1. Introduction
Signal compression techniques aim at decreasing the number of bits needed to represent the signal (such as speech, image, audio and video), enhancing the efficiency both of transmission and storage. Compression techniques are widely used in applications with storage and bandwidth constraints, such as: storage of medical images, satellite transmissions, voice communication in mobile telephony and videoconference. One of the many techniques used to achieve signal compression is vector quantization (VQ), in which a codebook is used for signal reconstruction.
Vector quantization [
1,
2] is a lossy compression technique, which uses a mapping
Q of a vector
X, in a
K-dimensional Euclidean space, into another vector belonging to a finite subset
W of
:
The finite subset
W is called a
codebook. Each codebook element
,
, is called a
codevector. The number of components in the codevectors is the
dimension (
K). The size of the codebook is the number of codevectors, denoted by
N. In several speech coding [
3,
4,
5] and image coding [
6,
7,
8,
9] systems, VQ has been used successfully, leading to high compression rates. VQ has also been used in other applications, such as speaker identification [
10,
11], information security such as steganography and digital watermarking [
12,
13,
14,
15,
16,
17,
18], and classification of pathological voice signals [
19].
Vector quantization is an extension of scalar quantization in a multidimensional space. The performance of VQ depends on the designed codebooks. The prevailing algorithm for codebook design is Linde-Buzo-Gray (LBG) [
20], also known as
Generalized Lloyd Algorithm (GLA) or
K-
means. Other examples of codebook design algorithms are:
fuzzy [
7,
21,
22], competitive learning [
23], memetic [
24], genetic [
25], firefly [
26] and honey bee mating optimization [
27].
In vector quantization of a digital image, a codebook of size N is used, consisting in K-dimensional vectors. The process replaces blocks of pixels from the corresponding image by the most similar blocks of pixels in the codebook. So, the better the codebook, the higher the quantized image quality.
Typical grouping approaches used in VQ split in two categories:
crisp and
fuzzy clustering. Traditionally, crisp clustering is executed by the
K-
means algorithm. Due to initialization dependency,
K-
means can be stuck in undesired local minima. On the other hand, fuzzy clustering is usually performed by the
fuzzy K-
means (FKM) algorithm [
28]. FKM attributes each training pattern to every other cluster with different pertinence degrees [
29]. Therefore, FKM is able to reduce the random initialization dependency [
7,
29,
30,
31] at a high computational cost.
The
K-
means (KM) and
fuzzy clustering algorithms, e.g.,
fuzzy K-
means (FKM), have been used in a wide range of scenarios and applications, such as: digital soil pattern recognition [
32], archaeology [
33], indoor localization [
34], discrimination of cabernet sauvignon grapevine elements [
35], white blood cell segmentation [
36], abnormal lung sounds diagnosis [
37], intelligent sensor networks in agriculture [
38], magnetic resonance image (MRI) segmentation [
39,
40], speaker recognition [
41] and image compression by VQ [
29,
42,
43].
The aforementioned works show that clustering algorithm applications include image coding, biometric authentication, pattern recognition, among others. The performance evaluation of the clustering algorithms depends on the application. In signal compression, an important aspect is the quality of the reconstructed signal. In pattern recognition systems, an important figure of merit is the recognition rate. The processing time of the clustering algorithms is also a relevant aspect. In this paper, techniques are presented for accelerating families of fuzzy K-means algorithms applied to VQ codebook design for image compression. Simulations show that the presented techniques lead to a decrease in processing time for codebook design, while preserving its overall quality.
One of the many techniques used in this work is the
Equal-
average Nearest Neighbor Search (ENNS) [
44,
45], which is usually used in the minimum distance coding phase of VQ. However, in this paper, ENNS is used in some of
fuzzy K-
means families, precisely in the partitioning of the training set. The acceleration of FKM algorithms is also obtained by the use of a lookahead approach in the crisp phase of such algorithms, leading to a decrease in the number of iterations.
The remaining sections are organized as follows:
Section 2 covers
K-
means algorithm and
fuzzy K-
means families.
Section 3 presents modified versions of
fuzzy K-
means families. In
Section 4, nearest neighbor search techniques are introduced with focus in the scenario of accelerating codebook design. The results and final considerations are presented in
Section 5 and
Section 6, respectively.
2. Codebook Desing Techniques
Vector quantization performance is highly dependent on codebook quality. The codebook is a set of reference patterns or templates. In digital image coding, the codebook corresponds to a set of reference blocks of pixels. In this paper, K-means algorithm and fuzzy K-means families are the techniques under consideration for codebook design.
