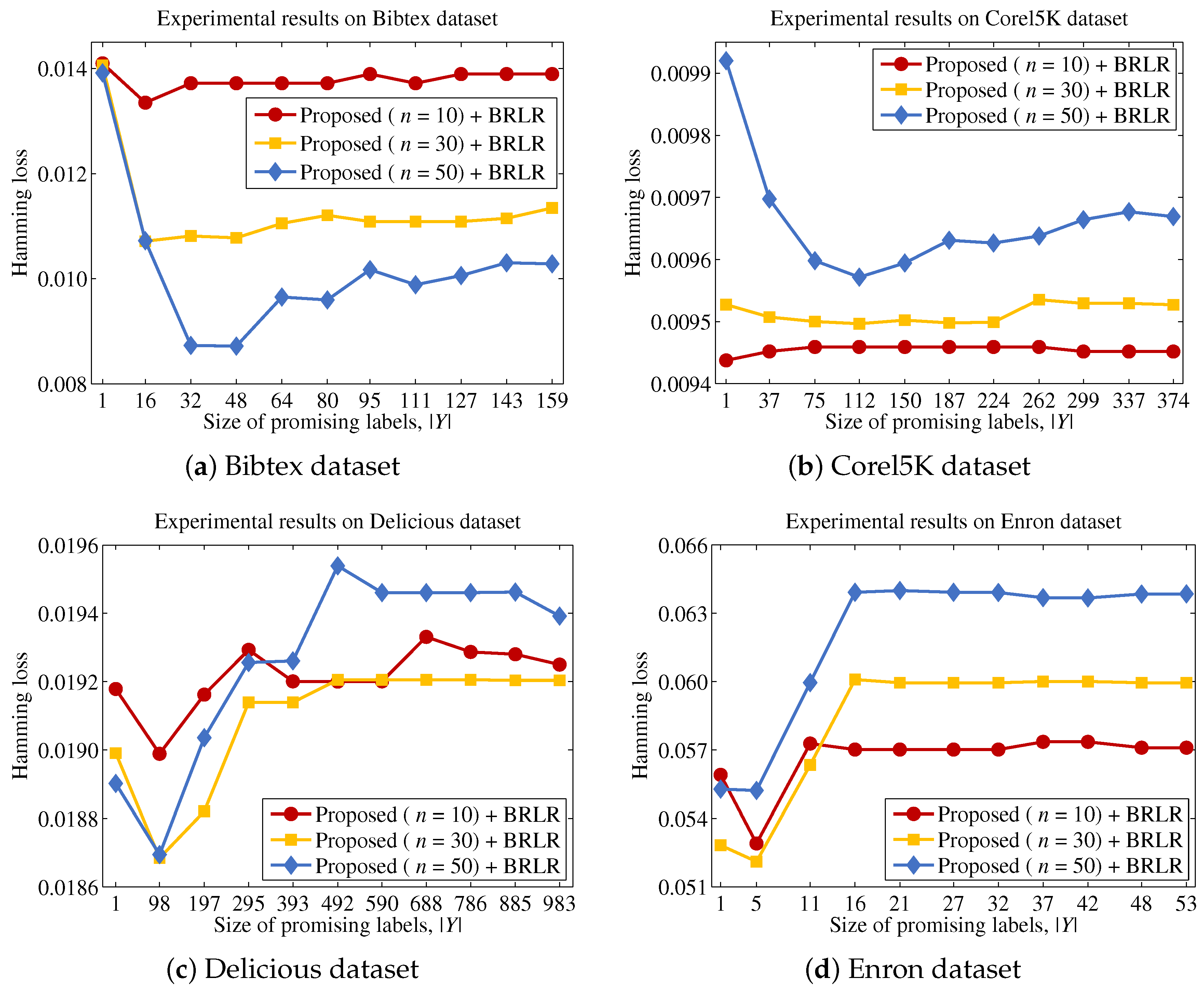
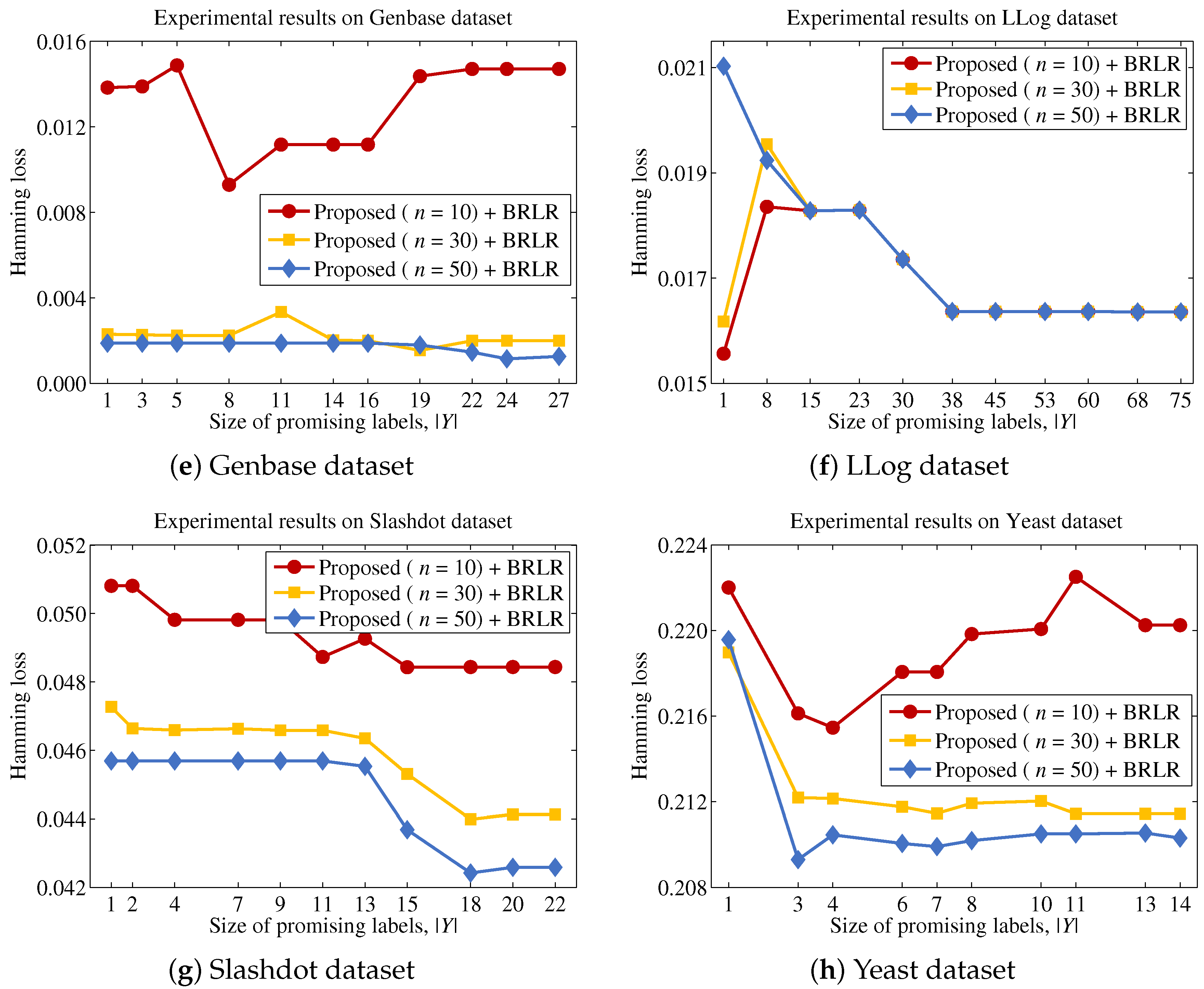
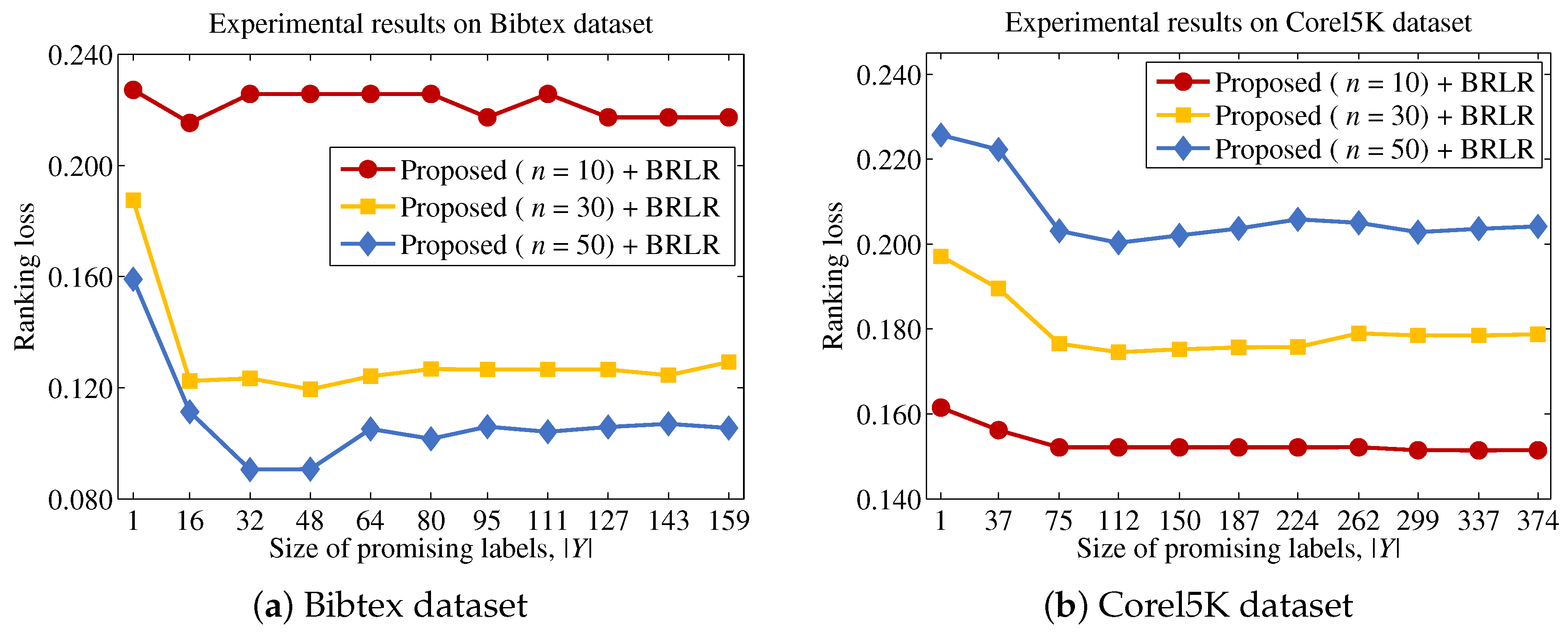
3.1. Characteristics of Feature Importance and a Strategy to Reduce the Computational Cost
In this study, we focus on a mutual information-based multi-label feature selection method, owing to the existence of thorough discussions regarding its theoretical background [
14,
17,
18,
43] and its popularity [
15,
26,
30,
44,
45]. Given a feature set
F and label set
L, the dependency, or shared entropy, between
F and
L can be measured using mutual information as follows [
46]:
where
is the joint entropy with probability function
. If
x is a joint state of variables in
X, then the entropy can be calculated directly. On the other hand, if the given variable set
X contains a set of numerical variables, then the entropy of
X can be obtained by discretizing each variable in
X [
47] or using the concept of differential entropy [
48]. In practice, direct computation of Equation (
1) can be impractical, because an inaccurate probability estimation can occur on account of the high dimensionality of a large label set
L or an insufficient number of patterns [
14]. To circumvent this difficulty, Equation (
1) can be rewritten as [
18]:
where × is the Cartesian product between two sets and
is the sum of a
k-degree interaction, defined as [
14]:
where
is a power set of
X without
,
Y is a possible element from
and
is the interaction information involving a variable set
Y. Specifically, this is defined as [
49]:
For example, if
and
, then
can be rewritten as:
Equation (
2) indicates that the interaction information for all possible variable subsets across
F and
L influences the dependency between
F and
L. Thus, it also indicates that the computational cost of calculating Equation (
2) increases exponentially according to the number of labels. To circumvent intractable computational costs, Equation (
2) can be approximated by setting a parameter that adjusts the maximum allowed cardinality of variable subsets [
14,
17]:
where
. Equation (
5) indicates that the computational cost can be significantly reduced by setting
, as follows:
Equation (
6) indicates that the dependency between
F and
L can be approximated by summing over all of the interaction information terms of variable subsets containing a feature and a label. Thus, a function
that measures the dependency between
F and
L can be written as:
For simplicity, the interaction information term for a variable subset involving only two variables can be rewritten using the mutual information terms relating to the variable subset, as follows:
As a result,
can be rewritten as:
Equation (
8) indicates that all mutual information terms for all possible pairs
with
and
should be calculated to perform a multi-label feature selection based on
. Because each feature in
F contributes to
independently, the optimal feature subset can be obtained by selecting the top
n features with the largest contributions (i.e., importance) to the value of
. This is calculated as:
where
. Equation (
9) indicates that when the label set
L is large, the scoring process may incur high computational costs, because it must calculate the joint entropy term
. To reduce the computational cost,
should be approximated. Shannon’s inequality for information entropy indicates that
is bounded as [
46]:
where
. Because the term
does not involve the calculation of the joint entropy term
, the scoring process can be accelerated by approximating the
term using the
term. As a result,
can be approximated as:
In this study, Equation (
11) will be used to calculate the dependency between features and influential labels, in order to reduce computational costs. Suppose that a multi-label feature selection method employs Equation (
11) to evaluate the feature importance, where the joint dependency between features and labels is not considered. Then, the importance of features is determined by the features’ own entropy values.
Proposition 1. If , then .
Proof. Suppose that there are two features
, where
. Because the importance of a and the importance of b are calculated using
and
, the inequality
will hold if each
value is greater than or equal to the corresponding
value with the same label
l. When
, the value of
is always greater than or equal to the corresponding
value, because the following relations are satisfied:
If , then .
If , then and , and thus, .
If , then and , and thus, .
Because these relations hold for all pairs , a will correspond to a value that is greater than or equal to the value of . ☐
Proposition 1 indicates that the computational cost can be significantly reduced, because the scoring process can be performed without calculating the terms . On the other hand, it also indicates that features with higher entropy values will be included in the final feature subset S, regardless of their dependencies with labels. Because the feature subset should depend on L, a strategy to enhance the dependency between S and L without incurring an excessive computational cost is required. To establish a proper strategy, the characteristics of against should be investigated. First, we state Proposition 2 as follows.
