1. Introduction
The identification of drug–target interactions (DTI) has recently emerged as an area of intense research activity due to its important role in finding new proteins to target for drug development and discovering new drug candidates [
1,
2]. However, the target proteins of many drugs are not complete or even not known. In the past years, much effort has been devoted to using experimental methods to identify drug–protein interactions. But these experimental methods are both time-consuming and expensive. It often costs billions of dollars for developing a successful novel chemistry-based drug and takes nearly a decade for introducing the drug to market. However, there are only few drug candidates that can be approved to reach the market by Food and Drug Administration (FDA) [
3,
4,
5]. This is partially caused by the unacceptable toxicity for those drug candidates with the satisfactory activity, due to the deficient of the knowledge of drug–target interactions. Thus, it is necessary to develop fast and reliable computational methods for identifying drug–target interactions. Therefore, it is becoming more and more important to use computational approaches to detect DTI. The cost and time of experimental methods can be reduced and new potential drug–target interaction candidates can be found by using computational methods.
With the emergence of molecular medicine and the completion of the human genome project, the body of publicly-available knowledge of biology and chemistry is increasing rapidly. It makes the researchers restudy DTI questions by a systematic integration. A number of related databases that focus on drug–target relations have been constructed. We can freely obtain some of them from the public sector, such as SuperTarget and Matador [
6], Kyoto Encyclopedia of Genes and Genomes (KEGG) [
7], DrugBank [
8,
9], Therapeutic Target Database (TTD) [
10,
11], etc. It is much useful for many researchers that a number of important experimental materials can be obtained from these databases to develop new computational approaches for identifying DTI on a genome-wide scale [
12,
13].
All the time, in order to predict drug–target interactions, traditional computational methods are divided into the ligand-based virtual screening method and the docking approach. The ligand-based virtual screening method compares the similarity of a given proteins represented based on chemical structure with a classic SAR framework, which is used to predict DTI [
14]. However, there is an obvious shortcoming that the information of protein domains is not used for the method. The docking simulation is a much useful molecular modeling method that can detect the positive interactions by using dynamic simulation when drug molecule and protein bound to each other [
15,
16,
17]. However, the method has also a significant disadvantage that it can be only applied to proteins whose 3D structures are known. However, up to now, the proteins whose 3D structures are known comprise only a small part of all proteins. As a result, it is difficult to satisfy the experimental condition of the docking simulation method. Furthermore, the number of detected protein sequence data related to the known 3D structure data are increasing exponentially. Therefore, this promotes the need for developing new computational approaches based on protein sequence for detecting drug–target interactions.
In recent years, a number of computational approaches have been proposed to predict drug–target interactions. For example, Yang et al. [
18] developed a new computational method to detect multiple target optimal intervention solutions in a disease network. The method attempts to identify effective points of intervention and the combination of interventions within a given disease network, which can best restore the disease network to a desired normal state. Yan et al. [
19] developed a representation of drug–target pairs based on drug chemical similarity and target sequence similarity and employed the random forest as classifier to build the prediction models. By comparing the method and the state-of-the-art methods, it produces satisfying performance on the benchmark datasets. Kuang et al. [
20] developed a novel method that proposed an eigenvalue transformation technique and applied this technique to two representative algorithms for predicting DTI, the Regularized Least Squares classifier (RLS) and the semi-supervised link prediction classifier (SLP). The prediction results show that the method achieved better performance on drug–target interaction prediction. Bharadwaja et al. [
21] proposed a new approach for identifying novel interactions for drugs and targets with no prior interaction information, which improved a machine learning method by integrating more correlated information of the drug compounds and extended it to a weighted profile method. Peng et al. [
22] proposed a prediction model name as NormMulInf which is a semi-supervised-based learning framework through collaborative filtering theory, employing labeled and unlabeled interaction information. Firstly, the method determines similarity principles, for example samples’ similarities and local correlations between samples’ labels by integrating biological information. Secondly, the similarity information can be integrated into the NormMulInf model, which solves the problem of augmented Lagrange multipliers. Wang et al. [
23] proposed a new computational method, namely PDTD (Predicting Drug Targets with Domains), for identifying potential target proteins of new drugs based on derived interactions between drugs and protein domains. Zhang et al. [
24] proposed a stacking-based ensemble learning method to boost performance of previous DTI prediction methods by using a state-of-the-art support vector machine (SVM) model as classifier to integrate the prediction results of previous methods. Although these methods have achieved good prediction accuracy, however, the proposed prediction model focuses on improving the prediction accuracy. Thus, there is still room to improve the prediction accuracy to identify DTI.
