
SPGD: Search Party Gradient Descent Algorithm, a Simple Gradient-Based Parallel Algorithm for Bound-Constrained Optimization



Abstract
:1. Introduction
GD—A Brief Recap
| Algorithm 1: Constant Learning Rate GD. |
| Input: Objective function ; Learning rate Output: Vector representing the location of the minimum found. Initialize with random weights t = 1 Repeat until convergence: = # Represents gradient of objective function. t = t+1 Return |
2. SPGD Algorithm
2.1. Divide, Conquer, Assemble, and Repeat (DCA)
- The SP’s members search the island from different locations at their own pace. This indicates a division of labor.
- Every member of the SP does nothing but a meticulous search for the treasure.
- Periodically, some SP members assemble at the most tempting location (as of now) of the island and resume their search from there.
2.2. Exploration vs. Exploitation
2.3. Defining the Algorithm
| Algorithm 2: SPGD. |
Input: Objective Function, ; Dimension of objective function, D; Lower and Upper bound vectors, and ; Number of GD Instances/Threads/Humans, N; Number of Episodes, Ep; Number of Iterations per Episode, Nip; Number of Stable Episodes, NSEp; Output: Best representing the location of the global optimum. i.e.: CBML (current best minima location) and (CBML) INIT: Init_Loc[N] # Generate and store N random Locations such that . Learning_Rate[N] #An Array containing N evenly spaced numbers between the interval (0.9,0.001) GLOBAL: CBML = Ø # At any point in time, the best location encountered so far will be stored in this variable. Epsilon = 0.9 Decay = Epsilon/Ep Minima_List = Ø #The CBML found in every episode will be stored in this list. For i = 1:N Create Thread_i. Pass Grad_Descent ( i, Init_Loc[i], Learning_Rate[i]) as the target function to Thread_i For j = 1:Ep Start all N threads parallelly #, Each thread will run Grad_Descent for Nip steps Join all N threads # Wait for all the threads to complete execution CToss = Generate a random number between (0,1) #Assemble Step Begins #Exploration vs Exploitation Trade-off Based on MAB IF (CToss ≤ Epsilon): #EXPLORATION For Each Thread_k, k = 1:N temp1 = Generate a random number between (0,1) IF(temp1 > 0.5): #ACTION 2, Pure Exploration Init_Loc[k] = Triangular_Distribution(LB, CBML, UB) ELSE: #Action 3 Continue As and Where you are ELSE: #EXPLOITATION For Each Thread_k, k = 1: N temp2 = Generate a random number between (0,1) IF(temp2 > 0.1): #ACTION 1 Pure Exploitation viz Assemble Init_Loc[k] = CBML ELSE: #ACTION 2 Init_Loc[k] = Triangular_Distribution(LB, CBML, UB) IF (j == Ep/2): Learning_Rate[N] = Assign N evenly spaced numbers between 0.1 to 0.0001 For Each Dimension, d=1:D Look through the Minima_List to find out the min and maximum location (for each dimension) and overwrite LB[d] and UB[d] respectively IF (There is no improvement for the past NSEp episodes): Break and Return: CBML Minima_list.append(CBML) Epsilon = Epsilon − Decay Return: CBML |
| Algorithm 3: Grad_Descent (Thread_Id, Weight[i], Learning_rate[i]): |
| For i: = 1:Nip Old_Weight = Weight # Represents gradient of objective function. Weight = Old_Weight − Learning_rate[Thread_Id] * IF (Weight < OR Weight > ): # If new weight is out of bounds Weight = Generate a random Location (uniformly) such that IF ( (Weight) < (CBML)): CBML = Weight END Grad_Descent |
2.4. A GA Perspective to SPGD
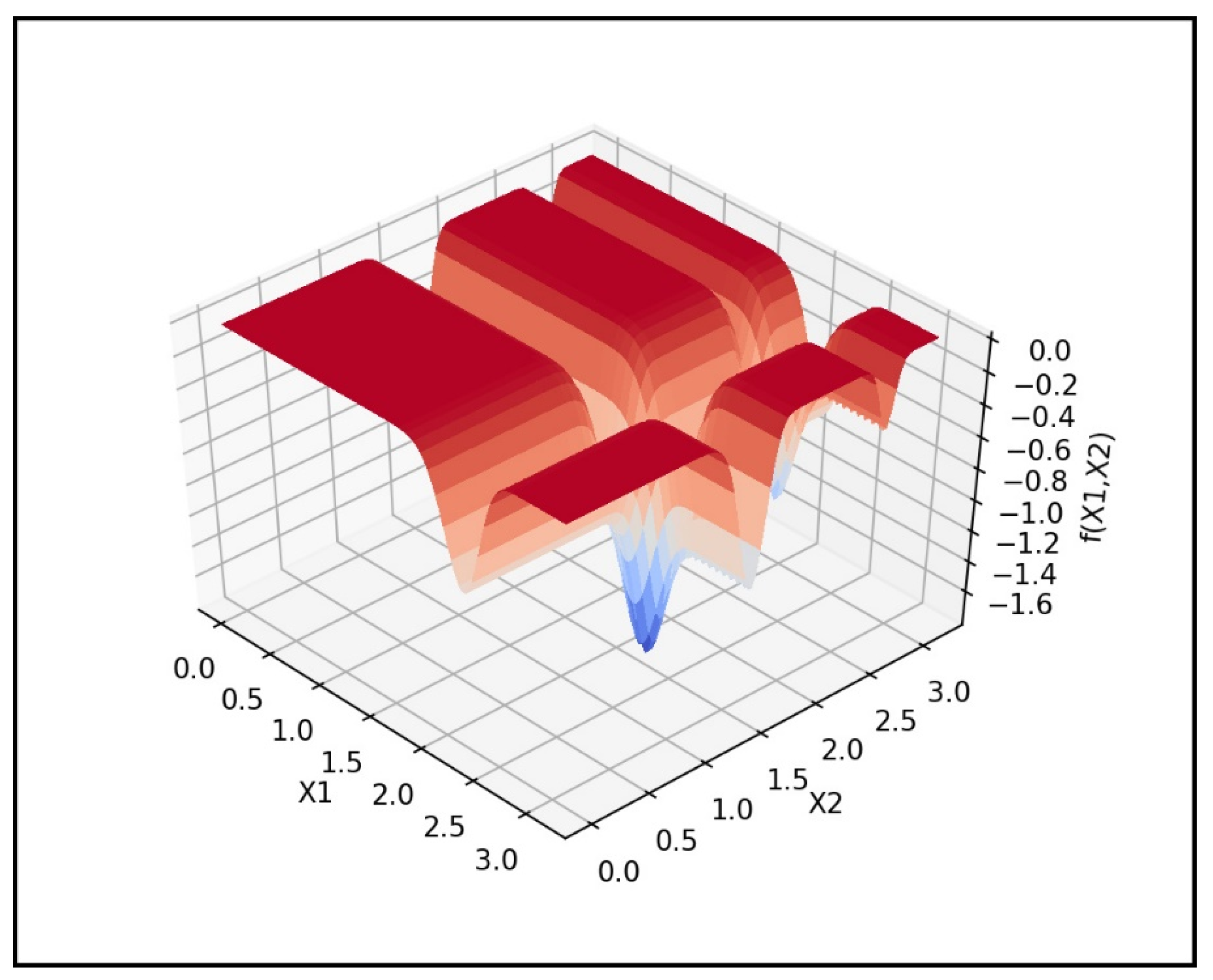
3. Numerical Experiments
3.1. Empirical Analysis of SPGD Parameter Sensitivity
- Functions in which the global minima is very close to the local minima (F6).
- Functions with a narrowed curved valley (F2, F8, F11).
- Functions in which the area that contains the global optimum is small with respect to the whole function space (F10).
- Functions with a significant magnitude difference between their hypersurface and domain (F4).
3.2. Comparison
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- D’Angelo, G.; Palmieri, F. GGA: A modified genetic algorithm with gradient-based local search for solving constrained optimization problems. Inf. Sci. 2021, 547, 136–162. [Google Scholar] [CrossRef]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. (TOMS) 1997, 23, 550–560. [Google Scholar] [CrossRef]
