1. Introduction
The temperature in cold areas sometimes drops to below −40
C [
1]. To survive at subzero temperatures, many overwintering organisms have developed a high level of freezing tolerance to protect themselves from fatal ice crystal growth [
2]. The antifreeze effect is largely due to a family of antifreeze proteins (AFPs) that were first recognized in the Antarctic fishes by DeVries [
3] and later identified in a wide range of organisms, including bacteria [
4], fungi [
5], plants [
6] and insects [
7]. AFPs have the ability to adsorb onto the surface of ice crystals and inhibit their growth [
8], which if left uncontrolled would be fatal to cells. The interaction between AFPs and ice crystals lowers the freezing temperature of ice without significantly affecting the melting temperature, a phenomenon referred to as thermal hysteresis [
9]. Excellent progress has been made in the study of antifreeze-ice interactions. Kuiper
et al. [
10] presented a theoretical three-dimensional model of a plant antifreeze protein from Lolium perenne, which can be conducive to deciphering the underlying mechanisms of the properties of antifreeze proteins. Guz
et al. [
11] revealed the functional annotation of a putative antifreeze protein gene. However, as the details of the antifreeze effect are difficult to test experimentally, the ice-binding mechanisms of antifreeze proteins are not completely understood [
12]. Some emphasized that hydrogen bonding to ice water molecules was the major driving force of the AFP-ice association [
13,
14]. Some suggested that hydrophobic interactions could be the main contributor to the AFP-ice association [
2,
15]. Thus, accurate identification of AFPs may provide important clues to decipher the underlying mechanisms of AFPs in ice-binding. Ultimately, knowledge about the ice-binding mechanisms of antifreeze proteins may allow the design of an improved or more efficient macromolecular antifreeze.
AFPs have a wide range of applications in numerous fields due to the role of their antifreeze property in the protection of tissue or cell damage by freezing [
16]. The presence of AFPs may improve the quality of frozen foods by inhibiting recrystallization and maintaining a smooth texture [
16,
17]. There is rising evidence that AFPs have potential applications in agriculture for improving the production of crops and fishes in cooler climates [
18]. AFPs are also used to preserve cells, tissues and organs for transplant or transfusion in medicine at a low temperature [
19]. The other proposed applications of AFPs are found in cryosurgery of tumors and therapy for hypothermia [
20]. However, as indicated in [
21], the quantity of AFPs that may produce superior performance at the molecular level is insufficient for practical use. The identification of AFPs may facilitate the selection of the most appropriate AFPs for several industrial and biomedical applications.
The AFPs show great diversity in their primary sequences and structures [
8]. Distinguishing an antifreeze protein from a non-antifreeze protein has challenged the antifreeze field for some considerable time [
22]. With the avalanche of genome sequences generated in the postgenomic age, various computational methods based on sequence information have been developed for identification of AFPs. Kandaswamy
et al. [
23] proposed the first computational program called AFP-Pred for the prediction of antifreeze proteins from protein sequences. Zhao
et al. [
24] developed a different predictor named AFP-PSSM utilizing support vector machine (SVM) and position-specific scoring matrix (PSSM) profiles. Recently, according to Chou’s pseudo amino acid composition-based protein features, Mondal and Pai [
25] proposed a predictor called AFP-PseAAC (pseudo amino acid composition) to identify AFPs.
Though these methods have facilitated the identification of AFPs to some extent, some limitations should be noted. First, earlier work did not give a real solution to the class imbalance problem. The existing methods for predicting AFPs [
23,
24,
25] have tried to change the distribution of positive and negative samples by randomly selecting AFPs and non-AFPs with the same size as the training set. However, they failed to make full use of the negative sample information in the original dataset. Second, the existing methods did not take the protein sequence features directly related to the binding properties of AFPs into consideration, such as the disorder score, solvent accessible surface and functional domains. Third, the methods of feature extraction in most of the papers were based on a single technique. Multiple feature types have not been investigated simultaneously to get a more robust and discerning feature set. It is inevitable that some useful information would be missed. Therefore, further development for identifying AFPs is definitely needed for the above-mentioned limitations.
