A Nonlinear Adaptive Beamforming Algorithm Based on Least Squares Support Vector Regression

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
: To overcome the performance degradation in the presence of steering vector mismatches, strict restrictions on the number of available snapshots, and numerous interferences, a novel beamforming approach based on nonlinear least-square support vector regression machine (LS-SVR) is derived in this paper. In this approach, the conventional linearly constrained minimum variance cost function used by minimum variance distortionless response (MVDR) beamformer is replaced by a squared-loss function to increase robustness in complex scenarios and provide additional control over the sidelobe level. Gaussian kernels are also used to obtain better generalization capacity. This novel approach has two highlights, one is a recursive regression procedure to estimate the weight vectors on real-time, the other is a sparse model with novelty criterion to reduce the final size of the beamformer. The analysis and simulation tests show that the proposed approach offers better noise suppression capability and achieve near optimal signal-to-interference-and-noise ratio (SINR) with a low computational burden, as compared to other recently proposed robust beamforming techniques.1. Introduction
As one important branch of modern array signal processing, the beamforming technique has been widely studied and applied in the radar, wireless communication, sonar, medical imaging, as well as astronomy domains. The standard beamforming approach, such as the minimum variance distortionless response (MVDR) beamformer [1], was usually established based on an ideal antenna array with exactly known array manifold. Thus, it is very sensitive to practical circumstances, and its performance would be seriously degraded by diverse factors, such as the steering vector mismatch, array calibration errors and snapshot number restrictions.
During the last decades, in order to resist the model mismatches and possible environment changes, the robust beamforming approach have been largely studied [2–5]. Among others, by introducing a penalty term into the objective function, the diagonal loading (DL) algorithm could effectively reduce the eigenvalue spread of the noise and prevent the distortion of beampattern [6]. Nevertheless, how to get the optimal loading factor for DL is still a serious issue when the desired steering vector and/or the available snapshot numbers are uncertain [7]. A robust adaptive beamforming, based on the worst-case performance optimization, would delimit the uncertainty set of steering vectors by upper bounding the norm of the steering vector mismatch [8]. However, neither the mismatch vector nor its upper bound is known in practice. To overcome this model defect in standard DL algorithm, an adaptive beamforming method was developed, which estimates iteratively the difference between the actual and presumed steering vectors in order to maximize the output signal-to-noise plus interference ratio (SINR) [9–11]. But this adaptive beamforming algorithm is not sufficiently reliable in the case when the snapshots are small.
In order to reject jamming signals, poor array calibration, signal wave-front distortions, the minimum-variance-distortionless-response (MVDR) beamforming is modified by the means of incorporating multiple linear constrains [12–14]. Whereas, the augmentation of constrains would reduce the array freedom degrees in the linear beamforming framework. Nonlinear beamforming approaches provide a novel idea to address this issue for they can adapt better to the statistical properties of the given data than linear ones [15]. Neural network has been applied to beamforming among other nonlinear array processing tasks. But this approach suffers from serious drawbacks such as over-fitting or local minima, which leads to suboptimal solutions [16].
Support Vector Machines (SVM), introduced by Vapnik [17], is an important new methodology for pattern classification and nonlinear function approximation. This method addresses the beamforming problem by means of incorporating additional inequality constrains to penalize sidelobe levels and allowing a certain error in the desired signal direction [18]. Thus the MVDR beamforming method is reformulated and the cost function turns out to be equivalent to SVM for regression. However, the time consumed to train SVM beamformer scales super linearly to the number of observations, and it leads to an insurmountable computational burden in online operation modes [19]. The least-squares support vector machine (LS-SVM) inherits the SVM's generalization capacity. By solving linear equations instead of a quadratic programming (QP) problem in the standard SVM, the training procedure and the computational complexity of the standard SVM would be effectively simplified [20]. The main drawback of LS-SVM is that it works in batch mode. Thus, it is difficult to be used in large-scale applications. Recent researches about LS-SVM continuously focus on the improvement of the training algorithms, model selection and sparseness [21,22].
This paper presents a new LS-SVR-based approach to address the robust beamforming issue. This approach alleviates the array output SINR degradation in the presence of steering vector mismatches, strict restrictions on the number of available snapshots, and numerous interferences by replacing the conventional linearly constrained minimum variance cost function with a squared-loss function, and achieves better generalization capacity by applying Gaussian kernels to the array observations. We also present a fast recursive procedure to estimate the weight vectors on real-time, and a novelty criterion to perform model reduction. The paper is organized as follows. The signal model, also the minimum mean square error (MMSE) and the MVDR-beamformer solutions are presented in Section 2. The basic principle of LS-SVR-based beamforming method is introduced in Section 3. In Section 4, a recursive procedure to calculate the regression parameters is provided. And a sparse mode is presented in Section 5. The simulation tests under different mismatch scenarios are illustrated in Section 6. A summary conclusion is given at the last of this paper.
