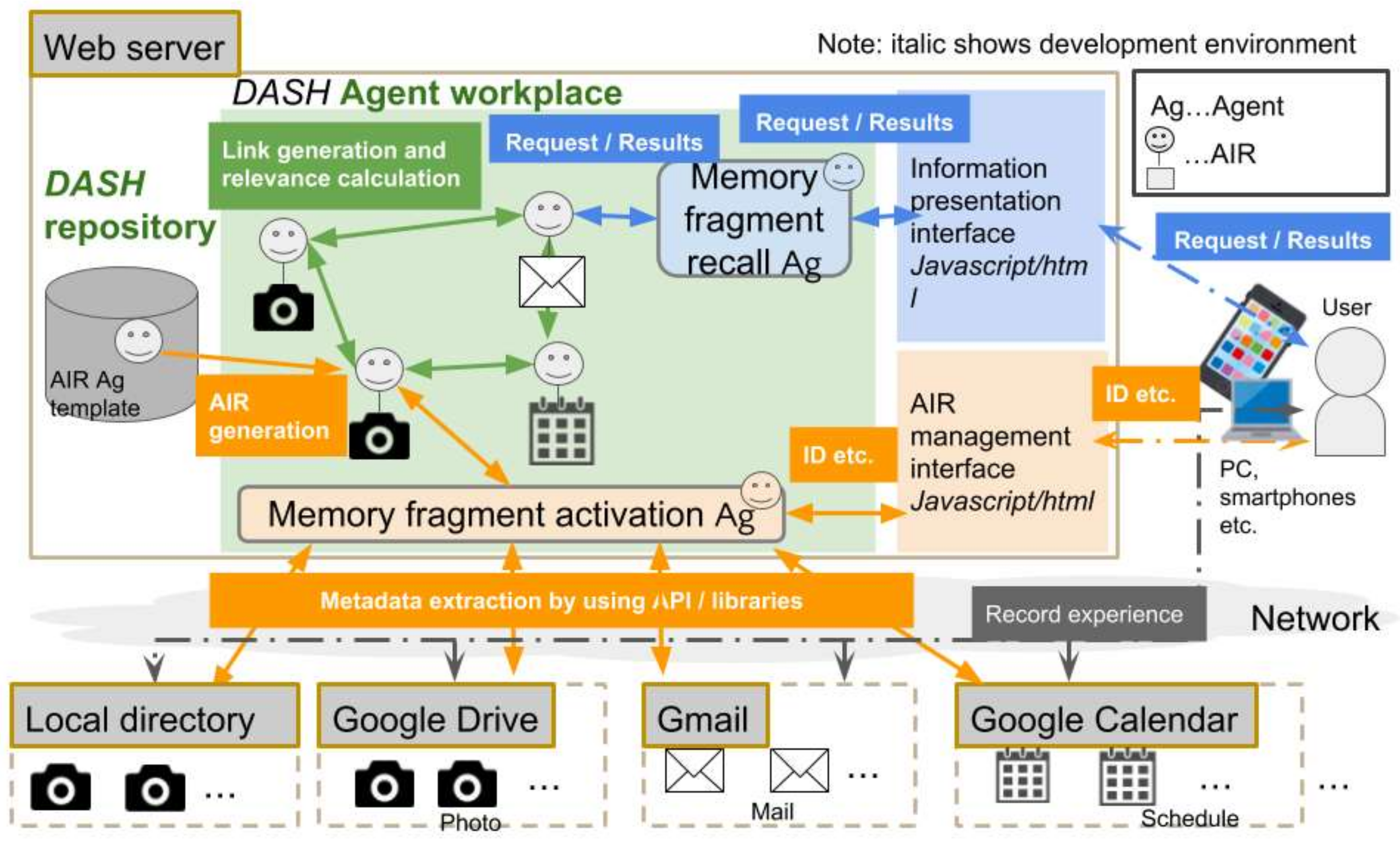
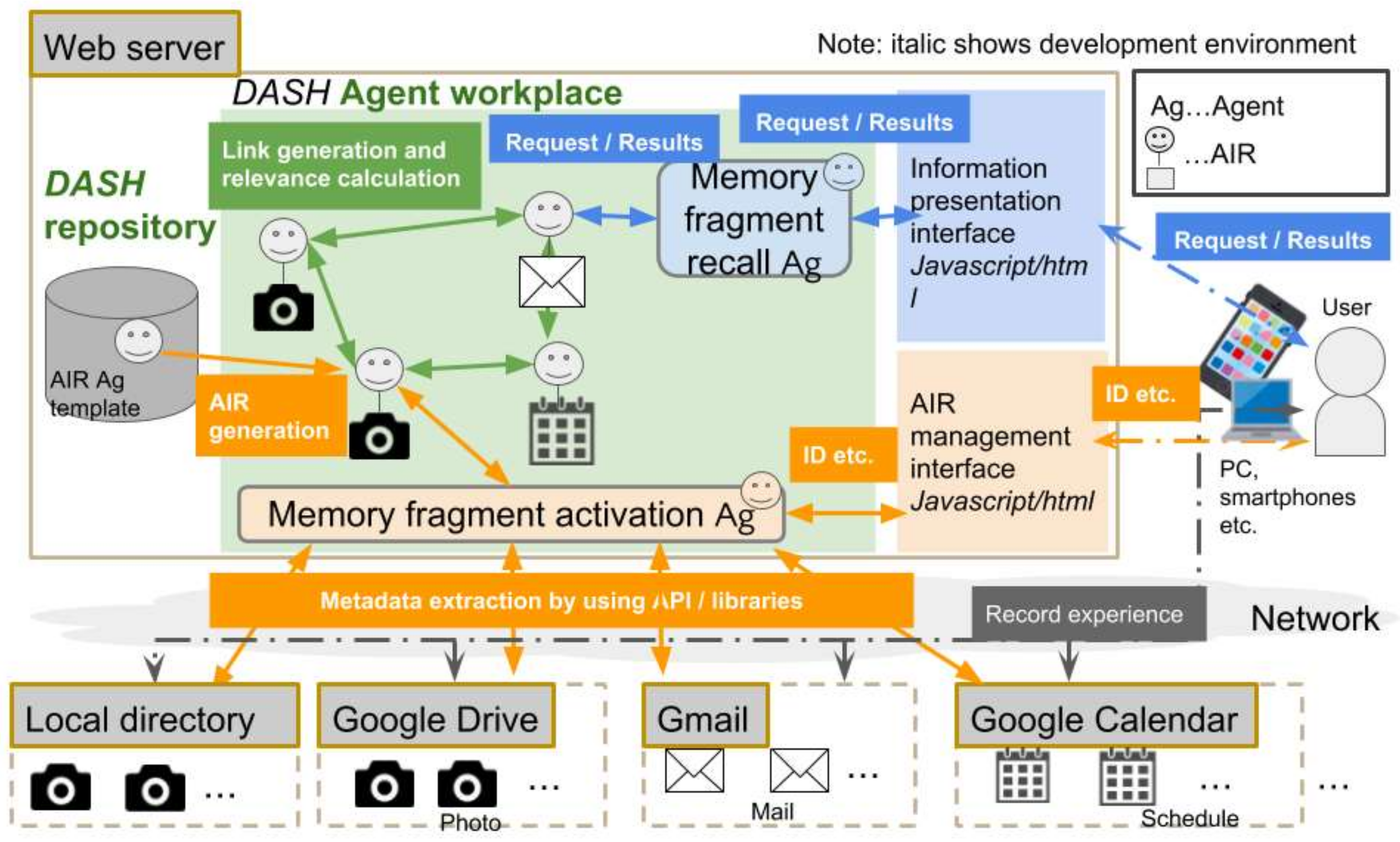
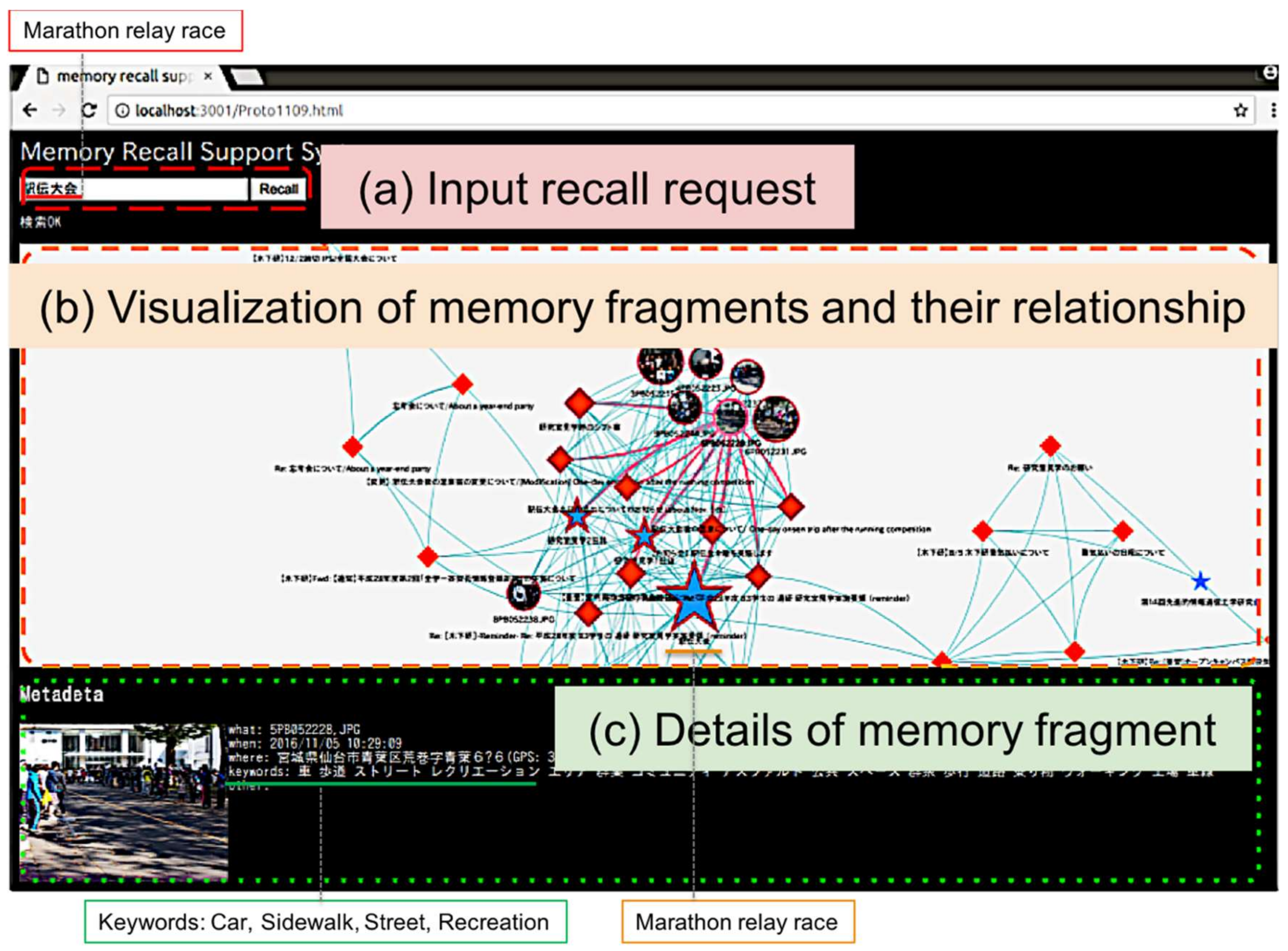
5.1. Purpose and Overview of Experiments
Using the system implemented in the previous section, we try to experimentally confirm that the technical problem described in
Section 2 is solved by the proposed functions (S1, S2, and S3), and the effective memory recall support system is realized. We conducted the following two experiments.
Experiment 1: Experiment of acquiring, accumulating and providing memory fragments
In Experiment 1, a graduate student is the user, and the usefulness of each function of the proposed system is evaluated, that is, we confirm that the following three points have been achieved.
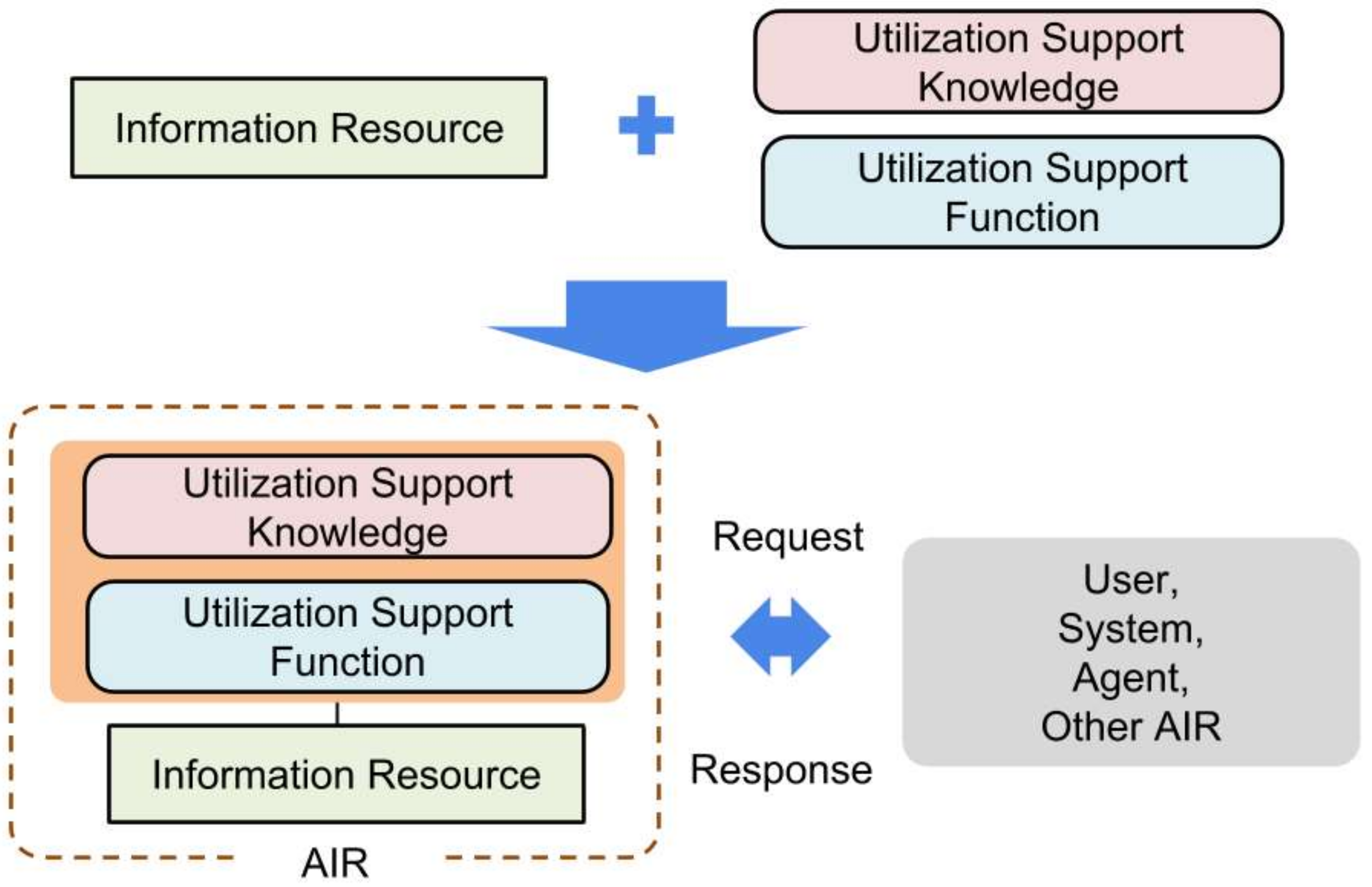
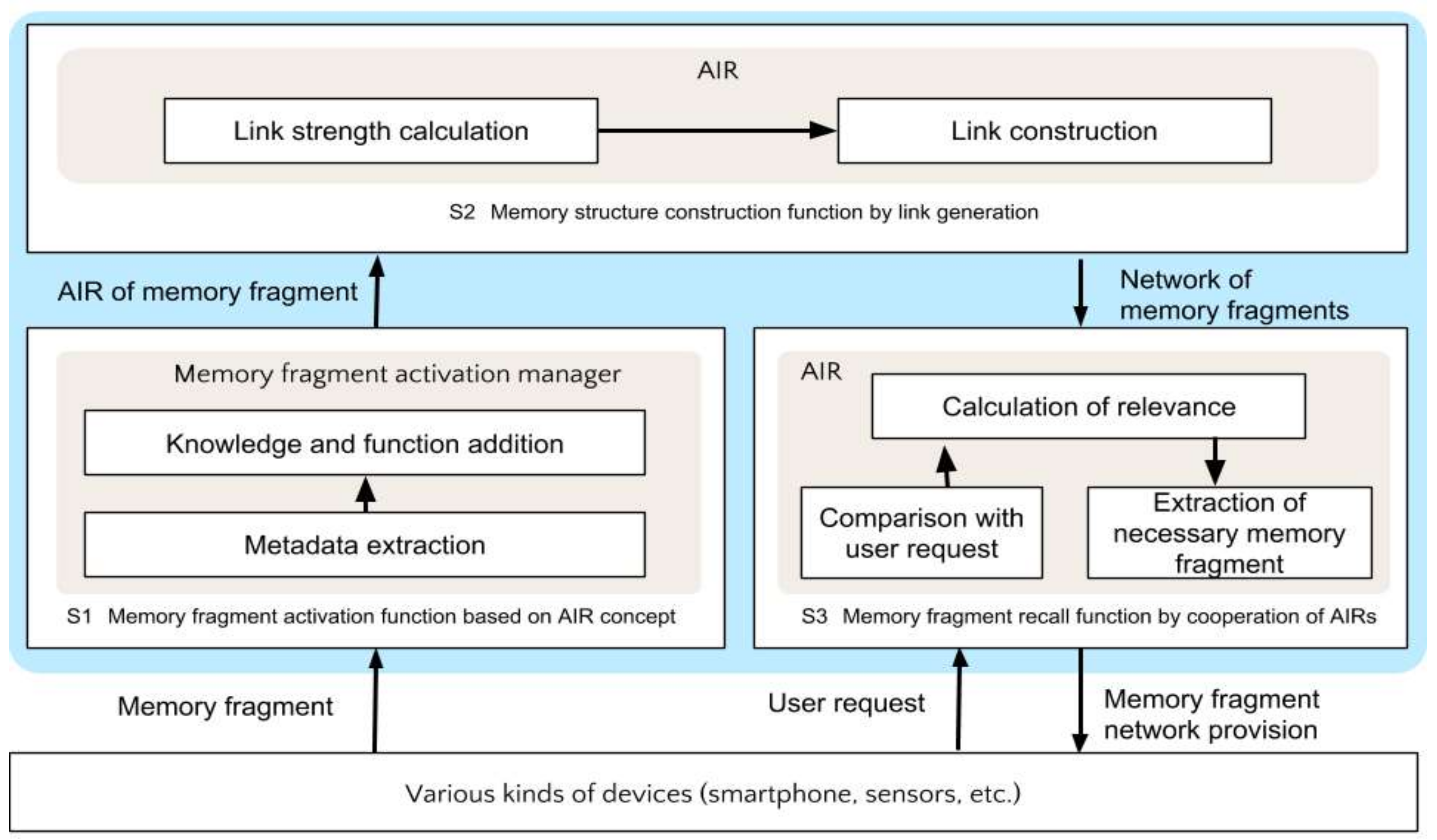
Acquisition of memory fragments of the user’s experience and the conversion of memory fragments into AIRs that can be used in the system
Autonomous association of memory fragments
Memory structure construction based on an AIR driven by the user’s request, and the memory structure presentation functionality to the user
Therefore, we confirm that the proposed system can acquire the user’s memory fragment and structure the experience.