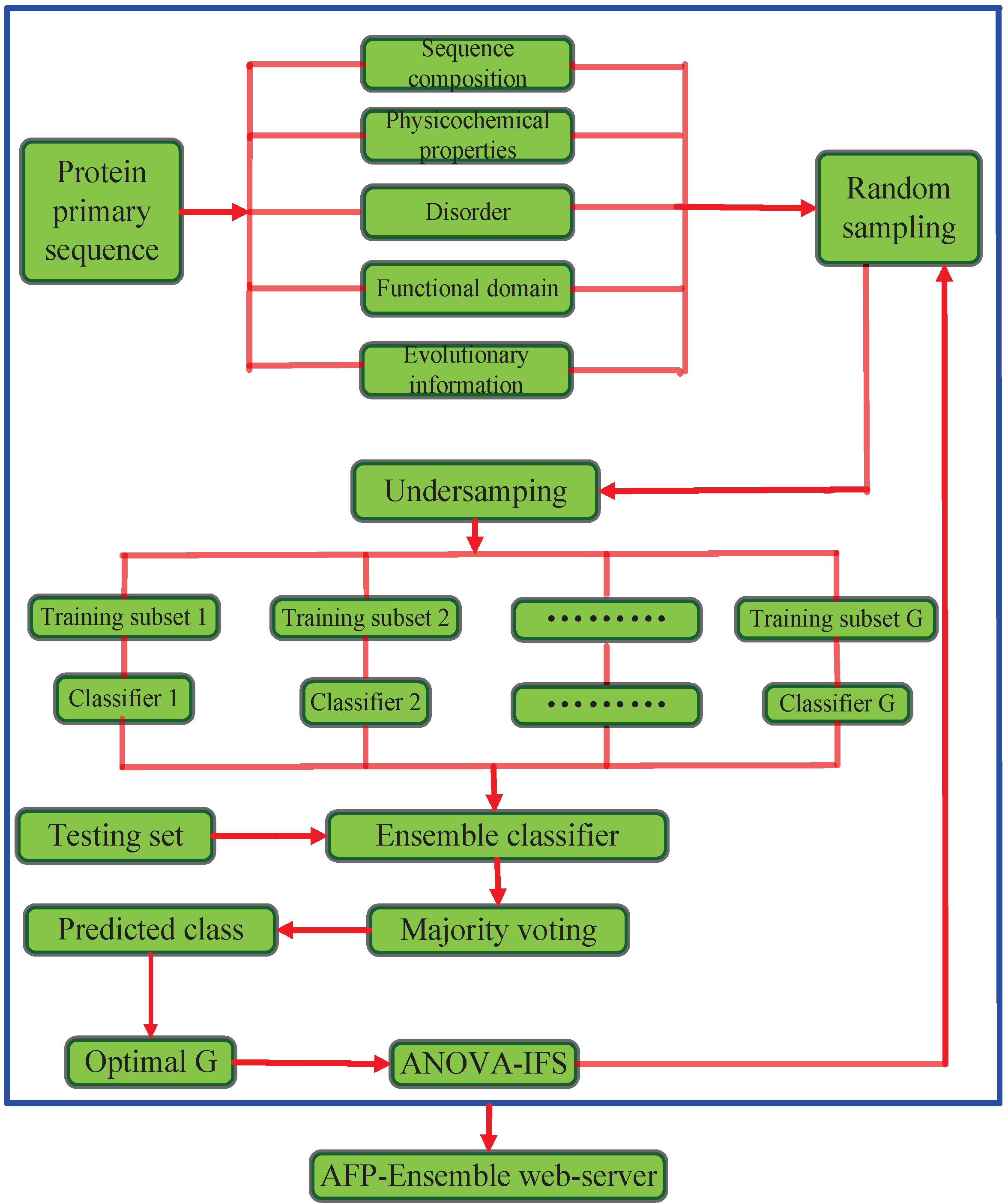
In this paper, we propose a novel AFP classification system (AFP-Ensemble) that performs ensemble classification of samples based on discriminatory capabilities of hybrid feature spaces. The proposed method is implemented in the following steps. (i) Protein sequences are mapped into feature vectors. The feature space is constructed from different types of sequence-derived features,
i.e., sequence composition, physicochemical properties, disorder, functional domain and evolutionary information; (ii) Negative samples in the training set are randomly sampled to make sure that the sampled negative samples are
G times the number of the positive samples in the training set, where
; (iii) The training set is divided into
G training subsets through the undersampling approach; (iv) The
G training subsets respectively train random forest classifiers to form ensemble classifiers; (v) Based on the ensemble classifiers, the predicted class labels of the test set are determined through the majority voting method. The parameter
G is determined based on the prediction performance of the full feature space; (vi) With the optimal parameter
G, the analysis of variance with incremental feature selection (ANOVA-IFS) procedure is employed to select high discriminative features from the hybrid feature space. To be easy to access and utilize by the public, the presented approach is realized on a user-friendly web-server called AFP-Ensemble. The system architecture of the proposed method is illustrated in
Figure 1.
Figure 1.
The system architecture of the proposed method. ANOVA-IFS: Analysis of variance with incremental feature selection.
Figure 1.
The system architecture of the proposed method. ANOVA-IFS: Analysis of variance with incremental feature selection.
3. Experimental Section
3.1. Datasets
The dataset composed of 481 AFPs and 9193 non-AFPs, downloaded from [
28], is employed to construct the training dataset and independent testing dataset. Two hundred twenty one AFPs are taken from seed proteins of the Pfamdatabase. To enrich the dataset, a PSI-BLAST (position-specific iterated basic local alignment search tool) search for each sequence against the non-redundant sequence database is performed. None of the proteins has 25% sequence identity to any other in the dataset. The final positive dataset contained 481 non-redundant antifreeze proteins. The negative dataset was constructed from 9193 seed proteins (representative members) of Pfam protein families, which are unrelated to antifreeze proteins. These positive and negative samples are employed to construct the training dataset and independent testing dataset.
