
A Biologically-Inspired Framework for Contour Detection Using Superpixel-Based Candidates and Hierarchical Visual Cues


Abstract
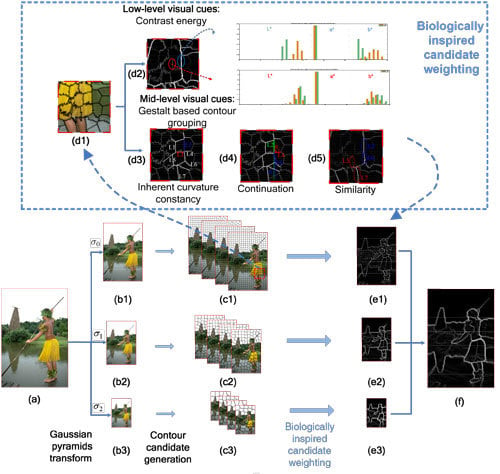
:
1. Introduction
2. Related Work
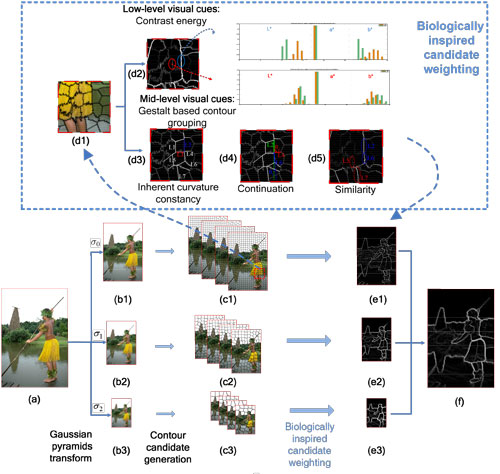
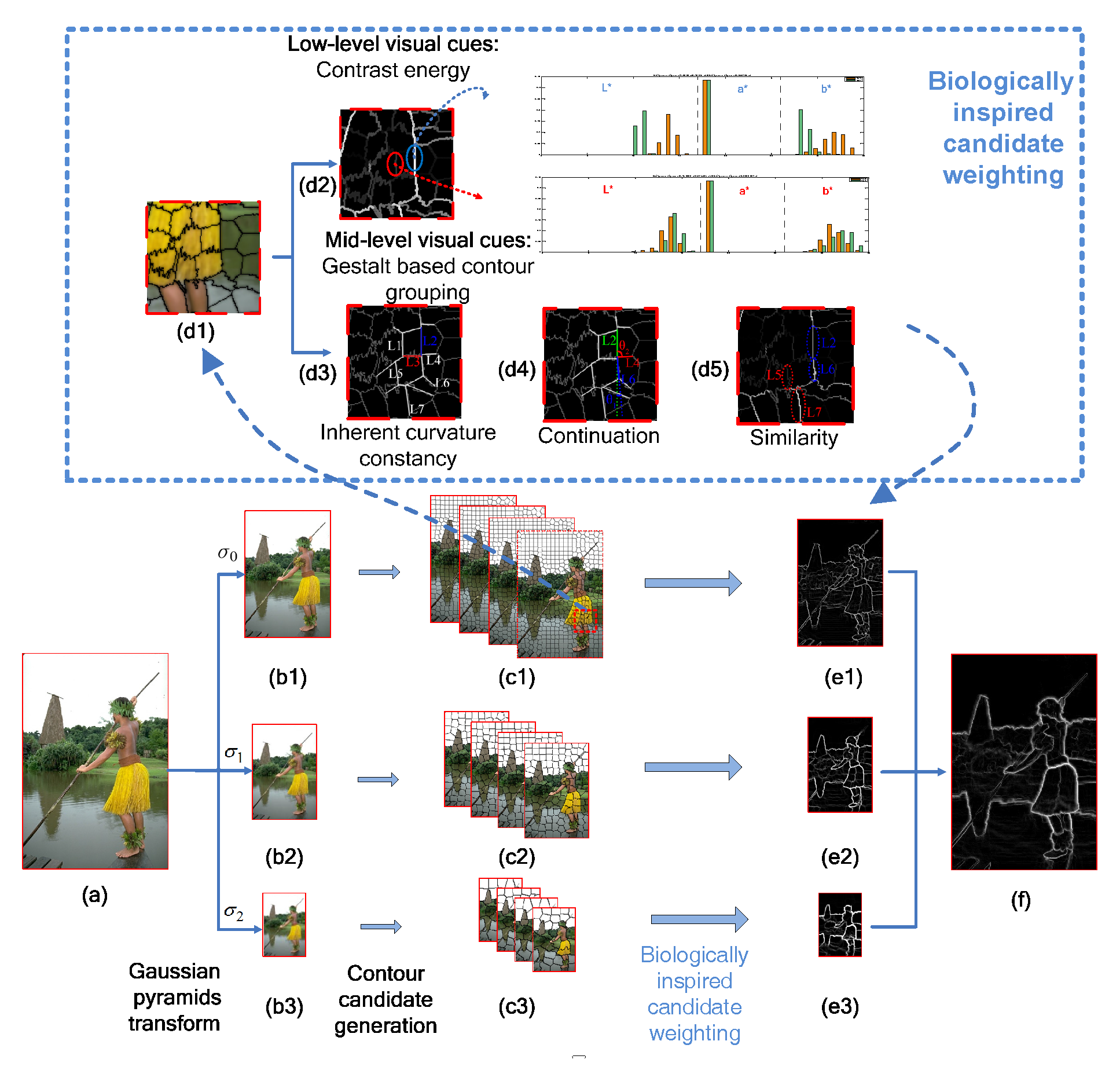
3. Method of Biologically-Inspired Candidate Weighting Framework for Contour Detection
