1. Introduction
The use of sensors, especially vision sensors and force sensors, which provide robots with their sensing ability, plays an important role in the intelligent robotic field. Legged robots, after having a good knowledge of the spot environment, can previously select a safe path and a set of appropriate footholds, then plan the feet and body locomotion effectively in order to traverse rough terrains automatically with high stability, velocity and low energy consumption. There have been some related examples in recent years. HyQ [
1] can trot on uneven ground based on its vision-enhanced reactive locomotion control scheme, by using an IMU and a camera. Messor [
2] uses a Kinect to classify various terrains in order to achieve automatic walking on different terrains. The DLR Crawler [
3] can navigate in unknown rough terrain using a stereo camera. Little Dog [
4] uses a stereo camera and the ICP algorithm to build the terrain model. Messor [
5] uses a laser range finder to build the elevation map of rough terrains, and chooses appropriate foothold points based on the elevation map. Planetary Exploration Rover [
6] builds a map model with a LIDAR sensor based on the objects’ distance and plans an optimized path. AMOS II [
7] uses a 2D laser range finder to detect the distance to obstacles and gaps in front of the robot, and it also can classify terrains based on the detected data. A humanoid robot [
8] uses a 3D TOF camera and a webcam camera to build a digital map, and after that plans a collision avoiding path. Another humanoid robot [
9] can walk along a collision avoiding path based on fuzzy logic theory with the help of a webcam camera. The RHEX robot [
10] is able to achieve reliable 3D sensing and locomotion planning with a stereo camera and an IMU mounted on it.
In robotics, if a vision sensor is mounted on the robot, its pose with respect to the robot frame must be known, otherwise the vision information can’t be used by the robot. However, only a few works describe how to compute it. In related fields, problems of extrinsic calibration of two or more vision sensors have been studied extensively. Herrera [
11] proposed an algorithm that could calibrate the intrinsic parameters and the relative position of a color camera and a depth camera at the same time. Li, Liu
et al. [
12] used the straight line features to identify the extrinsic parameters of a camera and a LRF. Guo
et al. [
13] solved the identification problem of a LRF and a camera by using the least squares method twice. Geiger
et al. [
14] presented a method which can automatically identify the extrinsic parameters of a camera and a range sensor using one shot. Pandey and McBride [
15] successfully performed an automatic targetless extrinsic calibration of a LRF and a camera by maximizing the mutual information. Zhang and Robert [
16] proposed a theoretic algorithm calibrating extrinsic parameters of a camera and a LRF by using a chessboard, and they also verified the theory by experiments. Huang
et al. [
17] calibrated the extrinsic parameters of a multi-beam LIDAR system by using V-shaped planes and infrared images. Fernández-Moral
et al. [
18] presented a method for identifying the extrinsic parameters of a set of range finders by finding and matching planes in 5 s. Kwak [
19] used a V-shaped plane as the target to calibrate the extrinsic parameters of a LIDAR and a camera by minimizing the distance between corresponding features. By using a spherical mirror, Agrawal [
20] could achieve extrinsic calibration parameters of a camera without a direct view. When two vision sensors don’t have overlapping detection regions, Lébraly
et al. [
21] could obtain the extrinsic calibration parameters using a planar mirror. By using a mirror to observe the environment from different viewing angles, Hesch
et al. [
22] determined the extrinsic identification parameters of a camera and other fixed frames. Zhou [
23] proposed a solution for the extrinsic calibration of a 2D LIDAR and a camera using three plane-line correspondences. Kelly [
24] used GPS measurements to establish the scale of both the scene and the stereo baseline, which could be used to achieve simultaneous mapping.
A more related kind of work is the coordinate identification between a vision system and manipulators. Wang [
25] proposed three methods to identify the coordinate systems of manipulators and a vision sensor, then compared them by simulations and experiments. Strobl [
26] proposed an optimized robot hand-eye calibration method. Dornaika and Horaud [
27] presented two solutions to perform the robot-world and the hand-eye calibration simultaneously, one was a closed-formed method which used the quaternion algebra and a positive quadratic error function, the other one was based on a nonlinear constrained minimization, they found that the nonlinear optimization method was more stable with respect to noises and measurements errors. Wong wilai [
28] used a Softkinetic Depthsense, which could acquire distance images directly, to calibrate an eye-in-hand system.
Few papers and researches involve identifying the coordinate relationship between the vision system and legged robots. The most similar and recent work to our own is that of Hoepflinger [
29], which calibrated the pose of a RGB-D camera with respect to a legged robot. Their method needed to recognize the foot position in the camera coordinate system based on the assumption that the robot’s foot has a specific color and shape. Then identification parameters can be obtained by comparing the foot position in different coordinate systems, the camera frame and the robot frame. Our research target is the same with theirs, while the solution is totally different.
Existing methods to identify extrinsic parameters of the vision sensor suffer from several disadvantages, such as a difficult featuring matching or recognition, requirement for external equipment and the involvement of human interventions. Current identification approaches are often elaborate procedures. Moreover, work has seldom been done for the pose identification of the vision sensor mounted on legged robots. To overcome limitations of the existing methods and supplement relevant study in legged robots, in this paper we propose a novel coordinate identification methodology for a 3D vision system mounted on a legged robot without involving other people or additional equipment. This paper makes the following contributions:
A novel coordinate identification methodology for a 3D vision system of a legged robot is proposed, which needs no additional equipment or human inventions.
We use the ground as the reference target, which makes it possible for our methodology to be widely used. At the same time, an estimation approach is introduced based on the optimization and statistical methods to calculate the ground plane accurately.
The relationship between the legged robot and the ground is modeled, which can be used to precisely obtain the pose of the legged robot with respect to the ground.
We integrate the proposed methodology on “Octopus”, which can traverse rough terrains after obtaining the identification parameters. Various experiments are carried out to validate the accuracy and robust of the method.
The remainder of this paper is organized as follows:
Section 2 provides a brief introduction to the robot system.
Section 3 describes the problem formulation and the definition of coordinate systems.
Section 4 presents the modeling and the method in detail.
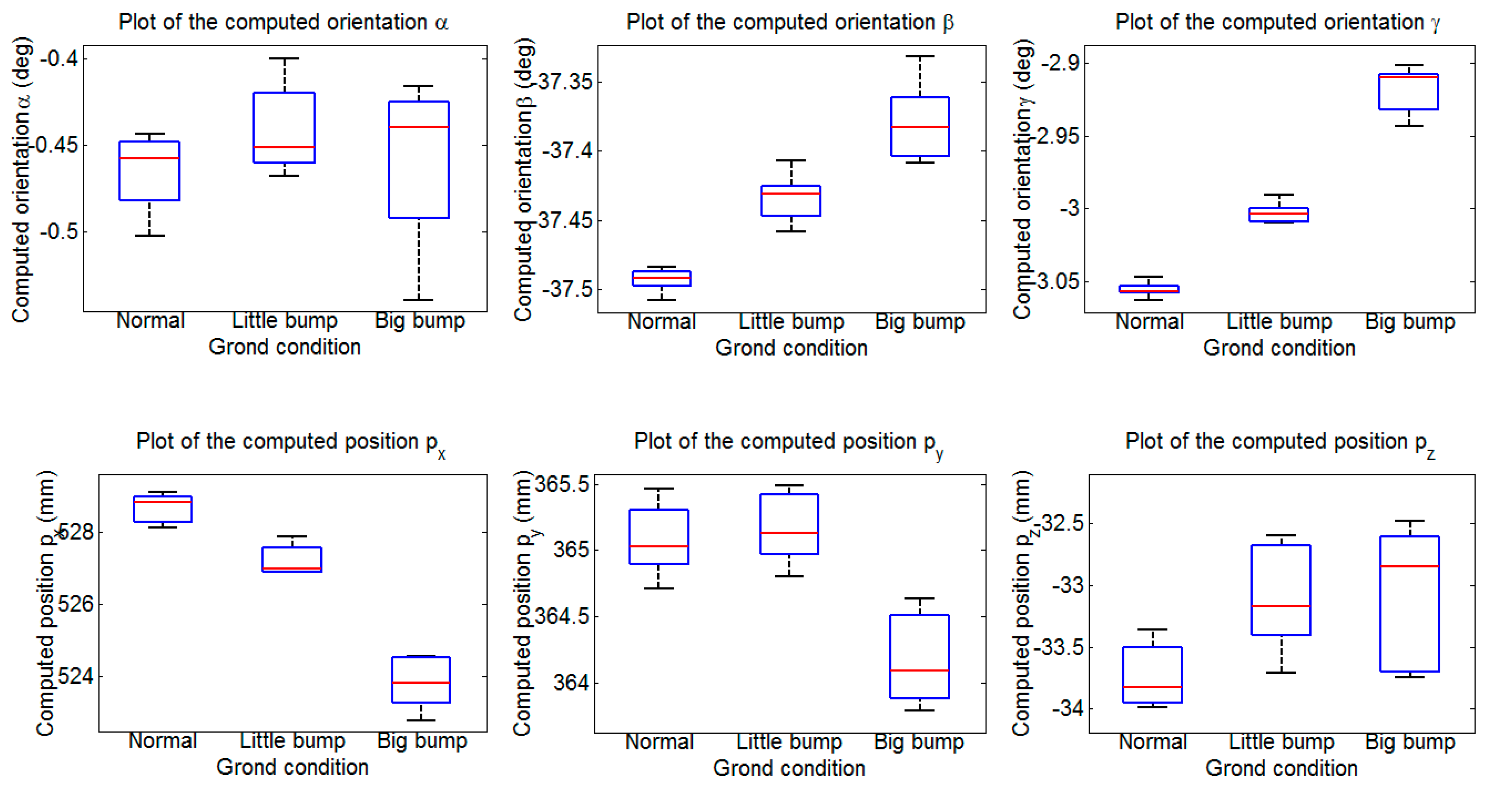
Section 5 describes the experiments and discusses the error and robust analysis results.
Section 6 summarizes and concludes the paper.
2. System Description
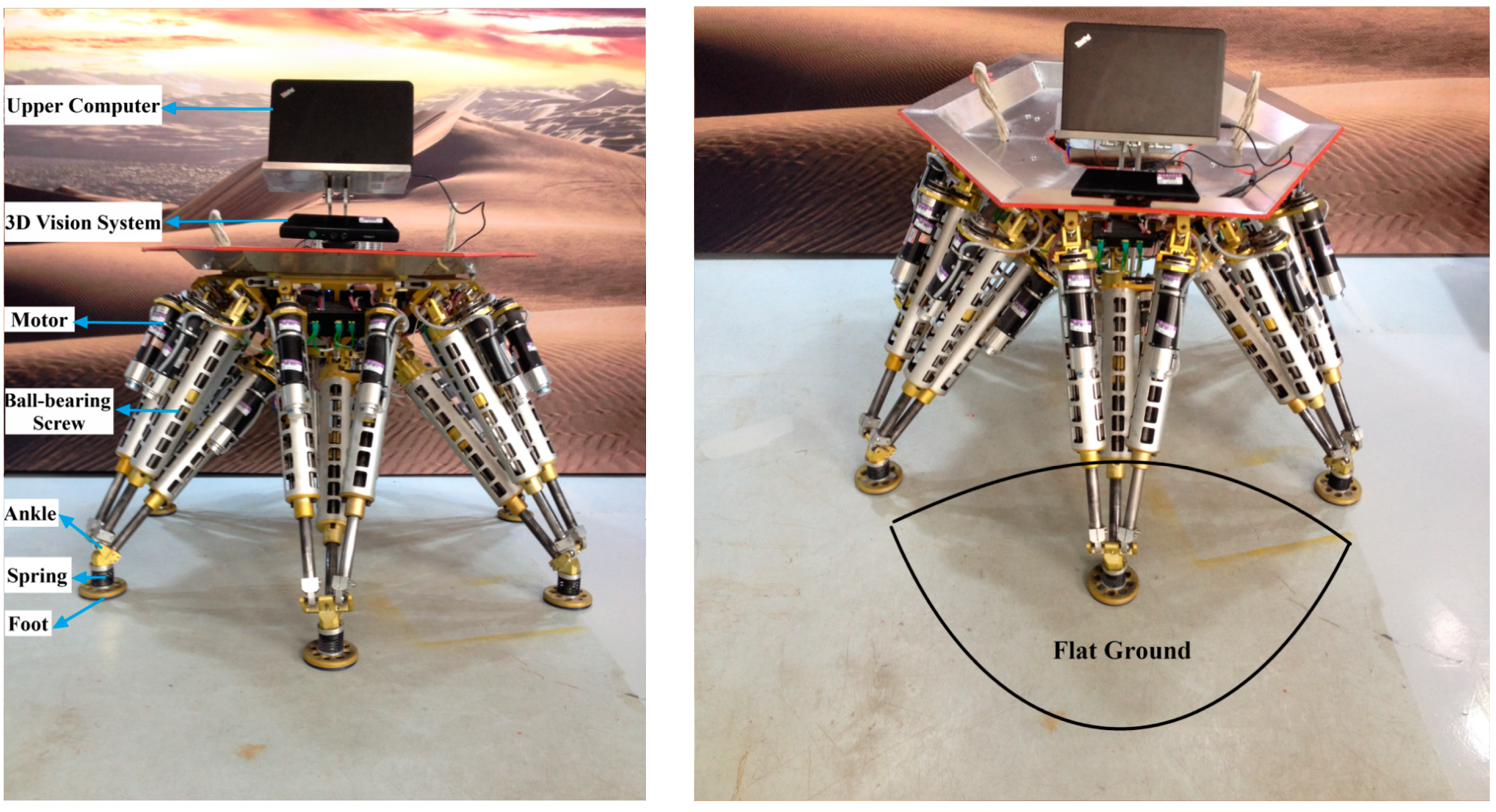
The legged robot is called “Octopus” [
30,
31], which has a hexagonal body with six identical legs arranged in a diagonally symmetrical way around its body as shown in
Figure 1. The robot is a six DOFS moving platform that integrates walking and manipulating. A vision system is necessary for building a terrain map, and its mounting position and orientation with respect to the robot frame, which is essential for locomotion planning, need to be acquired.
