

Flexible Extension of the Lomax Distribution for Asymmetric Data under Different Failure Rate Profiles: Characteristics with Applications for Failure Modeling and Service Times for Aircraft Windshields
 ,
,  ,
, 
Abstract
:1. Introduction
- I.
- The Lx distribution can be used to model the occurrence of severe traffic congestion events. By fitting the distribution to historical data on congestion levels or travel times, transportation planners can estimate the probability of extreme congestion events. This information helps in designing appropriate mitigation strategies and optimizing traffic management plans.
- II.
- The Lx distribution can be utilized to model the occurrence of rare but severe accidents. By analyzing historical accident data, transportation agencies can estimate the probability of extreme accident events, which aids in prioritizing safety interventions and allocating resources effectively.
- III.
- In transportation systems, extreme weather events can significantly affect operations and safety. The Lx distribution can be applied to model the occurrence of extreme weather phenomena, such as heavy rainfall, snowstorms, or high winds. By understanding the tail behavior of these events, transportation planners can develop strategies to minimize the impact of adverse weather conditions.
- IV.
- When analyzing transportation demand, the Lx distribution can be used to model the tail behavior of high-demand events. This is particularly relevant for scenarios in which sudden spikes in demand occur, such as during major events, holidays, or rush hours. By incorporating the Lx distribution into demand forecasting models, transportation planners can estimate the probability of extreme demand levels and ensure appropriate resource allocation.
- V.
- The Lx distribution can aid in analyzing the tail behavior of traffic or transportation infrastructure capacity. By fitting the distribution to the data on infrastructure utilization, transportation planners can estimate the probability of extreme capacity constraints. This information is valuable for designing infrastructure expansion projects or optimizing capacity allocation strategies.
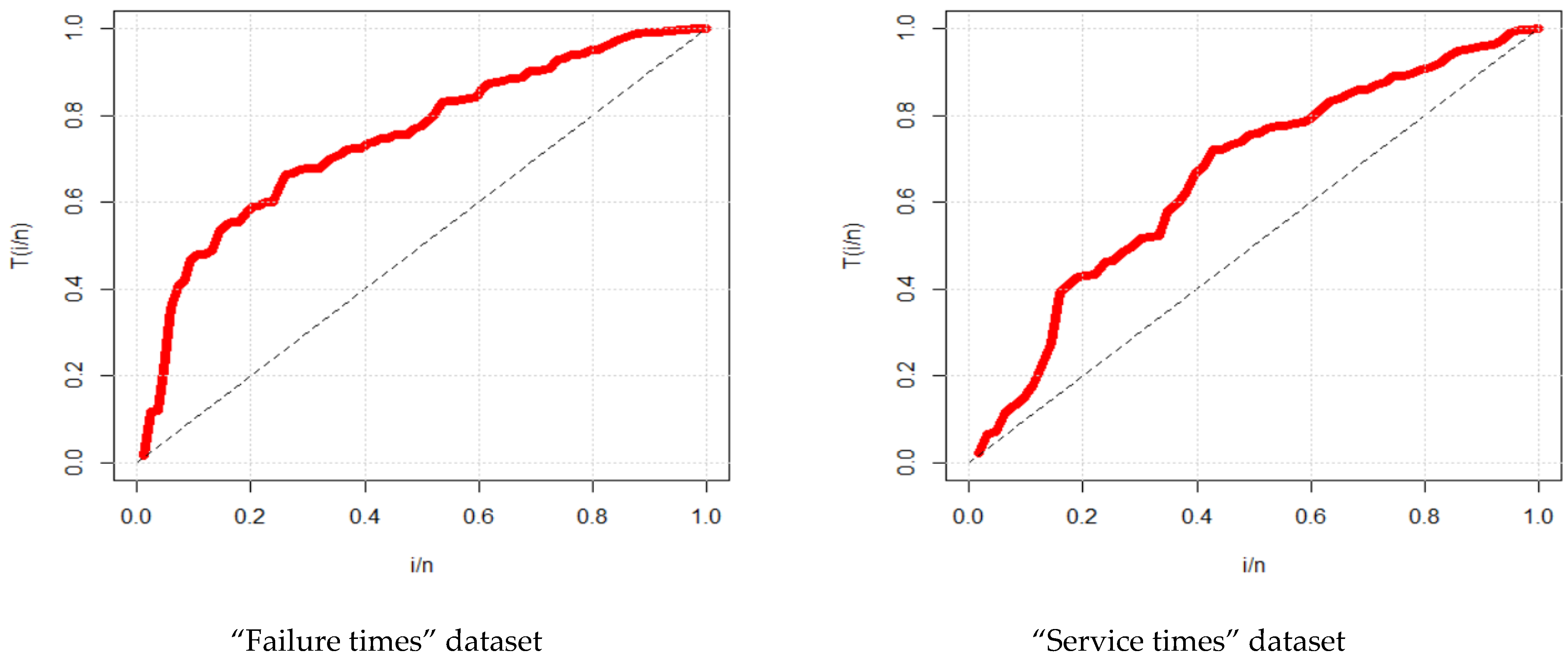
- The real datasets whose kernel density is semi-symmetric (slightly skewed to the left and slightly skewed to the left) and have a bimodal form, as illustrated in Figure 3, are the ones that are discussed here.
- The real-life datasets, which, as shown in the application Section, do not contain any observations that fall into the extreme category.
- The GOGELx model is compared to many relevant models, such as the special generalized mixture Lx distribution, the Kumaraswamy Lx distribution, beta Lx distribution, gamma Lx distribution, Transmuted Topp–Leone Lx distribution, reduced Transmuted Topp–Leone Lx distribution, odd log-logistic Lx distribution, reduced odd log-logistic Lx distribution, reduced Burr–Hatke Lx distribution, exponentiated Lx distribution, standard Lx distribution, reduced GOGELx distribution, and proportional reversed hazard rate Lx distribution in modeling the failure times of aircraft windshield data.
- The GOGELx distribution is compared to many relevant models, such as the odd log-logistic Lx distribution, the Kumaraswamy Lx distribution, the special generalized mixture Lx distribution, beta Lx distribution, gamma Lx distribution, Transmuted Topp–Leone Lx distribution, reduced Transmuted Topp–Leone Lx distribution, reduced odd log-logistic Lx distribution, reduced Burr–Hatke Lx distribution, exponentiated Lx distribution, standard Lx distribution, reduced GOGELx distribution, and proportional reversed hazard rate Lx distribution in modeling the service times of aircraft windshield data.
- Creating new probability density functions that may take on several beneficial forms, such as “right skewed” with a heavy tail shape and “right skewed” with one peak.
- Any new model may be used to analyze a variety of environmental datasets because of the great flexibility of the probability density function. But the new model has shown flexibility and high efficiency in the statistical and mathematical modeling processes of different sets of reliability and engineering data.
- Introducing a few new one-of-a-kind models that come with a variety of hazard rate functions, such as “decreasing constant HRF,” “monotonically increasing HRF,” “bathtub HRF,” and “constant HRF.” The number of distinct failure rate categories has a positive correlation with the elasticity of the distribution. These forms make the work of a wide variety of practitioners, including those who would use the new distribution in statistical modeling and mathematical analysis, significantly simpler. The matter of checking the success rate function for this particular endeavor has received a significant amount of focus and consideration from our team.
