In this section, experiments of Dynamic Deep Forest has been conducted against other popular machine learning methods. In the classification problems of network intrusion detection, our evaluations were performed using Scikit-learn and Tensorflow. The hardware and software configurations of the simulation computer are as follows: Intel Core i7 processor, 16 GB RAM memory, and Ubuntu 16.04.
4.1. Dataset chosen
KDD’99 is considered as a standard benchmark dataset for network intrusion detection [
23]. It is constituted by a wide variety of TCP dump connections simulated in a military network environment for nine weeks. Each sample in KDD’99 contains 41 features and a column of label types. We give a description of some features in
Table 1 and the attack types in
Table 2.
It is common practice to use the “kddcup.data_10_percent_corrected” data file as training data, which contains around 10% of complete dataset and 494,021 samples. The “corrected” data file is utilized as testing data and contains 311,029 samples. By the way, different feature selection methods were done before the model training process in network intrusion papers. In our experiments, we abandoned the operation of feature selection and only compared model performance to guarantee a relatively fair evaluation.
4.2. Performance Evaluation Metrics
This section discusses the parameters used to evaluate the performance of the network intrusion detection model with respect to Accuracy, Precision, Recall, False Alarm, and F-Score calculated as follows:
The accuracy measures the proportion of the total number of correct classifications.
The precision measures the number of correct classifications penalised by the number of incorrect classifications.
The recall measures the number of correct classifications penalised by the number of missed entries.
The false alarm measures the proportion of benign events incorrectly classified as malicious.
The F-score measures the harmonic mean of precision and recall, which serves as a derived effectiveness measurement.