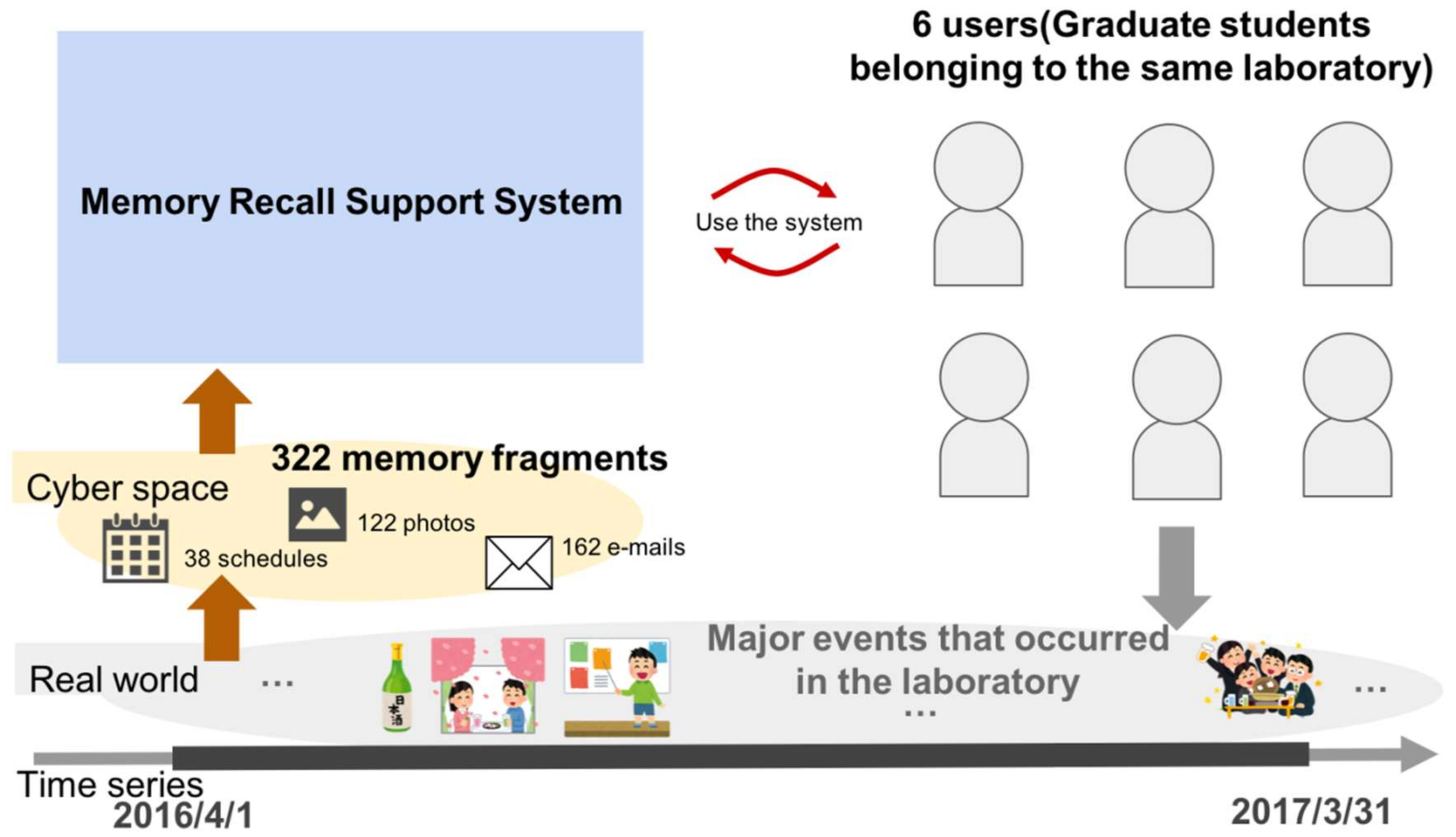
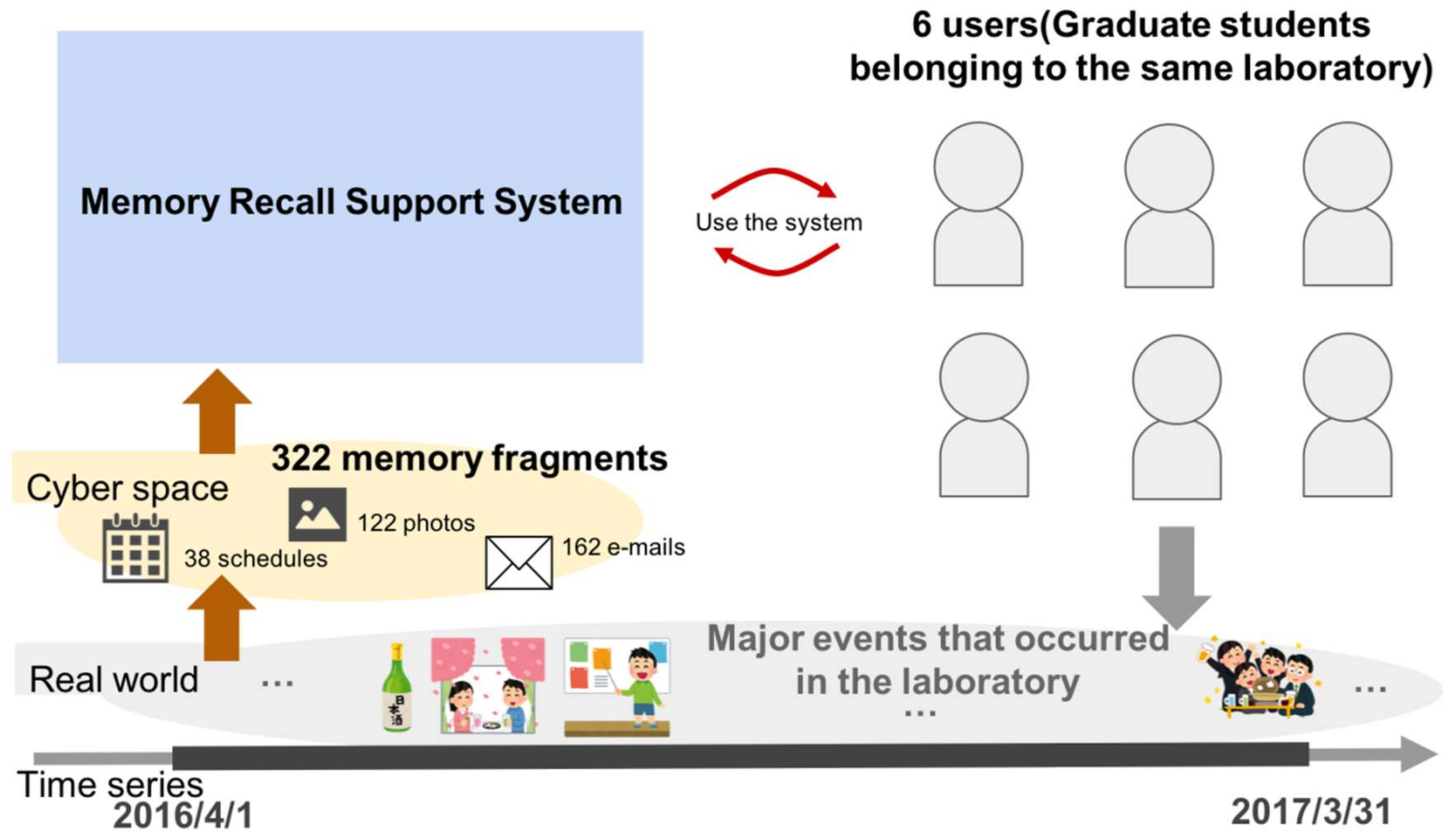
As a memory fragment, a total of 322 memory fragments related to major events occurring in a laboratory in the term 1 April 2016 to 30 March 2017 were introduced in the experiment, as follows:
38 schedules entered into Google Calendar
122 photos on the shared file directory hosted in a PC
162 e-mails saved in Gmail
The reason for using the above three kinds of memory fragments in this experiment is because generally people accumulate these memory fragments on a daily basis. We confirm the operation and effect of each proposed function by confirming the operation of the proposed system using these 322 memory fragments.
Experiment 2: Recall experiment by the user
In Experiment 2, six graduate students are the users, and we confirm the usefulness of the proposed system. By using the proposed system, we examine
the accuracy,
level of detail,
and speed,
of recalling information about past experiences. We conducted an experiment of answering questions and describing information about the experience freely within the time limit. We also conducted questionnaires to investigate the user’s feelings about using the proposed system. Experiment 2 was performed using 322 memory fragments prepared in Experiment 1. We confirm the effect of the proposed system by actually recalling information using the system.
We describe the coefficients and threshold values of various calculation formulas in experiments and their setting methods.
Table 6 shows each coefficient and threshold value in this experiment and the setting criteria.
In this system, values
k,
t, and
p in Equation (1) are derived by the method shown in
Table 4. For each coefficient,
K,
T, and
P, the values shown in
Table 6 were set. We explain the setting policy of this coefficient using the case of
K. The intermediate value is derived from the minimum value and the maximum value of the keyword matching number between all memory fragments, and
K = 0.025, which is
k ≈ 0.1, when
num is the intermediate value. This is because when the number of matched keywords is equal to an intermediate value,
k is set to a small value that does not substantially affect the link strength.
For the coefficients α, β, and γ that determine the degree of influence of k, t, and p, it is necessary that the sum of three coefficients is 1 in order to make the maximum value of l equal to 1. In this example, α = 0.5, β = 0.35, and γ = 0.15. This is because the amount of metadata possessed by the introduced memory fragment is large in the order of keywords, time, and place, and the difference detected from these metadata should be reflected in the link strength.
Also, l* = 0.34 was set so that the maximum number of links of one AIR was 50 or less. This is to prevent the user’s waiting time from becoming too long when calculating the degree of relevance according to the user’s request.
In this system, coefficient
δ and thresholds
r* and
m* of Equation (5) are set as shown in
Table 6. In order to present the results in less than 30 s for one recall request, several recall experiments were attempted, and
δ = 1,
r* = 0.3, and
m* = 3.
Since the information presentation in response to the recall request is performed sequentially from the memory fragment first judged to be useful for recalling, it is possible to browse the first memory fragment in approximately 1 s after the recall request.
The results and considerations of Experiments 1 and 2 and the summary of the experiment will be described below.
5.2. Evaluation of Usefulness of Each Function
Using the results of Experiment 1, we evaluate the usefulness of each function in the proposed system.
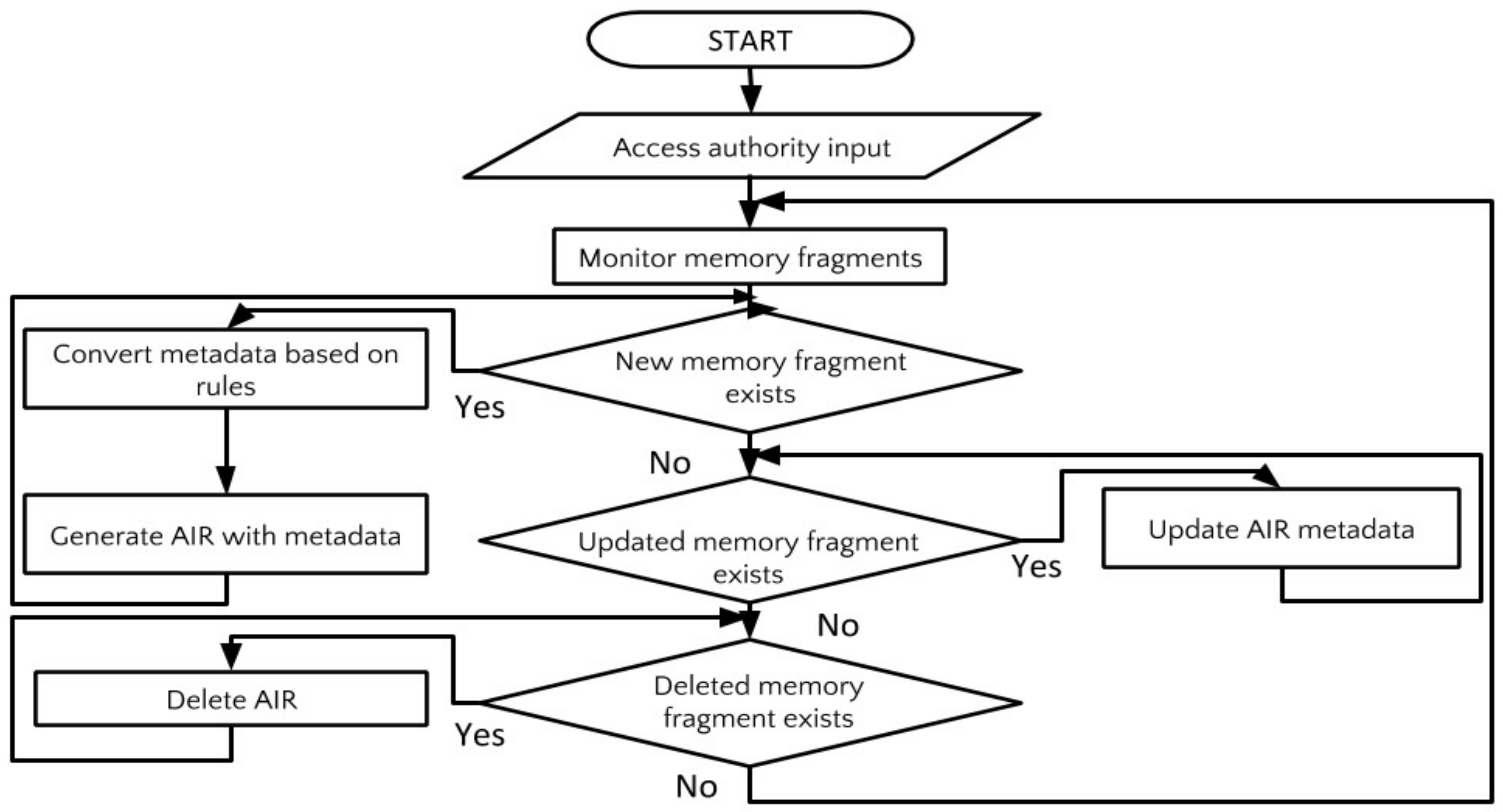
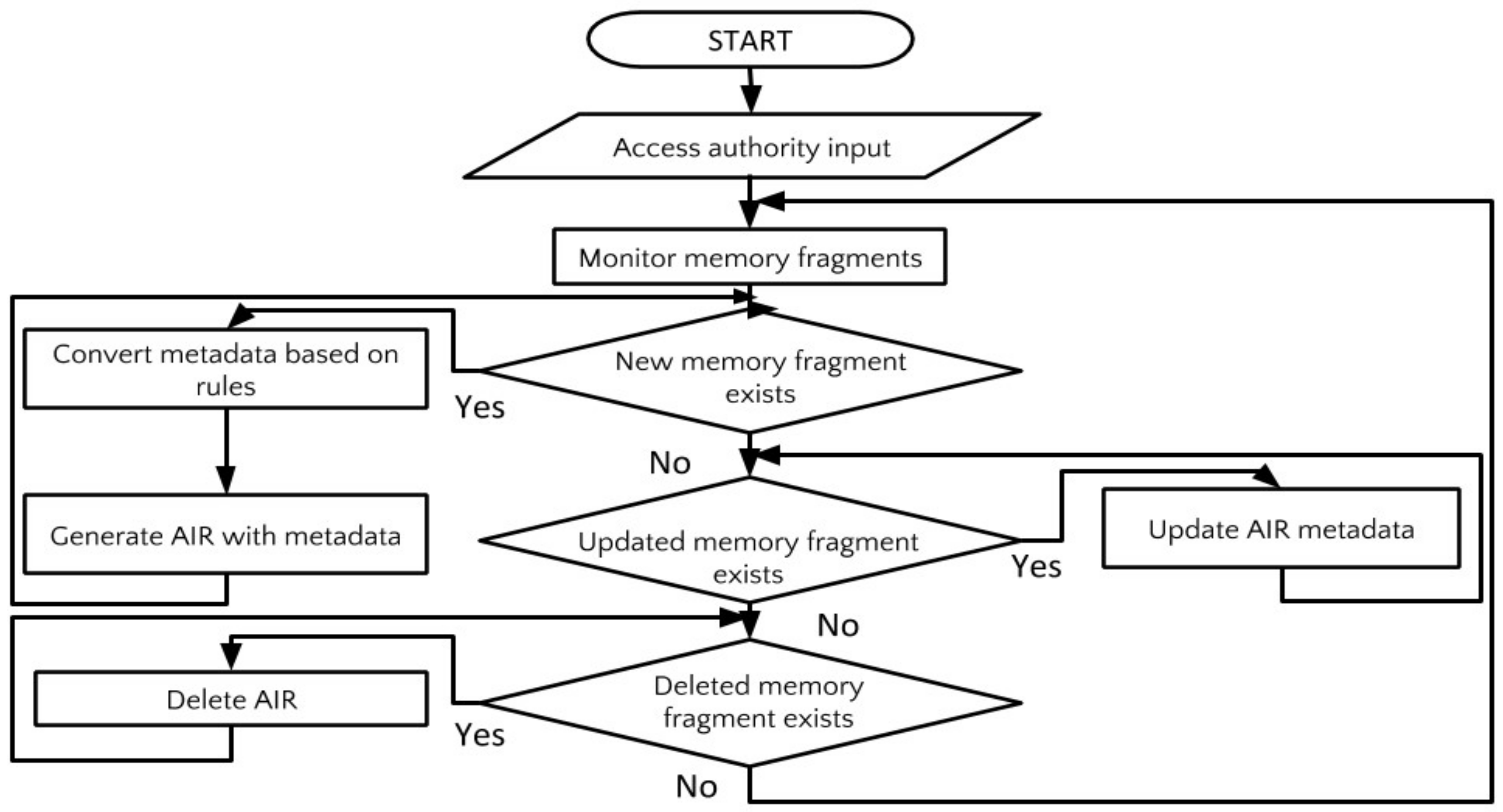
5.2.1. Evaluation of Memory Fragment Activation Function Based on the AIR Concept (S1)
- (1)
Evaluation of Memory Fragment Acquisition/Conversion
We confirm that a wide variety of the user’s memory fragments can be captured and used by the memory fragment activation function (S1) based on AIR. Three kinds of memory fragments—schedule, photograph, and mail—were targeted for acquisition as an AIR using the AIR management interface. As a result, 322 memory fragments were prepared properly in this experiment.