- The degree to which the new distribution is flexible can be determined, in part, by looking at the skew coefficient, the kurtosis coefficient, the failure rate function, and the variety of the PDF and failure rate functions. In this context, it is of the utmost importance to give some thought to the accuracy with which the probability distribution may be modeled statistically, as well as the accuracy with which it can be employed. As a direct consequence of this, we examined the probability distribution in great detail. It is essential to emphasize in this piece that the new family has distinct characteristics, such as the broadening of the skew coefficient and the widening of the kurtosis coefficient. These are just two of the characteristics that are discussed and two of the many traits that were noticed during the investigation. The new family has an advantage over all other connected families in the competition due to the high degree of flexibility offered by this arrangement. This spreading of the skewness and kurtosis coefficients is one of the most crucial elements that may be depended upon in order to assess the extent to which the distribution is elastic. In addition to this, it is one of the most significant characteristics that can be depended upon in order to discern one probability distribution from another probability distribution.
2. Copula
2.1. BGOGELx Version via FGM Copula
2.2. BvGOGELx Version via MFGM Copula
2.2.1. Type-I BGOGELx-FGM Model
2.2.2. Type-II BGOGELx-FGM Model
2.2.3. Type-III BGOGELx-FGM Model
2.2.4. Type-IV BGOGELx-FGM Model
2.3. BGOGELx and MvGOGELx Versions via Clayton Copula
2.4. BGOGELx Version of the GOGELx Model via Renyi’s Entropy
3. Statistical Properties
3.1. Stochastic Property
3.2. Moments
- I.
- For fixed , and a = (1,5,10,50,100), started with 2 and ended with 12,573.89; started with 10 and ended with 28,319,119; started with 4.869908 and ended with 2.352625; started with 48.96 and ended with 9.025842, i.e., skewness was always positive and kurtosis was greater than three.
- II.
- For fixed , and b = (0.5,1,20,50,150,500,1500), started with 27.442188 and ended with 12,573.89; started with 243.1643 and ended with 6793.388; started with 6.486595 and ended with 1.849833; started with 84.35094 and ended with 9.833175, i.e., skewness was always positive and kurtosis was greater than three.
- III.
- For fixed , and τ = (0.1,0.25,0.5,1), started with 1580.635 and ended with 31.56381; started with 89,355,253 and ended with 399.7604; started with 7.129449 and ended with 1.538719; started with 57.24885 and ended with 6.792048, i.e., skewness was always positive and kurtosis was greater than three.
- IV.
- For fixed , and σ = (0.5,1,5,20,100,500,1500), started with 17,833.71 and ended with 2.346624; started with 491,455,358 and ended with 193,026.4; started with 1.680768 and ended with 192.9097; started with 5.232642 and ended with 38,056.81, i.e., skewness was always positive and kurtosis was greater than three.
3.3. Reliability Measures
3.4. Entropies
3.5. Order Statistics
4. Estimation
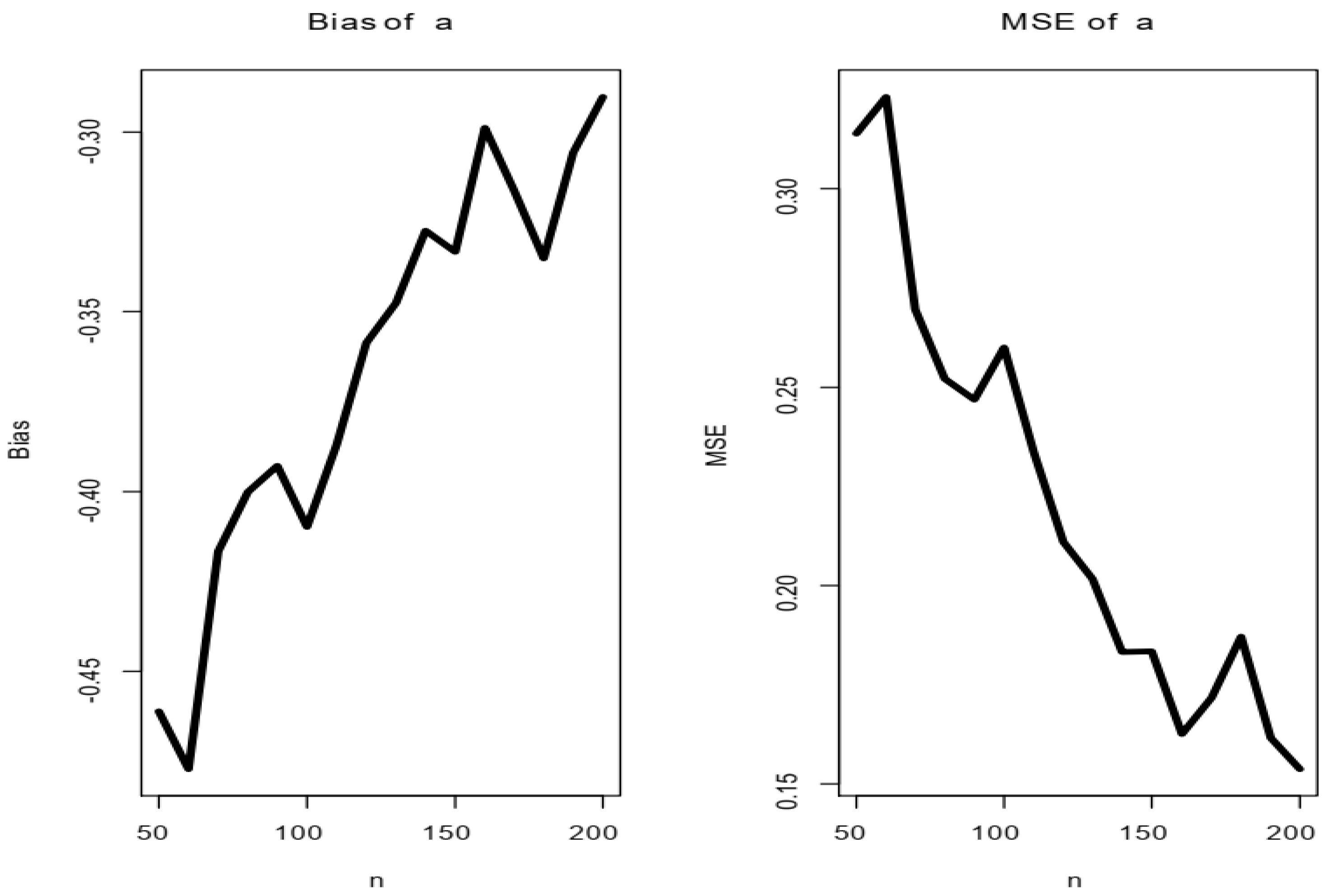
5. Simulation
- (1)
- Generate = 1000 samples of size from the GOGELx distribution;
- (2)
- Compute the MLEs for the samples;Compute the SEs of the MLEs for the 1000 samples;
- (3)
- The standard errors (STEs) can be computed by inverting the information matrix;
- (4)
- Obtain the MSE and for and
- N = NN[i]
- cat(“i=”,i,“ n=”,N,‘\n’)
- ml = matrix(NA, nr=M, nc=4, byrow=T)
- j = 1
- while(j <= M){
- P = log(1-(runif(N))^(1/b))
- Q = ((-P)/(1-P))^(1/a)
- x = sigma*((1-(Q)^(-1/tau))-1)
- fit = goodness.fit(pdf=pdf_ GOGELx, cdf=cdf_ GOGELx, starts=c(1,1,1,1), data=x, method=“”, domain=c(0,Inf), mle=NULL)
- if(fit$Convergence == 0) {
- ml[j,] = fit$mle
- j = j + 1}
6. Applications
- I.
