1. Introduction
In human resource management of universities and scientific research institutes, it is essential to mine useful information from the individual research outputs (IRO) of professional faculties. Particularly, for the competitors in promotion, tenure and faculty positions, a fair metrics model is required to evaluate the quality and quantity of IRO, such as the academic papers, research awards and scientific research projects. As pointed out in [
1], owing to complexity and uncertainty in many decision situations, effective and quantitative models are helpful to the managers’ decision-making and planning.
With regard to the quality of the IRO, two main approaches, the so-called bibliometric measure (objective) and peer review (subjective) approaches, have been proposed for the IRO evaluation in the literature. Because the bibliometric analysis cannot be applied across the board to all departments in a large number of universities and scientific research institutes [
2], peer review has become the principal method of assessment [
3]. Although the objective evaluation approach represented by citation-based models and bibliometric indicators cannot replace the subjective evaluation based on an in-depth peer-review analysis of scientific products, it is helpful to elaborate large quantities of data when peer reviewing becomes difficult to implement [
4]. Actually, the so-called h-index (Hirsch index) has been widely accepted as a measure of individual research achievement, which is advantageous compared to other bibliometric indicators such as the total number of citations or the number of papers published in journals of high impact factor [
3,
5]. Similar to the h-index in [
6], the A-index(average index), R-index(root index), and AR-index(Age-dependent R-index) presented in [
7] are also useful measure tools of IRO quality. In addition, The g-index was defined by Leo Egghe in [
8] to measure the quality of the published articles. Specifically, given a set of articles ranked in decreasing order of the number of citations that they received, the g-index is the (unique) largest number such that the top
g articles received (together) at least
g2 citations.
However, to the best of our knowledge, there exist few efficient metrics models to calculate the quantity of the IRO. Especially, if there is more than one participant in the same IRO, it becomes difficult to exactly measure the outputs of the competitors such that the inequality relation of contribution in the same IRO can be quantified. For example, if there are
p published journal papers for a scientist, all of which are completed by multiple authors, then it is obvious that the number of the papers is less than
p for the scientist since the other authors’ contributions should be subtracted. The difficulty lies in calculating the contribution of each author in the same paper unless there is a statement: “All authors contributed equally to all aspects of this work” in the paper. In the case that there are multiple authors in the same journal paper, a linear measurement method was presented. to calculate the number of the paper for each author in [
9,
10].
Instead of the method in [
9], this article intends to formulate the nonlinearity existing in the distribution of the participant’ contribution in the same IRO, including the journal paper. We will first define some nonlinear functions, called credit functions, to calculate the credit of each participant in the same academic paper, research award or scientific research project for the authors, winners or proposers. Then, we will calculate the number of the IRO for each participant by the participant’s share in the total credit. It will be shown that, in virtue of different credit functions, the corresponding quantification methods of achievement and the ranking result may be distinct for the scientists. Especially, by the proposed nonlinear methods in this paper, the obtained rank of the scientists appears more acceptable than the existing linear methods available in the literature.
Since it is common that there are multiple criteria (papers, awards and projects) to evaluate the IRO, the final rank for all the participants is involved in multi-criteria decision-making problems. Specifically, it is required to determine the weight of each criterion such that an integrated evaluation is obtained for all the participants. Therefore, this article will focus on a new ranking method based on the credit functions.
The rest of this paper is organized as follows. In the next section, new nonlinear credit functions will be proposed to quantify the IRO.
Section 3 is devoted to the differences of the credit functions in evaluating the number of IRO. In
Section 4, an extended TOPSIS method will be developed. In
Section 5, the proposed method is applied into solving some practical problems, especially combined with the technique for order preference by similarity to an ideal solution (TOPSIS).
2. New Nonlinear Measure on IRO
In this section, a new nonlinear approach is proposed to quantify the individual research output.
It is noted that, in [
9], for an author who has
papers and is ranked
among the
authors in the
j-th paper (
), the contribution of the author in the
j-th paper is quantified by
and the total number of papers is calculated by
From (
1), it is clear that the author’s contribution
is decreasing in rank
, and that of all the authors form an arithmetic progression, (
,
,
,
…, 1), from the first to the last author. In other words, the authors’ contribution is computed by the following linear function
where
x is the rank of the author in the paper, and
y is the author’s contribution.
