




An Experimental Study of Grouping Mutation Operators for the Unrelated Parallel-Machine Scheduling Problem

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Grouping Genetic Algorithm for
2.1. Genetic Encoding, Fitness Function, and Initial Population
2.2. Adapted Gene-Level Crossover Operator
| Algorithm 1 AGLX operator |
Input: Two parent solutions and , and the number of machines m. Output: Two offspring solutions and .
|
2.3. Download Mutation Operator
| Algorithm 2 Download mutation operator |
Input: A solution S. Output: A mutated solution .
|
2.4. Selection and Replacement Strategies
| Algorithm 3 Ranking strategy |
Input: The population P. Output: The population rearranged en sets the G, R, and B.
|
2.5. Impact Analysis of Crossover and Mutation Rate on GGA
3. Grouping Mutation Operators
3.1. The Swap Operator
3.2. The Insertion Operator
3.3. The Elimination Operator
3.4. The Merge and Split Operator
4. Computational Experiments
4.1. State-of-the-Art Mutation Operators
| Algorithm 4 Swap operator |
Input: A solution S. Output: A mutated solution .
|
| Algorithm 5 Insertion operator |
Input: A solution S. Output: A mutated solution .
|
| Algorithm 6 Elimination operator |
Input: A solution S. Output: A mutated solution .
|
| Algorithm 7 Merge and Split operator |
Input: A solution S. Output: A mutated solution .
|
4.2. Handled Machines and Removed Jobs
| Algorithm 8 Elimination operator-v2 |
Input: A solution S, number of machines f and jobs h handle. Output: A mutated solution .
|
4.3. Machines Selection Strategy
4.4. Rearrangement Heuristics
| Algorithm 9 Rearrangement heuristic Insertion |
Input: A solution S and two machines w and o. Output: A mutated solution .
|
| Algorithm 10 Rearrangement heuristic Assemble |
Input: A solution S and two machines w and o. Output: A mutated solution .
|
5. Comparing GGA with the Old and the New Mutation Operators
5.1. Comparing the Effectiveness of GGA with the Old and the New Mutation Operators
5.2. Comparing the Efficiency of GGA with the Old and the New Mutation Operators
6. Conclusions and Paths of Work
Author Contributions
Funding
Conflicts of Interest
References
