1. Introduction
Since the invention of bicycles in the 19th century, cycling has become a significant part of everyday life. It is a popular mode of transportation for short-to-medium distances, as well as a recreational activity. It is promoted by ecology activists as an environmentally-friendly, inexpensive and convenient alternative to fossil fuel-based vehicles. It is also a beneficial exercise, which improves fitness and cardiovascular health, while having a relatively low impact upon leg joints compared to jogging [
1], as well as being a popular professional sport.
Fatiguing training sessions are beneficial for building up muscle power, raising lactate threshold and improving maximal oxygen consumption [
2]. However, excessive fatigue with limited recovery can lead to over-training and, consequently, increased susceptibility to injuries, which may have a long-term negative impact on an athlete’s career [
3,
4]. Therefore, establishing methods that evaluate fatigue in a non-invasive manner and that adjust the training regimen accordingly to improve its quality, as well as to avoid the risk of overuse injuries is very important. However, this is a complicated task: fatigue is a phenomenon that has not only physical, but also psychological factors, making subjective assessment of fatigue, such as Borg’s Rating of Perceived Exertion (RPE) scale [
5], unreliable; motivated athletes would be willing to continue the task much longer than unmotivated ones.
There are a number of known techniques that can be used to monitor muscle activity non-invasively during an exercise, including, but not limited to, surface electromyography (sEMG), sonomyography (SMG), near-infrared spectroscopy (NIRS) and mechanomyography (MMG) [
6]. Of these, sEMG seems to be the most prevalent due to the relative ease of obtaining the signals compared to other modes.
It has been established for over a century [
7] that during a sustained static muscle contraction of medium to high force, the spectral components of an sEMG signal are compressed towards the lower frequencies. However, the exact physiological mechanism of muscle fatigue has been explained only relatively recently. As long as the respiratory and cardiovascular systems can deliver oxygen, aerobic respiration is the primary means of converting nutrients into energy. However, once the supply of oxygen is no longer maintained, less effective anaerobic glycolysis dominates as a means of energy production. During this process, lactic acid is accumulated in the working muscle cells. The hydrogen ions contribute to the lower pH of interstitial fluid, which, in turn, reduces the propagation velocity of the action potential along the muscle fibers [
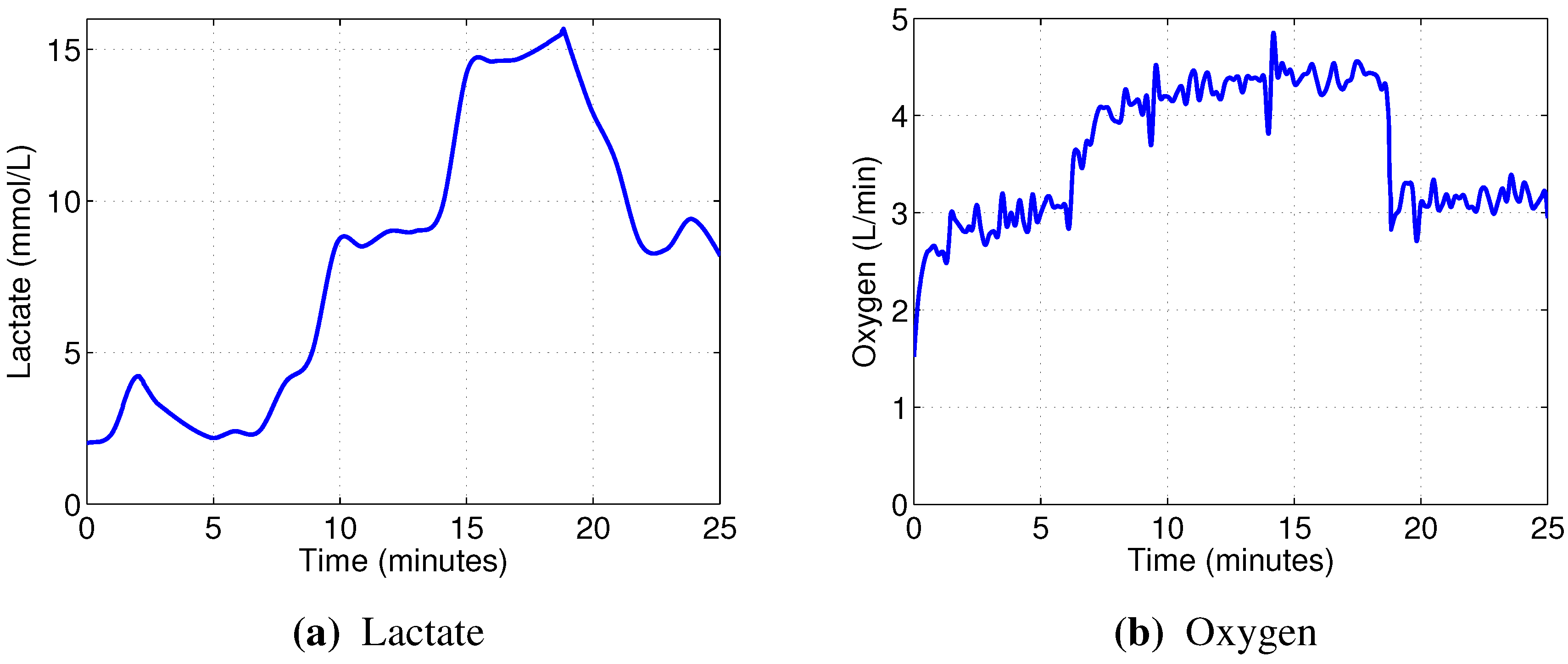
8]. Thus, it has become common to monitor levels of blood lactate, as well as oxygen consumption (
) during exercise as biochemical indicators of anaerobic glycolysis and, indirectly, fatigue.
During a static load exercise, the generated sEMG signal can be assumed to be a result of a wide-sense stationary (WSS) random process, which allows using established techniques, like autoregressive modeling or the short-time Fourier transform (STFT) to observe the compression of the spectral components. A common way to track this effect is obtaining median power frequency (MPF), which decreases as the frequency content shifts to the lower range. This, however, is not feasible for dynamic activities, such as cycling, because the frequency content of the sEMG signal is altered by variations in muscle force and muscle length [
9]. Additionally, movement of the muscles under the skin can cause a displacement of the electrodes in relationship to muscle fibers, which may influence the frequency content of the signal unpredictably. This means that techniques designed for the analysis of non-stationary signals should be used instead [
10].
Karlsson
et al. [
11] in 2000 compared four time-frequency analysis techniques, the continuous wavelet transform (CWT), the Wigner–Ville distribution, the Choi–Williams distribution and the short-time Fourier transform (STFT), for estimation accuracy and precision of time-dependent spectral moments, including mean, standard deviation, skewness and kurtosis. All four techniques showed very similar results, although CWT was the most, while STFT was the least precise and accurate. However, it must be also noted that STFT is computationally much less complex than CWT.
However, in 2001, Bonato
et al. showed [
9] that for periodic dynamic tasks, it is possible to avoid a lot of complicating factors by assuming the cyclic stationarity of the signal. This assumption is valid, if the following conditions are true:
The task is mechanically repeatable in a fairly precise manner, i.e., the trajectory of the task is fixed;
The EMG signal is partitioned in such a way as to ensure that only the segments, corresponding to the same phases of a task, are compared;
While not strictly necessary, the results can be further improved by averaging over a few such segments to diminish the variance.
In 1998, Jammes
et al. investigated correlations between the parameters of an EMG of vastus lateralis (VL) muscle, oxygen uptake and blood lactate concentration during a cycling exercise [
12]. They showed that the root mean squared (RMS) amplitude of the EMG signal was very strongly correlated to the measured workload of the muscle. Oxygen uptake increased sharply at the beginning, but later on, it would level out; as a result, the
ratio could reach as much as 150% of its initial value by the end of the second minute of the exercise and then drop back to normal or even dip below the initial value during the recovery period after the exercise. The rates of change in this ratio were found to be in correlation with both peak values of
and blood lactate concentration.
In 2002, Pringle and Jones [
13] hypothesized that maximal lactate steady state, critical power and electromyographic fatigue threshold were all equal. They also aimed to show that continuous work at levels above maximal lactate steady state caused an increase in oxygen uptake and integrated EMG. Results showed that the investigated measures were strongly correlated, but not equivalent; critical power was always significantly higher for all test subjects. When tested at power levels about 20 W above maximal lactate steady state (but still below critical power), all test subjects exhibited an increase in blood lactate concentration and oxygen uptake, suggesting that the maximal lactate steady state is the boundary for the heavy exercise domain. Most significant to our study is the fact that the change in integrated EMG was insignificant in almost all cases.
The conclusions of Pringle and Jones [
13] may be further supported by results from Tenan
et al. in 2011, who investigated a relationship between blood lactate, blood potassium and MPF of the EMG signal of VL during a progressive cycling exercise [
14]. Every test subject repeated the protocol twice, once normally and once while in a glycogen-reduced state. In both cases, potassium concentration increased to similar levels. Lactate concentration also increased in both cases, although not as much as in the glycogen-reduced state. However, in either case, they were not correlated strongly with MPF, although for five out of eight subjects, MPF did decrease with time. The authors make the conclusion that local fatigue of VL muscle is not the limiting factor on the duration of the exercise; rather, it is the incapacity of the cardiovascular system to provide muscles with enough oxygen.
Another study of interest is one by Bercier
et al. done in 2009 [
15]. While it was concentrated on all-out sprints and, thus, did not concern fatigue, it found that during the first seven cycles of acceleration from a stationary position, the MPF of EMG recorded from VL increased with cycling velocity. The authors suggest that this is due to differentiated employment of motor units in VL. A similar result was obtained in 2003 by Linnamo
et al. [
16] while investigating an explosive power exercise on leg press equipment. The authors observed that the MPF for VL increased during the exercise and was higher when movements were faster.
While research on fatigue during cycling is mostly concentrated around the VL muscle, some studies also incorporated other muscles. For example, in a study published in 2003, Knaflitz and Molinari investigated changes in EMG of rectus femoris (RF), biceps femoris (BF) and gastrocnemius (GC), as well as coordination of their activation patters, during a 30-min constant-load cycling exercise [
17]. Despite test subjects reporting fatigue, the study showed no significant changes to the instantaneous frequency of EMG signals nor muscle activation patterns. It should be noted that the study was conducted at relatively low power levels.
