
Adaptive Connectivity Restoration from Node Failure(s) in Wireless Sensor Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Unlike most previous studies, CSFR restores the network connectivity via cooperative communication after an arbitrary single node fails (not only cut-vertex). Then, CSFR-M, which is the extension of CSFR, is presented to solve the problem of single node failure with the combination of cooperative communication and node mobility. With the combination of these two technologies, CSFR-M can overcome the shortcomings of CSFR and address the drawbacks of the existing mechanisms.
- CCRA is proposed to handle all of the problems of multiple node failure, not only the problems of multiple cut-vertex failure and network partition caused by the failures. CCRA is a localized and reactive scheme that limits the scope of node movements and the energy consumption of each node during the recovery process.
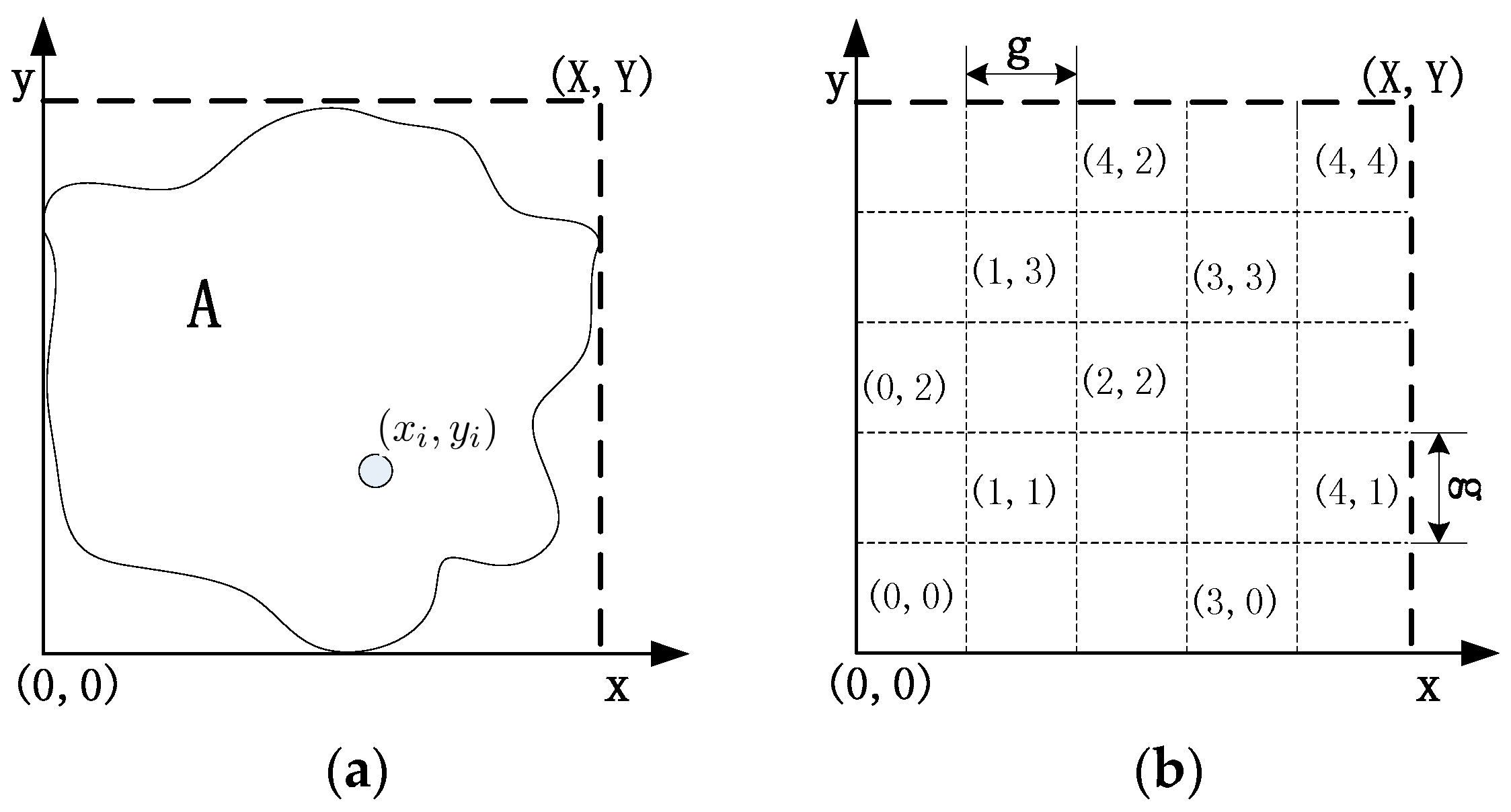
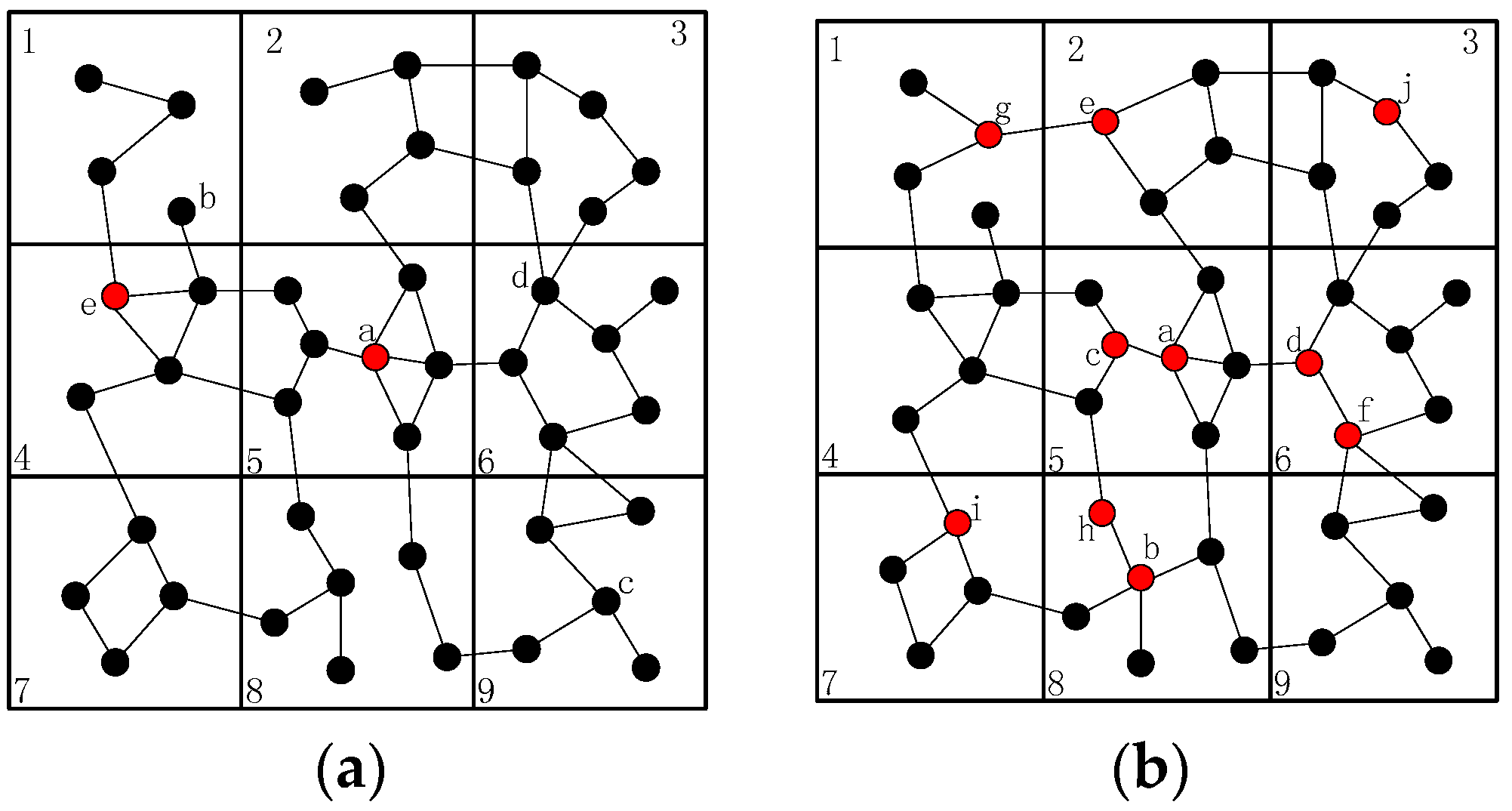
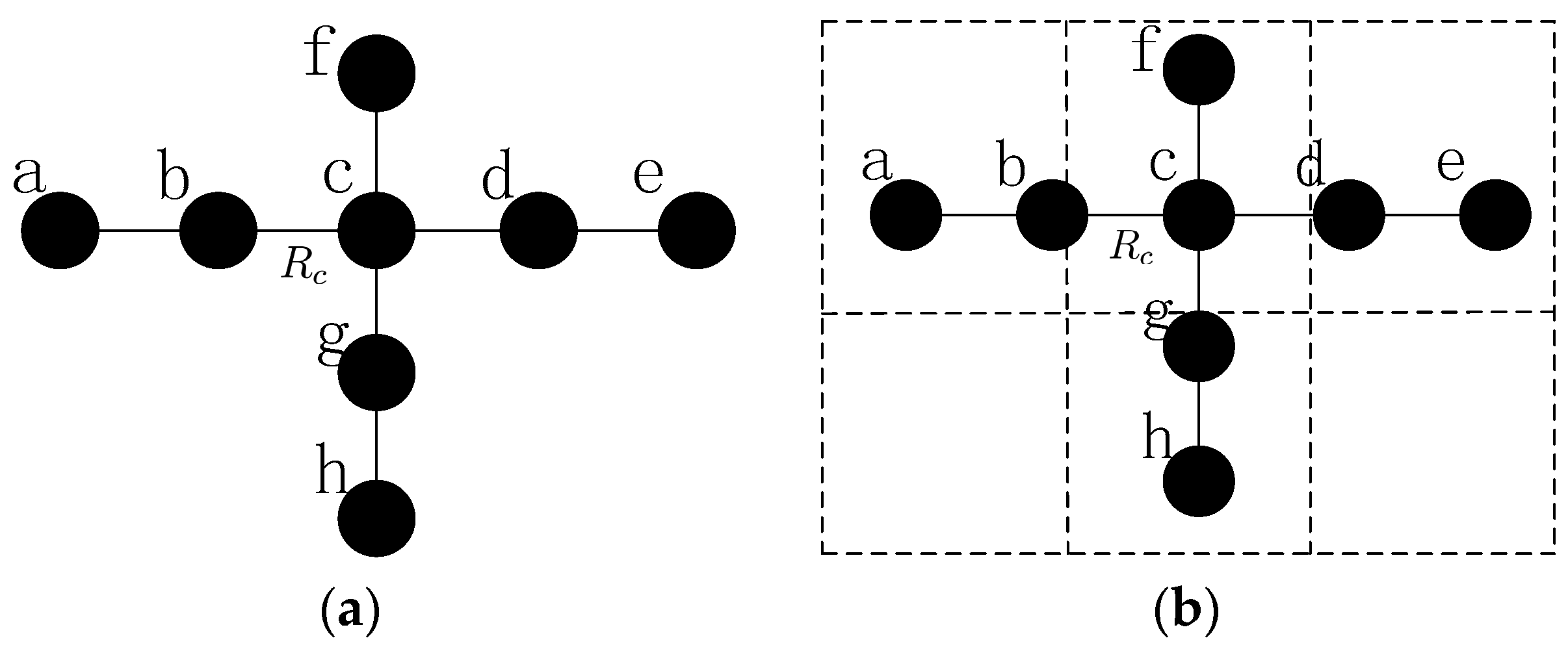
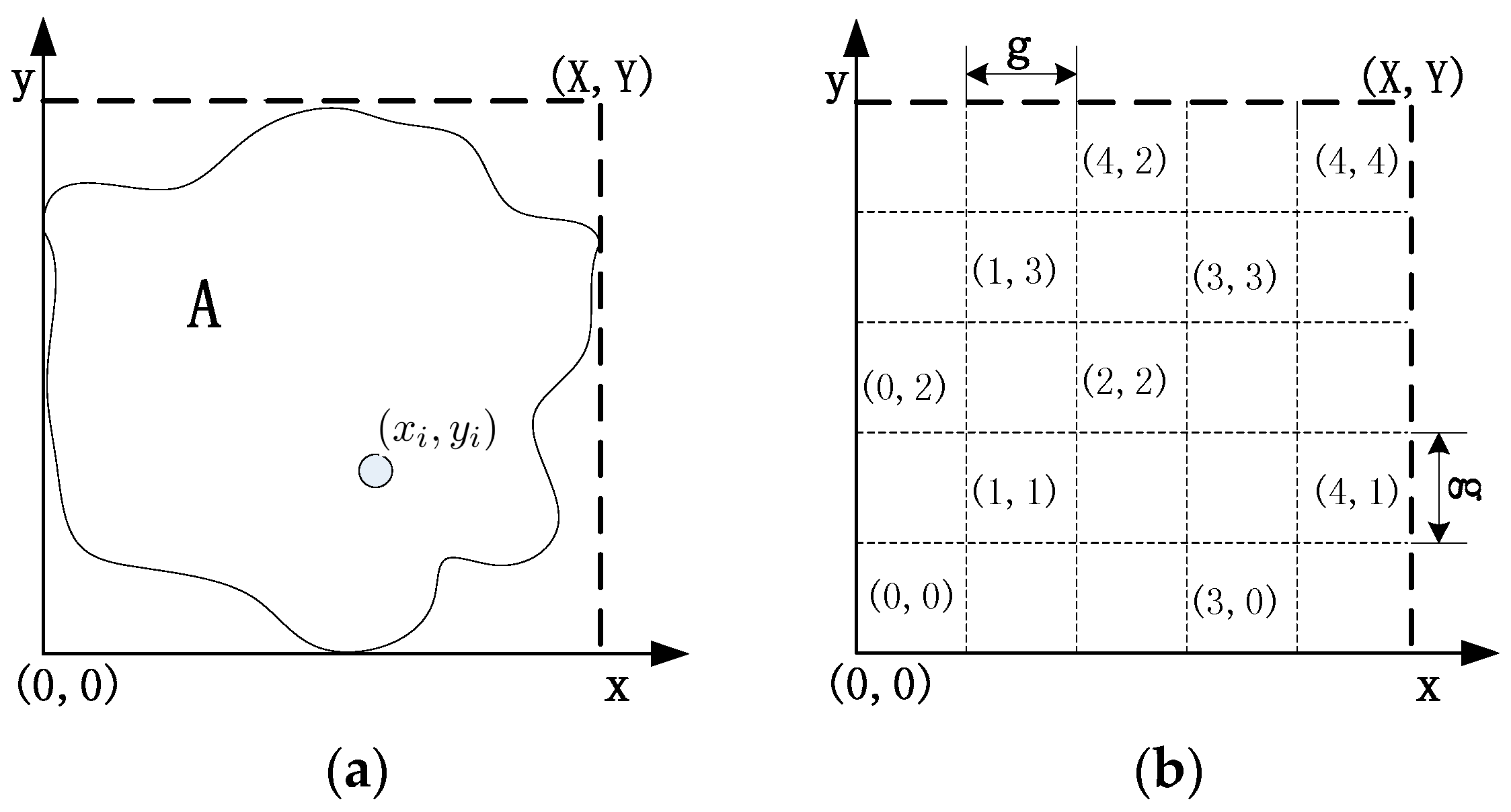
- In order to finish the recovery process in small scopes, CCRA divides the network into grids during the topology self-organization. The main idea is to reestablish the disconnected paths that are caused by the node failures via cooperative communication and the movement of some suitable sensor nodes. The principle is that the involved nodes only move out of corresponding grid when certain scenarios occur.