- Cong, Y.; Wang, J.; Li, X. Traffic Flow Forecasting by a Least Squares Support Vector Machine with a Fruit Fly Optimization Algorithm. Procedia Eng. 2016, 137, 59–68. [Google Scholar] [CrossRef] [Green Version]
- Mashwani, W.K. Comprehensive survey of the hybrid evolutionary algorithms. Int. J. Appl. Evol. Comput. (IJAEC) 2013, 4, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Ferreiro, A.M.; García-Rodríguez, J.A.; Vázquez, C.; e Silva, E.C.; Correia, A. Parallel two-phase methods for global optimization on GPU. Math. Comput. Simul. 2019, 156, 67–90. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wu, H.S.; Zhang, F.M. Wolf pack algorithm for unconstrained global optimization. Math. Probl. Eng. 2014, 2014, 465082. [Google Scholar] [CrossRef] [Green Version]
- Mohamed, A.W.; Hadi, A.A.; Mohamed, A.K. Gaining-sharing knowledge based algorithm for solving optimization problems: A novel nature-inspired algorithm. Int. J. Mach. Learn. Cybern. 2020, 11, 1501–1529. [Google Scholar] [CrossRef]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 1996, 26, 29–41. [Google Scholar] [CrossRef] [Green Version]
- Pourpanah, F.; Wang, R.; Lim, C.P.; Yazdani, D. A review of the family of artificial fish swarm algorithms: Recent advances and applications. arXiv 2020, arXiv:2011.05700. Available online: https://arxiv.org/abs/2011.05700 (accessed on 10 February 2022).
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Zhao, R.Q.; Tang, W.S. Monkey algorithm for global numerical optimization. J. Uncertain Syst. 2008, 2, 165–176. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.-S. A New Metaheuristic Bat-Inspired Algorithm. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. [Google Scholar]
- Das, S.; Biswas, A.; Dasgupta, S.; Abraham, A. Bacterial Foraging Optimization Algorithm: Theoretical Foundations, Analysis, and Applications. Auton. Robot. Agents 2009, 3, 23–55. [Google Scholar]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Karaboga, D.; Akay, B. A comparative study of Artificial Bee Colony algorithm. Appl. Math. Comput. 2009, 214, 108–132. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Alavi, A.H. Krill herd: A new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4831–4845. [Google Scholar] [CrossRef]
- Rao, R. Review of applications of TLBO algorithm and a tutorial for beginners to solve the unconstrained and constrained optimization problems. Decis. Sci. Lett. 2016, 5, 1–30. [Google Scholar]
- Kashan, A.H. League Championship Algorithm (LCA): An algorithm for global optimization inspired by sport championships. Appl. Soft Comput. 2014, 16, 171–200. [Google Scholar] [CrossRef]
- Eskandar, H.; Sadollah, A.; Bahreininejad, A.; Hamdi, M. Water cycle algorithm—A novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput. Struct. 2012, 110, 151–166. [Google Scholar] [CrossRef]
- Cuevas, E.; Cienfuegos, M.; Zaldivar-Navarro, D.; Perez-Cisneros, M.A. A swarm optimization algorithm inspired in the behavior of the social-spider. Expert Syst. Appl. 2013, 40, 6374–6384. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009. [Google Scholar]
- Moghdani, R.; Salimifard, K. Volleyball premier league algorithm. Appl. Soft Comput. 2018, 64, 161–185. [Google Scholar] [CrossRef]
- Rand, D.; Greene, J.D.; Nowak, M.A. Spontaneous giving and calculated greed. Nature 2012, 489, 427–430. [Google Scholar] [CrossRef] [PubMed]
- Grossack, M.M. Some effects of cooperation and competition upon small group behavior. J. Abnorm. Soc. Psychol. 1954, 49, 341. [Google Scholar] [CrossRef]
- Forsyth, D.R. Group Dynamics; Cengage Learning: Boston, MA, USA, 2018. [Google Scholar]
- Schwartz, S.H. Individualism-collectivism: Critique and proposed refinements. J. Cross-Cult. Psychol. 1990, 21, 139–157. [Google Scholar] [CrossRef]
- Khalil, A.M.; Fateen, S.-E.K.; Bonilla-Petriciolet, A. MAKHA—A New Hybrid Swarm Intelligence Global Optimization Algorithm. Algorithms 2015, 8, 336–365. [Google Scholar] [CrossRef] [Green Version]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. Available online: https://arxiv.org/abs/1609.04747 (accessed on 10 February 2022).
