1. Introduction
Spatial econometric models have been extensively used to study regional effects and interdependence between different spatial units. Most of the widely used spatial models are variants of the benchmark models developed in Cliff and Ord (1973, 1981) [
1,
2] and Anselin (1988a) [
3]. Based on the form of spatially correlated error components and/or spatially lagged dependent variables, these models better fit the real world data generating process by explicitly considering the spatial interdependence. Hypothesis testing for spatial dependence has been developed rapidly in the recent literature. For standard LM tests of spatial dependence in cross section models, see Anselin (1988a, b) [
3,
4], Anselin and Bera (1998) [
5], and Anselin (2001) [
6]. For standard LM tests of spatial dependence in panel data models, Baltagi
et al., (2003) [
7] provide tests for random effects and/or spatial error correlation. Baltagi and Liu (2008) [
8] provide tests for random effects and/or spatial lag dependence. Debarsy and Ertur (2010) [
9] derive tests in the spatial panel data model with individual fixed effects based on Lee and Yu (2010) [
10]. Qu and Lee (2012) [
11] consider tests in spatial models with limited dependent variables. Baltagi
et al., (2013) [
12] extend the model in Kapoor
et al., (2007) [
13] by allowing for different spatial correlation parameters in the individual random effects and in the disturbances, and they derive the corresponding LM tests. Further, standardized versions of the LM tests are discussed in Yang (2010) [
14], Baltagi and Yang (2013a) [
15] to remedy distributional misspecifications in finite sample and sensitivity to spatial layout. Born and Breitung (2011) [
16], Baltagi and Yang (2013b) [
17] discuss versions of LM tests that are robust against unknown heteroskedasticity. Recently, Yang (2015) [
18] provides residual-based bootstrap procedure to obtain improved approximations to the finite sample critical values of the LM test statistics in spatial econometric models.
However, to the best of our knowledge, there are no test statistics treating the individual random effects, the spatial error correlation, and the spatial lag dependence simultaneously. We contribute to the literature by constructing various LM test statistics in such a general framework, or the so-called spatial autoregressive model with autoregressive disturbances (SARAR). Our results are useful for applied researchers to implement and perform model diagnostic testing in the SARAR framework. In particular, we first derive the joint LM test for the individual random effects and the two spatial effects. We next derive LM tests for the individual random effects. Finally, we derive LM tests for the two spatial effects. In addition, we provide robust LM tests in some cases as needed in order to guard against local misspecification. We emphasize some key features of the robust LM test in the following.
Bera and Yoon (1993) [
19] argue that the LM test with specific values of the nuisance parameters (marginal LM test) might suffer from local misspecification in the nuisance parameters. They propose robust LM test to guard against such local misspecification, see also Anselin
et al., (1996) [
20], Bera
et al., (2001, 2009, 2010) [
21,
22,
23], and He and Lin (2013) [
24]. Here, we emphasize two advantages of the robust LM test. First, the asymptotic size of marginal LM test will be distorted under local misspecification in the nuisance parameters since it follows a non-central
distribution. On the other hand, robust LM test follows a
distribution under such misspecification, thus it can provide valid asymptotic size as long as the misspecification is local. Second, while LM test without specifying values of the nuisance parameters (conditional LM test) does not suffer from such size distortion, it generally needs the maximum likelihood estimator (MLE), which could be costly in computation. In contrast, the robust LM test only requires restricted estimator under the relevant joint null hypothesis, which is simply the ordinary least square (OLS) estimator in most cases. Therefore, the robust LM test can provide result as good as the conditional LM test at a lower computational cost, provided that the deviation of nuisance parameters is local. However, there is one potential loss in using the robust LM test. If the values of nuisance parameters are correctly specified, the robust LM test is in general less powerful than the marginal LM test. Also, when the nuisance parameters deviate far away from the pre-specified values, the robust LM test is generally invalid. In sum, the standard LM tests (marginal and conditional LM tests) and the robust LM tests complement each other, and they should be used together for inference purposes.
In this paper, we maintain the assumption of random effects model, while an alternative specification is the fixed effects model with spatial dependence as in Lee and Yu (2010) [
10], Debarsy and Ertur (2010) [
9], and He and Lin (2013) [
24]. On the one hand, the random effects specification is a parsimonious way to allow for individual effects in different spatial units and it will be particularly useful for testing and selection in microeconometric applications when the number of units is very large. On the other hand, the fixed effects specification, which allows for correlation between the individual effects and the covariates, is more suited for many macro studies when the number of units is not very large (see Elhorst (2014) [
25] for more discussion on comparison of the random effects model and the fixed effects model).
The rest of the paper is organized as follows. Model specification is discussed in
Section 2. The LM test statistics are presented In
Section 3. In
Section 4, we report the Monte Carlo simulation results to show their satisfactory finite sample size and power performances. In
Section 5, we provide an empirical example to illustrate our testing procedures.
Section 6 concludes with suggestions for future research. All mathematical derivations are relegated to the Appendices.
4. Monte Carlo Experiment
In this section, we conduct and present a small Monte Carlo experiment to show satisfactory performances of the above LM test statistics. In our Monte Carlo experiment, the data generating process is, for
,
where
.
is a single variable and is generated as
, where
is generated according to a uniform distribution on
. The initial value
is set to be
. The random effects term
is generated according to
, and the innovation term
is generated according to
.
takes values 0, 0.2, 0.5, and 0.8, while
is fixed to be 1. The spatial weights matrices
M and
W are set to be first-order rook and queen contiguity matrices with row-standardization, respectively. The spatial error correlation parameter
ρ and spatial lag parameter
λ vary in
, with increment 0.2. Two combinations of sample size
are considered, namely
and
. Each experiment is replicated 1000 times, and the nominal size is set to be 0.05.
Frequency of rejection (FoR) of the joint test
is summarized in
Table 1, where the upper part and lower part correspond to different sample sizes. We only report the case when
. For other cases, that is,
, FoRs are uniformly higher than that when
. This is because we are jointly testing
. The empirical sizes of
are 0.049 and 0.050 for the
and the
sample, respectively. They are almost the same as the nominal size, reflecting that the limiting
distribution approximates the finite sample null distribution very well. As
ρ or
λ deviates from 0, FoR increases very fast. For example, when the sample size is
, FoR is 0.995 when
, and it reaches 1 when
. The power performance when sample size is
is better than that when the sample size is
. The good size and power performance demonstrates that the joint test
should be very useful for applied researcher to determine whether there are individual random effects and spatial effects in a preliminary diagnostic testing process.