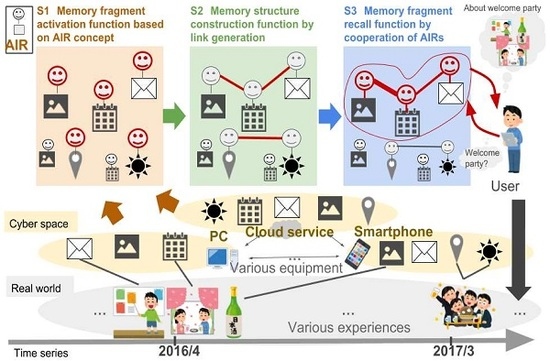
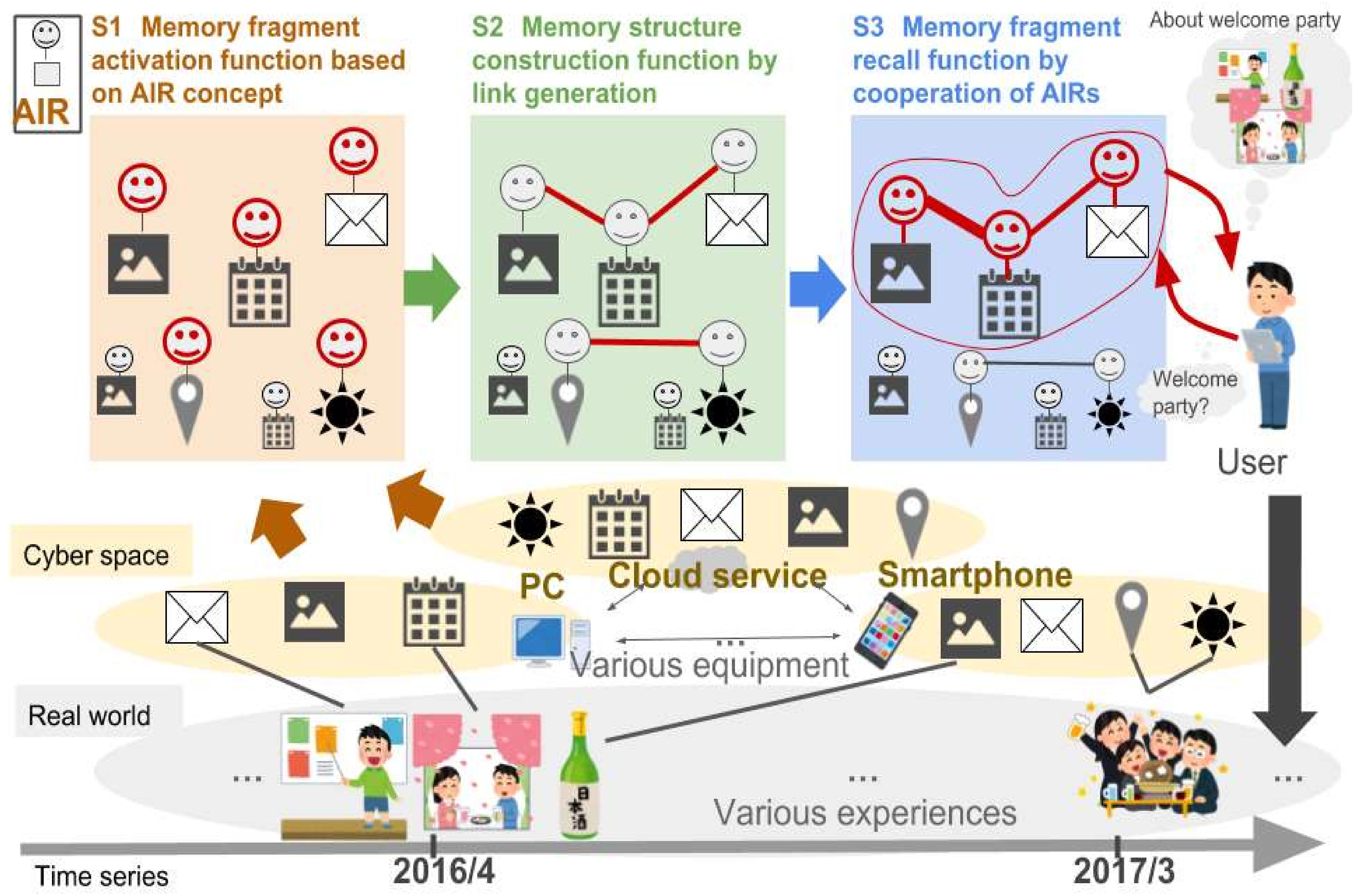
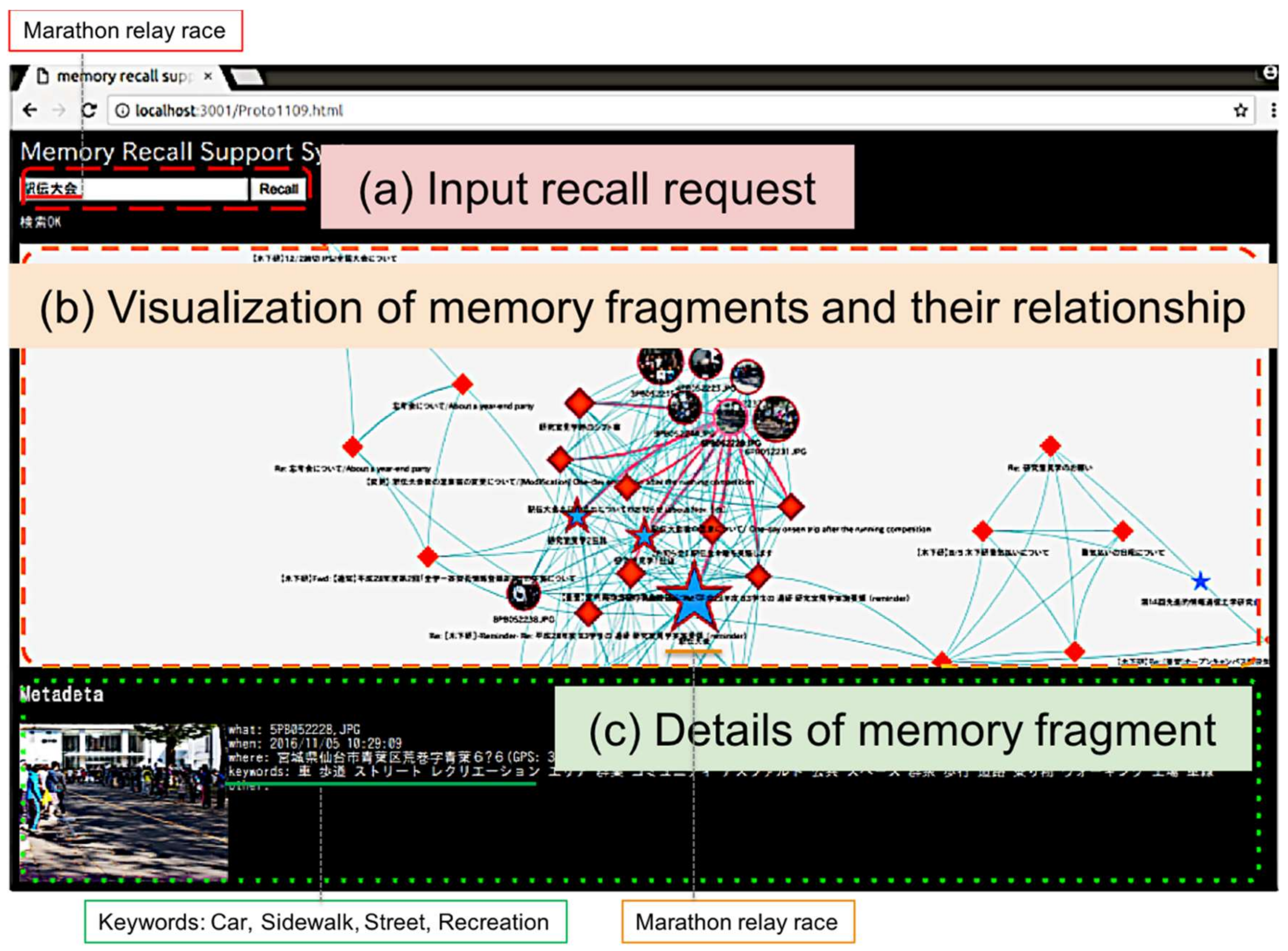
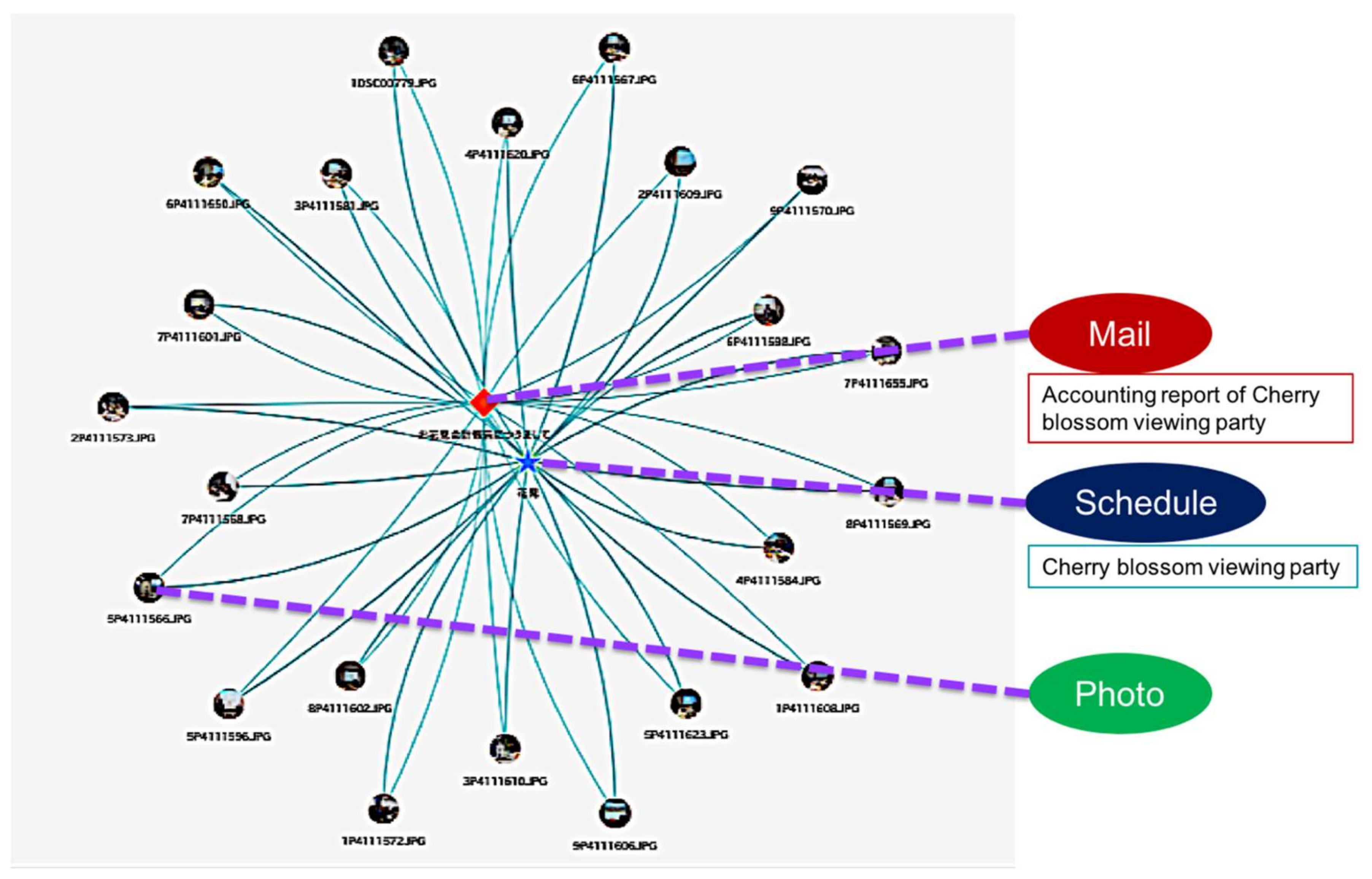
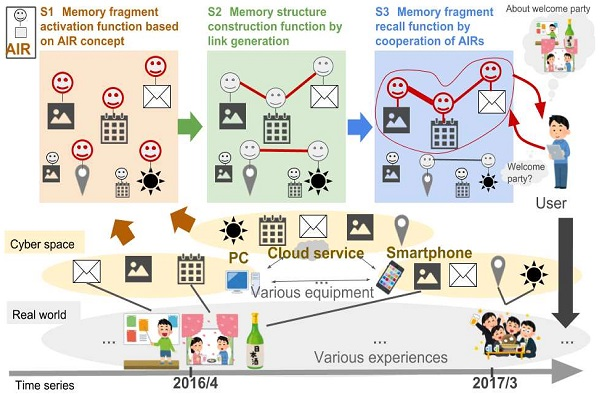
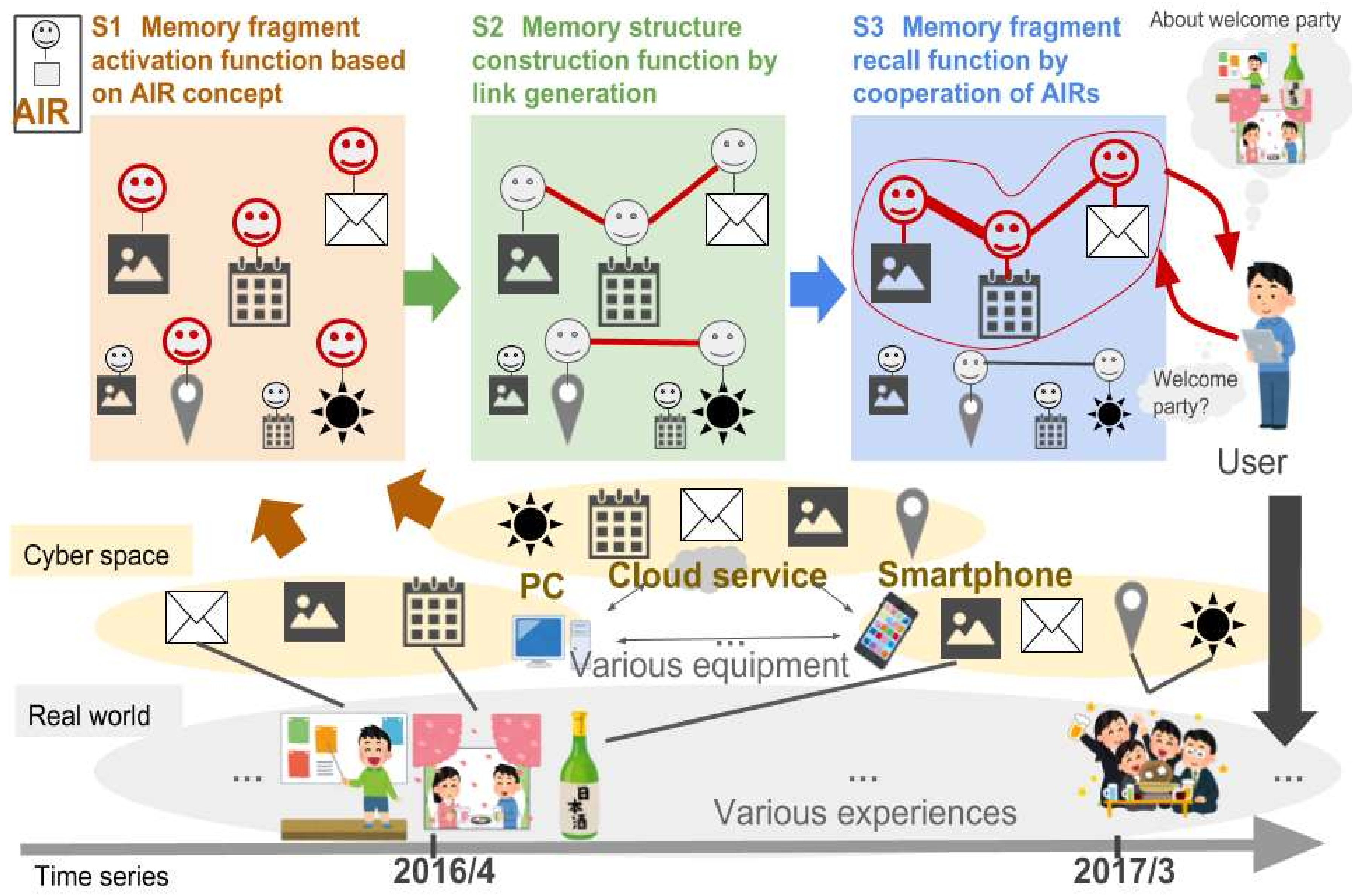
Figure 10 shows the result of generating AIRs of memory fragments about the user’s one-day experience.
Figure 10 shows the schedule of the event performed on this day, the email related to the event sent on this day, and 22 pictures taken during the user’s events. Even if they are heterogeneous resources, the memory fragments are gathered together as shown in
Figure 10, and became available on the unified interface.