Figure 1.
The legged robot “Octopus”.
Figure 1.
The legged robot “Octopus”.
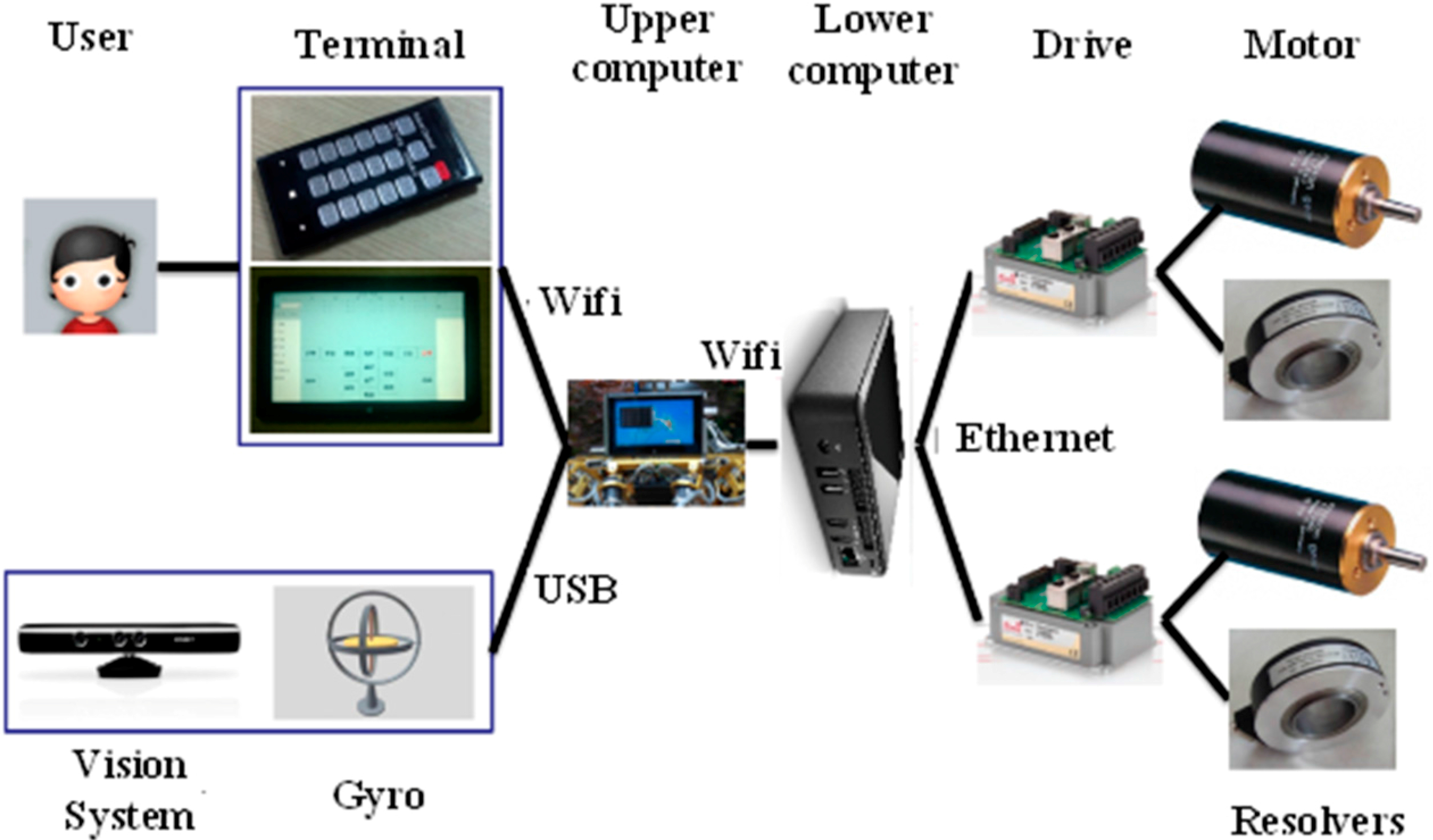
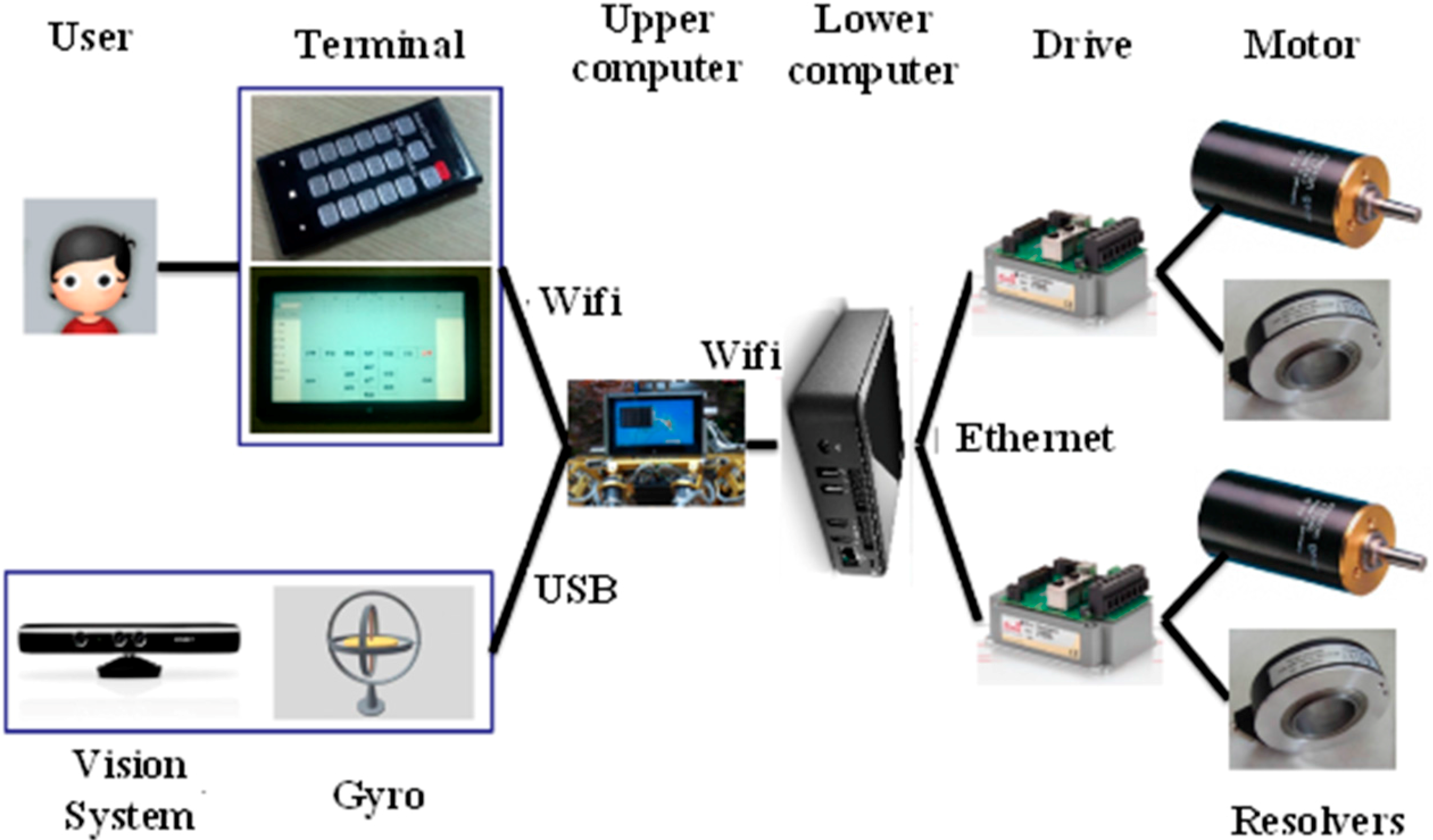
Figure 2 shows the control architecture of the robot. Users send commands to the upper computer via a control terminal, which can be a smart phone or a pad and communicates with the upper computer via Wi-Fi. The sensor system contains a 3D vision sensor, a gyro, a compass and an accelerometer. The 3D vision sensor detects the terrain in front of the robot and provides the 3D coordinate data. The 3D vision sensor connects with the upper computer via USB. The compass helps the robot navigate in the right direction in outdoor environments. The gyro and the accelerometer can measure the inclination, the angle velocity and the linear acceleration of the robot. The upper computer is a super notebook, which receives and processes useful data from the sensor system. The upper computer sends instructions to the lower computer via Wi-Fi too. The Wi-Fi networking is created by the upper computer. The lower computer runs a real-time Linux OS. The lower computer analyzes messages sent by the upper computer, then plans locomotion and sends planned data to drivers via Ethernet at run time. Drivers provide current to motors, and servo control motors using the feedback data from resolvers.
Figure 2.
The control architecture of the robot.
Figure 2.
The control architecture of the robot.
The current work we are doing is try to make the robot walk and operate automatically in unknown environments with the help of the 3D vision sensor. Automatic locomotion planning needs the 3D coordinates of the surroundings, which can be transferred from depth images captured by the 3D vision sensor. Common laser range finders can only measure distances to objects that are located in the laser line of sight, while the 3D vision sensor can measure all the distances to objects in the range of the detection region, which is the reason why we choose a 3D vision sensor. The 3D vision sensor we use is a Kinect (as
Figure 3 shows), which integrates multiple kinds of useful sensors, consisting of a RGB camera, an infrared emitter and camera, and four microphones. The RGB camera can capture 2D RGB images, the infrared emitter and camera constitute a 3D depth sensor which can measure the distance. Speech recognition and sound source localization can be achieved by processing voice messages obtained by the four microphones at the same time.
Figure 3.
The 3D vision sensor.
Figure 3.
The 3D vision sensor.
Equipped with the 3D vision sensor, the robot can see objects from 0.8 m to 4 m and has a 57.5° horizontal vision angle and 43.5° vertical vision angle. The range from 1.2 m to 3.5 m is a sweet spot, in which the measuring precision can reach millimeter level [
32,
33]. Additionally, a small motor inside the 3D vision sensor allows it to tilt up and down from −27° to 27°. The 3D vision sensor is installed at the top of the robot as
Figure 4 shows. The motor is driven to make the 3D vision sensor tilt down in order to ensure it can detect the terrain in front. The blue area is the region that the 3D vision sensor can detect, and the green area is the sweet spot. The height of the 3D vision sensor, denoted by
h, is about 1 m. The short border VA of the green area is about 1.2 m and the long border VB is about 3.5 m through geometric calculations. We can make sure the depth data in the green area have a higher precision.
Figure 4.
Installation schematic diagram of the 3D vision system.
Figure 4.
Installation schematic diagram of the 3D vision system.