Experiment results for
and
are summarized in
Table 2. For
, we only report results when
and
here to save space. The results when
ρ takes other values are very similar, and they are available upon request. First, for the (49,7) sample, the empirical sizes of
are
and
when
and
, respectively. As
increases from 0, the FoR of
increases very fast. Actually, when
, FoR of
is
even when
is only
. Second, we discussed in
Section 3.2 that the robust LM test corresponding to
is the same as
, which implies that
itself is robust against local deviation of
λ from 0. This is confirmed by the column for
in
Table 2. Given
, for the (49,7) sample, when
λ varies in
, the FoRs of
are in the range of
. Thus
itself does not suffer from size distortion under local misspecification of the nuisance parameter
λ. As expected, the performance of
for the
sample is even better than that for the
sample. Next, for
, we choose to report the simulation results for a few combinations of
ρ and
λ as shown in the table. Results for other cases are very similar. For the (49,7) sample, the empirical sizes of
vary in
, and the FoR increases rapidly as
increases from 0. As expected, the performance of
for the
sample is even better than that for the
sample. Both
and
are useful in testing for the random effects.
is useful in testing for the random effects when the researcher does not have any knowledge about the spatial effects, while
is particularly useful when the researcher has information that there is only spatial error correlation.
Table 1.
Frequency of rejection (FoR) of , , Sample Sizes: Upper Part: ; Lower Part: .
Table 1.
Frequency of rejection (FoR) of , , Sample Sizes: Upper Part: ; Lower Part: .
| ρ | -0.8 | -0.6 | -0.4 | -0.2 | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|
| | | | | | | | | |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 0.996 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.980 | 0.942 | 0.998 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 0.946 | 0.692 | 0.861 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.984 | 0.389 | 0.290 | 0.954 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.681 | 0.049 | 0.623 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 0.994 | 0.515 | 0.552 | 0.995 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 0.998 | 0.957 | 0.997 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| ρ | -0.8 | -0.6 | -0.4 | -0.2 | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
| | | | | | | | | |
| -0.8 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| -0.6 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| -0.4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.988 | 1.000 | 1.000 | 1.000 |
| -0.2 | 1.000 | 1.000 | 1.000 | 1.000 | 0.864 | 0.758 | 1.000 | 1.000 | 1.000 |
| 0.0 | 1.000 | 1.000 | 1.000 | 0.989 | 0.050 | 0.986 | 1.000 | 1.000 | 1.000 |
| 0.2 | 1.000 | 1.000 | 1.000 | 0.911 | 0.926 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0.4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0.6 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0.8 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
The simulation results for
and
are presented in
Table 3 and
Table 4, respectively. From
Table 3, the empirical sizes of
are
and
for the
and
sample, respectively. As either
ρ or
λ deviates from 0, the FoR of increases very fast, indicating good power performance of
. For example, when
, FoR of
is
for the
sample, while it is 1 for the
sample. In
Table 4, we only report the results for the case when
to save space, results for the other two cases are similar and available upon request. The empirical sizes of
are
and
for the
and the
sample, respectively. Similar to
, as either
ρ or
λ deviates from 0, the FoR of increases rapidly. Both
and
are useful in jointly detecting spatial error correlation and spatial lag dependence.
is useful when we assume pooled panel data model, while
is useful when we assume random effects panel data model.
Table 2.
FoR of LM Tests for Random Effects, Sample Sizes: Upper Part: ; Lower Part: .
Table 2.
FoR of LM Tests for Random Effects, Sample Sizes: Upper Part: ; Lower Part: .
| | | | 0.2 | 0.5 | 0.8 |
|---|
| | | 0.057 | 0.974 | 1.000 | 1.000 |
| | | 0.043 | 0.978 | 1.000 | 1.000 |
| | 0.0 | 0.043 | 0.976 | 1.000 | 1.000 |
| | | 0.048 | 0.973 | 1.000 | 1.000 |
| | | 0.051 | 0.970 | 1.000 | 1.000 |
| | | 0.047 | 0.968 | 1.000 | 1.000 |
| | | 0.046 | 0.969 | 1.000 | 1.000 |
| | | 0.036 | 0.976 | 1.000 | 1.000 |
| | | 0.052 | 0.982 | 1.000 | 1.000 |
| | | 0.053 | 0.969 | 1.000 | 1.000 |
| | | 0.035 | 0.976 | 1.000 | 1.000 |
| | | 0.043 | 0.982 | 1.000 | 1.000 |
| | | 0.035 | 0.970 | 1.000 | 1.000 |
| | | 0.039 | 0.976 | 1.000 | 1.000 |
| | | 0.044 | 0.983 | 1.000 | 1.000 |
| | | | | | |
| | | 0.052 | 1.000 | 1.000 | 1.000 |
| | | | 0.047 | 1.000 | 1.000 | 1.000 |
| | | | 0.049 | 1.000 | 1.000 | 1.000 |
| | | | 0.045 | 1.000 | 1.000 | 1.000 |
| | | | 0.057 | 1.000 | 1.000 | 1.000 |
| | | | 0.053 | 1.000 | 1.000 | 1.000 |
| | | | 0.054 | 1.000 | 1.000 | 1.000 |
| | | | 0.038 | 1.000 | 1.000 | 1.000 |
| | | | 0.047 | 1.000 | 1.000 | 1.000 |
| | | | 0.049 | 1.000 | 1.000 | 1.000 |
| | | 0.041 | 1.000 | 1.000 | 1.000 |
| | | | 0.045 | 1.000 | 1.000 | 1.000 |
| | | | 0.041 | 1.000 | 1.000 | 1.000 |
| | | | 0.047 | 1.000 | 1.000 | 1.000 |
| | | | 0.042 | 1.000 | 1.000 | 1.000 |
Table 3.
FoR of , , Sample Sizes: Upper Part: ; Lower Part: .
Table 3.
FoR of , , Sample Sizes: Upper Part: ; Lower Part: .
| ρ | -0.8 | -0.6 | -0.4 | -0.2 | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|
| | | | | | | | | |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 0.986 | 0.965 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 0.982 | 0.752 | 0.919 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.993 | 0.487 | 0.374 | 0.969 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.746 | 0.053 | 0.684 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 0.995 | 0.573 | 0.576 | 0.994 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 0.995 | 0.972 | 0.996 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| ρ | -0.8 | -0.6 | -0.4 | -0.2 | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
| | | | | | | | | |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.993 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 0.916 | 0.829 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.992 | 0.050 | 0.990 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.933 | 0.953 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
Table 4.
