A Low-Complexity Geometric Bilateration Method for Localization in Wireless Sensor Networks and Its Comparison with Least-Squares Methods




Abstract
: This research presents a distributed and formula-based bilateration algorithm that can be used to provide initial set of locations. In this scheme each node uses distance estimates to anchors to solve a set of circle-circle intersection (CCI) problems, solved through a purely geometric formulation. The resulting CCIs are processed to pick those that cluster together and then take the average to produce an initial node location. The algorithm is compared in terms of accuracy and computational complexity with a Least-Squares localization algorithm, based on the Levenberg–Marquardt methodology. Results in accuracy vs. computational performance show that the bilateration algorithm is competitive compared with well known optimized localization algorithms.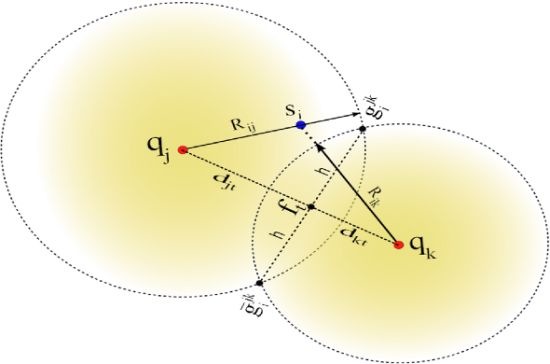
1. Introduction
Recent advances in microelectronics have led to the development of autonomous tiny devices called sensor nodes. Such devices, in spite of their physical limitations, contain the essential components of a computer, such as memory, I/O ports, sensors, and wireless transceivers which are typically battery-powered. Once deployed (randomly or not) over a certain area, sensor nodes have the ability to be in touch via wireless communications with neighboring nodes forming a wireless sensor network (WSN). The great advantage of using WSNs is that they can be applied in important areas such as disaster and relief, military affairs, medical care, environmental monitoring, target tracking, and so on [1–3]. However, most of WSN applications are based on local events. This means that each sensor node needs to detect and share local phenomenons with neighboring nodes, implying that the location of such events (i.e., sensor locations) are crucial for the WSN application. In this way, sensor self-positioning represents the first startup process in most WSN projects. It is well known that using a GPS in each sensor node represents the primary solution to infer position estimates. However, this option is not suitable to be considered in all nodes if parameters like size, price, and energy-consumption in a sensor node are of concern [4]. In order to optimize such parameters, a good option consists of reducing to a small fraction of sensors with GPS, and the remainder sensors (i.e., unknown sensors), commonly above 90% of total deployed sensors, should use alternatives to estimate its own positions like radio-frequency transmissions or connectivity with neighboring sensors [5–7].
In order to provide position estimates many localization algorithms have been proposed, coming from different perspectives as described in [8,9]. Basically, localization algorithms can be categorized according to range-based vs. range-free methods, anchor-based vs. anchor-free models, and distributed vs. centralized processing [10,11]. Range-based methods consist of estimating node locations (using a localization algorithm) based on ranging information among sensor nodes. Range estimation between pairs of nodes is achieved using techniques of Time-of-Arrival (ToA), Receive-Signal-Strength (RSS), or Angle-of-Arrival (AoA) [12]. This approach has the disadvantage of requiring extra-hardware in each sensor board, increasing the cost per sensor. However, as far as is known, this approach provides the best cost-accuracy performance in localization algorithms. A less expensive but more inaccurate alternative consists of using just connectivity among sensor nodes to estimate node locations, called range-free [13]. On the other hand, if position estimates are obtained by considering absolute references (e.g., sensors with GPS or Anchors), the resulted position estimates (also with absolute positions) will be closely related to such reference positions, called an anchor-based model. By the contrary, if no reference positions are used to estimate locations, relative coordinates will be obtained, called an anchor-free model.
One of the most interesting and relevant aspects in WSN localization is associated with the way to compute the location of sensor nodes. For example, if all pairwise distance measurements among sensor nodes are sent to a central node to compute position estimates, the localization algorithm becomes centralized. This kind of central processing has the advantage of global mapping, but it has basically two important disadvantages which demerit its use in many cases when robustness and saving-energy have high priority in a WSN [14]. Some important centralized schemes are the next. In [15] an iterative descent procedure (i.e., Gauss–Newton method) is used in a centralized way to solve the Non-Linear Least-Square (NLLS) problem. Another interesting centralized scheme was proposed in [16] where the WSN localization problem is modeled as linear or semidefinite program (SDP), and a convex optimization is used to solve problem.
In contrast, when each sensor node estimates its own location using available information of neighboring nodes (e.g., range, connectivity, location, etc.), the localization process becomes distributed. Distributed processing is much less energy consuming in WSNs than centralized processing because centralized schemes need to collect relevant information from all nodes in the network which implies re-transmissions in multi-hop environments. Also, distributed algorithms are tolerant to node failures due to node redundancy. Thus, basically a distributed algorithm allows robustness, saving-energy, and scalability [14,17,18], which overcomes the limitations imposed by the centralized approach. In [19], a robust least squares scheme (RLS) for multi-hop node localization is proposed. This approach reduces the effects of error propagation by introducing a regularization parameter in the covariance matrix. However, the computational cost to mitigate the adverse effects of error propagation is too high at energy-constrained nodes. Similarly, [20] proposes two weighted least squares techniques to gain robustness when a non-optimal propagation model is considered however they failed to introduce a covariance matrix in the localization process that can effectively decrease the computational complexity. On the other hand, the authors of [21] propose a Quality of Trilateration method (QoT) for node localization. This approach provides a quantitative evaluation of different geometric forms of trilaterations. However, it seems to be that the main idea of this methodology depends on the quality or resolution of geometric forms (i.e., like image processing) which is impractical to be implemented in resource-constrained devices with limited memory and processing capabilities (i.e., nodes).
In this paper, we analyze a range-based bilateration algorithm (BL) that can be used in a distributed way to provide initial estimates for unknown sensors in a wireless sensor network (our analysis consider that each unknown sensor can determine its initial position communicating directly with several anchors). In this case, each node uses a set of two anchors and their respective ranges at a time to solve a set of circle intersection problems using a geometric formulation. The solutions from these geometric problems are processed to pick those that cluster around the location estimate and then take the average to produce an initial node location. Finally, we present a computational/accuracy comparison between the BL algorithm, based on closed-formulas, and a classical Least Squares (LS) approach for localization, based on the iterative Levenberg–Marquardt algorithm (LM).
The outline of this paper is as follows. In Section 2 we examine a popular ranging technique for WSNs used in our simulations. In Section 3 we explore the localization problem from the Least Squares point of view. In Section 4 we analyze in detail the BL algorithm. In Sections 5 and 6 we evaluate the accuracy and computational-complexity performance respectively between the bilateration algorithm vs. LS schemes. Finally, we present our conclusions.
2. Ranging Techniques
This section presents a brief overview of an existing ranging technique used to estimate the true distance between two sensor nodes using power measurements, called Received Signal Strength (RSS). This technique is popular because sensor nodes do not require special hardware support to estimate distances. As a first approximation, considering the free space path loss model, the distance dij between two sensors si and sj can be estimated by assuming that the power signal decreases in a way that is inversely proportional to the square of the distance . However, in real environments the signal power is attenuated by a factor d−ηp. The path-loss factor ηp is closely related to geometrical and environmental factors, and it varies from 2 to 4 for practical situations [22]. In noiseless environments the power signal traveling from a sensor sj to a sensor si can be measured according to the relation [23]
3. Least-Squares Multilateration Localization Algorithms
In this section, we describe multilateration schemes that provide solutions to the Least-Square (LS) problem for location estimates using noisy ranging information derived from ToA or RSS ranging techniques. Consider a set of N wireless sensor nodes S = {s1, s2,..., sN}, randomly distributed over a 2-D region whose locations are unknown. We represent these unknown locations with vectors zi = [xi, yi]T. Further, we assume the presence of a set A = {a1,a2,...,aM} of M reference or anchor nodes with known position qj = [xj, yj]T. Anchor nodes, ai, are equipped with GPS or a similar scheme to self localize. Also, for practical situations M ≪ N with M > 2. We develop our discussion assuming a 2-D scenario, but it can be easily generalized to the 3-D case.