- Ramos-Figueroa, O.; Quiroz-Castellanos, M.; Mezura-Montes, E.; Schütze, O. Metaheuristics to solve grouping problems: A review and a case study. Swarm Evol. Comput. 2020, 53, 100643. [Google Scholar] [CrossRef]
- Garey, M.R. A Guide to the Theory of NP-Completeness. In Computers and Intractability; W. H. Freeman and Company: New York, NY, USA, 1979. [Google Scholar]
- Sels, V.; Coelho, J.; Dias, A.M.; Vanhoucke, M. Hybrid tabu search and a truncated branch-and-bound for the unrelated parallel machine scheduling problem. Comput. Oper. Res. 2015, 53, 107–117. [Google Scholar] [CrossRef]
- Fanjul-Peyro, L. Models and an exact method for the unrelated parallel machine scheduling problem with setups and resources. Expert Syst. Appl. X 2020, 5, 100022. [Google Scholar] [CrossRef]
- Bitar, A.; Dauzère-Pérès, S.; Yugma, C. Unrelated parallel machine scheduling with new criteria: Complexity and models. Comput. Oper. Res. 2021, 132, 105291. [Google Scholar] [CrossRef]
- Moser, M.; Musliu, N.; Schaerf, A.; Winter, F. Exact and metaheuristic approaches for unrelated parallel machine scheduling. J. Sched. 2022, 25, 507–534. [Google Scholar] [CrossRef]
- Shim, S.O.; Kim, Y.D. Minimizing total tardiness in an unrelated parallel-machine scheduling problem. J. Oper. Res. Soc. 2007, 58, 346–354. [Google Scholar] [CrossRef]
- Terzi, M.; Arbaoui, T.; Yalaoui, F.; Benatchba, K. Solving the Unrelated Parallel Machine Scheduling Problem with Setups Using Late Acceptance Hill Climbing. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Phuket, Thailand, 23–26 March 2020; pp. 249–258. [Google Scholar]
- Arroyo, J.E.C.; Leung, J.Y.T.; Tavares, R.G. An iterated greedy algorithm for total flow time minimization in unrelated parallel batch machines with unequal job release times. Eng. Appl. Artif. Intell. 2019, 77, 239–254. [Google Scholar] [CrossRef]
- Diana, R.O.M.; de Souza, S.R. Analysis of variable neighborhood descent as a local search operator for total weighted tardiness problem on unrelated parallel machines. Comput. Oper. Res. 2020, 117, 104886. [Google Scholar] [CrossRef]
- Yepes-Borrero, J.C.; Villa, F.; Perea, F.; Caballero-Villalobos, J.P. GRASP algorithm for the unrelated parallel machine scheduling problem with setup times and additional resources. Expert Syst. Appl. 2020, 141, 112959. [Google Scholar] [CrossRef]
