
Principal Component Analysis of Process Datasets with Missing Values


Abstract
:1. Introduction
2. Methods
2.1. Introduction to PCA
2.2. PCA Methods for Missing Data
3. Case Study
3.1. Simulations of Gaussian Data
3.2. Tennessee Eastman Problem
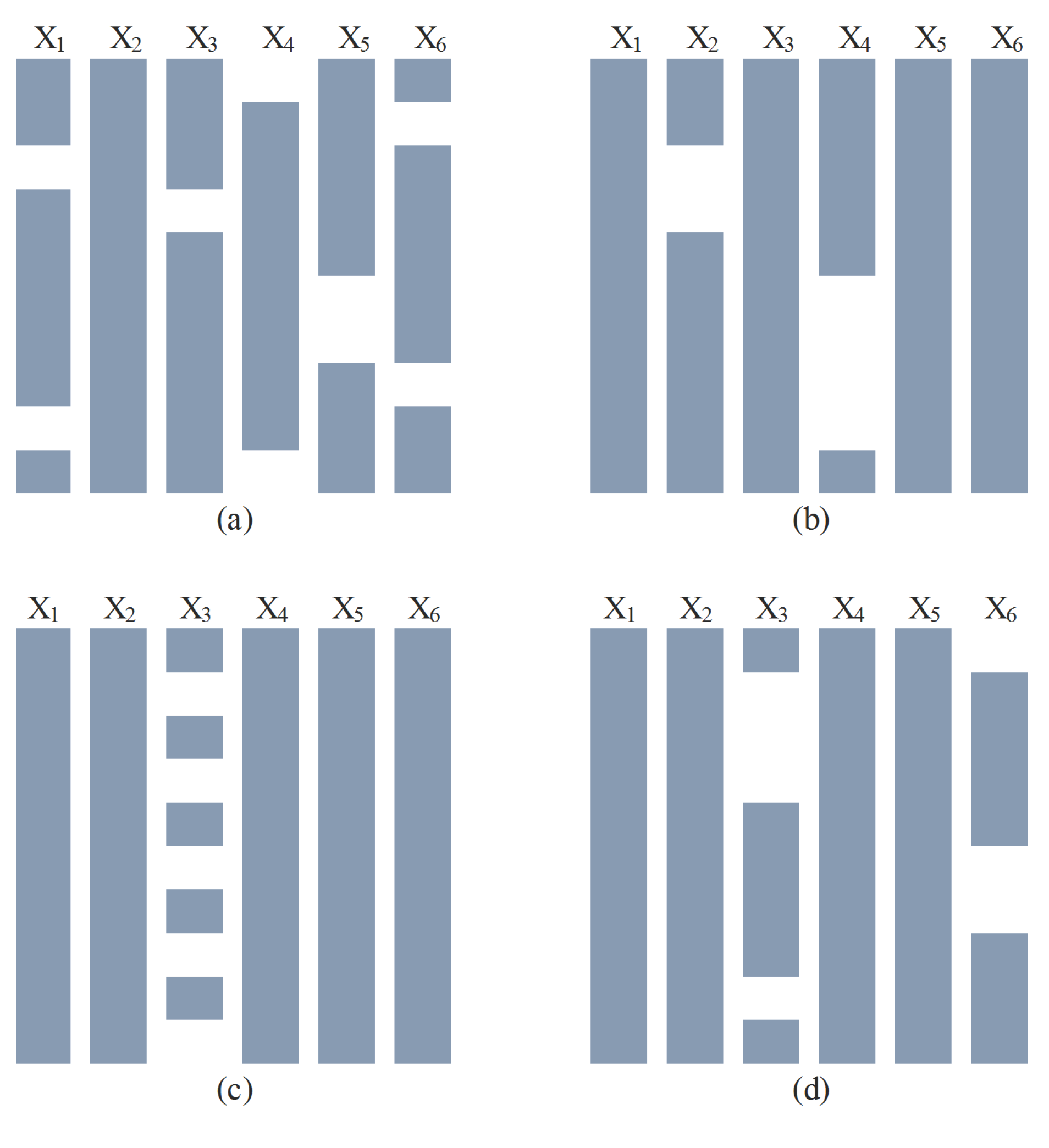
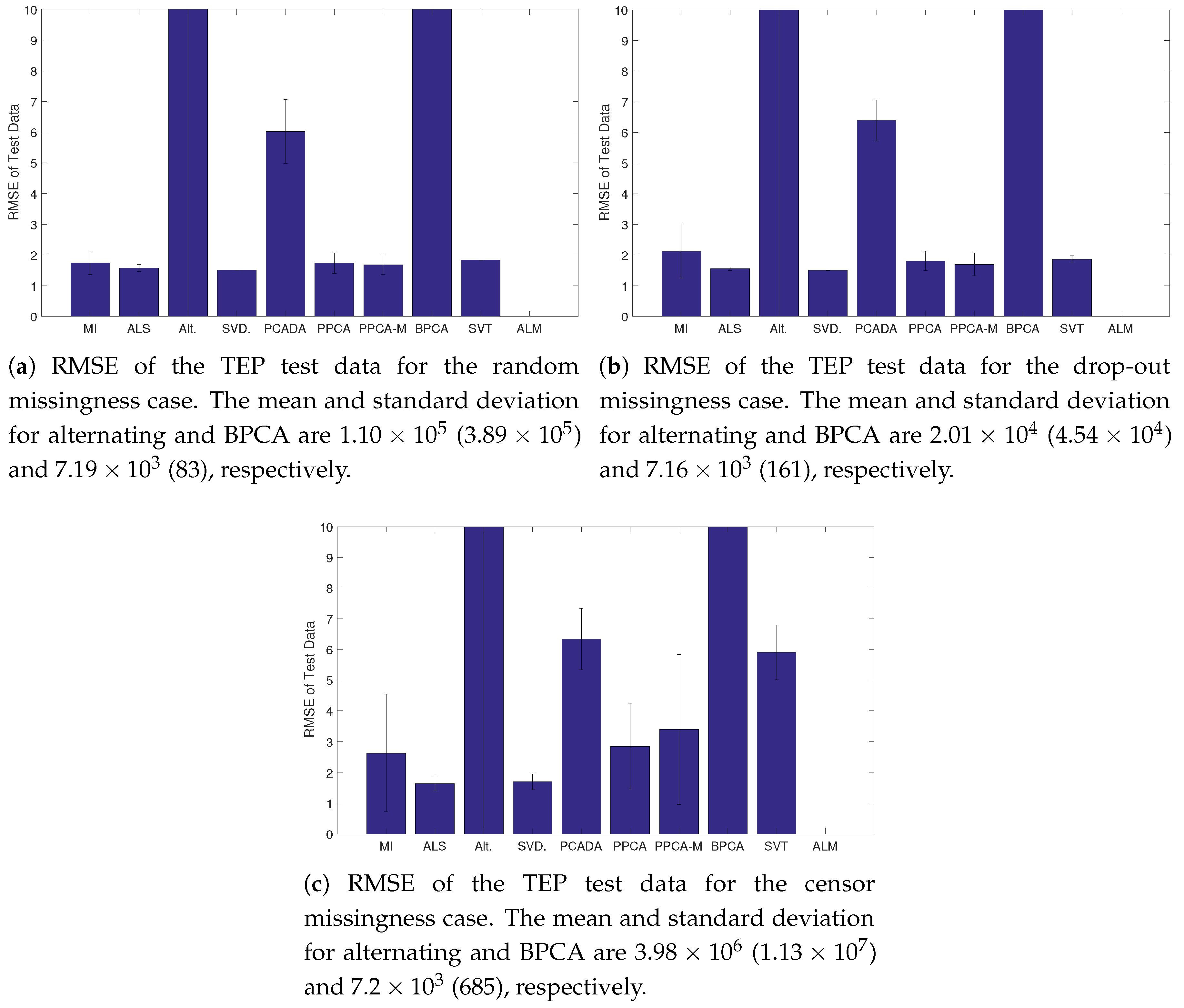
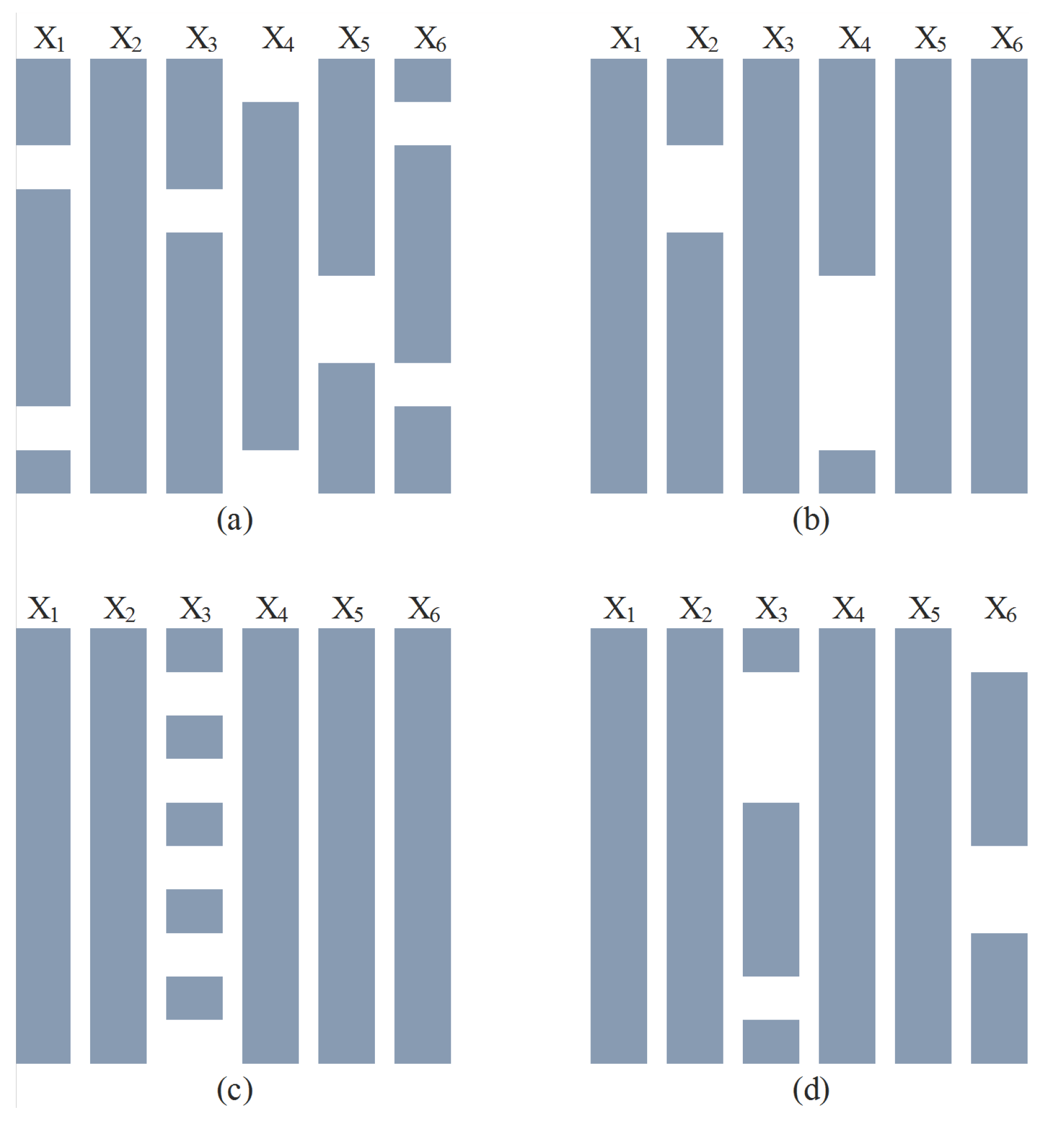
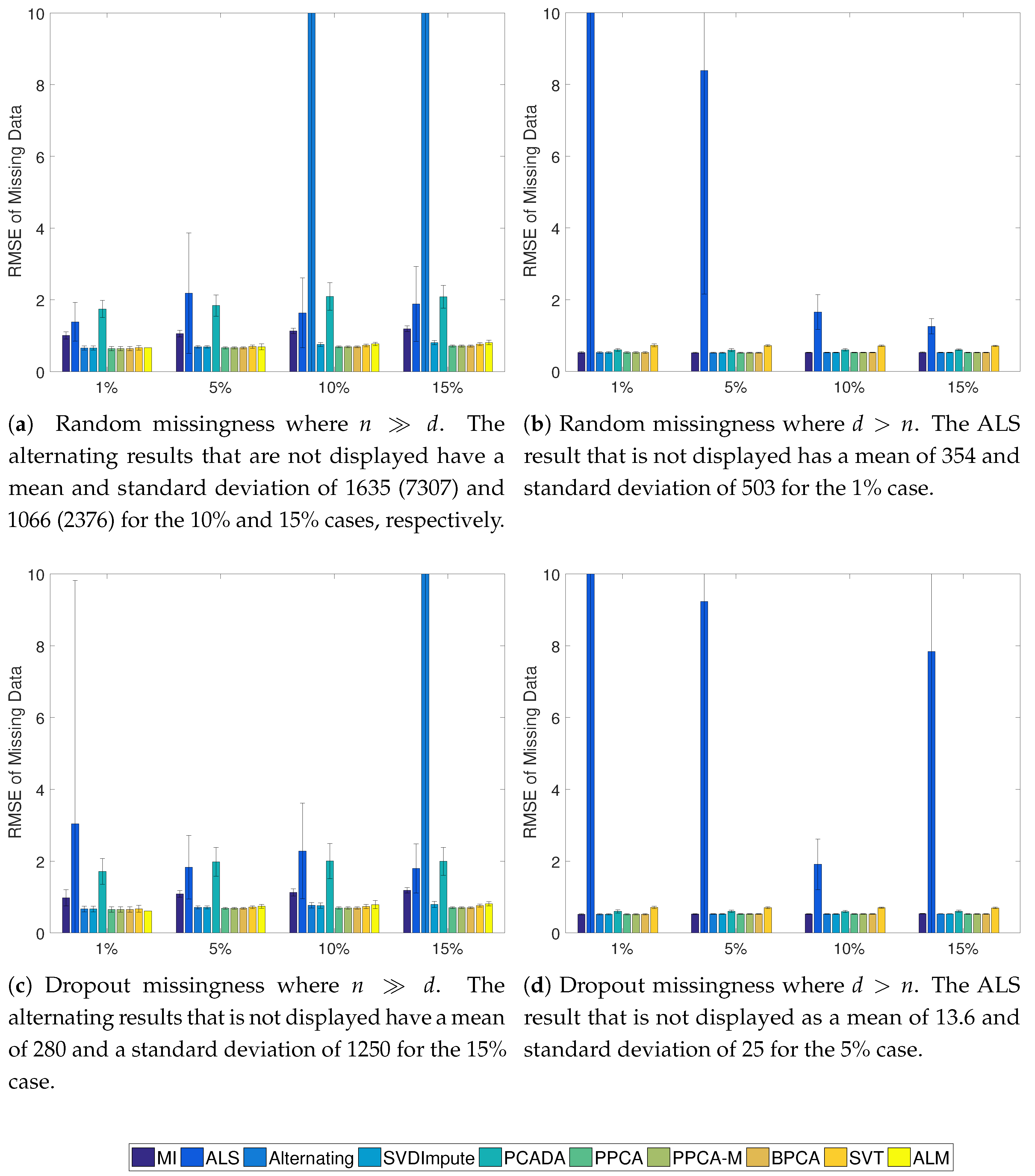
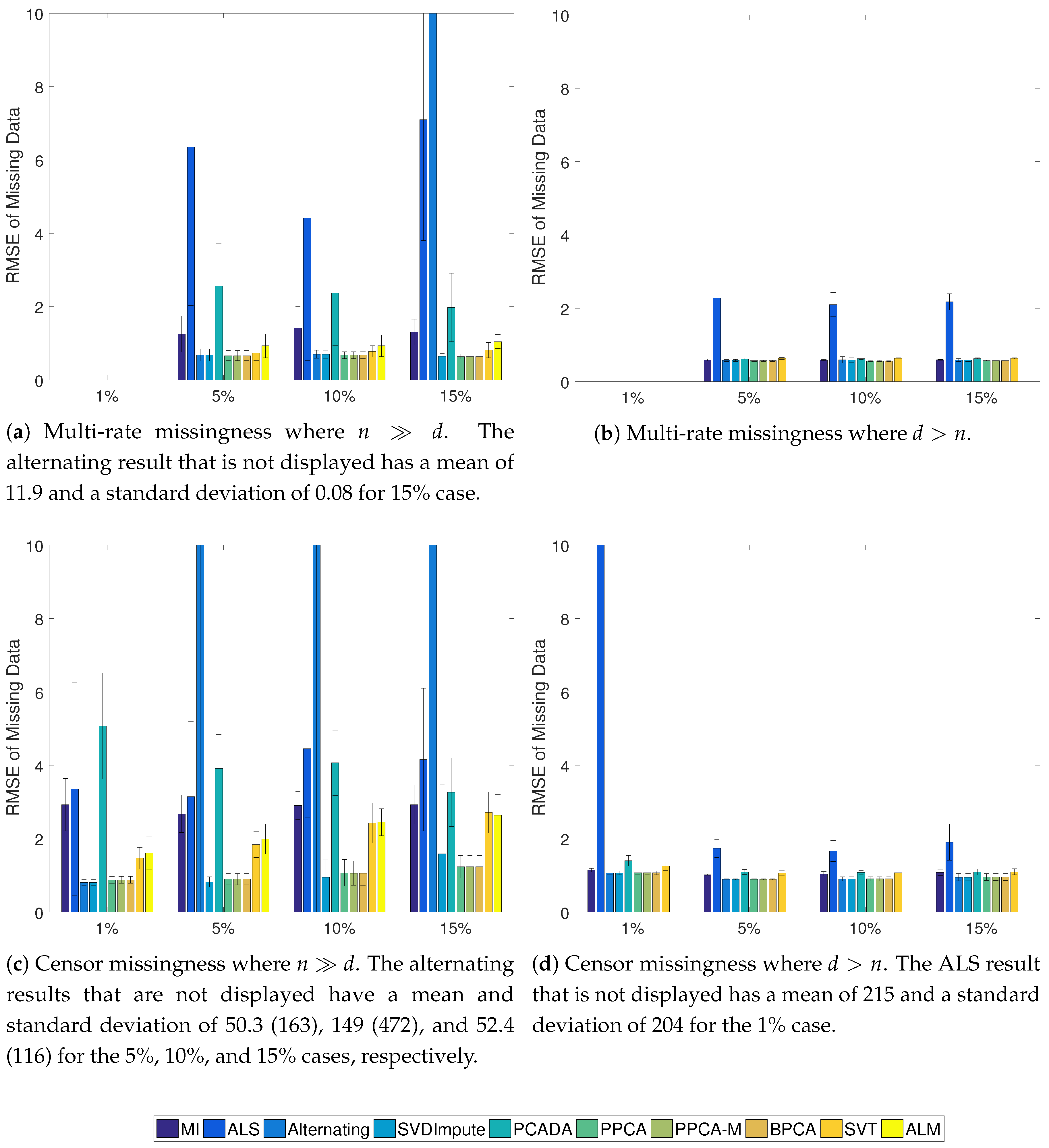
3.3. Addition of Missing Data
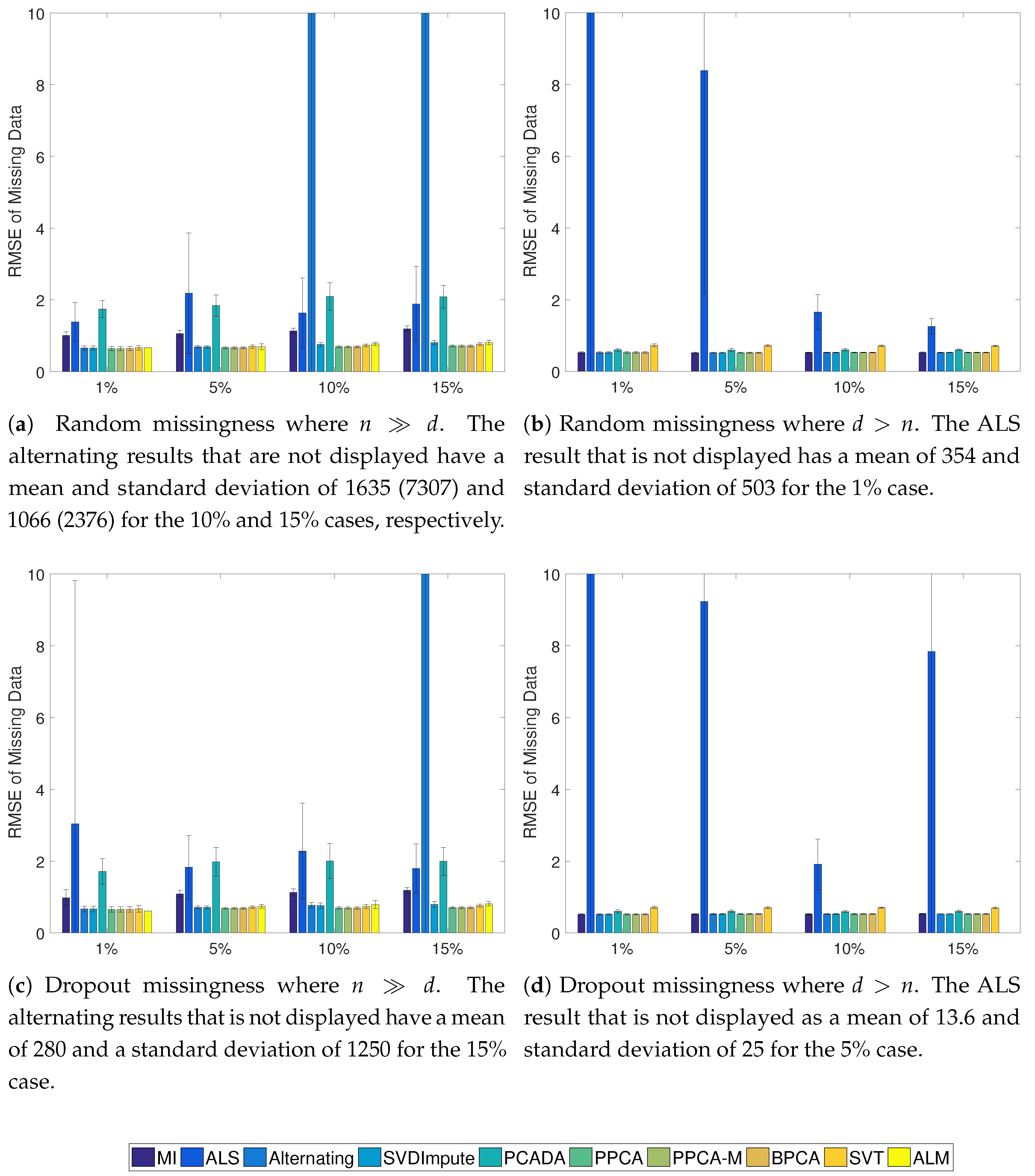
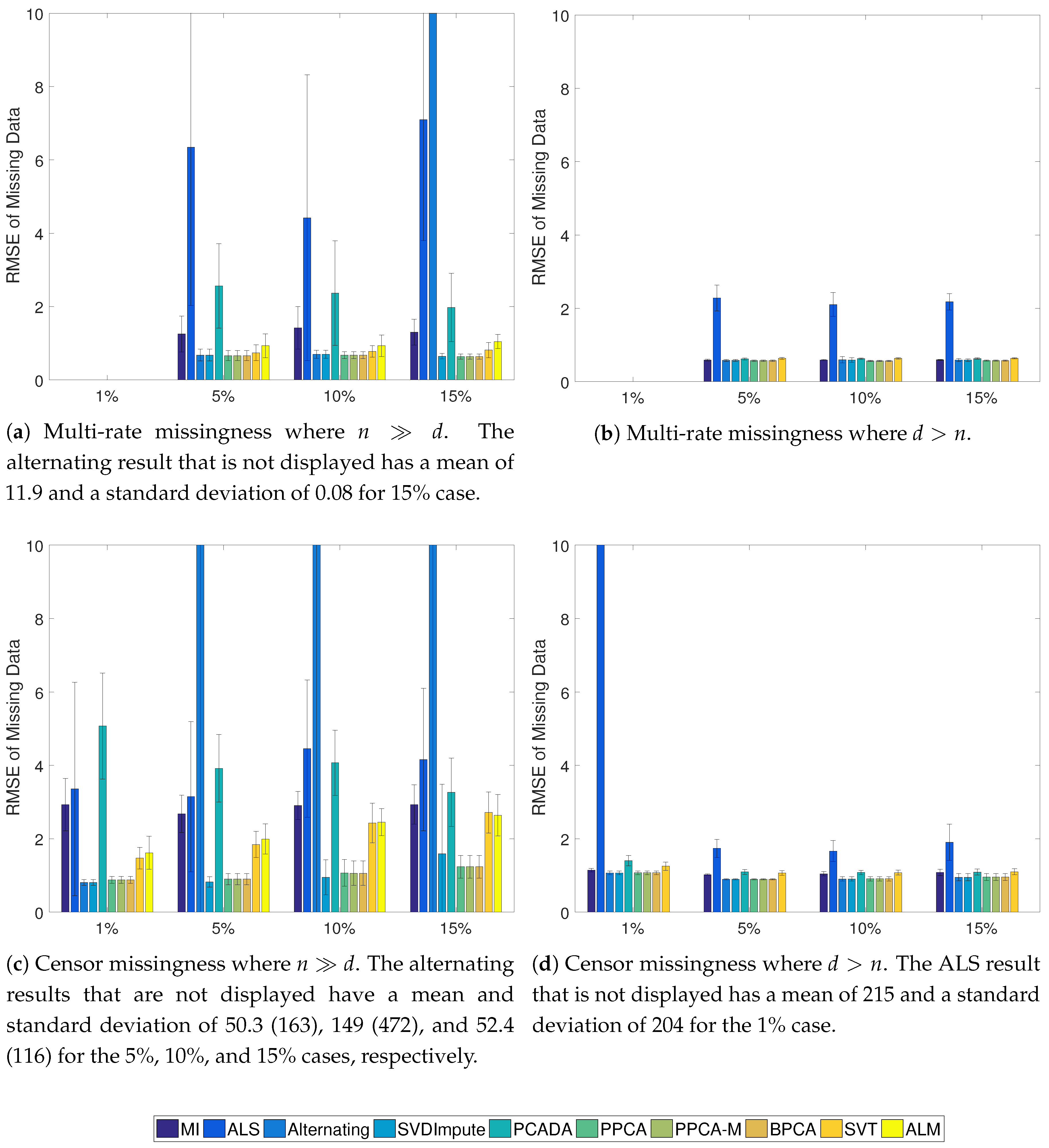
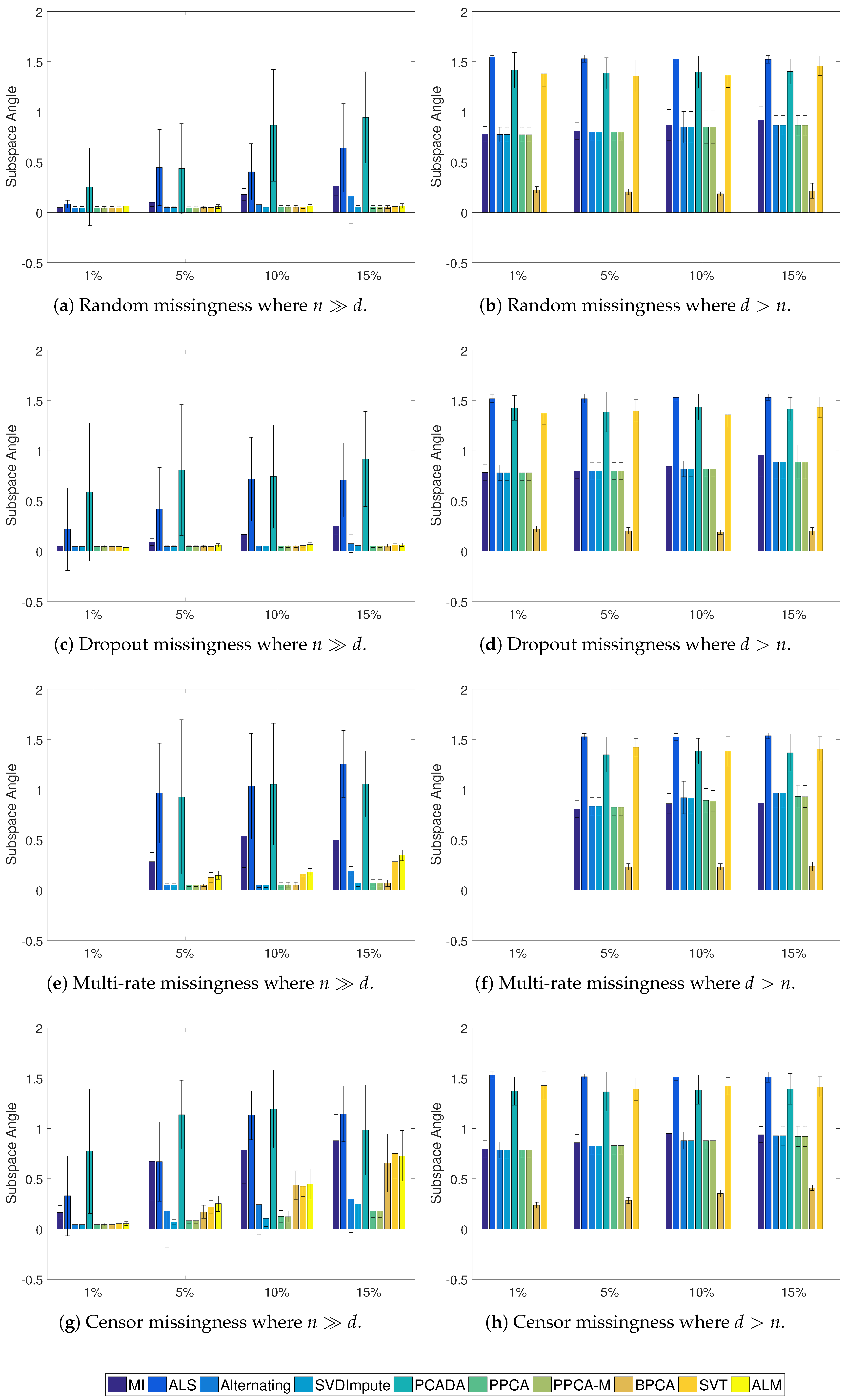
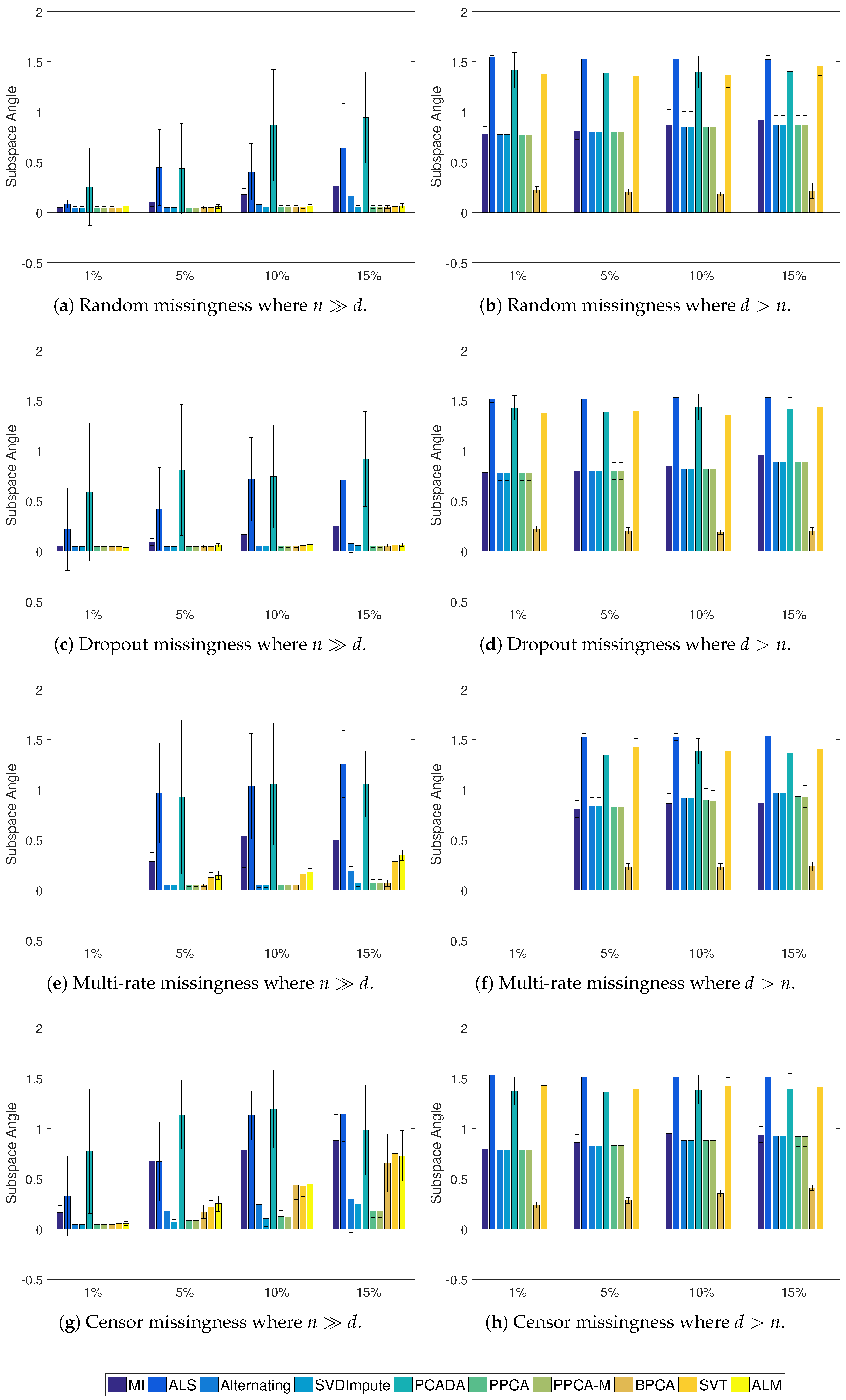
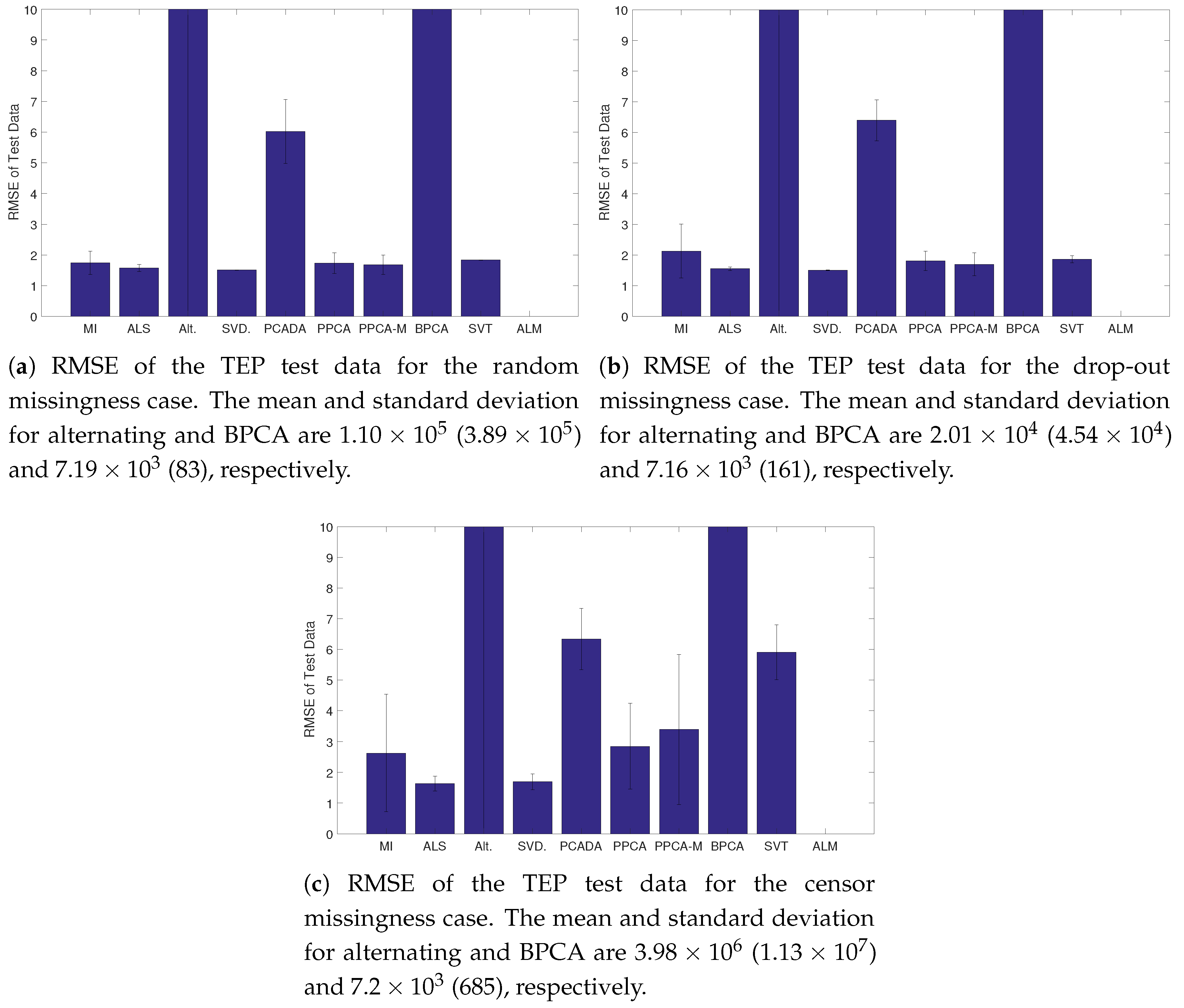
3.4. Results
4. Discussion
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ALM | Augmented Lagrange multipliers |
| BPCA | Bayesian PCA |
| EM | Expectation maximization |
| HLV | Heteroscedastic latent variable model |
| MAR | Missing at random |
| MCAR | Missing completely at random |