2. Sensor Signal Model
Consider a linear array of M sensors receives signals from D narrowband source. The vector of array observations x(t) ∈ CM×1 at time t could be modeled as:
The output of the beamformer is defined as:
If certain observations are known during the procedure of training parameters, then, according to the MMSE criterion, the complex vector of beamformer weights w can be described as:
The classical MVDR beamformer minimizes the array output energy, and the weights subject to a constraint of unity array response on the desired array steering vectors, that is:
The constraint wHa(θ1) = 1 prevents the gain at the look direction from being reduced, and the solution of Equation (5) can be easily estimated by means of using Largrange multiplier method:
In practice, it is not feasible to calculate the exact covariance matrix R and it would be estimated by the sample covariance matrix where K is the number of observed snapshots.
The performance of MVDR beamformer in Equation (5) is sensitive to mismatch between the presumed and actual steering vectors due to the uncertainty of the desired signal DOA, strict restrictions on the number of available snapshots, and numerous interferences.
3. LS-SVR-Based Beamforming Method
3.1. Nonlinear SVM-Based Beamforming
Consider a set of snapshots xi, i = 1, N at time t from an array and the corresponding set of desired symbols yi, i = 1, N, are available for training purpose. The basic idea of nonlinear beamforming is to transform the data set xi, i = 1, N into a higher (possibly infinite) dimension feature space H by a nonlinear transformation φ(·). Thus, the beamformer's output can be formulated as a linear regression in H. It could be expressed as:
The parameter set w can be estimated by minimizing a certain cost function on output error ei. For SVM regression, the parameter set w and the ε–intensive loss function could be estimated by the minimum risk criterion, i.e.,
The weight vector w is regularized by solving Equation (8), Thus, the generalization capacity of the beamformer will be remarkably improved.
3.2. Nonlinear LS-SVR Beamforming
Instead of the inequality constrains in standard SVM algorithm, the equality ones are taken in LS-SVR, and the linear equation of the ε–intensive loss function is replaced by a quadratic equation. Therefore, The LS-SVR beamformer can be described as the following quadratic optimization problem [20]:
The array observations of the beamformer are complex, whereas the variables in the objective function of SVM are real. So, it is necessary to rewrite the complex variables as real variables. For this reason, the array observations xi, the beamformer outputs yi and the weight vectors wt are rewritten as:
The result of the quadratic optimization problem of Equation (10) is the saddle point of the following Lagrange function:
According to the Karush-Kuhn-Tucker (KKT) conditions, differentiating the above function with respect to the Lagrange multipliers αt and x̄i,t, bt, ei,t yields:
The system obtained from the KKT conditions is linear. Its result is obtained by solving the linear system which is expressed as following matrix:
The outputs of the nonlinear LS-SVR beamformer are:
4. Recursive Algorithms
From Equation (16), it could be known that once the regression parameters αt and bt are computed, the beamformer outputs can be obtained. Denoting Ut = Ht−1 = (Qt + C−1I)−1, the result of LS-SVR (Equation (14)) can be represented as:
Then, we have:
As the number of snapshots increases, the dimension of Gramm matrix Qi will be increasing because it is in proportional to the number of snapshots. Therefore, the computation for the regression parameters αt and bt would be very intensive as the snapshots increase, and it is key issue for LS-SVR beamformer to find out a fast algorithm to improve the computation efficiency of Ui.
At time step t, Qi and Hi are the matrixes with dimension of 2N × 2N:
As time run to t + 1, new input snapshots xt+1 and the corresponding desired array output yt+1 are added to the current training set. So Qt+1 and Ht+1 can be represented as:
Comparing the elements of Ht and Ht+1, the matrix Ht+1 could be reconstructed by the matrix Ht plus an additional row and column, i.e.,
According to the theorem of inverting block matrix, the inverse of Ht+1 can be expressed by the inverse of Ht and the new column vt+1 as:
5. Sparsification
The crucial drawback of LS-SVR beamformer is that it deals with high-dimension matrix, which is equal to the number of the snapshots due to the use of a quadratic constraint function. This would bring a big implementation problem to the proposed beamforming method since it is required to increase memory and computational resources as time evolves. Several methods have been proposed to cope with these problems [23,24]. The sliding-window approach [25] fixes the size of LS-SVR beamformer and allows it to be operated online in time-varying environments by keeping only the last N input snapshots in the sliding-window and simply abandoning those out of it. In [26], an exponential forgetting mechanism is introduced to describe the influence, which is imposed on the present situation by the past data [26]. This paper employs the novelty criterion, presented by Platt [27,28], to reduce the final size of the proposed beamformer, keep the algorithm complexity bounded and realize online sparsification. The basic idea of this approach is to construct a dictionary with center set C and update it appropriately according to the novelty criterion. The stages of the proposed specification are given as follows:
Step 1: Initialing an empty center set C0;
Step 2: Calculating the distance between the new snapshot xt and the present dictionary dis=minck ∈ Ci ‖xt − ck‖;
Step 3: If the distance obtained from Step 2 is smaller than the preset threshold δ1, xt is not added into the dictionary, otherwise the prediction error ei = yi − ŷi is calculated;
Step 4: if |e|i is larger than another preset threshold δ2, xt is accepted as a new center and Ci is updated to Ci+1, otherwise go to Step 2.