Apart from evaluation metrics mentioned above, we introduce average-cost [
24] to evaluate the model security. Average-cost measures the risk levels caused by various intrusion types when misclassification happens. And we also conduct experiments on the famous intrusion detection dataset KDD99. Results show that our research has superior performance gains because in real network instrusion environment, different kinds of misclassification will cause different degrees of loss. For instance, it is more dangerous to misclassify the attack type R2L to Normal than Dos to Normal. To deal with this problem, KDDCUP 99 published a cost matrix to measure the loss, and it is displayed in
Table 3.
Based on the
Table 3 above, the columns represent the true label and the rows represent the predicted label. The function of average-cost can be calculated as:
where
means the number of label
i misclassified as label
j,
means the corresponding value in cost matrix
C, and
N means the total number of testing data.
4.3. Evaluation Results
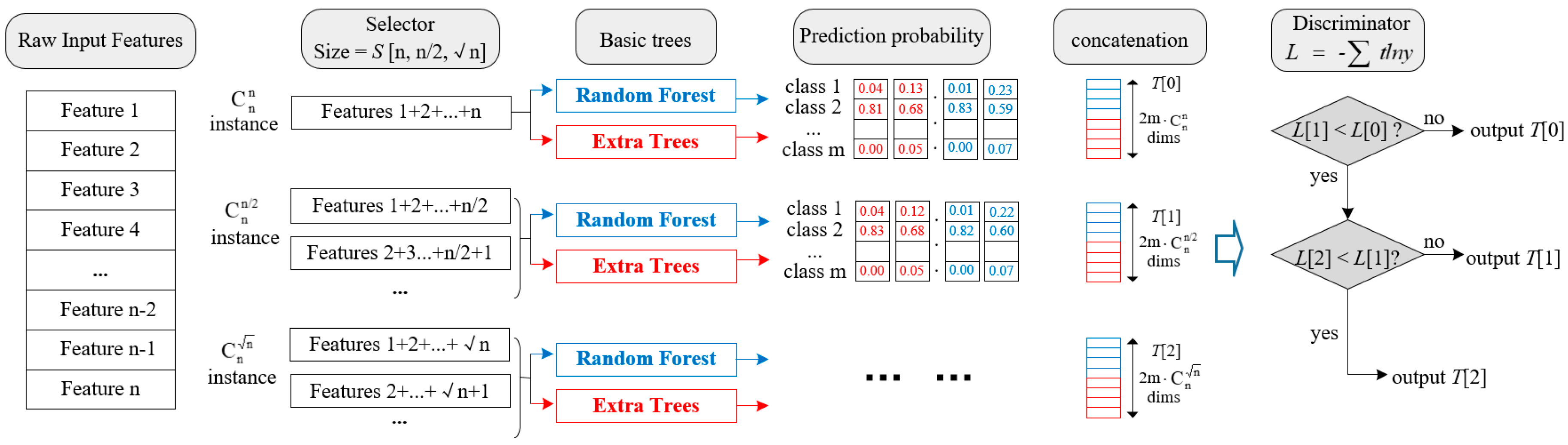
Although the four attack types can be classified to “abnormal”, in this way, we can consider it a simple binary classification problem. In order to evaluate the model sensitivity, all the experiments were done under the 5-class classification, and 5-fold cross-validation was utilized to reduce the risk of overfitting. In
Table 4, we compare Precision, Recall, F1_Score, and False Alarm of Dynamic Deep Forest (GTC Forest) against XGBoost with 500 trees, the Deep Belief Network (DBN) published in [
25] with eight hidden layers. In
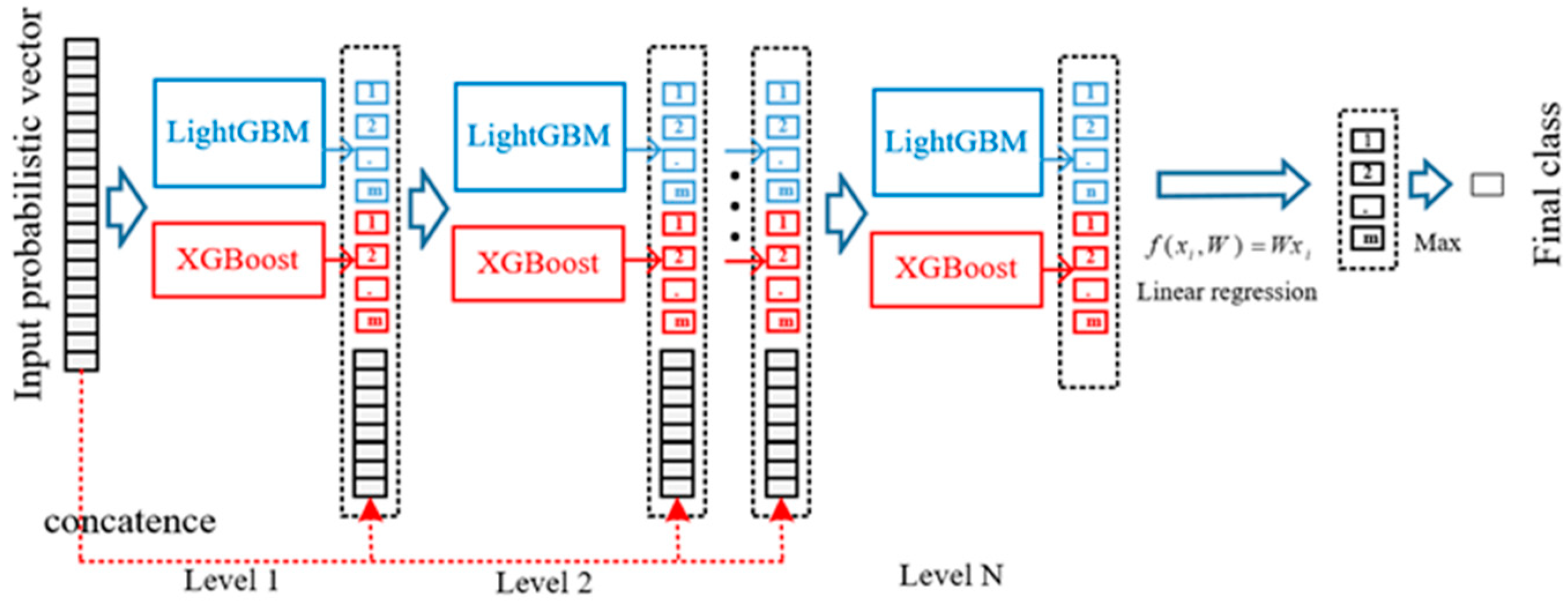
Table 5, we compare the evaluation indexes of accuracy and training time. XGBoost is the ensemble method which has grown popular in recent machine learning competitions, while DBN is one of the deep learning methods and represents another way of intrusion classification. We performed these comparative experiments to make our model persuasive.