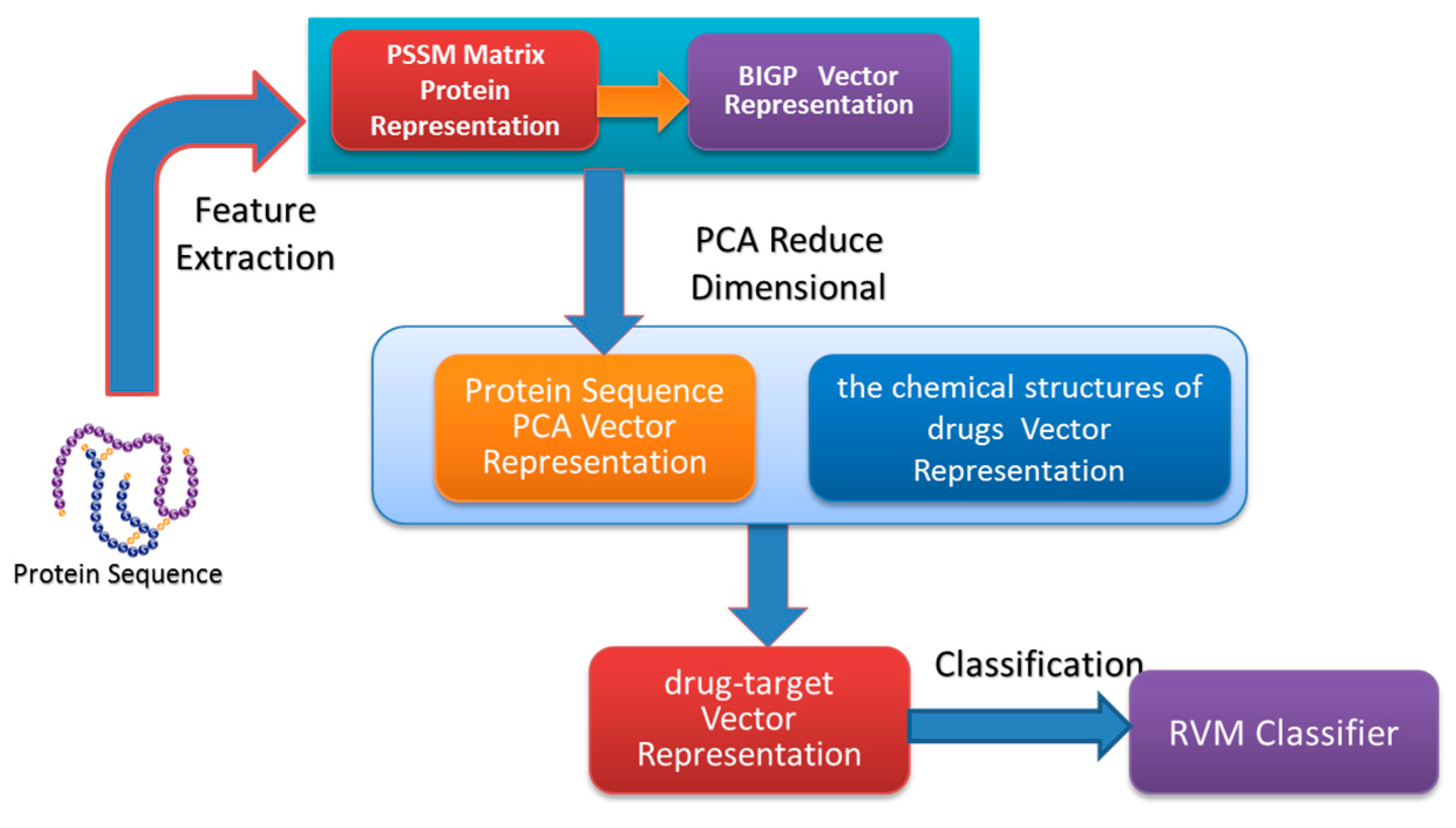
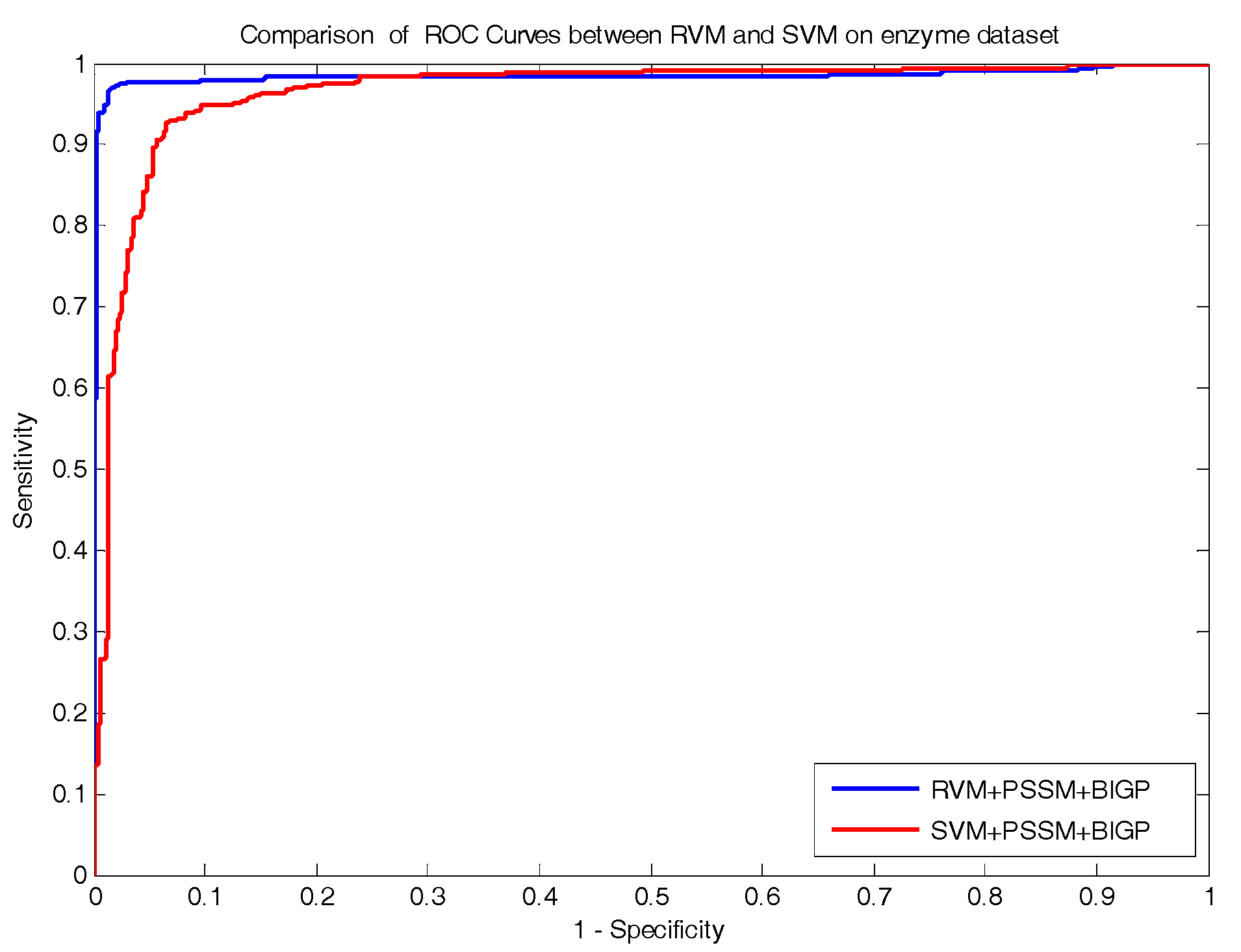
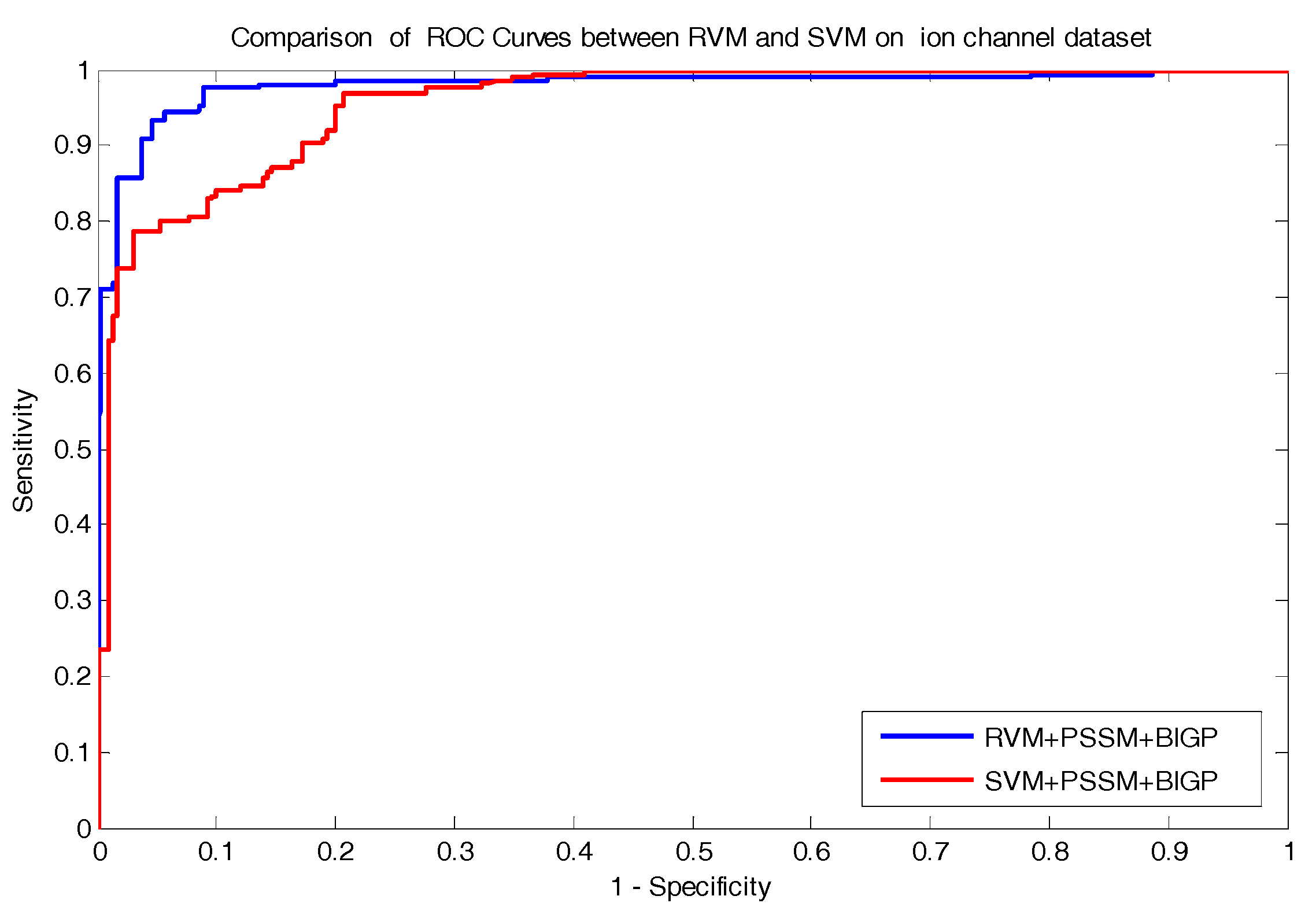
In the paper, we proposed a novel computational approach based on protein sequence, namely PDTPS (Predicting Drug Targets with Protein Sequence), to predict drug–target interactions (DTI). The PDTPS method combines Bi-gram probabilities (BIGP), Position Specific Scoring Matrix (PSSM), and Principal Component Analysis (PCA) with Relevance Vector Machine (RVM). In order to evaluate the prediction capacity of the PDTPS, we carry out the experiment on enzyme, ion channel, GPCR, and nuclear receptor datasets by using five-fold cross-validation tests. The proposed PDTPS method achieved average accuracy of 97.73%, 93.12%, 86.78%, and 87.78% on enzyme, ion channel, GPCR, and nuclear receptor datasets respectively. The experimental results showed that our method has good prediction performance. Furthermore, in order to further evaluate the prediction performance of the proposed PDTPS method, we compared it with the state-of-the-art support vector machine (SVM) classifier on enzyme and ion channel datasets and other exiting methods on four datasets. The promising comparison results further demonstrate the efficiency and robustness of the proposed PDTPS method. This makes it a useful tool and suitable for predicting DTI, as well as other bioinformatics tasks. The flow chart of the proposed prediction model is shown in
Figure 1.