Increasing δ1 and δ2, the final size of the LS-SVR beamformer will be decreased. But this will result to performance degradation. In practical applications, δ1 is set to around one tenth of the kernel bandwidth, and δ2 is around the square root of the steady-state mean square error (MSE). Cross-validation also can be used to select these appropriate thresholds.
Applying the above sparsification procedure, the computation complexity of the proposed beamformer will be reduced from O(N2) to O(K2), where K is the effective number of centers in the network at time t. As K is finite, the online real-time beamforming will be practical.
6. Simulation Tests
To evaluate the performance of the proposed LS-SVR-based beamformer, simulation tests are carried out. A 10 elements uniform linear array with half-wavelength spacing is taken into account. The desired signal comes from a presumed direction θ = 3° and two irrelevant interferences, with interference-to-noise ratio (INR) of 20 dB, impinge on the array from θ2 = −32° and θ3 = 17° respectively. The additive noise is assumed to be a 0-dB complex white Gaussian distributed random variable. For comparison purpose, the conventional MVDR, the diagonal loading MVDR (MVDR-DL), the ES [29], the SQP [9] and the RR [30] method are considered. The parameters of the proposed beamformer, σ, δ1 and δ2, are chosen as 1.0, 0.1 and 0.08 respectively. The load value of MVDR-DL beamformer is set to (Pe+10 dB), where Pe denotes the power of desired signal. All results are obtained from 100 independent simulation runs.
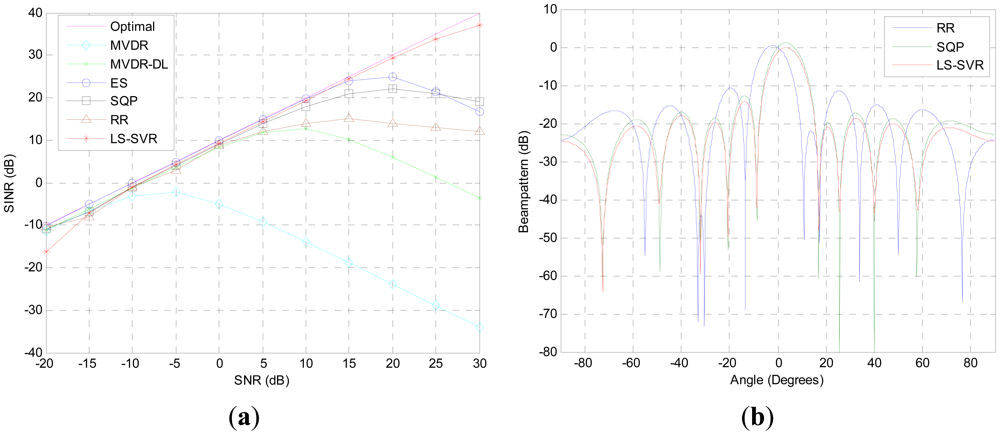
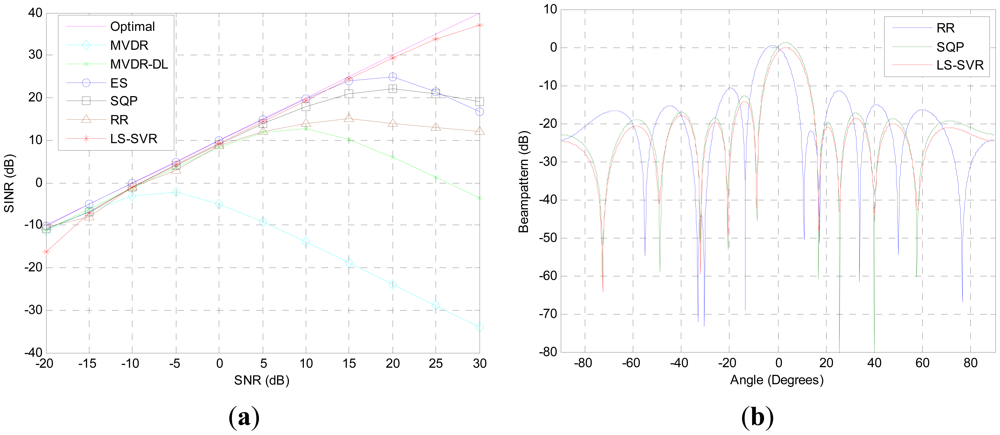
The first simulation aims to compare the performance of these beamformers when steering vector mismatch is presented. From Figure 1(a), we observe that the proposed LS-SVR beamformer consistently improves its output SINR as SNR increases and performs much closer as the idea one when the input SNR is varied from −20 dB to 30 dB. Due to the DOA mismatch, the interested signal is considered as interference and a null is allocated in the desired signal direction by the MVDR beamformer. As a result, the output SINR is decreased. When input SNR is larger than −5 dB, the output SINR of MVDR beamformer degrades seriously. In comparing with the MVDR beamformer, the MVDR-DL, ES, SQP and RR methods get more robustness against DOA mismatch. But they still suffer from a degradation of performance while the input SNR becomes higher.