In general, we can see that our model performs better than other two mainstream machine learning methods. The classification accuracy of Deep Dynamic Forest in
Table 5 reaches 92.7%. Specifically, it runs more than one percentage ahead of XGBoost and ten percentage ahead of DBN, which proved to be the most powerful in network intrusion problems. Apart from accuracy, our model also showed advantages in other four evaluation indexes in
Table 4. In total precision and total recall, Deep Dynamic Forest is 2% ahead of both XGBoost and DBN. Besides, our model is 1.7% ahead of XGBoost in total F1_score and nearly 1% ahead of DBN in total false alarm.
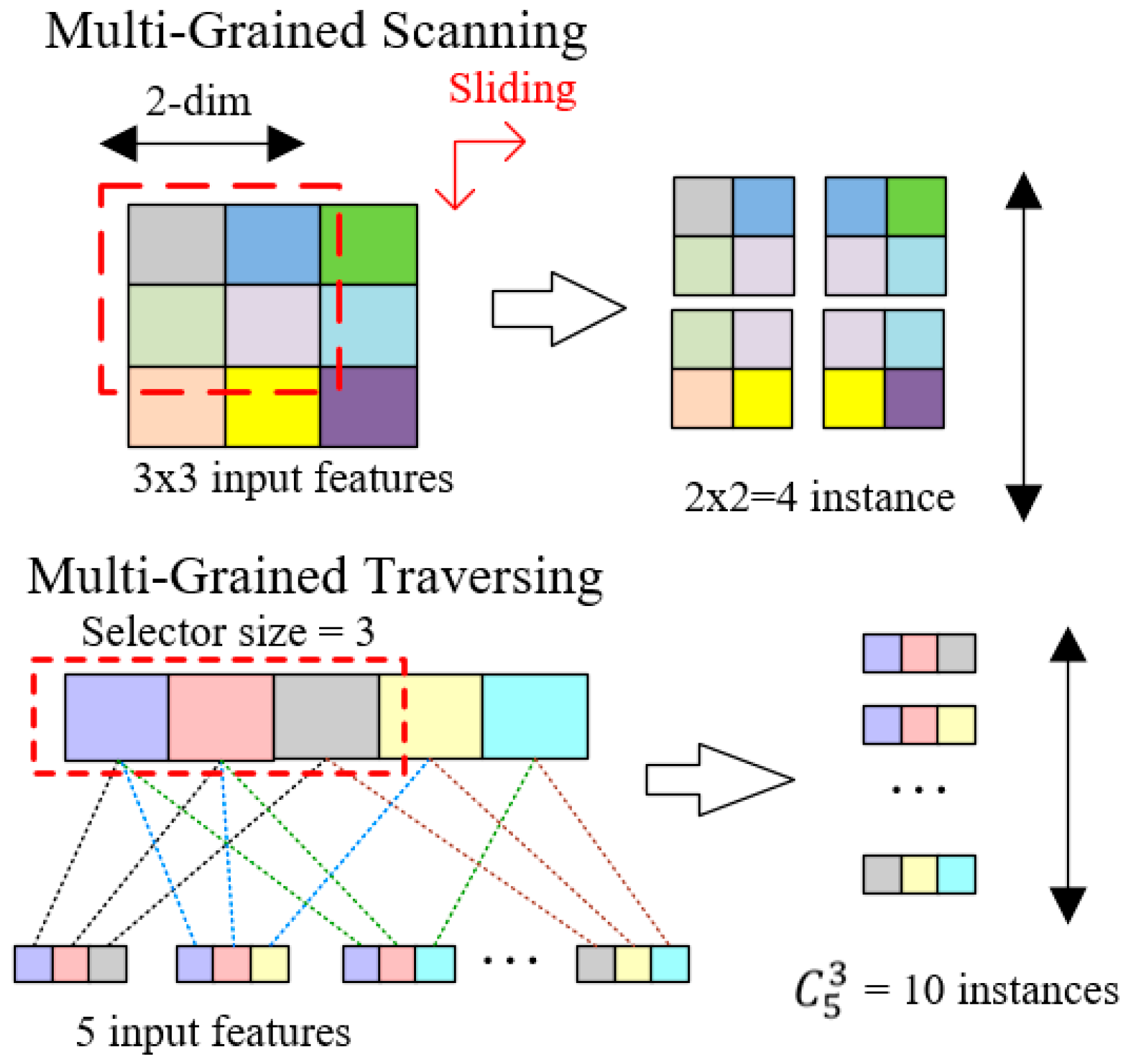
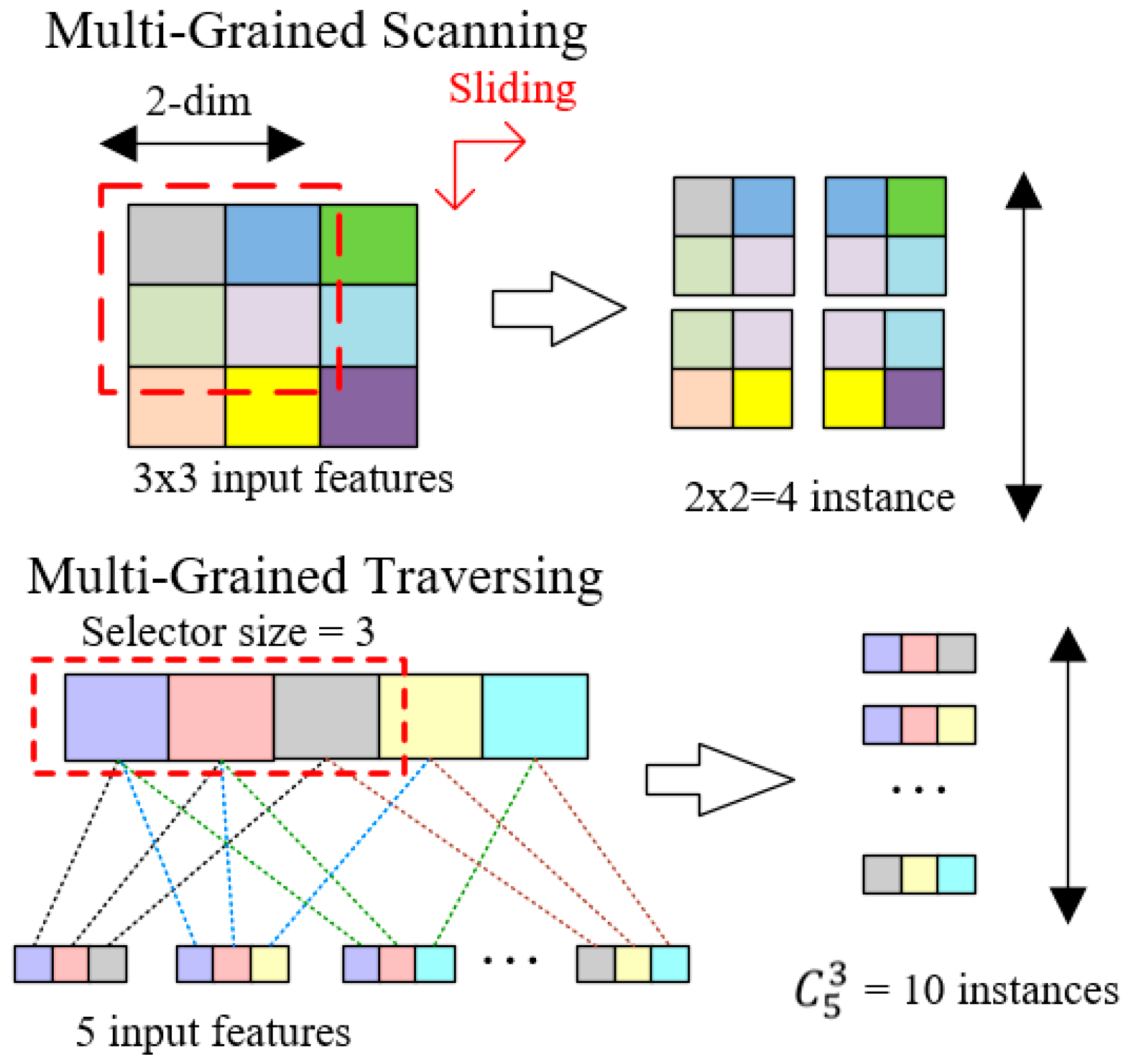
In the aspect of training time, DBN costs 27,330 s (7.6 h) to finish the training process, which is too slow in real network environment. Although dynamic deep forest is slower than XGBoost, it only costs 256 s (4.3 min). And we consider a total training within 5 min to be acceptable. For sequence data training, only adjacent features need to be combined. So, efficiency will be decreased if all the feature combinations are considered in multi-grained traversing.