In 1996, Jansen
et al. measured the systematic effect of blood lactate concentration on the median power frequency of EMG signals taken from both exercising (VL) and non-exercising (flexor digitorum superficialis, FDS) muscles [
18]. It was assumed that the MPF would decrease for both muscles as byproducts of anaerobic glycolysis were spread through blood. The results based on 12 subjects were opposite from what was expected, with the MPF in VL increasing for eight subjects out of 12 during the exercise. Only three subjects showed a decrease in median frequency, and one subject had no significant changes at all. Moreover, for all subjects, FDS did not show any changes, suggesting that any chemical substance that would affect the characteristics of EMG signals is not transported to other muscles in substantial amounts.
In contrast, in the year 2000, Gerdle
et al. used an iso-kinetic knee extension exercise to validate EMG mean frequency and RMS as fatigue indicators for that type of dynamic exercise [
19]. Twenty one healthy volunteers performed 100 iso-kinetic knee extensions, and EMG signals were recorded for VL, RF and vastus medialis (VM) of the right thigh. The peak torque was used as an indicator for fatigue. The study found that the mean frequency of EMG was strongly correlated to the peak torque and, thus, provided a good indication of the state of fatigue. No such correlations were found for the RMS of the signal.
In 2008, Dingwell
et al. performed a series of studies on the changes of muscle activity and the kinematics of highly-trained cyclists during fatigue [
20]. Kinematic data and EMG signals from four muscles—VL, tibial anterior (TA), BF and GC—were collected throughout the exercise of cycling at 90 RPM at their
power level. The study determined significant correlations between changes in kinematics and EMG, and a reduction in MPF was found in 18 out of 28 muscles tested, most notably in BF and GC.
There is a discrepancy between the findings of various studies whether the spectral characteristics of EMG signals are indicative of the general body fatigue during cycling exercise. Thus, the main aim of our research was to investigate if characteristics of the EMG power spectrum lend themselves to building accurate models from experimental data to predict physiological indicators, namely blood lactate concentration and oxygen uptake, as well as which parameters of the power spectrum are the most informative. For this purpose, multiple statistical characteristics of the power distribution across various frequencies in the spectra of sEMG signals were considered, and both linear and non-linear models were explored. A variety of muscles have been studied by other researchers throughout the years with mixed results; therefore, we included four muscles, considered important in bicycling: vastus lateralis, rectus femoris, biceps femoris and semitendinosus (ST).
2. Materials and Methods
2.1. Testing Protocol
For each of the test subjects, their
and blood lactate threshold were determined several weeks before the main experiments. The subjects were asked to maintain constant cadence at 90–100 rpm throughout the experiment. A blood sample was obtained at the end of each minute. The experiment was divided into three distinct phases:
Six minutes of cycling at 60% of power.
Cycling at 90%–95% of power until the test subject was unable to maintain the required cadence.
Six minutes of cycling at 60% of power.
For test Subjects 7 and 8, the first and third phases were different, both including 5 min of cycling at 50% of and a further 5 min of cycling at 75% of . Since in this experiment, only direct moment-by-moment relationships between EMG and physiological indicators are investigated, we do not consider this difference in protocol execution to be significant for our purposes.
2.2. Volunteers and Equipment
Nine volunteers (4 women, 5 men, aged 18–56 (average 37), height 158–189 cm (average 174 cm), weight 56–90 kg (average 71 kg)) participated in the experiments with full written informed consent and ethical approval of Regional Ethics Committee in Lund (Regionala Etikprövningsnämnden Lund; Reg.No. 2014/162). The experiments were conducted on a stationary bicycle ergometer (Monark, Vansbro, Sweden). Throughout all of the tests, the following measurements were taken:
EMG signals were obtained from VL, RF, BF and ST muscles of both left and right legs using bipolar surface electrodes (BlueSensor, AMBU, Copenhagen, Denmark) connected to an eight-channel EMG recorder (Muscle Tester 6000, Megawin, Kuopio, Finland) at a sampling rate of 1000 Hz. The skin was shaved and cleaned with a 0.5-mg/mL solution of chlorhexidine (Fresenius Kabi, Bad Homburg, Germany) and was let to air dry for 1 min before application of electrodes. EMG cross-talk was minimized by placing the electrodes within the border of the specific muscle and with a center-to-center inter-electrode distance of 22 mm [
21].
Oxygen uptake () was measured every 10 s throughout the tests using Jaeger Oxycon Pro (CareFusion, San Diego, CA, USA) and proprietary software supplied with the machine.
Blood samples were collected every minute using finger prick and analyzed using LactatePro2 (Arkray Europe B.V., Amstelveen, The Netherlands).
Due to technical issues with the hardware, oxygen uptake measurements were unavailable for Subjects 1, 3 and 9.
Volunteers were also asked to rate their perceived exertion on the 6–20-point Borg RPE scale. However, these data were not used, because they appeared to closely follow measurements, which were sampled more frequently, with higher numeric precision, and were not affected by subjective biases.
The collected data were analyzed off-line using custom-written Java 7 (Oracle, Redwood City, CA, USA) applications for data segmentation, combined with MATLAB R2012b (MathWorks, Natick, MA, USA) for statistical analysis.
2.3. Signal Preprocessing
The sampled sEMG signals were filtered to remove electronic noise, as well as motion artifacts using Butterworth filters [