To obtain high quality data, protein sequences with less than 50 amino acids are screened out, because their information is redundant and not integral. Protein sequences deleted from UniProt or containing nonstandard amino acids, such as “B”,“J”, “O”, “U”, “X” and “Z”, are also removed because their meanings are ambiguous. Thus, the final dataset consists of 464 AFPs and 9083 non-AFPs.
The dataset used in this paper for performance analysis and comparison is divided into two parts: the training dataset and independent testing dataset. In order to not change the distribution of protein samples in the dataset, 20% of the positive dataset and 20% of the negative dataset are randomly chosen to construct the independent testing dataset. The remaining protein sequences are utilized as the training dataset. The number of samples in each dataset is given in
Table 6. The final training and independent testing datasets are available in
Table S1.
Table 6.
The number of samples in the training dataset and independent testing dataset.
Table 6.
The number of samples in the training dataset and independent testing dataset.
| Dataset | AFPs | Non-AFPs | Total |
|---|
| Training dataset | 371 | 7266 | 7637 |
| Independent testing dataset | 93 | 1817 | 1910 |
3.2. Feature Extraction
To develop a powerful predictor, it is significant to formulate protein samples with a comprehensive and proper feature vector that could really reflect the intrinsic correlation with the desired target [
29]. To realize this, some sequence-derived encoding schemes that have been observed to be closely related to the AFPs are employed to represent each protein sequence.
Previous research work indicated that an individual feature extraction strategy can only represent a partial target’s knowledge. Feature extraction methods from different sources can complement each other in capturing the valuable information of protein samples [
30,
31]. Hybrid features extracted from sequence composition, physicochemical properties, disorder, the functional domain and evolutionary information are employed in this study for the numerical description of protein samples. In the following subsections, these feature extraction strategies will be explained in detail.
3.2.1. Sequence Composition
It has been reported that functional groups positioned to match the ice lattice on a particular plane may lead to ice binding and antifreeze activity [
32]. We categorize amino acids into 10 functional groups based on the presence of side chain chemical groups, such as phenyl (F/W/Y), carboxyl (D/E), imidazole (H), primary amine (K), guanidino (R), thiol (C), sulfur (M), amido (Q/N), hydroxyl (S/T) and non-polar (A/G/I/L/V/P) [
33]. Based on 10 functional groups, amino acid composition (AAC) and dipeptide composition (DPC) are computed for every sequence.
The amino acid composition (AAC) is calculated using the following formula:
where
denotes the number of functional group
in a given protein sequence and
L is the sequence length of the given protein sample.
The dipeptide composition (DPC) is defined as:
where
denotes the number of the dipeptides encoded as “
” in a given protein sequence.
3.2.2. Physicochemical Properties
A physicochemical property is the most intuitive feature for protein biochemical reactions [
34]. The specificity and diversity of a protein’s structure and function are largely attributed to various physicochemical properties of amino acids. Incorporating features extracted from physicochemical properties might contribute to a prospective improvement for protein attribute predictions. A previous study has shown that the feature groups used to reveal global and local discriminatory information can both effectively enhance the prediction performance [
35]. The global and local features extracted from physicochemical properties will be explained in detail.
Previous studies have chosen several antifreeze proteins to investigate their physicochemical properties [
13,
17,
18]. The results suggest that the physicochemical parameters, including theoretical isoelectric point (pI), total number of negatively-charged residues of Asp and Glu, total number of positively-charged residues of Arg and Lys, the instability index, the aliphatic index and the grand average of hydropathicity (GRAVY), may provide important clues to decipher the mechanism of AFP binding. In this study, these 6 physicochemical parameters are computed using Expasy’s ProtParam [
36] and selected as global features extracted from physicochemical properties.
The pseudo amino acid composition (PseAAC) [
37] was proposed to avoid losing local sequence order information hidden in protein sequences and, hence, has rapidly penetrated into almost all of the fields of protein attribute predictions [
38,
39,
40,
41]. For a detailed description about its recent development and applications, refer to the comprehensive review [
29]. Various modes of PseAAC by extracting different features from protein sequences were proposed in [
42,
43,
44]. In this work, we adopt the auto covariance (AC) model to capture local discriminatory information from physicochemical properties.