Another thing which has to be mentioned is that the four attack types can be subdivided into more specific classes. For example, back, land, neptune, and pod all belong to Denial of Service (DOS) attack. There are 15 extra subclasses only in the testing dataset. This way of data segmentation decreases the scores of accuracy and recall, but can get a better inspection of model generalization performance.
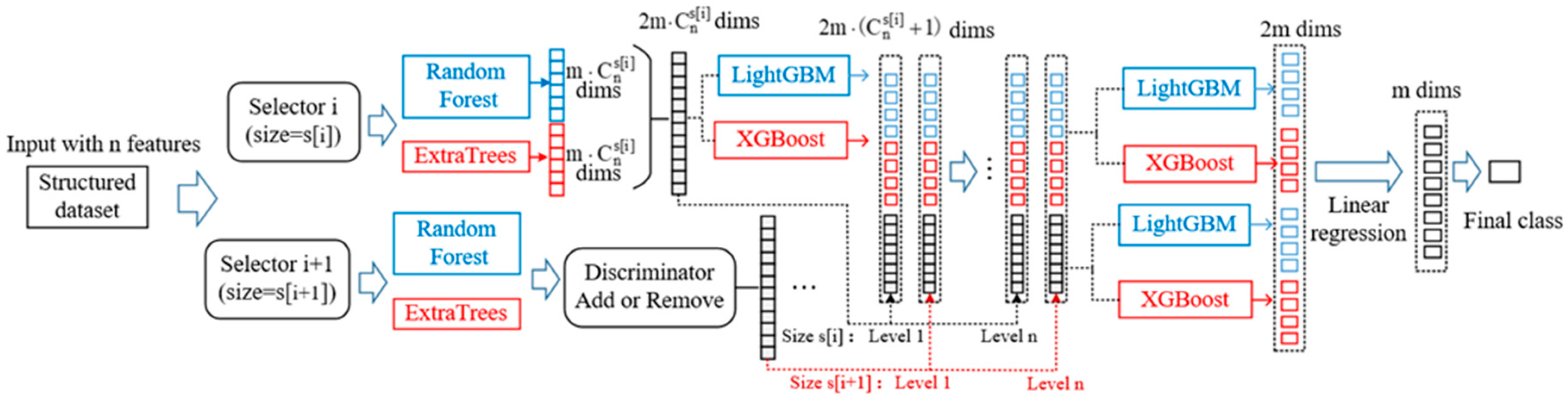
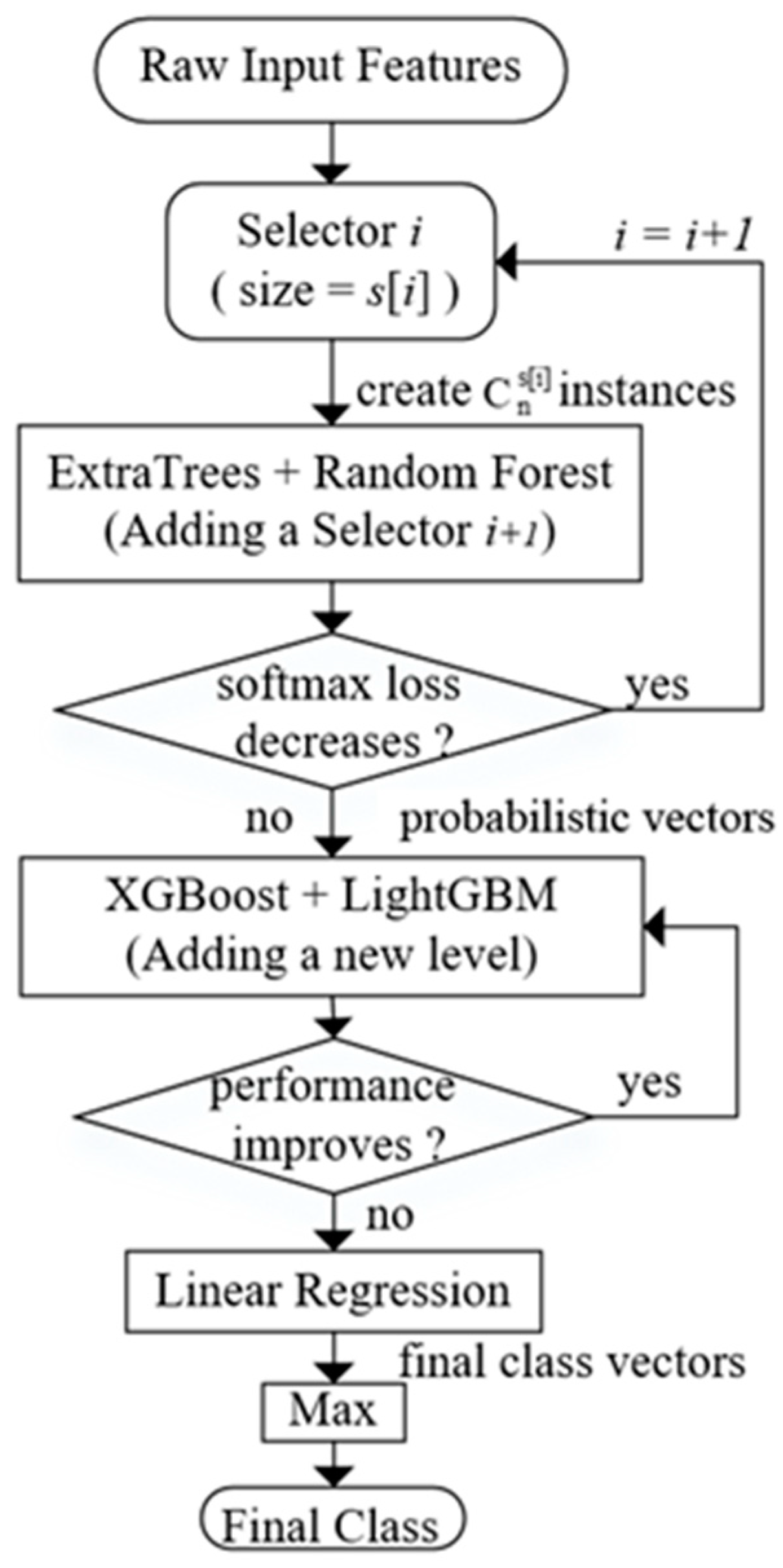
Dynamic Deep Forest has good generalization performance for two points: (1) In the KDD’99 [
23], most of the new attacks are variants of known attacks and the “signature” of known attacks can be sufficient to catch these variants. Our model has a dynamic selector to combine network features and strengthen representation learning ability. So, it has good generalization performance to capture features from new attacks. (2) As experiment results show, Dynamic Deep Forest obtains higher recall and precision in the situation that 15 extra subclasses are only included in the testing dataset.
Besides, we calculate average-cost to measure the consequence of misclassification. Using Equation (8), the values of average-cost are 0.192 in DBN, 0.178 in XGB, and 0.171 in DDF. The lower the average-cost is, the fewer risks will be taken in real network intrusion environment. Therefore, dynamic deep forest is the most reliable among the comparative models.