3. Problem Formulation and Definition of Coordinate Systems
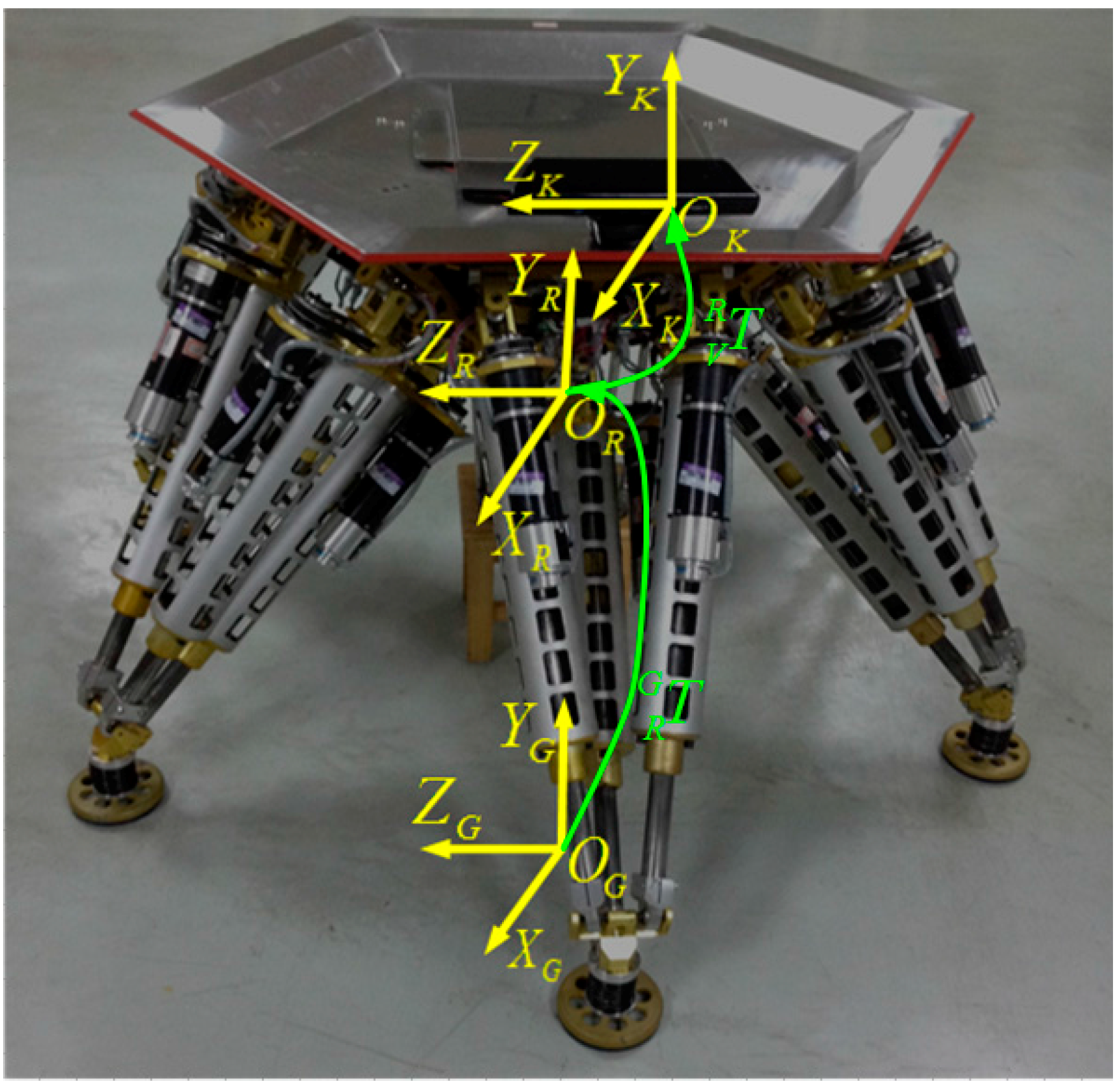
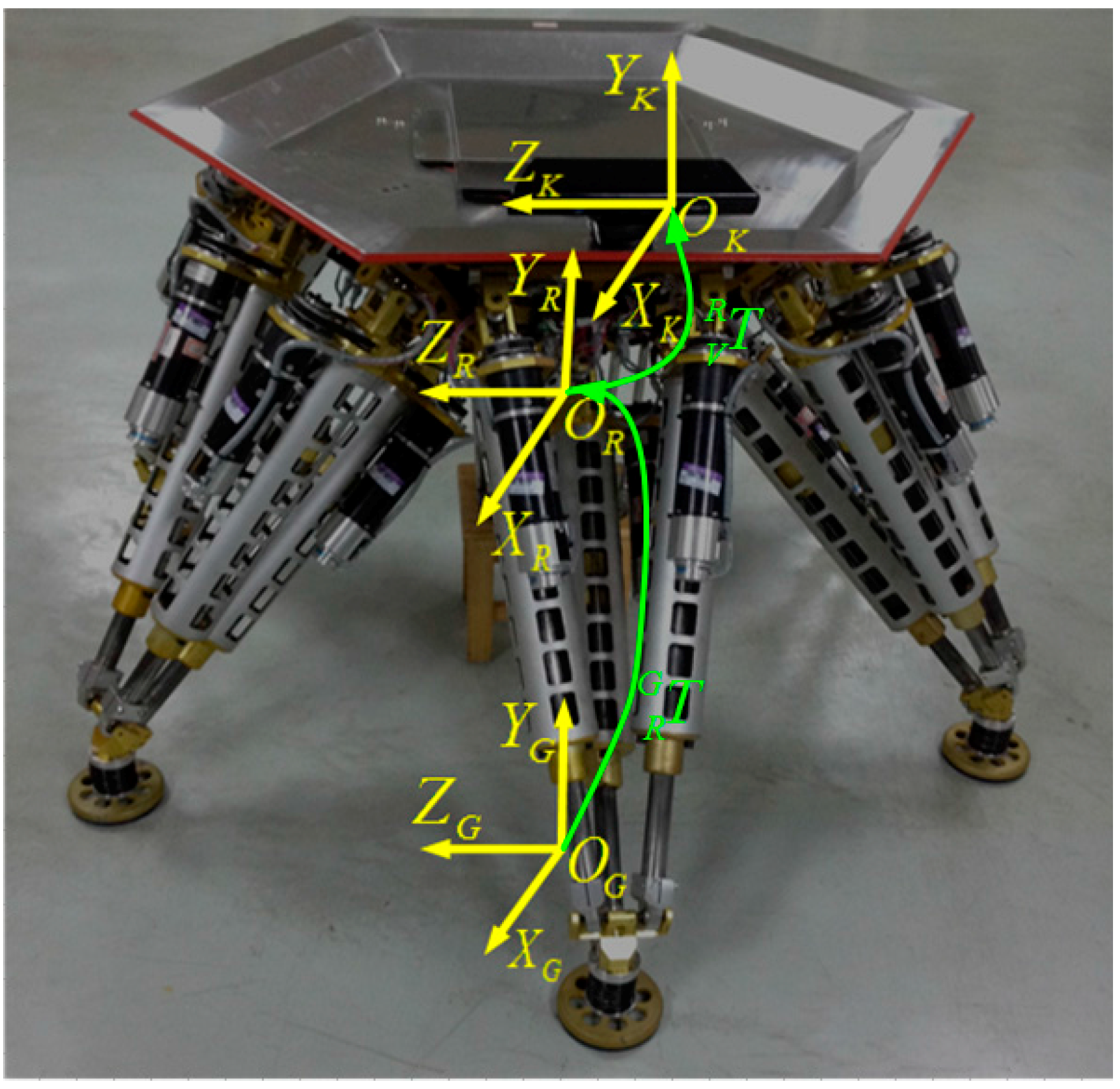
As mentioned above, it is very important to know the exact relationship between the 3D vision sensor coordinate system and the robot coordinate system. In other words, the mounting position and orientation of the 3D vision sensor must be identified. In order to express this simply, we us G-CS as short notation for the ground coordinate system, R-CS is short for the robot coordinate system, and V-CS is short for the 3D vision sensor coordinate system. As
Figure 5 shows, the G-CS is represented by
, which is used as the reference target with respect to the V-CS represented by
and the R-CS represented by
.
Figure 5.
Definition of coordinate systems.
Figure 5.
Definition of coordinate systems.
The transformation matrix
in
Figure 5 describes the position and the orientation of the R-CS with respect to the G-CS. Similarly, the identification matrix
describes the position and orientation of the V-CS with respect to the R-CS, which can be denoted by the
X-Y-Z fixed angles of the R-CS. Concretely, set the R-CS fixed, the V-CS rotates
along the
XR-axis, then rotates
β along the
ZR-axis, and rotates α along the
YR-axis, at last translates
qx,
qy,
qz along the
XR-axis,
YR-axis,
ZR-axis, respectively. After that we can get the current V-CS.
Table 1 shows the identification parameters, and our goal is to determine the six identification parameters. The 3D coordinates of the terrain obtained by the vision sensor can be transferred to the R-CS by the transformation of the identification matrix
.
Table 1.
The identification parameters.
Table 1.
The identification parameters.
| Fixed Axes | Identification Angles | Identification Positions |
|---|
| XR | γ | qx |
| YR | α | qy |
| ZR | β | qz |
Equation (1) describes
in detail:
where:
4. Proposed Identification Methodology
Section 4 presents the novel identification model and method in detail.
Figure 6.
Modeling of the method.
Figure 6.
Modeling of the method.
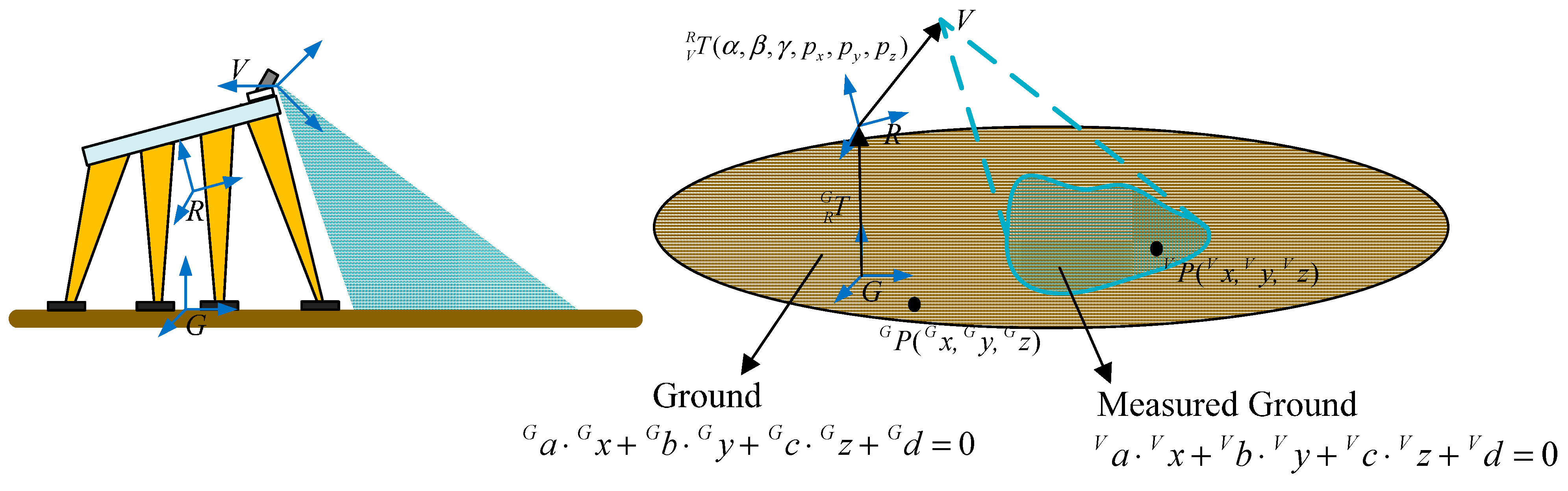
As
Figure 6 shows,
is an arbitrary point on the ground plane,
is with respect to the V-CS and
is with respect to the G-CS.
and
fulfill Equation (4):
where
is the identification matrix we proposed in
Section 3, and
is the transformation matrix from the R-CS to the G-CS.
can be detected by the 3D vison system and fulfills a standard plane Equation (5):
where
and
fulfill the formula
. The upper left mark
in Equation (5) denotes the variables are with respect to the V-CS
, which is with respect to the G-CS, fulfills the following standard plane Equation (6):
where
and
fulfill the formula
. The upper left mark
in Equation (6) denotes the variables are with respect to the G-CS. In our work, the ground fulfills the following plane Equation (7):
The term
can be computed by solving the constraint Equation (4).
, representing the relationship between the robot and the ground, can be obtained using the model presented in
Section 4.2. In our methodology,
is not computed by recognizing some certain points
P. Instead, we estimate the ground plane from the point cloud detected by the 3D vision system. Then we have developed an algorithm which will be presented in
Section 4.3 that formulates the identification problem as an optimization problem. The above modeling can reduce recognition errors and avoid measurement errors.