- Watt, J.; Borhani, R.; Katsaggelos, A.K. Machine Learning Refined: Foundations, Algorithms, and Applications; Cambridge University Press: Cambridge, UK, 2020; Chapters 3, 3.5, 3.6. [Google Scholar]
- Wang, X. Method of steepest descent and its applications. IEEE Microw. Wirel. Compon. Lett. 2008, 12, 24–26. [Google Scholar]
- Wu, X.; Ward, R.; Bottou, L. Wngrad: Learn the learning rate in gradient descent. arXiv 2018, arXiv:1803.02865. Available online: https://arxiv.org/pdf/1803.02865.pdf (accessed on 10 February 2022).
- Search Party Definition and Meaning. Available online: https://www.dictionary.com/browse/search-party (accessed on 4 January 2022).
- Dion, K.L. Group cohesion: From “field of forces” to multidimensional construct. Group Dyn. Theory Res. Pract. 2000, 4, 7. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Cohen, J.D.; McClure, S.M.; Yu, A.J. Should I stay or should I go? How the human brain manages the trade-off between exploitation and exploration. Philos. Trans. R. Soc. B Biol. Sci. 2007, 362, 933–942. [Google Scholar] [CrossRef]
- Volchenkov, D.; Helbach, J.; Tscherepanow, M.; Kühnel, S. Treasure Hunting in Virtual Environments: Scaling Laws of Human Motions and Mathematical Models of Human Actions in Uncertainty. In Nonlinear Dynamics and Complexity; Springer International Publishing: Cham, Switzerland, 2014; pp. 213–234. [Google Scholar]
- Maroti, A. RBED: Reward Based Epsilon Decay. arXiv 2019, arXiv:1910.13701. Available online: https://arxiv.org/abs/1910.13701 (accessed on 10 February 2022).
- Numpy.Random.Triangular.—NumPy v1.21 Manual. Available online: https://numpy.org/doc/stable/reference/random/generated/numpy.random.triangular.html (accessed on 27 December 2021).
- Kotz, S.; Van Dorp, J.R. Beyond Beta: Other Continuous Families of Distributions with Bounded Support and Applications; World Scientific: Singapore, 2004; Chapter 1. [Google Scholar]
- Hesse, R. Triangle distribution: Mathematica link for Excel. Decis. Line 2000, 31, 12–14. [Google Scholar]
- Leng, J. Optimization techniques for structural design of cold-formed steel structures. In Recent Trends in Cold-Formed Steel Construction; Woodhead Publishing: Sawston, UK, 2016; pp. 129–151. [Google Scholar]
- Hong, T.P.; Wang, H.S.; Lin, W.Y.; Lee, W.Y. Evolution of appropriate crossover and mutation operators in a genetic process. Appl. Intell. 2002, 16, 7–17. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Holland, J.H. Genetic Algorithms and Machine Learning. Mach. Learn. 1988, 3, 95–99. [Google Scholar] [CrossRef]
- Jamil, M.; Yang, X.-S. A literature survey of benchmark functions for global optimisation problems. Int. J. Math. Model. Numer. Optim. 2013, 4, 150–194. [Google Scholar] [CrossRef] [Green Version]
- Surjanovic, S.; Bingham, D. Virtual Library of Simulation Experiments: Test Functions and Datasets. 2013. Available online: http://www.sfu.ca/~ssurjano (accessed on 25 December 2021).
- Nathanrooy. Landscapes/Single_Objective.Py at Master Nathanrooy/Landscapes. GitHub. Available online: https://github.com/nathanrooy/landscapes/blob/master/landscapes/single_objective.py (accessed on 27 December 2021).
- Tansui, D.; Thammano, A. Hybrid nature-inspired optimization algorithm: Hydrozoan and sea turtle foraging algorithms for solving continuous optimization problems. IEEE Access 2020, 8, 65780–65800. [Google Scholar] [CrossRef]
- Abiyev, R.H.; Tunay, M. Optimization of High-Dimensional Functions through Hypercube Evaluation. Comput. Intell. Neurosci. 2015, 2015, 967320. [Google Scholar] [CrossRef] [Green Version]
- Tenne, Y.; Armfield, S.W. A memetic algorithm using a trust-region derivative-free optimization with quadratic modelling for optimization of expensive and noisy black-box functions. In Evolutionary Computation in Dynamic and Uncertain Environments; Springer: Berlin/Heidelberg, Germany, 2007; pp. 389–415. [Google Scholar]
- Molga, M.; Smutnicki, C. Test functions for optimization needs. Test Funct. Optim. Needs 2005, 101, 48. [Google Scholar]
- Cho, H.; Olivera, F.; Guikema, S.D. A derivation of the number of minima of the Griewank function. Appl. Math. Comput. 2008, 204, 694–701. [Google Scholar] [CrossRef]
- Blanchard, A.; Sapsis, T. Bayesian optimization with output-weighted optimal sampling. J. Comput. Phys. 2020, 425, 109901. [Google Scholar] [CrossRef]
- Optimization and Root Finding (Scipy.Optimize)—SciPy v1.7.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/optimize.html (accessed on 27 December 2021).
