We aim to develop a framework of inferring significant activity using mobile devices. Our solution is based on real-time computation of various contexts on a single mobile device. Group sensing and global sensing are out of the scope of this study.
The framework requires defining a set of significant activities to be inferred and a set of significant locations in advance. The mobile device computes all required contexts automatically in a real-time manner. Depending on the scope of the context-aware application, the definitions of the significant locations and activities can be different. However, an “undefined” significant location is always required to cover all other locations so that we can form a complete set of locations. Similarly, an “undefined” significant activity is also required to cover all other activities to form a complete set of significant activities.
For step 1, Android and iOS application program interfaces (APIs) offer sufficient functions and sample codes to access the measurements of the smartphone sensors and signal strengths of the radio signals. There is no need to address this issue in this paper. We next focus on real-time computation of the spatial contexts, spatiotemporal contexts, user contexts, and the inference of the significant activity.
3.1. Determination of the Spatial Contexts
The ultimate goal of spatial context determination is to identify the user’s current significant location, which is defined as a geofence that is, directly or indirectly, associated with one or more significant activities. Typical significant locations in our daily working life include e.g., offices, meeting rooms, dining halls, coffee stores, libraries, bus stops and so forth.
Satellite positioning has become a fairly mature technology and is adequate for determining the topological relationship between the user location and the predefined significant location. In challenging outdoor environments with reduced signal quality such as urban canyons, auxiliary techniques such as assisted GPS and dead reckoning can be employed to improve the positioning performance. On the other hand, indoor positioning does not benefit much from satellites as signals are affected by attenuation, reflection, and blockage.
In order to achieve a real-time seamless indoor/outdoor positioning solution for deriving spatial contexts, we integrate measurements from a smartphone GPS receiver, motion sensors, inertial sensors and WiFi signals using an unscented Kalman filter (UKF). In this solution, if an activity takes place outdoors, the spatial context is purely determined by the GPS module, whereas measurements from motion sensors, inertial sensors and WiFi signals are utilized for indoor environments. The transition between indoor and outdoor environments is detected by measuring the GPS and WiFi signal strengths [
20]. Since indoor positioning solution is usually more complex compared to the outdoor solution, we primarily discuss the indoor positioning solution in this paper.
Based on the received signal strength indication (RSSI), fingerprinting is a common approach for positioning indoors. A radio map (fingerprinting database) is needed for this approach. Once the radio signal patterns in the significant locations are mapped, the user can then be located at a reference point
P that has the best match between its fingerprints and the observed RSSIs. Our matching algorithm is to find the reference point
P in the database that has the shortest mean signal distance as follows:
where
n is the total number of matched access points that can be found from both observed RSSIs and fingerprints,
wi is the weight of the RSSI measurement to the
ith access point,
is the
ith RSSI fingerprint saved in the fingerprinting database, and
is the normalized observed RSSI measurement, which is estimated with:
where
a is the bias between the observed and normalized RSSI measurements.
a is introduced here to compensate common RSSI bias in order to utilize the same fingerprinting database for different types of smartphones. The weight
is estimated with:
The weighting scheme is in favor of the solutions with a larger number of matched RSSI measurements.
Intermittent positioning outage occurs in the areas where the WiFi access points are not evenly distributed leading to poor signal reception. Therefore, pedestrian dead reckoning (PDR) is adopted to fill the gap between two consecutive WiFi fingerprinting updates. Equation (4) presents the PDR solution for propagating the planar coordinates:
where
and
are east and north propagated coordinates given the known coordinates
and
,
Δt represents the time interval between epochs
k − 1 and
k,
s and
α depict the pedestrian speed and heading, respectively.