22]. To remove the electronic noise and other high frequency content from the signal, a 10th order 400-Hz low-pass filter (450-Hz stop band with at least −60-dB attenuation) was used. The signal was then processed further through a 10th order 20-Hz high-pass filter (10-Hz stop band with at least −60-dB attenuation) to remove motion artifacts. The parameters were selected per recommendations set out in other works [
23]. The filtered signal is referred to as
in the following text.
The physiological data were interpolated where necessary using Hermite cubic splines with Catmull–Rom tangents [
24].
2.4. Segmentation of EMG Signals
To ensure that comparisons are made between the same phases of the pedaling task, the filtered sEMG signals were segmented into cycles, each corresponding to a single revolution of bicycle pedals. For that, the following algorithm was applied. First, the backwards difference
of the filtered signal
as described in the previous subsection was obtained:
Then, assuming a window length of
N samples, a function
, characterizing the signal variability in the window, could be defined as follows:
It must be noted, that the raw signal could also be used in this definition, basing segmentation on the signal amplitudes instead of variability. However, the variability approach gave more robust and consistent results.
For the purpose of our study, the window length N was selected to be 256 samples (256 ms) long, approximately matching a third of a single pedal cycle.
Once the variability function
is established, it can be determined if any particular point in time is the beginning or the end of an activity burst by comparing the variability of windows of equal length before and after the point in question:
If
t is the initial moment of a burst, the function
will reach its local minimum. Similarly, if
t is the end of a burst, the same function will reach its local maximum.
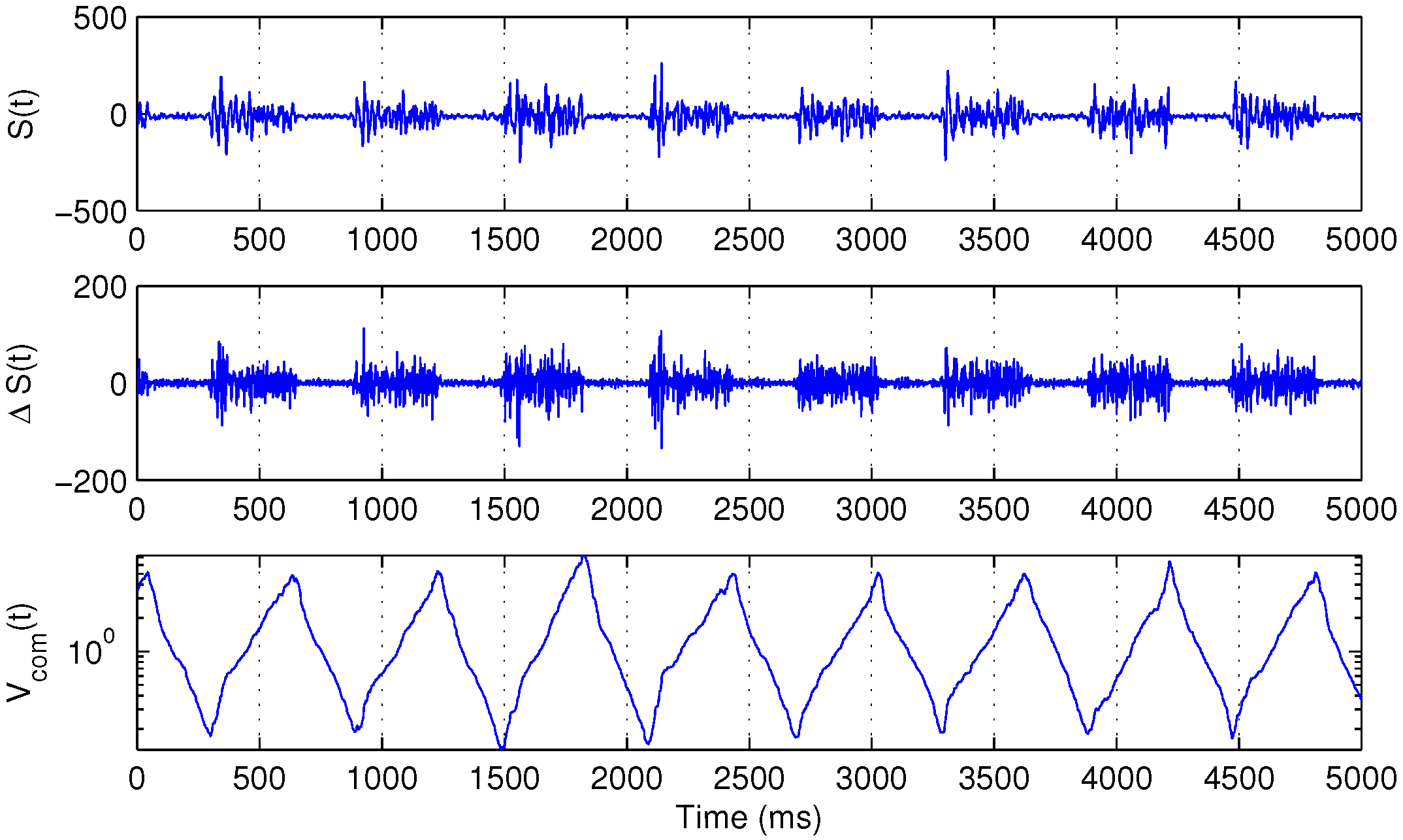
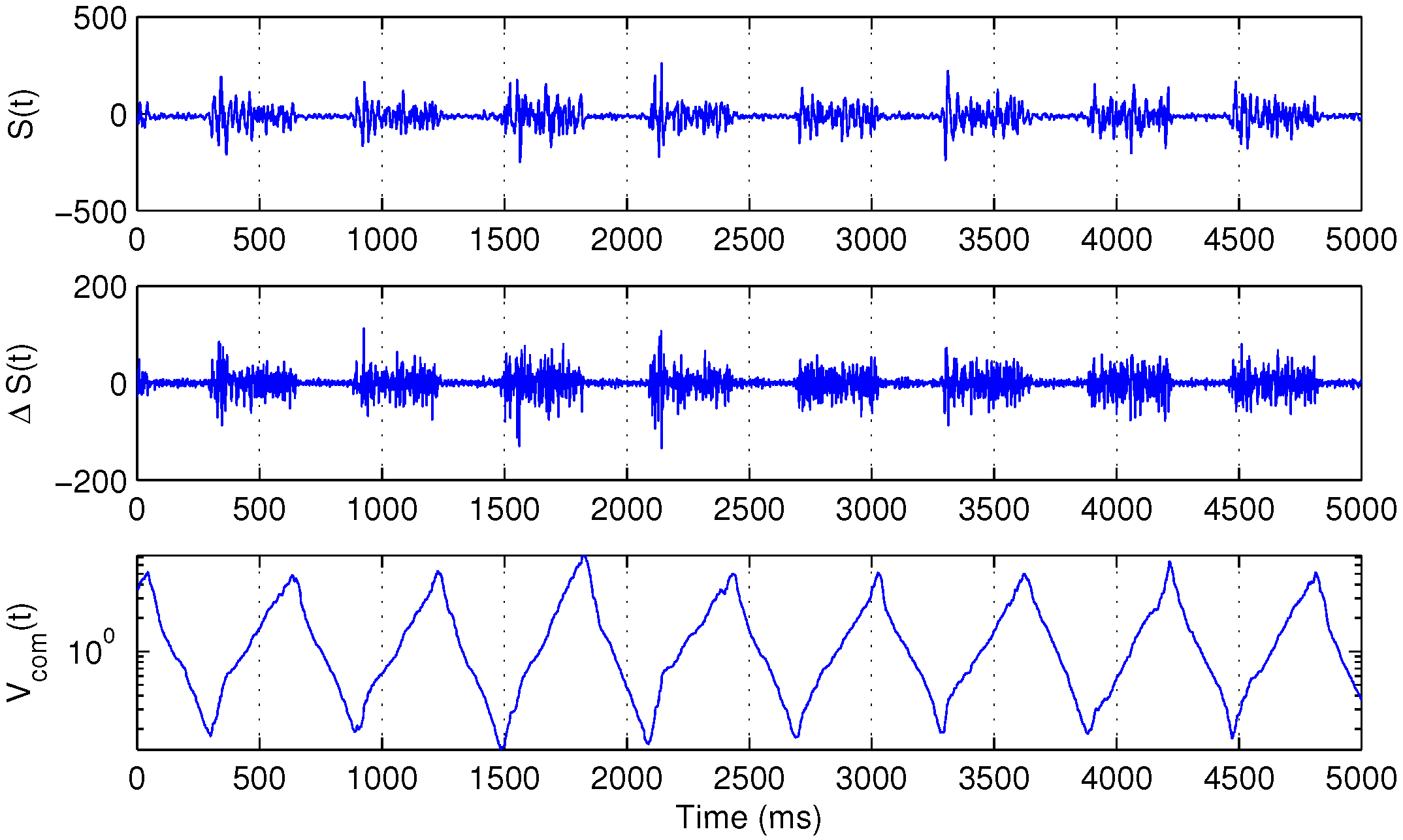
Figure 1 illustrates the behavior of
.
Figure 1.
Several bursts of the surface electromyography (sEMG) signal
(
top), its backward difference
(
middle) and the corresponding
function, defined in Equation (
3) (
bottom).
Figure 1.
Several bursts of the surface electromyography (sEMG) signal
(
top), its backward difference
(
middle) and the corresponding
function, defined in Equation (
3) (
bottom).
For the purpose of further analysis, first, 256 samples of the raw filtered signal after each local minimum of were extracted.
2.5. Characterizing the Power Distribution
The segmentation performed in the previous subsection allows us to perform calculations that are essentially equivalent to a non-overlapping STFT. Normally, the STFT requires the signal to be WSS in its analysis window. This assumption is probably too strong for windows that are 256 ms long, as cycling involves non-isometric voluntary muscle contractions of changing force. However, based on the fact that cycling is a mechanically-repeatable task, our segmentation algorithm allows assuming cyclic stationarity instead (as discussed in paragraph 7 of
Section 1), that is we expect muscle activity to follow the same pattern in each extracted segment. Therefore, while the extracted spectral information from these segments is likely to be affected somewhat by the non-WSS nature of the signal, these effects should be consistent between segments. This, in turn, means that the spectral information is comparable between different segments, and any expected changes, such as energy compression towards lower frequencies, should be observed unhindered.
An alternative way to tackle the stationarity issue could be using any of the time-frequency domain techniques outlined by Karlsson
et al. [
11] or simply shortening the analysis window considerably. However, the latter solution necessarily comes at a cost of lost frequency resolution due to Gabor’s uncertainty principle of signal analysis [
25].
To minimize spectral leakage, the segments were multiplied element-wise by the Hamming window function [
26] before performing any further operations. Then, for each extracted segment of the signal
(where
i denotes the ordinal number of the segment), a power distribution over different frequencies
was calculated by taking the power spectrum
(Equation (
4)) of the segment and normalizing it to enclose a unitary area (Equation (
5)).
where
is the Nyquist frequency (500 Hz for our experiments).
A number of properties defining the segment of the signal were calculated. While usually, this is limited to one or a few properties, such as median power frequency or instantaneous frequency, the set of selected input variables for this research was much larger:
Time-domain features—root mean square of the signal (RMS, 1) and its backward difference (dRMS, 2), instantaneous frequency (defined as the number of zero-crossings in a given segment of EMG, divided by two) (IF, 3)—were obtained from ;
Standard moments of the power distribution across frequencies given by —mode (ModF, 4), mean (MnF, 5), standard deviation (StD, 6), skewness (Skew, 7) and excess kurtosis (Kurt, 8);
Every tenth percentile of the above distribution (–, 9–17), in particular, median power frequency (MPF, 13);
Relative power contained in 23.44 Hz-wide frequency bands of the power spectrum with 11.72-Hz overlaps, starting with 23.44–46.88 Hz and ending with 234.4–257.8 Hz (–, 18–36), see below for an explanation.
Frequency bands were selected this way, as 23.44 Hz was the width of 6 DFT bins, and the relative power was calculated by summing the contents of these DFT bins with an offset of 3 bins between each measure.
To avoid the inherent variability of EMG signals during the dynamic exercise and to make sure that general trends are not masked by noise, each input variable was passed through an 11 data-point-long sliding window (approximately equivalent to 9–10 s of experiment time) median filter.
The defined input variables were then used to predict blood lactate concentration and oxygen uptake.
2.6. Modeling Relations between Input and Output Parameters
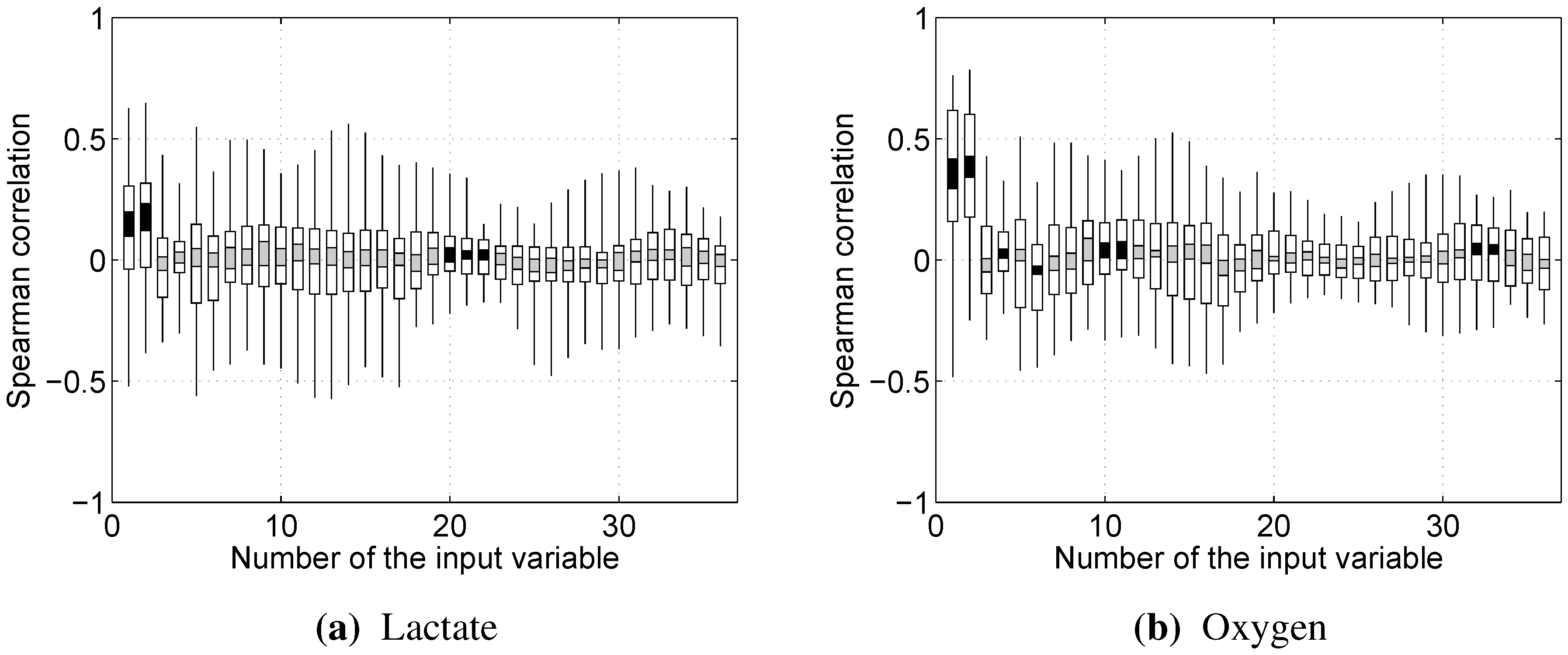
The 36 input and 2 output variables, defined in the previous subsection, were used for modeling the relations between them and determining the strongest connections between them using techniques described further.