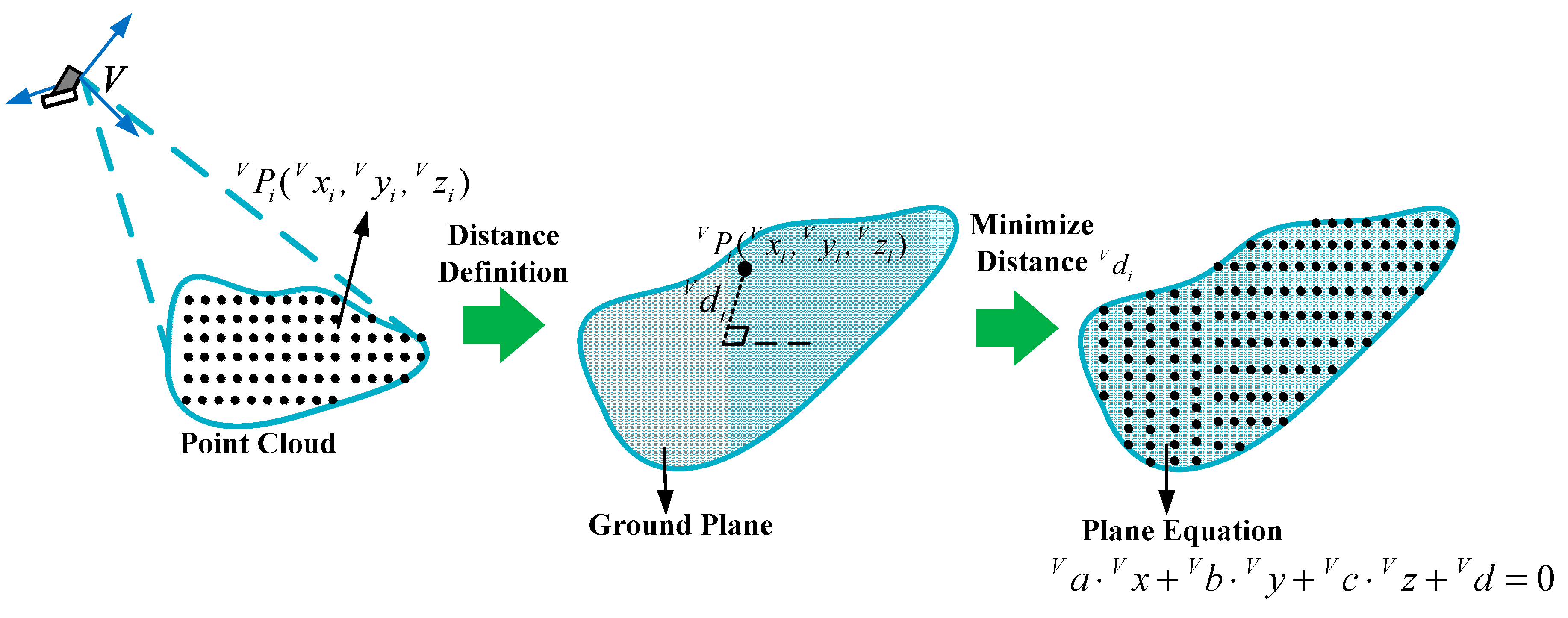
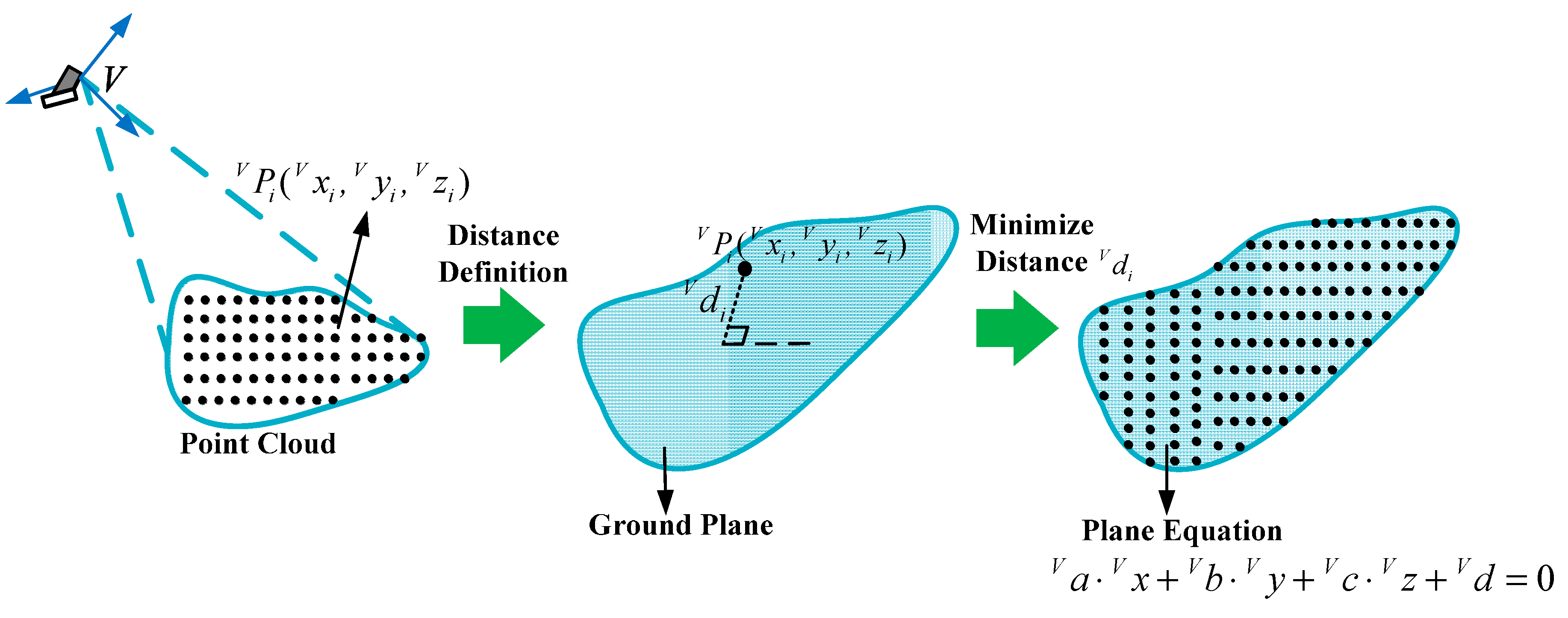
4.1. Estimation of the Ground Plane
in Equation (8) is the distance from the detected point to the ground plane, as
Figure 7 shows:
Figure 7.
Estimation approach of the ground plane.
Figure 7.
Estimation approach of the ground plane.
Most detected points belong to the ground plane, and
should be 0. So the planar parameters
can be computed by minimizing the value of
:
in Equation (9) is defined to facilitate the computation. The Lagrange multiplier method is used to find the minimum value of
. The Lagrange function is given by:
The following formula exists:
Equation (12) can be obtained from Equation (11):
Substituting Equation (12) into Equation (8), we can obtain the Equation (13):
There also exist the following equations:
Equation (14) can be rewritten as a matrix equation:
Observing Equation (15), we can find that is the eigenvector of matrix A and is the corresponding eigenvalue, so can be computed using the matrix eigenvector calculation method. Generally, matrix A has three eigenvalues and three different groups of eigenvectors correspondingly. can be obtained from Equation (13). The set of minimizing is the right set. After that, can be computed from Equation (12).
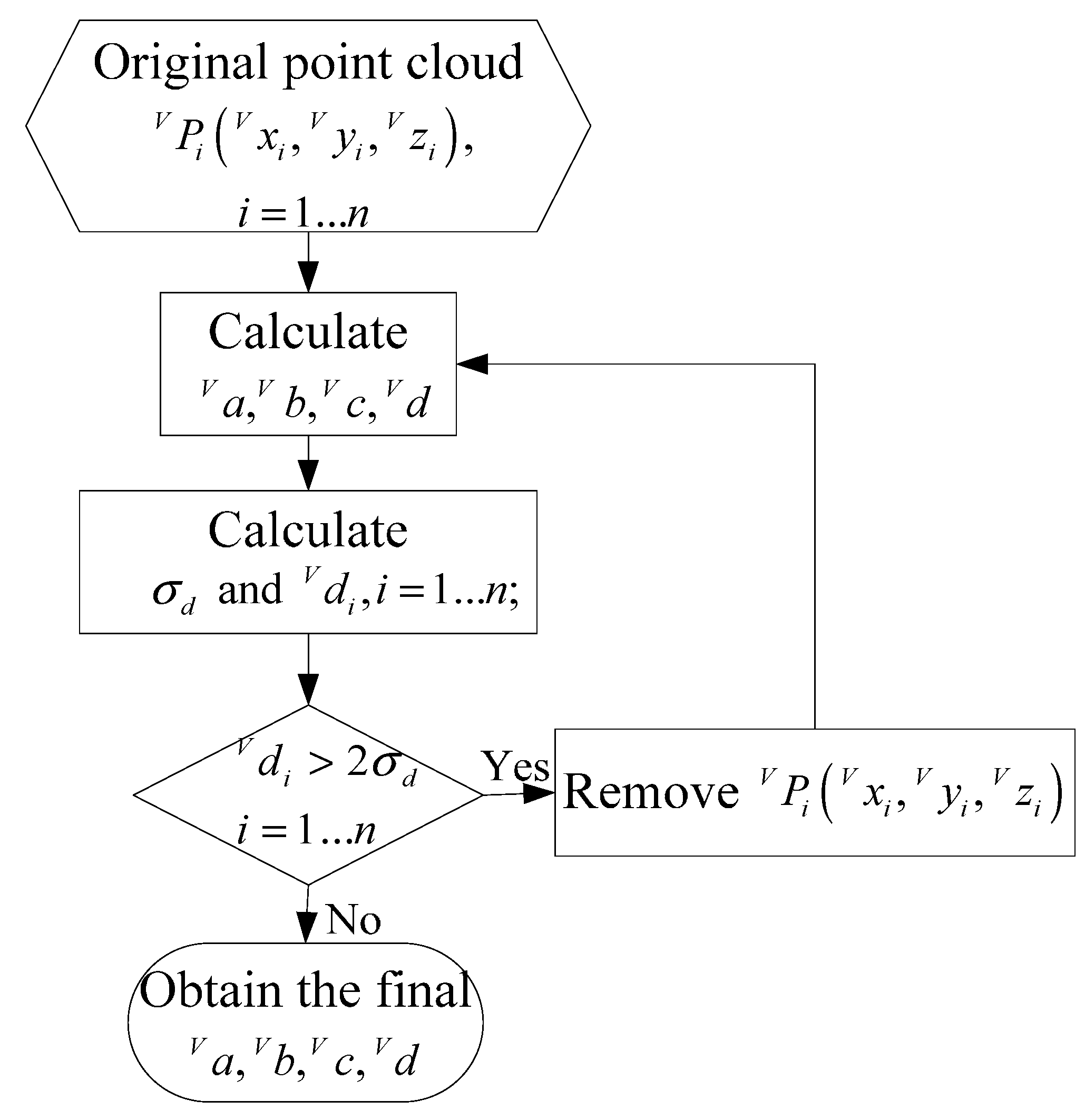
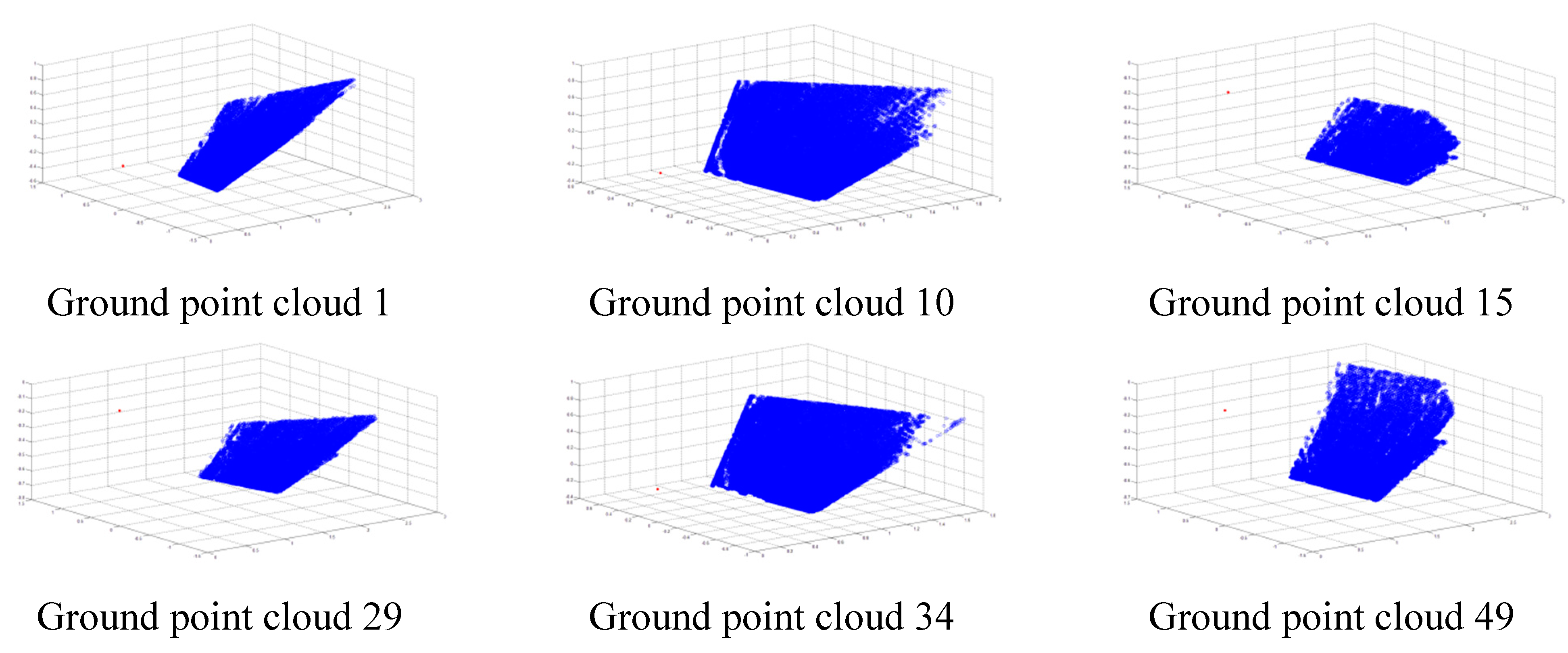
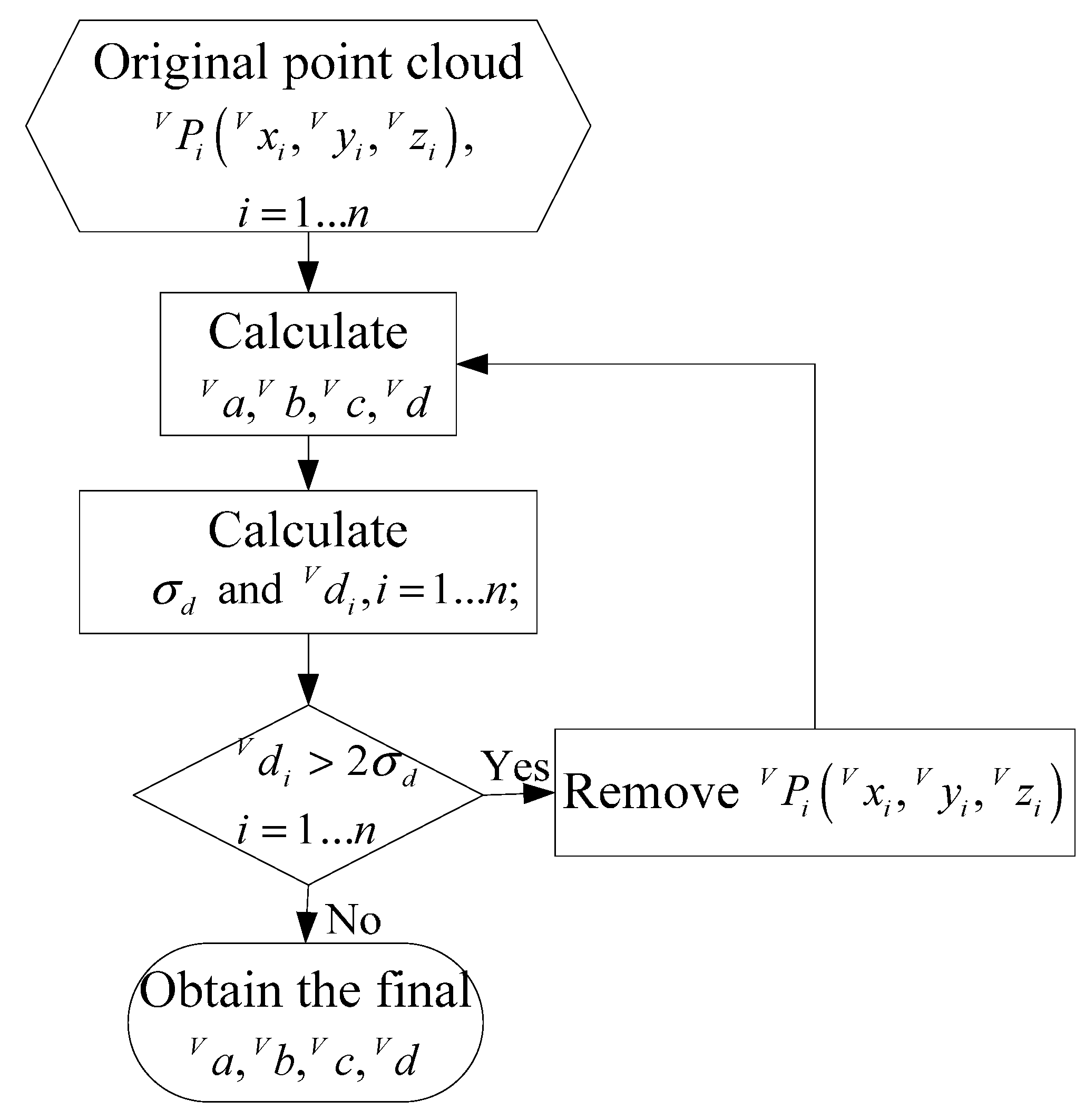
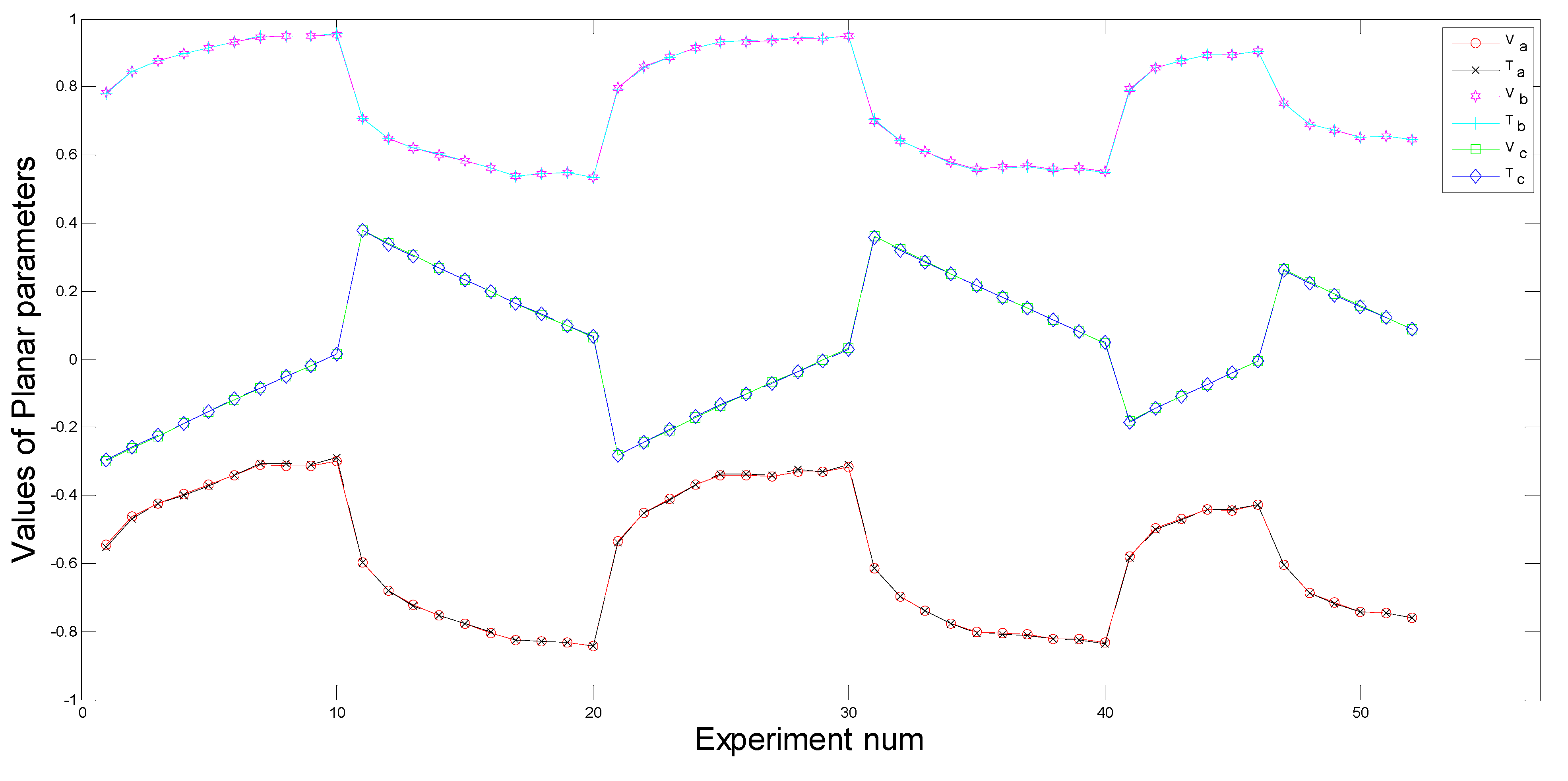
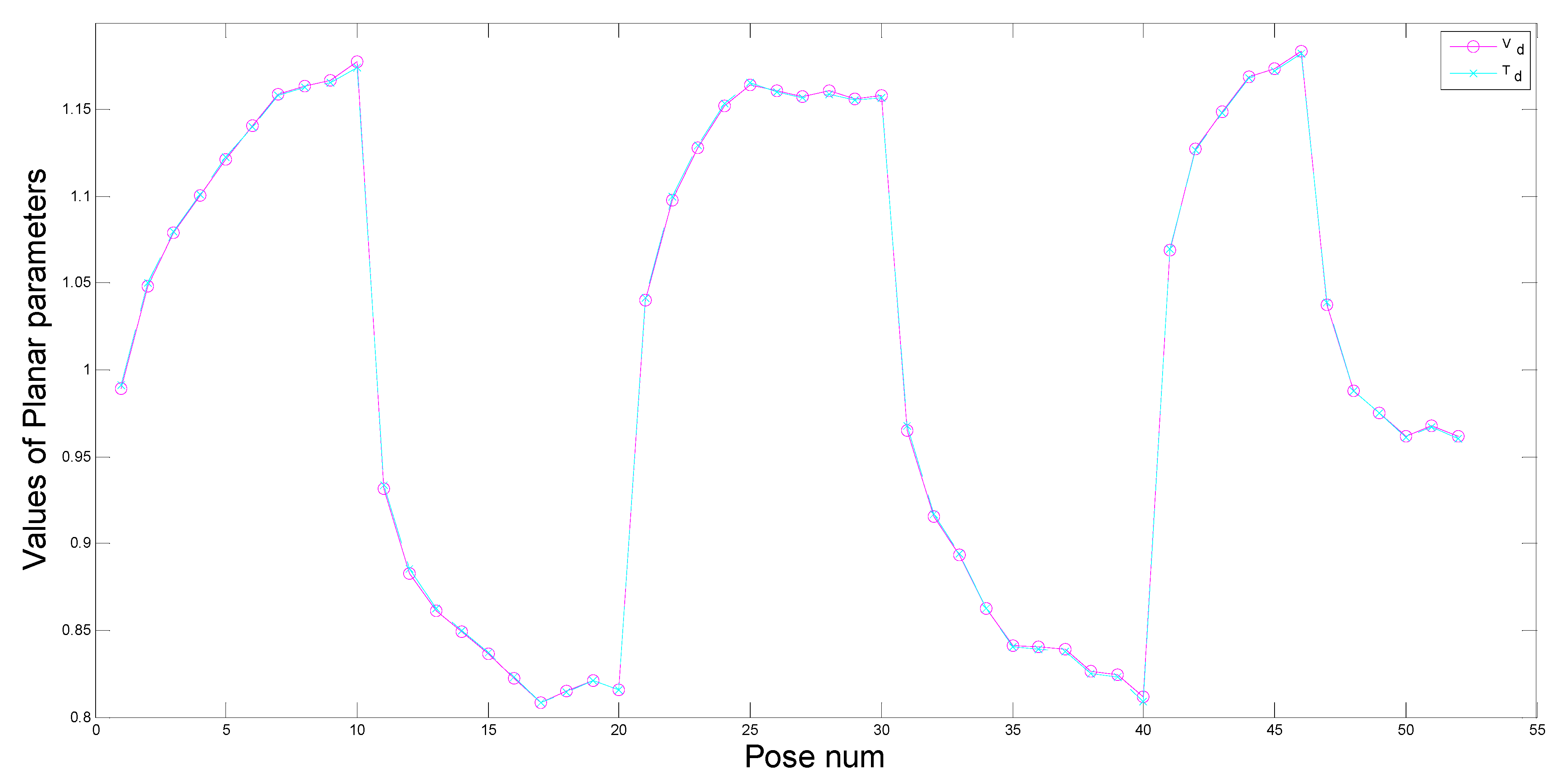
