A Fast Recommender System for Cold User Using Categorized Items


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
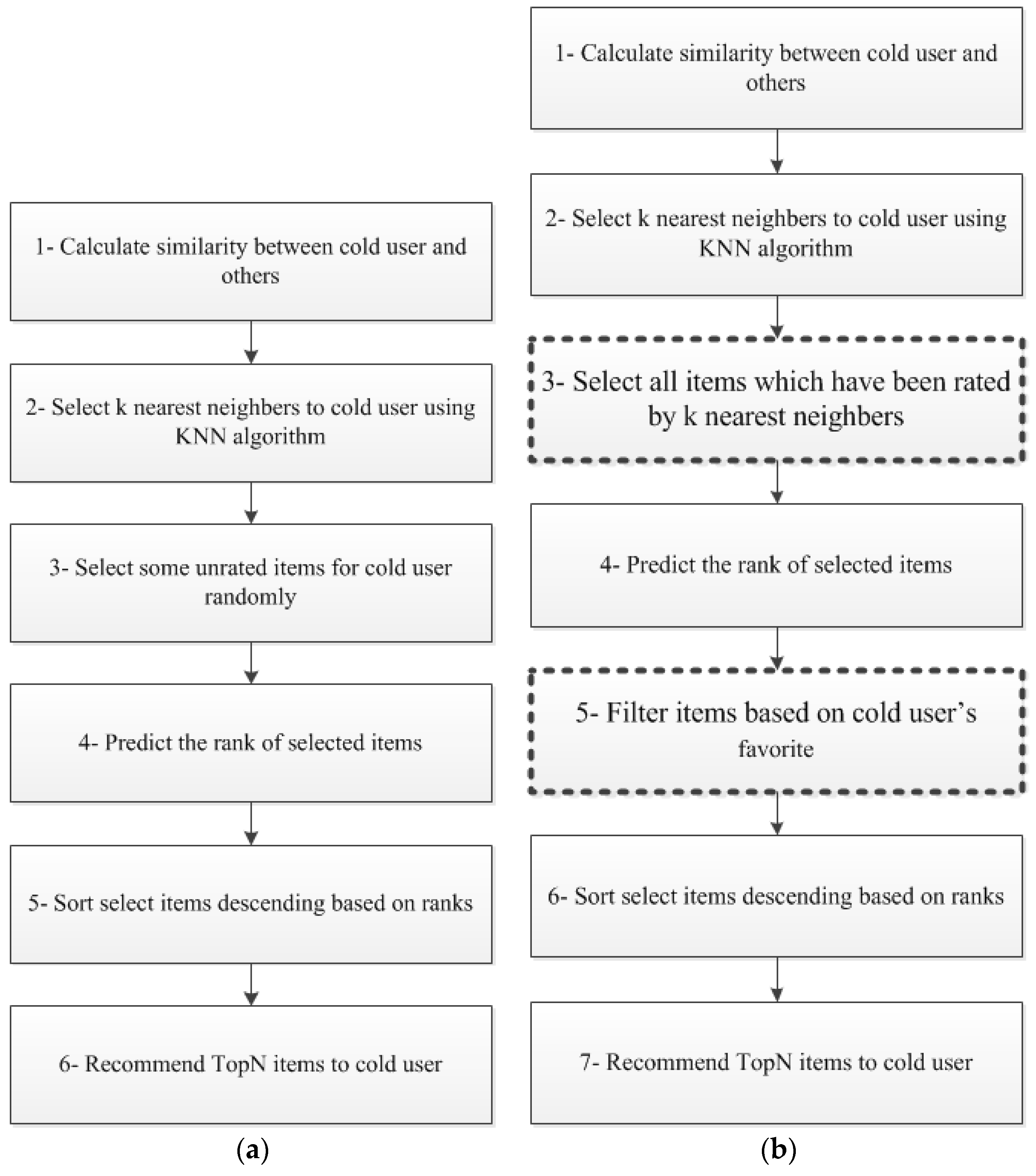
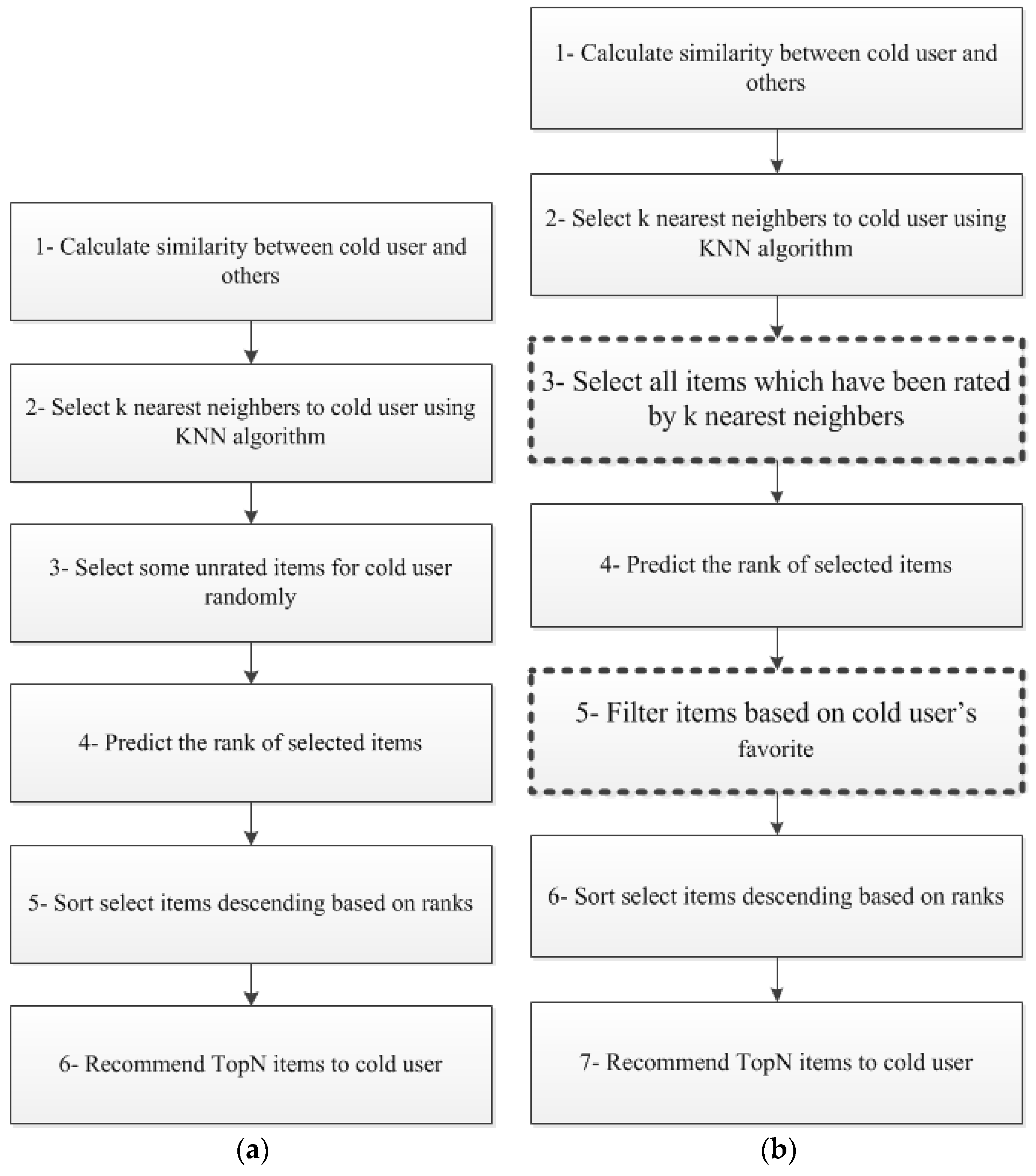
3. Proposed Method
4. Implementation and Evaluation of the Results
4.1. Selecting Similar Users
4.2. Selecting Items for Recommendation
4.3. Evaluation Criteria
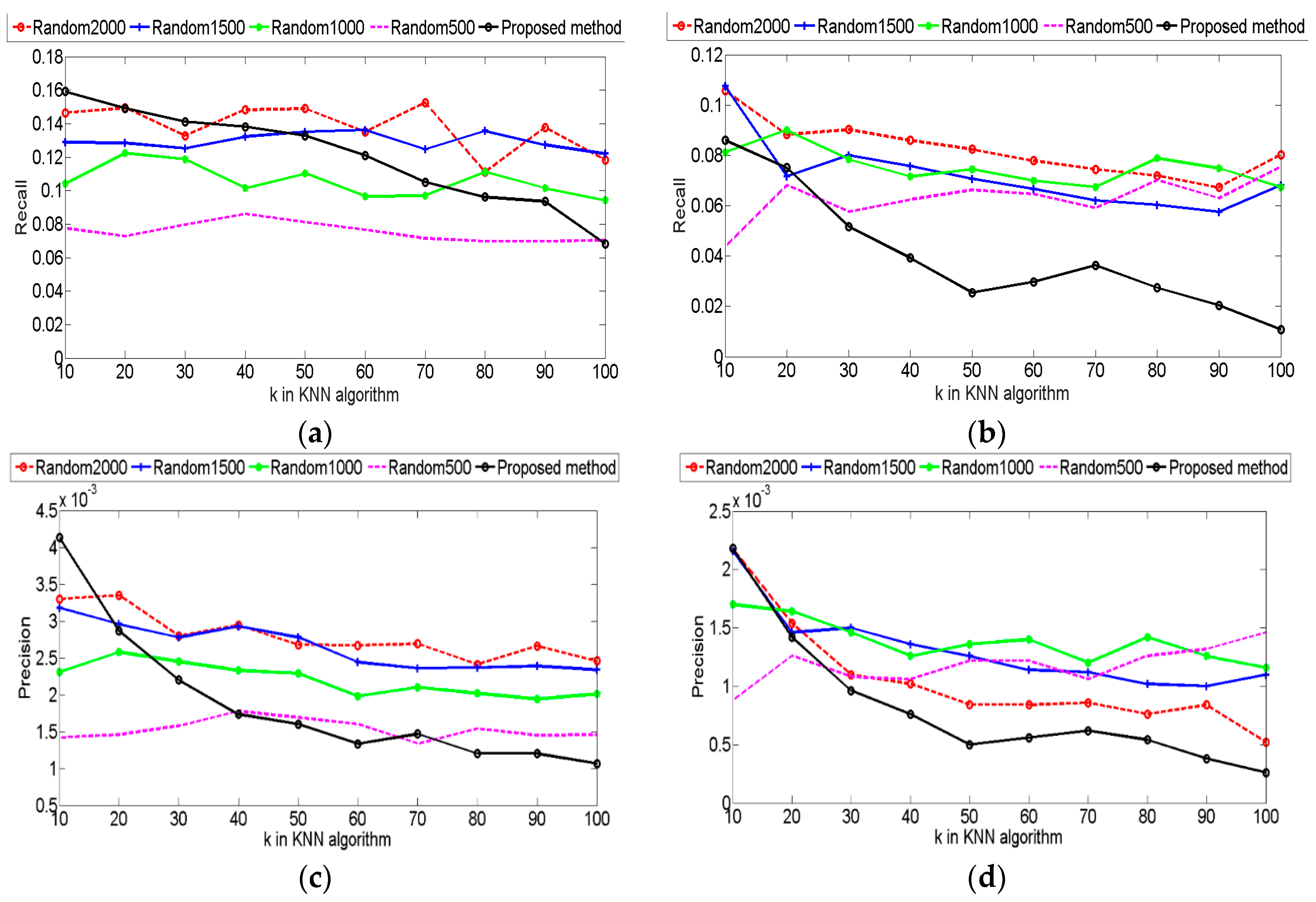
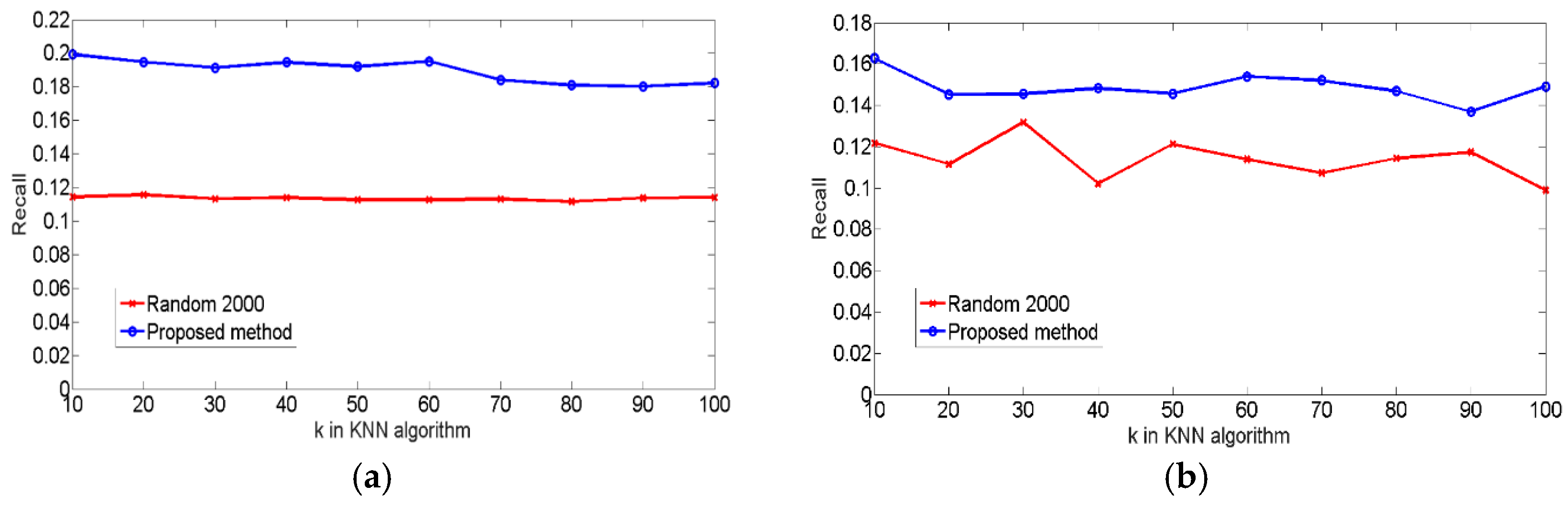
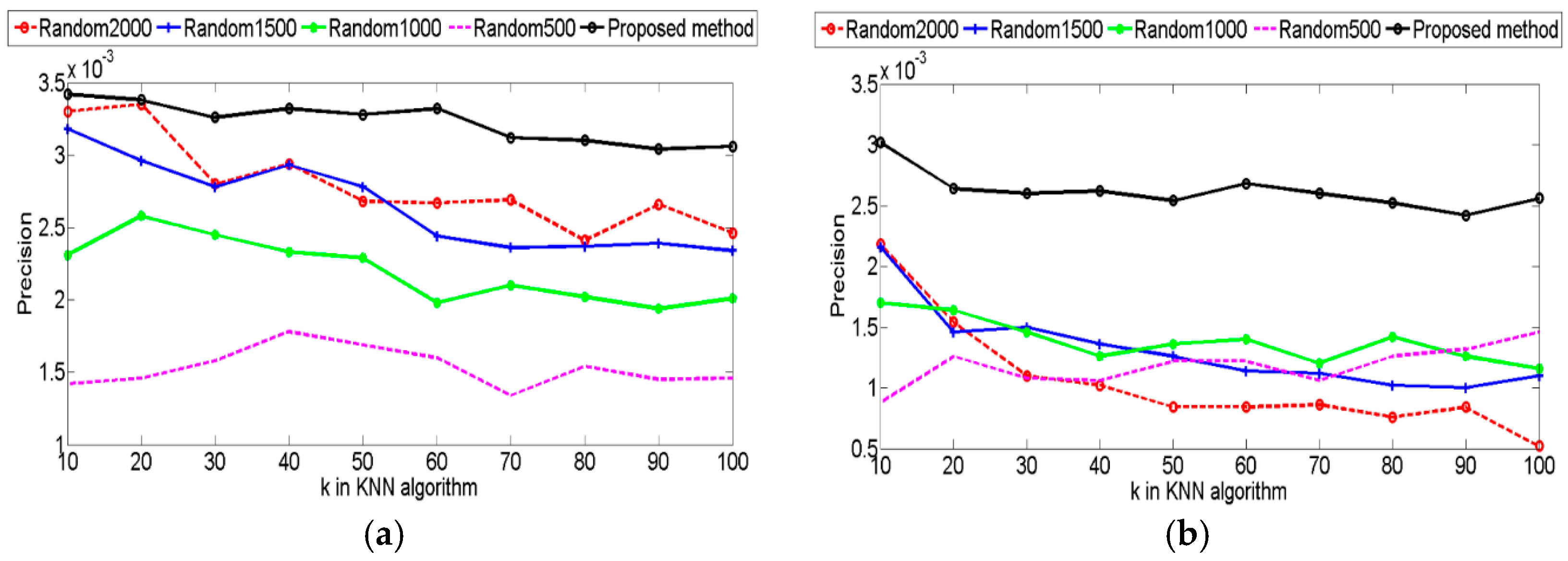
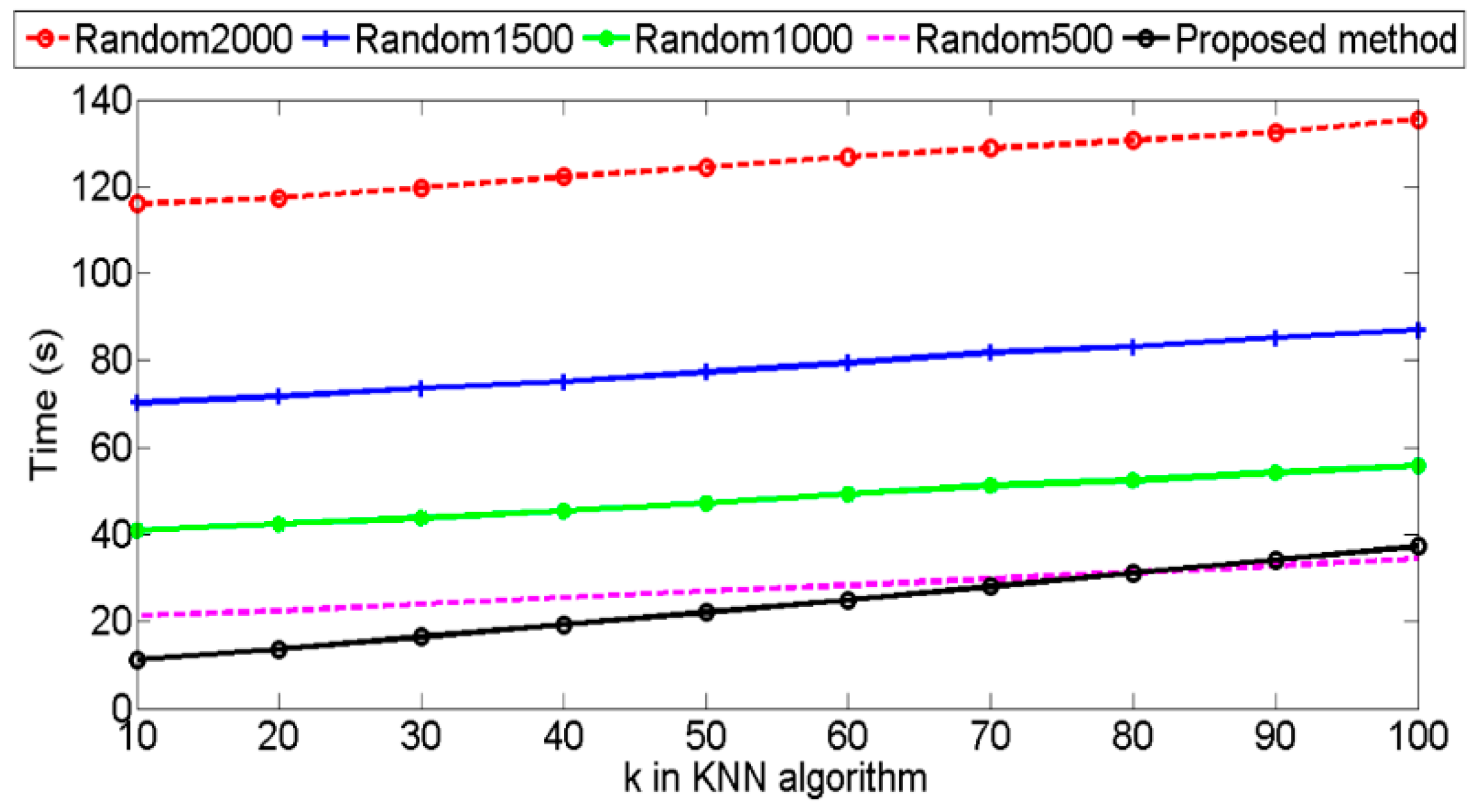
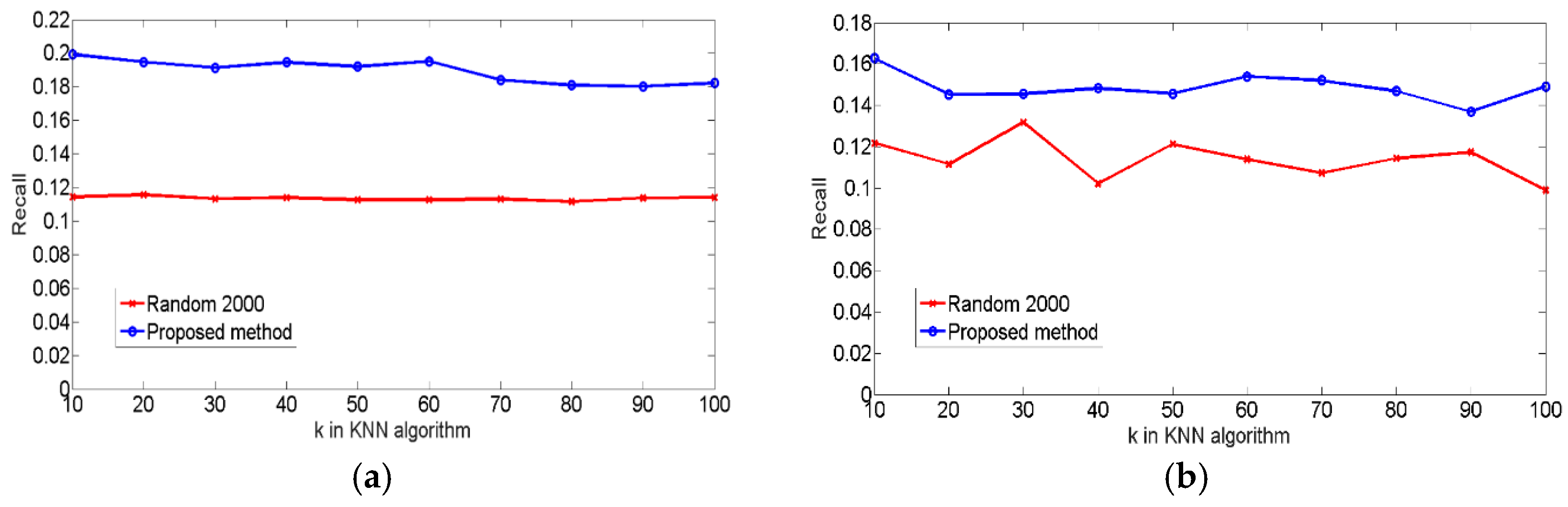
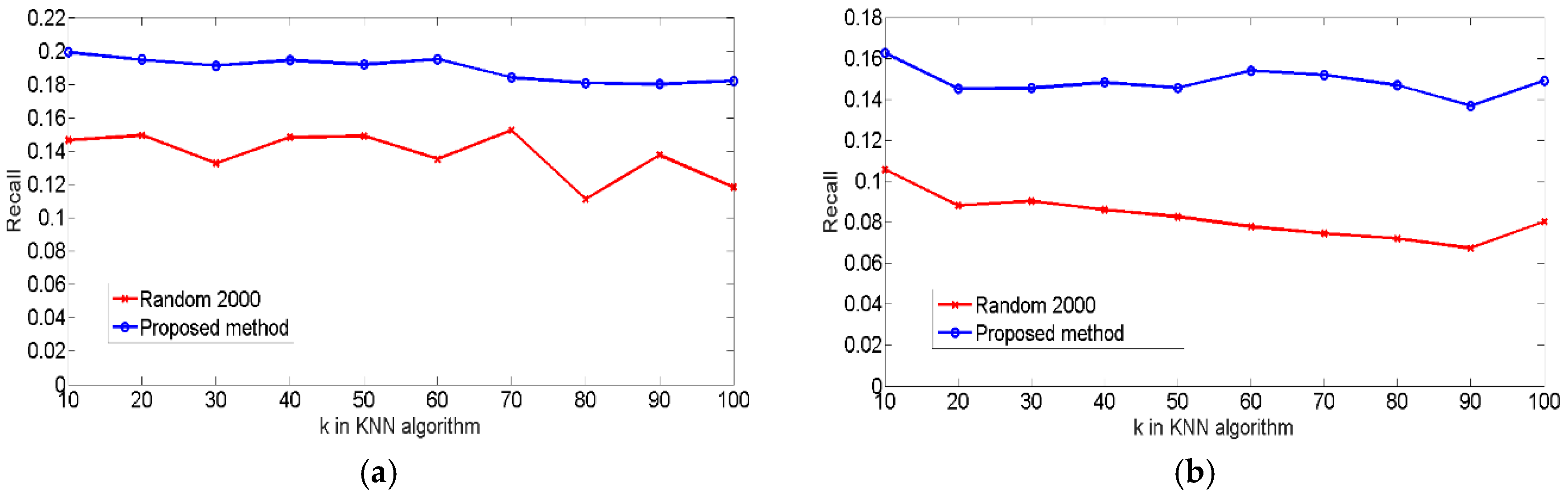
4.4. Experiments
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Baker, T.; Mackay, M.; Randles, M.; Taleb-Bendiab, A. Intention-oriented programming support for runtime adaptive autonomic cloud-based applications. Comput. Electr. Eng. 2013, 39, 2400–2412. [Google Scholar] [CrossRef]
- Baker, T.; Taleb-Bendiab, A.; Randles, M. Auditable intention-oriented Web applications using PAA auditing/accounting paradigm. In Proceedings of the 2009 Conference on Techniques and Applications for Mobile Commerce (TAMoCo 2009), Mérida, Spain, 16–17 September 2009; IOS Press: Tepper Drive Clifton, VA, USA, 2009. [Google Scholar]