- The main properties of CSFR-M and CCRA are their simplicity and effectiveness. CSFR-M and CCRA avoid sophisticated diagnostics for evaluating the effects of node failure on the network connectivity, e.g., by determining whether the failed node is a cut-vertex or not. The entire process is distributed and enables the network to be self-healing without any external supervision.
2. Related Work
3. Network Model and Problem Formulation
3.1. Network Model
3.2. Problem Formulation
4. Node Failure Restoration via Cooperative Communication
4.1. Collaborative Single Node Failure Restoration (CSFR)
4.1.1. Source and Destination Nodes Selection
4.1.2. Helper Nodes Selection
4.1.3. Cooperative Communication
| Algorithm 1 CSFR |
| 1: : the failed node; : the 1-hop neighbors of node |
| 2: : the node connectivity materiality |
| 3: if then |
| 4: for every node j and in , which do |
| 5: if the distance and is the shortest distance among the 1-hop neighbors then |
| 6: , ; |
| 7: end if |
| 8: end for |
| 9: Algorithm 2 CC-link establishment |
| 10: end if |
| Algorithm 2 CC-link establishment |
| 1: : the failed node; : the 1-hop neighbors of node |
| 2: : the node connectivity materiality |
| 3: : the source node; : the destination node |
| 4: includes all the neighbor nodes of ; : the total number of neighbors of |
| 5: : the helper set of source node ; : the cooperation set |
| 6: |
| 7: while and do |
| 8: |
| 9: end while |
| 10: if then |
| 11: if then |
| 12: Return , |
| 13: else |
| 14: Announce the failure of CC-link establishment |
| 15: end if |
| 16: else |
| 17: if then |
| 18: Return , |
| 19: else |
| 20: |
| 21: end if |
| 22: end if |
