

Predicting Bulk Density for Agglomerated Raspberry Ketone via Integrating Morphological and Size Metrics Using Artificial Neural Networks
Abstract
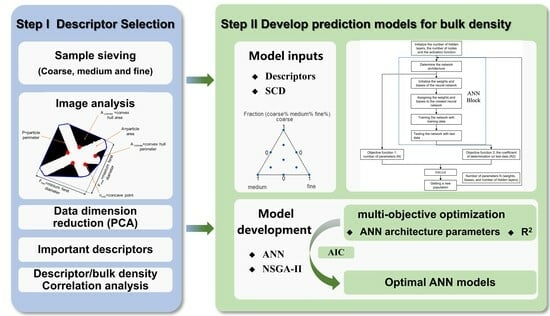
:
1. Introduction
2. Experimental Section
2.1. Materials and Design
2.2. Sample Preparation and Sieving
2.3. Simplex-Lattice Design
3. Methodology
3.1. Image Processing and Analysis
3.2. Principal Component Analysis (PCA)
3.3. Artificial Neural Networks
3.4. Neural Architecture Search Optimization Network Architecture (NSGA-II-ANN)
3.5. Non-Dominated Sorting Genetic Algorithm II
- Step 1: Create the initial parent population of size N.
- Step 2: Generate an offspring population through crossover and mutation.
- Step 3: Merge the parent and child populations to create a new population of size 2N.
- Step 4: All individuals in the population are ranked by non-dominated sorting, and the crowding distance is computed if the individuals have the same rank, then the suitable individuals are selected to create the next population of size N.
- Step 5: Determine the termination conditions and perform the above steps until the termination conditions are satisfied.
4. Results and Discussion
4.1. Image Descriptor Analysis
4.2. Quantitative Analysis between Typical Descriptors and Tapped Bulk Density
4.3. Multi-Objective Optimization Results Based on NSGA-II
4.4. Selection of Optimal ANN Model Based on AIC
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kalman, H.; Portnikov, D. Analyzing Bulk Density and Void Fraction: B. Effect of Moisture Content and Compression Pressure. Powder Technol. 2021, 381, 285–297. [Google Scholar] [CrossRef]
- Kalman, H.; Portnikov, D. Analyzing Bulk Density and Void Fraction: A. the Effect of Archimedes Number. Powder Technol. 2021, 381, 477–487. [Google Scholar] [CrossRef]
- Juliano, P.; Muhunthan, B.; Barbosa-Cánovas, G.V. Flow and Shear Descriptors of Preconsolidated Food Powders. J. Food Eng. 2006, 72, 157–166. [Google Scholar] [CrossRef]
- Sharma, A.; Jana, A.H.; Chavan, R.S. Functionality of Milk Powders and Milk-Based Powders for End Use Applications—A Review. Compr. Rev. Food Sci. Food Saf. 2012, 11, 518–528. [Google Scholar] [CrossRef]
- Jallo, L.J.; Ghoroi, C.; Gurumurthy, L.; Patel, U.; Davé, R.N. Improvement of Flow and Bulk Density of Pharmaceutical Powders Using Surface Modification. Int. J. Pharm. 2012, 423, 213–225. [Google Scholar] [CrossRef] [PubMed]
- Nijdam, J.J.; Langrish, T.A.G. An Investigation of Milk Powders Produced by a Laboratory-Scale Spray Dryer. Dry. Technol. 2005, 23, 1043–1056. [Google Scholar] [CrossRef]
- Abdullah, E.C.; Geldart, D. The Use of Bulk Density Measurements as Flowability Indicators. Powder Technol. 1999, 102, 151–165. [Google Scholar] [CrossRef]
- Kalman, H. Effect of Particle Shape on Void Fraction. Powder Technol. 2022, 407, 117665. [Google Scholar] [CrossRef]
- Kalman, H. Bulk Densities and Flowability of Non-Spherical Particles with Mono-Sized and Particle Size Distributions. Powder Technol. 2022, 401, 117305. [Google Scholar] [CrossRef]