Proposition 2. is the upper bound of ,
written as: Proof. Equation (
9) shows that
is the sum of the mutual information terms between
f and all labels. Because each
term is bounded above by each
term with the same label
l and
is the sum of all the
terms,
is always greater than or equal to
. ☐
Proposition 2 indicates that a multi-label feature selection method employing for the scoring process, such as multi-label feature selection based on , may imply the identification of a feature subset that is far away from a designated solution if the value of is dissimilar to . Thus, a strategy for fine-tuning the function towards the function, within the constraints of given computational resources, would be beneficial. In a multi-label feature selection method based on , the method may repeatedly calculate the mutual information terms, along with , in order to obtain the value of . Within this loop, let us define a function , where j is the number of labels considered for calculating the mutual information terms, as follows:
Definition 1. Let be the labels for which the actual mutual information between given features f and is calculated, where .
Then, the score function is defined as:
where
Y is a set of labels already considered during the loop,
,
is a complementary set of
Y and
. Thus,
and
. The number of calculated mutual information terms will be incremented by one during each loop iteration, leading to a series of intermediate bounds, as described in Lemma 1.
Lemma 1. Let be the label subset Y for calculating .
Then, a series of bounds can be identified as:where .
Proof. For the inequality to hold, the following relation should be satisfied:
Equation (
15) can be simplified as:
Because
, where
y is a label and
, the label subset
in Part 1 can be simplified as:
Thus, Equation (
16) can be simplified as follows:
Equation (
18) indicates that
is always greater than or equal to zero. Because this relation holds for
, Lemma 1 can be obtained, which represents a series of bounds. ☐
Lemma 1 indicates that it is possible to obtain a better approximation for estimating by increasing the size of Y. That is, the ability of the function to measure the importance of f in terms of the dependency between f and labels is enhanced. In other words, the algorithm is able to reduce the computational cost by selecting a proper label subset Y, because the calculation for the terms incurs a lower computational cost than that for the terms. Suppose that the algorithm is able to identify a promising label set Y prior to the actual scoring process. Then, Lemma 1 can be generalized as Theorem 1.
Theorem 1. Suppose that the algorithm identifies a label subset Y prior to the scoring process. By calculating the mutual information terms between f and the labels in Y, the following relation can be obtained: Proof. Let us begin with the lower bound of
. For the inequality to hold,
should be greater than or equal to
. Thus, the following equation should be satisfied:
Equation (
20) can be simplified as follows:
Equation (
21) shows that Part 2 is always greater than or equal to zero, because each
term is the upper bound of the corresponding
term with the same label
l. Thus, the lower bound is always satisfied. Next, let us focus on the upper bound of
. To satisfy the inequality,
should be less than or equal to
. Thus, the following equation should be satisfied:
Equation (
22) can be simplified as follows:
Equation (
23) shows that Part 3 is always greater than or equal to zero, because each
term is the upper bound of the corresponding
term with the same label
l. Thus, the upper bound is also always satisfied. ☐
Theorem 1 indicates that the value of
is closer to
than
for any given label set
Y, except for
. In addition, in order to obtain a value
similar to the value
for efficient feature scoring with a small
Y, the identification of a promising label set
Y becomes an important task. Because Lemma 1 implies that
monotonically decreases to
as the size of
Y increases and both
and
are independent of each other where
, a promising label set
Y that minimizes the difference between
and
can be identified by including
in
Y sequentially in a manner that maximizes
, as shown in Equation (
18). However, this task is inefficient, because it requires the calculation of all of the mutual information terms during the loop. Moreover, in this manner, the promising label set
Y can be different for each feature, owing to the mutual information terms involved in Equation (
18). This results in an excessive computational cost for identifying a promising label set for each feature.