Moreover, we assume that any sensor can estimate pairwise ranges with its neighbors using time-of-arrival (ToA) or radio signal strength (RSS) techniques [24]. Denote the range estimate between the node si and anchor aj as
3.1. Closed-Form LS Multilateration
Closed-Form methods have the advantage of fast time processing, which is useful for constrained devices (i.e., motes) where the energy conservation represents one of the major concerns. However, this approach is also subject to inaccurate estimates due to noisy ranging measurements, so in most cases this approach is not a suitable option in real WSN scenarios where current ranging techniques are not able to provide the required accuracy on the ranging measurements. For example, Spherical Intersection (SX), Spherical Interpolation (SI), and Global Spherical Least Squares (GSLS) [25] can solve a nonlinear set of equations using closed-formulas. These approaches provide good accuracy in the estimated positions under conditions like small biases and small standard deviations, but they also provide meaningless estimates under noisy environments [26]. A more robust closed-form scheme consists of using the classical LS multilateration discussed next [19,27,28].
Consider that a sensor si with Cartesian position pi = [xi, yi]T has already estimated its range Rij to M anchors. For each anchor aj with position qj = [xj, yj]T, an equation is generated as shown the next formulas:
The system of Equations (7) can be linearized by subtracting the first equation (j = 1) from the last M − 1 equations arriving to a linear system that can be represented in a matrix form as
Now the least squares solution to Equation (8) is to determine an estimate for pi that minimizes
After some manipulations we obtain the following:
Solving for Equation (14) may not work properly if AT A is close singular, so a recommended approach is to use a Tikhonov regularization as follows:
For μ > 0 (e.g., close to zero)
Then the gradient of fμ at pi is
Factorizing we arrive to a robust estimate for the LS problem where the idea is to modify eigenvalues to avoid working with zero eigenvalues [19,29].
3.2. Iterative LS Algorithms
Iterative methods are usually employed either when large-data set of information need to be processed or when an exact solution to a certain problem is not feasible (e.g., non-linear systems of equations) [30]. Optimization techniques represent a good alternative to solve such non-linear equations using an iterative procedure. Optimization algorithms that solve Non-Linear Least-Square (NLLS) problems (i.e., the WSN localization problem) have been extensively proposed where the Newton or Quasi-Newton methods are iteratively used to minimizing some residuals [15,31,32]. The next paragraphs describe two well known iterative algorithms that are used to solve the NLLS problem: the Levenberg–Marquardt (LM) and the Trust-Region-Reflective (TRR).
Assuming that a node denoted si, with Cartesian position pi = [xi, yi]T, estimates its distance Rij to M anchors denoted aj, with positions qj = [xj, yj]T, with j = 1, ..., M. Consider the following residual error vector:
Therefore, to find the more likely position of pi, the program
To solve Equation (19) we employ the TRR algorithm and the LM algorithm. The TRR algorithm uses a sub-space trust-region method to minimize a function f(x). Here, approximations to f inside of a trust-region are iteratively required. The three main concerns in this algorithm are how to choose and compute the approximation to the function, how to choose and modify the trust region, and, finally, how to minimize over the sub-space trust-region. Even though the TRR algorithm provides an accurate solution for the WSN initial estimates, it is expensive (computationally speaking) for constrained sensor nodes [33].