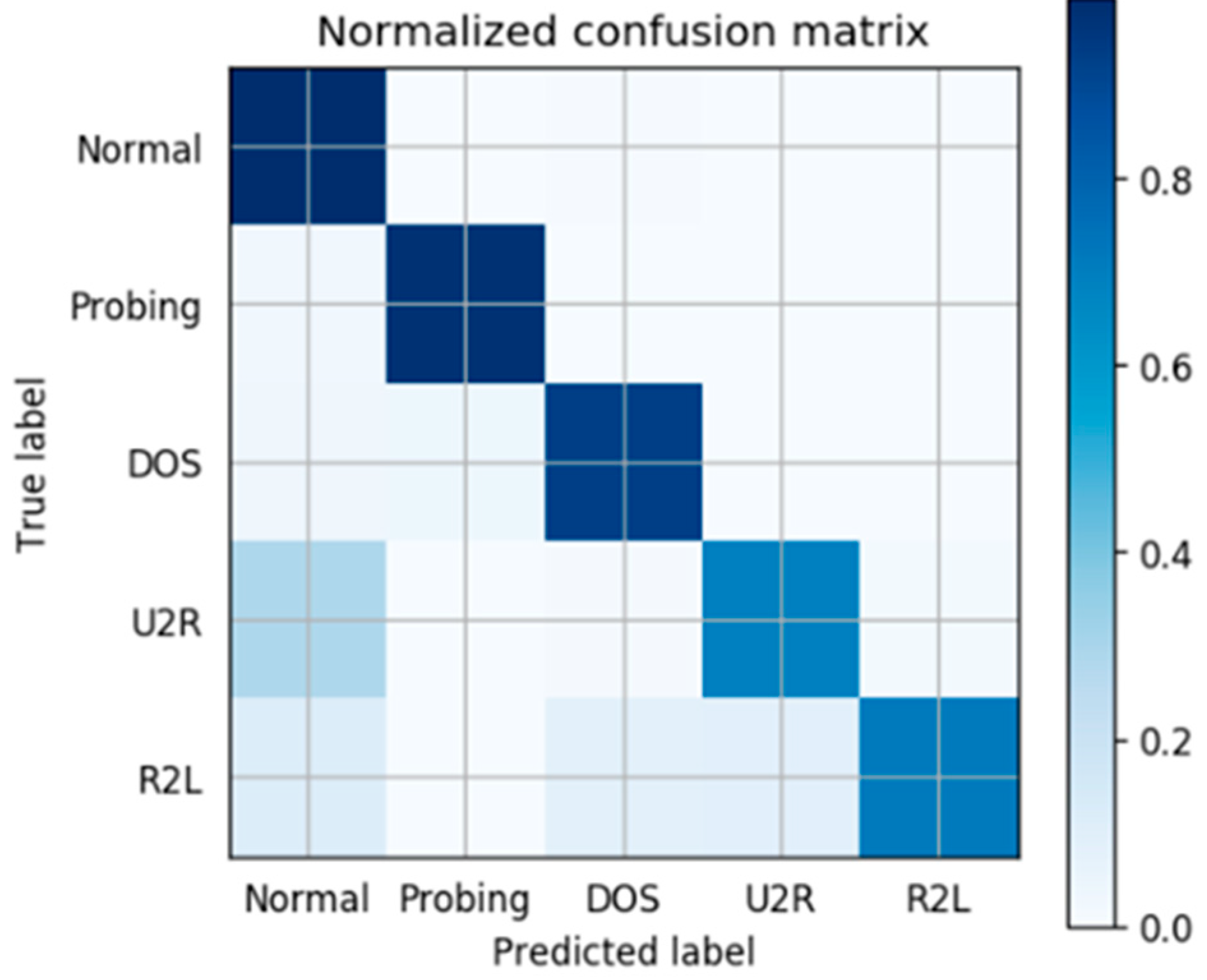
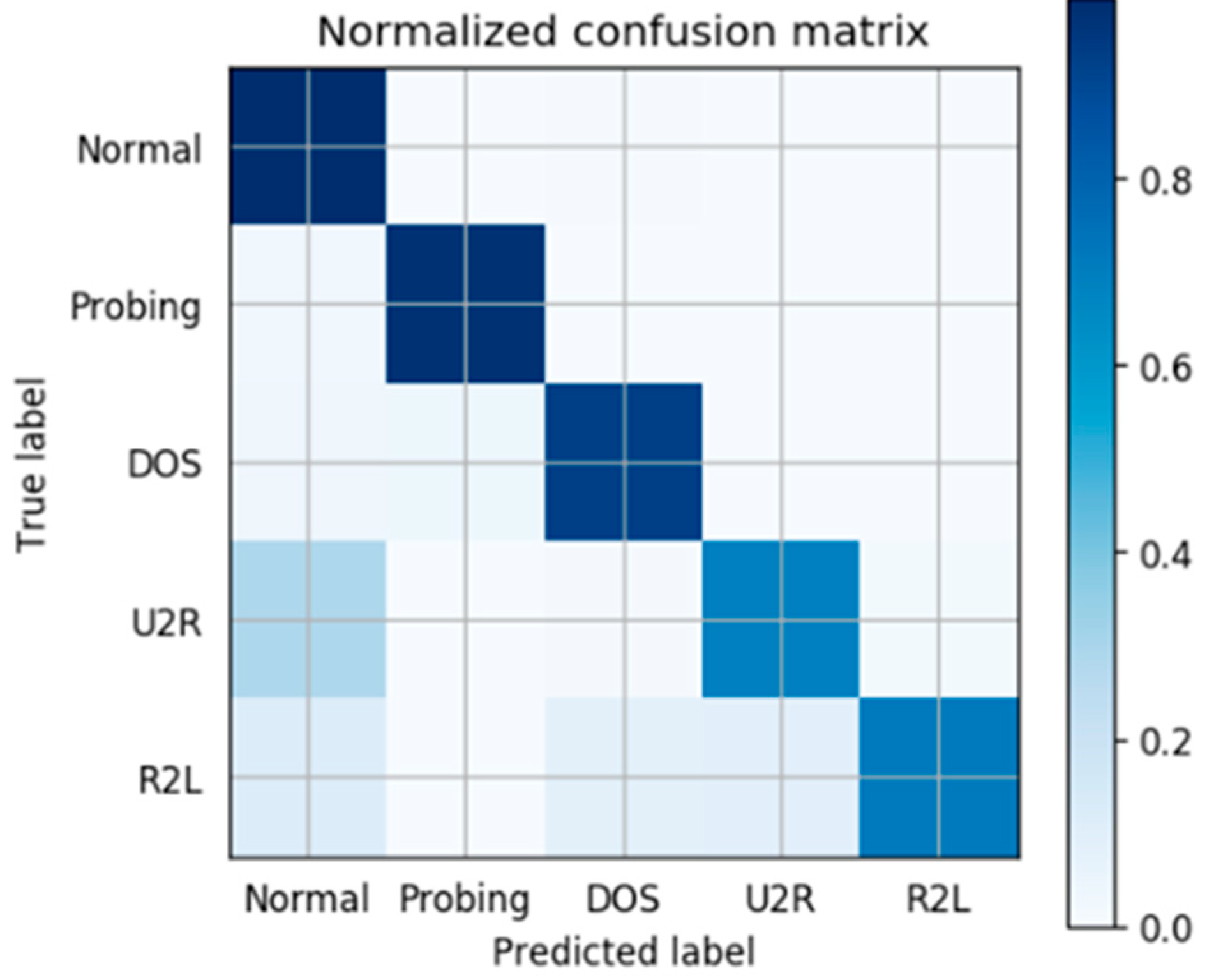
We also make a further analysis for wrongly classified cases. Based on our model,
Figure 6 shows the confusion matrix of classification accuracy. On the horizontal axis is the predicted label we trained and on the vertical is the True label. The darker the color of a grid is, the higher accuracy it possesses. So it’s obvious to conclude that most of the abnormal traffic is labeled correctly. The misclassification we made is mainly due to the real intrusion U2R labeled to Normal and R2L labeled to other abnormal classes. It also makes sense in actual situations because the training samples of U2R and R2L are really limited, leading to an incomplete classification. Higher accuracy will be acquired if more training data labeled U2R and R2L can be provided.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}