The main difference between K-means and fuzzy K-means algorithms is that, in the former, each training vector belongs to one quantization cell. In the latter, each training vector can be associated to more than one quantization cell, with some degree of pertinence to each cell.
K-
means algorithm partitions the
vector space by associating each training vector to a single cluster using nearest neighbor search. Therefore, given an input vector
, it belongs to the cluster (cell or Voronoi region):
where
is a distance measure. Euclidean square distance between
and
is widely used in digital image vector quantization. In this case,
is the nearest neighbor (NN) of
, that is,
is the quantized version of
. This is equivalent to
. The nearest neighbor search can be associated to a pertinence function:
The distortion, obtained by representing the training vectors by their corresponding nearest neighbors, is:
in which
is the
i-th training vector,
. As
is a function of
, in order to minimize the distortion, vectors
are updated according to:
Equations (2) and (5) are related to the partitioning of the training set and to the codebook update. The algorithm stops at the end of the
-th iteration if:
The input parameters of the K-means algorithm are: codebook size (N), codevectors dimension (K) and a distortion threshold ε used as stop criterion.
The
fuzzy K-
means algorithm aims at minimizing the distortion between training vectors
and codevectors
which compose the codebook. Unlike
K-
means algorithm,
fuzzy K-
means measures the distortion by [
29]:
subject to the following conditions:
As stated in [
29],
function minimization results:
Therefore, for a given pertinence degree set of functions, the codevectors evolve at each iteration to minimize
, according to [
29]:
The nebulosity at clusters transitions is controlled by parameter and increases with this parameter.
The input parameters of the FKM algorithm are: the codebook size (N), the codevector dimension (K), the nebulosity control parameter , and the distortion threshold .
This work uses two
fuzzy K-
means families, as proposed in [
29]. The development of those algorithms is based on transition from
fuzzy to crisp mode, being the latter mode equivalent to
K-
means algorithm strategy. The algorithm
fuzzy 1 (FKM1) presents three modifications in its construction when compared to FKM. The first is how the pertinence function is calculated:
in which
gives the maximum distance between the training vectors and codevectors, and
is a positive integer. The second modification concerns the codebook update, defined by Equation (5). The last modification is found in the transition from
fuzzy to crisp mode. For that purpose, a distortion threshold
is defined, with
. Therefore, FKM1 algorithm has the following parameters as input:
,
,
and two distortion thresholds—precisely,
represents the
fuzzy to crisp mode transition threshold and
represents the stop criterion.
The fuzzy 2 family (FKM2) uses the same codebook update and pertinence function calculations as proposed by fuzzy K-means algorithm, that is, Equations (9) and (10), respectively. The only difference is the inclusion of fuzzy to crisp mode transition.
4. Nearest Neighbor Search Techniques for Accelerating the Codebook Design
When FKM1 and FKM2 algorithms change to crisp mode (which is equivalent to the conventional K-means algorithm), the complexity of the nearest neighbor search, performed by the K-means, can be minimized by efficient search techniques. Usually, K-means algorithm uses Full Search (FS) to compute the nearest neighbor, which is highly time consuming.
A great number of operations can be saved by eliminating poor codevector candidates to the nearest neighbor. This can be accomplished by using search techniques, such as
Partial Distortion Search (PDS) [
48] and
Equal-
average Nearest Neighbor Search (ENNS) [
44,
45]. Both were originally proposed to VQ encoding phase. Instead, in this paper, they are used in FKM1 and FKM2 algorithms. PDS and ENNS apply rejection criteria on codevectors, decreasing, by that means, the time spent in the nearest neighbor search.
PDS algorithm, as proposed in [
48], consists of a traditional technique to computational complexity reduction involved in nearest neighbor search. PDS determines, for any
, if the accumulated distance to the first
codevector components is greater than
(the minimum distance found in the search so far). If the condition is true, that codevector does not represent the NN. So, it is assumed that the following expression is satisfied:
where
,
is the
l-th component of training (input) vector
and
is the
l-th component of codevector
. When this condition is satisfied there is no need to perform the hole calculation for the Euclidean distance between
and
. With this approach, the number of multiplications, subtractions and additions is reduced, decreasing the search time and, therefore, accelerating the codebook design in comparison to the full search.
In the ENNS algorithm, the mean for each codevector is calculated and sorted previously. Then, a lookup is performed, using some search algorithm, to find the codevector with mean closest to the mean
of the current input vector
x. When such codevector is found, searches do not need to be performed for codevectors whose means
satisfy the criterion:
where
is the mean of the
i-th codevector,
is the mean of current input vector and
is the distance between the input vector and the codevector with the nearest mean.