| 23: the source and destination nodes will interchange and establish the CC-link again in reverse |
4.2. Collaborative Single Node Failure Restoration with Node Mobility (CSFR-M)
| Algorithm 3 CSFR-M |
| 1: : the failed node; : the node connectivity materiality; : the node partition character |
| 2: if then |
| 3: if there are orphan nodes after the failure then |
| 4: the orphan which is nearest to node will be chosen and move to replace it |
| 5: else |
| 6: if then |
| 7: Algorithm 2 CC-link establishment |
| 8: if receiving the announcement then |
| 9: the neighbors with minimum number of neighbors will be chosen to replace |
| 10: end if |
| 11: else |
| 12: if Then |
| 13: the neighbors with minimum number of neighbors will be chosen to replace |
| 14: else |
| 15: Algorithm 2 CC-link establishment |
| 16: if receiving the announcement then |
| 17: the neighbors with minimum number of neighbors will be chosen to replace |
| 18: end if |
| 19: end if |
| 20: end if |
| 21: end if |
| 22: end if |
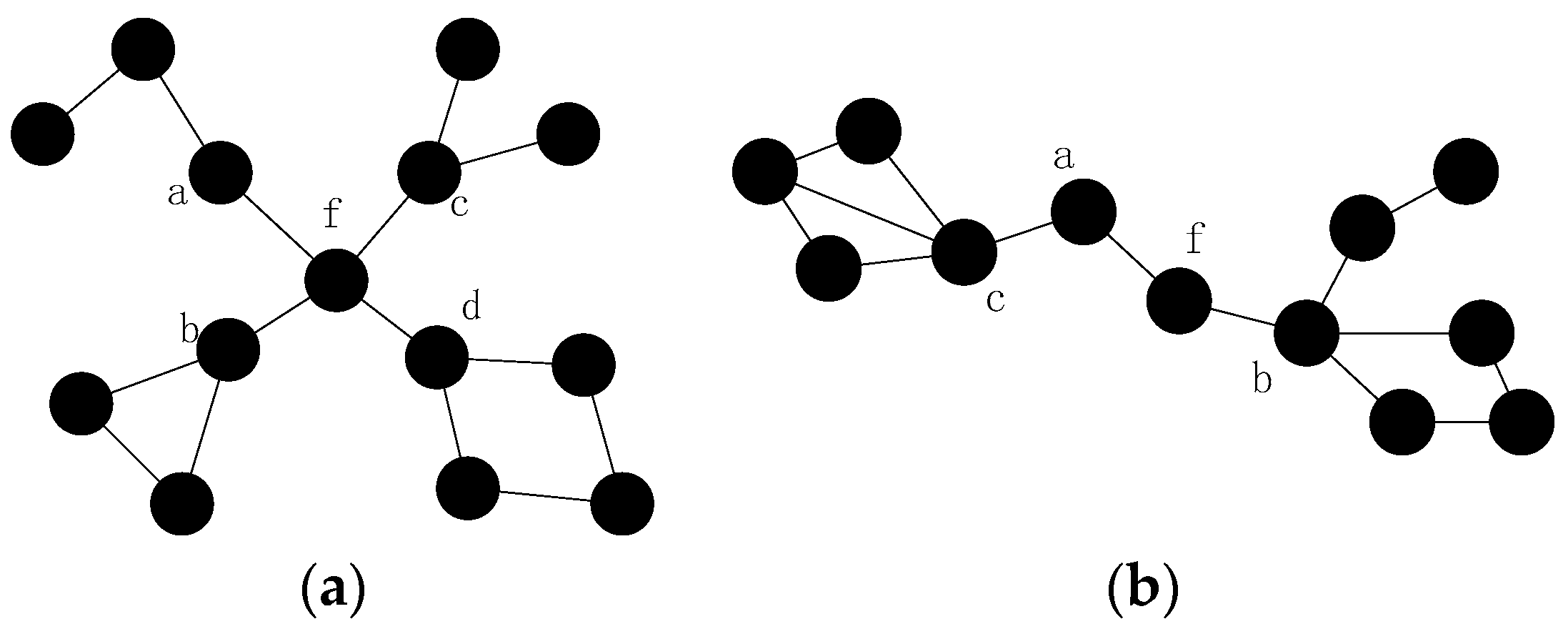
4.3. Collaborative Connectivity Restoration Algorithm (CCRA)
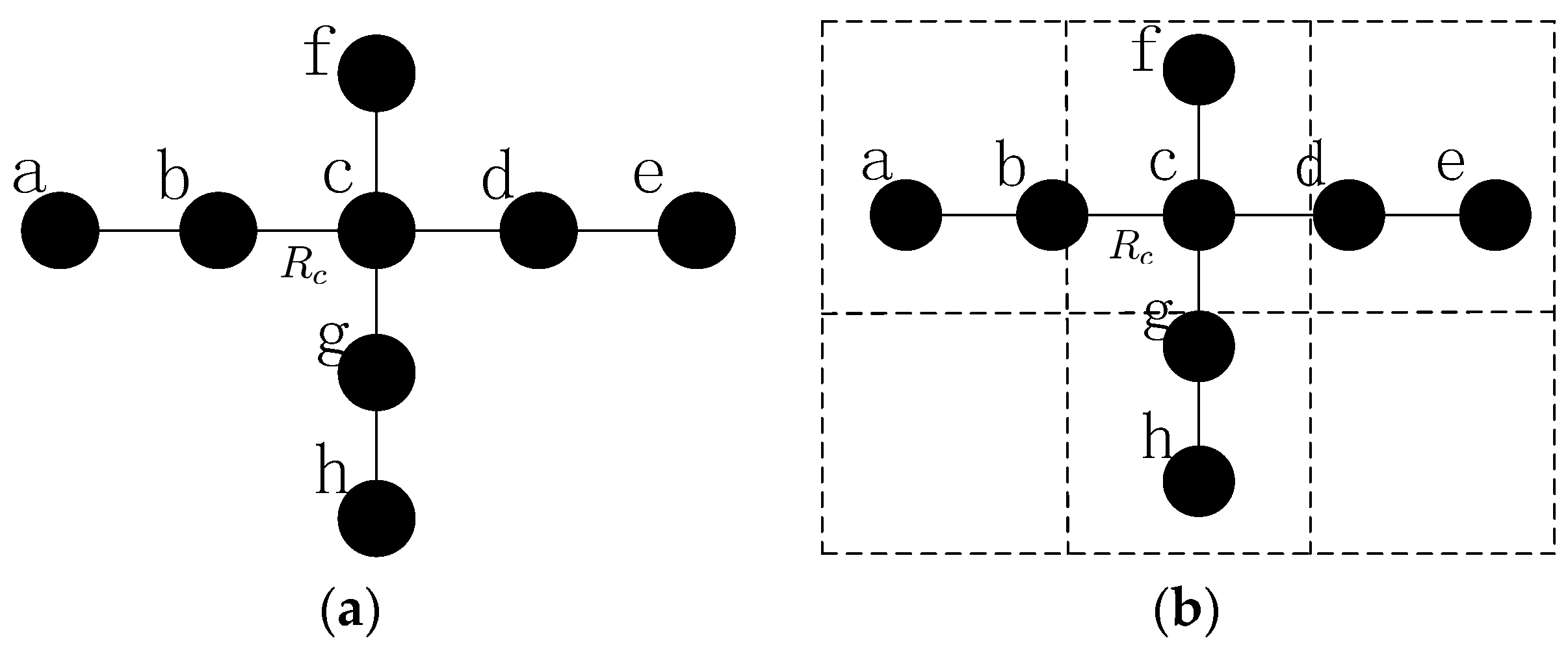
4.3.1. Problem Description
- (1)
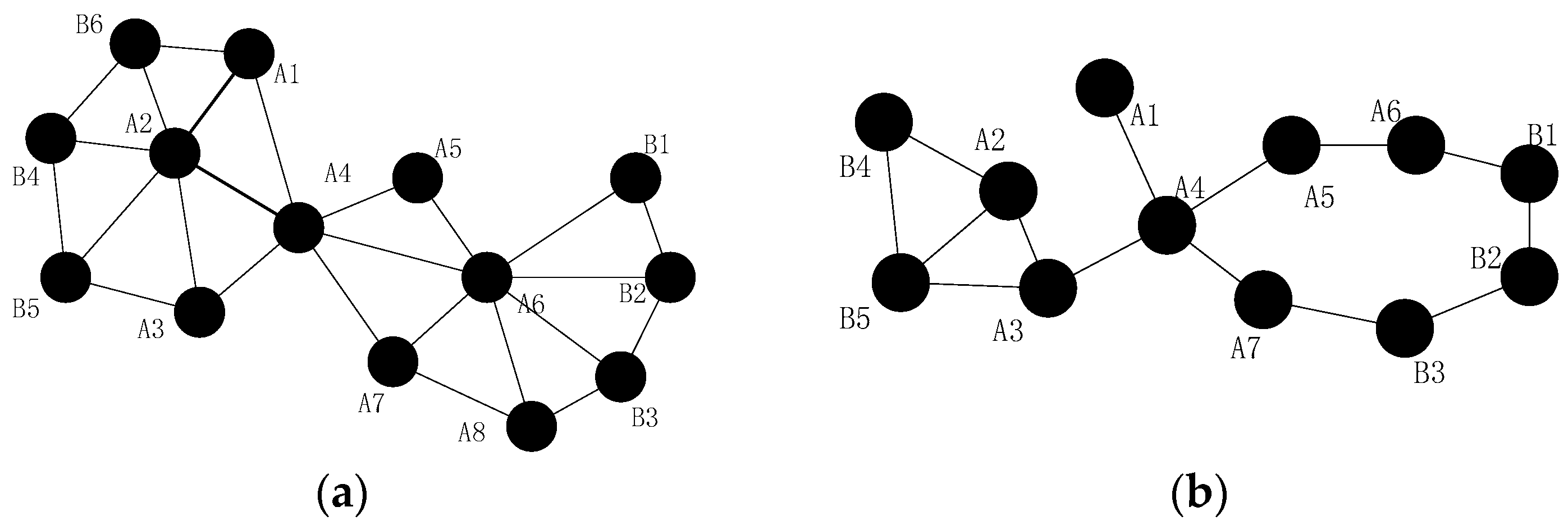
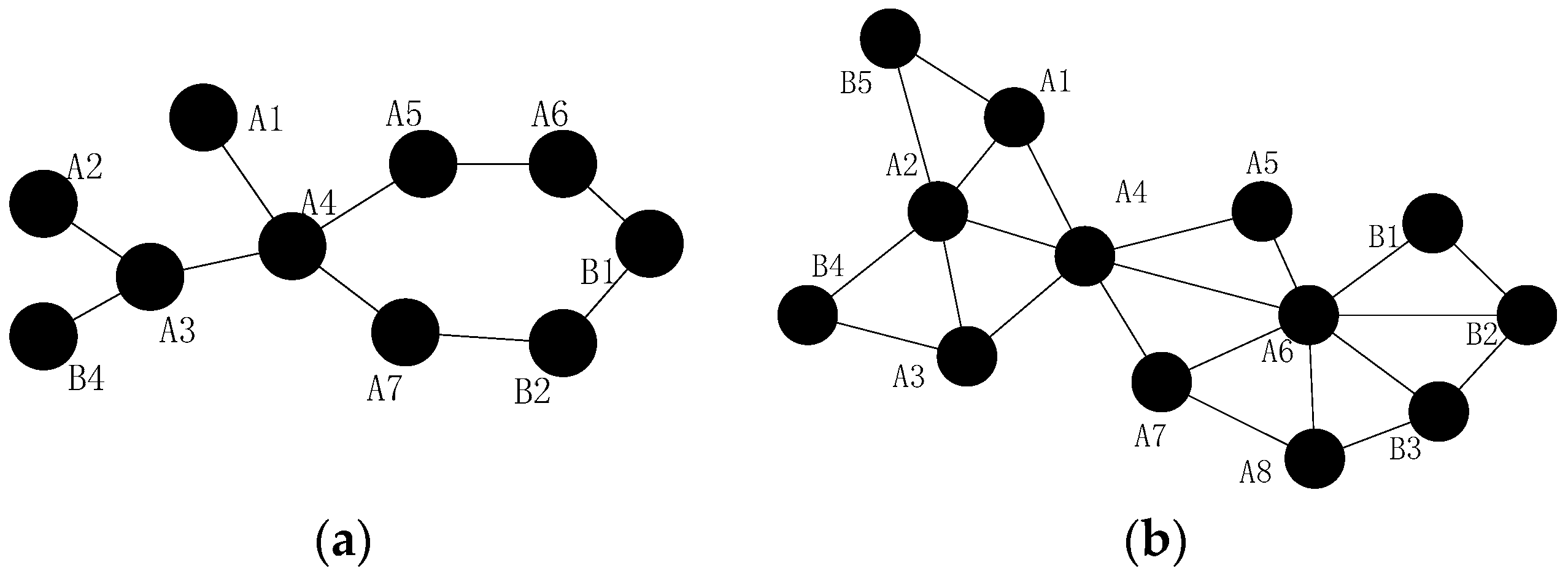
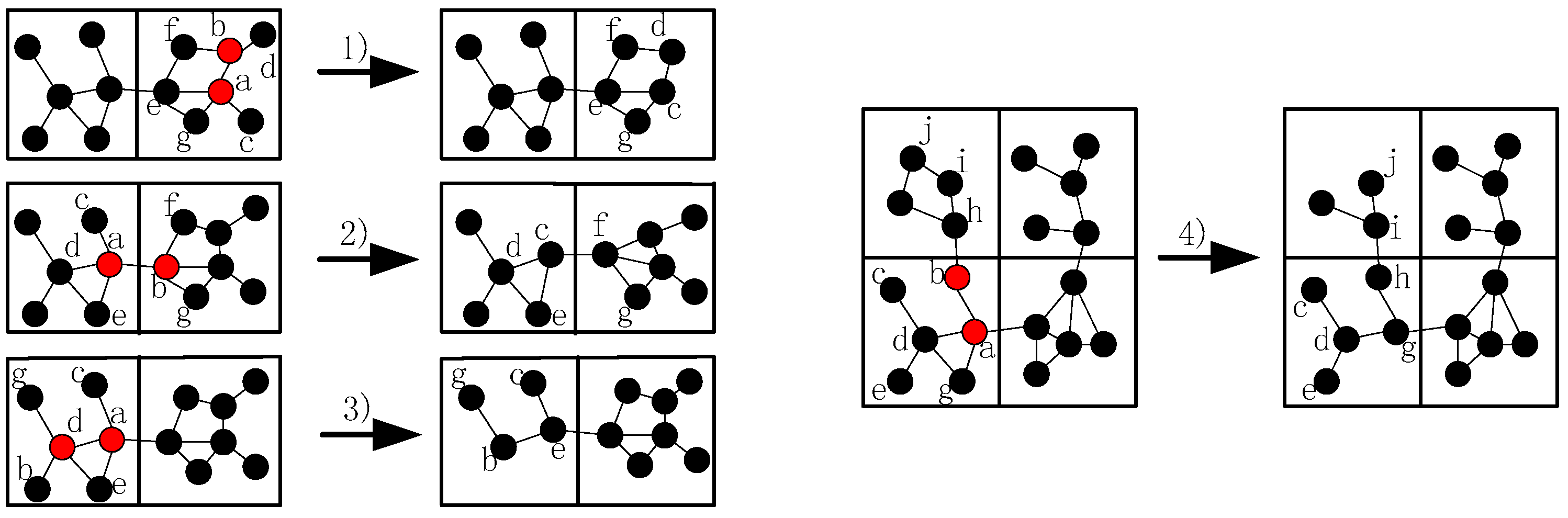
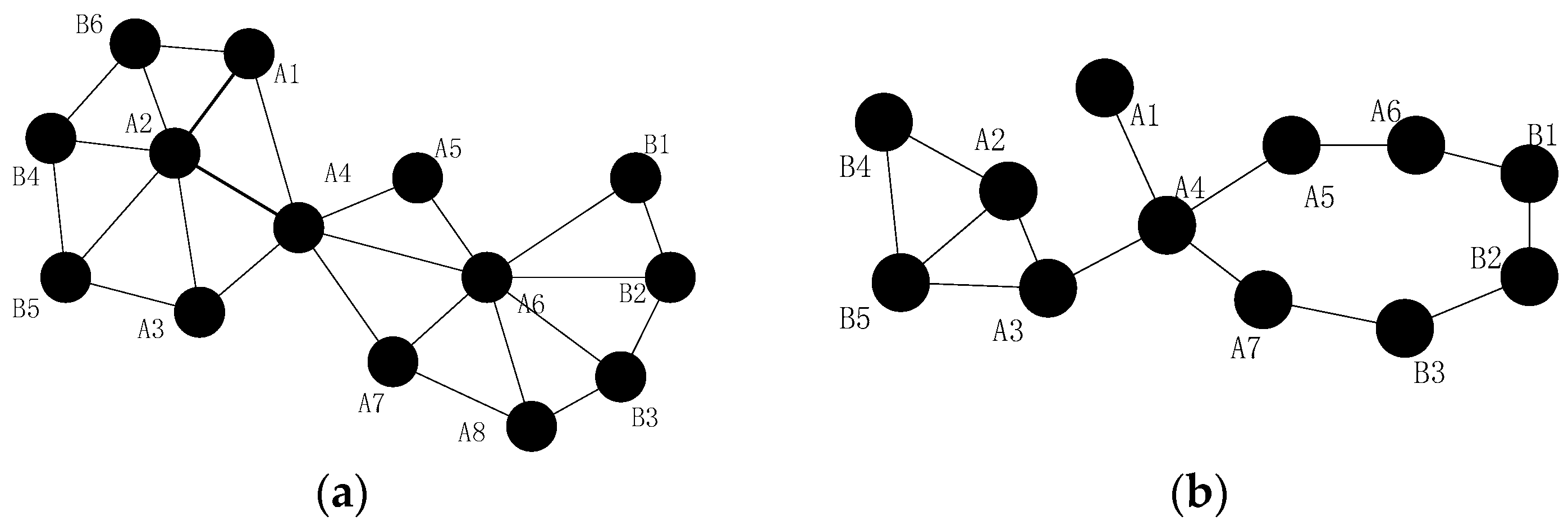
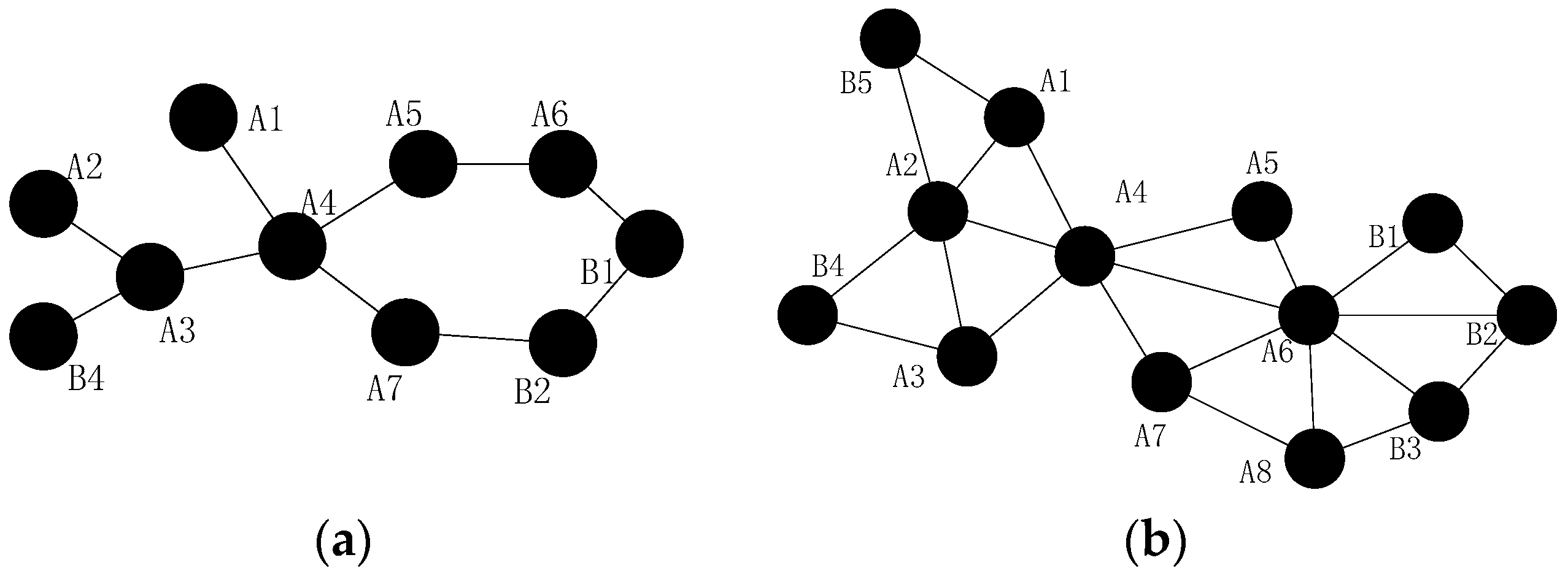
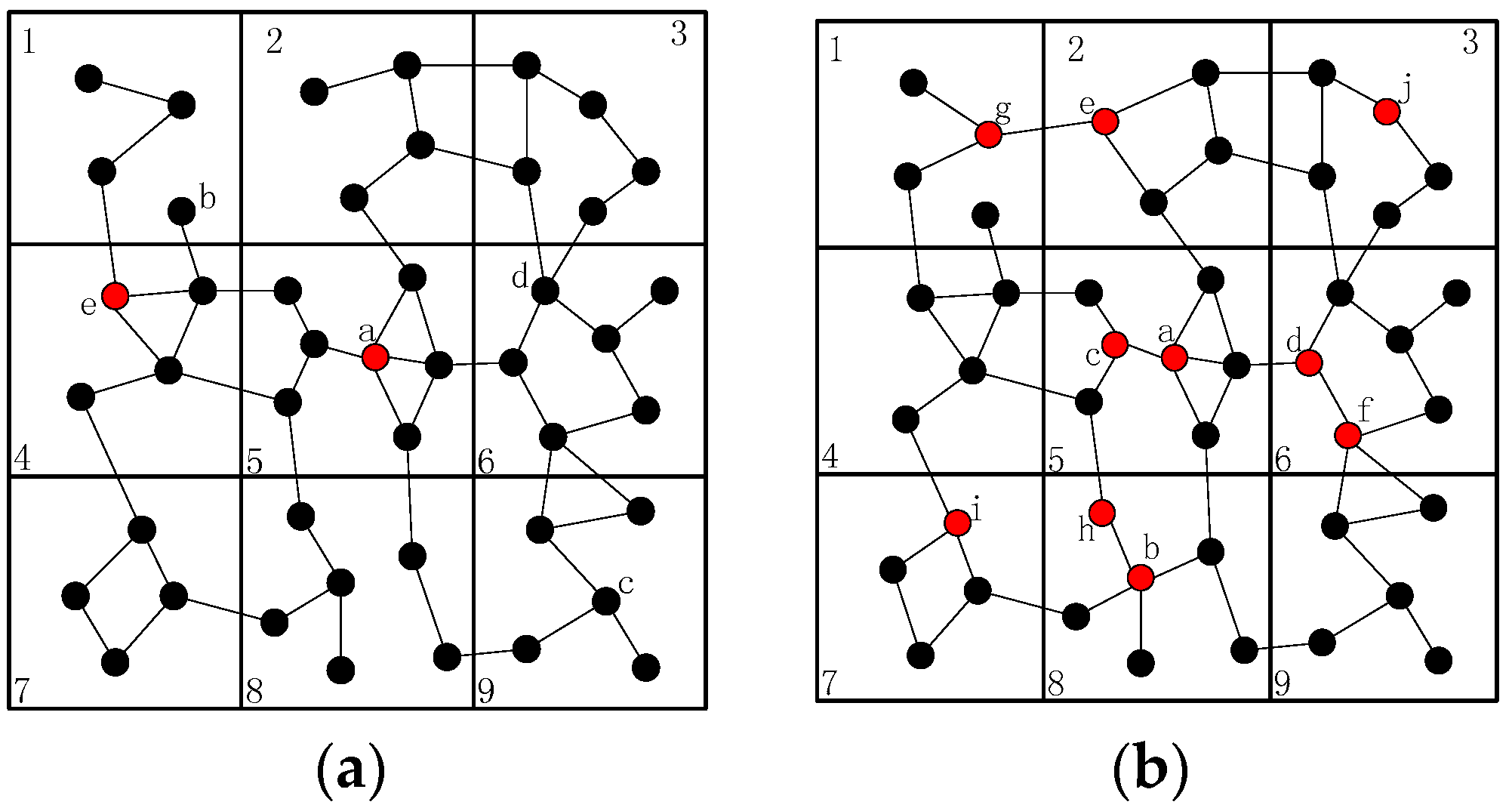
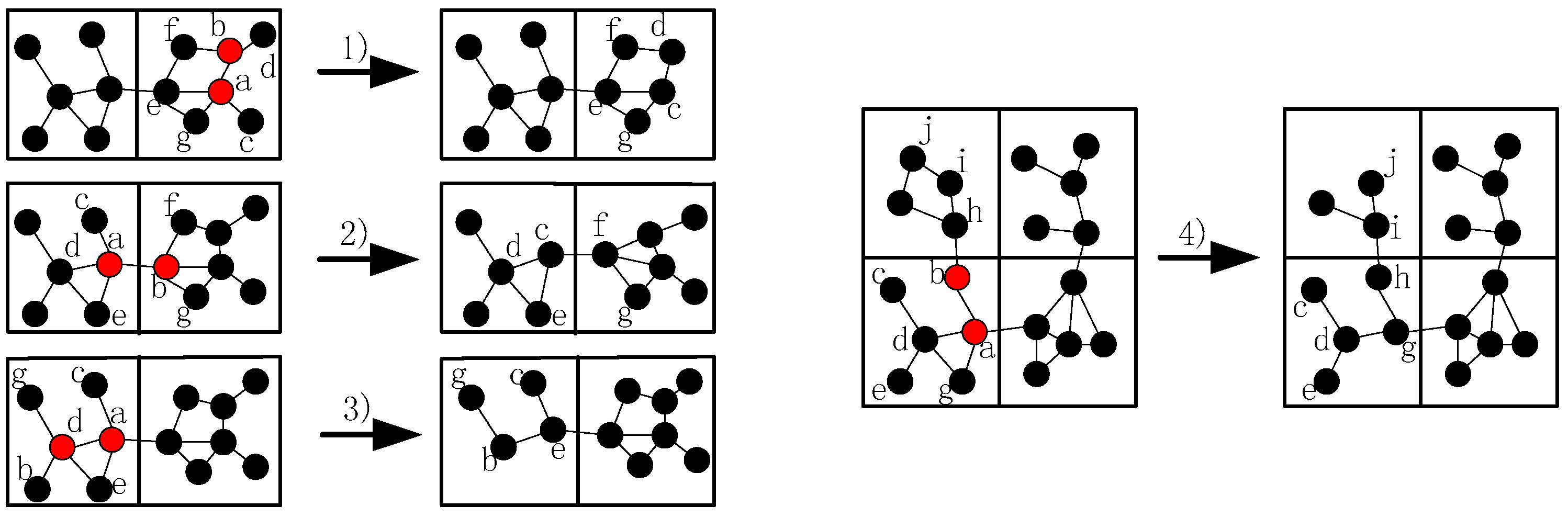