3. Materials and Methods
3.1. Dataset
In this study, we carried out the experiment using the proposed method on four protein targets datasets: enzymes, ion channels, GPCRs, and nuclear receptors. These data can be freely obtained from the KEGG BRITE [
7], BRENDA [
30], SuperTarget [
6], and Drug Bank [
8] databases and were used as the gold-standard datasets by Yamanishi et al [
27] The number of drugs known to target enzymes, ion channels, GPCRs, and nuclear receptors are 445, 210, 233, and 54, respectively. The numbers of proteins known to be targeted by the drugs are 664, 204, 95, and 26 respectively. These drug–target pairs were carefully screened, 5127 pairs of them are known to interact with each other. The numbers of known interactions involving enzymes, ion channels, GPCRs, and nuclear receptors are 2926, 1476, 635, and 90, respectively. Then, all known interactions of the drug–target pairs were chosen as positive sample sets for four datasets in our experiment.
A bipartite graph is usually used to represent a drug–target interaction network, whose nodes represent target proteins or drug molecules and the edges describe the real drug–target interactions that have been already identified through experiments or other ways. It can be observed from bipartite graph that the number of the real drug–target interactions edges are small. Here, we take the enzyme dataset as an example; there are a total of 295,480 (445 × 664) connections in the corresponding bipartite and only 2926 edges of them are known drug–target interactions. Therefore, the possible number of negative samples (295,480 − 2926 = 29,2554) is significantly more than the number of positive samples (2926), which is a bias problem. In order to solve this problem, we randomly selected the negative samples as much as the positive sample. As a result, there are 2926, 1476, 635, and 90 negative samples of enzymes, ion channels, GPCRs, and nuclear receptors datasets. In other words, there are 5852, 2952, 1270, and 180 drug–target pairs of enzymes, ion channels, GPCRs, and nuclear receptors datasets in the experiment.
3.2. Position Specific Scoring Matrix
Position Specific Scoring Matrix (PSSM) can be represented an M × 20 matrix
, where M represents the length of a given protein sequence, 20 is the number of 20 amino acids, and
represents the score of the
amino acid relative to the
position for a query protein sequence [
31]. The score
can be expressed as
, where
represents the appearing frequency of the
amino acid at position
of the probe, and
is the value of Dayhoff’s mutation matrix between
and
amino acids. Thus, a high score represents a highly-conserved position; on the contrary, a low score represents a weakly-conserved position.
In the study, in order to create experimental datasets, we used Position Specific Iterated BLAST (PSI-BLAST) [
32] to construct PSSMs for each protein sequence. The e-value and number of iterations are set up as the default values in PSI-BLAST. For achieving highly and widely homologous sequences, an e-value of 0.001 and three iterations were selected. It is possible that features may be different if we use different parameters, however, in the work we concentrated on exploring general PSSM features for predicting DTI by employing mostly default settings. Thus, each PSSMs feature vector can be represented as M × 20 matrix by using PSI-BLAST, where M is the number of residues of a given protein sequence and the 20 columns are the number of 20 amino acids.