To present new nonlinear measures on the quantity of IRO, we first present a general definition of a credit function to evaluate the share of each participant to the total contribution of the same IRO.
Definition 1. is called a credit function if the following conditions are satisfied: (1) f is continuous and decreasing in the interval ; (2) .
Definition 2. Let
be a credit function. If an IRO is involved with
m participants, we call the share of the
j-th participant:
in the total credits of all the participants in the IRO as a measure of IRO.
By definition, we know that the following functions
,
and
are examples of credit functions:
where
and
b are given constants such that
,
where
and
are given constants,
where
,
and
are fixed constants.
By virtue of a certain credit function, we can quantify the contribution for each professional faculty even if the article, the research award and the scientific research project are completed by lots of participants. For example, if
and
in (
5), i.e., the credit function is specified by
Suppose that the number of authors in a published paper is
m. Then, we can calculate the number of paper for each author in this paper by (
8). Let
represent the number of the paper for the
j-th author. We calculate
by
Actually, in the case that
, the credit of each author defined by (
9) turns out to be that by the method (
1) proposed in [
9]. In other words, the method in [
9] is just a special case associated with the linear credit function (
8).
With the other credit functions, we obtain a series of formulae to quantify the contribution of all the authors in the same paper, of the winners in the same research awards, or of the proposers in the same research project.
In (
6), set
. Then, the credit function
is specified by
If there are
m winners in a research award, then the credit of the
j-th winner is measured by
, and the total credit of all the winners in the same research award is expressed by
. Thus, with the help of (
10), the contribution of the
j-th winner is quantified by the share of the
j-th winner in the total credit:
Similarly, set
,
in (
7). Then, the credit function
is defined by
If there are
m participants in a research project, then by (
12), the contribution of the
j-th participant is quantified by
Actually, if we regard the credit of the j-th participant as , then the credits from the first author to the last author form an arithmetic progression: (1,, …, ). The total credit of all the participants is
The contribution of the j-th participant, , is defined as the share in the total credit.
On the basis of the above preparation, we finally present a new concept, called the standardized IRO number of the participant (SNP).
Definition 3. Let n be the original IRO number of a participant. Let be the total number of the participants in the IRO, . is the order of the participant in the participants, . We call
the standardized IRO number of the participant.
3. Difference of Credit Functions in Evaluation of IRO
In this section, we intend to show the differences of the proposed credit functions in quantifying the IRO.
For simplification, we only focus on computing the number of a published paper with one or multiple authors. The method can be easily extended to quantify the other kinds of individual outputs.
If
in (
9), (
11) and (
13), then it is easy to see that
Obviously, for all the three methods, the result (
15) is in accordance with the practical observation on one paper with a sole author.
If there are two authors in a paper, i.e.,
in (
9), (
11) and (
13), then it is obtained that
Refs. (
15) and (
16) indicate that there are not any differences among the three credit functions if the number of the authors is one or two. However, if
, we can show their differences.
In
Table 1,
Table 2,
Table 3 and
Table 4, we report the distribution of contribution to the same paper for all the authors in the cases
, respectively.
(1) By the credit functions (
11) and (
13), the contribution of the first author to the paper is more emphasized than that by the first method proposed in [
9]. It demonstrates that it is more reasonable and fair in practice if some nonlinear measures are designed to quantify the IRO.
(2) In the share of each author in
Table 1,
Table 2,
Table 3 and
Table 4, the largest one for the last author is obtained by the credit function (
11) in all the cases of
. It shows that (
11) can reflect the significance of all the signatures in the same paper, especially for the contribution of the last author. In other words, by choosing a suitable nonlinear measure, we can pay great attention to the contribution of all the participants as well as put emphasis on the role of the first participant in the same IRO.
In the end of this section, we give an example to show that the ranking result may be different if we use the different linear or nonlinear measurement methods. In
Table 5, we list two teachers’ information (Teachers
A and
B) about their published academic papers.