- Arnaout, J.P. A worm optimization algorithm to minimize the makespan on unrelated parallel machines with sequence-dependent setup times. Ann. Oper. Res. 2020, 285, 273–293. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Akutsah, F. An improved firefly algorithm for the unrelated parallel machines scheduling problem with sequence-dependent setup times. IEEE Access 2018, 6, 54459–54478. [Google Scholar] [CrossRef]
- Lei, D.; Liu, M. An artificial bee colony with division for distributed unrelated parallel machine scheduling with preventive maintenance. Comput. Ind. Eng. 2020, 141, 106320. [Google Scholar] [CrossRef]
- Zheng, X.l.; Wang, L. A two-stage adaptive fruit fly optimization algorithm for unrelated parallel machine scheduling problem with additional resource constraints. Expert Syst. Appl. 2016, 65, 28–39. [Google Scholar] [CrossRef]
- Afzalirad, M.; Shafipour, M. Design of an efficient genetic algorithm for resource-constrained unrelated parallel machine scheduling problem with machine eligibility restrictions. J. Intell. Manuf. 2018, 29, 423–437. [Google Scholar] [CrossRef]
- Jaklinović, K.; Ðurasević, M.; Jakobović, D. Designing dispatching rules with genetic programming for the unrelated machines environment with constraints. Expert Syst. Appl. 2021, 172, 114548. [Google Scholar] [CrossRef]
- Lei, D.; Yuan, Y.; Cai, J.; Bai, D. An imperialist competitive algorithm with memory for distributed unrelated parallel machines scheduling. Int. J. Prod. Res. 2020, 58, 597–614. [Google Scholar] [CrossRef]
- Bitar, A.; Dauzère-Pérès, S.; Yugma, C.; Roussel, R. A memetic algorithm to solve an unrelated parallel machine scheduling problem with auxiliary resources in semiconductor manufacturing. J. Sched. 2016, 19, 367–376. [Google Scholar] [CrossRef]
- Wu, X.; Che, A. A memetic differential evolution algorithm for energy-efficient parallel machine scheduling. Omega 2019, 82, 155–165. [Google Scholar] [CrossRef]
- De, P.; Morton, T.E. Scheduling to minimize makespan on unequal parallel processors. Decis. Sci. 1980, 11, 586–602. [Google Scholar] [CrossRef]