- Real-life data often exhibit characteristics that cannot be accurately described using common probability distributions, such as normal, exponential, or Poisson distributions. By modeling data under a new probability distribution, we can capture the nuances and complexities of the data, leading to a more accurate representation of the underlying phenomenon.
- II.
- If we attempt to model real-life data using a distribution that does not accurately capture its characteristics, our predictions and inferences may be misleading or inaccurate. By utilizing a new probability distribution that closely matches the data, we can improve the accuracy of the predictions and make more reliable decisions based on the modeling results.
- III.
- Different domains may have unique characteristics and data patterns that are not adequately captured by standard probability distributions. For example, financial data often exhibit heavy-tailed or skewed distributions due to extreme events or outliers. By tailoring the modeling approach to the specific domain and using a new probability distribution, we can better understand the underlying processes and derive insights that are directly applicable to the domain of interest.
- IV.
- Real data modeling under a new probability distribution can reveal previously unseen patterns, relationships, or anomalies. By exploring alternative distributions, we may discover new statistical properties or uncover hidden dependencies that were not apparent using traditional approaches. This can lead to valuable insights, scientific discoveries, or improved decision making in various fields.
- V.
- Traditional statistical models and machine learning algorithms often assume specific distributions for simplicity and tractability. However, these assumptions may not hold in real-life scenarios, leading to biased or unreliable results. Modeling data under a new probability distribution can enhance the robustness and generalizability of the analysis, allowing the model to handle a wider range of data and perform well in different contexts.
- VI.
- Modeling real data under a new probability distribution provides a framework to quantify and characterize uncertainties. By accurately representing the data distribution, we can estimate confidence intervals, calculate prediction intervals, or perform Monte Carlo simulations to capture the inherent uncertainty in the modeling process. This information is crucial for decision making and risk assessment in various applications.
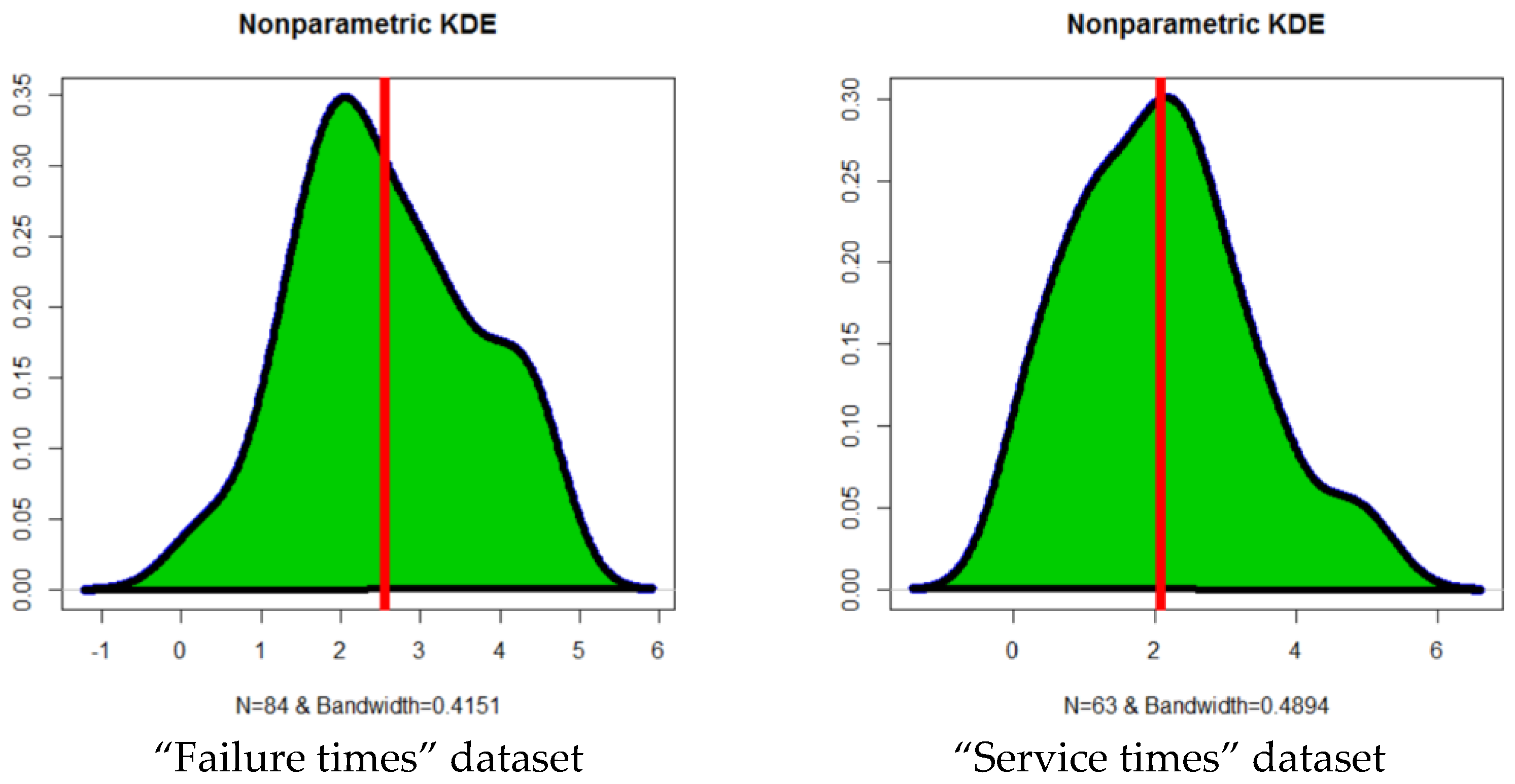
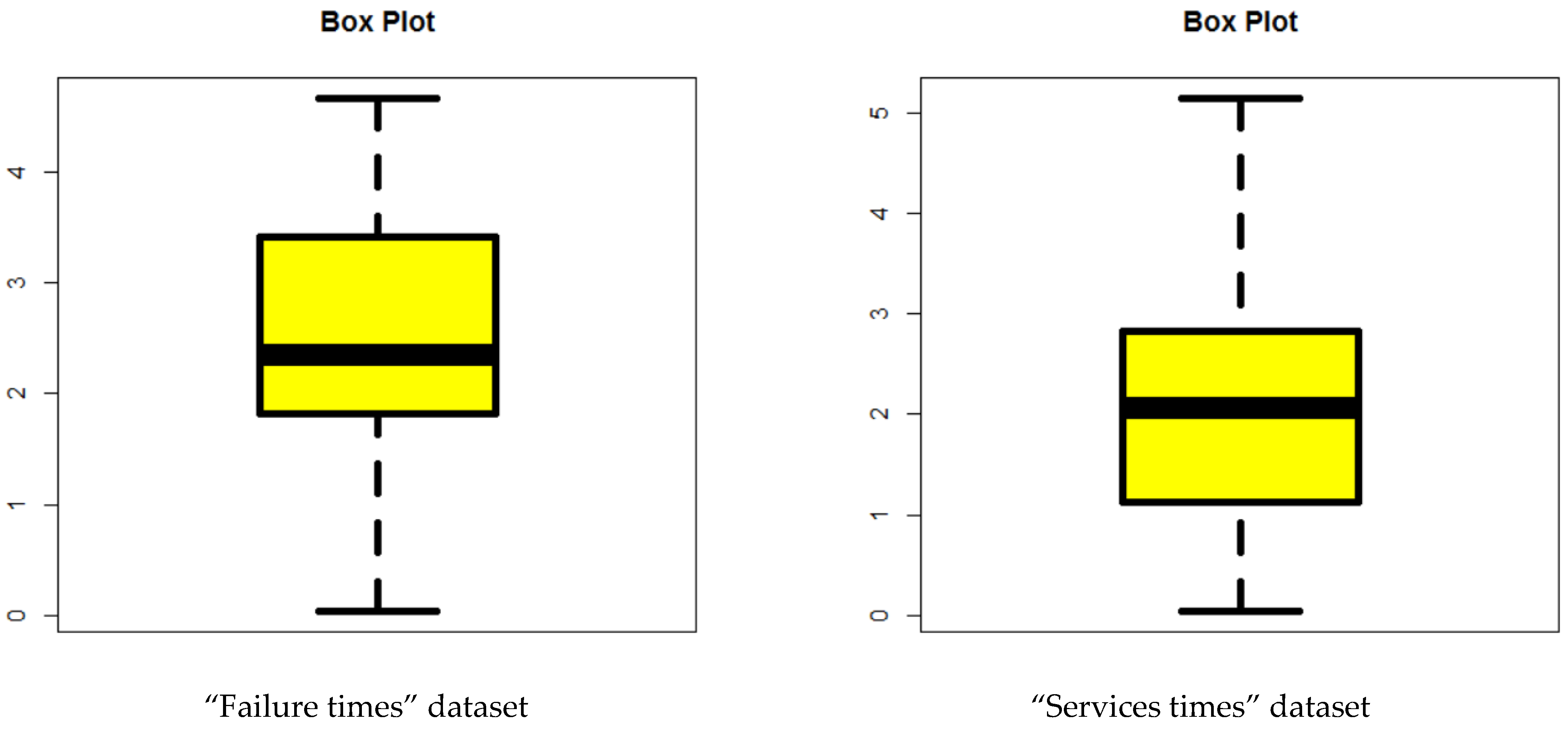
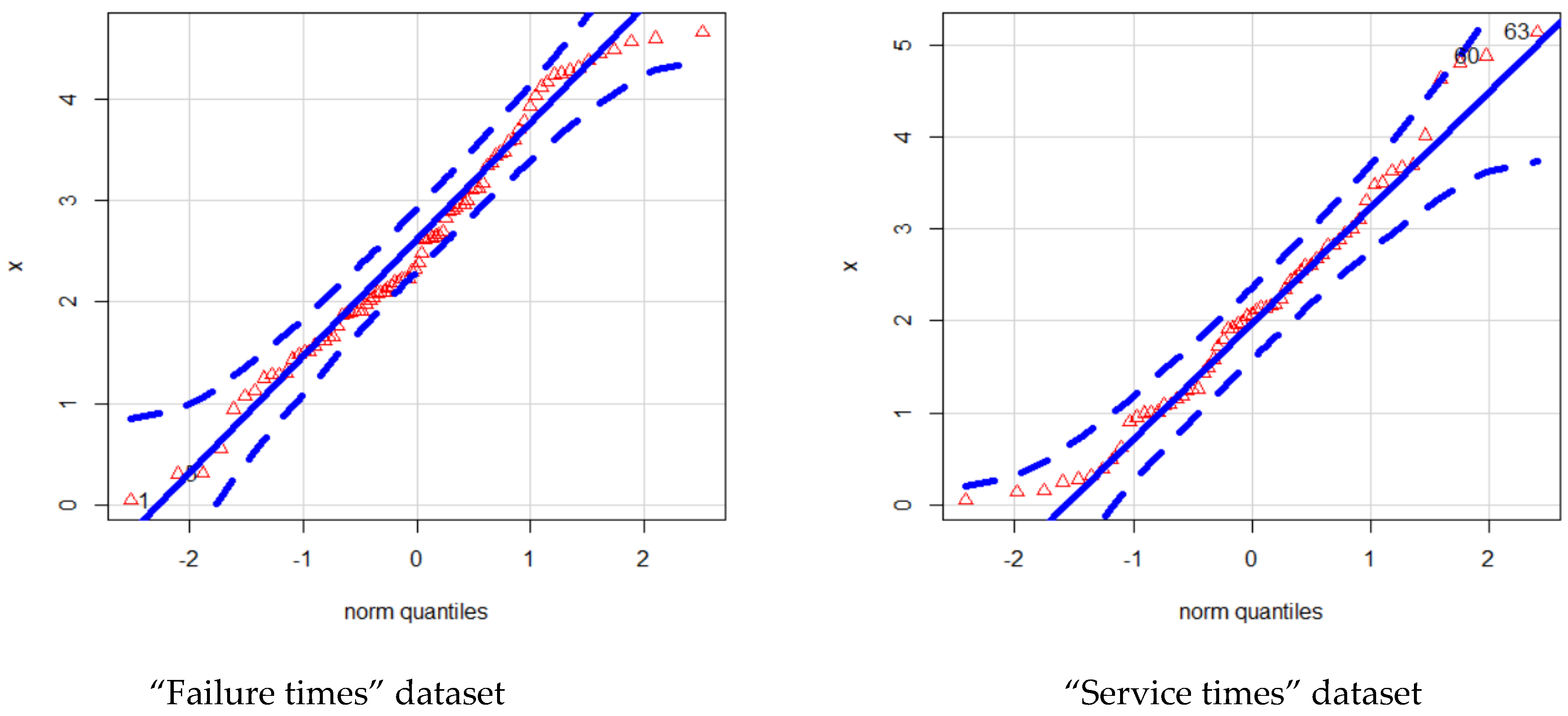
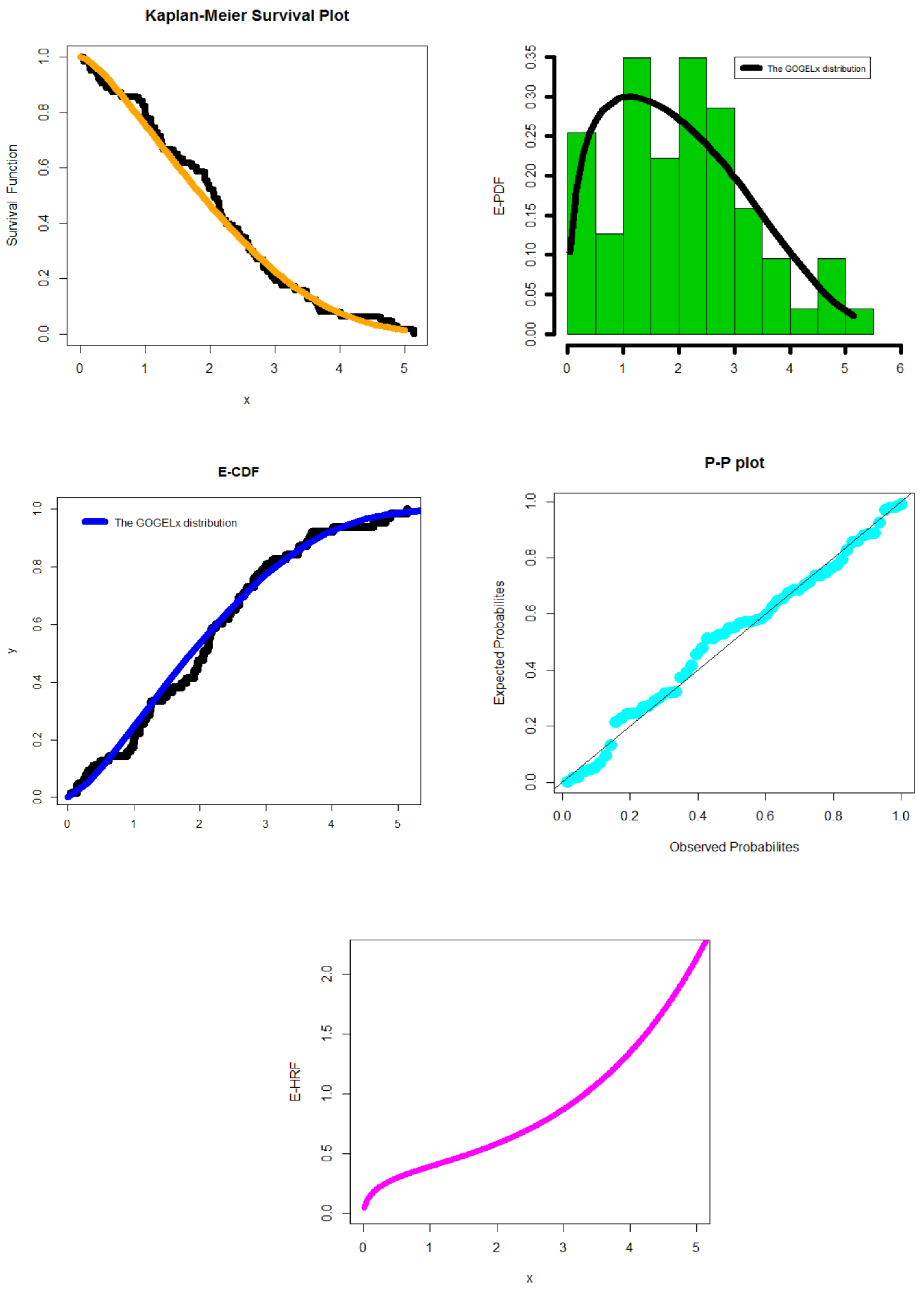
6.1. First Dataset
6.2. Second Dataset
7. Conclusions and Discussion
- I.
- Big data sources, such as traffic sensors, GPS data, and social media feeds, generate vast amounts of information regarding traffic patterns. By analyzing this data using probability distribution theory, transportation planners can model and predict traffic flow. Probability distributions, such as Poisson or Gaussian distributions, can be used to describe the frequency and duration of traffic congestion, accidents, or other events. This analysis helps in optimizing traffic management strategies, such as signal timing, route planning, and congestion mitigation.
- II.
- Transportation systems need to anticipate future demands to optimize operations and allocate resources efficiently. The probability distribution theory can be employed to model demand patterns based on historical data. By analyzing big data on factors like population density, demographics, weather, and events, transportation planners can develop probabilistic models to forecast travel demands. These models can help in determining the need for additional infrastructure, adjusting transit schedules, and optimizing fleet deployment.