- Bhandari, B. Spray drying and powder properties. In Food Drying Science and Technology: Microbiology, Chemistry, Applications; DEStech Publications, Inc.: Lancaster, PA, USA, 2008; pp. 215–249. [Google Scholar]
- Pisecky, J. Handbook of Milk Powder Manufacture; Niro: Søborg, Denmark, 1997; ISBN 978-87-986606-0-6. [Google Scholar]
- Gaiani, C.; Ehrhardt, J.J.; Scher, J.; Hardy, J.; Desobry, S.; Banon, S. Surface Composition of Dairy Powders Observed by X-Ray Photoelectron Spectroscopy and Effects on Their Rehydration Properties. Colloids Surf. B Biointerfaces 2006, 49, 71–78. [Google Scholar] [CrossRef]
- Elmaz, F.; Büyükçakır, B.; Yücel, Ö.; Mutlu, A.Y. Classification of Solid Fuels with Machine Learning. Fuel 2020, 266, 117066. [Google Scholar] [CrossRef]
- Zhong, H.; Xiong, Q.; Yin, L.; Zhang, J.; Zhu, Y.; Liang, S.; Niu, B.; Zhang, X. CFD-Based Reduced-Order Modeling of Fluidized-Bed Biomass Fast Pyrolysis Using Artificial Neural Network. Renew. Energy 2020, 152, 613–626. [Google Scholar] [CrossRef]
- Hu, L.; Zhang, J.; Xiang, Y.; Wang, W. Neural Networks-Based Aerodynamic Data Modeling: A Comprehensive Review. IEEE Access 2020, 8, 90805–90823. [Google Scholar] [CrossRef]
- Jin, Y. A Comprehensive Survey of Fitness Approximation in Evolutionary Computation. Soft Comput. 2005, 9, 3–12. [Google Scholar] [CrossRef]
- Yahya, H.S.M.; Abbas, T.; Amin, N.A.S. Optimization of Hydrogen Production via Toluene Steam Reforming over Ni–Co Supported Modified-Activated Carbon Using ANN Coupled GA and RSM. Int. J. Hydrog. Energy 2021, 46, 24632–24651. [Google Scholar] [CrossRef]
- Randolph, A.D.; Larson, M.A. Chapter 3—The Population Balance. In Theory of Particulate Processes, 2nd ed.; Randolph, A.D., Larson, M.A., Eds.; Academic Press: Cambridge, MA, USA, 1988; pp. 50–79. ISBN 978-0-12-579652-1. [Google Scholar]
- Singh, M.; Singh, R.; Singh, S.; Walker, G.; Matsoukas, T. Discrete Finite Volume Approach for Multidimensional Agglomeration Population Balance Equation on Unstructured Grid. Powder Technol. 2020, 376, 229–240. [Google Scholar] [CrossRef]
- Szilágyi, B.; Agachi, P.Ş.; Lakatos, B.G. Numerical Analysis of Crystallization of High Aspect Ratio Crystals with Breakage. Powder Technol. 2015, 283, 152–162. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, W.; Lu, H.; Wang, J. Multi-Step Forecasting for Wind Speed Using a Modified EMD-Based Artificial Neural Network Model. Renew. Energy 2012, 37, 241–249. [Google Scholar] [CrossRef]
- Miriyala, S.S.; Pujari, K.N.; Naik, S.; Mitra, K. Evolutionary Neural Architecture Search for Surrogate Models to Enable Optimization of Industrial Continuous Crystallization Process. Powder Technol. 2022, 405, 117527. [Google Scholar] [CrossRef]
- Miriyala, S.S.; Mitra, K. Deep Learning Based System Identification of Industrial Integrated Grinding Circuits. Powder Technol. 2020, 360, 921–936. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimizationb. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar] [CrossRef]