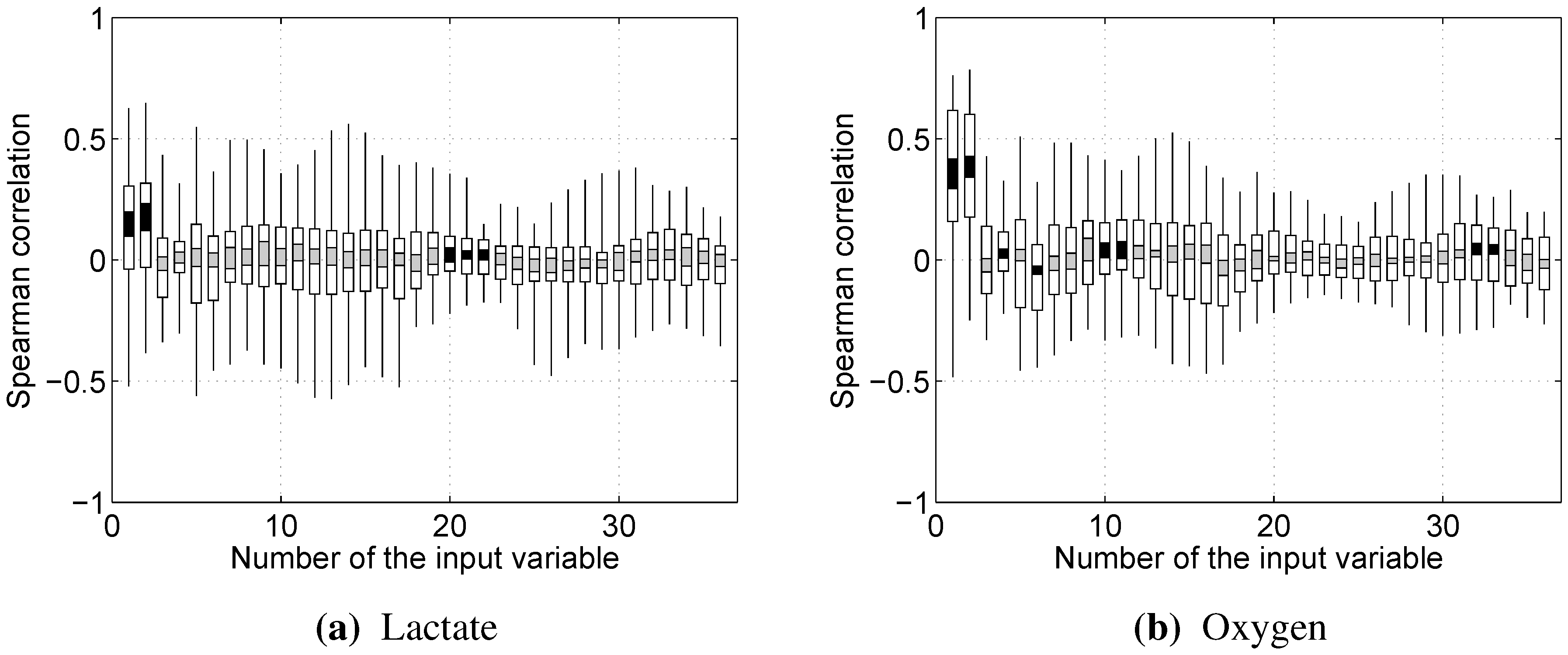
2.6.1. Spearman’s Rank Correlation
Spearman’s rank correlation coefficient was used to determine whether certain input variables had any significant monotonic trends in relationship with blood lactate concentration and oxygen uptake. Given the ranks of an input variable
and corresponding ranks of an output variable
, Spearman’s rank correlation coefficient can then be obtained from this formula:
is equal to 1 if the relationship between and is purely monotonically increasing, −1 if the relationship is purely monotonically decreasing and in between otherwise.
2.6.2. Linear Regression Models
Given a set of vectors
of z-scores of input variables and a corresponding set of z-scores of an output
, the linear regression model for predicting the output
is given by:
The weights
, when using the ordinary least squares method, are estimated in a manner that minimizes the sum of squared error of predictions
:
These estimates of weights are unbiased; however, their variance is high, especially if the input variables are multicollinear, which may cause excessive values of
. Since this was expected to be the case in our study due to the relatively large number of variables in the model, Tikhonov’s (ridge) regularization [
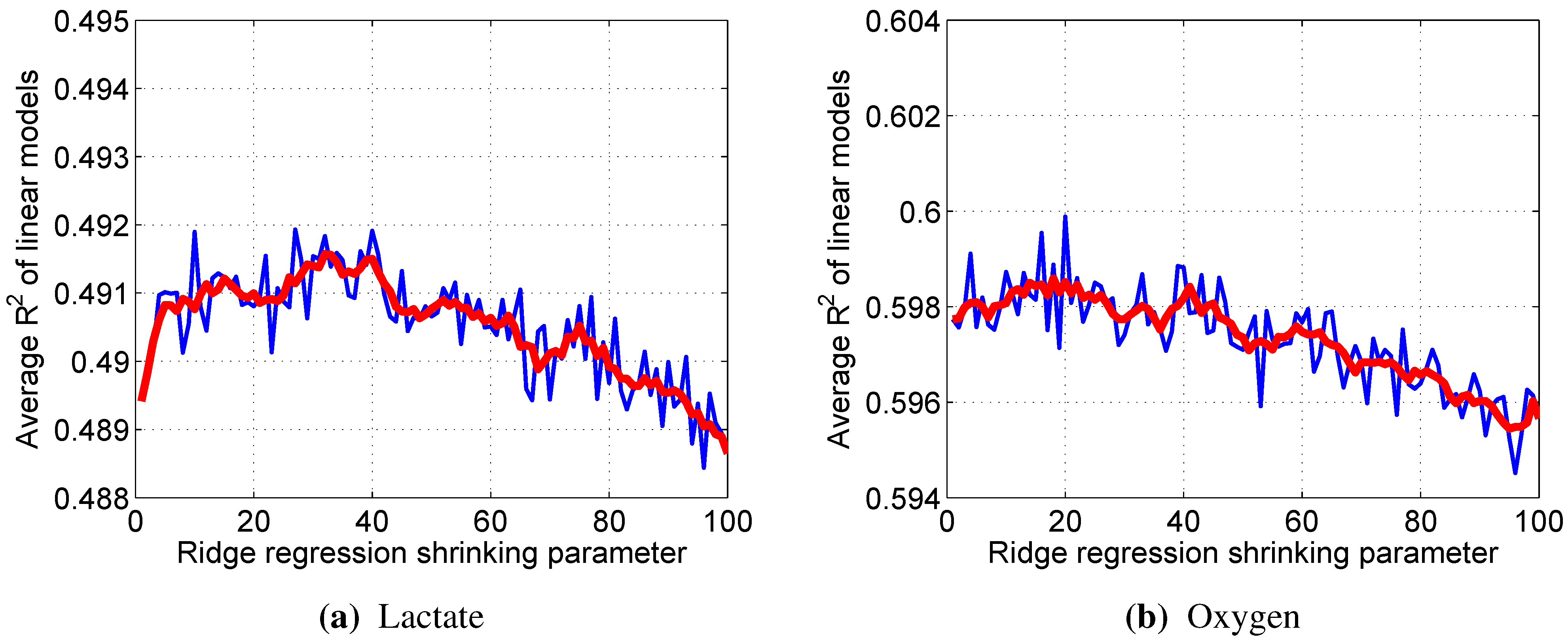
27] was employed to counter the multicollinearity effects:
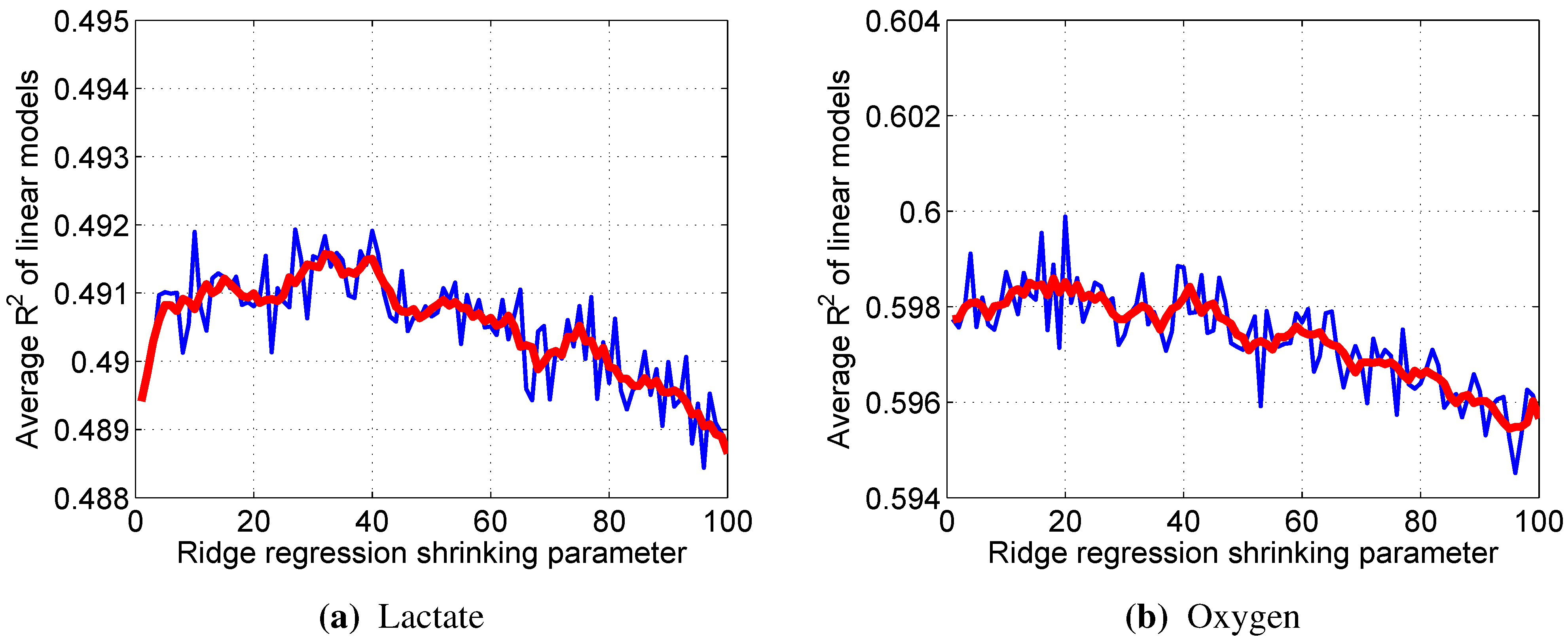
λ is the shrinkage parameter and is selected in such a way as to minimize the sum of bias and variance, which is estimated using a 10-fold cross-validation technique.