Smartphone compass provides absolute heading information by leveraging the accelerometer and magnetometer measurements, however, heading estimation can be severely contaminated wherever strong magnetic perturbation exists, particularly for indoor environments [
5,
19]. As a complementary sensor, gyroscopes generate angular rate without any adverse effect from magnetic field, yet they lack absolute orientation and are prone to drift significantly over time. In this study, we integrate these two sensors and take advantage of the floor plans to provide heading clues in indoor environments. On the other hand, user step frequency and walking speed can be estimated using accelerometer measurements. The detailed algorithm will be further discussed in
Section 3.3.
To effectively integrate various data sources, an UKF filter is adopted to take into account both nonlinear dynamics and computational load on smartphone platforms. Based on Equation (4), we can define a user state vector as follows:
where
depicts heading rate. The user dynamics can then be described as follows
where
are Gaussian system noises, the superscripts − and + stand for the prediction and the update of the state vector
x, respectively. The measurement equation is as follows:
where measurement vector
, measurement matrix
H is 5 × 5 identity matrix,
is a Gaussian measurement noise vector with zero mean and
is the covariance matrix of the measurement vector.
During the time update phase, each sigma point is propagated via the nonlinear models. The mean and covariance of the forecast sigma points are computed with:
contains a set of 2
L + 1 sigma points calculated by unscented transformation;
are the associated weights that can be determined according to [
26];
L represents the dimension of the state vector (
L = 5 in this study);
and
are predicted sigma points through the nonlinear models;
and
are the means of the corresponding predictions and
is the covariance matrix of
. Once the WiFi and smartphone sensor measurements are available, the state vector is updated via
where
is the innovation covariance matrix,
is the cross correlation matrix;
is the gain matrix,
is the updated state vector, and
is the associated covariance matrix.
3.3. Determination of User Contexts
A user context is a flexible parameter in a contextual tuple. Its general form is a combination of different categories of user related contexts, for example, including but not limited to:
- (1)
User mobility contexts such as motion patters;
- (2)
User psychological contexts such as levels of fatigue, excitement, nervousness, and depression;
- (3)
User environmental contexts such as ambient noise level, light intensity, temperature, and weather conditions;
- (4)
User social contexts such as calling, messaging/chatting, and using applications.
Table 2 summarizes the potential user contexts and their related observable sets. It serves as an example for showing the potential and complexity of the user contexts, rather than as a final list. More user contexts can be added to the framework without jeopardizing the theoretical fundamentals of the framework as long as the observables in the user contexts are independent. Depending on the complexity of the activities to be inferred, the user contexts might be complex. Adding more user contexts to the solution will increase the complexity of the probability model. However, it will increase the inferring capability of the framework. The powerful computational capability of smartphones allows us to explore a complex model for inferring complex activities.
The vector of user contexts is a complex but useful element in a contextual tuple because it increases the observability of the significant activities, leading to a better capability for inferring a wide range of significant activities. For example, the user motion patterns are observable from most human activities such as working in office (static), walking in a park (slow walking), and driving a car (fast moving). For other activities such as sleeping in a bedroom, both mobility context (static) and user environmental contexts (ambient noise level and light intensity) are observable.
Table 2.
Initial list of user contexts.
Table 2.
Initial list of user contexts.
| Category | User Context | Observable Set of Each User context |
|---|
| Mobility | Motion pattern | static, slow walking, walking, fast moving |
| Environment | Light intensity | low, normal, high |
| Noise level | low, normal, high |
| Temperature | freeze, low, comfortable, high |
| Weather | sunny, cloudy, raining, hazardous weather |
| Psychology | Level of fatigue | low, medium, high |
| Level of excitement | low, medium, high |
| Level of nervousness | low, medium, high |
| Level of depression | low, medium, high |
| Social | Social contexts | calling, texting/chatting, using App |
In this initial study, only the following user mobility contexts are included: static, slow walking, walking, and fast moving. To determine the user mobility context, the user speed is determined based on a model developed by Chen
et al. [
8]. The user speed
v is estimated with:
where
SL is the step length,
SF is the step frequency,
H is the height of the pedestrian, and
a,
b, and
c are the model coefficients with the values of 0.371, 0.227 and 1. The step frequency
SF is detected in real time by analyzing the cyclic patterns of the accelerometer measurements. This model has a performance with the error of less than 3% in terms of travelled distance [
8]. A pedestrian height of 1.75 m is adopted in this study instead of taking it from input of pedestrians. In the model,
c is a personal factor that can be calibrated and adjusted on line if a known travelled distance is available. With this approach, user mobility context determination is an unsupervised process. The solution is rather stable and independent of the smartphone orientations. The user speed derived from Equation (10) is also applied to Equations (4)–(6) in
Section 3.1.