- Pypi Stats. PyPI Download Stats—SciPy. 2021. Available online: https://pypistats.org/packages/scipy (accessed on 27 December 2021).
- Varoquaux, G.; Gouillart, E.; Vahtras, O.; Haenel, V.; Rougier, N.P.; Gommers, R.; Pedregosa, F.; Jędrzejewski-Szmek, Z.; Virtanen, P.; Combelles, C.; et al. Scipy Lecture Notes. Zenodo, 2015, ⟨10.5281/zenodo.31736⟩. ⟨hal-01206546⟩. Available online: https://hal.inria.fr/hal-01206546/file/ScipyLectures-simple.pdf (accessed on 24 January 2022).
- Nunez-Iglesias, J.; Van Der Walt, S.; Dashnow, H. Elegant SciPy: The Art of Scientific Python; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Basinhopping. Scipy.Optimize.Basinhopping—SciPy v1.7.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.basinhopping.html (accessed on 27 December 2021).
- SHGO. Scipy.Optimize.Shgo—SciPy v1.7.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.shgo.html (accessed on 27 December 2021).
- Dual_Annealing. Scipy.Optimize.Dual_Annealing—SciPy v1.7.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.dual_annealing.html (accessed on 27 December 2021).
- Differential Evolution. Scipy.Optimize.Differential_Evolution—SciPy v1.7.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.differential_evolution.html (accessed on 27 December 2021).
- Brute. Scipy.Optimize.Brute—SciPy v1.7.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.brute.html (accessed on 27 December 2021).
- PSOPy. PyPI. Available online: https://pypi.org/project/psopy/ (accessed on 24 December 2021).
- Stefan Endres (MEng, BEng (Hons) in Chemical Engineering. “Shgo”. Available online: https://stefan-endres.github.io/shgo/ (accessed on 25 December 2021).
- Aly, A.; Weikersdorfer, D.; Delaunay, C. Optimizing deep neural networks with multiple search neuroevolution. arXiv 2019, arXiv:1901.05988. Available online: https://arxiv.org/abs/1901.05988 (accessed on 10 February 2022).
- Yang, E.; Barton, N.H.; Arslan, T.; Erdogan, A.T. A novel shifting balance theory-based approach to optimization of an energy-constrained modulation scheme for wireless sensor networks. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 2749–2756. [Google Scholar]



{kind=link}
{kind=link}
| Nature-Inspired Algorithm | Comments |
|---|---|
| Ant Colony Optimization (ACO) [9] | It is inspired by the pheromone-laying phenomenon of ants. Artificial ants simulate the pheromone behavior by recording position information and using it in the subsequent iterations to guide to the optimum possibly. |
| Artificial Fish Swarm Optimization (AFSO) [10] | The schooling behavior of fishes inspires AFSO, particularly their swimming, preying, following, and random behaviors. These movements serve as guidance to explore the function surface to be optimized. |
| Moth-Flame Optimization Algorithm (MFO) [11] | Moths can navigate in a straight line for long distances by maintaining a fixed angle with the moon as the reference. Artificial lights can deceive the moths into entering into a deadly spiral path. This navigation behavior is simulated to perform optimization. |
| Monkey Algorithm (MA) [12] | The movement pattern of monkeys inspires the MA. Climbing, watch-jump, and the somersault process are the three movement patterns employed to search through the function surface. It is suitable for higher-dimensional OP problems. |
| Grey Wolf Optimizer (GWO) [13] | The GWO mimics grey wolves’ hunting strategy, which involves search, encircling, and finally hunting. Alpha, beta, delta, and omega wolves are the four types that dictate the leadership ladder and are simulated to navigate the search space to find the optimum. |
| Bat Algorithm (BA) [14] | The BA is based on the echolocation capabilities of microbats. Virtual bats move through the objective function space depending on their velocity, frequency, and loudness, searching for their prey/optimum. |
| Bacterial Foraging Algorithm (BFA) [15] | The way in which bacterium E. coli searches for nutrients is termed chemotaxis. The BFA simulates this chemotaxis with virtual bacterium moving in the search space. |