- Davis, E.; Jaffe, J.M. Algorithms for scheduling tasks on unrelated processors. J. ACM 1981, 28, 721–736. [Google Scholar] [CrossRef]
- Kumar, V.; Marathe, M.V.; Parthasarathy, S.; Srinivasan, A. A unified approach to scheduling on unrelated parallel machines. J. ACM JACM 2009, 56, 28. [Google Scholar] [CrossRef]
- Lin, Y.; Pfund, M.; Fowler, J. Minimizing makespans for unrelated parallel machine scheduling problems. In Proceedings of the 2009 IEEE/INFORMS International Conference on Service Operations, Logistics and Informatics, Chicago, IL, USA, 22–24 July 2009; pp. 107–110. [Google Scholar]
- Ghirardi, M.; Potts, C.N. Makespan minimization for scheduling unrelated parallel machines: A recovering beam search approach. Eur. J. Oper. Res. 2005, 165, 457–467. [Google Scholar] [CrossRef]
- Fanjul-Peyro, L.; Ruiz, R. Iterated greedy local search methods for unrelated parallel machine scheduling. Eur. J. Oper. Res. 2010, 207, 55–69. [Google Scholar] [CrossRef]
- Glass, C.; Potts, C.; Shade, P. Unrelated parallel machine scheduling using local search. Math. Comput. Model. 1994, 20, 41–52. [Google Scholar] [CrossRef]
- Quiroz-Castellanos, M.; Cruz-Reyes, L.; Torres-Jimenez, J.; Gómez, C.; Huacuja, H.J.F.; Alvim, A.C. A grouping genetic algorithm with controlled gene transmission for the bin packing problem. Comput. Oper. Res. 2015, 55, 52–64. [Google Scholar] [CrossRef]
- Carmona-Arroyo, G.; Quiroz-Castellanos, M.; Mezura-Montes, E. Variable Decomposition for Large-Scale Constrained Optimization Problems Using a Grouping Genetic Algorithm. Math. Comput. Appl. 2022, 27, 23. [Google Scholar] [CrossRef]
- Alharbe, N.; Aljohani, A.; Rakrouki, M.A. A Fuzzy Grouping Genetic Algorithm for Solving a Real-World Virtual Machine Placement Problem in a Healthcare-Cloud. Algorithms 2022, 15, 128. [Google Scholar] [CrossRef]
- Falkenauer, E. The grouping genetic algorithms-widening the scope of the GAs. Belg. J. Oper. Res. Stat. Comput. Sci. 1992, 33, 2. [Google Scholar]
- Ramos-Figueroa, O.; Quiroz-Castellanos, M.; Mezura-Montes, E.; Kharel, R. Variation Operators for Grouping Genetic Algorithms: A Review. Swarm Evol. Comput. 2020. [Google Scholar] [CrossRef]