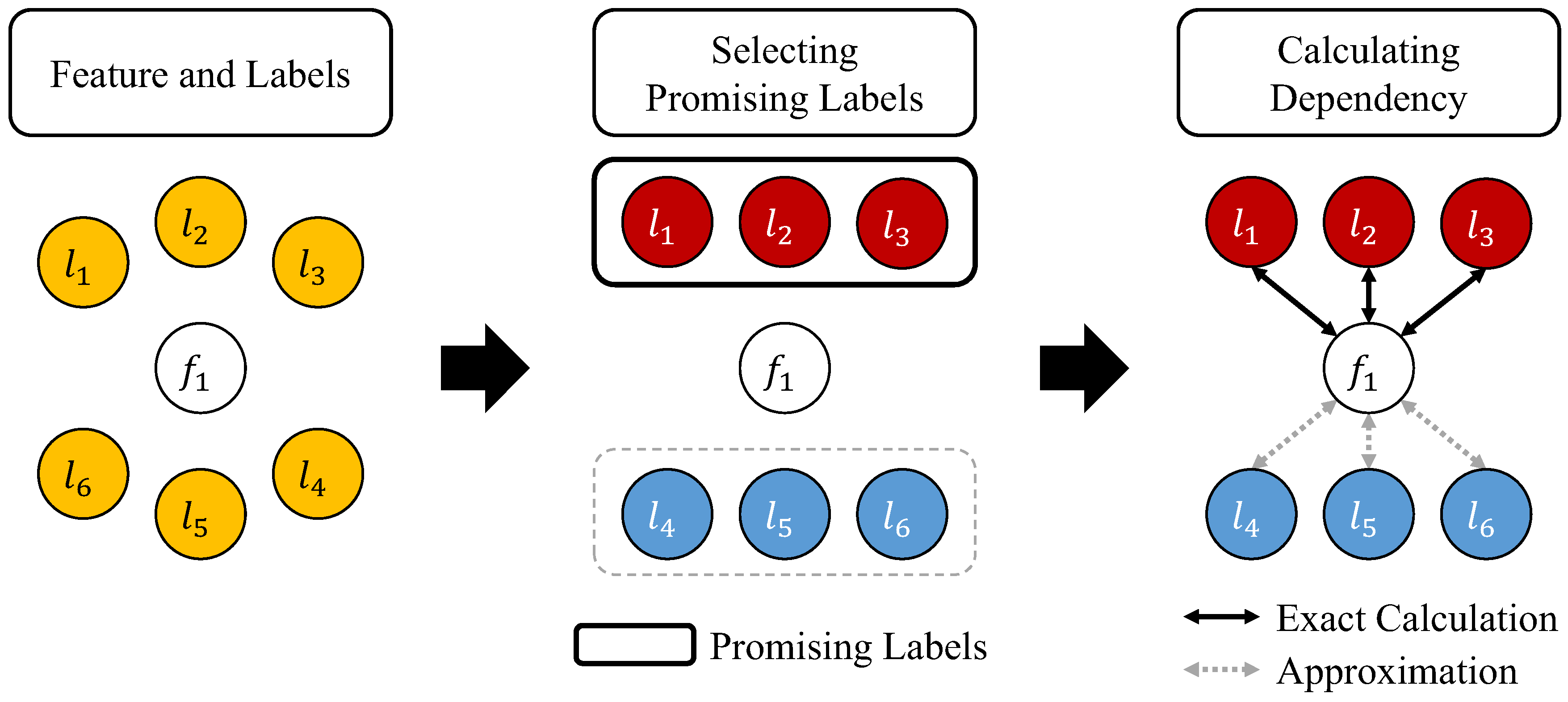
3.2. An Efficient Process for Identifying a Promising Label Set
In the work of [
14], it was demonstrated that the feature subset can reduce the uncertainty of labels (i.e., the remaining entropy) by using its selected features. A feature is selected because it reduces the uncertainty of labels to a greater extent than unselected features. Suppose that the algorithm identifies a label subset
Y for accelerating the scoring process. Because the algorithm precisely calculates the dependency between features and labels in
Y and approximates the dependency between features and labels in
, the feature subset will be specialized to reduce the uncertainty of labels in
Y. However, there can be a subset of labels that does not significantly contribute to the uncertainty of labels, particularly in large label sets, and these labels are known to lack influence on the importance of features [
17]. These observations indicate that a value
similar to
can be obtained if the algorithm identifies a
Y that maintains the uncertainty of
L as far as possible, with a fixed number
. If the uncertainty of
Y is similar to that of
L, then the importance of features will not change significantly compared to cases in which the importance is evaluated based on
L. The uncertainty of
L can be measured by using the entropy function [
46]:
Because the calculation of Equation (
24) is impractical, owing to the high dimensionality of large label set
L, it can be rewritten as follows [
14]:
Equation (
25) shows that the computational cost will increase exponentially according to
, indicating that this can incur an intractable computational cost. To circumvent prohibitive computational costs, Equation (
25) can be approximated using Equation (