FoR of , , Sample Sizes: Upper Part: , Lower Part: .
Table 4.
FoR of , , Sample Sizes: Upper Part: , Lower Part: .
| ρ | -0.8 | -0.6 | -0.4 | -0.2 | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|
| | | | | | | | | |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.997 | 0.999 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.984 | 0.956 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.999 | 0.963 | 0.738 | 0.907 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.989 | 0.458 | 0.331 | 0.971 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.743 | 0.050 | 0.687 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 0.998 | 0.536 | 0.542 | 0.993 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 0.996 | 0.962 | 0.998 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| ρ | -0.8 | -0.6 | -0.4 | -0.2 | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
| | | | | | | | | |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.993 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 0.898 | 0.815 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.993 | 0.043 | 0.991 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 0.928 | 0.944 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
Now we discuss simulation results of the test statistics for spatial error correlation, their FoRs are summarized in
Table 5 and
Table 6 for different sample sizes. We focus on the
sample for discussion. For
, the empirical size is
. Moreover,
is very powerful in detecting spatial error correlation given that
. For example, FoR of
is
when
. However, as discussed in
Section 3.3.2,
is not robust against local misspecification, and this is confirmed by the simulation results. Given
, when
and
λ deviate locally from 0, the large FoRs of
are undesirable. For example, when
but
, FoR of
is
. However, this size distortion is avoided by using
. When
,
takes values
and
, FoRs of
are in the range of
. Although it is a little oversized in some cases, it is much better than that of
. On the other hand, the robust LM test is supposed to be less powerful than the corresponding LM test when the nuisance parameters are correctly specified. This is also confirmed by the simulation results, that is, when
,
is less powerful than
. For example, when
, FoR of
is
, while that of
is
. Next,
tests for spatial error correlation in a pooled panel data model with spatial lag dependence. When
, the empirical sizes of
vary in
. As
ρ deviates from 0, FoR increases as expected. Furthermore, as discussed in
Section 3.3.2, the robust LM test in this case is the same as
, implying that
is robust against local deviation of
from 0. This is confirmed by the simulation results. When
, the empirical sizes of
vary in
. Next, we discuss
and
.
tests for spatial error correlation in a random effects panel data model without spatial lag dependence. We only present the representative result when
to save space, results in other cases are very similar. The empirical size of
is
, and the FoR increases as
ρ deviates away from 0. For example, FoR is
when
. However,
suffers from size distortion when the nuisance parameter
λ deviates away from 0. For example, when
, the FoR of
is
, which is undesirably high. For the same case, FoR of
is
. On the other hand, the robust LM test is less powerful when the nuisance parameter is correctly specified. This is also confirmed by the simulation results. For example, when
, FoR of
is
, while that of
is
. Lastly, we discuss the performance of
.
tests for spatial error correlation in a random effects panel data model with spatial lag dependence. The empirical sizes of
vary in
. As expected, when
ρ moves away from 0, FoR increases rapidly, suggesting its good power performance. For all of the above tests, their performances are even better for the
sample than for the
sample and follow a similar discussion. In sum, the test statistics
,
,
,
,
, and
are all useful for detecting the spatial error correlation, but they are suited for different assumptions about the nuisance parameters. In practice, researchers are suggested to analyze them together to draw correct inference on
ρ.
Table 5.
FoR of LM Tests for the Spatial Error Correlation, Sample Size: .
Table 5.
FoR of LM Tests for the Spatial Error Correlation, Sample Size: .
| | | | | | | 0 | | | | |
|---|
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.738 | 0.023 | 0.671 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.986 | 0.305 | 0.193 | 0.975 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.856 | 0.048 | 0.754 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.996 | 0.340 | 0.452 | 0.993 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.753 | 0.210 | 0.965 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.998 | 0.747 | 0.037 | 0.620 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.984 | 0.324 | 0.189 | 0.971 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.999 | 0.822 | 0.065 | 0.743 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.992 | 0.372 | 0.416 | 0.989 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.756 | 0.206 | 0.954 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.976 | 0.485 | 0.071 | 0.539 | 0.961 | 1.000 | 0.999 |
| | | | 1.000 | 1.000 | 0.990 | 0.562 | 0.056 | 0.482 | 0.941 | 1.000 | 0.999 |
| | | | 1.000 | 1.000 | 0.995 | 0.626 | 0.039 | 0.431 | 0.952 | 0.999 | 0.989 |
| | | | 1.000 | 1.000 | 0.997 | 0.639 | 0.052 | 0.460 | 0.969 | 1.000 | 0.961 |
| | | | 1.000 | 1.000 | 0.996 | 0.524 | 0.046 | 0.597 | 0.980 | 1.000 | 0.880 |
| | | | 1.000 | 1.000 | 0.975 | 0.495 | 0.081 | 0.535 | 0.937 | 1.000 | 0.999 |
| | | | 1.000 | 1.000 | 0.987 | 0.553 | 0.080 | 0.465 | 0.923 | 1.000 | 0.999 |
| | | | 1.000 | 1.000 | 0.988 | 0.607 | 0.075 | 0.432 | 0.926 | 0.998 | 0.991 |
| | | | 1.000 | 1.000 | 0.990 | 0.648 | 0.056 | 0.461 | 0.943 | 0.999 | 0.957 |
| | | 1.000 | 1.000 | 0.994 | 0.533 | 0.054 | 0.510 | 0.967 | 0.999 | 0.869 |
| | | 1.000 | 1.000 | 0.999 | 0.665 | 0.050 | 0.479 | 0.957 | 0.998 | 1.000 |
| | | | 1.000 | 1.000 | 0.999 | 0.641 | 0.046 | 0.469 | 0.940 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 0.997 | 0.646 | 0.040 | 0.448 | 0.951 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.997 | 0.646 | 0.060 | 0.457 | 0.961 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 0.996 | 0.639 | 0.046 | 0.497 | 0.966 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.995 | 0.651 | 0.058 | 0.458 | 0.939 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 0.995 | 0.619 | 0.080 | 0.455 | 0.927 | 0.998 | 1.000 |
| | | | 1.000 | 1.000 | 0.991 | 0.619 | 0.072 | 0.454 | 0.920 | 0.997 | 1.000 |
| | | | 1.000 | 1.000 | 0.992 | 0.662 | 0.069 | 0.463 | 0.939 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.995 | 0.610 | 0.063 | 0.487 | 0.951 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.747 | 0.036 | 0.657 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.987 | 0.301 | 0.192 | 0.975 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.835 | 0.045 | 0.771 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.991 | 0.353 | 0.427 | 0.993 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.758 | 0.194 | 0.957 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.979 | 0.480 | 0.064 | 0.522 | 0.945 | 1.000 | 0.998 |
| | | | 1.000 | 1.000 | 0.990 | 0.551 | 0.060 | 0.460 | 0.934 | 1.000 | 0.998 |
| | | | 1.000 | 1.000 | 0.993 | 0.602 | 0.040 | 0.412 | 0.943 | 0.999 | 0.985 |
| | | | 1.000 | 1.000 | 0.993 | 0.617 | 0.035 | 0.429 | 0.954 | 1.000 | 0.944 |
| | | 1.000 | 1.000 | 0.991 | 0.508 | 0.042 | 0.550 | 0.972 | 0.999 | 0.852 |
| | | 1.000 | 1.000 | 0.997 | 0.660 | 0.049 | 0.417 | 0.933 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 0.998 | 0.607 | 0.049 | 0.422 | 0.936 | 0.996 | 1.000 |
| | | | 1.000 | 1.000 | 0.992 | 0.627 | 0.058 | 0.433 | 0.952 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 0.996 | 0.602 | 0.054 | 0.427 | 0.952 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.995 | 0.630 | 0.038 | 0.480 | 0.948 | 1.000 | 1.000 |
Table 6.