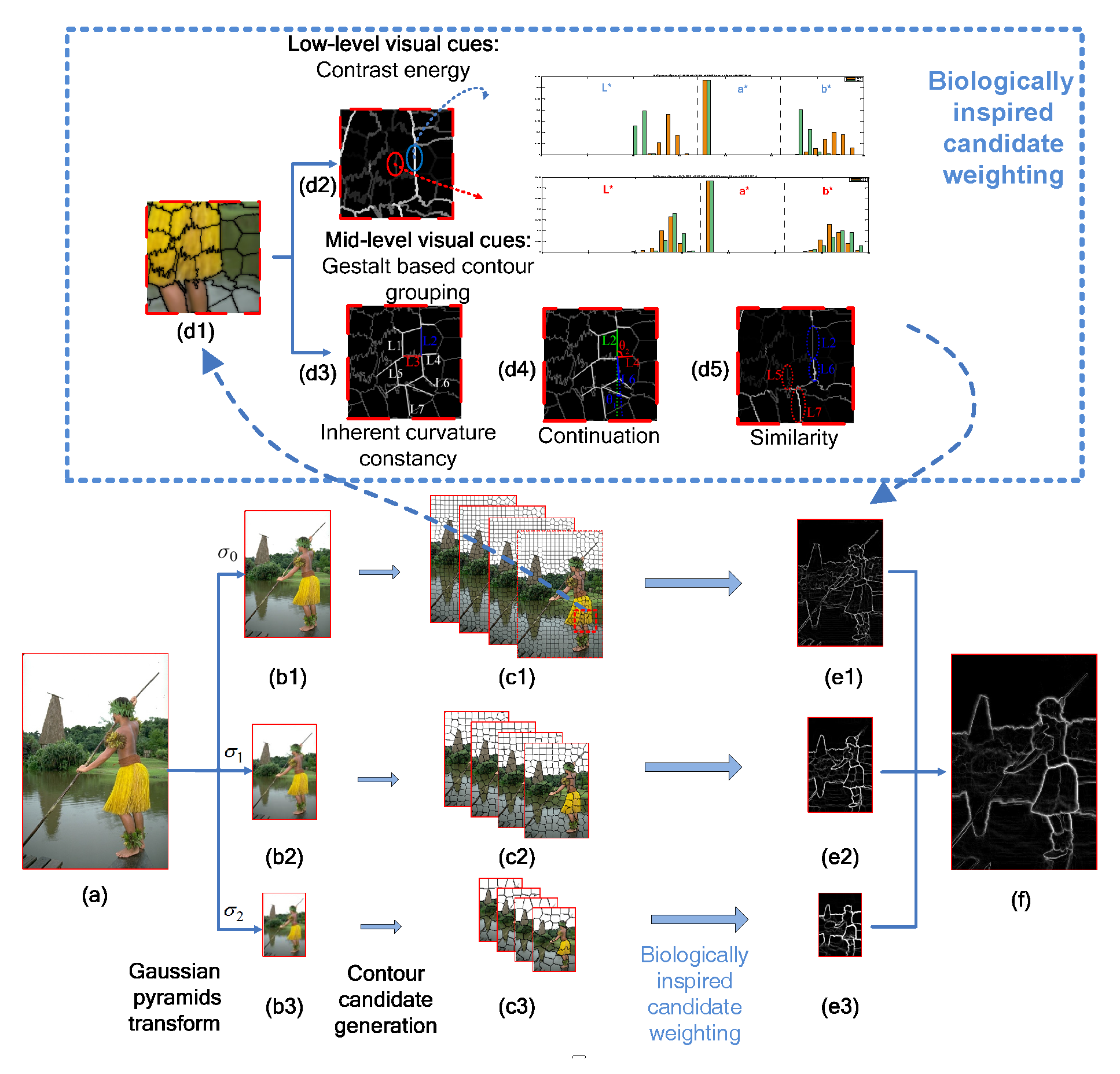
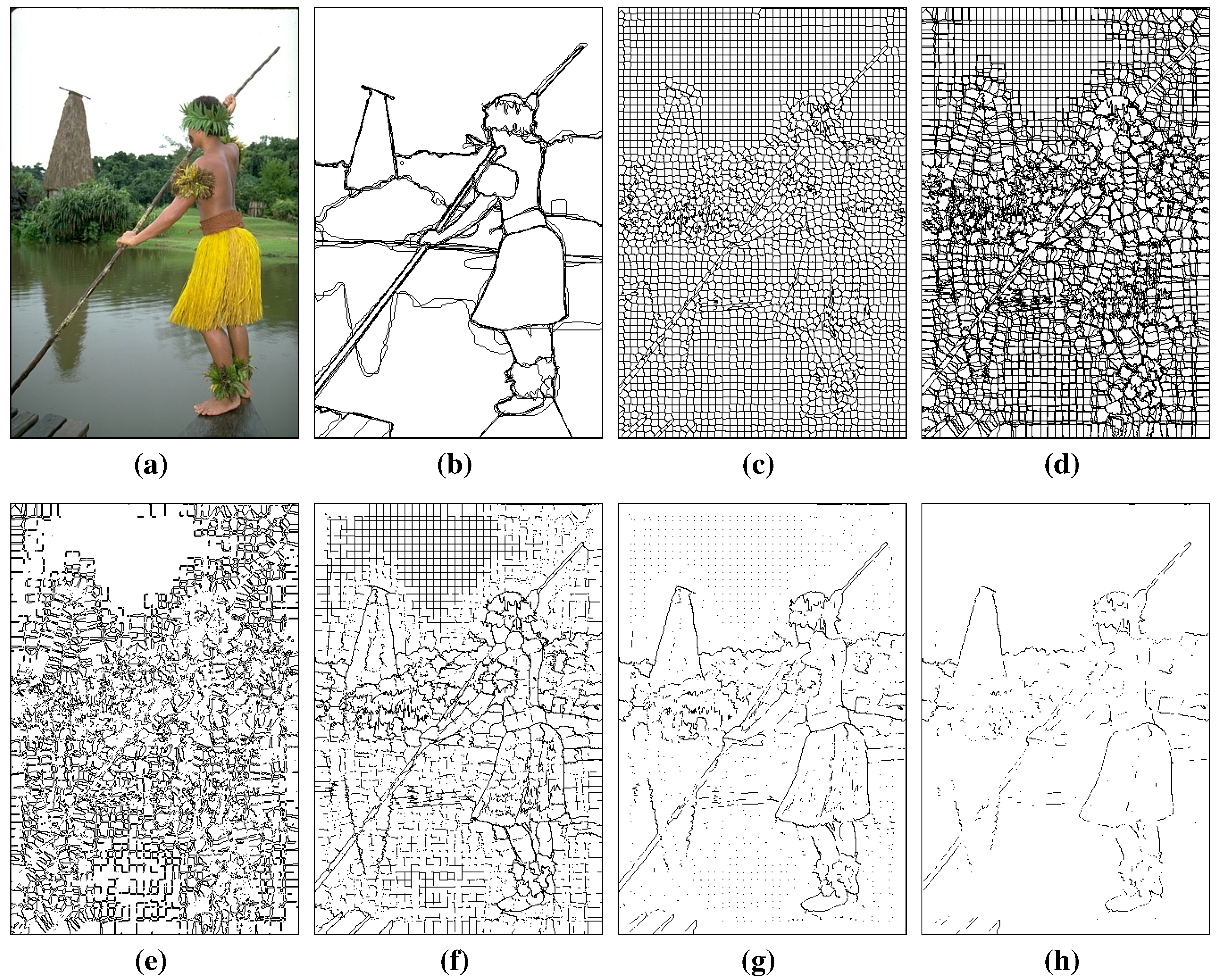
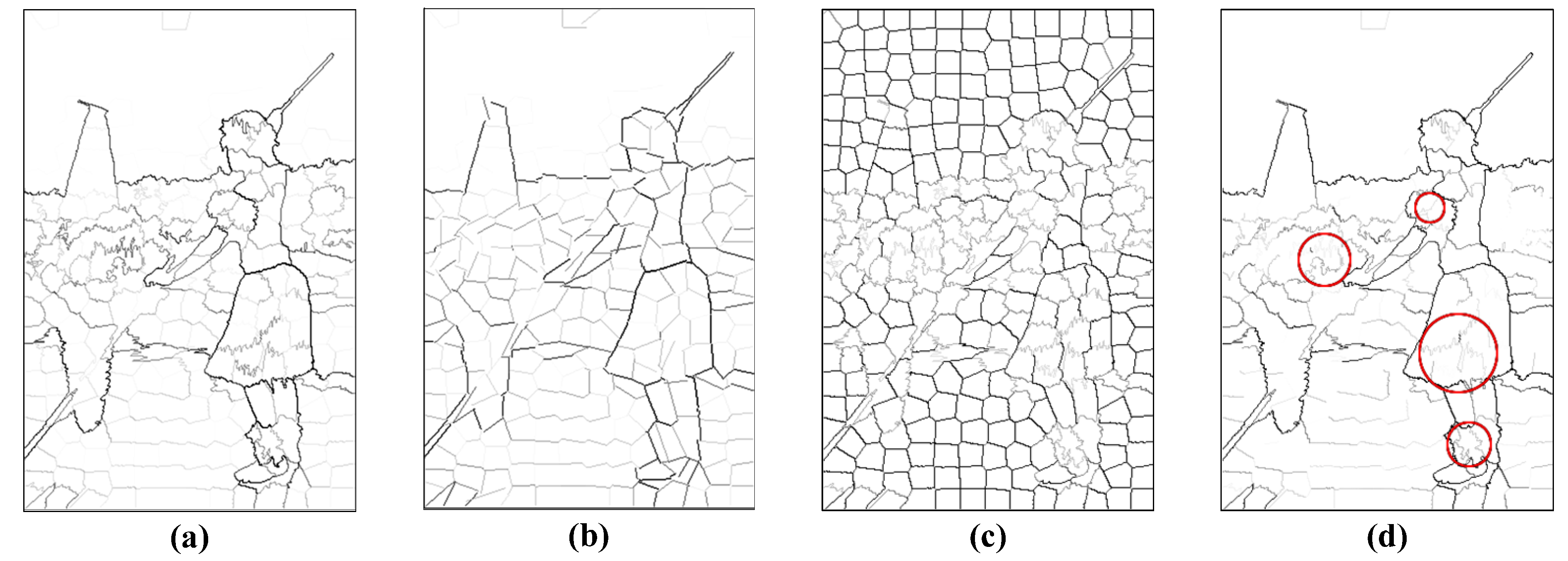
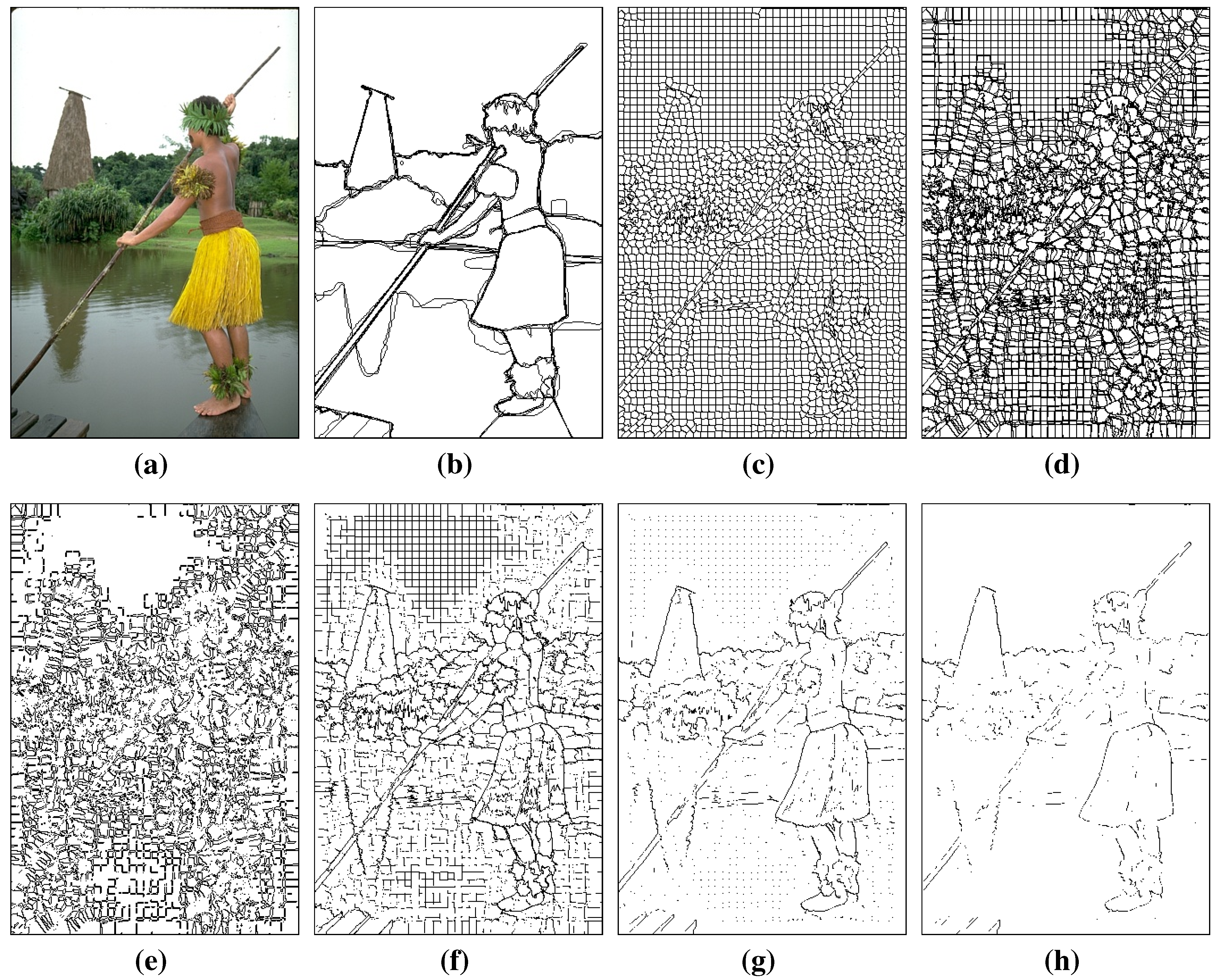
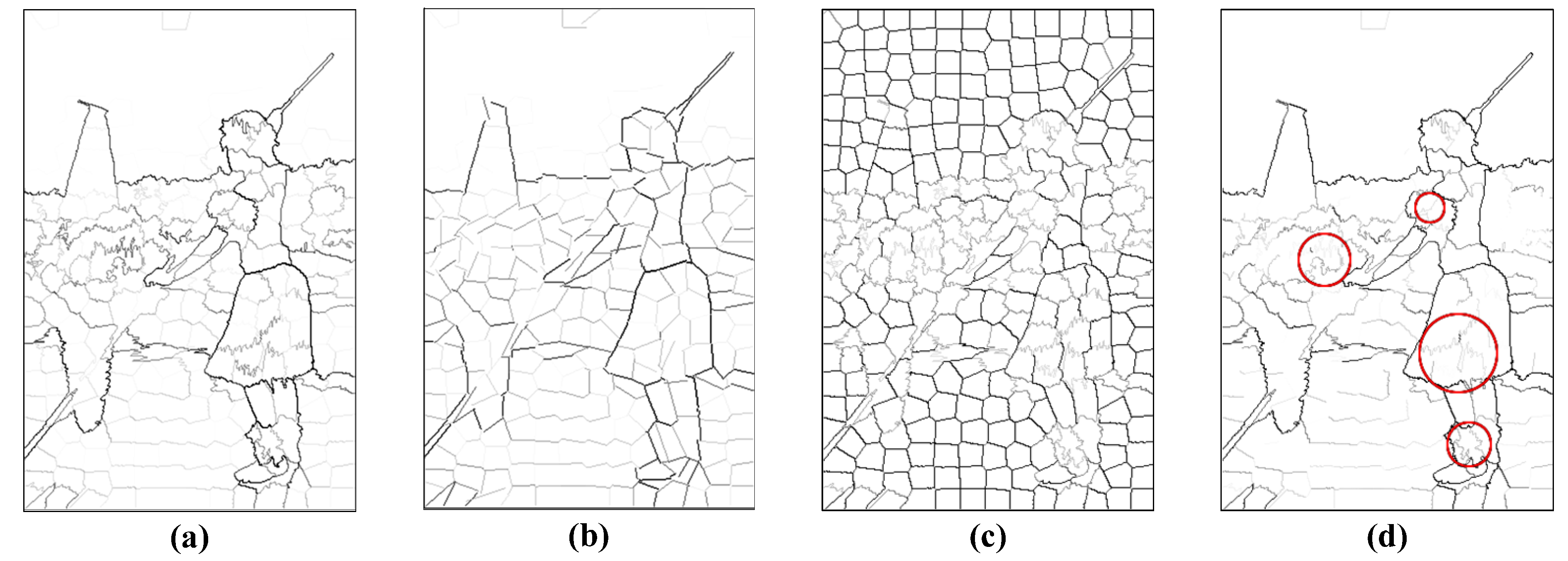
3.1. Generation of Contour Candidates
3.2. Extraction of Hierarchical Cues
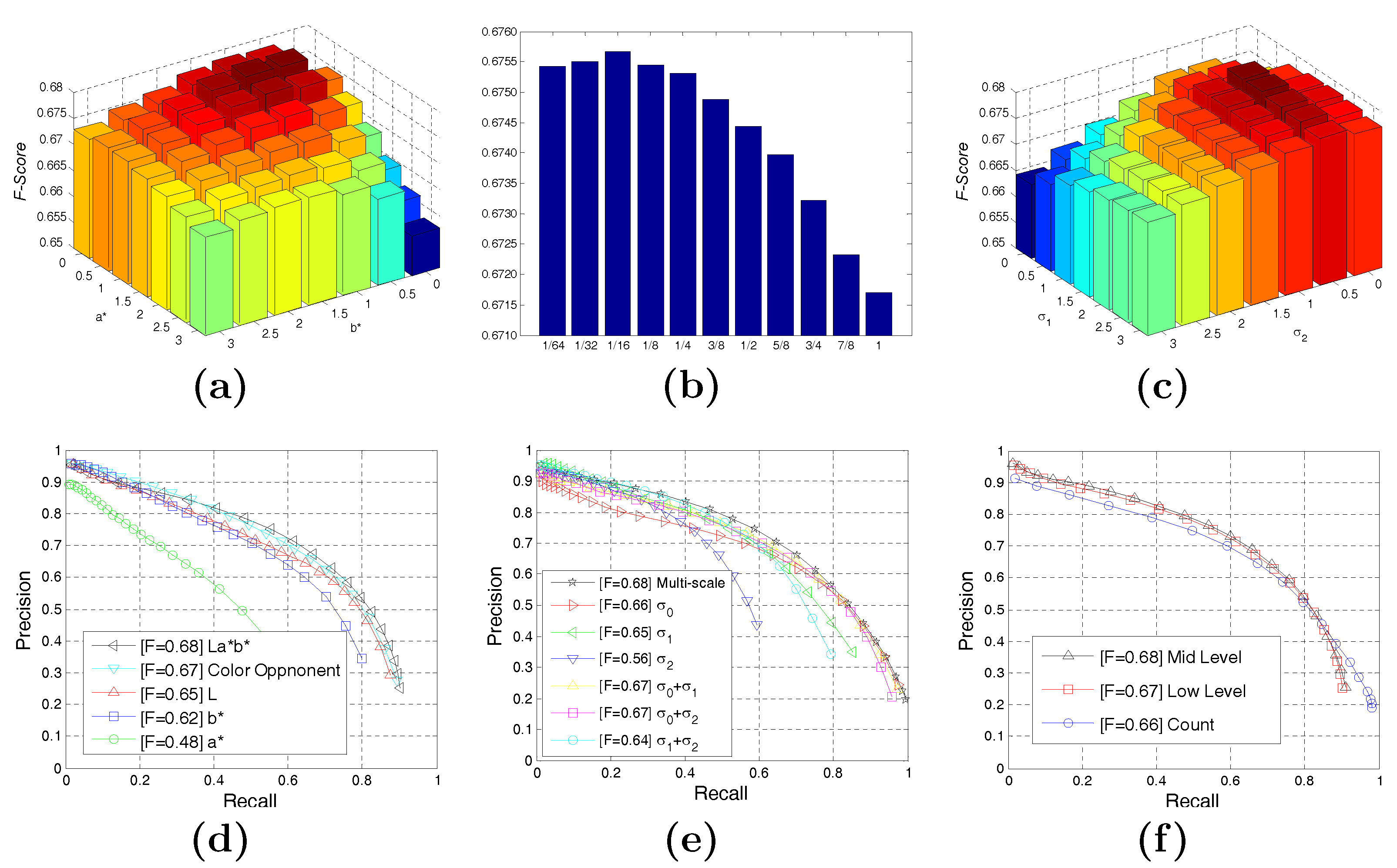
3.2.1. Low-Level Cues
3.2.2. Mid-Level Cues