When the elimination criterion is not satisfied for a given vector, it enters in a waiting list to be looked up later. After all winner candidates to that input vector are collected, a search is performed calculating the square Euclidean distance and the PDS is used.
ENNS decreases the computational time compared to the full search with
N (codebook size) memory allocations penalty, compared to PDS. That fact is proved in [
49]. Because ENNS was originally used in coding phase, it performs one means sorting, since the codebook vectors were previously designed. However, as for the codebook design, the
K-
means algorithm (on the crisp mode of FKM families), at each iteration, updates its codevectors, hereby a new average sorting is needed for each iteration. Acceleration alternatives in the scenario of FKM2 are presented as follows (see Algorithms 1–3). The notation MFKM2 stands for modified
fuzzy K-
means family 2, that is, an acceleration (savings in the number of iterations) obtaining by using the scale factor
s in codebook update.
| Algorithm 1. Partitioning step of the conventional FKM2 algorithm in crisp mode |
For Calculate , Determine the smallest of the calculated distances. The nearest neighbor of is such that . In this case, is allocated to the Voronoi region
Codebook update step of the FKM2 algorithm:
Calculate
Codebook update with , in which is the codevector at the -th iteration |
| Algorithm 2. Partitioning step of the MFKM2 algorithm in crisp mode |
For Calculate , Determine the smallest of the calculated distances. The nearest neighbor of is such that . In this case, is allocated to the Voronoi region
Codebook update step of the MFKM2 algorithm:
Calculate
Codebook update with |
It is worth mentioning that other approaches have been proposed in the literature for the purpose of fast codebook search. As an example, the method introduced by Chang and Wu [
50] is an interesting partial-search technique based on a graph structure which leads to computational cost savings.
| Algorithm 3. Partitioning step of the MFKM2 algorithm in crisp mode with the use of ENNS |
(Calculate off-line the mean of each input vector)
Calculate the mean of each codevector and order the means in ascending order
For Determine the codevector with the minimum absolute difference between its mean and the input vector mean. Obtain as the squared Euclidean distance between this codevector and the input vector Eliminate from the search process the codevectors that satisfy: For the remaining codevectors, i.e., those who were not eliminated from the search, apply the PDS algorithm for calculating the distance and update (the minimum distance found in the search so far) At the end of the process, the codevector corresponding to is the nearest neighbor of . In this case, is allocated to the Voronoi region
Codebook update step of the MFKM2 algorithm:
Calculate
Codebook update with |
5. Results
Simulations have been performed in a
core I5-
2450m (2.50 GHz)
Intel computer using nine 256 × 256 pixel images: Lena, Barbara, Elaine, Boat, Clock, Goldhill, Peppers, Mandrill and Tiffany. Each image has 256 gray scale levels, as shown in
Figure 1. The parameters used for the simulations were:
K = 16 (4 × 4 pixel blocks),
N = 32, 64, 128 and 256,
u = 2 and two distortion thresholds,
and
. For each parameter combination of dimension
K and codebook size
N (for example
N = 32 and
K = 16), 20 random initializations were used for each algorithm.
Results are presented in terms of average number of iterations and average execution time (in seconds) of the codebook design algorithms, as well as average peak signal noise ratio (PSNR) and structural similarity (SSIM) index [
51] of reconstructed images. The notation adopted for the methods are presented in
Table 1. Results are organized in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15.
Regarding
Table 2, all algorithms under consideration led to close values of PSNR. It can be noted that the use of the scale factors led to a decrease in the average number of iterations. In other words, it is observed, for instance, that the average number of iterations of MFKM is smaller than that of FKM. The decrease in the number of iterations is also observed when one compares MFKM1 with FKM1, as well as when one compares MFKM2 with FKM2. The use of PDS for nearest neighbor search contributes to reduce the time spent for codebook design. For instance, considering Elaine image, for FKM1 and FKM1-PDS, the use of PDS in the partitioning step of the second phase (crisp phase) of FKM1 led to a codebook design average time 0.34 s, which is lower than 0.38 s spent for codebook design using the full search (FS) or brute force in that phase. If the ENNS is used in substitution to FS, the time spent is 0.27 s. The highest time savings, concerning FKM1, is obtained by using the scale factor
to decrease the number of iterations combined with the use of ENNS for efficient nearest neighbor search. Indeed, regarding Elaine image, that combination led to an average time spent for codebook design equals 0.25 s.