| MLPCA | Maximum likelihood PCA |
| NMAR | Not missing at random |
| PCA | Principal component analysis |
| PCADA | PCA-data augmentation |
| PPCA | Probabilistic PCA |
| RMSE | Root mean square error |
| SVD | Singular value decomposition |
| SVT | Singular value thresholding |
| TEP | Tennessee Eastman problem |
Appendix A. Definition of the Subspace Angle
References
- MacGregor, J.F.; Kourti, T. Statistical process control of multivariate processes. Control Eng. Pract. 1995, 3, 403–414. [Google Scholar] [CrossRef]
- Dunia, R.; Qin, S.J.; Edgar, T.F.; McAvoy, T.J. Identification of faulty sensors using principal component analysis. AIChE J. 1996, 42, 2797–2812. [Google Scholar] [CrossRef]
- Liu, J. On-line soft sensor for polyethylene process with multiple production grades. Control Eng. Pract. 2007, 15, 769–778. [Google Scholar] [CrossRef]
- Kirdar, A.O.; Conner, J.S.; Baclaski, J.; Rathore, A.S. Application of multivariate analysis toward biotech processes: Case study of a cell-culture unit operation. Biotechnol. Prog. 2007, 23, 61–67. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; MacGregor, J.F. Multivariate image analysis and regression for prediction of coating content and distribution in the production of snack foods. Chemom. Intell. Lab. 2003, 67, 125–144. [Google Scholar] [CrossRef]
- Ku, W.; Storer, R.H.; Georgakis, C. Disturbance detection and isolation by dynamic principal component analysis. Chemom. Intell. Lab. 1995, 30, 179–196. [Google Scholar] [CrossRef]
- Nomikos, P.; MacGregor, J.F. Monitoring batch processes using multiway principal component analysis. AIChE J. 1994, 40, 1361–1375. [Google Scholar] [CrossRef]
- Nomikos, P.; MacGregor, J.F. Multivariate SPC charts for monitoring batch processes. Technometrics 1995, 37, 41–59. [Google Scholar] [CrossRef]
- Imtiaz, S.A.; Shah, S.L. Treatment of missing values in process data analysis. Can. J. Chem. Eng. 2008, 86, 838–858. [Google Scholar] [CrossRef]