FoR of LM Tests for the Spatial Error Correlation, Sample Size: .
Table 6.
FoR of LM Tests for the Spatial Error Correlation, Sample Size: .
| | | | | -0.6 | -0.4 | -0.2 | 0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.989 | 0.016 | 0.996 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.654 | 0.573 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.999 | 0.048 | 0.994 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.628 | 0.819 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.984 | 0.369 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.983 | 0.030 | 0.993 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.654 | 0.548 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.999 | 0.086 | 0.993 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.633 | 0.781 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.976 | 0.344 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.852 | 0.076 | 0.938 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.934 | 0.061 | 0.899 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.952 | 0.051 | 0.899 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.950 | 0.036 | 0.930 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.901 | 0.067 | 0.977 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.826 | 0.103 | 0.914 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.917 | 0.086 | 0.870 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.948 | 0.079 | 0.864 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.921 | 0.052 | 0.890 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.896 | 0.070 | 0.961 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.961 | 0.046 | 0.910 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.958 | 0.047 | 0.896 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.954 | 0.048 | 0.892 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.948 | 0.047 | 0.902 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.950 | 0.048 | 0.913 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.955 | 0.064 | 0.876 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.948 | 0.064 | 0.865 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.933 | 0.066 | 0.864 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.934 | 0.061 | 0.870 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.942 | 0.056 | 0.885 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.990 | 0.018 | 0.998 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.658 | 0.577 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.999 | 0.049 | 0.996 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.642 | 0.810 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.983 | 0.351 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.853 | 0.086 | 0.932 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.933 | 0.060 | 0.893 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.949 | 0.049 | 0.884 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.940 | 0.035 | 0.921 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.903 | 0.058 | 0.974 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.958 | 0.055 | 0.899 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.949 | 0.048 | 0.888 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.947 | 0.050 | 0.884 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.949 | 0.046 | 0.897 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.953 | 0.046 | 0.911 | 1.000 | 1.000 | 1.000 |
Finally, the performances of the test statistics for spatial lag dependence are summarized in
Table 7 and
Table 8. We focus on the
sample for discussion. For
, the empirical size is
, and it is very powerful in detecting the spatial lag dependence given that
. For example, FoR of
is
when
. However, as discussed in
Section 3.3.3,
is not robust against local misspecification, and this is confirmed by the simulation results. Given
, when
and
ρ deviate locally from 0, the large FoRs of
are undesirable. For example, when
but
, FoR of
is
. This size distortion is to some extent avoided by
. When
and
takes values
and
, FoRs of
are in the range of
. However,
should be used with caution in this case, since the range of
ρ in which
provides valid size is narrow, and this becomes even worse for the
sample. On the other hand, the robust LM test is supposed to be less powerful than the corresponding LM test when the nuisance parameters are correctly specified. When
,
is less powerful than
. For example, when
, FoR of
is
, while that of
is
. Next,
tests for the spatial lag dependence in a pooled panel data model with spatial error correlation. The empirical sizes of
vary in
. As
λ deviates from 0, FoR increases. Moreover, as discussed in
Section 3.3.3, the robust LM test in this case is the same as
, implying that
itself is robust against local deviation of
from 0. This is confirmed in the simulation results. When
, the FoRs of
vary in
. Next, we discuss
and
.
tests for the spatial lag dependence in a random effects panel data model without spatial error correlation. We only present the representative result when
, results in other cases are very similar. The empirical size of
is
, and the FoR increases as
λ deviates away from 0. For example, FoR is
when
. However,
suffers from size distortion when the nuisance parameter
ρ deviates away from 0. For example, when
, the FoR of
is
, which is undesirably high. For the same case, FoR of
is
. However, as
,
should also be used with caution, since the range of
ρ in which
provides valid size is narrow, and it becomes even worse for the
sample. On the other hand,
is less powerful than
when
. For example, when
, FoR of
is
, while that of
is
. Lastly, we discuss the performance of
.
tests for the spatial lag dependence in a random effects panel data model with spatial error correlation. The empirical sizes of
vary in
. As expected, when
λ moves away from 0, FoR increases, suggesting its good power performance. For all of the above tests, their performances for the
sample follows a similar discussion. In sum, the test statistics
,
,
,
,
, and
are all useful for detecting the spatial lag dependence, but they are suited for different assumptions about the nuisance parameters. In practice, researchers are suggested to analyze them together to draw correct inference on
λ.
Table 7.
FoR of LM Tests for the Spatial Lag Dependence, Sample Size: .
Table 7.