| Whale Optimization Algorithm (WOA) [16] | Humpback whales hunt their prey in a spiral motion called the bubble-net feeding strategy. The WOA simulates the movement pattern depicted by the whales during the bubble-net strategy to search through the objective function surface. |
| Artificial Bee Colony Optimization (ABC) [17] | In ABC, possible solutions are represented as food sources, and two types of artificial bees search for the food source. Employed bees perform exploitation while scout bees explore new food sources. Information exchange happens through the bee dancing phenomena. |
| Krill-Herd Optimization Algorithm (KH) [18] | Krill is a marine animal whose foraging behavior inspired the KH algorithm. Individual krill and their foraging activity influence the krill-herd movement. Further random diffusion happens, which helps in exploration. |
| Teaching Learning Based Optimization (TLBO) [19] | TLBO is a human-inspired two-phase OP algorithm. This algorithm does not require algorithm-specific hyperparameters. Common hyperparameters like the number of generations and population size are alone needed. |
| League Championship Algorithm (LCA) [20] | Artificial human teams play a league of matches in the LCA for several iterations. Team formation represents a solution, and team strength represents fitness (objective function value). The formation evolves in each iteration to attain peak fitness. |
| Water Cycle Algorithm (WCA) [21] | The WCA is inspired by the natural phenomena of the water cycle. Rivers and streams flow downhill to reach the sea. The sea is the most downhill location and hence represents the optimum. The water flow serves as the inspiration to guide the search in the objective function surface. |
| Social Spider Optimization (SSO) [22] | SSO mimics the cooperative behavior depicted by social spiders to search for the optimum. Male and female spiders exhibit different collective behaviors. SSO avoids premature convergence and escapes the local optimum efficiently. |
| Cuckoo Search (CS) [23] | The breeding behavior of cuckoo birds and the Levy flight behavior of birds, in general, serve as the inspiration for this algorithm. The cuckoo lays eggs. Surviving eggs become mature cuckoos and move to a better location to lay eggs. This migration pattern is simulated to find the optimum of the objective function. |
| Function Id | Function Name | Dimension | Global Minimum | Characterstics | Search Range |
|---|---|---|---|---|---|
| F1 | Ackley | 2 | 0 | MM, NS | (−35, 35) |
| F2 | Beale | 2 | 0 | UM, NS | (−4.5, 4.5) |
| F3 | Eggholder | 2 | −959.6407 | MM, NS | (−512, 512) |
| F4 | Goldstein-Price | 2 | 3 | MM, NS | (−2, 2) |
| F5 | Matyas | 2 | 0 | UM, NS | (−10, 10) |
| F6 | Schaffer N.4 | 2 | 0.292579 | UM, NS | (−100, 100) |
| F7 | Tripod | 2 | 0 | MM, NS | (−100, 100) |
| F8 | Colville | 4 | 0 | UM, NS | (−10, 10) |
| F9 | Griewank | 5 | 0 | MM, NS | (−600, 600) |
| F10 | Michalewicz (m = 10) | 5 | −4.687658 | MM, S | (0, 3.14) |
| F11 | Rosenbrock | 10 | 0 | UM, NS | (−30, 30) |
| F12 | Rotated Hyper Ellipsoid | 10 | 0 | UM, NS | (−65.536, 65.536) |
| F13 | Zakharov | 10 | 0 | UM, NS | (−5, 10) |
| F14 | Rastrigin | 20 | 0 | MM, S | (−5.12, 5.12) |
| Name of The Hyperparameter Combination | Number of GD Instances (N) | Number of Episodes (Ep) | Number of Iterations per Episodes (Nip) | Number of Stable Episodes (NSEp) | Number of Iterations at Worst Case (IF Ep(Converge) = N) |
|---|---|---|---|---|---|
| C1 | 100 | 50 | 20 | 10 | 100,000 |
| C2 | 50 | 50 | 20 | 10 | 50,000 |
| C3 | 25 | 50 | 30 | 10 | 37,500 |
| C4 | 25 | 50 | 20 | 10 | 25,000 |
| C5 | 25 | 50 | 25 | 5 | 25,000 |
| Function Id | Hyper Parameter Combination | Best | Worst | Mean | SD | SR | Mean_Ep(Converge) |
|---|---|---|---|---|---|---|---|
| F1 (Ackley) | C1 | 0 | 0 | 0 | 0 | 1 | 16 |
| C2 | 0 | 0 | 0 | 0 | 1 | 15.9 | |
| C3 | 0 | 0 | 0 | 0 | 1 | 16 | |
| C4 | 0 | 0 | 0 | 0 | 1 | 16.46 | |
| C5 | 0 | 0 | 0 | 0 | 1 | 10.92 | |