3.3. Bi-Gram Probabilities
The Bi-gram Probabilities (BIGP) have been used for protein fold recognition. In the literature [
33], it was described how to use a given protein’s original primary sequence or its consensus sequence for protein fold recognition. Instead, we employed the BIGP feature extraction method that the literature [
34] proposed to represent a given protein sequence based on its PSSM (PSSM has been mentioned in the
Section 3.2 of the paper). In detail, the bi-gram feature vector was computed through counting the bi-gram frequencies of occurrence in PSSM. It is assumed that
P represents the PSSM of a protein sequence, which contains
L rows and 20 columns, where
L is the length of a given protein sequence and 20 columns represents a number of 20 amino acids. The PSSM element
can be interpreted as the relative probability of
amino acid at the
location of the primary protein sequence,
can be expressed as
. The frequency of occurrence of transition from
amino acid to
amino acid can be defined as follows:
Equation (1) gives 400 frequencies of occurrence
for 400 bi-gram transitions, the matrix BIGP called the bi-gram occurrence matrix, the number of the 400 whose elements represent the bi-gram feature vector [
34] are as follows:
These bi-gram features can also be expressed as follows:
where
is the dimensionality of the feature vector
the
can be represented as follows:
Finally, each protein sequence was converted into a 400-dimensional vector by using BIGP method. In the paper, to reduce the influence of noise and improve the prediction accuracy, the dimensions of enzymes, ion channels, GPCRs, and nuclear receptors datasets were reduced from 400 to 350 by using Principal Component Analysis (PCA) method.
3.4. Relevance Vector Machine
The related theory of the Relevance Vector Machine describes in details in the literature [
35]. We assumed
,
is the training set for binary classification question, where
represents the training set label,