- Wu, J.; Chen, S.; Liu, X. Efficient Hyperparameter Optimization through Model-Based Reinforcement Learning. Neurocomputing 2020, 409, 381–393. [Google Scholar] [CrossRef]
- Jiao, D.; Shi, C.; Yuan, Q.; An, X.; Liu, Y. Mixture Design of Concrete Using Simplex Centroid Design Method. Cem. Concr. Compos. 2018, 89, 76–88. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Hasan, B.M.S.; Abdulazeez, A.M. A Review of Principal Component Analysis Algorithm for Dimensionality Reduction. J. Soft Comput. Data Min. 2021, 2, 20–30. [Google Scholar]
- Pan, A.; Bosch, D.; Ma, H. Assessing Water Poverty in China Using Holistic and Dynamic Principal Component Analysis. Soc. Indic. Res. 2017, 130, 537–561. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Mathew, R.K.; Begum, K.M.M.S.; Anantharaman, N. Hydrodynamic Studies on Fluidized Beds with Internals: Experimental and ANN Approach. Powder Technol. 2014, 264, 423–429. [Google Scholar] [CrossRef]
- Krishna, M.S.V.; Begum, K.M.M.S.; Anantharaman, N. Hydrodynamic Studies in Fluidized Bed with Internals and Modeling Using ANN and ANFIS. Powder Technol. 2017, 307, 37–45. [Google Scholar] [CrossRef]
- Serrano, D.; Golpour, I.; Sánchez-Delgado, S. Predicting the Effect of Bed Materials in Bubbling Fluidized Bed Gasification Using Artificial Neural Networks (ANNs) Modeling Approach. Fuel 2020, 266, 117021. [Google Scholar] [CrossRef]
- Chew, J.W.; Cocco, R.A. Application of Machine Learning Methods to Understand and Predict Circulating Fluidized Bed Riser Flow Characteristics. Chem. Eng. Sci. 2020, 217, 115503. [Google Scholar] [CrossRef]
- Argatov, I.I.; Chai, Y.S. An Artificial Neural Network Supported Regression Model for Wear Rate. Tribol. Int. 2019, 138, 211–214. [Google Scholar] [CrossRef]
- Nguyen, H.; Bui, X.-N. Predicting Blast-Induced Air Overpressure: A Robust Artificial Intelligence System Based on Artificial Neural Networks and Random Forest. Nat. Resour. Res. 2019, 28, 893–907. [Google Scholar] [CrossRef]
- Taherei Ghazvinei, P.; Hassanpour Darvishi, H.; Mosavi, A.; Yusof, K. bin W.; Alizamir, M.; Shamshirband, S.; Chau, K. Sugarcane Growth Prediction Based on Meteorological Parameters Using Extreme Learning Machine and Artificial Neural Network. Eng. Appl. Comput. Fluid Mech. 2018, 12, 738–749. [Google Scholar] [CrossRef]
- Kemppinen, J.; Niittynen, P.; Riihimäki, H.; Luoto, M. Modelling Soil Moisture in a High-Latitude Landscape Using LiDAR and Soil Data. Earth Surf. Process. Landf. 2018, 43, 1019–1031. [Google Scholar] [CrossRef]
- Zhong, H.; Sun, Z.; Zhu, J.; Zhang, C. Prediction of Solid Holdup in a Gas–Solid Circulating Fluidized Bed Riser by Artificial Neural Networks. Ind. Eng. Chem. Res. 2021, 60, 3452–3462. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Li, S.; Deng, Z.; Liu, J.; Liu, D. Multi-Objective Optimization of Plate-Fin Heat Exchangers via Non-Dominated Sequencing Genetic Algorithm (NSGA-II). Appl. Sci. 2022, 12, 11792. [Google Scholar] [CrossRef]
