1. Introduction
Proteins are involved in almost all biological processes, such as gene expression, cell proliferation and cell signaling. Most proteins work as a multiprotein complex or together with partner proteins and rarely function alone. Interactions between protein molecules are essential for the function of the proteins, including multimeric assembly like cytoskeleton and viral capsid. Proteins form a transient complex like signal transducing proteins or a permanent complex as a certain multi-subunit enzyme. In such protein–protein interactions, the contact region between the two protein molecules is referred to as the binding surface of the proteins. An analysis of the protein binding surfaces could provide an understanding of functions and action mechanisms of the proteins in the complex, while also offering information for the dynamics of the complexes and development of drugs that can interfere with these interactions [
1,
2,
3,
4,
5,
6,
7,
8].
Since analyzing the features of the contact regions between two protein molecules is very important for various usages, many research attempts have already been made [
9,
10,
11,
12,
13,
14,
15,
16]. They provide information such as the area of binding surface, the binding strength, residues involved in the binding, and the types of their interaction.
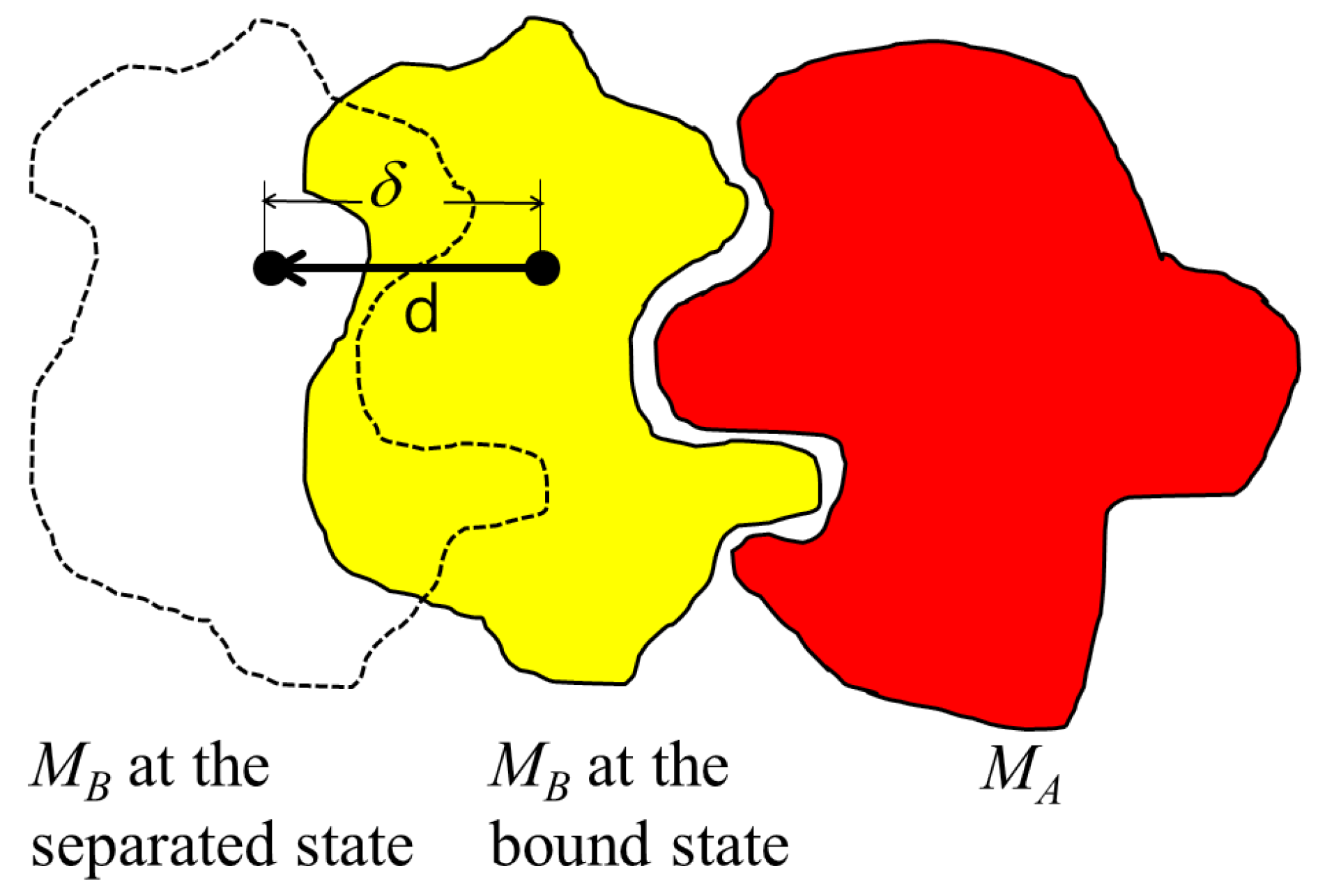
In a natural state, a protein assembly can exist under certain conditions and yet dissociate under other conditions. It depends on the binding strength of the proteins and possible modifications of the binding surface. Protein–protein interactions can be stabilized mostly by ionic interactions, hydrogen-bond, and hydrophobic interaction. The binding strength may be higher with a greater binding surface area as more atoms participate in the interaction between the two molecules. In particular, a hydrophobic interaction is the most important factor for protein binding in an aquatic solution as it removes the water molecules surrounding the hydrophobic regions of the proteins. Thus, when two proteins are combined, the water molecules surrounding the proteins are reduced according to the binding area, which means the binding area can represent the strength of the protein–protein interaction. Therefore, many programs have been developed to calculate the binding area for solvation. However, the solvation area is a two-dimensional value, and cannot present the three-dimensional shape of the binding surface whether it is flat or has ruggedness.
Lee and Richards [
17] introduced the concept of solvent accessible surface area (SASA) in 1971, where solvent accessible surface is the center trajectory of the solvent which rolls and contacts all over the molecule without penetration. When the molecule is represented by a set of van der Waals spheres, the solvent accessible surface corresponds to the offset surface of the spheres with the radius of the solvent.
Wodak and Janin [
18] suggested a method to compute SASA by using an analytical approximation. They derived the analytic equation to compute the solvation surface area for two atoms by computing the surface area of two intersecting spheres
and
, with the radii
,
i = 1,2, where
is the van der Waals radius of the corresponding atom and
is the radius of the water molecule. For more than two intersecting spheres, it is hard to analytically compute the surface area, because of the buried surfaces. Therefore they approximated the solvation surface area of atoms by computing the probability for a point on the surface of the sphere to be outside of all intersecting spheres based on the analytic equation.
Richmond [
19] proposed an analytical way to compute SASA. They derived an analytic formula to compute the spherical surface area which is bounded by piecewise regular curves by using the concepts from differential geometry. Then, SASA is computed by evaluating the formula. They also presented an analytical formula for computing the enclosed volume by the solvent accessible surface.
For the binding specificity in protein–protein interactions, two major factors are complementary shape and charges of the binding area between two proteins. To evaluate or predict the binding interface of one protein to its real or potential partners, the ruggedness, which is a numerical value describing the degree of prominence and depression on the binding surface, is an important factor. It puts weight, on shape rather than charge, for evaluating binding specificity.