- When more than one inner-grid nodes fail in the same grid, such as node and , as mentioned above, the restoration should be localized in the grid as far as possible. Then, the neighbors of them (denote as hereafter) will check whether they could build the CC-link first, if not, the nodes in will initial the recovery process based on the node mobility. The fundamental principle is that once the neighbor node has been selected to replace one failed node, such as node , it can only move to replace node and another node will be chosen as the candidate of node .
- (2)
- When different inter-grid nodes fail in the neighboring grid, such as node and , if there are no neighboring orphan nodes and the CC-link is hard to build after the failure, the neighbor node of the failed node in the same grid that has the shortest distance to the failed node will move to repair the failure. The node with least number of inter-grid neighbors will be selected if the previous parameter is the same. Finally, the smallest node ID is preferred.
- (3)
- When inner-grid and inter-grid nodes fail in the same grid, such as node and , as mentioned above, the inner-grid node restoration goes first, so node will be replaced by node primarily in this case, then node will move to the location of node .
- (4)
- When more than one inter-grid nodes fail in the same grid, such as node and , since each node maintains a 2-hop neighbors’ table, node has the information of the failed nodes in this case and it can find out that one of the only two neighbors of node (i.e., node ) has also failed, so it will estimate that there are no enough nodes to replace node and decides to move to recover the connectivity, the topology after the restoration is shown in Figure 6.
