 106, 15274–15278. [Google Scholar] [CrossRef] [PubMed]
- Woerndl, W.; Groh, G. Utilizing physical and social context to improve recommender systems. In Proceedings of the 2007 IEEEAVIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology-Workshops, Silicon Valley, CA, USA, 5–12 November 2007; pp. 123–128.
- Wang, Y.; Qiao, X.; Li, X.; Meng, L. Research on Context-Awareness Mobile SNS Service Selection Mechanism. Chin. J. Comput. 2010, 33, 2126–2135. [Google Scholar] [CrossRef]
- Huang, W.; Meng, X.; Wang, L. A Collaborative Filtering Algorithm Based on Users’ Social Relationship Mining in Mobile Communication Network. J. Electron. Inf. Technol. 2011, 33, 3002–3007. [Google Scholar]
- Huang, D.; Arasan, V. On measuring email-based social network trust. In Proceedings of the IEEE Global Telecommunications Conference (GLOBECOM), Miami, FL, USA, 6–10 December 2010; pp. 1–5.
- Hong, J.Y.; Suh, E.H.; Kim, J.Y.; Kim, S.Y. Context-aware system for proactive personalized service based on context history. Expert Syst. Appl. 2009, 36, 7448–7457. [Google Scholar] [CrossRef]
- McBurney, S.; Papadopoulou, E.; Taylor, N.; Williams, H. Adapting pervasive environments through machine learning and dynamic personalization. In Proceedings of the IEEE International Symposium on Parallel and Distributed Processing with Applications, Miami, FL, USA, 14–18 April 2008; pp. 395–402.
- Rao, N.M.; Naidu, P.M.M.; Seetharam, P. An intelligent location management approaches in GSM mobile network. Int. J. Adv. Res. Artif. Intell. 2012, 1, 30–37. [Google Scholar]
- Xie, H.; Meng, X. A Personalized Information Service Model Adapting to User Requirement Evolution. Acta Electron. Sin. 2011, 39, 643–648. [Google Scholar]
- Gao, Q.; Cho, Y.I. A Multi-Agent Personalized Query Refinement Approach for Academic Paper Retrieval in Big Data Environment. J. Adv. Comput. Intell. Intell. Inf. 2012, 7, 874–880. [Google Scholar]
- Gao, Q.; Cho, Y.I. A Multi-Agent Personalized Ontology Profile Based Query Refinement Approach for Information Retrieval. In Proceedings of the 13th International Conference on Control, Automation and System, Gwangju, Korea, 20–23 October 2013; pp. 543–547.
- Gao, Q.; Dong, X.; Fu, D. A Context-Aware Mobile User Behavior Based Preference Neighbor Finding Approach for Personalized Information Retrieval. Proced. Comput. Sci. 2015, 56, 471–476. [Google Scholar] [CrossRef]
- Yin, G.; Cui, X.; Ma, Z. Forgetting curve-based collaborative filtering recommendation model. J. Harbin Eng. Univ. 2012, 33, 85–90. [Google Scholar]
- Yuan, W.W.; Guan, D.H.; Lee, Y.K.; Lee, S.Y. The small-world trust network. Appl. Intell. 2011, 35, 399–410. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Q.; Fu, D.; Dong, X. A Context-Aware Mobile User Behavior-Based Neighbor Finding Approach for Preference Profile Construction. Sensors 2016, 16, 143. https://doi.org/10.3390/s16020143
Gao Q, Fu D, Dong X. A Context-Aware Mobile User Behavior-Based Neighbor Finding Approach for Preference Profile Construction. Sensors. 2016; 16(2):143. https://doi.org/10.3390/s16020143
Chicago/Turabian StyleGao, Qian, Deqian Fu, and Xiangjun Dong. 2016. "A Context-Aware Mobile User Behavior-Based Neighbor Finding Approach for Preference Profile Construction" Sensors 16, no. 2: 143. https://doi.org/10.3390/s16020143