3.4. Activity Inference
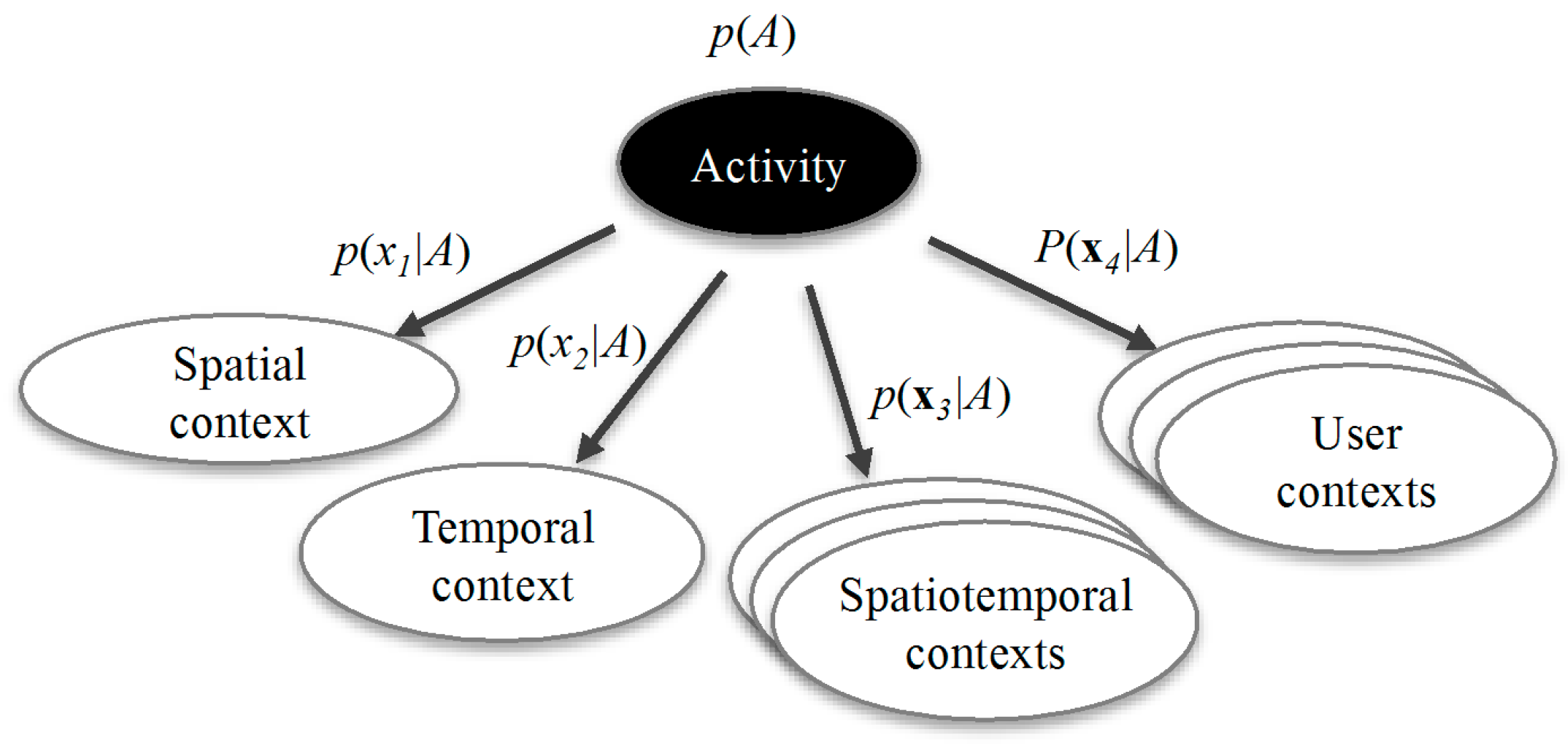
Having obtained a time series of contextual tuples, the significant activity can then be inferred by using a Naïve Bayes classifier as shown in
Figure 1. The conditional probability
p(
Ak|
x), which is the probability of activity
Ak given the observed contextual tuple
x = [
a temporal context, a spatial context, a set of spatiotemporal contexts, a set of user contexts], can be derived with:
where
na is the total number of significant activities to be inferred,
d is the dimension of a contextual tuple, which is dependent on the number of the spatiotemporal contexts and the user contexts included in the model.