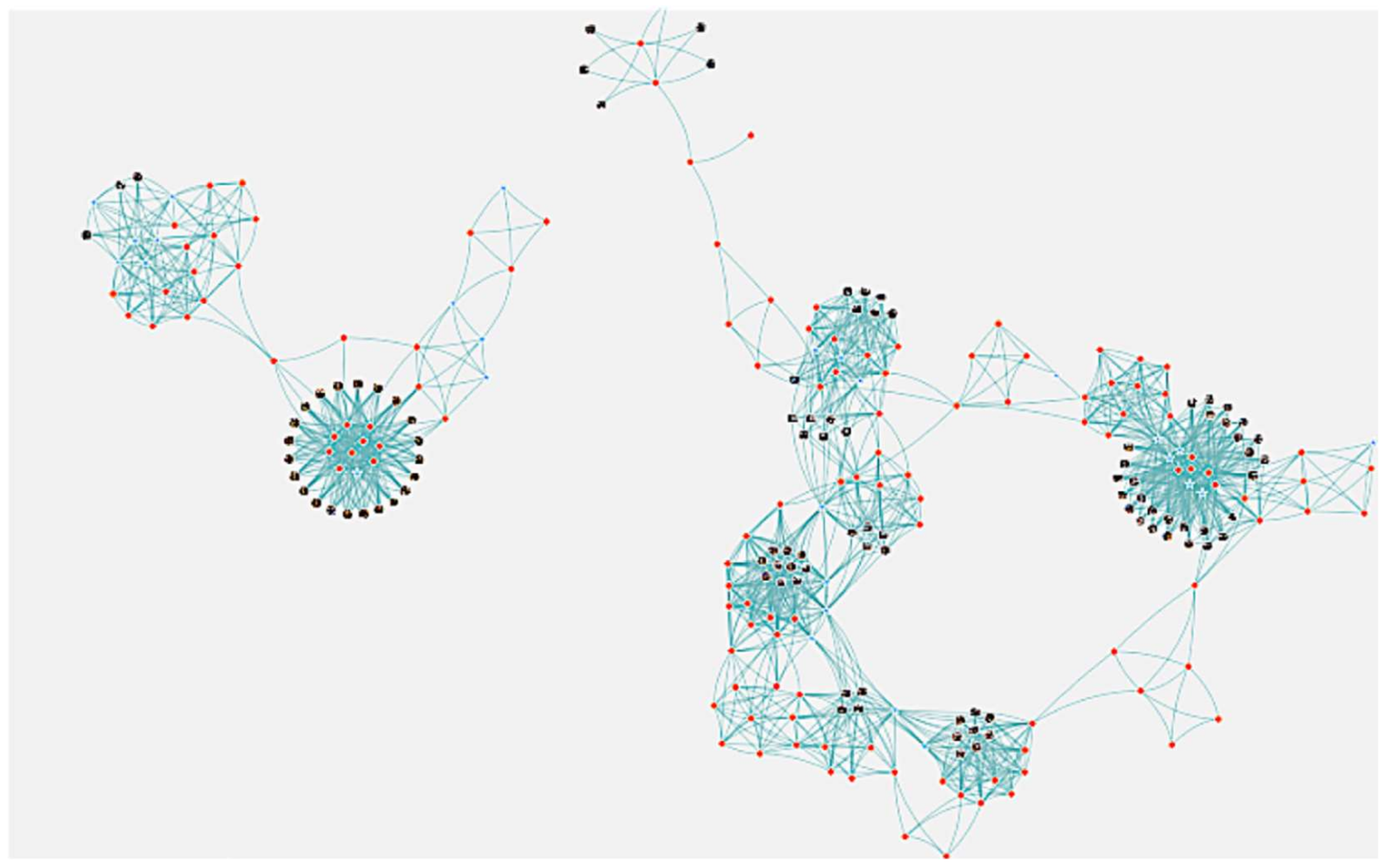
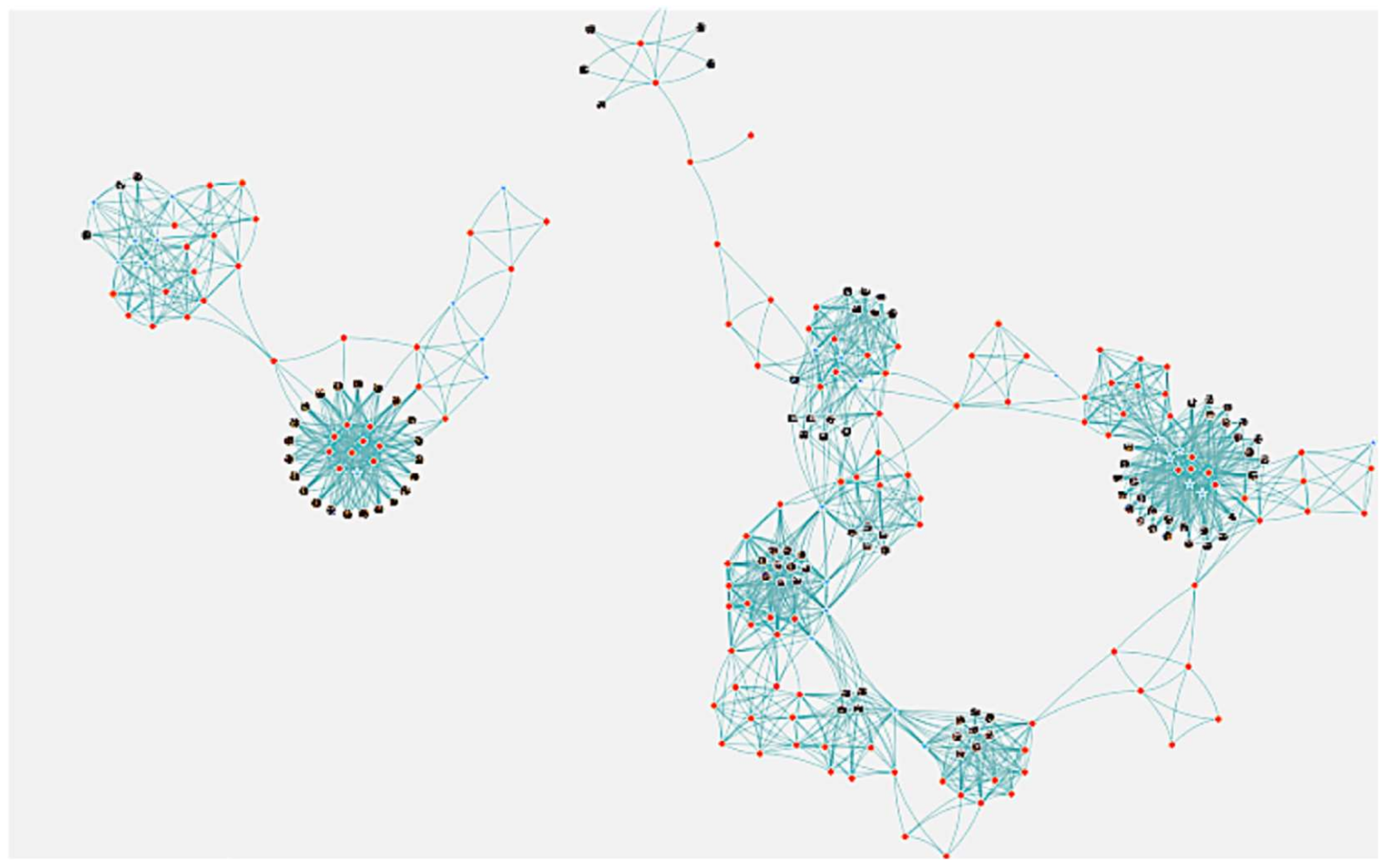
Figure 11 shows the results of acquiring one year of memory fragments from 1 April 2016 to 30 March 2017. In this result, 322 memory fragments can be used, which indicates that all the memory fragments to be targeted in this experiment became available. In addition to the 24 memory fragments shown in
Figure 10, other memory fragments also became available on the same interface. It can be seen that different memory fragments are associated with each other as necessary.
From these results, it is confirmed that a wide variety of memory fragments related to the user’s experience can be used in a unified manner.
- (2)
Evaluation of Time Required for Memory Fragment Activation
This function enables the system to automatically perform the structuring of the memory fragment. In order to confirm that this function reduces the burden on users and that the operation of the system is sufficient for practical use, the execution speed of the process that generated the memory fragment as an AIR was measured.
First, we measure the time taken when the user manually creates an AIR. The schedule is used in this experiment because it contains information on time and place, sentences for extracting keywords indicating content, and it is possible to perform the conversion process manually. In the case of manual work, a user browses the specified schedule in Google Calendar, extracts information based on the metadata format of the AIR, and enters it into the template file. Five schedules were targeted, and metadata extraction and conversion were performed once for each schedule manually, and the average time taken was calculated. As a result, it took an average of 206.2 s for one schedule. In this system, which is expected to use a large number of memory fragments, the method, which takes several minutes to generate one AIR, is not practical. It is a heavy burden for the user to manually perform these tasks.
The function of memory fragment activation automates the AIR generation process and reduces the time and effort required. Therefore, when the system automatically generates an AIR, we check whether the time to extract and convert the metadata is sufficiently short and it is possible to handle a large number of memory fragments. For each of the five schedules used for calculation in the case of manual work, AIR was generated five times using the proposed system. The average time taken for one operation was calculated to be 0.67 s. Therefore, by using the proposed system, the time has been greatly shortened compared to manual work. It is possible to generate about 300 memory fragments as an AIR within the time that a single memory fragment is generated manually as an AIR.
From the above results, it was confirmed that the introduction of this function can reduce the burden caused by users having to input and accumulate information.
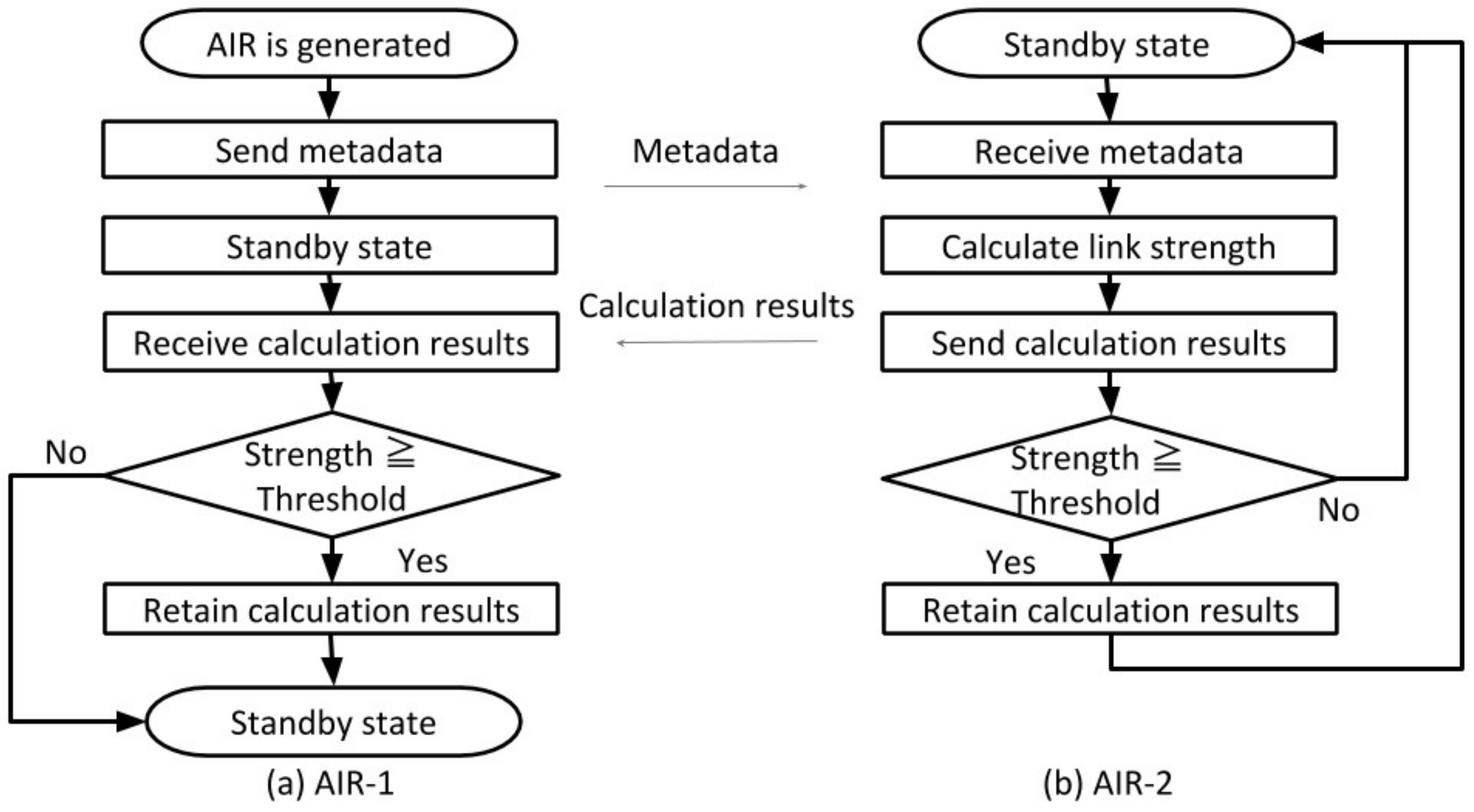
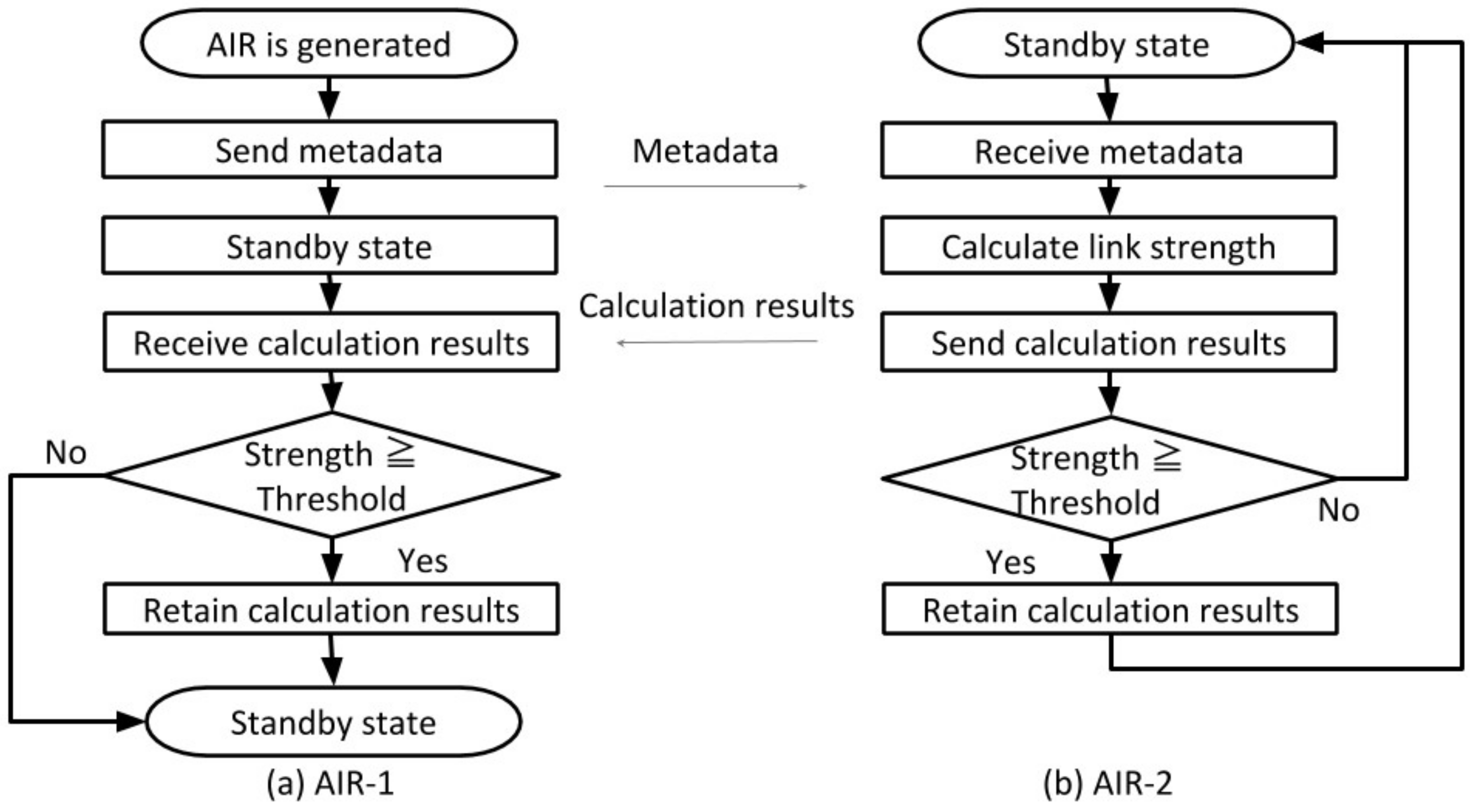
5.2.2. Evaluation of the Memory Structure Construction Function by Link Generation (S2)
We confirm that links were autonomously built among memory fragments by this function.
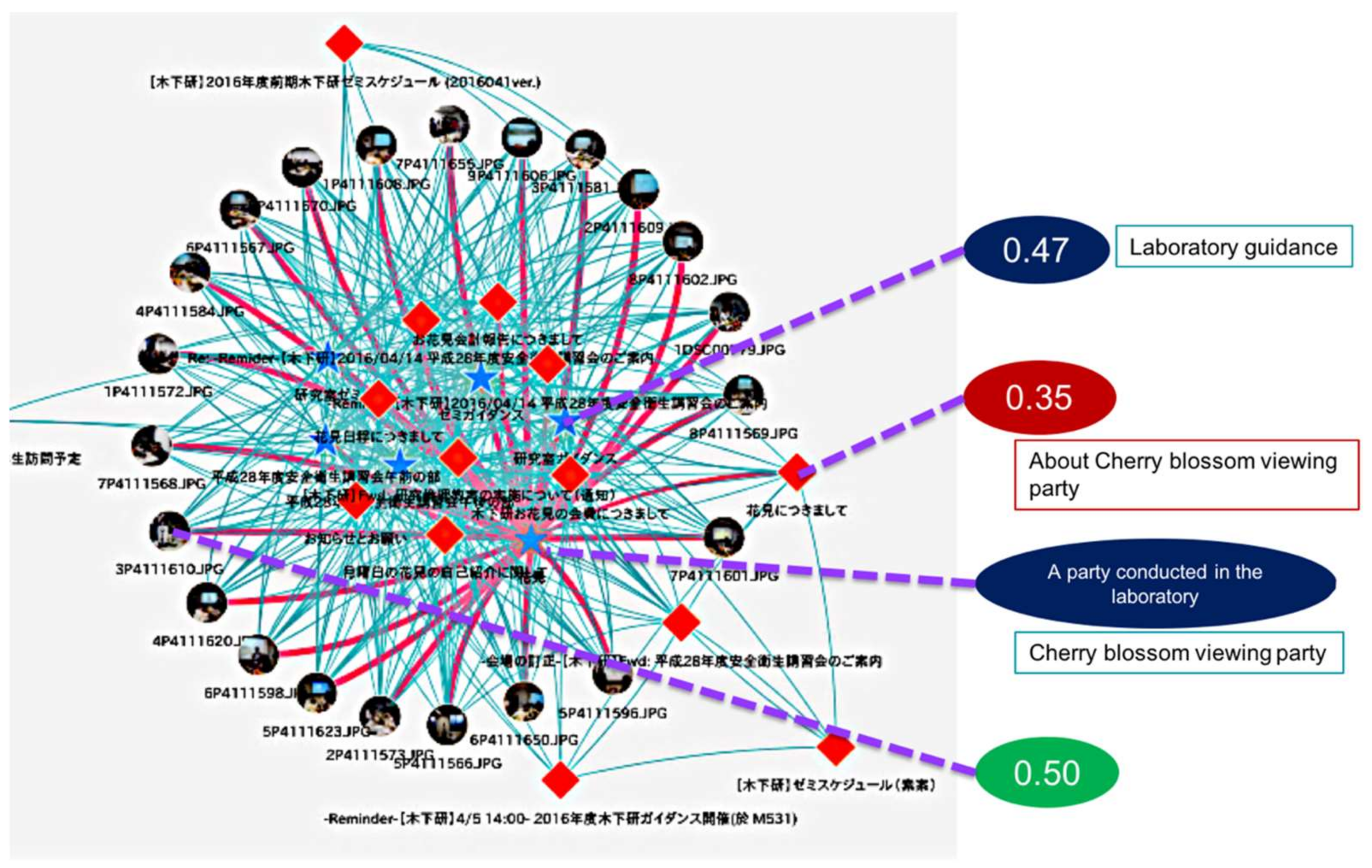
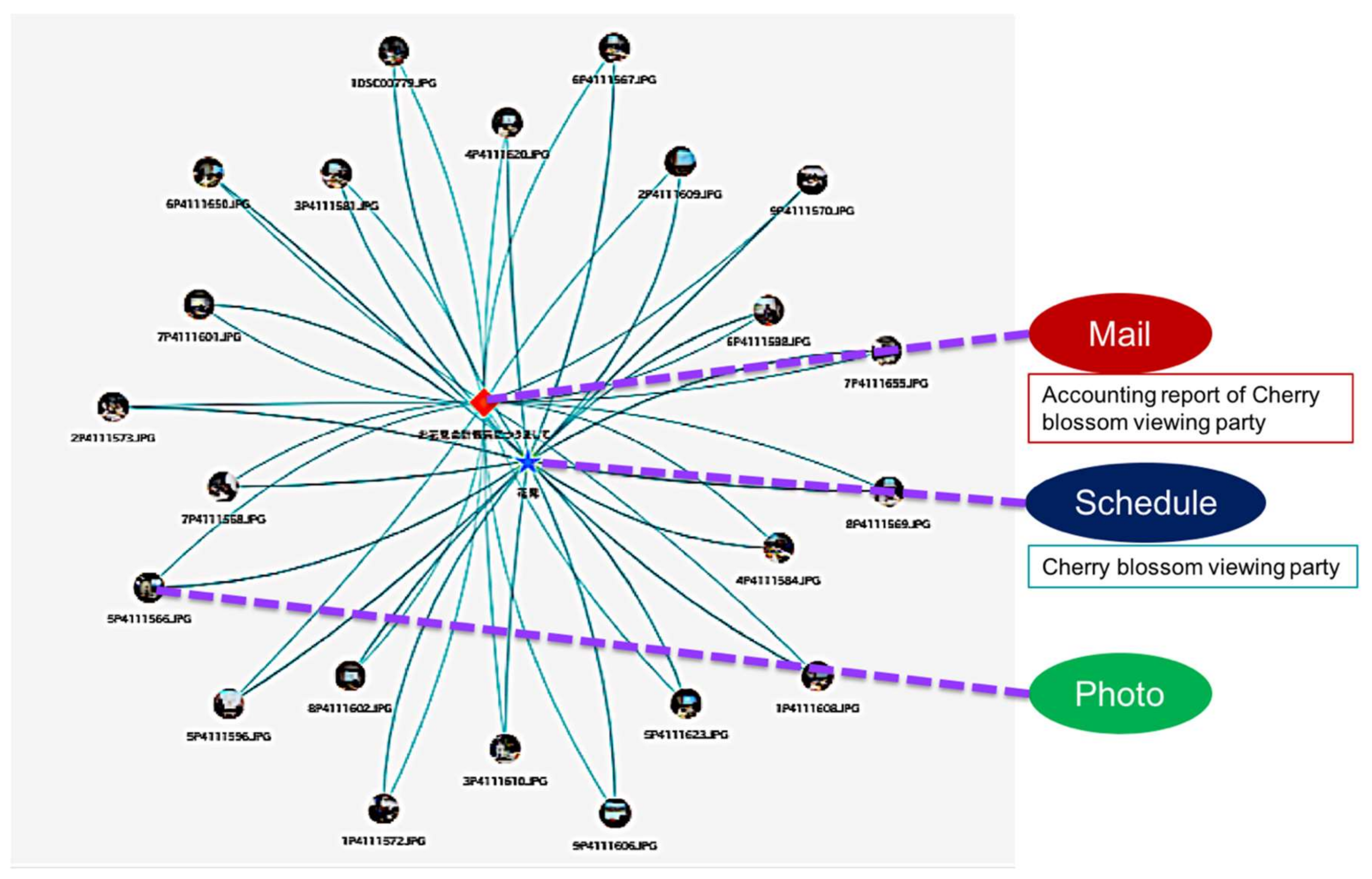
Figure 12 shows connections among the memory fragments centered on a party (cherry blossom viewing party) conducted in the laboratory. This association was made automatically as soon as the memory fragment was generated as an AIR.