is the testing set label, and
, where
is the classification model;
is the additional noise, with a mean value of zero and a variance of
σ2, where
It is assumed that the training sets are independent and identically distributed; the vector
t submits to as follows distribution:
where
is defined as follows:
The training set label
t is employed to detect the testing set label
, given by
Due to making the value of most components of the weight vector
zero and reducing the number of calculation of the kernel function, additional conditions are attached to the weight vector
Assuming that
obeys a distribution with a mean value of zero and a variance of
, the mean
,
where
α is a hyper-parameter vector of the prior distribution of the weight vector
.
Because
cannot be obtained by an integral, it must be resolved using a Bayesian formula, given as
The integral of the product of
and
is as follows:
Because
)
and
) cannot be solved by means of integration, the solution is approximated using the maximum likelihood method, represented by
The iterative process of
and
is given by:
Here is th element in the diagonal and the initial value of α and σ2 can be decided via the approximation of and using Formula (15) continuously updated. After enough iterations, most of will be close to infinity, the corresponding parameters in will be zero, and other values will be close to finite. The resulting corresponding parameters of are now referred to as the relevance vector.
3.5. Performance Evaluation
In the paper, we used the following evaluation criteria as a measure for evaluating the performance of the proposed classifier and feature extraction method in our experiment. There are Ac (Accuracy), Sn (Sensitivity), Pe (precision), and Mcc (Matthews’s correlation coefficient). The definition is as follows:
where true positives (
TP) represents the number of positive pairs that are predicted as interacting drug–target pairs, false positives (