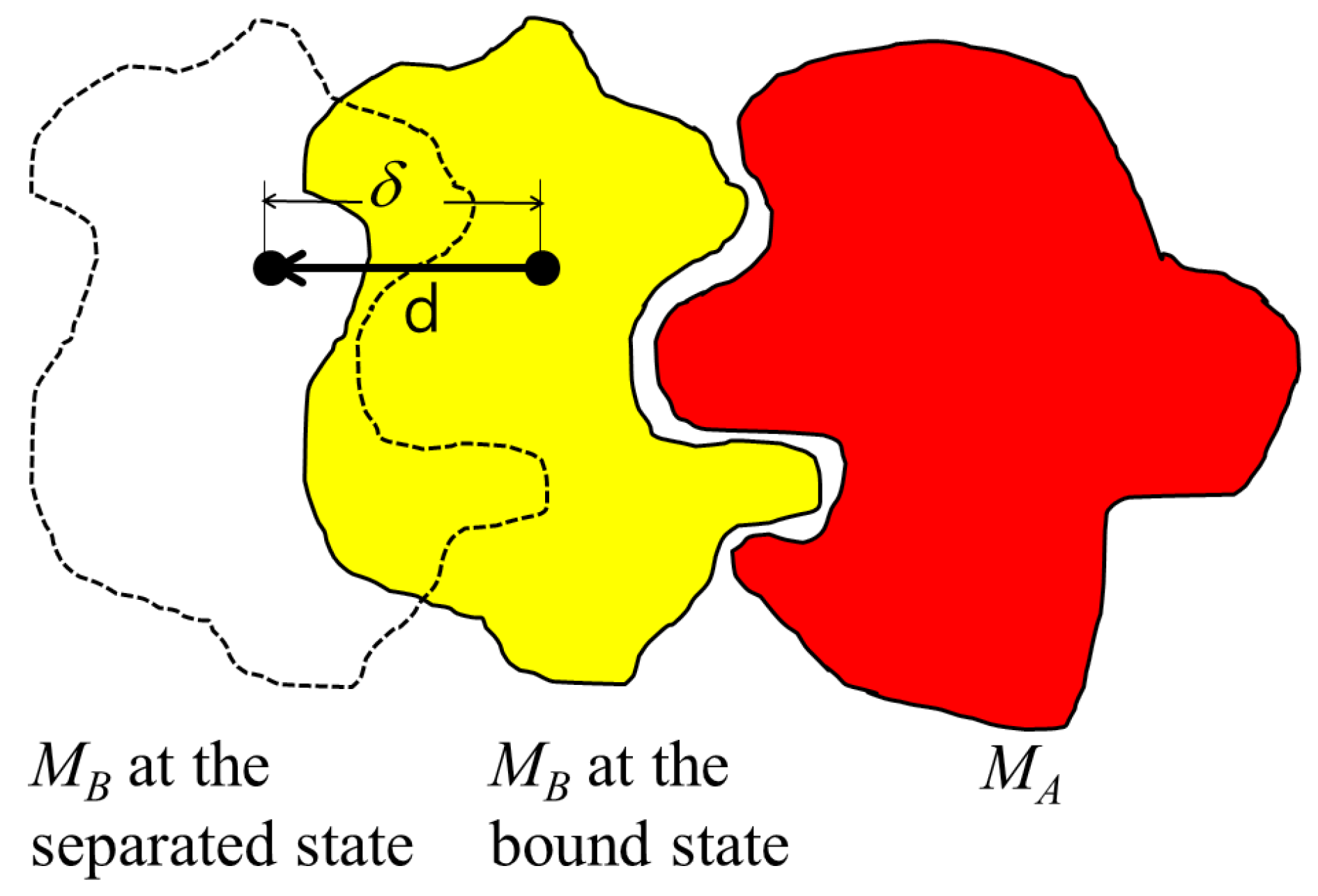
When we imagine an island, the two-dimensional area in a map helps to estimate the size of the island whether it has a big mountain or not. If we apply this concept to a binding interface of a protein, two-dimensional flatted area for the interface can present a size for the interface other than the solvation area. Additionally, by dividing the solvation area value with flatted area of the binding surface, we can obtain numerical value describing the degree of prominence or depression on the binding surface. Thus, it is necessary to define a sea level for the proteins in a complex representing the flattened binding interface.
According to the ‘collision theory’ explanation of chemical reaction rates, the impact between reactants in the right direction with sufficient energy leads to a successful reaction [
20]. For the binding reaction of two protein molecules, they must approach each other according to the direction of their binding interfaces in order to make a complex. Thus, considering the protein contact region in terms of the appropriate angle is also important for a protein–protein interaction. Therefore, identifying the binding direction of proteins in a complex can reveal the appropriate orientation required to create a complex between the partner proteins. This binding direction can then be used to find sectional planes, which are perpendicular to the direction. One of the sectional planes in the complex can be considered as the sea level for the binding area of a protein like an island, and the two-dimensional flattened binding area can be calculated.
This paper presents a novel approach for estimating the interaction between two proteins in a protein complex from coordinate files containing three-dimensional protein structures, which are deposited in Protein Data Bank. First, the binding direction of two protein molecules is computed, and the contact area is then calculated with respect to . A comparison of the sectional area and contact area of the proteins in the protein complex is also used to estimate the degree of prominence and depression on the binding surface. Finally, an example of further analysis for the binding interface is suggested using a series of the sectional area like contour lines in a map.
This paper is organized as follows.
Section 2 discusses related work.
Section 3 explains the proposed method for deciding the binding direction, while
Section 4 explains the proposed method for computing the sectional area of the contact region. Experimental results are presented in
Section 5, and some final conclusions are given in
Section 6.
2. Related Work
The PSIMAP algorithm uses the Euclidean distance between two protein structures to check their interaction [
9,
10,
21]. Thus, the contact region between two protein structures is determined based on the five-five rule, which assumes that two protein molecules only interact with each other if there are at least five residue pairs within a 5
. The Sampled Atom Contact PSIMAP and Full Atom Contact PSIMAP are two variants of the basic PSIMAP algorithm.
Dafas et al. [
22] improved on the basic PSIMAP with the bounding box contact PSIMAP algorithm. In this algorithm, each protein structure is bounded with a bounding shape (bounding box or convex hull), thereby restricting the search space for interacting atoms to the intersecting area of the two bounding shapes. The application of parallel processing when computing the interacting atoms also dramatically improved the computation time. PSIbase [
10] is also a database used to construct an interactome map for two protein structures based on the PSIMAP algorithm.
Nye et al. [
23] proposed a method to predict the domain–domain contact of protein super families based on the statistical significance of interacting protein pairs measured using a
p-value. However, this approach is not consistently effective as the training genomic data does not contain clear information. Hence, Nye et al. [
11] improved the prediction strength by defining the contact area of a superfamily using the number of atoms within a 5
from another molecule, which is not found in experimental data. Meanwhile, Steinkellner et al. [
13] detected the contact patches from crystals, and analyzed them according to the RNA, DNA, or ligand contacts. To determine the interactions between protein structures, they used the solvent-excluded surface (SES) for each protein structure, measured the distance between point pairs from two solvent-excluded surfaces, and then determined the contact patches according to the distance cutoff.
Arab et al. [
14] also presented a method for computing the potential energy of protein contacts based on the pairwise residue contact area. They defined the contact area as the spherical surface of the residue atoms contacting with the other molecule. They located probes at sample points on the surface of the atoms, and considered the number of points that intersected with the other molecule as the contact area.
PISA [
16,
24] is a software tool that computes the contact area of a protein complex using a finite element analysis as the average difference between the surface area of each molecular component and the total accessible surface area. Plus, the graph theoretical approach [
12] was proposed to discover the assemblies in a crystal using an assembly enumeration algorithm, where the chemical stability of an assembly is determined using the consequences of entropy in the case of molecules bound to proteins.
In [
15], the issue of docking failure due to the falsification of protein-protein interactions in crystals is addressed. PISA is used to select the dimeric structure in the PDB (Protein Data Bank). A fast Fourier transform is used to find the relative position between two protein molecules, and secondary structure matching is used to align the residues.
CAPRI [
25] is a protein–protein structure interaction prediction experiment and provides a forum for analyzing protein-docking methods in the case of blind prediction. A user can obtain the atomic coordinates of two proteins that make organically significant interactions, model a complex of the proteins, and submit their results for valuation on the CAPRI Web site. Since macromolecular interactions are a central theme in functional genomics, this promotes the development of prediction methods for the association of two proteins based on their three-dimensional structure.
Gu et al. [
26] presented a method for protein–protein docking based on shape complementarity. They characterized the local shape of each protein surface by using the surface-histogram. By measuring the distance between two surface-histograms, they found the possible contact region between two proteins.
In this paper, we use ePISA to select a protein complex in the PDB for the experiments, since it provides information for the interfaces and assemblies of all components in an asymmetric unit and symmetry-related molecules in the given crystal structure.
3. Computation of Binding Direction
To the best of our knowledge, there have not been previous researches to compute the binding direction between two molecules in a protein complex. As a novel attempt, we propose a method for computing the binding direction based on the visibility concept from the computational geometry area. When a protein complex is composed of three or more molecules, the proposed algorithm can be directly applied to compute the binding direction between each pair of molecules. The protein complex is represented by a PDB file (
http://www.pdb.org) that includes a snapshot location of every atom’s center in the complex.