Because detection errors and influences of the outer environment exist in the identification process, some abnormal points have large errors, and some other points do not belong to the ground plane. These two kinds of points are called bad points, and a statistical method is used to exclude the bad points. Bad points can be removed, when the distances from them to the ground plane are larger than the standard value.
Figure 8 describes the estimation process of the ground plane. First,
are computed using all the point cloud, and
can be calculated from Equation (13), respectively. Then the standard deviation
of
is obtained from Equation (16). Bad points are removed by comparing
with
, the planar parameters are computed using the remaining point cloud again. We do so repeatedly until all the values of
are less than
, and the final
can be obtained. We have verified the estimation approach by simulations and experiments, the results show that the approach has well robustness and high precision:
where
.
Figure 8.
The flow chart of the ground plane estimation.
Figure 8.
The flow chart of the ground plane estimation.
4.2. Relationship Model between the Legged Robot and the Ground
In this section, the relationship model between the legged robot and the ground is established to accurately compute the robot’s position and orientation (denoted by
) with respect to the G-CS. The detailed expression of
is shown in Equation (17), whose formation process is similar to
.
are angles that the robot rotates along the
successively with respect to the fixed G-CS, and
are distances that the robot translates along the
and
respectively.
is the orientation matrix, and
is the translation vector:
where:
Figure 9.
Initial state of the robot.
Figure 9.
Initial state of the robot.