FoR of LM Tests for the Spatial Lag Dependence, Sample Size: .
| | | | | -0.6 | -0.4 | -0.2 | 0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.965 | 0.221 | 0.405 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.982 | 0.446 | 0.063 | 0.938 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.987 | 0.591 | 0.044 | 0.693 | 0.998 | 1.000 | 1.000 |
| | | | 1.000 | 0.984 | 0.631 | 0.067 | 0.576 | 0.988 | 1.000 | 1.000 | 1.000 |
| | | | 0.979 | 0.510 | 0.061 | 0.593 | 0.992 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 1.000 | 0.964 | 0.285 | 0.305 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.968 | 0.505 | 0.071 | 0.892 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.985 | 0.620 | 0.051 | 0.637 | 0.998 | 1.000 | 1.000 |
| | | | 1.000 | 0.987 | 0.637 | 0.094 | 0.526 | 0.981 | 1.000 | 1.000 | 1.000 |
| | | | 0.963 | 0.502 | 0.081 | 0.599 | 0.981 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 0.626 | 0.318 | 0.128 | 0.121 | 0.337 | 0.801 | 0.995 | 1.000 | 1.000 |
| | | | 0.968 | 0.855 | 0.547 | 0.163 | 0.054 | 0.497 | 0.983 | 1.000 | 1.000 |
| | | | 0.999 | 0.974 | 0.809 | 0.338 | 0.035 | 0.459 | 0.978 | 1.000 | 1.000 |
| | | | 0.999 | 0.991 | 0.858 | 0.305 | 0.066 | 0.649 | 0.993 | 1.000 | 1.000 |
| | | | 1.000 | 0.976 | 0.651 | 0.121 | 0.323 | 0.922 | 1.000 | 1.000 | 1.000 |
| | | | 0.582 | 0.318 | 0.157 | 0.153 | 0.353 | 0.753 | 0.992 | 1.000 | 1.000 |
| | | | 0.961 | 0.812 | 0.510 | 0.181 | 0.088 | 0.450 | 0.964 | 1.000 | 1.000 |
| | | | 0.998 | 0.963 | 0.773 | 0.366 | 0.063 | 0.421 | 0.963 | 1.000 | 1.000 |
| | | | 0.999 | 0.985 | 0.824 | 0.324 | 0.082 | 0.614 | 0.991 | 1.000 | 1.000 |
| | | | 1.000 | 0.952 | 0.641 | 0.145 | 0.309 | 0.904 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.958 | 0.490 | 0.050 | 0.484 | 0.981 | 1.000 | 1.000 |
| | | | 1.000 | 0.998 | 0.941 | 0.444 | 0.037 | 0.422 | 0.966 | 1.000 | 0.973 |
| | | | 1.000 | 0.998 | 0.900 | 0.406 | 0.055 | 0.371 | 0.909 | 0.997 | 0.757 |
| | | | 1.000 | 0.988 | 0.862 | 0.360 | 0.049 | 0.285 | 0.769 | 0.923 | 0.556 |
| | | | 0.998 | 0.971 | 0.756 | 0.263 | 0.046 | 0.233 | 0.575 | 0.766 | 0.366 |
| | | | 1.000 | 1.000 | 0.978 | 0.543 | 0.067 | 0.493 | 0.990 | 1.000 | 1.000 |
| | | | 1.000 | 0.999 | 0.929 | 0.478 | 0.074 | 0.446 | 0.964 | 1.000 | 0.962 |
| | | | 1.000 | 0.998 | 0.924 | 0.478 | 0.060 | 0.367 | 0.934 | 0.998 | 0.701 |
| | | | 1.000 | 0.996 | 0.869 | 0.338 | 0.067 | 0.299 | 0.818 | 0.946 | 0.462 |
| | | | 0.999 | 0.977 | 0.750 | 0.294 | 0.068 | 0.225 | 0.591 | 0.772 | 0.531 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 0.970 | 0.269 | 0.291 | 0.999 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.979 | 0.476 | 0.063 | 0.917 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.981 | 0.591 | 0.035 | 0.676 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.984 | 0.612 | 0.067 | 0.557 | 0.989 | 1.000 | 1.000 | 1.000 |
| | | | 0.965 | 0.461 | 0.080 | 0.629 | 0.986 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 0.577 | 0.285 | 0.130 | 0.137 | 0.353 | 0.779 | 0.991 | 1.000 | 1.000 |
| | | | 0.966 | 0.823 | 0.515 | 0.153 | 0.063 | 0.453 | 0.972 | 1.000 | 1.000 |
| | | | 0.999 | 0.971 | 0.778 | 0.328 | 0.051 | 0.421 | 0.973 | 1.000 | 1.000 |
| | | | 0.999 | 0.983 | 0.830 | 0.287 | 0.072 | 0.642 | 0.996 | 1.000 | 1.000 |
| | | | 1.000 | 0.952 | 0.623 | 0.103 | 0.326 | 0.928 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 0.961 | 0.504 | 0.064 | 0.532 | 0.992 | 1.000 | 0.998 |
| | | | 1.000 | 0.999 | 0.933 | 0.477 | 0.070 | 0.484 | 0.982 | 1.000 | 0.964 |
| | | | 1.000 | 0.997 | 0.899 | 0.442 | 0.078 | 0.438 | 0.935 | 0.996 | 0.644 |
| | | | 1.000 | 0.999 | 0.918 | 0.475 | 0.079 | 0.347 | 0.818 | 0.892 | 0.371 |
| | | | 1.000 | 0.995 | 0.855 | 0.381 | 0.063 | 0.205 | 0.460 | 0.522 | 0.275 |
Table 8.
FoR of LM Tests for the Spatial Lag Dependence, Sample Size: .
Table 8.