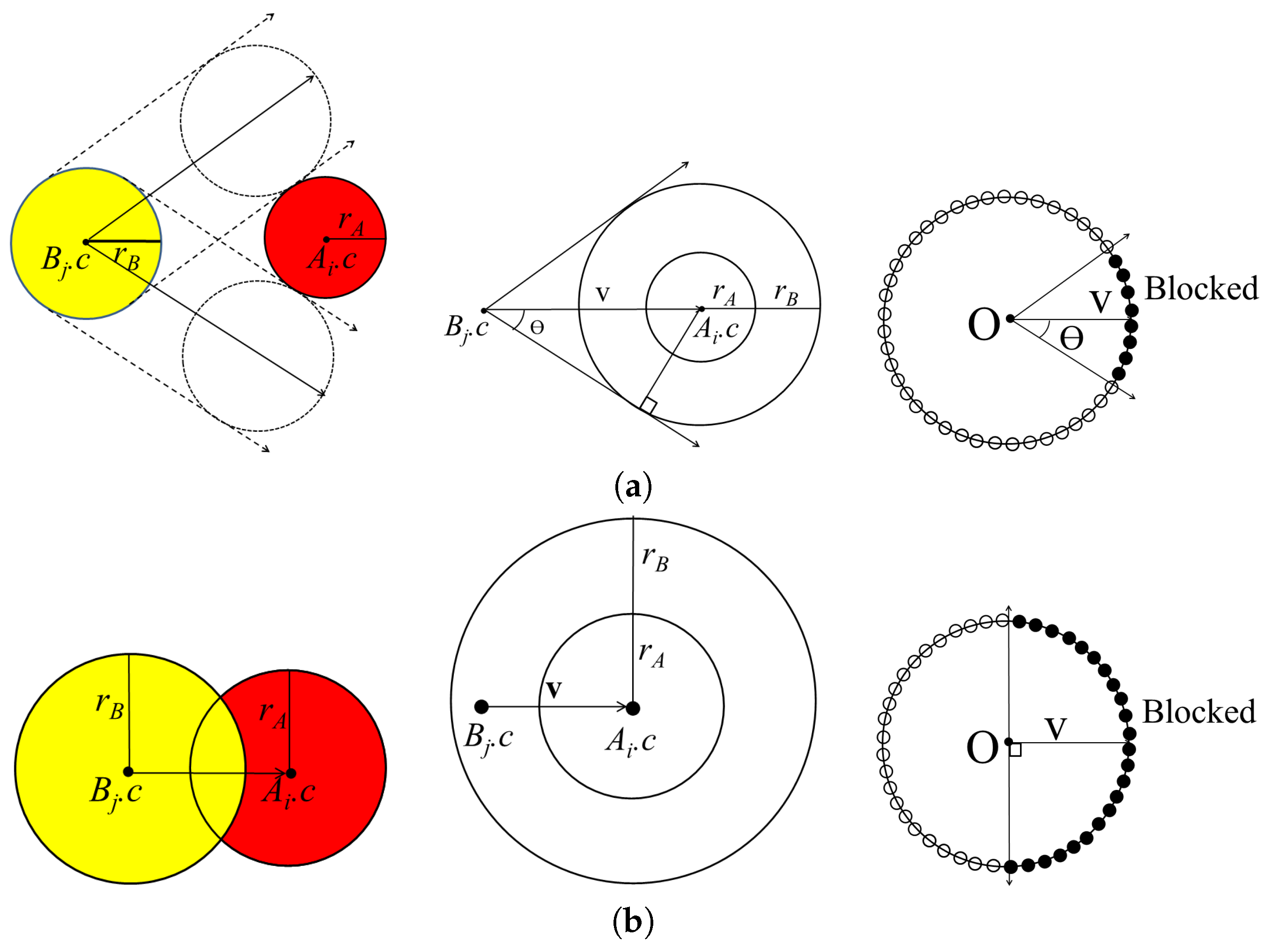
From a geometric perspective, a protein molecule is generally represented as a set of spheres, where each atom in the protein molecule corresponds to a sphere with a Van der Waals radius. Let denote the set of spheres corresponding to one molecule in the given complex, while denotes the set of spheres corresponding to the other molecule in the complex.
While the PDB file provides the location and orientation of rigid bodies
and
that are already bound, the binding direction is unknown. Thus, the binding direction of
with respect to
is computed using the separating direction based on the location of the atoms in
and
in the protein complex. The separating direction is the direction in which
moves away from
without any collisions. As such, the separating direction can be considered as opposite of the binding direction. In
Figure 1, the separating direction is denoted as
, where the binding direction is
.
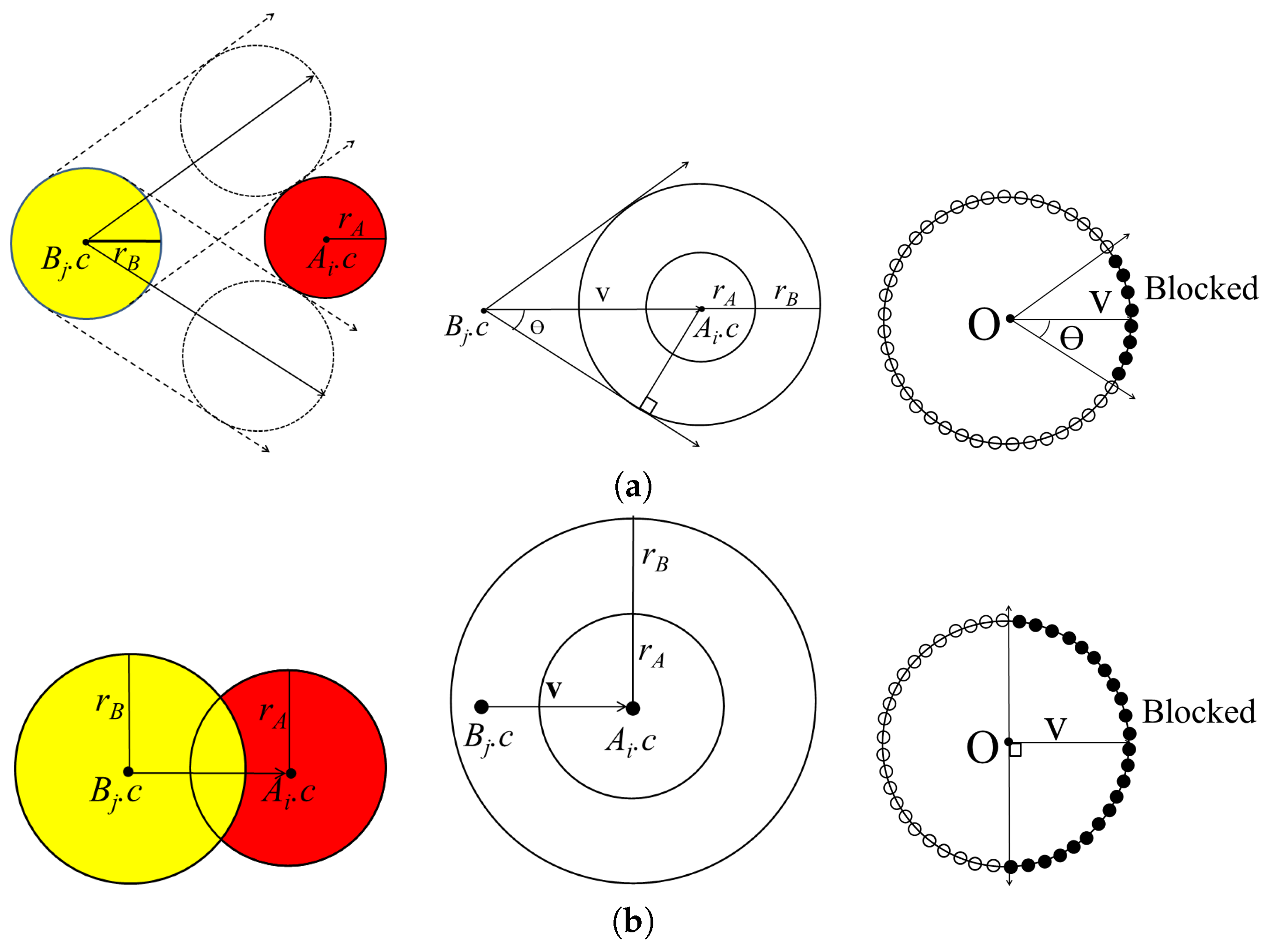
The separating direction is computed based on determining the moving direction of when it does not intersect with while moving within distance . When the restriction of the maximum moving distance is given as , we select the atoms that never collide with the partner molecule within . For each atom in , the closest atoms in are computed, along with the minimum distance between them. If the minimum distance is less than , there is a possibility that and may collide when is moving. Otherwise, and will not collide when is moving, as the distance between them is longer than the maximum moving distance of . Thus, the selected set of atoms is and where the minimum distance from the atom in A to the atom in B is less than or equal to .