- III.
- The probability distribution theory is useful for predicting equipment failures and optimizing maintenance schedules. By analyzing big data collected from sensors embedded in vehicles, trains, or infrastructure, probabilistic models can be built to predict the likelihood and timing of component failures. This enables proactive maintenance, reduces unplanned downtime, and improves the overall system reliability. Probability distributions, such as the Weibull distribution, can help in estimating the remaining useful life of assets and optimizing maintenance resources.
- IV.
- Big data analytics combined with probability distribution theory can enhance safety in transportation. By analyzing historical accident data, weather conditions, road characteristics, and other relevant factors, transportation agencies can model accident probabilities and severity. These models can identify high-risk areas and support the development of targeted safety interventions. By understanding the probability distributions of different types of accidents, transportation planners can allocate resources effectively to reduce fatalities and injuries.
- V.
- Intelligent transportation systems leverage big data and the probability distribution theory to improve traffic efficiency and safety. By integrating data from various sources, such as traffic cameras, vehicle sensors, and weather stations, probabilistic models can be developed to optimize signal timing, manage adaptive traffic control systems, and enable real-time incident detection. These models can help predict travel times, estimate congestion levels, support dynamic route guidance, and enhance the overall system performance.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tadikamalla, P.R. A look at the Burr and realted distributions. Int. Stat. Rev. 1980, 48, 337–344. [Google Scholar] [CrossRef] [Green Version]
- Corbellini, A.; Crosato, L.; Ganugi, P.; Mazzoli, M. Fitting Pareto II distributions on firm size: Statistical methodology and economic puzzles. In Proceedings of the International Conference on Applied Stochastic Models and Data Analysis, Chania, Greece, 29 May–1 June 2007. [Google Scholar]
- Alizadeh, M.; Ghosh, I.; Yousof, H.M.; Rasekhi, M.; Hamedani, G.G. The generalized odd-generalized exponential family of distributions: Properties, characterizations and applications. J. Data Sci. 2017, 15, 443–466. [Google Scholar] [CrossRef]
- Schumann, H.H.; Haitao, H.; Quddus, M. Passively generated big data for micro-mobility: State-of-the-art and future research directions. Transp. Res. Part D Transp. Environ. 2023, 121, 103795. [Google Scholar] [CrossRef]
- Afify, A.Z.; Nofal, Z.M.; Yousof, H.M.; El Gebaly, Y.M.; Butt, N.S. The transmuted Weibull Lomax distribution: Properties and application. Pak. J. Stat. Oper. Res. 2015, 11, 135–152. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, M.; Yousof, H.M. A new generalized Lomax model: Statistical properties and applications. J. Data Sci. 2020, 18, 190–217. [Google Scholar] [CrossRef]
- Elbiely, M.M.; Yousof, H.M. A new extension of the Lomax distribution and its Applications. J. Stat. Appl. 2018, 2, 18–34. [Google Scholar]
- Yadav, A.S.; Goual, H.; Alotaibi, R.M.; Rezk, H.; Ali, M.M.; Yousof, H.M. Validation of the Topp-Leone-Lomax model via a modified Nikulin-Rao-Robson goodness-of-fit test with different methods of estimation. Symmetry 2020, 12, 57. [Google Scholar] [CrossRef] [Green Version]
- Elsayed, H.A.; Yousof, H.M. A new Lomax distribution for modeling survival times and taxes revenue data sets. J. Stat. Appl. 2019, 2, 35–58. [Google Scholar]
