
Use of Machine Learning with Fused Spectral Data for Prediction of Product Sensory Characteristics: The Case of Grape to Wine
 , and
, and
Abstract
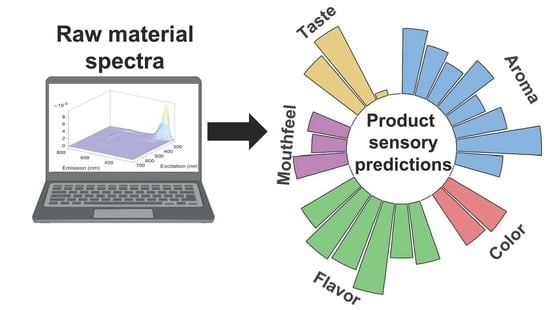
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Materials and Methods
2.1. Grape and Wine Samples
2.2. A-TEEM and CIELAB Data Collection
2.3. Wine Sensory Profiling
2.4. PARAFAC Modelling
2.5. Data Pre-Processing and Fusion
2.6. XGBoost Regression Modelling
2.7. Software
3. Results and Discussion
3.1. PARAFAC Examination of EEM Data
3.2. Feature Extraction and Data Fusion
3.3. Performance of XGBoost Models
3.4. Prediction of Sensory Scores


4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clark, J.E. Taste and flavour: Their importance in food choice and acceptance. Proc. Nutr. Soc. 1998, 57, 639–643. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, Q.; Zhao, J.; Chen, Q. Instrumental intelligent test of food sensory quality as mimic of human panel test combining multiple cross-perception sensors and data fusion. Anal. Chim. Acta 2014, 841, 68–76. [Google Scholar] [PubMed]
- Cetó, X.; Voelcker, N.H.; Prieto-Simón, B. Bioelectronic tongues: New trends and applications in water and food analysis. Biosens. Bioelectron. 2016, 79, 608–626. [Google Scholar] [CrossRef] [PubMed]
- Borràs, E.; Ferré, J.; Boqué, R.; Mestres, M.; Aceña, L.; Busto, O. Data fusion methodologies for food and beverage authentication and quality assessment—A review. Anal. Chim. Acta 2015, 891, 1–14. [Google Scholar] [CrossRef]
- Cozzolino, D.; Smyth, H.E.; Lattey, K.A.; Cynkar, W.; Janik, L.; Dambergs, R.G.; Francis, I.L.; Gishen, M. Combining mass spectrometry based electronic nose, visible–near infrared spectroscopy and chemometrics to assess the sensory properties of Australian Riesling wines. Anal. Chim. Acta 2006, 563, 319–324. [Google Scholar] [CrossRef]
- Curto, B.; Moreno, V.; García-Esteban, J.A.; Blanco, F.J.; González, I.; Vivar, A.; Revilla, I. Accurate prediction of sensory attributes of cheese using near-infrared spectroscopy based on artificial neural network. Sensors 2020, 20, 3566. [Google Scholar] [CrossRef]
- Esteban-Díez, I.; González-Sáiz, J.M.; Pizarro, C. Prediction of sensory properties of espresso from roasted coffee samples by near-infrared spectroscopy. Anal. Chim. Acta 2004, 525, 171–182. [Google Scholar] [CrossRef]
- Karoui, R.; Blecker, C. Fluorescence spectroscopy measurement for quality assessment of food systems—A review. Food Bioproc. Technol. 2011, 4, 364–386. [Google Scholar]
- Ranaweera, R.K.R.; Capone, D.L.; Bastian, S.E.P.; Cozzolino, D.; Jeffery, D.W. A review of wine authentication using spectroscopic approaches in combination with chemometrics. Molecules 2021, 26, 4334. [Google Scholar] [CrossRef]
- Quatela, A.; Gilmore, A.M.; Gall, K.E.S.; Sandros, M.; Csatorday, K.; Siemiarczuk, A.; Yang, B.; Camenen, L. A-TEEMTM, a new molecular fingerprinting technique: Simultaneous absorbance-transmission and fluorescence excitation-emission matrix method. Methods Appl. Fluoresc. 2018, 6, 027002. [Google Scholar] [CrossRef]
- Ranaweera, R.K.R.; Gilmore, A.M.; Capone, D.L.; Bastian, S.E.P.; Jeffery, D.W. Authentication of the geographical origin of Australian Cabernet Sauvignon wines using spectrofluorometric and multi-element analyses with multivariate statistical modelling. Food Chem. 2021, 335, 127592. [Google Scholar] [CrossRef] [PubMed]