With respect to
Table 3, it is observed that the highest time spent for codebook design was for FKM algorithm. It is important to mention that this behavior is observed for all images and codebook sizes considered in the present work. As an example, for the Boat image and codebook size
N = 32, the codebook design average time spent by FKM is 1.64 s, which is 8.2 times higher than the average time spent by KM and about 3.8 times higher than the average time spent by FKM2.
Table 3 results also confirm the benefits of using the modified versions of the codebook design algorithms (
versions, with the use of the scale factor
s) and nearest search algorithms for codebook design time savings when compared to the standard versions of the codebook design algorithms. For each image under consideration, it is observed that all algorithms lead to close PSNR values.
From the results presented in
Table 4 and
Table 5, it is observed that the codebook design average time spent by FKM2 is higher than that one of FKM1. It is important to mention that the same behavior is observed for all the images under consideration, for codebook sizes 128 and 256. Regarding the number of iterations, it is observed in
Table 4 and
Table 5 that the modified versions with the use of the scale factor
(algorithms MFKM, MFKM1 and MFKM2) have and average execution time lower than that of the corresponding standard versions (FKM, FKM1 and FKM2 respectively)—due to the savings in the number of iterations.
Table 4 and
Table 5 point out that the lowest codebook design average time is obtained with the combination of the scale factor
and ENNS. Indeed, considering for instance
fuzzy K-
means family 2 and Clock image, in
Table 5 the average time of MFKM2-ENNS is 0.92 s, which is lower than the average time presented by all the other versions (FKM2, MFKM2, FKM2-PDS, MFKM2-PDS and FKM2-ENNS).
It is observed in
Table 2,
Table 3,
Table 4 and
Table 5 that the best PSNR results, for five out of six images under consideration, for
N = 32 and
N = 64, are obtained by using algorithms MFKM2, MFKM2-PDS and MFKM2-ENNS.
From
Table 6 and
Table 7, for all images under consideration and for all codebook sizes, the modified versions (those using the scale factor
s) of the algorithms led to average number of iterations smaller than that of the original versions. For instance, for Lena image, the average number of iterations of MFKM is 21.25 and the corresponding number of FKM is 27.60; for Goldhill image, MFKM1 average number of iterations is 16.30 and FKM1 average number of iterations is 20.60; for Boat image, the average number of iterations of MFKM2 is 14.15, and the corresponding number of FKM2 is 16.25. The use of ENNS has proved to be an effective alternative for codebook design time savings. Consider, for instance, Elaine image, for which the codebook design average time of FKM1-ENNS is 0.77 s, while the corresponding time for FKM1 is 1.13 s. For all images under consideration, for each family of
fuzzy K-
means algorithm, the highest codebook design time savings is obtained by combining the use of scale factor
s (M version of the codebook design algorithm) with ENNS. As an example, for all images under consideration, the codebook design average time spent by MFKM2-ENNS is lower than the corresponding one of FKM2, MFKM2, FKM2-PDS, MFKM2-PDS and FKM2-ENNS.
As can be observed in
Table 8 and
Table 9, in comparison with FKM1 family, the modified version MFKM1 has a smaller average number of iterations, which lead to a lower codebook design average time. Additional time savings is obtained by the use of efficient nearest neighbor search methods, that is, PDS or ENNS. It is important to observe that the modified versions generally lead to higher PSNR values when compared to the original versions. As an example, for Lena image, MFKM1 led to 30.13 dB average PSNR, while the original version led to a corresponding 29.74 dB PSNR; for the same image, the substitution of FKM2 by MFKM2 led to an increase of 0.20 dB in terms of average PSNR.
According to
Table 8 and
Table 9, for codebook size
N = 256, for four out of six images under consideration, the best PSNR results are obtained by using algorithms MFKM2, MFKM2-PDS and MFKM2-ENNS. Particularly, for Lena image, the substitution of KM by MFKM2-ENNS lead to a PSNR gain of 0.54 dB.
According to
Table 10, the best performance in terms of SSIM is obtained by using MFKM codebooks—the highest SSIM values are observed for MFKM in five out of seven training sets. P-M-T is a training set corresponding to the concatenation of images Peppers, Mandrill and Tiffany. It is important to point out that, for a fixed training set (with the exception of Lena), the absolute difference between the best SSIM result and the worst SSIM result is below 0.0090.