- Karam, Y.; Baker, T.; Taleb-Bendiab, A. Intention-oriented modelling support for socio-technical driven elastic cloud applications. In Proceedings of the IEEE International Conference on Innovations in Information Technology (IIT), Abu Dhabi, United Arab Emirates, 18–20 March 2012. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutirrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Chesnevar, C.I.; Maguitman, A.G.; Simari, G.R. A first approach to argument-based recommender systems based on defeasible logic programming. In Proceedings of the 10th International Workshop on Non-Monotonic Reasoning (NMR 2004), Whistler, BC, Canada, 6–8 June 2004; pp. 109–117. [Google Scholar]
- Pazzani, J.M.; Billsus, D. Content-Based Recommendation Systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Lu, J.; Shambour, Q.; Xu, Y.; Lin, Q.; Zhang, G. BizSeeker: A hybrid semantic recommendation system for personalized government-to-business e-services. Internet Res. 2010, 20, 342–365. [Google Scholar] [CrossRef]
- Breese, S.J.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 43–52. [Google Scholar]
- Kim, H.-N.; Ji, A.-T.; Ha, I.; Jo, G.-S. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation. Electron. Commer. Res. Appl. 2010, 9, 73–83. [Google Scholar] [CrossRef]
- Bobadilla, J.; Hernando, A.; Ortega, F.; Bernal, J. A framework for collaborative filtering recommender systems. Expert Syst. Appl. 2011, 38, 14609–14623. [Google Scholar] [CrossRef]
- Bobadilla, J.S.; Ortega, F.; Hernando, A.; Bernal, J.S. Generalization of recommender systems: Collaborative filtering extended to groups of users and restricted to groups of items. Expert Syst. Appl. 2012, 39, 172–186. [Google Scholar] [CrossRef]
- Cacheda, F.; Carneiro, V.; Fernandez, D.; Formoso, V. Comparison of collaborative filtering algorithms: Limitations of current techniques and proposals for scalable, high-performance recommender systems. ACM Trans. Web 2011, 5. [Google Scholar] [CrossRef]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Pennock, D.M.; Horvitz, E.; Lawrence, S.; Giles, C.L. Collaborative filtering by personality diagnosis: A hybrid memory-and model-based approach. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, Stanford, CA, USA, 30 June–3 July 2000; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2000. [Google Scholar]