On the other hand, the LM algorithm uses the search direction approach (a mix between the Gauss–Newton direction and the steepest descent direction) to find the solution to Equation (19). This algorithm outperforms the simple gradient descent methodology [34], and also it avoids dangerous operations with singular matrices as the pure Newton method does, so this methodology represents a good algorithm for comparison with the bilateration approach due to its robustness, speed, and accuracy [35]. Following the procedure presented in [29], Equation (19) can be solved by the Line Search Levenberg–Marquardt methodology shown in Algorithm 1, where ‖·‖ is the ℓ-2 norm, I is the identity matrix, Rij is the estimated distance between the mote si and the anchor aj, J(pk) represents the Jacobian of R(pk) at the iteration k, and Mf(pk) is the merit function given by

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Require: an initial position p0 |
| Ensure: a solution pk+1 |
| 1: Initialize: k = 0,τ = Threshold, ρ = 0.05 |
| 2: do |
| 3: Solve: (JT (pk)J(pk) + μkI)ΔLM = −JT (pk)R(pk) |
| 4: Find the sufficient decrease (Armijo’s condition): |
| 5: such that for t = 0,1,... |
| 6: satisfies Mf(pk + αkΔLM) ≤ Mf (pk) + 10−4αkM′f(p)T ΔLM |
| 7: Update position: pk+1 = p + αkΔLM |
| 8: Update μk: μk = ρ‖JT(pk)R(pk)‖ |
| 9: while(‖pk+1 − pk‖ ≤ τ or k ≤ 100) |
4. A Bilateration Localization Method
In this section we present the bilateration method for WSN localization which can be used as the initialization step for iterative localization schemes. This algorithm avoids iterative procedures, gradient calculations, and matrix operations that increase the internal processing in a constrained device. This research was done independently of the work presented in [36]. Even though both schemes share the same idea (i.e., bilateration), the procedure and the scope of both works are different as shown in Subsection 4.1. We show that it is possible to obtain a position estimate by solving a set of bilateration problems between a sensor node and its neighboring anchors, and then fusing the solutions according to the geometrical relationships among the nodes. Our aim is to find a scheme that can be deployed on a computationally constrained node. We argue that bilateration is an attractive option as the localization problem is divided on smaller sub-problems which can be efficiently solved on a mote. Next we start our development by introducing the typical assumptions and definitions considered in a WSN localization problem.
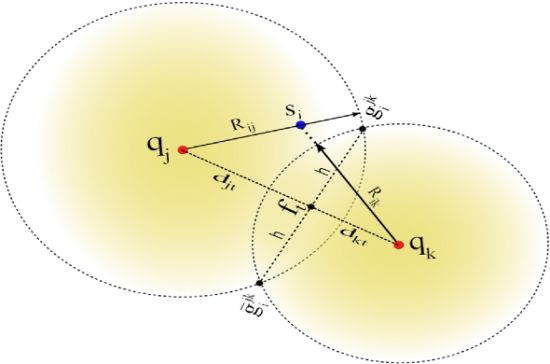
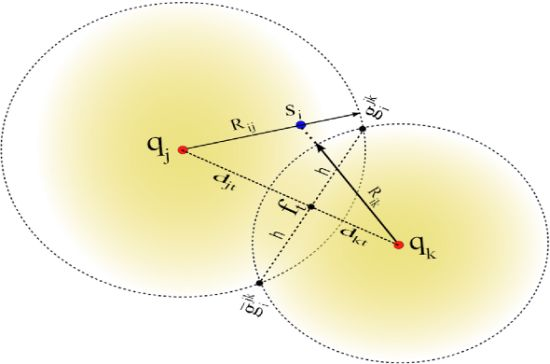
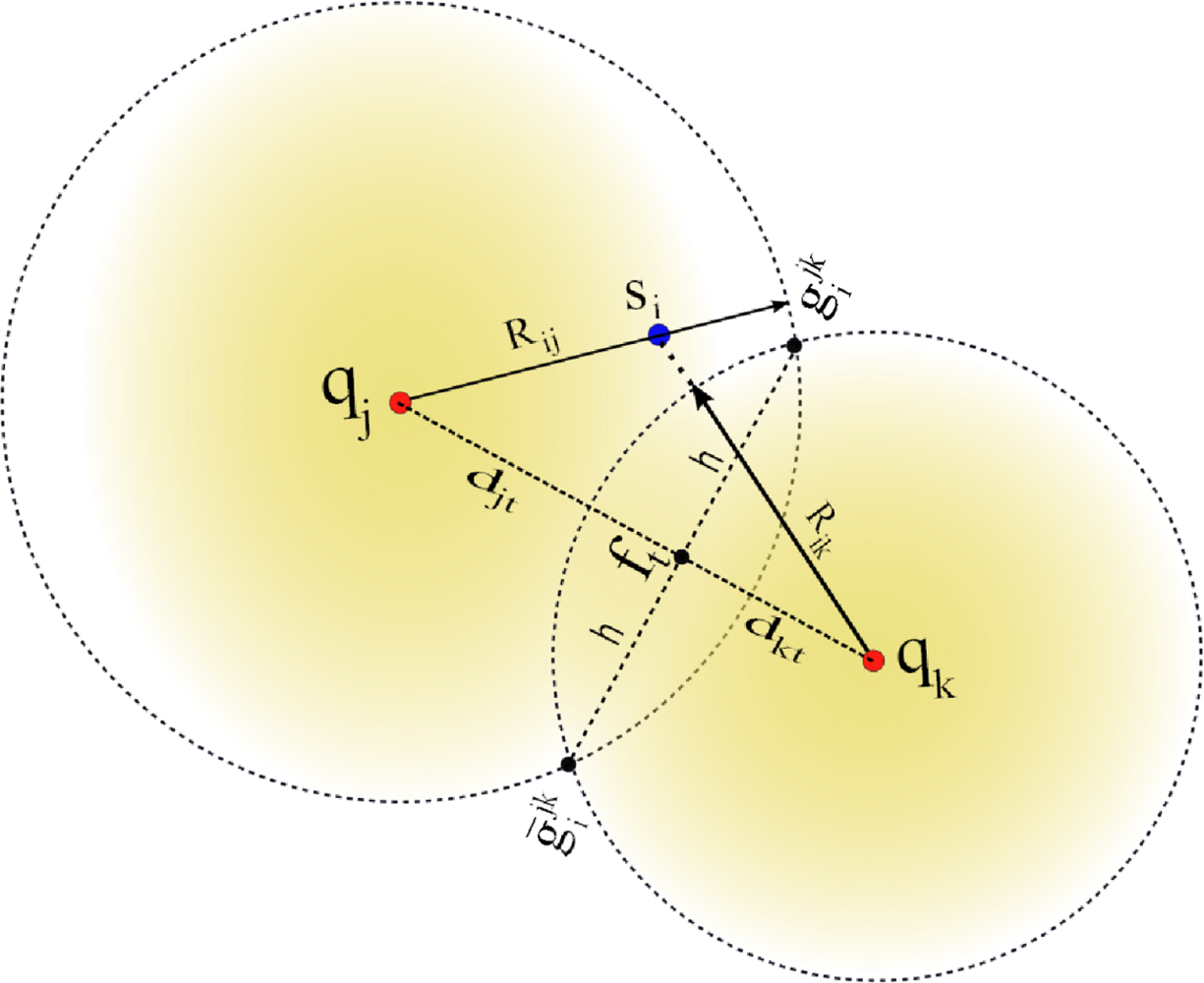
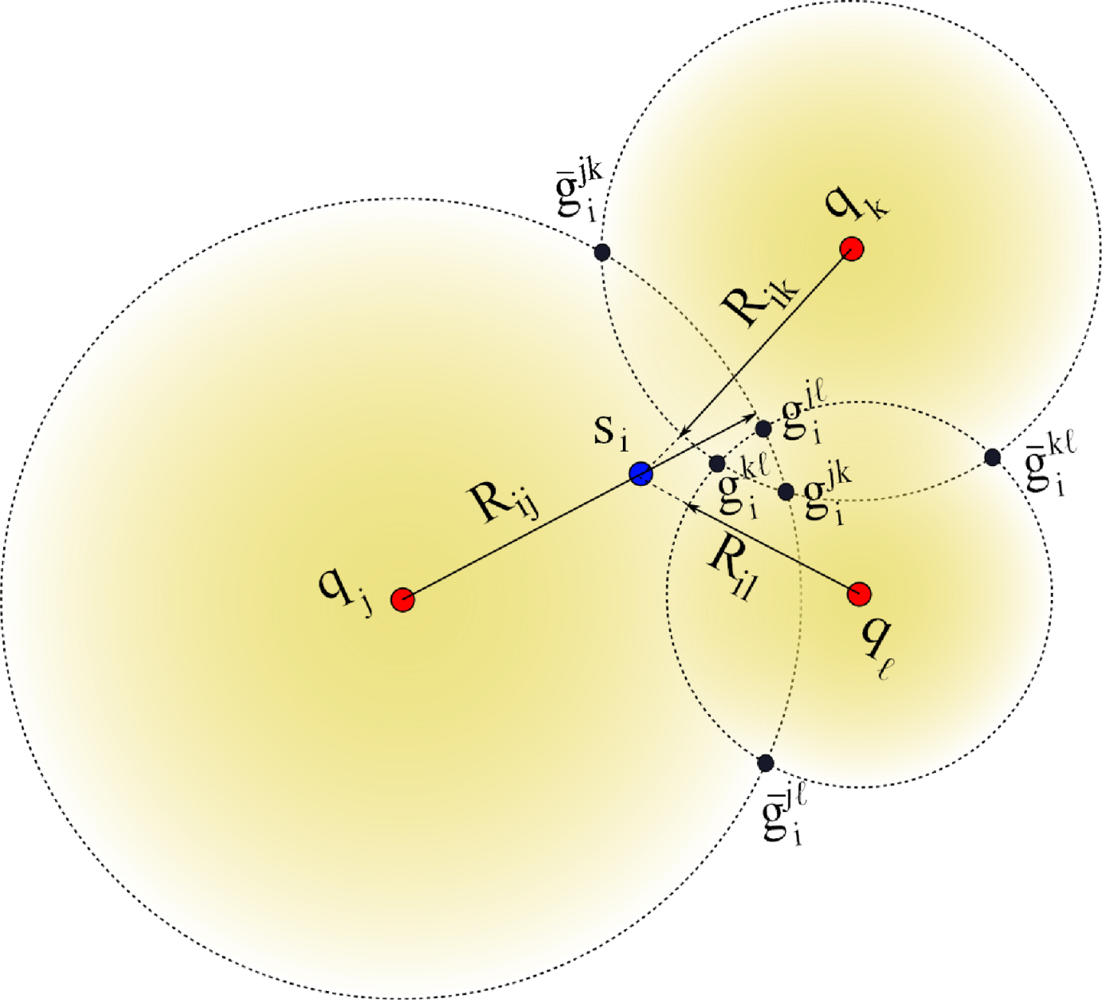
Let us define anchor subsets Ajk ⊂ A such that Ajk = {aj, ak} with j ≠ k. Hence, there is a total of anchor subsets. Without loss of generality, consider the case for one node si that receives from a subset Ajk the anchor positions qj and qk, and computes the respective ranges Rij and Rik using RSS or ToA measurements. A possible geometrical scenario for this configuration is shown in Figure 1. We can appreciate from this example that the range estimates Rij is larger than dij and Rik is shorter than dik. Now, consider the two range circles shown in the figure; one with its origin at qj and radius Rij, and the second with center in qk and radius Rik. Next, define the two circle intersection points as and , where is the reflection of with respect to the (imaginary) line that connects qj and qk. In this case, the superscript jk represents the anchor subset Ajk. To simplify our discussion, we drop the superscripts, and only use them when more than one anchor subset is involved in our discussion.