- Farlie, D.J.G. The performance of some correlation coefficients for a general bivariate distribution. Biometrika 1960, 47, 307–323. [Google Scholar] [CrossRef]
- Morgenstern, D. Einfache beispiele zweidimensionaler verteilungen. Mitteilingsblatt Math. Stat. 1956, 8, 234–235. [Google Scholar]
- Gumbel, E.J. Bivariate logistic distributions. J. Am. Stat. Assoc. 1961, 56, 335–349. [Google Scholar] [CrossRef]
- Gumbel, E.J. Bivariate exponential distributions. J. Amer. Statist. Assoc. 1960, 55, 698–707. [Google Scholar] [CrossRef]
- Elgohari, H.; Yousof, H.M. A Generalization of Lomax Distribution with Properties, Copula and Real Data Applications. Pak. J. Stat. Oper. Res. 2020, 16, 697–711. [Google Scholar] [CrossRef]
- Ghosh, I.; Ray, S. Some alternative bivariate Kumaraswamy type distributions via copula with application in risk management. J. Stat. Theory Pract. 2016, 10, 693–706. [Google Scholar] [CrossRef]
- Mansour, M.; Yousof, H.M.; Shehata, W.A.M.; Ibrahim, M. A new two parameter Burr XII distribution: Properties, copula, different estimation methods and modeling acute bone cancer data. J. Nonlinear Sci. Appl. 2020, 13, 223–238. [Google Scholar] [CrossRef] [Green Version]
- Pougaza, D.B.; Djafari, M.A. Maximum entropies copulas. In Proceedings of the 30th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering 2011, Chamonix, France, 4–9 July 2010; pp. 329–336. [Google Scholar]
- Chesneau, C.; Yousof, H.M. On a special generalized mixture class of probabilistic models. J. Nonlinear Model. Anal. 2021, 3, 71–92. [Google Scholar]
- Lemonte, A.J.; Cordeiro, G.M. An extended Lomax distribution. Statistics 2013, 47, 800–816. [Google Scholar] [CrossRef]
- Lomax, K.S. Business failures: Another example of the analysis of failure data. J. Am. Stat. Assoc. 1954, 49, 847–852. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Popović, B.V. The gamma-Lomax distribution. J. Stat. Comput. Simul. 2015, 85, 305–319. [Google Scholar] [CrossRef]
- Altun, E.; Yousof, H.M.; Hamedani, G.G. A new log-location regression model with influence diagnostics and residual analysis. Facta Univ. Ser. Math. Inform. 2018, 33, 417–449. [Google Scholar] [CrossRef]
- Yousof, H.M.; Alizadeh, M.; Jahanshahiand, S.M.A.; Ramires, T.G.; Ghosh, I.; Hamedani, G.G. The Transmute-Topp-Leone G family of distributions: Theory, characterizations and applications. J. Data Sci. 2017, 15, 723–740. [Google Scholar] [CrossRef]
- Altun, E.; Yousof, H.M.; Chakraborty, S.; Handique, L. Zografos-Balakrishnan Burr XII distribution: Regression modeling and applications. Int. J. Math. Stat. 2018, 19, 46–70. [Google Scholar]
- Gupta, R.C.; Gupta, P.L.; Gupta, R.D. Modeling failure time data by Lehman alternatives. Commun. Stat.-Theory Methods 1998, 27, 887–904. [Google Scholar] [CrossRef]
- Yousof, H.M.; Altun, E.; Ramires, T.G.; Alizadeh, M.; Rasekhi, M. A new family of distributions with properties, regression models and applications. J. Stat. Manag. Syst. 2018, 21, 163–188. [Google Scholar] [CrossRef]
- Murthy, D.N.P.; Xie, M.; Jiang, R. Weibull Models; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Aryal, G.R.; Ortega, E.M.; Hamedani, G.G.; Yousof, H.M. The Topp Leone Generated Weibull distribution: Regression model, characterizations and applications. Int. J. Stat. Probab. 2017, 6, 126–141. [Google Scholar] [CrossRef]
- Yousof, H.M.; Ahsanullah, M.; Khalil, M.G. A New Zero-Truncated Version of the Poisson Burr XII Distribution: Characterizations and Properties. J. Stat. Theory Appl. 2019, 18, 1–11. [Google Scholar] [CrossRef]
- Yousof, H.M.; Majumder, M.; Jahanshahi, S.M.A.; Ali, M.M.; Hamedani, G.G. A new Weibull class of distributions: Theory, characterizations and applications. J. Stat. Res. Iran 2018, 15, 45–83. [Google Scholar] [CrossRef] [Green Version]