- Kim, H.-N.; El-Saddik, A.; Jo, G.-S. Collaborative error-reflected models for cold-start recommender systems. Decis. Support Syst. 2011, 51, 519–531. [Google Scholar] [CrossRef]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A new user similarity model to improve the accuracy of collaborative filtering. Knowl. Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef]
- Bobadilla, J.S.; Ortega, F.; Hernando, A.; Bernal, J.S. A collaborative filtering approach to mitigate the new user cold start problem. Knowl. Based Syst. 2012, 26, 225–238. [Google Scholar] [CrossRef]
- Herlocker, L.J.; Konstan, A.J.; Terveen, G.L.; Riedl, T.J. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Shardanand, U.; Maes, P. Social information filtering: Algorithms for automating “word of mouth”. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’95), Denver, CO, USA, 7–11 May 1995; ACM Press: New York, NY, USA, 1995. [Google Scholar]
- Koutrika, G.; Bercovitz, B.; Garcia-Molina, H. FlexRecs: Expressing and combining flexible recommendations. In Proceedings of the 35th SIGMOD International Conference on Management of Data (SIGMOD ’09), Providence, RI, USA, 29 June–2 July 2009; ACM Press: New York, NY, USA, 2009. [Google Scholar]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; ACM Press: New York, NY, USA, 1994. [Google Scholar]
- Ahn, H.J. A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem. Inf. Sci. 2008, 178, 37–51. [Google Scholar] [CrossRef]
- Bobadilla, J.S.; Ortega, F.; Hernando, A. A collaborative filtering similarity measure based on singularities. Inf. Process. Manag. 2012, 48, 204–217. [Google Scholar] [CrossRef]
- Patra, K.B.; Launonen, R.; Ollikainen, V.; Nandi, S. A new similarity measure using Bhattacharyya coefficient for collaborative filtering in sparse data. Knowl. Based Syst. 2015, 82, 163–177. [Google Scholar] [CrossRef]
- Leung, W.-K.C.; Chan, C.-F.S.; Chung, F.-L. An empirical study of a cross-level association rule mining approach to cold-start recommendations. Knowl. Based Syst. 2008, 21, 515–529. [Google Scholar] [CrossRef]