3.2.3. Combination of Hierarchical Cues
4. Tests and Results
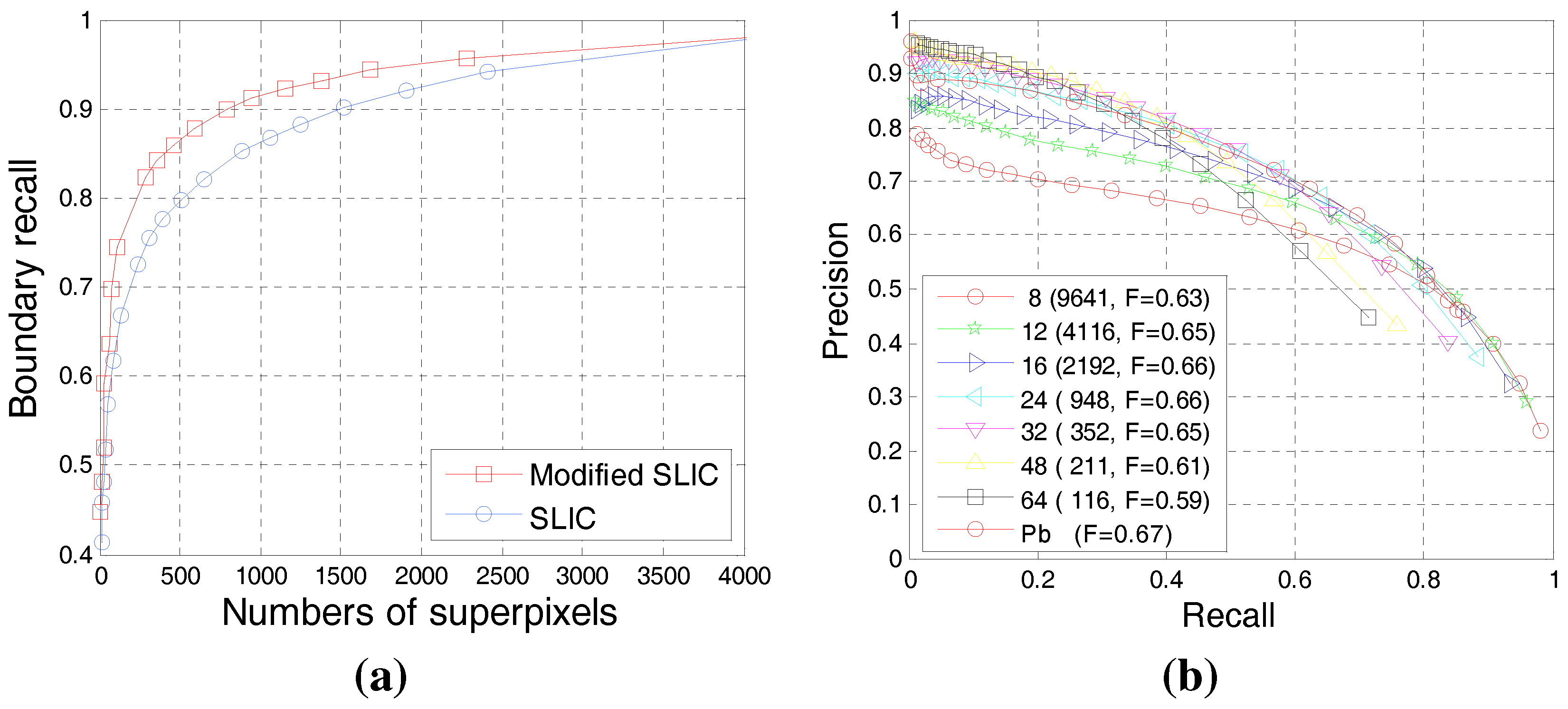
4.1. Evaluation of the Superpixel-Based Contour Candidate
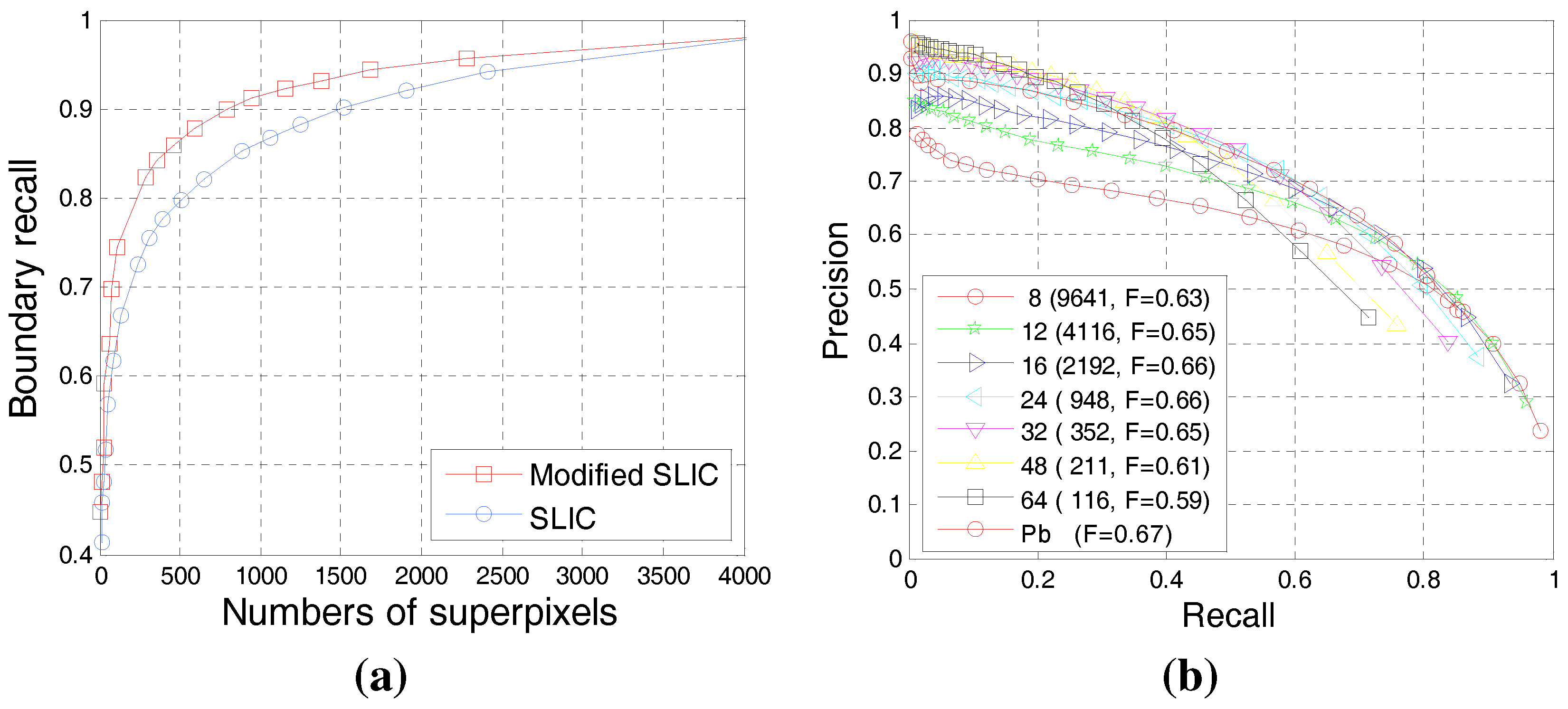
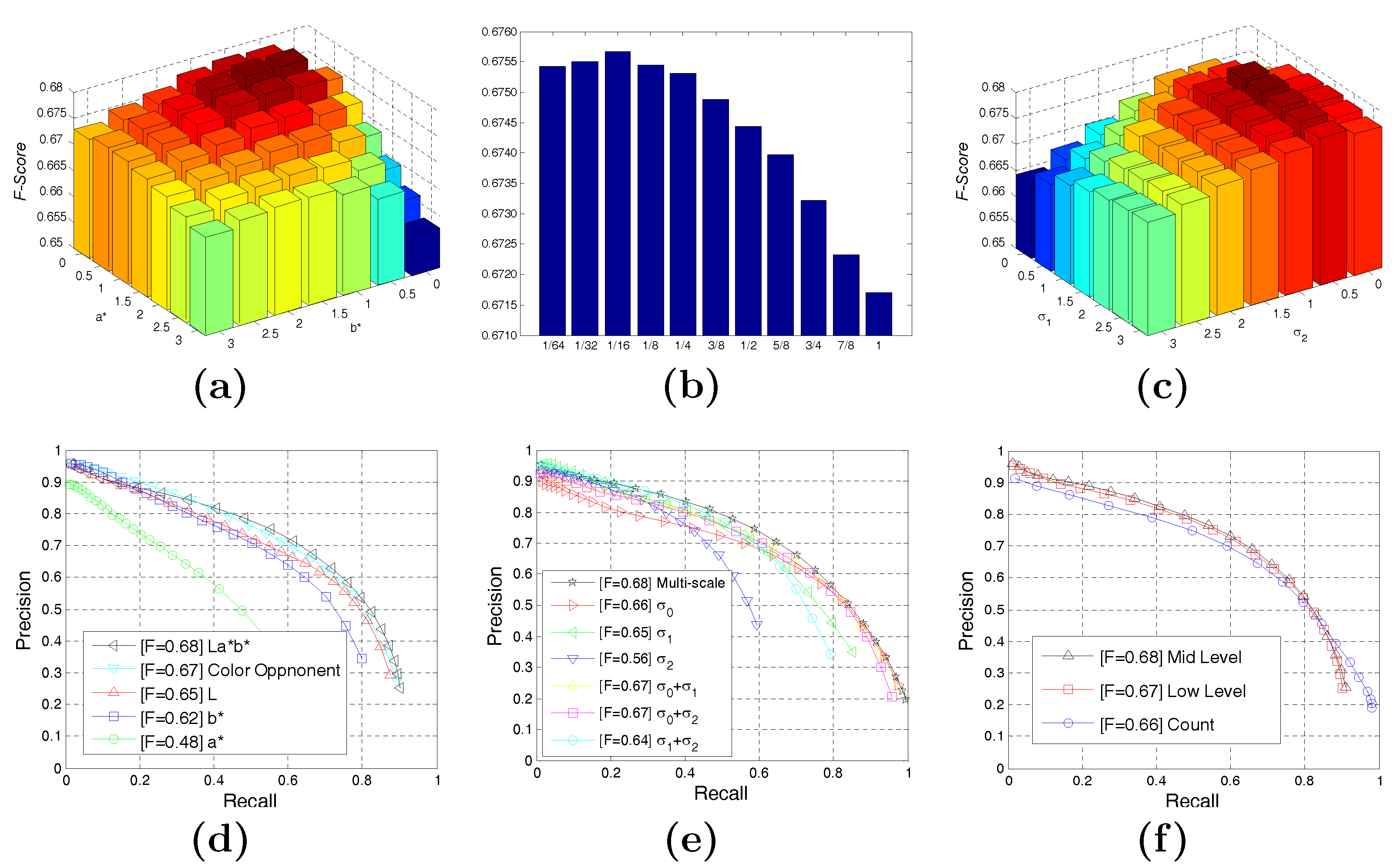
4.2. Experimental Evaluation of Our BICW Algorithm

| Parameter | Description | Equation | Setting |
|---|---|---|---|
| Low-level: Relative contribution of each color channel | (6) | 1,0.5,1 | |
| δ | Mid-level: Sensitivity of connection probability with contrast | (9) | 1/16 |
| Scales: Relative contribution of each scale | (12) | 1,1,0.5 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | F-Score on BSDS300 | F-Score on BSDS500 | Time (s) |
|---|---|---|---|
| Pb (2004) [26] | 0.65 | 0.67 | 51.00 |
| gPb (2012) [1] | 0.70 | 0.71 | 191.15 |
| CO (2013) [48] | 0.64 | 0.65 | 6.51 |
| MCI (2014) [55] | 0.62 | 0.64 | 48.60 |
| SCO (2015) [75] | 0.66 | 0.67 | 7.68 |
| Ours | 0.67 | 0.68 | 13.13 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Malik, J.; Belongie, S.; Leung, T.; Shi, J. Contour and texture analysis for image segmentation. Int. J. Comput. Vis. 2001, 43, 7–27. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust point matching via vector field consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar]
- Shen, W.; Wang, X.; Wang, Y.; Bai, X.; Zhang, Z. DeepContour: A Deep Convolutional Feature Learned by Positive-sharing Loss for Contour Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3982–3991.