In our approach, node si determines the circle-circle intersections (CCI) gi and ḡi by solving the closed-form expression reported in [37]. For instance, consider the two right triangles formed by the coordinates (qj,gi,ft) and (qk,gi, ft) in Figure 1, which satisfy the following relationships:
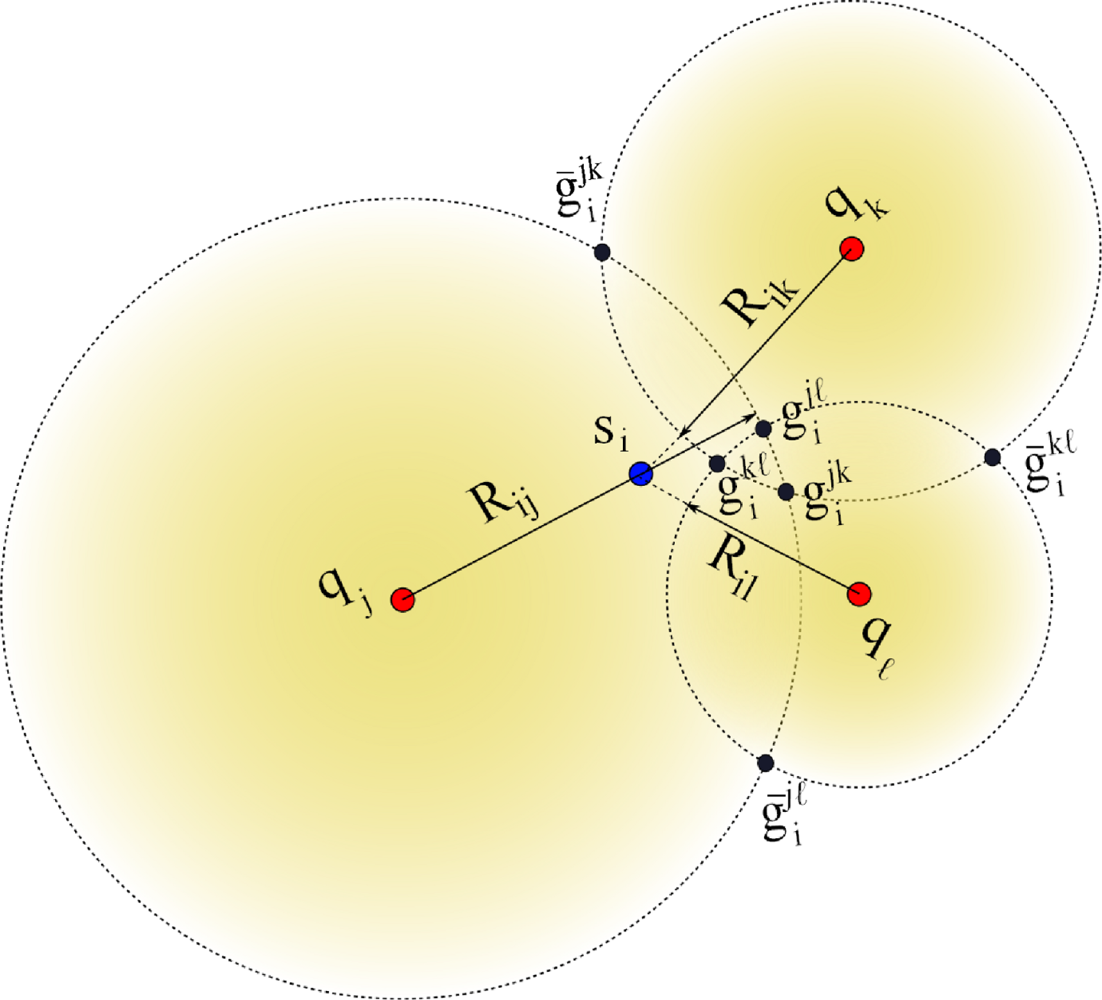
Each node si applies the CCI procedure using all Q subsets Ajk. For instance, and are obtained from the subset Ajk, and are obtained from the subset Ajℓ, and so on. Hence, a sensor node will have 2Q possible initial position estimates where half are considered mirror solutions which should be eliminated through the selection process described next. Geometrically, we expect that the true location will be located around the region where solutions form a cluster (i.e., half of the circle intersections should ideally intersect at the solution). Let us to consider the example shown in Figure 2.
There are three anchors named aj, ak and aℓ and a node si that needs to be localized. The range estimate Rij is larger than dij, the range estimate Rik is shorter than dik, and the range estimate Riℓ is shorter than diℓ. Hence, si computes a set of of six location candidates given by . As seen in the figure, all the mirror circle intersection estimates will tend to be isolated while the correct circle intersections will tend to cluster around the node location. For example, to decide between and candidate positions, generated using the anchors (aj, ak), the sensor si obtains the minimum Square Euclidean sum from the location to each pair of candidate positions as follows:
On the other hand, the sensor si also obtains the minimum Square Euclidean sum from the location to each pair of candidate positions as follows:
Finally, the lowest value of ψ and φ helps to decide between choosing or . The process is repeated for all Q solution pairs to generate a set of disambiguated locations.
| Require: qk, Rik, with {k ← 1, …, M}, and |
| Ensure: |
| 1: Initialize: T ← [0,0]T |
| 2: for each subset two-anchor subsets do |
| 3: ψ ← 0 |
| 4: φ ← 0 |
| 5: ← CCI (qj, qk, Rij, Rik) {Return the two circle intersections} |
| 6: for each subset two-anchor subsets do |
| 7: ← CCI (qℓ, qm, Riℓ, Rim) {Return the two circle intersections} |
| 8: |
| 9: |
| 10: ψ ← ψ+min (v1,v2) {Return the minimum between v1 and v2} |
| 11: |
| 12: |
| 13: φ ← φ+min (w1,w2) {Return the minimum between w1 and w2} |
| 14: end for |
| 15: if (ψ < φ) then |
| 16: |
| 17: else |
| 18: |
| 19: end if |
| 20: end for |
| 21: |
1The algorithm omits the special cases where there are no circle intersections. The procedure for these instances is described further in the text.
Referring to our example, once node si removes the mirror locations, then an estimate of the node position can be formed by taking the average of the disambiguated set .
The complete bilateration scheme is described in Algorithm 2. This is a distributed localization algorithm in the sense that each node can implement it and determine its position estimate, given the anchor positions and the range estimates Rij between each node and all the anchors. Since Algorithm 2 uses only anchor measurement, it can be used as an initialization step to generate a set of position estimates that can be used with algorithms that integrate more information from anchor and non-anchor nodes (i.e., iterative distributed algorithms).
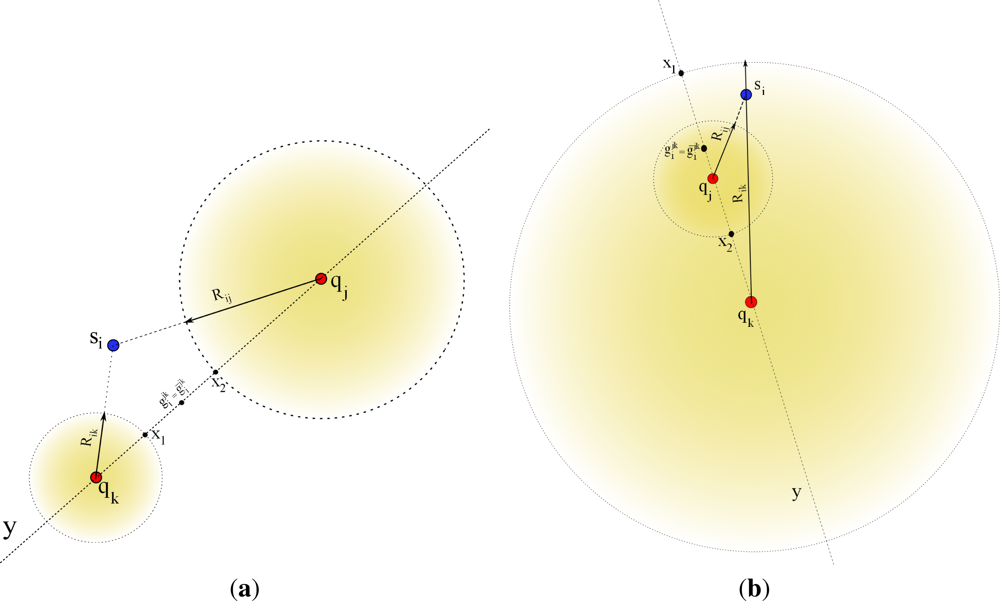
There are some anomalous cases which should be considered in the bilateration algorithm. In order to get its initial estimation , it is essential that every sensor si gets the two location estimations from each one of the Q subsets even if the solutions are not feasible. For example, assume the two special cases shown in Figure 3. If we consider the left-side case on the figure, Rik is shorter than dik, and Rij is shorter than dij, clearly the triangle inequalities are not satisfied since
4.1. Comparison with the Previous Bilateration Scheme
As described before, the research reported in [36] is focused on a distributed bilateration scheme that finds initial estimates. Using two anchors at a time, each sensor node si finds two possible candidates (i.e., circle intersections). If sufficient anchors are available, the sensor node si averages the cloud of candidates which tend to be close to each other. The average of such candidates provides the initial estimate.
As can be seen the general idea for this approach is quite similar to our bilateration approach. However, there are relevant differences between the two schemes that should be taken into account. These differences make that our bilateration approach be an alternative for the scheme proposed in [36]. For example, one of the differences is that [36] does not take into account special cases when a sensor si is not able to compute circle intersections of two anchors (i.e., the circles are not in touch) as shown Figure 3. Therefore, under this perspective this scheme is limited to naive scenarios in which estimated distances between sensors and anchors should have good accuracy. Thus, noisy RSS measurements, commonly used in realistic scenarios, may not provide useful information for this scheme. Hence, if a sensor si is not able to find sufficient circle intersections from two neighboring pair of anchors at time, the localization process will fail. In our case, the bilateration scheme is able to obtain initial estimates under the most severe scenarios (i.e., not circle intersections).