Figure 1(b) shows the normali\zed beampattern plots when the input SNR is equal to 10 dB. As it is illustrated, all beam-patterns of the robust beamformers have nulls at the DOAs of the interferences. But the proposed LS-SVR still outperforms others by markedly lower sidelobe level, and maintaining distortionless response for the desired signal.
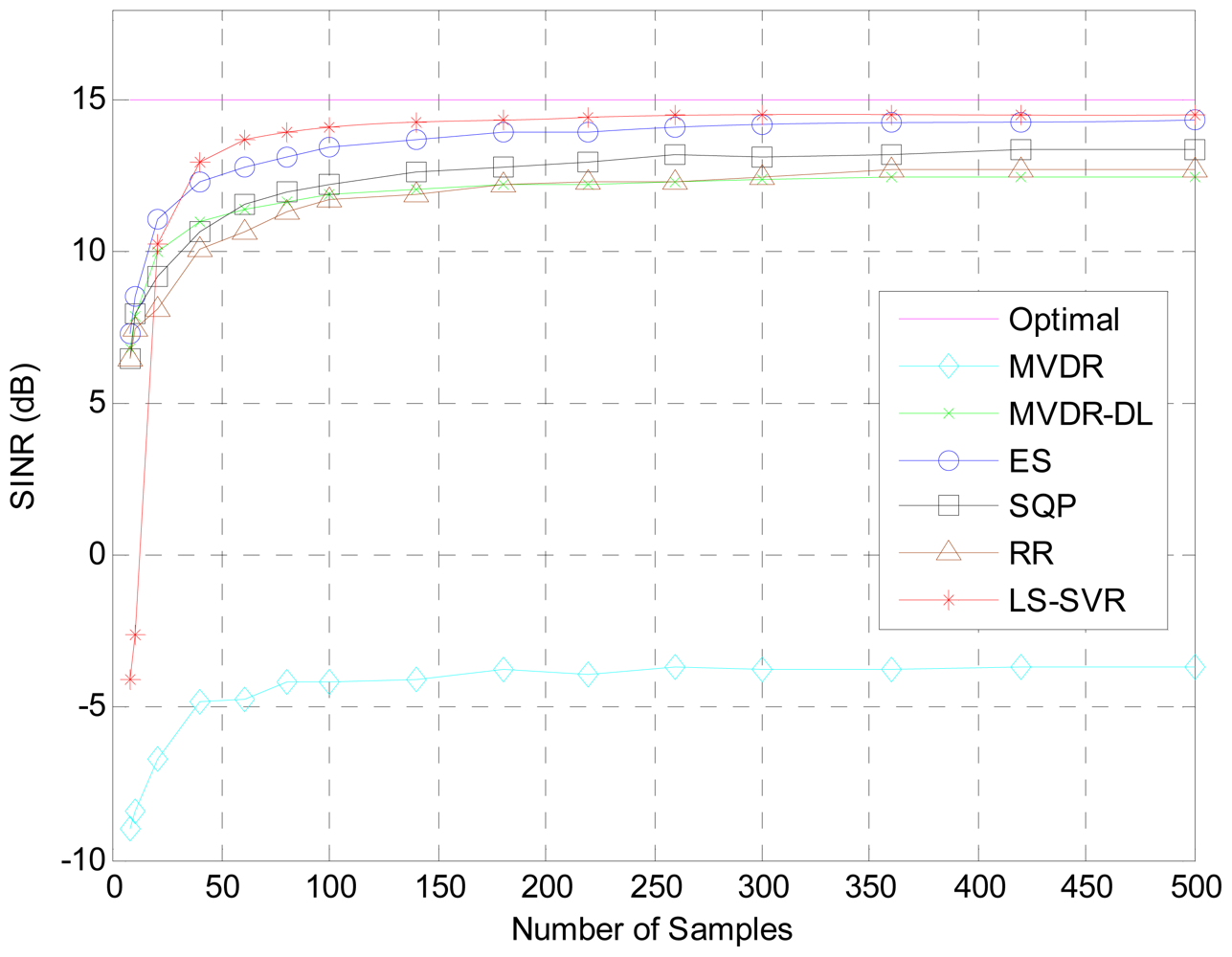
The covariance matrix would be inaccurately estimated owing to insufficient snapshots, DOA mismatch of desired signal and array calibration errors. This kind of inaccuracy may result in the degradation of array response. Hence, both the errors of insufficient snapshots and DOA mismatch are considered to verify the proposed beamformer in our second simulation tests. Figure 2 shows the resulting output SINRs versus the snapshot number K. When snapshots are over 20, the LS-SVR clearly outperforms other beamformers tested. Owing to the steering vector mismatch, the MVDR beamformer see the desired signal as interference and fails in its operation.