5), by setting a parameter
b:
where
. Equation (
26) indicates that the most efficient approximation of
can be obtained by setting
, as follows:
Because interaction information terms with only one variable can be rewritten using an entropy term involving that variable, Equation (
27) can be rewritten as follows:
Equation (
28) indicates that the uncertainty for a label set can be approximated by the sum of the entropies for each label. Because
, the optimal label set
Y that maximizes
can be obtained by selecting the top
labels with the largest entropy values.
In our multi-label feature selection,
becomes similar to
by replacing each
term with the corresponding
term that has the same label. As a result, the importance among features can be changed, because this situation occurs on all features. Let us focus on the start of the loop where
. In this step, all of the mutual information terms between
f and all labels are approximated by their upper bounds, and the final score
f is determined by summing over all of these values. Thus,
terms where
will contribute to the final score differently, because their magnitudes can vary. Based on Equation (
28), the proposed method will choose a label
y with the largest entropy from
and update the final score by replacing the
term with the
term. In this case, the value of the replaced
term is the largest among the values of the remaining
terms on account of Theorem 2, where
.
Theorem 2. The label that implies the largest value with is the label with the largest entropy value.
Proof. Suppose that there are two labels , with and . In this case, it also holds that , because is fixed, and the function outputs a smaller value lying between and the entropy value of the corresponding label. Because this relation always holds for all label pairs that can be drawn from , the inequality is always satisfied if . ☐