FP) is the count of negative pairs that are predicted as interacting drug–target pairs, true negatives (
TN) is the total of negative pairs that are predicted as non-interacting drug–target pairs and false negatives (
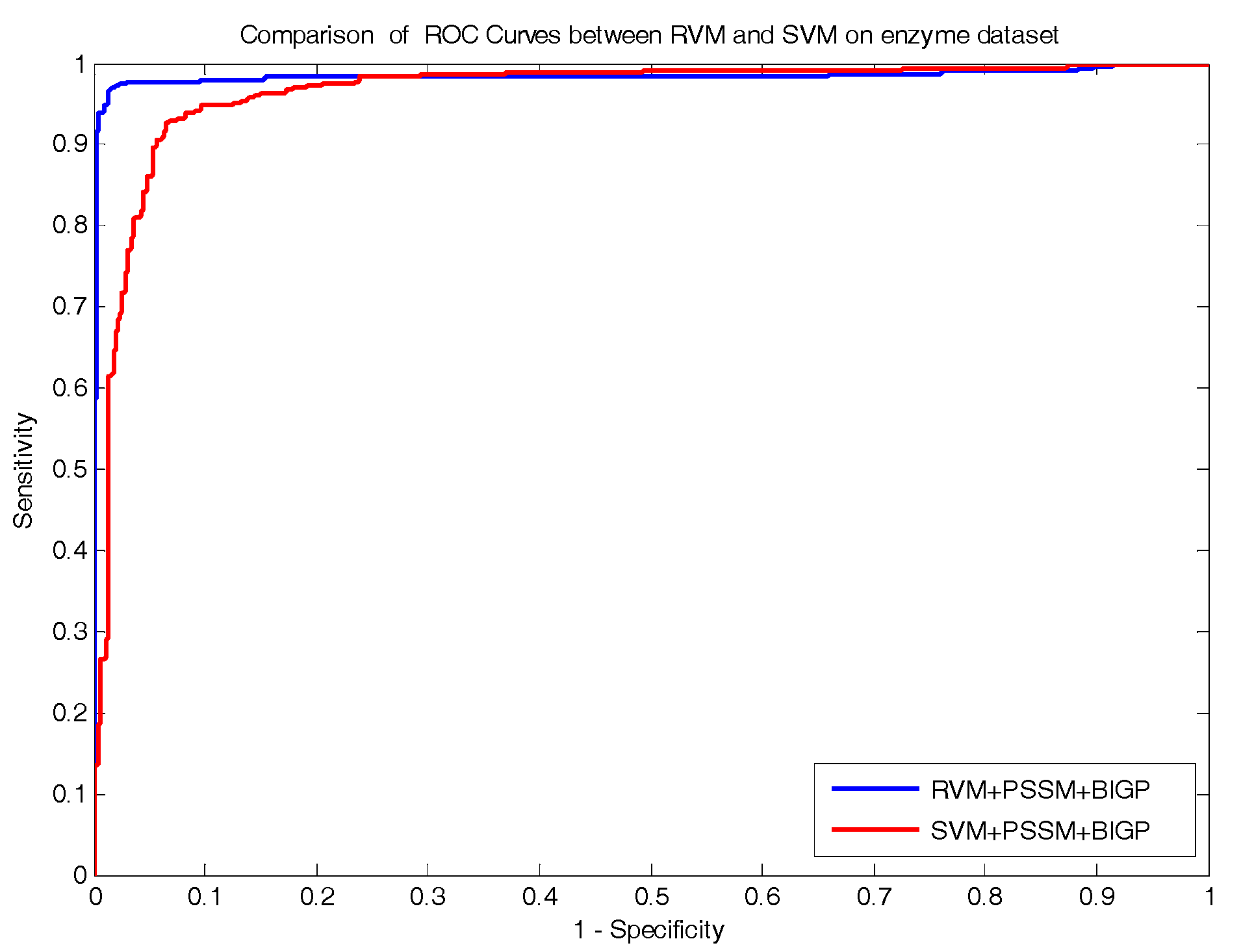
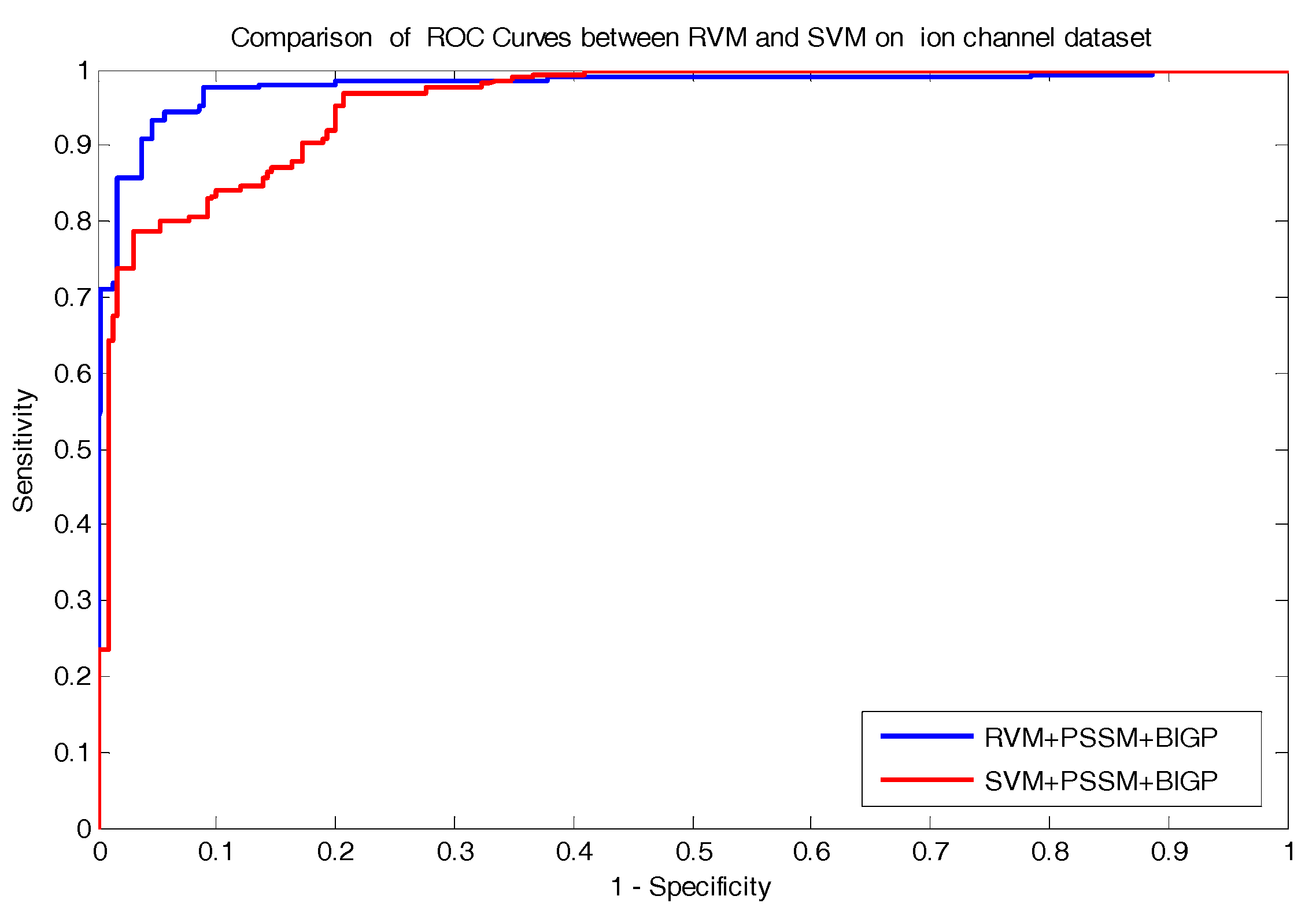
FN) represents the number of positive pairs that are predicted as non-interacting drug–target pairs. In addition, the Receiver Operating Curve (ROC) was established to evaluate the performance of the proposed approach in the experiment.
4. Conclusions
In the paper, we proposed a novel computational approach based on protein sequence, namely PDTPS (Predicting Drug Targets with Protein Sequence), to predict drug–target interactions (DTI). The PDTPS method combines bi-gram probabilities (BIGP), Position Specific Scoring Matrix (PSSM), and Principal Component Analysis (PCA) with Relevance Vector Machine (RVM). In order to evaluate the prediction capacity of the PDTPS, we carried out the method on enzyme, ion channel, GPCR, and nuclear receptor datasets by using five-fold cross-validation tests. The proposed PDTPS method achieved average accuracy of 97.73%, 93.12%, 86.78%, and 87.78% on enzyme, ion channel, GPCR, and nuclear receptor datasets, respectively. The experimental results showed that our method has good prediction performance. Furthermore, in order to evaluate the prediction performance of the proposed PDTPS method, we compared it with the state-of-the-art support vector machine (SVM) classifier on enzyme and ion channel datasets and other existing methods on four datasets. The promising comparison results further demonstrate the efficiency and robustness of the proposed PDTPS method. This makes it a useful tool and suitable for predicting DTI, as well as performing other bioinformatics tasks. For future studies, more effective feature extraction approaches and machine learning algorithms can be developed for predicting DTI.



{kind=link}
{kind=link}
{kind=link}