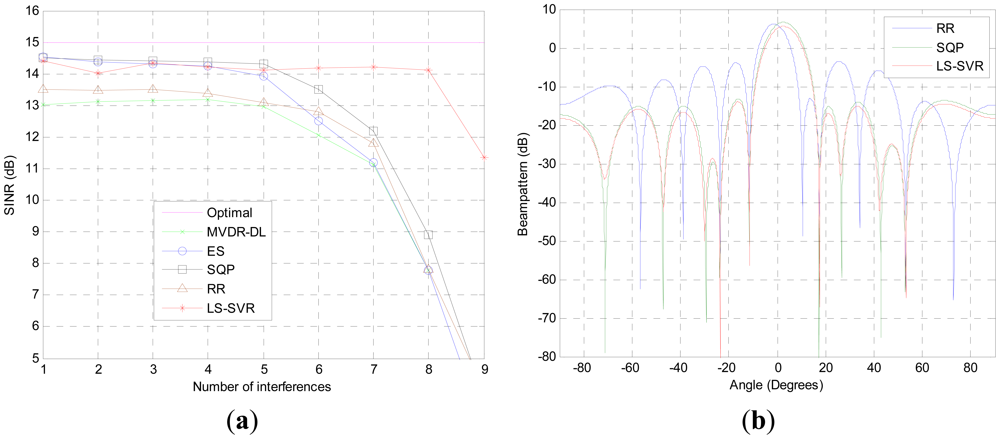
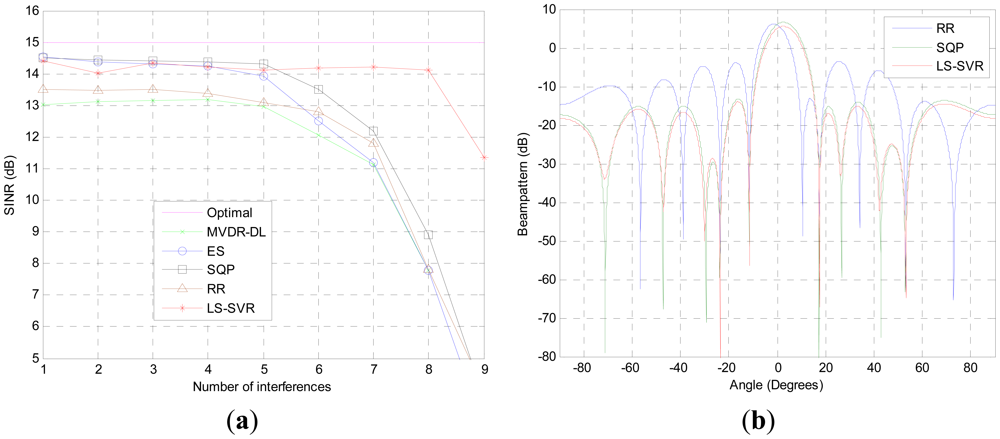
The performance of the proposed beamformer in the scenario with multiple interferences is demonstrated in the third test. The steering vector mismatch is also presented. As it can be seen from Figure 3(a), the proposed algorithm performs equally well as ES and SQP when the number of interferences less than 5. When the interference numbers is increased to 8, the output SINR of the proposed LS-SVR beamformer is only 1 dB lower than that of idea beamformer. In contrast, the output SINRs of other beamformers tested are dramatically decreased due to the decrease of the available freedom degrees which are devoted to suppress the interference.
The corresponding beampatterns of the beamformers are demonstrated in Figure 3(b), where the four interferences with DOAs of θi = [17.4°, −11.5°, 53.1°, −23.5°] are taken into account. It can be seen that the LS-SVR beamformer not only presents deep nulls at the DOAs of interference, but also achieves better sidelobe suppression than other beamformers tested. Thus, the proposed LS-SVR method can get better SINR performance than the usual robust linear beamforming algorithms in the case of numerous interferences.