It is clear that the paper number of Teacher
B (6) is larger than that of Teacher
A (2) if we do not take into account the number of the authors and their order. However, by virtue of the three different credit functions (
8), (
10) and (
12), we can quantify the contribution of the author in the same paper such that the two teachers are ranked based on a more precise quantification method. The example we construct in
Table 5 demonstrates that different quantification methods may generate distinct ranking results (see
Table 6).
From
Table 6, it follows that:
By (
9), Teacher
A is good as Teacher
B.
By (
13), Teacher
A is better than Teacher
B.
By (
11), Teacher
B is more excellent than Teacher
A.
Since the nonlinear credit function (
11) may pay sufficient respect to the contribution of the last author in the same paper, the obtained results appear more acceptable in practice (
).
4. Combination of Nonlinear Measures with TOPSIS
In this section, we will present a ranking method by combining the new measurement method on the IRO with the TOPSIS method in the multi-criteria decision-making (see, for example, [
11,
12,
13]).
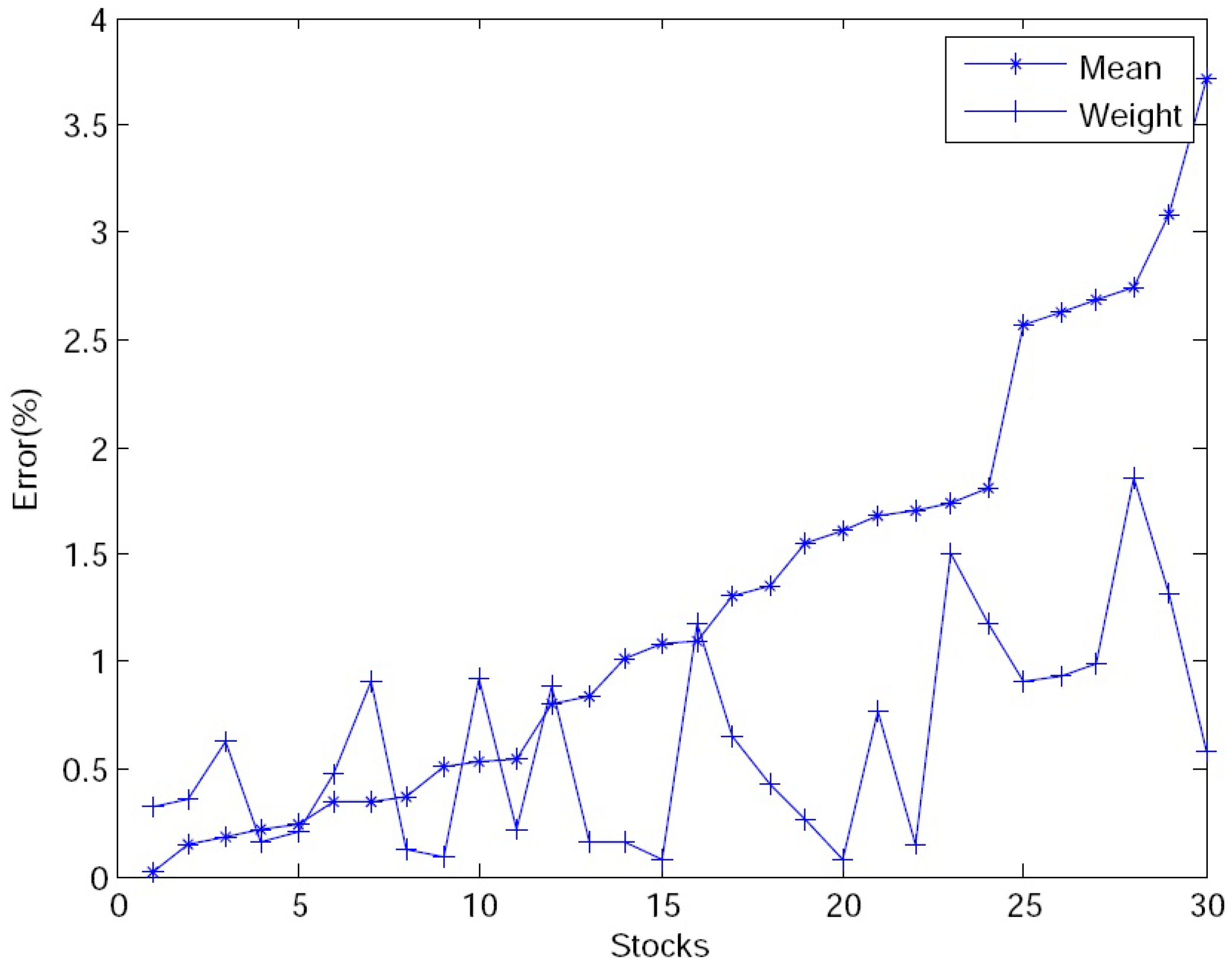
In quantifying the IRO of the scientists, papers, awards and research projects are regarded as three criteria to evaluate the final achievement of each scientist in this paper. Thus, the rank problem of the scientists’ IRO is a multi-criteria decison-making problem. However, for any a multi-criteria decison-making problem, it is a critical step to determine a valid and acceptable original evaluation matrix. In particular, for the rank problem of the scientists’ IRO, it is certain that how to quantify the research output of each scientist directly affects the ranking result.
In the following, we shall present an extended TOPSIS algorithm to obtain the rank of the scientists’ IRO based on the new measurement methods in
Section 3.
Algorithm 1. (Extended TOPSIS Algorithm)
Step 1 (
Calculation of the evaluation matrix): Calculate the original evaluation matrix
by virtue of a credit function such as (
8), (
11) or (
13), where
represents the modified output number of the
i-th scientists by the
j-th criterion. Denote
.
Step 2 (
Normalization): Each component of the evaluation matrix is normalized such that its value is in the interval
. For example,
can be normalized by
Step 3 (
Weights of criteria): For the
j-th criterion, we first calculate the entropy (see, for example, [
14]) by
where