- Zhang, M.; Tang, J.; Zhang, X.; Xue, X. Addressing cold start in recommender systems: A semi-supervised co-training algorithm. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval (SIGIR ’14), Gold Coast, Australia, 6–11 July 2014; ACM Press: New York, NY, USA, 2004. [Google Scholar]
- Zheng, X.; Da Xu, L.; Chai, S. QoS Recommendation in Cloud Services. IEEE Access 2017, 5, 5171–5177. [Google Scholar] [CrossRef]
- Cremonesi, P.; Koren, Y.; Turrin, R. Performance of recommender algorithms on top-n recommendation tasks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; ACM Press: New York, NY, USA, 2010. [Google Scholar]
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; ACM Press: New York, NY, USA, 2007. [Google Scholar]
- Rosaci, D.; Sarné, G.M.; Garruzzo, S. MUADDIB: A distributed recommender system supporting device adaptivity. ACM Trans. Inf. Syst. 2009, 27. [Google Scholar] [CrossRef]
- Brodén, B.; Hammar, M.; Nilsson, B.J.; Paraschakis, D. Bandit Algorithms for e-Commerce Recommender Systems. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; ACM Press: New York, NY, USA, 2017. [Google Scholar]
- Jazayeriy, H.; Azmi-Murad, M.; Sulaiman, N.; Udzir, N.I. Generating Pareto-Optimal Offers in Bilateral Automated Negotiation with One-Side Uncertain Importance Weights. Comput. Inf. 2013, 31, 1235–1253. [Google Scholar]