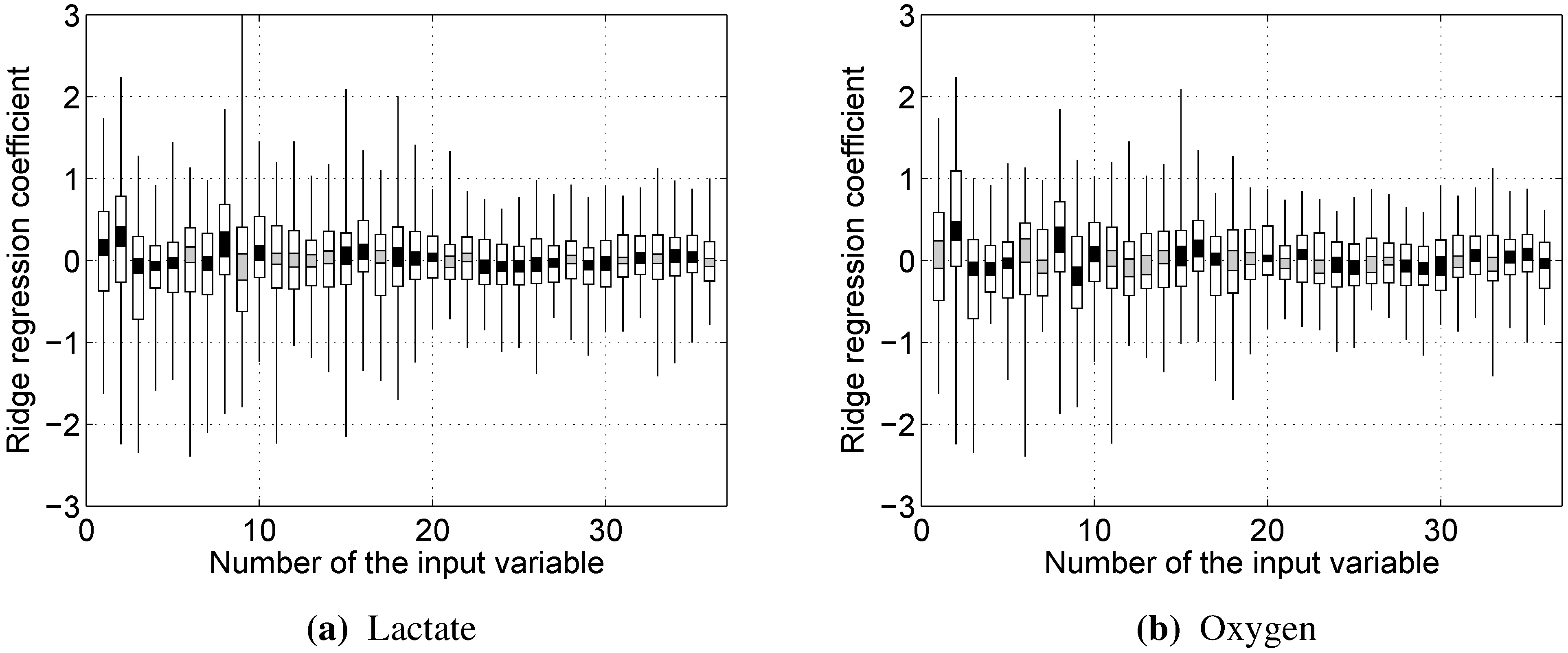
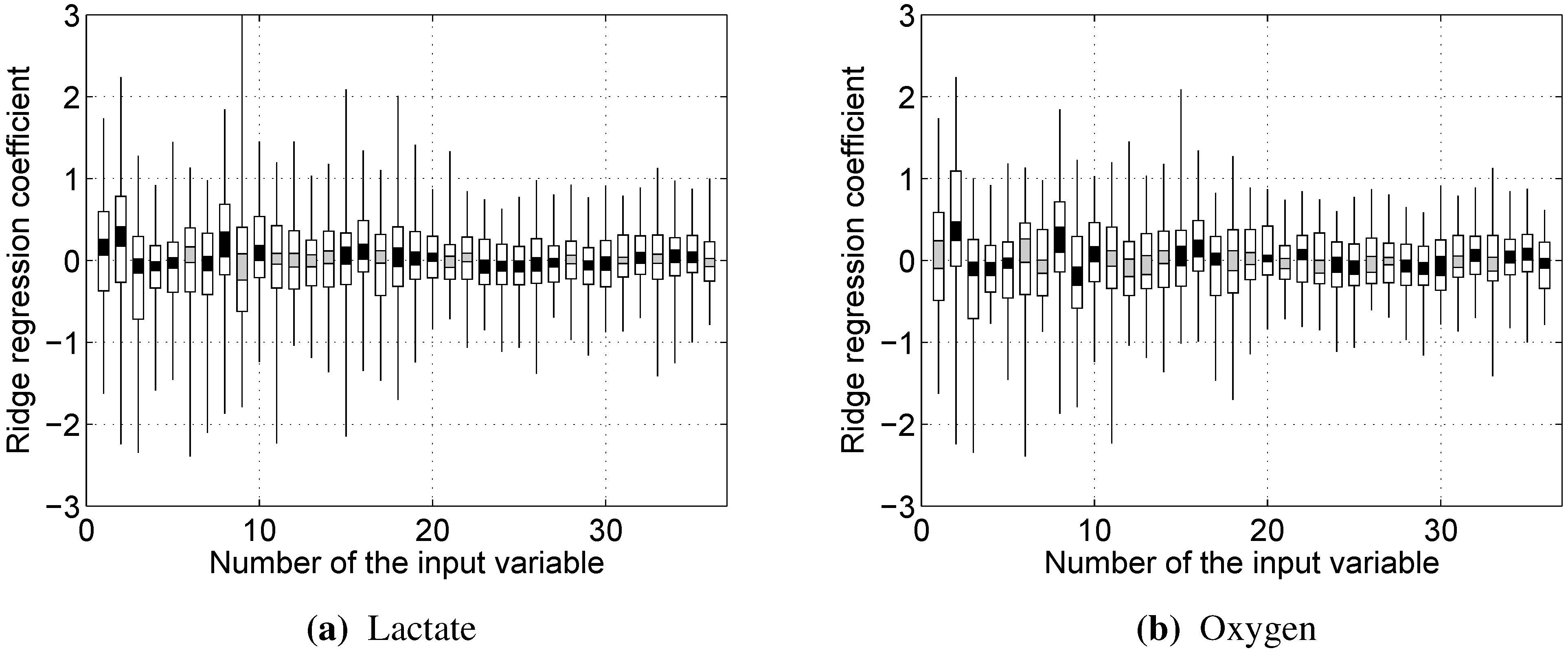
Since all of the variables were used via their z-scores, the impact of a particular input variable on the output can be estimated simply by the value of the corresponding weight .
2.6.3. Random Forest Nonlinear Models
A random forest (RF) [
28] is a general data mining tool, used successfully in different research fields for both classification and regression [
29]. Random forests have multiple desirable properties, among them robustness to overfitting, robustness to multicollinearity, robustness to outliers, invariance to monotonic transformations and good handling of mixed-type data. In practice, random forest models show similar performance to support vector machines, which is another widely-used classification and regression technique [
29].
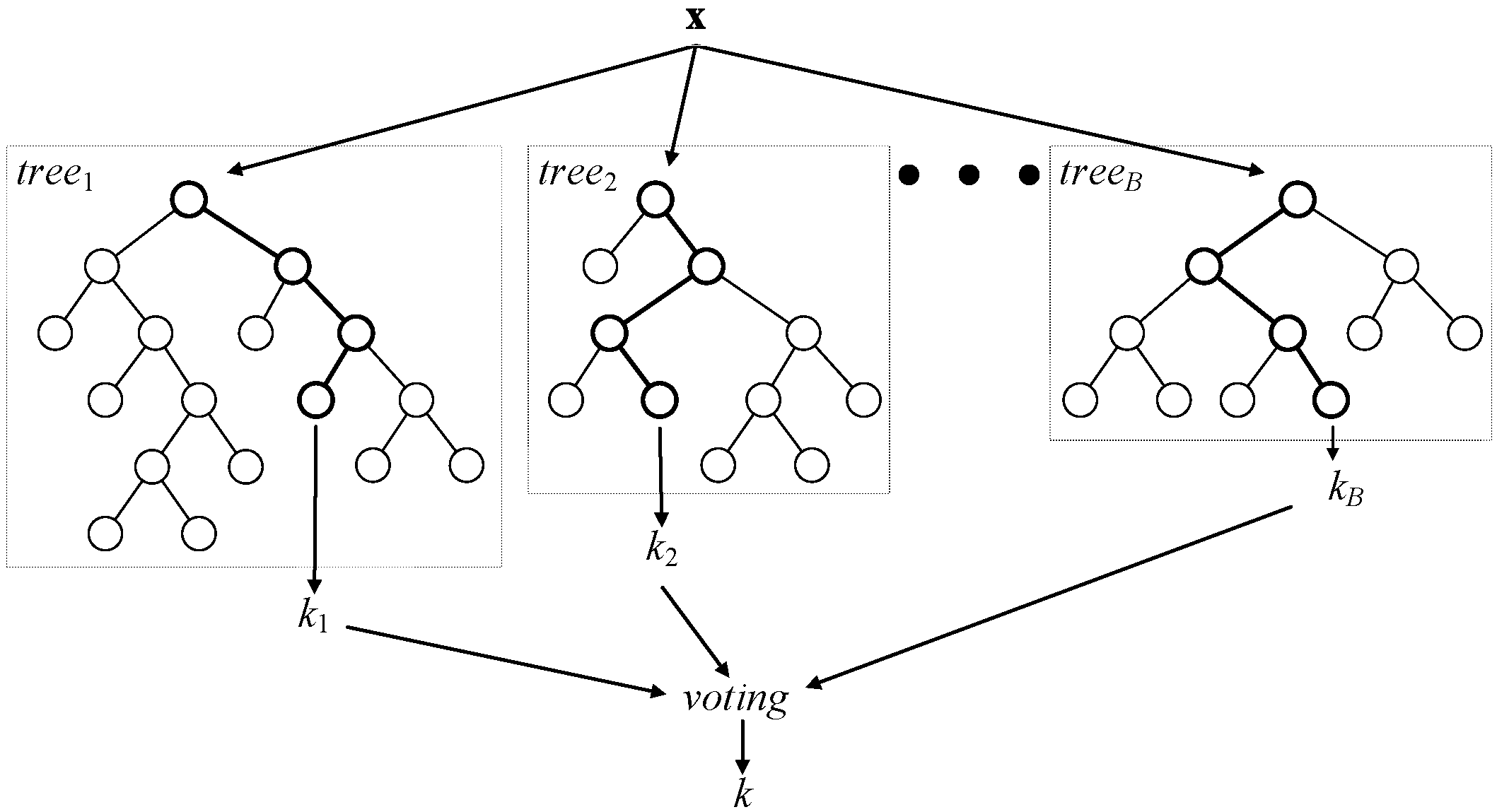
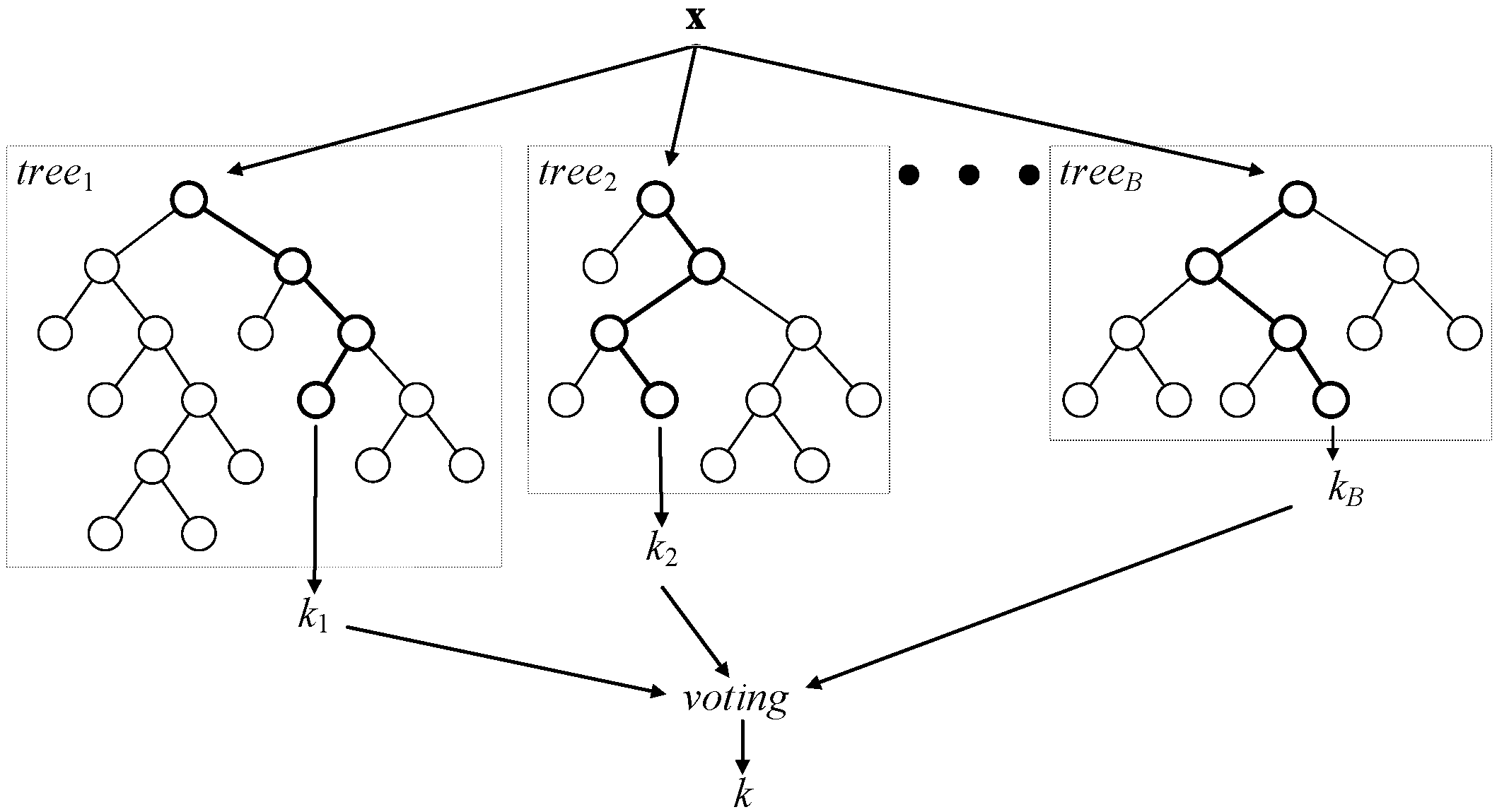
Classification random forest is a committee of decision trees, as shown in
Figure 2. In regression random forests, combination by voting is replaced by averaging. To achieve a low correlation of trees, two-step randomization is applied:
Each tree of the RF is grown on a bootstrap-aggregated (bagged) sample of the training set. About one third of the samples in the training set do not end up in this sample and, thus, form the out-of-bag dataset for that particular tree. The out-of-bag dataset can then be used for evaluating model performance and variable importance, among other things.
When growing a tree, at each node, n variables are randomly selected out of the N available. At each node, only one variable, providing the best split, is used out of the n selected.
Figure 2.
A general architecture of a random forest.
Figure 2.
A general architecture of a random forest.
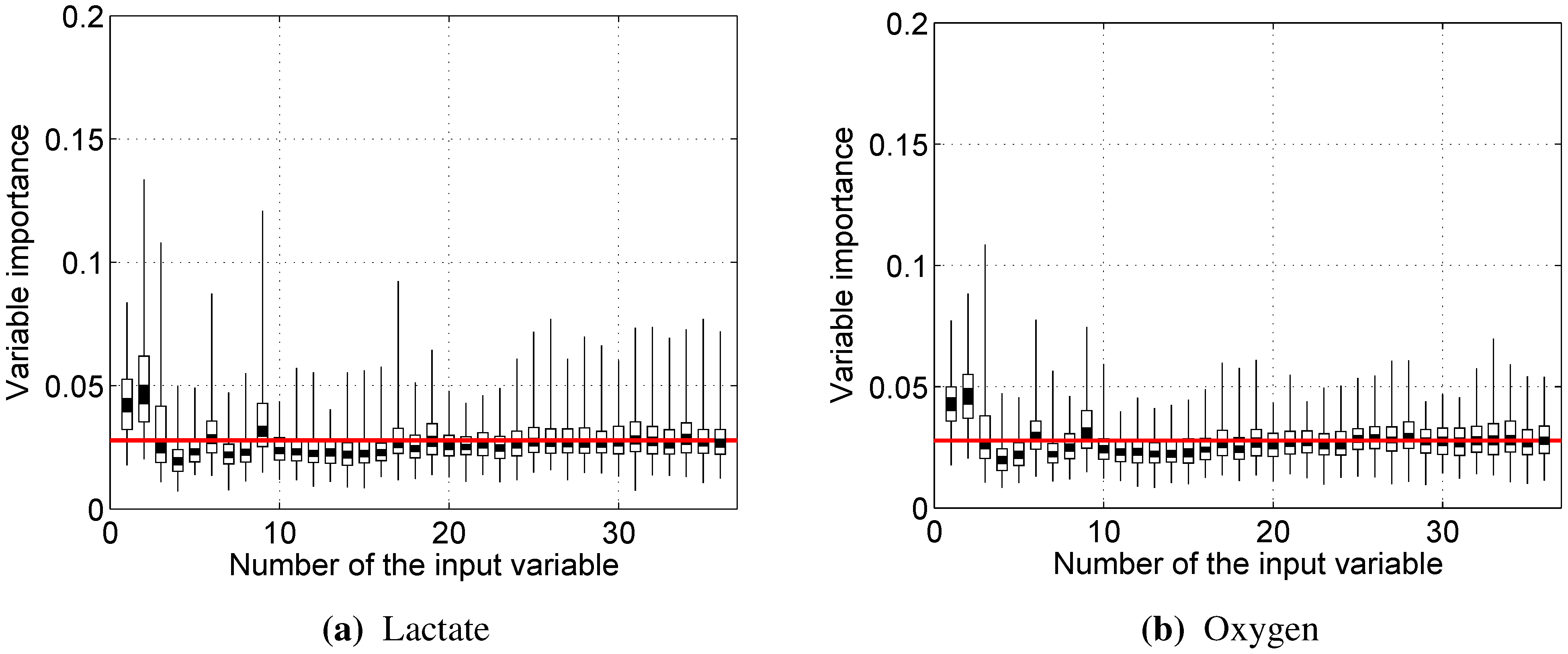
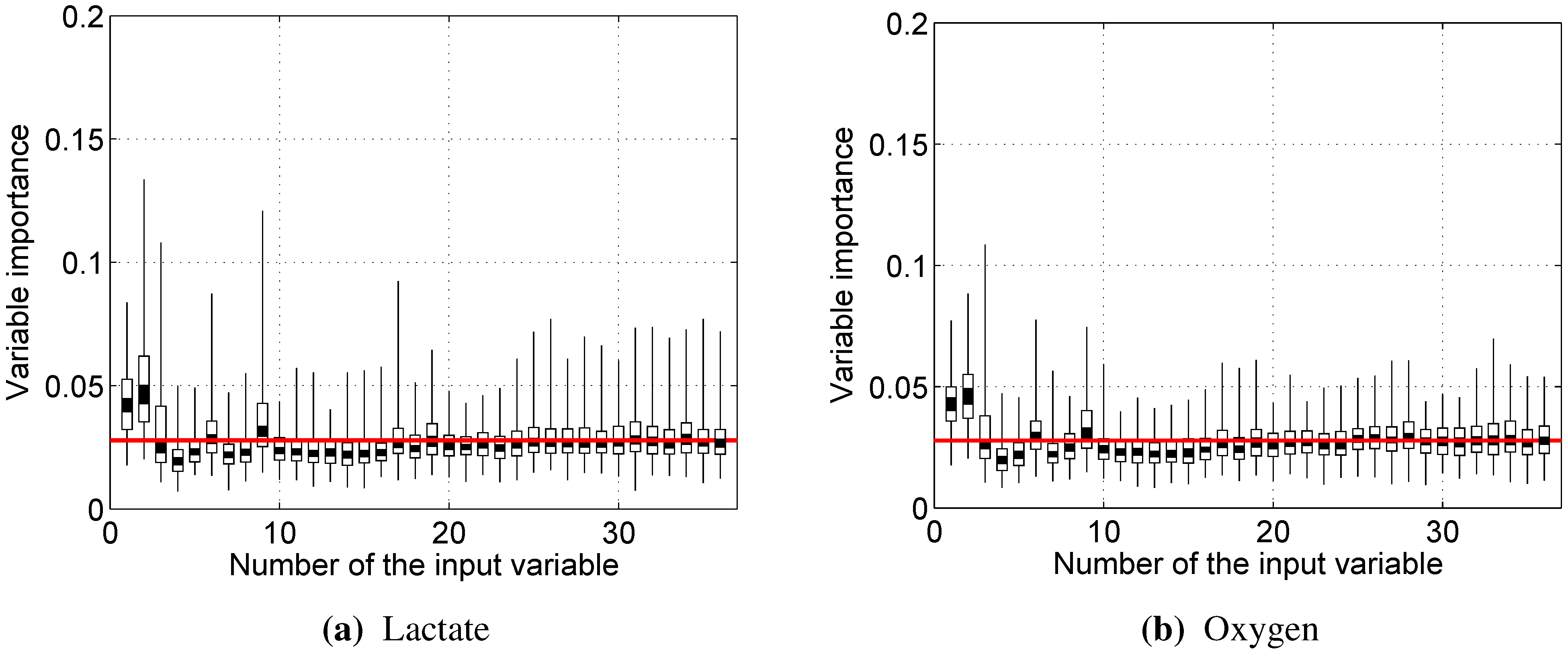
As the number of trees in the random forest increases, out-of-bag dataset error decreases and converges to a limit, after which adding further trees no longer improves the performance of the random forest. Moreover, by randomly permuting the values of a certain variable, the out-of-bag dataset can be used to estimate variable importance: variables, for which the deterioration of prediction accuracy due to random permutation is larger, are assumed to be more important for the built random forest model.