- Goual, H.; Yousof, H.M.; Ali, M.M. Lomax inverse Weibull model: Properties, applications, and a modified Chi-squared goodness-of-fit test for validation. J. Nonlinear Sci. Appl. (JNSA) 2020, 13, 330–353. [Google Scholar] [CrossRef] [Green Version]
- Goual, H.; Yousof, H.M. Validation of Burr XII inverse Rayleigh model via a modified chi-squared goodness-of-fit test. J. Appl. Stat. 2019, 47, 393–423. [Google Scholar] [CrossRef]
- Aarset, M.V. How to identify a bathtub hazard rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
- Aboraya, M.; Ali, M.M.; Yousof, H.M.; Ibrahim, M. A Novel Lomax Extension with Statistical Properties, Copulas, Different Estimation Methods and Applications. Bull. Malays. Math. Sci. Soc. 2022, 45, 85–120. [Google Scholar] [CrossRef]
- Abdul-Moniem, I.B.; Abdel-Hameed, H.F. On exponentiated Lomax distribution. Int. J. Math. Arch. 2012, 3, 2144–2150. [Google Scholar]
- Ali, M.M.; Korkmaz, M.Ç.; Yousof, H.M.; Butt, N.S. Odd Lindley-Lomax Model: Statistical Properties and Applications. Pak. J. Stat. Oper. Res. 2019, 419–430. [Google Scholar] [CrossRef]
- Ali, M.M.; Yousof, H.M.; Ibrahim, M. A New Lomax Type Distribution: Properties, Copulas, Applications, Bayesian and Non-Bayesian Estimation Methods. Int. J. Stat. Sci. 2021, 21, 61–104. [Google Scholar]
- Atkinson, A.B.; Harrison, A.J. Distribution of Personal Wealth in Britain; Cambridge University Press: Cambridge, UK, 1978. [Google Scholar]
- Ansari, S.; Rezk, H.; Yousof, H. A New Compound Version of the Generalized Lomax Distribution for Modeling Failure and Service Times. Pak. J. Stat. Oper. Res. 2020, 16, 95–107. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Yousof, H.M.; Ramires, T.G.; Ortega, E.M.M. The Burr XII system of densities: Properties, regression model and applications. J. Stat. Comput. Simul. 2018, 88, 432–456. [Google Scholar] [CrossRef]
- Durbey, S.D. Compound gamma, beta and F distributions. Metrika 1970, 16, 27–31. [Google Scholar]
- Hamed, M.S.; Cordeiro, G.M.; Yousof, H.M. A New Compound Lomax Model: Properties, Copulas, Modeling and Risk Analysis Utilizing the Negatively Skewed Insurance Claims Data. Pak. J. Stat. Oper. Res. 2022, 18, 601–631. [Google Scholar] [CrossRef]
- Harris, C.M. The Pareto distribution as a queue service descipline. Oper. Res. 1968, 16, 307–313. [Google Scholar] [CrossRef]
- Hassan, A.S.; Al-Ghamdi, A.S. Optimum step stress accelerated life testing for Lomax distibution. J. Appl. Sci. Res. 2009, 5, 2153–2164. [Google Scholar]
- Gad, A.M.; Hamedani, G.G.; Salehabadi, S.M.; Yousof, H.M. The Burr XII-Burr XII distribution: Mathematical properties and characterizations. Pak. J. Stat. 2019, 35, 229–248. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| a | b | τ | σ | ||||
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.5 | 0.5 | 2.000000 | 10.00000 | 4.869908 | 48.96000 |
| 5 | 41.69429 | 4866.206 | 5.390024 | 59.50146 | |||
| 10 | 160.5733 | 75,199.88 | 5.47479 | 61.27429 | |||
| 50 | 3853.447 | 42,379,209 | 4.581347 | 35.19993 | |||
| 100 | 12,573.89 | 28,319,119 | 2.352625 | 9.025842 | |||
| 1.5 | 0.5 | 0.5 | 1.5 | 7.442188 | 243.1643 | 6.486595 | 84.35094 |
| 1 | 12.77717 | 413.2616 | 5.051232 | 52.5969 | |||
| 20 | 69.81196 | 2045.452 | 2.583400 | 16.34851 | |||
| 50 | 99.62102 | 2824.205 | 2.323810 | 13.82921 | |||
| 150 | 142.9996 | 3920.139 | 2.113328 | 11.95878 | |||
| 500 | 200.0016 | 5324.653 | 1.955009 | 10.65224 | |||
| 1500 | 260.5952 | 6793.388 | 1.849833 | 9.833175 | |||
| 3.5 | 2 | 0.1 | 5 | 1580.635 | 89,355,253 | 7.129449 | 57.24885 |
| 0.25 | 13,671.96 | 426,237,588 | 2.090623 | 6.94757 | |||
| 0.5 | 342.3346 | 194,485.9 | 4.268613 | 38.6757 | |||
| 0.75 | 70.27614 | 3256.276 | 2.226533 | 11.51443 | |||
| 1 | 31.56381 | 399.7604 | 1.538719 | 6.792048 | |||