4.3.2. Algorithm Details
| Algorithm 4 CCRA |
| 1: : the set of failed nodes which need to be restored |
| 2: if node has no failed neighbor(s) in the same grid then |
| 3: if node has no failed neighbor(s) in the neighbor grid then |
| 4: recovery process goes to case 2) |
| 5: else |
| 6: restore the connectivity similar to CSFR-M |
| 7: end if |
| 8: else |
| 9: if the connected failed nodes are all inner-grid nodes then |
| 10: recovery process goes to case 1) |
| 11: else |
| 12: if the connected failed nodes are all inter-grid nodes then |
| 13: recovery process goes to case 4) |
| 14: else |
| 15: recovery process goes to case 3) |
| 16: end if |
| 17: end if |
| 18: end if |
5. Algorithm Analysis
6. Simulation Results
6.1. Single Node Failure Restoration
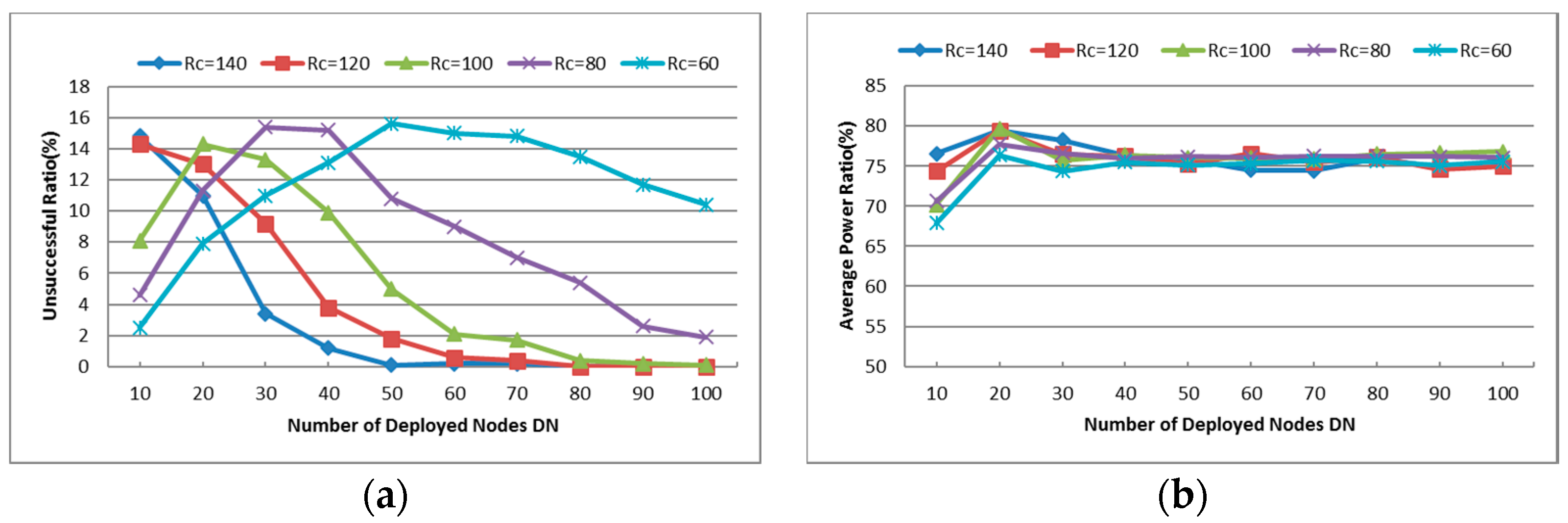
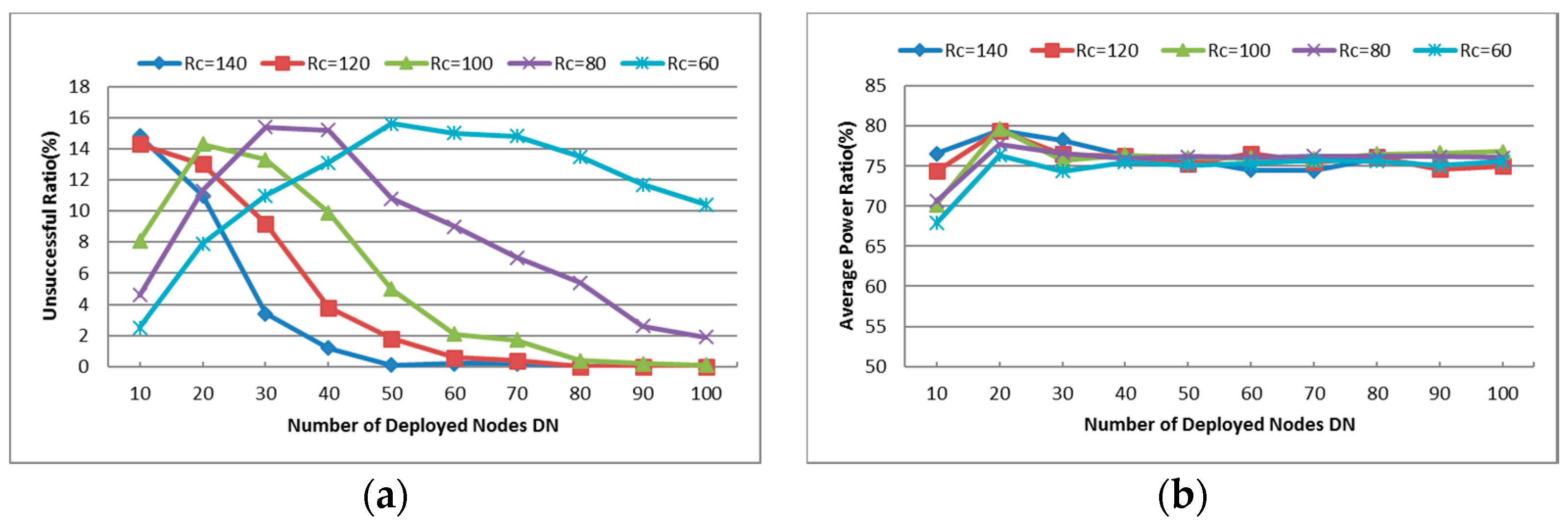
- Unsuccessful Repair Ratio: The ratio of unsuccessful repair times and the times that the CSFR works. As mentioned before, the cooperative communication is established based on Equation (6). In some cases, the source node or destination node may have no enough neighbors to build the CC-link, so the restoration maybe unsuccessful.
- Cooperative Communication Power Ratio (PR): reports the ratio of the average assigned cooperative power and the initial power, where the average assigned cooperative power is the mean value of assigned cooperative power that required for the source node, destination node and their respective helper nodes to build the CC-link according to Equation (6). It is expressed as percentages in the Figures hereafter.
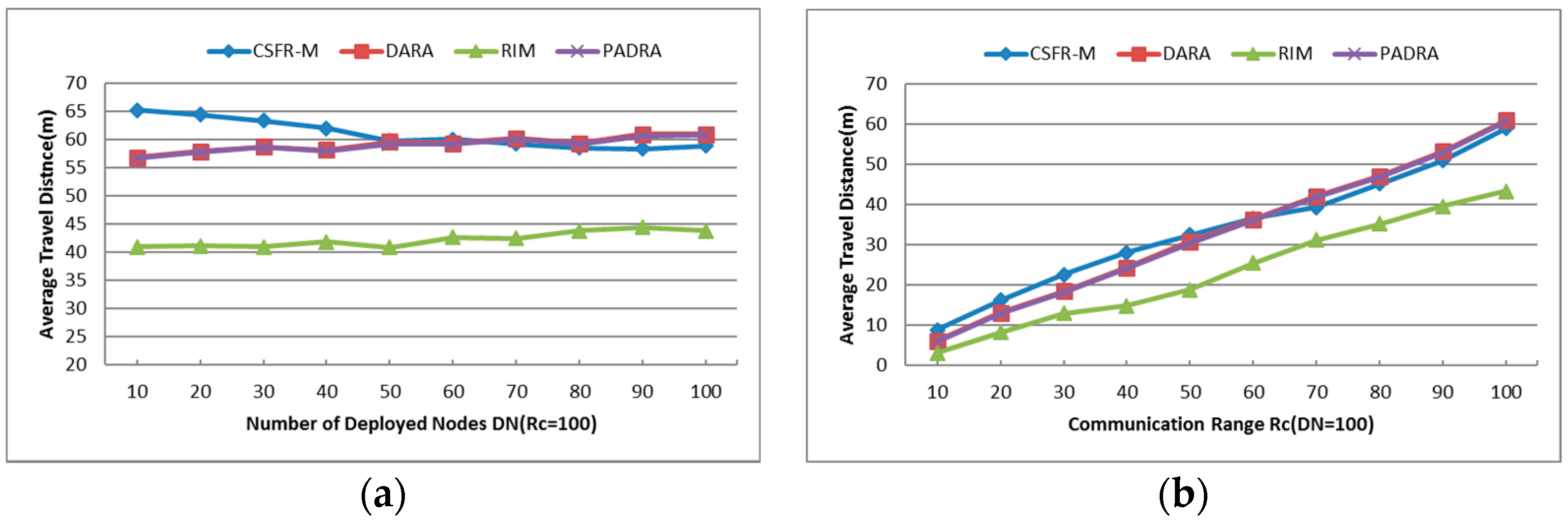
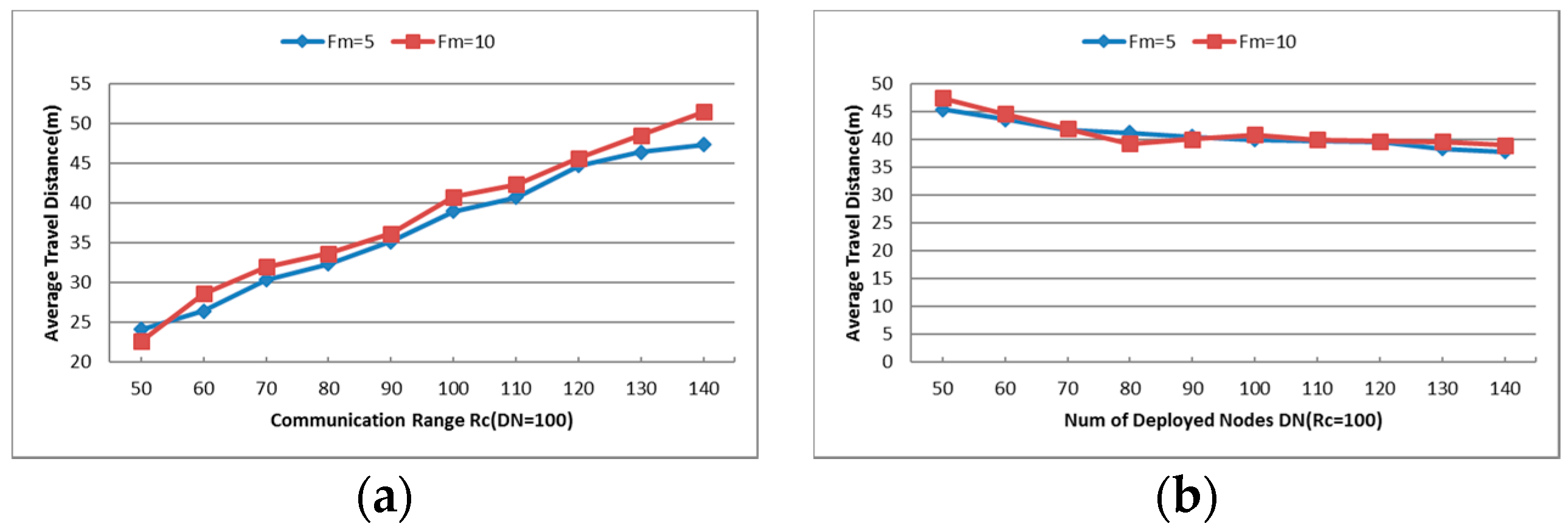
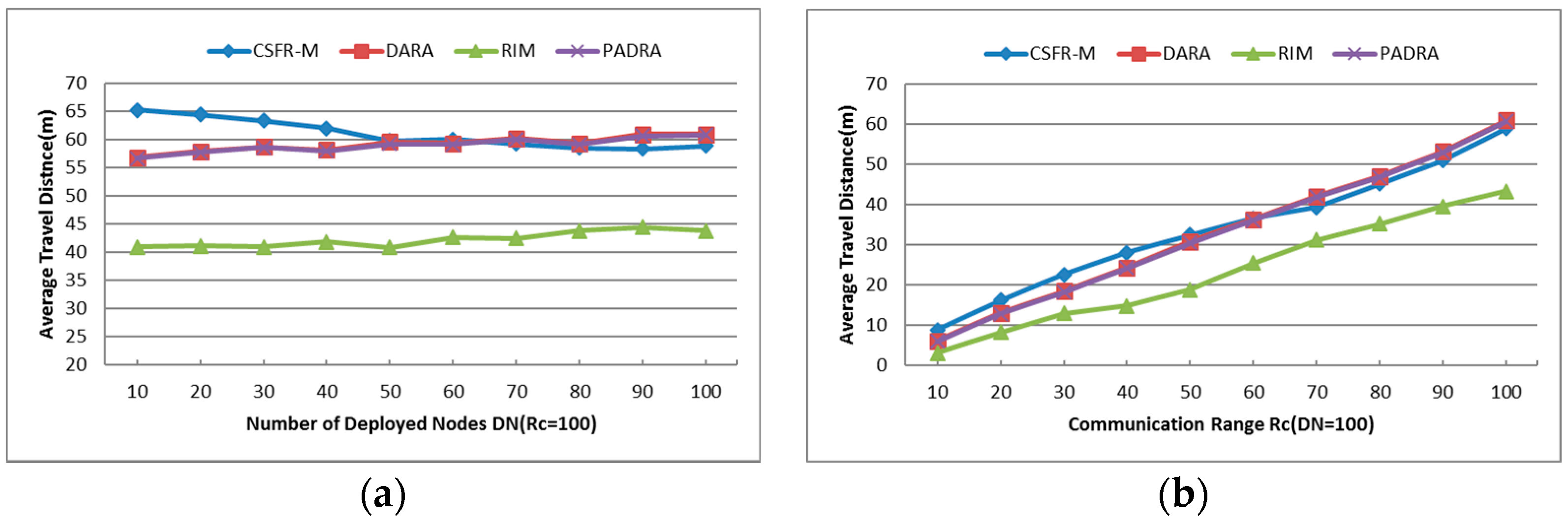
- Average Travel Distance (TD): The average travel distance experienced by every node that gets involved in the recovery process. The unit of measure is meter hereafter.