- Ibarra, O.H.; Kim, C.E. Heuristic algorithms for scheduling independent tasks on nonidentical processors. J. ACM JACM 1977, 24, 280–289. [Google Scholar] [CrossRef]
- Cuadra, L.; Aybar-Ruíz, A.; Del Arco, M.; Navío-Marco, J.; Portilla-Figueras, J.A.; Salcedo-Sanz, S. A Lamarckian Hybrid Grouping Genetic Algorithm with repair heuristics for resource assignment in WCDMA networks. Appl. Soft Comput. 2016, 43, 619–632. [Google Scholar] [CrossRef]
- Singh, K.; Sundar, S. A new hybrid genetic algorithm for the maximally diverse grouping problem. Int. J. Mach. Learn. Cybern. 2019, 10, 2921–2940. [Google Scholar] [CrossRef]
- Ülker, Ö.; Özcan, E.; Korkmaz, E.E. Linear linkage encoding in grouping problems: Applications on graph coloring and timetabling. In Proceedings of the International Conference on the Practice and Theory of Automated Timetabling, Brno, Czech Republic, 30 August–1 September 2006; pp. 347–363. [Google Scholar]
- Chen, C.H.; Lu, C.Y.; Lin, C.B. An intelligence approach for group stock portfolio optimization with a trading mechanism. Knowl. Inf. Syst. 2020, 62, 287–316. [Google Scholar] [CrossRef]
- Mutingi, M.; Mbohwa, C. Home Healthcare Worker Scheduling: A Group Genetic Algorithm Approach. In Proceedings of the World Congress on Engineering, London, UK, 3–5 July 2013; Volume 1. [Google Scholar]
- Vin, E.; De Lit, P.; Delchambre, A. A multiple-objective grouping genetic algorithm for the cell formation problem with alternative routings. J. Intell. Manuf. 2005, 16, 189–205. [Google Scholar] [CrossRef]
- Fukunaga, A.S. A new grouping genetic algorithm for the multiple knapsack problem. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 2225–2232. [Google Scholar]
- Erben, W. A grouping genetic algorithm for graph colouring and exam timetabling. In Proceedings of the International Conference on the Practice and Theory of Automated Timetabling, Konstanz, Germany, 16–18 August 2000; pp. 132–156. [Google Scholar]
- Yasuda, K.; Hu, L.; Yin, Y. A grouping genetic algorithm for the multi-objective cell formation problem. Int. J. Prod. Res. 2005, 43, 829–853. [Google Scholar] [CrossRef]