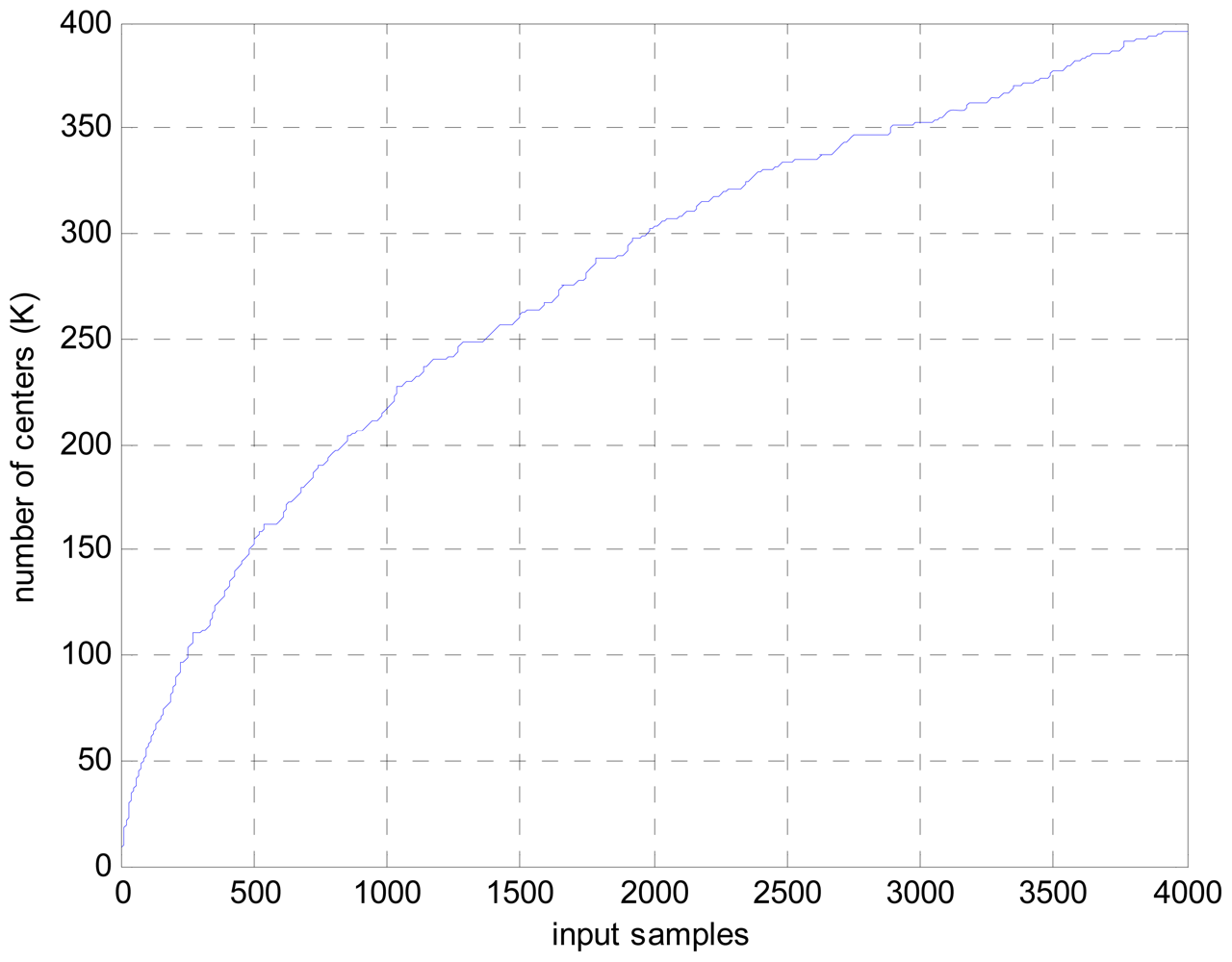
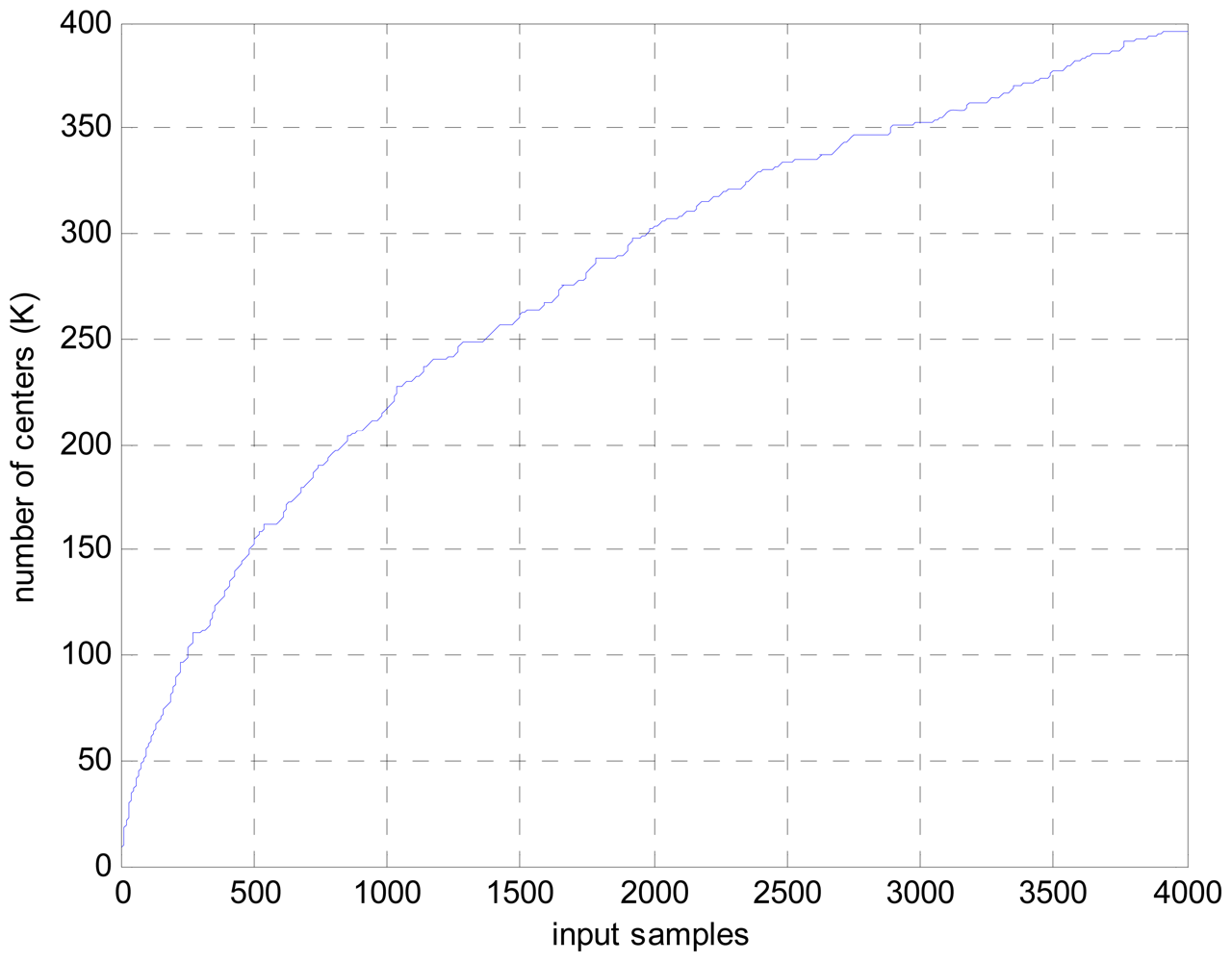
To show the computation complexity of the novel approach, the dictionary size growth with the input samples is given in Figure 4. As it can be seen in Figure 4, only 396 center numbers are needed to calculate the beamformed output for 4,000 input samples. In comparison with the original LS-SVR algorithm, in which 4,000 centers are needed for the same case. Thus, the computation cost is largely reduced.
7. Conclusions
We present a novel nonlinear LS-SVR-based beamforming approach in this paper. This approach first uses a squared-loss function to replace the conventional linearly constrained minimum variance cost function, which can significantly increase robustness against mismatch problems and provide additional control over the sidelobe level. The method also applies Gaussian kernels to the array observations to improve the generalization capacity. Finally, the method uses a recursive regression procedure to estimate the weight vectors on real-time and performs mode reduction to reduce the final size of the beamformer.
The simulation tests, with steering vector mismatch, numerous interferences and limited available snapshots, are carried out to verify the performance of the proposed beamforming algorithm in comparison with other recently proposed ones. The test results show that the proposed beamforming method significantly outperforms many other recently proposed linear robust beamforming techniques in terms of signal distortion in the desired signal and noise reduction in scenarios with DOA mismatch, limited observation samples, and numerous interferences.
Acknowledgments
This research was supported by the National Natural Science Foundation of China (Grant No.61071191) and Natural Science Foundation of Chongqing (CSTC 2011BB2048).
References