Seven physicochemical properties, including hydrophobicity, hydrophilicity, net charge, van der Waals, free energy of solution in water, side chain interaction parameter and average accessible surface area, are taken into account to calculate the AC model on the basis of the following reasons. (i) The hydrophobicity and hydrophilicity of the native amino acids play an important role in protein folding, interior packing, catalytic mechanism, as well as the interaction with other molecules [
45]; (ii) Charged amino acids tend to form an internal salt bridge, which is considered to maintain a long helix for stable structure; (iii) As an alternative to the H-bond model, van der Waals and hydrophobic interactions were also suggested to play important roles in AFP binding [
2]; (iv) AFPs should obviously be water-soluble and interact with ice [
2], which may be attributed to the free energy of the solution in water and the side chain interaction parameter; (v) The ice-binding sites of AFPs are relatively flat and engage a substantial proportion of the protein’s surface area in ice binding [
8]. To facilitate contacting ice, the binding residues are always well exposed to solvents. The values of these properties can be obtained from the Amino Acid Index database [
46].
To encode a protein sequence, AC variables describe the average interactions between two residues with a certain distance throughout the whole sequence. The AC variables are calculated through the following equation.
where
j represents one physicochemical property,
L is the length of the protein sequence,
is the
j-th physicochemical property value of the amino acid at the
i-th position in the sequence and λ is the distance between one residue and its neighbor at a certain number of residues away. Thus, AC encodes a protein sequence with the seven physicochemical properties into a vector of size
, where
is the maximum of λ (
) and chosen as 10.
3.2.3. Disorder
A protein region is defined as “disorder” if it fails to form well-defined three-dimensional structures in its native state [
47]. The disorder regions are always rich in binding sites and carry out important roles in regulating protein functions, including enzyme catalysis, cell signaling pathways and ligand binding [
48]. One can think of AFPs binding to ice as a receptor-ligand interaction (in which the AFP is the receptor and ice is the ligand) [
22], which suggests that there may exist a certain relationship between AFP-ice binding and disorder regions.
The disorder predictor “VSL2” [
49] is employed in this study to calculate the disorder score of each residue in a given protein sequence. The disorder score ranges from 0 to 1, where the higher the score is, the more likely the residue lacks a fixed structure. The following 28 features are designed to encode each protein sequence: (i) mean/standard deviation of all residues’ disorder scores (2 features); (ii) number of disorder/non-disorder segments (2 features); (iii) minimum/maximum length of disorder/non-disorder segments (4 features); and (iv) the average disorder score of each native amino acid (20 features).
3.2.4. Functional Domain
It is widely accepted that the protein structure could directly reveal its function mechanics, and thus, the availability of structure information about a given protein should be conducive to improving the performance of protein attribute predictions [