- Palopoli, L.; Rosaci, D.; Sarné, G.M. A distributed and multi-tiered software architecture for assessing e-Commerce recommendations. Concurr. Comput. Pract. Exp. 2016, 28, 4507–4531. [Google Scholar] [CrossRef]
- Pirasteh, P.; Hwang, D.; Jung, J.J. Exploiting matrix factorization to asymmetric user similarities in recommendation systems. Knowl. Based Syst. 2015, 83, 51–57. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Rossetti, M.; Stella, F.; Zanker, M. Contrasting offline and online results when evaluating recommendation algorithms. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016. [Google Scholar]
- Xie, F.; Chen, Z.; Shang, J.; Fox, C.G. Grey Forecast model for accurate recommendation in presence of data sparsity and correlation. Knowl. Based Syst. 2014, 69, 179–190. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Hung, C. Cluster ensembles in collaborative filtering recommendation. Appl. Soft Comput. 2012, 12, 1417–1425. [Google Scholar] [CrossRef]
- Da Silva, Q.E.; Camilo-Junior, G.C.; Pascoal, L.L.M.; Rosa, C.T. An evolutionary approach for combining results of recommender systems techniques based on collaborative filtering. Expert Syst. Appl. 2016, 53, 204–218. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.-M.; Saerens, M. Random-Walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]



© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jazayeriy, H.; Mohammadi, S.; Shamshirband, S. A Fast Recommender System for Cold User Using Categorized Items. Math. Comput. Appl. 2018, 23, 1. https://doi.org/10.3390/mca23010001
Jazayeriy H, Mohammadi S, Shamshirband S. A Fast Recommender System for Cold User Using Categorized Items. Mathematical and Computational Applications. 2018; 23(1):1. https://doi.org/10.3390/mca23010001
Chicago/Turabian StyleJazayeriy, Hamid, Saghi Mohammadi, and Shahaboddin Shamshirband. 2018. "A Fast Recommender System for Cold User Using Categorized Items" Mathematical and Computational Applications 23, no. 1: 1. https://doi.org/10.3390/mca23010001
APA StyleJazayeriy, H., Mohammadi, S., & Shamshirband, S. (2018). A Fast Recommender System for Cold User Using Categorized Items. Mathematical and Computational Applications, 23(1), 1. https://doi.org/10.3390/mca23010001