| F2 (Beale) | C1 | 0 | 7.57467 × 10−5 | 1.51734 × 10−6 | 1.07118 × 10−5 | 0.98 | 36.16 |
| C2 | 0 | 6.0145 × 10−4 | 2.38475 × 10−5 | 1.0895 × 10−4 | 0.94 | 45.6 | |
| C3 | 0 | 1.05487 × 10−5 | 0 | 2.41421 × 10−6 | 0.92 | 45.76 | |
| C4 | 0 | 2.20053 × 10−3 | 7.19695 × 10−5 | 3.4012 × 10−4 | 0.86 | 47.4 | |
| C5 | 0 | 5.29452 × 10−3 | 1.29834 × 10−3 | 1.58691 × 10−3 | 0.34 | 22.18 | |
| F3 (EggHolder) | C1 | −959.640662 | −935.337951 | −956.512989 | 7.4296201 | 0.0 | 25.76 |
| C2 | −959.640662 | −894.578898 | −945.252029 | 21.331546 | 0.0 | 33.86 | |
| C3 | −959.640588 | −786.525994 | −931.834921 | 32.667300 | 0.0 | 30.16 | |
| C4 | −959.639814 | −786.525994 | −927.660588 | 34.371745 | 0.0 | 30 | |
| C5 | −959.636808 | −786.525994 | −925.475682 | 38.169414 | 0.0 | 13.58 | |
| F4 (Gold-Stein Price) | C1 | 3.0 | 3.0 | 3.0 | 0 | 1 | 11 |
| C2 | 3.0 | 3.0 | 3.0 | 0 | 1 | 34.22 | |
| C3 | 3.0 | 3.0 | 3.0 | 0 | 1 | 11.16 | |
| C4 | 3.0 | 3.0 | 3.0 | 0 | 1 | 11.14 | |
| C5 | 3.0 | 3.0 | 3.0 | 0 | 1 | 6 | |
| F5 (Matyas) | C1 | 0 | 0 | 0 | 0 | 1 | 16.57 |
| C2 | 0 | 0 | 0 | 0 | 1 | 22.02 | |
| C3 | 0 | 0 | 0 | 0 | 1 | 26.78 | |
| C4 | 0 | 0 | 0 | 0 | 1 | 23.1 | |
| C5 | 0 | 0 | 0 | 0 | 1 | 17.48 | |
| F6 (Schaffer) | C1 | 0.29257863 | 0.29257863 | 0.29257863 | 0 | 1 | 22.42 |
| C2 | 0.29257863 | 0.29257863 | 0.29257863 | 0 | 1 | 25.58 | |
| C3 | 0.29257863 | 0.29257863 | 0.29257863 | 0 | 1 | 28.12 | |
| C4 | 0.29257863 | 0.29257876 | 0.29257863 | 0 | 1 | 30.12 | |
| C5 | 0.29257863 | 0.29261529 | 0.29257941 | 5.18320 × 10−6 | 0.96 | 21.96 | |
| F7 (Tripod) | C1 | 0 | 0.02197657 | 0.00091925 | 0.00322785 | 0.18 | 37.6 |
| C2 | 0 | 0.11337406 | 0.00637666 | 0.01931453 | 0.14 | 37.02 | |
| C3 | 0 | 0.12792996 | 0.00730648 | 0.02230414 | 0.1 | 35.34 | |
| C4 | 0 | 0.08701752 | 0.00514379 | 0.01680644 | 0.04 | 36.62 | |
| C5 | 2.25691 × 10−5 | 0.22906872 | 0.03468707 | 0.05019722 | 0 | 18.74 | |
| F8 (Colville) | C1 | 0 | 0 | 0 | 0 | 1 | 16.22 |
| C2 | 0 | 0 | 0 | 0 | 1 | 16.92 | |
| C3 | 0 | 0 | 0 | 0 | 1 | 16.78 | |
| C4 | 0 | 0 | 0 | 0 | 1 | 17.38 | |
| C5 | 0 | 1.58140399 | 0.03205936 | 0.22360284 | 0.96 | 12.56 | |
| F9 (Griewank) | C1 | 0 | 0.00986467 | 0.00034521 | 0.00172647 | 0.96 | 40.65 |
| C2 | 0 | 0.16277361 | 0.01084491 | 0.03119835 | 0.8 | 44.76 | |
| C3 | 0 | 0.39174897 | 0.01843029 | 0.06740692 | 0.72 | 43.61 | |
| C4 | 0 | 0.12318531 | 0.00808213 | 0.02397737 | 0.74 | 47.1 | |
| C5 | 0 | 5.82227555 | 0.15844181 | 0.86088410 | 0.7 | 39.86 | |
| F10 (Michaelwicz) | C1 | −4.687658 | −3.52489854 | −4.48758298 | 0.29075257 | 0.26 | 44.86 |
| C2 | −4.687658 | −3.52498727 | −4.38087234 | 0.3646653 | 0.18 | 46.28 | |
| C3 | −4.6876581 | −3.4938926 | −4.32720985 | 0.3697356 | 0.18 | 45.9 | |
| C4 | −4.6876581 | −3.22626745 | −4.2453005 | 0.3777910 | 0.1 | 47.44 | |
| C5 | −4.6868078 | −2.13186393 | −3.08535244 | 0.64314420 | 0 | 16.78 | |
| F11 (Rosenbrock) | C1 | 0 | 9.97379 × 10−5 | 1.99475 × 10−6 | 1.41050 × 10−5 | 0.98 | 41.56 |
| C2 | 0 | 7.92577600 | 0.15851552 | 1.1208739 | 0.98 | 29.5 | |
| C3 | 0 | 0.02173848 | 0.00043476 | 0.00307428 | 0.98 | 39.14 | |
| C4 | 0 | 2.33355643 | 0.05058394 | 0.33060934 | 0.96 | 42.98 | |
| C5 | 0 | 99824.3438 | 2544.21169 | 14557.6125 | 0.66 | 32.06 | |
| F12 (Rotated Hyper Ellipsoid) | C1 | 0 | 0 | 0 | 0 | 1 | 22.22 |
| C2 | 0 | 0 | 0 | 0 | 1 | 23.98 | |
| C3 | 0 | 0 | 0 | 0 | 1 | 21.26 | |
| C4 | 0 | 0 | 0 | 0 | 1 | 24.12 | |
| C5 | 0 | 1.85962 × 10−5 | 0 | 2.62984 × 10−7 | 0.96 | 16.3 | |
| F13 (Zakharov) | C1 | 0 | 0 | 0 | 0 | 1 | 44.96 |
| C2 | 0 | 0 | 0 | 0 | 1 | 48.46 | |
| C3 | 0 | 0 | 0 | 0 | 1 | 46.84 | |
| C4 | 0 | 0 | 0 | 0 | 1 | 49.04 | |
| C5 | 0 | 58.1560150 | 6.75172438 | 15.3146739 | 0.54 | 30.42 | |
| F14 (Rastrigin) | C1 | 0 | 0 | 0 | 0 | 1 | 12 |
| C2 | 0 | 0 | 0 | 0 | 1 | 12.34 | |
| C3 | 0 | 0 | 0 | 0 | 1 | 11.76 | |
| C4 | 0 | 0 | 0 | 0 | 1 | 13.4 | |
| C5 | 0 | 0 | 0 | 0 | 1 | 8.44 |
| S.NO | Algorithm | Hyperparameters with Default Values |
|---|---|---|