50]. Protein domains are distinct functional and/or structural units in transcriptional activities and other intermolecular interactions [
51]. Many protein domains often have similar or identical folding patterns, even if they show great variations in their sequences.
As indicated in [
52], multiple ice-binding domains may be responsible for the ability of the diverse AFPs to bind to ice crystals. Therefore, we perform the feature extraction work from the functional domain information through the following steps. First, the functional domain composition of each antifreeze protein in the training dataset is obtained from the Intepro database [
53]. Then, functional domains present in more than or equal to 10 antifreeze proteins are chosen to extract features. The result covers a total of 15 Intepro entries, as listed in
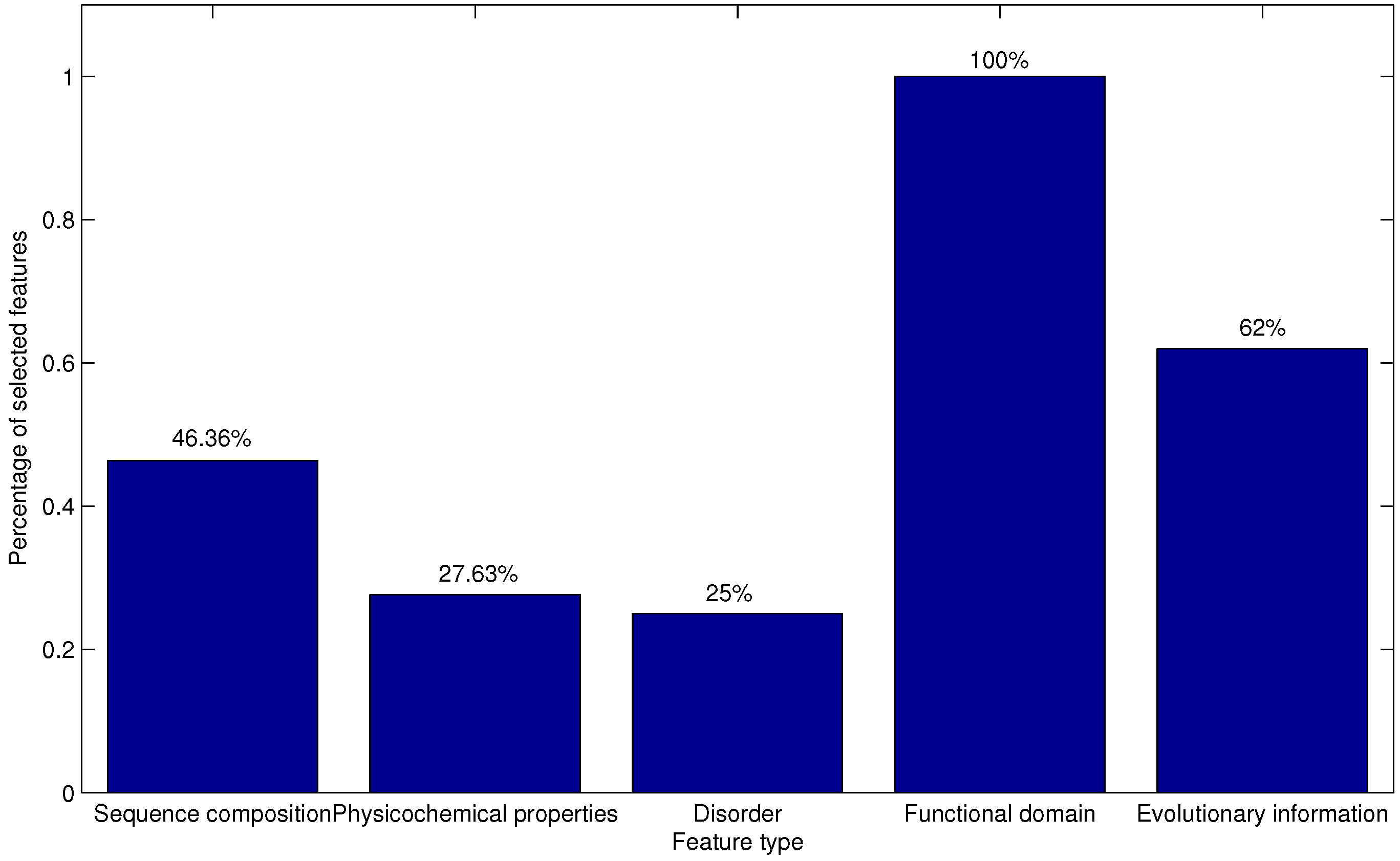
Table 7, which may contribute to the AFP-ice interactions. Finally, the information of each of the 15 functional domains is represented by a binary score: 1 if present and 0 otherwise.
Table 7.
The 15 Intepro entries that are present in more than or equal to 10 antifreeze proteins in the training dataset.
Table 7.
The 15 Intepro entries that are present in more than or equal to 10 antifreeze proteins in the training dataset.
| Rank | Intepro Entries | Rank | Intepro Entries | Rank | Intepro Entries |
|---|
| 1 | IPR001304 | 6 | IPR000742 | 11 | IPR000152 |
| 2 | IPR016186 | 7 | IPR000436 | 12 | IPR001881 |
| 3 | IPR016187 | 8 | IPR000538 | 13 | IPR003599 |
| 4 | IPR018378 | 9 | IPR007110 | 14 | IPR018097 |
| 5 | IPR013032 | 10 | IPR013783 | 15 | IPR013106 |
3.2.5. Evolutionary Information
Evolutionary conservation is one of the most important aspects in biological sequence analysis. A more conserved residue prefers to locating at a functionally important region [
54]. Protein evolution involves changes of single residues, insertions and deletions of several residues, gene doubling and gene fusion. With these changes accumulated for a long period of time, many similarities between initial and resultant protein sequences are gradually eliminated, but the corresponding proteins may still share many common features [
26]. Protein sequences’ evolutionary conservation serves as evidence for structural and functional conservation [
55]. To incorporate the evolutionary information of proteins, the position-specific scoring matrix (PSSM) [
56] profiles are adopted here.
The PSSM is a matrix of score values generated from PSI-BLAST with 3 iterations and a cutoff
E-value of 0.001. The rows and columns of the generated PSSM matrix are indexed by the protein residues and the 20 native amino acids, respectively. PSSM can be expressed for a protein sequence
P with
L residues as follows:
where
represents the score of the amino acid in the
i-th position of the query sequence mutating to amino acid type
j during the evolution process. Positive scores indicate that this change
occurs more frequently than expected occasionally, while negative scores indicate the opposite.
The elements of PSSM are scaled to the range from 0 to 1 using the following sigmoid function:
where
x is the original PSSM value.
We sum all of the rows and columns in the PSSM corresponding to the same functional group as given in
Section 3.2.1 and then divide each element by the length of the sequence. In the prediction of AFPs, we use PSSM profiles to generate 100-dimensional (
functional group pairs) input vectors as parameters.