Another important aspect to consider in [36], is the use of a threshold, δ, which reduces the number of possible candidate positions, making this approach more selective. However, the value of δ is hard to determine in practice and also it does not guarantee good results in noisy environments. Additionally, in [36] each sensor node si should create a table of its neighboring anchors. All anchors have a specific position inside of the table, and they are weighted by the sensor si according to the candidate positions that they generate. The value of δ is used to select a certain group of candidate positions. The anchors are weighted according to the candidates that they generated. Finally, all tables are broadcast by sensors. Once all sensors have received the anchor tables of their neighbors, they run a post-processing stage to determine which anchors are more reliable than others. These anchors are used to obtain initial estimates. As can be seen, the drawback of this approach are extra wireless transmissions required to share anchor tables among sensors. In our case we present an extension of the earlier BL algorithm which avoids any kind of wireless transmission with the goal to save energy. Finally, we should remark that we are using a sorting algorithm (lines 10,13, and 15–18 of the Algorithm 2) to determine initial positions. Analysis results shown in next section demonstrate that the alternative BL algorithm is competitive in comparison with well known accurate and efficient algorithms based on least-squares methodologies.
5. Accuracy Performance Between Closed-Formulas and Iterative Procedures in the WSN Localization Problem
In this section we analyze the accuracy performance of both methodologies, optimized and closed-formula schemes. Even though the strength of a closed-formula for solving the WSN localization problem is its low complexity compared with an iterative algorithm, closed-formulas can present large errors in the presence of inaccurate ranging measurements. However, in many cases it is desirable to sacrifice accuracy to save energy (i.e., increase battery lifetime). On the other hand, the weakness for closed-form methods (i.e., noise sensitivity) represents the strong point for iterative methods and vice versa. The goal of both methodologies seems to be in opposite directions. However, the main effort in WSN localization research is focused on developing an strategy that can join the strength of both methodologies to create an efficient algorithm that can save energy providing the best accuracy in the estimated positions.
Next we present an evaluation of accuracy between closed-formulas and iterative methodologies. For the former methods we are considering the classical LS Multilateration, the Min-max method (The Min-max approach is based on the intersection of rectangles instead of circle intersections. It provides a more simple technique than lateration schemes to obtain position estimates at the expenses of accuracy) [38,39], and the bilateration algorithm. For iterative methodologies we are considering two algorithms to solve the NLLS: the LM and the TRR algorithms.
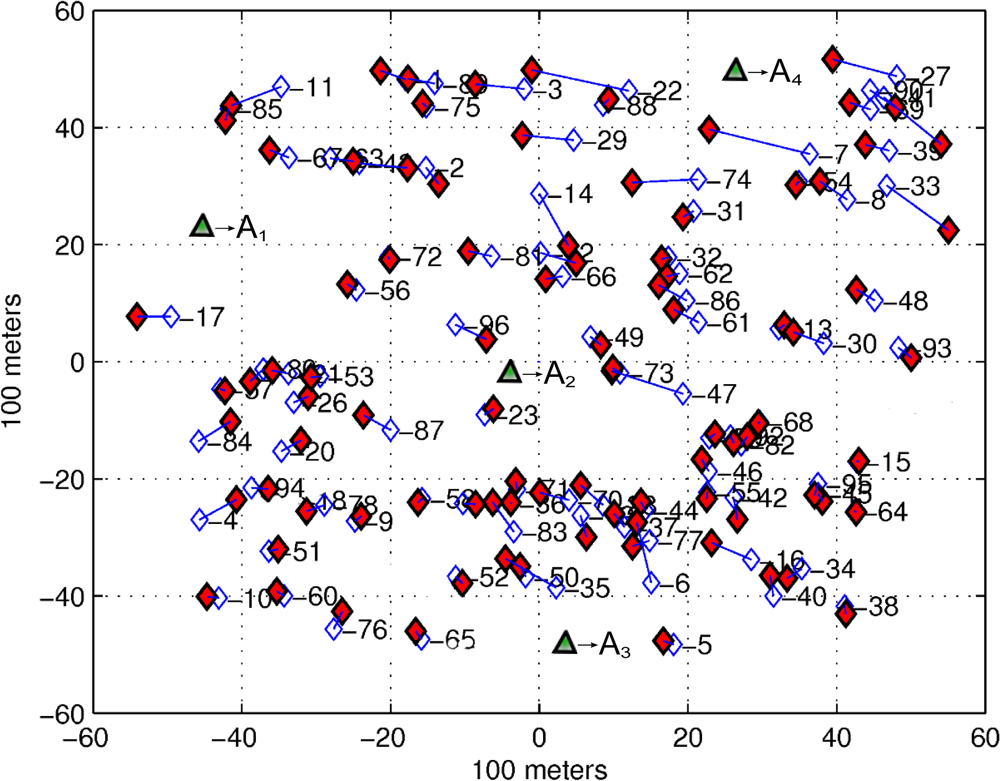
For the simulations that follow, we consider 20 different sensor networks where each one is composed by N = 96 unknown sensors, randomly distributed over 100 m by 100 m area. Also, we add M = 4 non-collinear anchors with full-connectivity on every realization as shown in Figure 4.
For each network, we add noise to the true distances between anchors and nodes using the log-distance path loss model described in Equation (4). The estimated distances are simulated using σSH = 6dB and ηP = 2.6, typical parameters for the propagation models on outdoors scenarios, and P0 = −52dB is selected according to current commercial specifications for wireless motes [40]. Finally, we assume that all nodes have the sensitivity to detect any RF signal coming from anchors.
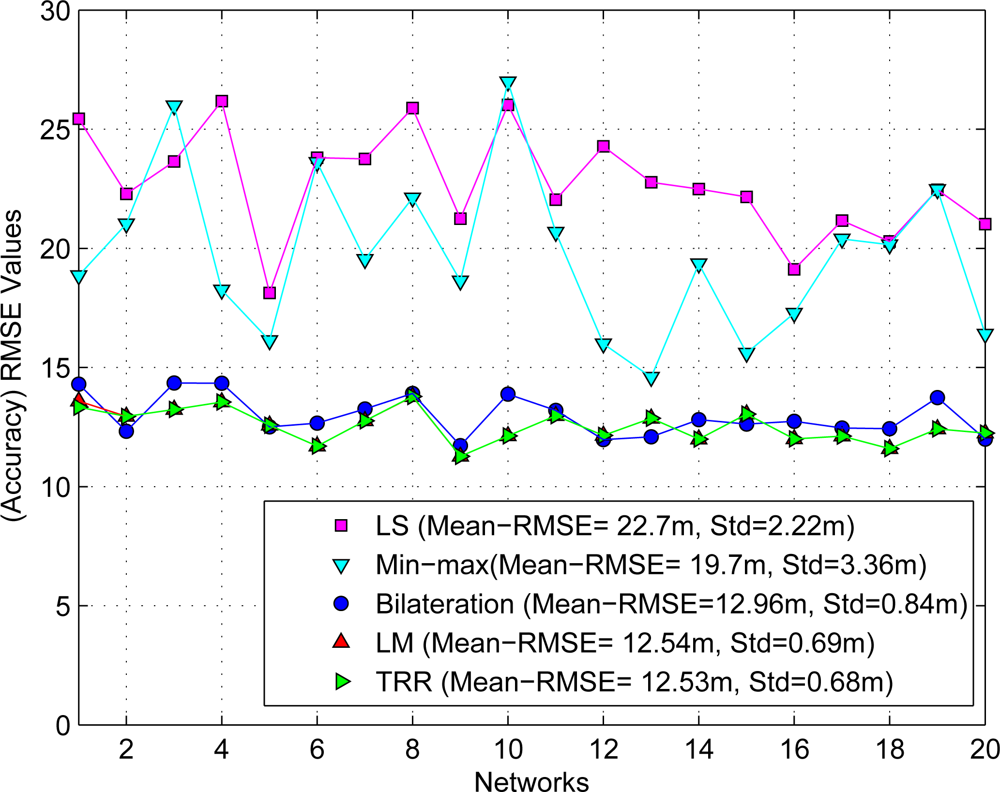
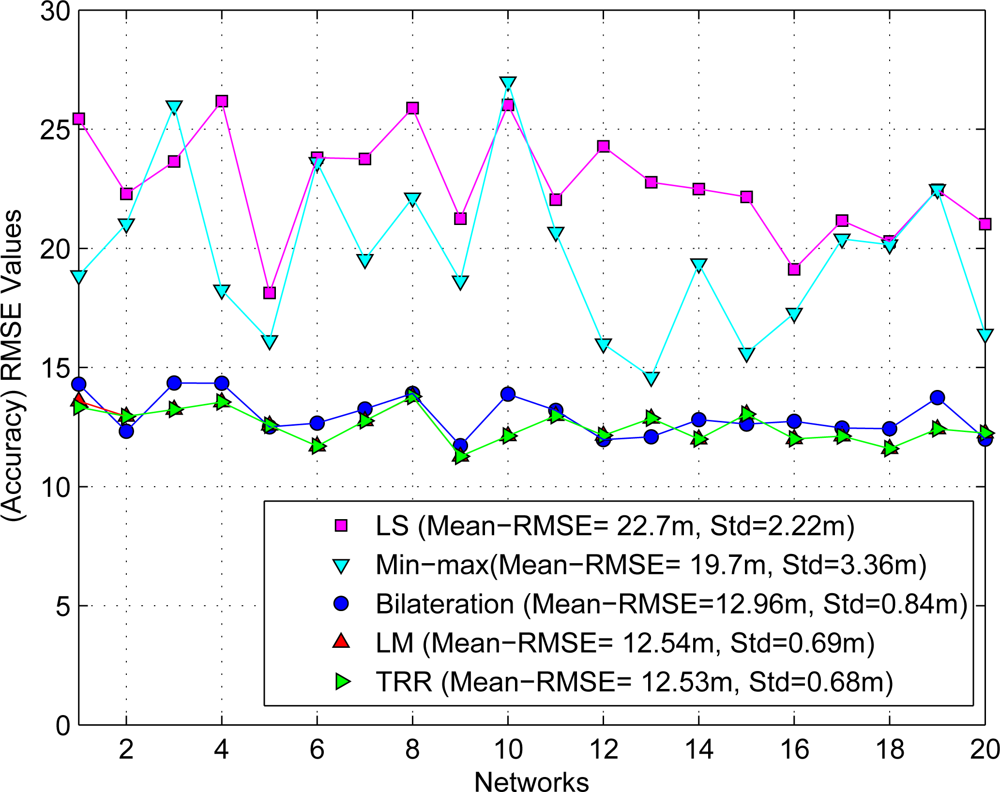
To compare the accuracy performance between both methodologies it was necessary to use the same set of range measurements for each closed-form method and iterative algorithm. Figure 5 summarizes the initial estimates obtained by both methodologies using the RMSE metric as shown the next equation:
As can be seen, the closed-form LS approach provides the least accurate initial estimates (mean = 22.7 m and standard deviation = 2.22 m) compared with iterative algorithms as expected due to the noisy ranging measurements. In a similar way, the Min-max scheme also provides large errors (mean = 19.7 m and standard deviation = 3.36 m). On the other hand, we can appreciate that both iterative algorithms, the LM and the TRR, provide practically the best and similar results for initial estimates (mean = 12.54 m and standard deviation = 0.69 m) as expected, and finally the bilateration algorithm presents very acceptable initial estimates compared with the last two algorithms (mean = 12.96 m and standard deviation = 0.84 m). However, we should consider that the computational complexity for the LM and the TRR algorithms is significantly larger than the bilateration algorithm. This discussion will be expanded in the next section.
Also, we tested the SX, SI and GSLS algorithms [25] using the same set of networks. The estimated positions presented large errors under this scheme as indicated by [26]. Then, these results were disregarded in our analysis.
6. Computational Complexity Analysis between the Bilateration and the LM Algorithm