Examples of a memory fragment having a strong link with this party schedule are shown in
Figure 12. For example, a certain photograph taken during a party has a link strength of 0.50 because the date and time are close to each other. In addition, the mail related to the party sent five days before the party was close to the date and time, and the content was similar, so the link strength was 0.35. In addition, the schedule of laboratory guidance that seemed not to be related to the party was also similar in both date and time, and was held at the same place, so the link strength was 0.47.
From these results, it was confirmed that the memory fragments relating to the same experiences, and the memory fragments having similar time, place, and content were automatically correlated. In other words, we confirmed that a link can be constructed autonomously by information exchange and the calculation function of this function.
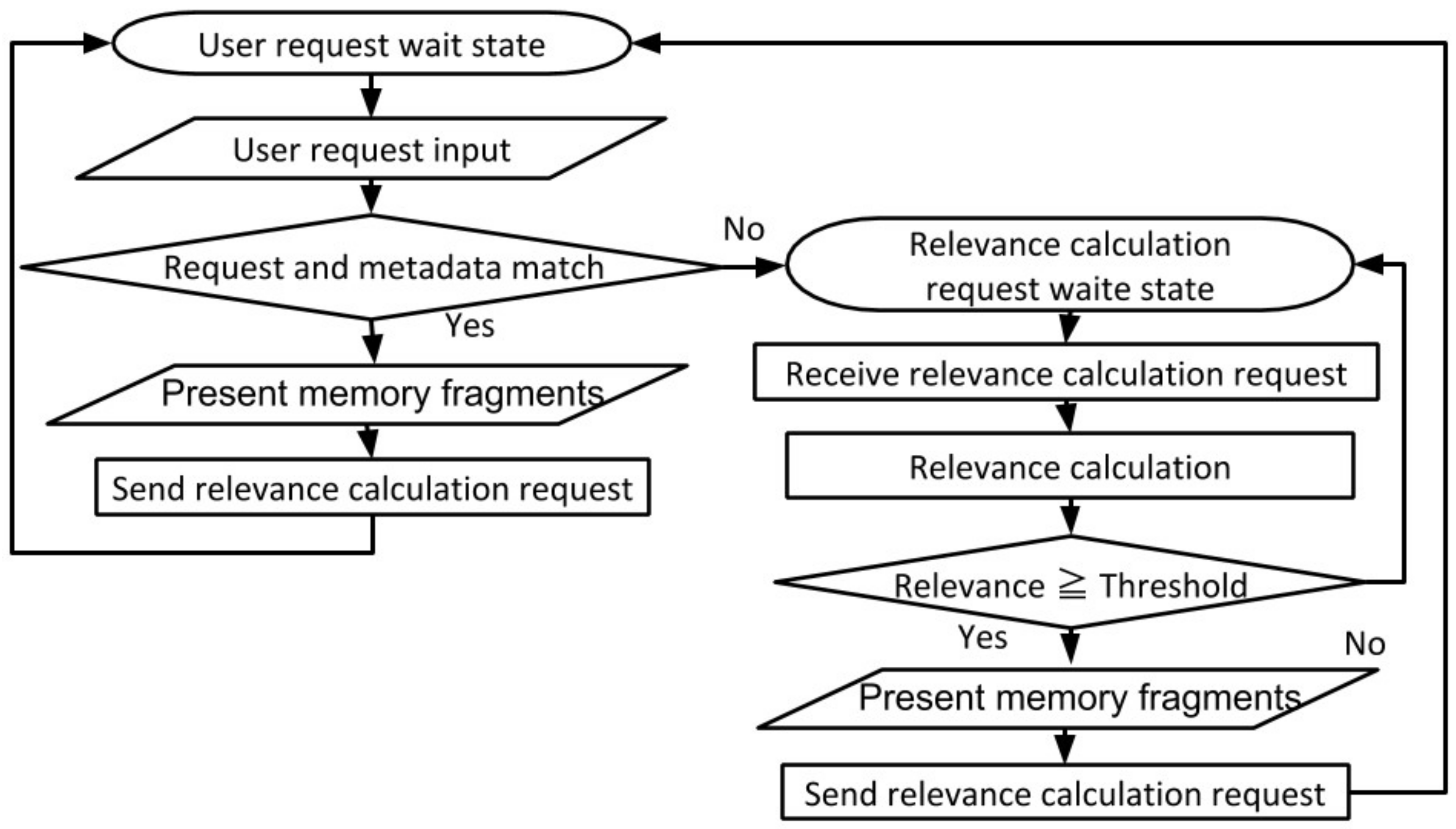
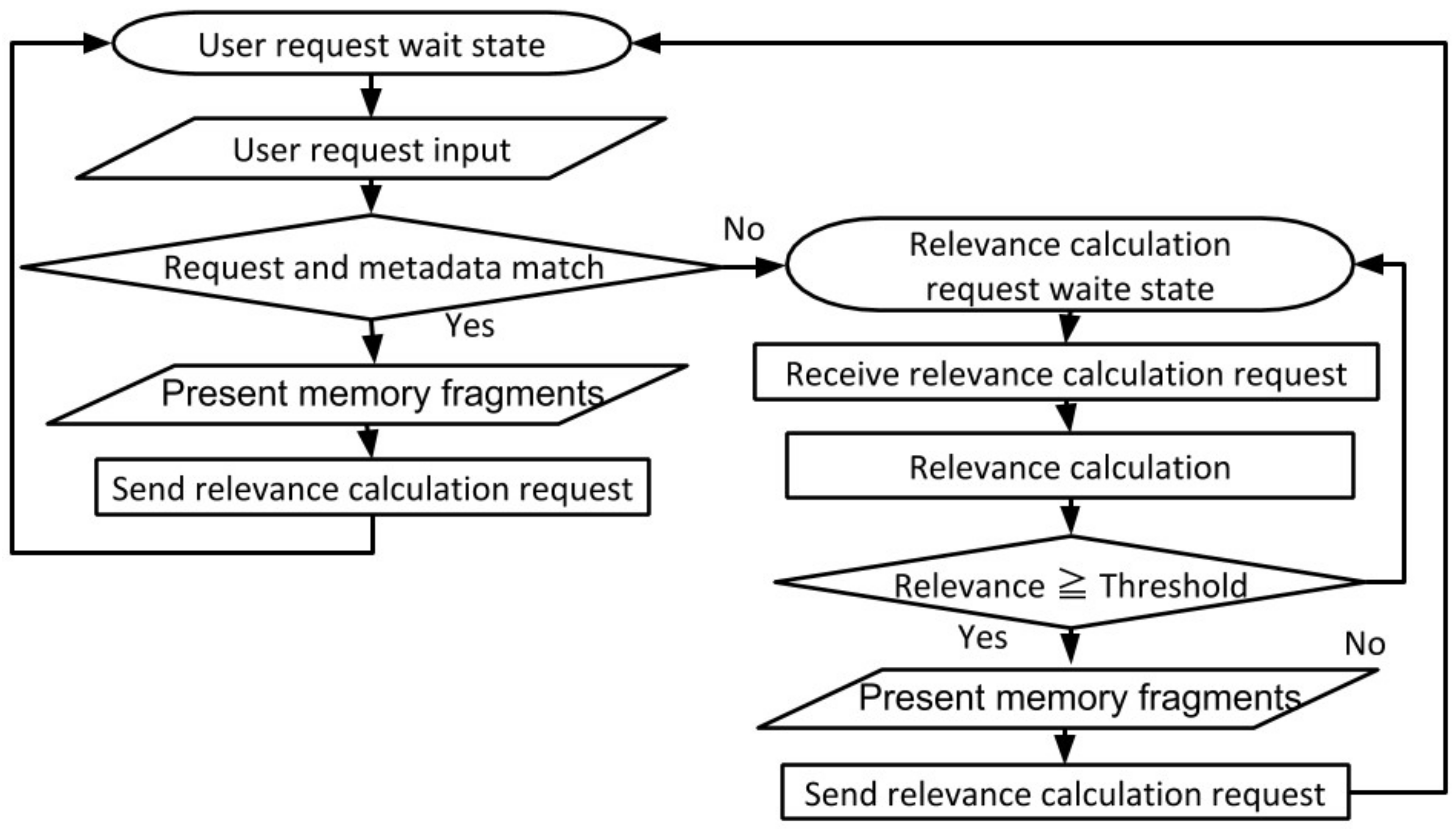
5.2.3. Evaluation of the Memory Fragment Recall Function by Cooperation of AIRs (S3)
- (1)
Qualitative Evaluation of the Construction and Presentation of the Memory Structure Driven by User Request
First, we confirm the operation of the system, incorporating the proposed function. Based on the user input of keywords to recall an experience, it is necessary to confirm that the memory fragments related to the experience the user wishes to remember are presented by this function.
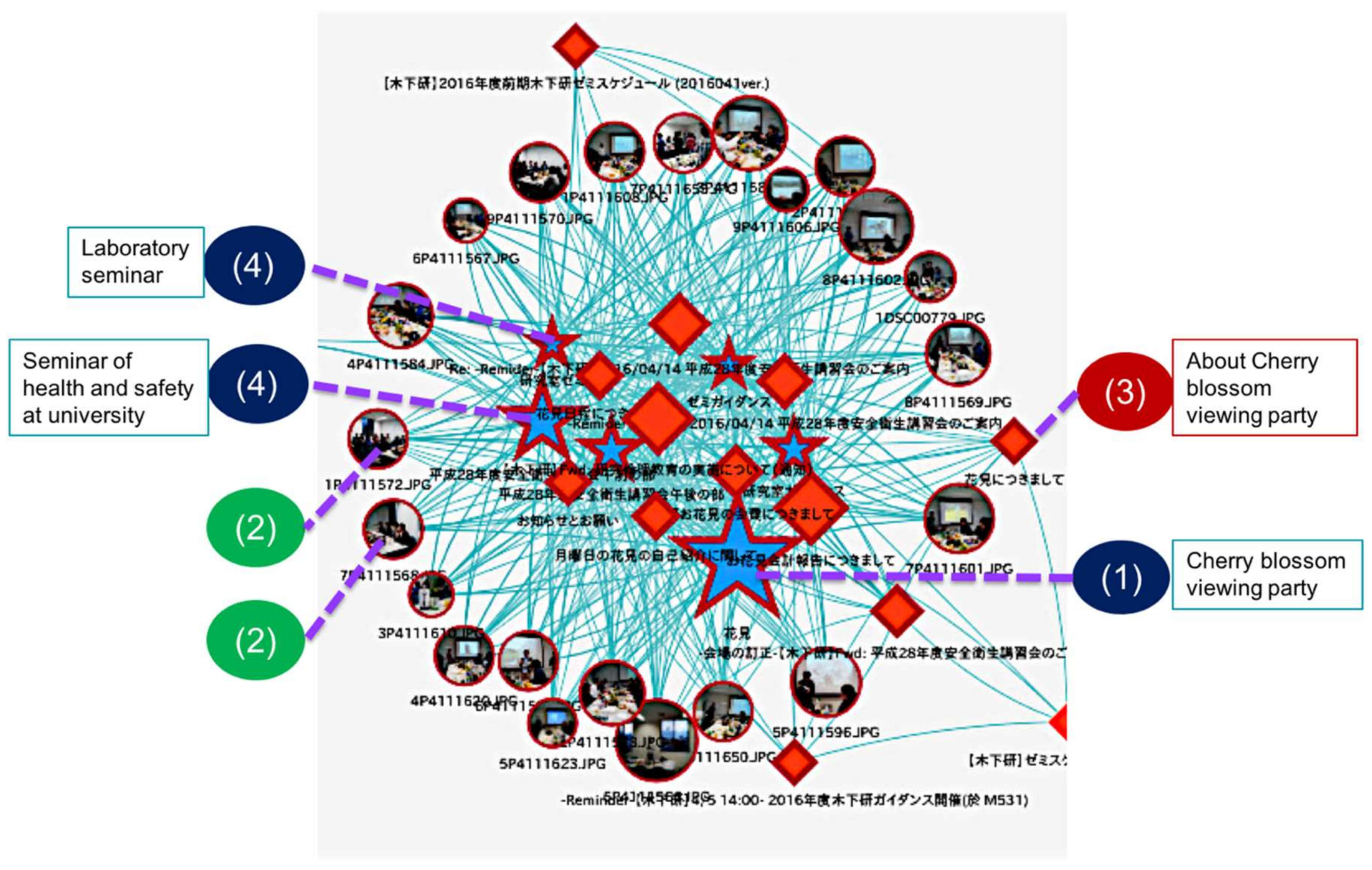
An example of recall experience is the “cherry blossom viewing party”. The user has a request that he/she wants to recall information such as the day, place, preparation for the event, and the feelings of the day about the party.
Therefore, the user inputs the keywords “cherry blossom viewing party” to the information presentation interface as a recall request. As a result, the memory fragments that are useful for recalling are emphasized with a red borderline as shown in
Figure 13.
(1)
Figure 13 shows a schedule of the “cherry blossom viewing party”, and memory fragments to be recalled are presented centering on this memory fragment. By viewing (clicking on) this schedule, the user can recall basic information of the “cherry blossom viewing party”. Presented (2) in
Figure 13 is a picture of the party, which is helpful for the user to recall the scene of the event. (3)
Figure 13 shows mail related to the party, which can help to recall the attendance fee and schedule adjustment.
Figure 13 (4) is an event held around the “cherry blossom viewing party”. These remind the user that the party was an event in a new semester. These memory fragments also helped to recall situations where the user attended the meetings with new members on a day close to the event.
In this way, we confirmed that memory fragments that support recall are presented in response to the recall request entered by the user.
- (2)
Quantitative Evaluation of the Construction and Presentation of the Memory Structure Driven by the User Request
We quantitatively evaluated whether the information presented by this function is useful for recalling. In this experiment, we confirmed that it is possible to present the memory fragment, which could not be recalled using the existing system.
We confirmed that this function makes it possible to determine effective memory fragments for recall in response to the user’s request. In this experiment, we evaluated how many useful memory fragments are presented for three recall requests. We define the existing system as a user search based on recall request keywords using Google Calendar, Gmail, and Windows Explorer. We make a comparison between the existing system and the proposed system. In addition, when the recall is insufficient, only with the memory fragment matching the keyword, the user can re-search using information such as the time, place, content, etc., of the memory fragment that were presented in the first search.
For memory fragments prepared for a recall experiment, a system user browses all the memory fragments and classifies them based on the following conditions:
The experiences of the recall request itself are shown
There is a high degree of similarity with the content of the experiences of the recall request
It is possible to connect memories to fragments because the date and time of the memory fragment are close to the experiences of the recall request (before and after 1 month)
The place of the memory fragment is close to the experiences of the recall request (before and after 1 month)
When using the existing system and the proposed system, we calculated the
precision,
recall, and
F-
measure of the memory fragment presentation. The
precision,
recall, and
F-
measure were calculated by the following Equations (6), (7), and (8).
Table 7 shows the results of calculating the
precision,
recall, and
F-
measure using the presentation results recalled for three patterns of recall requests using each system. The number of presented memory fragments has increased from 5 to 10 times in the case of the proposed system compared to the existing systems. We evaluated the results in order to confirm that the proposed system presents more necessary items and not unnecessary items.
First of all, we describe the precision, indicating how many of the memory fragments are useful for recalling. The precision was higher in the existing system for the two types of recall requests and was the same for one type of recall request. This is because the existing system presents only the memory fragments explicitly including the keyword of the recall request, so it is unlikely to present an incorrect memory fragment. In the proposed system, although the date, time, and place are similar values, it is not possible to determine if a memory fragment is useful for recalling by the user, so the precision is low.
Next, the recall showing the coverage of how many of the memory fragments are useful for recalling was higher in the proposed system for all three recall requests. This is because the existing system cannot present memory fragments which do not include the recall request keyword even if they are useful memory fragments, but in the proposed system memory fragments can be presented using the dates, times, places, and content links.
The precision and the recall exist in a trade-off relationship. Therefore, we calculated the F-measure as a comprehensive evaluation and confirmed that the proposed method is higher for all three requests. It was confirmed that the accuracy of the recall, supported by the proposed function, is higher than that of the existing system.
From the above, it can be said that the memory fragment recall function enables the presentation of various memory fragment groups with reasonable relevance to the user’s recall request with little effort.
5.3. Evaluation of System Utility
In Experiment 2, we asked users to recall using the actual memory recall support system, and confirmed the effect. The users were six graduate students (four master’s degree students and two doctoral degree students) from the same laboratory. This means that the users in our evaluation share common experiences which are related to the same memory fragments, e.g., photographs of a party that everyone attended, the schedule information of a particular laboratory event, etc., as shown in
Figure 14.
The experiment was conducted between 11 and 14 November 2017 using 322 memory fragments concerning experiences that occurred from 1 April 2016 to 30 March 2017. These memory fragments contain 38 events, and the questions that were presented in the experiment concern these events. Since all of the users participated in all of these events, these memory fragments would support each user’s own memory.
In this experiment, we conducted experiments using 322 memory fragments that became available in Experiment 1. These 322 memory fragments are known information for all users, and in Experiment 2, all users conducted experiments using these memory fragments. For all users, these 322 memory fragments dealt with experiences that occurred in their laboratories in the period during which they shared experiences. Therefore, they can be regarded as shared memory fragments and can be used for recall support.