| 1 | Basinhopping (BH) [59] | func, x0, niter = 100, T = 1.0, stepsize = 0.5, minimizer_kwargs = None, take_step = None, accept_test = None, callback = None, interval = 50, disp = False, niter_success = None, seed = None |
| 2 | Simplicial Homology Global Optimization (SHGO) [60] | func, bounds, args = (), constraints = None, n = None, iters = 1, callback = None, minimizer_kwargs = ’SLSQP’, options = None, sampling_method = ‘simplicial’ |
| 3 | Dual Annealing (DAE) [61] | func, bounds, args = (), maxiter = 1000, local_search_options = {}, initial_temp = 5230.0, restart_temp_ratio = 2 × 10−5, visit = 2.62, accept = −5.0, maxfun = 10,000,000.0, seed = None, no_local_search = False, callback = None, x0 = None |
| 4 | Differential Evolution (DE) [62] | func, bounds, args = (), strategy = ‘best1bin’, maxiter = 1000, popsize = 15, tol = 0.01, mutation = (0.5, 1), recombination = 0.7, seed = None, callback = None, disp = False, polish = True, init = ‘latinhypercube’, atol = 0, updating = ‘immediate’, workers = 1, constraints = (), x0 = None |
| 5 | Brute [63] | func, ranges, args = (), Ns = 20, full_output = 0, finish = <function fmin>, disp = False, workers = 1 |
| 6 | Particle Swarm Optimization (PSO) [64,65] | fun, x0, confunc = None, friction = 0.8, max_velocity = 5., g_rate = 0.8,l_rate = 0.5, max_iter = 1000, stable_iter = 100, ptol = 1 × 10−6, ctol = 1 × 10−6, callback = None |
| Function Id | Algorithm | Best | Worst | Mean | SD | SR |
|---|---|---|---|---|---|---|
| F1 (Ackley) | BH | 0 | 1.36472421 | 0.13514784 | 0.25274851 | 0.68 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| Dual_Ann | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 0.2801272 | 0.0056025 | 0.0396159 | 0.98 | |
| Brute | 0.78352294 | 0.78352294 | 0.78352294 | 0 | 0 | |
| PSO | 0 | 0 | 0 | 0 | 1 | |
| SPGD | 0 | 0 | 0 | 0 | 1 | |
| F2 (Beale) | BH | 0 | 0 | 0 | 0 | 1 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| Dual_Ann | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 0.7336411 | 0.0146728 | 0.1037525 | 0.98 | |
| Brute | 0 | 0 | 0 | 0 | 1 | |
| PSO | 0 | 0 | 0 | 0 | 1 | |
| SPGD | 0 | 0.00220053 | 7.196953 × 10−5 | 0.00034012 | 0.86 | |
| F3 (EggHolder) | BH # | −1102.97164 | −88.3042594 | −546.101393 | 222.441807 | 0 |
| SHGO | −935.337951 | −935.337951 | −935.337951 | 0 | 0 | |
| Dual_Ann | −959.640662 | −888.949125 | −931.473470 | 29.64637 | 0 | |
| DiffEvoul | −959.640662 | −786.52599 | −910.403744 | 49.9705672 | 0 | |
| Brute # | −976.911000 | −976.911000 | −976.911000 | 0 | 0 | |
| PSO # | −976.911000 | −716.67150 | −893.762654 | 69.4243212 | 0 | |
| SPGD | −959.639814 | −786.525994 | −927.660588 | 34.3717458 | 0 | |
| F4 (Gold-Stein Price) | BH | 3.0 | 3.0 | 3.0 | 0 | 1 |
| SHGO | 3.0 | 3.0 | 3.0 | 0 | 1 | |
| Dual_Ann | 3.0 | 3.0 | 3.0 | 0 | 1 | |
| DiffEvoul | 3.0 | 3.0 | 3.0 | 0 | 1 | |
| Brute | 3.0 | 3.0 | 3.0 | 0 | 1 | |
| PSO | 3.0 | 3.0 | 3.0 | 0 | 1 | |
| SPGD | 3.0 | 3.0 | 3.0 | 0 | 1 | |
| F5 (Matyas) | BH | 0 | 0 | 0 | 0 | 1 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| Dual_Ann | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 0 | 0 | 0 | 1 | |
| Brute | 0 | 0 | 0 | 0 | 1 | |
| PSO | 0 | 0 | 0 | 0 | 1 | |
| SPGD | 0 | 0 | 0 | 0 | 1 | |
| F6 (Schaffer) | BH | 0.29257863 | 0.49741695 | 0.42685063 | 0.07275457 | 0.14 |
| SHGO | 0.50113378 | 0.50113378 | 0.50113378 | 0 | 0 | |
| DualAnn | 0.29257863 | 0.29387375 | 0.29260453 | 0.00018315 | 0.98 | |
| DiffEvoul | 0.29257863 | 0.29258103 | 0.29257869 | 0 | 0.98 | |
| Brute | 0.36131449 | 0.36131449 | 0.36131449 | 0 | 0 | |
| PSO | 0.29257863 | 0.29257863 | 0.29257863 | 0 | 1 | |
| SPGD | 0.29257863 | 0.29257876 | 0.29257863 | 0 | 1 | |
| F7 (Tripod) | BH | 0 | 2.000000008 | 0.820000004 | 0.84972984 | 0.46 |
| SHGO | 1.00000001 | 1.00000001 | 1.00000001 | 0 | 0 | |
| DualAnn | 0 | 1.000064264 | 0.620001309 | 0.49031536 | 0.38 | |
| DiffEvoul | 0 | 2.000000694 | 0.80000008 | 0.75592899 | 0.4 | |
| Brute | 1.00003641 | 1.00003641 | 1.00003641 | 0 | 0 | |
| PSO | 0 | 2.000000003 | 0.56000000 | 0.61145527 | 0.5 | |