- Gao, C.; Lan, X.; He, Z.; Xin, G.; Wang, X.; Xin, Q. Temperature Uniformity Analysis and Multi-Objective Optimization of a Small-Scale Variable Density Alternating Obliquely Truncated Microchannel. Therm. Sci. Eng. Prog. 2023, 38, 101652. [Google Scholar] [CrossRef]
- Abolpour, B.; Hekmatkhah, R.; Shamsoddini, R. Multi-Objective Optimum Design for Double Baffle Heat Exchangers. Therm. Sci. Eng. Prog. 2021, 26, 101132. [Google Scholar] [CrossRef]
- Akaike, H. Factor Analysis and AIC. Psychometrika 1987, 52, 317–332. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mixture Ratio | Tapped Bulk Density (kg/m3) | |||||
|---|---|---|---|---|---|---|
| Fine | Medium | Coarse | Sample 1 a | Sample 2 b | Sample 3 c | Sample 4 d |
| 1 | 0 | 0 | 611.2 ± 1.5 | 515.4 ± 0.3 | 558.5 ± 1.3 | 569.0 ± 1.1 |
| 0 | 1 | 0 | 612.5 ± 1.7 | 408.3 ± 1.1 | 528.7 ± 2.2 | 506.0 ± 2.4 |
| 0 | 0 | 1 | 484.6 ± 2.6 | 398.6 ± 1.8 | 515.0 ± 3.3 | 454.4 ± 3.2 |
| 0 | 1/2 | 1/2 | 5155 ± 3.2 | 578.1 ± 1.7 | 486.6 ± 1.8 | 485.8 ± 1.3 |
| 1/2 | 0 | 1/2 | 538.1 ± 1.5 | 499.3 ± 1.1 | 606.5 ± 3.1 | 459.6 ± 2.1 |
| 1/2 | 1/2 | 0 | 725.9 ± 1.0 | 508.7 ± 0.6 | 551.6 ± 0.8 | 522.9 ± 1.1 |
| 1/6 | 1/6 | 2/3 | 472.7 ± 2.3 | 452.6 ± 1.2 | 509.9 ± 1.1 | 568.3 ± 3.7 |
| 1/6 | 2/3 | 1/6 | 538.2 ± 1.7 | 445.2 ± 1.3 | 480.1 ± 2.6 | 478.1 ± 2.1 |
| 2/3 | 1/6 | 1/6 | 545.8 ± 0.3 | 571.5 ± 0.6 | 686.2 ± 1.5 | 636.2 ± 1.8 |
| 1/3 | 1/3 | 1/3 | 730.1 ± 1.0 | 499.6 ± 1.5 | 666.0 ± 1.7 | 563.6 ± 2.0 |
| Parameter | Value |
|---|---|
| Number of decision variables in NSGA-II | 4 |
| Number of population and generations in NSGA-II | 100 and 100 |
| Mutation and Crossover Probability in NSGA-II | 0.01 and 0.9 |
| Choice of activation function | nonlinear activation function (tansigmoid, logsigmoid) |
| Lower and upper bound on number of hidden layers | 1 and 3 |
| Lower and upper bound on nodes in each hidden layer | {1, 0, 0} and {15, 15, 15} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Xuanyuan, S.; Ye, Y.; Sun, Y.; Du, H.; Qi, L.; Li, C.; Xie, C. Predicting Bulk Density for Agglomerated Raspberry Ketone via Integrating Morphological and Size Metrics Using Artificial Neural Networks. Processes 2024, 12, 902. https://doi.org/10.3390/pr12050902
Zhou X, Xuanyuan S, Ye Y, Sun Y, Du H, Qi L, Li C, Xie C. Predicting Bulk Density for Agglomerated Raspberry Ketone via Integrating Morphological and Size Metrics Using Artificial Neural Networks. Processes. 2024; 12(5):902. https://doi.org/10.3390/pr12050902
Chicago/Turabian StyleZhou, Xiaomeng, Shutian Xuanyuan, Yang Ye, Ying Sun, Haowen Du, Luguang Qi, Chang Li, and Chuang Xie. 2024. "Predicting Bulk Density for Agglomerated Raspberry Ketone via Integrating Morphological and Size Metrics Using Artificial Neural Networks" Processes 12, no. 5: 902. https://doi.org/10.3390/pr12050902