First, we compute the moving directions of all the atoms in
B that are blocked by atoms in
A. By computing the union set of the blocked directions for each atom, we can then compute the blocked direction for the molecule
. Let
and
denote an atom in
A and
B with centers
and
, respectively. When
moves along a linear trajectory, it is blocked by
in a certain direction. The union of the directions blocked by
is represented by a cone centered at
. The cone
is constructed, where
K is the vertex at the origin, the axis
, and the half-angle
:
if
is not contained in the sphere with center
and radius
.
Figure 2a shows the cone constructed for
and
.
In some cases, atoms from different molecules intersect with each other when there is a strong bond between them. For this case, atoms
and
can be separated in the opposite direction in the half-space constructed by a plane with reference point
and normal vector
.
Figure 2b shows the cone constructed for
and
with axis
and half-angle
.
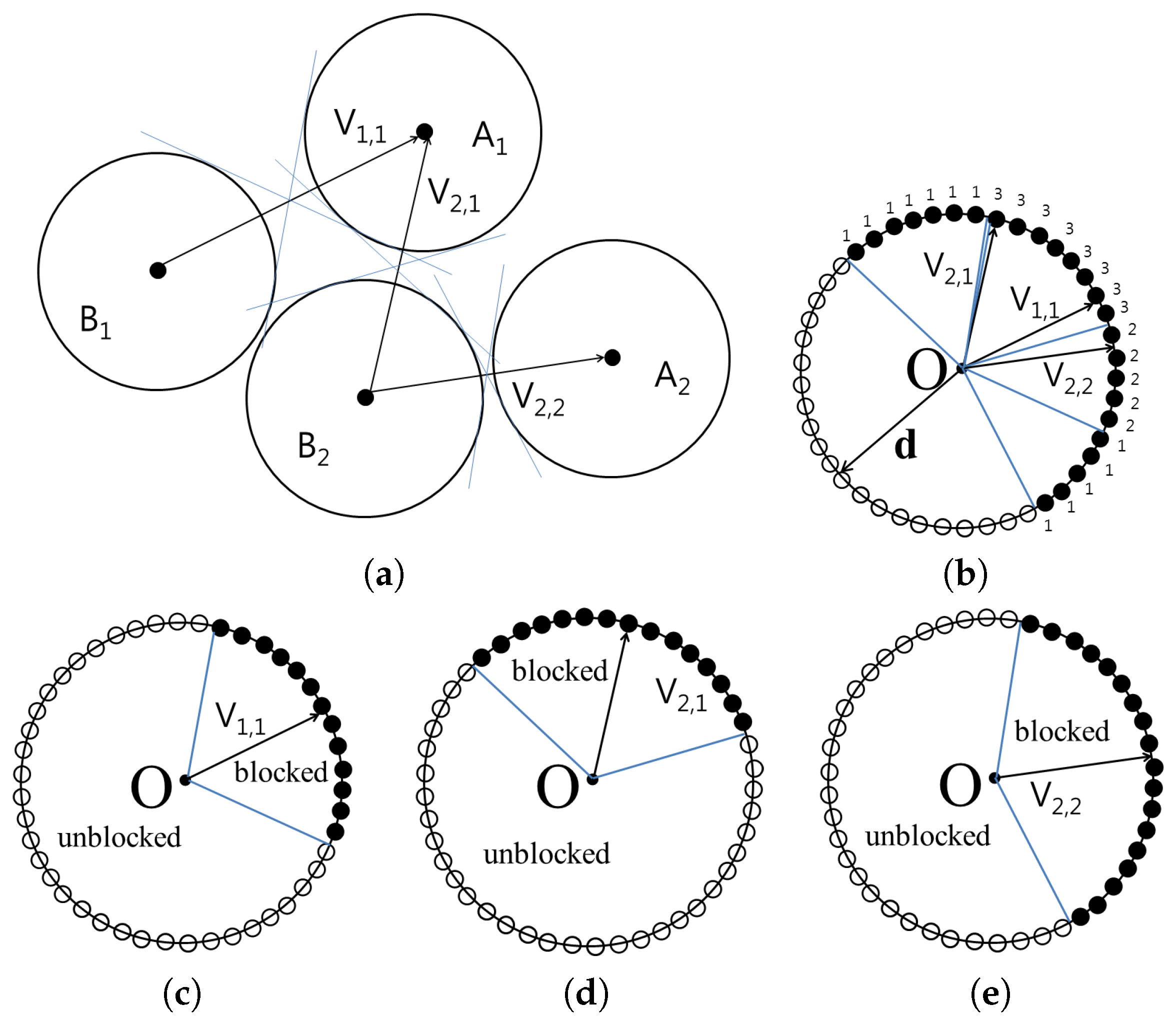
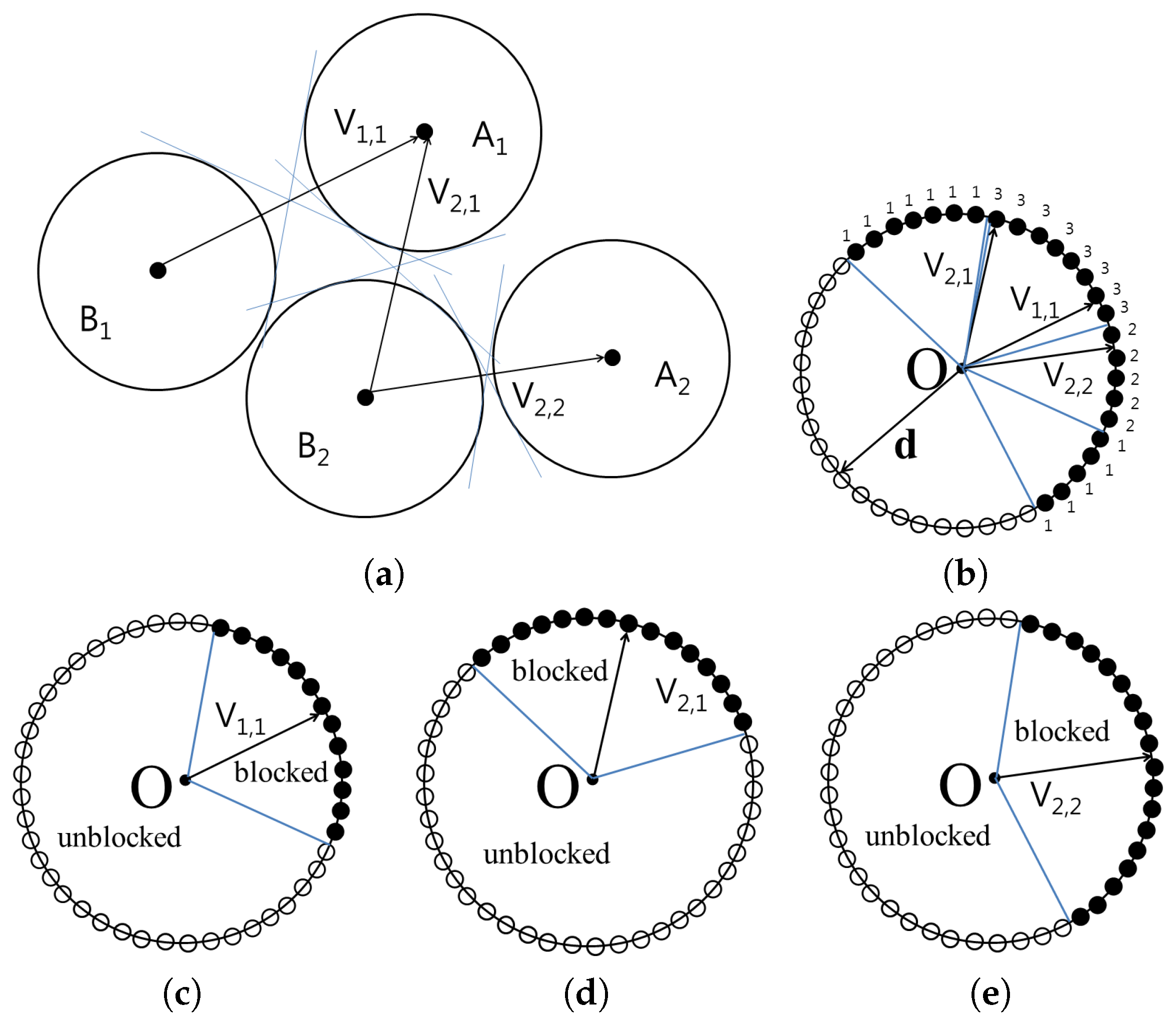
The
Figure 3 shows the cone constructed for the set
and
. The vertices of the cones containing blocked directions are then translated to the origin in order to compute the union of the cones. From the origin, all possible directions are represented as surface points on a unit sphere. For each point
on the unit sphere, the number of cones that encompass
is counted and stored as
. If
is 0,
and
can be separated by translating
using vector
with distance
without collision. However, if
is
n,
,
and
can be separated by translating
using vector
with distance
, and there will be
n collisions.