FoR of LM Tests for the Spatial Lag Dependence, Sample Size: .
| | | | | -0.6 | -0.4 | -0.2 | 0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|
| | | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.608 | 0.699 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 1.000 | 0.853 | 0.108 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.953 | 0.056 | 0.975 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.939 | 0.068 | 0.922 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.825 | 0.102 | 0.978 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.660 | 0.581 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 1.000 | 0.861 | 0.105 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.929 | 0.082 | 0.959 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.930 | 0.087 | 0.889 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.787 | 0.148 | 0.961 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 0.955 | 0.579 | 0.152 | 0.198 | 0.731 | 0.995 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.997 | 0.908 | 0.316 | 0.101 | 0.893 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.993 | 0.723 | 0.058 | 0.844 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.997 | 0.642 | 0.111 | 0.959 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.946 | 0.128 | 0.704 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | | 0.927 | 0.542 | 0.175 | 0.238 | 0.715 | 0.988 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.989 | 0.860 | 0.327 | 0.137 | 0.849 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.994 | 0.684 | 0.093 | 0.798 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.992 | 0.612 | 0.131 | 0.948 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.921 | 0.153 | 0.679 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.897 | 0.052 | 0.904 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.864 | 0.054 | 0.860 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.794 | 0.053 | 0.794 | 1.000 | 1.000 | 0.995 |
| | | | 1.000 | 1.000 | 0.997 | 0.712 | 0.055 | 0.679 | 0.994 | 1.000 | 0.883 |
| | | | 1.000 | 1.000 | 0.987 | 0.588 | 0.045 | 0.522 | 0.957 | 0.993 | 0.624 |
| | | | 1.000 | 1.000 | 1.000 | 0.870 | 0.068 | 0.858 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.810 | 0.075 | 0.800 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.795 | 0.075 | 0.732 | 0.999 | 1.000 | 0.989 |
| | | | 1.000 | 1.000 | 0.993 | 0.679 | 0.070 | 0.630 | 0.993 | 1.000 | 0.888 |
| | | | 1.000 | 1.000 | 0.989 | 0.592 | 0.073 | 0.491 | 0.951 | 0.993 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.648 | 0.634 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 1.000 | 0.868 | 0.086 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.941 | 0.053 | 0.975 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.930 | 0.056 | 0.930 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.795 | 0.124 | 0.980 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 0.941 | 0.531 | 0.132 | 0.227 | 0.726 | 0.995 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 0.995 | 0.884 | 0.305 | 0.105 | 0.874 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.995 | 0.702 | 0.055 | 0.813 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.999 | 0.624 | 0.100 | 0.961 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 0.940 | 0.137 | 0.731 | 1.000 | 1.000 | 1.000 | 1.000 |