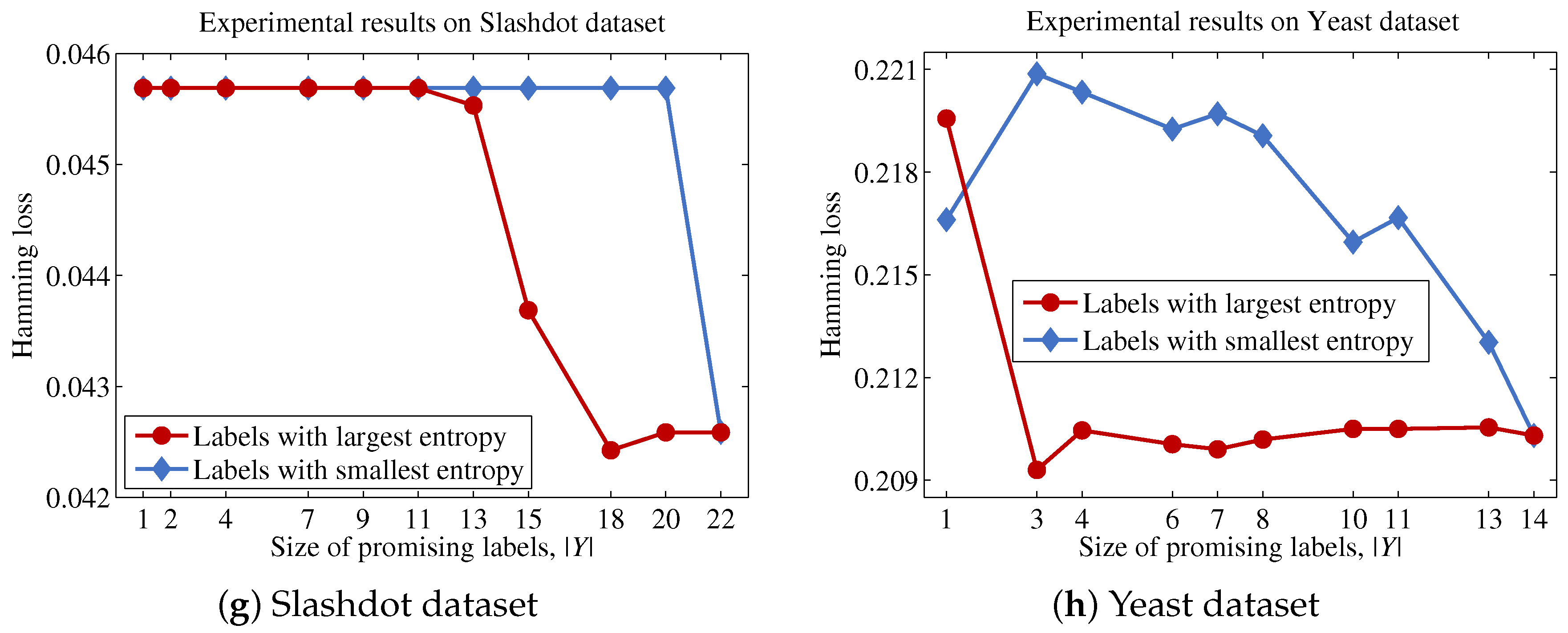
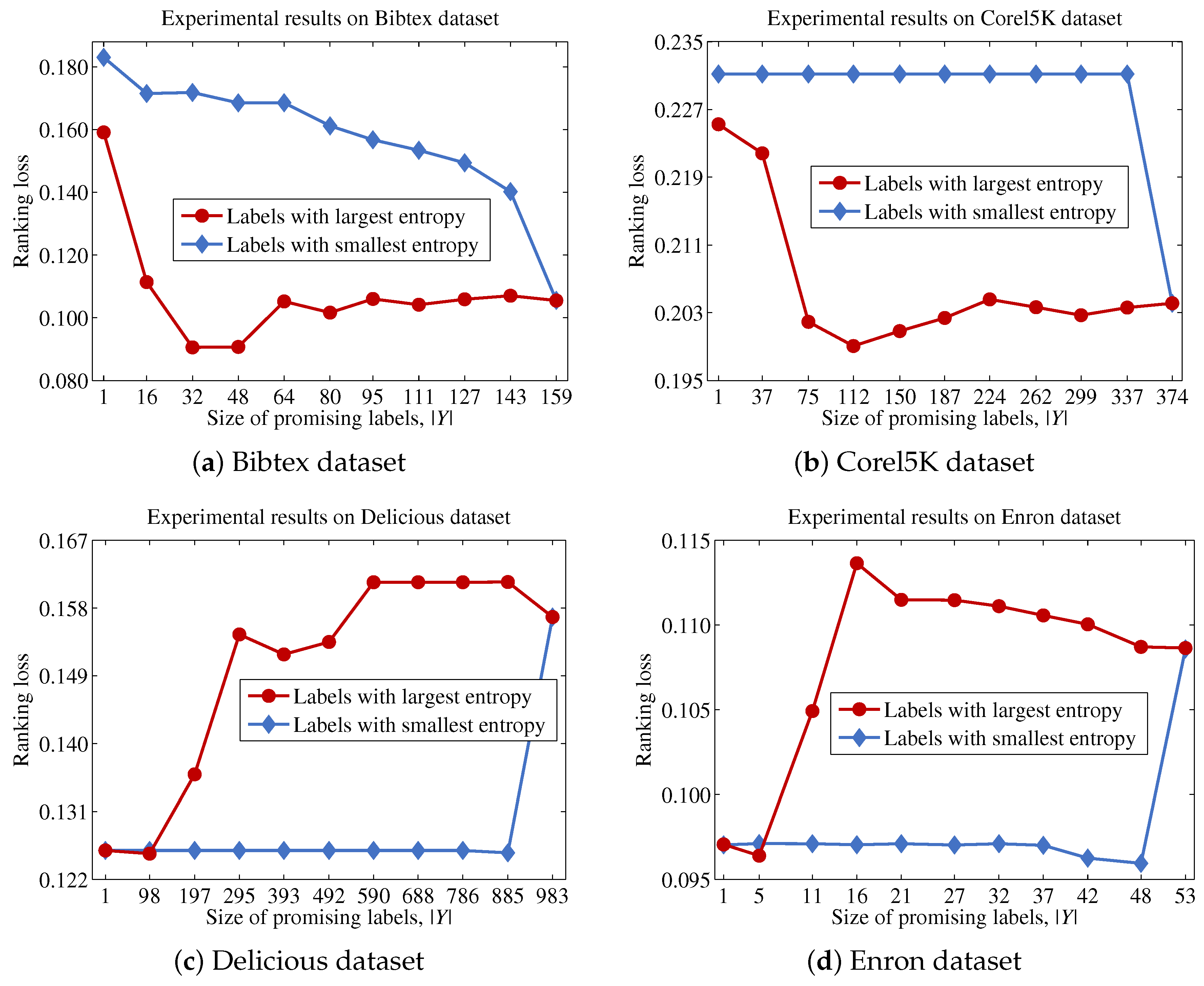
Because Theorem 2 is satisfied for all features, which means that the promising label at each step is the same for all features, the proposed method is able to efficiently identify the label to be considered from each step, after sorting labels based on their entropy values and choosing the label with the largest entropy from sequentially. Thus, the proposed method will determine the importance of a feature by summing the mutual information values between f and labels that significantly contribute to the uncertainty of the original label set and the approximated values between f and labels with small contributions to the original label set.
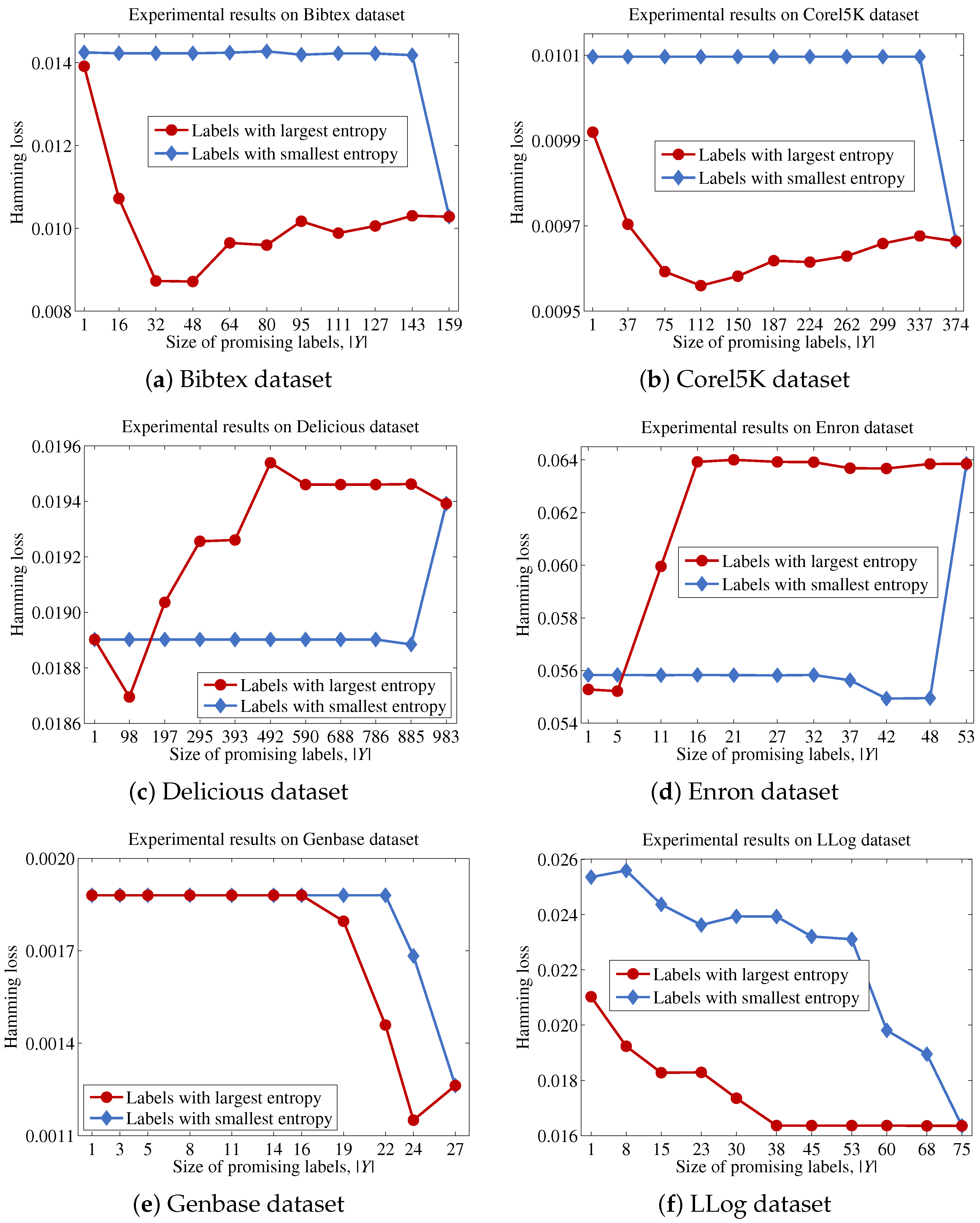
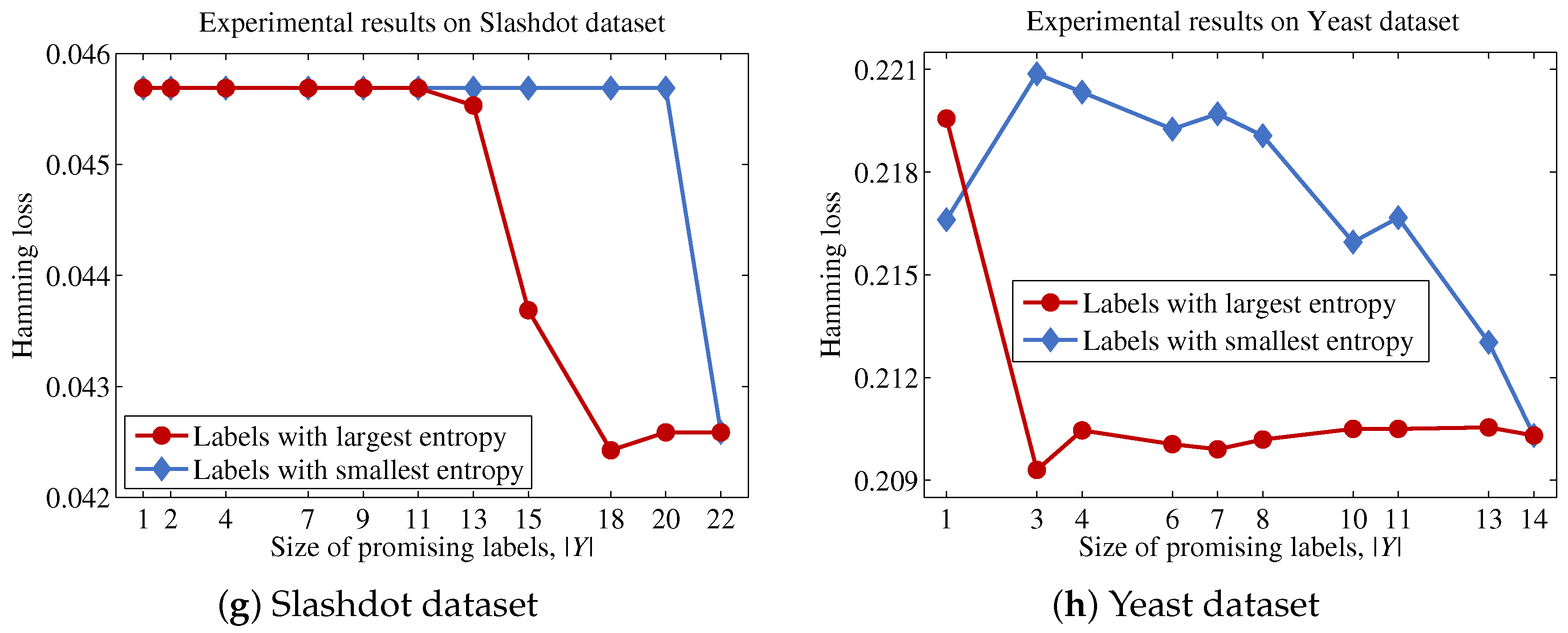
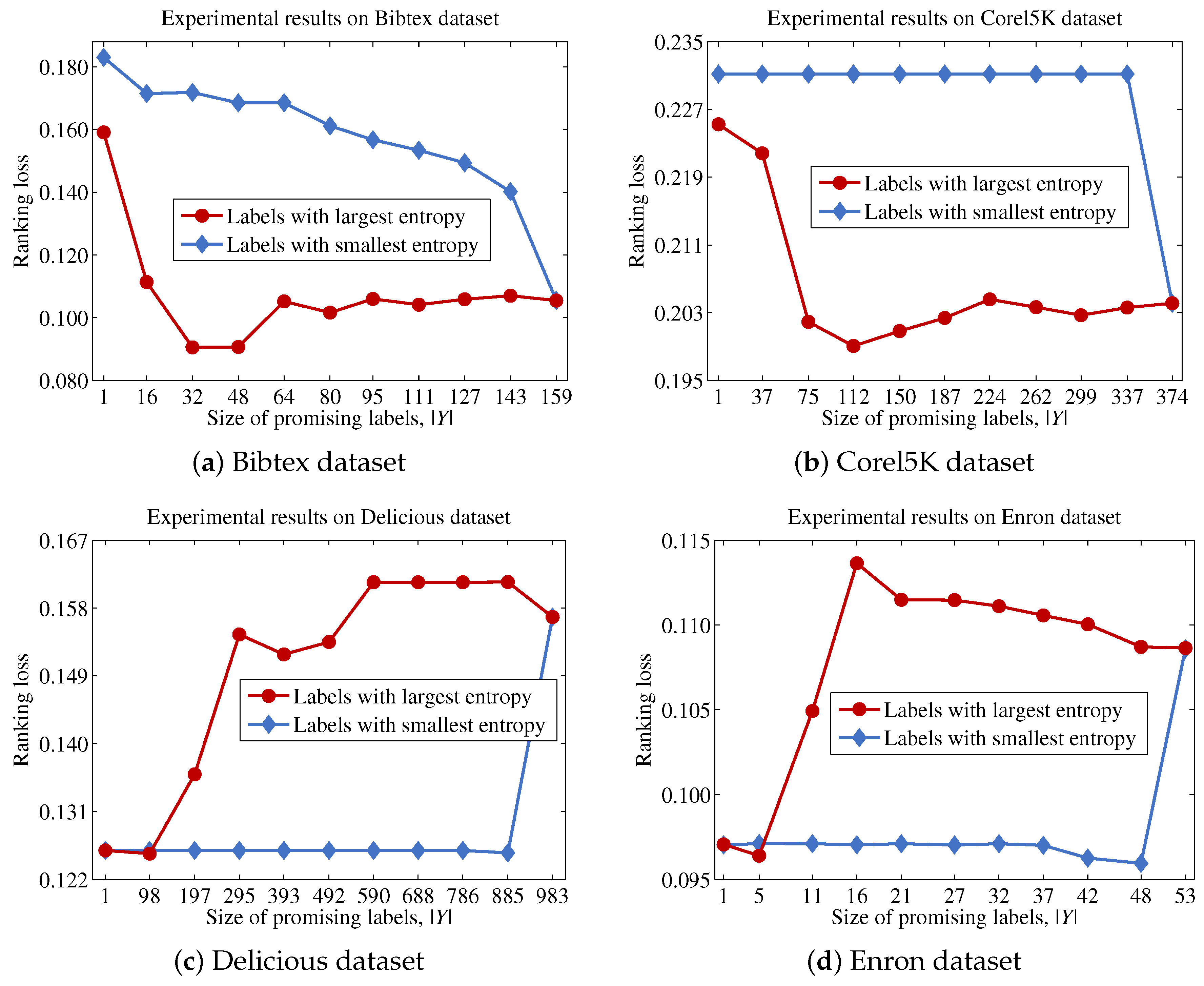
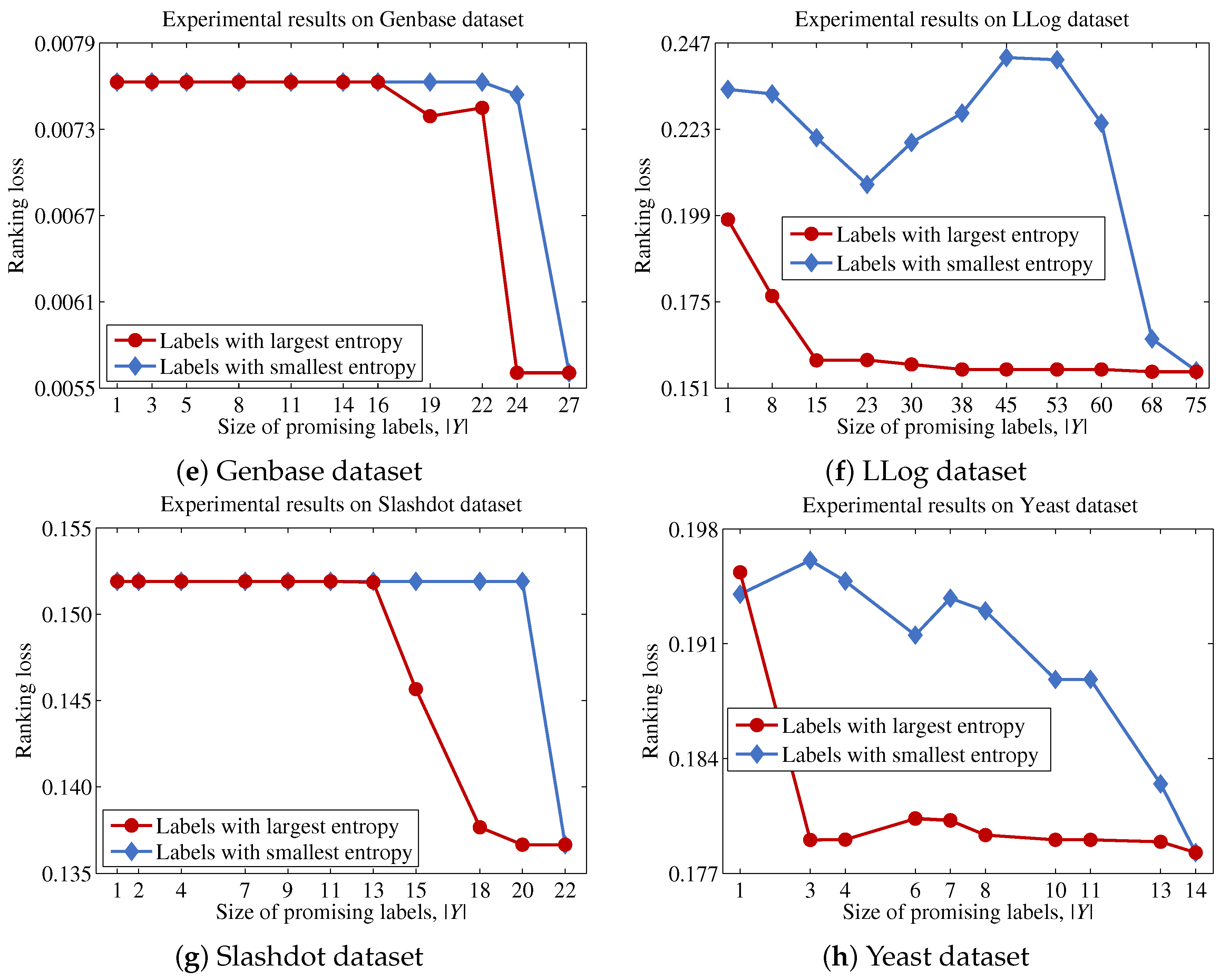
Algorithm 1 describes the procedural steps of the proposed method. The proposed method first initializes using F (Line 6). Next, the entropy of each label in L is calculated, and then, is created by sorting labels based on their entropy values (Line 7). This process prevents the occurrence of repetitive sorting operations for each feature in identifying the most promising label at each step. Next, the proposed method calculates the contribution of each feature (Lines 8–10). It should be noted that the recalculation of to obtain and is unnecessary, because these values have been calculated in Line 7. Finally, the proposed method sorts features in based on the values for each feature and then outputs the top n features in (Lines 11 and 12).