| SPGD | 0 | 0.0870175274 | 0.0051437912 | 0.01680644 | 0.04 | |
| F8 (Colville) | BH | 0 | 0 | 0 | 0 | 1 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| Dual_Ann | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 0 | 0 | 0 | 1 | |
| Brute | 0 | 0 | 0 | 0 | 1 | |
| PSO | 0 | 7.84998268 | 0.6040938 | 1.3746632 | 0.46 | |
| SPGD | 0 | 0 | 0 | 0 | 1 | |
| F9 (Griewank) | BH | 0.24868915 | 132.830121 | 17.4293518 | 22.128654 | 0 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| DualAnn | 0 | 0.066493 | 0.0220203 | 0.0154676 | 0.1 | |
| DiffEvoul | 0 | 0.05662099 | 0.0136467 | 0.0106129 | 0.14 | |
| Brute | 1.19740690 | 1.19740690 | 1.19740690 | 0 | 0 | |
| PSO | 0.00985728 | 0.30542824 | 0.08472009 | 0.0560294 | 0 | |
| SPGD | 0 | 0.12318531 | 0.00808213 | 0.02397737 | 0.74 | |
| F10 (Michaelwicz) | BH # | −4.74614390 | −3.33129293 | −4.38273363 | 0.3484707 | 0.1 |
| SHGO | −3.53609746 | −3.53609746 | −3.53609746 | 0 | 0 | |
| DualAnn | −4.68765817 | −4.68765817 | −4.68765817 | 0 | 1 | |
| DiffEvoul | −4.68765817 | −4.3748963 | −4.6408507 | 0.0651459 | 0.38 | |
| Brute | −4.6876580 | −4.6876580 | −4.6876580 | 0 | 1 | |
| PSO | −4.64589536 | −2.6401023 | −3.8328507 | 0.5415107 | 0 | |
| SPGD | −4.6876581 | −3.22626745 | −4.2453005 | 0.3777910 | 0.1 | |
| F11 (Rosenbrock) | BH | 0 | 0 | 0 | 0 | 1 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| DualAnn | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 3.98658234 | 0.55812114 | 1.3973353 | 0.86 | |
| Brute | Memory Error | |||||
| PSO | 0.62903529 | 458.440177 | 53.6217016 | 93.8592738 | 0 | |
| SPGD | 0 | 2.33355643 | 0.05058394 | 0.33060934 | 0.96 | |
| F12 (Rotated Hyper Ellipsoid) | BH | 0 | 0 | 0 | 0 | 1 |
| SHGO | 0 | 0 | 0 | 0 | 1 | |
| DualAnn | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 0 | 0 | 0 | 1 | |
| Brute | Memory Error | |||||
| PSO | 0 | 0.03187133 | 0.00107759 | 0.005112 | 0.76 | |
| SPGD | 0 | 0 | 0 | 0 | 1 | |
| F13 (Zakharov) | BH | 0 | 0 | 0 | 0 | 1 |
| SHGO | 20.5109595 | 20.5109595 | 20.5109595 | 0 | 0 | |
| DualAnn | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 0 | 0 | 0 | 0 | 1 | |
| Brute | Memory Error | |||||
| PSO | 0 | 1.26451010 | 0.09737653 | 0.21157360 | 0.02 | |
| SPGD | 0 | 0 | 0 | 0 | 1 | |
| F14 (Rastrigin) | BH | 4.97479528 | 26.8638491 | 11.541520 | 4.2641043 | 0 |
| SHGO * | Maximum Time Limit Exceeded | |||||
| DualAnn | 0 | 0 | 0 | 0 | 1 | |
| DiffEvoul | 8.95463151 | 46.7629849 | 21.2125049 | 7.7342163 | 0.0 | |
| Brute | Memory Error | |||||
| PSO | 28.4366707 | 98.5430492 | 55.253022 | 15.376534 | 0 | |
| SPGD | 0 | 0 | 0 | 0 | 1 | |
| Algorithms | Functions | Number of Functions |
|---|---|---|
| BH | F2, F4, F5, F8, F11, F12, F13 | 7 |
| SHGO | F1, F2, F4, F5, F8, F9, F11, F12 | 8 |
| DAE | F1, F2, F4, F5, F6, F8, F10, F11, F12, F13, F14 | 11 |
| DE | F1, F2, F4, F5, F6, F8, F12, F13 | 8 |
| Brute | F2, F4, F5, F6, F8, F10 | 6 |
| PSO | F1, F2, F4, F5, F6 | 5 |
| SPGD | F1, F4, F5, F6, F8, F11, F12, F13, F14 | 9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syed Shahul Hameed, A.S.; Rajagopalan, N. SPGD: Search Party Gradient Descent Algorithm, a Simple Gradient-Based Parallel Algorithm for Bound-Constrained Optimization. Mathematics 2022, 10, 800. https://doi.org/10.3390/math10050800
Syed Shahul Hameed AS, Rajagopalan N. SPGD: Search Party Gradient Descent Algorithm, a Simple Gradient-Based Parallel Algorithm for Bound-Constrained Optimization. Mathematics. 2022; 10(5):800. https://doi.org/10.3390/math10050800
Chicago/Turabian StyleSyed Shahul Hameed, A. S., and Narendran Rajagopalan. 2022. "SPGD: Search Party Gradient Descent Algorithm, a Simple Gradient-Based Parallel Algorithm for Bound-Constrained Optimization" Mathematics 10, no. 5: 800. https://doi.org/10.3390/math10050800
APA StyleSyed Shahul Hameed, A. S., & Rajagopalan, N. (2022). SPGD: Search Party Gradient Descent Algorithm, a Simple Gradient-Based Parallel Algorithm for Bound-Constrained Optimization. Mathematics, 10(5), 800. https://doi.org/10.3390/math10050800