Then, the weight vector of the criterion,
, is determined by
Step 4 (
Weighted evaluation matrix): With (
20), we obtain the weighted and normalized evaluation matrix as follows.
Step 5 (
Final score of IRO): On the basis of the standard IRO in (
21), we calculate the final score of each scientist:
where
and
Finally, the values of
,
, in descending order form an IRO rank of all the scientists.
Remark 1. In Step 1 of Algorithm 1, the credit functions (
8), (
11) and (
13) are just three examples for the implementation of Algorithm 1. Since different credit function may affect the distribution fairness of contribution, more new suitable credit functions are worthy of further investigation to obtain an acceptable final ranking on the IRO.
Remark 2. In Algorithm 1, as well as the original evaluation matrix
X, the weights of the criteria in Step 3 also play critical roles in computing the final scores of the scientists (see, for example, [
15,
16,
17]). Thus, if the weights of the criteria can be optimized by other new models, the above extended TOPSIS can be further improved in ranking the IRO of the scientists.
6. Conclusions
In this paper, we have proposed new nonlinear credit functions and nonlinear measurement methods to quantify the IRO, such as the numbers of academic papers, research awards and scientific research projects. An example has been constructed to show that there exist differences among these credit functions in ranking the IRO of the scientists. In virtue of the standardized evaluation matrix obtained from the proposed methods, an extended TOPSIS algorithm has been developed to determine the rank even if the achievement of a scientist is associated with the numbers of the papers, awards and projects in the scientific research. The above research results highlight the following managerial implications for building efficient management systems for human resources:
(1) By suitable choice of a linear or nonlinear credit function, we can obtain a fair contribution distribution for all the participants in the same IRO, as well as put emphasis on the role of the first participant.
(2) By virtue of the extended TOPSIS algorithm, an acceptable fair ranking on the IRO can be obtained, even if it is associated with a multi-criteria decision-making problem.
(3) Construction of suitable credit function can provide an efficient forecast method.
(4) The TOPSIS method can be further improved if the weights of the criteria are optimized by new models.
yes



{kind=link}