When
, every separating direction can be found using the points in
.
can be composed of one or more segments. Each sample point on the unit sphere keeps information on the neighbor points. To group the connected points in
as one segment, we used the function
GroupingPoints that is based on the flood-filling method [
27]. Flood-filling method is used in computer graphics applications to recursively fill the area surrounded by a closed boundary starting from a seed point in the area. From an arbitrary point
, we apply the function
GroupingPoints to group the connected points from
p as
. After assigning group number
to every point connected from
p, another seed point from
whose group is not decided yet is chosen. Then, we can apply the function
GroupingPoints from it to detect the points which will be in group
. The process is repeated until every point in
is assigned its group number.
| Function GroupingPoints (p) |
| /* p: a point in P’ */ |
| Begin |
| if the group of p is not decided yet then |
| begin |
| Set the group p as G1; |
| for each pi ∈ P’, where pi is a neighbor of p, do |
| GroupingPoints (pi); |
| end |
| End |
When are given, their groups are identical, if and can be connected by neighbors, and different if and are not connected. After deciding the groups for each point in , the representative direction is determined for each group. In the algorithm BindingDirection, the separating direction is computed as the average of the unblocked directions, and the binding direction is then returned.
| Function BindingDirection(, , ) |
| /* is a ball representing an atom, */ |
| /* is a ball representing an atom, */ |
| /* : maximum moving distance */ |
| Begin |
| A = the atoms in whose minimum distance to is less than ; |
| B = the atoms in whose minimum distance from is less than ; |
| P = {sample points on the unit sphere}; |
| Set for every ; |
| for each do begin |
| for each do begin |
| ; |
| if dist then // Refer Figure 2a |
| Construct an infinite cone K with vertex , |
| axis v, and half-angle ; |
| else if dist then //Refer Figure 2b |
| Construct an infinite cone K with vertex , axis v, |
| and half-angle ; |
| for each do |
| Increment if is inside K; // Refer Figure 3b |
| end |
| end |
| d = the average of the vectors , |
| for whose is less than the given threshold; |
| return −d; |
| End |
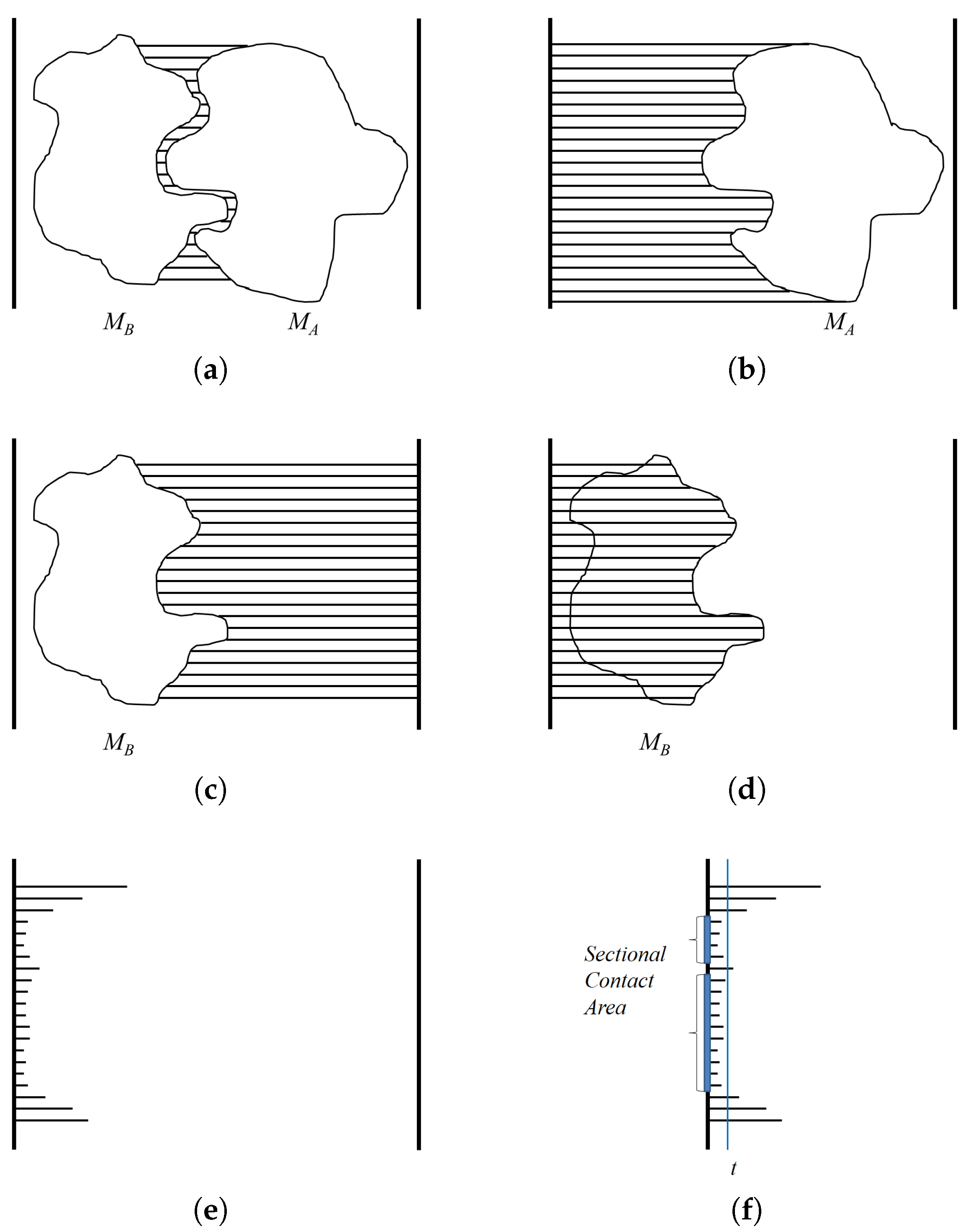
4. Computing Sectional Contact Area