- Van Trees, H.L. Part IV Detection, Estimation and Modulation Theory. In Optimum Array Processing; John Wiley & Sons, Inc.: New York, NY, USA, 2002; pp. 439–440. [Google Scholar]
- Liu, J.; Gershman, A.B.; Luo, Z.Q.; Wong, K.M. Adaptive beamforming with sidelobe control: A second-order cone programming approach. IEEE Signal Process. Lett. 2003, 10, 331–334. [Google Scholar]
- Li, J.; Stoica, P.; Wang, Z. Doubly constrained robust Capon beamformer. IEEE Trans. Signal Process 2004, 52, 2407–2423. [Google Scholar]
- Li, J.; Stoica, P. Robust Adaptive Beamforming; John Wiley & Sons, Inc.: New York, NY, USA, 2006. [Google Scholar]
- Liu, C.; Liao, G. Robust capon beamformer under norm constraint. Signal Process 2010, 90, 1573–1581. [Google Scholar]
- Li, J.; Stoica, P.; Wang, Z. On robust capon beamforming and diagonal loading. IEEE Trans. Signal Process 2003, 51, 1702–1715. [Google Scholar]
- Lorenz, R.G.; Boyd, S.R. Robust minimum variance beamforming. IEEE Trans. Signal Process 2005, 53, 1684–1696. [Google Scholar]
- Vorobyov, S.A.; Gershman, A.B.; Luo, Z.Q. Robust adaptive beamforming using worst-case performance optimization: A solution to the signal mismatch problem. IEEE Trans. Signal Process 2003, 51, 313–324. [Google Scholar]
- Hassanien, A.; Vorobyov, S.A.; Wong, K.M. Robust adaptive beamforming using sequential quadratic programming: An iterative solution to the mismatch problem. IEEE Signal Process. Lett. 2008, 15, 733–736. [Google Scholar]
- Lie, J.P.; Ser, W.; See, C.M. Adaptive uncertainty based iterative robust capon beamformer using steering vector mismatch estimation. IEEE Trans. Signal Process 2011, 59, 4483–4488. [Google Scholar]
- Landau, L.; de, Lamare, R.C.; Haardt, M. Robust Adaptive Beamforming Algorithms Using Low-Complexity Mismatch Estimation. Proceedings of the IEEE Statistical Signal Processing Workshop, Jachranka, Poland, 28– 30 June 2011; pp. 445–448.