| | | 1.000 | 1.000 | 1.000 | 0.884 | 0.062 | 0.992 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.858 | 0.076 | 0.880 | 1.000 | 1.000 | 1.000 |
| | | | 1.000 | 1.000 | 1.000 | 0.830 | 0.084 | 0.812 | 1.000 | 1.000 | 0.979 |
| | | | 1.000 | 1.000 | 1.000 | 0.759 | 0.076 | 0.696 | 0.994 | 1.000 | 0.761 |
| | | | 1.000 | 1.000 | 0.994 | 0.647 | 0.070 | 0.497 | 0.925 | 0.966 | 0.746 |
5. Empirical Illustration
In this section, we revisit the empirical example in Baltagi and Levin (1992) [
32]. For the purpose of illustrating usefulness of the test statistics in our framework, we estimate a static demand model for cigarettes as in Elhorst (2014) [
25]. The data is obtained from the Wiley website, it is a panel data of 45 U.S. states and Washington D.C. over the period of 1963–1992.
4 We estimate the regression equation
for
. In the above specification,
is the vector of average cigarettes consumption (in packs) per capita (14 years and older) for all the states in a given year
t.
is the corresponding price (per pack) vector in year
t, with
capturing the price effect on the demand for cigarettes.
is the vector of per capita disposable income in year
t, with
capturing the income effect on the demand for cigarettes. In the regression analysis, in addition to the standard price and income effects, we are particularly interested in whether and how the consumption of cigarettes in one state is related to those of its neighboring states. This is reflected by the spatial lag dependence structure (or the corresponding parameter
λ). Further, we use the error component structure to allow for individual random effects and spatial correlation in the error term. For the spatial weights matrices, we choose two specifications and try different combinations of them. One is the standard row-normalized first-order rook contiguity matrix. The other one is the row-standardized border length weights matrix as suggested in Debarsy
et al., (2012) [
33].
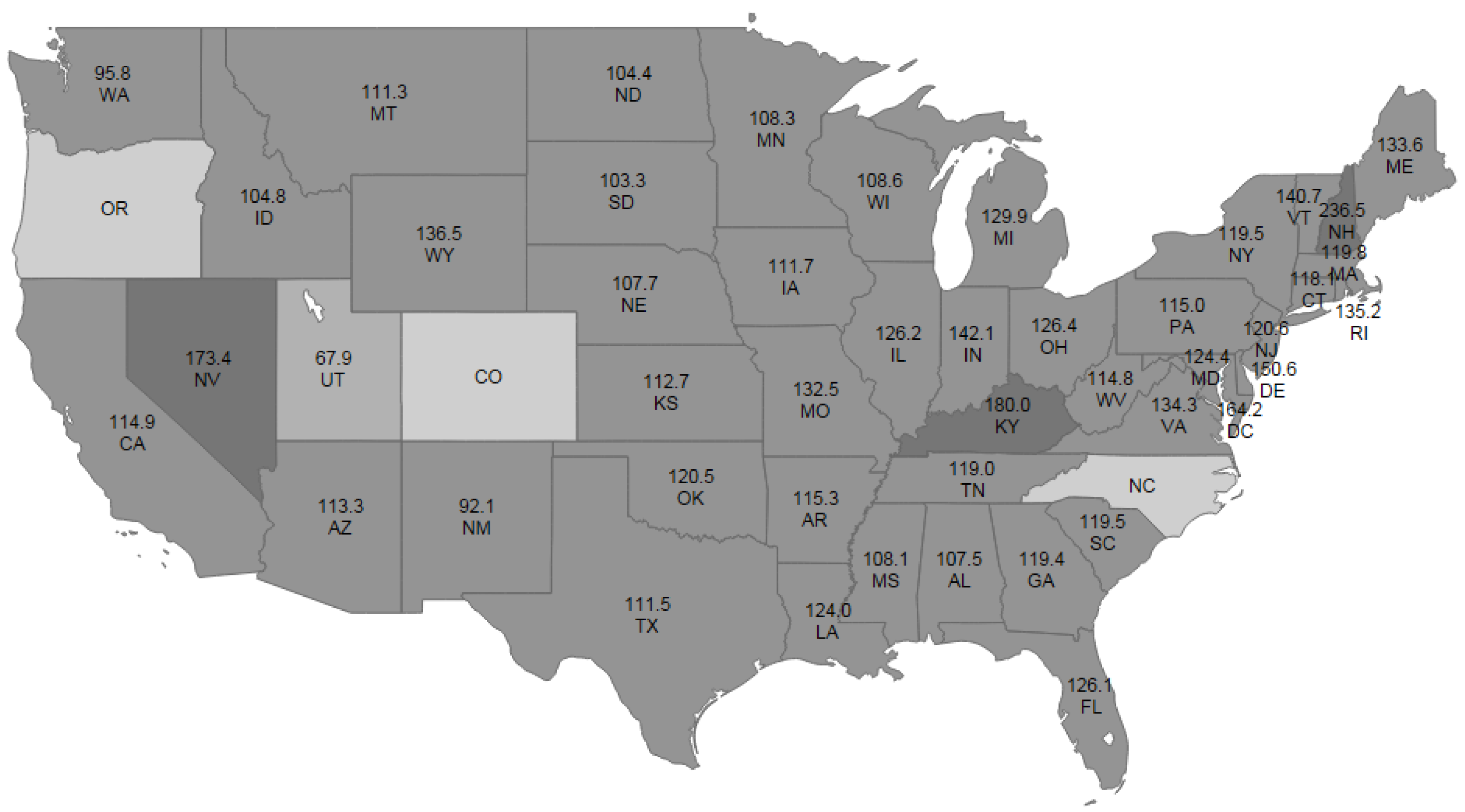
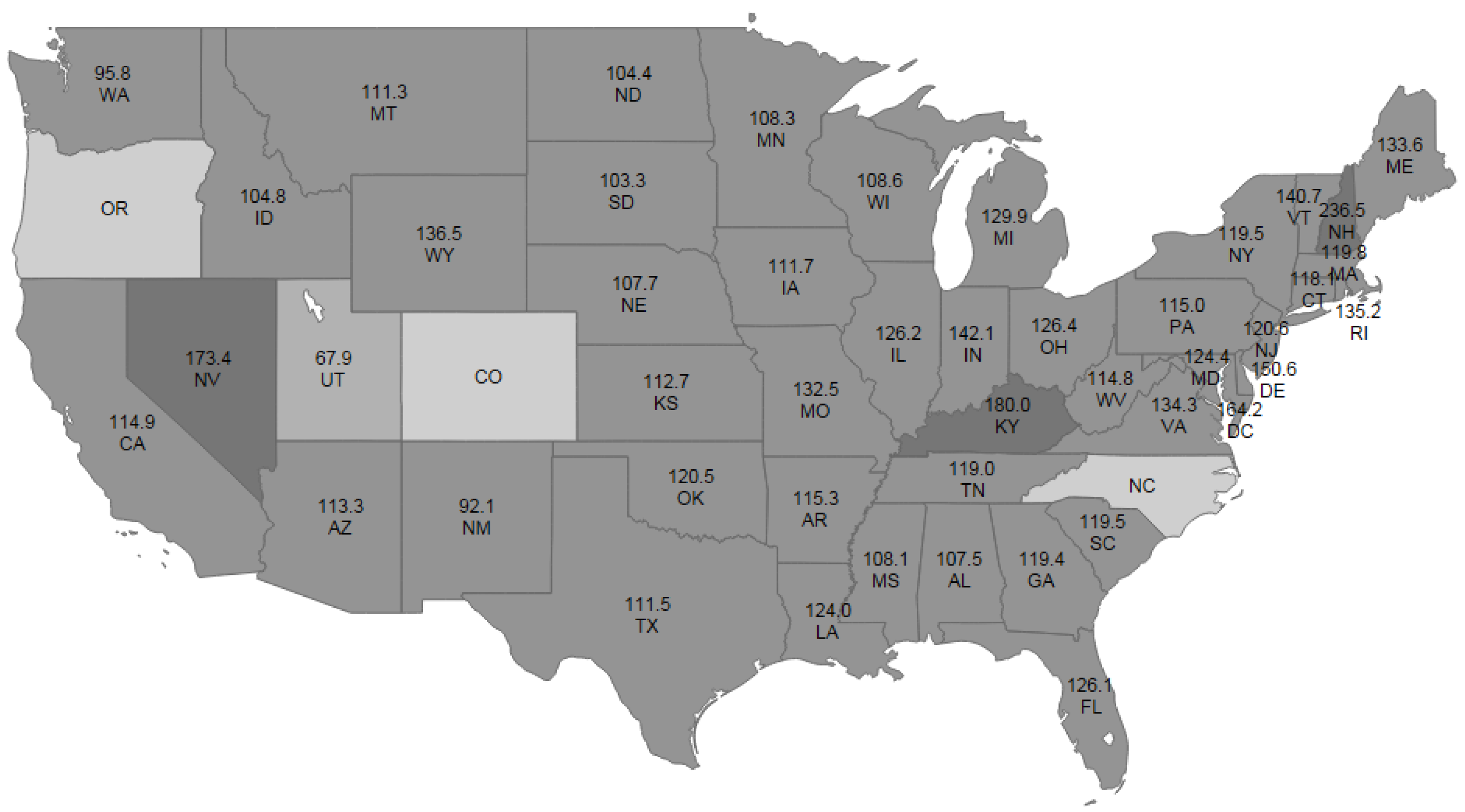
5Since we are particularly interested in whether the consumptions of cigarettes are spatial correlated and how they are correlated, we plot the average consumption of cigarettes (in packs) per capita over the 30 years for all the states in
Figure 1. On the one hand, we see that the cigarette consumptions in some states are negatively correlated with those of its neighboring states. For example, Utah, which has a high percentage of Mormon population,
6 has the lowest consumption of cigarettes, with the average consumption to be 67.9 packs per capita per year. In sharp contrast, the consumption of cigarettes in Nevada is nearly 2.6 times of that of Utah, and this could be attributed to the fact that Nevada is a highly tourist state with many casinos. The cigarette consumption in Utah is negatively correlated with those of its neighboring states. This similar pattern also hold for Nevada, New Mexico, Kentucky, and New Hampshire. On the other hand, we see that the consumptions of cigarettes among many other states tend to be similar and thus positively correlated, examples include Iowa, Wisconsin, Pennsylvania, Alabama, Georgia, and so on. The overall spatial dependence is not clear and we will use the formal regression analysis to assess it below.
Figure 1.
Average Consumption of Cigarettes (in packs) per Capita per Year by States, 1963–1992.
Figure 1.
Average Consumption of Cigarettes (in packs) per Capita per Year by States, 1963–1992.