| Algorithm 1 Pseudo-code of the proposed method. |
| 1: | Input: |
| 2: | F, L, n, ; where F is a set of original features, L is a set of original labels, n is the number of features to be selected and is the number of labels to be considered. |
| 3: | Output: |
| 4: | S; where S is the final feature subset with n features. |
| 5: | Process: |
| 6: | Create by assigning F to ; |
| 7: | Create by sorting L using where ; |
| 8: | for all do |
| 9: | ; |
| 10: | end for |
| 11: | Sort based on values; |
| 12: | Output the top n features in . |
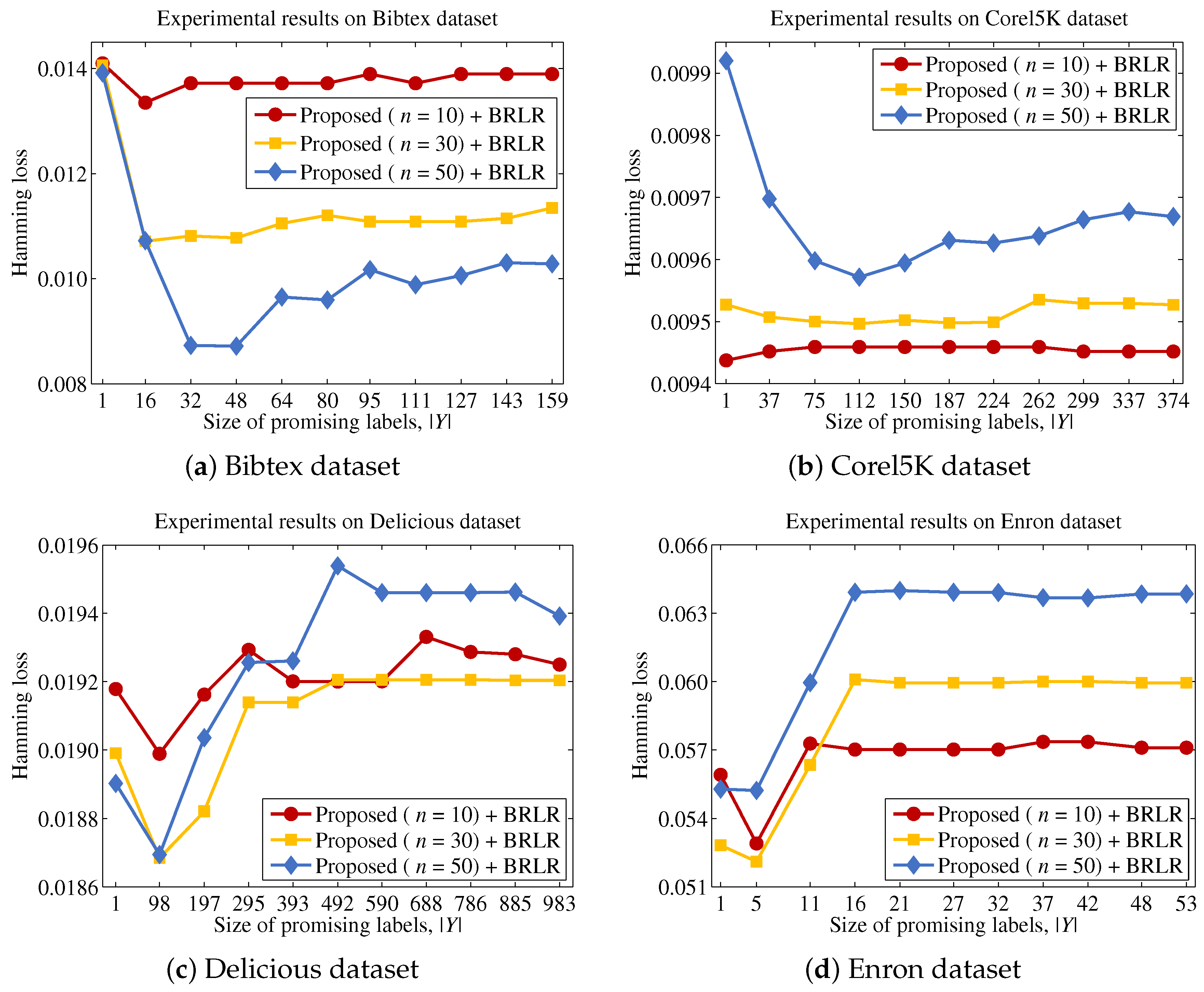
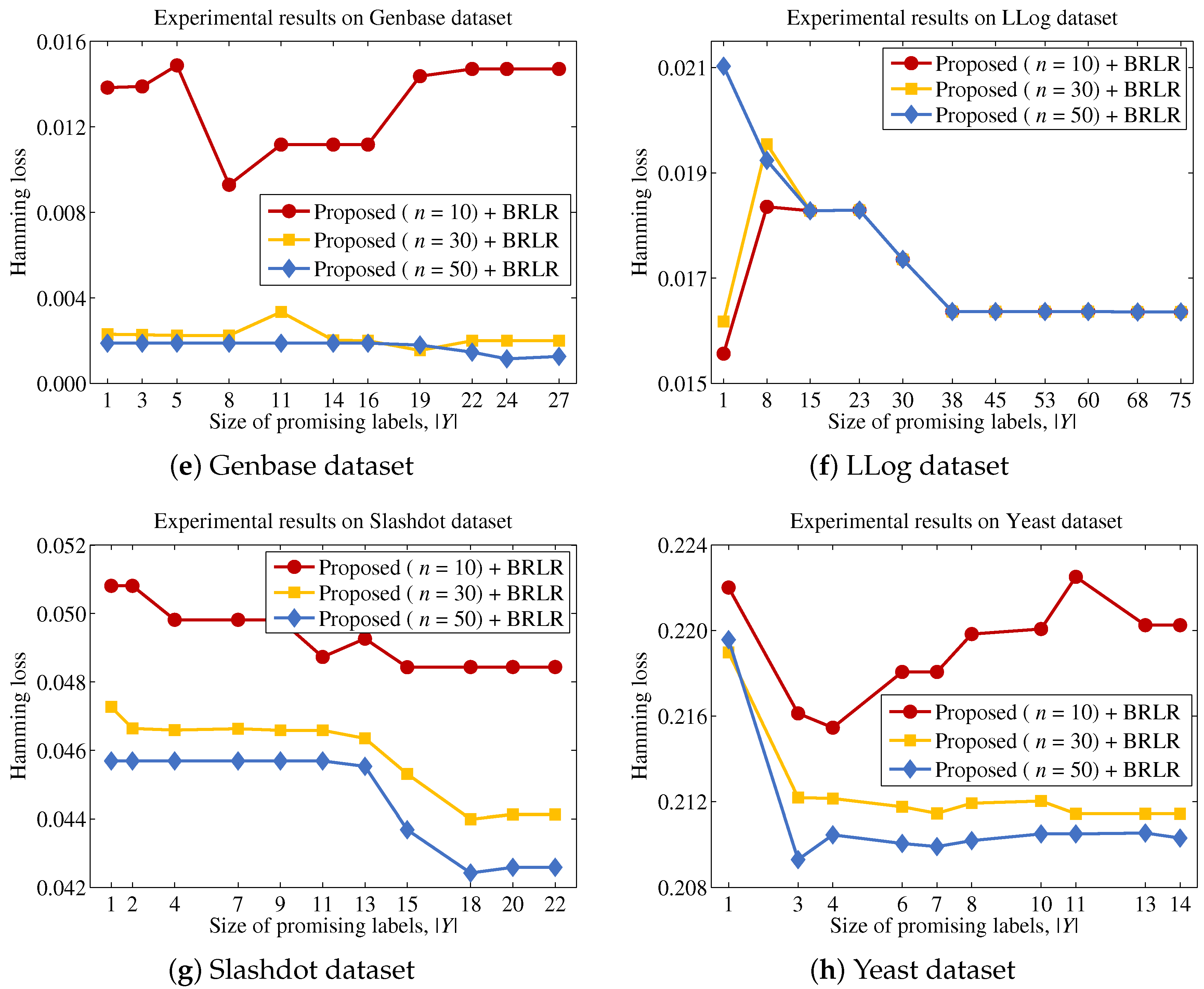
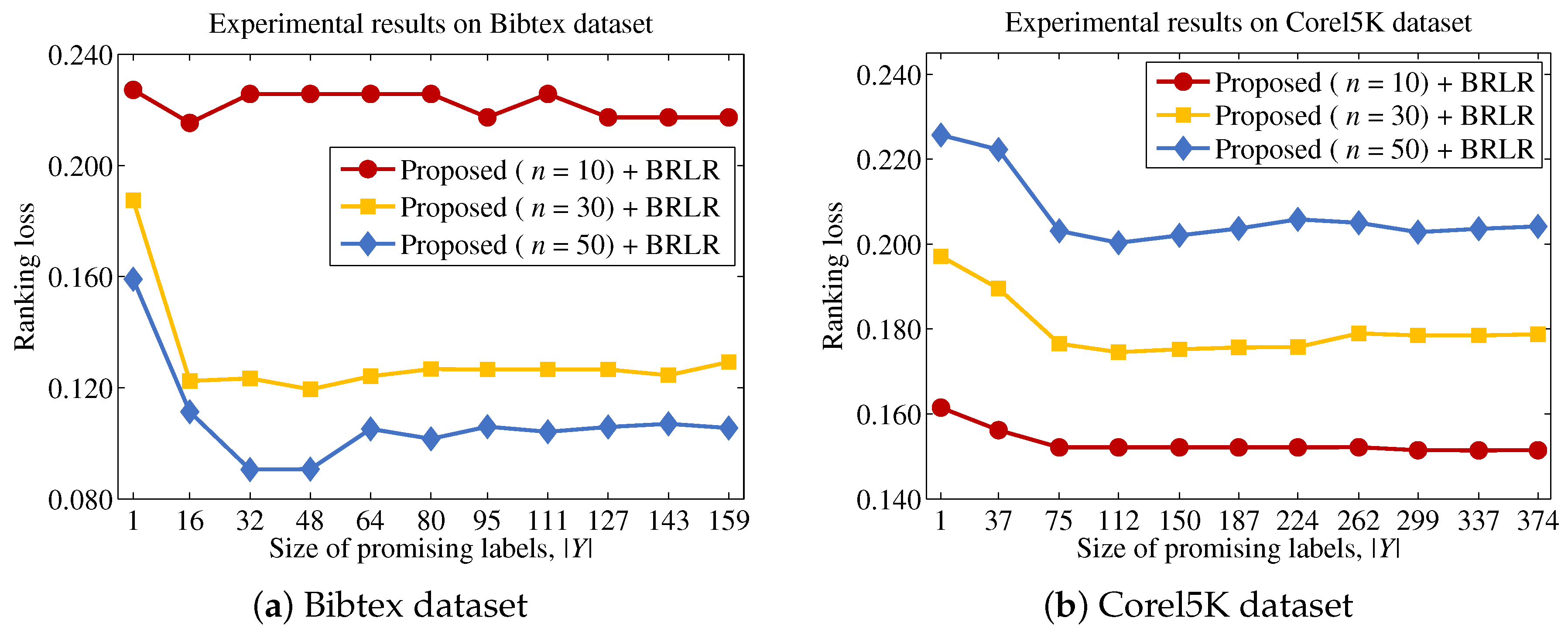
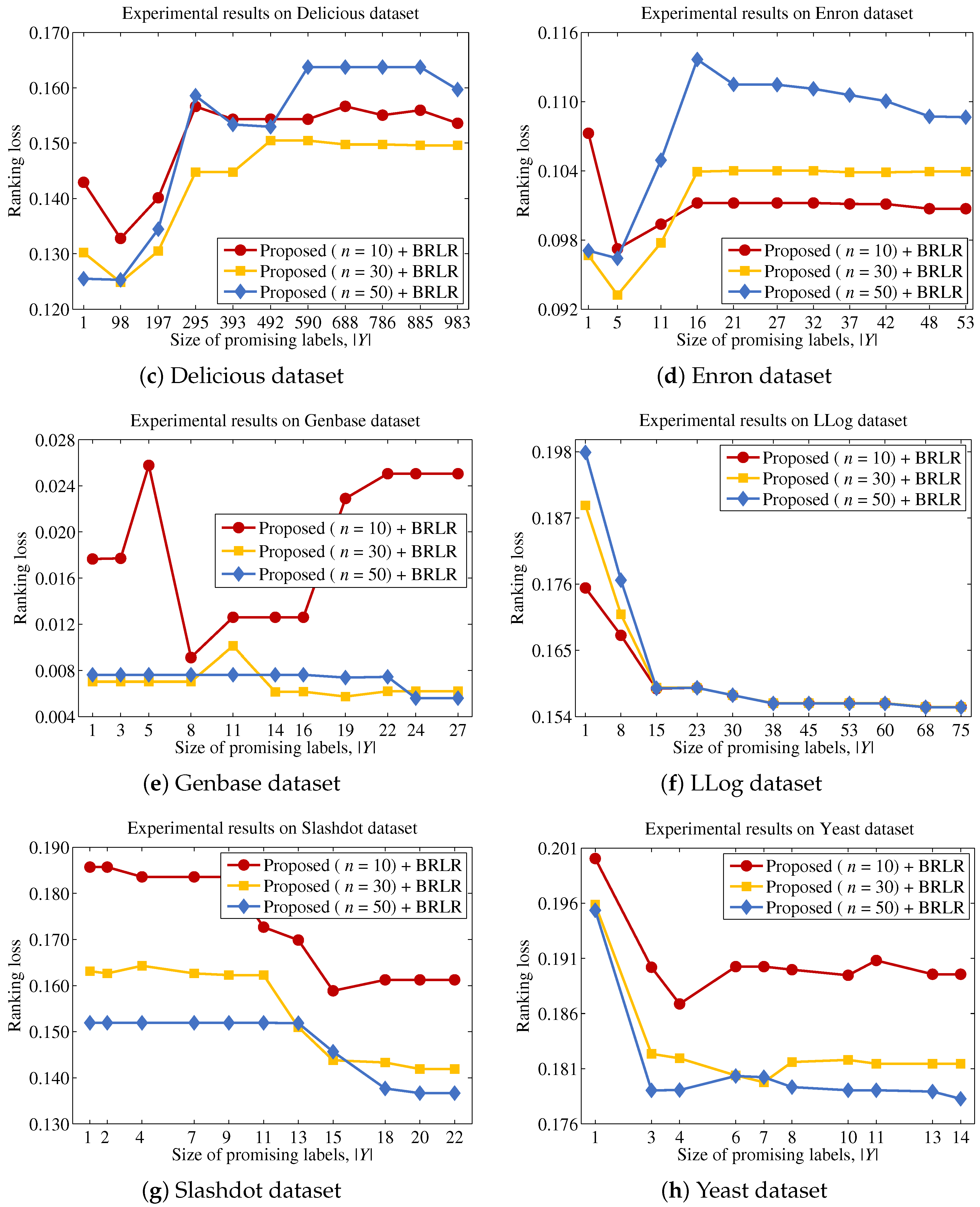