As a comparison with the proposed system, we define the existing system as the combination of the search functions of Google Calendar, Gmail, and Windows Explorer. In the existing system, the same 322 memory fragments are usable.
Using the proposed system and the existing system, the degree of recalling was confirmed by the following three experiments.
Experiment 2-1: Evaluation of recall support efficiency based on the percentage of questions answered correctly, and the response time of answering to past experiences
Experiment 2-2: Evaluation of the efficiency of multilateral recall support based on the percentage of questions answered correctly, and the response time of answering to past experiences
Experiment 2-3: Evaluation of the level of detail and number of recalled episodes
Questionnaires on Experiments 2-1, 2-2, and 2-3: After the above three experiments, we conducted questionnaires about the convenience of the existing system and the proposed system, and the degree of recall support efficiently
The details, the results of Experiments from 2-1 to 2-3, and analysis of the results are described below. In addition, the results of the questionnaire on the system at 5.3.4 and the summary of the experiment 2 at 5.3.5 are described.
5.3.1. Experiment 2-1: Evaluation of Recall Support Efficiency Based on the Percentage of Questions Answered Correctly, and the Response Time of Answering to Past Experiences
In this experiment, we asked six users the same 10 questions. For each question, we designated three users who answered using the existing system and three users who answered using the proposed system. Therefore, six users answered five questions using the existing system and five questions using the proposed system, and the allocation of questions differed among all users; this was to eliminate the bias due to individuals’ familiarity with the system and the experience.
Table 8 shows the questions that were presented in this experiment. To protect privacy, experience name, person name, and place name are hidden in this paper, but in the experiment we used the real names. These questions could be answered by browsing the appropriate memory fragments.
For all 10 questions, the correct answer rate using the existing system was 100%, and the correct answer rate using the proposed system was 93.3%. The reason why the proposed system answer rate was not 100% was that two out of 30 questions were incorrect. One incorrect answer was due to the ambiguity of date specification, i.e., the definition of “a week” in question 8; as no explanation was given to the user that “a week means exactly 7 days”, the user answered with a 6-day experience (about a week). Another incorrect answer was due to a misinterpreted question (question 7); the name of the lecture was answered instead of the name of the speaker. Based on these results, we confirmed that if the users understood the question correctly, accurate recall could be performed using either the existing system or the proposed system.
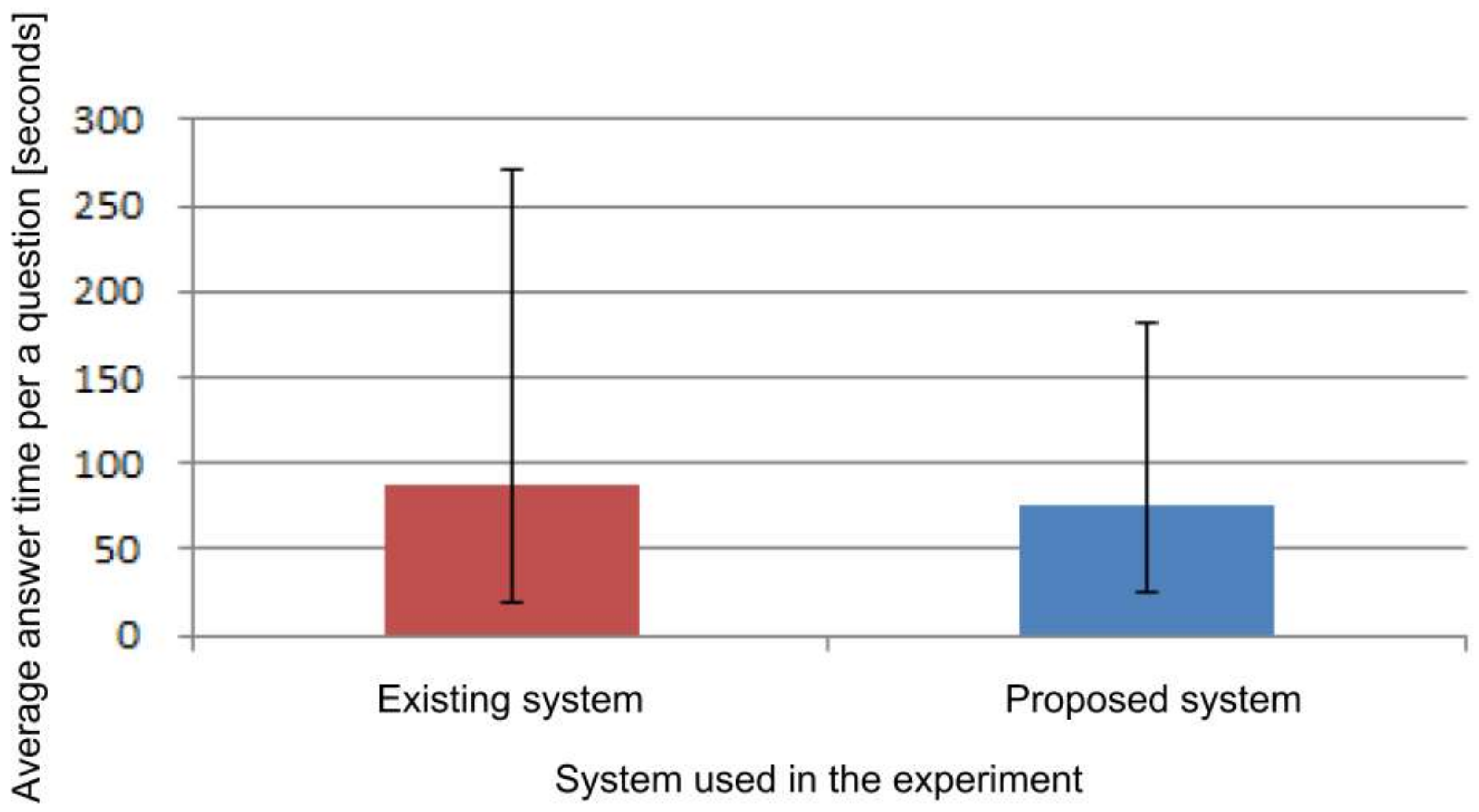
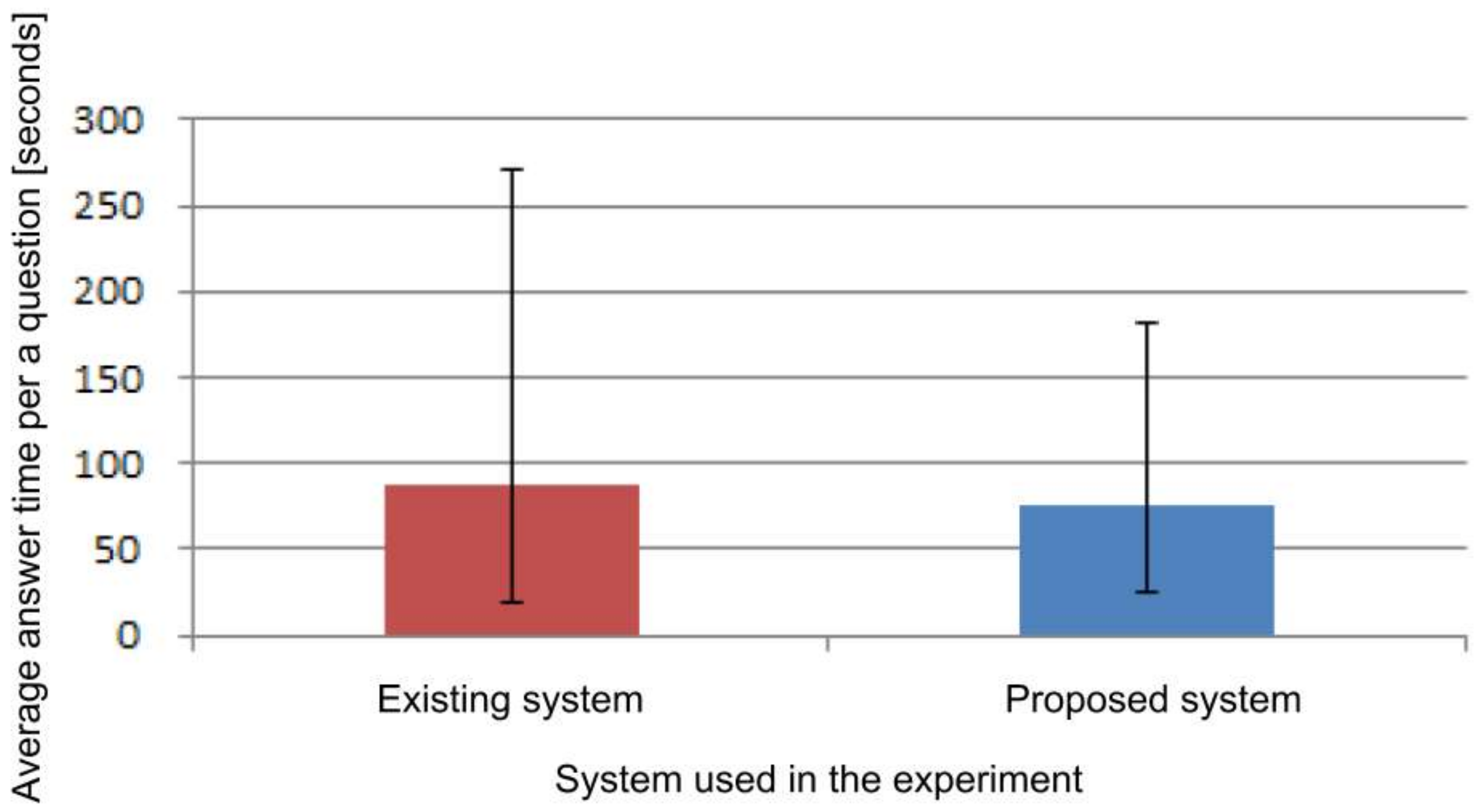
From the time it took to answer 10 questions, the average time taken to answer a question is shown in
Figure 15. The average time using the existing system was 87.0 s, and the average time using the proposed system was 75.6 s.
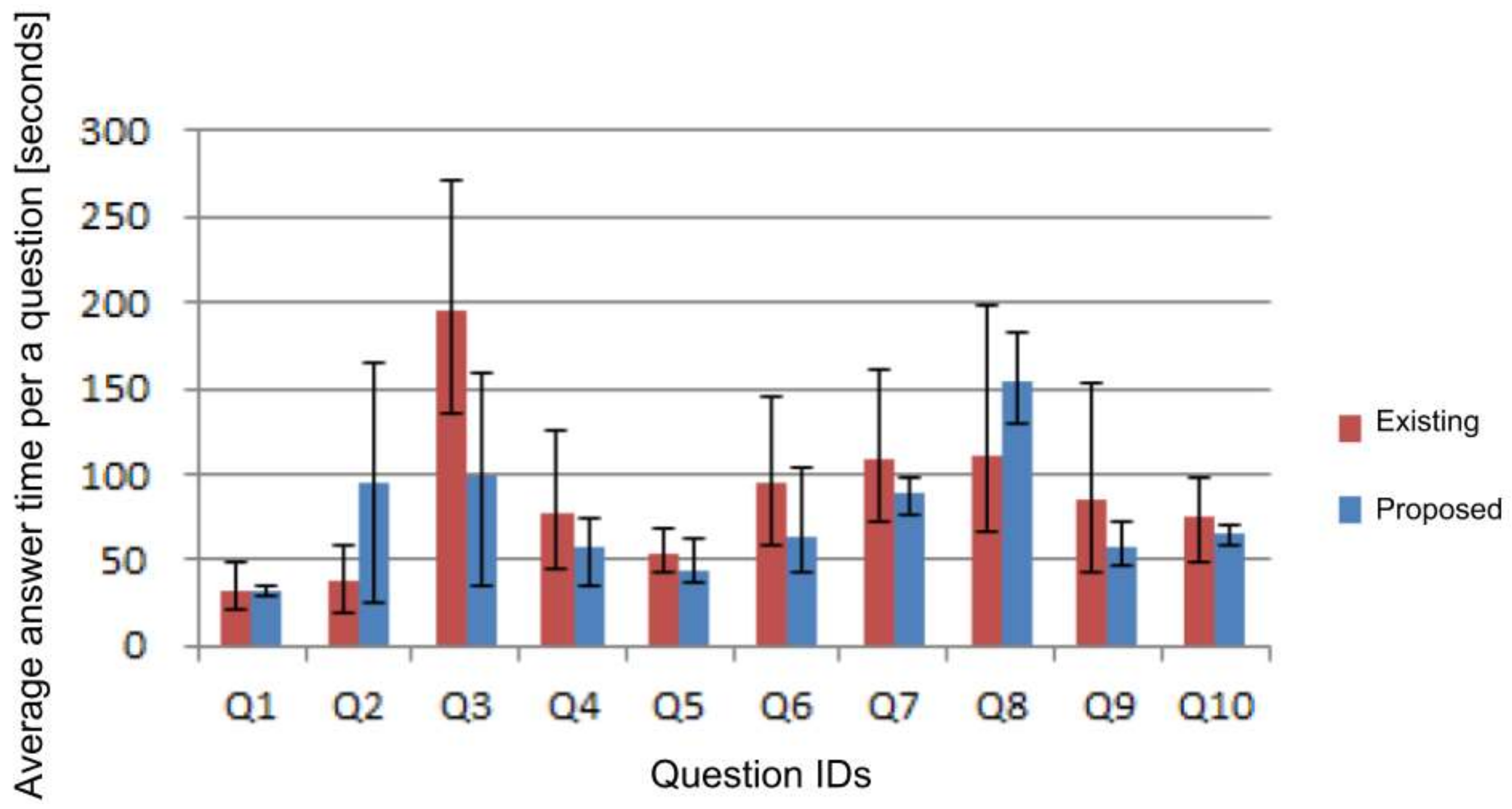
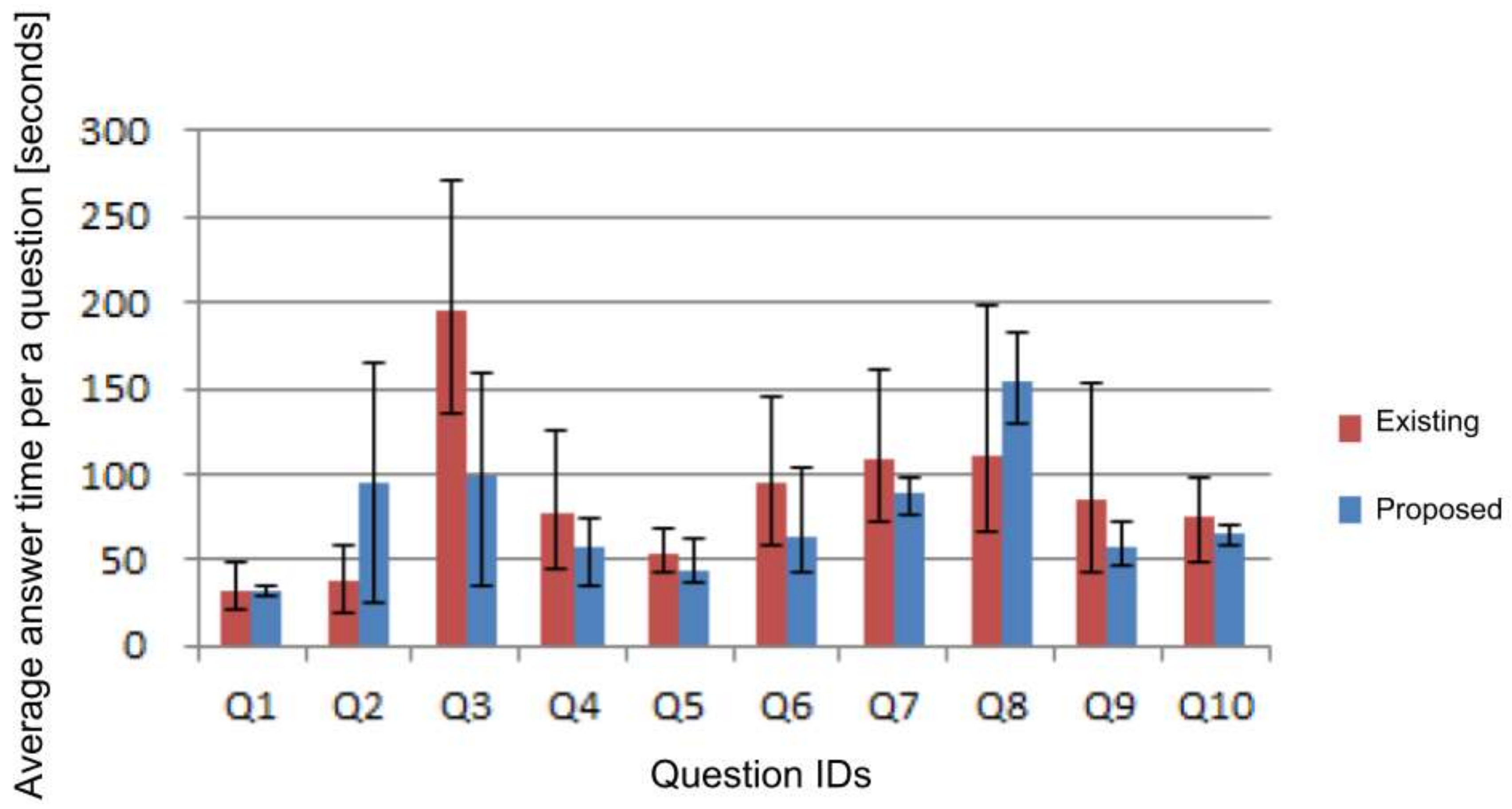
For each of the 10 questions, the average times using the existing system and the proposed system are shown in
Figure 16. Two of the ten questions were answered in a shorter time using the existing system. Seven questions were answered in a shorter time using the proposed system. The relationships between the features of each question and the characteristics of the system are described below.
Case where users can answer in the same amount of time using either system (Q1)
When there is one memory fragment to be viewed for answering and it is easy to find, there is almost no difference in recall time between the existing system and the proposed system.
In order to answer Q1, it was necessary to view an email (titled “About membership fee of experience A”), which informs members about the fee of the recall target experience A. When using the existing system, users decided to search for emails in Gmail and could use the corresponding mail by searching “Experience A”, “Membership Fee”, or a combination thereof. When using the proposed system, the users gave a recall request “Experience A”; they found the corresponding email based on the presented result and could use it.
Cases where users can answer quickly using the existing system (Q 2, 8)
When it is necessary to narrow down the appropriate memory fragment from a large number of memory fragments with similar characteristics, it is easier to answer using the existing system.
For example, in question 2, there is a large number of memory fragments related to experience B; by searching for a certain email from these memory fragments, the user could find a room name (answer) written in the content. When using the existing system, the users were able to narrow down by keywords “Experience B”, “Room”, or “Place” using the search engine, and could answer. On the other hand, in the proposed system, several memory fragments were presented at once, but the title of the email did not include the room name or it was written in the email itself. As a result, it was not easy to find a memory fragment that contained the information necessary to provide an answer simply by checking the email titles. In the implementation of this proposed system, when searching for a memory fragment that matches the recall request, only the memory fragments with the metadata exactly matching the input word were searched. Therefore, it was difficult to narrow down the options compared to the search engine of the existing system.
Thus, in cases where narrowing down a large number of memory fragments is required in order to extract a certain memory fragment, it is sometimes possible to recall a memory in a short time using the existing system. The response time of the proposed system can be greatly shortened depending on the improvement of the search engine.