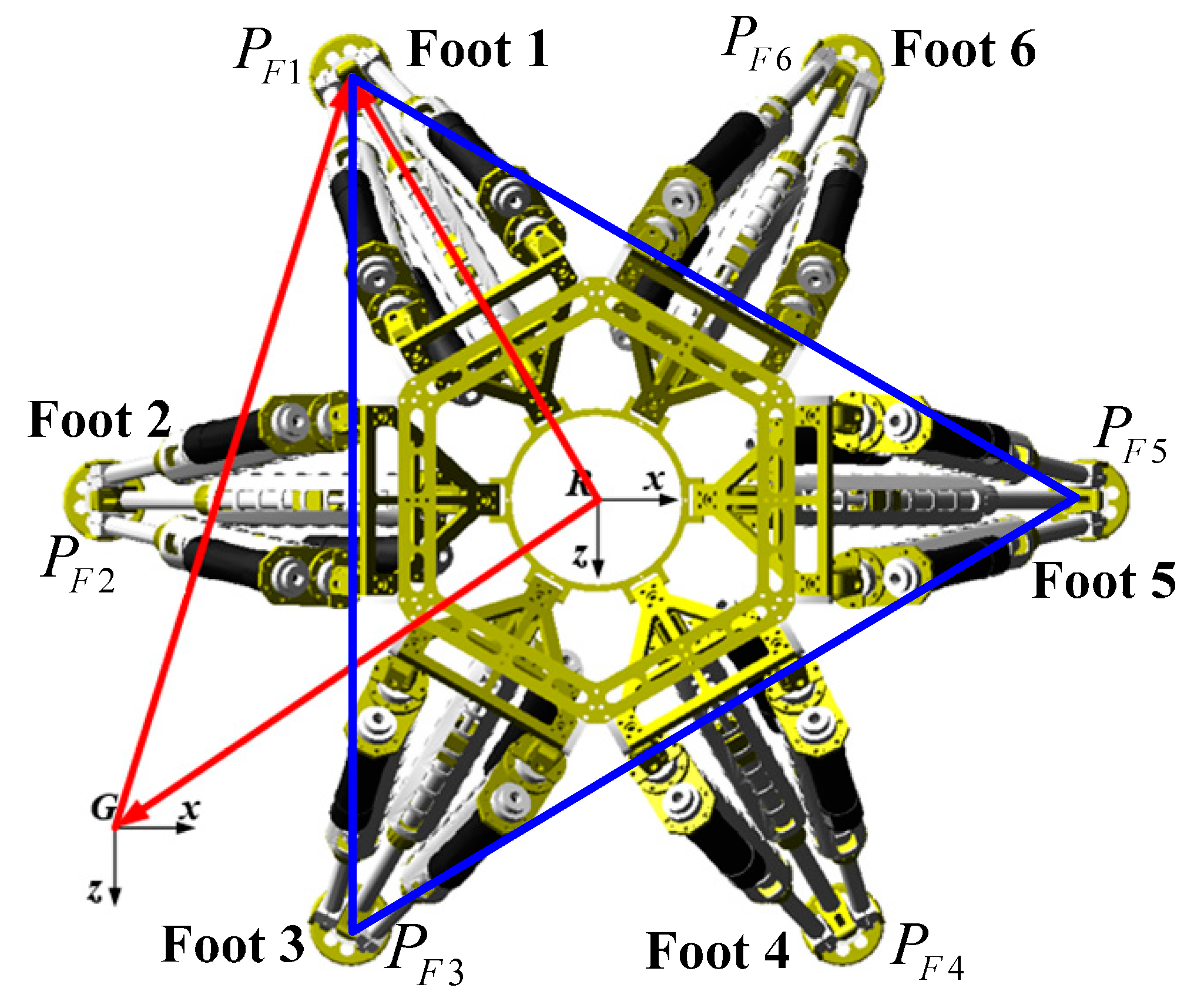
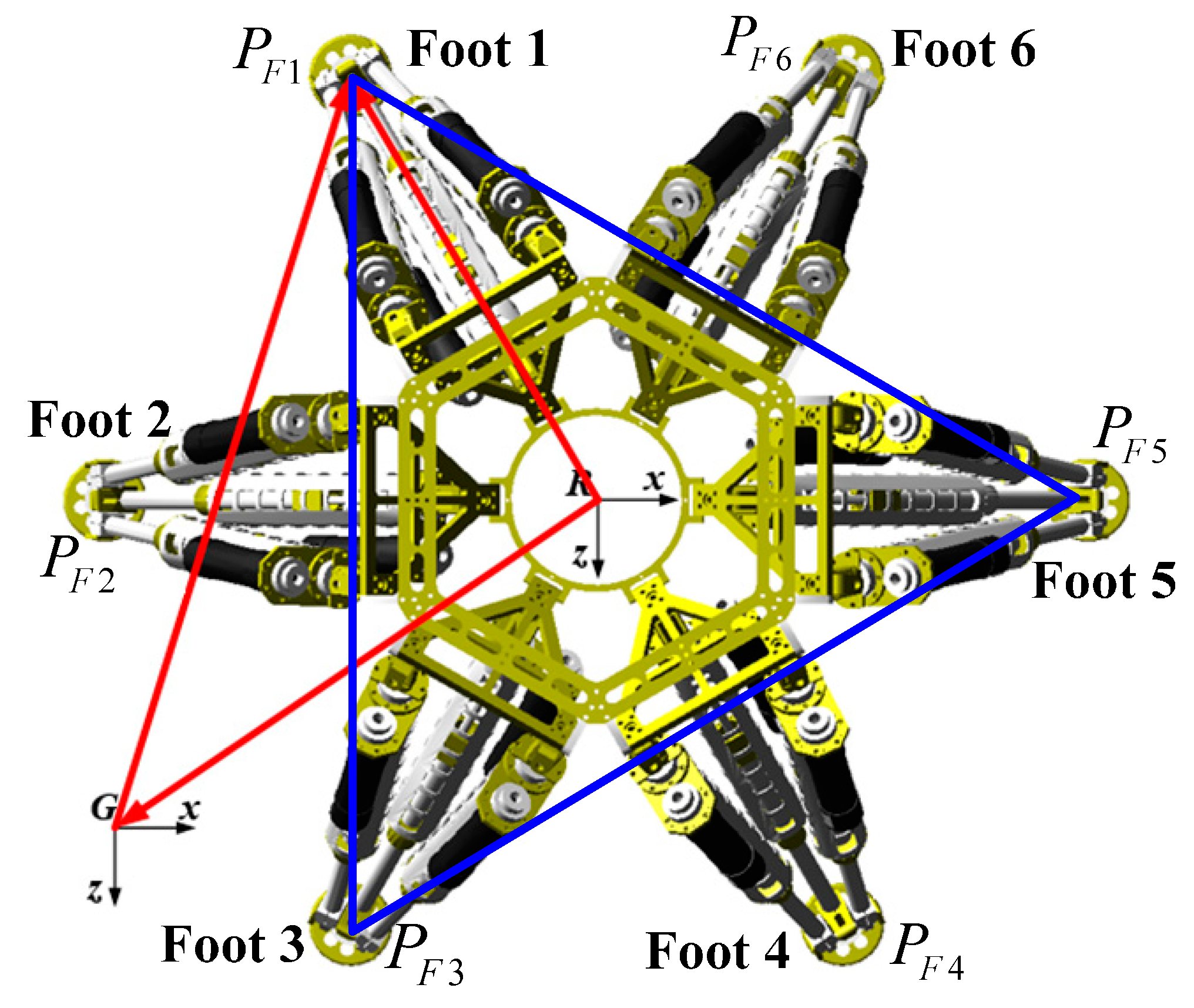
The initial position and orientation of the robot is shown in
Figure 9,
denote positions of its feet. The positions of actuation joints are needed to be solved in order to set the robot to a known pose matrix
.
There exists Equation (20):
where
is the position of Foot 1 with respect to the R-CS, and
is a known position of Foot 1 with respect to the G-CS. Similarly, other feet have the same equations, we can obtain
too. Then the positions of actuation joints can be obtained by the robot inverse kinematics.
The robot can reach the set pose if the actuation joints are driven to the calculated positions. The important point here is that there may be deviations between the real pose and the set pose because of the manufacture and installation errors. However, it is quite important to reduce errors during the whole identification process in order to increase the identification precision. Therefore, the real pose is calculated by the following derivations.
Similarly,
are known. Foots 1, 3 and 5 are chosen to calculate the real pose. As
Figure 9 shows, there exist the following relations:
where the upper left mark
G represents all the geometric relations are built with respect to the G-CS. Equation (22) can be obtained from Equation (21):
where
denotes the coordinates of Foot 1 with respect to the G-CS. Equation (23) can be derived based on the robot forward kinematics:
where
denotes the coordinates of Foot 1 with respect to the R-CS. The norms of vectors
are constant, so the following equations can be obtained:
By solving the above equations, the real translation vector
are calculated. Additionally, there exists Equation (25):
From Equation (25), the real orientation matrix is computed too. Thus, the real translation matrix can be calculated from Equations (24) and (25).
4.3. Formulation of the Identification Function
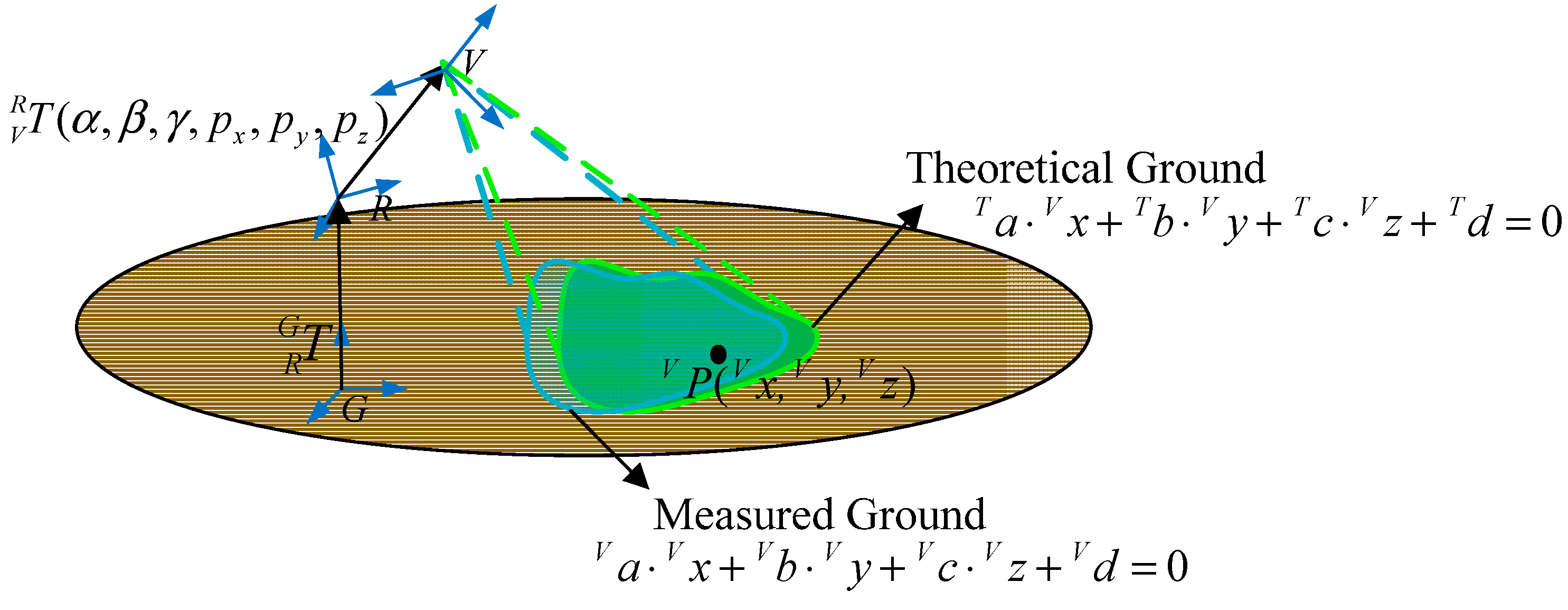
The following equations are obtained from Equation (4):
Because
fulfills Equation (7), the following Equation is obtained from the second expression of Equation (26):
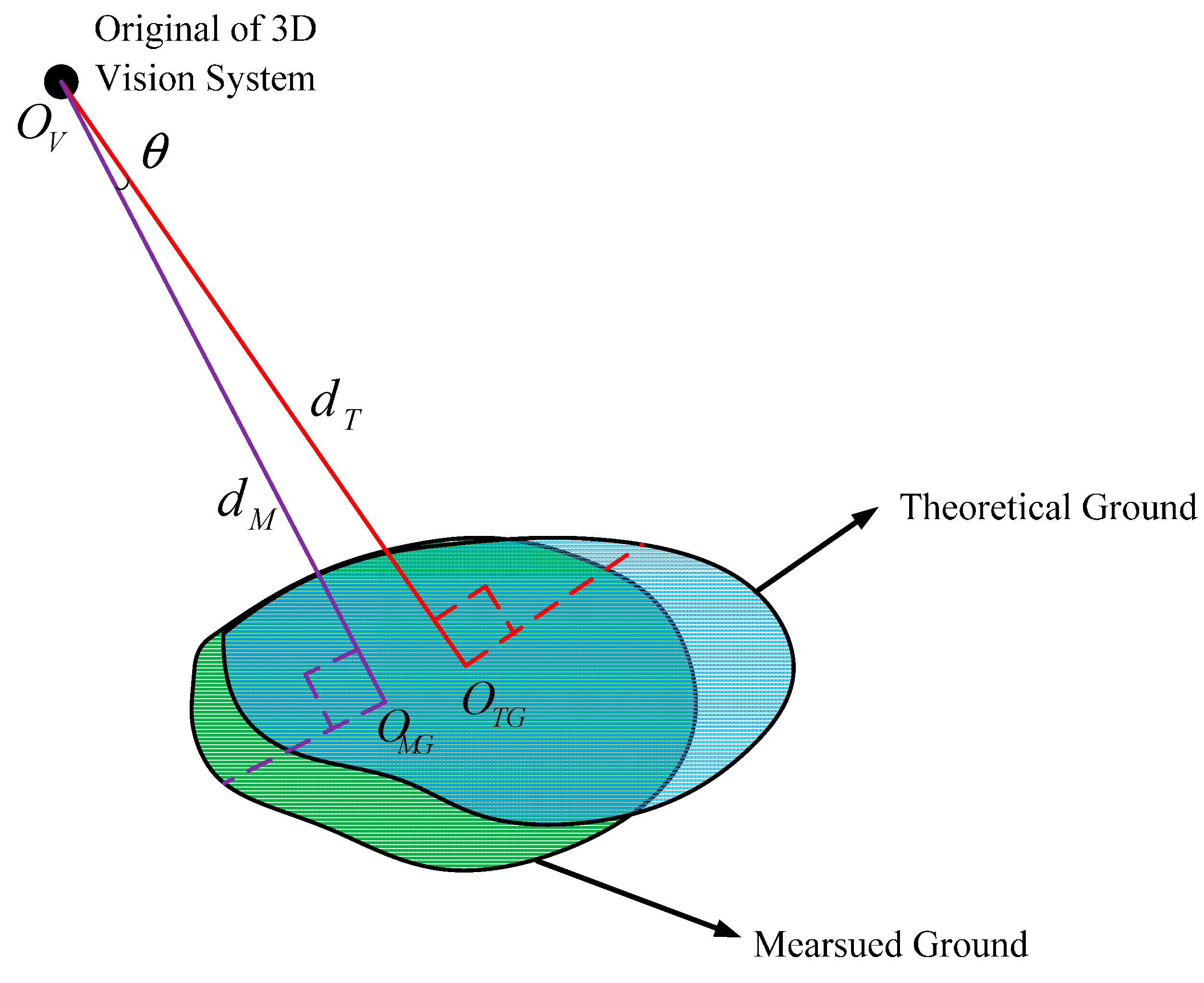
Figure 10.