It is observed in
Table 11 that MFKM leads to the highest SSIM values for five out of seven training sets. For a fixed training set (with the exception of Elaine and Clock), the absolute difference between the best SSIM result and the worst SSIM result is below 0.0090.
For
N = 256, it is observed in
Table 13 that MFKM leads to the best SSIM results for 5 out of 7 traning sets considered. An interesting performance nuance must be pointed out—MFKM2, MFKM2-PDS and MFKM2-ENNS are the techniques that lead to the highest PSNR results (according to
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9), but do not lead to the best SSIM results (as can be observed from
Table 10,
Table 11,
Table 12 and
Table 13). It is important to observe that codebook design aims to decrease the distortion (mean square error) obtained in representing the training vectors by the corresponding nearest neighbors, that is, by the corresponding codevectors with minimum distance. In other words, higher PSNR values are obtained by codebooks that are more “tuned” with the training set, that is, by codebooks that introduce less distortion in terms of MSE, which do not necessarily correspond to higher SSIM values. PSNR and SSIM results are presented in
Table 14 for images reconstructed by codebooks designed with the training set P-M-T. The method MFKM2-ENNS was used for codebooks designed for
K = 16 and
N = 32, 64, 128 and 256, leading to corresponding code rates 0.3125 bpp, 0.375 bpp, 0.4375 bpp and 0.5 bpp. It is observed that, for a given image, both PSNR and SSIM increases with
N, that is, the distortion decreases with the code rate.
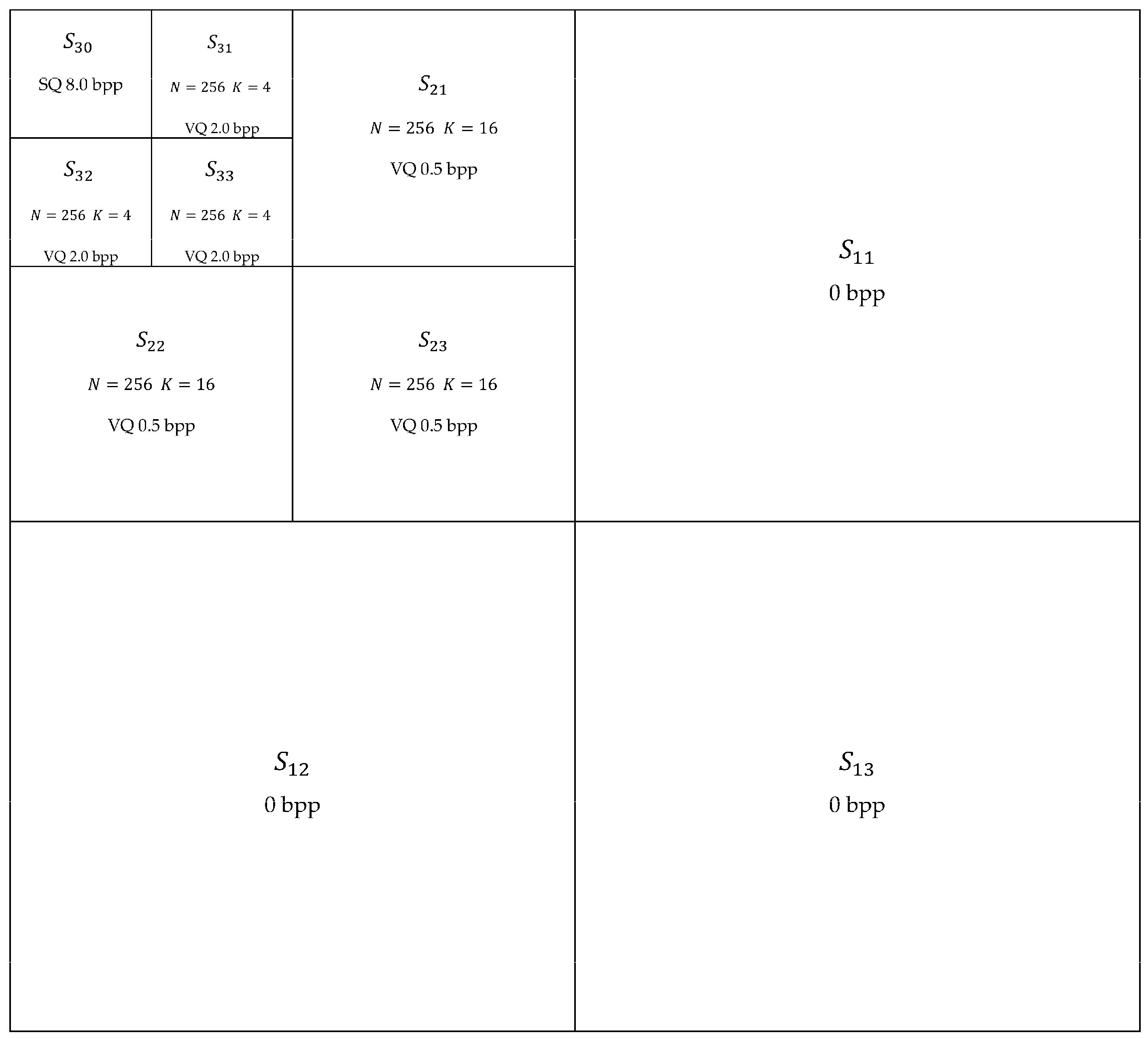
The last set of simulations show that vector quantization in the Discrete Wavelet Transform (DWT) domain (that is, by quantizing the wavelet coefficients) lead to reconstructed images with better quality when compared to the ones obtained by VQ in the spatial domain (that is, by quantizing the gray scale values of pixels). For the purpose of DWT VQ [
52] at the code rate 0.3125 bpp, a three level multiresolution wavelet decomposition was performed [
53] with the wavelet family Daubechies 6. The resulting subbands
are submitted to quantization schemes according to
Figure 2.