| 5 | 5 | 0.25 | 0.5 | 17,833.71 | 491,455,358 | 1.680768 | 5.232642 |
| 1 | 20,714.77 | 614,667,664 | 1.360643 | 3.970398 | |||
| 5 | 17,183.43 | 732,718,933 | 1.488382 | 3.996878 | |||
| 20 | 7558.414 | 442,743,284 | 2.853365 | 10.08447 | |||
| 100 | 1203.06 | 85,555,038 | 8.177842 | 71.41334 | |||
| 500 | 55.60601 | 4,343,589 | 39.21416 | 1589.049 | |||
| 1500 | 2.346624 | 193,026.4 | 192.9097 | 38,056.81 |
| Special generalized mixture Lx (SGMLx) | Chesneau and Yousof [18] |
| Kumaraswamy-Lx (KumLx) | Lemonte and Cordeiro [19] |
| Beta-Lx (BLx) | Lemonte and Cordeiro [19] |
| Lx | Lomax [20] |
| Gamma-Lx (GamLx) | Cordeiro et al. [21] |
| Odd-loglogistic-Lx (OLLLx) | Altun et al. [22] |
| Transmute-Topp-Leone Lx (TTLLx) | Yousof et al. [23] |
| Reduced TTLLx (RTTLLx) | Yousof et al. [23] |
| Proportional reversed hazard rate Lx (PRHRLx) | New |
| Reduced GOGELx (RGOGELx) | New |
| Reduced-OLLLx (R-OLLLx) | Altun et al. [24] |
| Exponentiated-Lx (Exp-Lx) | Gupta et al. [25] |
| Reduced-Burr-Hatke-Lx (R-BHLx) | Yousof et al. [26] |
| Model | Estimates (STEs) | |||
|---|---|---|---|---|
| GOGELx(a,b,τ,σ) | 2.25105 | 1.10598 | 6254.02 | 13,008.31 |
| (1.83474) | (0.74238) | (1836.7) | (573.462) | |
| TTLLx(a,b,τ,σ) | −0.807522 | 2.47663 | (15,608.2) | (386,228) |
| (0.13961) | (0.54176) | (1602.37) | (123.943) | |
| KumLx(a,b,τ,σ) | 2.615042 | 100.2760 | 5.27716 | 78.6775 |
| (0.38226) | (120.488) | (9.8117) | (186.4111) | |
| BLx(a,b,τ,σ) | 3.603603 | 33.63872 | 4.83074 | 118.874 |
| (0.6187) | (63.7145) | (9.2382) | (428.993) | |
| PRHRLx(b,β,ξ) | 3.723 × 106 | 4.71 × 10−1 | 4.5 × 106 | |
| 1.312 × 106 | (0.00011) | 37.1470 | ||
| RTTLLx(a,b,β) | −0.84732 | 5.520572 | 1.15678 | |
| (0.10010) | (1.184791) | (0.09592) | ||
| SGMLx(a,β,ξ) | −1.04 × 10−1 | 9.831 × 106 | 1.18 × 107 | |
| (0.12223) | (4843.33) | (501.043) | ||
| OLLLx(a,β,ξ) | 2.326363 | (7.17 × 105) | 2.342 × 106) | |
| (2.14 × 10−1) | (1.19 × 104) | (2.613 × 101) | ||
| GamLx(a,β,ξ) | 3.587602 | 52,001.49 | 37,029.66 | |
| (0.51333) | (7955.00) | (81.16441) | ||
| Exp−Lx(a,β,ξ) | 3.626101 | 20074.51 | 26257.68 | |
| (0.623612) | (2041.831) | (99.74177) | ||
| R−OLLLx(a,β) | 3.890564 | 0.5731643 | ||
| (0.36524) | (0.01946) | |||
| R−BHLx(β,ξ) | 10,801,754 | 513,670,891 | ||
| (9,833,192) | (2,323,222) | |||
| Lx(β,ξ) | 51,425.362 | 131,789.61 | ||
| (5932.492) | (296.0193) | |||
| Model | -ℓ | AKIC | C-AKIC | BYIC | HNQIC | ADg | CVMs | KS (p-Value) |
|---|---|---|---|---|---|---|---|---|
| GOGELx | 129.6054 | 267.2108 | 267.7172 | 276.9341 | 271.1195 | 0.6334 | 0.0705 | 0.0716 (0.8716) |
| OLLLx | 134.4235 | 274.8470 | 275.1470 | 282.1394 | 277.7785 | 0.9407 | 0.1009 | 0.0776 (0.7822) |
| TTLLx | 135.5700 | 279.1400 | 279.6464 | 288.8633 | 283.0487 | 1.1257 | 0.1270 | 0.0799 (0.7201) |
| GamLx | 138.4042 | 282.8083 | 283.1046 | 290.1363 | 285.7559 | 1.3666 | 0.1618 | 0.0802 (0.7199) |
| BLx | 138.7177 | 285.4354 | 285.9354 | 295.2060 | 289.3654 | 1.4084 | 0.1680 | 0.0833 (0.7190) |
| Exp-Lx | 141.3997 | 288.7994 | 289.0957 | 296.1273 | 291.7469 | 1.7435 | 0.2194 | 0.0866 (0.7187) |
| R-OLLLx | 142.8452 | 289.6904 | 289.8385 | 294.5520 | 291.6447 | 1.9566 | 0.2554 | 0.0900 (0.7182) |
| SGMLx | 143.0874 | 292.1747 | 292.4747 | 299.4672 | 295.1062 | 1.3467 | 0.1578 | 0.0924 (0.7180) |
| RTTLLx | 153.9809 | 313.9618 | 314.2618 | 321.2542 | 316.8933 | 3.7527 | 0.5592 | 0.0939 (0.7170) |
| PRHRLx | 162.8770 | 331.7540 | 332.0540 | 339.0464 | 334.6855 | 1.3672 | 0.1609 | 0.0950 (0.7151) |
| Lx | 164.9884 | 333.9767 | 334.1230 | 338.8620 | 335.9417 | 1.3976 | 0.1665 | 0.0944 (0.7133) |
| R-BHLx | 168.6040 | 341.2081 | 341.3562 | 346.0697 | 343.1624 | 1.6711 | 0.2069 | 0.0971 (0.7111) |
| Model | Estimates (STEs) | |||
|---|---|---|---|---|