- Yu, Z.L.; Er, M.H. A robust minimum variance beamformer with new constraint on uncertainty of steering vector. Signal Process 2006, 86, 2243–2254. [Google Scholar]
- Nai, S.E.; Ser, W.; Yu, Z.L.; Rahardja, S. A robust adaptive beamforming framework with beampattern shaping constraints. IEEE Trans. Antennas Propagat 2009, 57, 2198–2203. [Google Scholar]
- Yu, Z.L.; Ser, W.; Er, M.H.; Gu, Z.; Li, Y. Robust adaptive beamformers based on worst-case optimization and constraints on magnitude response. IEEE Trans. Signal Process 2009, 57, 2615–2628. [Google Scholar]
- Martinez-Ramon, M.; Rojo-Alvarez, J.L.; Camps-Valls, G.; Christodoulou, C.G. Kernel antenna array processing. IEEE Trans. Antennas Propagat 2007, 55, 642–650. [Google Scholar]
- Chang, P.R.; Yang, W.H.; Chan, K.K. A neural network approach to MVDR beamforming problem. IEEE Trans. Antennas Propagat 1992, 40, 313–322. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer-Verlag Inc.: New York, NY, USA, 1995. [Google Scholar]
- Gaudes, C.C.; Santamaria, I.; Via, J.; Gomez, E.M.M.; Paules, T.S. Roubust array beamforming with sidelobe control using support vector machines. IEEE Trans. Signal Process 2007, 55, 574–584. [Google Scholar]
- Ramon, M.M.; Xu, N.; Christodoulou, C.G. Beamforming using support vector machines. IEEE Antenn. Wirel. Propag. Lett. 2005, 4, 439–442. [Google Scholar]
- Suykens, J.A.K.; De Brabanter, J.; Lukas, L.; Vandewalle, J. Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar]
- Chu, W.; Ong, C.J.; Keerthi, S.S. An improved conjugate gradient scheme to the solution of least squares svm. IEEE Trans. Neural Networks 2005, 16, 498–501. [Google Scholar]
- Adankon, M.M.; Cheriet, M. Model selection for LSSVM application to handwriting recognition. Pattern Recognit 2009, 42, 3264–3270. [Google Scholar]
- Hoegaerts, L.; Suykens, J.A.K.; Vandewalle, J.; de Moor, B. Subset based least squares subspace regression in RKHS. Neurocomputting 2005, 63, 293–323. [Google Scholar]
- Jiao, L.; Bo, L.; Wang, L. Fast sparse approximation for least square support vector machine. IEEE Trans. Neural Networks 2007, 18, 685–697. [Google Scholar]
- Vaerenbergh, S.V.; Via, J.; Santamaria, I. A Sliding-Window Kernel RLS Algorithm and Its Application to Nonlinear Channel Indentification. Proceedings of the Acoustics, Speech and Signal Processing, Toulouse, France, 14–19 May 2006; pp. 789–792.
- Slavakis, K.; Theodoridis, S.; Yamada, I. On line classification using kernels and projection based adaptive algorithm. IEEE Trans. Signal Process 2008, 56, 2781–2797. [Google Scholar]
- Platt, J. A resource allocating network for function interpolation. Neural Comput. 1991, 3, 213–225. [Google Scholar]
- Liu, W.F.; Jose, C.P.; Simon, H. Kernel Adaptive Filtering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2010. [Google Scholar]
- Yu, J.L.; Yeh, C.C. Generalized eigenspace-based beamformers. IEEE Trans. Signal Process 1995, 43, 2453–2461. [Google Scholar]
- Selen, Y.; Abrahamsson, R.; Stoica, P. Automatic robust adaptive beamforming via ridge regression. Signal Process 2008, 88, 33–49. [Google Scholar]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Wang, L.; Jin, G.; Li, Z.; Xu, H. A Nonlinear Adaptive Beamforming Algorithm Based on Least Squares Support Vector Regression. Sensors 2012, 12, 12424-12436. https://doi.org/10.3390/s120912424
Wang L, Jin G, Li Z, Xu H. A Nonlinear Adaptive Beamforming Algorithm Based on Least Squares Support Vector Regression. Sensors. 2012; 12(9):12424-12436. https://doi.org/10.3390/s120912424
Chicago/Turabian StyleWang, Lutao, Gang Jin, Zhengzhou Li, and Hongbin Xu. 2012. "A Nonlinear Adaptive Beamforming Algorithm Based on Least Squares Support Vector Regression" Sensors 12, no. 9: 12424-12436. https://doi.org/10.3390/s120912424
APA StyleWang, L., Jin, G., Li, Z., & Xu, H. (2012). A Nonlinear Adaptive Beamforming Algorithm Based on Least Squares Support Vector Regression. Sensors, 12(9), 12424-12436. https://doi.org/10.3390/s120912424