In this study, we use an RF of 100 trees, and the number of variables considered at each node split was one third of the total number (as recommended by Breiman in his guidelines to using random forests [
30]),
i.e., 12.
2.6.4. Assessing Model Performance
The coefficient of determination (
) was used to assess the performance of the regression models. The coefficient is a normalized measure of regression quality comparing the regressor with a perfect regressor (
) and a naive regressor (the mean value of teaching data,
):
where
y and
stand for the actual values and the model prediction, respectively. The
values presented in this paper represent the average of values obtained through 10-fold cross-validation (ridge regression, independent of 10-fold cross-validation used to obtain an optimal value for shrinkage parameter λ) or 10 different random seeds (random forests).
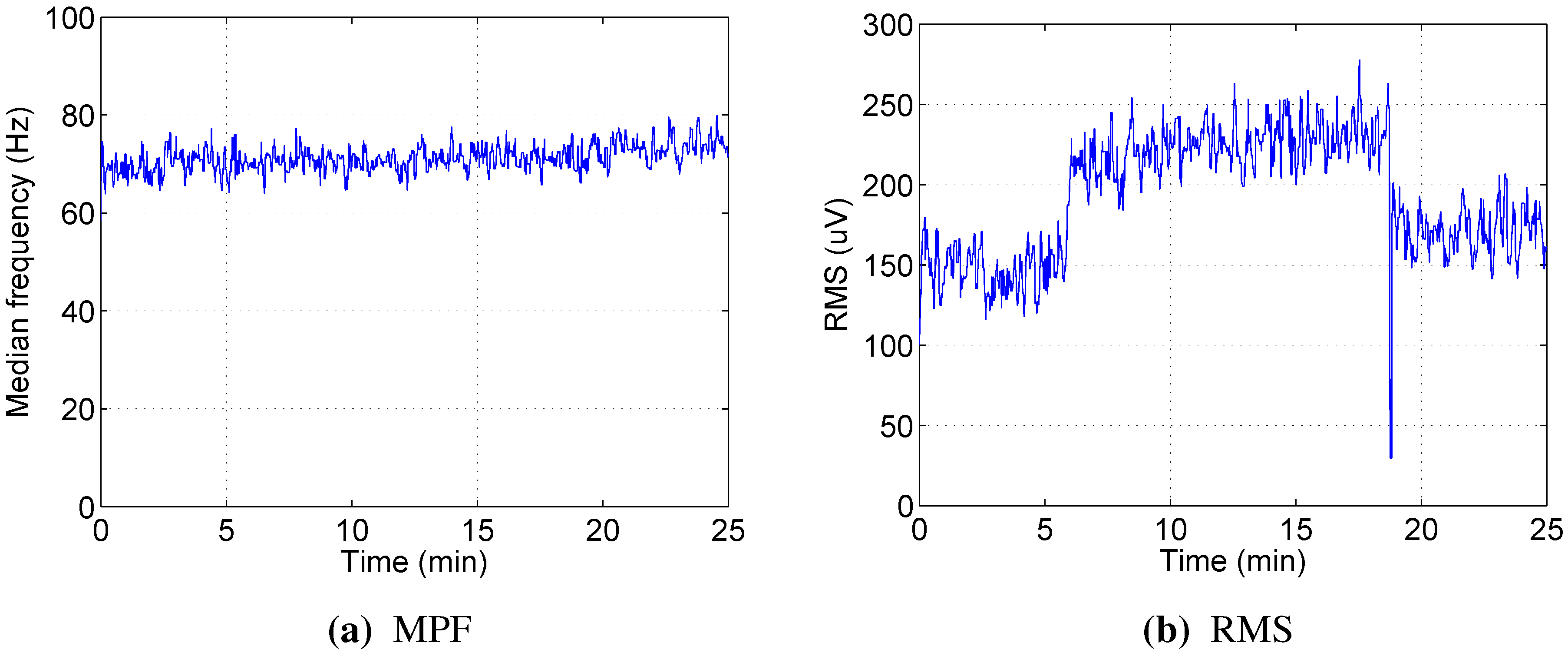
4. Discussion
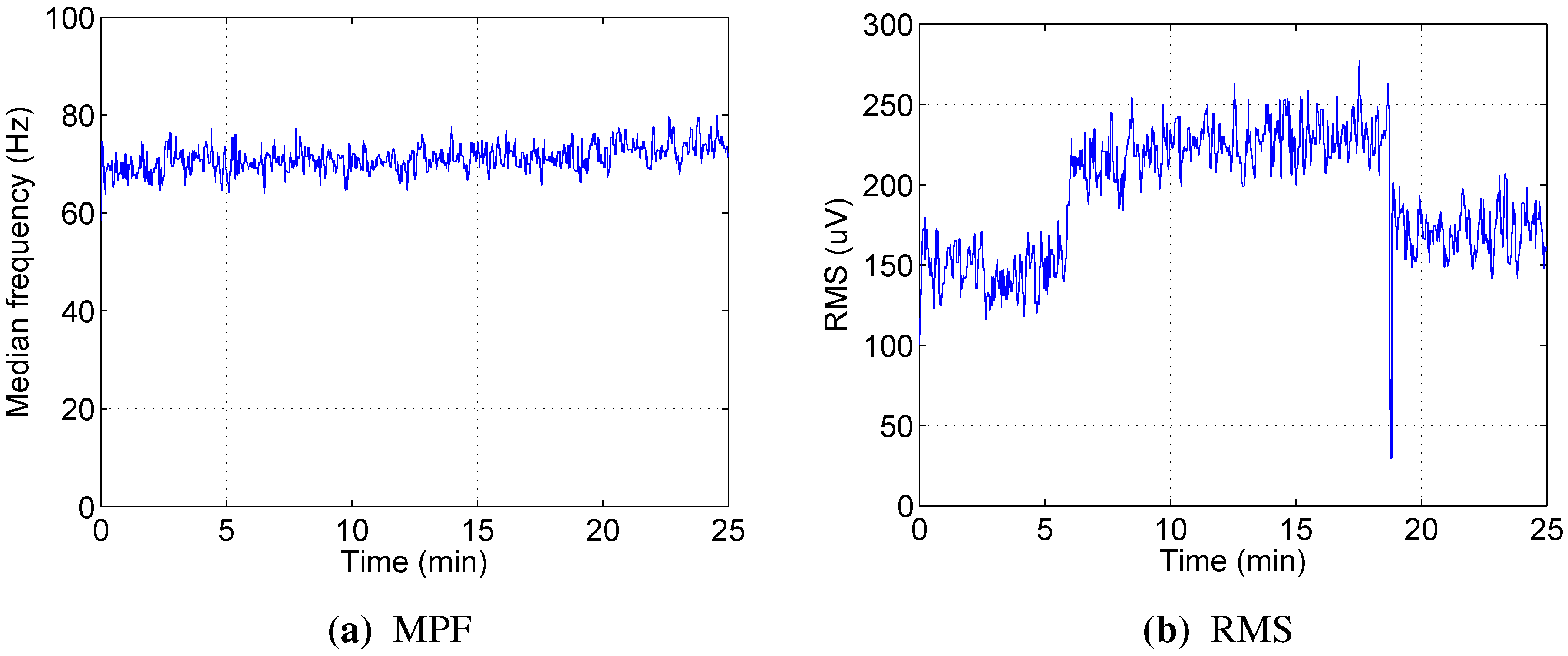
The median power frequency, which is regarded as one of the best indicators for muscle fatigue in high static load experiments, was not informative in dynamic load exercises using our protocol. Moreover, different patterns of MPF change were observed for different subjects participating in the experiment. The decrease over time was observed only for a few muscles in a few participants, and in most cases, MPF remained stable or even increased slightly as the test progressed. This agrees with studies from Knaflitz [
17], Jansen [
18] and Tenan [
14] and supports the belief that the limiting factor for this type of exercise is the inability of cardiovascular and respiratory systems to supply enough oxygen to the muscles, not local muscle fatigue.