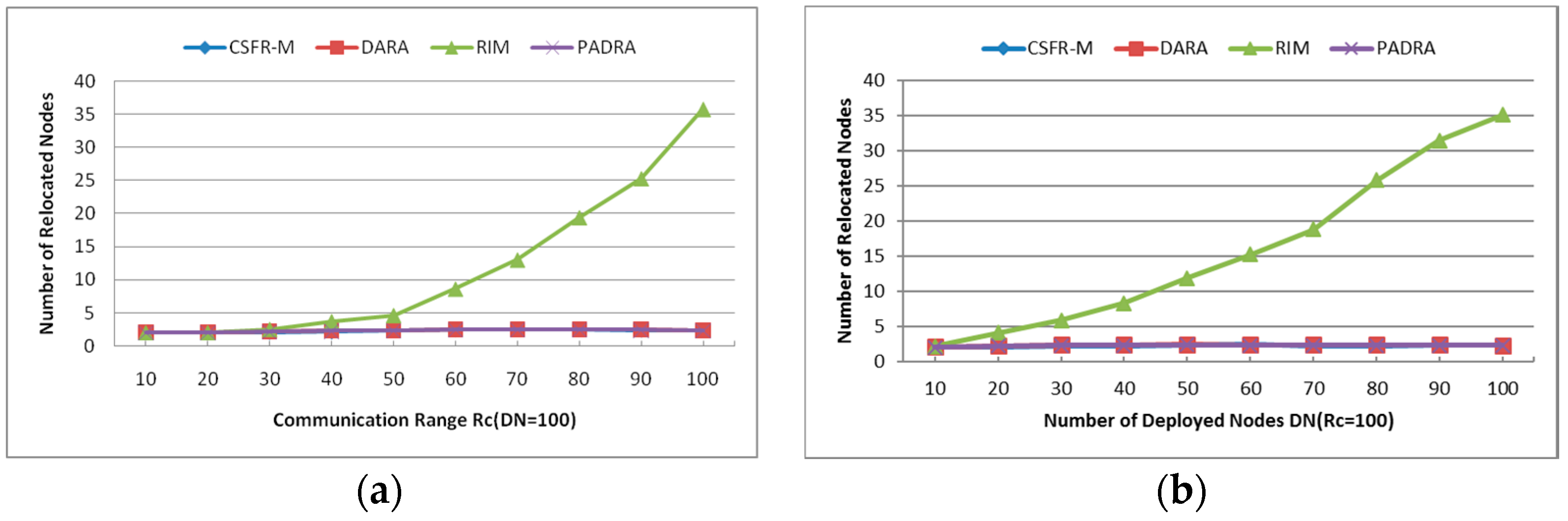
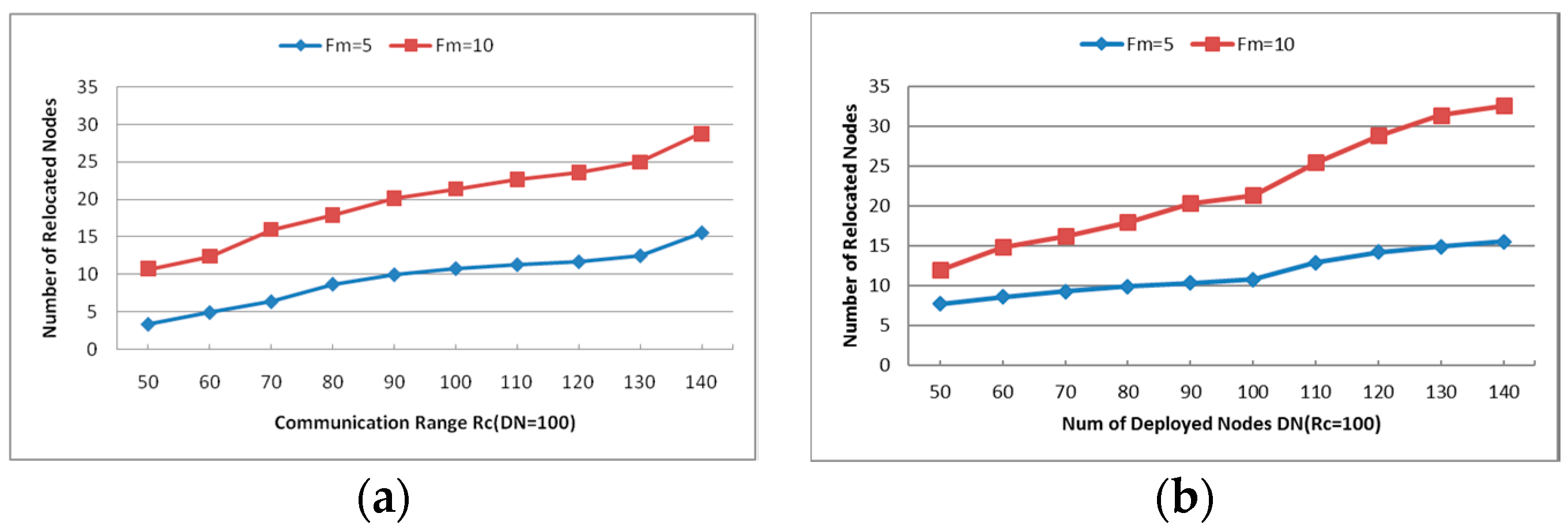
- Number of Relocated Nodes (RN): The average number of nodes that move during the restoration process. This metric reveals the scope of recovery process within the network and it works on CSFR-M and CCRA during the simulation.
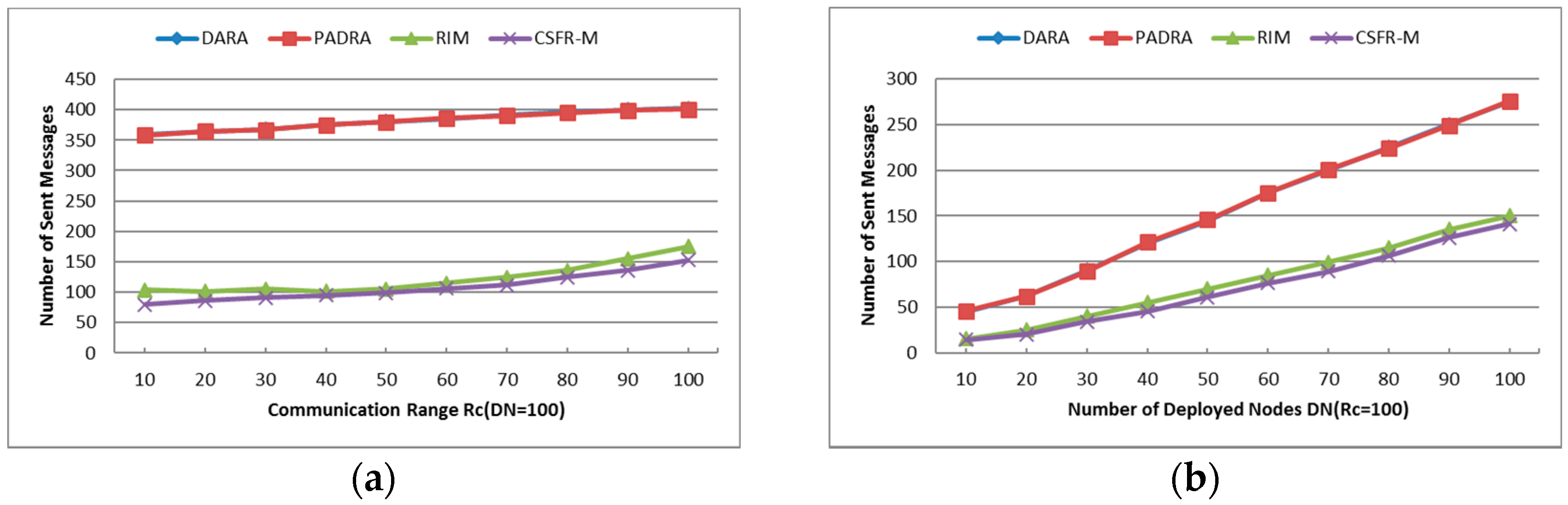
- Number of Sent Messages (SN): The total number of messages that has been sent among the nodes during the restoration.
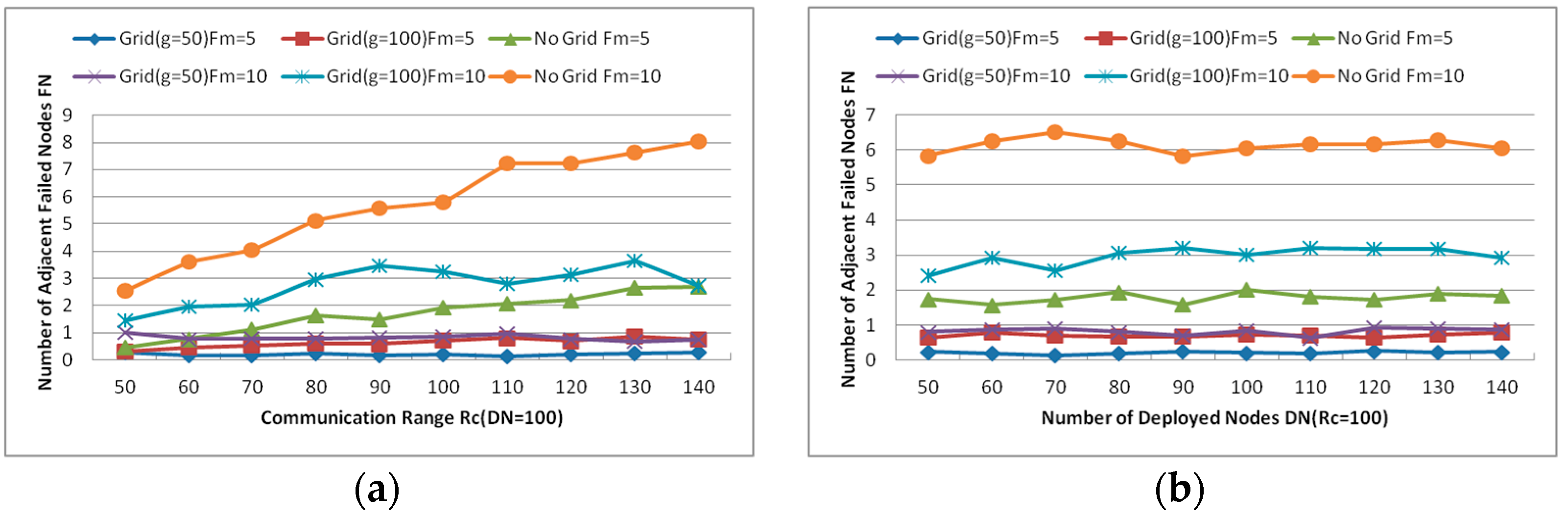
- Number of Deployed Nodes (DN): This parameter influences the node density so that the network connectivity will be affected. Since large Number of Deployed Nodes increases the node density, the number of neighbors of each node grows and it is more beneficial for establishing the CC-link.
- Communication Range (): As assumed before, all deployed nodes have the same communication range and the value of is directly proportional to the initial power of each node. Small will create a sparse network topology while the large increases the connectivity of the holistic network. The CC-link can be built or not with different values of and the number of nodes which get involved in the cascaded movement during the restoration process will also be affected.