- Balasch-Masoliver, J.; Muntés-Mulero, V.; Nin, J. Using genetic algorithms for attribute grouping in multivariate microaggregation. Intell. Data Anal. 2014, 18, 819–836. [Google Scholar] [CrossRef]
- Wilcoxon, F. Individual comparisons by ranking methods. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 196–202. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
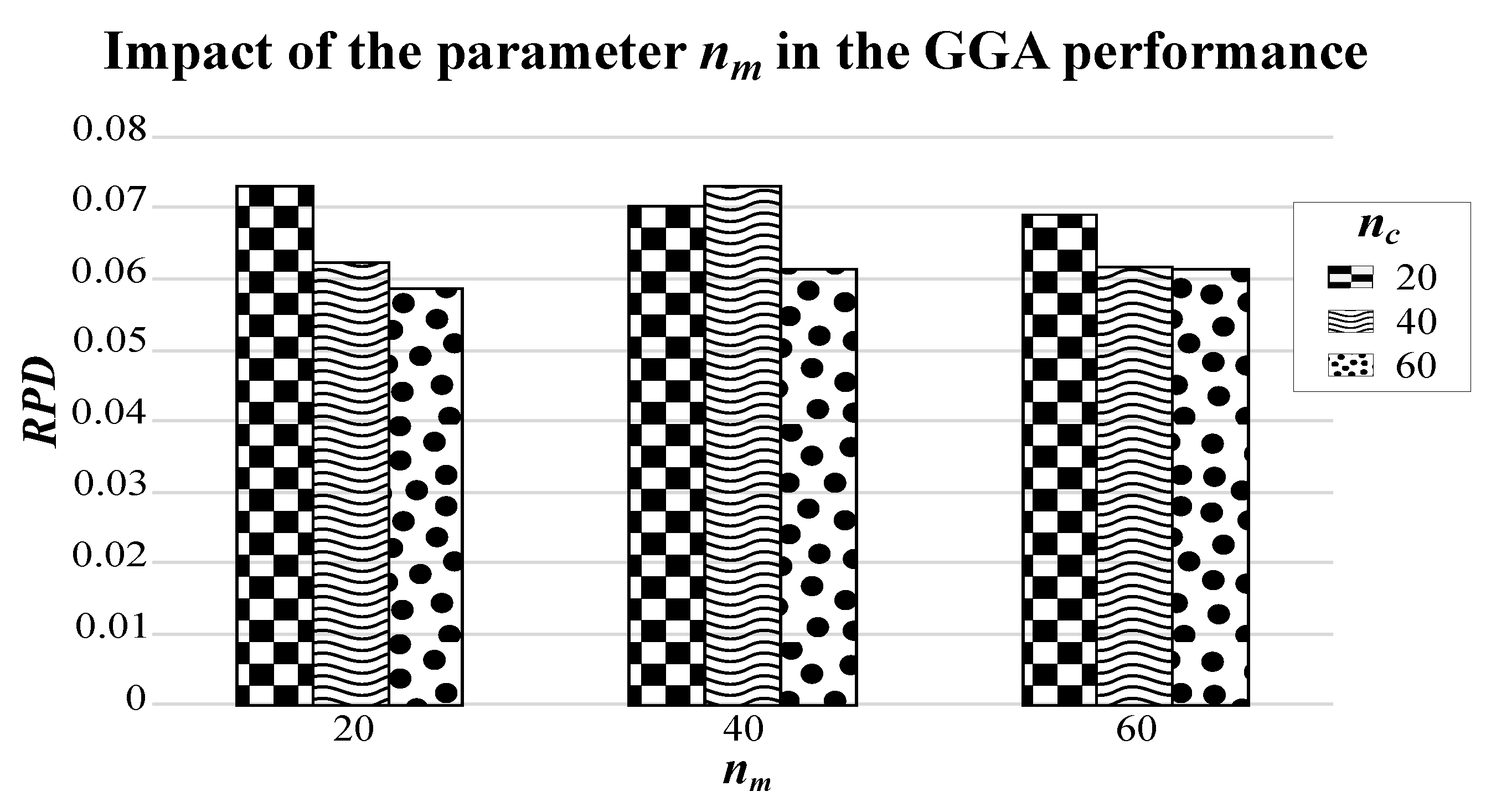{kind=link}
{kind=link}
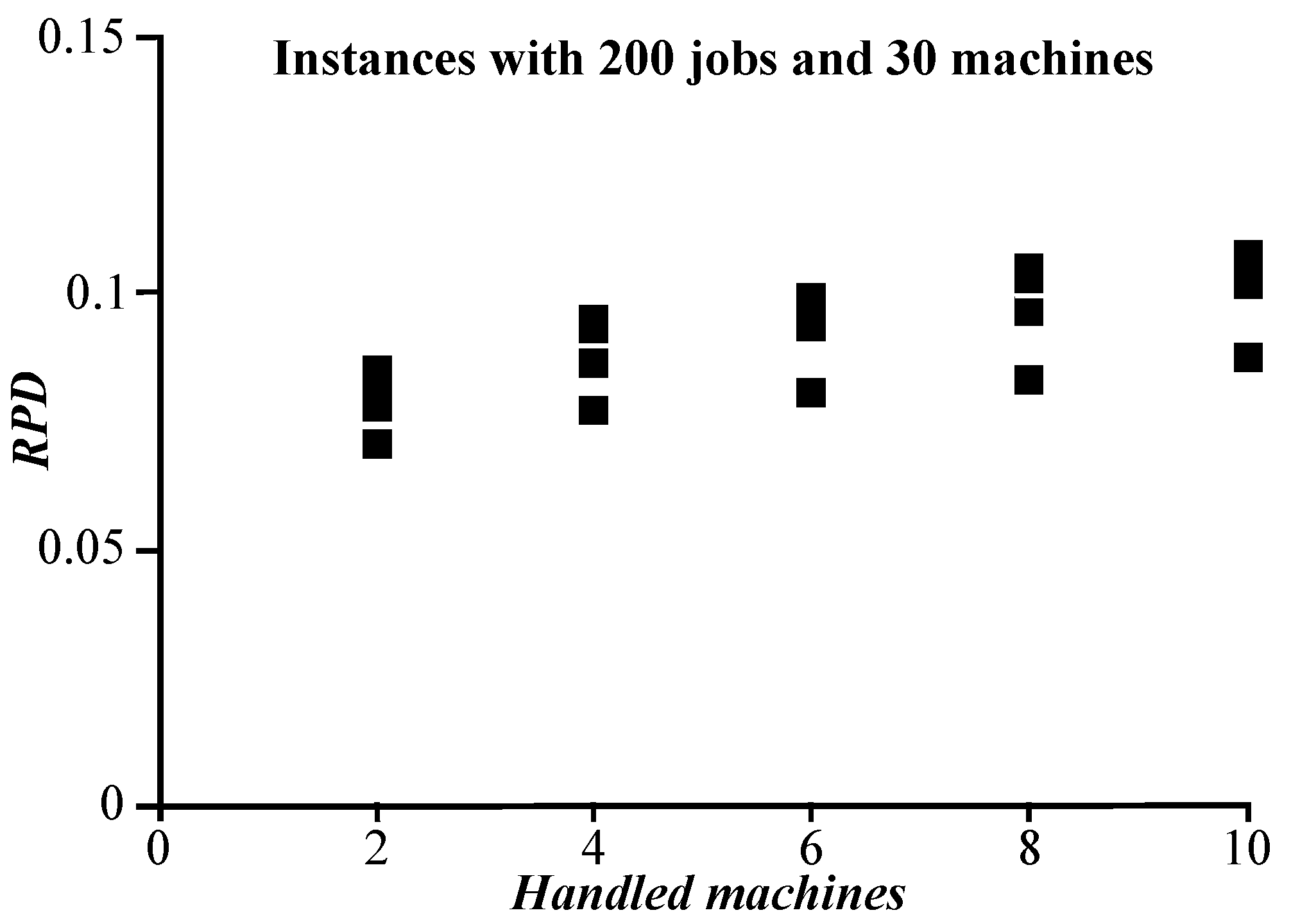{kind=link}
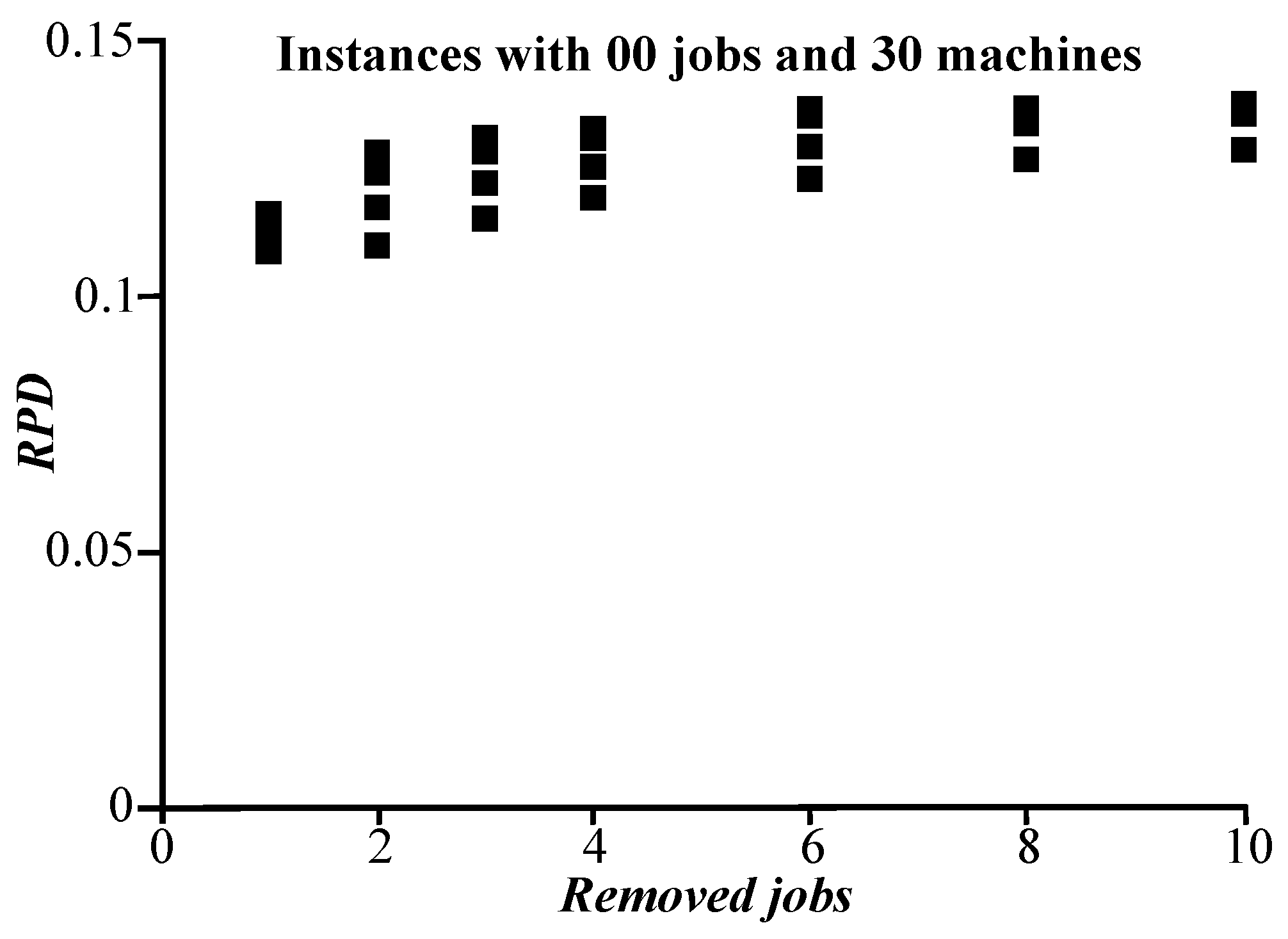{kind=link}
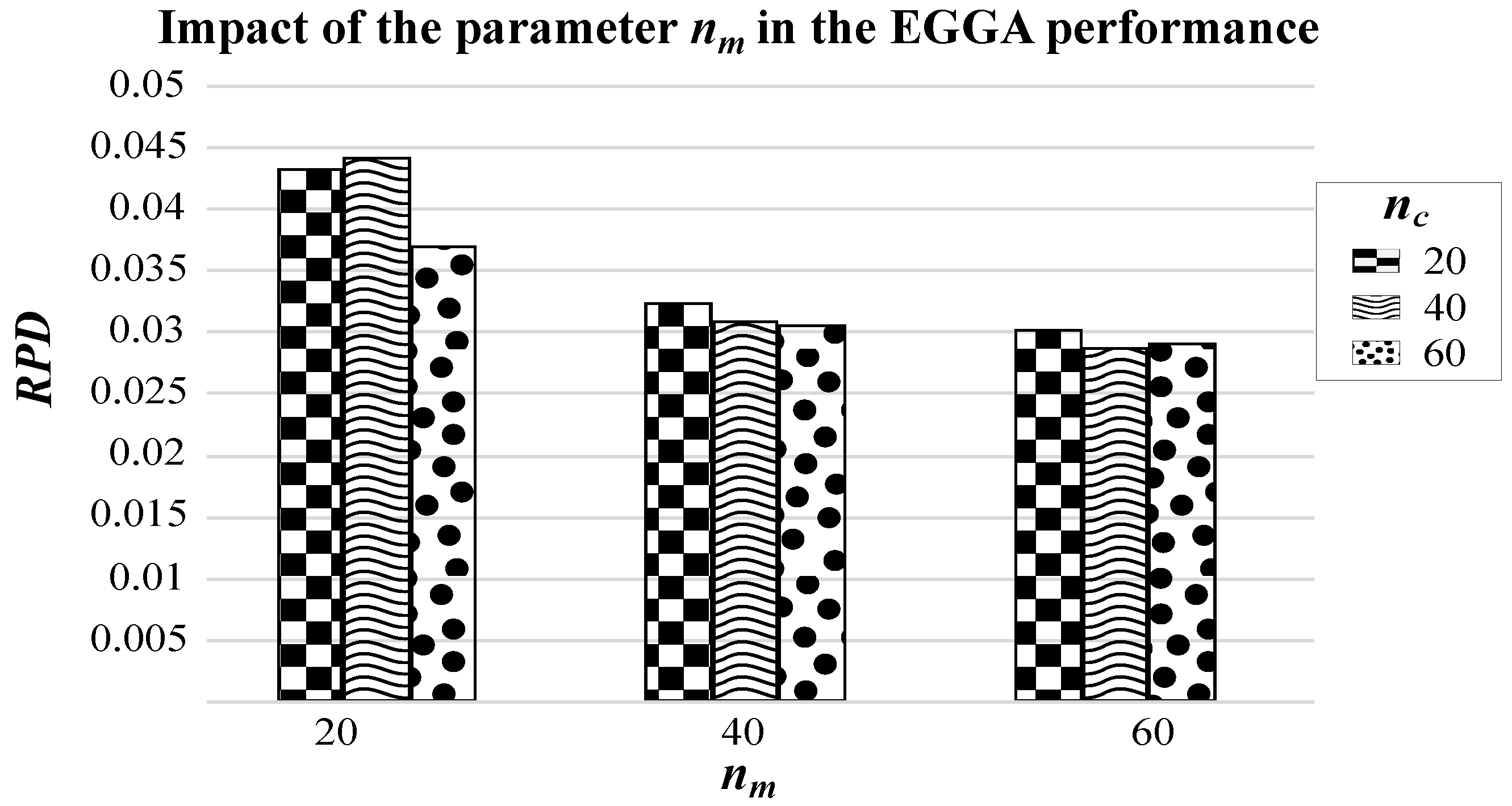{kind=link}
| Instance Set | Swap | Insertion | Merge and Split | Elimination | |
|---|---|---|---|---|---|
| 100 | 0.1213 | 0.1219 | 0.1071 | 0.0804 | |
| n | 200 | 0.1408 | 0.1432 | 0.1353 | 0.1154 |
| 500 | 0.1365 | 0.1371 | 0.1372 | 0.1281 | |
| 1000 | 0.1380 | 0.1381 | 0.1387 | 0.1350 | |
| 10 | 0.1291 | 0.1290 | 0.1291 | 0.1178 | |
| 20 | 0.1391 | 0.1402 | 0.1344 | 0.1229 | |
| m | 30 | 0.1256 | 0.1252 | 0.1220 | 0.1074 |
| 40 | 0.1310 | 0.1331 | 0.1270 | 0.1084 | |
| 50 | 0.1460 | 0.1478 | 0.1353 | 0.1172 | |
| 0.2802 | 0.2740 | 0.2632 | 0.2107 | ||
| 0.2080 | 0.2060 | 0.2039 | 0.1802 | ||
| 0.0417 | 0.0438 | 0.0408 | 0.0384 | ||
| 0.1230 | 0.1248 | 0.1198 | 0.1164 | ||
| 0.0218 | 0.0230 | 0.0214 | 0.0201 | ||
| 0.1259 | 0.1307 | 0.1194 | 0.1049 | ||
| 0.1385 | 0.1432 | 0.1384 | 0.1326 | ||
| 1400 instances | 0.1341 | 0.1351 | 0.1296 | 0.1147 |
| Handled Machines | Removed Jobs | RPD |
|---|---|---|
| 1 | 0.091437 | |
| 2 | 0.094475 | |
| 3 | 0.097644 | |
| 2 | 4 | 0.100010 |
| 6 | 0.102259 | |
| 8 | 0.103456 | |
| 10 | 0.103984 | |
| 1 | 0.093067 | |
| 2 | 0.100647 | |
| 3 | 0.104505 | |
| 4 | 4 | 0.107246 |
| 6 | 0.109475 | |
| 8 | 0.111302 | |
| 10 | 0.111263 | |
| 1 | 0.095776 | |
| 2 | 0.105834 | |
| 3 | 0.109519 | |
| 6 | 4 | 0.111925 |
| 6 | 0.114454 | |
| 8 | 0.115151 | |
| 10 | 0.115754 | |
| 1 | 0.09889 | |
| 2 | 0.109016 | |
| 3 | 0.112681 | |
| 8 | 4 | 0.114861 |
| 6 | 0.116797 | |
| 8 | 0.117525 | |
| 10 | 0.117800 | |
| 1 | 0.102228 | |
| 2 | 0.110804 | |
| 3 | 0.114677 | |
| 10 | 4 | 0.116184 |
| 6 | 0.117627 | |
| 8 | 0.118031 | |
| 10 | 0.117819 |
| Instance Set | Random | Worst | Worst Best | Worst Random | |
|---|---|---|---|---|---|