Before the regression analysis, we first perform the diagnostic procedures and the results are summarized in
Table 9. The first row in
Table 9 shows that the joint null hypothesis
is strongly rejected, thus the classical pooled panel data model not appropriate for this data set, and the OLS estimator is biased. The next four rows show that the random effects model is strongly favored against the pooled panel data model, regardless of the assumptions imposed on the spatial parameters. Next, when we test for the spatial error effect and the spatial lag effect jointly, the values of
and
show that the null hypothesis
is rejected no matter we assume
or allow for the case
. This points us to a random effects model with at least one type of spatial effects. In the next six rows, we focus on testing for the spatial error correlation. Although these test statistics unanimously reject the null hypothesis
in favor of a model with spatial error correlation, we point out that the appropriate statistics should be
,
, and
given the presence of random effects but not spatial lag dependence yet at this stage. Finally, we test for the spatial lag dependence, the results in the last six rows suggest rejecting the null hypothesis of no spatial lag dependence, although there is a small value of
. Given that the random effects and the spatial error correlation are present by results above, we point out that the appropriate statistics should be
,
, and
. From the estimation results in
Table 10, the estimated
ρ is between
and
and thus it is not proper to consider such value of
ρ as local deviation from 0. As a result, the robust LM tests do not apply. We are left with
, and it points to the presence of spatial lag dependence. In the following, we first estimate the random effects model with spatial error correlation using two types of spatial weights matrices, then we add in the spatially lagged dependent variable as suggested by our test statistics.
The estimation results are summarized in
Table 10. The first column provides the OLS benchmark estimation result for comparison purpose. Although it is biased, all the parameter estimates have expected signs. Price has a negative effect on the consumption of cigarettes per capita, and the disposable income per capita has a positive effect on the consumption of cigarettes per capita, which are consistent with the standard consumption theory. In Columns 2 and 4, we include the spatial error correlation for the two different spatial weights matrices. Compared to the OLS estimates, the price and income elasticity all become smaller in magnitude but have the same signs. The estimated spatial error correlation are positive as
and
, which do not differ much for the two different spatial weights matrices. In Columns 3, 5, 6, and 7, we estimate the full model with different combinations of the weights matrices. The estimates for the spatial lag dependence is negative and statistically significant, which is consistent with our diagnostic testing results. We thus conclude that the full model is the more appropriate specification, and overall we find that the negative correlation dominates in the spatial dependence among cigarette consumptions.
Table 9.
LM Testing Statistics.
Table 9.
LM Testing Statistics.
| | | | |
|---|
| | | |
|---|
| Joint Test | 12559 *** | 12542 *** | 12532 *** | 12555 *** |
| Testing for Random Effects | | | | |
| 12471 *** | 12471 *** | 12471 *** | 12471 *** |
| 12207 *** | 12260 *** | 12260 *** | 12207 *** |
| 12471 *** | 12530 *** | 12471 *** | 12530 *** |
| 1354.7 *** | 1662.7 *** | 1573.1 *** | 1457.8 *** |
| Testing for Spatial Effects | | | | |
| Spatial Error and Lag | | | | |
| 88.13 *** | 70.78 *** | 60.82 *** | 83.76 *** |
| 172.81 *** | 188.36 *** | 174.62 *** | 143.68 *** |
| Spatial Error | | | | |
| 76.35 *** | 60.72 *** | 60.72 *** | 76.35 *** |
| 51.78 *** | 42.07 *** | 24.47 *** | 55.05 *** |
| 32.39 *** | 23.68 *** | 10.33 *** | 38.02 *** |
| 138.96 *** | 156.08 *** | 156.08 *** | 138.96 *** |
| 126.82 *** | 126.41 *** | 128.63 *** | 81.72 *** |
| 94.01 *** | 112.90 *** | 99.03 *** | 58.83 *** |
| Spatial Lag | | | | |
| 36.35 *** | 28.71 *** | 36.35 *** | 28.71 *** |
| 11.77 *** | 10.06 *** | 0.10 | 7.41 *** |
| 1147.00 *** | 1385.40 *** | 1028.20 *** | 580.53 *** |
| 45.99 *** | 61.95 *** | 45.99 *** | 61.95 *** |
| 33.85 *** | 32.28 *** | 18.53 *** | 4.72 *** |
| 133.96 *** | 283.36 *** | 108.62 *** | 80.05 *** |
Table 10.
Estimation of the Cigarette Demand Function.
Table 10.
Estimation of the Cigarette Demand Function.
| Model | OLS | MLE | MLE | MLE | MLE | MLE | MLE |
|---|
| | | () | () | () | () |
|---|
| () | () |
|---|
| 2.825 *** | 2.918 *** | 4.267 *** | 2.949 *** | 3.737 *** | 4.634 *** | 3.227 *** |
| | (0.098) | (0.086) | (0.241) | (0.087) | (0.196) | (0.261) | (0.169) |
| -0.773 *** | -0.739 *** | -0.867 *** | -0.729 *** | -0.821 *** | -0.851 *** | -0.788 *** |
| | (0.026) | (0.021) | (0.026) | (0.021) | (0.027) | (0.025) | (0.030) |
| 0.586 *** | 0.559 *** | 0.645 *** | 0.551 *** | 0.616 *** | 0.628 *** | 0.595 *** |
| | (0.022) | (0.018) | (0.022) | (0.018) | (0.022) | (0.022) | (0.024) |
| | | -0.329 *** | | -0.204 *** | -0.388 *** | -0.088 ** |
| | | | (0.044) | | (0.039) | (0.044) | (0.038) |
| | 0.353 *** | 0.586 *** | 0.364 *** | 0.510 *** | 0.622 *** | 0.419 *** |
| | | (0.030) | (0.034) | (0.028) | (0.034) | (0.032) | (0.039) |
| | 0.152 *** | 0.140 *** | 0.154 *** | 0.145 *** | 0.140 *** | 0.149 *** |
| | | (0.015) | (0.014) | (0.016) | (0.015) | (0.014) | (0.015) |
| | 0.075 *** | 0.069 *** | 0.073 *** | 0.071 *** | 0.067 *** | 0.074 *** |
| | | (0.001) | (0.002) | (0.001) | (0.002) | (0.002) | (0.001) |
| log-likelihood | 450.94 | 1489.2 | 1514.7 | 1502.4 | 1514.6 | 1537.9 | 1491.7 |



{kind=link}