| Function DistMap(, ) |
| /* and are transformed molecules */ |
| Begin |
| Generate a view volume as the bounding box containing and ; |
| := the size of the view volume along z-axis; |
| Create two windows and with size; |
| // When the depth buffer is rendered, |
| // the depth values are automatically normalized to the range [0, 1] |
| In , render the depth buffer for with viewpoint (0, 0, ) |
| in orthographic view, then save the result to DA[w][h]; // Figure 5b |
| In , render the depth buffer for molecule with viewpoint (0, 0, ) |
| in orthographic view, then save the result to DB[w][h]; // Figure 5c |
| For each i, j do |
| DB[i][j] = 1 - DB[i][j]; // Figure 5d |
| For each i, j do begin |
| if DA[i][j] is 0 or 1 then |
| DA[i][j] = ∞; |
| if DB[i][j] is 0 or 1 then |
| DB[i][j] = ∞; |
| end |
| Create distMap[w][h]; |
| For each i,j do |
| if (DA[i][j] != ∞ AND DB[i][j] != ∞) |
| distMap[i][j] = (DA[i][j] - DB[i][j])*NormFact; // Figure 5e |
| else distMap[i][j] = ∞; |
| return distMap; |
| End |
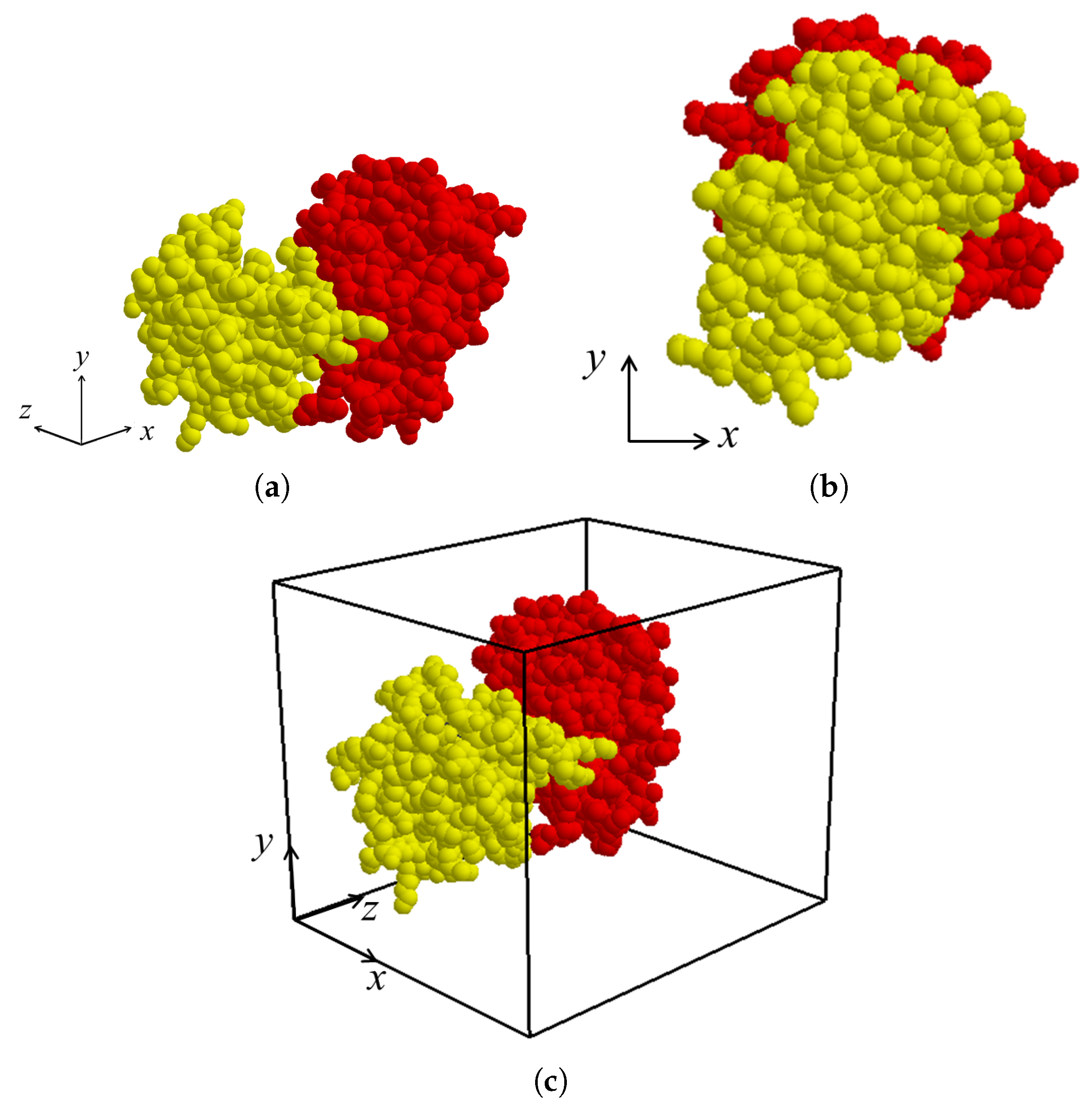
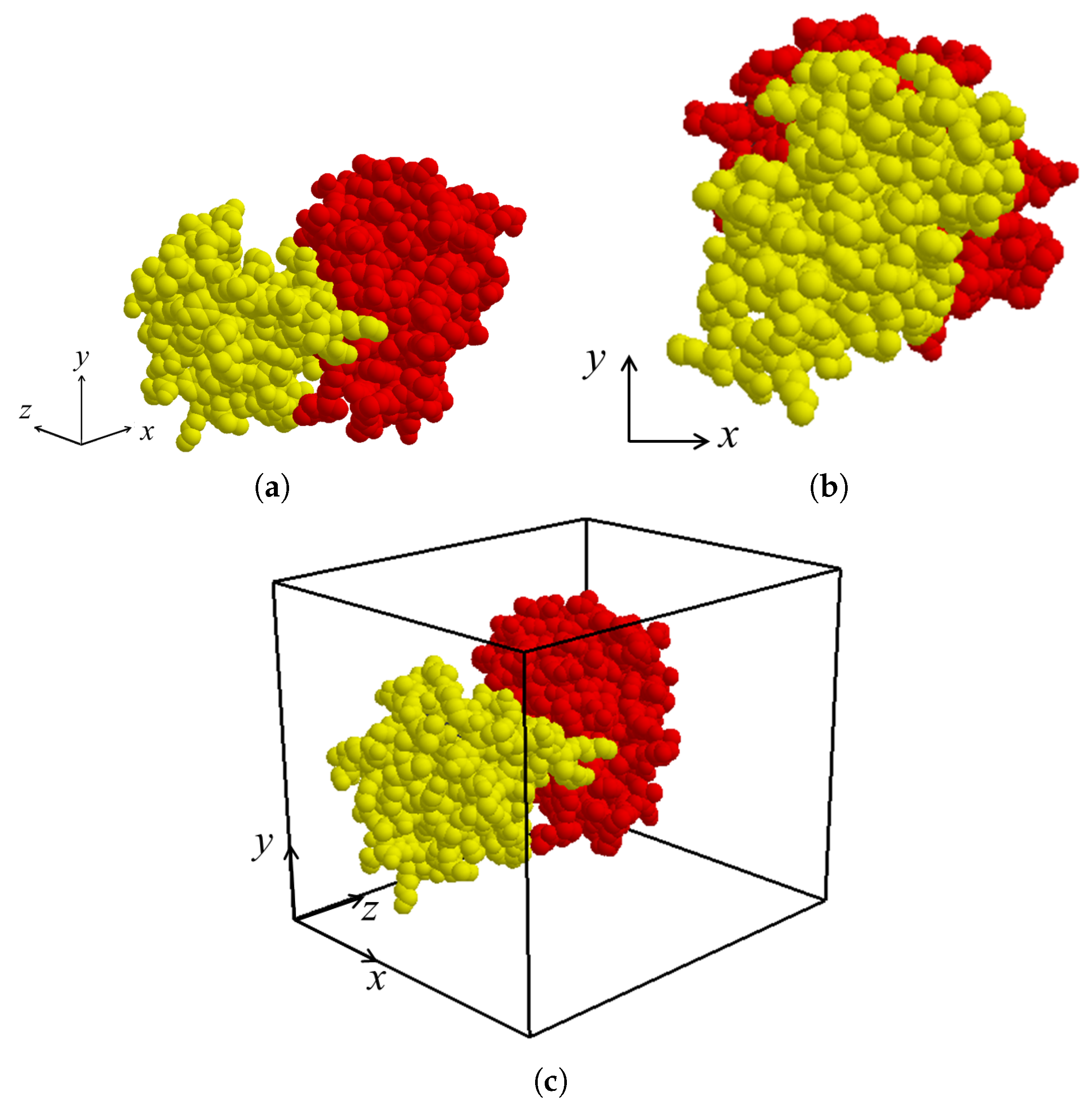
After the binding direction for
and
in the protein complex is determined as
, the binding direction is located along the
z-axis by applying rigid-body rotation and translation for both molecules
and
if necessary (
Figure 4a,b). The view volume for the protein complex can then be constructed as an axis-aligned bounding box containing both
and
. (
Figure 4c). Thereafter, the sectional contact area of
and
is computed using a depth buffer that renders the molecules within the view volume.
A depth buffer is used for hidden surface removal in the OpenGL graphics library (
http://www.opengl.org). When three-dimensional objects are rendered using the OpenGL library, a depth buffer is used to store the minimum distance information of the rendered objects from the view plane. For example, when rendering a protein molecule using a depth buffer, each screen pixel should render a particular part of the molecule. When a pixel corresponds to several parts, the part closest to the view plane is rendered. Thus, a depth buffer keeps the minimum distance value from the view plane to the object for each pixel. The depth value is computed by selecting the closest part to the projection plane, and implemented using hardware, so the computation speed is very fast and the resolution easily adjusted by rendering the object larger or smaller.