| GOGELx(a,b,τ,σ) | 2.546132 | 0.593723 | 110.2577 | 224.6193 |
| (0.62763) | (0.09477) | (623.014) | (450.5222) | |
| BLx(a,b,τ,σ) | 1.921811 | 30.999493 | 4.968421 | 168.5724 |
| (0.31842) | (316.8218) | (50.5281) | (330.223) | |
| TTLLx(a,b,τ,σ) | (−0.6277) | 1.7858821 | 2122.393 | 4823.798 |
| (0.21371) | (0.415221) | (163.9125) | (200.219) | |
| KumLx(a,b,τ,σ) | 1.669151 | 60.56752 | 2.564912 | 64.06404 |
| (0.25722) | (86.0131) | (4.75897) | (176.599) | |
| PRHRLx(a,β,ξ) | 1.6666 × 106 | 3.899 × 10−1 | 1.338 × 106 | |
| 2.112 × 103 | 0.0014 × 10−1 | 0.985 × 106 | ||
| RTTLLx(a,b,β) | −0.671425 | 2.744962 | 1.012384 | |
| (0.187462) | (0.669612) | (0.114051) | ||
| SGMLx(a,β,ξ) | −1.04 × 10−1 | 6.4511 × 106 | 6.334 × 106 | |
| (4.13 × 10−10) | (3.2142 × 106) | (3.854734) | ||
| OLLLx(a,β,ξ) | 1.664193 | 6.348 × 105 | 2.015 × 106 | |
| (1.79 × 10−1) | (1.73 × 104) | 7.252 × 106 | ||
| GamLx(a,β,ξ) | 1.907323 | 35,842.433 | 39,197.557 | |
| (0.321323) | (6945.073) | (151.6553) | ||
| Exp-Lx(a,β,ξ) | 1.91453 | 22,971.153 | 32,881.999 | |
| (0.34821) | (3209.553) | (162.2302) | ||
| R-OLLLx(a,β) | 2.372331 | 0.691209 | ||
| (0.268253) | (0.044915) | |||
| R-BHLx(β,ξ) | 14,055,512 | 53,203,423 | ||
| (422.0131) | (28.52323) | |||
| Lx(β,ξ) | 99,269.83 | 207,019.41 | ||
| (11,863.52) | (301.2374) | |||
| Model | -ℓ | AKIC | C-AKIC | BYIC | HNQIC | ADg | CVMs | KS (p-Value) |
|---|---|---|---|---|---|---|---|---|
| GOGELx | 98.92234 | 205.8447 | 206.5343 | 214.4172 | 209.2163 | 0.4389 | 0.0721 | 0.0995 (0.75531) |
| KumLx | 100.8676 | 209.7353 | 210.4249 | 218.3078 | 213.1069 | 0.7391 | 0.1219 | 0.1001 (0.73769) |
| TTLLx | 102.4498 | 212.8996 | 213.5893 | 221.4722 | 216.2713 | 0.9431 | 0.1554 | 0.1002 (0.72560) |
| GamLx | 102.8332 | 211.6663 | 212.0730 | 218.0958 | 214.1951 | 1.1120 | 0.1836 | 0.1002 (0.71561) |
| SGMLx | 102.8940 | 211.7881 | 212.1949 | 218.2175 | 214.3168 | 1.1134 | 0.1839 | 0.1002 (0.71500) |
| BLx | 102.9611 | 213.9223 | 214.6119 | 222.4948 | 217.2939 | 1.1336 | 0.1872 | 0.1002 (0.70206) |
| Exp-Lx | 103.5498 | 213.0995 | 213.5063 | 219.5289 | 215.6282 | 1.2331 | 0.2037 | 0.1002 (0.70233) |
| OLLLx | 104.9041 | 215.8082 | 216.2150 | 222.2376 | 218.3369 | 0.9424 | 0.1545 | 0.1003 (0.6978) |
| PRHRLx | 109.2986 | 224.5973 | 225.004 | 231.0267 | 227.126 | 1.1264 | 0.1861 | 0.1005 (0.6944) |
| Lx | 109.2988 | 222.5976 | 222.7976 | 226.8839 | 224.2834 | 1.1265 | 0.1861 | 0.1003 (0.6956) |
| R-OLLLx | 110.7287 | 225.4573 | 225.6573 | 229.7436 | 227.1431 | 2.3472 | 0.3908 | 0.1004 (0.6001) |
| RTTLLx | 112.1855 | 230.3710 | 230.7778 | 236.8004 | 232.8997 | 2.6875 | 0.4532 | 0.1006 (0.58801) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Essa, L.A.; Eliwa, M.S.; El-Morshedy, M.; Alqifari, H.; Yousof, H.M. Flexible Extension of the Lomax Distribution for Asymmetric Data under Different Failure Rate Profiles: Characteristics with Applications for Failure Modeling and Service Times for Aircraft Windshields. Processes 2023, 11, 2197. https://doi.org/10.3390/pr11072197
Al-Essa LA, Eliwa MS, El-Morshedy M, Alqifari H, Yousof HM. Flexible Extension of the Lomax Distribution for Asymmetric Data under Different Failure Rate Profiles: Characteristics with Applications for Failure Modeling and Service Times for Aircraft Windshields. Processes. 2023; 11(7):2197. https://doi.org/10.3390/pr11072197
Chicago/Turabian StyleAl-Essa, Laila A., Mohamed S. Eliwa, Mahmoud El-Morshedy, Hana Alqifari, and Haitham M. Yousof. 2023. "Flexible Extension of the Lomax Distribution for Asymmetric Data under Different Failure Rate Profiles: Characteristics with Applications for Failure Modeling and Service Times for Aircraft Windshields" Processes 11, no. 7: 2197. https://doi.org/10.3390/pr11072197