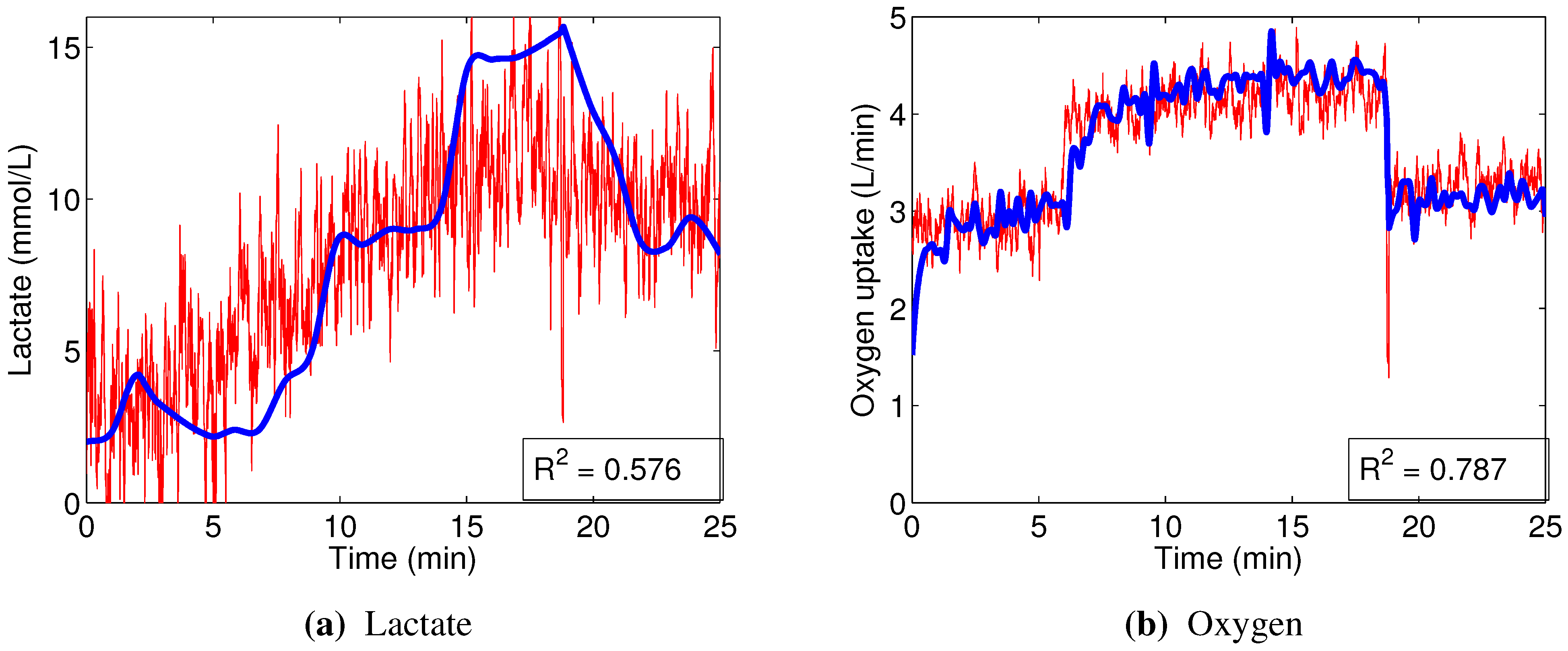
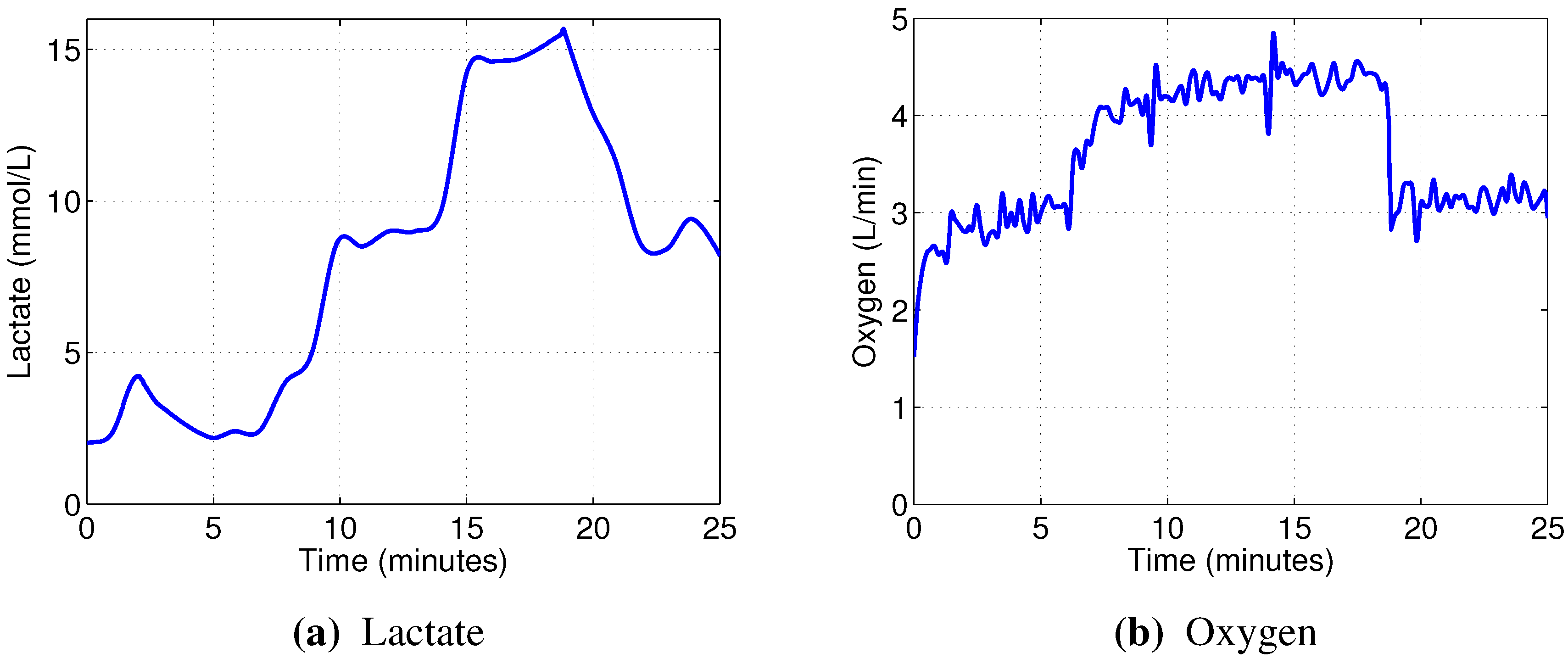
The linear models designed to predict oxygen uptake were rather successful in their capacity to track the general change in dynamics. Predicting blood lactate concentration, on the other hand, was a more difficult task. In particular, the general linear models, built from the combined data, barely outperformed the naive predictor (mean of the training set), as evidenced by the coefficients of determination
ranging between 0.05 and 0.3. This, combined with significantly higher accuracy of nonlinear models in general (as shown in
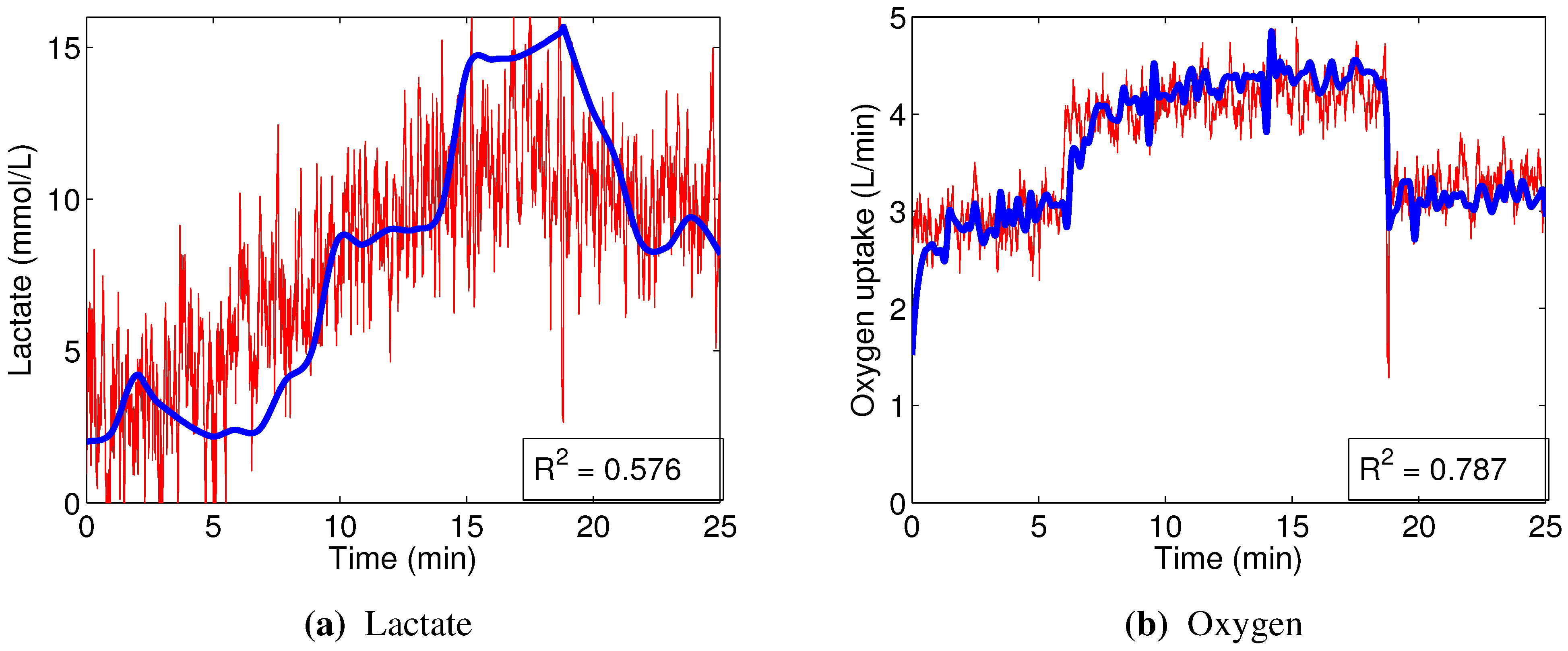
Section 3.2.2), strongly suggests that the relationships between the input variables that we used and blood lactate concentration are non-linear.
In contrast, the non-linear random forest models built to predict blood lactate concentration showed very good performance, evidenced by the high out-of-bag prediction accuracy. Even better results were obtained when predicting oxygen uptake. Those models were able to reflect not only the major changes in oxygen consumption, but also the minor details.
Almost every model built showed rather strong reliance on the RMS and/or dRMS features. This result is not unexpected for prediction, since they are directly linked and closely follow the load a cyclist is experiencing. However, the same being true for prediction of lactate accumulation suggests that changes in RMS and dRMS also reflect the exertion of the cyclist to some extent. More interestingly, our results suggest that, while neither mean nor median power frequency were important in predicting blood lactate concentration or oxygen uptake, the tails of the EMG power distribution carry useful information to predict these two physiological parameters.
Having said that, it must be understood that the main goal of our experiments was not the identification of a simple relationship between blood lactate concentration or oxygen uptake and one or two input variables, characterizing the EMG signal. Indeed, the success of random forest models using a large set of moderately-important variables suggests that this relationship is rather complex and non-linear.
As already discussed in
Section 2.5, our results rely on the assumption of cyclic stationarity of the extracted sEMG segments, as outlined in a 2001 article by Bonato
et al. [
9]. While this assumption allows meaningful comparison between these segments, employing alternative, more complicated methods of time-frequency analysis, such as continuous wavelet transform, could yield even better results without assuming any type of stationarity.
Due to the relatively low number of test subjects, it would be quite hard to draw any firm conclusions on within-group differences in the results, e.g., between male and female participants. Having said that, we did not observe any strong gender or age biases in either the performance of the subjects during the tests or the results we obtained during the analysis.
Random forests show a great potential for analyzing EMG data and could be used successfully in this context. In particular, more advanced time-frequency domain techniques could be used when extracting the spectral information from EMG signals, which would likely further increase the prediction accuracy that random forests were able to achieve. In addition, EMG signal analysis needs not be limited to the frequency or time-frequency domain, as useful information could be extracted from multichannel sEMG recordings by analyzing the timing of certain events, e.g., muscle activation and deactivation. This particular approach could also provide some insight into the changes in cycling kinematics as the exercise progresses and fatigue increases.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}