- Bai, X.; Rao, C.; Wang, X. A Robust and Efficient Shape Representation for Shape Matching. IEEE Trans. Image Process. 2014, 23, 3935–3949. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Qiu, W.; Zhao, J.; Ma, Y.; Yuille, A.L.; Tu, Z. Robust L2E estimation of transformation for non-rigid registration. IEEE Trans. Signal Process. 2015, 63, 1115–1129. [Google Scholar] [CrossRef]
- Papari, G.; Petkov, N. Edge and line oriented contour detection: State of the art. Image Vis. Comput. 2011, 29, 79–103. [Google Scholar] [CrossRef]
- Tian, Y.; Guan, T.; Wang, C. Real-time occlusion handling in augmented reality based on an object tracking approach. Sensors 2010, 10, 2885–2900. [Google Scholar] [CrossRef] [PubMed]
- Opelt, A.; Pinz, A.; Zisserman, A. A boundary-fragment-model for object detection. In Computer Vision–ECCV 2006; Springer: Berlin, Germany, 2006; pp. 575–588. [Google Scholar]
- Ma, J.; Zhou, H.; Zhao, J.; Gao, Y.; Jiang, J.; Tian, J. Robust feature matching for remote sensing image registration via locally linear transforming. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6469–6481. [Google Scholar] [CrossRef]
- García-Garrido, M.A.; Ocana, M.; Llorca, D.F.; Arroyo, E.; Pozuelo, J.; Gavilán, M. Complete vision-based traffic sign recognition supported by an I2V communication system. Sensors 2012, 12, 1148–1169. [Google Scholar] [CrossRef] [PubMed]
- Borza, D.; Darabant, A.S.; Danescu, R. Eyeglasses lens contour extraction from facial images using an efficient shape description. Sensors 2013, 13, 13638–13658. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhao, J.; Ma, Y.; Tian, J. Non-rigid visible and infrared face registration via regularized Gaussian fields criterion. Pattern Recognit. 2015, 48, 772–784. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, R.; Han, Z.; Lu, T. Efficient single image super-resolution via graph-constrained least squares regression. Multimed. Tools Appl. 2014, 72, 2573–2596. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, R.; Wang, Z.; Han, Z. Noise robust face hallucination via locality-constrained representation. IEEE Trans. Multimed. 2014, 16, 1268–1281. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, R.; Wang, Z.; Han, Z. Face Super-Resolution via Multilayer Locality-Constrained Iterative Neighbor Embedding and Intermediate Dictionary Learning. IEEE Trans. Image Process. 2014, 23, 4220–4231. [Google Scholar] [CrossRef] [PubMed]
- Barron, J.; Malik, J. Shape, illumination, and reflectance from shading. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 37, 1670–1687. [Google Scholar] [CrossRef] [PubMed]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Lawrence, G.R. Machine Perception of Three-Dimensional Solids. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Prewitt, J.M. Object enhancement and extraction. Pict. Process. Psychopictorics 1970, 10, 15–19. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Kim, J.H.; Park, B.Y.; Akram, F.; Hong, B.W.; Choi, K.N. Multipass active contours for an adaptive contour map. Sensors 2013, 13, 3724–3738. [Google Scholar] [CrossRef] [PubMed]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Caselles, V.; Kimmel, R.; Sapiro, G. Geodesic active contours. Int. J. Comput. Vis. 1997, 22, 61–79. [Google Scholar] [CrossRef]
- Lu, X.; Song, L.; Shen, S.; He, K.; Yu, S.; Ling, N. Parallel Hough Transform-based straight line detection and its FPGA implementation in embedded vision. Sensors 2013, 13, 9223–9247. [Google Scholar] [CrossRef] [PubMed]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef] [PubMed]
- Konishi, S.; Yuille, A.L.; Coughlan, J.M.; Zhu, S.C. Statistical edge detection: Learning and evaluating edge cues. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 57–74. [Google Scholar] [CrossRef]
- Lim, J.J.; Zitnick, C.L.; Dollár, P. Sketch tokens: A learned mid-level representation for contour and object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3158–3165.
- Dollár, P.; Zitnick, C.L. Structured forests for fast edge detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 1841–1848.
- Ren, X.; Bo, L. Discriminatively trained sparse code gradients for contour detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 584–592. [Google Scholar]
- Zhao, J.; Ma, J.; Tian, J.; Ma, J.; Zheng, S. Boundary extraction using supervised edgelet classification. Opt. Eng. 2012, 51. [Google Scholar] [CrossRef]
- Wei, H.; Lang, B.; Zuo, Q. Contour detection model with multi-scale integration based on non-classical receptive field. Neurocomputing 2013, 103, 247–262. [Google Scholar] [CrossRef]
- Stettler, D.D.; Das, A.; Bennett, J.; Gilbert, C.D. Lateral connectivity and contextual interactions in macaque primary visual cortex. Neuron 2002, 36, 739–750. [Google Scholar] [CrossRef]
- Bosking, W.H.; Zhang, Y.; Schofield, B.; Fitzpatrick, D. Orientation selectivity and the arrangement of horizontal connections in tree shrew striate cortex. J. Neurosci. 1997, 17, 2112–2127. [Google Scholar] [PubMed]
- Knierim, J.J.; van Essen, D.C. Neuronal responses to static texture patterns in area V1 of the alert macaque monkey. J. Neurophysiol. 1992, 67, 961–980. [Google Scholar] [PubMed]
- Stemmler, M.; Usher, M.; Niebur, E. Lateral interactions in primary visual cortex: A model bridging physiology and psychophysics. Science 1995, 269, 1877–1880. [Google Scholar] [CrossRef] [PubMed]
- Hess, R.F.; May, K.A.; Dumoulin, S.O. Contour integration: Psychophysical, neurophysiological and computational perspectives. In Oxford Handbook of Perceptual Organization; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Grigorescu, C.; Petkov, N.; Westenberg, M. Contour detection based on nonclassical receptive field inhibition. IEEE Trans. Image Process. 2003, 12, 729–739. [Google Scholar] [CrossRef] [PubMed]
- Petkov, N.; Westenberg, M.A. Suppression of contour perception by band-limited noise and its relation to nonclassical receptive field inhibition. Biol. Cybern. 2003, 88, 236–246. [Google Scholar] [CrossRef] [PubMed]
- Papari, G.; Campisi, P.; Petkov, N.; Neri, A. A biologically motivated multiresolution approach to contour detection. EURASIP J. Appl. Signal Process. 2007, 2007. [Google Scholar] [CrossRef] [Green Version]
- Tang, Q.; Sang, N.; Zhang, T. Extraction of salient contours from cluttered scenes. Pattern Recognit. 2007, 40, 3100–3109. [Google Scholar] [CrossRef]
- Tang, Q.; Sang, N.; Zhang, T. Contour detection based on contextual influences. Image Vis. Comput. 2007, 25, 1282–1290. [Google Scholar] [CrossRef]
- Long, L.; Li, Y. Contour detection based on the property of orientation selective inhibition of non-classical receptive field. In Proceedings of the IEEE Conference on Cybernetics and Intelligent Systems, Chengdu, China, 21–24 September 2008; pp. 1002–1006.