Cases where users can answer quickly using the proposed system (Q3, 4, 5, 6, 7, 9, 10)
In cases where users using the proposed system can answer quickly, there is a common point: It is necessary to view multiple memory fragments to answer a single question. As an example, one question asks what a user ate in an experience (Q4). In the existing system, it is necessary to recall the time of the specified experience using Google Calendar, and search the photo corresponding to that time using Windows Explorer. Using the proposed system, when the name of a designated experience is entered as a recall request, relevant photos taken during that time are presented, so it was possible to answer with fewer steps.
Even when it is difficult to judge which type of memory fragment is necessary for answering it is possible to answer in a short time using the proposed system. For example, in question 3, in order to answer the name of a guest participant, it is necessary to view the photograph. However, in the first step, one could think that there is information in the email, and in the case of using the existing system, it was possible to conduct a search using various search words. By using the proposed system, users can browse related memory fragments. As a result, memory fragments of the type that do not contain guest information will not be browsed, thus shortening the time required to answer the question.
As described above, when the number of searches increases in the existing system or a search needs to be performed using multiple search systems, it is often possible to shorten the response time by using the proposed system. This is because there is no need to move windows and tabs, and the connection between memory fragments including heterogeneous intervals can be used. It is also because thinking time is reduced regarding, for example, which search word to use, which search system to use and how long to search.
From these analyses, it was confirmed that accurate recall can be achieved using the proposed system. In addition, it was confirmed that it is possible to shorten the recall time, especially when it is necessary to view multiple memory fragments for answering a single question. This is because the necessary, relevant memory fragments are presented.
5.3.2. Experiment 2-2: Evaluation of the Efficiency of Multilateral Recall Support Based on the Percentage of Questions Answered Correctly and Response Time to Past Experiences
In Experiment 2-2, questions were presented to users and the correct answer rate and response time were measured. In this experiment, unlike Experiment 2-1, we asked five questions related to the same experience and measured the total response time. We confirmed that the time required to recall from various perspectives of one experience can be shortened.
In this experiment, two events were presented as recall targets. Both of these events were parties organized at the laboratory to which the users belong; the number of participants and the length of the party are similar. The number of photographs taken during the party, and the number of emails including party names are also similar. In addition, all six users participated in two events.
Six users were divided into group A and group B. When answering the question about the first event, group A used the existing system and group B used the proposed system. For the second event, group A used the proposed system and group B used the existing system. This is to eliminate bias due to individuals’ familiarity with the system and the events.
The questions (common for the two events) that were asked in the experiments were as follows:
Date of the event
Place of the event
Time when people toasted at that event
The organizer of the event
What was done at that event
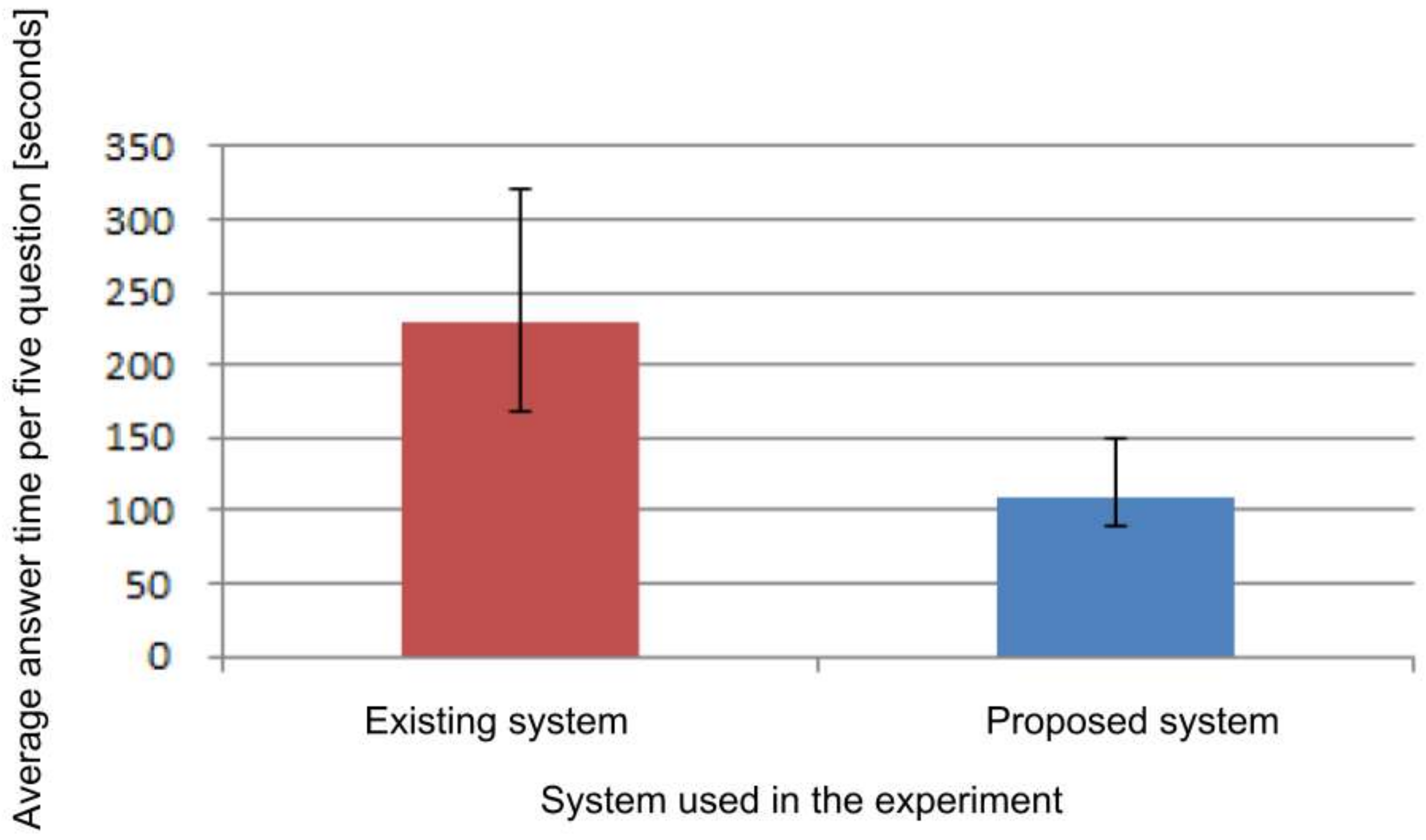
The correct answer rates when answering the questions related to the event using the existing system and the proposed system were both 100%. As shown in
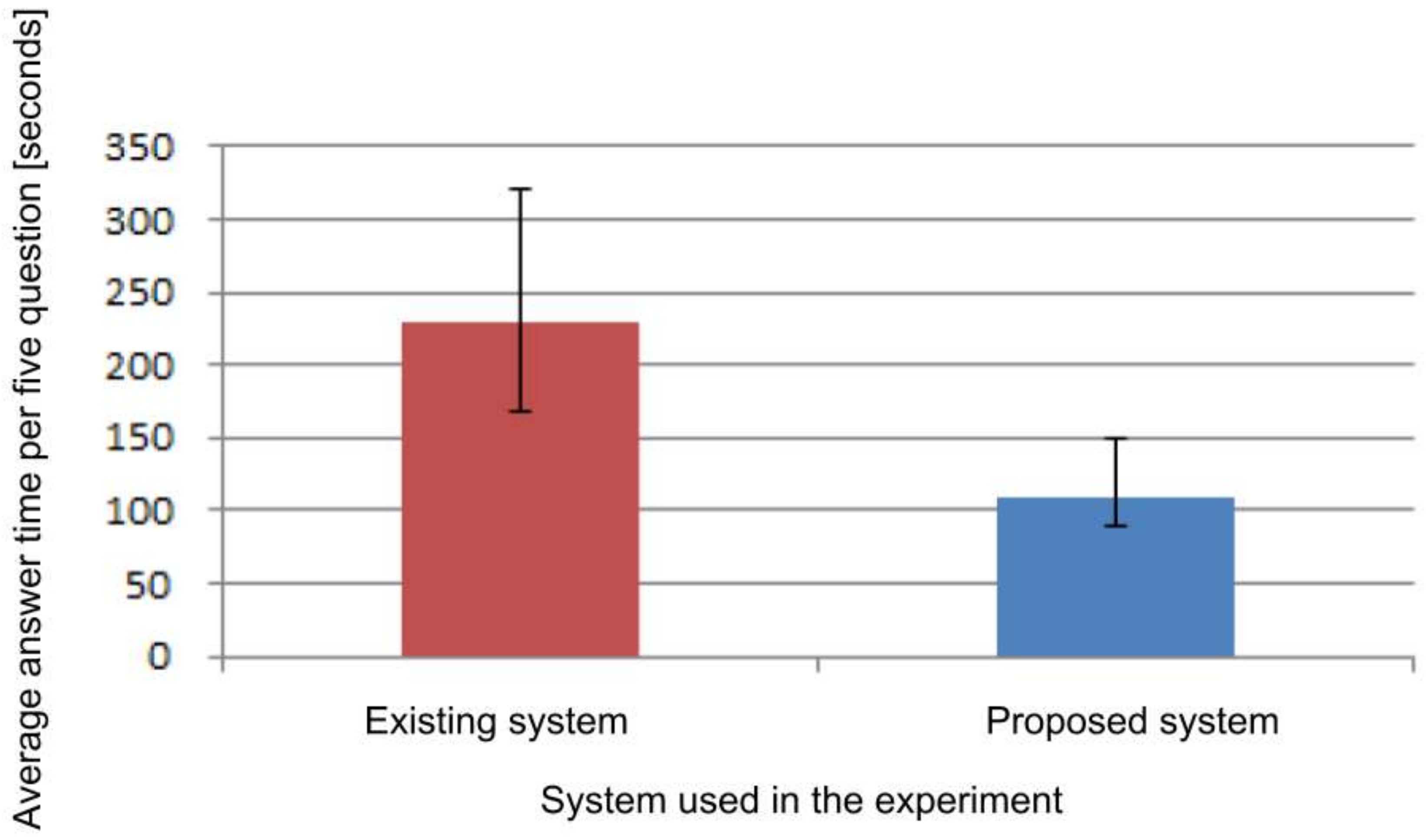
Figure 17, the average response time was 230.33 s when using the existing system and the average was 110.17 s when using the proposed system. In addition, when a t-test with a significance level of 5% was applied to the response time value, the t-value was 4.771 and the p-value was 0.005, which means that there was a significant difference. From these results, we confirmed that, using the proposed system, accurate information can be recalled in a shorter time compared with the existing system when multiple types of information are recalled for one experience.
5.3.3. Experiment 2-3: Evaluation of the Level of Detail and Number Recalled Episodes
In Experiment 2-3, we presented the event name to the users and asked them to describe the result of recalling the experience. By measuring the number of recalled episodes, we confirmed that detailed recalling becomes possible when using the proposed system.
The events which were presented in this experiment are the same as the two experiences used in Experiment 2-2. Also, the grouping of six users and the systems they use are the same as in Experiment 2-2.
In this experiment, the users recalled episodes within the time limit for the designated event, and the recalled episodes were described in detail each time. We instructed the users to write everything they recalled, including information directly related to what happened at the designated event, and information on different experiences associated with it. The users were instructed to describe the recalled episodes as a sentence including nominatives and predicates. The users tried to write one piece of information in one sentence, but if this was difficult and time-consuming, they wrote all information in one sentence. Therefore, after the experiment, the sentence was divided according to a certain criterion.
Before recalling using the existing system and the proposed system, we asked users to describe the episodes which could be easily recalled by oneself. This was in preparation for eliminating bias due to the difference in ease of recalling each event. After finishing the self-recall, we set a time to recall the episodes using the system and described it for 15 min.
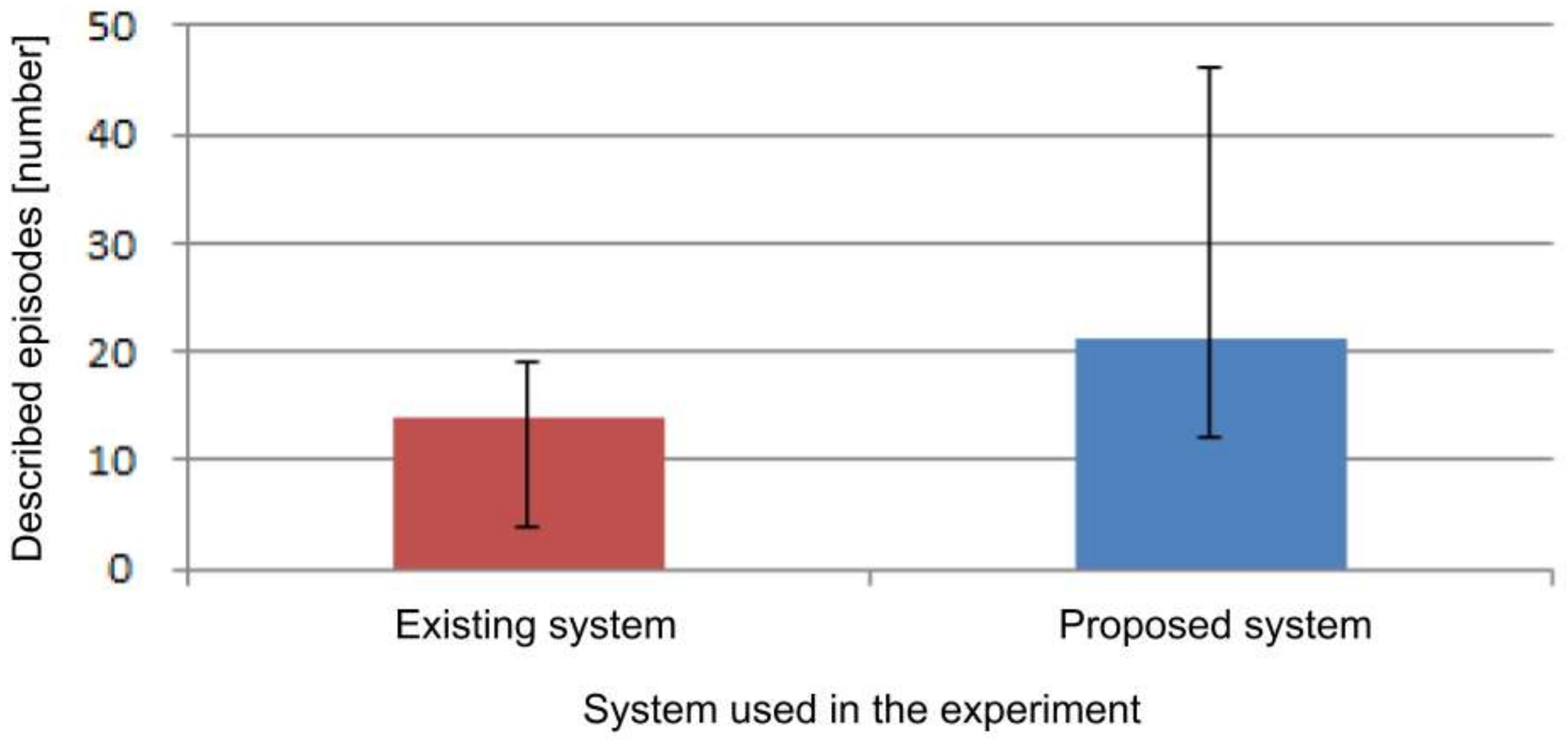
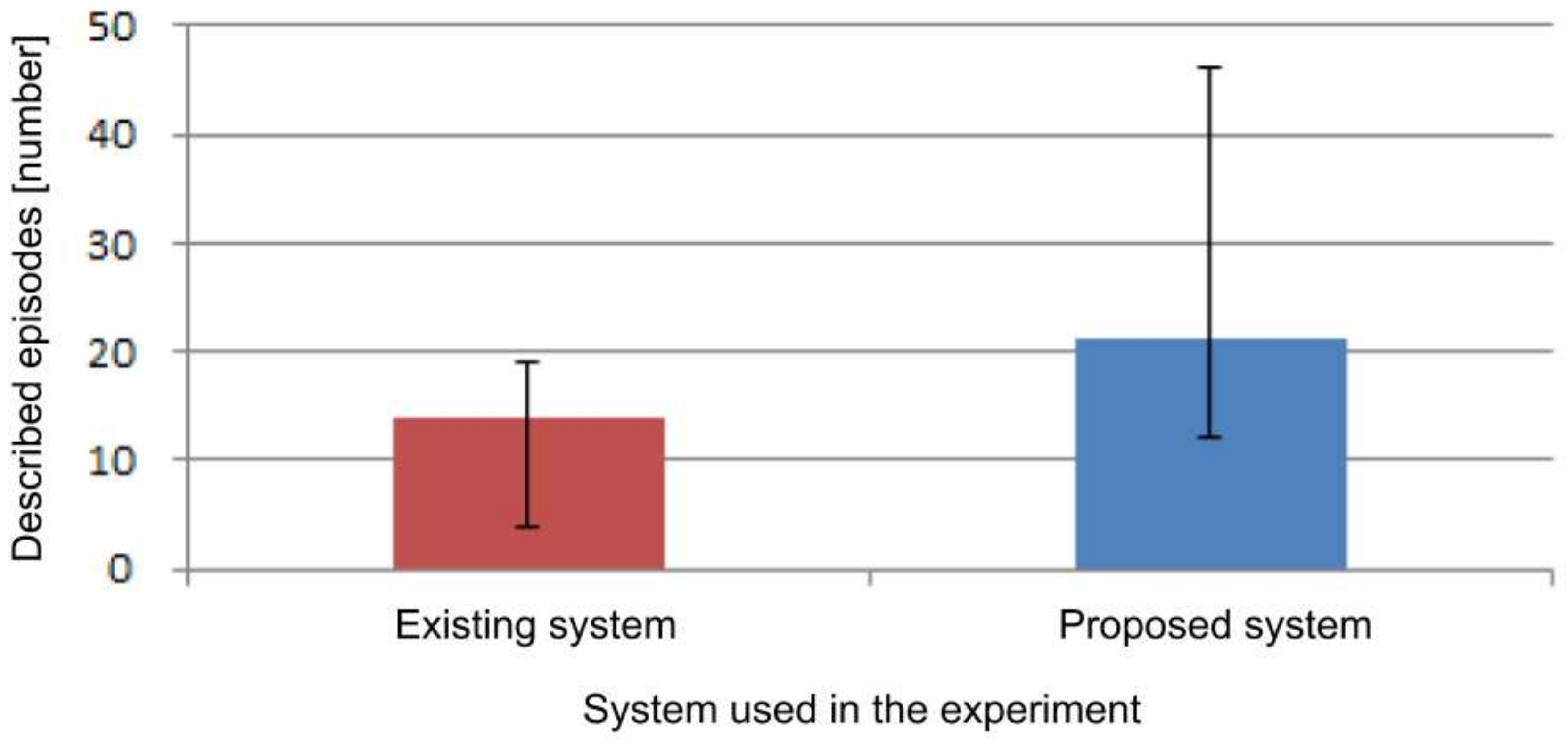
The result of the number of episodes when using each system is shown in
Figure 18. The amount of self-recalled episodes was not counted. The average number of episodes when using the existing system was 13.83 and the average when using the proposed system was 21.17. From these results, it was confirmed that by using the proposed system, it is possible to quickly recall one experience in detail.
Additionally, the content of the description was discussed. Using the proposed system, we found that there were several episodes about other experiences related to the designated event. For example, “There was a laboratory seminar on the day”, “There was a schedule to make a research presentation in the near future”, and “There was a work taking over the research was done at this time”.