6.1.1. Unsuccessful Repair Ratio
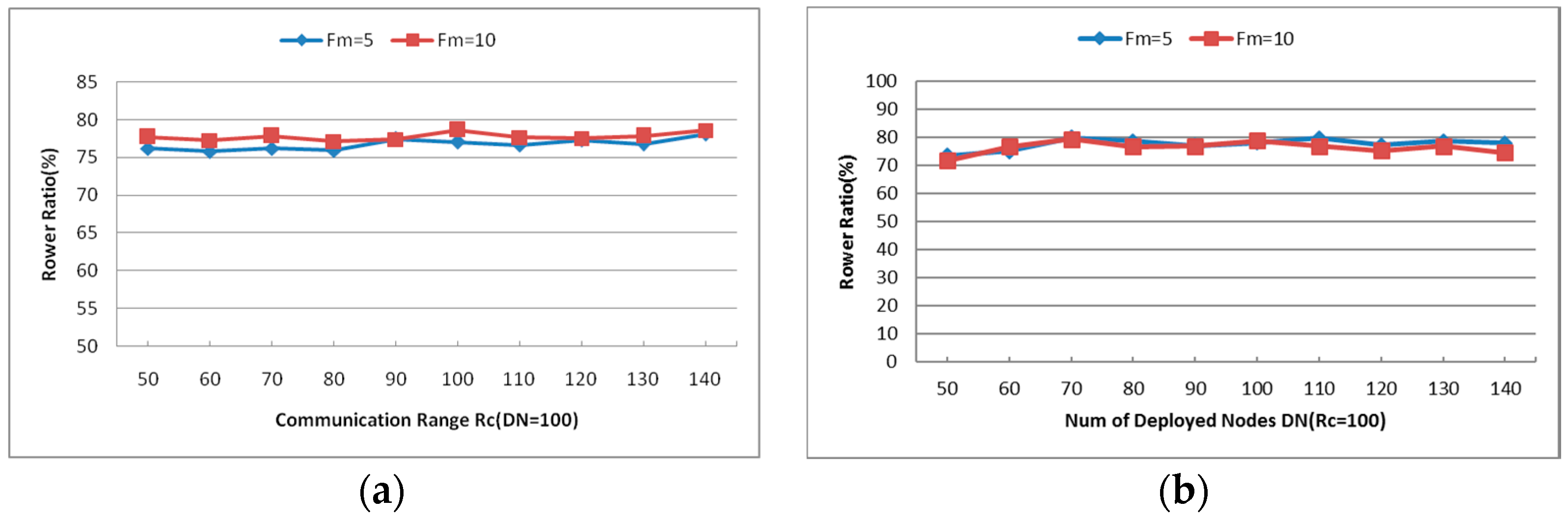
6.1.2. Cooperative Communication Power Ratio (PR)
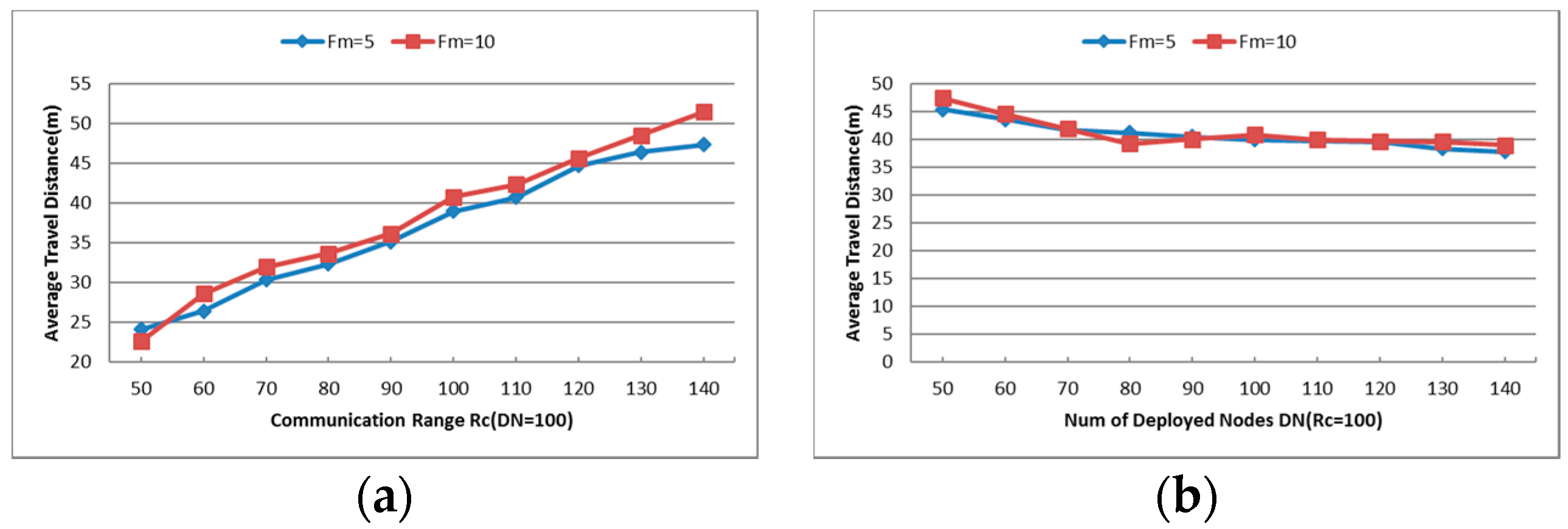
6.1.3. Average Travel Distance (TD)
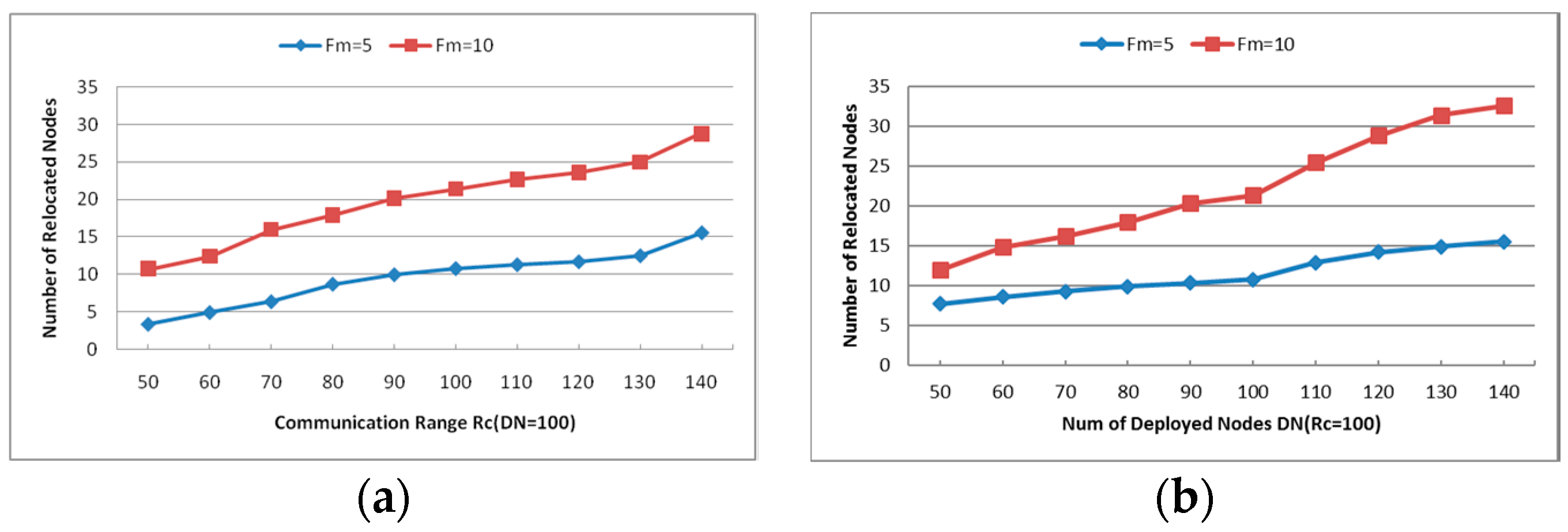
6.1.4. Number of Relocated Nodes (RN)
6.1.5. Number of Sent Messages (SN)
6.2. Multiple Nodes Failure Recovery
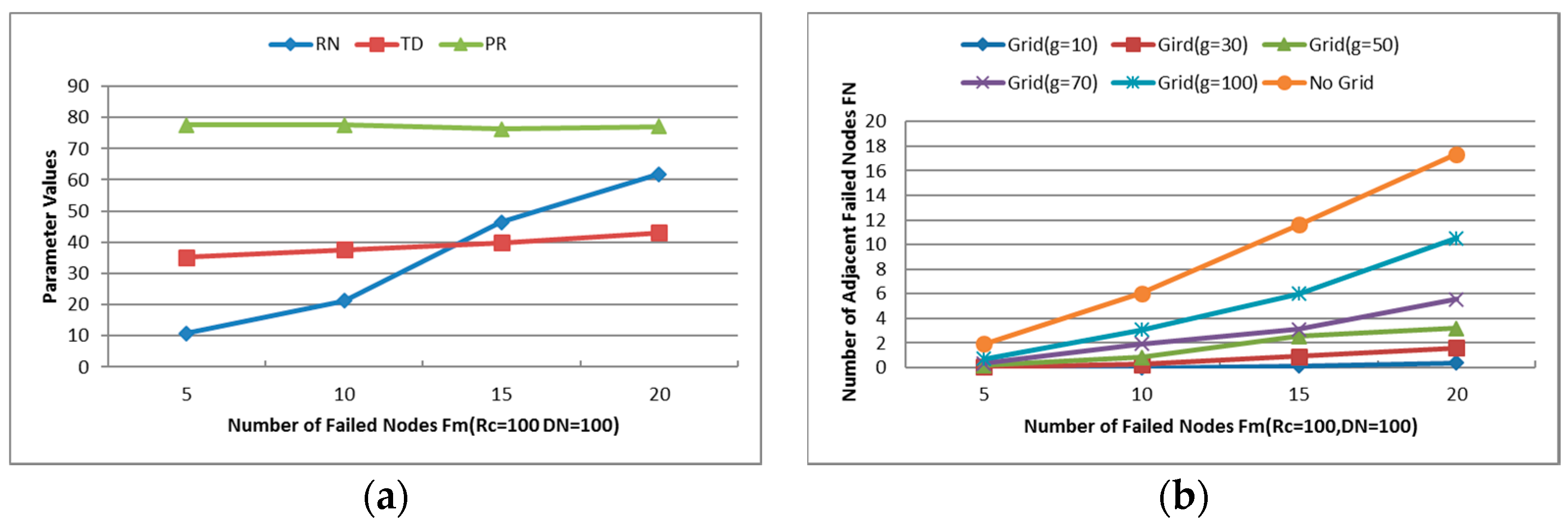
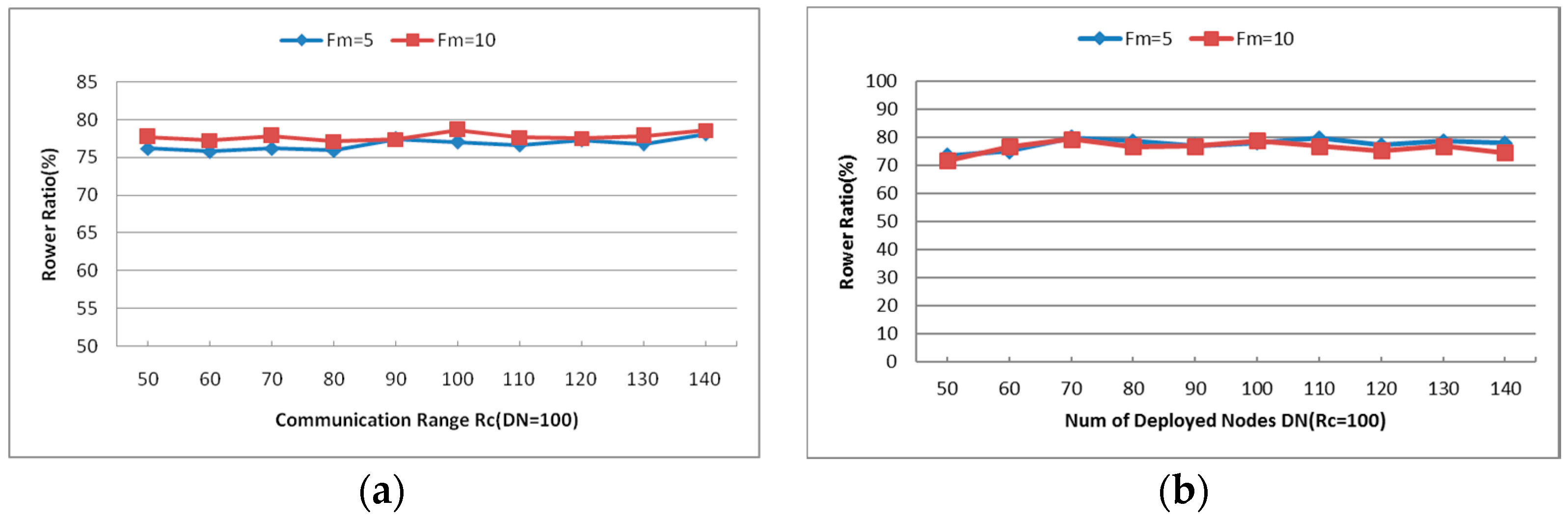
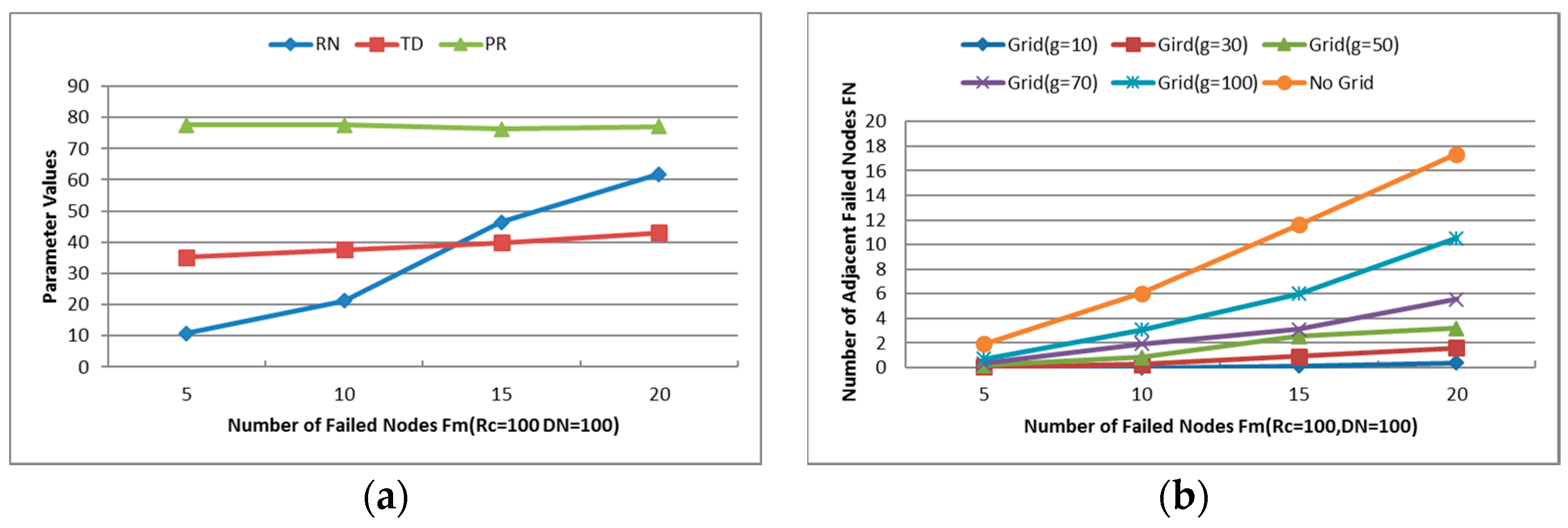
- Maximum Number of Failed Nodes (Fm): Indicates the maximum number of failed nodes in each experiment. As shown in Figure 14a, the average power ratio maintains around 75% and the average travel distance holds about 40%, but the number of relocated nodes increases significantly with the increase of Fm. When Fm is set as 20, approximately 60% of the residual healthy nodes moved in the simulations. The network topology is nearly rebuilt when so many nodes change their positions, so the next simulations will be tested with Fm = 5 and 10.
6.2.1. Number of Relocated Nodes (RN)
6.2.2. Average Travel Distance (TD)
6.2.3. Cooperative Communication Power Ratio (PR)
7. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Akyildiz, I.F.; Kasimoglu, I.H. Wireless sensor and actor networks: Research challenges. Ad Hoc Netw. 2004, 2, 351–367. [Google Scholar] [CrossRef]
- Younis, M.; Senturk, I.F.; Akkaya, K.; Lee, S.; Senel, F. Topology management techniques for tolerating node failures in wireless sensor networks: A survey. Comput. Netw. 2014, 58, 254–283. [Google Scholar] [CrossRef]
- Sitanayah, L.; Brown, K.N.; Sreenan, C.J. A fault-tolerant relay placement algorithm for ensuring k vertex-disjoint shortest paths in wireless sensor networks. Ad Hoc Netw. 2014, 23, 145–162. [Google Scholar] [CrossRef]
- Sitanayah, L.; Brown, K.; Sreenan, C. Planning the deployment of multiple sinks and relays in wireless sensor networks. J. Heuristics 2015, 21, 197–232. [Google Scholar] [CrossRef]
- Tang, J.; Hao, B.; Sen, A. Relay node placement in large scale wireless sensor networks. Comput. Commun. 2006, 29, 490–501. [Google Scholar] [CrossRef]
- Abbasi, A.A.; Younis, M.; Akkaya, K. Movement-assisted connectivity restoration in wireless sensor and actor networks. IEEE Trans. Parallel Distrib. Syst. 2009, 20, 1366–1379. [Google Scholar] [CrossRef]
- Akkaya, K.; Senel, F.; Thimmapuram, A.; Uludag, S. Distributed recovery from network partitioning in movable sensor/actor networks via controlled mobility. IEEE Trans. Comput. 2010, 59, 258–271. [Google Scholar] [CrossRef]
- Imran, M.; Younis, M.; Said, A.M.; Hasbullah, H. Volunteer-Instigated Connectivity Restoration Algorithm for Wireless Sensor and Actor Networks. In Proceedings of the 2010 IEEE International Conference on Wireless Communications, Networking and Information Security (WCNIS), Beijing, China, 25–27 June 2010; pp. 679–683.
- Imran, M.; Younis, M.; Md Said, A.; Hasbullah, H. Localized motion-based connectivity restoration algorithms for wireless sensor and actor networks. J. Netw. Comput. Appl. 2012, 35, 844–856. [Google Scholar] [CrossRef]
- Younis, M.; Sookyoung, L.; Abbasi, A.A. A localized algorithm for restoring internode connectivity in networks of moveable sensors. IEEE Trans. Comput. 2010, 59, 1669–1682. [Google Scholar] [CrossRef]
- Du, J.; Xie, L.; Sun, X.; Zheng, R. Application-oriented fault detection and recovery algorithm for wireless sensor and actor networks. Int. J. Distrib. Sens. Netw. 2012, 2012, 273792. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, X.; Huang, C. Adaptive topology reconfiguration from an actor failure in wireless sensor-actor networks. Int. J. Distrib. Sen. Netw. 2015, 2015, 602471. [Google Scholar] [CrossRef]