Subbands
,
and
are submitted to the respective wavelet VQ codebooks with
N = 256 and
K = 16 (blocks of 4 × 4 wavelet coefficents). Subbands
,
and
are submitted to the respective wavelet VQ codebooks with
N = 256 and
K = 4 (blocks of 2 × 2 wavelet coefficents). Subband
is submitted to scalar quantization (SQ) with 8.0 bpp. Subbands
,
and
are excluded (that is, code rate 0 bpp)—one can observe in
Figure 3 that the application of the inverse discrete wavelet transform after exclusion of subbands
,
and
, preserving all the other subbands with the wavelet coefficients unchanged, leads to images close to the respective original ones (
Figure 1), with good quality, as revealed by visual inspection.
It is worth mentioning that, in the general case, after the application of a multiresolution discrete wavelet transform (DWT) with resolution levels, the subbands , with and , are submitted to multiresolution VQ codebooks. In other words, with the exception of subband (corresponding to the approximation component in the lowest resolution level), each subband is quantized with a specific codebook. The subband is submitted to 8.0 bpp scalar quantization, since it is the subband with the highest importance to the quality of the image obtained from the inverse discrete wavelet transform (IDWT).
Assume the general case of an image with
pixels. The number of wavelet coefficients in
, with
, is
. Let
be the code rate (in bpp or, correspondingly, in bit/coefficient) of VQ for subband
,
and
, and
be the code rate (in bpp) of scalar quantization for subband
. The final code rate
(in bpp) of the image coding using DWT (with
resolution levels) and VQ is given by:
that is:
For VQ with dimension
and codebook size
, it follows that the corresponding code rate is
. Hence, according to
Figure 2, it follows that:
and:
From
Figure 2, it follows that
and
. Thus, from Equation (17), the corresponding overall code rate under the conditions presented in
Figure 2 is
It is worth mentioning that the importance of subbands
for the image quality increases with
that is the reason why
, for
.
As can be observed in
Figure 4 and
Figure 5, visual inspections of the reconstructed images reveal the superiority of DWT VQ over vector quantization in the spatial domain. The superiority is also confirmed in terms of PSNR and SSIM values.
The superiority of DWT VQ over spatial domain VQ is also observed in
Table 15. As an example, by using P-M-T as the training set, PSNR gain of 3.10 dB for Elaine image is obtained by substituting spatial domain VQ by DWT VQ. For a given image, one can observe that better PSNR and SSIM results are obtained by DWT VQ with codebooks designed by P-M-T when compared to spatial domain VQ with codebook designed by the image itself. Consider, for instance, the Lena image. If the Lena image is reconstructed using spatial domain VQ with codebook designed by itself as training set, a PSNR 26.72 dB and a SSIM 0.7791 are obtained. If the Lena image is reconstructed in the DWT domain with multiresolution codebooks designed by P-M-T as training set, a PSNR 29.35 dB and a SSIM 0.8367 are obtained.
As a final comment, image coding based on VQ is one of the possible applications of the families of fuzzy K-means algorithms considered in this paper. The focus of the present work is to assess the fact that the proposed acceleration techniques make VQ codebook design faster, since other efficient image coding techniques exist.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}