The efficiency of an algorithm can be described in terms of the time or space complexity [41]. Time complexity refers to the relation between the number of required computations for a given input. The space used for a given input provides the space complexity of an algorithm. The computational complexity of an algorithm could be described as the number of operations that it takes to find a solution [42].
In this section we provide an operation count on the number of additions (ADDs), multipliers (MULs), divides (DIVs), and square roots (SQRTs) exactly in the way that DSP algorithms are described [43]. This will allow an “apple-to-apple” comparison. Moreover, an accurate description lends itself to a cycle accurate description for any microprocessor and more significantly, the use of energy models based on computing cycles to estimate the energy consumption for a given algorithm. An energy analysis will be a discussion of a future work. In next subsections we present the computational complexity analysis for the iterative LS and the bilateration algorithm.
6.1. Computational Analysis of the LM Algorithm
The LM algorithm could be considered as too expensive for motes given its iterative nature and the need to estimate first and second order information (i.e., gradients, Jacobians, and Hessians). The number of iterations K is highly dependent on the initial point x0 and could be considered a random variable. On the other hand, if a good initial estimate, x0, is provided, then the number of iterations is expected to be low given the convergence properties of LM.
We are interested in providing an algorithmic analysis that provides a detailed description in terms of additions and subtractions (jointly referred as ADDs), multiplications (MULs), divisions (DIVs), and square roots (SQRTs). For simplicity in the next paragraphs we let Jk ≡ J(xk) and Rk ≡ R(xk).
The square root is a relevant operation as the error function Rk and the Jacobian estimate requires ℓ2 norms to compute distances between sensor and anchors. We also note that the complexity of the operations is not the same in terms of the processing resources (hardware and software) they take. Abusing notation we have
This analysis also focuses on the most efficient implementation in terms of the proper operation sequencing in order to favor reuse of terms (i.e., avoid computing the same quantity twice).
We perform the analysis for a single iteration of the LM algorithm, and the total cost for each operation is multiplied by K. We also note that K can be modeled as a random variable; the usefulness of this approach is discussed later. We assume there are M anchors which have broadcast their position to all the nodes. Each node will run the LM algorithm to find its initial position as described in Subsection 3.2. We identify three core operations: ℓ2 or Euclidean norm, the error vector Rk and an estimate of Jk.
The ℓ2 norm will be used to compute the magnitude of the difference between two vectors a, b ∈ ℝ2 given by . This requires three ADDS, two MULs and one SQRT. The norm is used to compute Rk given in Equation (18) and to estimate the Jacobian as follows:
For Rk we see that we require M ADDs and M ℓ2-norms. Accounting for the norms, the error function requires 4M ADDs, 2M MULs, and M SQRTs. These numbers are recorder in Table 1. A similar analysis follows for Jk. A direct look at Equation (34) indicates that we have the same norm across rows, so we can compute them first and then we would need an additional 2M ADDs and 2M DIVs. However, a better approach would be to compute the terms 1/‖xj − xk‖ first so that we would require M DIVs, 2M MULs, and 2M ADDs. We exchange M DIVs by 2M MULs under the typical case that MULs have a much lower complexity than DIVs, particularly for the case of floating point operations. The complexity for the Jacobian estimate is also shown on Table 1.
Once these two quantities have been evaluated, their use trickles down through the algorithm. The costs for the different steps or operations is presented in the remaining part of Table 1. We just make two more remarks on the algorithm complexity. First, note that the approximation to the Hessian matrix
Second, satisfying the sufficient decrease condition is also an iterative procedure where different values of αk are tested. We identify T as the number of iterations needed to satisfy this condition. As we discuss later, we will model T as a random variable.
The last row of the table provides the total which we identify as TADD, TMUL, TDIV and TSQRT respectively. These numbers are the operations for a single iteration of the LM algorithm. Then, for K iterations we have the total number of operations to be KADD = K · TADD, KMUL = K · TMUL, KDIV = K · TDIV, and KSQRT = K · TSQRT .
Since the values of T and K are random variables, then a more convenient approach to quantify the number of operations would be to look at the average number of operations, i.e., the expected value. It is intuitive to assume that T and K are independent, and that for a given network their distributions will be identical. Hence, we define
6.2. Computational Analysis of the Bilateration Algorithm
The bilateration algorithm is very simple and non-iterative. For M anchors, a sensor node picks pairs of sensors and computes the intersections of the imaginary circles around each anchor with a radius given between the anchor and the sensor node. These intersections are computed using geometry with a procedure described by Equations (24–28). Then, a cluster with half of the computed intersections is found, providing an indication of the area where the node position is located. The number of operations required to compute two intersections is presented in Table 2.