- Ranaweera, R.K.R.; Gilmore, A.M.; Capone, D.L.; Bastian, S.E.P.; Jeffery, D.W. Spectrofluorometric analysis combined with machine learning for geographical and varietal authentication, and prediction of phenolic compound concentrations in red wine. Food Chem. 2021, 361, 130149. [Google Scholar] [CrossRef] [PubMed]
- Souza Gonzaga, L.; Bastian, S.E.P.; Capone, D.L.; Ranaweera, R.K.R.; Jeffery, D.W. Modelling Cabernet Sauvignon wine sensory traits from spectrofluorometric data. OENO One 2021, 55, 19–33. [Google Scholar] [CrossRef]
- Gilmore, A.M.; Elhendawy, M.A.; Radwan, M.M.; Kidder, L.H.; Wanas, A.S.; Godfrey, M.; Hildreth, J.B.; Robinson, A.E.; ElSohly, M.A. Absorbance-transmittance excitation emission matrix method for quantification of major cannabinoids and corresponding acids: A rapid alternative to chromatography for rapid chemotype discrimination of Cannabis sativa varieties. Cannabis Cannabinoid Res. 2022. [Google Scholar] [CrossRef]
- Schober, D.; Gilmore, A.; Chen, L.; Zincker, J.; Gonzalez, A. Determination of Cabernet Sauvignon wine quality parameters in Chile by Absorbance-Transmission and fluorescence Excitation Emission Matrix (A-TEEM) spectroscopy. Food Chem. 2022, 392, 133101. [Google Scholar] [CrossRef]
- Ranaweera, R.K.R.; Gilmore, A.M.; Bastian, S.E.P.; Capone, D.L.; Jeffery, D.W. Spectrofluorometric analysis to trace the molecular fingerprint of wine during the winemaking process and recognise the blending percentage of different varietal wines. OENO One 2022, 56, 189–196. [Google Scholar] [CrossRef]
- Christensen, J.; Nørgaard, L.; Bro, R.; Engelsen, S.B. Multivariate autofluorescence of intact food systems. Chem. Rev. 2006, 106, 1979–1994. [Google Scholar] [CrossRef]
- Lenhardt Acković, L.; Zeković, I.; Dramićanin, T.; Bro, R.; Dramićanin, M.D. Modeling food fluorescence with PARAFAC. In Reviews in Fluorescence 2017; Geddes, C.D., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 161–197. [Google Scholar]
- Apetrei, C.; Apetrei, I.M.; Villanueva, S.; de Saja, J.A.; Gutierrez-Rosales, F.; Rodriguez-Mendez, M.L. Combination of an e-nose, an e-tongue and an e-eye for the characterisation of olive oils with different degree of bitterness. Anal. Chim. Acta 2010, 663, 91–97. [Google Scholar] [CrossRef]
- Vera, L.; Aceña, L.; Guasch, J.; Boqué, R.; Mestres, M.; Busto, O. Discrimination and sensory description of beers through data fusion. Talanta 2011, 87, 136–142. [Google Scholar] [CrossRef]
- Ulloa, P.A.; Guerra, R.; Cavaco, A.M.; Rosa da Costa, A.M.; Figueira, A.C.; Brigas, A.F. Determination of the botanical origin of honey by sensor fusion of impedance e-tongue and optical spectroscopy. Comput. Electron. Agric. 2013, 94, 1–11. [Google Scholar] [CrossRef]
- Niimi, J.; Boss, P.K.; Jeffery, D.; Bastian, S.E.P. Linking sensory properties and chemical composition of Vitis vinifera cv. Cabernet Sauvignon grape berries to wine. Am. J. Enol. Vitic. 2017, 68, 357. [Google Scholar]
- Niimi, J.; Boss, P.K.; Jeffery, D.W.; Bastian, S.E.P. Linking the sensory properties of Chardonnay grape Vitis vinifera cv. berries to wine characteristics. Am. J. Enol. Vitic. 2018, 69, 113–124. [Google Scholar]
- Waterhouse, A.L.; Sacks, G.L.; Jeffery, D.W. Understanding Wine Chemistry; John Wiley & Sons: Chichester, UK, 2016. [Google Scholar]
- Thomas-Danguin, T.; Sinding, C.; Tournier, C.; Saint-Eve, A. Multimodal interactions. In Flavor; Etiévant, P., Guichard, E., Salles, C., Voilley, A., Eds.; Woodhead Publishing: Duxford, UK, 2016; pp. 121–141. [Google Scholar]