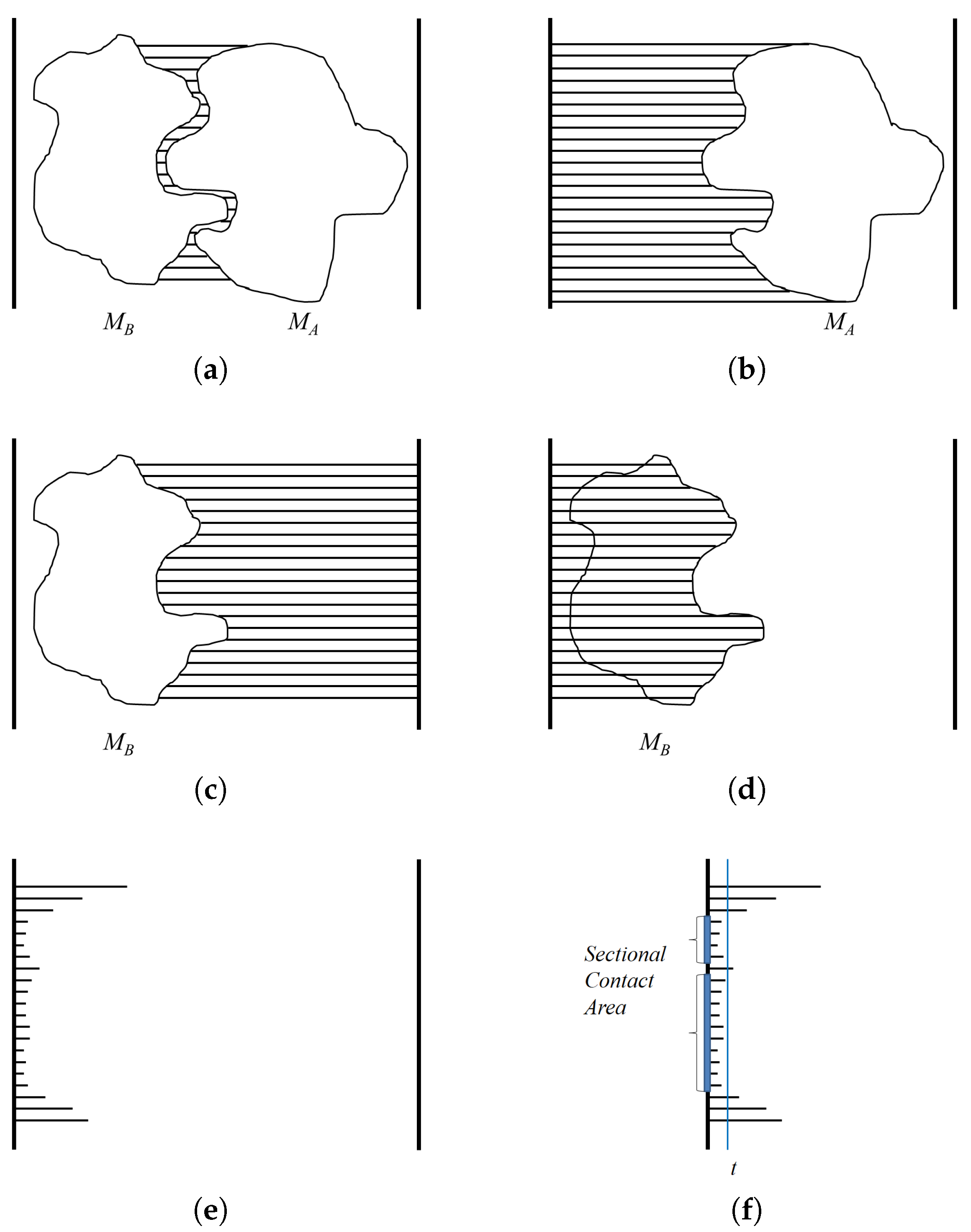
The goal of using a depth buffer is to compute the minimum distance between two molecules
A and
B along the binding direction (Refer
Figure 5a). When a depth buffer is used, the resulting depth values are normalized between zero and one, where one corresponds to the view volume size along the
z-axis. An orthogonal projection is also used so the given viewpoint actually works as a view direction. For the case of
, the depth values are computed for viewpoint
(
Figure 5b). However, for the case of
, the depth values are computed for viewpoint
(
Figure 5c). After computing the depth values for viewpoint
, the distance to the binding surface of
in the opposite direction can be computed by subtracting the depth values from one (
Figure 5d). Meanwhile, subtracting the depth values of
from
reveals the distance between
and
(
Figure 5e). The actual distance can be derived from the normalized distance by multiplying the view volume size along the
z-axis. The algorithm
DistMap shows the procedure for computing the distance between two molecules along the binding direction.
The depth values of interest are restricted to the contact region of
and
. The algorithm
ContactArea shows the procedure for computing the sectional area between
and
. Along the binding direction, when the threshold for the contact region is given as
t, we consider the pixels in the algorithm
DistMap that show the distance as smaller than or equal to
t as in the contact region. The pixels with a distance value that satisfies this condition are counted, and the area of the contact region is then computed by multiplying the unit area for each pixel. The unit area for a pixel
u is computed using the ratio between the window size of the screen coordinate and the width and height of the three-dimensional view volume (
Figure 5f).
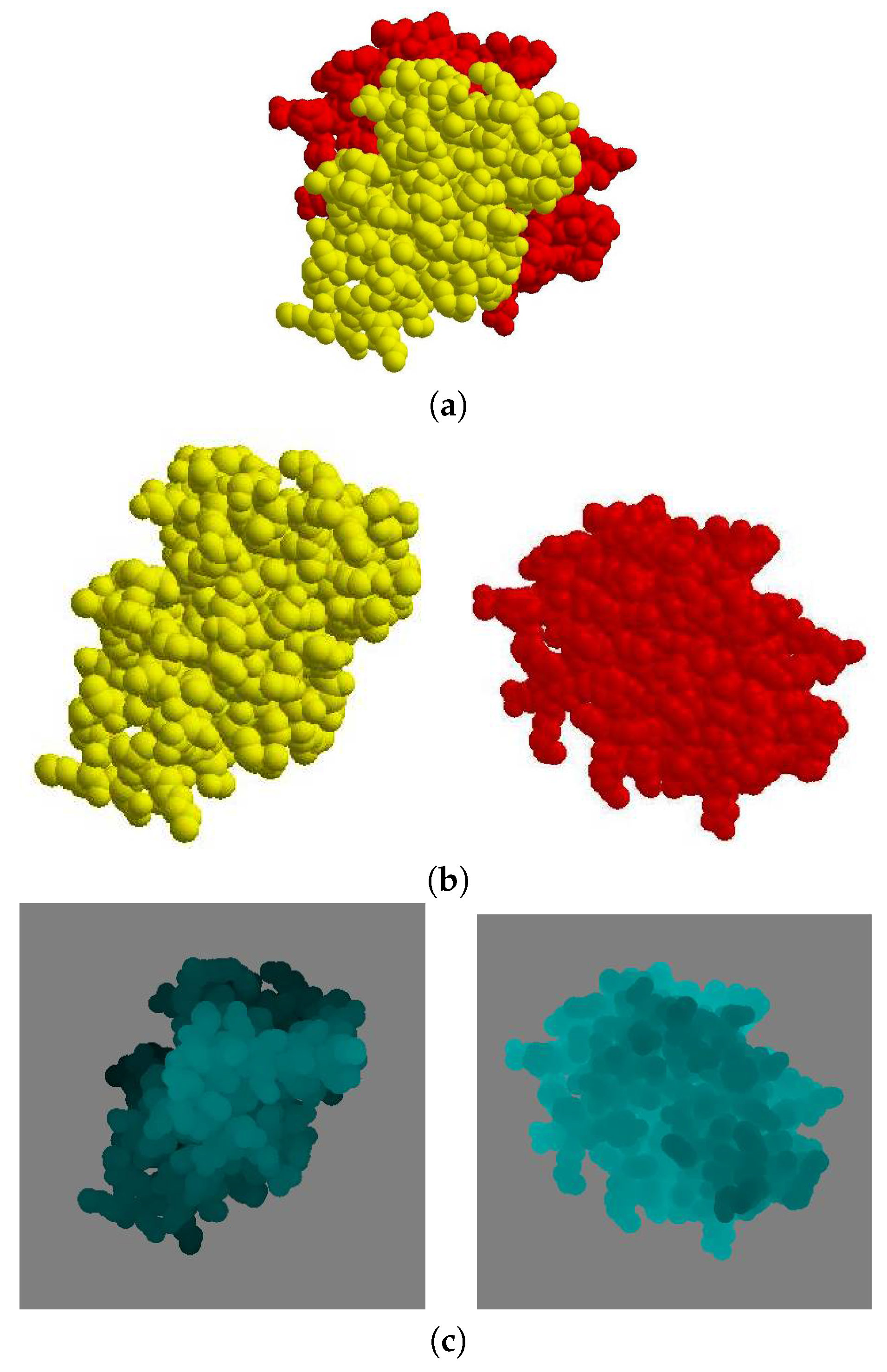
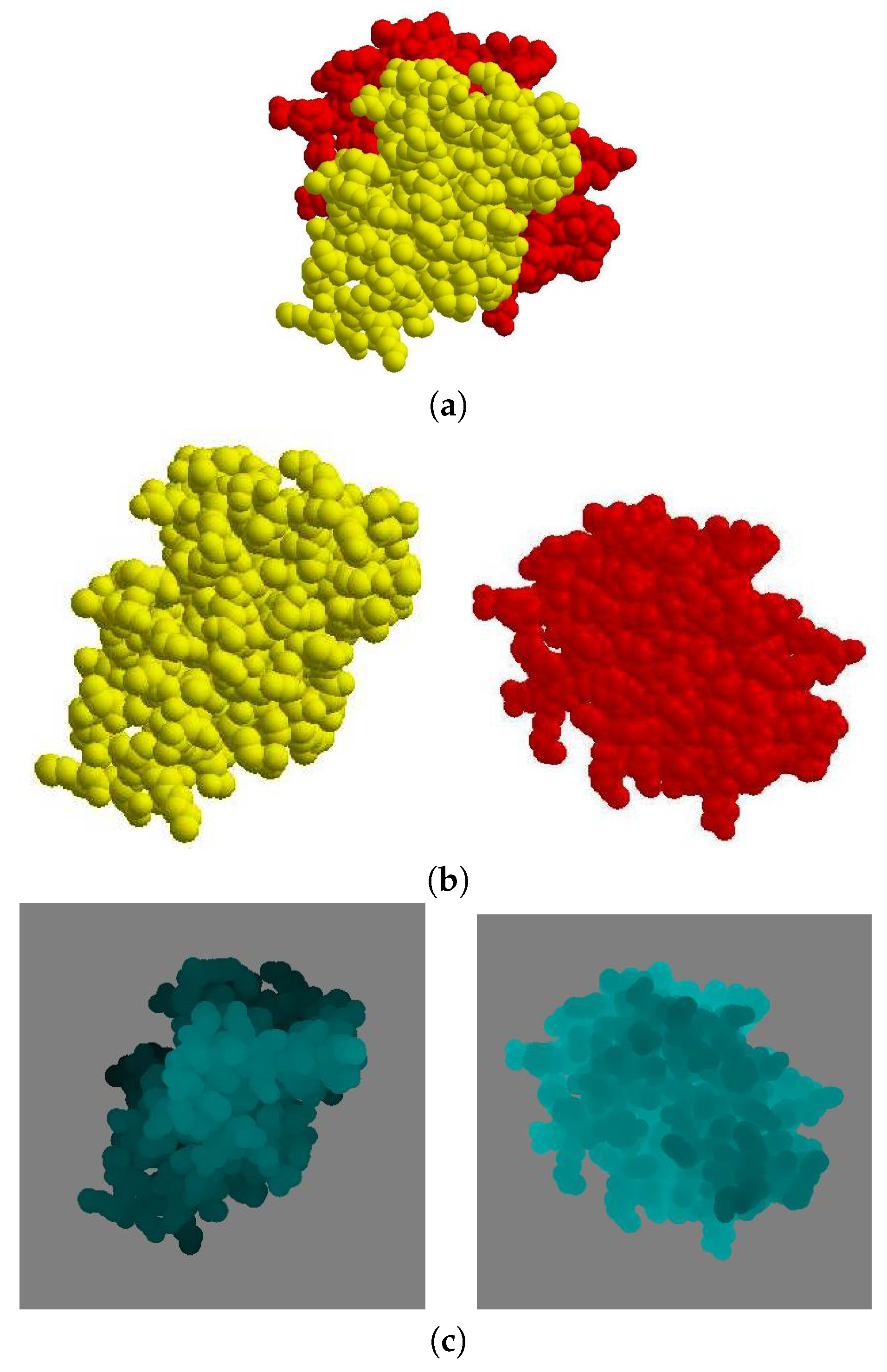
Given a protein complex in a crystal that has a binding direction coincident with the
axis (
Figure 6a), the separate images of each molecule
and
are shown in (
Figure 6b). The depth buffer images of
and
are then shown in (
Figure 6c), where the gray color pixels are the background and the other pixels are the molecule. When the depth value is higher, the corresponding pixel in the image is brighter.
The difference between the depth values of
and
is computed by subtracting the depth value of
from
. The resulting difference image is shown in
Figure 7.
| Function ContactArea(, ) |
| /* , : molecules */ |
| /* t: threshold for meaningful distance */ |
| /* u: unit area for one pixel */ |
| Begin |
| = 0; |
| For each distMap[i][j] begin |
| if distMap[i][j] ≤t then |
| + distMap[i][j]; |
| End |
| Return ; |
| End |
5. Experimental Results
In the previous section, the binding direction was determined based on the best approach for two proteins to bind with each other. The perpendicular plane to the binding direction was used to view the binding interface and describe the binding surface in a two-dimensional way. Based on the perpendicular plane, a two-dimensional sectional binding area of the proteins was calculated for the viewpoint of the binding direction. This sectional area can also be used to analyze the protein–protein interaction, where the shape of the binding surface can be very diverse.