Since this process is repeated times, then the final row reflects the total operations multiplied by this factor. As the intersections are computed, the search for the cluster is performed by Equations (29) and (30). Since there are 2Q intersections, we need to select the Q that cluster together (i.e., eliminate mirrors). The clustering is based on looking at the distance between all possible pairs of intersections and selecting those that exhibit the closets distances among themselves. This requires the calculation of squared norms, and the use of a clustering or sorting algorithm to find the smallest Q elements from the list of S norm values. Taking advantage of the structure of the location points (i.e., the two intersections from the same anchor pair are not compared), we can expect an average complexity of O(S) sorting steps using an algorithm like Quickselect algorithm [45]. Hence the final computational cost for the bilateration algorithm is presented in Table 3.
As with the LM algorithm, we close this subsection by providing an expression in terms of processor cycles. Using the same characterization for all main operations of the algorithm, we can provide a total cycle count that can be directly compared with other algorithms. Obviously, a lower cycle implies lower complexity when the hardware and software development tools are identical. The expression for total cycles is
It is easy to see that the bilateration scheme uses a significantly less number of cycle for all operations. Experimental data in [45] indicates that the cycle count for the complete sorting step with the QuickSelect algorithm with a pipelined architecture can be achieved within 2500 and 3000 clock cycles.
To complete the computational complexity analysis, we need the number of CPU cycles required for the four basic operations as floating point operations. These values are highly dependent on the architecture of the mote processor. An extensive study in [46] provides good representative values for processors with some level of hardware support. The values are summarized on Table 4, and it shows the relation between basic operations and CPU cycles.
Next, we use Tables 1 and 2 to obtain the number of CPU cycles required by each initialization stage, BL and LM respectively. For the LM initialization stage we are using M = 4 anchors and the random variables T and k. We recall that k is the number of iterations spent by the LM algorithm to find a solution. These values are obtained through simulations where ε{T} = 2 and ε{k} = 13. In this way the total cycles required by the LM algorithm according to Equation (42) is given by
Similarly, the total number of cycles used by the BL stage is given by Equation (43) as
7. Conclusions
In this research, we analyzed a localization algorithm that can be realistically deployed over real WSNs which can provide good accuracy performance with low computational complexity. The bilateration algorithm is a distributed scheme that can be used as an initialization stage to find an initial set of locations.
Most initialization algorithms demand very high computing power to provide a set of initial estimates for an N-node WSN. The analyzed algorithm is capable to provide competitive initial estimates at low processing power. This approach is basically formed by two stages. The first stage consists of finding all circle intersections formed by anchor positions and their respective range estimates to a sensor node, obtained by ranging techniques like ToA or RSS. The great advantage of this approach is to use “closed-formulas” to find all circle intersections (i.e., candidate positions) using two anchors at a time. In the second stage, the algorithm uses a sorting algorithm to find the cluster of candidate positions that tend to be closer to each other around the true location. The cluster with the nearby candidate positions is averaged to finally obtain the initial location. This scheme can be used by any WSN localization algorithm that needs initial approximations. Also, it is implementable in constrained devices with low processing and memory capabilities (i.e., motes). Results show that this initialization algorithm is well behaved (e.g., computational and accuracy performance) in comparison with other well known algorithms like LS methodologies.
Finally, we are interested in exploring iteratively, at the refinement process, the Levenberg–Marquardt approach for node localization. We believe that this methodology can play a crucial role in producing excellent position estimates with high accuracy and low energy consumption due to the rate of convergence associated with this optimization technique.
Acknowledgments
The authors wish to express their gratitude to the anonymous reviewers for their invaluable comments.
References
- Zhong, Z.; Wang, D.; He, T. Sensor Node Localization Using Uncontrolled Events. Proceedings of the 28th International Conference on Distributed Computing Systems (ICDCS ’08), Beijing, China, 17–20 June 2008; pp. 438–445.
- Youssef, A.; Youssef, M. A Taxonomy of Localization Schemes for Wireless Sensor Networks. Proceedings of the International Conference on Wireless Networks, Las Vegas, NV, USA, 25–28 June 2007.
- Chan, F.; So, H. Accurate distributed range-based positioning algorithm for wireless sensor networks. IEEE Trans. Signal Process 2009, 57, 4100–4105. [Google Scholar]
- Niculescu, D.; Nath, B. DV based positioning in ad hoc networks. Telecommun. Syst 2003, 22, 267–280. [Google Scholar]
- He, T.; Huang, C.; Blum, B.; Stankovic, J.; Abdelzaher, T. Range-free localization and its impact on large scale sensor networks. ACM Trans. Embed. Comput. Syst 2005, 4, 877–906. [Google Scholar]
- Stoleru, R.; Stankovic, J. Probability Grid: A Location Estimation Scheme for Wireless Sensor Networks. Proceedings of the 2004 1st Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks (IEEE SECON ’04), Santa Clara, CA, USA, 4–7 October 2004; pp. 430–438.
- Goldenberg, D.; Bihler, P.; Cao, M.; Fang, J.; Anderson, B.; Morse, A.; Yang, Y. Localization in Sparse Networks Using Sweeps. Proceedings of the 12th Annual International Conference on Mobile Computing and Networking, Los Angeles, CA, USA, 24–29 September 2006; pp. 110–121.
- Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag 2002, 40, 102–114. [Google Scholar]
- Gezici, S. A survey on wireless position estimation. Wirel. Pers. Commun 2008, 44, 263–282. [Google Scholar]
- Li, M.; Liu, Y. Rendered path: Range-free localization in anisotropic sensor networks with holes. IEEE/ACM Trans. Netw 2010, 18, 320–332. [Google Scholar]
- Jordt, G.; Baldwin, R.; Raquet, J.; Mullins, B. Energy cost and error performance of range-aware, anchor-free localization algorithms. Ad Hoc Netw 2008, 6, 539–559. [Google Scholar]
- Mao, G.; Fidan, B.; Anderson, B. Wireless sensor network localization techniques. Comput. Netw 2007, 51, 2529–2553. [Google Scholar]
- Stoleru, R.; He, T.; Stankovic, J. Range-Free Localization. In Secure Localization and Time Synchronization for Wireless Sensor and Ad Hoc Networks; Springer: Berlin, Germany, 2007; pp. 3–31. [Google Scholar]
- Yu, K.; Guo, Y. Robust Localization in Multihop Wireless Sensor Networks. Proceedings of the Vehicular Technology Conference (VTC Spring 2008), Singapore, 11–14 May 2008; pp. 2819–2823.
- Moses, R.; Krishnamurthy, D.; Patterson, R. A self-localization method for wireless sensor networks. EURASIP J. Appl. Signal Process 2003, 4, 348–358. [Google Scholar]
- Doherty, L.; El Ghaoui, L. Convex Position Estimation in Wireless Sensor Networks. Proceedings of the 20th Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM ’01), Anchorage, AK, USA, 22–26 April 2001; 3, pp. 1655–1663.
- Chan, F.; So, H. Efficient weighted multidimensional scaling for wireless sensor network localization. IEEE Trans. Signal Process 2009, 57, 4548–4553. [Google Scholar]
- Weng, Y.; Xiao, W.; Xie, L. Diffusion-based em algorithm for distributed estimation of gaussian mixtures in wireless sensor networks. Sensors 2011, 11, 6297–6316. [Google Scholar]
- Liu, J.; Zhang, Y.; Zhao, F. Robust Distributed Node Localization with Error Management. Proceedings of the 7th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Florence, Italy, 22–25 May 2006; pp. 250–261.