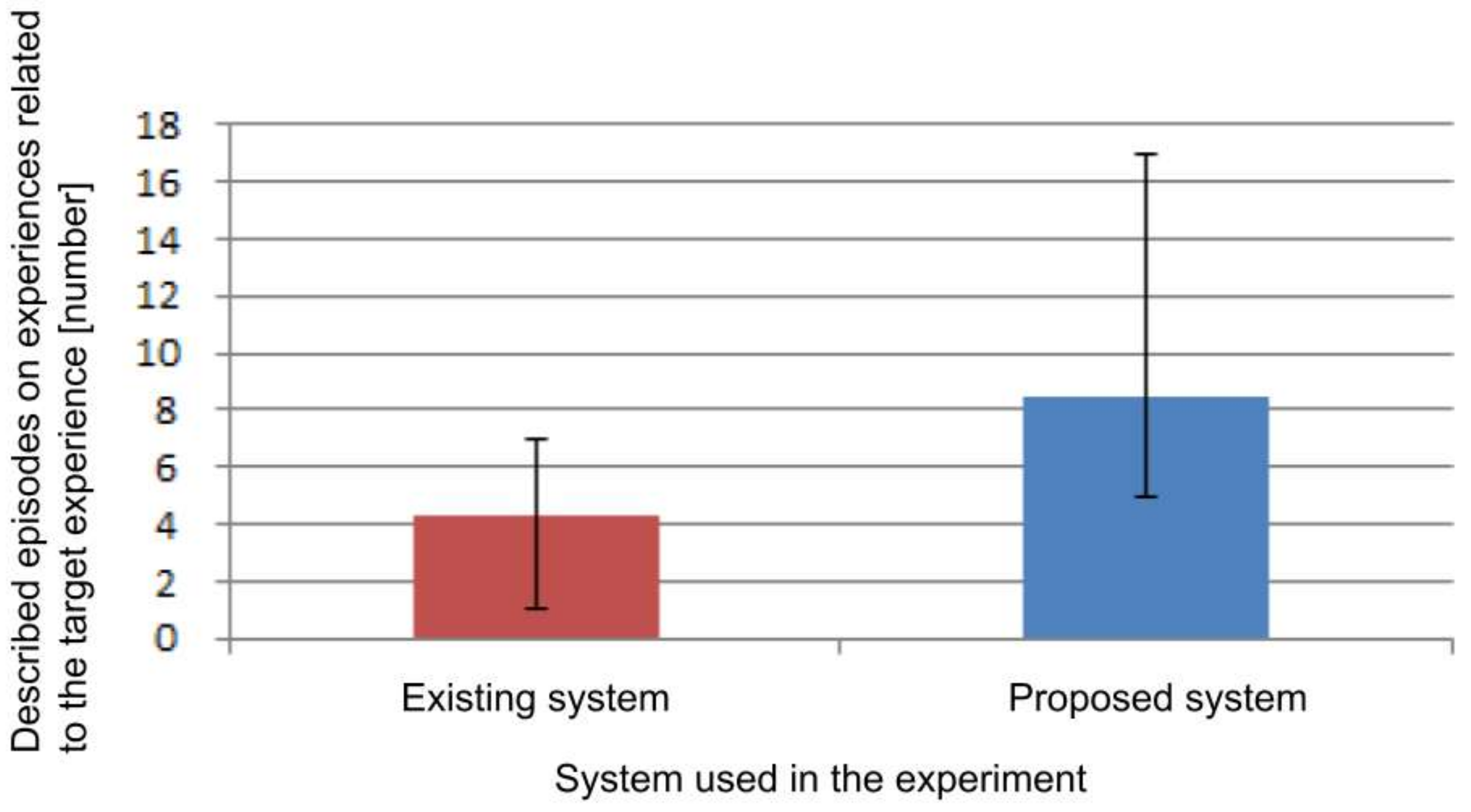
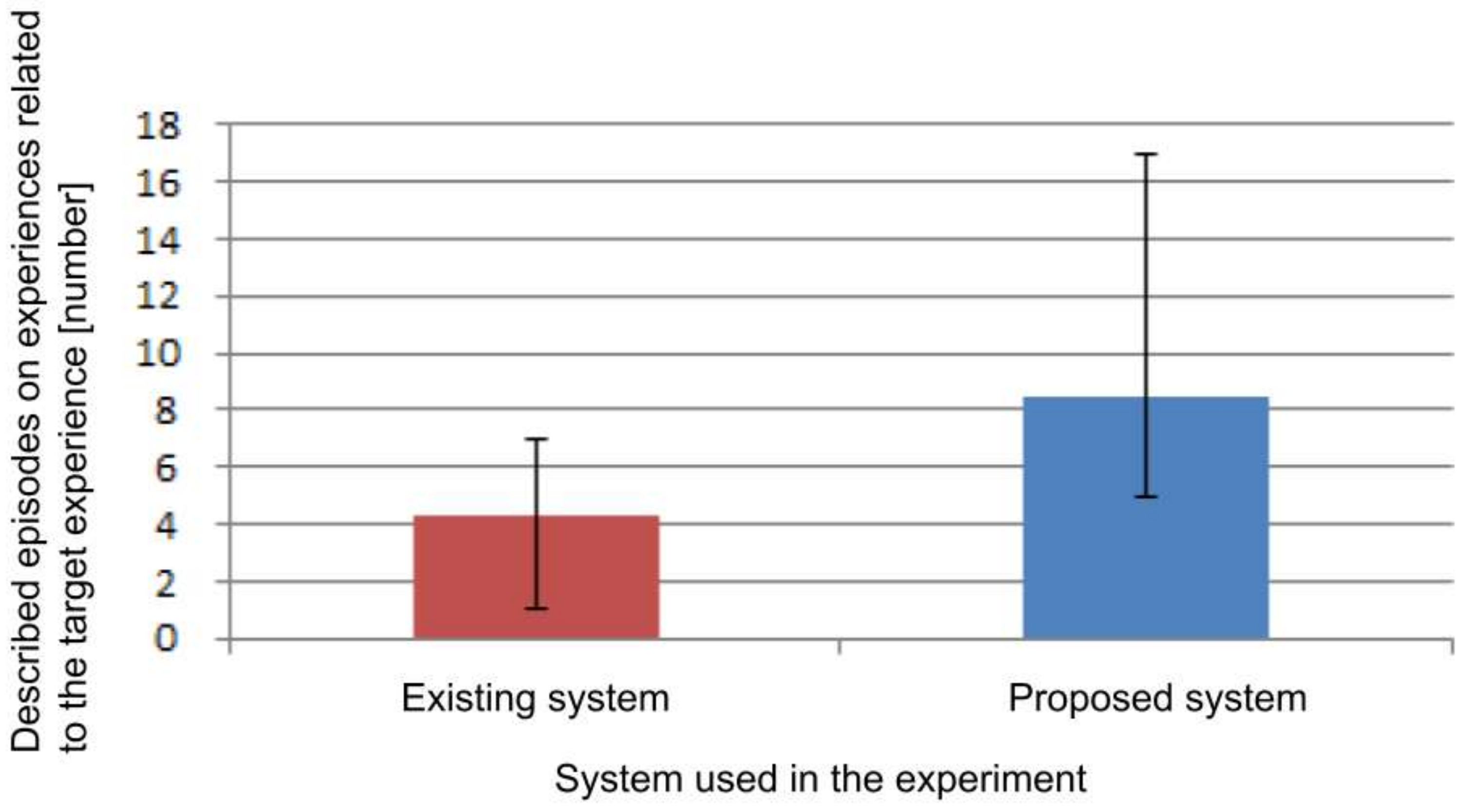
Figure 19 shows the number of episodes of the experiences related to the designated event when using each system. The average when using the existing system was 4.33, and the average when using the proposed system was 8.50. The reason why the proposed system is greater is because the memory fragments are presented in association, so recalling becomes easier without conscious re-searching. From these results, we confirmed that detailed information including not only directly related information, but also indirectly related information can be recalled by using the proposed system.
5.3.4. Questionnaires for Experiments 2-1, 2-2, and 3
After conducting Experiments 2-1, 2-2, and 2-3, we conducted questionnaires on the existing system and the proposed system for the users. In the questionnaire, we asked the following four points on memory recall using the existing system and proposed system.
Q1: I was able to find necessary information quickly
Q2: I am confident of the answers I recalled
Q3: I was able to recall details about what was asked
Q4: There are additional types of information that I could recall in relation to what was asked
The questions were answered in 5 levels (1 to 5). The meanings indicated by 1 to 5 are as follows.
1: No
2: Yes, but poorly
3: Yes, a little
4: Yes, good
5: Yes, very good
Additionally, we asked the users to freely describe how they felt using the system.
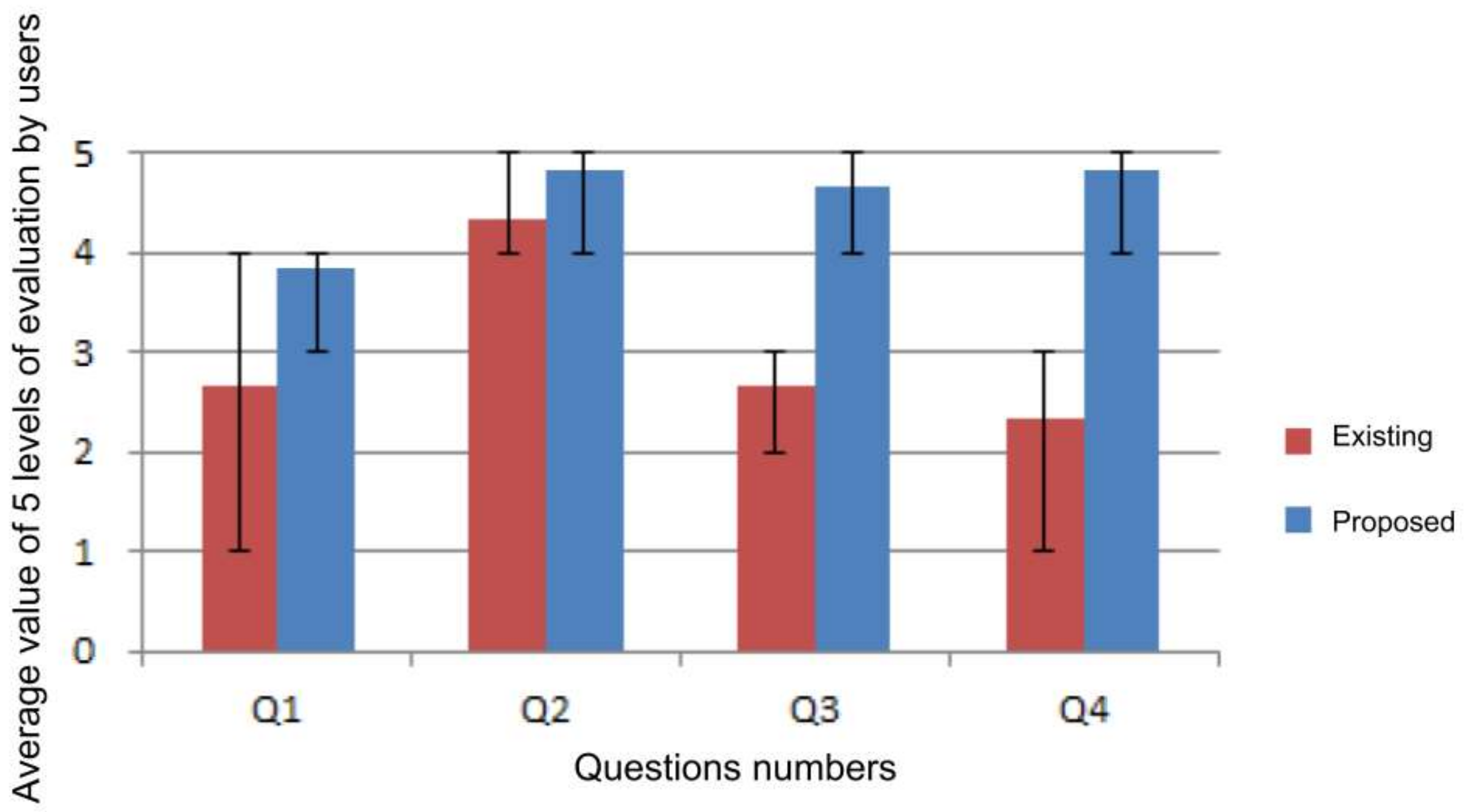
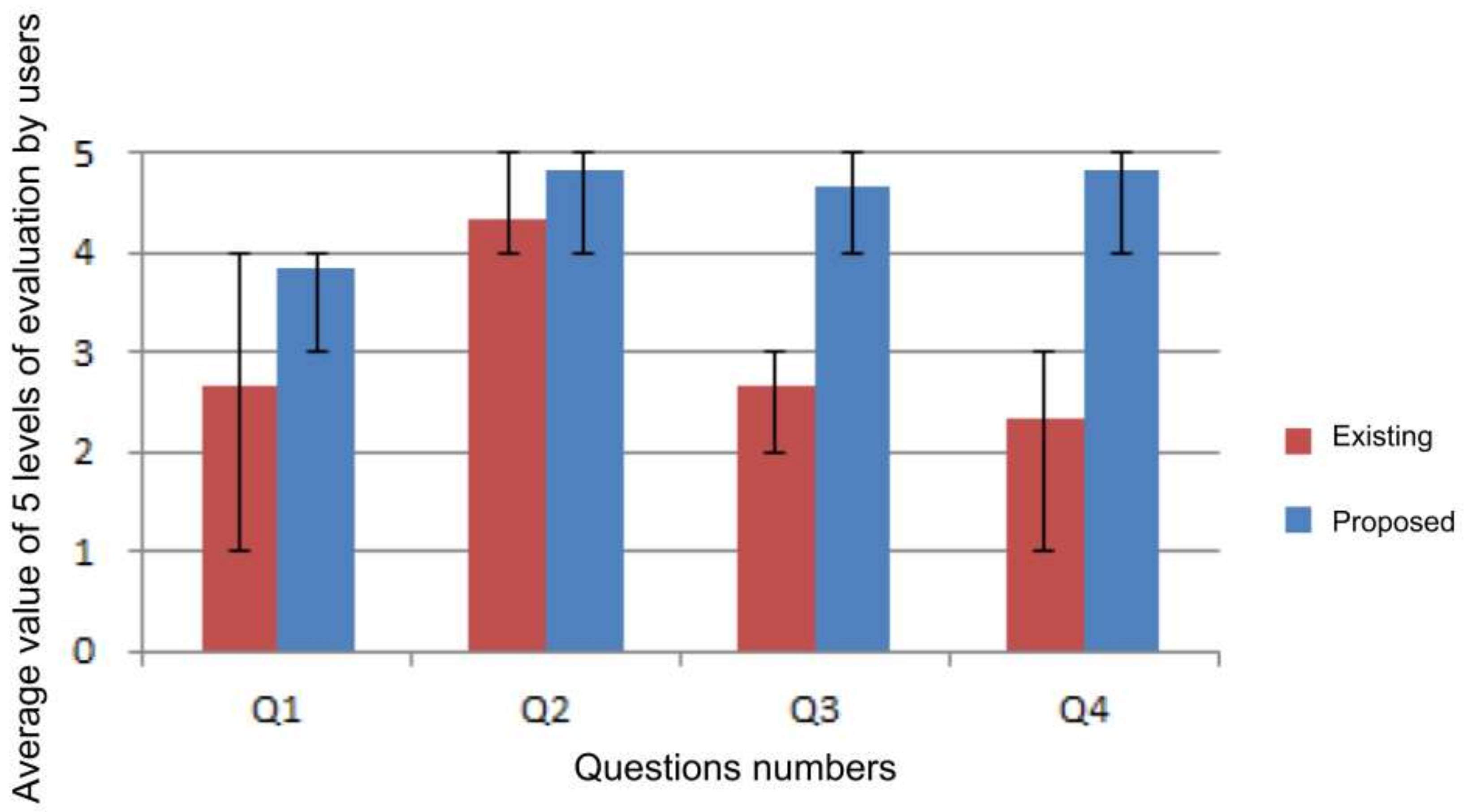
The results of these questionnaires are shown in
Figure 20. For all questions, the value is higher when using the proposed system. In addition, when the t-test was performed at a significance level of 0.05, it was found that there was a significant difference in Q3 and Q4.
We asked Q1 to see whether the user was able to recall quickly using the proposed system. As a result, the average when using the existing system was 2.67, and the average when using the proposed system was 3.83, and the opinions were that it was faster to recall when using the proposed system. These results also show that the time taken to recall in Experiments 2-1 and 2-2 was shorter using the proposed system.
We asked Q2 to see whether the users had feelings that they recalled correctly. As a result, the average when using the existing system was 4.33, and the average when using the proposed system was 4.83, both of which are high values. This is consistent with the fact that the correct answer rate in Experiments 2-1 and 2-2 was close to 100%. Although the difference was small, the proposed system had a higher value. Opinions were obtained in the free description part of the questionnaire. For example, there was an opinion that “It was good to be able to check across multiple information resources using the proposed system.” Confirming multiple, varying kinds of memory fragments at the same time is considered to be one of the reasons why users felt confident with their answers.
We asked Q3 to see whether the user recalled several things about the experience by using the proposed system. As a result, the average when using the existing system was 2.67, and the average when using the proposed system was 4.67, and it was confirmed by t-test that there was a significant difference. This is supported by the fact that the number of episodes in Experiment 2-3 was greater when using the proposed system.
We asked Q4 in order to confirm whether the user could recall information indirectly related to the target experience using the proposed system. As a result, the average when using the existing system was 2.33, the average when using the proposed system was 4.83, and it was confirmed by t-test that there was a significant difference. This is supported by the fact that the number of episodes related to the target experience in the description of Experiment 2-3 was greater when using the proposed system.
Furthermore, we obtained opinions such as “I was able to recall the scene of the lab at that time in detail” and “I was able to recall even the smell and the cold feeling at that time” using the proposed system. It is considered that users have such an opinion because of the provision of associated memory fragments around the target memory fragment.
From the results of these questionnaires and their analysis, we confirmed the results that users can recall quickly and accurately using the proposed system. In addition, it was confirmed that details can be recalled as well as information related indirectly to the recalled target experience. In addition, it was confirmed that the user had the same tendency, as shown in the results of Experiments 2-1, 2-2, and 2-3.
5.3.5. Summary of Experiment and Evaluation
We conducted experiments to confirm the effect of each proposed function using the prototype system.
In Experiment 1, it was possible to acquire various memory fragments as AIRs from different services and applications; we confirmed that issue P1 was solved. We confirmed that problem P2 was solved because the imported memory fragments were related and autonomously composed the memory structure of the experience. In response to the user’s request, since the proposed system presented effective memory fragments and their relationships, we confirmed that problem P3 was solved.
In Experiment 2, we confirmed that it was possible to support the memory recall accurately, quickly, and in detail; so we confirmed that effective memory recall support became possible using the system based on the proposals.
From these results, it was confirmed that each proposed function solved each problem, and collectively realized the effective recall support. As a result, the burden of work was reduced when supporting human activities using information obtained by information collection means such as a lifelog, which is the objective of this research.
In the evaluation carried out in this paper, we confirmed the feasibility of the system using big data. In this system, the time it takes for the memory fragment to be presented for the first time is about 1 s which can withstand practical use. However, a limitation of the system implemented in this paper is that memory fragments are presented one after another, and the time it takes to present all fragments is on the order of tens of seconds. Therefore, when the order of the number of AIRs reaches 1000 or more, it is possible that it takes much computation time or that display convenience is impaired. It is possible to deal with this problem by distributing the calculation cost by applying multi-agent hierarchy technology.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}