Figure 1.
Structure of the Naïve Bayes classifier used for classifying significant activities.
Figure 1.
Structure of the Naïve Bayes classifier used for classifying significant activities.
In order to estimate the conditional probability
p(
Ak|
x), we need to know the probability model
P = (
A,
B), which includes:
The probability distributions of the significant activities including an undefined activity: A = [p(A1), p(A2), ..., P(Ana)], with ,
The observation probability matrix B for all p(xi|Ak), where i = 1,…,d, and k =1,...,na. B is a d × na dimensional matrix of probability density functions (PDFs). Each PDF is a histogram with various bins depending on the size of the sample set of the corresponding observable, e.g. the size of the sample set of a user mobility context [static, slow walking, walking, fast moving] is four. For each PDF, we have , where Pj is the probability of the jth element in the sample set, and nb is the size of the sample set.
The traditional way of obtaining the probability model P = (A, B) is through training. It is a tedious task, as it requires a large training dataset with labeled classes in order to obtain an accurate model. A dedicated machine learning algorithm is needed in this scenario. Model training is supported in our framework using e.g., a hidden Markov model. We will address this topic in a separate paper.
Another approach to obtain the probability model is to adopt an empirical model based on existing knowledge. For example, people normally have lunch between 11:00 a.m. and 1:00 p.m. Thus, the probability distribution of the observable local time (temporal context) given the activity of “having a lunch” can be described by a histogram shown in
Figure 2. In practice, the empirical model can be adopted as an initial model. This initial model can be improved with labeled or inferred classes by a self-learning process.
Figure 2.
An empirical probability distribution of the observable local time given the activity of “having a lunch”.
Figure 2.
An empirical probability distribution of the observable local time given the activity of “having a lunch”.
Figure 3 shows the diagram of the procedure for inferring significant activities. It mainly consists of two parts: user input and mobile sensing. The part of user input includes the definitions of the significant locations and activities, while the mobile sensing part includes the real-time computation of the contextual tuples. The probability model can be derived either by user input (empirical model) or by mobile sensing (model trained using labeled activities).
Figure 3.
Diagram of the procedure for inferring significant activities. The probability model can be either from user input (empirical model) or from training process using labeled activities.
Figure 3.
Diagram of the procedure for inferring significant activities. The probability model can be either from user input (empirical model) or from training process using labeled activities.
This paper focuses on introducing the multi-context approach for inferring human activity, rather than assessing the performances of various machine learning based activity inference algorithms. The Naïve Bayes classifier is chosen to demonstrate the functionality of our activity inference engine because it is
- (1)
A computationally efficient approach that can be implemented in smartphones;
- (2)
Flexible in supporting incremental learning;
- (3)
Insensitive to irrelevant features.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}