- Tian, J.; Liang, X.; Wang, G. Deployment and reallocation in mobile survivability-heterogeneous wireless sensor networks for barrier coverage. Ad Hoc Netw. 2016, 36, 321–331. [Google Scholar] [CrossRef]
- Joshi, Y.K.; Younis, M. Autonomous Recovery from Multi-Node Failure in Wireless Sensor Network. In Proceedings of the 2012 IEEE Global Communications Conference (GLOBECOM), Anaheim, CA, USA, 3–7 December 2012; pp. 652–657.
- Lee, S.; Younis, M. Recovery from multiple simultaneous failures in wireless sensor networks using minimum steiner tree. J. Parallel Distrib. Comput. 2010, 70, 525–536. [Google Scholar] [CrossRef]
- Truong, T.T.; Brown, K.N.; Sreenan, C.J. Multi-objective hierarchical algorithms for restoring wireless sensor network connectivity in known environments. Ad Hoc Netw. 2015, 33, 190–208. [Google Scholar] [CrossRef]
- Shuguang, C.; Goldsmith, A.J.; Bahai, A. Energy-efficiency of mimo and cooperative mimo techniques in sensor networks. IEEE J. Sel. Areas Commun. 2004, 22, 1089–1098. [Google Scholar]
- Goeckel, D.; Benyuan, L.; Towsley, D.; Liaoruo, W.; Westphal, C. Asymptotic connectivity properties of cooperative wireless ad hoc networks. IEEE J. Sel. Areas Commun. 2009, 27, 1226–1237. [Google Scholar]
- Kashi, S.S.; Sharifi, M. Connectivity weakness impacts on coordination in wireless sensor and actor networks. IEEE Commun. Surv. Tutor. 2013, 15, 145–166. [Google Scholar] [CrossRef]
- Almasaeid, H.M.; Kamal, A.E. On the Minimum K-Connectivity Repair in Wireless Sensor Networks. In Proceedings of the IEEE International Conference on Communications (ICC ′09), Dresden, Germany, 14–18 June 2009; pp. 1–5.
- Deniz, F.; Bagci, H.; Korpeoglu, I.; Yazıcı, A. An adaptive, energy-aware and distributed fault-tolerant topology-control algorithm for heterogeneous wireless sensor networks. Ad Hoc Netw. 2016, 44, 104–117. [Google Scholar] [CrossRef]
- Nosratinia, A.; Hunter, T.E.; Hedayat, A. Cooperative communication in wireless networks. IEEE Commun. Mag. 2004, 42, 74–80. [Google Scholar] [CrossRef]
- Cardei, M.; Jie, W.; Shuhui, Y. Topology control in ad hoc wireless networks using cooperative communication. IEEE Trans. Mob. Comput. 2006, 5, 711–724. [Google Scholar] [CrossRef]
- Wang, H.; Wu, X.; Zhang, S.; Wang, L. Node Failure Restoration in WSN via Cooperative Communication. In Proceedings of the 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 7709–7714.
- Gokturk, M.S.; Gurbuz, O.; Erman, M. A practical cross layer cooperative MAC framework for WSNS. Comput. Netw. 2016, 98, 57–71. [Google Scholar] [CrossRef]
- Ulusoy, A.; Gurbuz, O.; Onat, A. Wireless model-based predictive networked control system over cooperative wireless network. IEEE Trans. Ind. Inf. 2011, 7, 41–51. [Google Scholar] [CrossRef] [Green Version]
- Guiling, W.; Irwin, M.J.; Berman, P.; Haoying, F.; Porta, T.L. Optimizing Sensor Movement Planning for Energy Efficiency. In Proceedings of the 2005 International Symposium on Low Power Electronics and Design (ISLPED ′05), San Diego, CA, USA, 8–10 August 2005; pp. 215–220.
- Gokturk, M.S.; Gurbuz, O. Cooperation with multiple relays in wireless sensor networks: Optimal cooperator selection and power assignment. Wirel. Netw. 2013, 20, 209–225. [Google Scholar] [CrossRef]




© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Ding, X.; Huang, C.; Wu, X. Adaptive Connectivity Restoration from Node Failure(s) in Wireless Sensor Networks. Sensors 2016, 16, 1487. https://doi.org/10.3390/s16101487
Wang H, Ding X, Huang C, Wu X. Adaptive Connectivity Restoration from Node Failure(s) in Wireless Sensor Networks. Sensors. 2016; 16(10):1487. https://doi.org/10.3390/s16101487
Chicago/Turabian StyleWang, Huaiyuan, Xu Ding, Cheng Huang, and Xiaobei Wu. 2016. "Adaptive Connectivity Restoration from Node Failure(s) in Wireless Sensor Networks" Sensors 16, no. 10: 1487. https://doi.org/10.3390/s16101487