Similar to two molecules in an enzyme-substrate interaction or ligand-receptor binding, two proteins in a complex have a binding specificity and this specificity comes from the reciprocal shape of their binding surfaces, like a lock-and-key. Thus, the prominence and depression patterns found on the surface of one protein are the opposite patterns found on its binding partner. Of course, the specificity also includes additional components, such as the pairing of opposite electro potentials, where a negatively charged region is matched with a positively charged region, while neutral regions provide hydrophobic interactions. In some protein–protein interactions, the binding region can be quite flat. In this case, the specificity is mainly derived from the potentials of the surface or the proteins could be promiscuous. The flatness of the binding surfaces can be estimated by comparing the two-dimensional sectional area with the three-dimensional surface area of the binding interface, thereby revealing the degree of convexity or concaveness of the binding surfaces.
To obtain the coordinates of protein–protein complexes, 32 crystal structures were randomly selected from a protein data bank. The binding direction of the proteins in the 32 complexes were then determined and the binding interfaces were analyzed (
Table 1). The sectional area of the proteins in each complex was calculated at a distance of 5
between the two proteins based on the five-five rule. The areas of the complexes were 268∼610
. The binding surface areas were also obtained using ePISA, which calculates the area based on the solvation and represents the three-dimensional contact area. Thus, the sectional area is the two-dimensional projection plan of the three-dimensional actual binding surface. Therefore, if the shape of the binding region is flat, the sectional area will be similar to the three-dimensional solvation area from ePISA. Alternatively, when one protein has a convex surface for binding and the partner protein has a concave surface, the ratio of the ePISA value to the sectional area will be greater than one, whereas if the convexity of the binding surface is similar to a sphere, the ratio will be 4 (
). This ratio was calculated for the 32 complexes and ranged from 1.9 to 4.3 with an average of 2.8. A value lower suggested a relatively flat binding surface of the proteins in the complex.
The sectional area can also be divided according to the distance between the surfaces of two proteins. Different distances suggest different binding characteristics. In the case of hydrogen bonding, the distance between the surfaces of an atom from each protein has a negative value as the two atoms share a pair of electrons. Meanwhile, if there is a van der Waals interaction with close contact, the distance will be less than 1
. Plus, an interaction mediated by a water molecule should have a space for the water molecule between the two proteins. If there is space for more than two water molecules, this suggests that each protein possesses its own water shell and is not seemingly important for protein interaction. A series of sectional areas can be calculated based on different distance criteria. For example, three sectional area values from the 32 protein complexes were generated using the distance criteria of 1, 3, or 5
(
Table 2). As expected, longer distances produced a larger area like a series of contour lines. By subtracting the area of a shorter distance from the area of a longer distance, the total sectional area can be divided into a series of areas according to the distance, such as ∼1
, 1∼3
, and 3∼5
(
Table 2). The distance less than 1
implies the tight interaction between two proteins with hydrogen bond or van der Waals contact. In the analyzed 32 protein–protein interactions, average 24% of binding area was less than 1
compared to the area of 5
from the five-five rule, and rest of the binding area would have certain flexibility (
Table 2).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}