3.3. Random Forest Classifier
The random forest (RF) algorithm, proposed by Breiman [
57], has been successfully used in protein attribute prediction problems [
58,
59]. The RF is an ensemble classifier consisting of several decision trees. According to L. Breiman’s description [
57], each tree is constructed through the following procedures. (i) Suppose the number of training cases is
; take
samples at random, but with replacement, from the original data. These samples are to form the training set for growing the tree; (ii) At every node of the tree, a feature subset with
m features is randomly selected from all
n features without replacement; (iii) Based on the randomly-selected samples and features, each tree is grown to the largest extent possible without pruning. To classify a new query sample, each decision tree yields a predicted class. The final classification of RF is obtained by combining the prediction results of all trees via voting.
WEKA (Waikato Environment for Knowledge Analysis), developed by the research team from University of Waikato in New Zealand, is free software integrating several state-of-the-art machine learning algorithms and data analysis tools [
60]. In this study, the random forest classifier in WEKA software is employed to implement the classification and operated with the default parameters.
3.4. Ensemble Method
In classification problems, the composition of the training data has a significant effect on the classification accuracy. It is a remarkable fact that the data used to identify AFPs has an imbalanced class distribution,
i.e., the fraction of AFPs is relatively small compared to that of non-AFPs. The imbalanced data classification problem would result in high prediction accuracy for the majority class, but poor prediction accuracy for the minority class [
61].
The existing methods for predicting AFPs [
23,
24,
25] have tried to change the distribution of positive and negative samples by randomly selecting AFPs and non-AFPs with the same size as the training set. However, since only 300 non-AFPs were randomly selected from 9439 non-AFPs to form the negative samples of the training dataset, they failed to make full use of the negative sample information in the original dataset. This may lead to a biased estimate of the accuracy. Hence, it is urgent to adopt an effective method to get an unbiased prediction based on the imbalanced dataset.