- Niimi, J.; Tomic, O.; Næs, T.; Jeffery, D.W.; Bastian, S.E.P.; Boss, P.K. Application of sequential and orthogonalised-partial least squares (SO-PLS) regression to predict sensory properties of Cabernet Sauvignon wines from grape chemical composition. Food Chem. 2018, 256, 195–202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niimi, J.; Tomic, O.; Næs, T.; Bastian, S.E.P.; Jeffery, D.W.; Nicholson, E.L.; Maffei, S.M.; Boss, P.K. Objective measures of grape quality: From Cabernet Sauvignon grape composition to wine sensory characteristics. LWT 2020, 123, 109105. [Google Scholar]
- Niimi, J.; Liland, K.H.; Tomic, O.; Jeffery, D.W.; Bastian, S.E.P.; Boss, P.K. Prediction of wine sensory properties using mid-infrared spectra of Cabernet Sauvignon and Chardonnay grape berries and wines. Food Chem. 2021, 344, 128634. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Cozzolino, D.; Cynkar, W.U.; Dambergs, R.G.; Mercurio, M.D.; Smith, P.A. Measurement of condensed tannins and dry matter in red grape homogenates using near infrared spectroscopy and partial least squares. J. Agric. Food Chem. 2008, 56, 7631–7636. [Google Scholar] [CrossRef]
- Fragoso, S.; Guasch, J.; Aceña, L.; Mestres, M.; Busto, O. Prediction of red wine colour and phenolic parameters from the analysis of its grape extract. Int. J. Food Sci. 2011, 46, 2569–2575. [Google Scholar] [CrossRef]
- Armstrong, C.E.J.; Gilmore, A.M.; Boss, P.K.; Pagay, V.; Jeffery, D.W. Machine learning for classifying and predicting grape maturity indices using absorbance and fluorescence spectra. Food Chem. 2023, 403, 134321. [Google Scholar]
- Gilmore, A.M. How to collect National Institute of Standards and Technology (NIST) traceable fluorescence excitation and emission spectra. In Fluorescence Spectroscopy and Microscopy: Methods and Protocols; Engelborghs, Y., Visser, A.J.W.G., Eds.; Humana Press: Totowa, NJ, USA, 2014; pp. 3–27. [Google Scholar]
- Gerretzen, J.; Szymańska, E.; Jansen, J.J.; Bart, J.; van Manen, H.-J.; van den Heuvel, E.R.; Buydens, L.M.C. Simple and effective way for data preprocessing selection based on design of experiments. Anal. Chem. 2015, 87, 12096–12103. [Google Scholar] [CrossRef]
- Campos, M.P.; Reis, M.S. Data preprocessing for multiblock modelling—A systematization with new methods. Chemom. Intell. Lab. Syst. 2020, 199, 103959. [Google Scholar]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar]
- Joseph, V.R. Optimal ratio for data splitting. Stat. Anal. Data Min. ASA Data Sci. J. 2022, 15, 531–538. [Google Scholar] [CrossRef]
- González-Muñoz, B.; Garrido-Vargas, F.; Pavez, C.; Osorio, F.; Chen, J.; Bordeu, E.; O’Brien, J.A.; Brossard, N. Wine astringency: More than just tannin–protein interactions. J. Sci. Food. Agric. 2022, 102, 1771–1781. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Armstrong, C.E.J.; Niimi, J.; Boss, P.K.; Pagay, V.; Jeffery, D.W. Use of Machine Learning with Fused Spectral Data for Prediction of Product Sensory Characteristics: The Case of Grape to Wine. Foods 2023, 12, 757. https://doi.org/10.3390/foods12040757
Armstrong CEJ, Niimi J, Boss PK, Pagay V, Jeffery DW. Use of Machine Learning with Fused Spectral Data for Prediction of Product Sensory Characteristics: The Case of Grape to Wine. Foods. 2023; 12(4):757. https://doi.org/10.3390/foods12040757
Chicago/Turabian StyleArmstrong, Claire E. J., Jun Niimi, Paul K. Boss, Vinay Pagay, and David W. Jeffery. 2023. "Use of Machine Learning with Fused Spectral Data for Prediction of Product Sensory Characteristics: The Case of Grape to Wine" Foods 12, no. 4: 757. https://doi.org/10.3390/foods12040757