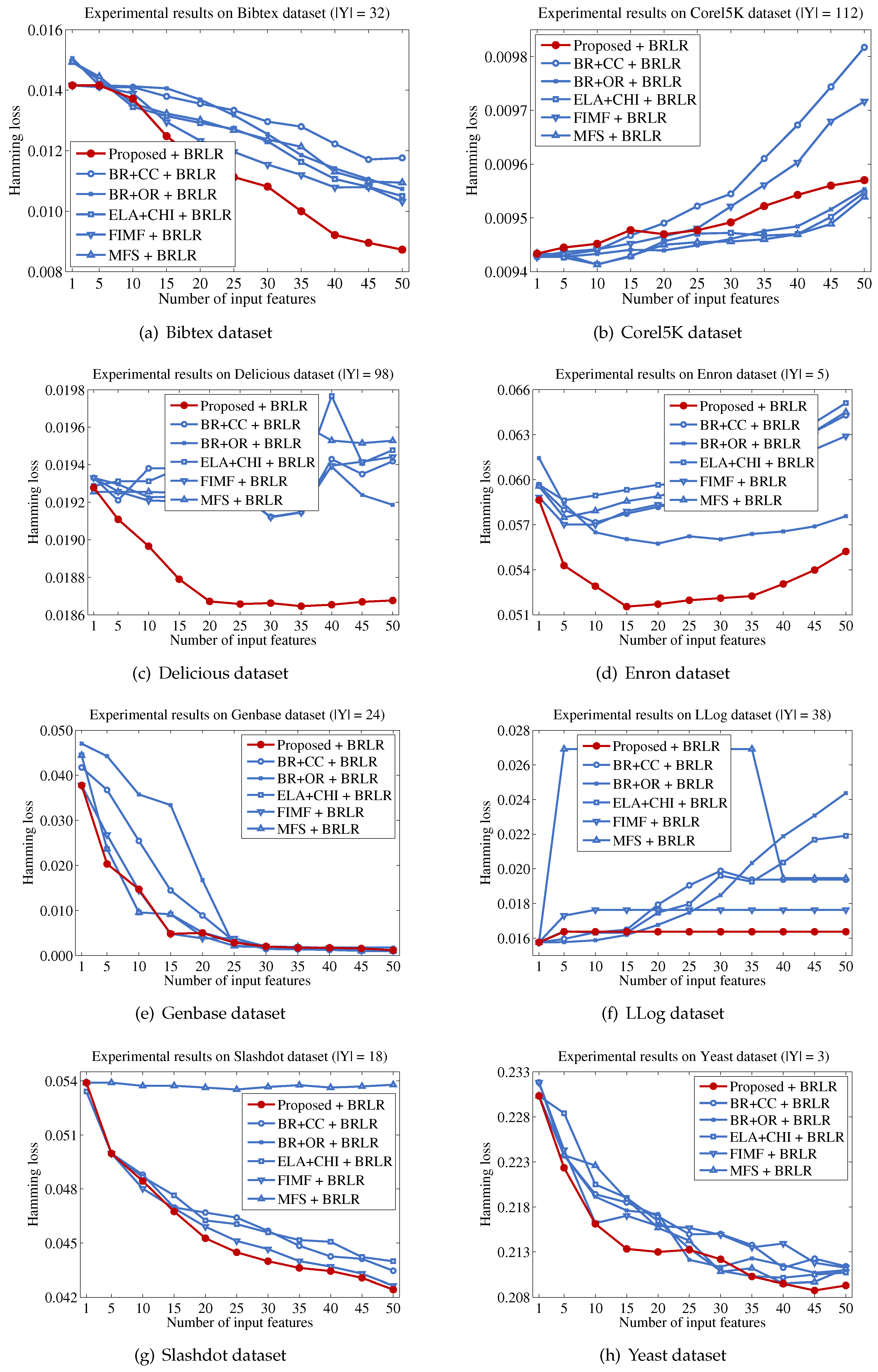
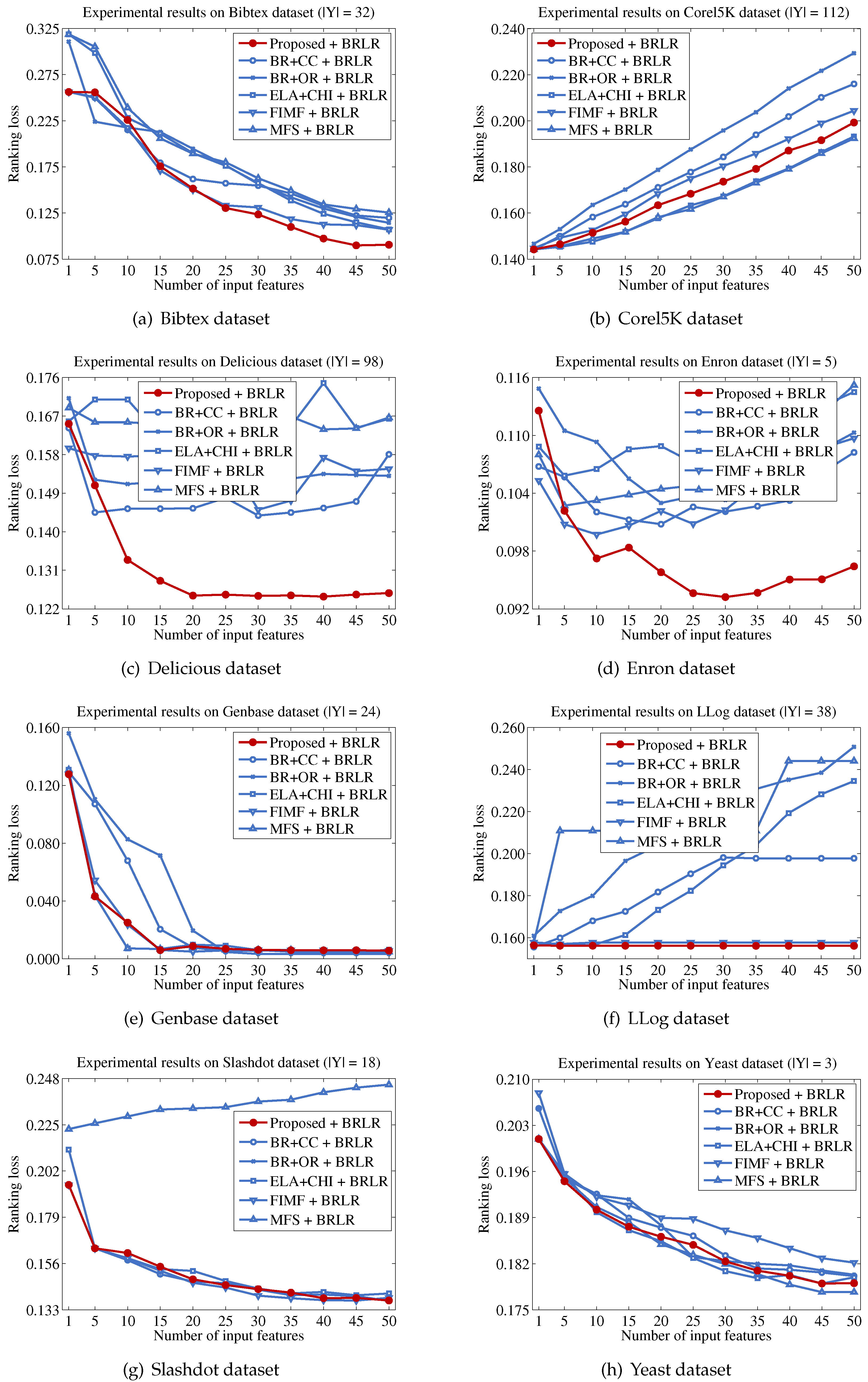
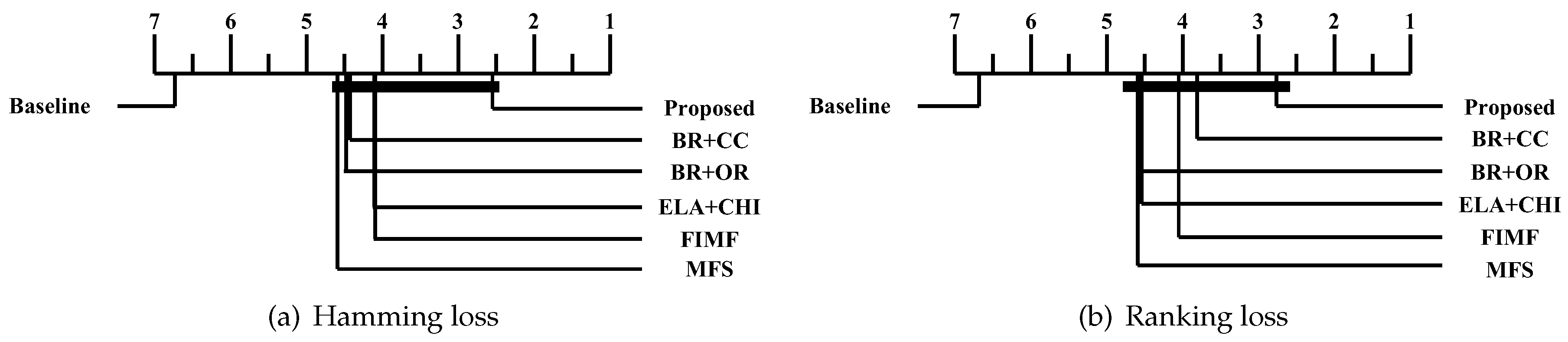
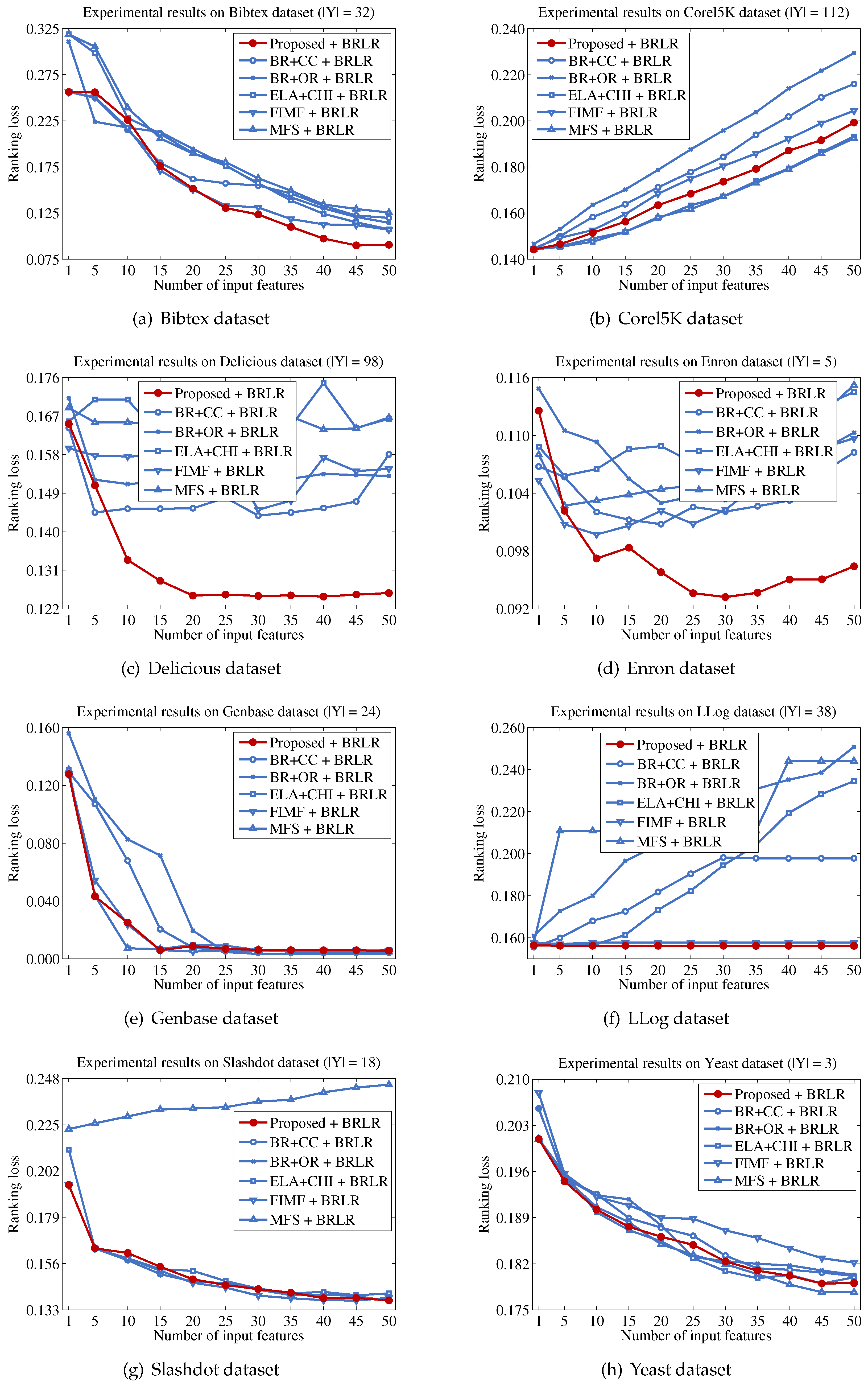
Finally, we describe the computational cost of the proposed method and compare this to a conventional binary relevance-based feature selection method, such as BR + CC, to show the efficiency of the proposed method. For a dataset with patterns, features and labels, the time complexity of BR + CC can be written as , because it evaluates the Pearson correlation coefficient between each feature and each label and then aggregates those values to identify the features to be included in the final feature subset. Let us assume that the computational cost for computing mutual information and Pearson correlation coefficients is the same, as both operations commonly involve two variables and have to examine patterns. Because the proposed method calculates the mutual information value between a feature and labels in Y, the computational cost for this process will be . It should be noted that the calculation results for the entropy of each feature and each label are used to calculate mutual information terms, thus calculating terms does not increase the computational cost. Our analysis indicates that the computational cost of the proposed method will be significantly influenced by the size of the promising label set Y.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}