- Christoffersson, A. The One Component Model with Incomplete Data. Ph.D. Thesis, Uppsala University, Uppsala, Sweden, 1970. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. 1987, 3, 37–52. [Google Scholar] [CrossRef]
- Nelson, P.R.C.; Taylor, P.A.; MacGregor, J.F. Missing data methods in PCA and PLS: Score calculations with incomplete observations. Chemom. Intell. Lab. 1996, 35, 45–65. [Google Scholar] [CrossRef]
- Grung, B.; Manne, R. Missing values in principal component analysis. Chemom. Intell. Lab. 1998, 42, 125–139. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statisical Analysis with Missing Data, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Qin, S.J. Process data analytics in the era of big data. AIChE J. 2014, 60, 3092–3100. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Tipping, M.E.; Bishop, C.M. Probabilistic Principal Component Analysis; Technical Report; Aston University: Birmingham, UK, 1997. [Google Scholar]
- Roweis, S. EM algorithms for PCA and SPCA. In Advances in Neural Information Processing Systems 10; Jordan, M.I., Kearns, M.J., Solla, S.A., Eds.; MIT Press: Cambridge, MA, USA, 1998; pp. 626–632. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Cattell, R.B. The scree test for the number of factors. Multivar. Behav. Res. 1966, 1, 245–276. [Google Scholar] [CrossRef] [PubMed]
- Horn, J.L. A rationale and test for the number of factors in factor analysis. Psychometrika 1965, 30, 179–185. [Google Scholar] [CrossRef] [PubMed]
- Donoho, D.L.; Gavish, M. The Optimal Hard Threshold for Singular Values Is ; Technical Report; Stanford University: Stanford, CA, USA, 2013. [Google Scholar]
- Schafer, J.L. Multiple imputation: A primer. Stat. Methods Med. Res. 1999, 8, 3–15. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Dorsey, A.W. Monitoring of batch processes through state-space models. AIChE J. 2004, 50, 1198–1210. [Google Scholar] [CrossRef]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed]