- La Cara, G.E.; Ursino, M. A model of contour extraction including multiple scales, flexible inhibition and attention. Neural Netw. 2008, 21, 759–773. [Google Scholar] [CrossRef] [PubMed]
- Li, Z. A neural model of contour integration in the primary visual cortex. Neural Comput. 1998, 10, 903–940. [Google Scholar] [CrossRef] [PubMed]
- Ursino, M.; La Cara, G.E. A model of contextual interactions and contour detection in primary visual cortex. Neural Netw. 2004, 17, 719–735. [Google Scholar] [CrossRef] [PubMed]
- Zeng, C.; Li, Y.; Li, C. Center–surround interaction with adaptive inhibition: A computational model for contour detection. NeuroImage 2011, 55, 49–66. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Gao, S.; Li, C.; Li, Y. Efficient color boundary detection with color-opponent mechanisms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2810–2817.
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 280–287.
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300 fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293.
- Ren, X. Multi-scale improves boundary detection in natural images. In Computer Vision–ECCV 2008; Springer: Berlin, Germany, 2008; pp. 533–545. [Google Scholar]
- Dollar, P.; Tu, Z.; Belongie, S. Supervised learning of edges and object boundaries. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2006, 2, 1964–1971. [Google Scholar]
- Felzenszwalb, P.; McAllester, D. A min-cover approach for finding salient curves. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, New York, NY, USA, 17–22 June 2006. [CrossRef]
- Isola, P.; Zoran, D.; Krishnan, D.; Adelson, E.H. Crisp boundary detection using pointwise mutual information. In Computer Vision–ECCV 2014; Springer: Berlin, Germany, 2014; pp. 799–814. [Google Scholar]
- Yang, K.F.; Li, C.Y.; Li, Y.J. Multifeature-based surround inhibition improves contour detection in natural images. IEEE Trans. Image Process. 2014, 23, 5020–5032. [Google Scholar] [CrossRef] [PubMed]
- Xiao, J.; Cai, C. Contour detection based on horizontal interactions in primary visual cortex. Electron. Lett. 2014, 50, 359–361. [Google Scholar] [CrossRef]
- Papari, G.; Petkov, N. An improved model for surround suppression by steerable filters and multilevel inhibition with application to contour detection. Pattern Recognit. 2011, 44, 1999–2007. [Google Scholar] [CrossRef]
- Elder, J.H.; Goldberg, R.M. Ecological statistics of Gestalt laws for the perceptual organization of contours. J. Vis. 2002, 2. [Google Scholar] [CrossRef] [PubMed]
- Geisler, W.; Perry, J.; Super, B.; Gallogly, D. Edge co-occurrence in natural images predicts contour grouping performance. Vis. Res. 2001, 41, 711–724. [Google Scholar] [CrossRef]
- Ming, Y.; Li, H.; He, X. Connected contours: A new contour completion model that respects the closure effect. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 829–836.
- Han, J.; Yue, J.; Zhang, Y.; Bai, L.F. Salient contour extraction from complex natural scene in night vision image. Infrared Phys. Technol. 2014, 63, 165–177. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Moore, A.P.; Prince, J.; Warrell, J.; Mohammed, U.; Jones, G. Superpixel lattices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and supervoxels in an energy optimization framework. In Computer Vision–ECCV 2010; Springer: Berlin, Geramy, 2010; pp. 211–224. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar]
- Avidan, S.; Shamir, A. Seam carving for content-aware image resizing. ACM Trans. Gr. 2007, 26. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In Computer Vision–ECCV 2008; Springer: Berlin, Germany, 2008; pp. 705–718. [Google Scholar]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 6, 583–598. [Google Scholar] [CrossRef]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. Turbopixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Sminchisescu, C. Constrained parametric min-cuts for automatic object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3241–3248.
- Palmer, S.E. Vision Science: Photons to Phenomenology; MIT Press: Cambridge, MA, USA, 1999; Volume 1. [Google Scholar]
- Zhang, J.; Barhomi, Y.; Serre, T. A new biologically inspired color image descriptor. In Computer Vision–ECCV 2012; Springer: Berlin, Germany, 2012; pp. 312–324. [Google Scholar]
- Yang, K.F.; Gao, S.; Guo, C.; Li, C.; Li, Y. Boundary detection using double-opponency and spatial sparseness constraint. IEEE Trans. Image Process. 2015, 24, 2565–2578. [Google Scholar] [CrossRef] [PubMed]
- Hou, X.; Koch, C.; Yuille, A. Boundary detection benchmarking: Beyond f-measures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2123–2130.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Shang, K.; Ming, D.; Tian, J.; Ma, J. A Biologically-Inspired Framework for Contour Detection Using Superpixel-Based Candidates and Hierarchical Visual Cues. Sensors 2015, 15, 26654-26674. https://doi.org/10.3390/s151026654
Sun X, Shang K, Ming D, Tian J, Ma J. A Biologically-Inspired Framework for Contour Detection Using Superpixel-Based Candidates and Hierarchical Visual Cues. Sensors. 2015; 15(10):26654-26674. https://doi.org/10.3390/s151026654
Chicago/Turabian StyleSun, Xiao, Ke Shang, Delie Ming, Jinwen Tian, and Jiayi Ma. 2015. "A Biologically-Inspired Framework for Contour Detection Using Superpixel-Based Candidates and Hierarchical Visual Cues" Sensors 15, no. 10: 26654-26674. https://doi.org/10.3390/s151026654
APA StyleSun, X., Shang, K., Ming, D., Tian, J., & Ma, J. (2015). A Biologically-Inspired Framework for Contour Detection Using Superpixel-Based Candidates and Hierarchical Visual Cues. Sensors, 15(10), 26654-26674. https://doi.org/10.3390/s151026654