Formulation of the identification function.
Figure 10.
Formulation of the identification function.
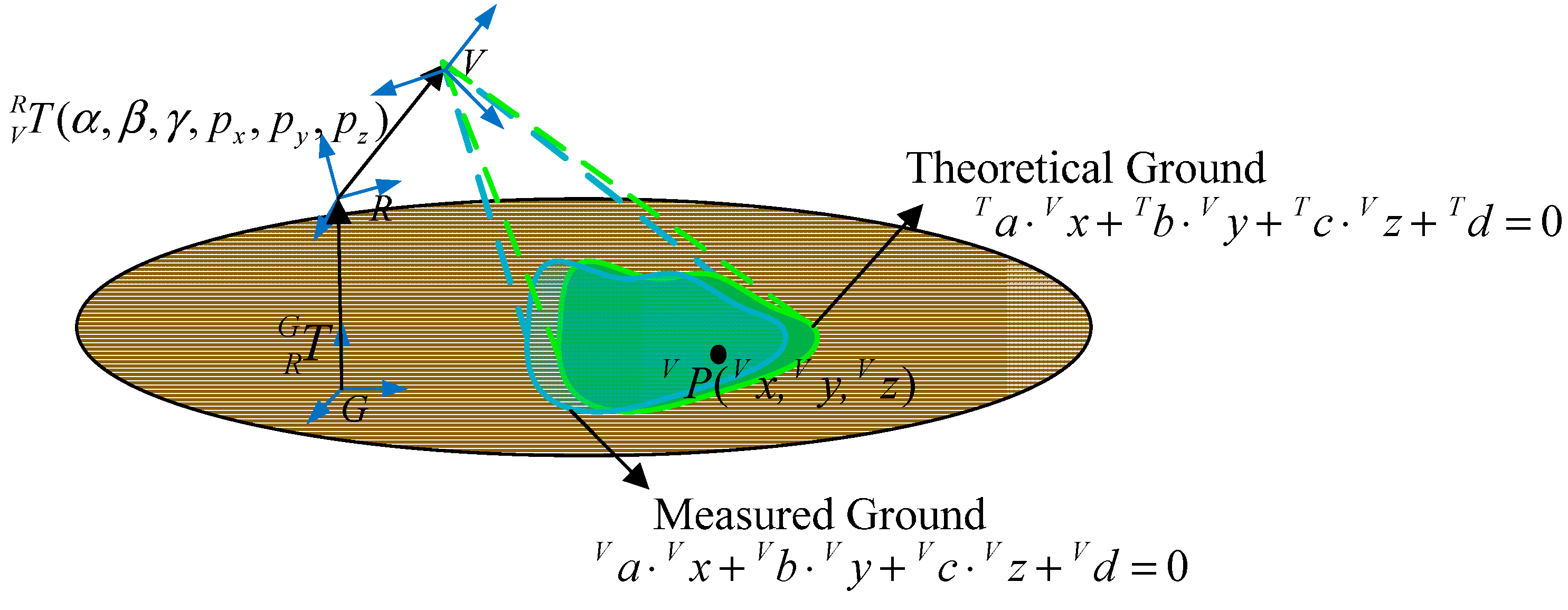
As
Figure 10 shows, Equation (27) is the theoretical ground equation with respect to the V-CS.
in Formula (28) represent theoretical ground planar parameters:
Through derivations, we find there exists Equation (29):
Theoretically, the measured ground coincides with the theoretical ground as shown in
Figure 10. Because of Equation (29), Equation (27) is a standard plane equation, so it is obvious that Equation (27) is the same as Equation (5) derived in
Section 4.1. Then the following four equations can be obtained:
where
are variables associated with
. A nonlinear function
F, which consists of six identification parameters, can be defined as Equation (31):
Generally, the legged robot has six DOFS, which can be used to simplify the identification process and increase the identification precision. At the beginning, the robot is located in an initial state, the -axis and the -axis are parallel with the and the respectively, the and the are collinear. Multiple groups of the robot poses and corresponding ground equations can be obtained by making the robot translate and rotate in space. Finally, identification parameters can be obtained by minimizing the nonlinear function F using the LM algorithm.
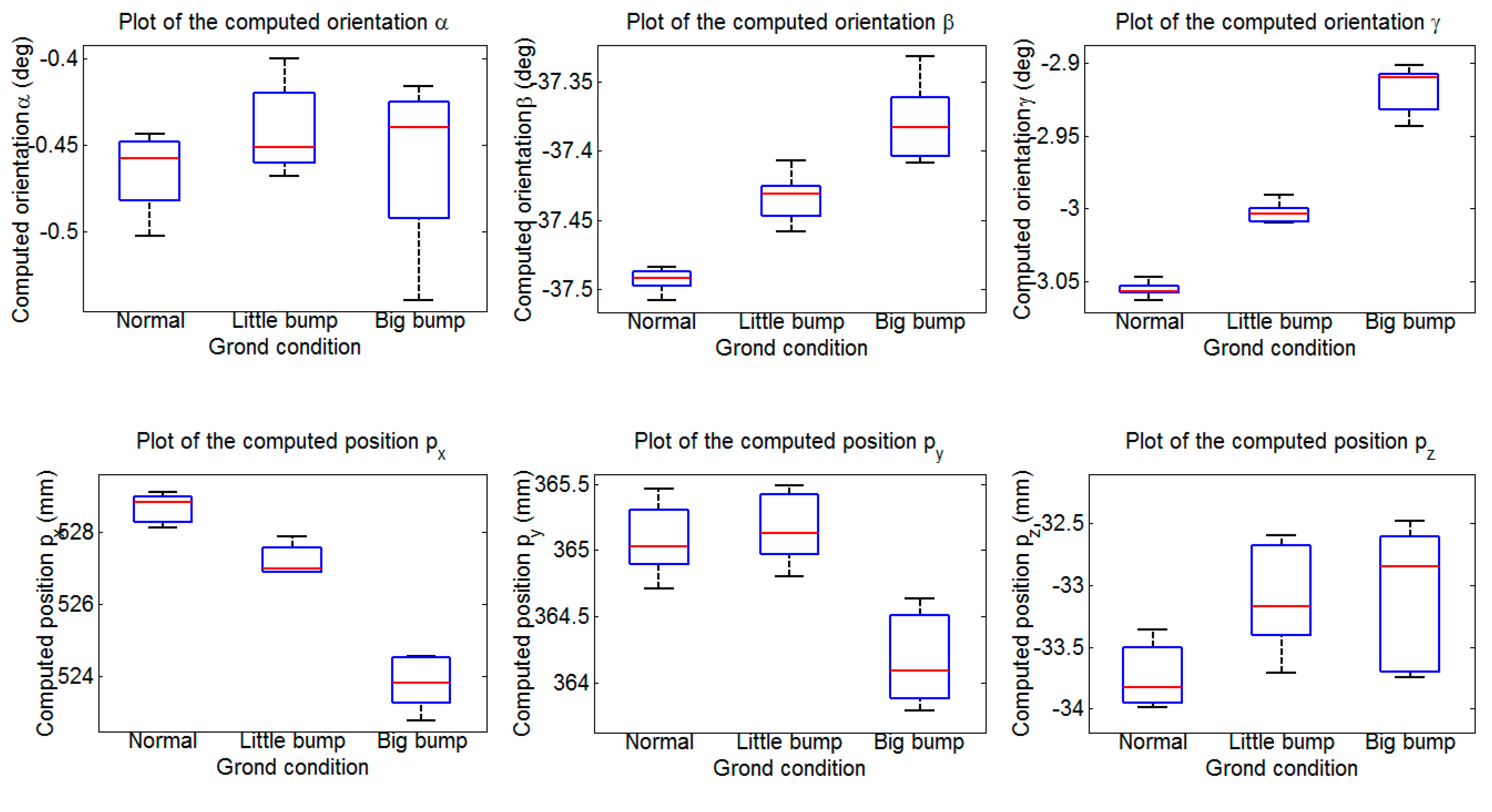
6. Use Case
A use case, underlying the importance and applicability of the methodology in the legged robots field, is presented next. In reality, a legged robot is often used in an unknown environment to execute daunting tasks. With the help of a vision sensor, the robot has a good knowledge of the environment. What’s more, after computing the extrinsic parameters relating the vision sensor and the legged robot, an accurate relationship between the robot and the terrain can be obtained. Thus the automatic locomotion can be implemented to execute tasks.
As
Figure 23 shows, the robot is in an unknown environment with obstacles. Based on the proposed methodology, the extrinsic parameters relating the sensor and the robot can be computed. The terrain map with respect to the robot can be built. Moreover, the accurate position and orientation of the obstacles are obtained from the terrain map. An automatic locomotion planning algorithm combining the terrain information is executed to plan the foot and body trajectories.
Figure 23.
External view of the legged robot passing through obstacles.
Figure 23.
External view of the legged robot passing through obstacles.
Figure 24 shows the whole process of passing through the obstacles, the robot body is regulated to move forward horizontally. During the whole process, the feet are placed at the planned footholds, so its body remains stable when walking on the obstacles. The results show a successful application of the methodology in the intelligent robotic field.
Figure 24.
Snapshots of the legged robot passing through obstacles.
Figure 24.
Snapshots of the legged robot passing through obstacles.
7. Conclusions
In this paper, we have presented a novel coordinate identification methodology for a 3D vision system mounted on a legged robot. Generally, the method can address the problem of extrinsic calibration between a 3D type vision sensor and legged robots, which few studies have worked on. The proposed method provides several advantages. Instead of using any kind of external tools (calibration targets and measurement equipment), our method only needs a small section of relatively flat ground, which can reduce recognition errors and avoid measurement errors. Moreover, the method needs no human intervention, and it is practical and easy to implement.