| n | 100 | 0.0605 | 0.0577 | 0.0618 | 0.0296 |
| 200 | 0.0848 | 0.0797 | 0.0832 | 0.0533 | |
| 500 | 0.1030 | 0.0987 | 0.1028 | 0.0827 | |
| 1000 | 0.1175 | 0.1147 | 0.1178 | 0.1046 | |
| m | 10 | 0.0873 | 0.0857 | 0.0894 | 0.0718 |
| 20 | 0.0978 | 0.0942 | 0.0977 | 0.0752 | |
| 30 | 0.0842 | 0.0824 | 0.0854 | 0.0635 | |
| 40 | 0.0908 | 0.0853 | 0.0885 | 0.0631 | |
| 50 | 0.0963 | 0.0900 | 0.0951 | 0.0634 | |
| 0.1430 | 0.1470 | 0.1522 | 0.1146 | ||
| 0.1321 | 0.1319 | 0.1362 | 0.1003 | ||
| 0.0351 | 0.0309 | 0.0329 | 0.0244 | ||
| 0.1017 | 0.0939 | 0.0970 | 0.0740 | ||
| 0.0182 | 0.0155 | 0.0171 | 0.0123 | ||
| 0.0909 | 0.0820 | 0.0810 | 0.0576 | ||
| 0.1179 | 0.1112 | 0.1220 | 0.0888 | ||
| 1400 instances | 0.0913 | 0.0875 | 0.0912 | 0.0674 |
| Instance Set | Insertion | Assemble | Download | |
|---|---|---|---|---|
| n | 100 | 0.0306 | 0.0185 | 0.0730 |
| 200 | 0.0480 | 0.0280 | 0.1125 | |
| 500 | 0.0631 | 0.0441 | 0.1328 | |
| 1000 | 0.0793 | 0.0671 | 0.1383 | |
| 10 | 0.0612 | 0.0416 | 0.1261 | |
| 20 | 0.0617 | 0.0429 | 0.1258 | |
| m | 30 | 0.0497 | 0.0366 | 0.1076 |
| 40 | 0.0507 | 0.0376 | 0.1054 | |
| 50 | 0.0528 | 0.0382 | 0.1048 | |
| 0.0523 | 0.0407 | 0.2307 | ||
| 0.0538 | 0.0331 | 0.1862 | ||
| 0.0286 | 0.0176 | 0.0358 | ||
| 0.0750 | 0.0362 | 0.1072 | ||
| 0.0150 | 0.0100 | 0.0182 | ||
| 0.0664 | 0.0654 | 0.0892 | ||
| 0.0952 | 0.0728 | 0.1304 | ||
| 1400 instances | 0.0552 | 0.0394 | 0.1139 |
| Parameter | Value |
|---|---|
| 100 | |
| 20 | |
| 83 | |
| 20 | |
| 500 |
| Instance Set | GGA | EGGA | |
|---|---|---|---|
| n | 100 | 0.0391 | 0.0176 |
| 200 | 0.0565 | 0.0224 | |
| 500 | 0.0665 | 0.0291 | |
| 1000 | 0.0724 | 0.0441 | |
| 10 | 0.0512 | 0.0220 | |
| 20 | 0.0606 | 0.0306 | |
| m | 30 | 0.0559 | 0.0275 |
| 40 | 0.0596 | 0.0308 | |
| 50 | 0.0657 | 0.0306 | |
| 0.0719 | 0.0465 | ||
| 0.0853 | 0.0361 | ||
| 0.0278 | 0.0092 | ||
| 0.0820 | 0.0229 | ||
| 0.0131 | 0.0036 | ||
| 0.0522 | 0.0380 | ||
| 0.0780 | 0.0419 | ||
| 1400 instances | 0.0586 | 0.0283 |
| Instance | p-Value | |
|---|---|---|
| n | 100 | 7.10 |
| 200 | 6.70 | |
| 500 | 2.30 | |
| 1000 | 8.16 | |
| 10 | 4.57 | |
| 20 | 1.63 | |
| m | 30 | 2.98 |
| 40 | 3.51 | |
| 50 | 3.37 | |
| 1.13 | ||