- TarrÃo, P.; Bernardos, A.M.; Casar, J.R. Weighted least squares techniques for improved received signal strength based localization. Sensors 2011, 11, 8569–8592. [Google Scholar]
- Yang, Z.; Liu, Y. Quality of trilateration: Confidence-based iterative localization. IEEE Trans. Parallel Distrib. Syst 2009, 21, 631–640. [Google Scholar]
- Patwari, N.; Ash, J.; Kyperountas, S.; Hero, A.; Moses, R.; Correal, N. Locating the nodes. IEEE Signal Process. Mag 2005, 22, 54–69. [Google Scholar]
- Andersen, J.; Rappaport, T.; Yoshida, S. Propagation measurements and models for wireless communications channels. IEEE Commun. Mag 1995, 33, 42–49. [Google Scholar]
- Rappaport, T.S. Wireless Communications: Principles and Practice; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1996; Volume 207. [Google Scholar]
- Huang, Y.; Benesty, J.; Chen, J. Acoustic MIMO Signal Processing; Springer: Berlin, Germany, 2006. [Google Scholar]
- Huang, Y.; Benesty, J.; Elko, G.; Mersereati, R. Real-time passive source localization: A practical linear-correction least-squares approach. IEEE Trans. Speech Audio Process 2002, 9, 943–956. [Google Scholar]
- Chen, H.; Sezaki, K.; Deng, P.; So, H. An Improved DV-Hop Localization Algorithm for Wireless Sensor Networks. Proceedings of the 3rd IEEE Conference on Industrial Electronics and Applications (ICIEA ’08), Singapore, 3–5 June 2008; pp. 1557–1561.
- Verdone, R.; Dardari, D.; Mazzini, G.; Conti, A. Wireless Sensor and Actuator Networks: Technologies, Analysis and Design; Elsevier: Amsterdam, The Netherlands, 2008; p. 211. [Google Scholar]
- Dennis, J.; Schnabel, R. Numerical Methods for Unconstrained Optimization and Nonlinear Equations; Society for Industrial Mathematics: Englewood Cliffs, NJ, USA, 1996; p. 227. [Google Scholar]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: Berlin, Germany, 2006; p. 8. [Google Scholar]
- Cheng, B.; Vandenberghe, L.; Yao, K. Distributed algorithm for node localization in wireless ad-hoc networks. ACM Trans. Sens. Netw 2009, 6, 1–20. [Google Scholar]
- Costa, J.A.; Patwari, N.; Hero, A.O., III. Distributed weighted-multidimensional scaling for node localization in sensor networks. ACM Trans. Sensor Netw 2006, 2, 39–64. [Google Scholar]
- Delbos, F.; Gilbert, J.; Glowinski, R.; Sinoquet, D. Constrained optimization in seismic reflection tomography: A Gauss–Newton augmented Lagrangian approach. Geophys. J. Int 2006, 164, 670–684. [Google Scholar]
- Roweis, S. Levenberg-Marquardt Optimization; University Of Toronto: Toronto, ON, Canada, 1996. [Google Scholar]
- Ye, N. The Handbook of Data Mining; Lawrence Erlbaum: Mahwah, NJ, USA, 2003. [Google Scholar]
- Li, X.; Hua, B.; Shang, Y.; Xiong, Y. A robust localization algorithm in wireless sensor networks. Front. Comput. Sci. China 2008, 2, 438–450. [Google Scholar]
- Bourke, P. Intersection of Two Circles, 1997. Available online: http://local.wasp.uwa.edu.au/~pbourke/geometry/2circle/ (accessed on 9 January 2010).
- Savvides, A.; Park, H.; Srivastava, M. The Bits and Flops of the N-Hop Multilateration Primitive for Node Localization Problems. Proceedings of the 1st ACM International Workshop on Wireless Sensor Networks and Applications, Atlanta, GA, USA, 28 September 2002; pp. 112–121.
- Langendoen, K.; Reijers, N. Distributed localization in wireless sensor networks: A quantitative comparison. Comput. Netw 2003, 43, 499–518. [Google Scholar]
- XST-AN019a, A.N. XBee and XBee-PRO OEM RF Module Antenna Considerations, 2005.Available online: http://www.digi.com (accessed on 9 January 2010).
- Cormen, T. Introduction to Algorithms; The MIT Press: Cambridge, MA, USA, 2001; p. 23. [Google Scholar]
- Schörghofer, N. The Third Branch of Physics: Essays in Scientific Computing; Nobert: Hamburg, Germany, 2005; pp. 53–71. [Google Scholar]
- Wang, A.; Chandrakasan, A. Energy-efficient DSPs for wireless sensor networks. IEEE Signal Process. Mag 2002, 19, 68–78. [Google Scholar]
- Sinha, A.; Chandrakasan, A. Energy Aware Software. Proceedings of the 13th International Conference on VLSI Design, Calcutta, India, 3–7 January 2000; pp. 50–55.
- TI-Algorithms. Optimized Sort Algorithms for DSP, 2011. Available online: http://processors.wiki.ti.com/index.php/Optimized_Sort_Algorithms_For_DSP (accessed on 9 January 2012).
- Dietz, H.; Dieter, B.; Fisher, R.; Chang, K. Floating-Point Computation with Just Enough Accuracy. Proceedings of the Computational Science (ICCS ’06), Reading, UK, 28–31 May 2006; pp. 226–233.
- Mansi, R. Enhanced quicksort algorithm. Int. Arab J. Inform. Technol 2010, 7, 161–166. [Google Scholar]



| Title | ADD | MUL | DIV | SQRT |
|---|---|---|---|---|
| Rk | 4M | 2M | 0 | M |
| Jk | 5M | 4M | M | M |
| Hk | 3M − 3 | 3M | 0 | 0 |
| M′f | 2M−2 | 2M | 0 | 0 |
| Mf | M−1 | M + 1 | 0 | 0 |
| μk | 3 | 3 | 0 | 1 |
| 3 | 6 | 1 | 0 | |
| ΔLM | 2 | 4 | 0 | 0 |
| Sufficient Decrease | T (M + 4) | T (M + 2) | 0 | 0 |
| Update | 2 | 2 | 0 | 2 |
| Stopping Condition | 3 | 2 | 0 | 1 |
| Total | (M + 4)T + 15M + 7 | (M + 2)T + 12M + 18 | M + 1 | 2M + 4 |
| Operations | ADD | MUL | DIV | SQRT |
|---|---|---|---|---|
| d | 3 | 2 | 0 | 1 |
| djt | 1 | 5 | 1 | 0 |
| h | 1 | 1 | 0 | 1 |
| 0 | 0 | 1 | 0 | |
| ft | 2 | 2 | 1 | 0 |
| xi | 1 | 1 | 0 | 0 |
| x̄i | 1 | 0 | 0 | 0 |
| yi | 1 | 1 | 0 | 0 |
| ȳi | 1 | 0 | 0 | 0 |
| Total (2 circle intersections) | 11 | 12 | 3 | 2 |
| Total Q node combinations | 11Q | 12Q | 3Q | 2Q |
| Action | ADD | MUL | DIV | SQRT | SORT |
|---|---|---|---|---|---|
| Circle Intersections | 11Q | 12Q | 3Q | 2Q | 0 |
| Squared Norms | 3S | 2S | 0 | 0 | 0 |
| Number of Comparisons | 0 | 0 | 0 | 0 | O(S) |
| ADD | MUL | DIV | SQRT |
|---|---|---|---|
| 11 | 25 | 112 | 119 |
© 2012 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Cota-Ruiz, J.; Rosiles, J.-G.; Sifuentes, E.; Rivas-Perea, P. A Low-Complexity Geometric Bilateration Method for Localization in Wireless Sensor Networks and Its Comparison with Least-Squares Methods. Sensors 2012, 12, 839-862. https://doi.org/10.3390/s120100839
Cota-Ruiz J, Rosiles J-G, Sifuentes E, Rivas-Perea P. A Low-Complexity Geometric Bilateration Method for Localization in Wireless Sensor Networks and Its Comparison with Least-Squares Methods. Sensors. 2012; 12(1):839-862. https://doi.org/10.3390/s120100839
Chicago/Turabian StyleCota-Ruiz, Juan, Jose-Gerardo Rosiles, Ernesto Sifuentes, and Pablo Rivas-Perea. 2012. "A Low-Complexity Geometric Bilateration Method for Localization in Wireless Sensor Networks and Its Comparison with Least-Squares Methods" Sensors 12, no. 1: 839-862. https://doi.org/10.3390/s120100839
APA StyleCota-Ruiz, J., Rosiles, J.-G., Sifuentes, E., & Rivas-Perea, P. (2012). A Low-Complexity Geometric Bilateration Method for Localization in Wireless Sensor Networks and Its Comparison with Least-Squares Methods. Sensors, 12(1), 839-862. https://doi.org/10.3390/s120100839