Ensemble classification is a method to combine various basic classifiers that have independent decision-making abilities. Previous experimental results show that the ensemble method is often superior to the individual classifier, which enhances not only the performance of the classification, but also the confidence of the results [
62,
63]. In this paper, a random forest-based ensemble method is applied to address the imbalanced problem.
The prediction performance of the training dataset is evaluated by 10-fold cross-validation. During 10-fold cross-validation, samples in each class are partitioned into 10 none-overlapped subsets. Then, 9 subsets of each class are chosen as the training set, and the remaining one of each class as the testing set. The processes mentioned above are repeated 10 times. For each run, the whole procedures of the random sampling followed by the ensemble method are given in following steps.
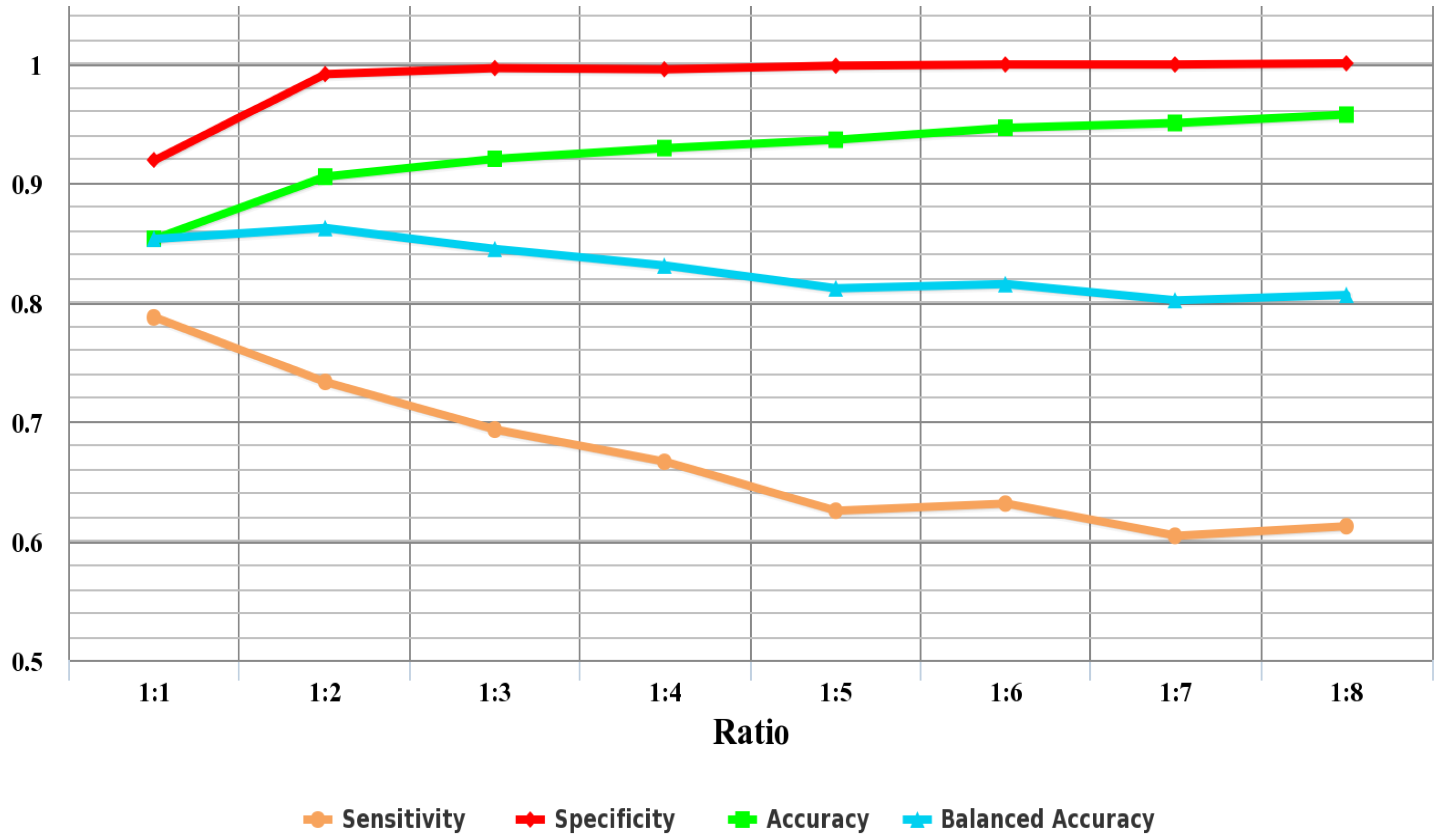
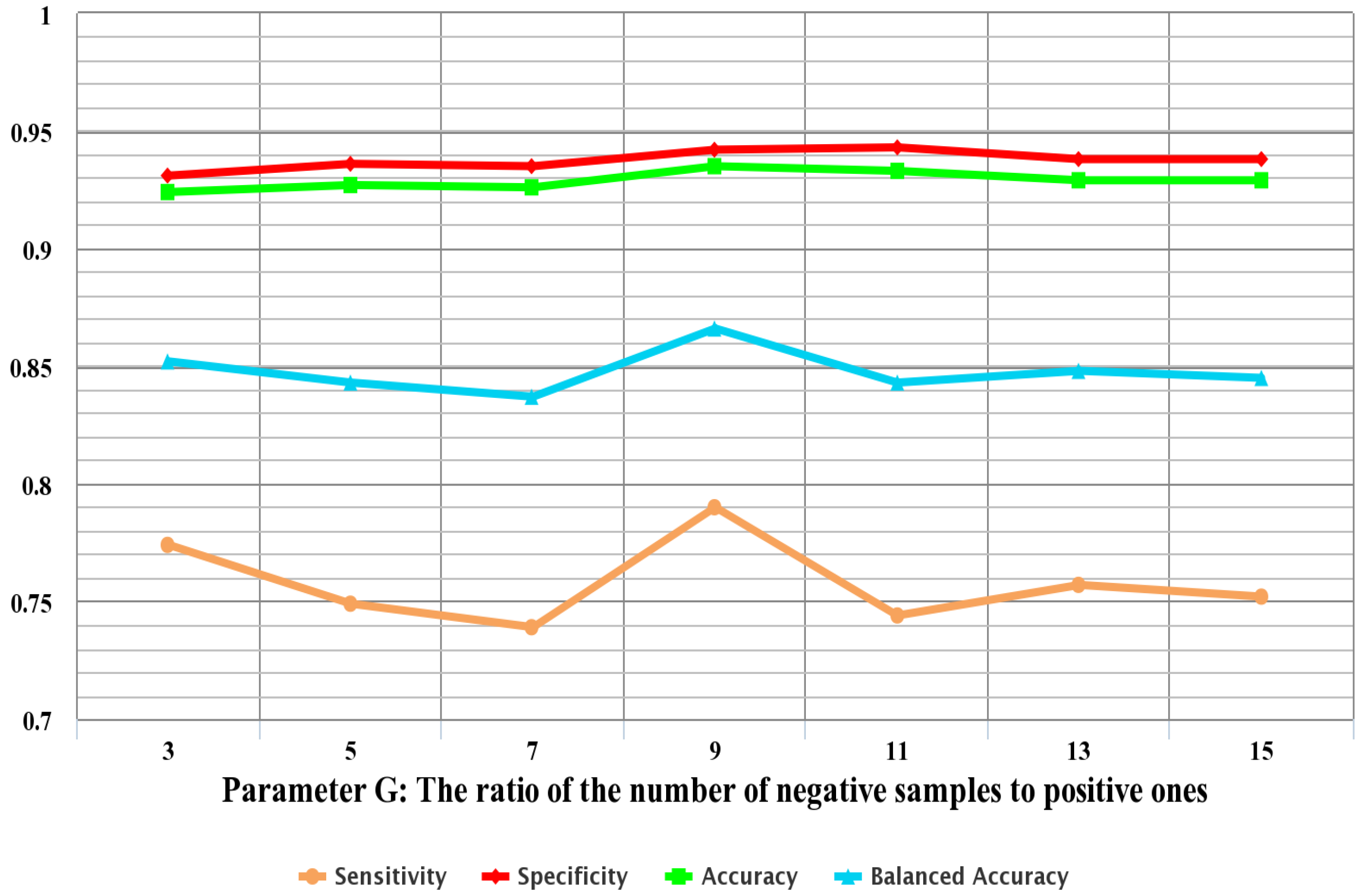
In order to deal with this imbalanced data problem, the negative sample set is divided into multiple subsets to make sure that the number of samples of each subset is approximately equal to that of the positive samples. In addition, to reduce computational complexity, negative samples in the training set are randomly sampled to make sure that the sampled negative samples are G times the number of the positive samples in the training set. As the ratio of negative to sampled positive samples is G, the negative dataset in the training set is undersampled and split into G groups. Each group is then combined with the positive samples in the training set as a training subset. After the procedure, G training subsets are obtained. G random forest classifiers are trained by the G training subsets, respectively, and the performance of the model is evaluated by the testing set. The final predicted class is determined by majority voting among the outputs of the G classifiers. In the majority voting scheme, a test instance is labeled the predicted class that obtains the highest number of votes.