| 1.59 | ||
| 2.03 | ||
| 1.01 | ||
| 2.25 | ||
| 2.19 | ||
| 4.44 | ||
| 1400 instances | 5.44 |
| Instance | GGA | EGGA | |
|---|---|---|---|
| n | 100 | 1.2 | 5.71 |
| 200 | 1.2 | 5.68 | |
| 500 | 1.24 | 5.49 | |
| 1000 | 1.36 | 9.44 | |
| 10 | 1.26 | 8.71 | |
| 20 | 1.24 | 7.66 | |
| m | 30 | 1.21 | 6.94 |
| 40 | 1.19 | 6.33 | |
| 50 | 1.17 | 5.79 | |
| 1.25 | 34.09 | ||
| 1.25 | 14.04 | ||
| 1.25 | 2.52 | ||
| 1.25 | 2.88 | ||
| 1.25 | 2.71 | ||
| 1.25 | 1.50 | ||
| 1.25 | 1.69 | ||
| 1400 instances | 1.25 | 8.49 |
| Instance | GGA | EGGA | |
|---|---|---|---|
| n | 100 | 9.27 | 358.34 |
| 200 | 8.00 | 369.31 | |
| 500 | 8.00 | 380.83 | |
| 1000 | 17.09 | 362.54 | |
| 10 | 16.35 | 358.46 | |
| 20 | 13.69 | 359.06 | |
| m | 30 | 11.79 | 359.78 |
| 40 | 11.05 | 360.96 | |
| 50 | 10.01 | 362.20 | |
| 64.80 | 218.56 | ||
| 8.00 | 305.34 | ||
| 8.00 | 360.44 | ||
| 8.00 | 391.96 | ||
| 8.00 | 390.13 | ||
| 8.00 | 474.82 | ||
| 8.00 | 392.95 | ||
| 1400 instances | 16.11 | 362.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos-Figueroa, O.; Quiroz-Castellanos, M.; Mezura-Montes, E.; Cruz-Ramírez, N. An Experimental Study of Grouping Mutation Operators for the Unrelated Parallel-Machine Scheduling Problem. Math. Comput. Appl. 2023, 28, 6. https://doi.org/10.3390/mca28010006
Ramos-Figueroa O, Quiroz-Castellanos M, Mezura-Montes E, Cruz-Ramírez N. An Experimental Study of Grouping Mutation Operators for the Unrelated Parallel-Machine Scheduling Problem. Mathematical and Computational Applications. 2023; 28(1):6. https://doi.org/10.3390/mca28010006
Chicago/Turabian StyleRamos-Figueroa, Octavio, Marcela Quiroz-Castellanos, Efrén Mezura-Montes, and Nicandro Cruz-Ramírez. 2023. "An Experimental Study of Grouping Mutation Operators for the Unrelated Parallel-Machine Scheduling Problem" Mathematical and Computational Applications 28, no. 1: 6. https://doi.org/10.3390/mca28010006
APA StyleRamos-Figueroa, O., Quiroz-Castellanos, M., Mezura-Montes, E., & Cruz-Ramírez, N. (2023). An Experimental Study of Grouping Mutation Operators for the Unrelated Parallel-Machine Scheduling Problem. Mathematical and Computational Applications, 28(1), 6. https://doi.org/10.3390/mca28010006