- Walczak, B.; Massart, D. Dealing with missing data: Part I. Chemom. Intell. Lab. 2001, 58, 29–42. [Google Scholar] [CrossRef]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Ilin, A.; Raiko, T. Practical approaches to principal component analysis in the presence of missing values. J. Mach. Learn. Res. 2010, 11, 1957–2000. [Google Scholar]
- Marlin, B.M. Missing Data Problems in Machine Learning. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2008. [Google Scholar]
- Yu, L.; Snapp, R.R.; Ruiz, T.; Radermacher, M. Probabilistic principal component analysis with expectation maximization (PPCA-EM) facilitates volume classification and estimates the missing data. J. Struct. Biol. 2012, 171, 18–30. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Variational principal components. In Proceedings of the 9th International Conference on Artificial Neural Networks, Edinburgh, UK, 1999; pp. 509–514. [Google Scholar]
- Neal, R.M.; Hinton, G.E. A view of the EM algorithm that justifies incremental, sparse, and other variants. In Learning in Graphical Models; Jordan, M.I., Ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1998; pp. 355–368. [Google Scholar]
- Oba, S.; Sato, M.; Takemasa, I.; Monden, M.; Matsubara, K.; Ishii, S. A Bayesian missing value estimation method for gene expression profile data. Bioinformatics 2003, 19, 2088–2096. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, R.; Su, Z. Linearized alternating direction method with adaptive penalty for low rank representation. In Advances in Neural Information Processing Systems; Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; MIT Press: Cambridge, MA, USA, 2011; pp. 612–620. [Google Scholar]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Russell, E.L.; Chiang, L.H.; Braatz, R.D. Tennessee Eastman Problem Simulation Data. Available online: http://web.mit.edu/braatzgroup/links.html (accessed on 12 April 2017).