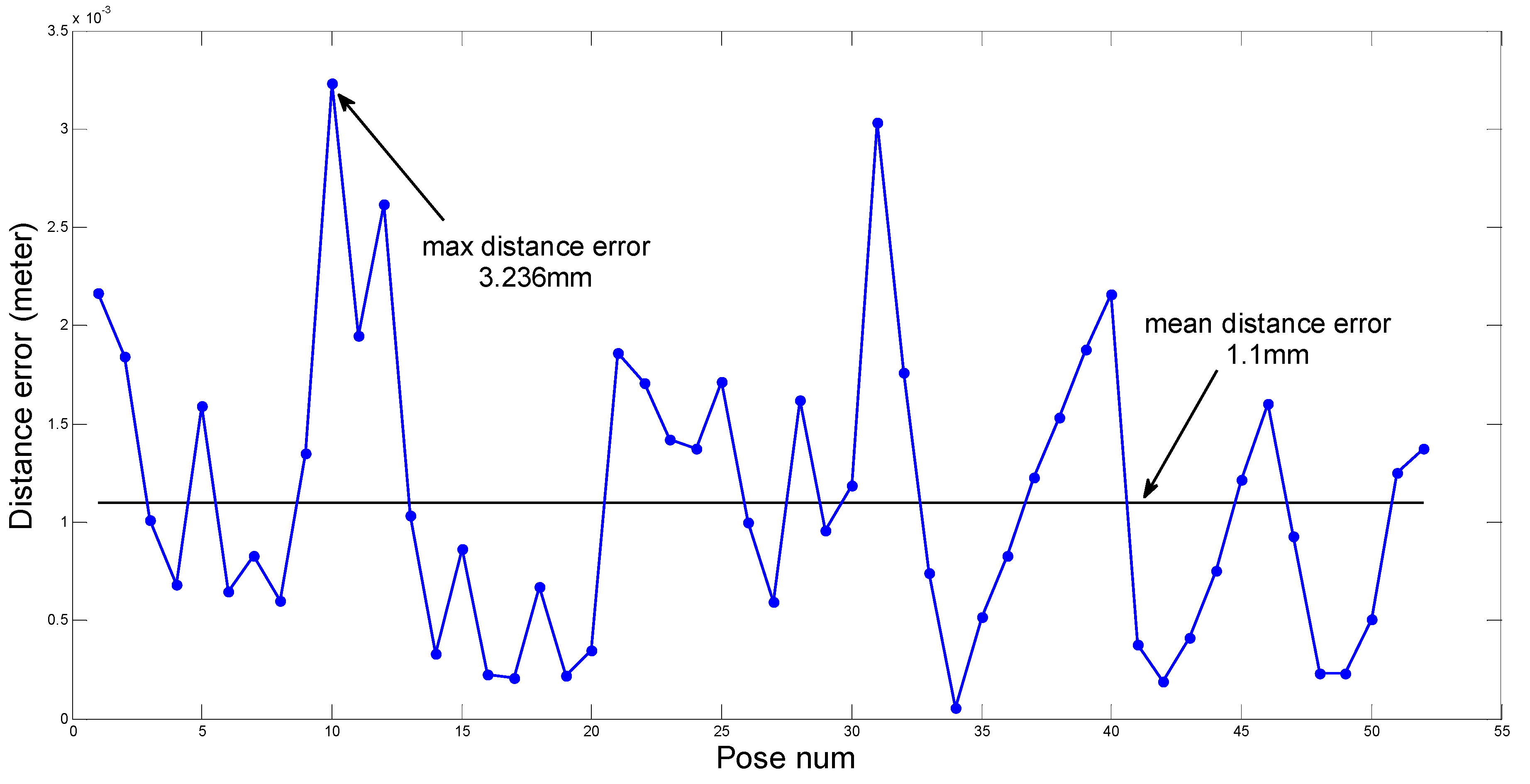
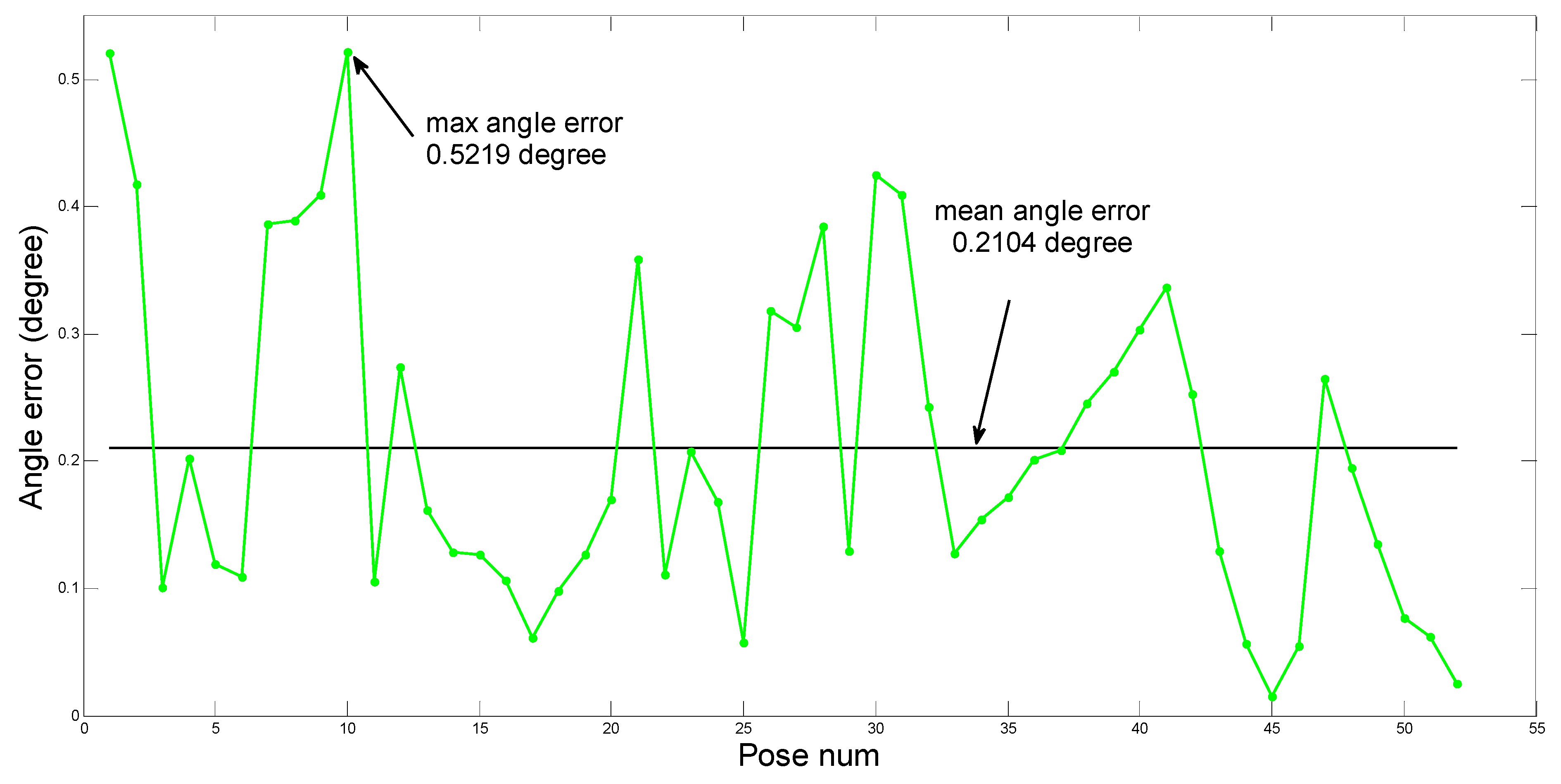
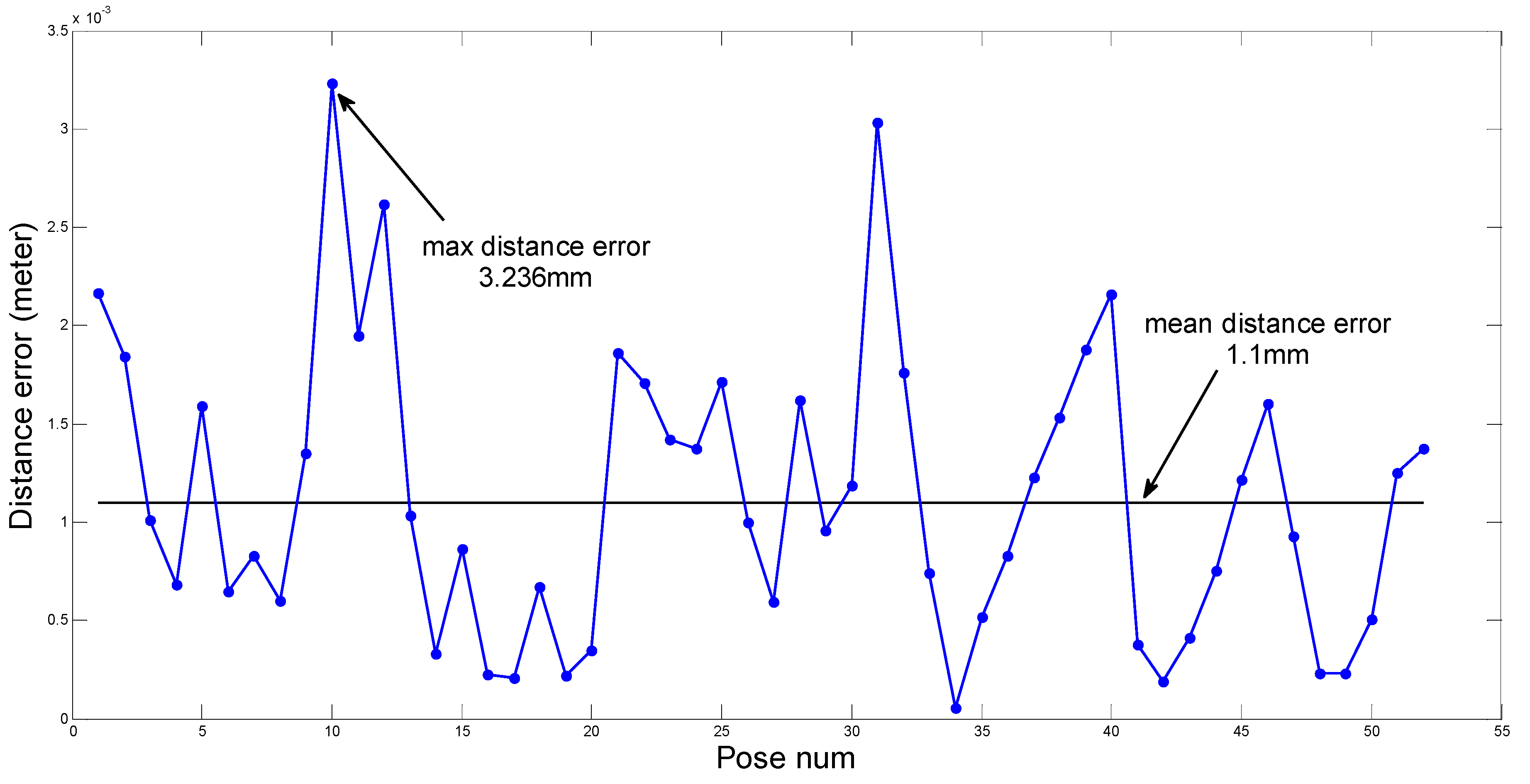
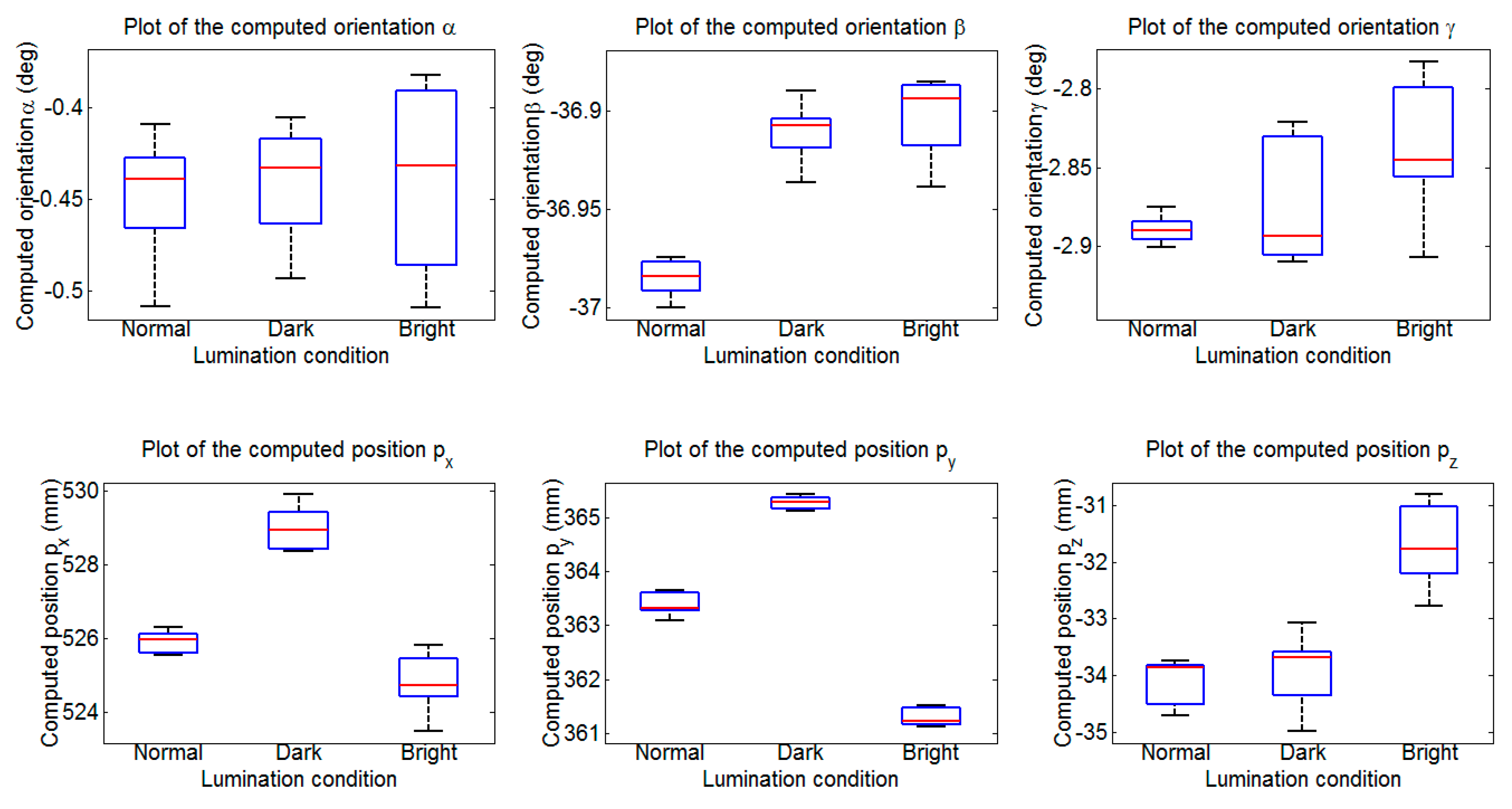
The theoretical contributions of this paper can be summarized as follows. An approach for estimating the ground plane is introduced based on optimization and statistical methods, and the relationship model between the robot and the ground is established too. The identification parameters are obtained from the identification function using the LM algorithm. Finally, a series of experiments are performed on a hexapod robot, and the identification parameters are computed using the proposed method. The calculated errors satisfy the requirements of the robot, which validates our theory. In addition, experiments in various environments are also performed, the results show that our methodology has good stability and robustness. A use case, in which the legged robot can pass through rough terrains after accurately obtaining the identification parameters, is also given to verify the practicability of the method. The work of this paper supplements relevant study in legged robots, and the method can be applied in a wide range of similar applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}