3.5. Feature Selection
After carrying out the above-mentioned feature extraction methods, all protein sequences are converted into numerical feature vectors with the same dimension. As we know, not all of the extracted features could contribute to the classification. Generally, the high dimensional vector in a feature set would cause 3 problems: over-fitting, information redundancy and dimension disaster [
64]. Therefore, it is necessary to select high discriminative features, to reduce noise and, consequently, enhance the speed and performance with feature selection techniques. In this study, the analysis of variance followed by incremental feature selection (ANOVA-IFS) method is performed to pick out informative features from the original feature set.
The analysis of variance (ANOVA), proposed by Fisher [
65], is a statistical technique to investigate the relationship between a response variable and one or more independent variables. The ANOVA is able to identify factors that statistically contribute to the dataset’s variability. Based on the ANOVA, a statistical test called the F test is usually used to measure the relevance of a feature with respect to groups. The
F value of the τ-th feature in the feature set is defined as:
where
is the τ-th feature variance between groups and
is the τ-th feature variance within groups. They are expressed as:
where
and
are the degrees of freedom for
and
, respectively.
k and
N represent the number of groups and the total number of observations, respectively.
and
are the sums of squares of the τ-th feature between groups and within groups, respectively, and are calculated by:
where
denotes the mean value of the τ-th feature in the
i-th group,
denotes the mean value of all of the observations of the τ-th feature,
is the
j-th observation of the τ-th feature in the
i-th group, and
denotes the number of observations in the
i-th group.
The F value will become large as the becomes increasingly larger than the . The feature with a larger F value indicates that it is a more highly relevant one for the target to be predicted. In other words, predicted groups have a stronger correlation with the -th feature than with the -th feature if . The features used in this study then can be ranked by the F value.
Based on the ranked feature list evaluated by the ANOVA approach, the IFS method is adopted to determine the optimal feature set. The IFS procedure [
66] starts with an empty feature set and adds features one by one from higher to lower rank. A new feature set is constructed when another feature has been added. Suppose the total number of the features is
N, then we can obtain
N new feature sets. The
i-th feature set is denoted as:
For each of the N feature sets, an AFP-Ensemble-based predictor is constructed and examined using the 10-fold cross-validation on the training dataset. Thus, the optimal feature set can be obtained when the corresponding predictor yields the best performance.
3.6. Performance Measures
In statistical prediction, the following 3 cross-validation methods are often used to examine a predictor for its anticipated accuracy: independent dataset test, subsampling (K-fold cross-validation) test and jackknife test [
67]. Among the 3 test methods, the jackknife test is deemed as the least arbitrary one that can always yield a unique result for a given benchmark dataset [
29]. However, taking the size of the benchmark dataset into consideration, the 10-fold cross-validation test instead of the jackknife test is used in this study to reduce the computational time. Meanwhile, the independent dataset test is also adopted in our study.
Sensitivity (), specificity (), accuracy () and balanced accuracy () are employed to evaluate the performance of the prediction system. These measurements are defined as follows.
where
,
,
and
represent true positive (correctly-predicted AFPs), false positive (non-AFPs incorrectly predicted as AFPs), true negative (correctly predicted non-AFPs) and false negative (AFPs incorrectly predicted as non-AFPs), respectively.
Sensitivity (
) measures the proportion of the known AFPs that are correctly predicted as AFPs, and specificity (
) measures the proportion of the known non-AFPs that are correctly predicted as non-AFPs. Accuracy (
) is the proportion of all samples that are correctly predicted.
is known to be inappropriate for an imbalanced dataset, since it may be high even if sensitivity or precision is low [
68]. However, a good prediction system is usually expected to provide both high sensitivity and specificity. Therefore, the balanced accuracy (
) is used throughout this study as the main evaluator for prediction performance.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}