- Lyman, P.R.; Georgakis, C. Plant-wide control of the Tennessee Eastman problem. Comput. Chem. Eng. 1995, 19, 321–331. [Google Scholar] [CrossRef]
- Jackson, J.E.; Mudholkar, G.S. Control procedures for residuals associated with principal component analysis. Technometrics 1979, 21, 341–349. [Google Scholar] [CrossRef]
- Kresta, J.V.; MacGregor, J.F.; Marlin, T.E. Multivariate statistical process monitoring of process operating performance. Can. J. Chem. Eng. 1991, 69, 35–47. [Google Scholar] [CrossRef]
- Russell, E.L.; Chiang, L.H.; Braatz, R.D. Data-Driven Methods for Fault Detection and Diagnosis in Chemical Processes; Springer: London, UK, 2000. [Google Scholar]
- Wentzell, P.D.; Andrews, D.T.; Hamilton, D.C.; Faber, K.; Kowalski, B.R. Maximum likelihood principal component analysis. J. Chemom. 1997, 11, 339–366. [Google Scholar] [CrossRef]
- Andrews, D.T.; Wentzell, P.D. Applications of maximum likelihood principal component analysis. Anal. Chim. Acta 1997, 350, 341–352. [Google Scholar] [CrossRef]
- Reis, M.S.; Saraiva, P.M. Heteroscedastic latent variable modelling with applications to multivariate statistical process control. Chemom. Intell. Lab. 2006, 80, 57–66. [Google Scholar] [CrossRef]
- Björck, A.; Golub, G.H. Numerical methods for computing angles between linear subspaces. Math. Comput. 1973, 27, 579–594. [Google Scholar] [CrossRef]
- Wedin, P. On angles between subspaces of a finite dimensional inner product space. In Matrix Pencils; Lecture Notes in Mathematics 973; Kagstrom, B., Ruhe, A., Eds.; Springer: Berlin, Germany, 1983; pp. 263–285. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MI | ALS | Alt. | SVD. | PCADA | PPCA | PPCA-M | BPCA | SVT | ALM | |
|---|---|---|---|---|---|---|---|---|---|---|
| Random | ||||||||||
| Min | 2 | 3 | 1 | 3 | 1 | 3 | 4 | 3 | 4 | – |
| Avg | 2.95 | 3.2 | 4.15 | 3 | 2.55 | 3 | 4.3 | 3 | 4.95 | – |
| Max | 3 | 4 | 7 | 3 | 4 | 3 | 5 | 3 | 5 | – |
| Drop | ||||||||||
| Min | 1 | 3 | 1 | 3 | 1 | 3 | 3 | 3 | 4 | – |
| Avg | 3.15 | 3.3 | 4.15 | 3 | 2.65 | 3 | 4.05 | 3 | 4.9 | – |
| Max | 4 | 4 | 6 | 3 | 5 | 3 | 5 | 3 | 5 | – |
| Censoring | ||||||||||
| Min | 1 | 3 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | – |
| Avg | 3 | 3.5 | 3.65 | 2.9 | 2.6 | 2.85 | 3.3 | 2.9 | 1.65 | – |
| Max | 4 | 5 | 7 | 3 | 7 | 3 | 5 | 3 | 4 | – |
| MI | ALS | Alt. | SVD. | PCADA | PPCA | PPCA-M | BPCA | SVT | |
|---|---|---|---|---|---|---|---|---|---|
| Fault 1 | |||||||||
| Random | 163.1 | 163 | 163 | 163 | – | 163.8 | 163.1 | – | 171.0 |
| Drop | 163 | 163 | – | 163 | – | 163.7 | 163.4 | – | 170.5 |
| Censor | 163.1 | 163.2 | 163 | 163.5 | – | 163.2 | 163.4 | – | – |
| Fault 13 | |||||||||
| Random | 182 | 181.8 | 210 | 182 | – | 180.3 | 183.2 | – | 174 |
| Drop | 182 | 181.4 | – | 181.3 | – | 182.3 | 179.3 | – | 174.5 |
| Censor | 180.3 | 181.9 | 411 | 184.9 | – | 185 | 189.7 | – | – |
| MI | ALS | Alt. | SVD. | PCADA | PPCA | PPCA-M | BPCA | SVT | |
|---|---|---|---|---|---|---|---|---|---|
| Fault 1 | |||||||||
| Random | 0 | 0 | 19 | 0 | 20 | 2 | 0 | 20 | 0 |
| Drop | 9 | 0 | 20 | 0 | 20 | 1 | 1 | 20 | 1 |
| Censor | 5 | 3 | 19 | 3 | 20 | 6 | 9 | 20 | 20 |
| Fault 13 | |||||||||
| Random | 7 | 3 | 19 | 1 | 20 | 4 | 4 | 20 | 0 |
| Drop | 11 | 4 | 20 | 5 | 20 | 5 | 4 | 20 | 0 |
| Censor | 12 | 9 | 19 | 8 | 20 | 19 | 17 | 20 | 20 |
| ALS/Alternating/PPCA/BPCA | SVDImpute/SVT/ALM | PCADA | PPCA-M |
|---|---|---|---|
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Severson, K.A.; Molaro, M.C.; Braatz, R.D. Principal Component Analysis of Process Datasets with Missing Values. Processes 2017, 5, 38. https://doi.org/10.3390/pr5030038
Severson KA, Molaro MC, Braatz RD. Principal Component Analysis of Process Datasets with Missing Values. Processes. 2017; 5(3):38. https://doi.org/10.3390/pr5030038
Chicago/Turabian StyleSeverson, Kristen A., Mark C. Molaro, and Richard D. Braatz. 2017. "Principal Component Analysis of Process Datasets with Missing Values" Processes 5, no. 3: 38. https://doi.org/10.3390/pr5030038
APA StyleSeverson, K. A., Molaro, M. C., & Braatz, R. D. (2017). Principal Component Analysis of Process Datasets with Missing Values. Processes, 5(3), 38. https://doi.org/10.3390/pr5030038